本文介绍关于Pod异常问题的诊断流程、排查方法、常见问题及解决方案。
本文目录
类别 | 内容 |
诊断流程 | |
常见排查方法 | |
常见问题及解决方案 |
诊断流程
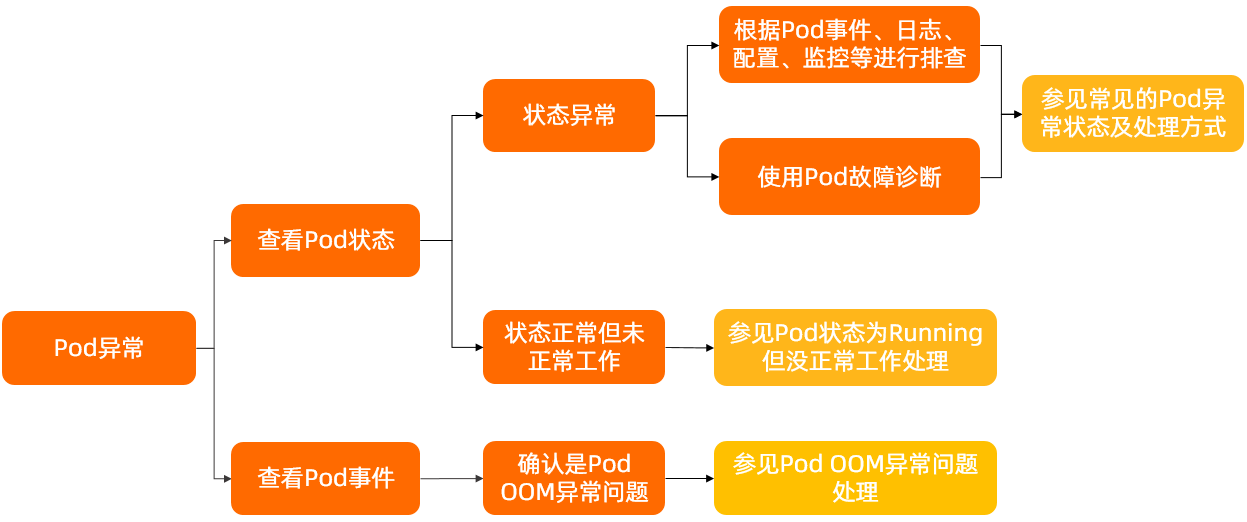
查看Pod是否处于异常状态,具体操作,请参见检查Pod的状态。
如果Pod状态异常,可通过查看Pod的事件、Pod的日志、Pod的配置等信息确定异常原因。具体操作,请参见常见排查方法。关于Pod异常状态及处理方式,请参见常见的Pod异常状态及处理方式。
如果Pod状态为Running但未正常工作,请参见Pod状态为Running但没正常工作。
若确认是Pod OOM异常问题,请参见Pod OOM异常问题处理。
如果问题仍未解决,请提交工单。
常见的Pod异常状态及处理方式
Pod状态 | Pod含义 | 解决方案 |
Pending | Pod未被调度。 | |
Init:N/M | Pod包含M个Init容器,其中N个已经启动完成。 | |
Init:Error | Init容器已启动失败。 | |
Init:CrashLoopBackOff | Init容器启动失败,反复重启。 | |
Completed | Pod的启动命令已执行完毕。 | |
CrashLoopBackOff | Pod启动失败,反复重启。 | |
ImagePullBackOff | Pod镜像拉取失败。 | |
Running |
| |
Terminating | Pod正在关闭中。 |
常见排查方法
检查Pod的状态
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 容器组。
在容器组页面左上角选择Pod所在的命名空间,查看Pod状态。
若状态为Running,说明Pod运行正常。
若状态不为Running,说明Pod状态异常,请参见常见的Pod异常状态及处理方式进行处理。
检查Pod的详情
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 容器组。
在容器组页面左上角选择Pod所在的命名空间,然后单击目标Pod名称或者目标Pod右侧操作列下的详情,查看Pod的名称、镜像、Pod IP等详细信息。
检查Pod的配置
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 容器组。
在容器组页面左上角选择Pod所在的命名空间,然后单击目标Pod名称或者目标Pod右侧操作列下的详情。
在Pod详情页面右上角单击编辑,查看Pod的YAML文件和详细配置。
检查Pod的事件
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 容器组。
在容器组页面左上角选择Pod所在的命名空间,然后单击目标Pod名称或者目标Pod右侧操作列下的详情。
在Pod详情页面右上角单击编辑,查看Pod的YAML文件和详细配置。
在Pod详情页面下方单击事件页签,查看Pod的事件。
说明Kubernetes默认保留最近1小时的事件,若需保存更长时间的事件,请参见创建并使用K8s事件中心。
检查Pod的日志
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 容器组。
在容器组页面左上角选择Pod所在的命名空间,然后单击目标Pod名称或者目标Pod右侧操作列下的详情。
在Pod详情页面下方单击日志页签,查看Pod的日志。
说明阿里云容器计算服务ACS集群集成了日志服务,您可以在创建集群时启用日志服务,快速采集集群的容器日志,包括容器的标准输出及容器内的文本文件。更多信息,请参见通过Pod环境变量配置应用日志采集。
检查Pod的监控
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 。
在Prometheus监控页面,单击集群监控概览页签,选择查看Pod的CPU、内存、网络I/O等监控大盘。
使用终端进入容器
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 容器组。
在容器组页面,单击目标容器组右侧操作列下的终端。
说明可通过终端进入容器,在容器内查看本地文件等信息。
Pod故障诊断
Pod状态为Pending
问题原因
若Pod停留在Pending状态,说明该Pod不能被调度。通常是由于资源依赖、quota不合理等原因导致集群中缺乏需要的资源。
问题现象
Pod的状态为Pending。
解决方案
查看Pod的事件,根据事件描述,定位Pod不能被调度的原因。主要原因有以下几类:
资源依赖
创建Pod时,需要依赖于集群中ConfigMap、PVC等资源。例如,Pod添加存储卷声明前,存储卷声明需要先与存储卷绑定。
quota不合理
在事件和审计日志查看。
Pod状态为Init:N/M(Init:Error和Init:CrashLoopBackOff)
问题原因
若Pod停留在Init:N/M状态,说明该Pod包含M个Init容器,其中N个已经启动完成,但仍有M-N个Init容器未启动成功。
若Pod停留在Init:Error状态,说明Pod中的Init容器启动失败。
若Pod停留在Init:CrashLoopBackOff状态,说明Pod中的Init容器启动失败并处于反复重启状态。
问题现象
Pod的状态为Init:N/M。
Pod的状态为Init:Error。
Pod的状态为Init:CrashLoopBackOff。
解决方案
Pod状态为ImagePullBackOff
问题原因
若Pod停留在ImagePullBackOff状态,说明此Pod已被后台调度,但拉取镜像失败。
问题现象
Pod的状态为ImagePullBackOff。
解决方案
通过查看该Pod的事件描述,查看具体拉取失败的镜像名称。
确认容器镜像名称是否正确。
如果您使用的是私有镜像仓库,请参见使用在镜像仓库中存放的镜像来创建ACS工作负载解决。
Pod状态为CrashLoopBackOff
问题原因
若Pod停留在CrashLoopBackOff状态,说明容器中应用程序有问题。
问题现象
Pod的状态为CrashLoopBackOff。
解决方案
查看Pod的事件,确认当前Pod是否存在异常。具体操作,请参见检查Pod的事件。
查看Pod的日志,通过日志内容排查问题。具体操作,请参见检查Pod的日志。
查看Pod的配置,确认容器中的健康检查配置是否正常。具体操作,请参见检查Pod的配置。关于Pod健康检查的更多信息,请参见配置存活、就绪和启动探测器。
Pod状态为Completed
问题原因
若Pod出现Completed状态,说明容器中的启动命令已执行完毕,容器中的所有进程都已退出。
问题现象
Pod的状态为Completed。
解决方案
Pod状态为Running但没正常工作
问题原因
部署使用的YAML文件有问题。
问题现象
Pod状态为Running但没正常工作。
解决方案
查看Pod的配置,确定Pod中容器的配置是否符合预期。具体操作,请参见检查Pod的配置。
使用以下方法,排查环境变量中的某一个Key是否存在拼写错误。
以command拼写成commnd为例,说明拼写问题排查方法。
说明创建Pod时,环境变量中的某一个Key拼写错误的问题会被集群忽略,如Command拼写为Commnd,您仍能够使用该YAML文件创建资源。但容器运行时,不会执行有拼写问题的YAML文件,而是执行镜像中的默认命令。
在执行
kubectl apply -f命令前为其添加--validate,然后执行kubectl apply --validate -f XXX.yaml命令。如果您将command拼写成commnd,将看到错误信息
XXX] unknown field: commnd XXX] this may be a false alarm, see https://gXXXb.XXX/6842pods/test。执行以下命令,将输出结果的pod.yaml文件与您创建Pod使用的文件进行对比。
kubectl get pods [$Pod] -o yaml > pod.yaml说明[$Pod]为异常Pod的名称,您可以通过kubectl get pods命令查看。pod.yaml文件比您创建Pod所使用的文件多几行,说明已创建的Pod符合预期。
如果您创建Pod所使用文件里的代码行在pod.yaml文件中没有,说明您创建Pod使用的文件存在拼写问题。
查看Pod的日志,通过日志内容排查问题。具体操作,请参见检查Pod的日志。
可通过终端进入容器查看容器内的本地文件是否符合预期。具体操作,请参见使用终端进入容器。
Pod状态为Terminating
问题原因
若Pod的状态为Terminating,则说明此Pod正处于关闭状态。
问题现象
Pod状态为Terminating。
解决方案
Pod停留在Terminating状态一段时间后会被自动删除。若Pod一直停留在Terminating状态,可执行如下命令强制删除:
kubectl delete pod [$Pod] -n [$namespace] --grace-period=0 --forcePod OOM异常问题处理
问题原因
当集群中的容器使用超过其限制的内存,容器可能会被终止,触发OOM(Out Of Memory)事件,导致容器异常退出。关于OOM事件,请参见为容器和Pod分配内存资源。
问题现象
若被终止的进程为容器的阻塞进程,可能会导致容器异常重启。
若出现OOM异常问题,在控制台的Pod详情页面单击事件页签将展示OOM事件pod was OOM killed。