
本文介绍如何创建MySQL Source Connector,通过DataWorks将数据从阿里云数据库RDS MySQL版导出至云消息队列 Kafka 版实例的Topic。
前提条件
在导出数据前,请确保您已完成以下操作:
为云消息队列 Kafka 版实例开启Connector。更多信息,请参见开启Connector。
重要请确保您的云消息队列 Kafka 版实例部署在华南1(深圳)、西南1(成都)、华北2(北京)、华北3(张家口)、华东1(杭州)、华东2(上海)或新加坡地域。
创建数据库表。常见的SQL语句,请参见常用语句。
阿里云账号和RAM用户均须授予DataWorks访问您弹性网卡ENI资源的权限。授予权限,请访问云资源访问授权。
重要如果您使用的是RAM用户,请确保您的账号有以下权限:
AliyunDataWorksFullAccess:DataWorks所有资源的管理权限。
AliyunBSSOrderAccess:购买阿里云产品的权限。
如何为RAM用户添加权限策略,请参见步骤二:为RAM用户添加权限。
请确保您是阿里云数据库RDS MySQL版实例(数据源)和云消息队列 Kafka 版实例(数据目标)的所有者,即创建者。
请确保阿里云数据库RDS MySQL版实例(数据源)和云消息队列 Kafka 版实例(数据目标)所在的VPC网段没有重合,否则无法成功创建同步任务。
背景信息
您可以在云消息队列 Kafka 版控制台创建数据同步任务,将您在阿里云数据库RDS MySQL版数据库表中的数据同步至云消息队列 Kafka 版的Topic。该同步任务将依赖阿里云DataWorks产品实现,流程图如下所示。
如果您在云消息队列 Kafka 版控制台成功创建了数据同步任务,那么阿里云DataWorks会自动为您开通DataWorks产品基础版服务(免费)、新建DataWorks项目(免费)、并新建数据集成独享资源组(需付费),资源组规格为4c8g,购买模式为包年包月,时长为1个月并自动续费。阿里云DataWorks的计费详情,请参见DataWorks计费概述。
此外,DataWorks会根据您数据同步任务的配置,自动为您生成云消息队列 Kafka 版的目标Topic。数据库表和Topic是一对一的关系,对于有主键的表,默认6分区;无主键的表,默认1分区。请确保实例剩余Topic数和分区数充足,不然任务会因为创建Topic失败而导致异常。
Topic的命名格式为<配置的前缀>_<数据库表名>,下划线(_)为系统自动添加的字符。详情如下图所示。
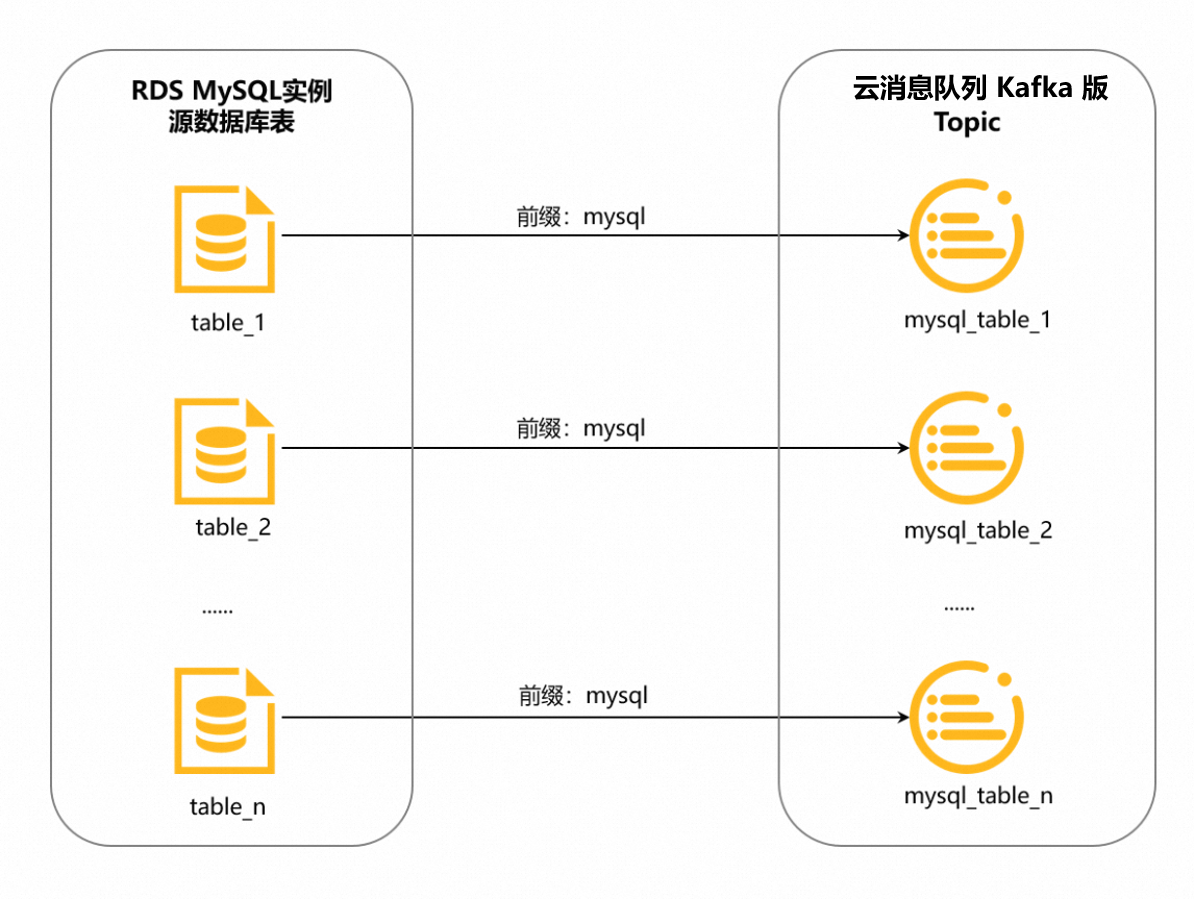
例如,您将前缀配置为mysql,需同步的数据库表名为table_1,那么DataWorks会自动为您生成专用Topic,用来接收table_1同步过来的数据,该Topic的名称为mysql_table_1;table_2的专用Topic名称为mysql_table_2,以此类推。
注意事项
地域说明
如果数据源和目标实例位于不同地域,请确保您使用的账号拥有云企业网实例,且云企业网实例已挂载数据源和目标实例所在的VPC,并配置好流量带宽完成网络打通。
否则,可能会新建云企业网实例,并将目标实例和独享资源组ECS全部挂载到云企业网实例来打通网络。这样的云企业网实例没有配置带宽,所以带宽流量很小,可能导致创建同步任务过程中的网络访问出错,或者同步任务创建成功后,在运行过程中出错。
如果数据源和目标实例位于同一地域,创建数据同步任务会自动在其中一个实例所在VPC创建ENI,并绑定到独享资源组ECS上,以打通网络。
DataWorks独享资源组说明
DataWorks的每个独享资源组可以运行最多3个同步任务。创建数据同步任务时,如果DataWorks发现您的账号名下有资源组的历史购买记录,并且运行的同步任务少于3个,将使用已有资源组运行新建的同步任务。
DataWorks的每个独享资源组最多绑定两个VPC的ENI。如果DataWorks发现已购买的资源组绑定的ENI与需要新绑定的ENI有网段冲突,或者其他技术限制,导致使用已购买的资源组无法创建出同步任务,此时,即使已有的资源组运行的同步任务少于3个,也将新建资源组确保同步任务能够顺利创建。
创建并部署MySQL Source Connector
在概览页面的资源分布区域,选择地域。
在左侧导航栏,单击Connector 任务列表。
在Connector 任务列表页面,从选择实例的下拉列表选择Connector所属的实例,然后单击创建 Connector。
在创建 Connector配置向导中,完成以下操作。
在配置基本信息页签的名称文本框,输入Connector名称,然后单击下一步。
参数
描述
示例值
名称
Connector的名称。命名规则:
可以包含数字、小写英文字母和短划线(-),但不能以短划线(-)开头,长度限制为48个字符。
同一个云消息队列 Kafka 版实例内保持唯一。
Connector的数据同步任务必须使用名称为connect-任务名称的Group。如果您未手动创建该Group,系统将为您自动创建。
kafka-source-mysql
实例
默认配置为实例的名称与实例ID。
demo alikafka_post-cn-st21p8vj****
在配置源服务页签,选择数据源为云数据库RDS MySQL版,配置以下参数,然后单击下一步。
参数
描述
示例值
RDS 实例所在地域
从下拉列表中,选择阿里云数据库RDS MySQL版实例所在的地域。
华南1(深圳)
云数据库 RDS 实例 ID
需要同步数据的阿里云数据库RDS MySQL版的实例ID。
rm-wz91w3vk6owmz****
数据库名称
需要同步的阿里云数据库RDS MySQL版实例数据库的名称。
mysql-to-kafka
数据库账号
需要同步的阿里云数据库RDS MySQL版实例数据库账号。
mysql_to_kafka
数据库账号密码
需要同步的阿里云数据库RDS MySQL版实例数据库账号的密码。
无
数据库表
需要同步的阿里云数据库RDS MySQL版实例数据库表的名称,多个表名以英文逗号(,)分隔。
数据库表和目标Topic是一对一的关系。
mysql_tbl
自动添加数据表
批量添加数据库中的其他表。当创建的新表匹配成功时,也可被识别并同步数据。
格式为正则表达式。例如,输入.*,表示匹配数据库中的所有表。
.*
Topic 前缀
阿里云数据库RDS MySQL版数据库表同步到云消息队列 Kafka 版的Topic的命名前缀,请确保前缀全局唯一。
mysql
重要请确保阿里云数据库RDS MySQL版数据库账号有以下最小权限:
SELECT
REPLICATION SLAVE
REPLICATION CLIENT
授权命令示例:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '同步账号'@'%'; //授予数据库账号的SELECT、REPLICATION SLAVE和REPLICATION CLIENT权限。在配置目标服务页签,显示数据将同步到目标云消息队列 Kafka 版实例,确认信息无误后,单击创建。
创建完成后,在Connector 任务列表页面,找到创建的Connector ,单击其操作列的部署。
在Connector 任务列表页面,您可以看到创建的任务状态为运行中,则说明任务创建成功。
说明如果创建失败,请再次检查本文前提条件中的操作是否已全部完成。
如需配置同步任务,单击其操作列的任务配置,跳转至DataWorks控制台完成操作。
验证结果
向阿里云数据库RDS MySQL版数据库表插入数据。
示例如下。
INSERT INTO mysql_tbl (mysql_title, mysql_author, submission_date) VALUES ("mysql2kafka", "tester", NOW())更多SQL语句,请参见常用语句。
使用云消息队列 Kafka 版提供的消息查询功能,验证数据能否被导出至云消息队列 Kafka 版目标Topic。
查询的具体步骤,请参见消息查询。
云数据库RDS MySQL版数据库表导出至云消息队列 Kafka 版Topic的数据示例如下。消息结构及各字段含义,请参见附录:消息格式。
{ "schema":{ "dataColumn":[ { "name":"mysql_id", "type":"LONG" }, { "name":"mysql_title", "type":"STRING" }, { "name":"mysql_author", "type":"STRING" }, { "name":"submission_date", "type":"DATE" } ], "primaryKey":[ "mysql_id" ], "source":{ "dbType":"MySQL", "dbName":"mysql_to_kafka", "tableName":"mysql_tbl" } }, "payload":{ "before":null, "after":{ "dataColumn":{ "mysql_title":"mysql2kafka", "mysql_author":"tester", "submission_date":1614700800000 } }, "sequenceId":"1614748790461000000", "timestamp":{ "eventTime":1614748870000, "systemTime":1614748870925, "checkpointTime":1614748870000 }, "op":"INSERT", "ddl":null }, "version":"0.0.1" }