
Lindorm宽表引擎中的表可以导出到本地文件,包括CSV、ORC、Parquet、TXT。通过DataWorks,您可以将Lindorm宽表导出到OSS,再从OSS下载CSV到本地。本文以导出CSV为例,介绍通过DataWorks和OSS将数据导出到本地文件的计费说明、注意事项和操作步骤。
前提条件
-
已创建DataWorks工作空间。创建步骤,请参见创建工作空间。
-
已创建DataWorks独享资源组。创建步骤,请参见使用独享数据集成资源组。
-
已创建OSS Bucket。创建步骤,请参见创建存储空间。
计费说明
本文介绍的方案需使用DataWorks和OSS,除Lindorm外,还涉及以下计费项:
使用限制
仅支持单表全量导出,不支持整库导出,也不支持增量导出。
步骤一:导出数据到OSS
1. 添加Lindorm数据源
进入管理中心页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入管理中心。
-
单击左侧导航栏的数据源,进入数据源列表页面。
-
单击页面右上角的新增数据源,选择数据源类型为Lindorm。按弹窗提示,填写数据源的配置项。
2. 添加OSS数据源
进入管理中心页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入管理中心。
-
单击左侧导航栏的数据源,进入数据源列表页面。
-
单击页面右上角的新增数据源,选择数据源类型为OSS。按弹窗提示,填写数据源的配置项。
3. 配置离线同步任务
-
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
-
鼠标悬停至
 图标,单击新建业务流程。
图标,单击新建业务流程。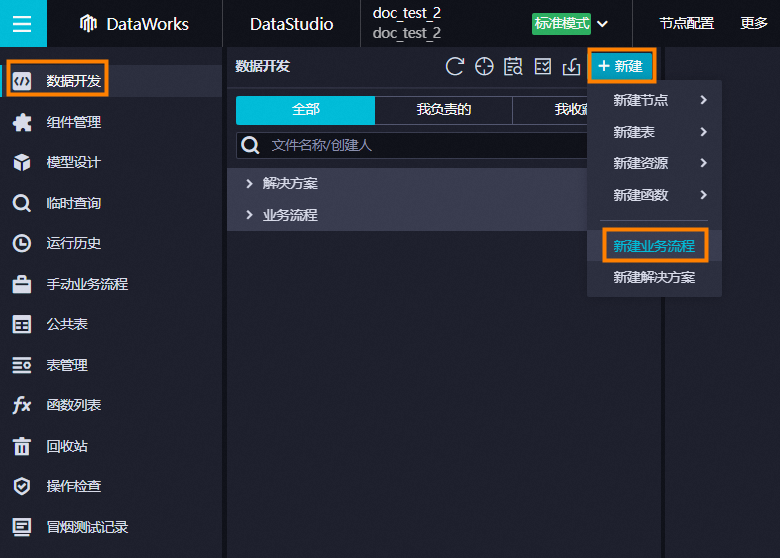
-
在新建业务流程对话框中,输入业务名称和描述。
-
单击新建。
-
配置网络与资源配置,并测试连通性,然后单击下一步。
-
数据来源选择Lindorm,数据源名称选择步骤1添加的Lindorm数据源。
-
数据去向选择OSS,数据源名称选择步骤2添加的OSS数据源。
-
我的资源组选择独享资源组。资源组用于执行同步任务。如果还没有创建独享资源组,创建方法请参见使用独享调度资源组。
-
-
配置数据来源。
-
选择表类型与表。
如果您的表是通过SQL创建的,表类型请选择TableService。如果您的表是通过HBase API创建的,表类型请选择WideColumn。如果表包含动态列,表类型请选择WideColumn。
如果没有找到您的表,可以切换表类型。
-
选择读取方式。
如果表中包含动态列,请选择竖表。否则请选择横表。
-
-
配置数据去向。
-
选择文本类型为csv。您也可以选择其他文本类型,详细介绍请参见OSS数据源。
-
设置文件名(含路径)和列分隔符等。
-
-
(可选)配置表头。如果希望导出的CSV文件包含表头,可参考本步骤。
-
单击工具栏中的转换脚本图标。
-
在OSS Writer脚本中增加
header配置。以下为导出包含表头的CSV文件的完整脚本示例。
导出SQL表
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "lindorm", "parameter": { "selects": [], "mode": "FixedColumn", "datasource": "lindorm", "columns": [ "id", "name", "address" ], "envType": 1, "tableMode": "tableService", "encoding": "UTF-8", "caching": 128, "table": "tb" }, "name": "Reader", "category": "reader" }, { "stepType": "oss", "parameter": { "fieldDelimiterOrigin": ",", "nullFormat": "null", "dateFormat": "yyyy-MM-dd HH:mm:ss", "datasource": "oss_lindorm", "header": [ "id", "name", "address" ], "envType": 1, "writeSingleObject": true, "writeMode": "truncate", "encoding": "UTF-8", "fieldDelimiter": ",", "fileFormat": "csv", "object": "lindorm_sql" }, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "0" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }导出HBase表
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "lindorm", "parameter": { "selects": [], "mode": "FixedColumn", "datasource": "lindorm", "columns": [ "STRING|rowkey", "STRING|cf:a", "STRING|cf:b", "STRING|cf:c" ], "envType": 1, "tableMode": "wideColumn", "encoding": "UTF-8", "caching": 128, "table": "test" }, "name": "Reader", "category": "reader" }, { "stepType": "oss", "parameter": { "fieldDelimiterOrigin": ",", "nullFormat": "null", "dateFormat": "yyyy-MM-dd HH:mm:ss", "datasource": "oss_lindorm", "envType": 1, "writeSingleObject": true, "header": [ "rowkey", "cf:a", "cf:b", "cf:c" ], "writeMode": "truncate", "encoding": "UTF-8", "fieldDelimiter": ",", "fileFormat": "csv", "object": "from_lindorm_hbase" }, "name": "Writer", "category": "writer" }, { "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" }, "name": "Processor", "category": "processor" } ], "setting": { "errorLimit": { "record": "0" }, "locale": "zh", "speed": { "throttle": false, "concurrent": 2 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }更多关于OSS数据源脚本的参考信息,请参见附录:脚本Demo与参数说明。
-
-
(可选)配置通道与调度属性。完成前7步,已经可以导出CSV。如果您还想进一步控制数据同步的过程属性,例如任务并发、同步速率等,请参见向导模式配置。
-
单击工具栏中的保存图标,然后单击运行图标。单击运行图标后,数据将导出至OSS。
步骤二:从OSS下载数据至本地
-
登录OSS管理控制台。
-
单击Bucket列表,然后单击目标Bucket名称。
-
根据配置离线同步任务步骤中设置的数据去向文件名,找到文件。单击操作列的下载,将文件下载到本地。