Marmaray集成DLA提供Hadoop parquet文件到云原生数据仓库AnalyticDB MySQL版数据传输服务。该服务原理是将包含用户传输配置的Marmaray spark jar包运行在DLA提供的执行环境中,实现源端hadoop parquet文件传输到目的端ADB的功能。本文主要对本功能进行详细说明。
数据类型
| 类别 | Parquet数据类型 | ADB3.0数据类型 |
|---|---|---|
| 简单类型 | INT32 | INT |
| INT64 | BIGINT | |
| FLOAT | FLOAT | |
| DOUBLE | DOUBLE | |
| 逻辑类型 | STRING | VARCHAR |
| DATE | DATE | |
| DECIMAL | DECIMAL | |
| TIMESTAMP | TIMESTAMP |
功能列表
- 字段映射
-
源端parquet文件对应schema的字段名可映射成目标端ADB对应表的新字段名。例:
parquet文件schema有三个字段,名称a、b、c,对应ADB表中a1、b1、c1三个字段。字段映射 a|a1,b|b1,c|c1。
- 异常恢复
-
- 记录级异常恢复
单次写入异常温和重试策略。异常后间隔阶梯递增时间重试。第一次失败1s后重试,最多重试12次,最长重试间隔34min。超过最长重试次数后子任务失败,进入子任务级异常恢复流程。阶梯递减重试时间间隔如下所示,单位毫秒。
[1000,2000,4000,8000,16000,32000,64000,128000,256000,512000,1024000,2048000] - 子任务级异常恢复
迁移任务被切分成多个子任务并发执行,单个子任务失败后转移至其他运算节点执行,失败转移次数按需配置。
默认失败转移次数4。可在任务配置文件conf中增加
spark.task.maxFailures配置参数自定义失败转移次数。超过最大转移失败次数后,子任务失败,整个迁移任务缺失子任务数据。
- 记录级异常恢复
- 并发流式处理
-
任务切分基于spark引擎,文件多分区并行读取。
每个分区读取的最大数据量默认128 MB,可通过参数
spark.sql.files.maxPartitionBytes调整,需在任务配置文件conf中增加该参数。更多参数配置请参见Spark官方文档。
- 任务执行可视化
-
任务执行集成DLA ServerLess spark任务,可在spark web 作业监控页面实时掌控作业运行情况。示例:
- 事件流水记录
可查看Executor和job随时间完成情况。
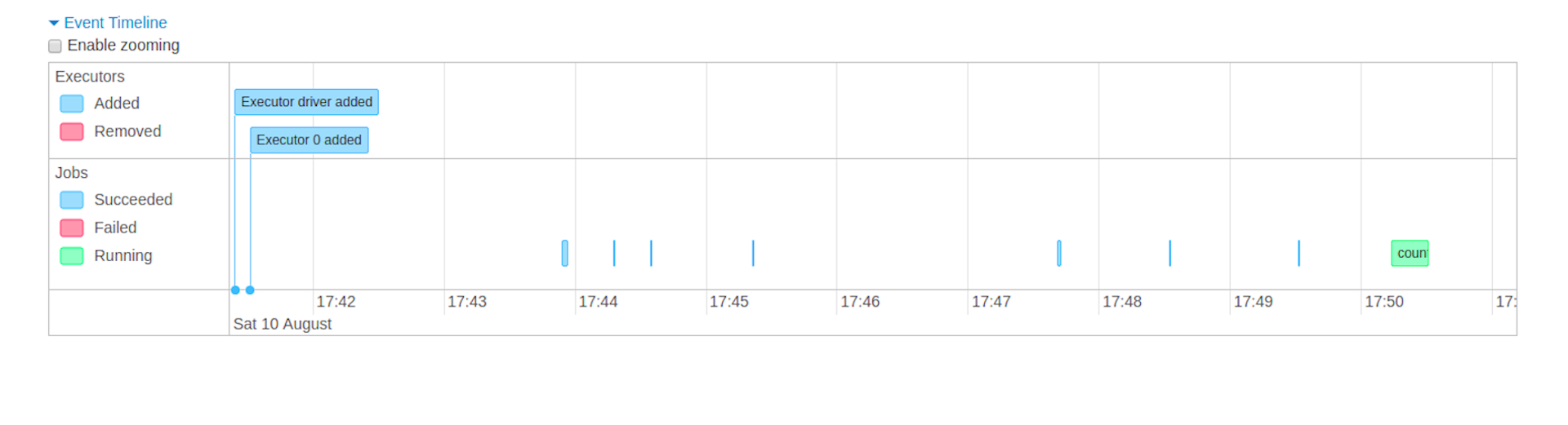
- 任务概况
可查看已完成和执行中任务进展。
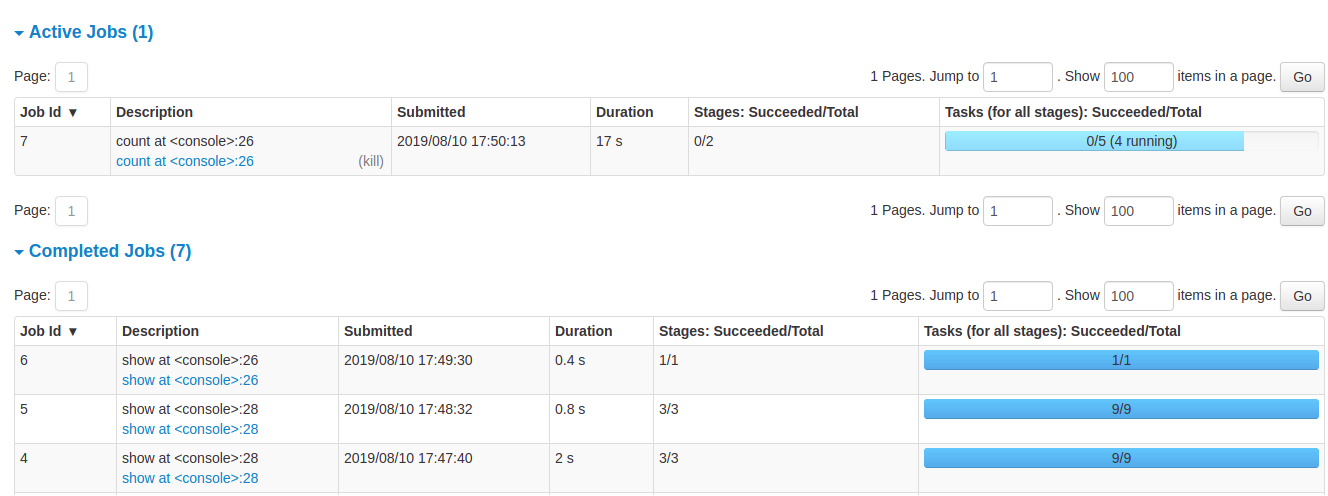
- 任务详情
可查看任务dag详情,完成stage等。
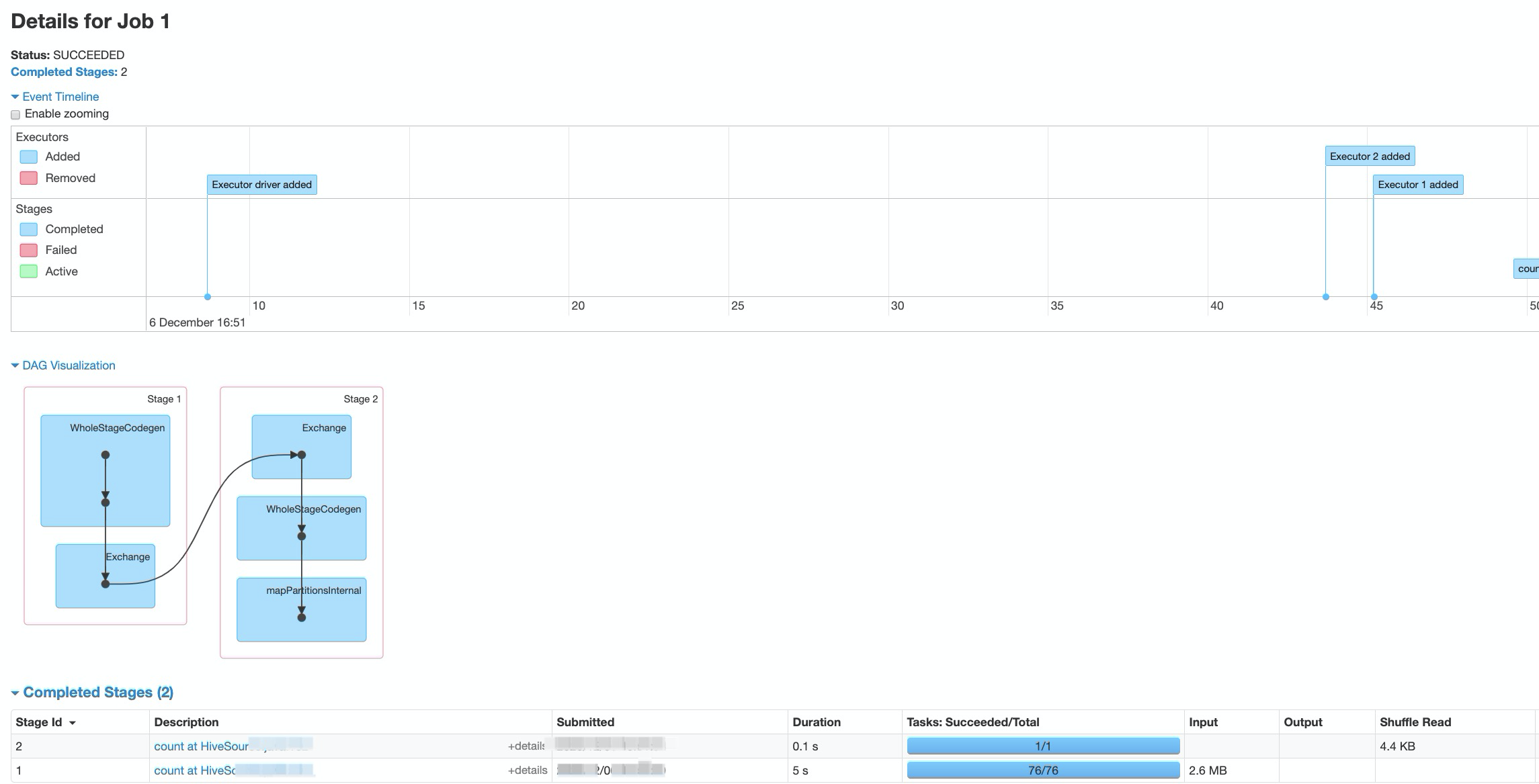
- 事件流水记录
使用限制
当任务失败后,不支持断点续传,需重跑任务完成迁移。
使用方法
使用方法,请参见操作步骤。