可观测监控 Prometheus 版支持通过node-exporter采集ECS Linux或Windows主机操作系统相关指标,也支持process-exporter采集进程相关监控数据,另外基于textfile的方式也支持采集用户写到文件中自定义监控指标。
前提条件
-
已开通可观测监控Prometheus版。具体操作,请参见Prometheus 实例计费。
-
已创建ECS实例。具体操作,请参见通过控制台使用ECS实例(快捷版)。
-
已开通阿里云资源中心。具体操作,请参见开通资源中心。
主机监控优势
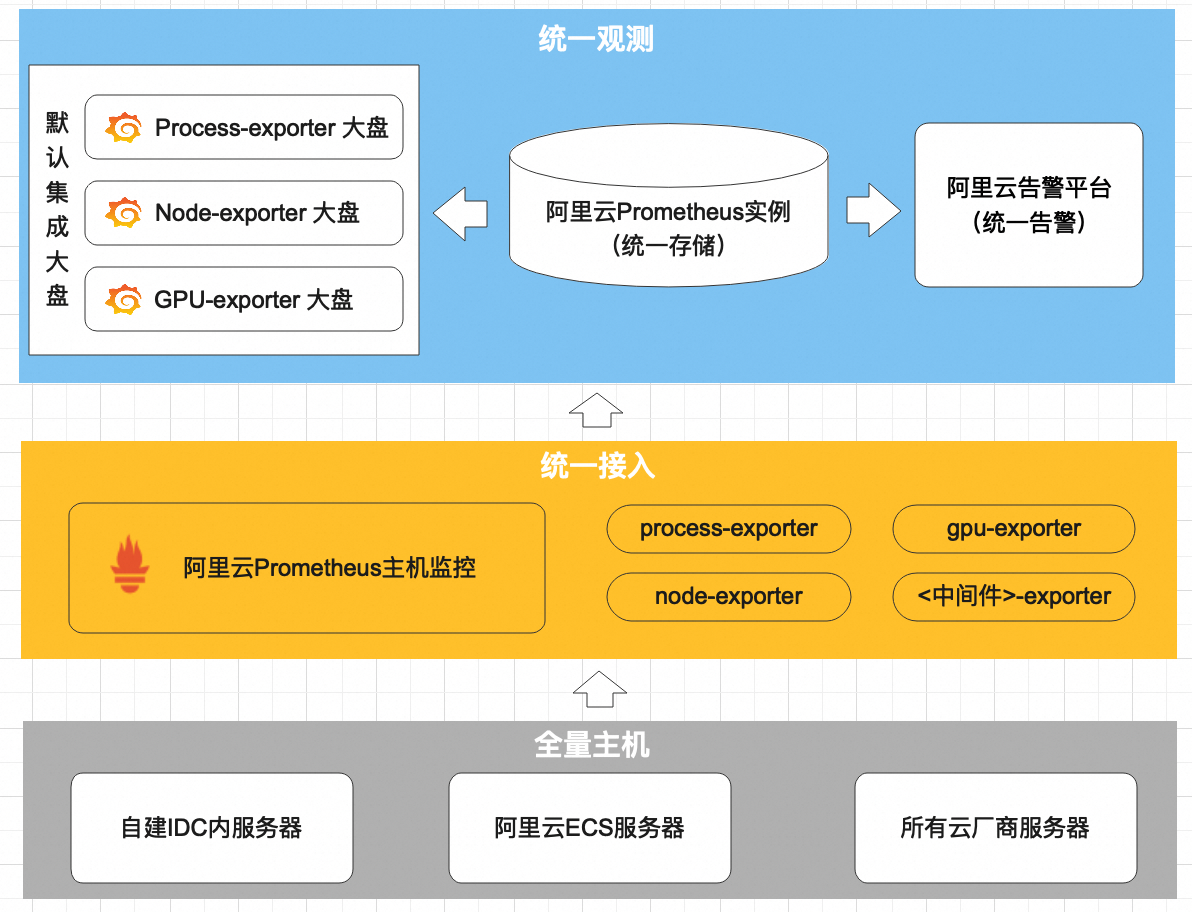
阿里云Prometheus主机监控针对阿里云ECS服务器提供了一个高效且易于管理的监控方案,这一方案的特点是顺应了现代云计算环境中对于可观测性和自动化管理的需求。
阿里云Prometheus提供的主机监控,具备阿里云ECS服务器、自建IDC内服务器、云厂商服务器全类型主机接入能力。针对阿里云ECS服务器可根据配置自动安装各类开源Exporter,各类Exporter采集配置自动生成。托管Prometheus Agent实现自动采集,采集数据统一存储、统一展示、统一告警。非阿里云主机不具备自动服务发现的能力,所以需要依赖用户在接入时手动安装阿里云采集探针,主动将监控数据上报到阿里云Prometheus存储。
|
优势 |
说明 |
|
主机秒级发现 |
|
|
探针秒级安装 |
|
|
指标秒级采集 |
主机从创建到纳入监控系统,整体可以在30 ~ 60s以内完成。主机所有指标数据可以支持1 ~ 60s时间间隔的灵活调整。整体实现主机全方位秒级监控能力。 |
|
探针Serverless化 |
|
|
智能指标标签 |
|
|
超大规模数据采集与存储 |
|
|
提供完善的上下游监控数据 |
|
|
进程级监控 |
|
|
默认提供Grafana专家级大盘 |
|
步骤一:接入主机监控数据
登录ARMS控制台,在左侧导航栏单击接入中心。
-
在接入中心页面,单击左侧基础设施,然后单击主机监控。
说明-
由于Prometheus依赖阿里云资源中心获取云产品当前登录账户的VPC、ECS等数据进行服务发现,如果没有开通资源中心,接入流程会引导您先开通资源中心,具体操作请参见开通资源中心。
-
开通资源中心是异步操作,重新检测后如果仍然是未开通状态,可以等待10~20秒左右再单击重新检测。
-
-
在弹出的页面中,选择目标ECS(VPC),然后按照下表说明填写配置信息。
指标
说明
NodeExporter 安装方式
-
自动安装(推荐):Prometheus会为用户选择的ECS默认安装node-exporter,您无需其他操作即可接入。
-
自助安装:自行安装node-exporter。
主机服务发现方式
-
污点标签选择:黑名单机制。标签匹配到的实例将不会接入Prometheus,没有匹配到的ECS监控指标将会接入Prometheus,默认不会采集容器监控服务的节点。
-
无条件:安装和采集当前VPC内所有ECS主机监控指标。
-
标签选择:白名单机制。标签匹配到的实例将会接入Prometheus,没有匹配到的ECS实例将不会接入Prometheus。
-
IP域选择:该方式是提供一个网段,当ECS的IP地址匹配该网段时,即被选中。如果填写VPC对应的网段,即代表命中当前VPC全部ECS。
-
实例ID:指定需要接入的实例ID,多个实例ID使用英文逗号分隔。
ECS 污点标签
每一个污点标签由key和value组成,可以设置多个污点标签。
采集 TextFile
采集指定文件中的Prometheus指标。
采集进程状态指标
默认会采集主机上的进程监控数据。
Node-Exporter 服务端口
默认端口9100。
Metric 采集间隔(单位/秒)
采集数据的时间间隔,默认为15秒。
自动配置安全组
默认打开。
自定义ECS Tag注入
指定ECS标签的Key,系统会自动将标签的键值对注入到Prometheus指标中。
-
-
单击确定,等待1~2分钟即可完成ECS主机监控指标接入。
接入成功后,如果监控大盘没有数据,需要确认ECS的安全组在入方向需要允许100.64.0.0/10和192.168.0.0/18网段对9100和9256的访问权限,查看ECS的安全组详情,请参见查询安全组。9100是node-exporter的默认端口,9256是process-exporter的默认端口,具体端口需要根据您自身配置进行调整。
步骤二:查看监控大盘
-
在左侧导航栏单击接入管理。
-
在接入管理页面的已接入环境页签中,选择ECS环境。
-
在ECS环境列表中,单击目标环境名称进入ECS环境详情页面。
-
在组件管理页签,单击组件类型区域的大盘,即可查看内置的Grafana大盘。
步骤三:配置告警
登录Prometheus控制台,在左侧导航栏单击接入管理。
-
在接入管理页面的已接入环境页签中,选择ECS环境。
-
在ECS环境列表中,单击目标环境名称进入ECS环境详情页面。
-
在组件管理页签,单击组件类型区域的告警规则,即可查看内置的告警规则。
-
内置的告警规则会产生告警事件,但不会进行告警通知。如果您希望将告警通知发送到邮件或其他平台,可以单击编辑配置通知方式。在告警配置页面您也可以自定义告警阈值、持续时间、告警内容等,具体操作,请参见创建Prometheus告警规则。
-
在极简模式下,您可以设置告警的通知对象、通知时段和重复策略。
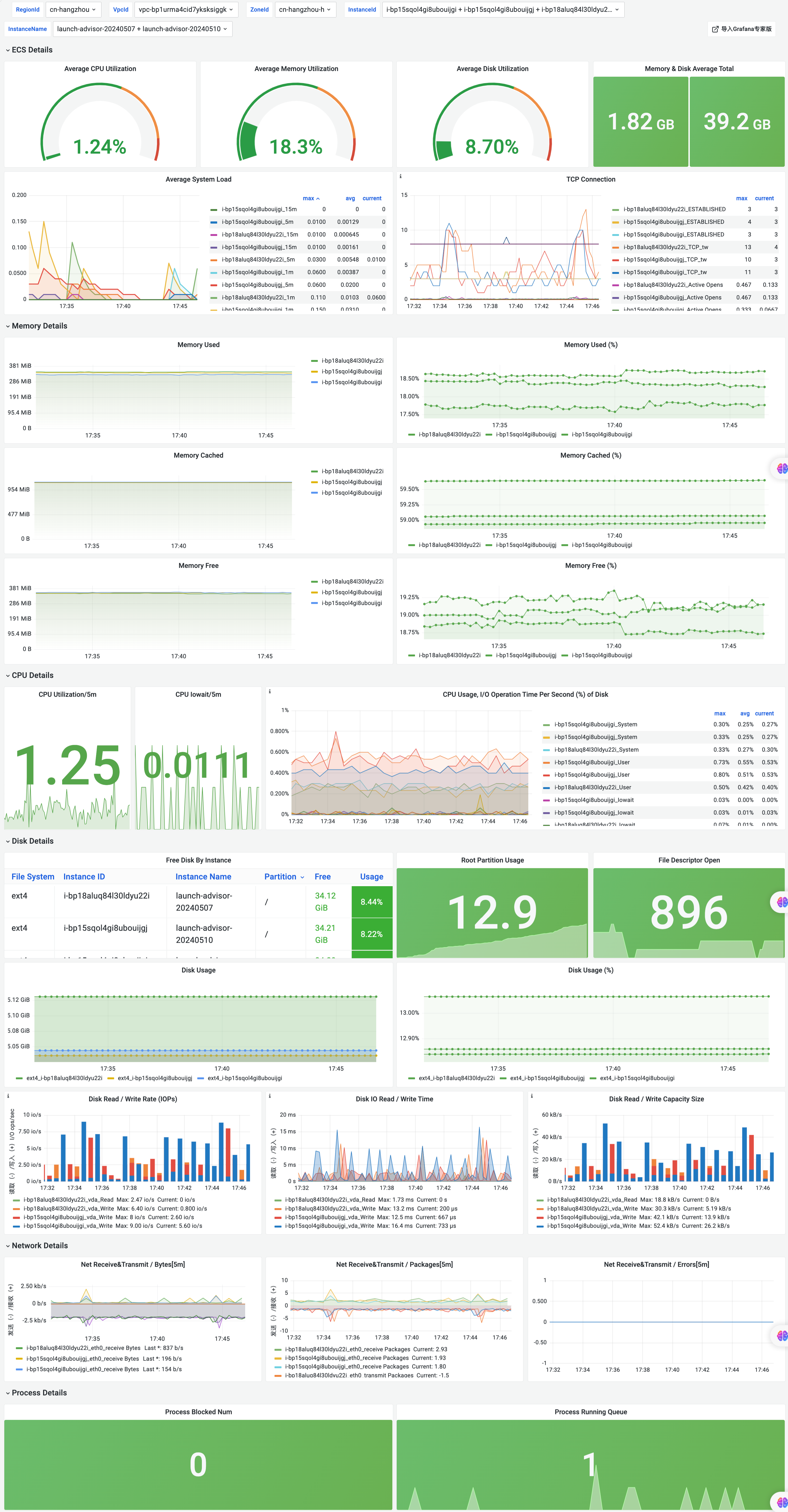
Grafana大盘图例
ECS Overview大盘
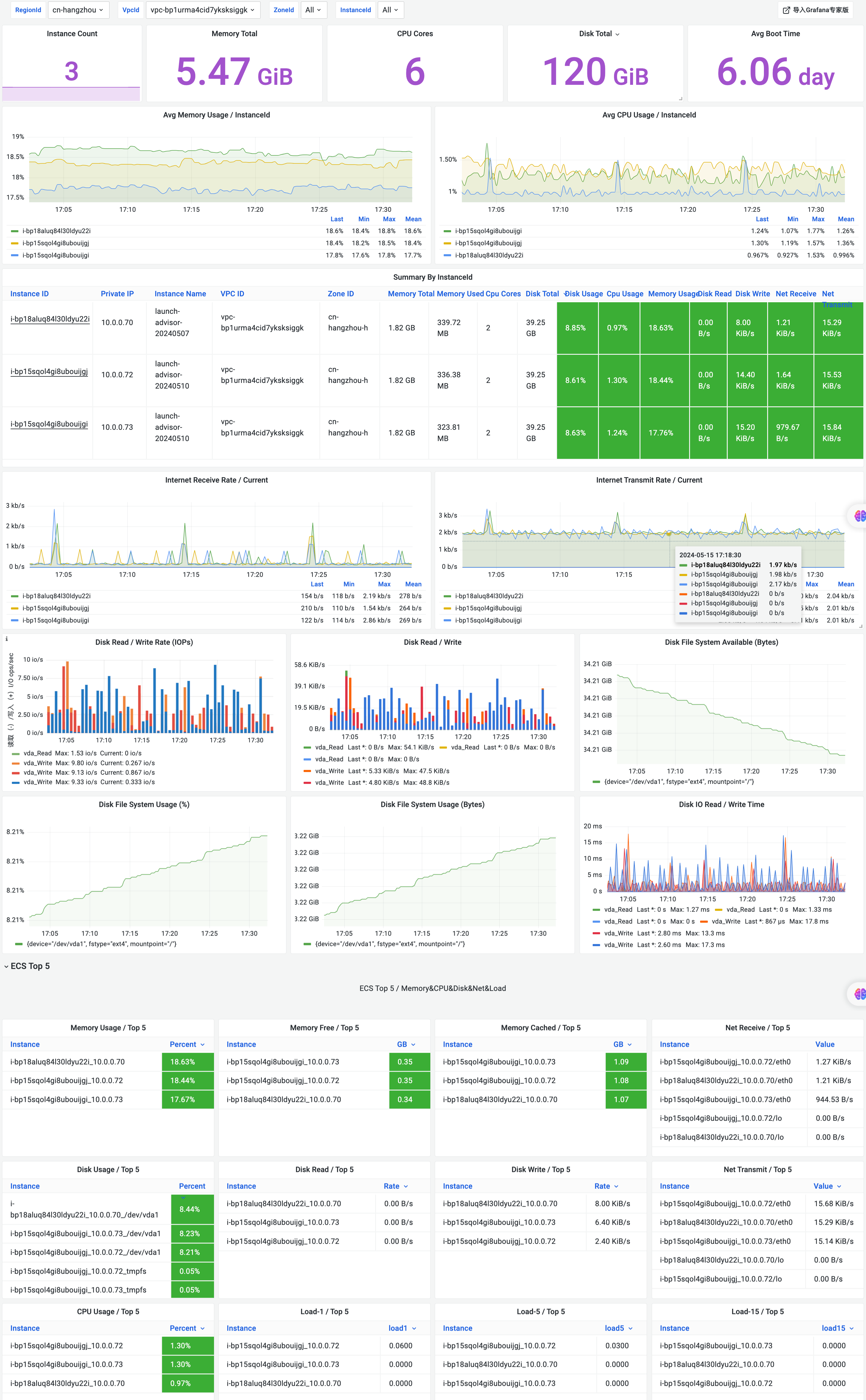
ECS Detail大盘