
百炼按主账号维度对模型调用设置限流,账号下所有RAM子账号、业务空间和API Key 的调用量合并计算。超出限制时请求会被拒绝,通常在一分钟内自动恢复。
限流规则
账号级别限流:限流按主账号维度计算,账号下所有RAM子账号、业务空间和API Key 的调用量合并计算。
模型独立限流:不同模型限流额度相互独立,具体参见下方表格。
FAQ
为什么触发限流?
根据错误信息判断触发了哪类限流:
Requests rate limit exceeded或You exceeded your current requests list:触发了每分钟请求数(RPM)限流。Allocated quota exceeded或You exceeded your current quota:触发了每分钟 Token 消耗(TPM)限流。Request rate increased too quickly:请求频率在短时间内激增,触发了系统稳定性保护——即使总调用量未达到 RPM 或 TPM 上限也会触发。其他报错,参见错误码确认原因。
除 RPM 和 TPM 外,限流策略可能按秒级 RPS(RPM/60)与 TPS(TPM/60)执行。即使每分钟总调用量未超限,短时间内的请求爆发也可能触发限流。
如何查看模型调用量?
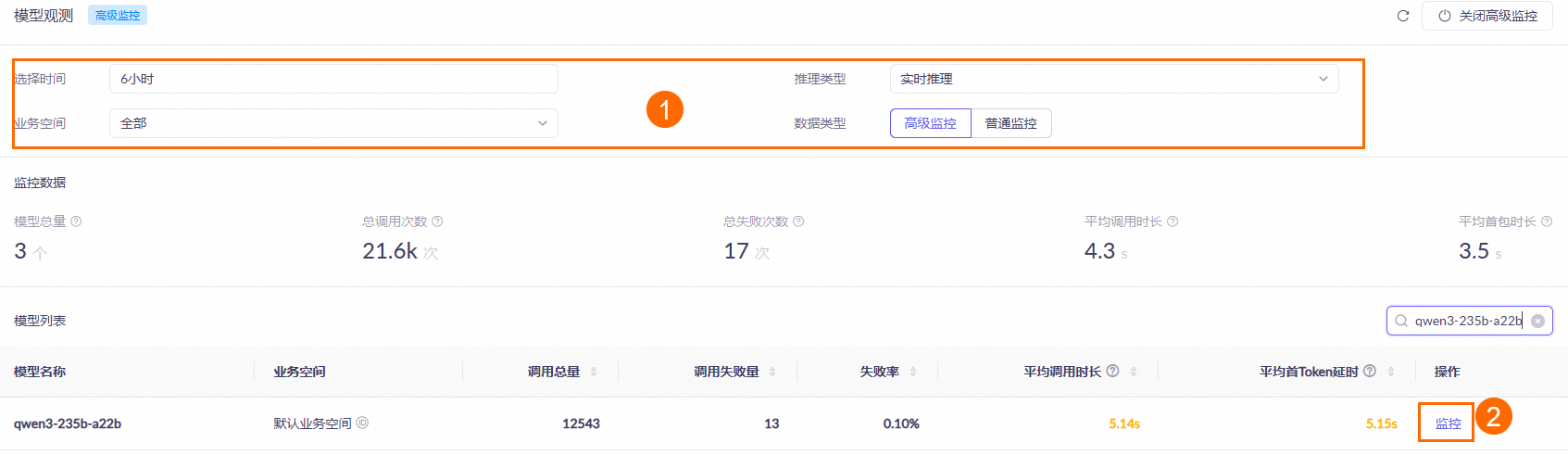
模型调用完一小时后,在模型监控(北京或新加坡)页面设置查询条件(例如,选择时间范围、业务空间等),再在模型列表区域找到目标模型并单击操作列的监控,即可查看该模型的调用统计结果。具体请参见模型监控文档。
数据按小时更新,高峰期可能有小时级延迟,请您耐心等待。
遇到限流后多久恢复?
通常在一分钟内恢复。如出现其他报错,参见错误码进行处理。
如何避免限流?
选用高限流模型
优先使用 qwen-plus 等限流额度更高的模型。
稳定版或最新版比带日期的快照版本限流更宽松。
优化调用策略
降低调用频率:收到
Requests rate limit exceeded或You exceeded your current requests list时,降低API调用频率。减少 Token 消耗:收到
Allocated quota exceeded或You exceeded your current quota时,缩短输入或限制输出长度。平滑请求速率:收到
Request rate increased too quickly时,采用匀速调度、指数退避或请求队列将请求均匀分散,避免瞬时高峰。
添加备选模型
触发限流后切换到备用模型继续生成,可降低失败概率、提升吞吐量。以下代码在调用
qwen-plus-2025-07-28触发限流后,自动改用qwen-plus-2025-07-14重试。拆分任务:长对话或大型文档会快速消耗大量 Token。将大批量任务拆分为小批次,分时段提交。
批量推理:无需实时响应时,使用批量推理(Batch API)。批量请求不受实时限流约束,但需考虑排队和处理时间。
提升限流额度:默认限流额度不足时,在百炼控制台的限流提额页面提升模型的临时 TPM 额度,提交后立即生效。详见提升临时限流额度。
如何控制 Token 用量或费用支出?
限流仅约束单位时间内的调用速率,不限制累计用量。如需控制 Token 用量或费用支出,可通过以下方式管理:
设置消费限额与费用告警:在账单费用卡片设置费用告警,开启月度消费限额并配置阈值通知,达到阈值即提醒,避免超额支出。详见账单查询与成本管理。
开启免费额度用完即停:对支持免费额度的模型,可开启免费额度用完即停,免费额度耗尽后自动停止调用,避免产生额外费用。详见新人免费额度。
监控模型调用量:定期查看各模型的 Token 用量,及时发现异常增长,参见上文如何查看模型调用量?。
提升临时限流额度
默认限流额度不足时,可在百炼控制台提升模型的临时 TPM 额度。提交后立即生效,有效期 30 天,到期后自动恢复为系统默认值。
目前支持华北2(北京)和新加坡地域。
登录百炼控制台,进入限流提额页面。
单击页面右上角的提升模型临时限流额度。
在弹窗中选择模型,填写期望的 Token 账号限流(Token/60 秒)值。弹窗中会显示当前额度和可设置上限。
单击确定,提额立即生效。
提额生效后,可通过以下方式确认:
支持临时提额的模型以限流提额页面弹窗的可选列表为准。
对已提额的模型再次提交视为重新申请,有效期随之重置为 30 天。
按实际需求申请额度。若配置容量长期显著超过实际使用量,系统可能在提前通知后将其恢复为默认值。
文本生成-千问
千问语言模型
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3.7-max 用Batch API调用服务时,不受限流限制。 | 30,000 | 5,000,000 |
qwen3.7-max-2026-06-08 | 600 | 1,000,000 |
qwen3.7-max-2026-05-20 | 600 | 1,000,000 |
qwen3.7-max-preview | 60 | 500,000 |
qwen3.7-max-2026-05-17 | 60 | 500,000 |
qwen3.6-max-preview | 600 | 1,000,000 |
qwen3-max 用Batch API调用服务时,不受限流限制。 | 30,000 | 5,000,000 |
qwen3-max-2026-01-23 | 600 | 1,000,000 |
qwen3-max-2025-09-23 | 60 | 100,000 |
qwen3-max-preview | 600 | 1,000,000 |
qwen-max 用Batch API调用服务时,不受限流限制。 | 1,200 | 1,000,000 |
qwen3.7-plus | 30,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | 600 | 1,000,000 |
qwen3.6-plus 用Batch API调用服务时,不受限流限制。 | 30,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | 600 | 1,000,000 |
qwen3.7-flash 用Batch API调用服务时,不受限流限制。 | 30,000 | 5,000,000 |
qwen3.7-flash-2026-07-15 | 600 | 1,000,000 |
qwen3.6-flash 用Batch API调用服务时,不受限流限制。 | 30,000 | 10,000,000 |
qwen3.6-flash-2026-04-16 | 600 | 1,000,000 |
qwen3.5-plus 用Batch API调用服务时,不受限流限制。 | 30,000 | 5,000,000 |
qwen3.5-plus-2026-04-20 | 600 | 1,000,000 |
qwen3.5-plus-2026-02-15 | 600 | 1,000,000 |
qwen-plus 用Batch API调用服务时,不受限流限制。 | 30,000 | 5,000,000 |
qwen-plus-latest 用Batch API调用服务时,不受限流限制。 | 15,000 | 1,200,000 |
qwen-plus-2025-12-01 | 120 | 1,000,000 |
qwen-plus-2025-09-11 | 60 | 1,000,000 |
qwen-plus-2025-07-28 (qwen-plus-0728) | 60 | 1,000,000 |
qwen-plus-2025-07-14 (qwen-plus-0714) | 60 | 100,000 |
qwen-plus-2025-04-28 (qwen-plus-0428) | 60 | 1,000,000 |
qwen-plus-2025-01-25 (qwen-plus-0125) | 60 | 150,000 |
qwen-plus-2025-01-12 (qwen-plus-0112) | 60 | 150,000 |
qwen-plus-2024-12-20 (qwen-plus-1220) | 60 | 150,000 |
qwen3.5-flash 用Batch API调用服务时,不受限流限制。 | 30,000 | 10,000,000 |
qwen3.5-flash-2026-02-23 | 600 | 1,000,000 |
qwen-flash 用Batch API调用服务时,不受限流限制。 | 30,000 | 10,000,000 |
qwen-flash-2025-07-28 | 60 | 1,000,000 |
qwen-turbo 用Batch API调用服务时,不受限流限制。 | 1,200 | 5,000,000 |
qwq-plus 用Batch API调用服务时,不受限流限制。 | 600 | 1,000,000 |
qwen-long 用Batch API调用服务时,不受限流限制。 | 1,200 | 3,000,000 |
qwen-long-latest 用Batch API调用服务时,不受限流限制。 | 1,200 | 60,000 |
qwen-long-2025-01-25 (qwen-long-0125) | 3 | 7,500 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.7-max | 全球 | 30,000 | 5,000,000 |
qwen3.7-max-us | 美国 | 600 | 1,000,000 |
qwen3.7-max-2026-06-08 | 全球 | 600 | 1,000,000 |
qwen3.7-max-2026-05-20 | 全球 | 600 | 1,000,000 |
qwen3-max | 全球 | 600 | 1,000,000 |
qwen3-max-preview | 全球 | 600 | 1,000,000 |
qwen3-max-2025-09-23 | 全球 | 60 | 100,000 |
qwen3.7-plus | 全球 | 30,000 | 5,000,000 |
qwen3.7-plus-us | 美国 | 15,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | 全球 | 600 | 1,000,000 |
qwen3.6-plus | 全球 | 30,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | 全球 | 600 | 1,000,000 |
qwen3.6-flash | 全球 | 15,000 | 5,000,000 |
qwen3.6-flash-2026-04-16 | 全球 | 60 | 1,000,000 |
qwen3.6-flash-us | 美国 | 15,000 | 5,000,000 |
qwen3.5-plus | 全球 | 30,000 | 5,000,000 |
qwen3.5-plus-2026-02-15 | 全球 | 600 | 1,000,000 |
qwen-plus | 全球 | 15,000 | 5,000,000 |
qwen-plus-us | 美国 | 600 | 1,000,000 |
qwen-plus-2025-12-01 | 全球 | 60 | 1,000,000 |
qwen-plus-2025-09-11 | 全球 | 60 | 1,000,000 |
qwen-plus-2025-07-28 | 全球 | 60 | 1,000,000 |
qwen-plus-2025-12-01-us | 美国 | 60 | 1,000,000 |
qwen3.5-flash | 全球 | 30,000 | 10,000,000 |
qwen3.5-flash-2026-02-23 | 全球 | 600 | 1,000,000 |
qwen-flash | 全球 | 15,000 | 10,000,000 |
qwen-flash-us | 美国 | 600 | 5,000,000 |
qwen-flash-2025-07-28 | 全球 | 60 | 1,000,000 |
qwen-flash-2025-07-28-us | 美国 | 600 | 5,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.7-max | 国际 | 600 | 1,000,000 |
qwen3.7-max-2026-06-08 | 国际 | 60 | 1,000,000 |
qwen3.7-max-2026-05-20 | 国际 | 60 | 1,000,000 |
qwen3.6-max-preview | 国际 | 600 | 1,000,000 |
qwen3-max | 国际 | 600 | 1,000,000 |
qwen3-max-2026-01-23 | 国际 | 600 | 1,000,000 |
qwen3-max-2025-09-23 | 国际 | 60 | 100,000 |
qwen3-max-preview | 国际 | 600 | 1,000,000 |
qwen-max 用Batch API调用服务时,不受限流限制。 | 国际 | 600 | 1,000,000 |
qwen3.7-plus | 国际 | 15,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | 国际 | 60 | 1,000,000 |
qwen3.6-plus | 国际 | 15,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | 国际 | 60 | 1,000,000 |
qwen3.7-flash | 国际 | 15,000 | 5,000,000 |
qwen3.7-flash-2026-07-15 | 国际 | 60 | 1,000,000 |
qwen3.6-flash | 国际 | 15,000 | 5,000,000 |
qwen3.6-flash-2026-04-16 | 国际 | 60 | 1,000,000 |
qwen3.5-plus | 国际 | 15,000 | 5,000,000 |
qwen3.5-plus-2026-04-20 | 国际 | 600 | 1,000,000 |
qwen3.5-plus-2026-02-15 | 国际 | 60 | 1,000,000 |
qwen-plus-latest | 国际 | 600 | 1,000,000 |
qwen-plus-2025-12-01 | 国际 | 120 | 1,000,000 |
qwen-plus-2025-09-11 | 国际 | 120 | 1,000,000 |
qwen-plus-2025-07-28 | 国际 | 60 | 100,000 |
qwen-plus-2025-07-14 (qwen-plus-0714) | 国际 | 60 | 100,000 |
qwen-plus-2025-04-28 (qwen-plus-0428) | 国际 | 60 | 1,000,000 |
qwen-plus-2025-01-25 (qwen-plus-0125) | 国际 | 60 | 100,000 |
qwen3.5-flash | 国际 | 15,000 | 5,000,000 |
qwen3.5-flash-2026-02-23 | 国际 | 60 | 1,000,000 |
qwen-flash | 国际 | 600 | 5,000,000 |
qwen-flash-2025-07-28 | 国际 | 600 | 5,000,000 |
qwq-plus | 国际 | 60 | 100,000 |
qwen-turbo 用Batch API调用服务时,不受限流限制。 | 国际 | 600 | 5,000,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.7-max | 全球 | 30,000 | 5,000,000 |
qwen3.7-max-2026-06-08 | 全球 | 600 | 1,000,000 |
qwen3.7-max-2026-05-20 | 全球 | 600 | 1,000,000 |
qwen3-max | 全球 | 600 | 1,000,000 |
qwen3-max | 欧盟 | 600 | 1,000,000 |
qwen3-max-preview | 全球 | 600 | 1,000,000 |
qwen3-max-2026-01-23 | 欧盟 | 600 | 1,000,000 |
qwen3-max-2025-09-23 | 全球 | 60 | 100,000 |
qwen3.7-plus | 全球 | 30,000 | 5,000,000 |
qwen3.7-plus-2026-05-26 | 全球 | 600 | 1,000,000 |
qwen3.6-plus | 全球 | 30,000 | 5,000,000 |
qwen3.6-plus-2026-04-02 | 全球 | 600 | 1,000,000 |
qwen3.6-flash | 全球 | 15,000 | 5,000,000 |
qwen3.6-flash-2026-04-16 | 全球 | 60 | 1,000,000 |
qwen3.5-plus | 全球 | 30,000 | 5,000,000 |
qwen3.5-plus-2026-02-15 | 全球 | 600 | 1,000,000 |
qwen-plus | 全球 | 15,000 | 5,000,000 |
qwen-plus | 欧盟 | 600 | 1,000,000 |
qwen-plus-2025-12-01 | 全球 | 60 | 1,000,000 |
qwen-plus-2025-12-01 | 欧盟 | 120 | 1,000,000 |
qwen-plus-2025-09-11 | 全球 | 60 | 1,000,000 |
qwen-plus-2025-07-28 | 全球 | 60 | 1,000,000 |
qwen3.5-flash | 全球 | 30,000 | 10,000,000 |
qwen3.5-flash | 欧盟 | 30,000 | 10,000,000 |
qwen3.5-flash-2026-02-23 | 全球 | 600 | 1,000,000 |
qwen3.5-flash-2026-02-23 | 欧盟 | 600 | 1,000,000 |
qwen-flash | 全球 | 15,000 | 10,000,000 |
qwen-flash-2025-07-28 | 全球 | 60 | 1,000,000 |
千问VL(视觉理解/图生文)
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3-vl-plus 用Batch API调用服务时,不受限流限制。 | 3,000 | 5,000,000 |
qwen3-vl-plus-2025-12-19 | 60 | 100,000 |
qwen3-vl-plus-2025-09-23 | 60 | 100,000 |
qwen3-vl-flash 用Batch API调用服务时,不受限流限制。 | 3,000 | 5,000,000 |
qwen3-vl-flash-2026-01-22 | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | 60 | 100,000 |
qwen-vl-max 用Batch API调用服务时,不受限流限制。 | 1,200 | 1,000,000 |
qwen-vl-plus 用Batch API调用服务时,不受限流限制。 | 1,200 | 1,000,000 |
qvq-max | 60 | 100,000 |
qvq-plus | 60 | 100,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-vl-plus | 全球 | 60 | 1,000,000 |
qwen3-vl-plus-2025-09-23 | 全球 | 60 | 100,000 |
qwen3-vl-flash | 全球 | 1,200 | 1,000,000 |
qwen3-vl-flash-us | 美国 | 1,200 | 1,000,000 |
qwen3-vl-flash-2025-10-15 | 全球 | 60 | 100,000 |
qwen3-vl-flash-2025-10-15-us | 美国 | 120 | 1,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-vl-plus | 国际 | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-12-19 | 国际 | 60 | 100,000 |
qwen3-vl-plus-2025-09-23 | 国际 | 120 | 1,000,000 |
qwen3-vl-flash | 国际 | 1,200 | 1,000,000 |
qwen3-vl-flash-2026-01-22 | 国际 | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | 国际 | 120 | 1,000,000 |
qwen-vl-max | 国际 | 1,200 | 1,000,000 |
qwen-vl-plus | 国际 | 1,200 | 1,000,000 |
qvq-max | 国际 | 60 | 100,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-vl-plus | 全球 | 1,200 | 1,000,000 |
qwen3-vl-plus | 欧盟 | 1,200 | 1,000,000 |
qwen3-vl-plus-2025-09-23 | 全球 | 60 | 100,000 |
qwen3-vl-flash | 全球 | 1,200 | 1,000,000 |
qwen3-vl-flash | 欧盟 | 1,200 | 1,000,000 |
qwen3-vl-flash-2026-01-22 | 欧盟 | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | 全球 | 60 | 100,000 |
qwen3-vl-flash-2025-10-15 | 欧盟 | 60 | 100,000 |
千问Omni
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3.5-omni-plus | 60 | 100,000 |
qwen3.5-omni-plus-2026-03-15 | 60 | 100,000 |
qwen3.5-omni-flash | 60 | 100,000 |
qwen3.5-omni-flash-2026-03-15 | 60 | 100,000 |
qwen3-omni-flash | 60 | 100,000 |
qwen3-omni-flash-2025-12-01 | 60 | 100,000 |
qwen3-omni-flash-2025-09-15 | 60 | 100,000 |
qwen-omni-turbo 用Batch API调用服务时,不受限流限制。 | 60 | 100,000 |
qwen-omni-turbo-latest | 60 | 100,000 |
qwen-omni-turbo-2025-03-26 (qwen-omni-turbo-0326) | 60 | 100,000 |
qwen-omni-turbo-2025-01-19 (qwen-omni-turbo-0119) | 60 | 100,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.5-omni-plus | 国际 | 60 | 100,000 |
qwen3.5-omni-plus-2026-03-15 | 国际 | 60 | 100,000 |
qwen3.5-omni-flash | 国际 | 60 | 100,000 |
qwen3.5-omni-flash-2026-03-15 | 国际 | 60 | 100,000 |
qwen3-omni-flash | 国际 | 60 | 100,000 |
qwen3-omni-flash-2025-12-01 | 国际 | 60 | 100,000 |
qwen3-omni-flash-2025-09-15 | 国际 | 60 | 100,000 |
qwen-omni-turbo | 国际 | 60 | 100,000 |
qwen-omni-turbo-latest | 国际 | 60 | 100,000 |
qwen-omni-turbo-2025-03-26 | 国际 | 60 | 100,000 |
千问Omni-Realtime
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3.5-omni-plus-realtime | 60 | 100,000 |
qwen3.5-omni-plus-realtime-2026-03-15 | 60 | 100,000 |
qwen3.5-omni-flash-realtime | 60 | 100,000 |
qwen3.5-omni-flash-realtime-2026-03-15 | 60 | 100,000 |
qwen3-omni-flash-realtime | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-12-01 | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-09-15 | 60 | 100,000 |
qwen-omni-turbo-realtime-latest | 60 | 100,000 |
qwen-omni-turbo-realtime-2025-05-08 | 60 | 100,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.5-omni-plus-realtime | 国际 | 60 | 100,000 |
qwen3.5-omni-plus-realtime-2026-03-15 | 国际 | 60 | 100,000 |
qwen3.5-omni-flash-realtime | 国际 | 60 | 100,000 |
qwen3.5-omni-flash-realtime-2026-03-15 | 国际 | 60 | 100,000 |
qwen3-omni-flash-realtime | 国际 | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-12-01 | 国际 | 60 | 100,000 |
qwen3-omni-flash-realtime-2025-09-15 | 国际 | 60 | 100,000 |
qwen-omni-turbo-realtime | 国际 | 60 | 10,000 |
qwen-omni-turbo-realtime-latest | 国际 | 60 | 10,000 |
qwen-omni-turbo-realtime-2025-05-08 | 国际 | 60 | 10,000 |
千问OCR(文字提取)
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3.5-ocr | 6,000 | 30,000,000 |
qwen-vl-ocr 用Batch API调用服务时,不受限流限制。 | 600 | 6,000,000 |
qwen-vl-ocr-latest 用Batch API调用服务时,不受限流限制。 | 6,000 | 30,000,000 |
qwen-vl-ocr-2025-11-20 | 6,000 | 30,000,000 |
qwen-vl-ocr-2025-08-28 | 600 | 6,000,000 |
qwen-vl-ocr-2025-04-13 | 600 | 6,000,000 |
qwen-vl-ocr-2024-10-28 | 600 | 6,000,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-vl-ocr | 全球 | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | 全球 | 1,200 | 6,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-vl-ocr | 国际 | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | 国际 | 1,200 | 6,000,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-vl-ocr | 全球 | 600 | 6,000,000 |
qwen-vl-ocr-2025-11-20 | 全球 | 1,200 | 6,000,000 |
千问Audio(音频理解)
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen-audio-turbo | 120 | 100,000 |
qwen-audio-turbo-latest | 60 | 100,000 |
千问数学模型
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen-math-plus | 1,200 | 1,000,000 |
qwen-math-plus-latest | 1,200 | 1,000,000 |
qwen-math-plus-2024-09-19 (qwen-math-plus-0919) | 60 | 100,000 |
qwen-math-plus-2024-08-16 (qwen-math-plus-0816) | 10 | 20,000 |
qwen-math-turbo | 1200 | 1,000,000 |
千问Coder
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3-coder-plus | 5,000 | 5,000,000 |
qwen3-coder-plus-2025-09-23 | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | 60 | 1,000,000 |
qwen3-coder-flash | 5,000 | 5,000,000 |
qwen3-coder-flash-2025-07-28 | 60 | 1,000,000 |
qwen-coder-plus | 1,200 | 1,000,000 |
qwen-coder-turbo | 1,200 | 1,000,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-coder-plus | 全球 | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | 全球 | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | 全球 | 60 | 1,000,000 |
qwen3-coder-flash | 全球 | 1,200 | 1,000,000 |
qwen3-coder-flash-2025-07-28 | 全球 | 60 | 1,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-coder-plus | 国际 | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | 国际 | 600 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | 国际 | 60 | 1,000,000 |
qwen3-coder-flash | 国际 | 600 | 5,000,000 |
qwen3-coder-flash-2025-07-28 | 国际 | 600 | 5,000,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-coder-plus | 全球 | 2,400 | 2,000,000 |
qwen3-coder-plus-2025-09-23 | 全球 | 60 | 1,000,000 |
qwen3-coder-plus-2025-07-22 | 全球 | 60 | 1,000,000 |
qwen3-coder-flash | 全球 | 1,200 | 1,000,000 |
qwen3-coder-flash-2025-07-28 | 全球 | 60 | 1,000,000 |
千问翻译模型
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen-mt-plus | 60 | 25,000 |
qwen-mt-flash | 60 | 35,000 |
qwen-mt-lite | 60 | 100,000 |
qwen-mt-turbo | 60 | 35,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-mt-plus | 全球 | 60 | 25,000 |
qwen-mt-flash | 全球 | 60 | 35,000 |
qwen-mt-lite | 全球 | 60 | 100,000 |
qwen-mt-lite-us | 美国 | 60 | 100,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-mt-plus | 国际 | 60 | 100,000 |
qwen-mt-flash | 国际 | 60 | 100,000 |
qwen-mt-lite | 国际 | 60 | 100,000 |
qwen-mt-turbo | 国际 | 60 | 100,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-mt-plus | 全球 | 60 | 25,000 |
qwen-mt-flash | 全球 | 60 | 35,000 |
qwen-mt-lite | 全球 | 60 | 100,000 |
千问数据挖掘模型
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen-doc-turbo | 600 | 3,000,000 |
千问深入研究模型
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen-deep-research | 120 | 1,200,000 |
通义晓蜜对话分析模型
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
tongyi-xiaomi-analysis-flash | 600 | 1,000,000 |
tongyi-xiaomi-analysis-pro | 600 | 1,000,000 |
文本生成-千问-开源版
千问语言模型开源版
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3.6-35b-a3b | 600 | 1,000,000 |
qwen3.6-27b | 600 | 1,000,000 |
qwen3.5-397b-a17b | 600 | 1,000,000 |
qwen3.5-122b-a10b | 600 | 1,000,000 |
qwen3.5-27b | 600 | 1,000,000 |
qwen3.5-35b-a3b | 600 | 1,000,000 |
qwen3-next-80b-a3b-thinking | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | 600 | 1,000,000 |
qwen3-30b-a3b-instruct-2507 | 600 | 1,000,000 |
qwen3-235b-a22b | 600 | 1,000,000 |
qwen3-30b-a3b | 600 | 1,000,000 |
qwen3-32b | 2400 | 1,000,000 |
qwen3-14b | 600 | 1,000,000 |
qwen3-8b | 600 | 1,000,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.6-35b-a3b | 全球 | 600 | 1,000,000 |
qwen3.5-397b-a17b | 全球 | 600 | 1,000,000 |
qwen3.5-122b-a10b | 全球 | 600 | 1,000,000 |
qwen3.5-27b | 全球 | 600 | 1,000,000 |
qwen3.5-35b-a3b | 全球 | 600 | 1,000,000 |
qwen3-next-80b-a3b-thinking | 全球 | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | 全球 | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | 全球 | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | 全球 | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | 全球 | 600 | 1,000,000 |
qwen3-30b-a3b-instruct-2507 | 全球 | 600 | 1,000,000 |
qwen3-235b-a22b | 全球 | 600 | 1,000,000 |
qwen3-32b | 全球 | 600 | 1,000,000 |
qwen3-30b-a3b | 全球 | 600 | 1,000,000 |
qwen3-14b | 全球 | 600 | 1,000,000 |
qwen3-8b | 全球 | 600 | 1,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.6-35b-a3b | 国际 | 600 | 1,000,000 |
qwen3.6-27b | 国际 | 600 | 1,000,000 |
qwen3.5-397b-a17b | 国际 | 600 | 1,000,000 |
qwen3.5-122b-a10b | 国际 | 600 | 1,000,000 |
qwen3.5-27b | 国际 | 600 | 1,000,000 |
qwen3.5-35b-a3b | 国际 | 600 | 5,000,000 |
qwen3-next-80b-a3b-thinking | 国际 | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | 国际 | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | 国际 | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | 国际 | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | 国际 | 600 | 5,000,000 |
qwen3-30b-a3b-instruct-2507 | 国际 | 600 | 5,000,000 |
qwen3-235b-a22b | 国际 | 600 | 1,000,000 |
qwen3-32b | 国际 | 600 | 1,000,000 |
qwen3-30b-a3b | 国际 | 600 | 1,000,000 |
qwen3-14b | 国际 | 600 | 1,000,000 |
qwen3-8b | 国际 | 600 | 1,000,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3.6-35b-a3b | 全球 | 600 | 1,000,000 |
qwen3.5-397b-a17b | 全球 | 600 | 1,000,000 |
qwen3.5-122b-a10b | 全球 | 600 | 1,000,000 |
qwen3.5-27b | 全球 | 600 | 1,000,000 |
qwen3.5-35b-a3b | 全球 | 600 | 1,000,000 |
qwen3-next-80b-a3b-thinking | 全球 | 600 | 1,000,000 |
qwen3-next-80b-a3b-instruct | 全球 | 600 | 1,000,000 |
qwen3-235b-a22b-thinking-2507 | 全球 | 600 | 1,000,000 |
qwen3-235b-a22b-instruct-2507 | 全球 | 600 | 1,000,000 |
qwen3-30b-a3b-thinking-2507 | 全球 | 600 | 1,000,000 |
qwen3-30b-a3b-instruct-2507 | 全球 | 600 | 1,000,000 |
qwen3-235b-a22b | 全球 | 600 | 1,000,000 |
qwen3-32b | 全球 | 600 | 1,000,000 |
qwen3-30b-a3b | 全球 | 600 | 1,000,000 |
qwen3-14b | 全球 | 600 | 1,000,000 |
qwen3-8b | 全球 | 600 | 1,000,000 |
Qwen-VL
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3-vl-32b-thinking | 600 | 1,000,000 |
qwen3-vl-32b-instruct | 600 | 1,000,000 |
qwen3-vl-30b-a3b-thinking | 600 | 1,000,000 |
qwen3-vl-30b-a3b-instruct | 600 | 1,000,000 |
qwen3-vl-8b-thinking | 600 | 1,000,000 |
qwen3-vl-8b-instruct | 600 | 1,000,000 |
qwen3-vl-235b-a22b-thinking | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | 60 | 100,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-vl-235b-a22b-thinking | 全球 | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | 全球 | 60 | 100,000 |
qwen3-vl-32b-thinking | 全球 | 600 | 1,000,000 |
qwen3-vl-32b-instruct | 全球 | 600 | 1,000,000 |
qwen3-vl-30b-a3b-thinking | 全球 | 600 | 1,000,000 |
qwen3-vl-30b-a3b-instruct | 全球 | 600 | 1,000,000 |
qwen3-vl-8b-thinking | 全球 | 600 | 1,000,000 |
qwen3-vl-8b-instruct | 全球 | 600 | 1,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-vl-32b-thinking | 国际 | 60 | 100,000 |
qwen3-vl-32b-instruct | 国际 | 60 | 100,000 |
qwen3-vl-30b-a3b-thinking | 国际 | 60 | 100,000 |
qwen3-vl-30b-a3b-instruct | 国际 | 60 | 100,000 |
qwen3-vl-8b-thinking | 国际 | 60 | 100,000 |
qwen3-vl-8b-instruct | 国际 | 60 | 100,000 |
qwen3-vl-235b-a22b-thinking | 国际 | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | 国际 | 60 | 100,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-vl-235b-a22b-thinking | 全球 | 60 | 100,000 |
qwen3-vl-235b-a22b-instruct | 全球 | 60 | 100,000 |
qwen3-vl-32b-thinking | 全球 | 600 | 1,000,000 |
qwen3-vl-32b-instruct | 全球 | 600 | 1,000,000 |
qwen3-vl-30b-a3b-thinking | 全球 | 600 | 1,000,000 |
qwen3-vl-30b-a3b-instruct | 全球 | 600 | 1,000,000 |
qwen3-vl-8b-thinking | 全球 | 600 | 1,000,000 |
qwen3-vl-8b-instruct | 全球 | 600 | 1,000,000 |
Qwen-Omni
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen2.5-omni-7b | 60 | 100,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen2.5-omni-7b | 国际 | 60 | 100,000 |
Qwen3-Omni-Captioner
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3-omni-30b-a3b-captioner | 60 | 100,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-omni-30b-a3b-captioner | 国际 | 60 | 100,000 |
Qwen-Math
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
Qwen-Coder
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3-coder-next | 600 | 1,000,000 |
qwen3-coder-480b-a35b-instruct | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | 600 | 1,000,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-coder-480b-a35b-instruct | 全球 | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | 全球 | 600 | 1,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-coder-next | 国际 | 600 | 1,000,000 |
qwen3-coder-480b-a35b-instruct | 国际 | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | 国际 | 600 | 1,000,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-coder-480b-a35b-instruct | 全球 | 600 | 1,000,000 |
qwen3-coder-30b-a3b-instruct | 全球 | 600 | 1,000,000 |
qwen3-coder-next | 欧盟 | 600 | 1,000,000 |
文本生成-第三方模型
DeepSeek
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
deepseek-v4-pro | 15,000 | 1,200,000 |
deepseek-v4-flash | 15,000 | 1,200,000 |
deepseek-v3.2 用Batch API调用服务时,不受限流限制。 | 15,000 | 1,200,000 |
deepseek-v3.2-exp | 15,000 | 1,200,000 |
deepseek-v3.1 | 15,000 | 1,200,000 |
deepseek-r1-0528 | 60 | 100,000 |
deepseek-r1 用Batch API调用服务时,不受限流限制。 | 15,000 | 1,200,000 |
deepseek-v3 用Batch API调用服务时,不受限流限制。 | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-7b | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-14b | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-32b | 15,000 | 1,200,000 |
deepseek-r1-distill-qwen-1.5b | 60 | 100,000 |
deepseek-r1-distill-llama-8b | 60 | 100,000 |
deepseek-r1-distill-llama-70b | 60 | 100,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
deepseek-v4-pro | 全球 | 15,000 | 1,200,000 |
deepseek-v4-pro-us | 国际 | 10,000 | 1,200,000 |
deepseek-v4-flash | 全球 | 15,000 | 1,200,000 |
deepseek-v4-flash-us | 国际 | 10,000 | 1,200,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
deepseek-v4-pro | 国际 | 10,000 | 1,200,000 |
deepseek-v4-flash | 国际 | 10,000 | 1,200,000 |
deepseek-v3.2 | 国际 | 10,000 | 1,200,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
deepseek-v4-pro | 全球 | 15,000 | 1,200,000 |
deepseek-v4-flash | 全球 | 15,000 | 1,200,000 |
DeepSeek-硅基流动直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
siliconflow/deepseek-v3.2 | 500 | 500,000 |
siliconflow/deepseek-v3.1-terminus | 500 | 500,000 |
siliconflow/deepseek-r1-0528 | 500 | 500,000 |
siliconflow/deepseek-v3-0324 | 500 | 500,000 |
DeepSeek-快手万擎直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
vanchin/deepseek-v3.2-think | 30 | 600,000 |
vanchin/deepseek-v3.1-terminus | 500 | 1,000,000 |
vanchin/deepseek-r1 | 500 | 1,000,000 |
vanchin/deepseek-v3 | 500 | 1,000,000 |
vanchin/deepseek-ocr | 500 | 1,000,000 |
Kimi
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
kimi-k2.7-code | 500 | 1,000,000 |
kimi-k2.6 | 500 | 1,000,000 |
kimi-k2.5 | 500 | 1,000,000 |
kimi-k2-thinking | 500 | 1,000,000 |
Moonshot-Kimi-K2-Instruct | 500 | 1,000,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
kimi-k2.7-code | 全球 | 500 | 1,000,000 |
kimi-k2.5 | 全球 | 500 | 1,000,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
kimi-k2.7-code | 全球 | 500 | 1,000,000 |
kimi-k2.5 | 全球 | 500 | 1,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
kimi-k2.7-code | 国际 | 500 | 1,000,000 |
Kimi-月之暗面直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
kimi/kimi-k3 | 500 同一个阿里云百炼API Key 下,在 5 个模型中共享 500 RPM 限流配额。即这 5 个模型的每分钟请求总数加起来不能超过 500。 | 3,000,000 同一个阿里云百炼API Key 下,在 5 个模型中共享 3000000 TPM 限流配额。即这 5 个模型的每分钟 Token 消耗总数加起来不能超过 3000000。 |
kimi/kimi-k2.7-code-highspeed | ||
kimi/kimi-k2.7-code | ||
kimi/kimi-k2.6 | ||
kimi/kimi-k2.5 | ||
GLM
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
glm-5.2 | 500 | 2,000,000 |
glm-5.1 | 500 | 1,000,000 |
glm-5 | 500 | 1,000,000 |
glm-4.7 | 500 | 1,000,000 |
glm-4.6 | 60 | 1,000,000 |
glm-4.5 | 60 | 1,000,000 |
glm-4.5-air | 60 | 1,000,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
glm-5.2 | 全球 | 500 | 1,000,000 |
glm-5.2-us | 国际 | 500 | 1,000,000 |
glm-5.1 | 全球 | 500 | 1,000,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
glm-5.2 | 全球 | 500 | 1,000,000 |
glm-5.1 | 全球 | 500 | 1,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
glm-5.2 | 国际 | 500 | 1,000,000 |
glm-5.1 | 国际 | 500 | 1,000,000 |
GLM-智谱直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
ZHIPU/GLM-5.2 | 200 | 3,000,000 |
ZHIPU/GLM-5.1 | 200 | 3,000,000 |
ZHIPU/GLM-5 | 200 | 3,000,000 |
MiniMax
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
MiniMax-M2.5 | 500 | 1,000,000 |
MiniMax-M2.1 | 500 | 1,000,000 |
MiniMax-稀宇科技直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
MiniMax/MiniMax-M3 | 500 | 20,000,000 |
MiniMax/MiniMax-M2.7 | 500 | 20,000,000 |
MiniMax/MiniMax-M2.5 | 500 | 20,000,000 |
MiniMax/MiniMax-M2.1 | 500 | 20,000,000 |
MiMo-小米直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
xiaomi/mimo-v2.5-pro | 100 | 10,000,000 |
Stepfun-阶跃星辰直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
stepfun/step-3.7-flash | 500 | 20,000,000 |
图像生成
千问(Qwen-Image)
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
任务下发接口调用限制 | 同时处理中任务数量(并发数) | |
qwen-image-3.0-pro | 1 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro-2026-06-22 | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro-2026-04-22 | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro-2026-03-03 | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0 | 2 次/秒 | 同步接口无限制 |
qwen-image-2.0-2026-03-03 | 2 次/秒 | 同步接口无限制 |
qwen-image-max | 2 次/分钟 | 同步接口无限制 |
qwen-image-max-2025-12-30 | 2 次/分钟 | 同步接口无限制 |
qwen-image-plus | 2 次/秒 | 同步接口无限制 / 异步接口 2 |
qwen-image-plus-2026-01-09 | 2 次/秒 | 同步接口无限制 |
qwen-image | 2 次/秒 | 同步接口无限制 / 异步接口 2 |
qwen-image-edit-max | 2 次/分钟 | 同步接口无限制 |
qwen-image-edit-max-2026-01-16 | 2 次/分钟 | 同步接口无限制 |
qwen-image-edit-plus | 2 次/秒 | 同步接口无限制 |
qwen-image-edit-plus-2025-12-15 | 2 次/秒 | 同步接口无限制 |
qwen-image-edit-plus-2025-10-30 | 2 次/秒 | 同步接口无限制 |
qwen-image-edit | 2 次/秒 | 同步接口无限制 |
qwen-mt-image | 1 次/秒 | 2 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
任务下发接口调用限制 | 同时处理中任务数量(并发数) | ||
qwen-image-3.0-pro | 国际 | 1 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro-2026-06-22 | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro-2026-04-22 | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0-pro-2026-03-03 | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-2.0 | 国际 | 2 次/秒 | 同步接口无限制 |
qwen-image-2.0-2026-03-03 | 国际 | 2 次/秒 | 同步接口无限制 |
qwen-image-max | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-max-2025-12-30 | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-plus | 国际 | 2 次/秒 | 同步接口无限制 / 异步接口 2 |
qwen-image-plus-2026-01-09 | 国际 | 2 次/秒 | 同步接口无限制 |
qwen-image | 国际 | 2 次/秒 | 同步接口无限制 / 异步接口 2 |
qwen-image-edit-max | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-edit-max-2026-01-16 | 国际 | 2 次/分钟 | 同步接口无限制 |
qwen-image-edit-plus | 国际 | 2 次/秒 | 同步接口无限制 |
qwen-image-edit-plus-2025-12-15 | 国际 | 2 次/秒 | 同步接口无限制 |
qwen-image-edit-plus-2025-10-30 | 国际 | 2 次/秒 | 同步接口无限制 |
qwen-image-edit | 国际 | 2 次/秒 | 同步接口无限制 |
文生图-Z-Image
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
z-image-turbo | 2 | 同步接口无限制 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
z-image-turbo | 国际 | 2 | 同步接口无限制 |
万相
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
wan2.7-image-pro | 5 | 5 |
wan2.7-image | 5 | 5 |
wan2.6-image | 5 | 5 |
wan2.6-t2i | 1 | 5 |
wan2.5-t2i-preview | 5 | 5 |
wan2.2-t2i-plus | 2 | 2 |
wan2.2-t2i-flash | 2 | 2 |
wanx2.1-t2i-plus | 2 | 2 |
wanx2.1-t2i-turbo | 2 | 2 |
wanx2.0-t2i-turbo | 2 | 2 |
wan2.5-i2i-preview | 5 | 5 |
wanx2.1-imageedit | 2 | 2 |
wanx-v1 | 2 | 1 |
wanx-x-painting | 2 | 1 |
wanx-sketch-to-image-lite | 2 | 1 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
wan2.6-t2i | 全球 | 5 | 5 |
wan2.6-image | 全球 | 5 | 5 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
wan2.7-image-pro | 国际 | 5 | 5 |
wan2.7-image | 国际 | 5 | 5 |
wan2.6-image | 国际 | 5 | 5 |
wan2.6-t2i | 国际 | 5 | 5 |
wan2.5-t2i-preview | 国际 | 5 | 5 |
wan2.2-t2i-flash | 国际 | 2 | 2 |
wan2.2-t2i-plus | 国际 | 2 | 2 |
wan2.1-t2i-turbo | 国际 | 2 | 2 |
wan2.1-t2i-plus | 国际 | 2 | 2 |
wan2.5-i2i-preview | 国际 | 5 | 5 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
wan2.6-t2i | 全球 | 5 | 5 |
wan2.6-image | 全球 | 5 | 5 |
图像编辑与生成
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
shoemodel-v1 | 2 | 1 |
wanx-virtualmodel | 2 | 1 |
wanx-style-repaint-v1 | 2 | 2 |
wanx-poster-generation-v1 | 2 | 1 |
virtualmodel-v2 | 2 | 1 |
wanx-background-generation-v2 | 2 | 1 |
image-instance-segmentation | 2 | 1 |
image-erase-completion | 2 | 1 |
image-out-painting | 2 | 10 |
人物写真生成-FaceChain
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
作业提交接口RPS限制 | 同时处理中任务数量 | |
facechain-facedetect | 5 | 同步接口无限制 |
facechain-finetune | 1 | 1 |
facechain-generation | 2 | 1 |
创意文字生成-WordArt锦书
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
作业提交接口RPS限制 | 同时处理中任务数量 | |
wordart-texture | 2 | 1 |
wordart-semantic | 2 | 1 |
AI试衣-OutfitAnyone
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
作业提交接口RPS限制 | 同时处理中任务数量 | |
aitryon | 10 | 5 |
aitryon-plus | 10 | 5 |
aitryon-parsing-v1 | 10 | 同步接口无限制 |
aitryon-refiner | 10 | 5 |
图像生成-第三方模型
可灵系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
kling/kling-v3-omni-image-generation | 5 | 10 同一阿里云百炼API Key 下,可灵系列的 4 个模型(图像及视频)共享 10 个并发数。即这 4 个模型处于运行状态的任务总数加起来不能超过 10 个。 |
kling/kling-v3-image-generation | ||
Vidu系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟请求数RPM限制 | 同时处理中任务数量(并发数) | |
vidu/vidu-image_reference2image | 300 | 5 同一个阿里云百炼API Key 下,Vidu参考生图系列的 4 个模型共享 5 个并发数。即这 4 个模型处于运行状态的任务总数加起来不能超过 5 个。 |
vidu/viduq3-fast_reference2image | ||
vidu/viduq2-pro_reference2image | ||
vidu/viduq2-fast_reference2image | ||
音乐生成
华北2(北京)
模型名称 | 每分钟调用次数(RPM) |
fun-music-preview | 180 |
fun-music-v1 | 180 |
语音对话
实时语音对话
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen-audio-3.0-realtime-plus | 60 | 100,000 |
qwen-audio-3.0-realtime-flash | 60 | 100,000 |
语音合成(文本转语音)
Qwen-Audio-TTS语音合成
华北2(北京)
|
模型名称 |
提交作业接口RPS限制 |
|
qwen-audio-3.0-tts-plus |
3 |
|
qwen-audio-3.0-tts-flash |
3 |
新加坡
|
模型名称 |
服务部署范围 |
提交作业接口RPS限制 |
|
qwen-audio-3.0-tts-plus |
国际 |
3 |
|
qwen-audio-3.0-tts-flash |
国际 |
3 |
千问语音合成
华北2(北京)
千问3-TTS-Instruct-Flash
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-instruct-flash |
180 |
|
qwen3-tts-instruct-flash-2026-01-26 |
180 |
千问3-TTS-VD
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-vd-2026-01-26 |
180 |
千问3-TTS-VC
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-vc-2026-01-22 |
180 |
千问3-TTS-Flash
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-flash |
180 |
|
qwen3-tts-flash-2025-11-27 |
180 |
|
qwen3-tts-flash-2025-09-18 |
10 |
千问-TTS
|
模型名称 |
限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 |
|
|
每分钟调用次数(RPM) |
每分钟消耗Token数(TPM) 含输入与输出Token |
|
|
qwen-tts |
10 |
100,000 |
|
qwen-tts-latest |
||
|
qwen-tts-2025-05-22 |
||
|
qwen-tts-2025-04-10 |
||
新加坡
千问3-TTS-Instruct-Flash
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-instruct-flash |
国际 |
180 |
|
qwen3-tts-instruct-flash-2026-01-26 |
国际 |
180 |
千问3-TTS-VD
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-vd-2026-01-26 |
国际 |
180 |
千问3-TTS-VC
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-vc-2026-01-22 |
国际 |
180 |
千问3-TTS-Flash
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-flash |
国际 |
180 |
|
qwen3-tts-flash-2025-11-27 |
国际 |
180 |
|
qwen3-tts-flash-2025-09-18 |
国际 |
10 |
千问实时语音合成
华北2(北京)
千问3-TTS-Instruct-Flash-Realtime
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-instruct-flash-realtime |
180 |
|
qwen3-tts-instruct-flash-realtime-2026-01-22 |
180 |
千问3-TTS-VD-Realtime
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-vd-realtime-2026-01-15 |
180 |
|
qwen3-tts-vd-realtime-2025-12-16 |
千问3-TTS-VC-Realtime
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-vc-realtime-2026-01-15 |
180 |
|
qwen3-tts-vc-realtime-2025-11-27 |
千问3-TTS-Flash-Realtime
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-tts-flash-realtime |
180 |
|
qwen3-tts-flash-realtime-2025-11-27 |
180 |
|
qwen3-tts-flash-realtime-2025-09-18 |
10 |
千问-TTS-Realtime
|
模型名称 |
限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 |
|
|
每分钟调用次数(RPM) |
每分钟消耗Token数(TPM) 含输入与输出Token |
|
|
qwen-tts-realtime |
10 |
100,000 |
|
qwen-tts-realtime-latest |
||
|
qwen-tts-realtime-2025-07-15 |
||
新加坡
千问3-TTS-Instruct-Flash-Realtime
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-instruct-flash-realtime |
国际 |
180 |
|
qwen3-tts-instruct-flash-realtime-2026-01-22 |
国际 |
180 |
千问3-TTS-VD-Realtime
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-vd-realtime-2026-01-15 |
国际 |
180 |
|
qwen3-tts-vd-realtime-2025-12-16 |
国际 |
千问3-TTS-VC-Realtime
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-vc-realtime-2026-01-15 |
国际 |
180 |
|
qwen3-tts-vc-realtime-2025-11-27 |
国际 |
千问3-TTS-Flash-Realtime
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-tts-flash-realtime |
国际 |
180 |
|
qwen3-tts-flash-realtime-2025-11-27 |
国际 |
180 |
|
qwen3-tts-flash-realtime-2025-09-18 |
国际 |
10 |
千问声音复刻
华北2(北京)
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen-voice-enrollment |
180 |
新加坡
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen-voice-enrollment |
国际 |
180 |
千问声音设计
华北2(北京)
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen-voice-design |
180 |
新加坡
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen-voice-design |
国际 |
180 |
CosyVoice语音合成
华北2(北京)
|
模型名称 |
提交作业接口RPS限制 |
|
cosyvoice-v3.5-plus |
3 |
|
cosyvoice-v3.5-flash |
|
|
cosyvoice-v3-plus |
|
|
cosyvoice-v3-flash |
|
|
cosyvoice-v2 |
|
|
cosyvoice-v1 |
新加坡
|
模型名称 |
服务部署范围 |
提交作业接口RPS限制 |
|
cosyvoice-v3-plus |
国际 |
3 |
|
cosyvoice-v3-flash |
国际 |
Qwen-Audio-TTS/CosyVoice声音复刻/设计
Qwen-Audio-TTS/CosyVoice声音复刻/设计共用一个模型,共用限流额度。
华北2(北京)
|
模型名称 |
提交作业接口RPS限制 |
|
voice-enrollment |
10 |
新加坡
|
模型名称 |
服务部署范围 |
提交作业接口RPS限制 |
|
voice-enrollment |
国际 |
10 |
Sambert语音合成
华北2(北京)
|
模型服务 |
提交作业接口RPS限制 |
|
Sambert系列模型 |
20 |
语音合成(文本转语音)-第三方模型
MiniMax-稀宇科技直供
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟调用次数(RPM) | 每分钟消耗字符数 仅含输入字符数 | |
MiniMax/speech-2.8-hd | 20 | 20,000 |
MiniMax/speech-02-hd | 20 | 20,000 |
MiniMax/speech-2.8-turbo | 20 | 20,000 |
MiniMax/speech-02-turbo | 20 | 20,000 |
语音识别(语音转文本)与翻译(语音转成指定语种的文本)
千问3-LiveTranslate-Flash
华北2(北京)
|
模型名称 |
限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 |
|
|
每分钟调用次数(RPM) |
每分钟消耗Token数(TPM) 含输入与输出Token |
|
|
qwen3-livetranslate-flash |
100 |
100,000 |
|
qwen3-livetranslate-flash-2025-12-01 |
||
新加坡
|
模型名称 |
服务部署范围 |
限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 |
|
|
每分钟调用次数(RPM) |
每分钟消耗Token数(TPM) 含输入与输出Token |
||
|
qwen3-livetranslate-flash |
国际 |
100 |
100,000 |
|
qwen3-livetranslate-flash-2025-12-01 |
国际 |
||
千问-LiveTranslate-Flash-Realtime
华北2(北京)
|
模型名称 |
限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 |
|
|
每分钟调用次数(RPM) |
每分钟消耗Token数(TPM) 含输入与输出Token |
|
|
qwen3.5-livetranslate-flash-realtime |
10 |
100,000 |
|
qwen3.5-livetranslate-flash-realtime-2026-05-19 |
||
|
qwen3-livetranslate-flash-realtime |
||
|
qwen3-livetranslate-flash-realtime-2025-09-22 |
||
新加坡
|
模型名称 |
服务部署范围 |
限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 |
|
|
每分钟调用次数(RPM) |
每分钟消耗Token数(TPM) 含输入与输出Token |
||
|
qwen3.5-livetranslate-flash-realtime |
国际 |
10 |
100,000 |
|
qwen3.5-livetranslate-flash-realtime-2026-05-19 |
国际 |
||
|
qwen3-livetranslate-flash-realtime |
国际 |
||
|
qwen3-livetranslate-flash-realtime-2025-09-22 |
国际 |
||
千问录音文件识别
华北2(北京)
千问3-ASR-Flash-Filetrans
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-asr-flash-filetrans |
100 |
|
qwen3-asr-flash-filetrans-2025-11-17 |
千问3-ASR-Flash
|
模型名称 |
每分钟调用次数(RPM) |
|
qwen3-asr-flash |
100 |
|
qwen3-asr-flash-2026-02-10 |
|
|
qwen3-asr-flash-2025-09-08 |
新加坡
千问3-ASR-Flash-Filetrans
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-asr-flash-filetrans |
国际 |
100 |
|
qwen3-asr-flash-filetrans-2025-11-17 |
国际 |
千问3-ASR-Flash
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-asr-flash |
国际 |
100 |
|
qwen3-asr-flash-2026-02-10 |
国际 |
|
|
qwen3-asr-flash-2025-09-08 |
国际 |
美国(弗吉尼亚)
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
qwen3-asr-flash-us |
美国 |
100 |
|
qwen3-asr-flash-2025-09-08-us |
美国 |
千问实时语音识别
华北2(北京)
|
模型名称 |
每秒钟调用次数(RPS) |
|
qwen3-asr-flash-realtime |
20 |
|
qwen3-asr-flash-realtime-2026-02-10 |
|
|
qwen3-asr-flash-realtime-2025-10-27 |
新加坡
|
模型名称 |
服务部署范围 |
每秒钟调用次数(RPS) |
|
qwen3-asr-flash-realtime |
国际 |
20 |
|
qwen3-asr-flash-realtime-2026-02-10 |
国际 |
|
|
qwen3-asr-flash-realtime-2025-10-27 |
国际 |
Fun-ASR录音文件识别
华北2(北京)
|
模型名称 |
每分钟调用次数(RPM) |
|
fun-asr |
600 |
|
fun-asr-2025-11-07 |
|
|
fun-asr-2025-08-25 |
|
|
fun-asr-mtl |
|
|
fun-asr-mtl-2025-08-25 |
|
|
fun-asr-flash-2026-06-15 |
新加坡
|
模型名称 |
服务部署范围 |
每分钟调用次数(RPM) |
|
fun-asr |
国际 |
600 |
|
fun-asr-2025-11-07 |
国际 |
600 |
|
fun-asr-2025-08-25 |
国际 |
600 |
|
fun-asr-mtl |
国际 |
100 |
|
fun-asr-mtl-2025-08-25 |
国际 |
100 |
|
fun-asr-flash-2026-06-15 |
国际 |
600 |
Fun-ASR实时语音识别
华北2(北京)
|
模型名称 |
提交作业接口RPS限制 |
|
fun-asr-realtime |
20 |
|
fun-asr-realtime-2026-02-28 |
|
|
fun-asr-realtime-2025-11-07 |
|
|
fun-asr-realtime-2025-09-15 |
|
|
fun-asr-flash-8k-realtime |
|
|
fun-asr-flash-8k-realtime-2026-01-28 |
新加坡
|
模型名称 |
服务部署范围 |
提交作业接口RPS限制 |
|
fun-asr-realtime |
国际 |
20 |
|
fun-asr-realtime-2025-11-07 |
国际 |
Paraformer语音识别
华北2(北京)
|
模型名称 |
提交作业接口RPS限制 |
|
paraformer-realtime-v2 |
20 |
|
paraformer-realtime-v1 |
|
|
paraformer-realtime-8k-v2 |
|
|
paraformer-realtime-8k-v1 |
|
模型名称 |
每分钟调用次数(RPM) |
|
paraformer-v2 |
1,200 |
|
模型名称 |
每分钟调用次数(RPM) |
每分钟消耗Token数(TPM) 含输入与输出Token |
|
paraformer-v1 |
600 |
6,000,000 |
|
paraformer-mtl-v1 |
600 |
6,000,000 |
|
模型名称 |
提交作业接口RPS限制 |
同时处理中任务数量(并发数) |
|
paraformer-8k-v2 |
20 |
100 |
|
paraformer-8k-v1 |
10 |
500 |
视频生成
HappyHorse系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
happyhorse-1.1-t2v | 5 | 5 |
happyhorse-1.1-i2v | 5 | 5 |
happyhorse-1.1-r2v | 5 | 5 |
happyhorse-1.0-t2v | 5 | 5 |
happyhorse-1.0-i2v | 5 | 5 |
happyhorse-1.0-r2v | 5 | 5 |
happyhorse-1.0-video-edit | 5 | 5 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
happyhorse-1.1-t2v | 全球 | 5 | 5 |
happyhorse-1.1-i2v | 全球 | 5 | 5 |
happyhorse-1.1-r2v | 全球 | 5 | 5 |
happyhorse-1.0-t2v | 全球 | 5 | 5 |
happyhorse-1.0-i2v | 全球 | 5 | 5 |
happyhorse-1.0-r2v | 全球 | 5 | 5 |
happyhorse-1.0-video-edit | 全球 | 5 | 5 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
happyhorse-1.1-t2v | 国际 | 5 | 5 |
happyhorse-1.1-i2v | 国际 | 5 | 5 |
happyhorse-1.1-r2v | 国际 | 5 | 5 |
happyhorse-1.0-t2v | 国际 | 5 | 5 |
happyhorse-1.0-i2v | 国际 | 5 | 5 |
happyhorse-1.0-r2v | 国际 | 5 | 5 |
happyhorse-1.0-video-edit | 国际 | 5 | 5 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
happyhorse-1.1-t2v | 全球 | 5 | 5 |
happyhorse-1.1-i2v | 全球 | 5 | 5 |
happyhorse-1.1-r2v | 全球 | 5 | 5 |
happyhorse-1.0-t2v | 全球 | 5 | 5 |
happyhorse-1.0-i2v | 全球 | 5 | 5 |
happyhorse-1.0-r2v | 全球 | 5 | 5 |
happyhorse-1.0-video-edit | 全球 | 5 | 5 |
日本(东京)
模型名称 | 服务部署范围 | 限流值(任何一个值超出即触发限流) | |
任务提交接口RPS限制 | 正在处理中的任务数(并发) | ||
happyhorse-1.1-t2v | 全球 | 5 | 5 |
happyhorse-1.1-i2v | 全球 | 5 | 5 |
happyhorse-1.1-r2v | 全球 | 5 | 5 |
happyhorse-1.0-video-edit | 全球 | 5 | 5 |
万相系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
wan2.7-r2v-2026-06-12 | 5 | 5 |
wan2.7-t2v-2026-06-12 | 5 | 5 |
wan2.7-t2v-2026-04-25 | 5 | 5 |
wan2.7-t2v | 5 | 5 |
wan2.6-t2v | 5 | 5 |
wan2.5-t2v-preview | 5 | 5 |
wan2.2-t2v-plus | 2 | 2 |
wanx2.1-t2v-turbo | 2 | 2 |
wanx2.1-t2v-plus | 2 | 2 |
wan2.7-i2v-2026-04-25 | 5 | 5 |
wan2.7-i2v | 5 | 5 |
wan2.6-i2v-flash | 5 | 5 |
wan2.6-i2v | 5 | 5 |
wan2.5-i2v-preview | 5 | 5 |
wan2.2-i2v-flash | 2 | 2 |
wan2.2-i2v-plus | 2 | 2 |
wanx2.1-i2v-turbo | 2 | 2 |
wanx2.1-i2v-plus | 2 | 2 |
wan2.2-kf2v-flash | 2 | 2 |
wanx2.1-kf2v-plus | 2 | 2 |
wanx2.1-vace-plus | 2 | 2 |
wan2.7-videoedit | 5 | 5 |
wan2.7-r2v | 5 | 5 |
wan2.6-r2v-flash | 5 | 5 |
wan2.6-r2v | 5 | 5 |
wan2.2-s2v-detect | 5 | 同步接口无限制 |
wan2.2-s2v | 5 | 1 |
wan2.2-animate-move | 5 | 1 |
wan2.2-animate-mix | 5 | 1 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
wan2.7-r2v-2026-06-12 | 国际 | 5 | 5 |
wan2.6-t2v | 全球 | 5 | 5 |
wan2.6-i2v | 全球 | 5 | 5 |
wan2.6-r2v | 全球 | 5 | 5 |
wan2.6-t2v-us | 美国 | 5 | 5 |
wan2.6-i2v-us | 美国 | 5 | 5 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
wan2.7-t2v-2026-06-12 | 国际 | 5 | 5 |
wan2.7-t2v-2026-04-25 | 国际 | 5 | 5 |
wan2.7-t2v | 国际 | 5 | 5 |
wan2.6-t2v | 国际 | 5 | 5 |
wan2.5-t2v-preview | 国际 | 5 | 5 |
wan2.2-t2v-plus | 国际 | 2 | 2 |
wan2.1-t2v-turbo | 国际 | 2 | 2 |
wan2.1-t2v-plus | 国际 | 2 | 2 |
wan2.7-i2v-2026-04-25 | 国际 | 5 | 5 |
wan2.7-i2v | 国际 | 5 | 5 |
wan2.6-i2v-flash | 国际 | 5 | 5 |
wan2.6-i2v | 国际 | 5 | 5 |
wan2.5-i2v-preview | 国际 | 5 | 5 |
wan2.2-i2v-plus | 国际 | 2 | 2 |
wan2.1-i2v-turbo | 国际 | 2 | 2 |
wan2.1-i2v-plus | 国际 | 2 | 2 |
wan2.1-kf2v-plus | 国际 | 1 | 2 |
wan2.1-vace-plus | 国际 | 2 | 2 |
wan2.7-videoedit | 国际 | 5 | 5 |
wan2.7-r2v | 国际 | 5 | 5 |
wan2.6-r2v-flash | 国际 | 5 | 5 |
wan2.6-r2v | 国际 | 5 | 5 |
wan2.2-animate-move | 国际 | 5 | 1 |
wan2.2-animate-mix | 国际 | 5 | 1 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | ||
wan2.6-t2v | 全球 | 5 | 5 |
wan2.6-i2v | 全球 | 5 | 5 |
wan2.6-r2v | 全球 | 5 | 5 |
舞动人像AnimateAnyone
华北2(北京)
模型名称 | 任务下发接口RPS限制 | 同时处理中任务数量 |
animate-anyone-detect-gen2 | 5 | 同步接口无限制 |
animate-anyone-template-gen2 | 5 | 1 在同一时刻,只有1个作业实际处于运行状态,其他队列中的作业处于排队状态。 |
animate-anyone-gen2 | 5 | 1 在同一时刻,只有1个作业实际处于运行状态,其他队列中的作业处于排队状态。 |
animate-anyone-detect | 5 | 1算力单元支持2并发 |
animate-anyone | 5 | 1算力单元支持1并发 |
悦动人像EMO
华北2(北京)
模型名称 | 任务下发接口RPS限制 | 同时处理中任务数量 |
emo-detect-v1 | 5 | 同步接口无限制 |
emo-v1 | 5 | 1 在同一时刻,只有1个作业实际处于运行状态,其他队列中的作业处于排队状态。 |
灵动人像LivePortrait
华北2(北京)
模型名称 | 任务下发接口RPS限制 | 同时处理中任务数量 |
liveportrait-detect | 5 | 同步接口无限制 |
liveportrait | 5 | 1 在同一时刻,只有1个作业实际处于运行状态,其他队列中的作业处于排队状态。 |
声动人像VideoRetalk
华北2(北京)
模型名称 | 任务下发接口RPS限制 | 同时处理中任务数量 |
videoretalk | 1 | 1 在同一时刻,只有1个作业实际处于运行状态,其他队列中的作业处于排队状态。 |
表情包Emoji
华北2(北京)
模型名称 | 任务下发接口RPS限制 | 同时处理中任务数量 |
emoji-detect-v1 | 1 | 同步接口无限制 |
emoji-v1 | 1 | 1 在同一时刻,只有1个作业实际处于运行状态,其他队列中的作业处于排队状态。 |
视频风格重绘
华北2(北京)
模型名称 | 任务下发接口RPS限制 | 同时处理中任务数量 |
video-style-transform | 20 | 2 在同一时刻,只有1个作业实际处于运行状态,其他队列中的作业处于排队状态。 |
视频生成-第三方模型
爱诗系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟任务下发接口RPM限制 | 同时处理中任务数量(并发数) | |
pixverse/pixverse-lipsync | 300 | 5 同一个阿里云百炼API Key 在 3 个模型间共享额度。即这 3 个模型处于运行状态的任务总数加起来不能超过 5 个。 |
pixverse/pixverse-motioncontrol | 300 | |
pixverse/pixverse-upscale | 300 | |
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
pixverse/pixverse-c1-t2v | 5 | 5 同一个阿里云百炼API Key 在 4个模型间共享额度。即这 4个模型处于运行状态的任务总数加起来不能超过 5 个。 |
pixverse/pixverse-c1-it2v | ||
pixverse/pixverse-c1-kf2v | ||
pixverse/pixverse-c1-r2v | ||
pixverse/pixverse-v6-t2v | 5 | 5 同一个阿里云百炼API Key 在 4 个模型间共享额度。即这 4 个模型处于运行状态的任务总数加起来不能超过 5 个。 |
pixverse/pixverse-v6-it2v | ||
pixverse/pixverse-v6-kf2v | ||
pixverse/pixverse-v6-r2v | ||
pixverse/pixverse-v5.6-t2v | 5 | 5 同一个阿里云百炼API Key 在 4 个模型间共享额度。即这 4 个模型处于运行状态的任务总数加起来不能超过 5 个。 |
pixverse/pixverse-v5.6-it2v | ||
pixverse/pixverse-v5.6-kf2v | ||
pixverse/pixverse-v5.6-r2v | ||
可灵系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
kling/kling-v3-omni-video-generation | 5 | 10 同一阿里云百炼API Key 下,可灵系列的 4 个模型(图像及视频)共享 10 个并发数。即这 4 个模型处于运行状态的任务总数加起来不能超过 10 个。 |
kling/kling-v3-video-generation | ||
Vidu系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
vidu/viduq3-ad_reference2video | 5 | 5 同一个阿里云百炼API Key 在 20 个模型间共享并发额度。即这 20 个模型处于运行状态的任务总数加起来不能超过 5 个。 |
vidu/viduq3-drama_reference2video | 5 | |
vidu/viduq3-pro-fast_img2video | 5 | |
vidu/viduq3-turbo_text2video | 5 | |
vidu/viduq3-pro_text2video | 5 | |
vidu/viduq2_text2video | 5 | |
vidu/viduq3-turbo_img2video | 5 | |
vidu/viduq3-pro_img2video | 5 | |
vidu/viduq2-turbo_img2video | 5 | |
vidu/viduq2-pro_img2video | 5 | |
vidu/viduq2-pro-fast_img2video | 5 | |
vidu/viduq3-turbo_start-end2video | 5 | |
vidu/viduq3-pro_start-end2video | 5 | |
vidu/viduq2-turbo_start-end2video | 5 | |
vidu/viduq2-pro_start-end2video | 5 | |
vidu/viduq3-mix_reference2video | 5 | |
vidu/viduq3_reference2video | 5 | |
vidu/viduq3-turbo_reference2video | 5 | |
vidu/viduq2-pro_reference2video | 5 | |
vidu/viduq2_reference2video | 5 | |
3D模型生成-第三方模型
Tripo系列
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量(并发数) | |
Tripo/Tripo-H3.1 | 5 | 10 同一个阿里云百炼API Key 在 2 个模型间共享额度。即这 2 个模型处于运行状态的任务总数加起来不能超过 10 个。 |
Tripo/Tripo-P1.0 | 5 | |
向量模型
文本向量
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM)/作业数 仅输入Token | |
qwen3.7-text-embedding | 1,800 | 1,000,000 |
text-embedding-v1 用Batch API调用服务时,不受限流限制。 | 1,800 | 1,200,000 |
text-embedding-v2 用Batch API调用服务时,不受限流限制。 | 1,800 | 1,200,000 |
text-embedding-v3 用Batch API调用服务时,不受限流限制。 | 1,800 | 1,200,000 |
text-embedding-v4 用Batch API调用服务时,不受限流限制。 | 1,800 | 1,200,000 |
text-embedding-async-v1 | 60 | 当前用户在系统通用文本向量异步作业排队中和运行中的作业数量不超过50个。 另外,为了避免大量突发的作业占据太多资源,限制并发的作业数为3个,即任意时间,单个用户最多只有3个通用文本向量的异步作业在并发运行,其他的作业只能在队列中等待。 |
text-embedding-async-v2 | 60 | 当前用户在系统通用文本向量异步作业排队中和运行中的作业数量不超过50个。 另外,为了避免大量突发的作业占据太多资源,限制并发的作业数为3个,即任意时间,单个用户最多只有3个通用文本向量的异步作业在并发运行,其他的作业只能在队列中等待。 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM)/作业数 含输入与输出Token | ||
text-embedding-v4 | 国际 | 1,800 | 1,000,000 |
text-embedding-v3 | 国际 | 6,000 | 24,000,000 |
多模态向量
华北2(北京)
模型名称 | 限流条件 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 仅输入Token | |
qwen3-vl-embedding | 2,400 | 1,200,000 |
qwen2.5-vl-embedding | 1,200 | 600,000 |
tongyi-embedding-vision-plus | 600 | 200,000 |
tongyi-embedding-vision-flash | 600 | 200,000 |
tongyi-embedding-vision-flash-2026-03-06 | 1,200 | 9,600,000 |
tongyi-embedding-vision-plus-2026-03-06 | 1,200 | 9,600,000 |
multimodal-embedding-v1 | 120 | 1,000,000 |
排序模型
排序模型
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen3-rerank | 5,400 | 5,000,000,000 |
qwen3-vl-rerank | 600 | 9,000,000 |
gte-rerank-v2 | 5,040 | 4,980,000,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen3-rerank | 国际 | 5,400 | 5,000,000,000 |
gte-rerank-v2 | 国际 | 5,040 | 4,980,000,000 |
行业
通义法睿(法律模型)
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
farui-plus | 240 | 1,000,000 |
意图理解
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
tongyi-intent-detect-v3 | 1,200 | 1,000,000 |
角色扮演
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
qwen-plus-character | 120 | 500,000 |
qwen-flash-character | 120 | 500,000 |
qwen-flash-character-2026-02-26 | 120 | 500,000 |
新加坡
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-plus-character | 国际 | 120 | 500,000 |
qwen-flash-character | 国际 | 120 | 500,000 |
qwen-plus-character-ja | 国际 | 120 | 500,000 |
美国(弗吉尼亚)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-plus-character | 全球 | 120 | 500,000 |
德国(法兰克福)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-plus-character | 全球 | 120 | 500,000 |
日本(东京)
模型名称 | 服务部署范围 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
qwen-plus-character | 全球 | 120 | 500,000 |
界面交互
华北2(北京)
模型名称 | 限流条件(超出任一数值时触发限流) 以下为每分钟限流条件,服务可能按 RPS(RPM/60)与 TPS(TPM/60)限制 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |
gui-plus | 80 | 540,000 |
gui-plus-2026-02-26 | 100 | 540,000 |
已下线模型
详细信息,请参见 模型下线机制说明 。
2026年5月13日下线
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
千问语言模型 | qwen-max-latest | 0 | 0 |
qwen-max-2025-01-25 | |||
qwen-max-2024-09-19 | |||
qwen-max-2024-04-28 | |||
qwen-turbo-latest | |||
qwen-turbo-2025-07-15 | |||
qwen-turbo-2025-04-28 | |||
qwen-turbo-2025-02-11 | |||
qwen-turbo-2024-11-01 | |||
qwq-plus-latest | |||
qwq-plus-2025-03-05 | |||
千问VL | qwen-vl-max-latest | ||
qwen-vl-max-2025-08-13 | |||
qwen-vl-max-2025-04-08 | |||
qwen-vl-max-2025-04-02 | |||
qwen-vl-max-2025-01-25 | |||
qwen-vl-max-1230 | |||
qwen-vl-max-1119 | |||
qwen-vl-plus-latest | |||
qwen-vl-plus-2025-08-15 | |||
qwen-vl-plus-2025-07-10 | |||
qwen-vl-plus-2025-05-07 | |||
qwen-vl-plus-2025-01-25 | |||
qwen-vl-plus-0102 | |||
qvq-max-latest | |||
qvq-max-2025-05-15 | |||
qvq-max-2025-03-25 | |||
qvq-plus-latest | |||
qvq-plus-2025-05-15 | |||
千问数学模型 | qwen-math-turbo-latest | ||
qwen-math-turbo-0919 | |||
千问Coder | qwen-coder-plus-latest | ||
qwen-coder-plus-2024-11-06 | |||
qwen-coder-turbo-latest | |||
qwen-coder-turbo-0919 | |||
文本生成-千问-开源版 | qwq-32b | ||
qwq-32b-preview | |||
qvq-72b-preview | |||
qwen2.5-vl-72b-instruct | |||
qwen2.5-vl-32b-instruct | |||
qwen2.5-vl-7b-instruct | |||
qwen2.5-vl-3b-instruct | |||
qwen2.5-7b-instruct-1m | |||
qwen2.5-14b-instruct-1m | |||
qwen2.5-72b-instruct | |||
qwen2.5-32b-instruct | |||
qwen2.5-14b-instruct | |||
qwen2.5-7b-instruct | |||
qwen2.5-math-72b-instruct | |||
qwen2.5-math-7b-instruct | |||
qwen2.5-math-1.5b-instruct | |||
qwen2.5-coder-32b-instruct | |||
qwen2.5-coder-14b-instruct | |||
qwen2.5-coder-7b-instruct | |||
qwen2.5-coder-3b-instruct | |||
qwen2.5-coder-1.5b-instruct | |||
qwen2.5-coder-0.5b-instruct | |||
qwen2.5-3b-instruct | |||
qwen2.5-1.5b-instruct | |||
qwen2.5-0.5b-instruct | |||
qwen3-0.6b | |||
qwen3-1.7b | |||
qwen3-4b | |||
2026年3月30日下线
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
千问语言模型 | qwen2-72b-instruct | 0 | 0 |
qwen2-57b-a14b-instruct | |||
qwen2-7b-instruct | |||
qwen2-1.5b-instruct | |||
qwen2-0.5b-instruct | |||
qwen1.5-110b-chat | |||
qwen1.5-72b-chat | |||
qwen1.5-32b-chat | |||
qwen1.5-14b-chat | |||
qwen1.5-7b-chat | |||
qwen1.5-1.8b-chat | |||
qwen1.5-0.5b-chat | |||
qwen2.5-coder-3b-instruct | |||
qwen2.5-coder-1.5b-instruct | |||
qwen2.5-coder-0.5b-instruct | |||
qwen2.5-math-1.5b-instruct | |||
千问VL | qwen2-vl-72b-instruct | ||
qwen2-vl-7b-instruct | |||
qwen2-vl-2b-instruct | |||
qwen-vl-v1 | |||
qwen-vl-chat-v1 | |||
MiniMax-abab | abab6.5g-chat | ||
abab6.5t-chat | |||
abab6.5s-chat | |||
StableDiffusion文生图 | stable-diffusion-xl | ||
stable-diffusion-v1.5 | |||
stable-diffusion-3.5-large | |||
stable-diffusion-3.5-large-turbo | |||
FLUX文生图 | flux-schnell | ||
flux-dev | |||
flux-merged | |||
千问Audio | qwen2-audio-instruct | ||
qwen-audio-chat | |||
OpenNLU | opennlu-v1 | ||
2026年1月30日下线
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
千问Max | qwen-max-2024-04-03 | 0 | 0 |
千问Plus | qwen-plus-2024-11-27 | ||
qwen-plus-2024-11-25 | |||
qwen-plus-2024-09-19 | |||
qwen-plus-2024-08-06 | |||
qwen-plus-2024-07-23 | |||
千问Turbo | qwen-turbo-2024-09-19 | ||
qwen-turbo-2024-06-24 | |||
千问VL | qwen-vl-max-2024-10-30 | ||
qwen-vl-max-2024-08-09 | |||
qwen-vl-plus-2024-08-09 | |||
千问Audio | qwen-audio-turbo-2024-12-04 | ||
qwen-audio-turbo-2024-08-07 | |||
qwen-audio-asr-2024-12-04 | |||
2025年7月30日下线
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
千问VL | qwen-vl-plus-2023-12-01 | 0 | 0 |
零一万物 | yi-large | ||
yi-medium | |||
yi-large-rag | |||
yi-large-turbo | |||
Dolly | dolly-12b-v2 | ||
2025年7月2日下线
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | ||
Llama-仅文本输入 | llama3.3-70b-instruct | 0 | 0 |
llama3.2-3b-instruct | |||
llama3.2-1b-instruct | |||
llama3.1-405b-instruct | |||
llama3.1-70b-instruct | |||
llama3.1-8b-instruct | |||
llama3-70b-instruct | |||
llama3-8b-instruct | |||
llama2-13b-chat-v2 | |||
llama2-7b-chat-v2 | |||
Llama-文本和图像输入 | llama3.2-90b-vision-instruct | ||
llama3.2-11b-vision | |||
百川-开源版 | baichuan2-13b-chat-v1 | ||
baichuan2-7b-chat-v1 | |||
baichuan-7b-v1 | |||
ChatGLM | chatglm3-6b | ||
chatglm-6b-v2 | |||
姜子牙 | ziya-llama-13b-v1 | ||
BELLE | belle-llama-13b-2m-v1 | ||
元语 | chatyuan-large-v2 | ||
BiLLa | billa-7b-sft-v1 | ||
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | |
每秒钟任务下发接口RPS限制 | 同时处理中任务数量 | ||
动漫人物生成 | wanx-style-cosplay-v1 | 0 | 0 |
图配文 | wanx-ast | ||
创意文字生成-WordArt锦书 | wordart-surnames | ||
AnyText图文融合 | wanx-anytext-v1 | ||
2025年5月8日下线
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | 替代模型 | |
每分钟调用次数(RPM) | 每分钟消耗Token数(TPM) 含输入与输出Token | |||
文本生成-千问 | qwen-max-2024-01-07 (qwen-max-0107) | 0 | 0 | qwen-max |
qwen-plus-2024-06-24 (qwen-plus-0624) | qwen-plus | |||
qwen-plus-2024-02-06 (qwen-plus-0206) | ||||
qwen-turbo-2024-02-06 (qwen-turbo-0206) | qwen-turbo | |||
qwen-vl-max-2024-02-01 (qwen-vl-max-0201) | qwen-vl-max | |||
文本生成-千问-开源版 | qwen-72b-chat | qwen2.5-72b-instruct | ||
qwen-14b-chat | qwen2.5-14b-instruct | |||
qwen-7b-chat | qwen2.5-7b-instruct | |||
qwen-1.8b-chat | qwen2.5-1.5b-instruct | |||
qwen-1.8b-longcontext-chat | qwen2.5-1.5b-instruct | |||
qwen2-math-72b-instruct | qwen2.5-math-72b-instruct | |||
qwen2-math-7b-instruct | qwen2.5-math-7b-instruct | |||
qwen2-math-1.5b-instruct | qwen2.5-math-7b-instruct | |||
类别 | 模型名称 | 限流条件(超出任一数值时触发限流) | 替代模型 | |
任务下发接口RPS限制 | 同时处理中任务数量 | |||
幻影人像Motionshop视频生成模型 | motionshop-video-detect | 0 | 0 | 使用animate-anyone-gen2的“按视频背景生成”功能,可达到近似效果 |
motionshop-gen3d | ||||
motionshop-synthesis | ||||