OpenLake大数据&AI一体化解决方案
手动部署
60
https://www.aliyun.com/solution/tech-solution/openlake-ai-solution
方案概览
阿里云OpenLake解决方案建立在开放可控的OpenLake湖仓之上,提供大数据搜索与AI一体化服务。基于OSS的公共湖仓,结合元数据管理平台DLF,支持结构化、半结构化及非结构化数据的管理,确保数据表和文件的安全访问,并具备增删改查与IO加速能力。
该方案支持大数据、搜索和AI多引擎对接,实现引擎平权协同计算。通过DataWorks一体化IDE或Notebook,用户可统一进行多引擎SQL或Python开发,享受多任务可视化调度与大规模并发执行的保障。
客户可以便捷构建OpenLake湖仓表,跨不同计算引擎进行数据操作,并通过构建多模态索引,实现搜索和RAG能力的数据透出。在同一开发环境中,用户可结合AI特征工程、模型训练和在线预测,全面提升数据处理和分析效率。
统一元服务和存储(Meta Service):数据湖构建(Data Lake Formation)提供了全托管的统一元数据服务,包括元数据管理、权限管理、引擎对接等能力。支持全托管/半托管OSS湖存储、Paimon/Iceberg/Hudi/Delta Lake湖表格式,以及图片/视频和AI模型等文件的统一存储管理。
平权的多计算引擎(Multi-Engine):跨数据、搜索和AI领域的数据共享,同时加速原生数据的读写速度,并保障数据的一致性。计算引擎包括Flink、EMR-Spark、EMR-Starrocks、Hologres、MaxCompute、PAI和Search等,这些引擎共同提供了各种数据实时/离线分析和处理的能力。
一体化开发平台(IDE/Notebook):提供了一个集成开发环境,该环境融合了大数据、搜索和AI的数据处理流程,并实现了数据与AI资产及其血缘关系的统一管理。相关组件包括Integration(集成)、Studio(工作室)、Workflow(工作流)、Governance(治理)和Visualization(可视化)等。
方案架构
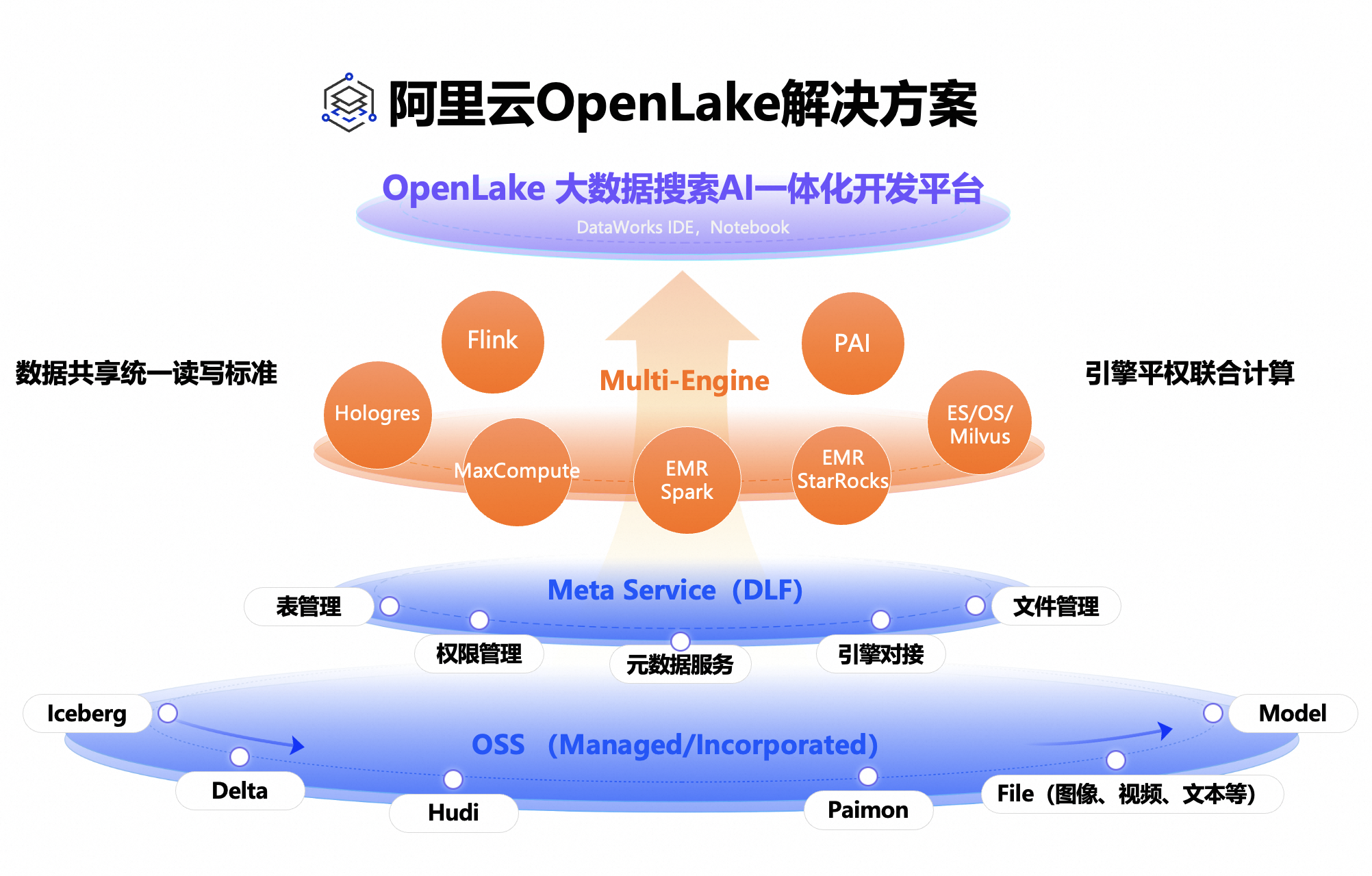
本方案的技术架构包括以下云服务:
数据湖构建 Data Lake Formation
大数据开发治理平台 DataWorks
实时计算 Flink版
开源大数据平台 EMR(Spark/StarRocks)
实时数仓 Hologres
云原生大数据计算服务 MaxCompute
智能开放搜索 OpenSearch
人工智能平台 PAI
对象存储 OSS
方案开通
15
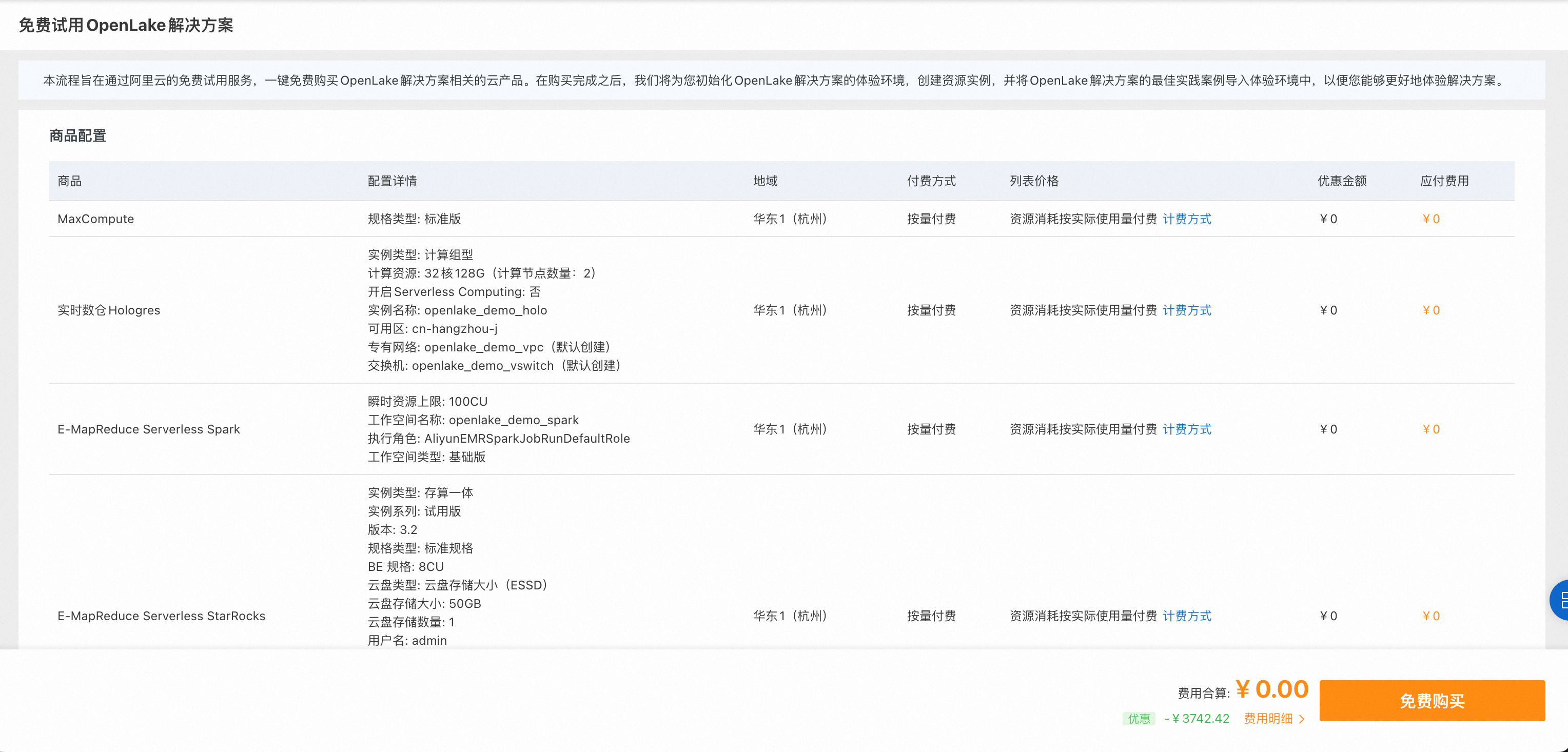
登录OpenLake解决方案开通页,符合条件的企业账号可免费领取一次资源抵扣包进行试用,个人账号开通后需要按量付费使用。
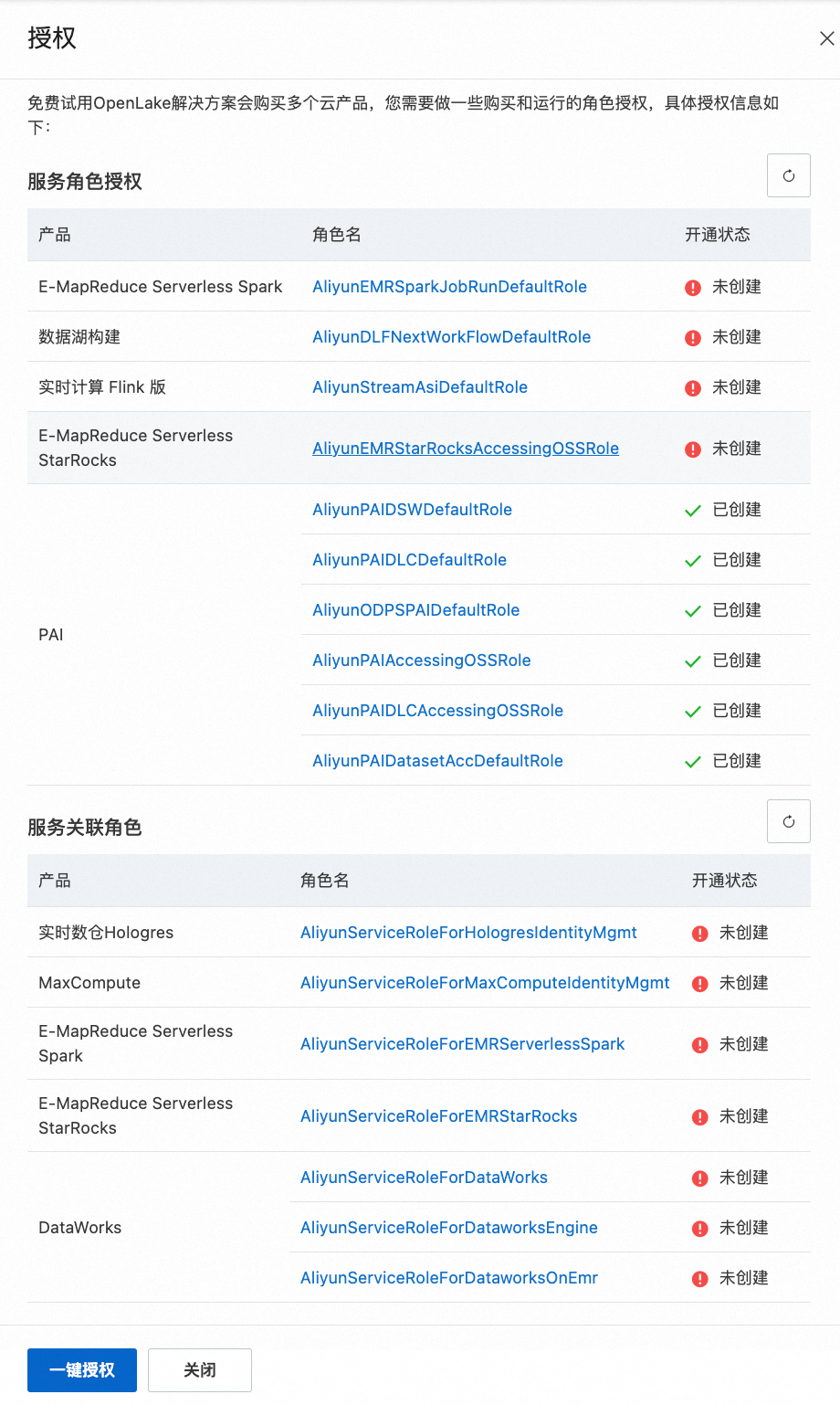
勾选服务协议并单击“立即开通”后,需要对OpenLake解决方案中各产品的服务角色和服务关联角色进行授权,可单击“一键授权”。
完成授权后再次单击“立即开通”,会自动初始化OpenLake解决方案的体验环境,创建资源实例,并将OpenLake解决方案的最佳实践案例导入体验环境中,以便您能够更好地体验解决方案,开通过程大约需要15分钟。
等待购买并启动实例完成。
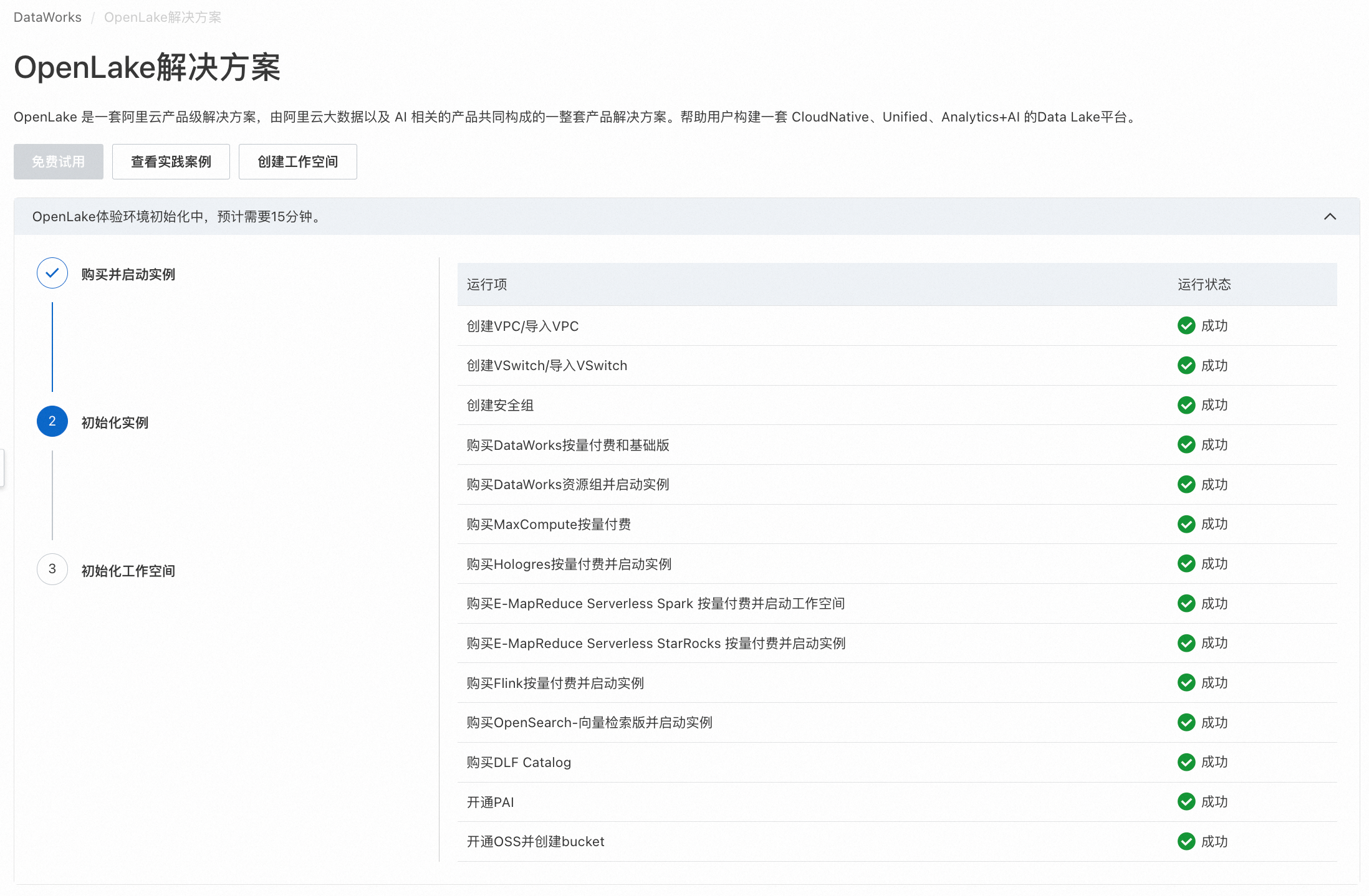
等待初始化实例完成。
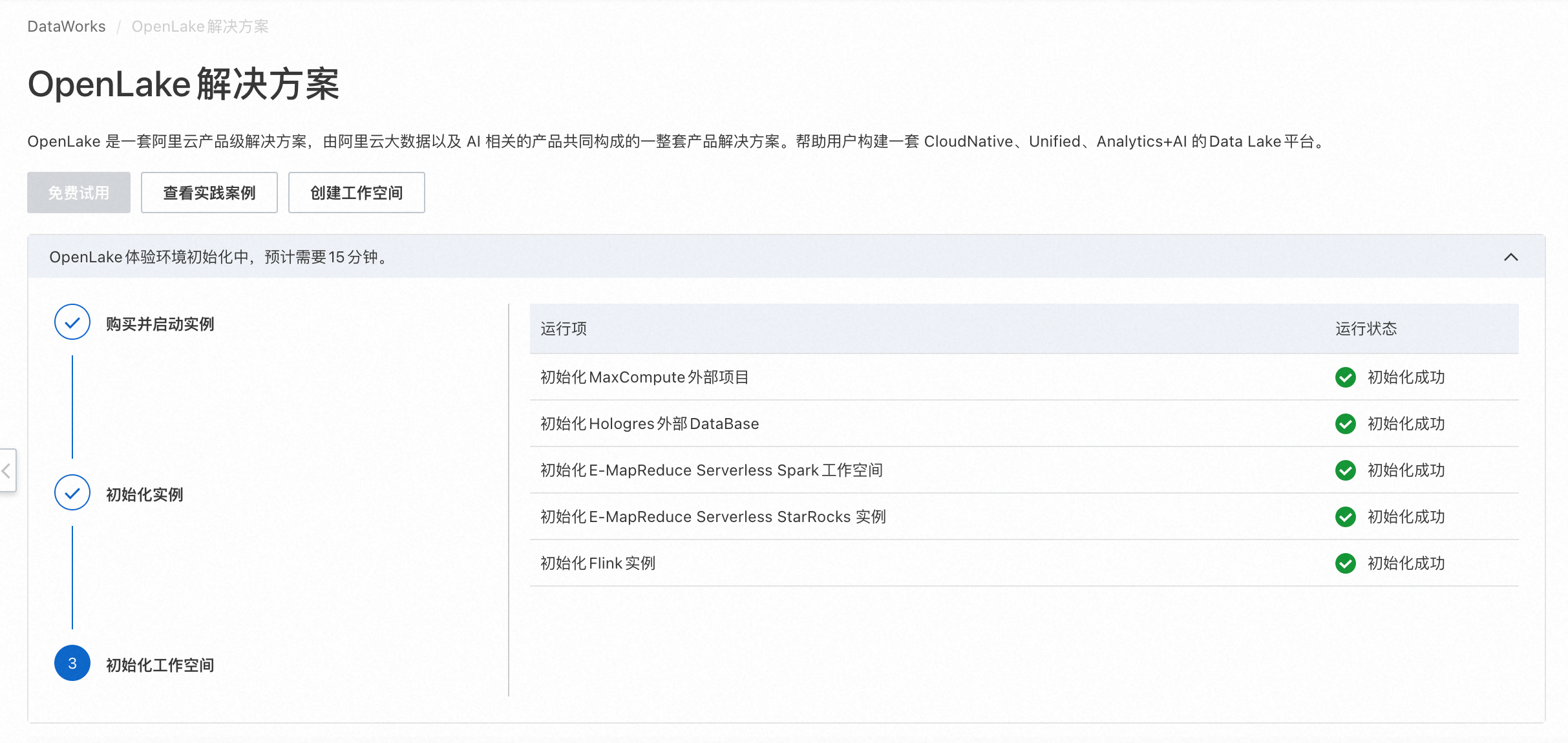
等待初始化工作空间完成。
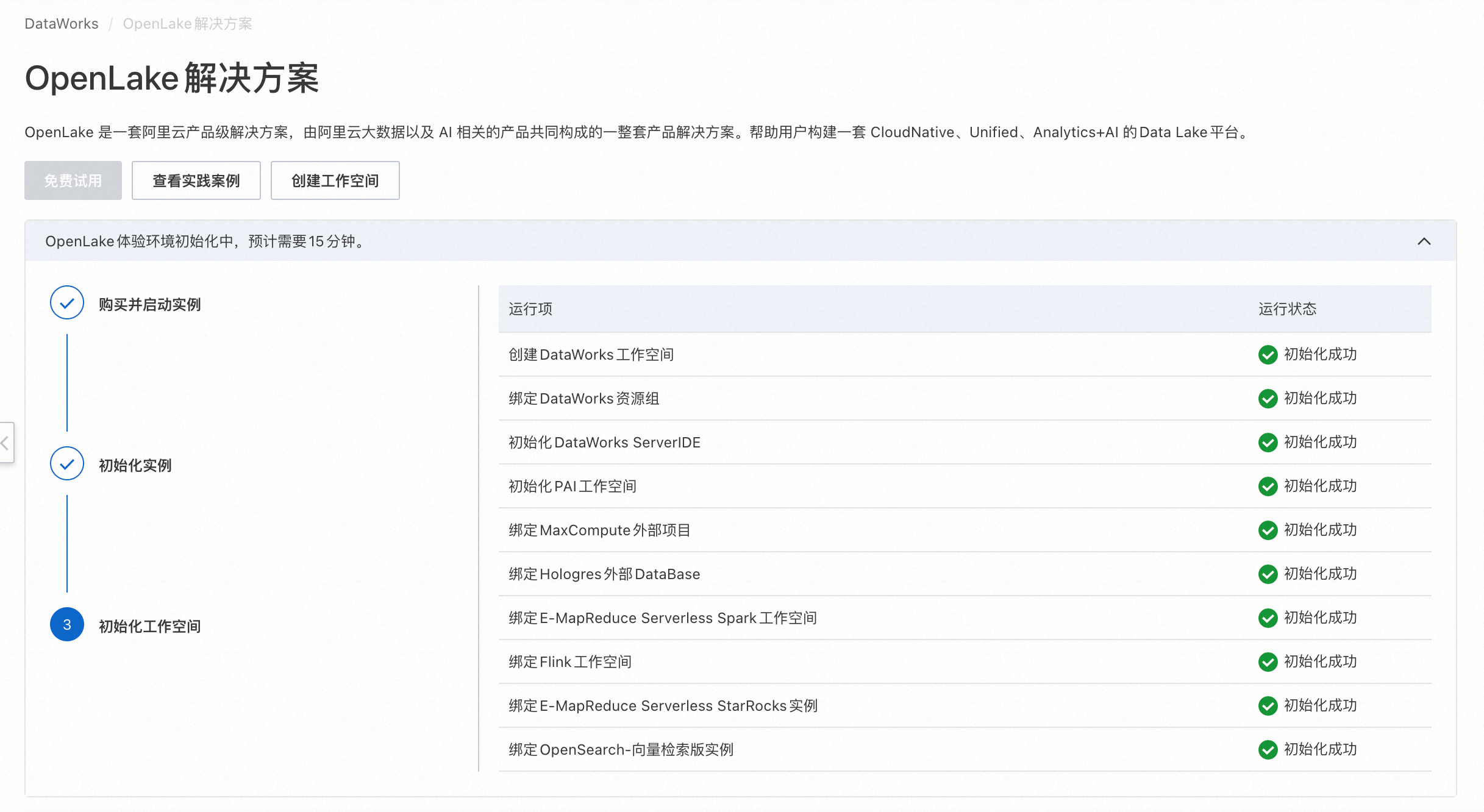
方案验证
30
OpenLake解决方案通过DataWorks Gallery提供了一些Notebook经典案例,可以直接在DataWorks里运行这些案例,以快速了解OpenLake解决方案的使用,也可以基于教程二次开发,适配实际业务场景。
说明:OpenLake解决方案开通时,会在DLF产品中默认创建一个myfirstcatalog,在运行以下案例时,需要将使用的DLF Catalog替换为myfirstcatalog。
OpenLake解决方案快速入门
本实践将基于公开数据集“中国大陆专利申请和授权数据集”,在DataWorks Notebook中使用SQL、Python和Markdown Cell来完成数据开发、分析和展示。公开数据集“中国大陆专利申请和授权数据集”存储在OSS中,包含了2003年至2021年间,中国大陆各省份的三大类专利申请和授权数据。基于该数据集,可以通过省份、年份来查询和探索各地区的发明专利、实用新型专利和外观设计专利的申请情况和授权数量。
前置步骤:载入Notebook案例
登录DataWorks Gallery控制台,找到对应的案例卡片,单击卡片中的“载入案例”,选择载入到的工作空间和实例,单击“确认”完成载入,进入DataWorks数据开发页面。
步骤1:环境准备
设置DataLakeFormation(DLF)相关的全局参数,便于在后续运行代码时直接引用。
连接DLF服务所需的全局参数
dlf.region:DLF 所在区域 ID,例如 cn-hangzhou、cn-beijing 等,详情请参见地域及访问域名。
dlf.catalog.id:DLF 数据目录 ID,请在数据湖构建控制台上查看数据目录对应的 ID,具体信息请参见数据目录。
dlf.catalog.accessKeyId:访问 DLF 服务所需的 Access Key ID,获取方法请参见查看RAM用户的AccessKey信息。
dlf.catalog.accessKeySecret:访问 DLF 服务所需的 Access Key Secret,获取方法请参见查看RAM用户的AccessKey信息。
# 请在下方填写全局参数1-4的值,再运行代码
# 1)请将 [dlf_region] 替换为您的DLF所在区域ID,例如cn-beijing
dlf_region = "[dlf_region]"
# 2)请将 [dlf_catalog_id] 替换为您DLF数据目录ID;如果已进行OpenLake一体化开通,推荐填写:"openlake_demo_dlf" 对应的DLF数据目录ID
dlf_catalog_id = "[dlf_catalog_id]"
# 3)请将 [dlf_catalog_accessKeyId] 替换为您访问DLF服务所需的AccessKeyId
dlf_catalog_accessKeyId = "[dlf_catalog_accessKeyId]"
# 4)请将 [dlf_catalog_accessKeySecret] 替换为您访问DLF服务所需的AccessKeySecret
dlf_catalog_accessKeySecret = "[dlf_catalog_accessKeySecret]"
# DLF服务的VPC网络Endpoint 和 Hologres访问DLF的Endpoint,格式已适配,以下配置无需修改
dlf_endpoint = f"dlfnext-vpc.{dlf_region}.aliyuncs.com"
dlf_endpoint_for_holo = f"dlfnext-share.{dlf_region}.aliyuncs.com"使用DLF数据目录、数据库和数据表所需的全局参数
dlf_catalog_name:DLF 数据目录名称,请在数据湖构建控制台上查看数据目录名称,具体信息请参见数据目录。
dlf.database_name:DLF 数据库名称,请在数据湖构建控制台上查看数据目录下的数据库名称,具体信息请参见数据库。
dlf_table_name:自定义表名称。
dlf_catalog_name_for_mc:MaxCompute外部项目名称,具体信息请参见MaxCompute控制台。
# 请在下方填写全局参数1-4的值,再运行代码
# 1)请将[dlf_catalog_name]替换为您的目标DLF Catalog名称。如果已进行OpenLake一体化开通,推荐填写:"MyFirstCatalog"。
dlf_catalog_name = "[dlf_catalog_name]"
# 2)请将[dlf_database_name]替换为您的目标DLF数据库名称。如果已进行OpenLake一体化开通,推荐填写:"default"。
dlf_database_name = "[dlf_database_name]"
# 3)请将[dlf_table_name]替换成自定义表名称,推荐填写:"mainland_domestic_patents_application"
dlf_table_name = "[dlf_table_name]"
# 4)请将[dlf_catalog_name_for_mc]替换为MC外部项目名称。如果已进行OpenLake一体化开通,推荐填写:"openlake_demo_mc_expj_随机字符"
dlf_catalog_name_for_mc = "[dlf_catalog_name_for_mc]"步骤2:数据准备
从OSS公开存储地址中获取原始数据,并存入Python Pandas DataFrame中(DataFrame对象的变量名称:df_data)。
读取OSS原始数据
import pandas as pd
df_data = pd.read_csv('https://dataworks-dataset-cn-shanghai.oss-cn-shanghai.aliyuncs.com/public-datasets/L1_update/L2_mainland_domestic_patents_application/full_title_03_21_mainland_domestic_patents_application.txt', sep=',', header=0)
df_data创建Paimon格式的数据表
import os
import pandas as pd
import pyarrow as pa
from paimon_python_java import Catalog
from paimon_python_api import Schema
# 连接DLF Catalog
catalog_options = {
'metastore': 'dlf-paimon',
'dlf.endpoint': dlf_endpoint,
'dlf.region': dlf_region ,
'dlf.catalog.id': dlf_catalog_id,
'dlf.catalog.accessKeyId': dlf_catalog_accessKeyId ,
'dlf.catalog.accessKeySecret': dlf_catalog_accessKeySecret,
}
catalog = Catalog.create(catalog_options)
# 新建Paimon表
record_batch = pa.RecordBatch.from_pandas(df_data)
schema = Schema(record_batch.schema)
catalog.create_table(f'{dlf_database_name}.{dlf_table_name}', schema, True)数据写入Paimon表
将之前步骤中获取的Python Pandas DataFrame对象(df_data)的数据写入Paimon表(表名为步骤1中定义的dlf_table_name参数取值)中。
# 将数据写入表
table = catalog.get_table(f'{dlf_database_name}.{dlf_table_name}')
write_builder = table.new_batch_write_builder()
table_write = write_builder.new_write()
table_commit = write_builder.new_commit()
record_batch = pa.RecordBatch.from_pandas(df_data)
table_write.write_arrow_batch(record_batch)
commit_messages = table_write.prepare_commit()
table_commit.commit(commit_messages)
table_write.close()
table_commit.close()
print("成功写入数据到Paimon表!")步骤3:交互式分析
使用Python构建ipywidgets交互组件
import ipywidgets as widgets
from IPython.display import display
# 中国的所有省份、自治区和直辖市
provinces = [
'北京市', '天津市', '上海市', '重庆市',
'河北省', '山西省', '辽宁省', '吉林省', '黑龙江省', '江苏省', '浙江省', '安徽省', '福建省', '江西省', '山东省',
'河南省', '湖北省', '湖南省', '广东省', '广西壮族自治区', '海南省', '四川省', '贵州省', '云南省', '西藏自治区',
'陕西省', '甘肃省', '青海省', '宁夏回族自治区', '新疆维吾尔自治区'
]
# 创建复选框组件
checkboxes = [widgets.Checkbox(description=province) for province in provinces]
# 将复选框按5列排列
checkbox_grid = widgets.GridBox(checkboxes, layout=widgets.Layout(grid_template_columns="repeat(5, 200px)"))
print("选择要查询的省市地区:")
# 显示复选框组件
display(checkbox_grid)
# 定义处理复选框变化的函数
def handle_checkbox_change(change):
global query_province
selected_provinces = [checkbox.description for checkbox in checkboxes if checkbox.value]
query_province = "'" + "','".join(selected_provinces) + "'"
# 绑定复选框变化事件
for checkbox in checkboxes:
checkbox.observe(handle_checkbox_change, names='value')使用SQL查询2021年不同省市地区的专利获批率
EMR Spark SQL
运行计算资源名称推荐选择Spark工作空间“openlake_demo_spark_随机字符”和SQL Compute“openlake_demo_sql_compute”。
如果选择了其他计算资源,请注意Spark工作空间中的数据目录是否已经添加了步骤1中"dlf_catalog_name"变量对应的DLF数据目录。
SELECT ROUND(designs_patents_granted/patents_application_granted*100,2) AS designs_patents_granted_rate, -- 专利申请获得授权的百分比
region, -- 地区
year -- 年份,枚举值从2003至2021
FROM ${dlf_catalog_name}.${dlf_database_name}.${dlf_table_name}
WHERE year = '2021'
AND region IN ('北京市', '山西省', '浙江省', '河南省', '海南省', '陕西省')
;Hologres SQL
运行计算资源名称推荐选择Hologres实例“openlake_demo_holo”。
SELECT (designs_patents_granted::float4/patents_application_granted *100)::decimal(19,2) AS designs_patents_granted_rate, -- 专利申请获得授权的百分比
region, -- 地区
year -- 年份,枚举值从2003至2021
FROM ${dlf_catalog_name}.${dlf_database_name}.${dlf_table_name}
WHERE year = '2021'
AND region IN ('北京市', '山西省', '浙江省', '河南省', '海南省', '陕西省')
;EMR StarRocks SQL
运行计算资源名称推荐选择EMR StarRocks实例“openlake_demo_sr_随机字符”。
-- 请先在EMR StarRocks中创建StarRocks External Catalog,映射至DLF Catalog
DROP CATALOG `${dlf_catalog_name}`;
CREATE EXTERNAL CATALOG `${dlf_catalog_name}`
PROPERTIES (
"type" = "paimon",
"paimon.catalog.type" = "dlf-paimon",
"dlf.catalog.instance.id" = "${dlf_catalog_id}"
);SELECT ROUND(designs_patents_granted/patents_application_granted*100,2) AS designs_patents_granted_rate, -- 专利申请获得授权的百分比
region, -- 地区
year -- 年份,枚举值从2003至2021
FROM `${dlf_catalog_name}`.`${dlf_database_name}`.${dlf_table_name}
WHERE year = '2021'
AND region IN ('北京市', '山西省', '浙江省', '河南省', '海南省', '陕西省')
;MaxCompute SQL
运行计算资源名称推荐选择MaxCompute外部项目“myfirstcatalog_随机字符”。
set odps.namespace.schema=true;
set odps.sql.allow.namespace.schema=true;
SELECT ROUND(designs_patents_granted/patents_application_granted*100,2) AS designs_patents_granted_rate, -- 专利申请获得授权的百分比
region, -- 地区
year -- 年份,枚举值从2003至2021
FROM `${mc_external_prj}`.`${dlf_database_name}`.${dlf_table_name}
WHERE year = '2021'
AND region IN ('北京市', '山西省', '浙江省', '河南省', '海南省', '陕西省')
;步骤4:可视化图表
步骤3中的数据查询结果均已经存储至Python Pandas DataFrame对象中,分别是:
EMR Spark SQL查询结果:df_spark
Hologres SQL查询结果:df_hologres
StarRocks SQL查询结果:df_starrocks
MaxCompute SQL查询结果:df_maxcompute
执行以下Python脚本,可视化展示不同省份的外形设计专利占比柱状图。
import pandas as pd
import matplotlib.pyplot as plt
import math
#省份及地区名称
province = list(df_spark['region']) # df_spark 支持替换为:df_spark 或 df_hologres 或 df_starrocks 或 df_maxcompute
province = [prov for prov in province]
#外形设计专利的占比
rate = list(df_spark['designs_patents_granted_rate']) # df_spark 支持替换为:df_spark 或 df_hologres 或 df_starrocks 或 df_maxcompute
rate = [math.floor(float(tmp_rate)) for tmp_rate in rate]
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = 'Source Han Serif SC'
#绘制柱状图
plt.bar(province, rate)
plt.ylim(0, 30)
plt.yticks(range(0, 30, 5))
plt.xlabel('province')
plt.xticks(rotation=45, ha="right")
plt.ylabel('designs_patents_granted_rate')
plt.title('designs_patents_granted_rate')
plt.show()基于PySpark的电影类型预测
使用PySpark和随机森林分类模型对电影类型进行预测,通过DataWorks的Notebook连接EMR Serverless Spark,对电影数据集中的特征(如上映年份、片长、评分等)进行处理和建模。本实践展示了如何在大数据平台上利用PySpark实现电影类型预测的基础框架,DLF提供底层元数据管理和表的数据读写能力。
前置步骤:载入Notebook案例
登录DataWorks Gallery控制台,找到对应的案例卡片,单击卡片中的“载入案例”,选择载入到的工作空间和实例,单击“确认”完成载入,进入DataWorks数据开发页面。
说明:完成载入后,请参见Notebook中的步骤创建Livy Gateway和Token,复制并保存Token信息。
步骤1:加载sparkmagic插件
执行以下命令,加载sparkmagic插件。Sparkmagic插件的更多详细信息和高级配置选项,请参见sparkmagic。
%load_ext sparkmagic.magics在启动session前,需要调大sparkmagic插件的启动session超时时间,否则可能会出现无法启动session的情况。
import sparkmagic.utils.configuration as conf
conf.override("livy_session_startup_timeout_seconds", 2000)步骤2:通过Spark Magic管理界面创建Spark Session
运行manage_spark cell后,会出现sparkmagic管理界面。
%manage_spark管理Endpoint配置,在【Add Endpoint】页签填写相关参数,并创建Endpoint
Auth type选择Basic_Access。
Address填写上述已经创建好的livy gateway endpoint,如http://{endpoint}。
Username为上述创建的livy gateway的token名称,Password为token密钥。
点击“Add Endpoint”。
启动Livy Session,在【Create Session】页签启动Livy Session
Endpoint选择前一个步骤添加成功的endpoint地址。
Name填写session名称。
Language选择python。
Properties是以JSON字符串传递给Serverless Spark的参数,参见Notebook中的Properties重点参数说明。
点击Create Session开始创建Spark Session,创建过程一般需要 1-3分钟,请耐心等待。在创建的过程中,在上方的cell load_ext sparkmagic.magics下会出现创建Spark Application的过程。
在Session完成创建之后,在上方的cell load_ext sparkmagic.magics中,会出现Spark Application的实例,以及Spark-UI信息。
点击Spark-UI下方的Link可以打开Spark-UI页面。
验证PySpark是否可以正常工作。
%%spark
sc.range(10000).sum()步骤3:数据摄取
设置默认Catalog为myfirstcatalog,并清空现有数据。
%%spark
spark.sql("use myfirstcatalog").show()
spark.sql("create database if not exists serverless_spark").show()
spark.sql("drop table if exists serverless_spark.summer_movies").show()
spark.sql("drop table if exists serverless_spark.summer_movie_genres").show()
spark.sql("drop table if exists serverless_spark.yearly_genre_stats").show()
spark.sql("show tables in serverless_spark").show()从OSS上加载CSV格式的电影数据集,并写入Catalog下的Paimon表。
%%spark
# 杭州
# oss://apsara-demo/dataset/openlake/summer_movies.csv
# oss://apsara-demo/dataset/openlake/summer_movie_genres.csv
# 北京
# oss://emr-workshop/dataset/openlake/summer_movies.csv
# oss://emr-workshop/dataset/openlake/summer_movie_genres.csv
# 上海
# oss://apsarademo/dataset/openlake/summer_movies.csv
# oss://apsarademo/dataset/openlake/summer_movie_genres.csv
# 以下代码以北京数据集加载为例
url = "oss://emr-workshop/dataset/openlake/summer_movies.csv"
df_summer_movies = spark.read.csv(url, header=True, inferSchema= True)
df_summer_movies.write.format("paimon").saveAsTable("serverless_spark.summer_movies")
# load summer_movie_genres
url = "oss://emr-workshop/dataset/openlake/summer_movie_genres.csv"
df_movie_genres = spark.read.csv(url, header=True, inferSchema= True)
df_movie_genres.write.format("paimon").saveAsTable("serverless_spark.summer_movie_genres")步骤4:SQL数据分析
查看每年发布的电影数量,了解电影发布的年度趋势。
SELECT year, COUNT(*) AS movie_count
FROM serverless_spark.summer_movies
GROUP BY year
ORDER BY year desc;统计每种类型的电影数量,了解各类型电影的分布情况。
SELECT genres, COUNT(*) AS genre_count
FROM serverless_spark.summer_movie_genres
GROUP BY genres
ORDER BY genre_count DESC limit 10按类型统计电影的平均评分,了解不同类型电影的评分情况。
SELECT sm.genres, AVG(average_rating) AS avg_rating
FROM serverless_spark.summer_movies sm
JOIN serverless_spark.summer_movie_genres sg ON sm.tconst = sg.tconst
GROUP BY sm.genres
ORDER BY avg_rating DESC limit 20步骤5:SQL数据ETL
生成一张新表,包含每年每种类型电影的数量和平均评分。
CREATE TABLE serverless_spark.yearly_genre_stats AS
SELECT
sm.year,
sg.genres,
COUNT(*) AS movie_count,
AVG(sm.average_rating) AS avg_rating
FROM
serverless_spark.summer_movies sm
JOIN
serverless_spark.summer_movie_genres sg ON sm.tconst = sg.tconst
GROUP BY
sm.year, sg.genres
ORDER BY
sm.year, sg.genres;select year, genres, sum(movie_count), avg(avg_rating)
from serverless_spark.yearly_genre_stats
GROUP BY year, genres
order by year, genres;步骤6:使用本地kernel python可视化展示每年电影类型的分布
运行以下脚本,可视化展示不同年份的电影数量和类型分布堆叠柱状图,从图中可以看出2000年以后,电影类型逐渐丰富,且喜剧类型的电影占比较重。
import pandas as pd
import matplotlib.pyplot as plt
trend_pd_df = df_30
# 如果某些列是字符串类型但应该是数值类型,可以进行转换
trend_pd_df['sum(movie_count)'] = pd.to_numeric(trend_pd_df['sum(movie_count)'], errors='coerce')
trend_pd_df['avg(avg_rating)'] = pd.to_numeric(trend_pd_df['avg(avg_rating)'], errors='coerce')
# 重新绘制堆叠柱状图
pivot_df = trend_pd_df.pivot(index='year', columns='genres', values='sum(movie_count)')
pivot_df.plot(kind='bar', stacked=True, figsize=(15, 8))
plt.xlabel('Year')
plt.ylabel('Number of Movies')
plt.title('Yearly Movie Count by Genre (Stacked)')
plt.legend(title='Genre', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()步骤7:使用PySpark和随机森林分类模型对电影类型进行预测
预测电影类型(Genres)
具体步骤:
数据合并:使用tconst作为连接键,将电影和类型数据集合并。
特征选择:使用year, runtime_minutes, average_rating等作为特征,同时将文本列title_type和simple_title转换为数值索引。
模型选择:选择随机森林分类器进行多分类任务。
模型评估:使用准确率作为性能指标,评估模型在测试集上的表现。
说明:在运行的过程中,您可以通过 Spark-UI 查看任务跑的情况。
%%spark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.ml.feature import StringIndexer, VectorAssembler, OneHotEncoder
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
# 加载数据集
movies_df = spark.table('serverless_spark.summer_movies')
genres_df = spark.table('serverless_spark.summer_movie_genres')
# 重命名 genres 列,以避免歧义
genres_df = genres_df.withColumnRenamed("genres", "target_genres")
# 合并数据集,基于 tconst 字段
combined_df = movies_df.join(genres_df, on="tconst", how="inner")
# 转换 year 和 runtime_minutes 列为数值类型
data = combined_df.withColumn("year", col("year").cast("int")) \
.withColumn("runtime_minutes", col("runtime_minutes").cast("int")) \
.withColumn("average_rating", col("average_rating").cast("double"))
# 去除缺失值
data = data.dropna(subset=["year", "runtime_minutes", "average_rating"])
# 将 target_genres 列转换为数值索引
genre_indexer = StringIndexer(inputCol="target_genres", outputCol="genresIndex")
data = genre_indexer.fit(data).transform(data)
# 将其他文本列转换为数值索引
indexers = [
StringIndexer(inputCol="title_type", outputCol="titleTypeIndex"),
StringIndexer(inputCol="simple_title", outputCol="simpleTitleIndex")
]
for indexer in indexers:
data = indexer.fit(data).transform(data)
# 组装特征向量
assembler = VectorAssembler(
inputCols=["year", "runtime_minutes", "average_rating", "titleTypeIndex", "simpleTitleIndex"],
outputCol="features"
)
data = assembler.transform(data)
# 划分数据集
train_data, test_data = data.randomSplit([0.8, 0.2])
# 初始化随机森林分类器
rf = RandomForestClassifier(featuresCol="features", labelCol="genresIndex", maxBins=1024)
# 训练模型
rf_model = rf.fit(train_data)
# 在测试集上进行预测
predictions = rf_model.transform(test_data)
# 评估模型
evaluator = MulticlassClassificationEvaluator(labelCol="genresIndex", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)
print(f"模型准确率: {accuracy:.2f}")使用电影的运行时间(runtime_minutes)和票数(num_votes)来预测电影的平均评分(average_rating)
具体步骤:
数据预处理:加载数据,处理缺失值,并转换数据类型。
特征工程:选择并准备特征和目标变量。
模型训练:使用线性回归模型进行训练。
模型评估:评估模型的表现。
说明:在运行的过程中,您可以通过 Spark-UI 查看任务跑的情况。
%%spark
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.ml.feature import StringIndexer, VectorAssembler, OneHotEncoder
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
# 加载数据集
movies_df = spark.table('serverless_spark.summer_movies')
genres_df = spark.table('serverless_spark.summer_movie_genres')
# 重命名 genres 列,以避免歧义
genres_df = genres_df.withColumnRenamed("genres", "target_genres")
# 合并数据集,基于 tconst 字段
combined_df = movies_df.join(genres_df, on="tconst", how="inner")
# 转换字符串类型到数值
data = combined_df.withColumn("runtime_minutes", col("runtime_minutes").cast("int")) \
.withColumn("num_votes", col("num_votes").cast("int")) \
.withColumn("average_rating", col("average_rating").cast("double"))
data = data.dropna(subset=["runtime_minutes", "num_votes", "average_rating"])
# 组装变量
assembler = VectorAssembler(
inputCols=["runtime_minutes", "num_votes"],
outputCol="features"
)
data = assembler.transform(data)
# 划分数据集
train_data, test_data = data.randomSplit([0.8, 0.2])
# 初始化Linear Regression model
lr = LinearRegression(featuresCol="features", labelCol="average_rating")
# 训练模型
lr_model = lr.fit(train_data)
# 在测试集上进行预测
predictions = lr_model.transform(test_data)
# 评估模型
evaluator = RegressionEvaluator(labelCol="average_rating", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
# 预测的电影平均评分与实际评分之间的差距。这个值越接近于 0,说明模型的预测越接近真实值。
print(f"Root Mean Squared Error (RMSE): {rmse:.2f}")
# 展示预测效果
predictions.select("runtime_minutes", "num_votes", "average_rating", "prediction").show(10)游戏玩家画像和行为分析
基于多款阿里云大数据产品构建一个实时数据分析平台,该平台能够收集玩家的行为日志,进行实时处理和分析,并最终将分析结果通过图表的形式展现给业务人员。由DLF提供底层元数据管理和表的数据读写能力,通过EMR Serverless StarRocks实现实时数据处理和分析,最后使用Quick BI完成数据可视化。
前置步骤:载入Notebook案例
登录DataWorks Gallery控制台,找到对应的案例卡片,单击卡片中的“载入案例”,选择载入到的工作空间和实例,单击“确认”完成载入,进入DataWorks数据开发页面。
步骤1:参数初始化
## 参数初始化
## 1. 在DLF中创建Catalog,通过DLF控制台页面创建,获取[your_dlf_catalog_id}]
## DLF控制台地址:https://dlf-next.console.aliyun.com/
DLF_CATALOG_ID="[your_dlf_catalog_id]"
## 2.将[your-region]替换为您当前Demo的Region,比如 cn-beijing,cn-hangzhou,cn-shanghai,cn-shenzhen
REGION="[your-region]"
## 切记,一定要执行该脚本,以使得变量生效。步骤2:创建StarRocks表,用于接收导入的OSS数据
运行以下SQL,创建用户画像(user_profile)与 用户行为表(user_event)。
CREATE DATABASE IF NOT EXISTS game_db;
use game_db;
--用户信息表
CREATE TABLE IF NOT EXISTS ods_user_profile (
user_id INT NOT NULL,
registration_date DATE NOT NULL,
last_login_date DATE,
age_group VARCHAR(20),
gender VARCHAR(10),
location VARCHAR(50),
game_hours INT,
favorite_game_mode VARCHAR(20),
play_frequency VARCHAR(20),
device_type VARCHAR(20),
os_version VARCHAR(20),
current_level INT,
total_deaths INT,
active_time VARCHAR(20),
language_preference VARCHAR(10)
)
PRIMARY KEY (user_id)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"replication_num" = "1"
);
-- 用户事件表
CREATE TABLE IF NOT EXISTS ods_user_event (
`user_id` INT,
`event_type` STRING,
`timestamp` datetime,
`location` STRING,
`level` INT,
`event_details` STRING
)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"replication_num" = "1"
);步骤3:使用Broker Load将OSS数据导入到StarRocks表中
运行以下SQL,进行数据导入。
use game_db;
--导入新的数据
LOAD LABEL game_db.user_profile_20240902_22
(
DATA INFILE("oss://emr-starrocks-benchmark-resource-${REGION}/sr_game_demo/user_profile/*")
INTO TABLE ods_user_profile
FORMAT AS "parquet"
)
WITH BROKER
(
"fs.oss.endpoint" = "oss-${REGION}-internal.aliyuncs.com"
)
PROPERTIES
(
"timeout" = "3600"
);
LOAD LABEL game_db.user_event_20240902_22
(
DATA INFILE("oss://emr-starrocks-benchmark-resource-${REGION}/sr_game_demo/user_event/*")
INTO TABLE ods_user_event
FORMAT AS "parquet"
)
WITH BROKER
(
"fs.oss.endpoint" = "oss-${REGION}-internal.aliyuncs.com"
)
PROPERTIES
(
"timeout" = "3600"
);步骤4:对玩家数据进行直接即席分析查询(示例:分析用户留存率)
StarRocks是极速的湖仓新范式计算引擎,针对ODS层的海量数据查询整体查询性能极高,有时候一些场景可以直接即席查询ODS表,直接进行日常分析。
USE game_db;
WITH daily_new_users AS (
SELECT
user_id,
registration_date
FROM
ods_user_profile
WHERE
registration_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE()
),
daily_login_events AS (
SELECT
user_id,
DATE(timestamp) AS login_date
FROM
ods_user_event
WHERE
timestamp BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 31 DAY) AND CURRENT_DATE()
),
retention AS (
SELECT
n.user_id,
n.registration_date,
l.login_date
FROM
daily_new_users n
LEFT JOIN
daily_login_events l ON n.user_id = l.user_id AND l.login_date = DATE_ADD(n.registration_date, INTERVAL 1 DAY)
)
SELECT
registration_date,
COUNT(DISTINCT user_id) AS new_users,
COUNT(DISTINCT CASE WHEN login_date IS NOT NULL THEN user_id END) AS retained_users,
COUNT(DISTINCT CASE WHEN login_date IS NOT NULL THEN user_id END) / COUNT(DISTINCT user_id) * 100.0 AS retention_rate
FROM
retention
GROUP BY
registration_date
ORDER BY
registration_date;步骤5:使用StarRocks物化视图,自动化构建数仓DWD和ADS层
构建DWD层
为简化逻辑,此处直接将ODS层数据插入DWD。然而,实际情况中应考虑更多业务逻辑的处理。
use game_db;
DROP MATERIALIZED VIEW IF EXISTS dwd_mv_user_profile;
CREATE MATERIALIZED VIEW IF NOT EXISTS dwd_mv_user_profile
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR) -- 每隔小时刷新一次
AS
SELECT * FROM ods_user_profile;
DROP MATERIALIZED VIEW IF EXISTS dwd_mv_user_event;
CREATE MATERIALIZED VIEW IF NOT EXISTS dwd_mv_user_event
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR) -- 每隔小时刷新一次
AS
SELECT * FROM ods_user_event;构建ADS层
use game_db;
--1. 创建ADS_MV_USER_RETENTION (用户留存率)
CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_RETENTION
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR)
AS
SELECT
DATE_TRUNC('day', registration_date) AS registration_day,
DATE_TRUNC('day', last_login_date) AS last_login_day,
COUNT(DISTINCT user_id) AS users_retained
FROM dwd_mv_user_profile
GROUP BY
DATE_TRUNC('day', registration_date),
DATE_TRUNC('day', last_login_date);
-- 2. ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION (用户地理分布)
CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR)
AS
SELECT
location AS geographic_location,
COUNT(DISTINCT user_id) AS total_users
FROM dwd_mv_user_profile
GROUP BY
location;
-- 3. ADS_MV_USER_DEVICE_PREFERENCE (设备使用习惯)
CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_DEVICE_PREFERENCE
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR)
AS
SELECT
device_type,
COUNT(DISTINCT user_id) AS total_users
FROM dwd_mv_user_profile
GROUP BY
device_type;
-- 4. ADS_MV_USER_PURCHASE_TRENDS (用户购买趋势)
-- 该视图用于分析玩家每天的购买趋势变化
CREATE MATERIALIZED VIEW IF NOT EXISTS ADS_MV_USER_PURCHASE_TRENDS
DISTRIBUTED BY RANDOM
REFRESH ASYNC EVERY(INTERVAL 1 HOUR)
AS
SELECT
DATE(timestamp) AS purchase_date,
COUNT(user_id) AS daily_purchase_events
FROM dwd_mv_user_event
WHERE event_type = '购买'
GROUP BY
purchase_date
ORDER BY
purchase_date;步骤6:向数据湖中写入数据(Paimon格式)
在StarRocks中创建External Catalog。
-- myfirstcatalog可以根据您的实际情况调整。
-- DROP CATALOG `myfirstcatalog`;
CREATE EXTERNAL CATALOG `myfirstcatalog`
PROPERTIES (
"type" = "paimon",
"paimon.catalog.type" = "dlf-paimon",
"dlf.catalog.instance.id" = "${DLF_CATALOG_ID}"
);
-- 如出现:Unexpected exception: Catalog 'myfirstcatalog' doesn't exist,您可以注释掉 -- DROP CATALOG `myfirstcatalog`; 重新执行再试一次。写数据到数据湖中(Paimon格式)。
CREATE DATABASE IF NOT EXISTS myfirstcatalog.game_db;
CREATE TABLE IF NOT EXISTS myfirstcatalog.game_db.ADS_USER_PURCHASE_TRENDS(
purchase_date DATE COMMENT '购买日期',
daily_purchase_events INT COMMENT '每日购买事件数量'
);
-- ADS:ETL加工数据
INSERT
INTO myfirstcatalog.game_db.ADS_USER_PURCHASE_TRENDS
SELECT * from ADS_MV_USER_PURCHASE_TRENDS;步骤7:通过Quick BI进行报表分析和展示
通过Quick BI可以直接查询StarRocks中最终ADS层的数据,进行报表页面展示。
登录Quick BI控制台。
配置StarRocks数据源。
设计报表和数据集。
数据集SQL1:select * from game_db.ADS_MV_USER_RETENTION;
数据集SQL2:select * from game_db.ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION;
数据集SQL3:select * from game_db.ADS_MV_USER_DEVICE_PREFERENCE;
数据集SQL4:select * from game_db.ADS_MV_USER_PURCHASE_TRENDS;
RAG知识库在线问答
基于RAG(Retrieval-Augmented Generation)的文档问答常用于企业内部知识库检索与总结、垂直领域的在线问答等业务场景。基于客户的专业知识库文档,通过RAG(检索增强生成)技术和LLM(大语言模型),理解和响应复杂的自然语言查询,帮助企业客户通过自然语言快速从PDF、WORD、表格、图片文档中检索到所需信息。
前置步骤:载入Notebook案例
登录DataWorks Gallery控制台,找到对应的案例卡片,单击卡片中的“载入案例”,选择载入到的工作空间和实例,单击“确认”完成载入,进入DataWorks数据开发页面。
步骤1:开发环境准备
在下方单元格中,包含了7个变量,请在运行前替换变量为具体值,确保运行的成功:
${your-search-platform-public-endpoint}:您可以进入AI搜索开放平台,查看endpoint
${your-search-platform-api-key}:您可以进入AI搜索开放平台,查看api-key
${your-opensearch-public_endpoint}:您可以进入OpenSearch引擎,打开相应实例的详情页,查看opensearch endpoint
${your-opensearch-instance_id}:您可以进入OpenSearch引擎,打开相应实例的详情页,查看opensearch instance id
${your-opensearch-table-name}:您可以进入OpenSearch引擎,打开相应实例的详情页,查看opensearch table name
${your-opensearch-instance-username}:您可以进入OpenSearch引擎,打开相应实例的详情页,查看opensearch username
${your-opensearch-instance-password}:您可以进入OpenSearch引擎,打开相应实例的详情页,查看opensearch password
# AI搜索开放平台配置
search_plat_host = "${your-search-platform-public-endpoint}"
search_plat_api_key = "${your-search-platform-api-key}"
# OpenSearch向量检索版配置
os_vectorstore_host = "${your-opensearch-public_endpoint}"
os_vectorstore_instance_id = "${your-opensearch-instance_id}"
os_vectorstore_table_name = "${your-opensearch-table-name}"
os_vectorstore_user_name = "${your-opensearch-instance-username}"
os_vectorstore_user_password = "${your-opensearch-instance-password}"
# 输入文档url,示例文档为opensearch产品说明文档
document_url = "https://help.aliyun.com/zh/open-search/search-platform/product-overview/introduction-to-search-platform"在下方单元格中,包含了7个变量,请在运行前替换变量为具体值,确保运行的成功:
${dlf_region}:您可以查看阿里云地域ID
${dlf_catalog_id}:您可以进入数据湖构建服务(DLF),打开相应的catalog,查看catalog id
${dlf_catalog_name}:您可以进入数据湖构建服务(DLF),打开相应的catalog,查看catalog name
${dlf_database_name}:您可以进入数据湖构建服务(DLF),打开相应的数据库,查看database name
${dlf_table_name}:您可以进入数据湖构建服务(DLF),打开相应的数据表,查看table name
${dlf_catalog_accessKeyId}:您可以进入云账号Access Key,查看您的账号的Access Key
${dlf_catalog_accessKeySecret}:您需要找到创建时保存的与Access Key对应的Access Secret
# 请在下方填写全局参数的值,再运行代码
dlf_region = "${dlf_region}" #请将 [dlf_region] 替换为您的DLF所在区域ID,例如cn-beijing
dlf_catalog_id = "${dlf_catalog_id}" #请将 [dlf_catalog_id] 替换为您DLF数据目录ID
dlf_catalog_name = "myfirstcatalog" #请将 [dlf_catalog_name]替换为您的目标DLF Catalog名称;如果已进行OpenLake一体化开通,推荐填写:"myfirstcatalog"
dlf_database_name = "opensearch_db" #请将 [dlf_database_name]替换为您的目标DLF 数据库名称;如果已进行OpenLake一体化开通,推荐填写:"opensearch_db"
dlf_table_name = "rag" #请将[dlf_table_name]替换成自定义表名称,推荐填写:"rag"
dlf_catalog_accessKeyId = "${dlf_catalog_accessKeyId}" #请将 [dlf_catalog_accessKeyId] 替换为您访问DLF服务所需的AccessKeyId
dlf_catalog_accessKeySecret = "${dlf_catalog_accessKeySecret}" #请将 [dlf_catalog_accessKeySecret] 替换为您访问DLF服务所需的AccessKeySecret
# DLF服务的Endpoint
dlf_endpoint = f"dlfnext-vpc.{dlf_region}.aliyuncs.com"需要提前安装Python 3.7及以上版本,请确保安装相应的Python版本。AI搜索开放平台和OpenSearch向量检索服务相关的环境依赖如下:
! pip install -q alibabacloud_searchplat20240529 alibabacloud_ha3engine_vector openai步骤2:开发环境初始化
这部分是离线文档处理和在线文档问答的公共代码,包含导入依赖包、初始化搜索开发平台client,搜索引擎配置等。
import asyncio
import json
from operator import attrgetter
from typing import List
from alibabacloud_ha3engine_vector import models, client
from alibabacloud_ha3engine_vector.models import QueryRequest, SparseData
from Tea.exceptions import TeaException, RetryError
from alibabacloud_tea_openapi.models import Config
from alibabacloud_searchplat20240529.client import Client
from alibabacloud_searchplat20240529.models import GetDocumentSplitRequest, CreateDocumentAnalyzeTaskRequest, \
CreateDocumentAnalyzeTaskRequestDocument, GetDocumentAnalyzeTaskStatusRequest, GetDocumentSplitRequestDocument, \
GetTextEmbeddingRequest, GetTextEmbeddingResponseBodyResultEmbeddings, GetTextSparseEmbeddingRequest, \
GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings, GetTextSparseEmbeddingResponseBodyResultSparseEmbeddingsEmbedding, \
GetImageAnalyzeTaskStatusResponse, CreateImageAnalyzeTaskRequest, GetImageAnalyzeTaskStatusRequest, \
CreateImageAnalyzeTaskRequestDocument, CreateImageAnalyzeTaskResponse,GetDocumentRankRequest, \
GetTextGenerationRequest, GetTextGenerationRequestMessages, GetQueryAnalysisRequest
from openai import OpenAI
workspace_name = "default"
service_id_config = {"document_analyze": "ops-document-analyze-001",
"split": "ops-document-split-001",
"image_analyze": "ops-image-analyze-ocr-001",
"rank": "ops-bge-reranker-larger",
"text_embedding": "ops-text-embedding-002",
"text_sparse_embedding": "ops-text-sparse-embedding-001",
"llm": "ops-qwen-turbo",
"query_analyze": "ops-query-analyze-001"}
# 生成AI搜索开放平台client
config = Config(bearer_token=search_plat_api_key, endpoint=search_plat_host, protocol="http", read_timeout=30000)
ops_client = Client(config=config)
openAIclient = OpenAI(
api_key=search_plat_api_key,
base_url="http://" + search_plat_host + "/compatible-mode/v1/"
)步骤3:离线文档处理并写入Paimon表
离线文档处理主要通过搜索开发平台上的文档理解、切片、和向量化等各类服务,将文档数据解析和提取、文档切片、切片Embedding并最终推送到Paimon表中。新的数据写入Paimon表之后,OpenSearch可以实时感知并构建实时索引,实现数据写入后的秒级实时查询。
# 初始化Paimon表信息
import os
import pandas as pd
import pyarrow as pa
from paimon_python_java import Catalog
from paimon_python_api import Schema
# create catalog
catalog_options = {
'metastore': 'dlf-paimon',
'dlf.endpoint': dlf_endpoint,
'dlf.region': dlf_region ,
'dlf.catalog.id': dlf_catalog_id,
'dlf.catalog.accessKeyId': dlf_catalog_accessKeyId ,
'dlf.catalog.accessKeySecret': dlf_catalog_accessKeySecret,
}
catalog = Catalog.create(catalog_options)
pa_schema = pa.schema([
('id', pa.string()),
('title', pa.string()),
('text', pa.string()),
('url', pa.string()),
('embedding', pa.string()),
('token_id', pa.string()),
('token_weight', pa.string())
])
schema = Schema(pa_schema=pa_schema)
# 创建Paimon表
catalog.create_table(f'{dlf_database_name}.{dlf_table_name}', schema, True)
import os
import pandas as pd
import pyarrow as pa
async def write_to_paimon(doc_list):
# get table
table = catalog.get_table(f"{dlf_database_name}.{dlf_table_name}")
# write data
# 1. Create table write and commit
write_builder = table.new_batch_write_builder()
table_write = write_builder.new_write()
table_commit = write_builder.new_commit()
# convert data source to arrow RecordBatch
df = pd.DataFrame(doc_list)
record_batch = pa.RecordBatch.from_pandas(df, pa_schema)
# 3. Write data. You can write many times.
table_write.write_arrow_batch(record_batch)
# 4. Commit data. If you commit, you cannot write more data.
commit_messages = table_write.prepare_commit()
table_commit.commit(commit_messages)
# 5. Close resources.
table_write.close()
table_commit.close()
async def poll_doc_analyze_task_result(ops_client, task_id, service_id, interval=5):
while True:
request = GetDocumentAnalyzeTaskStatusRequest(task_id=task_id)
response = await ops_client.get_document_analyze_task_status_async(workspace_name, service_id, request)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(interval)
elif status == "SUCCESS":
return response
else:
print("error: " + response.body.result.error)
raise Exception("document analyze task failed")
def is_analyzable_url(url:str):
if not url:
return False
image_extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.tiff'}
return url.lower().endswith(tuple(image_extensions))
async def image_analyze(ops_client, url):
try:
print("image analyze :" + url)
if url.startswith("//"):
url = "https:" + url
if not is_analyzable_url(url):
print(url + " is not analyzable.")
return url
image_analyze_service_id = service_id_config["image_analyze"]
document = CreateImageAnalyzeTaskRequestDocument(
url=url,
)
request = CreateImageAnalyzeTaskRequest(document=document)
response: CreateImageAnalyzeTaskResponse = ops_client.create_image_analyze_task(workspace_name, image_analyze_service_id, request)
task_id = response.body.result.task_id
while True:
request = GetImageAnalyzeTaskStatusRequest(task_id=task_id)
response: GetImageAnalyzeTaskStatusResponse = ops_client.get_image_analyze_task_status(workspace_name, image_analyze_service_id, request)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(5)
elif status == "SUCCESS":
return url + response.body.result.data.content
else:
print("image analyze error: " + response.body.result.error)
return url
except Exception as e:
print(f"image analyze Exception : {e}")
def chunk_list(lst, chunk_size):
for i in range(0, len(lst), chunk_size):
yield lst[i:i + chunk_size]
async def document_pipeline_execute(document_url: str = None, document_base64: str = None, file_name: str = None):
# 生成opensearch开发平台client
config = Config(bearer_token=search_plat_api_key,endpoint=search_plat_host,protocol="http")
ops_client = Client(config=config)
# Step 1: 文档解析
document_analyze_request = CreateDocumentAnalyzeTaskRequest(document=CreateDocumentAnalyzeTaskRequestDocument(url=document_url, content=document_base64,file_name=file_name, file_type='html'))
document_analyze_response = await ops_client.create_document_analyze_task_async(workspace_name=workspace_name,service_id=service_id_config["document_analyze"],request=document_analyze_request)
print("document_analyze task_id:" + document_analyze_response.body.result.task_id)
extraction_result = await poll_doc_analyze_task_result(ops_client, document_analyze_response.body.result.task_id, service_id_config["document_analyze"])
print("document_analyze done")
document_content = extraction_result.body.result.data.content
content_type = extraction_result.body.result.data.content_type
# Step 2: 文档切片
document_split_request = GetDocumentSplitRequest(
GetDocumentSplitRequestDocument(content=document_content, content_type=content_type))
document_split_result = await ops_client.get_document_split_async(workspace_name, service_id_config["split"],
document_split_request)
print("document-split done, chunks count: " + str(len(document_split_result.body.result.chunks))
+ " rich text count:" + str(len(document_split_result.body.result.rich_texts)))
# Step 3: 文本向量化
# 提取切片结果。图片切片会通过图片解析服务提取出文本内容
doc_list = ([{"id": chunk.meta.get("id"), "content": chunk.content} for chunk in document_split_result.body.result.chunks]
+ [{"id": chunk.meta.get("id"), "content": chunk.content} for chunk in document_split_result.body.result.rich_texts if chunk.meta.get("type") != "image"]
+ [{"id": chunk.meta.get("id"), "content": await image_analyze(ops_client,chunk.content)} for chunk in document_split_result.body.result.rich_texts if chunk.meta.get("type") == "image"]
)
chunk_size = 32 # 一次最多允许计算32个embedding
all_text_embeddings: List[GetTextEmbeddingResponseBodyResultEmbeddings] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_embedding_async(workspace_name,service_id_config["text_embedding"],GetTextEmbeddingRequest(chunk))
all_text_embeddings.extend(response.body.result.embeddings)
all_text_sparse_embeddings: List[GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_sparse_embedding_async(workspace_name,service_id_config["text_sparse_embedding"],GetTextSparseEmbeddingRequest(chunk,input_type="document",return_token=True))
all_text_sparse_embeddings.extend(response.body.result.sparse_embeddings)
paimon_doc_list = []
for i in range(len(doc_list)):
paimon_doc = {}
paimon_doc["id"] = doc_list[i]["id"]
paimon_doc["title"] = ""
paimon_doc["text"] = doc_list[i]["content"]
paimon_doc["url"] = document_url
paimon_doc["embedding"] = ','.join([str(embedding) for embedding in all_text_embeddings[i].embedding])
sorted_sparse_embedding_result = sorted(all_text_sparse_embeddings[i].embedding, key=attrgetter('token_id'))
token_ids = [str(sparse_embedding.token_id) for sparse_embedding in sorted_sparse_embedding_result]
token_wights = [str(sparse_embedding.weight) for sparse_embedding in sorted_sparse_embedding_result]
paimon_doc["token_id"] = ','.join(token_ids)
paimon_doc["token_weight"] = ','.join(token_wights)
paimon_doc_list.append(paimon_doc)
print("text-embedding done")
for doc in paimon_doc_list:
print(doc)
# Step 4: 写入Paimon表
await write_to_paimon(paimon_doc_list)执行以下脚本,运行离线异步任务。
if __name__ == "__main__":
import nest_asyncio # 如果在Jupyter notebook中运行,反注释这两行
nest_asyncio.apply() # 如果在Jupyter notebook中运行,反注释这两行
asyncio.run(document_pipeline_execute(document_url))步骤4:从Paimon表创建索引
从DataWorks左侧栏点击进入【数据目录】,找到前面创建的Paimon表,右键点击【管理OpenSearch向量索引】创建OpenSearch索引,选择id为{your-opensearch-instance_id}的OpenSearch实例,创建名为{your-opensearch-table-name}的索引表,等待索引创建完成,即可进入下一步。
步骤5:在线文档问答
将Query转化为Embedding,使用OpenSearch向量检索版提供的向量检索能力找到与Query相似的文档切片,组装成Prompt,交给大模型进行答案生成。
async def os_vector_store_retrieve(query_emb, query_sparse_emb: List[GetTextSparseEmbeddingResponseBodyResultSparseEmbeddingsEmbedding]):
os_vector_store_config = models.Config(
endpoint=os_vectorstore_host,
instance_id=os_vectorstore_instance_id,
protocol="http",
access_user_name=os_vectorstore_user_name,
access_pass_word=os_vectorstore_user_password
)
# 初始化OpenSearch向量引擎客户端
os_vector_store = client.Client(os_vector_store_config)
sorted_sparse_embedding_result = sorted(query_sparse_emb, key=attrgetter('token_id'))
token_ids = [sparse_embedding.token_id for sparse_embedding in sorted_sparse_embedding_result]
token_wights = [sparse_embedding.weight for sparse_embedding in sorted_sparse_embedding_result]
sparseData = SparseData(indices=token_ids, values=token_wights)
request = QueryRequest(table_name=os_vectorstore_table_name,
vector=query_emb,
sparse_data=sparseData,
include_vector=True,
output_fields=["id", "text"],
top_k=5)
result = await os_vector_store.query_async(request)
jsonResult = json.loads(result.body)
search_results = [result['fields']['text'] for result in jsonResult['result']]
return search_results
async def get_query_result(query):
# 获取query的稠密向量
query_emb_result = await ops_client.get_text_embedding_async(workspace_name, service_id_config["text_embedding"],
GetTextEmbeddingRequest(input=[query],
input_type="query"))
query_emb = query_emb_result.body.result.embeddings[0].embedding
# 获取query的稀疏向量
query_sparse_emb = await ops_client.get_text_sparse_embedding_async(workspace_name,
service_id_config["text_sparse_embedding"],
GetTextSparseEmbeddingRequest(
input=[query], input_type="query"))
# 使用query的稠密向量和稀疏向量去召回相关文档
search_results = await os_vector_store_retrieve(query_emb,query_sparse_emb.body.result.sparse_embeddings[0].embedding)
return search_results
# 在线问答,输入是用户问题
async def query_pipeline_execute(user_query):
# Step 1: query分析
query_analyze_response = ops_client.get_query_analysis(workspace_name, service_id_config["query_analyze"], GetQueryAnalysisRequest(query=user_query))
print("问题:" + user_query)
# Step 2: 召回文档
all_query_results = []
user_query_results = await get_query_result(user_query)
all_query_results.extend(user_query_results)
rewrite_query_results = await get_query_result(query_analyze_response.body.result.query)
all_query_results.extend(rewrite_query_results)
for extend_query in query_analyze_response.body.result.queries:
extend_query_result = await get_query_result(extend_query)
all_query_results.extend(extend_query_result)
# 对所有召回结果进行去重
remove_duplicate_results = list(set(all_query_results))
# Step 3: 对去重后的召回文档进行重排序
rerank_top_k = 3
score_results = await ops_client.get_document_rank_async(workspace_name, service_id_config["rank"],GetDocumentRankRequest(remove_duplicate_results, user_query))
rerank_results = [remove_duplicate_results[item.index] for item in score_results.body.result.scores[:rerank_top_k]]
# Step 4: 调用大模型回答问题
docs = '\n'.join([f"<article>{s}</article>" for s in rerank_results])
completion = openAIclient.chat.completions.create(
model = "ops-qwen-turbo",
messages = [
{"role": "user", "content": f"""已知信息包含多个独立文档,每个文档在<article>和</article>之间,已知信息如下:\n'''{docs}'''
\n\n根据上述已知信息,详细且有条理地回答用户的问题。确保答案充分回答了问题并且正确使用了已知信息。如果信息不足以回答问题,请说“根据已知信息无法回答该问题”。
不要使用不在已知信息中的内容生成答案,确保答案中每一个陈述在上述已知信息中有相应内容支撑。答案请使用中文。
\n问题是:'''{user_query}'''"""""}
],
stream=True
)
print("\n答案:", end="")
for resp in completion:
print(resp.choices[0].delta.content.replace("**",""), end="")设定输入的查询问题。
# 用户query:
user_query = "AI搜索开放平台有什么特点?"执行以下脚本,运行离线异步任务。
if __name__ == "__main__":
import nest_asyncio # 如果在Jupyter notebook中运行,反注释这行
nest_asyncio.apply() # 如果在Jupyter notebook中运行,反注释这行
asyncio.run(query_pipeline_execute(user_query))完成及清理
15
清理资源
测试完方案后,您可以参考以下规则处理对应产品的实例,避免继续产生费用:
1.释放Flink工作空间。
登录Flink控制台,在Flink全托管页签,单击工作空间操作列的更多> 释放资源,按照界面提示释放工作空间。
2. 释放EMR Serverless StarRocks实例。
登录 EMR Serverless StarRocks控制台,在实例列表页签,单击实例操作列的释放,并按照界面提示释放实例。
3. 删除EMR Serverless Spark工作空间。
登录 EMR Serverless Spark控制台,在工作空间列表页面,单击工作空间操作列的删除,并按照界面提示删除工作空间。
4. 停机并释放Hologres实例。
登录Hologres控制台,在实例列表页面,单击运行状态列中的停机,然后单击删除,并按照界面提示释放实例。
5. 删除MaxCompute项目。
登录 MaxCompute控制台,在项目列表页签,单击项目操作列的删除,并按照界面提示删除项目。
6. 删除PAI工作空间。
登录 PAI控制台,在工作空间列表页面,单击工作空间操作列的⋮> 删除,并按照界面提示删除工作空间 。
7. 删除OpenSearch实例。
登录 OpenSearch控制台,在实例列表页面,单击实例操作列的⋮> 删除,并按照界面提示删除实例 。
8. 删除DLF Catalog。
登录 DLF控制台,在Catalog列表页面,单击Catalog操作列的⋮> 删除,并按照界面提示删除Catalog(需要先删除Catalog下的数据库和表) 。
9. 删除DataWorks工作空间。
登录 DataWorks控制台,在工作空间列表页面,单击工作空间操作列的⋮> 删除工作空间,并按照界面提示删除工作空间。
10. 删除OSS Bucket。
登录OSS管理控制台,删除上述步骤在OSS Bucket存储空间下创建的目录及上传的文件。单击Bucket 列表,然后单击目标Bucket名称。在左侧导航栏,单击删除Bucket,并按照页面指引完成删除操作。