
背景
随着生成式AI技术“火爆出圈”,预示着人工智能未来发展趋势的同时,也为我国人工智能市场注入源源不断的活力,更多企业关注如何将“超级工具”应用到实际业务中去,生成式人工智能技术在通用任务上表现优秀,但面对垂直业务领域,还无法给出精确的回答。如何在垂直领域针对特定知识构建企业专属问答并且确保生成的内容可控,是垂直领域服务的关键。
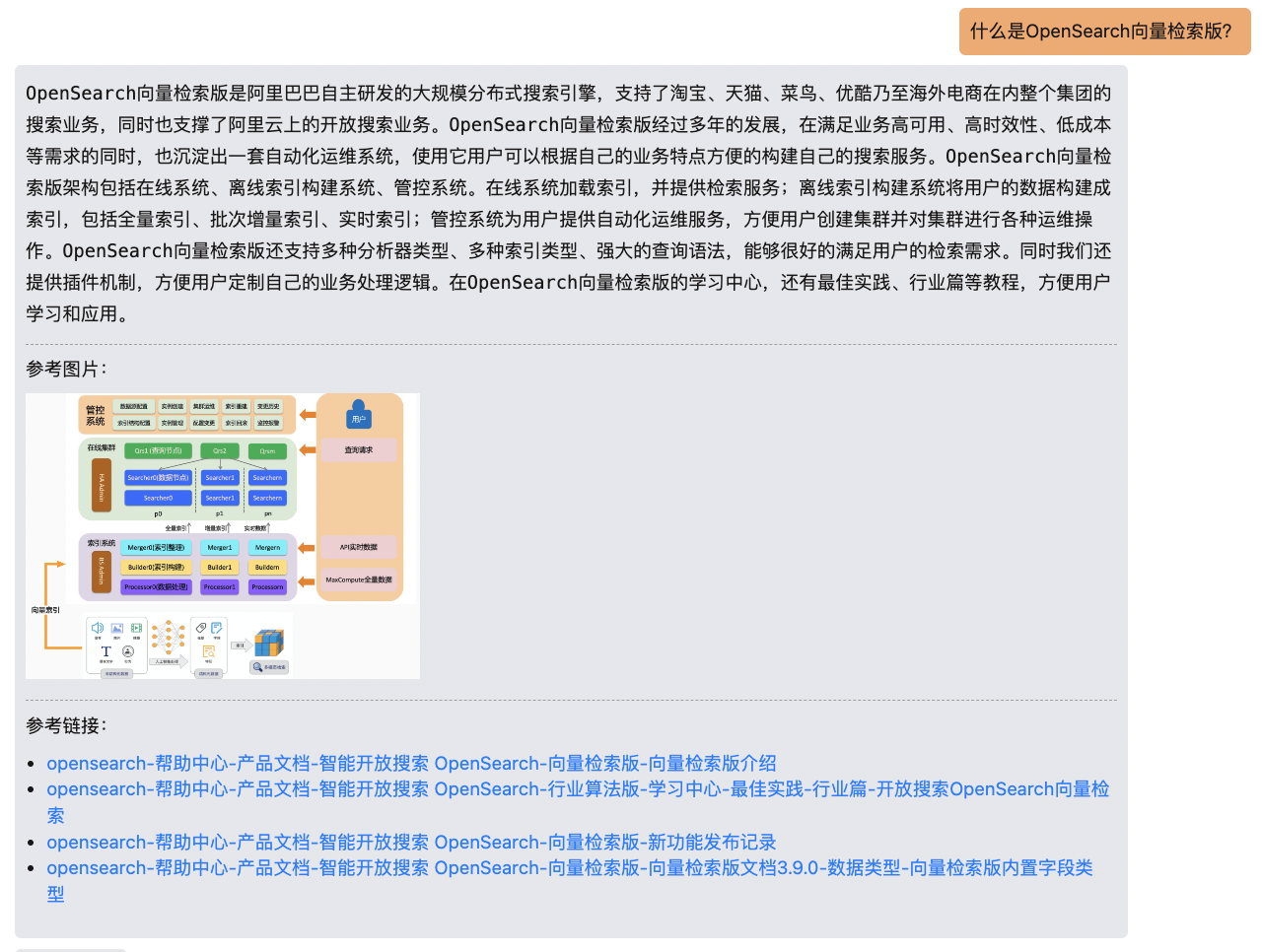
阿里云智能开放搜索OpenSearch一站式智能搜索业务开发平台,具备高性能向量检索能力,通过向量检索+大模型可以构建可靠的垂直领域的智能问答方案,同时快速在业务场景中进行实践及应用。
本文将详细介绍如何通过“OpenSearch向量检索版+大模型”的实践方案,帮助企业快速搭建智能问答系统。
-
该文档仅适用于向量检索传统版实例,即实例引擎版本号以ha3开头,如ha3_3.10.0,目前已停售。
在实例的基本信息页面中,当前引擎版本字段显示了实例的引擎版本号,以此判断实例类型。
-
在售实例是向量检索易用版实例,即引擎版本号以vector_service开头,如vector_service_1.4.2,对应的对话搜索解决方案请参见易用版-基于向量检索版+LLM构建对话式搜索。
企业专属模型方案
1. 方案介绍
OpenSearch+大模型方案整体分为2个部分,首先将业务数据进行向量化预处理,其次在线搜索服务进行检索及内容生成。
1.1. 业务数据预处理
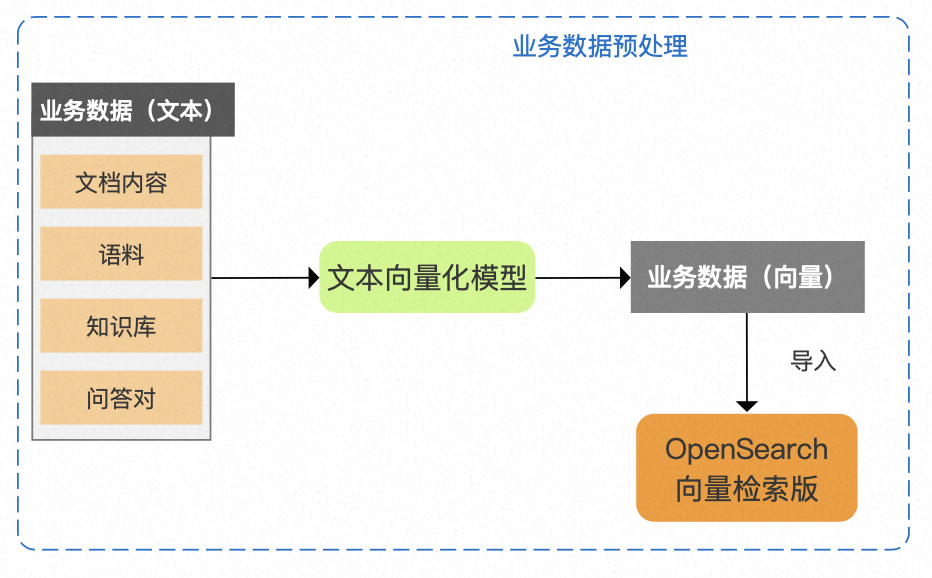
首先需要对业务数据进行向量化处理,然后构建向量索引。
步骤1:将文本形式的业务数据导入文本向量化模型中,得到向量形式的业务数据
步骤2:将向量形式的业务数据导入到OpenSearch向量检索版中,构建向量索引
1.2. 搜索问答在线服务
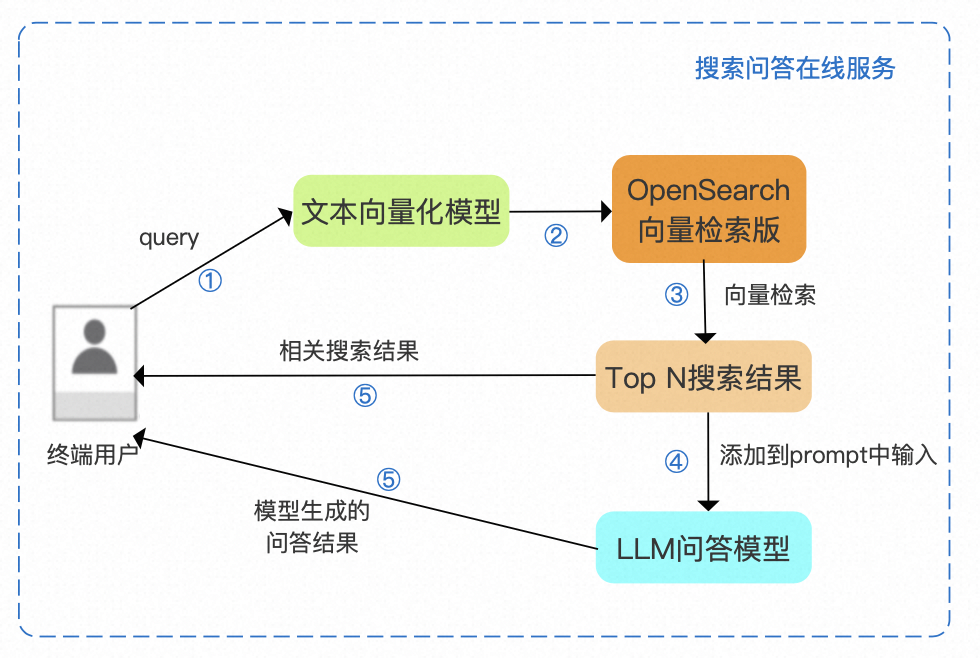
实现搜索功能后,结合Top N搜索结果,基于LLM问答模型返回搜索问答结果
步骤1:将终端用户输入的query输入文本向量化模型,得到向量形式的用户query
步骤2:将向量形式的用户query输入OpenSearch向量检索版
步骤3:使用OpenSearch向量检索版内置的向量检索引擎得到业务数据中的Top N搜索结果
步骤4:将Top N搜索结果整合作为prompt,输入LLM问答模型
步骤5:将问答模型生成的问答结果和向量检索得到的搜索结果返回给终端用户
2. 方案优势
优势一:高性能:自研的高性能向量检索引擎
-
OpenSearch向量检索版支持千亿数据毫秒级响应,实时数据更新秒级可见
-
OpenSearch向量检索版的检索性能优于开源向量搜索引擎数倍,在高QPS场景下召回率明显优于开源向量搜索引擎
OpenSearch向量检索版VS开源引擎性能:中数据场景
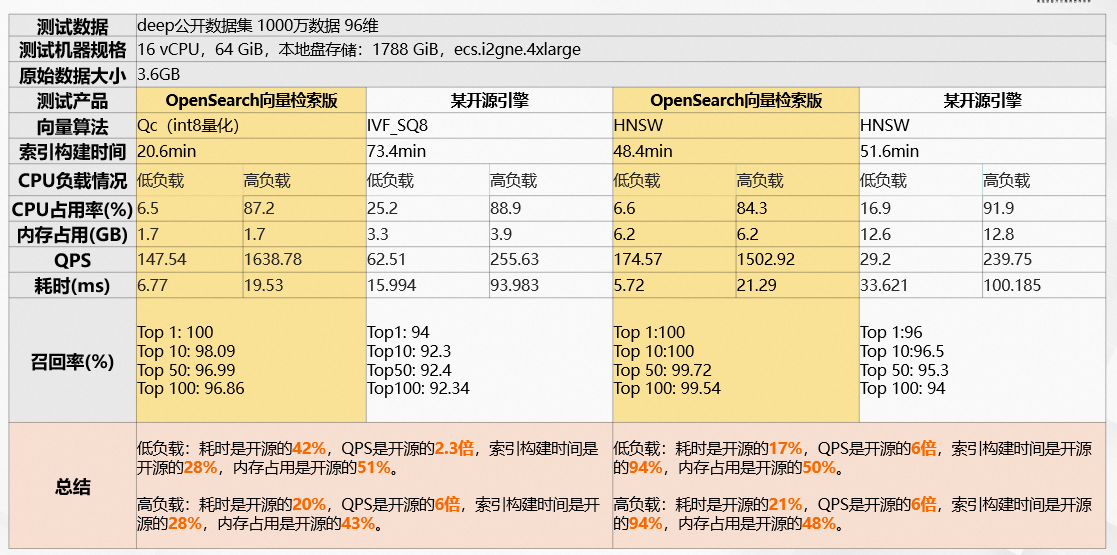
数据来源阿里巴巴智能引擎事业部团队,2022年11月
OpenSearch向量检索版VS开源引擎性能:大数据场景
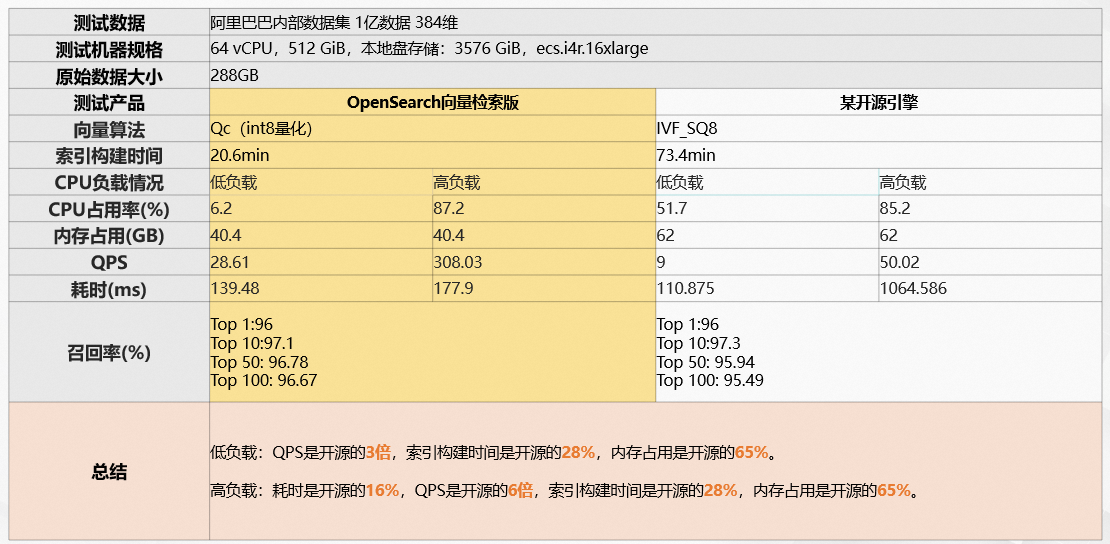
数据来源阿里巴巴智能引擎事业部团队,2022年11月
优势二:低成本:采用多种方式优化存储成本、减少资源消耗
-
数据压缩:可将原始数据转化为float形式存储,并再采用zstd等高效算法进行数据压缩,实现存储成本优化
-
精细索引结构设计:针对不容类型索引,可采用不同优化策略,降低索引大小
-
非全内存加载:可以使用mmap非lock的形式加载索引,有效降低内存开销
-
引擎优势:OpenSearch向量检索版引擎本身具备构建索引大小、GPU资源耗用的优势,同等数据条件下,OpenSearch向量检索版内存占用仅为开源向量检索引擎的50%左右
优势三:可灵活、快速搭建企业专属智能问答方案
-
稳定可靠:使用客户业务数据而非公开数据进行内容生成,输出结果更加稳定、可靠
-
交互升级:可同时满足用户搜索、问答需求,可使用问答式搜索交互形态取代常规搜索形式
方案实践
1. 购买OpenSearch向量检索版实例
开通OpenSearch向量检索版实例可参考通用版快速入门。记住购买时设置的用户名和密码,后面需要使用。
2. 配置OpenSearch向量检索版实例
新购买的实例,在其详情页中,实例状态为“待配置”,并且会自动部署一个与购买的查询节点和数据节点的个数及规格一致的空集群,之后需要为该集群配置数据源--->配置索引--->索引重建,之后才可正常搜索。
在实例管理页面中,找到目标实例,单击其右侧操作列中的配置。
2.1 配置API推送数据源:
在数据源配置页面中,数据源类型选择API推送数据源,设置数据源名称(如ha-cn-wwo38nf8q01_data)。API推送配置中的增量swift topic会自动生成。
数据源配置成功后,需点击下一步配置索引结构:
2.2 添加索引表:
在索引结构配置页面中,单击添加索引表。
2.3 选择刚创建的数据源,配置索引表,模板选择通用模板:
设置索引表名称为llm,数据源选择前面创建的数据源,数据分片数设置为1,编辑方式选择管理员模式。
2.4 设置字段,至少需要定义2个字段主键字段和向量字段(向量字段需要设置为多值float类型):
在字段设置中配置以下5个字段:pk(STRING类型,设为主键)、embedding(FLOAT类型,开启多值,分隔符为^])、content(STRING类型)、source_id(STRING类型)、url(STRING类型)。所有字段均勾选属性字段和搜索结果展示,数据压缩选择不压缩。
注:需要按照上述字段名称、类型等来设置,否则数据无法自动推送
2.5 设置索引,主键字段索引类型设置为PRIMARYKEY64,向量索引类型选择CUSTOMIZED:
注:向量索引名称必须为embedding_index。
为向量字段添加包含字段:
索引名称为embedding_index,在包含字段中,主键字段选择pk,向量字段选择embedding。
2.6 向量索引高级配置。可以参考如下配置向量索引参数,详情可参考向量索引:
配置参数如下:distance_type选择SquaredEuclidean,vector_index_type选择Qc,build_index_params中设置proxima.qc.builder.quantizer_class为Int8Quantizer,search_index_params中设置proxima.qc.searcher.scan_ratio为0.01。
向量维度(dimension)根据所选择的向量模型来配置,本例使用大模型的text-embedding-ada-002,配置dimension为1536维,enable_rt_build为true开启实时索引构建。
2.7 配置完成后,点击保存版本,并在弹框后填写备注(可选),点击发布:
等待索引发布完成后,可点击“下一步”进行索引重建:
2.8 索引重建,选择索引重建需要配置的参数项,点击“下一步”:
在索引重建页面中,确认数据源名称和数据源类型(API推送数据源),关联索引表为llm,数据来源选择空数据,设置时间戳后单击下一步。
2.9 可在运维中心>历史变更>数据源变更查看索引重建进度,进度完成后即可进行查询测试:
在数据源变更页面中可查看索引重建的详细进度,包括init、trigger、scan、bs_submit、build、suez_submit、switch等步骤,所有步骤完成后显示绿色对勾标记,即可进行查询测试。
3.向量检索版+大模型系统构建
3.1 下载大模型工具OpenSearch-LLM,并解压到llm目录
3.2 在llm目录中的.env文件中配置Chat相关信息,用户需自行购买Chat相关服务。
-
使用Chat
LLM_NAME=OpenAI
OPENAI_API_KEY=***
OPENAI_API_BASE=***
OPENAI_EMBEDDING_ENGINE=text-embedding-ada-002
OPENAI_CHAT_ENGINE=gpt-3.5-turbo
VECTOR_STORE=OpenSearch
# OpenSearch信息
OPENSEARCH_ENDPOINT=ha-cn-wwo38nf8q01.ha.aliyuncs.com
OPENSEARCH_INSTANCE_ID=ha-cn-wwo38nf8q01
OPENSEARCH_TABLE_NAME=llm
OPENSEARCH_DATA_SOURCE=ha-cn-wwo38nf8q01_data
OPENSEARCH_USER_NAME=opensearch #用户名是购买向量检索版时设置的用户名
OPENSEARCH_PASSWORD=chat001 #密码是购买向量检索版时设置的密码-
使用微软Azure OpenAI
LLM_NAME=OpenAI
OPENAI_API_KEY=***
OPENAI_API_BASE=***
OPENAI_API_VERSION=2023-03-15-preview
OPENAI_API_TYPE=azure
# 填写azure中OpenAI模型的deployment
OPENAI_EMBEDDING_ENGINE=embedding_deployment_id
OPENAI_CHAT_ENGINE=chat_deployment_id
VECTOR_STORE=OpenSearch
# opensearch信息
OPENSEARCH_ENDPOINT=ha-cn-wwo38nf8q01.ha.aliyuncs.com
OPENSEARCH_INSTANCE_ID=ha-cn-wwo38nf8q01
OPENSEARCH_TABLE_NAME=llm
OPENSEARCH_DATA_SOURCE=ha-cn-wwo38nf8q01_data
OPENSEARCH_USER_NAME=opensearch #用户名是购买向量检索版时设置的用户名
OPENSEARCH_PASSWORD=chat001 #密码是购买向量检索版时设置的密码注:
-
配置中的opensearch信息要和前面购买的向量检索版实例对应。
-
公网访问的OPENSEARCH_ENDPOINT 需要使用公网域名(公网域名需要给访问服务的机器加IP白名单),同时去掉
http://
3.3 数据处理和推送
使用llm目录中的embed_files.py脚本对用户数据文件进行处理,目前支持Markdown和PDF格式的文件。处理完成后会自动推送到前文配置好的向量检索实例中。 下面是一个例子,将用户目录${doc_dir}下的文档推送到ha-cn-wwo38nf8q01实例,并自动构建索引。
python -m script.embed_files -f ${doc_dir}-
使用-f选项指定需要处理的文档所在目录
3.4 启动问答服务
cd ~/llm
python api_demo.py3.5 使用curl命令测试
测试请求:
curl -H "Content-Type: application/json" http://127.0.0.1:8000/chat -d '{"query": "介绍一下opensearch"}'输出:
{
"success": true,
"result": "OpenSearch是一个分布式搜索引擎,由阿里巴巴开发。可以用于存储、处理和分析大规模数据,具有高可用性、可扩展性和高性能的特点。",
"prompt": "Human: 根据搜索结果回答问题。 Search Results: OpenSearch是一个分布式搜索引擎,由阿里巴巴开发。它支持 SQL 查询语句,并提供了内置的 UDF(User Defined Function)功能,允许客户以插件形式开发自己的 UDF。OpenSearch可以用于存储、处理和分析大规模数据,具有高可用性、可扩展性和高性能的特点。可以通过分布式运维工具进行部署,支持在物理机上拉起分布式集群,也可以在云平台上使用云原生架构进行部署。\n\n 根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说不知道,不允许在答案中添加编造成分,答案请使用中文。\n Query:介绍一下OpenSearch Assistant: "
}4.参考prompt
{
"prompt": "Human: 根据搜索结果回答问题。 Search Results: OpenSearch规格类型对比: 1.行业算法版与高性能检索版的区别:产品概述:OpenSearch简介 OpenSearch是基于阿里巴巴自主研发的大规模分布式搜索引擎搭建的一站式智能搜索业务开发平台,在大数据场景下实现千亿数据毫秒级响应,提供订单、物流、保单等场景检索方案。产品架构 SaaS平台,开发者可以通过控制台或API与系统交互。场景化配置,开发者仅需创建应用实例,配置数据源,配置字段结构、搜索属性,等待索引重建完成后,即可通过SDK/控制台进行搜索测试。大数据检索,较之行业算法版,高性能检索版取消了繁重的行业算法能力,在支持搜索通用能力(分析器、排序)的基础上,重点关注业务查询和写入的吞吐,为开发者提供了大数据集检索场景下,秒级响应、实时查询的能力。产品特性 高吞吐,单表支持万级别的写入TPS,秒级更新。安全、稳定 提供7×24小时的运行维护,并以在线工单和电话报障等方式提供技术支持,具备完善的故障监控、自动告警、快速定位等一系列故障应急响应机制。基于阿里云的AccessKeyId和AccessKeySecret安全加密对,从访问接口上进行权限控制和隔离,保证用户级别的数据隔离,用户数据安全有保障。数据冗余备份,保证数据不会丢失. Query: OpenSearch有哪些版本 Assistant: ",
}效果演示
总结与展望
本方案介绍了如何使用OpenSearch向量检索版结合LLM问答模型构建企业专属搜索问答系统。更多搜索解决方案可参考OpenSearch产品官网
未来OpenSearch还将针对搜索问答场景,推出智能问答版。SaaS化、一站式训练企业专属大模型,构建智能搜索问答系统,敬请期待
本解决方案中的“开源向量模型”、“大模型”等来自第三方(合称“第三方模型”)。阿里云无法保证第三方模型合规、准确,也不对第三方模型本身、及您使用第三方模型的行为和结果等承担任何责任。请您在访问和使用前慎重考虑。此外我们也提醒您,第三方模型附有“开源许可证”、“License”等协议,您应当仔细阅读并严格遵守这些协议的约定。