
单元化+云原生的弹性架构示意图
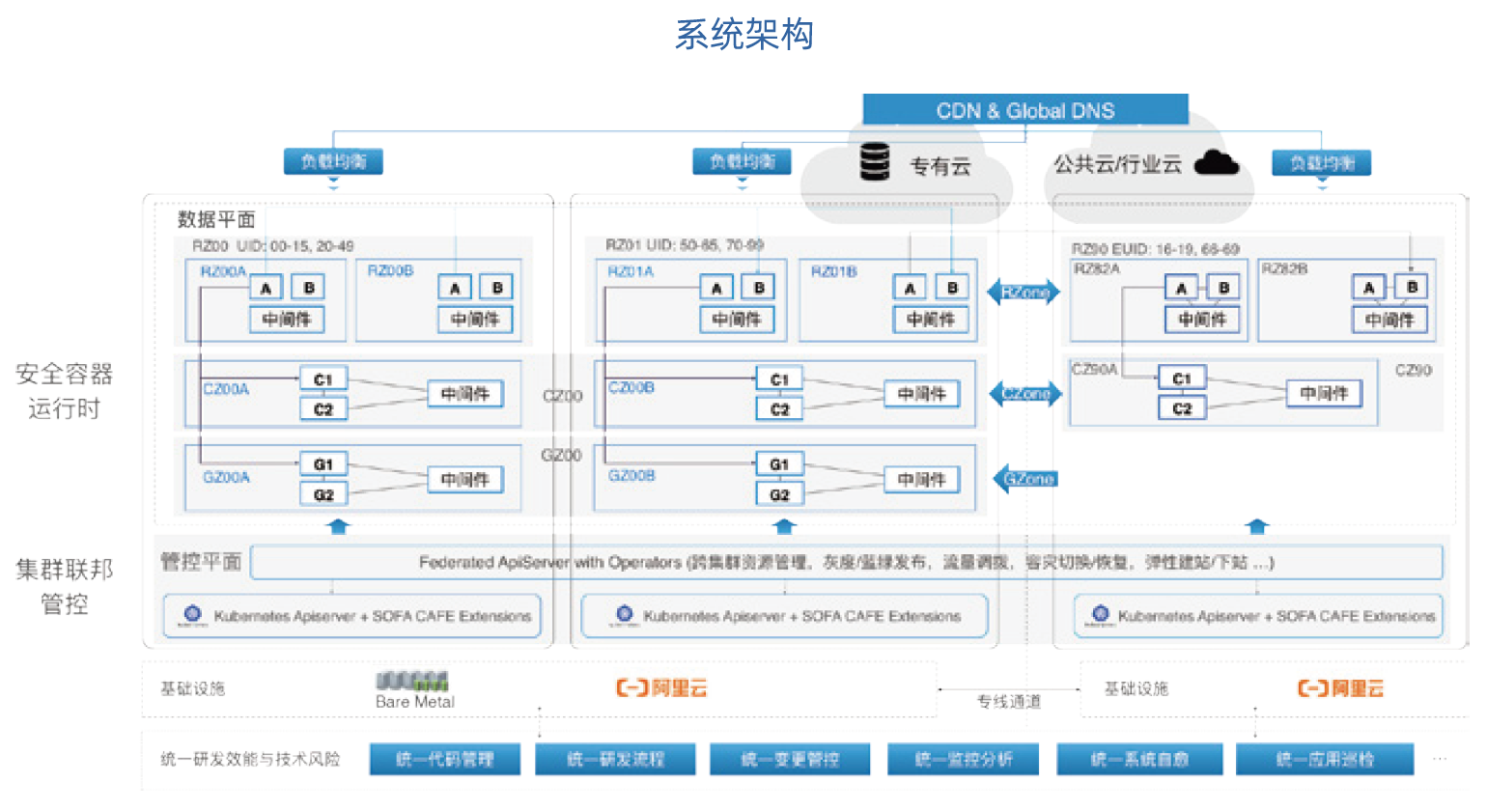
首先解释一下什么是“单元化”。大家可能比较容易理解数据库层的“分库分表”(即 Sharding),它通过分 片的方式解决了集中存储的计算性能问题。“单元化”的核心思想是把数据的分片提前到了入口请求的分片,在机房的网络接入层将用户请求根据某个纬度(比如用户 ID)进行 Sharding,这就好比把每个机房就当做了一个巨大无比的有状态的数据库分片。例如,一个 UserID 尾号为 007 的用户通过手机端或网页域名发送服务请求,接入层就能够识别出应该将该请求路由到华东地区还是华南地区,当请求转发到某个地区的机房时,大部分请求处理工作可以在机房内部完成。偶尔会有一些业务可能会发生跨机房的服务调用,比如说数据在 A 机房的用户给数据在 B 机房的用户转账,这个时候就需要在机房上去做有状态的设计。
我们走向云原生时代的时候,在大的架构上面用 Kubernetes为基础来设计。在单元化架构下,我们选择在每个单元里部署一个 Kubernetes 集群,将支持多 K8s 集群管理和管控指令下发的 Federated APIServer 做逻辑上的全局部署,其中管控元数据是存储在一个 ETCD 集群的,以保持全局数据一致。但大家知道 ETCD 也只能解决同城双机房的容灾,无法再应对多城市多数据中心的一致性,因此,我们正在把 ETCD 搬到我们的 OB 的 KV 引擎上,这样在引擎层还是保持 ETCD 的存储格式和语义,存储层就具备了三地五中心高可用能力。
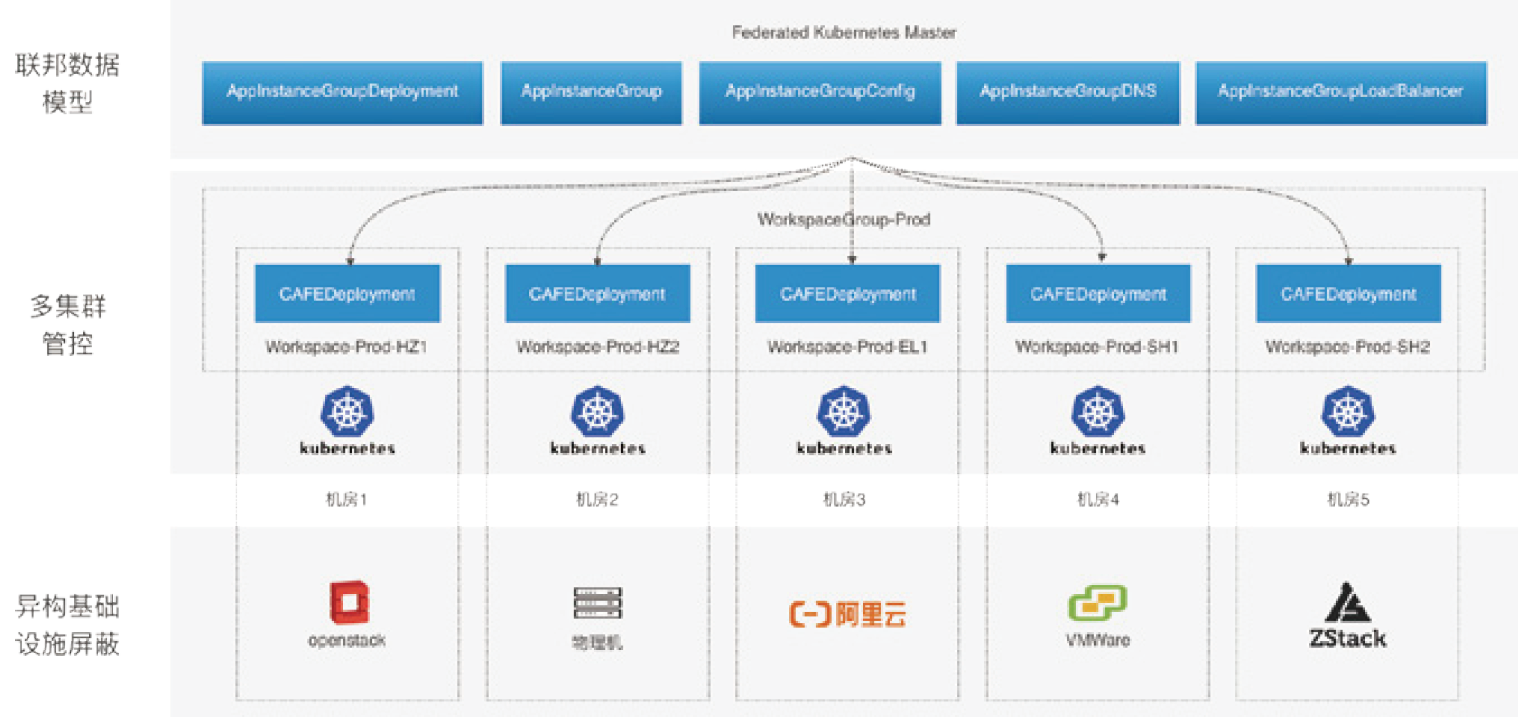
虽然这种架构是适合蚂蚁的,但在我们把技术开放给外部客户时又遇到很多新的问题,比方说,在客户的机房会有很多异构的基础设施,我们就需要以 Cloud Provider 的标准来实现多云适配。
而且,包括我们在内的很多金融机构,因为很多老系统并没有按照云原生的方式去设计,很多会对基础设施有状态依赖,比如依赖 IP,所以很难完全采用不可变基础设施的模式来支撑。有些时候,由于对业务连续性有极高要求,也很难接受原生 K8s Workload 的运维模式,比如原生 Deployment 做灰度或者金丝雀发布时,对应用和流量的处理都是非常简单粗暴的,这样会导致运维变更时的业务异常和不连续。为了解决这个问题,我们把原生的 Deployment 扩展成为了更适合金融业务要求的 CAFE Deployment,使得大规模集群发布、灰度发布和回滚时更加优雅,也符合我们的“技术风险三板斧原则”。
所以,金融级的混合云首要解决的问题是弹性和异构的问题,且要符合大规模金融级运维的稳定性要求。解决了这些问题,再往前去演进新业务的时候,金融行业会非常看重如何做稳妥的创新,即如何在开发和运维保持传统模式继续支持业务的同时,引入新的运维和开发模式,双模齐头并进。