阿里云容器计算服务ACS以Serverless形态提供容器算力,在使用GPU资源时,支持在Pod上声明GPU型号和驱动版本,极大降低了业务的基础设施管理和运维成本。本文主要介绍如何在创建Pod时指定GPU型号和驱动版本。
GPU型号说明
ACS支持多种GPU型号,您可以结合资源预留使用,也可在Pod创建时按需申请。对于不同的计算类型(compute-class),使用方式如下。
GPU型
支持按量使用、容量预留两种方式,Pod创建后会自动抵扣容量预留,详见GPU Pod容量预留。
目前支持的GPU具体型号列表请提交工单咨询。
为Pod指定GPU型号
对于GPU型,您需要在Pod的lables和nodeSelector中显式指定GPU型号。具体方式如下。
计算类 | 协议字段 | 样例 |
GPU型 | metadata.labels[ alibabacloud.com/gpu-model-series] | |
驱动版本说明
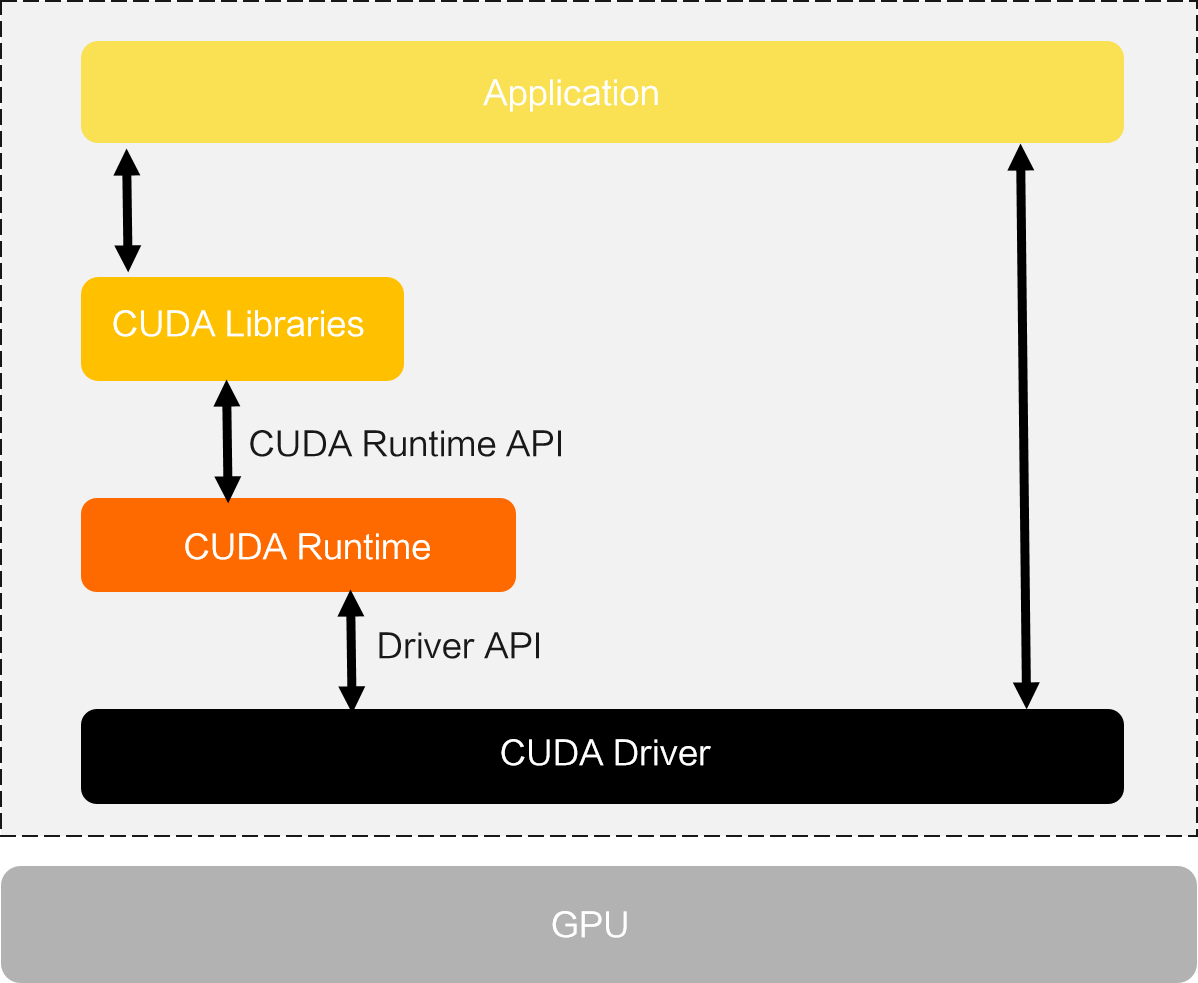
GPU应用通常需要依赖CUDA(Compute Unified Device Architecture)运行,CUDA是显卡厂商NVIDIA在2007年推出的并行计算平台和编程模型。下图为CUDA的架构体系,CUDA软件堆栈中的驱动层API和运行时层API有以下区别。
驱动层API(Driver API):功能较完整,但是使用复杂。
运行时API(CUDA Runtime API):封装了部分驱动的API,将某些驱动初始化操作隐藏,使用方便。
CUDA的Driver API由NVIDIA Driver包提供,而CUDA Library和CUDA Runtime由CUDA Toolkit包提供。
在使用ACS集群运行GPU应用时,您需要注意:
容器镜像中安装CUDA Toolkit时,使用NVIDIA提供的CUDA基础镜像。这些基础镜像已经安装了CUDA Toolkit。您可以基于基础镜像构建应用容器镜像。您也可以根据不同的CUDA Toolkit版本选择不同的CUDA基础镜像。
创建应用时指定Pod所需的驱动版本,详见为Pod指定驱动版本。
关于CUDA Toolkit与NVIDIA驱动的版本兼容性列表,请参见NVIDIA官方文档CUDA Toolkit Release Notes。
应用程序使用的CUDA运行时API版本与该应用的Docker镜像使用的CUDA基础镜像版本一致。例如,您的应用的Docker镜像基于CUDA基础镜像NVIDIA/CUDA:12.2.0-base-Ubuntu20.04构建,那么应用使用的CUDA运行时API版本为12.2.0。
为Pod指定驱动版本
ACS支持在应用使用GPU资源时,通过Pod的label标签指定驱动版本,具体格式如下。
计算类 | 协议字段 | 样例 |
GPU型 | metadata.labels[alibabacloud.com/gpu-driver-version] | |
在为Pod指定驱动版本时,需要确保驱动版本包含在ACS支持的驱动版本列表中。详细信息,请参见ACS支持的NVIDIA驱动版本列表。关于修改集群默认的驱动版本,请参见配置acs-profile实现Pod配置自动注入按需修改。
操作示例
使用以下YAML内容,创建gpu-pod-with-model-and-driver.yaml文件,文件中描述了一个compute-class为GPU的Pod,申请型号为example-mode的GPU资源和535.161.08驱动版本。
apiVersion: v1 kind: Pod metadata: name: gpu-pod-with-model-and-driver labels: # 指定compute-class为gpu类型 alibabacloud.com/compute-class: "gpu" # 指定GPU型号为example-model,请按实际情况填写 alibabacloud.com/gpu-model-series: "example-model" # 指定驱动版本为535.161.08 alibabacloud.com/gpu-driver-version: "535.161.08" spec: containers: - image: registry.cn-beijing.aliyuncs.com/acs/tensorflow-mnist-sample:v1.5 name: tensorflow-mnist command: - sleep - infinity resources: requests: cpu: 1 memory: 1Gi nvidia.com/gpu: 1 limits: cpu: 1 memory: 1Gi nvidia.com/gpu: 1执行以下命令,将gpu-pod-with-model-and-driver.yaml部署到集群。
kubectl apply -f gpu-pod-with-model-and-driver.yaml执行以下命令,查看Pod状态。
kubectl get pod预期输出:
NAME READY STATUS RESTARTS AGE gpu-pod-with-model-and-driver 1/1 Running 0 87s执行以下命令,查看Pod的GPU信息。
说明以下命令中的
/usr/bin/nvidia-smi为样例镜像中已经封装好的命令参数。kubectl exec -it gpu-pod-with-model-and-driver -- /usr/bin/nvidia-smi预期输出:
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI xxx.xxx.xx Driver Version: 535.161.08 CUDA Version: xx.x | |-----------------------------------------+----------------------+----------------------+ ... |=========================================+======================+======================| | x NVIDIA example-model xx | xxxxxxxx:xx:xx.x xxx | x | | xxx xxx xx xxx / xxxx | xxxx / xxx| x% xxxxxxxx| | | | xxx | +-----------------------------------------+----------------------+----------------------+预期输出的信息中GPU型号为example-model,驱动版本为535.161.08,与Pod标签中配置一致。
重要以上内容只是样例输出,实际数据以您的操作环境为准。