
本文以查询和分析网站日志为例,帮助您快速上手查询和分析操作。
前提条件
已采集到网站访问日志。配置Logtail采集配置的步骤,请参见采集主机文本日志。
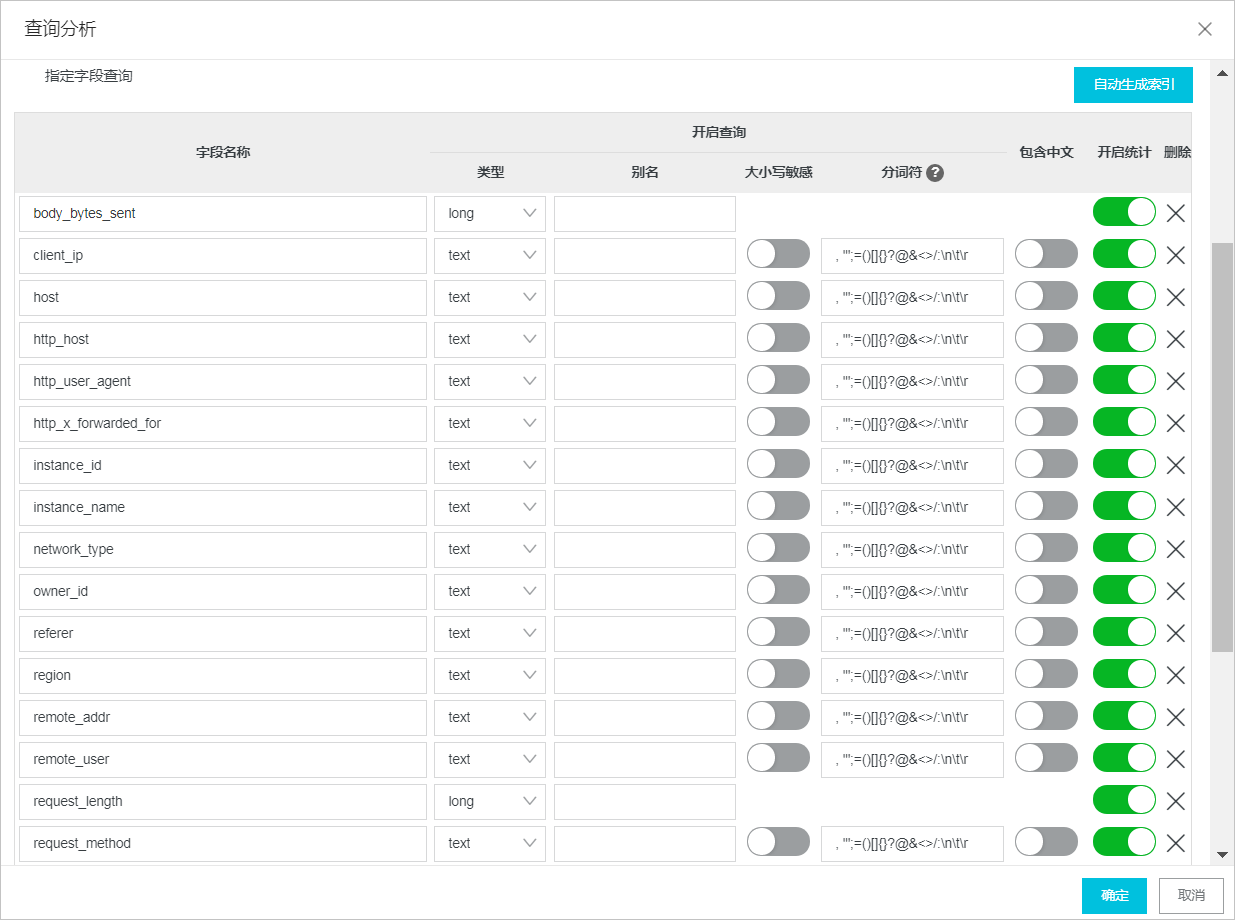
步骤一:创建索引
创建索引后,才能对日志进行查询分析,索引分为全文索引和字段索引,索引的概念、类型、配置示例、计费说明等信息,请参见创建索引。本文为网站日志创建字段索引。
登录日志服务控制台。
在Project列表区域,单击目标Project。

在页签中,单击目标Logstore。

-
在LogStore的查询和分析页面的右上角,选择。如果您还未开启索引,请单击开启索引。
-
配置字段索引,然后单击确定。可以手动逐条添加字段索引,也可以单击自动生成索引,日志服务会根据预览数据中的第一条日志自动配置索引。
步骤二:查询分析日志
在控制台对日志查询与分析的具体步骤,请参见查询与分析快速指引,查询和分析语句的格式为查询语句|分析语句。查询语句可单独使用,分析语句必须与查询语句一起使用。
执行查询和分析语句后,默认只返回100条结果,您可以使用LIMIT语句控制返回结果数量。更多信息,请参见LIMIT子句。
查询语句
-
查询包含Chrome的日志。
Chrome -
查询请求时间大于60秒的日志。
request_time > 60 -
查询请求时间在60秒~120秒之间的日志。
request_time in [60 120] -
查询GET请求成功(状态码为200~299)的日志。
request_method : GET and status in [200 299] -
查询
request_uri字段值为/request/path-2/file-2的日志。request_uri:/request/path-2/file-2
分析语句
-
统计网站访问PV。
使用count函数统计网站访问PV。
* | SELECT count(*) AS PV
-
根据每分钟的时间粒度,统计网站访问PV。
使用date_trunc函数将时间对齐到每分钟并根据时间进行分组,然后使用count函数计算每分钟的访问PV并根据时间排序。
* | SELECT count(*) as PV, date_trunc('minute', __time__) as time GROUP BY time ORDER BY time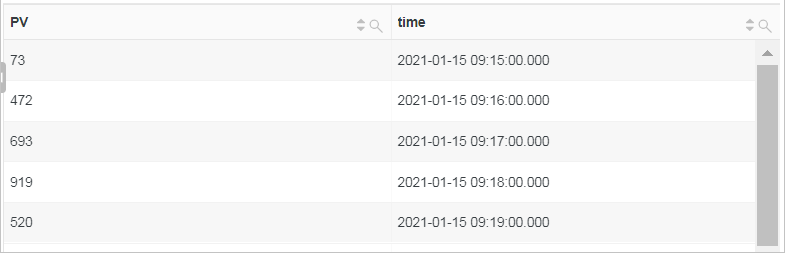
-
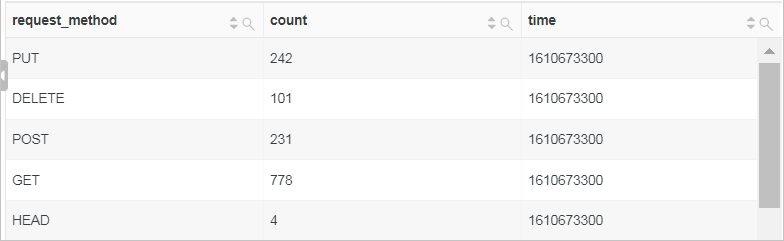
根据每5分钟的时间粒度,统计每个请求方法的请求次数。
使用
__time__ - __time__ %300将时间对齐到5分钟并根据时间进行分组,然后使用count函数计算每5分钟的请求次数并根据时间进行排序。* | SELECT request_method, count(*) as count, __time__ - __time__ %300 as time GROUP BY time, request_method ORDER BY time
-
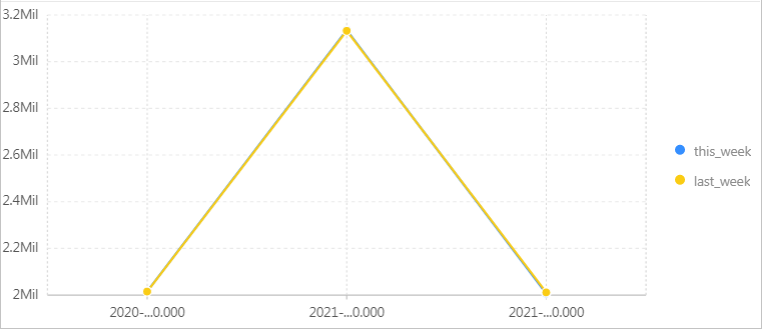
环比上周的网站访问PV。
使用count函数计算总PV数,再使用ts_compare函数得出本周与上周的环比。其中,
website_log为LogStore名称。* | SELECT diff[1] as this_week, diff[2] as last_week, time FROM (SELECT ts_compare(pv, 604800) as diff, time FROM (SELECT COUNT(*) as pv, date_trunc('week', __time__) as time FROM website_log GROUP BY time ORDER BY time) GROUP BY time) -
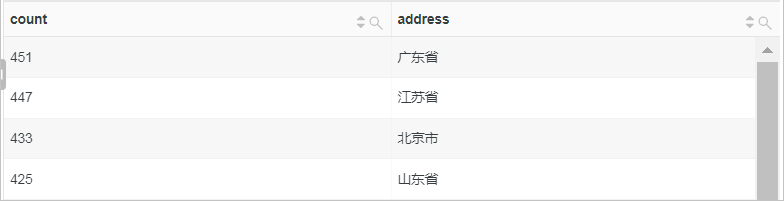
统计客户端地址分布情况。
使用ip_to_province函数获取IP地址对应的省份并根据省份进行分组,然后再使用count函数计算每个地址出现的次数并根据次数进行排序。
* | SELECT count(*) as count, ip_to_province(client_ip) as address GROUP BY address ORDER BY count DESC -
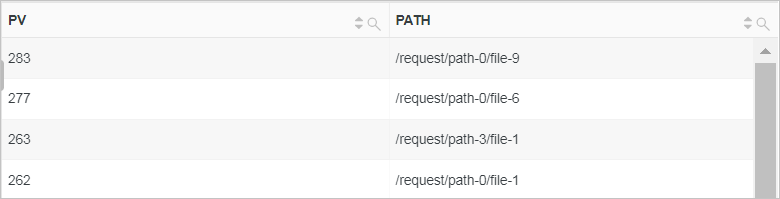
统计访问前10的请求路径。
根据请求路径进行分组,然后使用count函数计算每个路径的访问次数并根据访问次数排序。
* | SELECT count(*) as PV, request_uri as PATH GROUP BY PATH ORDER BY PV DESC LIMIT 10 -
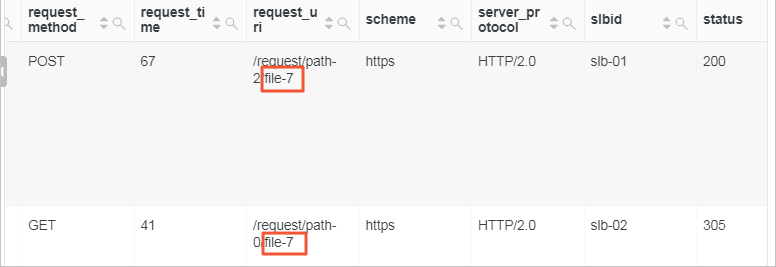
查询
request_uri字段的值以%file-7结尾的日志。重要在查询语句中,模糊查询的通配符星号(*)和问号(?)只能出现在词的中间或末尾。如果您要查询以某字符结尾的字段,可以在分析语句中使用LIKE语法进行查询。
* | select * from website_log where request_uri like '%file-7'其中,
website_log为LogStore名称。 -
统计请求路径访问情况。
使用regexp_extract函数提取
request_uri字段中的文件部分,然后再使用count函数计算各个请求路径的访问次数。* | SELECT regexp_extract(request_uri, '.*\/(file.*)', 1) file, count(*) as count group by file -
查询
request_uri字段中包含%abc%的日志。* | SELECT * where request_uri like '%/%abc/%%' escape '/'


参考信息:网站日志样例
__tag__:__client_ip__:192.0.2.0
__tag__:__receive_time__:1609985755
__source__:198.51.100.0
__topic__:website_access_log
body_bytes_sent:4512
client_ip:198.51.100.10
host:example.com
http_host:example.com
http_user_agent:Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10_5_8; ja-jp) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27
http_x_forwarded_for:198.51.100.1
instance_id:i-02
instance_name:instance-01
network_type:vlan
owner_id:%abc%-01
referer:example.com
region:cn-shanghai
remote_addr:203.0.113.0
remote_user:neb
request_length:4103
request_method:POST
request_time:69
request_uri:/request/path-1/file-0
scheme:https
server_protocol:HTTP/2.0
slbid:slb-02
status:200
time_local:07/Jan/2021:02:15:53
upstream_addr:203.0.113.10
upstream_response_time:43
upstream_status:200
user_agent:Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.33 (KHTML, like Gecko) Ubuntu/9.10 Chromium/13.0.752.0 Chrome/13.0.752.0 Safari/534.33
vip_addr:192.0.2.2
vpc_id:3db327b1****82df19818a72