云原生企业级数据湖
手动部署
135
https://www.aliyun.com/solution/tech-solution/datalake
方案概览
基于对象存储OSS构建的数据湖,可对接多种数据输入方式,存储任何规模的结构化、半结构化、非结构化数据,打破数据湖孤岛;无缝对接多种数据分析产品,对存储在对象存储OSS中的数据直接进行数据分析和机器学习,洞察业务价值。同时,数据湖提供多种存储类型的冷热分层转换能力,通过数据全生命周期管理优化存储成本。
本技术解决方案以搭建一个大数据分析服务和一个机器学习服务为例,为您演示:
如何使用OSS中的数据完成一个大数据分析任务
如何使用OSS中的数据训练一个深度学习模型
方案架构
方案提供的默认设置完成部署后在阿里云上搭建的运行环境如下图所示(蓝色高亮部分)。实际部署时您可以根据资源规划修改部分设置,但最终形成的运行环境与下图相似。
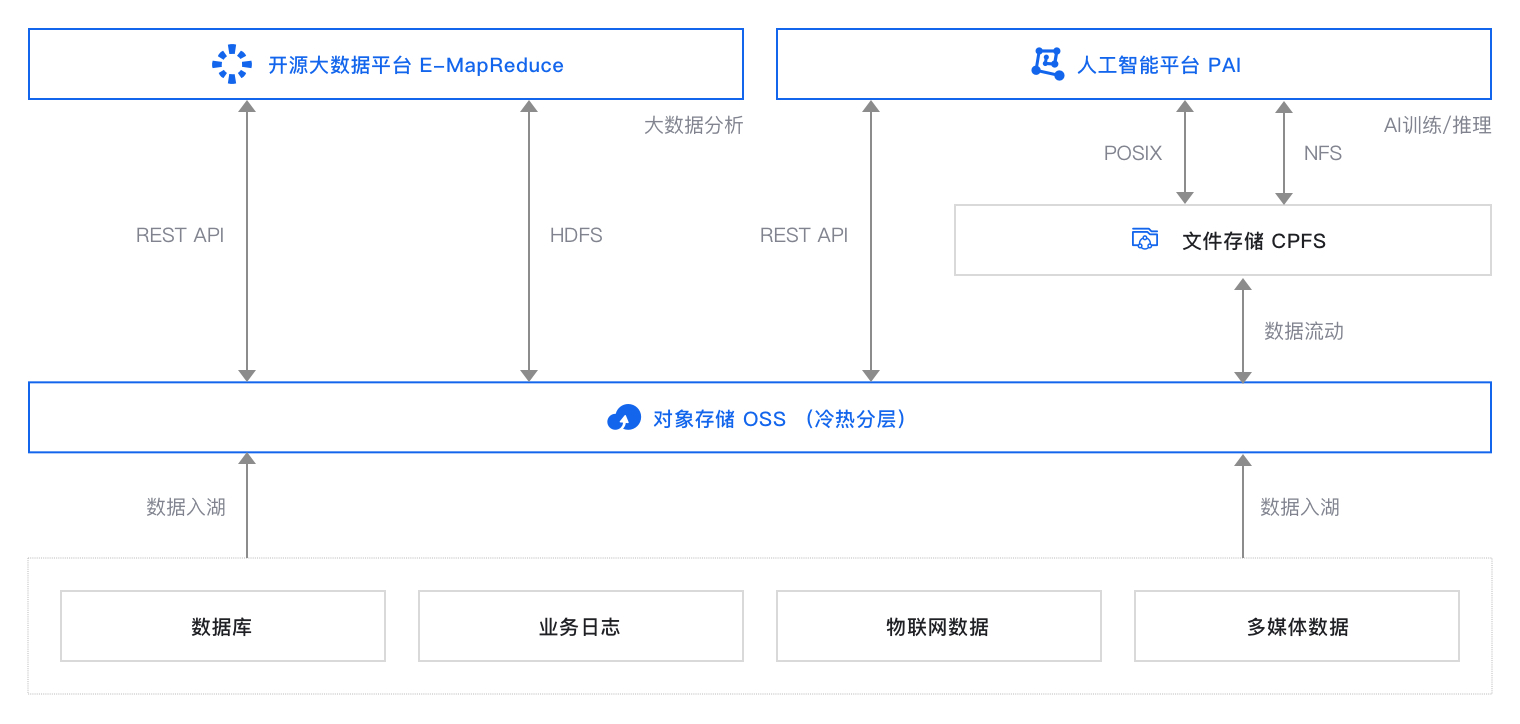
本方案以大数据分析场景和机器学习场景为例。本方案的技术架构包括以下基础设施和云服务:
1个对象存储OSS:提供数据存储。
1个EMR集群:提供大数据计算引擎。
1个PAI:提供机器学习引擎。
部署准备
10
开始部署前,请按以下指引完成账号申请、账号充值、RAM用户创建和授权。
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面,根据页面提示完成注册。阿里云账号是您使用云资源的付费实体,因此是部署方案的必要前提。
为节省成本,本方案默认选择使用按量付费及抢占式资源,使用按量付费资源需要确保账户余额不小于100元。
完成本方案的部署及体验,预计产生费用不超过5元(假设您选择最低规格资源,且资源运行时间不超过30分钟。如调整了资源规格,请以控制台显示的实际报价以及最终账单为准)。
序号
产品
费用来源
规格
地域
预估费用参考
说明
1
对象存储OSS
标准存储(本地冗余)容量(Storage)费
-
华东2(上海)
0.12元/GB/月
测试数据量较少
PUT类或GET类请求费
-
华东2(上海)
0.01元/万次
测试请求量较少
2
阿里云E-MapReduce
ECS产品费用
ecs.g6.xlarge*3
华东2(上海)
3.0元/小时
E-MapReduce服务费用
ecs.g6.xlarge*3
华东2(上海)
0.45元/小时
3
人工智能平台PAI
DLC深度学习训练费用
ecs.g6.xlarge*1
华东2(上海)
1.1元/小时
按量费用:4.71元/时
创建用于方案部署的RAM用户。
规划网络和资源
20
网络规划
请参考表格中的说明和方案默认示例值为每个规划项做详细规划并在实际部署时将默认示例值修改为您的实际规划。
规划项 | 数量 | 说明 |
地域 | 1 | 您的云服务部署的地域。选择地域的基本原则请参见地域和可用区。 |
专有网络VPC | 1 | 在部署过程中新建一个VPC作为本方案的专有网络。 |
交换机 | 1 | 本方案需要至少1台交换机,用来连接不同的云资源实例。 |
安全组 | 1 | 用于限制专有网络VPC下云服务器ECS的网络流入和流出规则。 |
规划云资源
请参考表格中的说明和方案默认示例值为每个规划项做详细规划并在实际部署时将默认示例值修改为您的实际规划。
规划项 | 数量 | 说明 |
OSS | 1 | 本方案需要1个OSS Bucket,用于数据湖存储。 |
EMR | 1 | 本方案需要1个EMR集群,用于提供大数据处理和分析的基础设施。 |
PAI | 1 | 本方案需要1个PAI工作空间,用于提供机器学习的基础设施。 |
部署资源
30
规划好资源后,请按照以下步骤部署方案中的所有资源。
1. 创建专有网络VPC和交换机
您需要创建1个专有网络和1个交换机。
登录专有网络管理控制台。
在顶部菜单栏,选择华东2(上海)地域。
在左侧导航栏,单击专有网络。
在专有网络页面,单击创建专有网络。
在创建专有网络页面上,配置1个专有网络和1台交换机。
项目
说明
示例值
VPC名称
建议您在部署过程中新建一个VPC作为本方案的专有网络。部署过程中填写VPC名称即可创建对应名称的VPC。
长度为2~128个字符,以英文字母或中文开头,可包含数字、下划线(_)和连字符(-)。
VPC_SH
IPv4网段
在创建VPC时,您必须按照无类域间路由块(CIDR block)的格式为您的专有网络划分私网网段。阿里云VPC支持的网段信息请参见专有网络组成部分。
在网络规划时可以按照管理网段-开发网段-测试网段-生产网段等规则做好规划。网段一旦投入使用,调整过程复杂,因此规划十分重要。
192.168.0.0/16
Vswitch名称
建议您在部署过程中在新建的VPC内创建虚拟交换机。部署过程中填写交换机名称即可创建对应名称的虚拟交换机。
长度为2~128个字符,以英文字母或中文开头,可包含数字、下划线(_)和连字符(-)。
vsw_001
可用区
在规划的地域内选择1个可用区,1台虚拟交换机分别部署在1个可用区。建议选择排序靠后的,一般此类可用区较新。新可用区资源更充沛,新规格也会在新的可用区优先上线。
可用区 I
IPv4网段
每台虚拟交换机需要一个IPv4网段
vsw_001:192.168.1.0/24
2. 创建安全组
接下来您需要创建1个安全组,用于限制该专有网络VPC下的交换机的网络流入和流出。
在左侧导航栏,选择网络与安全>安全组。
在顶部菜单栏,选择华东2(上海)地域。
在安全组页面,单击创建安全组。
在创建安全组页面,创建1个安全组。
项目
说明
示例值
名称
设置安全组的名称。
SecurityGroup_EMR
网络
选择之前规划的专有网络VPC。
VPC_SH
安全组类型
本方案需从公网拉取博客网站服务镜像,因此选择普通安全组,以实现公网出方向所有地址可访问。实际部署时,建议选择安全性更高的企业级安全组。
普通安全组
端口
测试环境可为全部对象放行全部端口。实际生产环境,请只为独享资源组放行全部端口。
1/65535
3. 创建EMR集群
接下来您需要创建1个EMR集群,用于提供大数据计算引擎。
在顶部菜单栏处,选择华东2(上海)地域。
在EMR on ECS页面,单击创建集群。
在创建集群页面,参考下表创建1个集群,其他保持默认值。
类型
项目
说明
示例值
软件配置
地域
集群节点ECS实例所在的物理位置。重要集群创建后,无法更改地域,请谨慎选择。
华东2(上海)
业务场景
默认为新版数据湖。
新版数据湖
产品版本
选择当前最新的软件版本。
EMR-5.13.0
可选服务
根据您的实际需求选择组件,被选中的组件会默认启动相关的服务进程。
HADOOP-COMMON
HDFS
Hive
Spark
Tez
YARN
硬件配置
付费类型
在测试场景下,建议使用按量付费,测试正常后可以释放该集群,再新建一个包年包月的生产集群正式使用。
按量付费
可用区
集群创建后,无法直接更改可用区,请谨慎选择。
可用区 I
专有网络
选择对应区域下的专有网络。
VPC_SH/vpc-bp1e49hpm1mcluyij4***
交换机
选择在对应专有网络下可用区的交换机。
vsw_001/vsw-bp12ic8yl36r2k0ne7***
默认安全组
EMR目前只支持普通安全组,不支持企业安全组。安全组提供类似虚拟防火墙功能,用于设置集群节ECS实例的网络访问控制,是重要的安全隔离手段。
sg_seurity/sg-bp17bpb8ucnsilrh5***
基础配置
集群名称
集群的名字,长度限制为1~64个字符,仅可使用中文、字母、数字、短划线(-)和下划线(_)。
Emr-DataLake
身份凭证
用于远程登录集群的Master节点。
Hello123****
登录密码和确认密码
请记录该配置,登录集群时您需要输入该密码。
Hello123****
4. 创建对象存储OSS Bucket
接下来您需要创建1个对象存储OSS Bucket,用于存储待分析的数据。
在顶部菜单栏,选择华东2(上海)地域。
在左侧导航栏,选择Bucket列表。
在Bucket列表页面,单击创建Bucket。
在创建Bucket面板,创建1个Bucket。
项目
说明
示例值
Bucket名称
Bucket 命名规范:
命名长度为3~63个字符。
只允许小写字母、数字、短横线(
-),且不能以短横线开头或结尾。Bucket名称在OSS范围内必须全局唯一。
example-bucket-data-lake
地域属性
本方案以华东2(上海)为例。
华东2(上海)
存储类型
数据会经常被访问,因此需要确保高可靠、高可用、高性能。
标准存储
读写权限
对数据的所有访问操作需要进行身份验证。
私有
配置数据分析和训练任务
30
1. 上传待分析的数据
将待分析的数据上传到OSS。
上传待分析的文件到OSS。
登录OSS管理控制台。
在左侧导航栏,选择Bucket列表。
Bucket列表页面,单击目标Bucket。
在左侧导航栏,选择文件管理 > 文件列表。
在文件列表页面,单击新建目录,新建inputs目录,然后单击上传文件,将待分析的文件上传到inputs目录下。
2. 编写数据分析作业
基于Hadoop的MapReduce框架在本地编写MR作业。
3. 创建并运行数据分析作业
在EMR集群中创建MR作业并运行。
在顶部菜单栏处,选择华东2(上海)地域。
在EMR on ECS页面,单击创建的集群的ID。
选择节点管理页签,单击emr-master节点组左侧的加号,然后单击master-1-1节点的ID。
在云服务器ECS的实例详情页面的基本信息中,单击远程连接,然后根据页面提示登录ECS。
在顶部菜单栏,选择文件 > 打开新文件管理 > root,单击上传文件,根据页面提示上传wordcountv2-1.0-SNAPSHOT.jar。
在root目录下执行以下命令创建并运行数据分析作业。
spark-submit --class com.aliyun.emr.hadoop.examples.WordCount2 wordcountv2-1.0-SNAPSHOT.jar oss://<OSS创建的Bucket名称>/inputs oss://<OSS创建的Bucket名称>/outputs
4. 上传训练数据
将待训练的数据上传到OSS。
上传待训练的文件夹到OSS。
登录OSS管理控制台。
在左侧导航栏,选择Bucket列表。
Bucket列表页面,单击目标Bucket。
在左侧导航栏,选择文件管理 > 文件列表。
在文件列表页面,然后单击上传文件,选择扫描文件夹,然后根据页面提示,上传待训练的文件夹。文件夹中的文件数量较多,请勿中途关闭上传页面,以免上传失败。
5. 创建数据集
使用OSS中的数据创建1个数据集。
登录PAI控制台。
在左侧导航栏,选择AI资产管理 > 数据集。
在数据集管理页面,单击创建数据集。
在创建数据集面板,参考下表填写参数,然后单击提交。
项目
说明
示例值
数据集名称
本文以常用数据集hymenoptera_data为例。该数据集用于图像分类任务,特别是昆虫分类。它包含了两个类别的昆虫图像:蚂蚁和蜜蜂。
hymenoptera_data
从阿里云云存储创建
选择上一步将训练数据上传到OSS Bucket后生成的文件路径。
oss://<OSS的Bucket>.oss-cn-shanghai.aliyuncs.com/hymenoptera_data/
6. 创建并运行模型训练任务
使用数据集训练1个深度学习模型。
在PAI控制台的左侧导航栏,选择模型开发与训练 > 分布式训练(DLC)。
在分布式训练页面,单击新建任务,参考下表填写参数,然后单击提交。
项目
说明
示例值
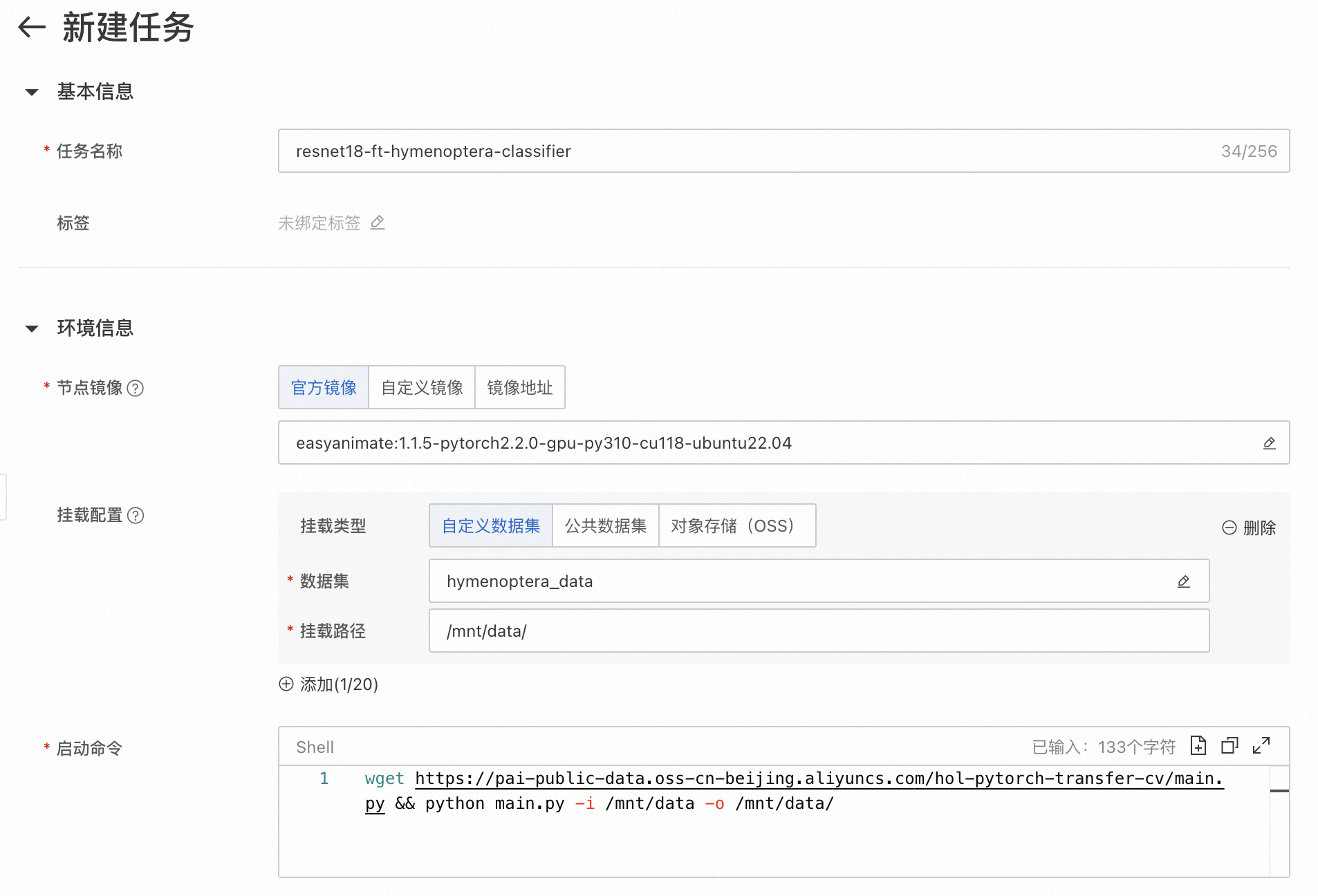
任务名称
本文要训练的模型是基于ResNet18架构进行微调的,用于图像分类任务。
resnet18-ft-hymenoptera-classifier
节点镜像
本文以pytorch社区镜像为例。
easyanimate:1.1.5-pytorch2.2.0-gpu-py310-cu118-ubuntu22.04
框架
本文以深度学习框架PyTorch为例。PyTorch提供了用于构建和训练神经网络的高级API和工具,是一个用于进行机器学习和深度学习的强大工具。
PyTorch
数据集配置
选择创建的数据集进行挂载。
hymenoptera_data
/mnt/data
执行命令
示例执行命令使用wget下载名为main.py的Python脚本文件,并通过python命令将输入目录
/mnt/data和输出目录/mnt/data/作为命令行参数传递给该脚本。wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/main.py && python main.py -i /mnt/data -o /mnt/data/任务资源
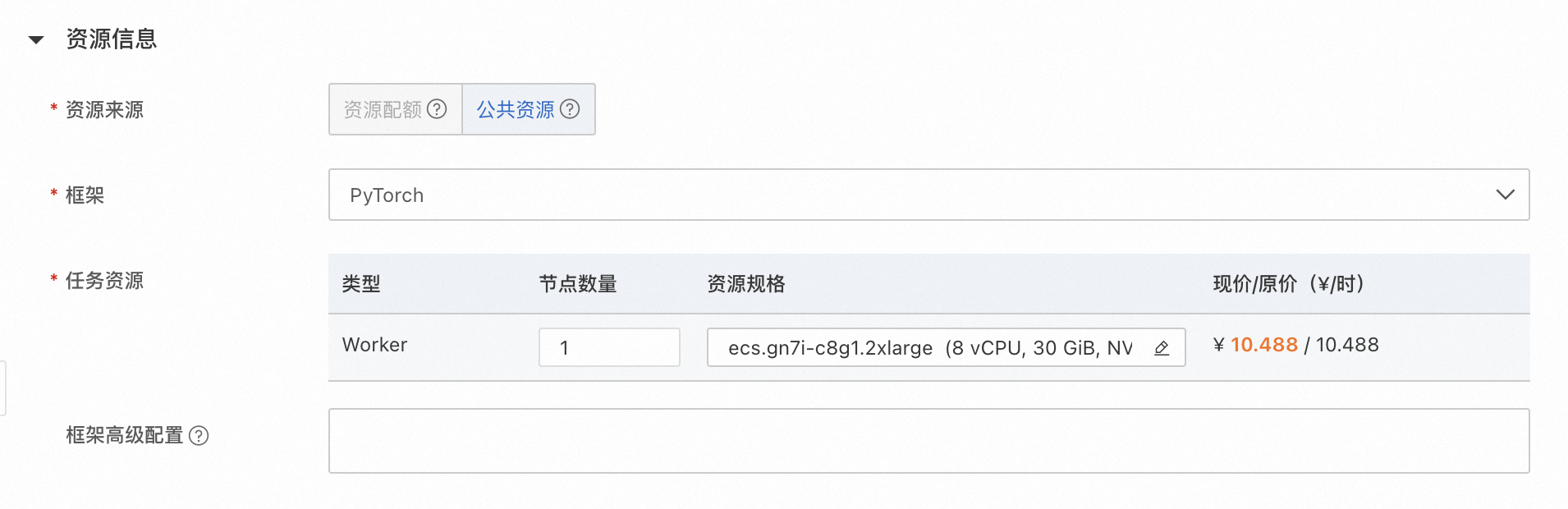
点击资源规格,在弹窗中选择GPU。
ecs.gn7i-c8g1.2xlarge
完成及清理
30
方案验证
一、通过监控大数据处理任务,验证EMR集群的数据处理能力
监控任务执行
在顶部菜单栏,选择华东2(上海)地域。
在EMR on ECS页面,单击创建的集群的ID。
选择监控诊断 > 指标监控,dashboard选择YARN-HOME。
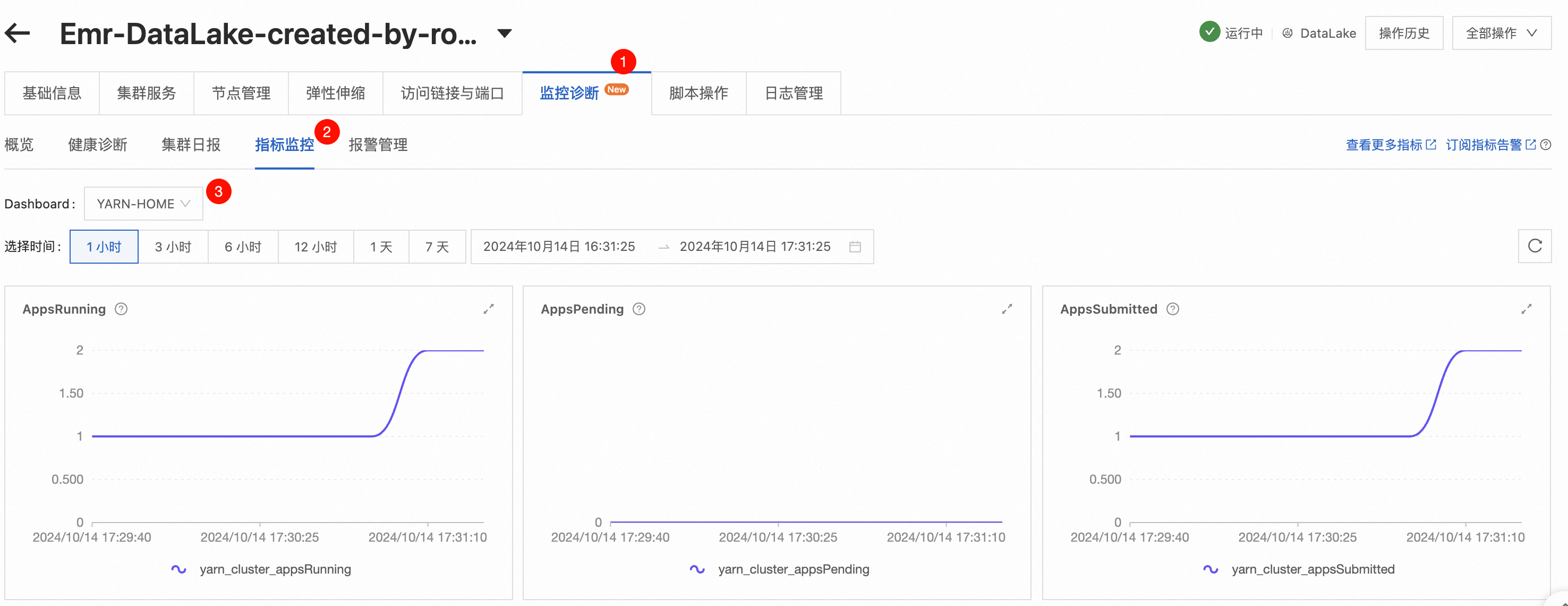
可以查看任务提交到Yarn后的执行情况。在当前页面,还可以进一步选择其他组件如Spark和HDFS,以查看它们的监控数据。这些指标和日志信息能帮助您全面了解集群的运行状态和性能表现,及时发现和解决潜在的问题。
验证数据分析结果
登录OSS管理控制台。
在左侧导航栏,选择Bucket列表。
Bucket列表页面,单击目标Bucket。
在左侧导航栏,选择文件管理 > 文件列表。
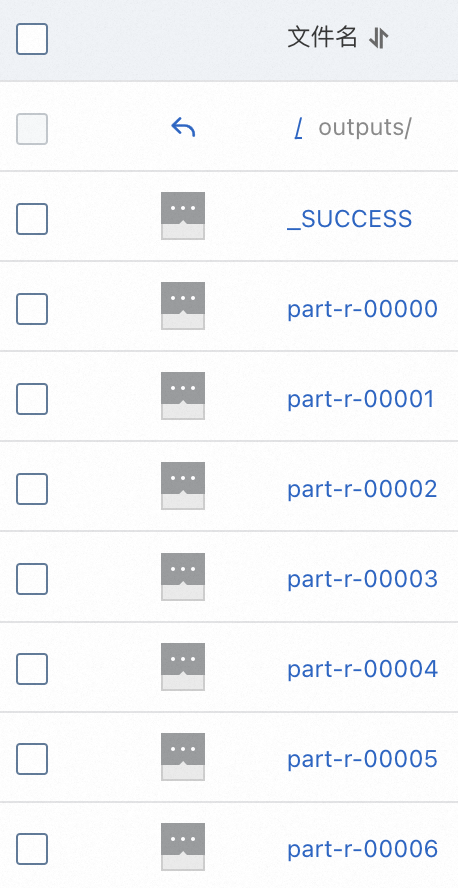
在outputs目录下,可以看到文件名为_SUCCESS,这表明MR作业执行成功;part-r开头的文件即为输出的结果文件。可以将这些结果文件下载到本地进行进一步查看和分析。
二、通过监控模型训练任务,验证PAI的模型训练能力
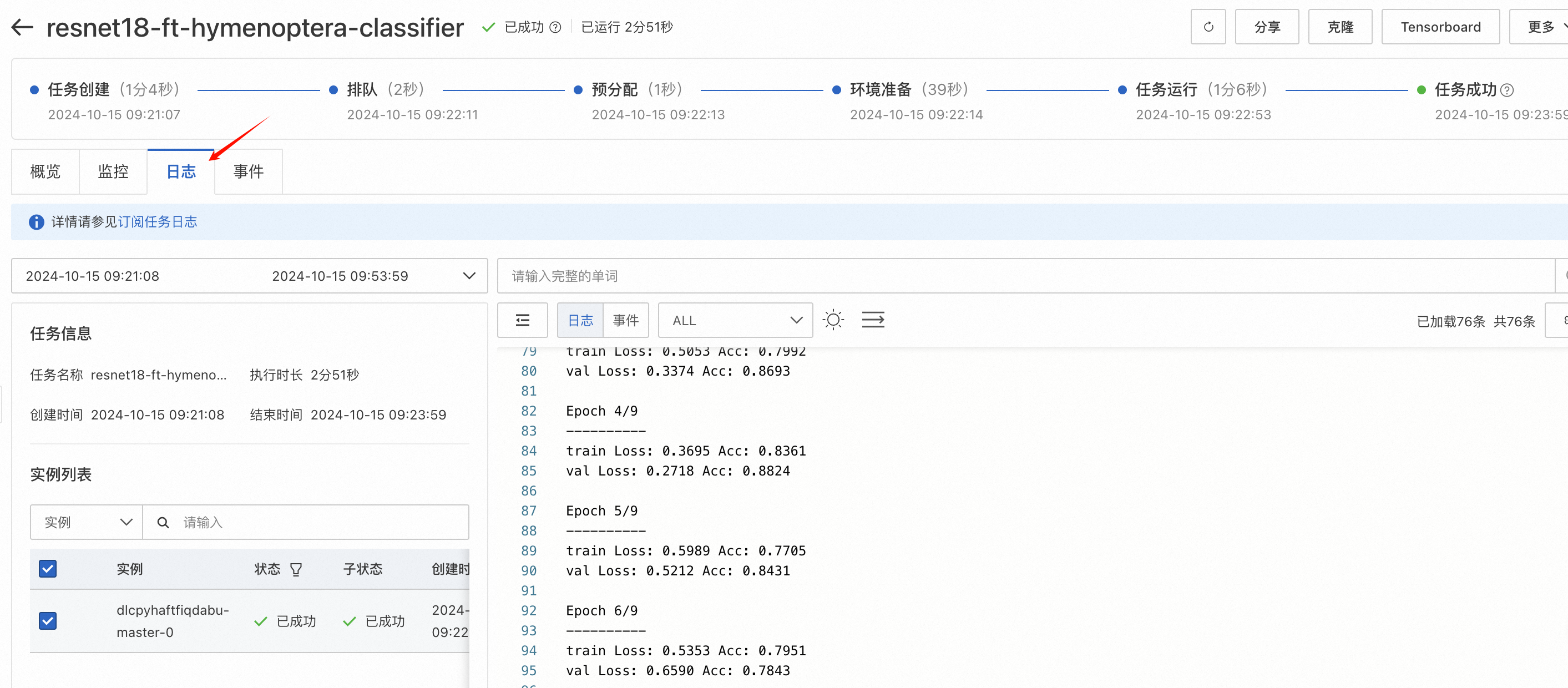
三、通过加载和测试模型文件,验证PAI模型训练结果
安装必要的依赖
确保本地环境中安装了PyTorch。如果没有安装,可以使用以下命令进行安装。
pip install torch torchvision加载并验证模型文件
将下载的模型文件model.pth加载到本地的深度学习环境中(如PyTorch),使用加载的模型进行推理,具体的代码示例如下。
import torch
import torchvision.transforms as transforms
from PIL import Image
import requests
from io import BytesIO
# 定义模型架构
from torchvision.models import resnet18
class_names = ['ant', 'bee'] # 定义类别名称:蚂蚁和蜜蜂
# 加载预训练模型并修改最后的全连接层
model = resnet18()
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, len(class_names)) # 修改最后的全连接层
# 加载预训练权重
model.load_state_dict(torch.load('model.pth', map_location=torch.device('cpu')))
model.eval() # 设置模型为评估模式
# 定义图像预处理步骤
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 下载并预处理一张测试图像(蚂蚁或蜜蜂)
url = "https://example.com/path/to/ant_or_bee_image.jpg" # 替换为实际的蚂蚁或蜜蜂图像URL
response = requests.get(url)
img = Image.open(BytesIO(response.content))
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
# 进行预测
with torch.no_grad():
out = model(batch_t)
_, predicted = torch.max(out, 1)
# 输出预测结果
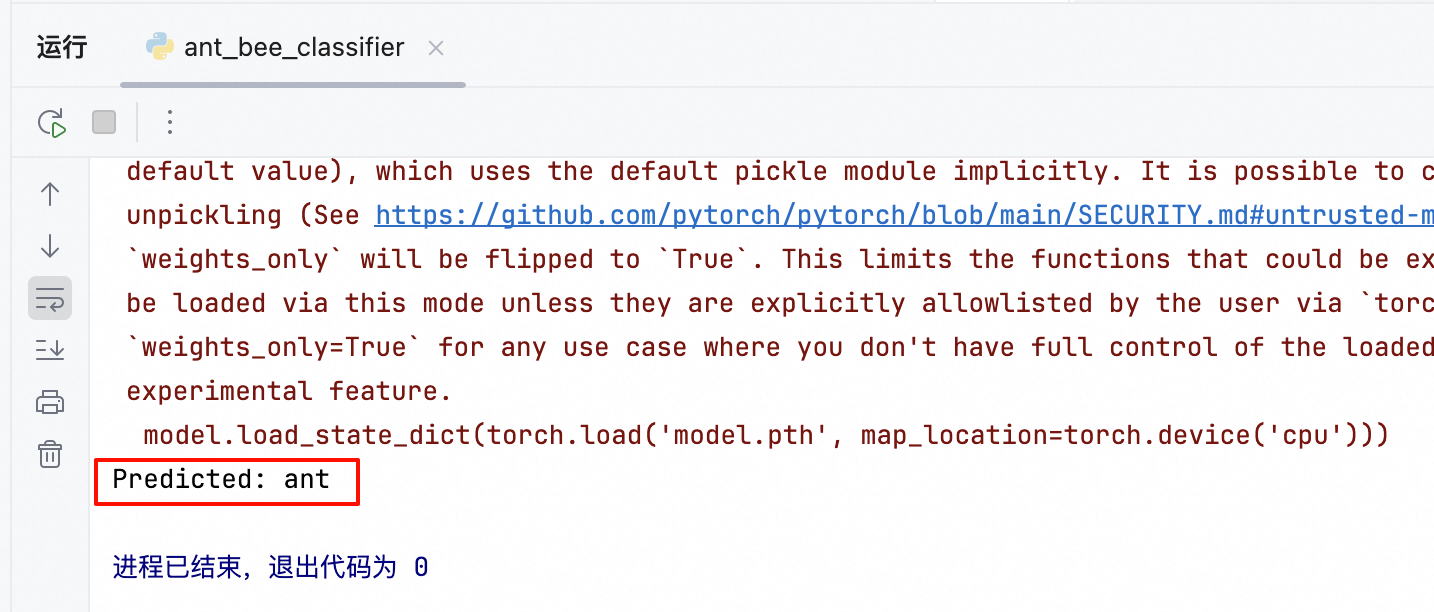
print(f'Predicted: {class_names[predicted[0]]}')代码运行后,输出预测结果如图所示。
清理资源
在本方案中,您创建了1个EMR集群、1台交换机、1个专有网络VPC、1个OSS Bucket、1个PAI工作空间和1个PAI默认工作空间。测试完方案后,您可以参考以下规则处理对应产品的实例,避免继续产生费用。其中,PAI按量付费,您无需考虑释放工作空间。
删除EMR集群:
登录EMR on ECS控制台,在EMR on ECS页面,找到目标EMR集群,然后在操作列选择
 > 释放,根据界面提示释放集群。
> 释放,根据界面提示释放集群。
一键部署
80
https://www.aliyun.com/solution/tech-solution/datalake
方案概览
基于对象存储OSS构建的数据湖,可对接多种数据输入方式,存储任何规模的结构化、半结构化、非结构化数据,打破数据湖孤岛;无缝对接多种数据分析产品,对存储在对象存储OSS中的数据直接进行数据分析和机器学习,洞察业务价值。同时,数据湖提供多种存储类型的冷热分层转换能力,通过数据全生命周期管理优化存储成本。
本技术解决方案以搭建一个大数据分析服务和一个机器学习服务为例,为您演示:
如何使用OSS中的数据完成一个大数据分析任务
如何使用OSS中的数据训练一个深度学习模型
方案架构
方案提供的默认设置完成部署后在阿里云上搭建的运行环境如下图所示(蓝色高亮部分)。实际部署时您可以根据资源规划修改部分设置,但最终形成的运行环境与下图相似。
本方案以大数据分析场景和机器学习场景为例。本方案的技术架构包括以下基础设施和云服务:
1个对象存储OSS:提供数据存储。
1个EMR集群:提供大数据计算引擎。
1个PAI:提供机器学习引擎。
部署准备
10
开始部署前,请按以下指引完成账号申请、账号充值、服务开通、RAM用户创建和授权。
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面,根据页面提示完成注册。阿里云账号是您使用云资源的付费实体,因此是部署方案的必要前提。
为节省成本,本方案默认选择使用按量付费及抢占式资源,使用按量付费资源需要确保账户余额不小于100元。
完成本方案的部署及体验,预计产生费用不超过5元(假设您选择最低规格资源,且资源运行时间不超过30分钟。如调整了资源规格,请以控制台显示的实际报价以及最终账单为准)。
序号
产品
费用来源
规格
地域
预估费用参考
说明
1
对象存储OSS
标准存储(本地冗余)容量(Storage)费
-
华东2(上海)
0.12元/GB/月
测试数据量较少
PUT类或GET类请求费
-
华东2(上海)
0.01元/万次
测试请求量较少
2
阿里云E-MapReduce
ECS产品费用
ecs.g6.xlarge*3
华东2(上海)
3.0元/小时
E-MapReduce服务费用
ecs.g6.xlarge*3
华东2(上海)
0.45元/小时
3
人工智能平台PAI
DLC深度学习训练费用
ecs.g6.xlarge*1
华东2(上海)
1.1元/小时
按量费用:4.71元/时
创建用于方案部署的RAM用户。
创建1个RAM用户。具体操作,请参见创建RAM用户。
为RAM用户授予以下云服务的访问权限以完成方案部署。具体操作,请参见为RAM用户授权。
云服务
需要的权限
描述
云服务器ECS
AliyunECSFullAccess
管理云服务器ECS的权限
专有网络VPC
AliyunVPCFullAccess
管理专有网络VPC的权限
对象存储OSS
AliyunOSSFullAccess
管理对象存储OSS权限
E-MapReduce
AliyunEMRFullAccess
管理E-MapReduce的权限
机器学习PAI
AliyunPAIFullAccess
管理机器学习(PAI)的权限
资源编排服务ROS
AliyunROSFullAccess
管理资源编排服务ROS的权限
运维编排服务OOS
AliyunOOSFullAccess
管理运维编排服务OOS的权限
配额Quotas
AliyunQuotasFullAccess
管理配额Quotas的权限
访问控制RAM
AliyunRAMFullAccess
管理访问控制RAM的权限,即管理用户以及授权的权限
标签服务TAG
AliyunTagManagerAccess
管理标签服务TAG的权限
一键部署
50
一键部署基于阿里云资源编排服务ROS(Resource Orchestration Service)实现,ROS模板已定义好脚本,可自动化地完成云资源的创建和配置,提高资源的创建和部署效率。ROS模板完成的内容包括:
操作步骤
您可以通过下方提供的ROS一键部署链接,来自动化地完成这些资源的创建和配置:
创建1个对象存储OSS Bucket。
创建并绑定1个EMR集群
创建1个PAI工作空间
一键部署EMR集群和OSS Bucket。
打开一键部署链接,并选择华东2(上海)地域。
在配置模板参数页面上修改资源栈名称,配置EMR集群、OSS Bucket、PAI工作空间,然后单击创建开始一键配置。
当资源栈信息页面的状态显示为创建成功时表示一键配置完成。
上传待分析的数据。
上传待分析的文件到OSS。
登录OSS管理控制台。
在左侧导航栏,选择Bucket列表。
Bucket列表页面,单击目标Bucket。
在左侧导航栏,选择文件管理 > 文件列表。
在文件列表页面,单击新建目录,新建inputs目录,然后单击上传文件,将待分析的文件上传到inputs目录下。
编写数据分析作业。
创建并运行数据分析作业。
在顶部菜单栏处,选择华东2(上海)地域。
在EMR on ECS页面,单击创建的集群的ID。
选择节点管理页签,单击emr-master节点组左侧的加号,然后单击master-1-1节点的ID。
在云服务器ECS的实例详情页面的基本信息中,单击远程连接,然后根据页面提示登录ECS。
在顶部菜单栏,选择文件 > 打开新文件管理 > root,单击上传文件,根据页面提示上传wordcountv2-1.0-SNAPSHOT.jar。
在root目录下执行以下命令创建并运行数据分析作业。
spark-submit --class com.aliyun.emr.hadoop.examples.WordCount2 wordcountv2-1.0-SNAPSHOT.jar oss://<OSS创建的Bucket名称>/inputs oss://<OSS创建的Bucket名称>/outputs
上传待训练的数据。
上传待训练的文件夹到OSS。
登录OSS管理控制台。
在左侧导航栏,选择Bucket列表。
Bucket列表页面,单击目标Bucket。
在左侧导航栏,选择文件管理 > 文件列表。
在文件列表页面,然后单击上传文件,选择扫描文件夹,然后根据页面提示,上传待训练的文件夹。文件夹中的文件数量较多,请勿中途关闭上传页面,以免上传失败。
创建数据集。
登录PAI控制台。
在左侧导航栏,选择AI资产管理 > 数据集。
在数据集管理页面,单击创建数据集。
在创建数据集面板,参考下表填写参数,然后单击提交。
项目
说明
示例值
数据集名称
本文以常用数据集hymenoptera_data为例。该数据集用于图像分类任务,特别是昆虫分类。它包含了两个类别的昆虫图像:蚂蚁和蜜蜂。
hymenoptera_data
从阿里云云存储创建
选择上一步将训练数据上传到OSS Bucket后生成的文件路径。
oss://<OSS的Bucket>.oss-cn-shanghai.aliyuncs.com/hymenoptera_data/
创建并运行模型训练任务。
在PAI控制台的左侧导航栏,选择模型开发与训练 > 分布式训练(DLC)。
在分布式训练页面,单击新建任务,参考下表填写参数,然后单击提交。
项目
说明
示例值
任务名称
本文要训练的模型是基于ResNet18架构进行微调的,用于图像分类任务。
resnet18-ft-hymenoptera-classifier
节点镜像
本文以pytorch社区镜像为例。
easyanimate:1.1.5-pytorch2.2.0-gpu-py310-cu118-ubuntu22.04
框架
本文以深度学习框架PyTorch为例。PyTorch提供了用于构建和训练神经网络的高级API和工具,是一个用于进行机器学习和深度学习的强大工具。
PyTorch
数据集配置
选择创建的数据集进行挂载。
hymenoptera_data
/mnt/data
执行命令
示例执行命令使用wget下载名为main.py的Python脚本文件,并通过python命令将输入目录
/mnt/data和输出目录/mnt/data/作为命令行参数传递给该脚本。wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/main.py && python main.py -i /mnt/data -o /mnt/data/任务资源
点击资源规格,在弹窗中选择GPU。
ecs.gn7i-c8g1.2xlarge
验证及清理
20
方案验证
一、通过监控大数据处理任务,验证EMR集群的数据处理能力
监控任务执行
在顶部菜单栏,选择华东2(上海)地域。
在EMR on ECS页面,单击创建的集群的ID。
选择监控诊断 > 指标监控,dashboard选择YARN-HOME。
可以查看任务提交到Yarn后的执行情况。在当前页面,还可以进一步选择其他组件如Spark和HDFS,以查看它们的监控数据。这些指标和日志信息能帮助您全面了解集群的运行状态和性能表现,及时发现和解决潜在的问题。
验证数据分析结果
登录OSS管理控制台。
在左侧导航栏,选择Bucket列表。
Bucket列表页面,单击目标Bucket。
在左侧导航栏,选择文件管理 > 文件列表。
在outputs目录下,可以看到文件名为_SUCCESS,这表明MR作业执行成功;part-r开头的文件即为输出的结果文件。可以将这些结果文件下载到本地进行进一步查看和分析。
二、通过监控模型训练任务,验证PAI的模型训练能力
三、通过加载和测试模型文件,验证PAI模型训练结果
安装必要的依赖
确保本地环境中安装了PyTorch。如果没有安装,可以使用以下命令进行安装。
pip install torch torchvision加载并验证模型文件
将下载的模型文件model.pth加载到本地的深度学习环境中(如PyTorch),使用加载的模型进行推理,具体的代码示例如下。
import torch
import torchvision.transforms as transforms
from PIL import Image
import requests
from io import BytesIO
# 定义模型架构
from torchvision.models import resnet18
class_names = ['ant', 'bee'] # 定义类别名称:蚂蚁和蜜蜂
# 加载预训练模型并修改最后的全连接层
model = resnet18()
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, len(class_names)) # 修改最后的全连接层
# 加载预训练权重
model.load_state_dict(torch.load('model.pth', map_location=torch.device('cpu')))
model.eval() # 设置模型为评估模式
# 定义图像预处理步骤
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 下载并预处理一张测试图像(蚂蚁或蜜蜂)
url = "https://example.com/path/to/ant_or_bee_image.jpg" # 替换为实际的蚂蚁或蜜蜂图像URL
response = requests.get(url)
img = Image.open(BytesIO(response.content))
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
# 进行预测
with torch.no_grad():
out = model(batch_t)
_, predicted = torch.max(out, 1)
# 输出预测结果
print(f'Predicted: {class_names[predicted[0]]}')代码运行后,输出预测结果如图所示。
清理资源
在本方案中,您创建了1个EMR集群、1台交换机、1个专有网络VPC、1个OSS Bucket、1个PAI工作空间和1个PAI默认工作空间。测试完方案后,您可以参考以下规则处理对应产品的实例,避免继续产生费用。其中,PAI按量付费,您无需考虑释放默认工作空间。
登录ROS控制台。
在左侧导航栏,选择资源栈。
在资源栈页面的顶部选择部署的资源栈所在地域,找到资源栈,然后在其右侧操作列,单击删除。
在删除资源栈对话框,选择删除方式为释放资源,然后单击确定,根据提示完成资源释放。