容器计算服务 ACS(Container Compute Service)为Kubernetes原生的工作负载提供了资源画像的能力,通过对资源使用量历史数据的分析,实现了容器粒度的资源规格推荐,可以有效降低配置容器资源请求(Request)和限制(Limit)的复杂度。本文介绍如何在ACS集群中通过命令行方式使用资源画像功能。
前提条件及注意事项
已安装ack-koordinator组件。具体操作,请参见ack-koordinator。
为了确保画像结果的准确性,建议您在开启工作负载的资源画像后观察等待1天以上,以便累积充足的数据。
费用说明
ack-koordinator组件本身的安装和使用是免费的,不过需要注意的是,在以下场景中可能产生额外的费用:
ack-koordinator安装后将申请2个通用型ACS Pod实例。您可以在安装组件时配置各模块的资源申请量。
ack-koordinator默认会将资源画像等功能的监控指标以Prometheus的格式对外透出。若您配置组件时开启了ACK-Koordinator开启Prometheus监控指标选项并使用了阿里云Prometheus服务,这些指标将被视为自定义指标并产生相应费用。具体费用取决于您的集群规模和应用数量等因素。建议您在启用此功能前,仔细阅读阿里云PrometheusPrometheus 实例计费,了解自定义指标的免费额度和收费策略。您可以通过用量查询,监控和管理您的资源使用情况。
使用限制
组件 | 版本要求 |
≥v0.3.9.7 | |
≥v1.5.0-ack1.14 |
资源画像介绍
Kubernetes为容器资源管理提供了资源请求(Request)的资源语义描述。当容器指定resources.requests时,调度器会将其与节点的资源容量(Allocatable)进行匹配,决定Pod应该分配到哪个节点。容器的资源请求一般基于人工经验填写,管理员会参考容器的历史利用率情况、应用的压测表现,并根据线上运行情况的反馈持续调整。但基于人工经验的资源规格配置模式存在以下局限性:
为了保障线上应用的稳定性,管理员通常会预留超量的资源Buffer来应对上下游链路的负载波动,容器的Request配置会远高于其实际的资源利用率,导致集群资源利用率过低,造成大量资源浪费。
当集群分配率较高时,为了提升集群资源利用率,管理员会主动缩小Request配置,协调更多的资源容量。该操作会提升容器的部署密度,当应用流量上涨时会影响集群的稳定性。
针对以上述问题,ack-koordinator提供资源画像能力,实现容器粒度的资源规格推荐,降低配置容器资源的复杂性。ACS提供通过命令行访问资源画像的方式,支持通过CRD直接对应用资源画像进行管理。关于资源画像的更多信息,请参见云栖号视频课程-ACK资源画像。
通过控制台使用资源画像
步骤一:开启资源画像
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在成本优化页面,单击资源画像页签,然后在资源画像区域,按照页面提示开启功能。
安装或升级组件:按照页面提示安装或升级ack-koordinator组件。首次使用时,需要安装ack-koordinator组件。
画像配置:首次使用时,在安装或升级组件完成后,您可以勾选启用默认配置控制资源画像的开启范围(推荐使用),也可后续在控制台中单击画像配置进行调整。
单击开启画像,进入资源画像页面。
步骤二:资源画像配置
在成本优化页面,单击资源画像页签,然后单击画像配置。
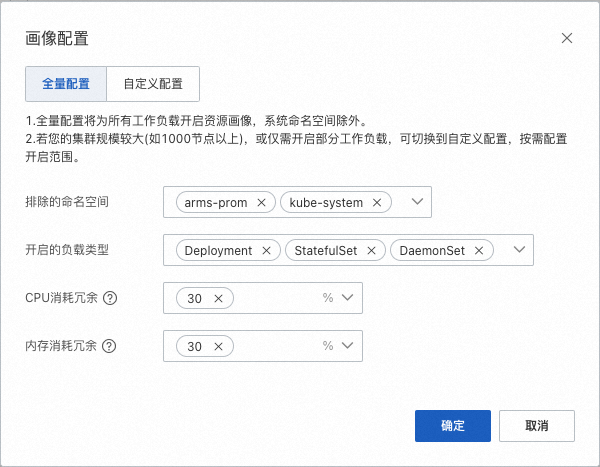
画像配置分为全量配置和自定义配置两种模式,资源画像组件安装过程中推荐的默认配置为全量配置模式。您可以在此对配置模式和配置参数进行修改,完成后单击确定生效。
全量配置模式(推荐)
全量配置模式将为所有工作负载开启资源画像,默认排除arms-prom和kube-system两个系统命名空间。
配置项
说明
取值范围
排除的命名空间
不开启资源画像的命名空间,一般为系统组件对应的命名空间。最终开启范围为命名空间和负载类型的交集。
当前集群内已经存在的命名空间,支持多选,默认值为kube-system和arms-prom。
开启的负载类型
开启资源画像的负载类型范围。最终开启范围为命名空间和负载类型的交集。
支持K8s原生的工作负载,包括Deployment、StatefulSet和DaemonsSet,支持多选。
CPU/内存资源消耗冗余
生成资源画像参考的安全冗余水位,详见下文描述。
要求为非负数,提供三档常用的冗余度70%、50%、30%。
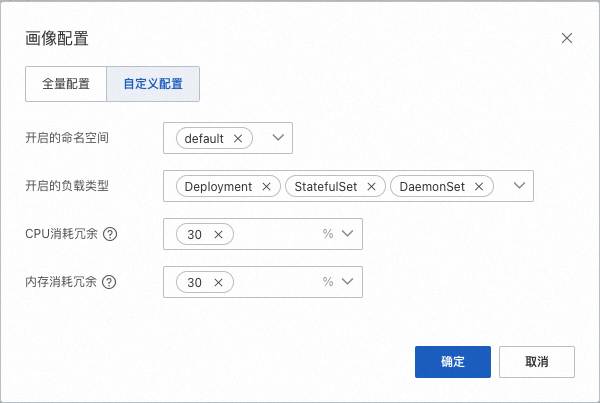
自定义配置模式
自定义配置模式仅开启一部分命名空间的工作负载,若您的集群规模较大(例如1000节点以上),或仅需试用开启一部分工作负载,可以通过自定义配置模式按需指定。
配置项
说明
取值范围
开启的命名空间
开启资源画像的命名空间,最终开启范围为命名空间和负载类型的交集。
当前集群内已经存在的命名空间,支持多选。
负载类型
开启资源画像的负载类型范围,最终开启范围为命名空间和负载类型的交集。
支持K8s原生的三类工作负载,包括Deployment、StatefulSet和DaemonsSet,支持多选。
CPU/内存资源消耗冗余
生成资源画像参考的安全冗余水位,详见下文描述。
要求为非负数,提供三档常用的冗余度(70%、50%、30%)。
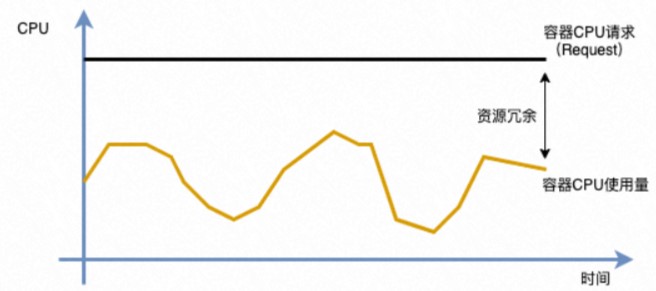
说明资源消耗冗余:管理员在评估应用业务容量时(例如QPS),通常不会将物理资源使用到100%。这既包括超线程等物理资源的局限性,也包括应用自身需要保留部分资源以应对高峰时段的负载请求。当画像值与原始资源请求的差距超过安全冗余时,会提示降配建议,具体算法参见应用画像概览部分中有关画像建议的说明。
步骤三:查看应用画像概览
资源画像的策略配置完成后,您可以在资源画像页面查看各工作负载的资源画像情况。
为提高画像结果准确性,首次使用时系统将提示需要至少累积24小时的数据。

画像总体概览以及各列的详细说明如下表所示。
 说明
说明下表中的“-”代表不涉及。
列名
含义
取值说明
是否支持字段筛选
工作负载名称
对应工作负载的名字(Name)。
-
支持。可在菜单栏顶部按名称进行精确查找。
命名空间
对应工作负载的名字(Namespace)
-
支持。默认筛选条件中不包括kube-system命名空间。
工作负载类型
对应工作负载的类型。
包括Deployment、DaemonSet和StatefulSet三种类型。
支持。默认筛选条件为全部。
CPU请求
工作负载Pod的CPU资源申请量(Request)。
-
不支持。
内存请求
工作负载Pod的内存资源申请量。
-
不支持。
画像数据状态
工作负载资源画像。
收集中:资源画像刚创建,累积的数据较少,首次使用时建议至少等待一天以上,确保工作负载稳定运行一段时间,完整覆盖了流量的波峰波谷之后再使用。
正常:资源画像结果已经生成。
工作负载已删除:对应的工作负载已经删除,画像结果将在保留一段时间后自动删除。
不支持。
CPU画像、内存画像
资源画像针对工作负载原始的资源请求量给出的规格(Request)调整建议,建议参考了资源画像值、原始资源请求量(Request)以及画像策略配置的资源消耗冗余。
包括升配、降配以及保持三种。对应的百分比为偏差幅度。计算公式为:Abs(画像值 - 原始请求量) / 原始请求量。
支持,默认筛选条件包括升配和降配。
创建时间
画像结果的创建时间。
-
不支持。
资源变配
评估画像结果和改配建议后,单击资源变配进行资源的升降配置。更多信息,请参见下文的步骤五:变更应用资源规格。
-
不支持。
说明ACS资源画像会为工作负载的每个容器资源规格生成画像值,通过对比画像值(Recommend)、原始资源请求量(Request),以及画像配置的资源消耗冗余(Buffer)。资源画像控制台会为工作负载生成操作的提示,例如对资源请求提高或降低(即升配或降配)。若工作负载有多个容器,则会提示偏差幅度最大的容器,具体计算原理如下。
画像值(Recommend)大于原始资源请求量(Request):表示容器长期处于资源超用状态(使用量大于申请量),存在稳定性风险,应及时提高资源规格,控制台提示“建议升配”。
画像值(Recommend)小于原始资源请求量(Request):表示容器可能有一定程度的资源浪费,可以降低资源规格,需要结合画像配置的资源消耗冗余进行判断,详情如下:
根据画像值和配置的资源消耗冗余,计算目标资源规格(Target):
Target = Recommend * (1 + Buffer)计算目标资源规格(Target)与原始资源请求量(Request)的偏离程度(Degree):
Degree = 1 - Request / Target根据画像值以及偏离程度(Degree)的水位,生成CPU和内存建议的提示操作,若偏离程度(Degree)的绝对值大于0.1,则提示建议降配信息
针对其他情况,资源画像为应用资源规格建议的提示为保持,表示可以暂时不调整。
步骤四:查看应用画像详情
在资源画像页面,单击工作负载名称,进入对应的画像详情页面。
详情页包括三部分功能:工作负载基本信息、各容器的画像详情资源曲线、针对应用进行资源规格变更窗口。
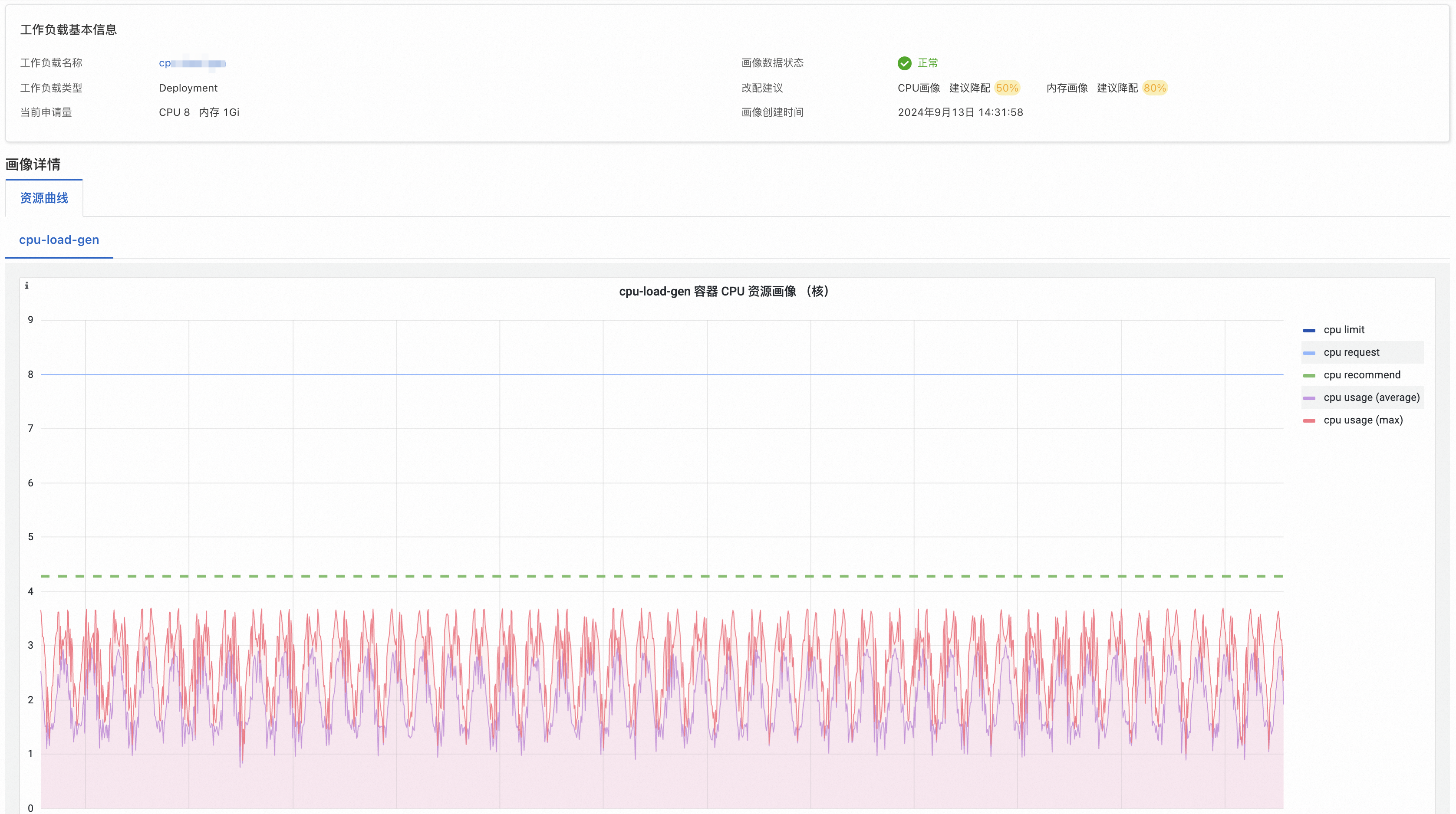 如上图所示,以CPU为例,画像详情资源曲线中各项指标的含义如下。
如上图所示,以CPU为例,画像详情资源曲线中各项指标的含义如下。曲线名称
含义
cpu limit
容器的CPU资源限制值。
cpu request
容器的CPU资源请求值。
cpu recommend
容器的CPU资源画像值。
cpu usage(average)
对应工作负载内,各容器副本CPU使用量的平均值。
cpu usage(max)
对应工作负载内,各容器副本CPU使用量的最大值。
步骤五:变更应用资源规格
在应用画像详情页面底部的资源变配区域,根据画像生成的画像值修改各容器的资源规格。
各列含义如下:
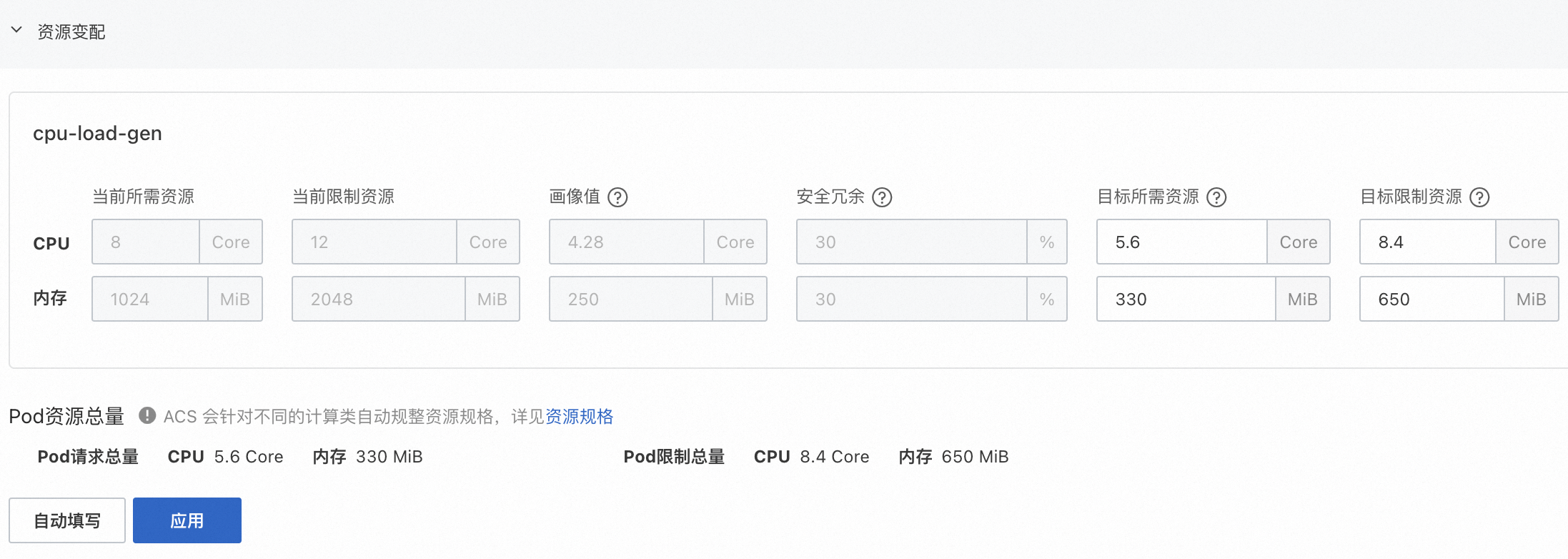
配置项
含义
当前所需资源
容器当前填写的资源请求量(Request)。
当前限制资源
容器当前填写的资源限制量(Limit)。
画像值
资源画像为容器生成的画像值,可作为资源请求量(Request)的参考值。
安全冗余
资源画像策略管理中配置的安全冗余,可作为目标所需资源的参考值,例如在画像值的基础上累加冗余系数(如上图4.28 * 1.3 = 5.6)。
目标所需资源
容器资源请求量(Request)计划调整的目标值。
目标限制资源
容器资源限制量(Limit)计划调整的目标值。注意,若工作负载使用了CPU拓扑感知调度,CPU资源的限制需要配置为整数。
重要资源画像生成的画像值为算法计算出来的实际推荐值。若您点击应用按钮执行资源变配,ACS会针对不同的计算类型规整应用的资源规格,请参见资源规格。
配置完成后,单击应用并确定对工作负载滚动更新,将执行资源规格更新操作并自动跳转到工作负载详情页。
重要资源规格更新后,控制器会对工作负载进行滚动更新并重新创建Pod,请谨慎操作。
通过命令行使用资源画像
步骤一:启用资源画像
使用以下YAML内容,创建
recommendation-profile.yaml文件,开启工作负载的资源画像。创建RecommendationProfile CRD,可以开启工作负载的资源画像,并获取容器的资源规格画像数据。RecommendationProfile CRD支持通过命名空间(Namespace)以及工作负载类型控制开启范围,开启范围为二者的交集。
apiVersion: autoscaling.alibabacloud.com/v1alpha1 kind: RecommendationProfile metadata: # 对象名称,nonNamespaced类型不需指定命名空间。 name: profile-demo spec: # 开启资源画像的工作负载类型。 controllerKind: - Deployment # 开启资源画像的命名空间范围。 enabledNamespaces: - default各项配置字段含义如下:
参数
类型
说明
metadata.nameString
对象的名称。若RecommendationProfile为nonNamespaced类型,则无需指定命名空间。
spec.controllerKindString
开启资源画像的工作负载类型。支持的工作负载类型包括Deployment 、StatefulSet和DaemonSet。
spec.enabledNamespacesString
开启资源画像的命名空间范围。
执行以下命令,为目标应用开启资源画像。
kubectl apply -f recommender-profile.yaml使用以下YAML内容,创建
cpu-load-gen.yaml文件。apiVersion: apps/v1 kind: Deployment metadata: name: cpu-load-gen labels: app: cpu-load-gen spec: replicas: 2 selector: matchLabels: app: cpu-load-gen-selector template: metadata: labels: app: cpu-load-gen-selector spec: containers: - name: cpu-load-gen image: registry.cn-zhangjiakou.aliyuncs.com/acs/slo-test-cpu-load-gen:v0.1 command: ["cpu_load_gen.sh"] imagePullPolicy: Always resources: requests: cpu: 8 # 该应用的CPU请求资源为8核。 memory: "1Gi" limits: cpu: 12 memory: "2Gi"执行以下命令,安装部署cpu-load-gen应用。
kubectl apply -f cpu-load-gen.yaml执行以下命令,获取资源规格画像结果。
kubectl get recommendations -l \ "alpha.alibabacloud.com/recommendation-workload-apiVersion=apps-v1, \ alpha.alibabacloud.com/recommendation-workload-kind=Deployment, \ alpha.alibabacloud.com/recommendation-workload-name=cpu-load-gen" -o yaml说明为了确保画像结果的准确性,建议您观察等待1天以上,以便累积充足的数据。
ack-koordinator为每个开启资源画像的工作负载生成对应的资源规格画像,并将结果保存在Recommendation CRD中。名为
cpu-load-gen的工作负载资源规格画像结果示例如下。apiVersion: autoscaling.alibabacloud.com/v1alpha1 kind: Recommendation metadata: labels: alpha.alibabacloud.com/recommendation-workload-apiVersion: app-v1 alpha.alibabacloud.com/recommendation-workload-kind: Deployment alpha.alibabacloud.com/recommendation-workload-name: cpu-load-gen name: f20ac0b3-dc7f-4f47-b3d9-bd91f906**** namespace: recommender-demo spec: workloadRef: apiVersion: apps/v1 kind: Deployment name: cpu-load-gen status: recommendResources: containerRecommendations: - containerName: cpu-load-gen target: cpu: 4742m memory: 262144k originalTarget: # 表示资源画像算法的中间结果,不建议直接使用。 # ...为了便于检索,Recommendation和工作负载的Namespace一致,同时在Label中保存了工作负载的API Version、类型以及名称,格式如下表所示。
Label Key
说明
示例
alpha.alibabacloud.com/recommendation-workload-apiVersion工作负载的API Version,由Kubernetes的Label规范约束,正斜线(/)将被替换为短划线(-)。
app-v1(替换前为app/v1)
alpha.alibabacloud.com/recommendation-workload-kind对应的工作负载类型,例如Deployment、StatefulSet等。
Deployment
alpha.alibabacloud.com/recommendation-workload-name工作负载名称,由Kubernetes的Label规范约束,长度不能超过63个字符。
cpu-load-gen
各容器的资源规格画像结果保存在
status.recommendResources.containerRecommendations中,各字段含义如下表所示。字段名称
含义
格式
示例
containerName表示容器名称。
string
cpu-load-gen
target表示资源规格画像结果,包括CPU和Memory两个维度。
map[ResourceName]resource.Quantity
cpu: 4742mmemory: 262144k
originalTarget表示资源规格画像算法的中间结果,不建议直接使用。
-
-
说明单个Pod画像的CPU最小值为0.025核,内存的最小值为250 MB。
通过对比目标应用
cpu-load-gen中声明的资源规格和本步骤画像检测结果,以CPU为例,可以发现该容器的Request申请过大。您可以通过调小Request来节省集群资源容量。类别
原始资源规格
资源画像规格
CPU
8核
4.742核
步骤二:(可选)通过Prometheus查看结果
ack-koordinator组件为资源画像结果提供了Prometheus查询接口。如果您使用了自建Prometheus监控,请参考以下监控项来配置大盘。
#指定工作负载中容器的CPU资源规格画像。
koord_manager_recommender_recommendation_workload_target{exported_namespace="$namespace", workload_name="$workload", container_name="$container", resource="cpu"}
#指定工作负载中容器的Memory资源规格画像。
koord_manager_recommender_recommendation_workload_target{exported_namespace="$namespace", workload_name="$workload", container_name="$container", resource="memory"}FAQ
资源画像的算法原理是什么?
资源画像算法涉及一套多维度的数据模型,算法原理可以总结为以下几点:
资源画像算法会持续不断地收集容器的资源使用数据,计算CPU和内存使用量的采样峰值、加权平均、分位值等聚合统计值。
最终给出的画像结果中,将CPU的推荐值设置为P95分位值,将内存的推荐值设置为P99分位值,并为二者再加上一定的安全边际,以确保工作负载的可靠性。
针对时间这一因素进行了优化,画像算法只会参考最近14天内的数据,并通过半衰期滑动窗口模型进行聚合统计,旧的数据采样点权重会逐渐降低。
算法参考了容器出现OOM等运行状态信息,可以进一步提高画像值的准确性。
更多信息,请参见资源画像技术原理介绍和资源画像原理介绍及使用建议。
资源画像对应用的类型有什么要求?
适合于在线服务类应用使用。
目前资源画像的结果优先考虑满足容器的资源需求,确保可以覆盖绝大部分数据样本。不过对于离线应用来说,这种批处理类型的任务更加关注整体的吞吐,可以接受一定程度的资源竞争,以提高集群资源的整体利用率,画像结果对于离线应用来说会显得有些保守。此外,对于关键的系统组件,通常以“主备”的形式部署多个副本,处于“备份”角色的副本长期处于闲置状态,这些副本的资源用量样本也会对画像算法产生一定程度的干扰。针对以上场景,请对画像结果按需加工后再使用,后续您可持续关注资源画像的产品动态。
是否可以直接使用画像值来设置容器的Request和Limit?
需要结合业务自身特点来判断,资源画像提供的结果是对应用当前资源需求情况的总结,管理员应结合应用自身特性,在画像值的基础之上加工后使用,例如考虑留有一定的容量来应对流量高峰,或是做“同城双活”的无缝切换,都需要留有一定数量的资源冗余;或者应用对资源较为敏感,无法在宿主机负载较高时平稳运行,也需要在画像值的基础上调高规格。
为什么参考画像值设置规格后,仍然提示需要升配或降配?
资源画像生成的画像值为算法计算出来的实际推荐值。若您点击应用按钮执行资源变配,ACS会针对不同的计算类型规整应用的资源规格,详见资源规格。规整后的应用规格与您设置的规格可能会有一定差异。
自建Prometheus如何查看资源画像监控指标?
资源画像的相关监控指标会在ack-koordinator组件的Koordinator Manager模块以Promethus的格式提供HTTP接口。您可以执行以下命令获取Pod IP,访问并查看指标数据。
# 执行以下命令获取Pod IP地址
$ kubectl get pod -A -o wide | grep koord-manager
# 预期输出,具体以实际情况为准
kube-system ack-koord-manager-5479f85d5f-7xd5k 1/1 Running 0 19d 192.168.12.242 cn-beijing.192.168.xx.xxx <none> <none>
kube-system ack-koord-manager-5479f85d5f-ftblj 1/1 Running 0 19d 192.168.12.244 cn-beijing.192.168.xx.xxx <none> <none>
# 执行以下命令查看指标数据(注意Koordinator Manager是双副本主备模式,数据只会在主副本Pod中提供)
# 其中IP地址和端口请参考Koordinator Manager模块对应的Deployment配置
# 访问前请确保当前执行命令的宿主机能与集群的容器网络互通。
$ curl -s http://192.168.12.244:9326/all-metrics | grep koord_manager_recommender_recommendation_workload_target
# 预期输出(具体以实际情况为准)
# HELP koord_manager_recommender_recommendation_workload_target Recommendation of workload resource request.
# TYPE koord_manager_recommender_recommendation_workload_target gauge
koord_manager_recommender_recommendation_workload_target{container_name="xxx",namespace="xxx",recommendation_name="xxx",resource="cpu",workload_api_version="apps/v1",workload_kind="Deployment",workload_name="xxx"} 2.406
koord_manager_recommender_recommendation_workload_target{container_name="xxx",namespace="xxx",recommendation_name="xxx",resource="memory",workload_api_version="apps/v1",workload_kind="Deployment",workload_name="xxx"} 3.861631195e+09ack-koordinator组件安装后,会自动创建Service和Service Monitor对象,关联对应的Pod。
由于Prometheus有多种采集方式,如果您使用的是自建Prometheus,请自行参见Prometheus官方文档进行配置,并在配置过程中参考以上过程进行调试。调试完成后,您可参见步骤二:(可选)通过Prometheus查看结果,在环境中配置对应的Grafana监控大盘。
如何清理资源画像结果和规则?
资源画像结果和规则分别保存在Recommendation和RecommendationProfile两个CRD中,执行以下命令删除所有资源画像结果和规则。
# 删除所有资源画像结果。
kubectl delete recommendation -A --all
# 删除所有资源画像规则。
kubectl delete recommendationprofile -A --all如何为子账号使用资源画像进行授权?
容器计算服务 ACS(Container Compute Service)的授权体系包含对基础资源层的RAM授权和对ACS集群层的RBAC(Role-Based Access Control)授权两部分,有关容器计算服务的授权体系介绍,请参见授权最佳实践。若您希望为某一子账号授权使用集群的资源画像功能,推荐您参考以下最佳实践进行授权:
RAM授权
您可以使用主账号登录RAM管理控制台,为该子账号授予系统内置的AliyunAccReadOnlyAccess只读权限。具体操作,请参见系统策略授权。
RBAC授权
完成RAM授权后,您还需要为该子账号授予目标集群中开发人员或以上的RBAC权限。具体操作,请参见配置RAM用户或RAM角色RBAC权限。
系统预置的开发人员或以上的RBAC权限拥有对集群中所有Kubernetes资源的读写权限。若您希望对子账号授予更精细化的权限,可以参考自定义RBAC授权策略创建或编辑自定义ClusterRole实例。资源画像功能需要为ClusterRole添加如下内容:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: recommendation-clusterrole
- apiGroups:
- autoscaling.alibabacloud.com
resources:
- '*'
verbs:
- '*'