分析型数据库PostgreSQL版(原HybridDB for PostgreSQL)为您提供简单、快速、经济高效的PB级云端数据仓库解决方案。本文主要介绍如何通过DLA
Serverless Spark访问云原生数仓AnalyticDB PostgreSQL。
前提条件
- 已经开通对象存储OSS(Object Storage Service)服务。具体操作请参考开通OSS服务。
- 已经创建云原生数仓AnalyticDB PostgreSQL实例。具体请参考创建实例。
- 在AnalyticDB PostgreSQL实例中已创建数据库和表,并插入数据。参考命令样例如下:
#建库语句
create database testdb
#建表语句:
CREATE TABLE "test_table"
(
"name" varchar(32) ,
"age" smallint ,
"score" double precision
)
WITH (
FILLFACTOR = 100,
OIDS = FALSE
)
;
ALTER TABLE "test_table" OWNER TO testuser;
#插入数据语句:
INSERT INTO "test_table" VALUES('aliyun01', 101, 10.0);
INSERT INTO "test_table" VALUES('aliyun02', 102, 10.0);
INSERT INTO "test_table" VALUES('aliyun03', 103, 10.0);
INSERT INTO "test_table" VALUES('aliyun04', 104, 10.0);
INSERT INTO "test_table" VALUES('aliyun05', 105, 10.0);
- 准备DLA Spark访问AnalyticDB PostgreSQL实例所需的安全组ID和交换机ID。具体操作请参见配置数据源网络。
- DLA Spark访问AnalyticDB PostgreSQL实例所需的交换机IP,已添加到AnalyticDB PostgreSQL实例的白名单中。具体操作请参见设置白名单。
操作步骤
- 准备以下测试代码和依赖包来访问AnalyticDB PostgreSQL,并将此测试代码和依赖包分别编译打包生成jar包上传至您的OSS。
测试代码示例:
package com.aliyun.spark
import java.util.Properties
import org.apache.spark.sql.SparkSession
object SparkOnADBPostgreSQL {
def main(args: Array[String]): Unit = {
val url = args(0)
val database = args(1)
val jdbcConnURL = s"jdbc:postgresql://$url/$database"
var schemaName = args(2)
val tableName = args(3)
val user = args(4)
val password = args(5)
//Spark侧的表名。
var sparkTableName = args(6)
val sparkSession = SparkSession
.builder()
.appName("scala spark on adb test")
.getOrCreate()
val driver = "org.postgresql.Driver"
//如果存在的话就删除表。
sparkSession.sql(s"drop table if exists $sparkTableName")
//Sql方式,Spark会映射数据库中表的Schema。
val createCmd =
s"""CREATE TABLE ${sparkTableName} USING org.apache.spark.sql.jdbc
| options (
| driver '$driver',
| url '$jdbcConnURL',
| dbtable '$schemaName.$tableName',
| user '$user',
| password '$password'
| )""".stripMargin
println(s"createCmd: \n $createCmd")
sparkSession.sql(createCmd)
val querySql = "select * from " + sparkTableName + " limit 1"
sparkSession.sql(querySql).show
//使用dataset API接口。
val connectionProperties = new Properties()
connectionProperties.put("driver", driver)
connectionProperties.put("user", user)
connectionProperties.put("password", password)
//读取数据。
var jdbcDf = sparkSession.read.jdbc(jdbcConnURL,
s"$database.$schemaName.$tableName",
connectionProperties)
jdbcDf.select("name", "age", "score").show()
val data =
Seq(
PersonADBPG("bill", 30, 170.5D),
PersonADBPG("gate", 29, 200.3D)
)
val dfWrite = sparkSession.createDataFrame(data)
//写入数据。
dfWrite
.write
.mode("append")
.jdbc(jdbcConnURL, s"$database.$schemaName.$tableName", connectionProperties)
jdbcDf.select("name", "age").show()
sparkSession.stop()
}
}
case class PersonADBPG(name: String, age: Int, score: Double)
AnalyticDB PostgreSQL依赖的pom文件:
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.5</version>
</dependency>
- 登录Data Lake Analytics管理控制台。
- 在页面左上角,选择AnalyticDB PostgreSQL实例所在地域。
- 单击左侧导航栏中的。
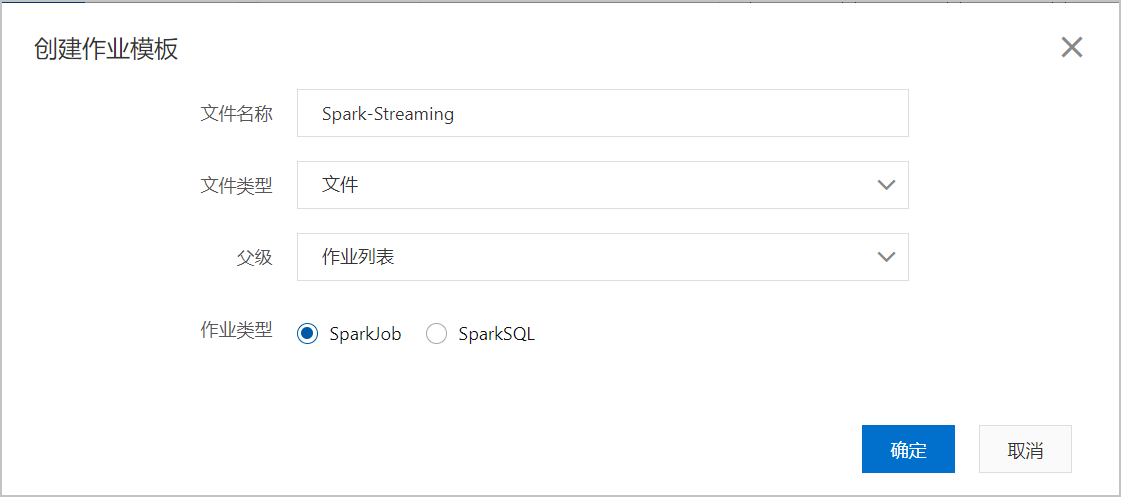
- 在作业编辑页面,单击创建作业。
- 在创建作业模板页面,按照页面提示进行参数配置后,单击确定创建Spark作业。
- 单击Spark作业名,在Spark作业编辑框中输入以下作业内容,并按照以下参数说明进行参数值替换。保存并提交Spark作业。
{
"args": [
"gp-xxx-master.gpdbmaster.rds.aliyuncs.com:5432", #AnalyticDB PostgreSQL内网地址和端口。
"testdb", #AnalyticDB PostgreSQL中的数据库名称。
"public", #AnalyticDB PostgreSQL中的schema名称。
"test_table", #AnalyticDB PostgreSQL中的表名。
"xxx1", #登录AnalyticDB PostgreSQL数据库的用户名。
"xxx2", #登录AnalyticDB PostgreSQL数据库的密码。
"spark_on_adbpg_table" #Spark中创建的映射AnalyticDB PostgreSQL表的表名。
],
"file": "oss://spark_test/jars/adbpg/spark-examples-0.0.1-SNAPSHOT.jar", #存放测试代码的OSS路径。
"name": "adbpg-test",
"jars": [
"oss://spark_test/jars/adbpg/postgresql-42.2.5.jar" #存放测试代码依赖包的OSS路径。
],
"className": "com.aliyun.spark.SparkOnADBPostgreSQL",
"conf": {
"spark.driver.resourceSpec": "small", #表示driver的规格,有small、medium、large、xlarge之分。
"spark.executor.instances": 2, #表示executor的个数。
"spark.executor.resourceSpec": "small", #表示executor的规格,有small、medium、large、xlarge之分。
"spark.dla.eni.enable": "true", #开启访问用户VPC网络的权限。当您需要访问用户VPC网络内的数据时,需要开启此选项。
"spark.dla.eni.vswitch.id": "vsw-xxx", #可访问的AnalyticDB PostgreSQL交换机id。
"spark.dla.eni.security.group.id": "sg-xxx" #可访问的AnalyticDB PostgreSQL安全组id。
}
}
执行结果
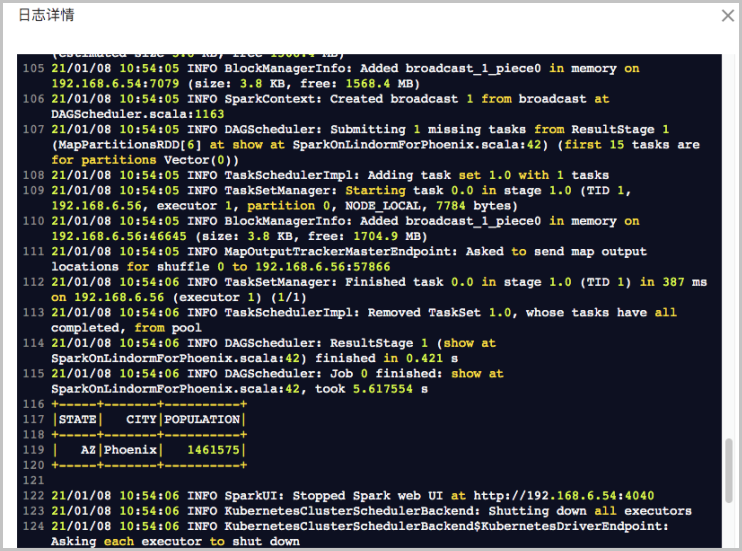
作业运行成功后,在任务列表中单击,查看作业日志。出现如下日志说明作业运行成功: