AnalyticDB MySQL湖仓版的用户运营分析实践
一键部署
85
https://www.aliyun.com/solution/tech-solution/adbmysql_uoap
方案概览
用户运营通常需要关注拉新数据、活跃数据、留存数据。在过去“湖+仓”的解决方案中,存在数据时效性差、一致性差、数据冗余。为了解决这些痛点,云原生数据仓库AnalyticDB MySQL湖仓版提供了“数据入湖+作业开发+在线分析”的一站式数据解决方案。
本方案模拟Kafka发送日志数据,将Kafka数据实时同步到云原生数据仓库AnalyticDB MySQL湖仓版,在AnalyticDB MySQL湖仓版中进行数据清洗、分库分表、与云数据库RDS MySQL同步到AnalyticDB MySQL湖仓版的维度表进行多表关联聚合分析。同时,利用数据管理DMS的任务编排功能实现周期性任务调度。
方案架构
方案提供的默认设置完成部署后在阿里云上搭建的用户运营分析看板如下图所示。实际部署时您可以根据资源规划修改部分设置,但最终形成的运行环境与下图相似。
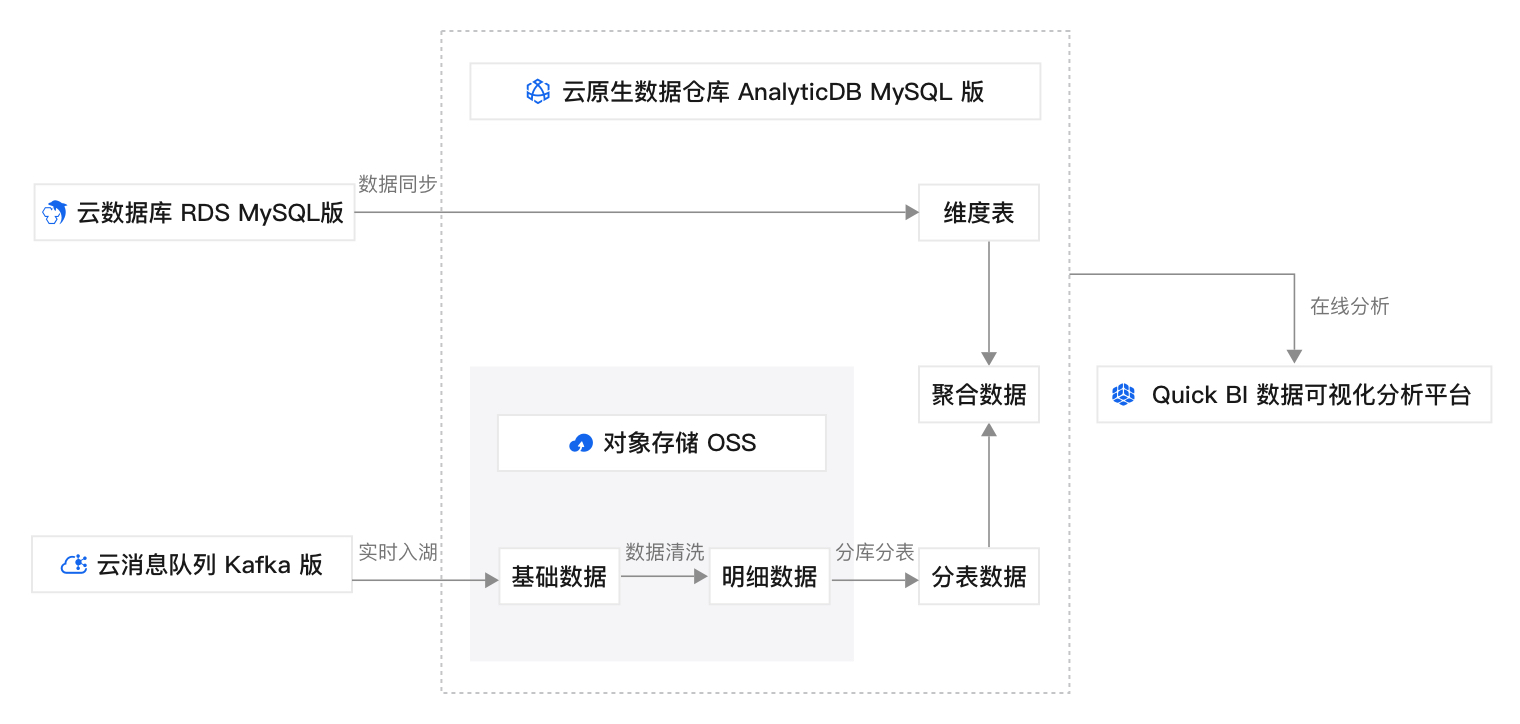
本方案的技术架构包括以下基础设施和云服务:
1个专有网络VPC:为云原生数据仓库AnalyticDB MySQL、云数据库RDS MySQL、消息队列Kafka版等云资源形成云上私有网络。
1台交换机:将上述云服务连接在同一网络上,实现它们之间的通信,并提供基本的网络分段和隔离功能。
1个云原生数据仓库AnalyticDB MySQL湖仓版集群:提供Kafka消息实时入湖、数据清洗、分库分表、聚合计算。
1个云数据库RDS MySQL版实例:为用户数据分析提供维度数据。
1个消息队列Kafka版实例:发送日志数据到云原生数据仓库AnalyticDB MySQL湖仓版集群。
1个对象存储OSS Bucket:存储数据湖中的数据。
数据传输DTS:同步RDS MySQL中的维度表到AnalyticDB MySQL湖仓版。
数据管理DMS:通过任务编排功能周期性执行数据清洗、分库分表、聚合计算。
Quick BI:展示数据分析报表。
部署准备
10
开始部署前,请按以下指引完成账号申请、账号充值、RAM用户创建和授权。
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面,根据页面提示完成注册。阿里云账号是您使用云资源的付费实体,因此是部署方案的必要前提。
本方案默认采用按量付费的方式创建资源。如果采用按量付费,请确保账户余额都大于等于100元。
完成本方案的部署及体验,预计产生费用不超过30元。该费用仅为购买本方案示例的资源规格,完成本方案的操作,且使用时长不超过1小时的预估费用。如果您调整了资源规格、使用时长,或者执行了本方案以外的其他操作,可能会导致费用有所变化。请以控制台显示的实际价格和最终账单为准。以下为本方案涉及资源的杭州地域单价,仅供参考。
产品
计费项
单价
云原生数据仓库AnalyticDB MySQL
预留计算资源(ACU)
0.35元/个
预留存储资源(CSTORE_ACU)
0.35元/个
弹性计算资源(ACU弹性资源)
0.37元/个
热存储空间
0.0028元/GB/小时
云数据库RDS
规格
0.416元/小时
存储空间
0.0034元/GB/小时
对象存储OSS
GET类请求次数
0.01元/万次
PUT类和其他请求次数
0.01元/万次
标准存储(本地冗余)容量
0.00016667元/GB/小时
消息队列Kafka
流量规格
2.42元/MB
磁盘容量
0.0006元/GB
数据传输DTS
链路规格micro
0.504元/小时
Quick BI
专业版30天免费试用。
如无试用资格或已免费试用了30天,需根据开通的版本支付费用。
个人版:0.1元/年
高级版:至少9000元/年
专业版:至少12000元/年
数据管理 DMS
免费
专有网络VPC
免费
资源编排ROS
免费
创建用于方案部署的RAM用户。
创建1个RAM用户。具体操作,请参见创建RAM用户。
为RAM用户授予以下云服务的访问权限以完成方案部署。具体操作,请参见为RAM用户授权。
云服务
需要的权限
描述
云原生数据仓库AnalyticDB MySQL
AliyunADBFullAccess
管理云原生数据仓库AnalyticDB MySQL(AnalyticDB MySQL) V3.0 的权限
云数据库RDS
AliyunRDSFullAccess
管理云数据库RDS的权限
专有网络VPC
AliyunVPCFullAccess
管理专有网络VPC的权限
消息队列Kafka
AliyunKafkaFullAccess
管理消息队列Kafka的权限
数据管理DMS
AliyunDMSFullAccess
管理数据管理服务(DMS)的权限
数据传输DTS
AliyunDTSFullAccess
管理数据传输服务(DTS)的权限
对象存储OSS
AliyunOSSFullAccess
管理对象存储OSS权限
资源编排ROS
AliyunROSFullAccess
管理资源编排服务(ROS)的权限
规划网络和资源
20
1. 网络规划
请参考表格中的说明和方案默认示例值为每个规划项做详细规划并在实际部署时将默认示例值修改为您的实际规划。
规划项 | 数量 | 说明 |
地域 | 1 | 您的云服务部署的地域。选择地域的基本原则请参见地域和可用区。 |
专有网络VPC | 1 | 在部署过程中新建1个VPC作为本方案的专有网络。 |
交换机 | 1 | 本方案需要1台交换机,用来连接不同的云服务实例。 |
2. 规划云资源
请参考表格中的说明和方案默认示例值为每个规划项做详细规划并在实际部署时将默认示例值修改为您的实际规划。
规划项 | 数量 | 说明 |
AnalyticDB MySQL湖仓版 | 1 | 本方案需要1个AnalyticDB MySQL湖仓版集群,用于Kafka数据实时入湖、数据清洗、分库分表、聚合计算。 |
云数据库RDS MySQL | 1 | 本方案需要1个RDS MySQL实例,用于存储用户维度表。 |
对象存储OSS | 1 | 本方案需要1个OSS Bucket,用于存储数据湖中的数据。 |
消息队列Kafka | 1 | 本方案需要1个Kafka Topic,用于发送日志消息。 |
数据管理DMS | 1 | 本方案需要DMS服务,用于任务编排。 |
数据传输DTS | 1 | 本方案需要DTS服务,用于RDS MySQL数据同步。 |
Quick BI | 1 | 本方案采用Quick BI进行数据可视化分析。 |
部署资源
10
规划好资源后,请按照以下步骤部署方案中的所有资源。
准备好资源后,您可以通过一键配置快速完成资源配置或应用搭建。一键配置基于阿里云资源编排服务ROS(Resource Orchestration Service)实现,旨在帮助开发者通过IaC(Infrastructure as Code)的方式体验资源的自动化配置。模板完成的内容包括:
创建专有网络VPC
创建交换机
创建云原生数据仓库AnalyticDB MySQL湖仓版集群
创建云数据库RDS MySQL版实例、高权限账号和测试数据库
创建消息队列Kafka版实例和Topic
创建对象存储OSS Bucket
打开一键配置模板链接前往ROS控制台,系统自动打开使用新资源创建资源栈的面板,并在模板内容区域展示YAML文件的详细信息。
ROS控制台默认处于您上一次访问控制台时的地域,请根据您创建的资源所在地域修改地域。确认好地域后,保持页面所有选项不变,单击下一步进入配置模板参数页面。
在配置模板参数页面修改资源栈名称,选择可用区,AnalyticDB MySQL湖仓版集群规格,RDS MySQL实例规格和账号密码,OSS存储空间的名称,Kafka Topic名称。填写完所有必选信息并确认后单击创建开始一键配置。
当资源栈信息页面的状态显示为创建成功时表示一键配置完成。
用户运营分析报告
40
1. 创建高权限账号与资源组
在资源部署的阶段,本方案已经创建了云原生数据仓库AnalyticDB MySQL湖仓版集群。接下来,您需要创建一个高权限账号和一个资源组,去执行数据分析的操作。
创建高权限账号:
在云原生数据仓库AnalyticDB MySQL控制台,在集群列表的湖仓版(3.0)页签,单击刚刚创建的集群。
在左侧导航栏单击账号管理。然后单击创建账号。
根据控制台提示,设置账号名称和密码。账号类型选择高权限账号。单击确定。本方案示例的账号为名称testUser,密码为testPassword。请勿在您的环境中使用本方案用于示例的账号名称和密码。
创建资源组并绑定RAM用户:
在左侧导航栏单击资源管理。然后单击资源组管理。
单击新增资源组,设置资源组名称(本方案示例为Kafka),任务类型为Job,计算预留资源为0ACU,计算最大资源为8ACU。选择完成后,单击确定。
单击绑定用户。在用户名下拉框选择RAM用户,然后单击绑定用户。
在弹出的绑定用户对话框,单击确定。单击右上角关闭图标。
2. 构建测试数据
本阶段构建用于测试的日志数据和维度表数据,为后续数据同步、清洗、分库分表、分析做准备。
构建日志测试数据:
在消息队列Kafka版控制台实例列表页,单击Kafka实例ID。
在左侧导航栏,单击Topic 管理。
在Topic 管理页面,找到刚刚创建的Topic,在操作列单击更多>体验发送消息。
在消息内容的文本框中,输入JSON格式的消息内容。本方案示例。
{"appid": "1234321","userid": "1","cost": "200","country": "china","city":"shanghai","appversion": "1.0","clickip": "192.168.0.1","clickTime": "2023-01-01 09:05:01","logintime": "2023-01-01 09:03:00","logouttime": "2023-01-01 10:28:00","reinstalledtime": "2023-01-01 09:00:00","fisrtinstalltime": "2022-01-11 23:10:00","installedtime":"2022-12-11 23:10:00"} {"appid": "1234322","userid": "2","cost": "220","country": "china","city":"hangzhou","appversion": "1.3","clickip": "192.168.11.1","clickTime": "2023-01-02 09:25:00","logintime": "2023-01-02 09:30:00","logouttime": "2023-01-02 11:20:00","reinstalledtime": "2023-01-02 09:00:00","fisrtinstalltime": "2022-07-03 23:11:00","installedtime":"2022-12-12 23:11:00"} {"appid": "1234322","userid": "3","cost": "40","country": "china","city":"shanghai","appversion": "1.0","clickip": "192.168.0.2","clickTime": "2023-01-03 09:05:01","logintime": "2023-01-03 09:03:00","logouttime": "2023-01-03 10:28:00","reinstalledtime": "2023-01-03 09:00:00","fisrtinstalltime": "2021-12-20 23:10:00","installedtime":"2022-12-13 23:10:00"} {"appid": "1234322","userid": "4","cost": "150","country": "china","city":"beijing","appversion": "2.0","clickip": "192.168.11.2","clickTime": "2023-01-04 09:25:00","logintime": "2023-01-04 09:30:00","logouttime": "2023-01-04 11:20:00","reinstalledtime": "2023-01-04 09:00:00","fisrtinstalltime": "2022-12-13 23:11:00","installedtime":"2022-12-13 23:11:00"}
构建维度表测试数据:
在云数据库RDS控制台示例列表页,单击刚刚创建的RDS实例ID。
在基本信息页面的右上角,单击登录数据库。
输入一键配置阶段配置的数据库账号和密码。单击登录。本方案数据库账号默认值为testuser,密码默认值为testPassword01。
在页面左侧,单击数据库实例,展开数据库实例。
在已登录实例中,单击之前创建的RDS实例,双击dim数据库,页面出现SQL Console。
在SQLConsole中输入SQL语句创建维度表。
在左上角单击
 ,然后单击。
,然后单击。在右上角单击测试数据构建。
输入任务名称,选择数据库dim和表dim_table。
在配置算法中,找到user_name列,在生成方式列单击随机(变长字符串 [1, 10])。在生成方式弹窗中,选择自定义,选择个人信息/英文名字。附加属性选择不限。单击确认算法配置。按相同方法设置city列的生成方式为地址位置/城市。
设置生成行数,即生成多少行测试数据。本方案以10行为例。
单击提交申请。
CREATE TABLE dim.dim_table(user_id INT PRIMARY KEY,user_name VARCHAR(255),city VARCHAR(255));
3. 同步日志数据
在构建测试数据的阶段,本方案利用创建的Kafka实例模拟发送了日志数据。接下来您要做的是将Kafka发送的日志数据同步到AnalyticDB MySQL湖仓版。
新建Kafka数据源
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域,华东1(杭州)。
在左侧导航栏,单击集群列表,在湖仓版(3.0)页签,单击目标集群ID。
在左侧导航栏,单击数据接入>数据源管理。
单击右上角新建数据源。在新建数据源页面进行参数配置。
项目
说明
示例值
数据源类型
选择数据源类型Kafka。
Kafka
数据源名称
系统默认按数据源类型与当前时间生成名称,可按需修改。
kafka-202307262*****
数据源描述
数据源备注描述,例如湖仓应用场景、应用业务限制等。
同步日志数据。
部署模式
目前仅支持阿里云实例。
阿里云实例
Kafka实例
Kafka实例ID。
登录消息队列Kafka版控制台,在实例列表页面查看实例ID。
alikafka_post-cn-5yd39qe*****
Kafka Topic
在Kafka中创建的Topic名称。
登录消息队列Kafka版控制台,在目标实例的Topic 管理页面查看Topic名称。
test_topic
消息数据格式
Kafka消息数据格式,目前仅支持JSON。
JSON
参数配置完成后,单击创建。
新建Kafka同步链路
在数据源管理页面,找到刚刚创建成功的Kafka数据源,在操作列单击新建链路>新建同步链路。
在新建同步链路页面的Kafka数据源页签,完成数据源及目标端配置、目标库表配置及同步配置。
数据源及目标端配置
项目
说明
示例值
数据链路名称
数据链路名称。
kafka-202307262*****
数据源
选择刚刚创建好的Kafka数据源。
kafka-202307262*****
目标端类型
目前仅支持数据湖-OSS存储。
数据湖-OSS存储
OSS路径
AnalyticDB MySQL湖仓数据在OSS中的存储路径。
选择部署资源阶段创建的OSS Bucket并创建目录。
oss://testBucketName/adb/
目标库表配置
项目
说明
示例值
库名
同步到AnalyticDB MySQL的数据库名称。如果不存在同名数据库,将新建库;如果已存在同名数据库,数据会同步到已存在的数据库中。库名命名规则,详见使用限制。
kafka
表名
同步到AnalyticDB MySQL的表名称。如果库中不存在同名表,将新建表;如果库中已存在同名表,数据同步会失败。表名命名规则,详见使用限制。
user_log
样例数据
自动从Kafka Topic中获取的最新数据作为样例数据。
不涉及
JSON解析层级
设置JSON的嵌套解析层数。
JSON的嵌套解析策略,请参见通过数据同步功能同步至湖仓版(推荐)。
1
Schema字段映射
展示样例数据经过JSON解析后的Schema信息。可在此调整目标字段名,类型或按需增删字段等。
本方案将目标表字段__key__、__topic__、__partition__、__offset__、__timestamp__中的
__删除,得到key、topic、partition、offset和timestamp。不涉及
分区键设置
建议按日志时间或者业务逻辑配置分区,以保证入湖与查询性能。如不设置,则目标表默认没有分区。
分区字段名:installedtime
源端字段格式:yyyyMMdd HH:mm:ss
目标分区格式:yyyyMMdd
目标分区字段名:
installedtime
同步配置
项目
说明
示例值
增量同步起始消费位点
同步任务启动时会从选择的时间点开始消费Kafka数据。取值说明:
最早位点(begin_cursor):自动从Kafka数据中最开始的时间点消费数据。
最近位点(end_cursor):自动从Kafka数据中最近的时间点消费数据。
自定义点位:您可以选择任意一个时间点,系统则会从Kafka中第一条大于等于该时间点的数据开始消费。
最早位点
Job型资源组
指定任务运行的Job型资源组。
kafka
增量同步所需ACU数
指定任务运行的Job型资源组ACU数量。
2
参数配置完成后,单击提交。
在操作列,单击启动。刷新浏览器,当状态显示正在运行时,说明启动成功。您可以在目标端列单击OSS路径,当您看到路径中有parquet格式的文件时,说明数据已同步至数据湖。
4. 数据清洗
在数据清洗阶段,我们可以对无用的字段进行删减,并转换部分字段的类型。
创建外库和外表
在OSS管理控制台,单击刚刚创建的Bucket,并在Bucket下创建目录log/。
在云原生数据仓库AnalyticDB MySQL控制台,在湖仓版(3.0)集群列表中单击集群ID,然后左侧导航栏单击Notebook开发。
单击创建Notebook。选择资源组为kafka,并设置Notebook名称和描述。
在Notebook中,添加多个段落,切换语言为Spark SQL,输入SQL创建外库、外表。
CREATE DATABASE LOG LOCATION "oss://testBucketName/log/";CREATE TABLE log.clean_data ( appid BIGINT, userid BIGINT, cost DOUBLE, city STRING, clicktime STRING, firstinstalltime STRING, logintime STRING, logouttime STRING, installedtime STRING ) USING hudi PARTITIONED BY (installedtime) tblproperties ( primaryKey = 'userid,installedtime,clicktime', preCombinedField='appid' ) LOCATION 'oss://testBucketName/log/clean_data';SELECT * FROM log.clean_data;在Notebook中,添加段落,切换语言为Spark SQL,输入SQL创建外表、导入、查询数据。
如果您希望实现定时自动写入数据到clean_data表,可以使用DMS任务编排,具体请参见ADB Spark-1。
INSERT INTO log.clean_data PARTITION (installedtime) SELECT appid, userid, cast(cost as double), city, clicktime, fisrtinstalltime, logintime, logouttime, installedtime FROM kafka.user_log;单击执行全部段落。
5. 分库分表
当前所有的日志数据都在log.clean_data中。接下来我们根据app_id,将不同app的日志数据放在不同的表中。
在Notebook中,添加段落,切换语言为Spark SQL,依次输入SQL创建库、创建两个明细表。
CREATE DATABASE app_warehouse;CREATE TABLE app_warehouse.app1_detail ( app_id BIGINT, user_id BIGINT, cost DOUBLE, click_time STRING, firstinstall_time STRING, login_time STRING, logout_time STRING, install_time STRING ) USING adb TBLPROPERTIES ( "distributeType"="HASH", "distributeColumns"="install_time", "partitionType"="value", "partitionCoLumn"="install_time", "partitionCount"="30" );CREATE TABLE app_warehouse.app2_detail ( app_id BIGINT, user_id BIGINT, cost DOUBLE, click_time STRING, firstinstall_time STRING, login_time STRING, logout_time STRING, install_time STRING ) USING adb TBLPROPERTIES ( "distributeType"="HASH", "distributeColumns"="install_time", "partitionType"="value", "partitionCoLumn"="install_time", "partitionCount"="30" );查询出app1的日志数据并导入app1的日志明细表app_warehouse.app1_detail。如果您希望实现定时自动写入数据到app1_detail表,可以使用DMS任务编排,具体请参见ADB Spark-2。
INSERT OVERWRITE app_warehouse.app1_detail SELECT appid, userid, cost, clicktime, firstinstalltime, logintime, logouttime, installedtime FROM log.clean_data WHERE appid="1234321";SELECT * FROM app_warehouse.app1_detail;按同样方法处理app2的日志数据。如果您希望实现定时自动写入数据到app2_detail表,可以使用DMS任务编排,具体请参见ADB Spark-3。
INSERT OVERWRITE app_warehouse.app2_detail SELECT appid, userid, cost, clicktime, firstinstalltime, logintime, logouttime, installedtime FROM log.clean_data WHERE appid="1234322";SELECT * FROM app_warehouse.app2_detail;
6. 同步维度数据
到目前为止,我们已对度量数据进行了清洗、分库分表。接下来我们需要将维度数据同步到AnalyticDB MySQL湖仓版。
登录DMS数据管理服务控制台,在左上角单击
,然后单击。单击创建任务。
配置任务名称,配置源库信息和目标库信息。然后单击测试连接以进行下一步。
配置源库信息
项目
说明
选择已有的DMS数据库实例
选择刚刚创建的RDS实例,下方数据库信息将自动填入,您无需重复输入。
数据库类型
选择MySQL。
接入方式
选择云实例。
实例地区
本方案选择华东1(杭州)。
是否跨阿里云账号
本方案为同一阿里云账号间迁移,选择不跨账号。
RDS实例ID
自动填充刚刚选择的RDS实例ID。
数据库账号
自动填充数据库账号。
数据库密码
自动填充数据库账号的密码。
连接方式
根据需求选择非加密连接或SSL安全连接。
本方案选择非加密连接。
配置目标库信息
选择已有的DMS数据库实例
您可以按实际需求,选择是否使用已有实例。
如使用已有实例,下方数据库信息将自动填入,您无需重复输入。
如不使用已有实例,您需要输入下方的数据库信息。
数据库类型
选择AnalyticDB MySQL 3.0。
接入方式
选择云实例。
实例地区
本方案选择华东1(杭州)。
实例ID
选择目标云原生数据仓库AnalyticDB MySQL版湖仓版(3.0)集群ID。
数据库账号
填入目标云原生数据仓库AnalyticDB MySQL版湖仓版(3.0)集群的数据库账号,需具备读写权限。
数据库密码
填入该数据库账号对应的密码。
在源库对象中选择刚刚创建的dim库,添加到右侧已选择对象中。其他配置保持默认。单击下一步高级配置。
高级配置、配置库表字段、配置库表字段保持默认。预检查通过后,单击下一步购买。
选择付费方式。本方案选择后付费,链路规格为micro。勾选服务条款后,单击购买并启动。
当运行状态为运行中,表示全量同步已完成,增量同步正常进行中。此时可进行聚合分析。
7. 聚合分析
接下来需要将维度表与分区表进行关联,并进行聚合分析。
登录云原生数据仓库AnalyticDB MySQL控制台,在湖仓版(3.0)集群列表中单击集群ID,在左侧导航栏单击SQL开发。
选择引擎为XIHE,资源组为Interactive。
在SQLConsole窗口,输入SQL。针对不同的应用,分别创建汇总表。
CREATE TABLE app_warehouse.app1_summary ( app_id bigint, active_user_count bigint, new_user_count bigint, total_income double, city string, time_in_hour string, primary key (time_in_hour) ) DISTRIBUTED BY HASH (time_in_hour) ;CREATE TABLE app_warehouse.app2_summary ( app_id bigint, active_user_count bigint, new_user_count bigint, total_income double, city string, time_in_hour string, primary key (time_in_hour) ) DISTRIBUTED BY HASH (time_in_hour) ;从明细表中查询数据并导入汇总表。如果您希望实现定时自动写入数据到汇总表,可以在DMS任务编排中实现聚合分析,具体请参见单实例SQL-1和单实例SQL-2。
INSERT INTO app_warehouse.app1_summary SELECT activeUser.app_id, activeUser.active_user_count, newUser.new_user_count, totalIncome.total_income, activeUser.city, activeUser.time_in_hour FROM (SELECT a.app_id AS app_id, COUNT(DISTINCT a.user_id) AS active_user_count, b.city, DATE_FORMAT(a.login_time,"%Y%m%d %H:00:00") AS time_in_hour FROM app_warehouse.app1_detail a JOIN dim.dim_table b ON a.user_id=b.user_id GROUP by time_in_hour, b.city ) activeUser LEFT JOIN ( SELECT COUNT (DISTINCT a.user_id) AS new_user_count, b.city, DATE_FORMAT(a.firstinstall_time,"%Y%m%d %H:00:00") AS time_in_hour FROM app_warehouse.app1_detail a JOIN dim.dim_table b ON a.user_id=b.user_id GROUP BY time_in_hour, b.city ) newUser ON activeUser.time_in_hour=newUser.time_in_hour AND activeUser.city=newUser.city LEFT JOIN ( SELECT ROUND(SUM(a.cost), 2) AS total_income, b.city, DATE_FORMAT(a.click_time,"%Y%m%d %H:00:00") AS time_in_hour FROM app_warehouse.app1_detail a JOIN dim.dim_table b ON a.user_id=b.user_id GROUP BY time_in_hour, b.city ) totalIncome ON activeUser.time_in_hour=totalIncome.time_in_hour and activeUser.city=totalIncome.city;INSERT INTO app_warehouse.app2_summary SELECT activeUser.app_id, activeUser.active_user_count, newUser.new_user_count, totalIncome.total_income, activeUser.city, activeUser.time_in_hour FROM (SELECT a.app_id AS app_id, COUNT(DISTINCT a.user_id) AS active_user_count, b.city, DATE_FORMAT(a.login_time,"%Y%m%d %H:00:00") AS time_in_hour FROM app_warehouse.app2_detail a JOIN dim.dim_table b ON a.user_id=b.user_id GROUP by time_in_hour, b.city ) activeUser LEFT JOIN ( SELECT COUNT (DISTINCT a.user_id) AS new_user_count, b.city, DATE_FORMAT(a.firstinstall_time,"%Y%m%d %H:00:00") AS time_in_hour FROM app_warehouse.app2_detail a JOIN dim.dim_table b ON a.user_id=b.user_id GROUP BY time_in_hour, b.city ) newUser ON activeUser.time_in_hour=newUser.time_in_hour AND activeUser.city=newUser.city LEFT JOIN ( SELECT ROUND(SUM(a.cost), 2) AS total_income, b.city, DATE_FORMAT(a.click_time,"%Y%m%d %H:00:00") AS time_in_hour FROM app_warehouse.app2_detail a JOIN dim.dim_table b ON a.user_id=b.user_id GROUP BY time_in_hour, b.city ) totalIncome ON activeUser.time_in_hour=totalIncome.time_in_hour and activeUser.city=totalIncome.city;查询汇总表数据。
SELECT * FROM app_warehouse.app1_summary;SELECT * FROM app_warehouse.app2_summary;
8. 任务调度
您还可以通过DMS任务编排,实现自动任务调度,提高数据开发效率。
在DMS中登录AnalyticDB MySQL。
登录云原生数据仓库AnalyticDB MySQL控制台,在湖仓版(3.0)集群列表中单击集群ID,然后在右上角单击登录数据库。
输入数据库账号和数据库密码,单击登录。
在白名单问题对话框中,单击复制IP网段。
在数据安全-白名单设置区域,单击default后面的修改。在组内白名单中粘贴步骤c复制的IP网段,然后单击确定。
关闭白名单问题对话框。在登录实例对话框中,单击登录。
在左上角单击
,然后单击任务编排。新增任务流。
单击新增任务流。
在新建任务流对话框中,输入任务流名称和描述,单击确认。
从左侧任务列表中,拖拽3个ADB Spark节点,2个单实例SQL节点到画布中,并连接成任务流。请根据您的业务场景设计任务流。本方案示例所示。

单击任务节点并选择
 ,配置任务节点。
,配置任务节点。
选择地域为华东1(杭州)。
选择ADB实例为刚刚创建的AnalyticDB MySQL湖仓版集群。
选择ADB资源组为刚刚创建的资源组。
任务类型选择SQL。
任务名称可自定义。
在作业配置中输入SQL语句。
单击保存。关闭ADB Spark-1页签。
选择地域为华东1(杭州)。
选择ADB实例为刚刚创建的AnalyticDB MySQL湖仓版集群。
选择ADB资源组为刚刚创建的资源组。
任务类型选择SQL。
任务名称可自定义。
在作业配置中输入SQL语句。
单击保存。关闭ADB Spark-2页签。
数据库选择之前创建的app_warehouse。
输入聚合分析的SQL语句。
单击保存。关闭单实例SQL-1页签。
选择ADB实例为刚刚创建的AnalyticDB MySQL湖仓版集群。
选择ADB资源组为刚刚创建的资源组。
任务类型选择SQL。
任务名称可自定义。
在作业配置中输入SQL语句。
单击保存。关闭ADB Spark-3页签。
数据库选择之前创建的app_warehouse。
输入聚合分析的SQL语句。
单击保存。关闭单实例SQL-2页签。
ADB Spark-1
-- Here is just an example of SparkSQL. Modify the content and run your spark program.
set spark.driver.resourceSpec=medium;
set spark.executor.instances=2;
set spark.executor.resourceSpec=medium;
-- Here are your sql statements
INSERT INTO
log.clean_data PARTITION (installedtime)
SELECT
appid,
userid,
cast(cost as double),
city,
clicktime,
fisrtinstalltime,
logintime,
logouttime,
installedtime
FROM
kafka.user_log;ADB Spark-2
-- Here is just an example of SparkSQL. Modify the content and run your spark program.
set spark.driver.resourceSpec=medium;
set spark.executor.instances=2;
set spark.executor.resourceSpec=medium;
-- Here are your sql statements
INSERT OVERWRITE app_warehouse.app1_detail
SELECT
appid,
userid,
cost,
clicktime,
firstinstalltime,
logintime,
logouttime,
installedtime
FROM
log.clean_data
WHERE
appid="1234321";单实例SQL-1
INSERT INTO
app_warehouse.app1_summary
SELECT
activeUser.app_id,
activeUser.active_user_count,
newUser.new_user_count,
totalIncome.total_income,
activeUser.city,
activeUser.time_in_hour
FROM
(SELECT
a.app_id AS app_id,
COUNT(DISTINCT a.user_id) AS active_user_count,
b.city,
DATE_FORMAT(a.login_time,"%Y%m%d %H:00:00") AS time_in_hour
FROM
app_warehouse.app1_detail a
JOIN dim.dim_table b ON a.user_id=b.user_id
GROUP by
time_in_hour,
b.city
) activeUser
LEFT JOIN (
SELECT
COUNT (DISTINCT a.user_id) AS new_user_count,
b.city,
DATE_FORMAT(a.firstinstall_time,"%Y%m%d %H:00:00") AS time_in_hour
FROM
app_warehouse.app1_detail a
JOIN dim.dim_table b ON a.user_id=b.user_id
GROUP BY
time_in_hour,
b.city
) newUser ON activeUser.time_in_hour=newUser.time_in_hour
AND activeUser.city=newUser.city
LEFT JOIN (
SELECT
ROUND(SUM(a.cost), 2) AS total_income,
b.city,
DATE_FORMAT(a.click_time,"%Y%m%d %H:00:00") AS time_in_hour
FROM
app_warehouse.app1_detail a
JOIN dim.dim_table b ON a.user_id=b.user_id
GROUP BY
time_in_hour,
b.city
) totalIncome ON activeUser.time_in_hour=totalIncome.time_in_hour
and activeUser.city=totalIncome.city;ADB Spark-3
-- Here is just an example of SparkSQL. Modify the content and run your spark program.
set spark.driver.resourceSpec=medium;
set spark.executor.instances=2;
set spark.executor.resourceSpec=medium;
-- Here are your sql statements
INSERT OVERWRITE app_warehouse.app2_detail
SELECT
appid,
userid,
cost,
clicktime,
firstinstalltime,
logintime,
logouttime,
installedtime
FROM
log.clean_data
WHERE
appid="1234322";单实例SQL-2
INSERT INTO
app_warehouse.app2_summary
SELECT
activeUser.app_id,
activeUser.active_user_count,
newUser.new_user_count,
totalIncome.total_income,
activeUser.city,
activeUser.time_in_hour
FROM
(SELECT
a.app_id AS app_id,
COUNT(DISTINCT a.user_id) AS active_user_count,
b.city,
DATE_FORMAT(a.login_time,"%Y%m%d %H:00:00") AS time_in_hour
FROM
app_warehouse.app2_detail a
JOIN dim.dim_table b ON a.user_id=b.user_id
GROUP by
time_in_hour,
b.city
) activeUser
LEFT JOIN (
SELECT
COUNT (DISTINCT a.user_id) AS new_user_count,
b.city,
DATE_FORMAT(a.firstinstall_time,"%Y%m%d %H:00:00") AS time_in_hour
FROM
app_warehouse.app2_detail a
JOIN dim.dim_table b ON a.user_id=b.user_id
GROUP BY
time_in_hour,
b.city
) newUser ON activeUser.time_in_hour=newUser.time_in_hour
AND activeUser.city=newUser.city
LEFT JOIN (
SELECT
ROUND(SUM(a.cost), 2) AS total_income,
b.city,
DATE_FORMAT(a.click_time,"%Y%m%d %H:00:00") AS time_in_hour
FROM
app_warehouse.app2_detail a
JOIN dim.dim_table b ON a.user_id=b.user_id
GROUP BY
time_in_hour,
b.city
) totalIncome ON activeUser.time_in_hour=totalIncome.time_in_hour
and activeUser.city=totalIncome.city;单击页面下方的任务流信息,打开开启调度的开关。根据实际业务场景设置调度类型、生效时间、调度周期、具体时间。本方案示例如下:调度类型为定时调度/周期调度,生效时间为2023-08-07至2023-08-15,调度周期为日,具体时间为00:00。
单击发布。
9. 可视化分析报告
接下来您要将数据制作成可视化分析报告。
在Quick BI控制台,根据控制台提示填写试用信息,单击开启专业版试用。
在左侧导航栏单击数据源。
单击Alibaba AnalyticDB for MySQL。
在配置连接页面,填写连接配置。
项目
说明
示例
连接方式
本方案选择自动连接。
自动连接
选择数据库
选择刚刚创建的AnalyticDB MySQL湖仓版(3.0)集群。
amv-bp1tv9mhg1******
显示名称
自定义数据源的名称。
adb
数据库地址
填写AnalyticDB MySQL湖仓版(3.0)集群的VPC地址。
如果您无法提供阿里云账号的AccessKeyID和AccessKeySecret,此处请填写公网地址。
amv-bp1tv9mhg1n*******0001031.ads.aliyuncs.com
端口
3306。
3306
数据库
填写汇总表所在的数据库。
app_warehouse
账号
填写AnalyticDB MySQL湖仓版(3.0)集群具有读权限的账号。本方案以刚刚创建的高权限账号为例。
testUser
密码
填写AnalyticDB MySQL湖仓版(3.0)集群账号的密码。
testPassword
VPC数据源
勾选后,通过VPC网络访问数据库。
勾选
购买者AccessId
填写阿里云账号的AccessKeyID。
LTAI5t9YYqutv5svx1******
购买者AccessKey
填写阿里云账号的AccessKeySecret。
5ZPYdKE4AblC4j4hZhWQycMv******
实例ID
填写AnalyticDB MySQL湖仓版(3.0)集群ID。
amv-bp1tv9mhg1******
区域
填写AnalyticDB MySQL湖仓版(3.0)集群所在的地域。
华东1(杭州)
将Quick BI的IP地址添加到AnalyticDB MySQL湖仓版(3.0)集群的白名单。
在云原生数据仓库AnalyticDB MySQL控制台,在左侧导航栏单击集群列表。
在湖仓版(3.0)页签中,单击集群名称。
在集群信息页的数据安全-白名单设置区域,单击创建白名单分组,设置分组名称为quickbi,在组内白名单中粘贴Quick BI的IP地址,单击确定。
单击连接测试。控制台提示数据源连通性正常,然后单击确定。
单击新建数据集。将想要分析的汇总表app2_summary拖拽到工作区,在右上角单击保存。将数据集命名为app2_summary,单击确定。
在右上角单击。
从右侧的数据区域,拖拽维度和度量到字段区域,生成图表。
拖拽维度time_in_hour和度量active_user_count,展示每小时的活跃用户数。
拖拽维度time_in_hour和度量new_user_count,展示每小时的新用户数。
拖拽维度city和度量total_income,展示每个城市的付费总额。
完成及清理
5
方案验证
制作可视化分析报告后,在仪表板的右上角单击保存并发布,即可看到用户运营分析报告。
清理资源
在本方案中,您创建了1个专有网络VPC、1台交换机、1个云原生数据仓库AnalyticDB MySQL湖仓版集群、1个云数据库RDS MySQL版实例、1个消息队列Kafka版实例、1个对象存储OSS Bucket。
测试完方案后,您可以参考以下规则处理对应产品的实例,避免继续产生费用:
登录ROS控制台。
在左侧导航栏,单击资源栈。
在资源栈列表中找到刚刚创建的资源栈,在操作列单击删除。
删除方式选择释放资源。
当前场景创建的所有按量付费资源将会同时释放。
单击确定。