本文介绍如何使用SDK来支持实时记录场景下的音频识别流程。
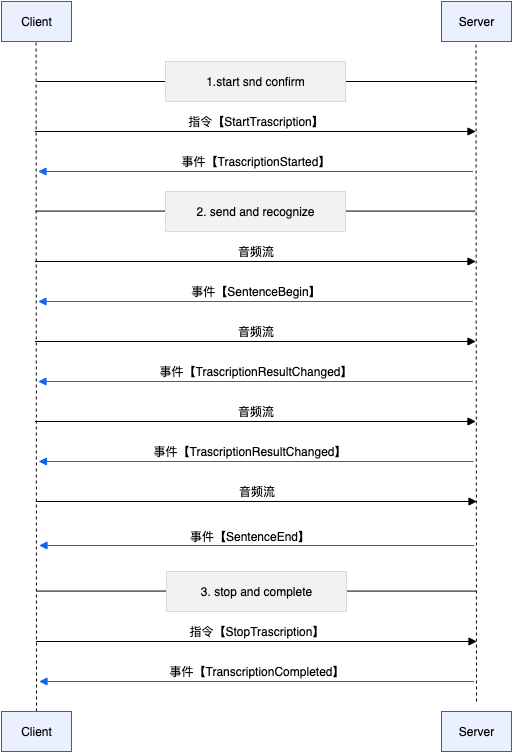
交互流程
前提条件
示例代码
package com.alibaba.tingwu.client.demo.realtimemeeting;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.alibaba.nls.client.protocol.NlsClient;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriber;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberListener;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberResponse;
import org.junit.BeforeClass;
import org.junit.Test;
import java.io.FileInputStream;
import java.util.Arrays;
/**
* @author tingwu2023
* @desc 演示了实时会议场景,在创建会议后,根据返回的MeetingJoinUrl进行实时语音识别的 调用。
*/
public class RealtimeTransTest {
private static NlsClient NLS_CLIENT;
/**
* 初始化语音识别SDK,可复用,可全局使用
*/
@BeforeClass
public static void before() {
NLS_CLIENT = new NlsClient("default");
}
/**
* 单路实时转写,绝大多数情况下,您可只参考此处实现即可。
*/
@Test
public void testRealtimeTrans() throws Exception {
// 此处url来自于用户通过OpenAPI创建会议时返回的推流url, url地址一般是:"wss://tingwu-realtime-cn-beijing.aliyuncs.com/api/ws/v1?mc={xxxxxxzzzzyyy}"
String meetingJoinUrl = "请输入您创建实时会议时返回的MeetingJoinUrl";
SpeechTranscriber speechTranscriber = new SpeechTranscriber(NLS_CLIENT, "default" ,createListener(), meetingJoinUrl);
speechTranscriber.start();
// 使用本地文件模拟 真实场景下音频流实时采集
String localAudioFile = "nls-sample-16k.wav";
byte[] buffer = new byte[3200];
FileInputStream fis = new FileInputStream(localAudioFile);
int len;
while ((len = fis.read(buffer)) > 0) {
// TODO 模拟实时发送的音频数据帧
speechTranscriber.send(Arrays.copyOf(buffer, len));
// TODO 模拟音频采集间隔
Thread.sleep(100L);
}
// 音频流结束后,发送stop结束实时转写处理。
// TODO 注意: 此时该会议并没有结束,会议的结束可以参考StopRealtimeMeetingTaskTest处理。
speechTranscriber.stop();
speechTranscriber.close();
}
public SpeechTranscriberListener createListener() {
return new SpeechTranscriberListener() {
@Override
public void onMessage(String message) {
System.out.println("onMessage " + message);
if (message == null || message.trim().length() == 0) {
return;
}
SpeechTranscriberResponse response = JSON.parseObject(message, SpeechTranscriberResponse.class);
if("ResultTranslated".equals(response.getName())) {
// 翻译事件输出,您可以在此处进行相关处理
System.out.println("--- ResultTranslated ---" + JSON.toJSONString(response, SerializerFeature.PrettyFormat));
} else {
// 原语音识别事件输出,交由父类负责回调
super.onMessage(message);
}
}
@Override
public void onTranscriberStart(SpeechTranscriberResponse response) {
// task_idf非常重要,但需要说明的是,该task_id是在音频流实时推送和识别过程中的标识,而非会议级别的TaskId
System.out.println("task_id: " + response.getTaskId() + ", name: " + response.getName() + ", status: " + response.getStatus());
}
@Override
public void onSentenceBegin(SpeechTranscriberResponse response) {
System.out.println("received onSentenceBegin: " + JSON.toJSONString(response));
}
@Override
public void onSentenceEnd(SpeechTranscriberResponse response) {
//识别出一句话。服务端会智能断句,当识别到一句话结束时会返回此消息。
System.out.println("received onSentenceEnd: " + JSON.toJSONString(response));
System.out.println("task_id: " + response.getTaskId() +
", name: " + response.getName() +
// 状态码“20000000”表示正常识别。
", status: " + response.getStatus() +
// 句子编号,从1开始递增。
", index: " + response.getTransSentenceIndex() +
// 当前的识别结果。
", result: " + response.getTransSentenceText() +
// 当前的词模式识别结果。
", words: " + response.getWords() +
// 开始时间
", begin_time: " + response.getSentenceBeginTime() +
// 当前已处理的音频时长,单位为毫秒。
", time: " + response.getTransSentenceTime());
}
@Override
public void onTranscriptionResultChange(SpeechTranscriberResponse response) {
// 识别出中间结果。仅当RealtimeResultLevel=2时,才会返回该消息。
System.out.println("received onTranscriptionResultChange: " + JSON.toJSONString(response));
System.out.println("task_id: " + response.getTaskId() +
", name: " + response.getName() +
// 状态码“20000000”表示正常识别。
", status: " + response.getStatus() +
// 句子编号,从1开始递增。
", index: " + response.getTransSentenceIndex() +
// 当前的识别结果。
", result: " + response.getTransSentenceText() +
// 当前的词模式识别结果。
", words: " + response.getWords() +
// 当前已处理的音频时长,单位为毫秒。
", time: " + response.getTransSentenceTime());
}
@Override
public void onTranscriptionComplete(SpeechTranscriberResponse response) {
// 识别结束,当调用speechTranscriber.stop()之后会收到该事件
System.out.println("received onTranscriptionComplete: " + JSON.toJSONString(response));
}
@Override
public void onFail(SpeechTranscriberResponse response) {
// 实时识别出错,请关注错误码,请记录此task_id以便排查
System.out.println("received onFail: " + JSON.toJSONString(response));
}
};
}
}
package main
import (
"errors"
"log"
"os"
"time"
nls "github.com/aliyun/alibabacloud-nls-go-sdk"
)
const (
TOKEN = "default"
APPKEY = "default"
)
func onTaskFailed(text string, param interface{}) {
logger, ok := param.(*nls.NlsLogger)
if !ok {
return
}
logger.Println("TaskFailed:", text)
}
func onStarted(text string, param interface{}) {
logger, ok := param.(*nls.NlsLogger)
if !ok {
return
}
logger.Println("onStarted:", text)
}
func onSentenceBegin(text string, param interface{}) {
logger, ok := param.(*nls.NlsLogger)
if !ok {
return
}
logger.Println("onSentenceBegin:", text)
}
func onSentenceEnd(text string, param interface{}) {
logger, ok := param.(*nls.NlsLogger)
if !ok {
return
}
logger.Println("onSentenceEnd:", text)
}
func onResultChanged(text string, param interface{}) {
logger, ok := param.(*nls.NlsLogger)
if !ok {
return
}
logger.Println("onResultChanged:", text)
}
func onCompleted(text string, param interface{}) {
logger, ok := param.(*nls.NlsLogger)
if !ok {
return
}
logger.Println("onCompleted:", text)
}
func onClose(param interface{}) {
logger, ok := param.(*nls.NlsLogger)
if !ok {
return
}
logger.Println("onClosed:")
}
func waitReady(ch chan bool, logger *nls.NlsLogger) error {
select {
case done := <-ch:
{
if !done {
logger.Println("Wait failed")
return errors.New("wait failed")
}
logger.Println("Wait done")
}
case <-time.After(20 * time.Second):
{
logger.Println("Wait timeout")
return errors.New("wait timeout")
}
}
return nil
}
func run_push_audio_stream(url string) {
// 使用本地pcm或者opus格式文件模拟真实场景下音频流实时采集
pcm, err := os.Open("tingwu-sample-16k.pcm")
if err != nil {
log.Default().Fatalln(err)
}
buffers := nls.LoadPcmInChunk(pcm, 320)
param := nls.DefaultSpeechTranscriptionParam()
config := nls.NewConnectionConfigWithToken(url, APPKEY, TOKEN)
logger := nls.NewNlsLogger(os.Stderr, "1", log.LstdFlags|log.Lmicroseconds)
logger.SetLogSil(false)
logger.SetDebug(true)
st, err := nls.NewSpeechTranscription(config, logger,
onTaskFailed, onStarted,
onSentenceBegin, onSentenceEnd, onResultChanged,
onCompleted, onClose, logger)
if err != nil {
logger.Fatalln(err)
return
}
logger.Println("Start pushing audio stream")
ready, err := st.Start(param, nil)
if err != nil {
logger.Fatalln(err)
return
}
err = waitReady(ready, logger)
if err != nil {
logger.Fatalln(err)
return
}
for _, data := range buffers.Data {
if data != nil {
st.SendAudioData(data.Data)
time.Sleep(10 * time.Millisecond)
}
}
ready, err = st.Stop()
if err != nil {
logger.Fatalln(err)
return
}
err = waitReady(ready, logger)
if err != nil {
logger.Fatalln(err)
return
}
st.Shutdown()
logger.Println("Push audio stream done")
}
func main() {
// 此处url来自于用户通过OpenAPI创建记录时返回的推流url
run_push_audio_stream("wss://tingwu-realtime-cn-hangzhou-pre.aliyuncs.com/api/ws/v1?mc=*********h-moSNWGZO5mq-uZzu1EQbVBABVn9y8VGzWmVcAEiLNE1idoml7JU_wr17G4dDdxwQ6jiMg8OCQCrptlCnSk4hJ9K_fVfP8ngWaYk2If*********")
}
#include <fstream>
#include <string>
#include <mutex>
#include <condition_variable>
#include <thread>
#include <chrono>
#include "nlsClient.h"
#include "nlsEvent.h"
#include "speechTranscriberRequest.h"
// 实现一个简易信号量,用于同步事件处理, 您在实际项目中,可以替换您项目中的信号量实现即可
class Semaphore {
public:
Semaphore(int count = 0) : count_(count) {
}
void notify() {
std::unique_lock<std::mutex> lock(mtx_);
++count_;
cv_.notify_one();
}
void wait() {
std::unique_lock<std::mutex> lock(mtx_);
cv_.wait(lock, [this](){ return count_ > 0; });
--count_;
}
// Wait with timeout
bool wait_for(const std::chrono::milliseconds& timeout) {
std::unique_lock<std::mutex> lock(mtx_);
if (!cv_.wait_for(lock, timeout, [this](){ return count_ > 0; })) {
return false; // Timeout occurred
}
--count_;
return true;
}
private:
std::mutex mtx_;
std::condition_variable cv_;
int count_;
};
Semaphore kSemaphore(0);
// 服务端返回的所有信息会通过此回调反馈
// cbEvent 回调事件结构, 详见nlsEvent.h
// cbParam 回调自定义参数,默认为NULL, 可以根据需求自定义参数
void onMessage(AlibabaNls::NlsEvent *cbEvent, void *cbParam) {
printf("onMessage: [%s]\n", cbEvent->getAllResponse());
int result = cbEvent->parseJsonMsg(true);
if (result) {
printf("onMessage: parseJsonMsg failed: [%d]", result);
return;
}
switch (cbEvent->getMsgType()) {
case AlibabaNls::NlsEvent::TaskFailed:
//识别过程(包含start(), sendAudio(), stop())发生异常时, sdk内部线程上报TaskFailed事件
//上报TaskFailed事件之后, SDK内部会关闭识别连接通道. 此时调用sendAudio会返回负值, 请停止发送
printf("onTaskFailed: status code=%d, task id=%s, error message=%s\n",
cbEvent->getStatusCode(),
cbEvent->getTaskId(),
cbEvent->getErrorMessage());
break;
case AlibabaNls::NlsEvent::TranscriptionStarted:
// 调用start()后, 成功与云端建立连接, sdk内部线程上报started事件
// 通知发送线程start()成功, 可以发送数据
kSemaphore.notify();
break;
case AlibabaNls::NlsEvent::SentenceBegin:
printf("##### %d, %d\n", cbEvent->getMsgType(), AlibabaNls::NlsEvent::SentenceBegin),
// 服务端检测到了一句话的开始, sdk内部线程上报SentenceBegin事件
printf("onSentenceBegin: status code=%d, task id=%s, index=%d, time=%d\n",
cbEvent->getStatusCode(), cbEvent->getTaskId(),
cbEvent->getSentenceIndex(), //句子编号,从1开始递增。
cbEvent->getSentenceTime()); //当前已处理的音频时长,单位:毫秒。
break;
case AlibabaNls::NlsEvent::TranscriptionResultChanged:
// 识别结果发生了变化, sdk在接收到云端返回到最新结果时,
printf("onTranscriptionResultChanged: status code=%d, task id=%s, index=%d, time=%d, result=%s\n",
cbEvent->getStatusCode(),
cbEvent->getTaskId(),
cbEvent->getSentenceIndex(), //句子编号,从1开始递增。
cbEvent->getSentenceTime(), //当前已处理的音频时长,单位:毫秒。
cbEvent->getResult()); // 当前句子的完整识别结果
break;
case AlibabaNls::NlsEvent::SentenceEnd:
// 服务端检测到了一句话结束, sdk内部线程上报SentenceEnd事件
printf("onSentenceEnd: status code=%d, task id=%s, index=%d, time=%d, begin_time=%d, result=%s\n",
cbEvent->getStatusCode(),
cbEvent->getTaskId(),
cbEvent->getSentenceIndex(), //句子编号,从1开始递增。
cbEvent->getSentenceTime(), //当前已处理的音频时长,单位:毫秒。
cbEvent->getSentenceBeginTime(), // 对应的SentenceBegin事件的时间。
cbEvent->getResult()); // 当前句子的完整识别结果。
break;
case AlibabaNls::NlsEvent::TranscriptionCompleted:
// 服务端停止实时音频流识别时, sdk内部线程上报Completed事件
kSemaphore.notify();
break;
case AlibabaNls::NlsEvent::Close:
//识别结束或发生异常时,会关闭连接通道, sdk内部线程上报ChannelClosed事件
//通知发送线程, 最终识别结果已经返回, 可以调用stop()
break;
default:
// 其他可能出现的事件, 比如若您开启了翻译功能,翻译结果报文会在此处返回,您可以在此处处理
printf("---otherEvent---\n");
break;
}
}
int main( int argc, char** argv ) {
// 此处url来自于用户通过OpenAPI创建会议时返回的推流url, url地址一般是:"wss://tingwu-realtime-cn-beijing.aliyuncs.com/api/ws/v1?mc={xxxxxxzzzzyyy}"
const char* websocketUrl = "请输入您创建实时会议时返回的MeetingJoinUrl";
const char* localAudioPath = "nls-sample-16k.wav"; // 本地测试用的音频文件路径, 该音频较短,可能无法测试到相关摘要结果
// 根据需要设置SDK输出日志。可选。
AlibabaNls::NlsClient::getInstance()->setLogConfig("log-transcriber", AlibabaNls::LogDebug, 400, 50);
// 启动工作线程, 在创建请求和启动前必须调用此函数, 可理解为对NlsClient的初始化,入参为负时, 启动当前系统中可用的核数。
AlibabaNls::NlsClient::getInstance()->startWorkThread(1);
//创建实时音频流识别SpeechTranscriberRequest对象
AlibabaNls::SpeechTranscriberRequest* request = AlibabaNls::NlsClient::getInstance()->createTranscriberRequest();
request->setUrl(websocketUrl);
// 设置所有服务端返回信息回调函数
request->setOnMessage(onMessage, NULL);
request->setEnableOnMessage(true);
int ret = request->start();
if(ret < 0) {
printf("start fail, error: [%d]", ret);
AlibabaNls::NlsClient::getInstance()->releaseTranscriberRequest(request);
return 0;
} else {
// 同步等待start返回,之后再继续发送音频数据
if (kSemaphore.wait_for(std::chrono::milliseconds(10000))) {
printf("start success\n");
} else {
printf("start timeout\n");
return -1;
}
}
std::ifstream fs;
fs.open(localAudioPath, std::ios::binary | std::ios::in);
while (!fs.eof()) {
const int FRAME_SIZE = 3200;
uint8_t data[FRAME_SIZE] = {0};
fs.read((char *) data, sizeof(uint8_t) * FRAME_SIZE);
size_t nlen = fs.gcount();
//发送音频数据: sendAudio为异步操作, 返回负值表示发送失败, 需要停止发送; 返回大于0 为成功.
ret = request->sendAudio(data, nlen);
if (ret < 0) {
// 发送失败,退出循环数据发送。
printf("send data fail, ret: %d.\n", ret);
break;
}
// 对于16K采样率音频来说,3200字节约为100ms数据;如果是8K音频,则1600字节约为100ms数据
// 实际使用中, 语音数据是实时的, 不用sleep控制速率, 直接发送即可。此处是用语音数据来自文件的方式进行模拟, 故发送时需要控制速率来模拟真实录音场景.
std::this_thread::sleep_for(std::chrono::milliseconds(200));
} // while
fs.close();
request->stop();
// 等待服务端将最后数据返回, 结束识别
kSemaphore.wait_for(std::chrono::milliseconds(10000));
AlibabaNls::NlsClient::getInstance()->releaseTranscriberRequest(request);
// 所有工作完成,进程退出前,释放nlsClient。
AlibabaNls::NlsClient::releaseInstance();
}反馈
- 本页导读 (0)
文档反馈