音视频处理最佳实践
您可以通过函数计算控制台来体验GPU实例的最佳实践。本文以Python语言为例,说明如何通过控制台将原始视频经过函数代码的转码处理,从.mp4转换为.flv格式。
应用场景和优势
随着越来越多的强交互应用场景的出现,例如社交直播、在线课堂以及远程医疗等,互联网流量正在向实时、准实时的趋势演进。视频平台通常要将原始视频内容根据码率、分辨率、渠道贴片、播放平台等维度,以1∶N的方式转码输出多种分发视频格式,以服务不同网络质量、各种播放平台的观看者。视频转码是视频生产分发中的关键一环,理想的视频转码解决方案需要在成本(人民币/流)和功率效率(瓦/流)方面具有成本效益。
在不同的应用场景下,函数计算提供的GPU实例与CPU相比所具备的优势如下。
实时、准实时的应用场景
提供数倍于CPU的转码效率,从而快速将生产内容推向终端用户。
成本优先的GPU应用场景
提供弹性预留模式,从而按需为您保留工作GPU实例,对比自购VM拥有较大成本优势。
效率优先的GPU应用场景
屏蔽运维GPU集群的繁重负担(驱动/CUDA版本管理、机器运行管理、GPU坏卡管理),使得开发者专注于代码开发、聚焦业务目标的达成。
GPU实例的更多信息,请参见实例类型及使用模式。
性能对比
函数计算GPU实例基于的Turing架构支持以下编码和解码格式:
编码格式
H.264 (AVCHD) YUV 4:2:0
H.264 (AVCHD) YUV 4:4:4
H.264 (AVCHD) Lossless
H.265 (HEVC) 4K YUV 4:2:0
H.265 (HEVC) 4K YUV 4:4:4
H.265 (HEVC) 4K Lossless
H.265 (HEVC) 8k
HEVC10-bitsupport
HEVCB Framesupport
解码格式
MPEG-1
MPEG-2
VC-1
VP8
VP9
H.264 (AVCHD)
H.265 (HEVC) 4:2:0
*H.265 (HEVC) 4:4:4
8 bit
10 bit
12 bit
8 bit
10 bit
12 bit
8 bit
10 bit
12 bit
原始视频信息如下表所示。
视频信息 | 数据 |
时长 | 2分05秒 |
码率 | 4085 Kb/s |
视频流信息 | h264 (High), yuv420p (progressive), 1920x1080 [SAR 1:1 DAR 16:9], 25 fps, 25 tbr, 1k tbn, 50 tbc |
音视频信息 | aac (LC), 44100 Hz, stereo, fltp |
CPU和GPU的测试机器指标如下表所示。
对比项 | CPU机型 | GPU机型 |
CPU | CPU Xeon® Platinum 8163 4C | CPU Xeon® Platinum 8163 4C |
RAM | 16 GB | 16 GB |
GPU | N/A | T4 |
FFmpeg | git-2020-08-12-1201687 | git-2020-08-12-1201687 |
视频转码(1∶1)
性能测试:1路输入、1路输出
分辨率 | CPU转码耗时 | GPU转码耗时 |
H264∶1920x1080 (1080p) (Full HD) | 3分19.331秒 | 0分9.399秒 |
H264∶1280x720 (720p) (Half HD) | 2分3.708秒 | 0分5.791秒 |
H264∶640x480 (480p) | 1分1.018秒 | 0分5.753秒 |
H264∶480x360 (360p) | 44.376秒 | 0分5.749秒 |
视频转码(1∶N)
性能测试:1路输入、3路输出
分辨率 | CPU转码耗时 | GPU转码耗时 |
H264∶1920x1080 (1080p) (Full HD) | 5分58.696秒 | 0分45.268秒 |
H264∶1280x720 (720p) (Half HD) | ||
H264∶640x480 (480p) |
转码命令
CPU转码命令
单路转码(1∶1)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg -y -i input.mp4 -c:v h264 -vf scale=1920:1080 -b:v 5M output.mp4多路转码(1∶N)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg \ -y -i input.mp4 \ -c:a copy -c:v h264 -vf scale=1920:1080 -b:v 5M output_1080.mp4 \ -c:a copy -c:v h264 -vf scale=1280:720 -b:v 5M output_720.mp4 \ -c:a copy -c:v h264 -vf scale=640:480 -b:v 5M output_480.mp4
表 1. 参数说明 参数
说明
-c:a copy
无需任何重新编码即可复制音频流。
-c:v h264
为输出流选择软件H.264编码器。
-b:v 5M
将输出比特率设置为5 Mb/s。
GPU转码命令
单路转码(1∶1)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg -y -hwaccel cuda -hwaccel_output_format cuda -i input.mp4 -c:v h264_nvenc -vf scale_cuda=1920:1080:1:4 -b:v 5M output.mp4多路转码(1∶N)
docker run --rm -it --volume $PWD:/workspace --runtime=nvidia willprice/nvidia-ffmpeg \ -y -hwaccel cuda -hwaccel_output_format cuda -i input.mp4 \ -c:a copy -c:v h264_nvenc -vf scale_npp=1920:1080 -b:v 5M output_1080.mp4 \ -c:a copy -c:v h264_nvenc -vf scale_npp=1280:720 -b:v 5M output_720.mp4 \ -c:a copy -c:v h264_nvenc -vf scale_npp=640:480 -b:v 5M output_480.mp4
表 2. 参数说明 参数
说明
-hwaccel cuda
选择合适的硬件加速器。
-hwaccel_output_format cuda
将解码的帧保存在GPU内存中。
-c:v h264_nvenc
选择NVIDIA硬件加速H.264编码器。
准备工作
为了确保您的业务正常进行,请加入钉钉用户群(钉钉群号:11721331),申请GPU实例的使用权限,同时提供以下信息。
组织名称,例如您所在的公司名称。
您的阿里云账号ID。
您期望使用GPU实例的地域,例如华南1(深圳)。
联系方式,例如您的手机号、邮箱或钉钉账号等。
您的镜像大小。
在GPU实例所在地域,完成以下操作:
创建容器镜像服务的企业版实例或个人版实例,推荐您创建企业版实例。具体操作步骤,请参见创建企业版实例。
创建命名空间镜像仓库。具体操作步骤,请参见步骤二:创建命名空间和步骤三:创建镜像仓库。
将需处理的音视频资源上传至在GPU实例所在地域的OSS Bucket中,且您对该Bucket中的文件有读写权限。具体步骤,请参见控制台上传文件。权限相关说明,请参见修改存储空间读写权限。
通过函数计算控制台部署GPU应用
- 部署镜像。
- 建容器镜像服务的企业版实例或个人版实例。推荐您创建企业版实例。具体操作步骤,请参见创建企业版实例。
- 创建命名空间和镜像仓库。具体操作步骤,请参见步骤二:创建命名空间和步骤三:创建镜像仓库。
- 在容器镜像服务控制台,根据界面提示完成Docker相关操作步骤。然后将上述示例app.py和Dockerfile推送至实例镜像仓库,文件信息,请参见通过ServerlessDevs部署GPU应用时/code目录中的app.py和Dockerfile。
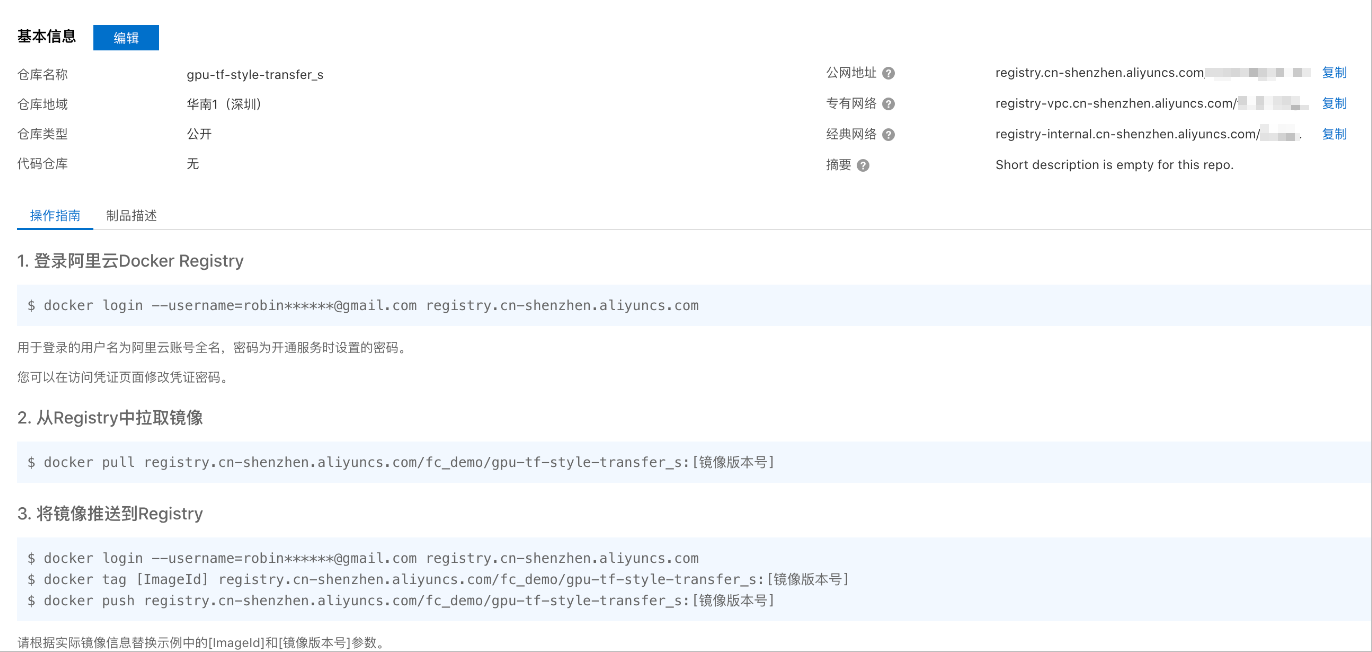
- 建容器镜像服务的企业版实例或个人版实例。
创建GPU函数。具体操作步骤,请参见创建Custom Container函数。
修改函数的执行超时时间。
在目标函数的配置页签,在左侧导航栏,选择运行时,然后单击运行时右侧的编辑。
在运行时面板,修改执行超时时间,然后单击确定。
说明CPU转码耗时会超过默认的60s,因此建议您修改执行超时时间为较大的值。
配置GPU预留实例。关于配置预留实例的具体操作,请参见配置预留实例。
配置完成后,您可以在规则列表查看预留的GPU实例是否就绪。即当前预留实例数是否为设置的预留实例数。
使用cURL测试函数。
在函数详情页面,单击触发器管理页签,查看触发器的配置信息,获取触发器的访问地址。
在命令行执行如下命令,调用GPU函数。
查看线上函数版本
curl -v "https://tgpu-ff-console-tgpu-ff-console-ajezot****.cn-shenzhen.fcapp.run" {"function": "trans_gpu"}使用CPU进行转码
curl "https://tgpu-ff-console-tgpu-ff-console-ajezot****.cn-shenzhen.fcapp.run" -H 'TRANS-MODE: cpu' {"result": "ok", "upload_time": 8.75510573387146, "download_time": 4.910430669784546, "trans_time": 105.37688875198364}使用GPU进行转码
curl "https://tgpu-ff-console-tgpu-ff-console-ajezotchpx.cn-shenzhen.fcapp.run" -H 'TRANS-MODE: gpu' {"result": "ok", "upload_time": 8.313958644866943, "download_time": 5.096682548522949, "trans_time": 8.72346019744873}
执行结果
您可通过在浏览器中访问以下域名,查看转码后的视频:
https://cri-zbtsehbrr8******-registry.oss-cn-shenzhen.aliyuncs.com/output.flv本域名仅为示例,需以实际情况为准。
- 本页导读 (1)