云数据库Cassandra是基于开源Apache Cassandra,融合阿里云数据库DBaaS能力的分布式NoSQL数据库。本文主要介绍如何通过DLA Serverless
Spark访问云数据库Cassandra。
前提条件
- 已经开通对象存储OSS(Object Storage Service)服务。具体操作请参考开通OSS服务。
- 已经创建云数据库Cassandra实例。具体请参考使用cqlsh访问cassandra。
- 已获取到Cassandra的私网连接点、CQL端口、数据库用户名、数据库密码。具体请参考多语言SDK访问(公网&内网)。
- 在Cassandra实例中已创建数据表,并插入数据。具体请参考使用cqlsh访问cassandra。参考命令样例如下:
CREATE KEYSPACE spark WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
use spark;
CREATE TABLE spark_test (first_name text , last_name text, PRIMARY KEY (first_name)) ;
INSERT INTO spark_test (first_name, last_name) VALUES ('hadoop', 'big data basic plateform');
INSERT INTO spark_test (first_name, last_name) VALUES ('spark', 'big data compute engine');
INSERT INTO spark_test (first_name, last_name) VALUES ('kafka', 'streaming data plateform');
INSERT INTO spark_test (first_name, last_name) VALUES ('mongodb', 'document database');
INSERT INTO spark_test (first_name, last_name) VALUES ('es', 'serarch egnine');
INSERT INTO spark_test (first_name, last_name) VALUES ('flink', 'streaming plateform');
- 准备DLA Spark访问Cassandra实例所需的安全组ID和交换机ID。具体操作请参见配置数据源网络。
操作步骤
- 准备以下测试代码和依赖包来访问Cassandra,并将此测试代码和依赖包分别编译打包生成jar包上传至您的OSS。
测试代码示例:
import org.apache.spark.sql.SparkSession
object SparkCassandra {
def main(args: Array[String]): Unit = {
//cassandra的私网连接点
val cHost = args(0)
//Cassandra的CQL端口
val cPort = args(1)
//Cassandra的数据库用户名和密码
val cUser = args(2)
val cPw = args(3)
//Cassandra的keystone和table
val cKeySpace = args(4)
val cTable = args(5)
val spark = SparkSession
.builder()
.config("spark.cassandra.connection.host", cHost)
.config("spark.cassandra.connection.port", cPort)
.config("spark.cassandra.auth.username", cUser)
.config("spark.cassandra.auth.password", cPw)
.getOrCreate();
val cData1 = spark
.read
.format("org.apache.spark.sql.cassandra")
.options(Map("table" -> cTable, "keyspace" -> cKeySpace))
.load()
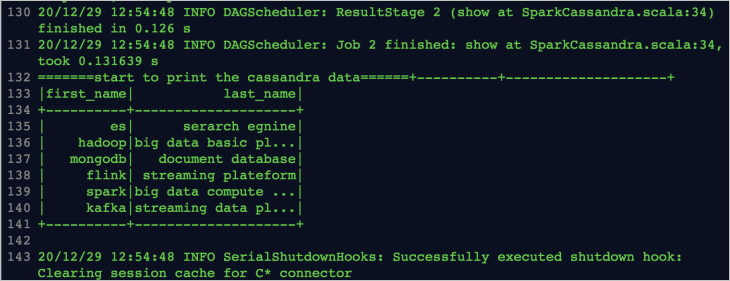
print("=======start to print the cassandra data======")
cData1.show()
}
}
Cassandra依赖的pom文件:
<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector_2.11</artifactId>
<version>2.4.2</version>
</dependency>
- 登录Data Lake Analytics管理控制台。
- 在页面左上角,选择Cassandra实例所在地域。
- 单击左侧导航栏中的。
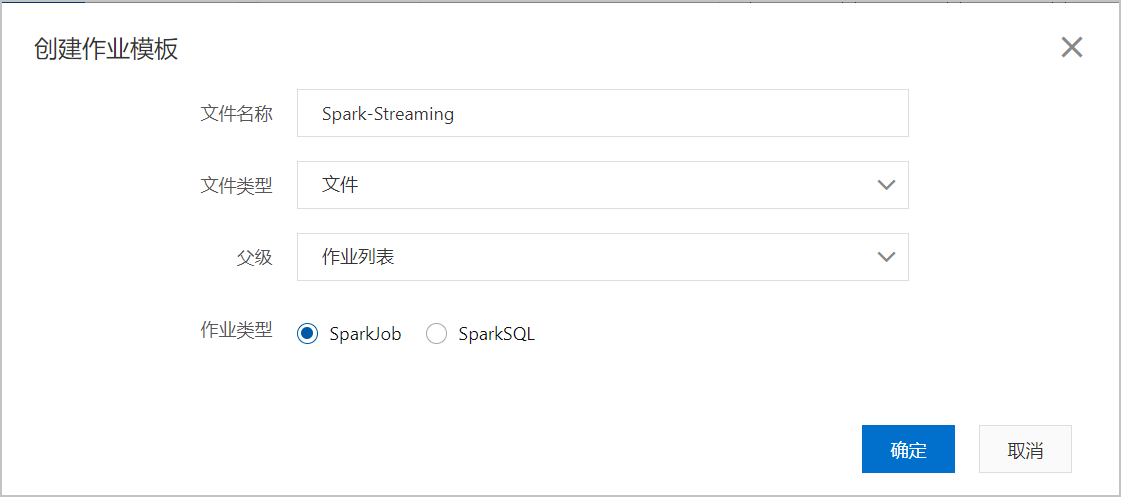
- 在作业编辑页面,单击创建作业。
- 在创建作业模板页面,按照页面提示进行参数配置后,单击确定创建Spark作业。
- 单击Spark作业名,在Spark作业编辑框中输入以下作业内容,并按照以下参数说明进行参数值替换。保存并提交Spark作业。
{
"args": [
"cds-xxx-1-core-001.cassandra.rds.aliyuncs.com", #Cassandra的私网连接点,私网连接点可能会有两个,任选其一即可。
"9042", #Cassandra的CQL端口。
"cassandra", #Cassandra的数据库用户名。
"test_1234", #Cassandra的数据库密码。
"spark", #Cassndra的keyspace。
"spark_test" #Cassandra的表名。
],
"file": "oss://spark_test/jars/cassandra/spark-examples-0.0.1-SNAPSHOT.jar", #测试代码的OSS路径。
"name": "Cassandra-test",
"jars": [
"oss://spark_test/jars/cassandra/spark-cassandra-connector_2.11-2.4.2.jar" #测试代码依赖包的OSS路径。
],
"className": "com.aliyun.spark.SparkCassandra",
"conf": {
"spark.driver.resourceSpec": "small", #表示driver的规格,有small、medium、large、xlarge之分。
"spark.executor.instances": 2, #表示executor的个数。
"spark.executor.resourceSpec": "small", #表示executor的规格,有small、medium、large、xlarge之分。
"spark.dla.eni.enable": "true", #开启访问用户VPC网络的权限。当您需要访问用户VPC网络内的数据时,需要开启此选项。
"spark.dla.eni.vswitch.id": "vsw-xxx", #可访问Cassandra 的交换机id。
"spark.dla.eni.security.group.id": "sg-xxx" #可访问Cassandra的安全组id。
}
}
执行结果
作业运行成功后,在任务列表中单击,查看作业日志。出现如下日志说明作业运行成功: