一键训练大模型及部署 GPU 共享推理服务
一键部署
80
https://www.aliyun.com/solution/tech-solution/one_gpu
方案概览
大模型训练和推理是机器学习和深度学习领域的重要应用,但企业和个人往往面临着 GPU 管理复杂、资源利用率低,以及 AI 作业全生命周期管理中工程效率低下等挑战。本方案通过创建ACK集群Pro版,使用云原生AI套件提交模型微调训练任务与部署GPU 共享推理服务。适用于机器学习和深度学习任务中的以下场景:
模型训练:基于 Kubernetes 集群微调开源模型,可以屏蔽底层资源和环境的复杂度,快速配置训练数据、提交训练任务,并自动运行和保存训练结果。
模型推理:基于 Kubernetes 集群部署推理服务,可以屏蔽底层资源和环境的复杂度,快速将微调后的模型部署成推理服务,将模型应用到实际业务场景中。
AI 作业生命周期管理:命令行工具 Arena 实现 AI 作业生命周期管理,包括模型训练、模型评测、模型推理等环节。Arena 可以完全屏蔽底层资源和环境管理、任务调度、GPU 分配和监控的复杂性,兼容主流AI框架和工具,例如 TensorFlow ,还提供多种语言 SDK ,便于您二次开发。
GPU 共享推理:支持 GPU 共享调度能力和显存隔离能力,可将多个推理服务部署在同一块GPU 卡上,提高 GPU 的利用率的同时也能保证推理服务的稳定运行。
方案架构
方案提供的默认设置完成部署后在阿里云上搭建的网站运行环境如下图所示。实际部署时您可以根据资源规划修改部分设置,但最终形成的运行环境与下图相似。
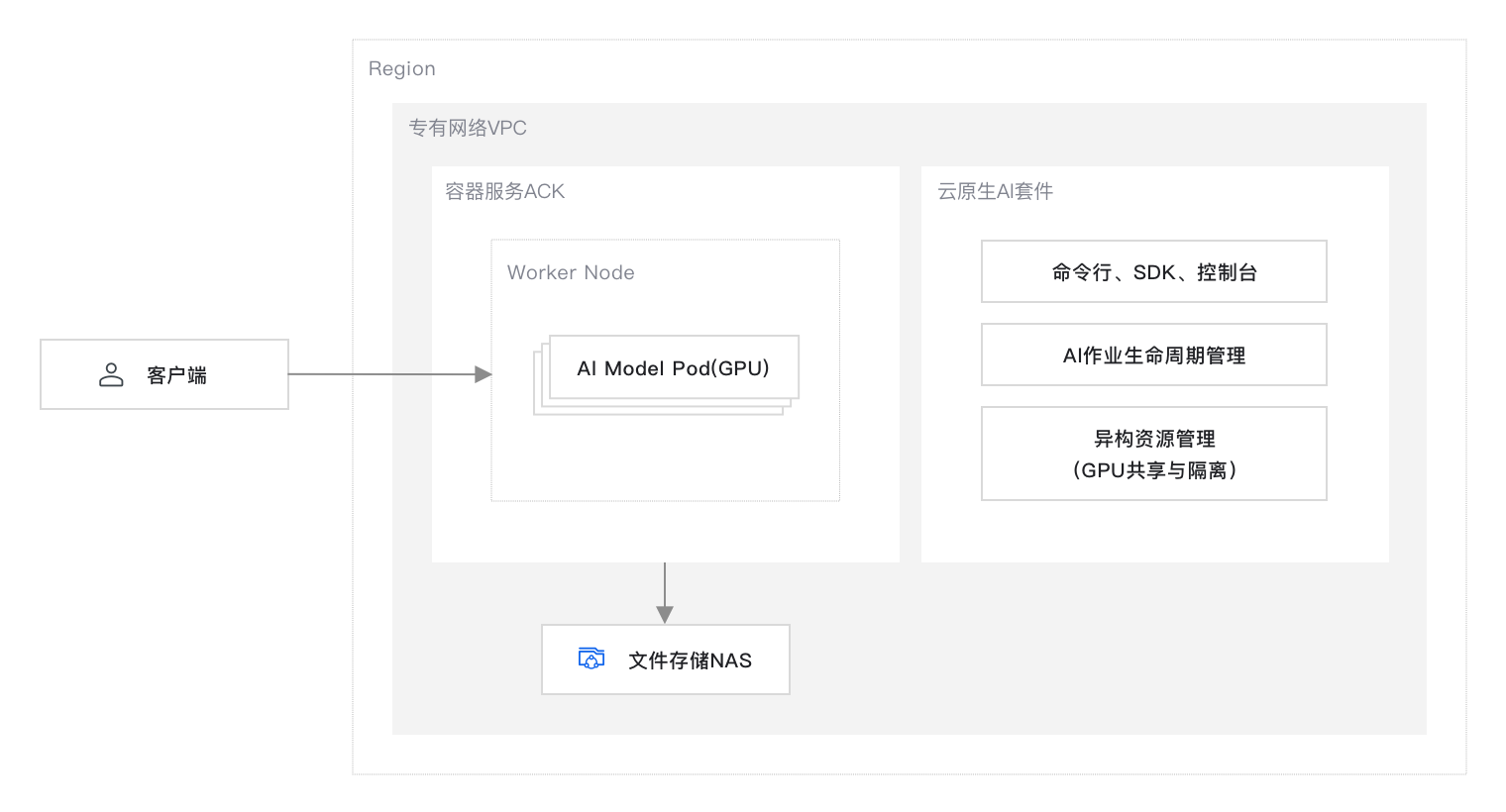
本方案的技术架构包括以下基础设施和云服务:
1 个地域:ACK 集群、云原生AI套件、文件存储 NAS 均部署在同一地域下。
1 个专有网络 VPC :为 ACK 、NAS 、云原生 AI 套件等云资源形成云上私有网络。
1 个ACK集群Pro版:简单、低成本、高可用的 Kubernetes 集群,支持应用管理,无需您管理控制面板。
云原生AI套件:容器服务 Kubernetes 版提供的云原生AI 技术和产品方案,以 Kubernetes 容器服务为底座,支持大模型训练及 GPU 共享推理服务部署。
1 个 NAS 实例:可共享访问,弹性扩展,高可靠,高性能的分布式文件系统,支持共享访问。
部署准备
10
开始部署前,请按以下指引完成账号申请、账号充值、RAM 用户创建和授权。
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面,根据页面提示完成注册。阿里云账号是您使用云资源的付费实体,因此是部署方案的必要前提。
为阿里云账号充值。本方案的云资源支持按量付费,且默认设置均采用按量付费引导操作。请确保您的账户余额大于等于 100 元。
阿里云账号拥有操作资源的最高权限,从云资源安全角度考虑,建议您创建 RAM 用户。RAM 用户需要获得相关云服务的访问权限才能完成方案部署,详情如下:
访问 RAM 控制台-用户页面,单击创建用户,填写相关信息,勾选控制台访问和 OpenAPI 调用访问,自定义密码并选择无需重置密码,创建一个 RAM 用户。
在 RAM 用户列表的操作列,单击目标RAM用户对应的添加权限。在添加权限面板,在选择权限策略的系统策略区域,搜索并新增如下权限,然后单击确定。
涉及的云服务:资源编排 ROS 、容器服务 Kubernetes 版、专有网络 VPC、云服务器 ECS、访问控制 RAM、费用中心 BSS、文件存储 NAS、弹性公网 IP、NAT 网关、Cloud Shell 。
每次支持最多绑定5条策略,请分多次操作添加如下权限。
云服务
需要的权限
描述
资源编排 ROS
AliyunROSFullAccess
管理资源编排服务 ROS 的权限。
容器服务 Kubernetes 版
AliyunCSFullAccess
首次登录容器服务 Kubernetes 版时,需要为服务账号授予的系统默认角色。
专有网络 VPC
AliyunVPCFullAccess
管理专有网络 VPC 的权限。
云服务器 ECS
AliyunECSFullAccess
管理云服务器服务 ECS 的权限。
访问控制 RAM
AliyunRAMFullAccess
管理访问控制 RAM 的权限,即管理用户以及授权的权限。
费用中心 BSS
AliyunBSSReadOnlyAccess
只读访问费用中心 BSS 的权限。
文件存储 NAS
AliyunNASFullAccess
管理文件存储 NAS 的权限。
弹性公网 IP
AliyunEIPFullAccess
管理弹性公网 IP(EIP)的权限。
NAT 网关
AliyunNATGatewayFullAccess
管理 NAT 网关(NAT Gateway)的权限。
弹性伸缩服务 ESS
AliyunESSFullAccess
管理弹性伸缩服务(ESS)的权限
Cloud Shell
AliyunCloudShellFullAccess
管理云命令行(Cloud Shell)的权限。
创建 RAM 用户后,您可以使用 RAM 用户登录阿里云控制台,开始本方案的部署和体验。
RAM 用户的使用请参见创建 RAM 用户、创建自定义权限策略和为 RAM 用户授权。
单击云资源访问权限,然后单击同意授权。
此页权限为可供容器服务 ACK 使用的角色。授权后,ACK 拥有对您云资源相应的访问权限。
一键部署
10
您可以通过下方提供的 ROS 一键部署链接,来自动化地完成以下资源的创建和配置。部署完成后,您可以参见教程实现并体验如何训练大模型以及部署 GPU 共享推理服务。
创建一个名为 ai-test 的ACK集群Pro版
创建一个容量型 NAS 实例
ROS 部署前置资源
单击一键部署前往 ROS 控制台,系统自动打开使用新资源创建资源栈的面板。在页面最上方选择部署地域,例如华东 1(杭州),然后设置配置项,单击创建。
说明因资源量有限,可能会出现所选地域下无可选可用区的情况,您可以切换部署地域如华北 2(北京)、西南 1(成都)继续尝试。
配置项
说明
示例
资源栈名称
支持自定义。
stack_2023-06-12_cBesTX8FB
集群名称
支持自定义。不能与现有 ACK集群重名。
ai-test
可用区
选择集群可用区。本方案使用一台指定规格的 ECS 实例作为节点,备选实例规格包括ecs.gn6i-c24g1.12xlarge 、
ecs.gn6v-c8g1.4xlarge 或
ecs.gn6i-c24g1.24xlarge 。如果当前可用区为空,请切换地域重新选择。
可用区 K
设置节点登录密码
设置节点登录密码。
自行设置
NAS 可用区
选择 NAS 可用区。
可选任意可用区
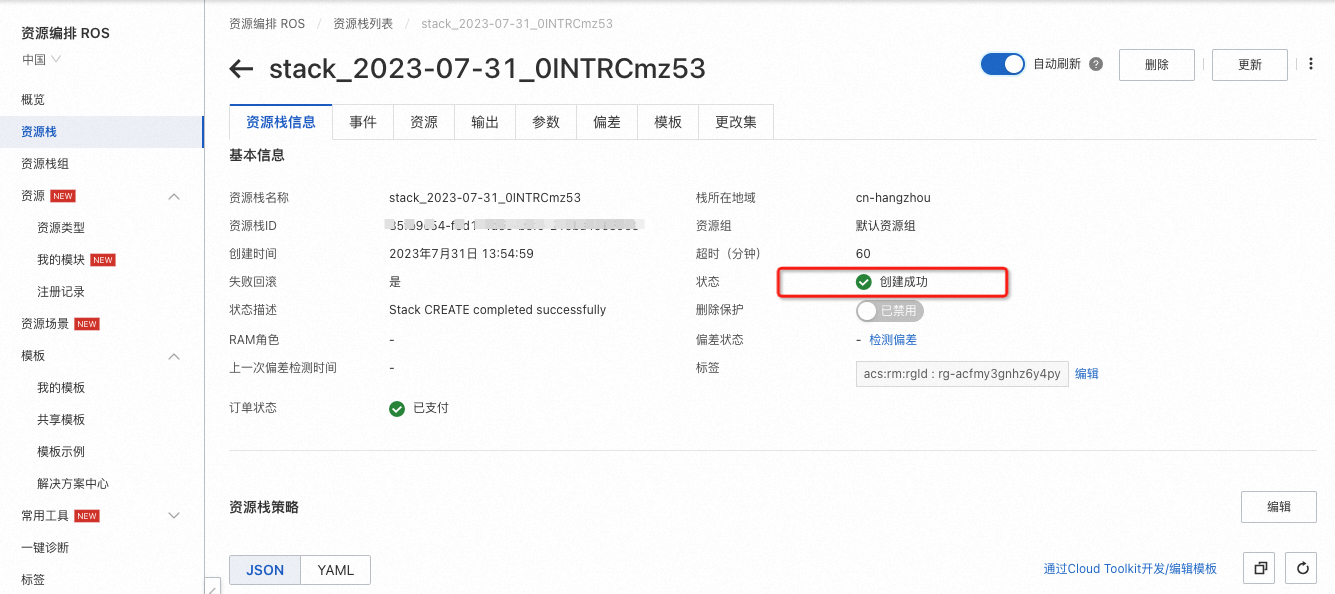
在页面右上角,打开自动刷新开关,每隔 5 秒自动刷新一次,观察资源创建情况。
在资源栈信息页签,显示状态为创建成功,表示快速创建成功。
若在资源栈信息页签,显示状态不为创建成功,表示快速创建不成功。可以根据界面提示单击创建一键诊断,查看详细信息。
安装云原生AI套件
5
登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,单击目标集群ai-test,然后在左侧导航栏,选择应用>云原生 AI 套件。
说明如果首次使用云原生AI套件,需要先单击开通服务。
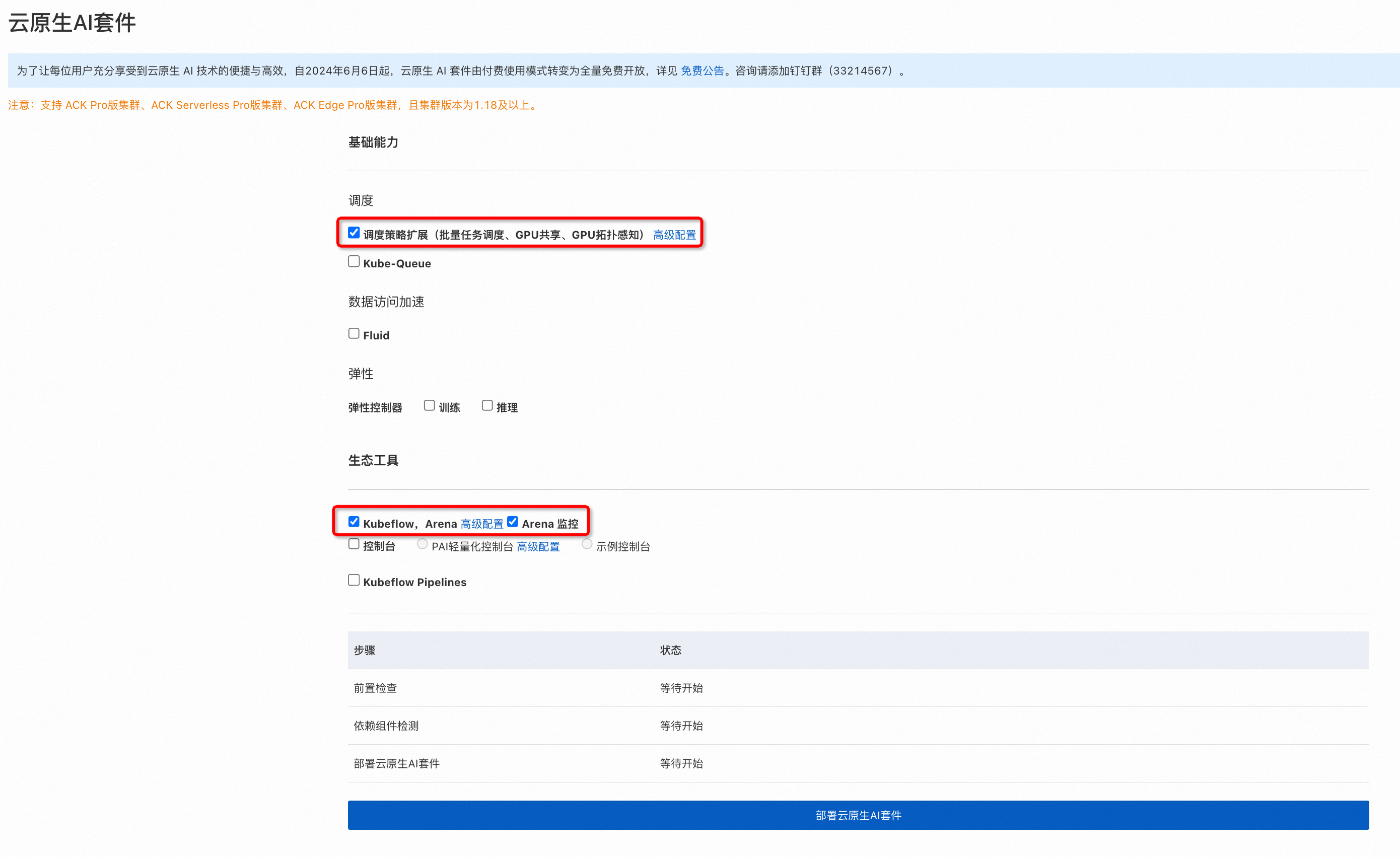
在云原生 AI 套件页面,单击一键部署。
在部署页面,参考下图所示完成设置。然后单击部署云原生 AI 套件。
配置NAS共享存储并下载数据
20
1. 查找 NAS 实例的挂载点
登录文件存储 NAS 控制台,在左侧导航栏选择文件系统 > 文件系统列表,在页面顶部选择创建的 NAS 实例所在区域。
在文件系统列表页面,找到系统自动 ROS 自动创建的NAS实例,即在文件系统 ID 列包含 ack-ai-nas 的 NAS 文件系统。
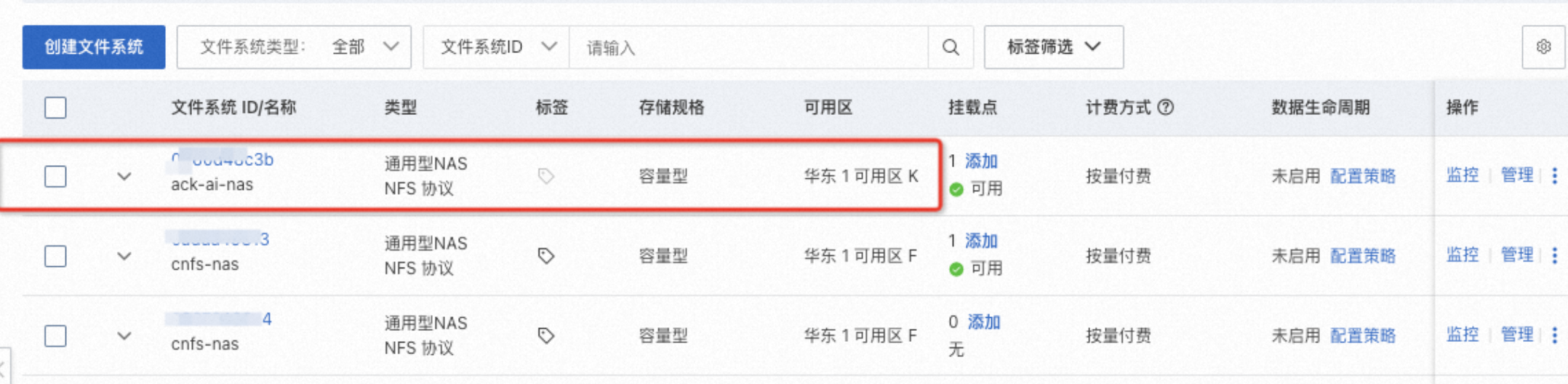
单击目标文件系统 ID 进入文件详情页面,单击挂载使用,在挂载点地址和挂载命令列,复制并记录此处的值供后续步骤使用。
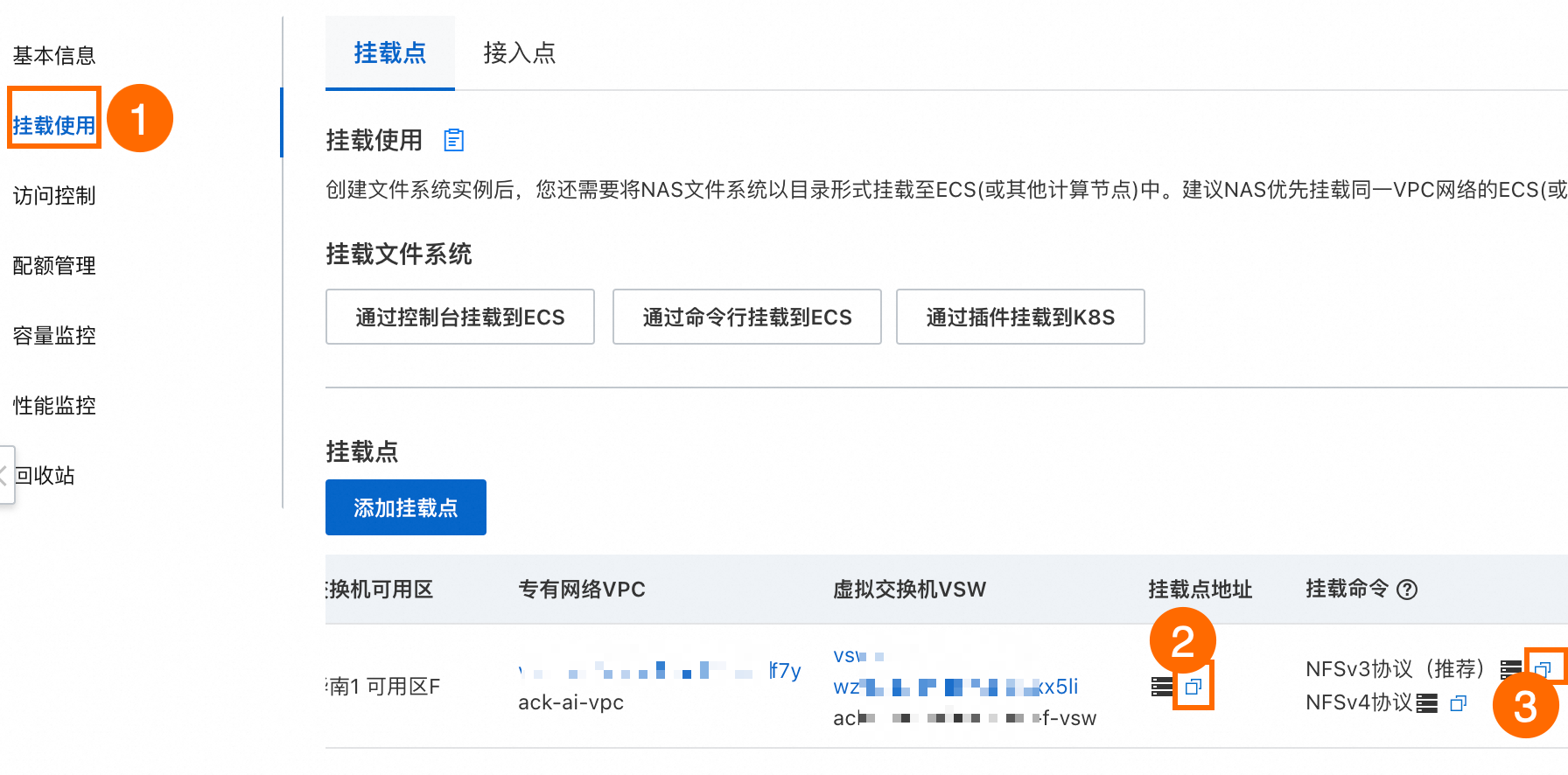
2. 配置目标 ai-test 集群的存储卷 PV 和存储声明 PVC
登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,单击目标集群 ai-test ,然后在左侧导航栏,选择存储 > 存储卷。
在存储卷页面右上方,单击创建。
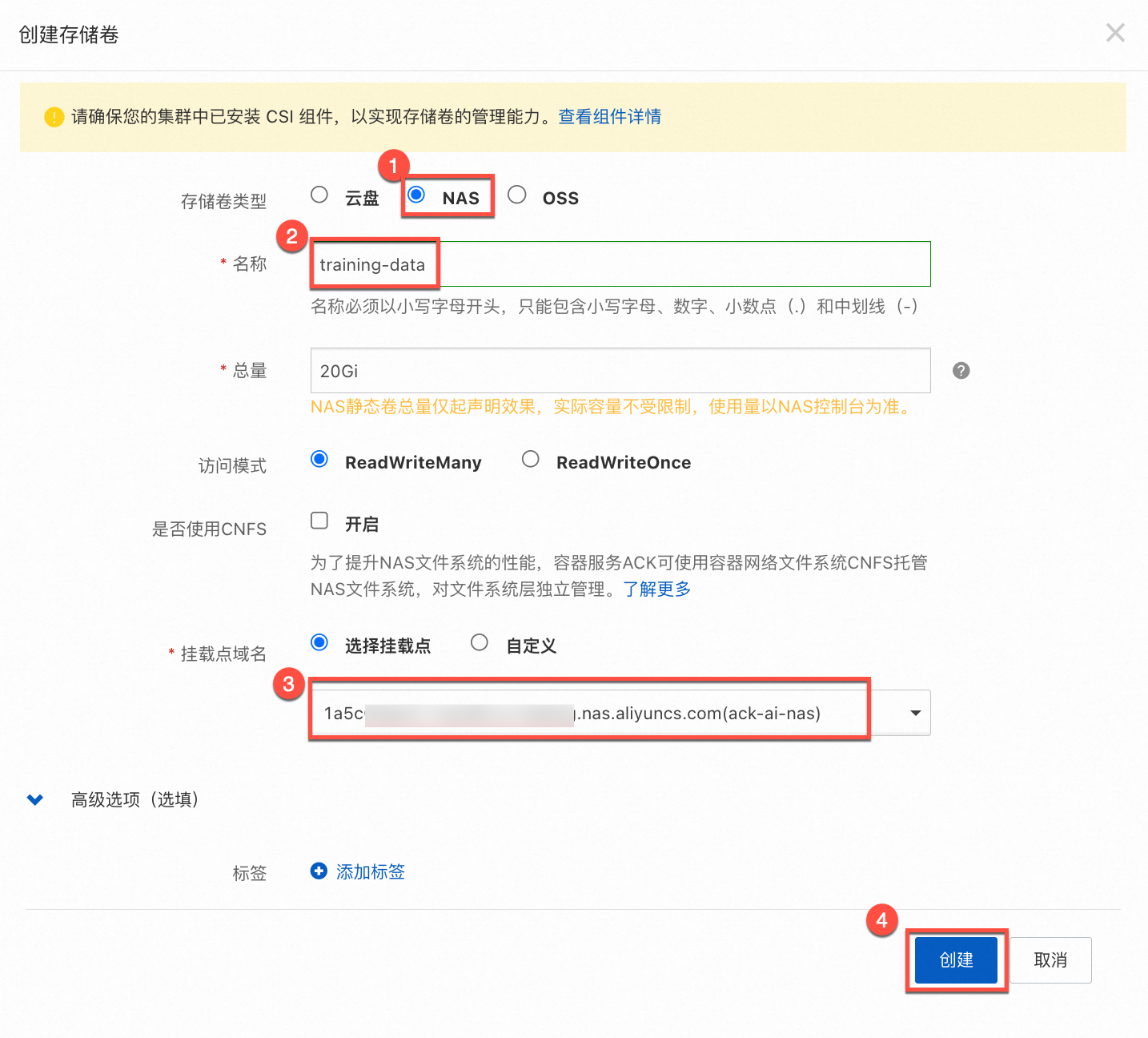
在创建存储卷对话框中,参考如下图示进行参数配置,选择挂载点域名为您上一步查询的挂载点地址,然后单击创建,创建名为 training-data 的存储卷。
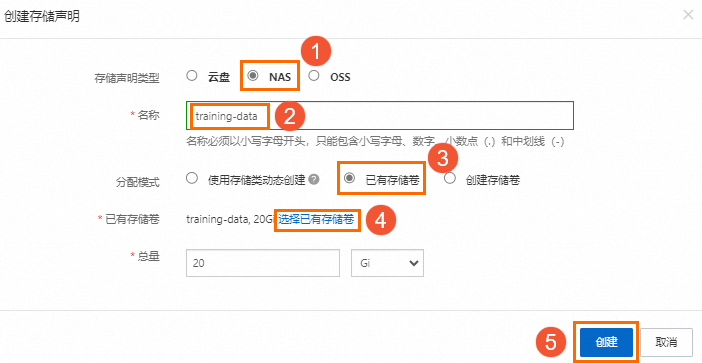
在左侧导航栏,选择存储 > 存储声明,在存储声明页面,单击创建,在创建存储声明对话框中,参考如下图示进行参数配置,然后单击创建,创建名为 training-data 的存储声明。
3. 下载数据到 NAS 中
登录 ECS 管理控制台。
在顶部菜单栏,选择华东 1(杭州)地域。
在左侧导航栏,选择实例与镜像>实例。
登录 ECS 控制台。
在实例页面,找到创建的一台 ECS 实例,在其右侧操作列,单击远程连接。
在远程连接对话框的通过 Workbench 远程连接区域,单击立即登录,然后根据页面提示登录。
使用前面记录复制的 NAS 文件的挂载命令,挂载 NAS 。
sudo mount -t nfs -o vers=3,nolock,proto=tcp,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport 0bbfb4915a-sdm14.cn-hangzhou.nas.aliyuncs.com:/ /mnt执行以下命令,下载 bloom 模型和训练数据。
cd /mnt/ wget http://ai-training-data.oss-cn-hangzhou.aliyuncs.com/bloom-560m-sft-data.tar出现如下提示,表明数据下载完成。

然后执行以下命令,解压下载文件。
tar -xvf bloom-560m-sft-data.tar
4. 在 GPU 节点上配置集群证书
登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,单击目标集群 ai-test 进入集群信息页面,单击连接信息,在内网访问页签下,复制内网访问凭证。
执行以下命令,将集群的内网访问的证书内容复制到节点的 config 文件中。
mkdir -p ~/.kube vi ~/.kube/config
5. 在 GPU 节点上安装 arena 客户端
执行下列命令,在 GPU 节点上安装 arena 客户端。
# 下载arena客户端并安装
cd /root && wget https://aliacs-k8s-cn-hongkong.oss-cn-hongkong.aliyuncs.com/arena/arena-installer-0.9.9-ce4a78d-linux-amd64.tar.gz
tar -xzvf arena-installer-0.9.9-ce4a78d-linux-amd64.tar.gz
cd arena-installer
bash install.sh --only-binary出现如下提示,表明 arena 客户端安装成功。

方案验证
20
执行以下命令,提交一个 Bloom 模型的微调训练任务。训练任务大概需要运行 8 分钟。
arena submit pytorchjob \ --name=bloom-sft \ --gpus=2 \ --image=registry.cn-hangzhou.aliyuncs.com/acs/deepspeed:v0.9.0-chat \ --data=training-data:/model \ --tensorboard \ --logdir=/model/logs \ "cd /model/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning && bash training_scripts/other_language/run_chinese.sh /model/bloom-560m-sft"训练任务提交成功后,任务状态将显示 RUNNING 。
执行以下命令,查看当前通过 Arena 提交的所有作业。
arena list预期输出:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE bloom-sft RUNNING PYTORCHJOB 17m 2 2 192.168.XX.XX执行以下命令,获取作业详情。
arena get bloom-sft预期输出:
Name: bloom-sft Status: RUNNING Namespace: default Priority: N/A Trainer: PYTORCHJOB Duration: 1m CreateTime: 2023-07-20 15:06:19 EndTime: Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- bloom-sft-master-0 Running 1m true 2 cn-hangzhou.192.168.XX.XX Tensorboard: Your tensorboard will be available on: http://192.168.XX.XX:32560记录此处 GPU 节点名称 cn-hangzhou.192.168.XX.XX ,用于后续部署推理服务。同时,记录此处 Tensorboard 的 Web 服务地址 http://192.168.XX.XX:32560 ,此处端口号为32560 ,以您的输出显示为准。
将上一步记录的端口号加入 GPU 实例的入方向安全组,例如 32560 。
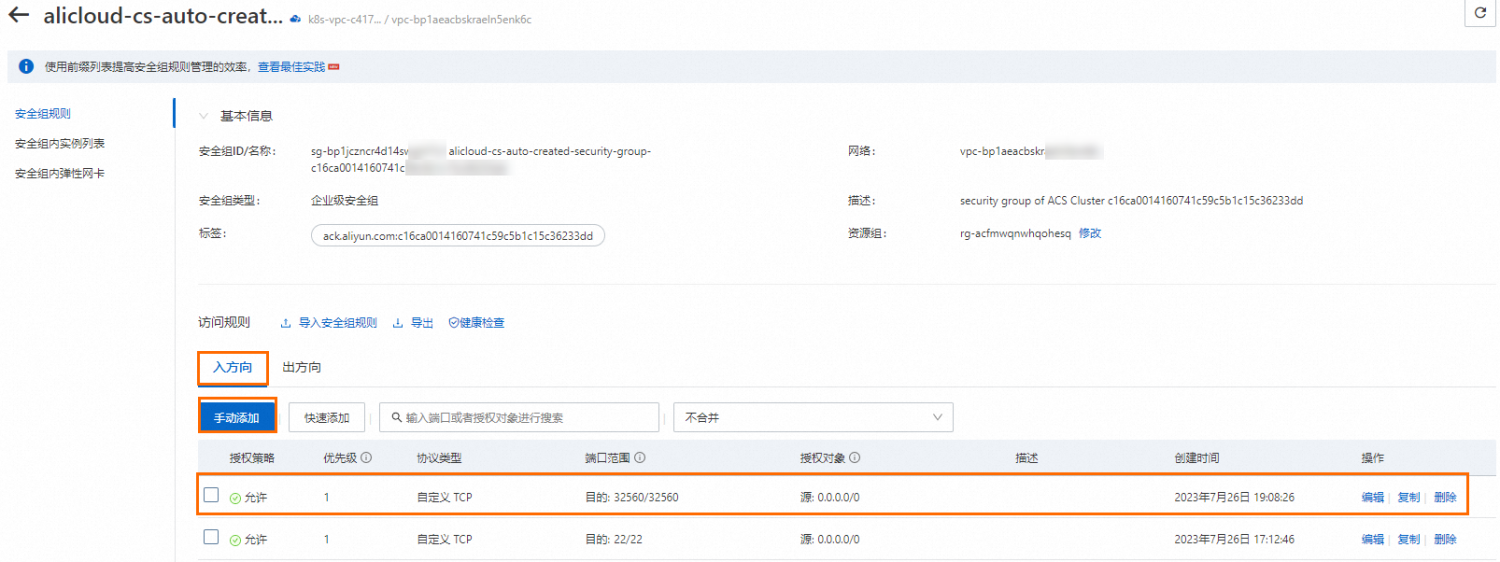
通过浏览器访问 Tensorboard 。在浏览器中输入 http://121.41.XX.XX:32560 ,此处将 IP地址替换为 GPU 节点公网 IP 。
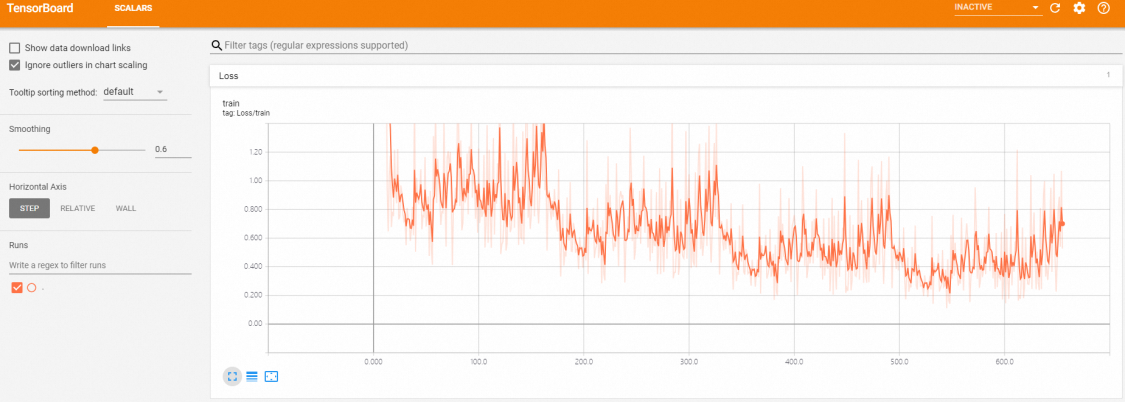
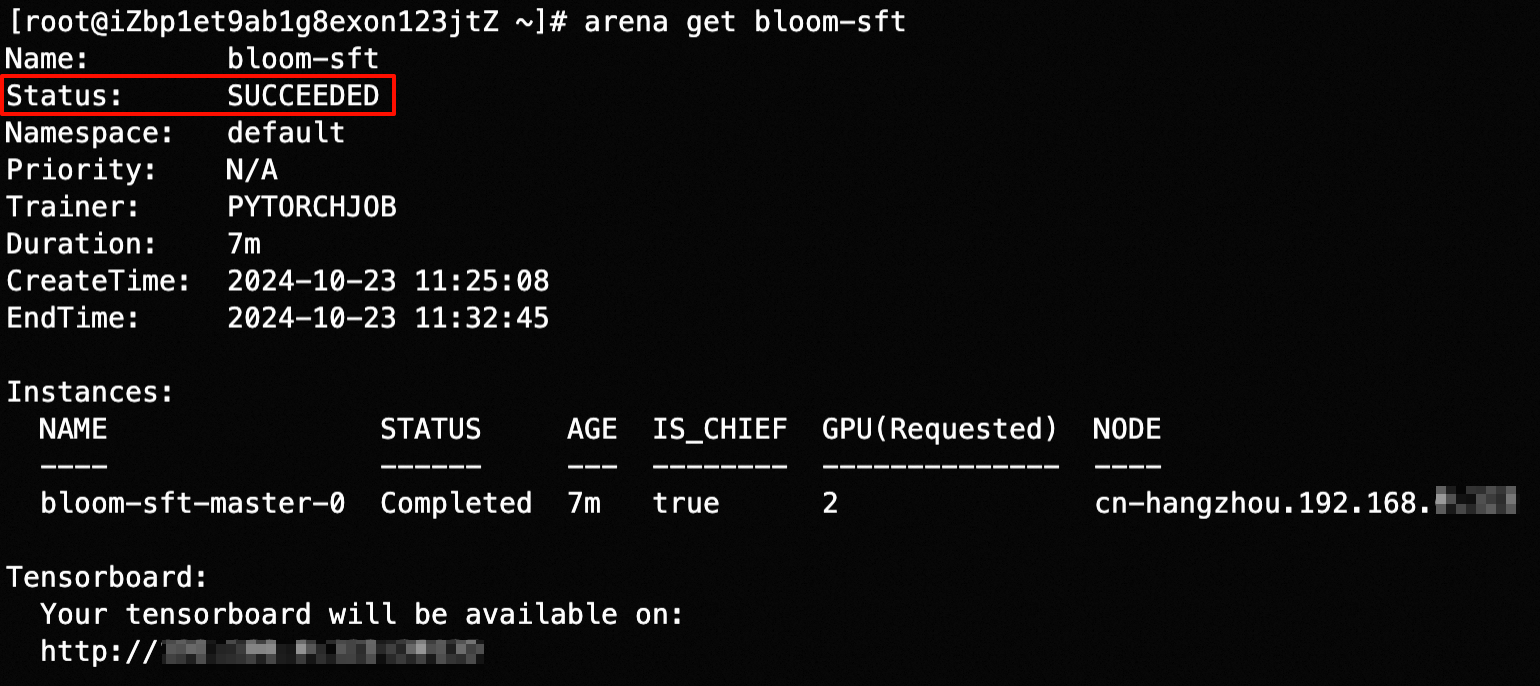
等待任务训练完成,大概需要 10 分钟,再次执行命令 arena get bloom-sft ,确认 status为 SUCCEEDED ,表明模型训练任务已经成功完成。
执行以下命令,查看微调后的模型目录,确保模型文件正确生成。
# 进入微调后的模型目录, training.log 为训练日志 cd /mnt/bloom-560m-sft/ # 目录内容如下 . ├── config.json ├── merges.txt ├── pytorch_model.bin ├── training.log ├── tokenizer_config.json ├── tokenizer.json └── vocab.json
完成及清理
5
清理资源
在本方案中,您使用了 ROS 资源栈和 NAS 文件存储系统。测试完方案后,您可以参考以下规则处理对应产品的实例,避免继续产生费用:
释放资源栈下的资源,释放创建的 ACK 集群、NAS 件存储系统等。
登录 ROS 控制台,在左侧导航栏,选择资源栈。
在资源栈页面的顶部选择部署的资源栈所在地域,找到资源栈,然后在其右侧操作列,单击删除。
本方案会自动创建两个资源栈,一个由您部署时创建,另一个以
k8s-开头,由ACK创建集群时创建。请删除非k8s-开头的资源栈,删除此资源栈时将自动删除k8s-开头的资源栈。在删除资源栈对话框,选择删除方式为释放资源,然后单击确定,根据提示完成资源释放。