
云原生大数据计算服务MaxCompute(原名ODPS)是阿里云自主研发的集高性价比、多模计算、企业级安全和AI驱动于一体的企业级SaaS化智能云数据仓库(AI-Native Datawarehouse)。
视频简介
产品简介
MaxCompute是面向分析的企业级SaaS模式智能化云数据仓库,以Serverless架构提供全托管、开箱即用的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制。
计算存储的智能优化能力、开放的湖仓一体架构、近实时和交互式查询加速能力以及Data+AI一体化建设,使用户最小化运维投入、经济并高效地分析处理海量数据。
数以万计的企业正基于MaxCompute进行数据计算与分析,将数据高效转换为业务洞察。
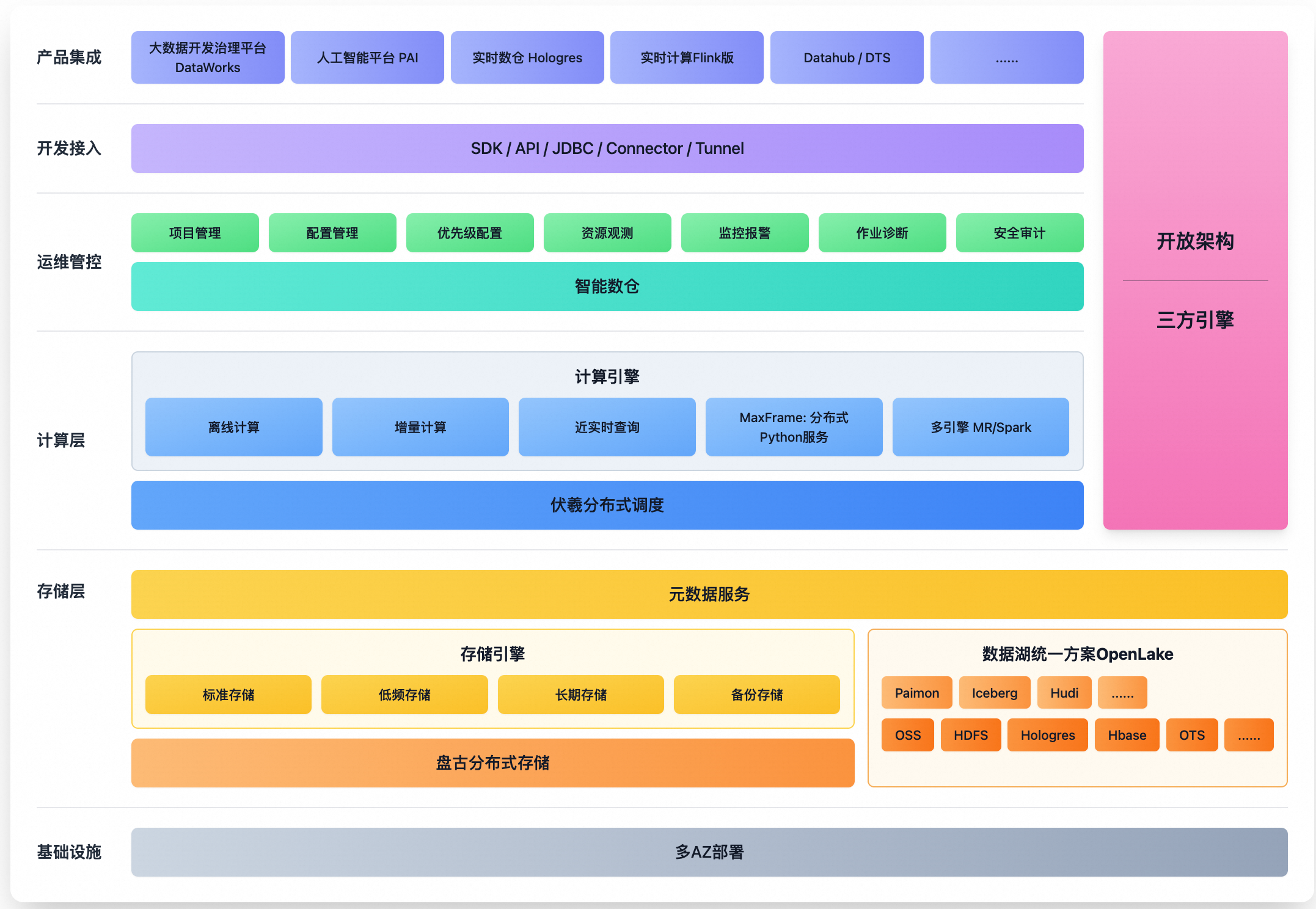
产品架构
MaxCompute的架构主要由存储层、计算层和统一的运维管控平台构成,共同构建在多可用区部署的稳固基础设施之上。
存储层通过其存储引擎,整合了由标准、低频、长期等存储类型构成的原生存储体系,并支持开放的湖仓一体(OpenLake)架构。
计算层通过多种引擎支持离线、近实时、Data+AI等多种计算任务。
运维管控层作为平台的管理与控制核心,提供从项目、配额到优先级的资源治理,从资源观测、监控报警到作业诊断的全方位监控,以及完整的安全审计能力。
整个平台通过标准的开发接入接口(如SDK/API/JDBC)与上层的DataWorks、PAI等产品集成。
产品优势
高性价比的企业级数仓
简单易用:多服务预集成、标准SQL开发简单,开箱即用。
弹性扩展:Serverless架构存算分离,无需提前规划,灵活弹性,按量付费,可以满足业务突增需求,支持实时根据业务峰谷变化分配资源。
安全稳定:内建完善的访问控制、安全和灾备能力,提供资源观测和作业诊断能力。
高性价比:提供智能分析方案,持续优化性能和成本。
多场景增全量一体计算优化
湖仓一体的开放架构
MaxCompute湖仓一体支持OpenLake解决方案,实现同一份OpenLakehouse数据多引擎互访。
支持联邦查询分析,兼容多种主流开源数据格式。
支持通过Storage API和Connector将MaxCompute数据向第三方开源引擎开放,简化计算引擎集成过程。例如Spark与MaxCompute计算资源、数据和权限体系深度集成。
Data+AI
分布式计算框架MaxFrame,提供Python编程接口,兼容Pandas算子并支持与人工智能PAI无缝集成。
MaxFrame内置第三方依赖包及通用模型,用户自定义镜像管理,通过云原生大数据预处理能力,为大模型等AI深度学习场景提供数据AI整合能力。
适用场景广泛
MaxCompute提供了面向多种计算场景的数据仓库解决方案及分析建模服务,以统一平台满足数据仓库、BI、近实时分析、数据湖分析、机器学习等多种场景,已在阿里巴巴集团内部得到大规模应用。发展历程、产品荣誉及客户案例请参见发展历程和客户案例。
产品生态丰富:
MaxCompute深度融合阿里云DataWorks、实时数仓Hologres、人工智能平台PAI、Quick BI等产品,满足数据分析场景下的不同需求。MaxCompute融合的更多阿里云产品信息,请参见支持的云服务。
基于DataWorks实现一站式的数据同步、业务流程设计、数据开发、管理和运维功能。
基于机器学习平台PAI的算法组件实现对MaxCompute数据进行模型训练等操作。
基于Hologres对MaxCompute数据进行外表查询加速,也可导出到Hologres交互式分析。
基于Quick BI将MaxCompute数据制作成报表,实现数据可视化分析。
核心功能
MaxCompute提供的核心功能如下,详细功能清单请参见功能特性。
功能分类 | 功能描述 |
数仓基础能力 |
|
多场景计算能力 |
|
开放架构 |
|
企业级能力 | |
安全、容灾与稳定性 |
|
产品动态
更多产品动态参见MaxCompute产品发布动态与公告。