基于函数计算部署 GPT-Sovits 模型实现语音生成
技术解决方案部署
35
https://www.aliyun.com/solution/tech-solution/fc-for-ai-server
方案概览
如果您需要通过文本生成语音,同时期望快捷地定制个性化声音,推荐您使用函数计算部署 GPT-Sovits 语音生成模型。GPT-Sovits 是一个热门的文本生成语音的大模型,只需要少量样本的声音数据源,就可以实现高度相似的仿真效果。使用函数计算部署 GPT-Sovits 模型,您无需关心 GPU 服务器维护和环境配置,即可快速部署和体验模型,同时,可以充分利用函数计算按量付费,弹性伸缩等优势,高效、低成本地为用户提供基于 GPT-Sovits 模型的文本到语音生成服务。
方案架构

本方案的技术架构包括以下基础设施和云服务:
函数计算:用于提供 GPT-Sovits 模型的应用服务。在 GPT-SoVITS 应用界面,用户选择 GPU 模型列表,然后上传一段自己准备的 3~10s 的样本语音或者使用函数计算提供的语音模板,输入需要生成的语音提示语开始生成语音。语音生成成功后,可以在 GPT-SoVITS 界面查看并播放生成的语音,也可以在 NAS 文件存储系统中下载生成的语音。
文件存储 NAS:用于存放预训练的 GPT-Sovits 模型以及生成的语音文件。
专有网络 VPC:用于配置专有网络,方便函数计算访问文件存储 NAS。
部署准备
5
开始部署前,请按以下指引完成账号申请和账号充值。
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面,根据页面提示完成注册。阿里云账号是您使用云资源的付费实体,因此是部署方案的必要前提。
已开通函数计算服务。具体操作,请参见开通函数计算服务。
已开通文件存储 NAS 服务。具体操作,请参见欢迎使用 NAS 文件系统。
为了节省成本,建议您根据情况领取新客户试用套餐,函数计算使用额度详情请参见试用额度。
部署 GPT-Sovits 应用
5
借助于函数计算应用模板,您可以便捷地将 GPT-Sovits 应用部署到函数计算上。
访问函数计算应用模板,参考图片,地域目前仅支持华东 1(杭州)或华东 2(上海),选择华东 1(杭州)。其余配置项保持默认值即可,单击创建应用。模型下载可能会花费 15 分钟左右,请耐心等待部署完成。
针对当前应用,角色权限可能会不足,此时需要单击前往授权为角色授予所需权限。

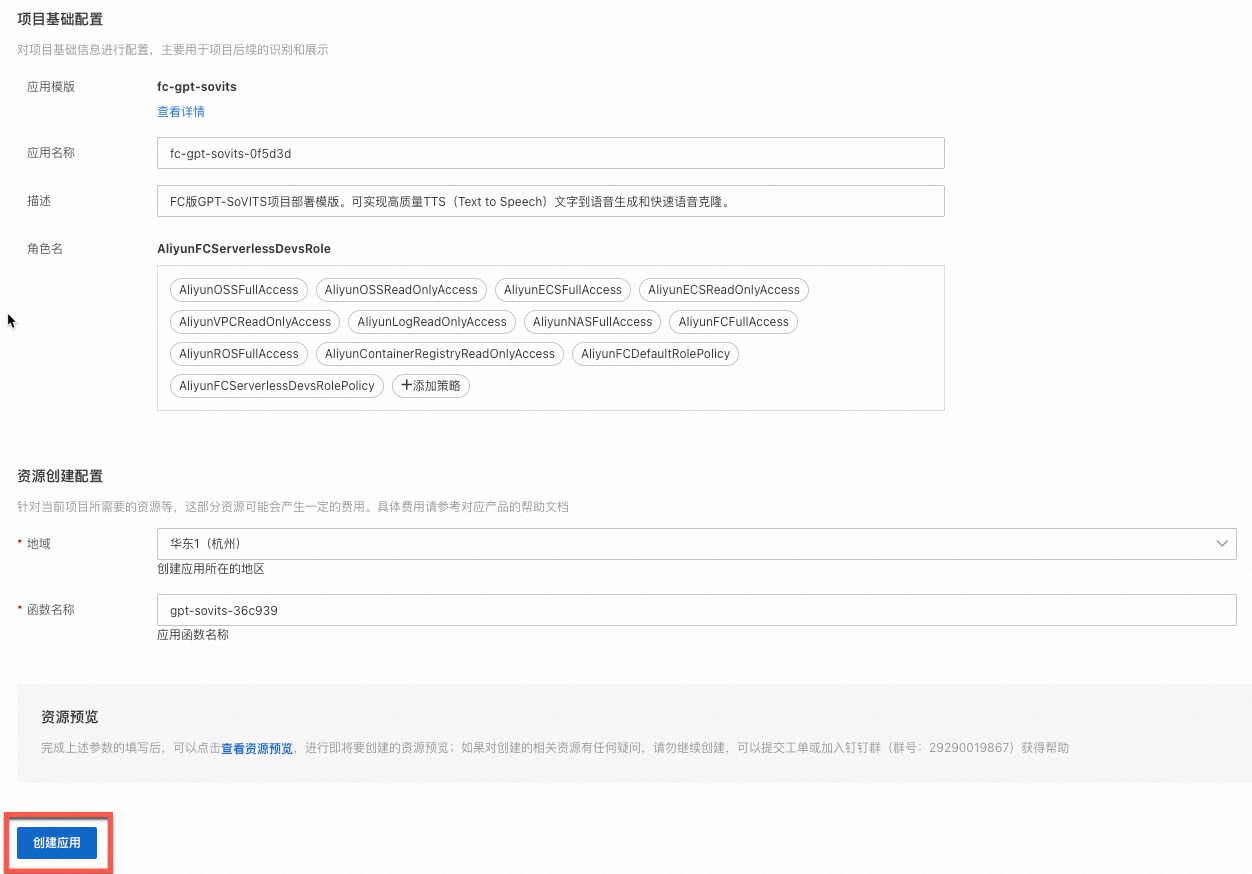
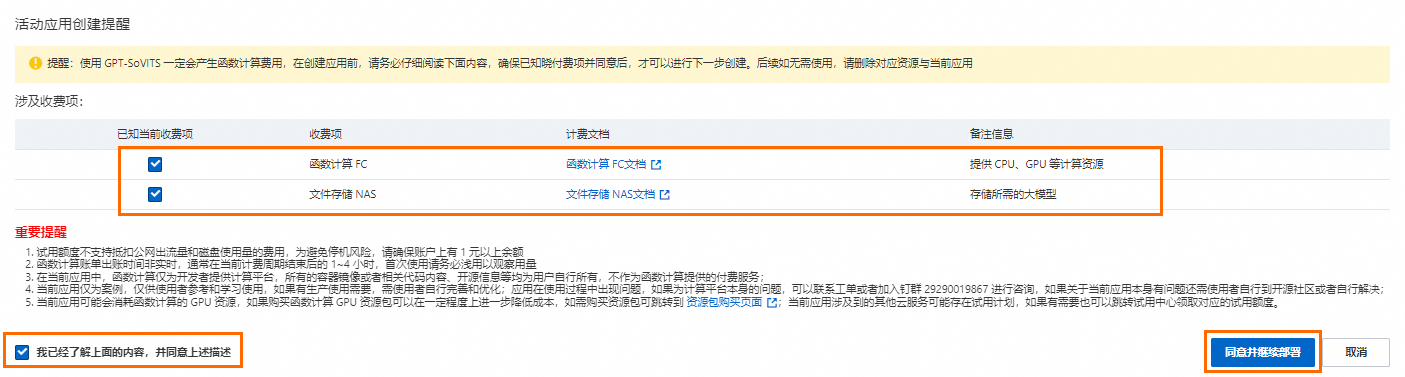
在弹出的对话框,仔细阅读应用创建提醒信息,勾选涉及的计费项和我已经了解上面的内容,并同意上述描述,然后单击同意并继续部署。
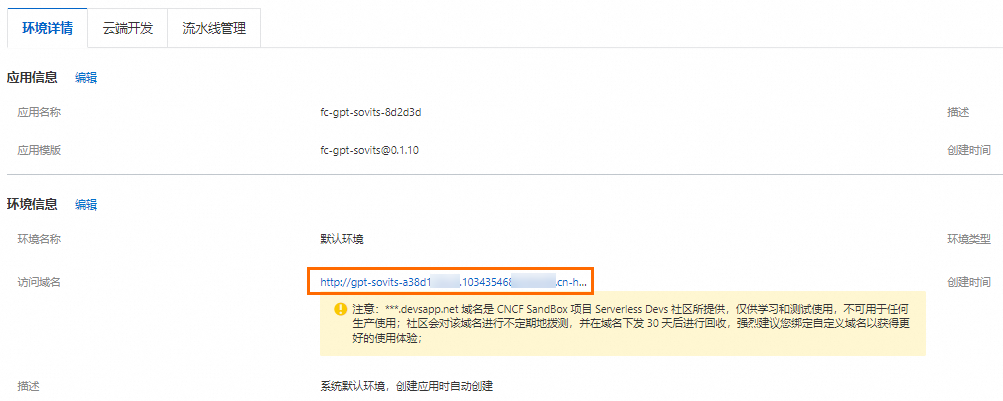
等待约 1 分钟,部署状态变为部署成功,表示应用部署成功,单击环境信息区域的访问域名开始体验应用。
首次访问,大约需要等待 30 秒,即可进入 FC 版 GPT-SoVITS 界面。
入门:快速体验使用 GPT-Sovits 合成语音
5
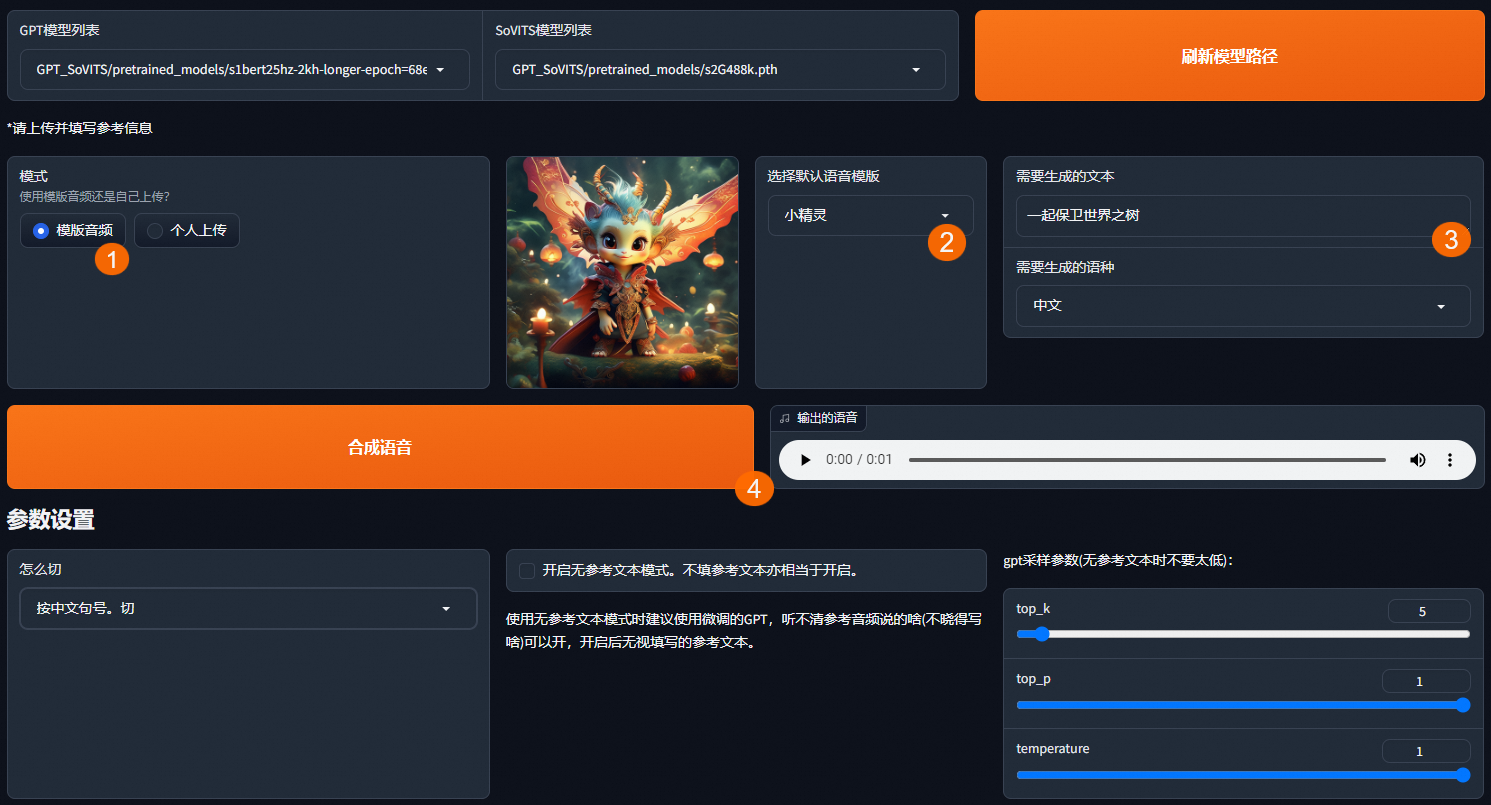
在 FC 版 GPT-SoVITS 界面,选择语音克隆&&推理页签,选择使用模板音频或个人上传音频作为参考音频,然后输入文本,单击合成语音,开始体验声音的合成。
使用模板音频
函数计算提供了小精灵和甜美女生的语音模板,您可以直接选择。
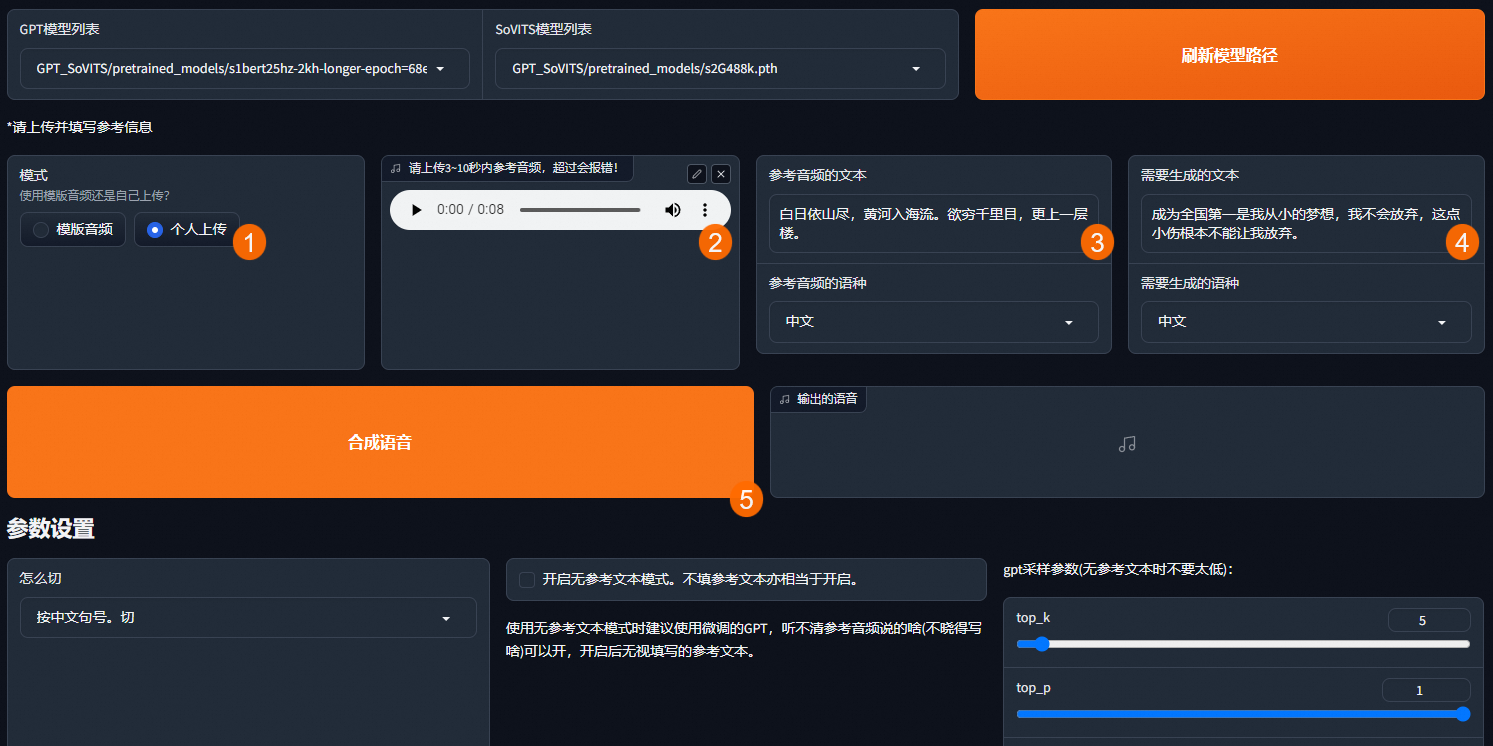
个人上传音频
如果您想生成特定音色、情感、语速的语音,需要上传 3~10 秒的参考音频,并填写参考音频的文本,选择参考音频的语种。
重要GPT-SoVITS 使用者和语音导出者需要对自己合成的语音进行妥善保管,因语音传播导致的法律问题不在函数计算负责范围内。
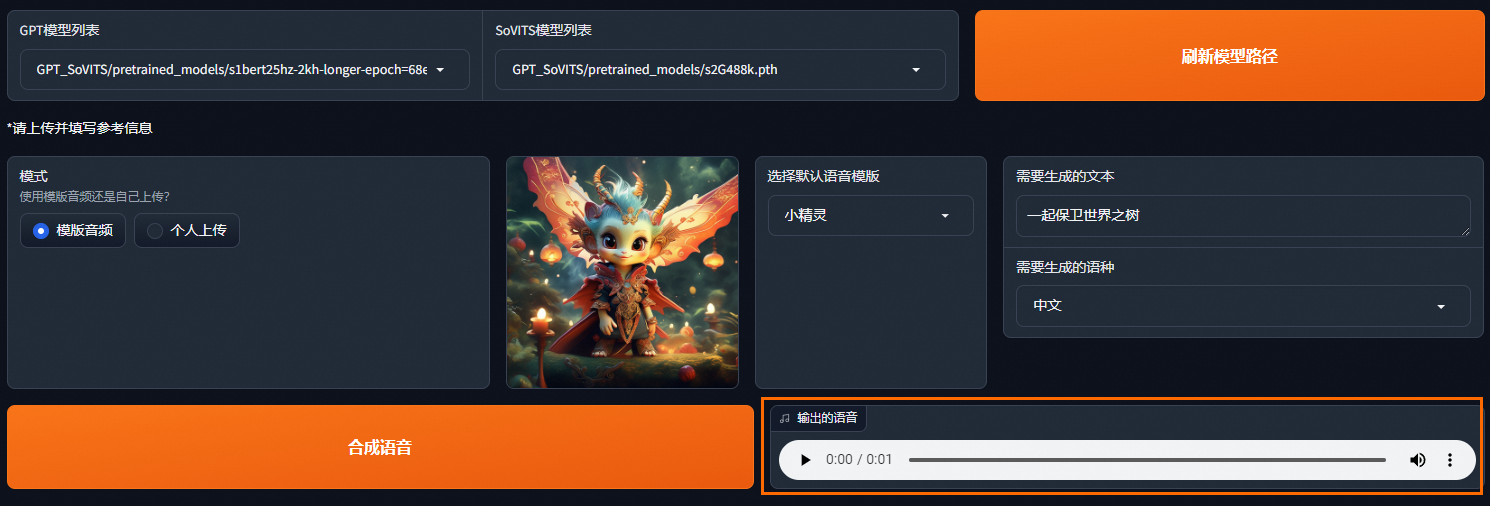
等待语音合成完成后,单击右下角的播放按钮播放语音,或可以单击
 > 下载,下载生成的语音。说明
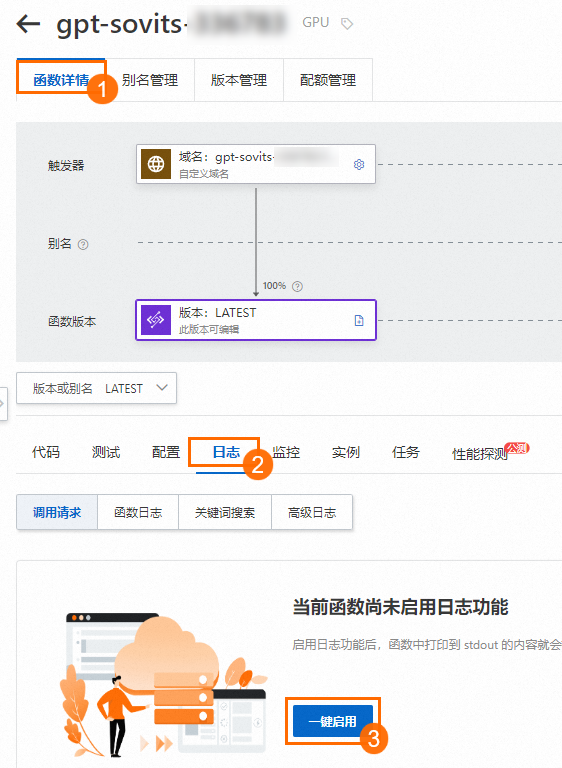
> 下载,下载生成的语音。说明如果语音合成失败,您可以为应用创建的函数一键启用日志功能,再次进行语音合成,并根据日志进行分析和定位问题。
进阶:使用 GPT-Sovits 进行语音模型训练
15
您可以通过声音源文件微调 GPT-Sovits 大模型,生成更加符合要求的语音。在微调训练过程中,训练步骤的所有中间产物将置于 NAS 文件管理系统的 output 文件夹下。训练将使用默认的 UVR5 和 AS 模型。若需要使用其他的 UVR5 和 ASR 模型,可根据官方 README下载,并分别置于 NAS 文件管理系统的tools/asr/models和tools/uvr5/uvr5_weights目录下。
步骤一:可视化管理 NAS 中的语音文件
为了方便后续查看预处理的音频文件和训练后的模型。您可以按照如下步骤创建一个新的函数计算应用部署 NAS 浏览器,实现可视化管理 NAS 上的文件。
在应用详情页的资源信息区域找到默认挂载的文件存储 NAS,然后单击挂载点链接跳转至 NAS 文件存储控制台。
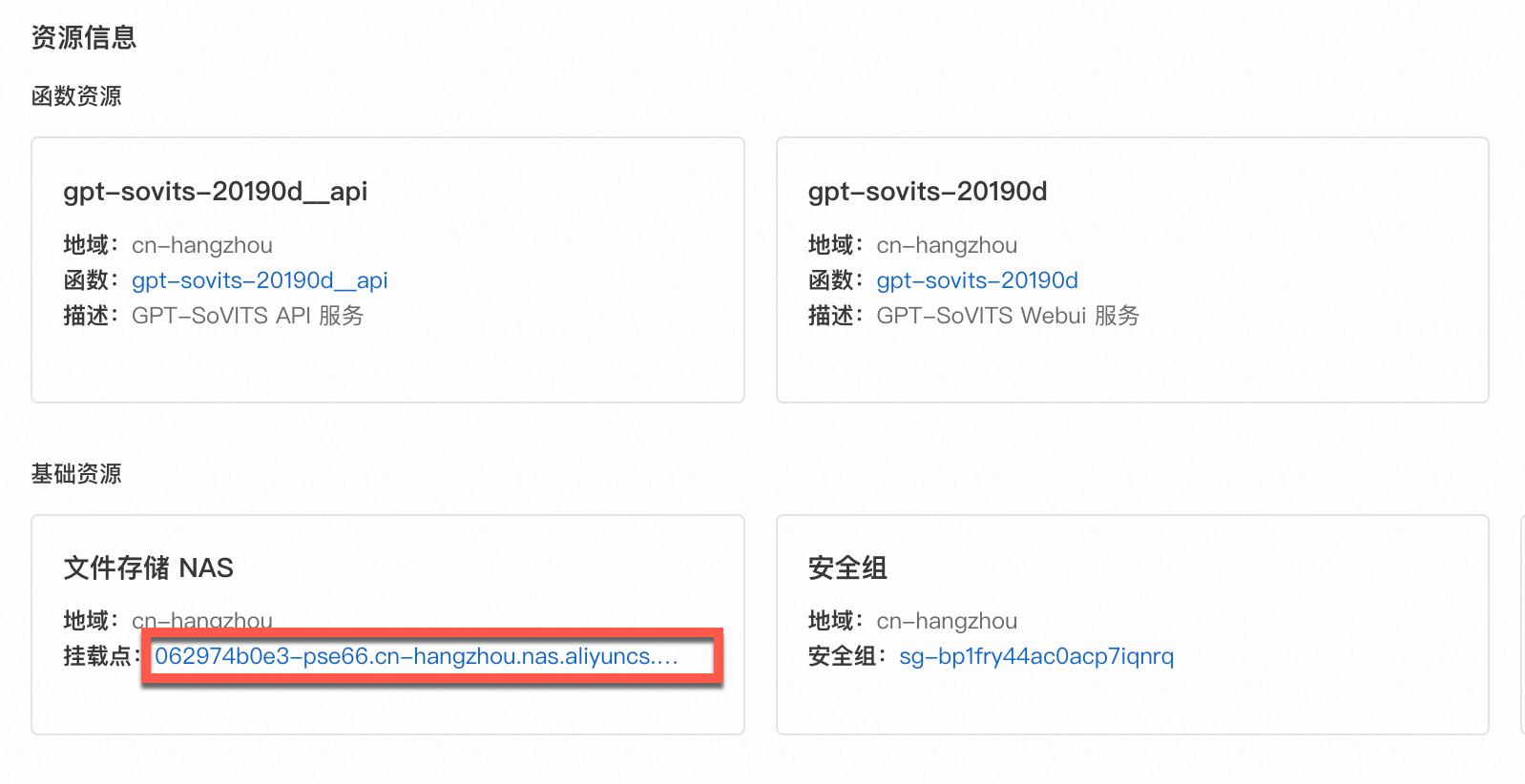
单击左侧菜单,返回文件系统列表页面。在列表中找到函数计算关联的 NAS 实例,单击目标 NAS 文件系统右侧操作列的
 > 浏览器。
> 浏览器。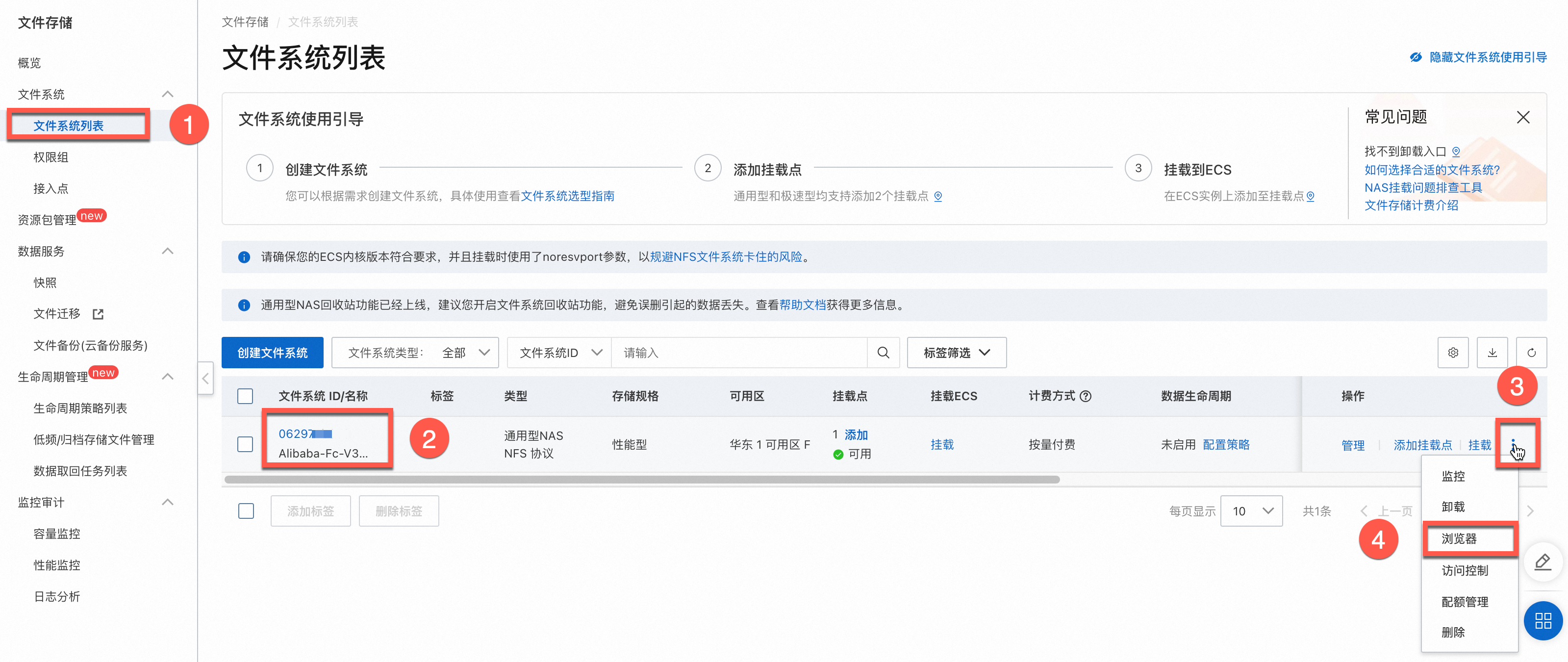
等待创建完成,再次单击目标 NAS 文件系统右侧操作列的
> 浏览器,即可打开 NAS 浏览器页面。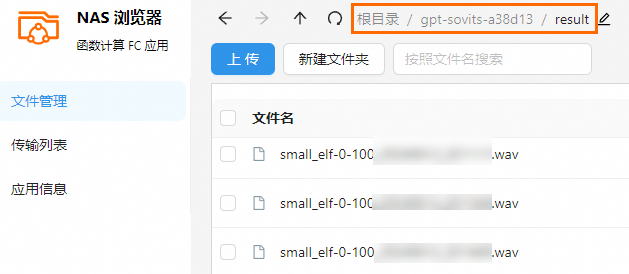
步骤二:数据预处理
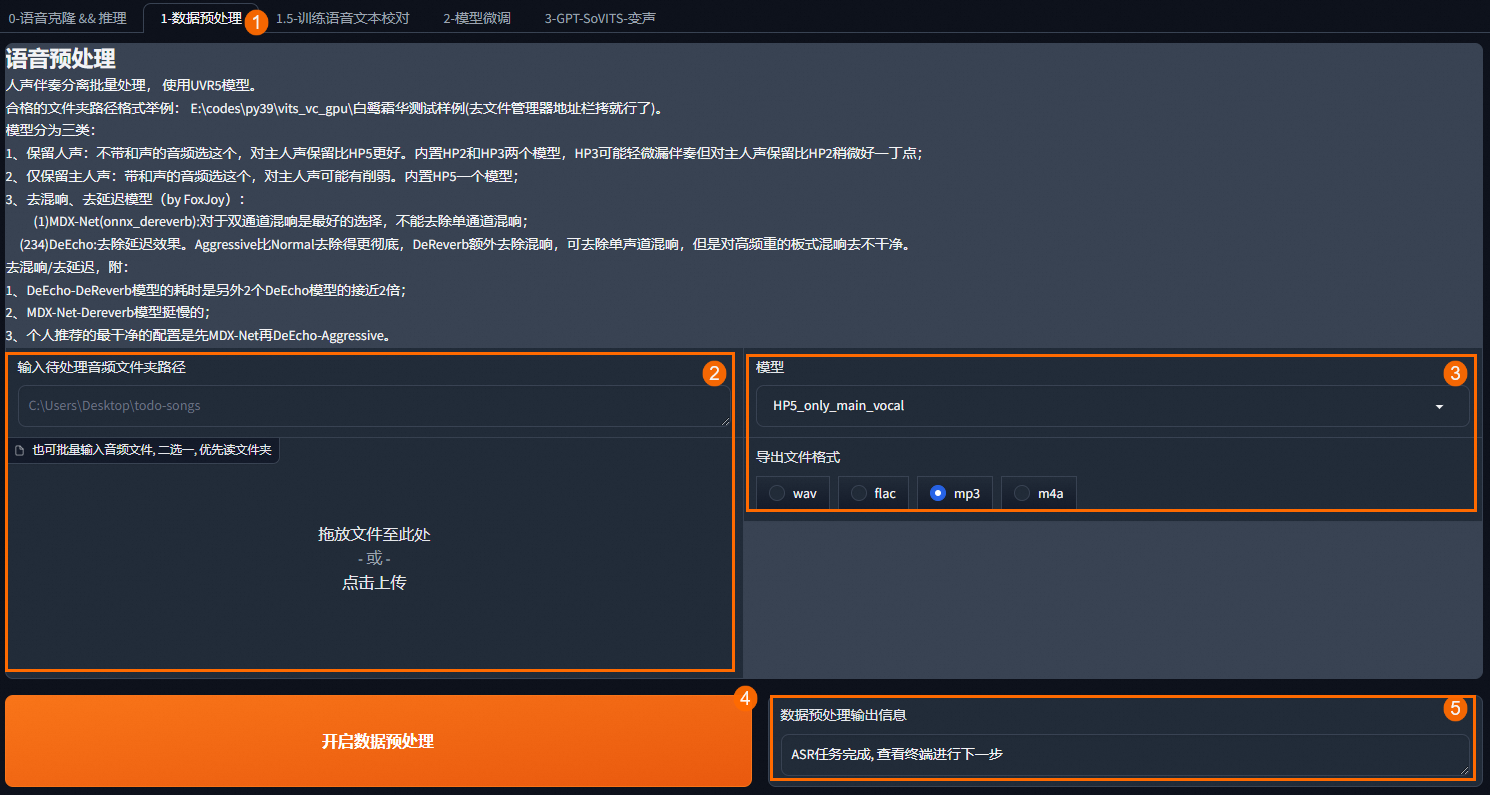
在 FC 版 GPT-SoVITS 界面,选择数据预处理页签。
在输入待处理音频文件夹路径输入框中输入您在 NAS 文件存储系统中存放的需要预处理的音频,或直接上传需要预处理的音频,选择模型以及需要导出的文件格式,然后单击开启数据预处理。
关于各种模型的介绍,请参见 FC 版 GPT-SoVITS 界面上方的介绍。
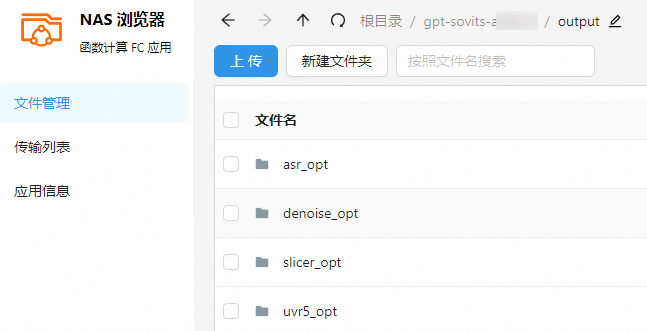
在数据预处理输出信息区域,提示 ASR 任务完成后,在对应的 NAS 文件系统的
/<函数名称>/output/目录,您可以获取预处理后的音频。各种预训练产物以及存储路径的对应关系如下。预训练流程产物
存储路径
降噪后的语音文件
<NAS url>:/<函数名>/output/denoise_opt
音频分割后的片段
<NAS url>:/<函数名>/output/slicer_opt
使用 ASR 模型自动语音识别后的文字
<NAS url>:/<函数名>/output/asr_opt
使用 UVR5 模型进行人声和伴奏分离后的文件
<NAS url>:/<函数名>/output/uvr5_opt
步骤三:(可选)训练语音文本校对
如果步骤二:数据预处理结果中,使用 ASR 模型自动语音识别到的文字与实际不相同,可通过文本校对工具进行修改。
在 FC 版 GPT-SoVITS 界面,选择训练语音文本校对页签。
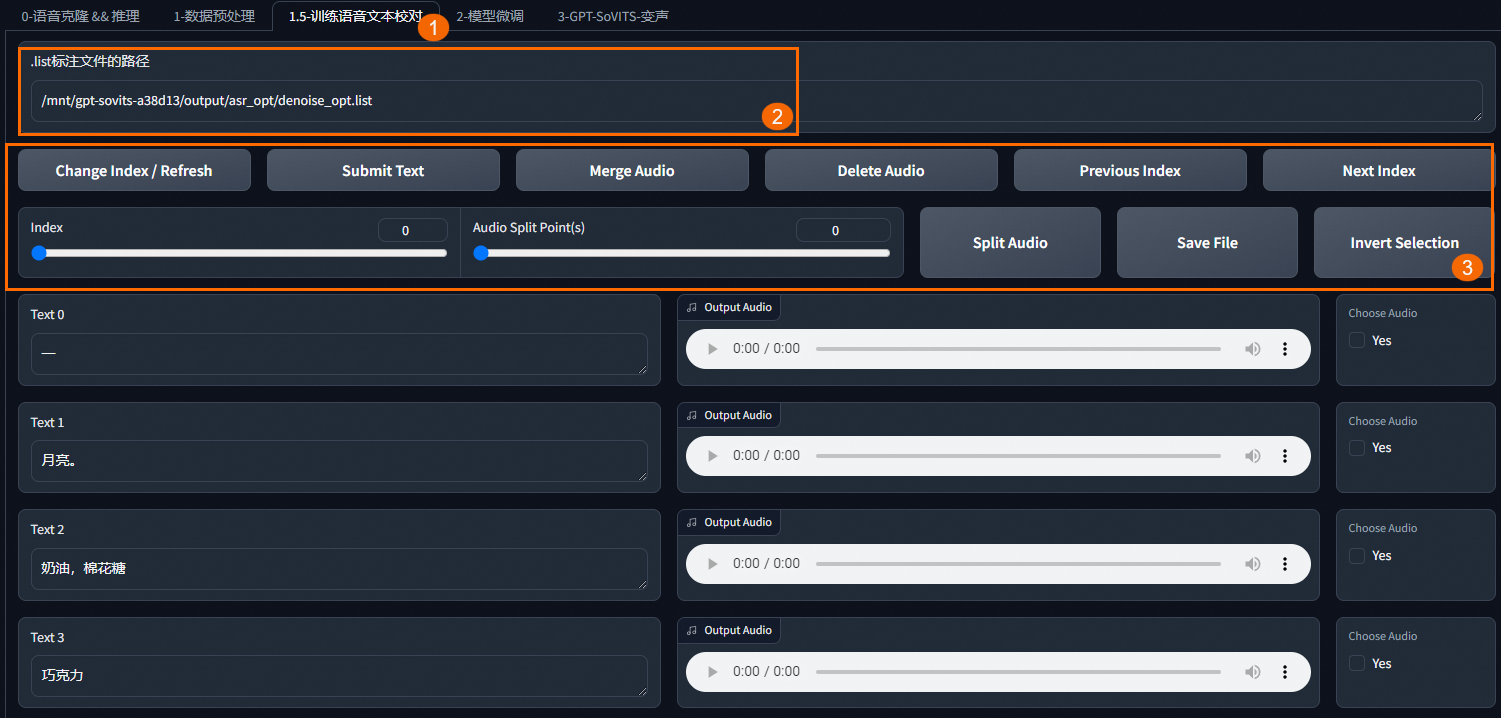
在.list标注文件的路径输入框中输入步骤二:数据预处理的结果中使用 ASR 模型自动语音识别后的文字对应的文件
denoise_opt.list所在的完整路径,然后依次单击下方的按钮进行调整。按钮功能介绍如下:按钮名称
按钮功能介绍
Change Index / Refresh
跳转页码。当前页面文字校对完成后,单击此按钮进行翻页。
Submit Text
保存修改。如果某个识别的文字错误,修改后需单击此按钮保存。
Merge Audio
合并音频。
Delete Audio
删除音频。请谨慎使用,删除音频后将不再进行训练。
Previous Index
上一页。
Next Index
下一页。
Split Audio
分割音频。
Save File
保存文件。校对完成后,要单击此按钮保存文件。
Invert Selection
反向选择。
步骤四:开始模型训练
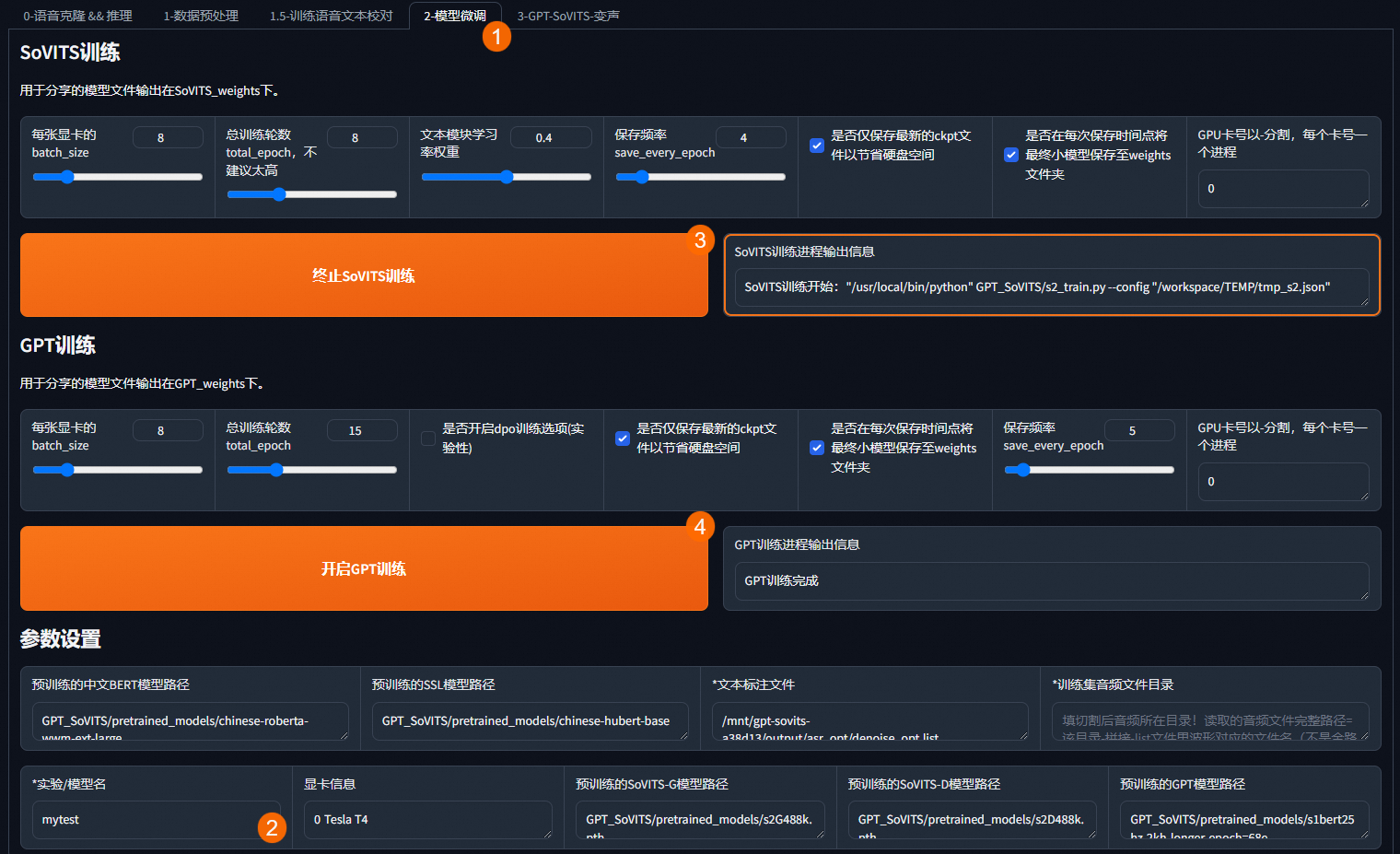
在 FC 版 GPT-SoVITS 界面,选择模型微调页签,在下方实验/模型名输入框输入您的模型名称,然后单击开启 SoVITS 训练或开启 GPT 训练进行模型训练。
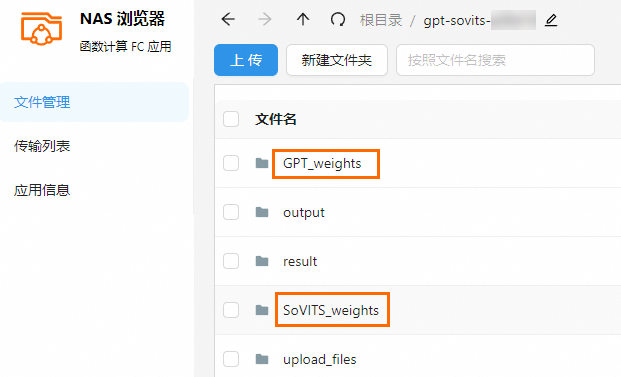
训练后的模型将存储在 NAS 下的 GPT_weights 和 SoVITS_weights 文件夹内。
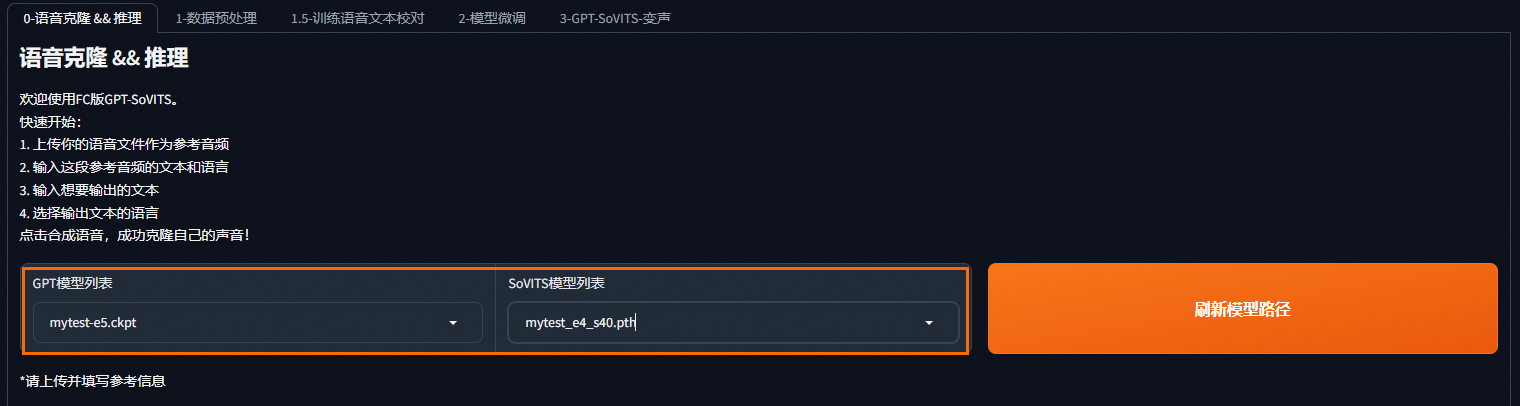
在 FC 版 GPT-SoVITS 界面,选择语音克隆&&推理页签,使用您自己的模型进行再次语音合成。
更多操作说明,请参见入门:快速体验使用 GPT-Sovits 合成语音。
说明如果 GPT 模型列表和 SoVITS 模型列表未找到您自己的模型,请单击右侧的刷新模型路径。
完成与清理
5
清理资源
在本方案中,您部署了 GPT-Sovits 应用使用了函数计算产品,创建了函数资源,创建模型管理器使用了文件存储 NAS产品,增加了 NAS 挂载点。函数计算的函数不调用不会计费,文件存储 NAS只要有模型存储在 NAS 文件系统下,就会收费。
因此,如果您后续不再使用 GPT-Sovits ,请及时删除以下两部分资源,避免继续产生费用。
删除 GPT-Sovits 使用的函数
登录函数计算控制台,在左侧导航栏,单击应用。
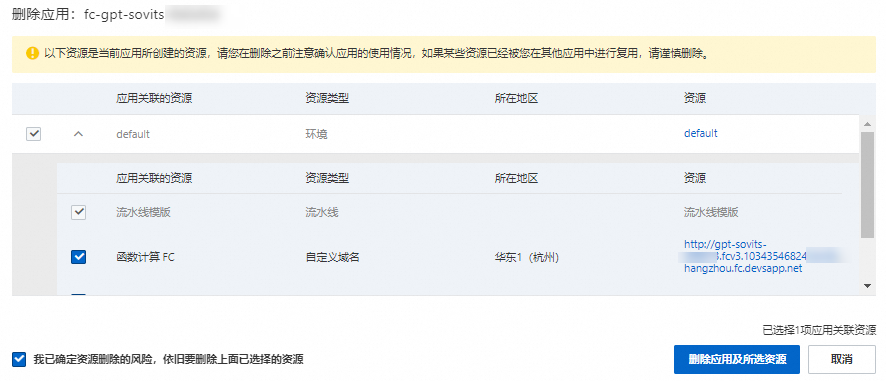
在应用页面,找到目标应用,单击右侧操作列的删除应用。
在弹出的对话框,勾选我已确定资源删除的风险,依旧要删除上面已选择的资源,然后单击删除应用及所选资源。
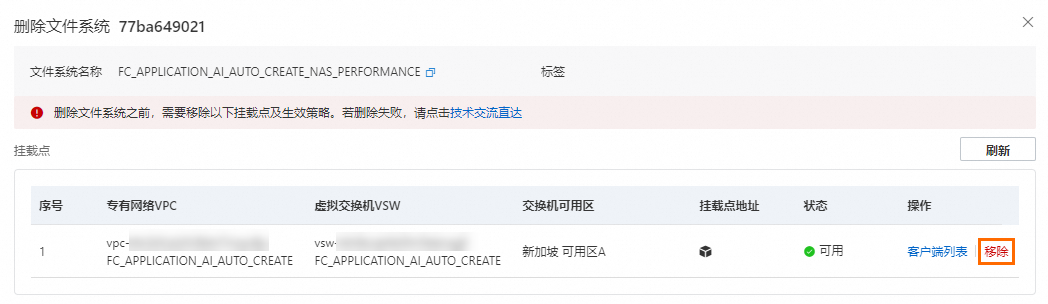
删除模型管理器使用的 NAS
登录 NAS 文件存储控制台,在左侧导航栏选择。
在文件系统列表,找到目标文件系统,在其右侧操作列,单击
 ,然后单击删除。
,然后单击删除。
在弹出的对话框,单击移除,移除挂载点,然后单击删除。