阿里云流式数据服务DataHub流式数据(Streaming Data)的处理平台,提供对流式数据的发布(Publish),订阅(Subscribe)和分发功能,让您可以轻松构建基于流式数据的分析和应用。本文主要介绍如何通过DLA
Serverless Spark访问DataHub。
前提条件
- 已经在DataHub中创建项目。本文档中假设DataHub的区域为华南1(深圳),Project名称为spark_test,Topic名称为topic01。具体请参考Project操作和Topic操作。
说明 目前内置的SparkOnDataHub Connectors仅支持TUPLE类型的Topic。
- 已经开通对象存储OSS(Object Storage Service)服务。具体操作请参见开通OSS服务。
背景信息
为了Spark能正常消费到DataHub数据,您需要将本地准备的模拟测试数据发送到DataHub,来测试Spark和DataHub的连通性。本文档假设您下载以下模拟测试代码到本地,并执行以下命令运行jar包来发送数据到
spark_test下的
topic01。
//下载模拟测试代码到本地。
wget https://spark-home.oss-cn-shanghai.aliyuncs.com/common_test/common-test-0.0.1-SNAPSHOT-shaded.jar
//运行jar包来发送数据到spark_test下的topic01。
java -cp /opt/jars/common-test-0.0.1-SNAPSHOT-shaded.jar com.aliyun.datahub.DatahubWrite_java spark_test topic01 xxx1 xxx2 https://dh-cn-shenzhen.aliyuncs.com
命令参数说明:
| 参数名称 |
参数说明 |
| spark_test |
DataHub的project名称。 |
| topic01 |
DataHub的topic名称。 |
| xxx1 |
访问阿里云API的AccessKey ID。 |
| xxx2 |
访问阿里云API的AccessKey Secret。 |
| https://dh-cn-shenzhen.aliyuncs.com |
DataHub访问域名中“华南1(深圳)”的“外网Endpoint”。 |
操作步骤
- 准备以下测试代码和依赖包来访问DataHub,并将此测试代码和依赖包分别编译打包生成jar包上传至您的OSS。
测试代码示例:
package com.aliyun.spark
import com.aliyun.datahub.model.RecordEntry
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.aliyun.datahub.DatahubUtils
import org.apache.spark.streaming.{Milliseconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
object SparkStreamingOnDataHub {
def main(args: Array[String]): Unit = {
val endpoint = args(0)
//RAM访问控制中的AccessKeyID。
val accessKeyId = args(1)
//RAM访问控制中的AccessKeySecret。
val accessKeySecret = args(2)
//dataHub的订阅ID。
val subId = args(3)
//dataHub的project名称。
val project = args(4)
//dataHub的topic名称。
val topic = args(5)
val batchInterval = Milliseconds(10 * 1000)
var checkpoint = "/tmp/SparkOnDatahubReliable_T001/"
if (args.length >= 7) {
checkpoint = args(6)
}
var shardId = "0"
if (args.length >= 8) {
shardId = args(7).trim
}
println(s"=====project=${project}===topic=${topic}===batchInterval=${batchInterval.milliseconds / 1000}=====")
def functionToCreateContext(): StreamingContext = {
val conf = new SparkConf().setAppName("Test DataHub")
//设置使用Reliable DataReceiver。
conf.set("spark.streaming.receiver.writeAheadLog.enable", "true")
val ssc = new StreamingContext(conf, batchInterval)
ssc.checkpoint(checkpoint)
var datahubStream: DStream[String] = null
if (!shardId.isEmpty) {
datahubStream = DatahubUtils.createStream(
ssc,
project,
topic,
subId,
accessKeyId,
accessKeySecret,
endpoint,
shardId,
read,
StorageLevel.MEMORY_AND_DISK_SER_2)
} else {
datahubStream = DatahubUtils.createStream(
ssc,
project,
topic,
subId,
accessKeyId,
accessKeySecret,
endpoint,
read,
StorageLevel.MEMORY_AND_DISK_SER_2)
}
datahubStream.foreachRDD { rdd =>
//注意,测试环境小数据量使用了rdd.collect(). 真实环境请慎用。
rdd.collect().foreach(println)
// rdd.foreach(println)
}
ssc
}
val ssc = StreamingContext.getActiveOrCreate(checkpoint, functionToCreateContext)
ssc.start()
ssc.awaitTermination()
}
def read(record: RecordEntry): String = {
s"${record.getString(0)},${record.getString(1)}"
}
}
DataHub依赖的pom文件:
<dependency>
<groupId>com.aliyun.apsaradb</groupId>
<artifactId>datahub-spark</artifactId>
<version>2.9.2-public_2.4.3-1.0.4</version>
</dependency>
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.9.2-public</version>
</dependency>
- 登录Data Lake Analytics管理控制台。
- 在页面左上角,选择DataHub所在的地域。
- 单击左侧导航栏中的。
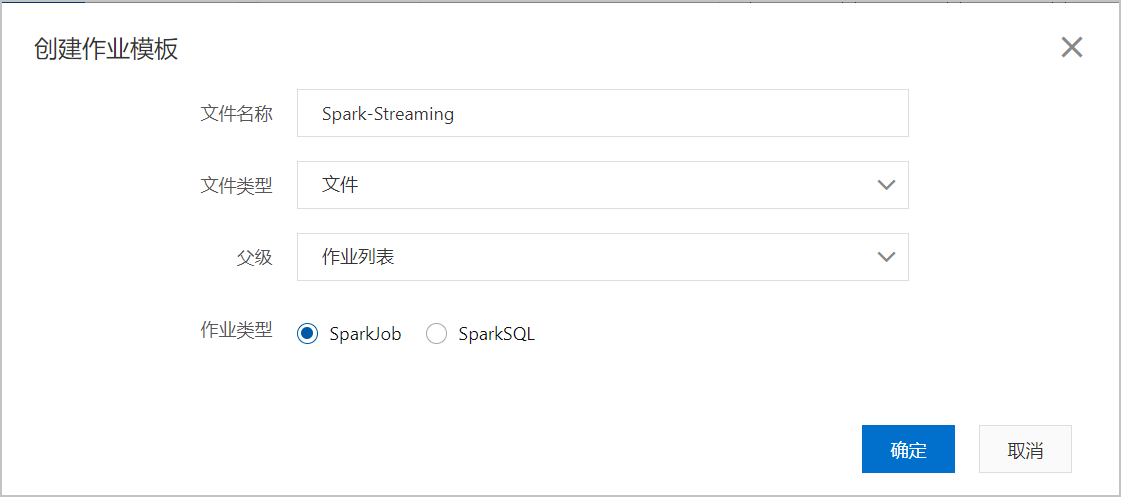
- 在作业编辑页面,单击创建作业。
- 在创建作业模板页面,按照页面提示进行参数配置后,单击确定创建Spark作业。
- 单击Spark作业名,在Spark作业编辑框中输入以下作业内容,并按照以下参数说明进行参数值替换。保存并提交Spark作业。
{
"args": [
"http://dh-cn-shenzhen-int-vpc.aliyuncs.com", #DataHub访问域名中“华南1(深圳)”的“外网Endpoint”。
"xxx1", #访问阿里云API的AccessKey ID。
"xxx2", #访问阿里云API的AccessKey Secret。
"xxx3", #DataHub中topic01的订阅ID。
"spark_test", #DataHub的project名称。
"topic01" #DataHub的topic名称。
],
"file": "oss://spark_test/jars/datahub/spark-examples-0.0.1-SNAPSHOT.jar", #测试代码的OSS路径。
"name": "datahub-test",
"jars": [
//#测试代码依赖包的OSS路径。
"oss://spark_test/jars/datahub/aliyun-sdk-datahub-2.9.2-public.jar",
"oss://spark_test/jars/datahub/datahub-spark-2.9.2-public_2.4.3-1.0.4.jar"
],
"className": "com.aliyun.spark.SparkStreamingOnDataHub",
"conf": {
"spark.driver.resourceSpec": "small", #表示driver的规格,有small、medium、large、xlarge之分。
"spark.executor.instances": 2, #表示executor的个数。
"spark.executor.resourceSpec": "small" #表示executor的规格,有small、medium、large、xlarge之分。
}
}
执行结果
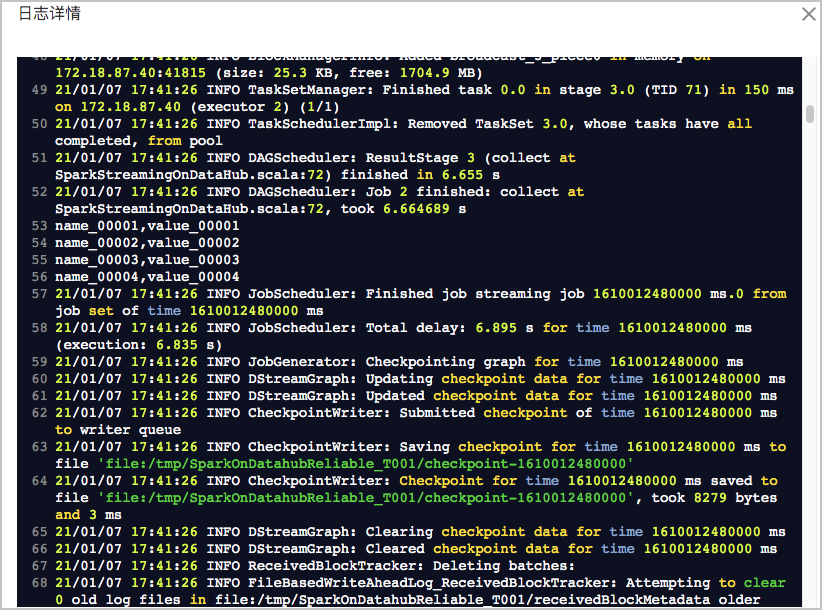
作业运行成功后,在任务列表中单击,查看作业日志。出现如下日志说明作业运行成功: