DataWorks数据建模
本实验通过使用DataWorks、MaxCompute服务,实现数据建模,使得数据可以最终以可视化的方式呈现,让使用者能够快速地、高效地获取到数据中有价值的信息,从而做出准确有效的决策。
场景简介
本实验将基于一台配置了Alibaba Cloud Linux 3操作系统的ECS实例(云服务器)、DataWorks和MaxCompute资源。通过本实验的操作,您可以使用DataWorks、MaxCompute服务实现数据建模,对维度建模方法有初步的了解,理解建模的流程和思路。
数据建模是一个用于定义和分析在组织的信息系统范围内支持商业流程所需的数据要求的过程。简单来说,数据建模是基于对业务数据的理解和数据分析的需要,将各类数据进行整合和关联,使得数据可以最终以可视化的方式呈现,让使用者能够快速地、高效地获取到数据中有价值的信息,从而作出准确有效的决策。
维度模型:
维度建模从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星形模型,以及在一些特殊场景下使用的雪花模型。
建模步骤:
选择业务过程。
业务过程可以是单个业务事件,比如交易的支付、退款等;也可以是某个事件的状态,比如当前的账户余额等;还可以是一系列相关业务事件组成的业务流程,具体需要看我们分析的是某些事件发生情况,还是当前状态,或是事件流转效率。
选择粒度。
在事件分析中,要预判所有分析需要细分的程度,从而决定选择的粒度。粒度是维度的一个组合。
识别维表。
选择好粒度之后,就需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选。
选择事实。
确定分析需要衡量的指标。
建模意义
性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐。
成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低大数据系统中的存储和计算成本。
效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率。
质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性。
实验目标
完成基于sakila DVD租赁模型的维度建模操作,开发完整的代码逻辑。
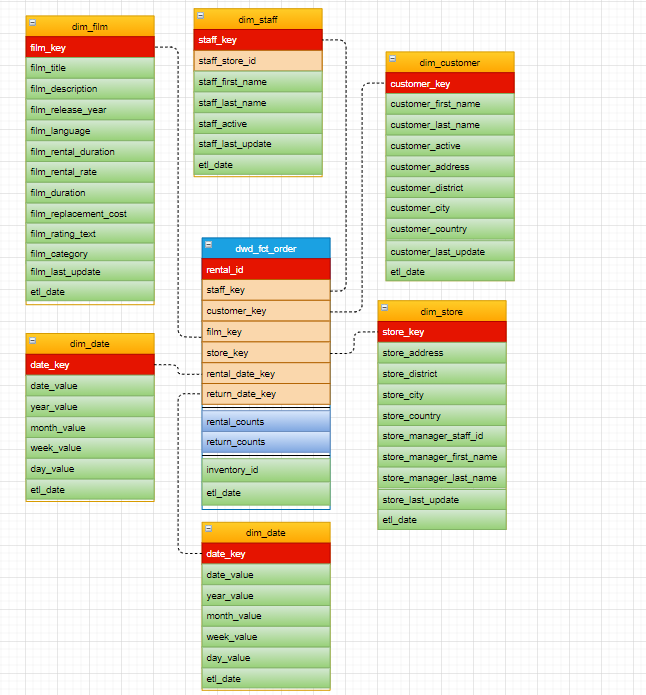
最终我们得到的模型如下:
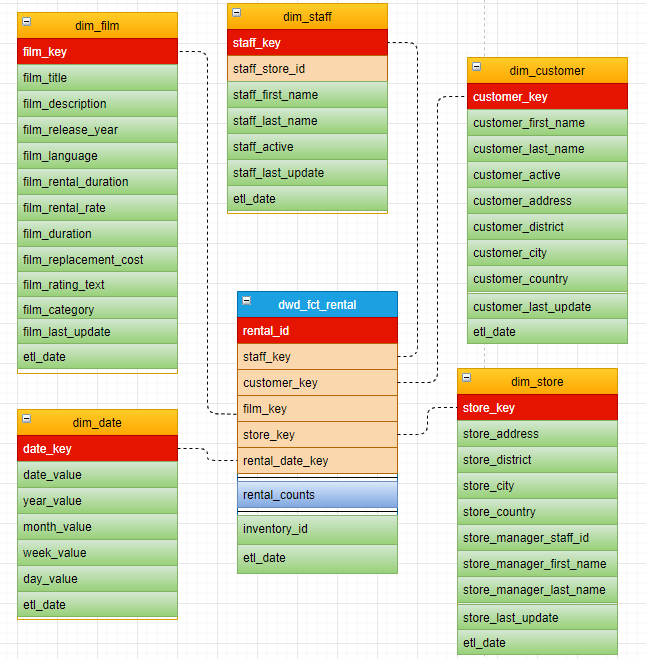
影碟租赁事实表。
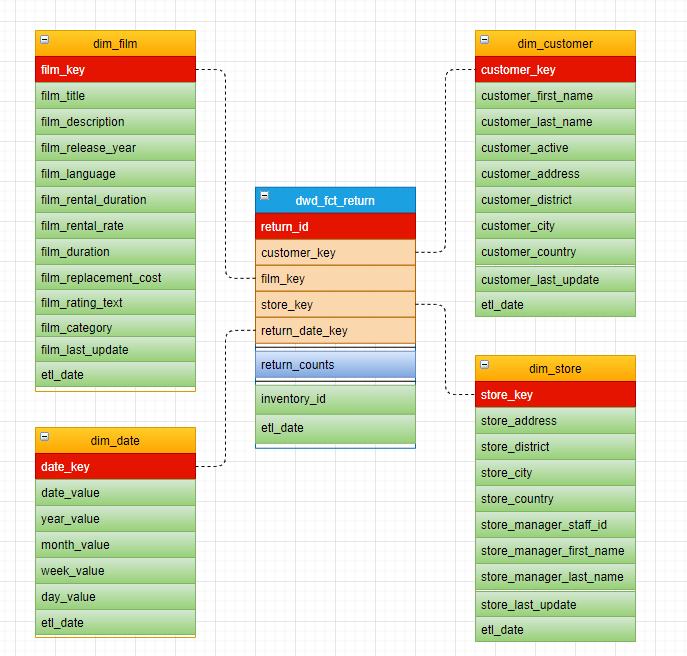
影碟归还事实表。
交易累积快照事实表。
费用说明
本实验时长2个小时,预计产生费用为1元。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
背景知识
本场景主要涉及以下云产品和服务:
创建实验资源
在实验页面,勾选我已阅读并同意《阿里云云起实践平台服务协议》和我已授权阿里云云起实践平台创建、读取及释放实操相关资源后,单击开始实操。
创建资源需要5分钟左右的时间,请您耐心等待。
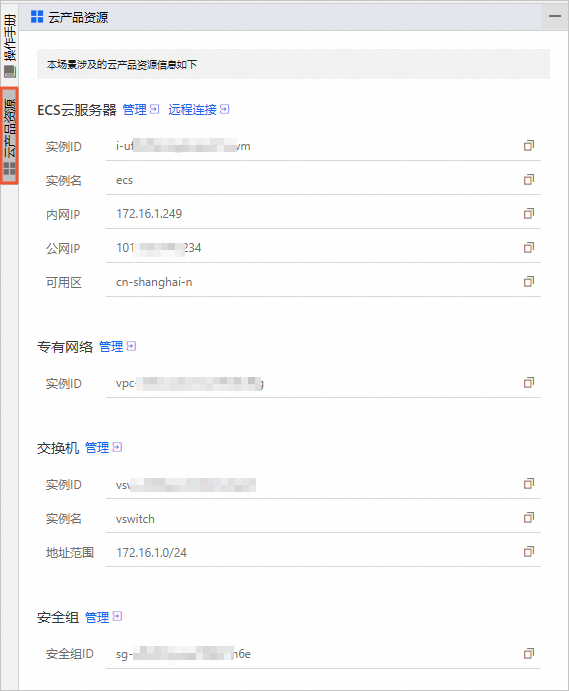
在云产品资源列表,您可以查看本场景涉及的云产品资源信息。
开通DataWorks服务
本步骤仅适用于DataWorks新用户。
如果您在华东2(上海)地域曾经开通过DataWorks,但DataWorks版本已到期,请您跳过本步骤操作,您需要登录DataWorks管理控制台,切换至华东2(上海)地域,单击购买版本,然后参考
新增和使用Serverless资源组文档创建资源组并绑定工作空间,参考绑定计算资源(参加新版数据开发公测)文档创建并绑定MaxCompute计算资源。
如果您在华东2(上海)地域已开通DataWorks,请您跳过本步骤操作,您需要参考
新增和使用Serverless资源组文档创建资源组并绑定工作空间,参考绑定计算资源(参加新版数据开发公测)文档创建并绑定MaxCompute计算资源。
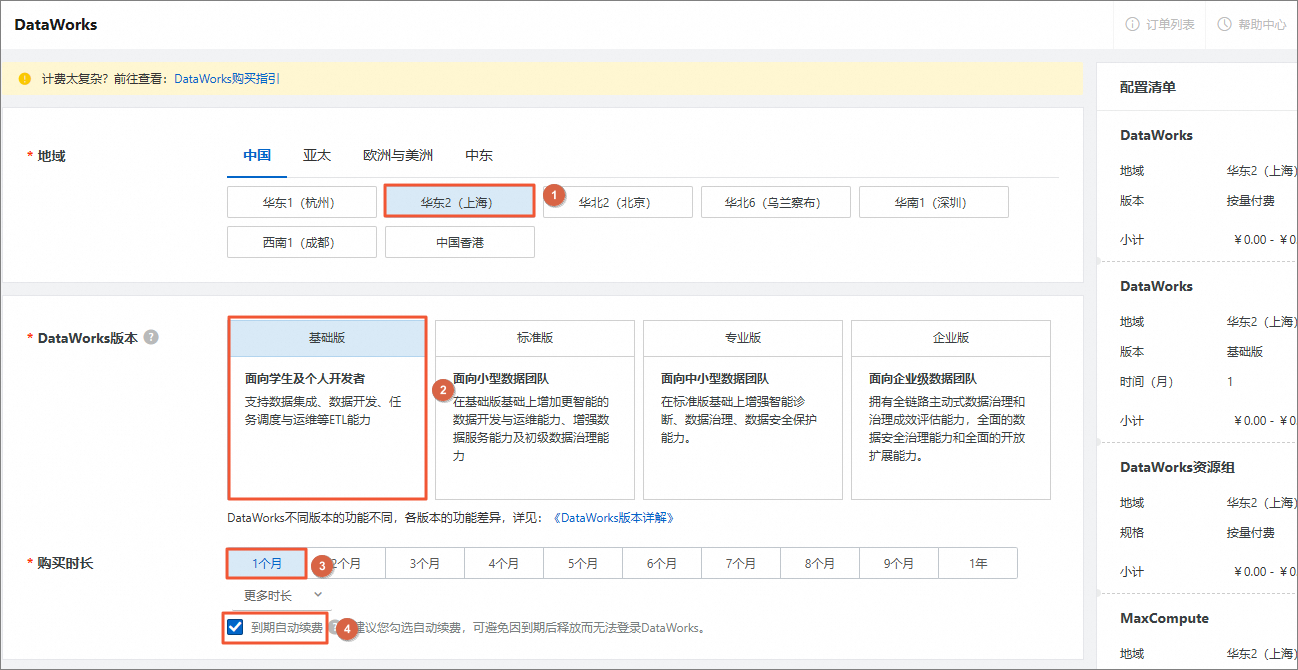
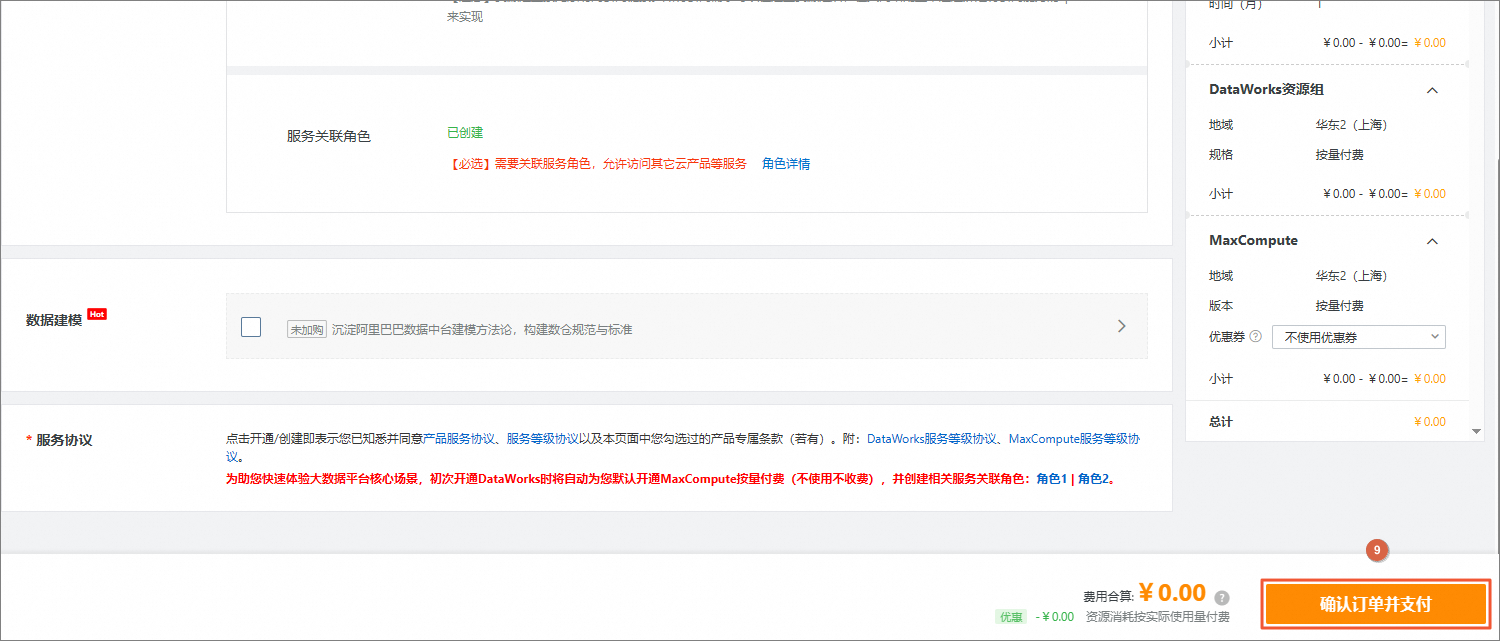
在DataWorks开通页面,根据如下说明配置参数,未提及的参数保持默认即可,单击确认订单并支付。
参数
说明
示例
地域
选择需要开通DataWorks的地域。
华东2(上海)
DataWorks
选择需要购买的DataWorks版本。
说明本教程以基础版为例,所有版本均可体验本教程所涉及的功能,您可以参考DataWorks各版本支持的功能详情,根据实际业务需要,选择合适的DataWorks版本。
基础版
购买时长
根据您的需要选择购买时长和是否开通到期自动续费。
1个月,并勾选到期自动续费。
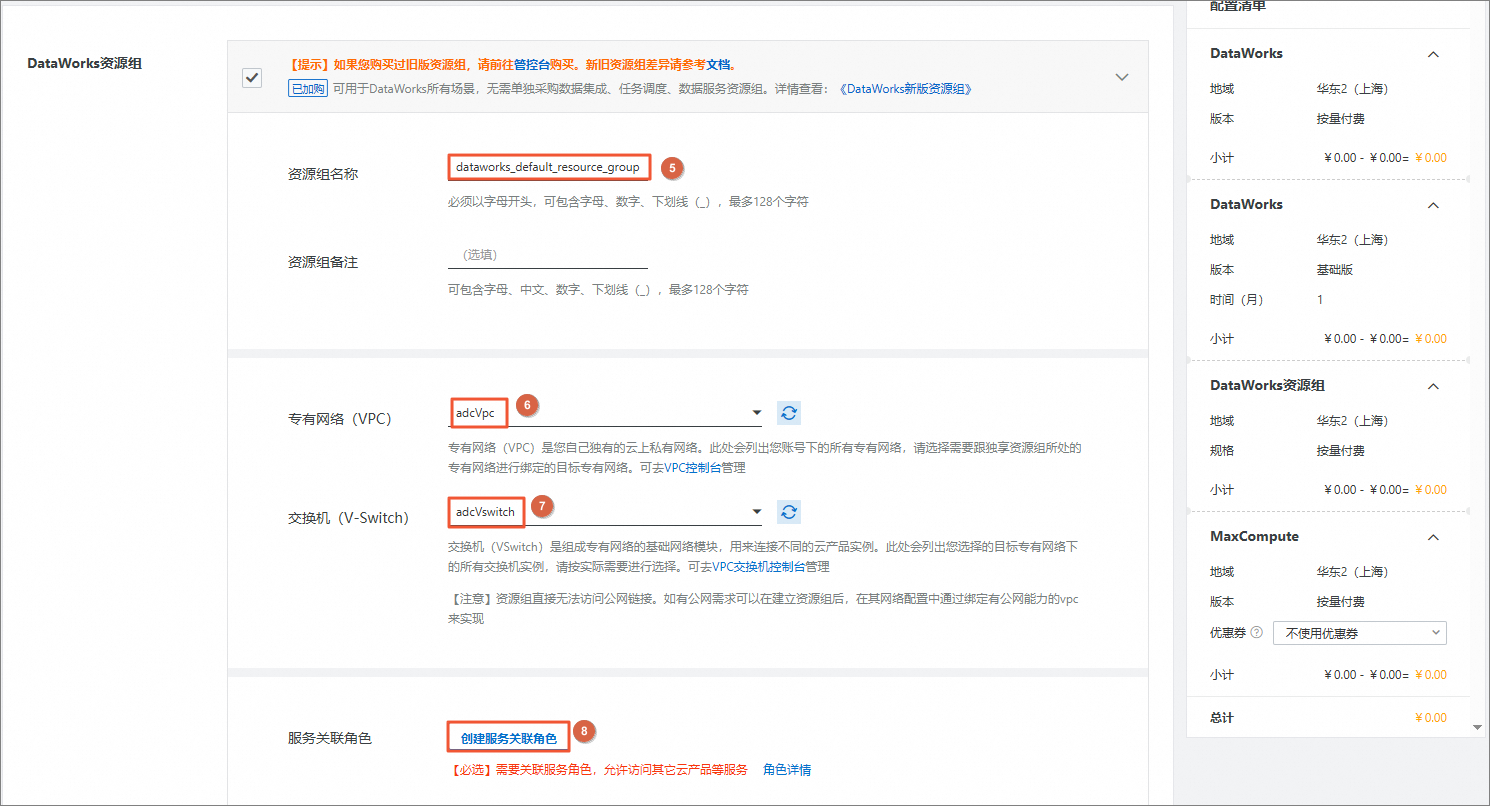
DataWorks资源组
通过DataWorks进行数据集成、数据开发、数据调度等任务时,需要消耗计算资源,您需要配套购买资源组,以确保后续任务的顺利运行。
说明关于新版资源组计费详情,请参见Serverless资源组计费。
资源组名称:自定义资源组名称。
专有网络(VPC):选择云服务器ECS同一个VPC。
交换机(V-Switch):选择云服务器ECS同一个VSwitch。
服务关联角色:根据页面提示,单击创建服务关联角色。
说明您可在左侧云产品资源列表中查看云服务器ECS所在的VPC和VSwitch。

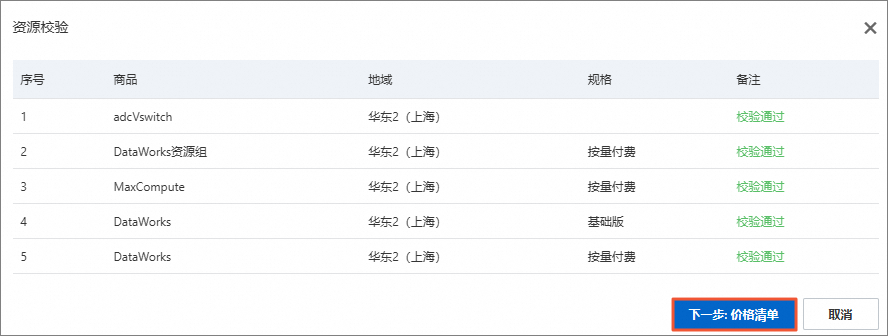
在资源校验对话框中,单击下一步:价格清单。
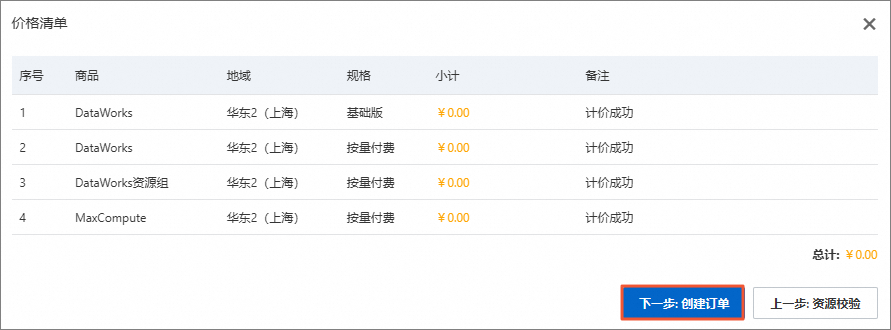
在价格清单对话框中,单击下一步:创建订单。
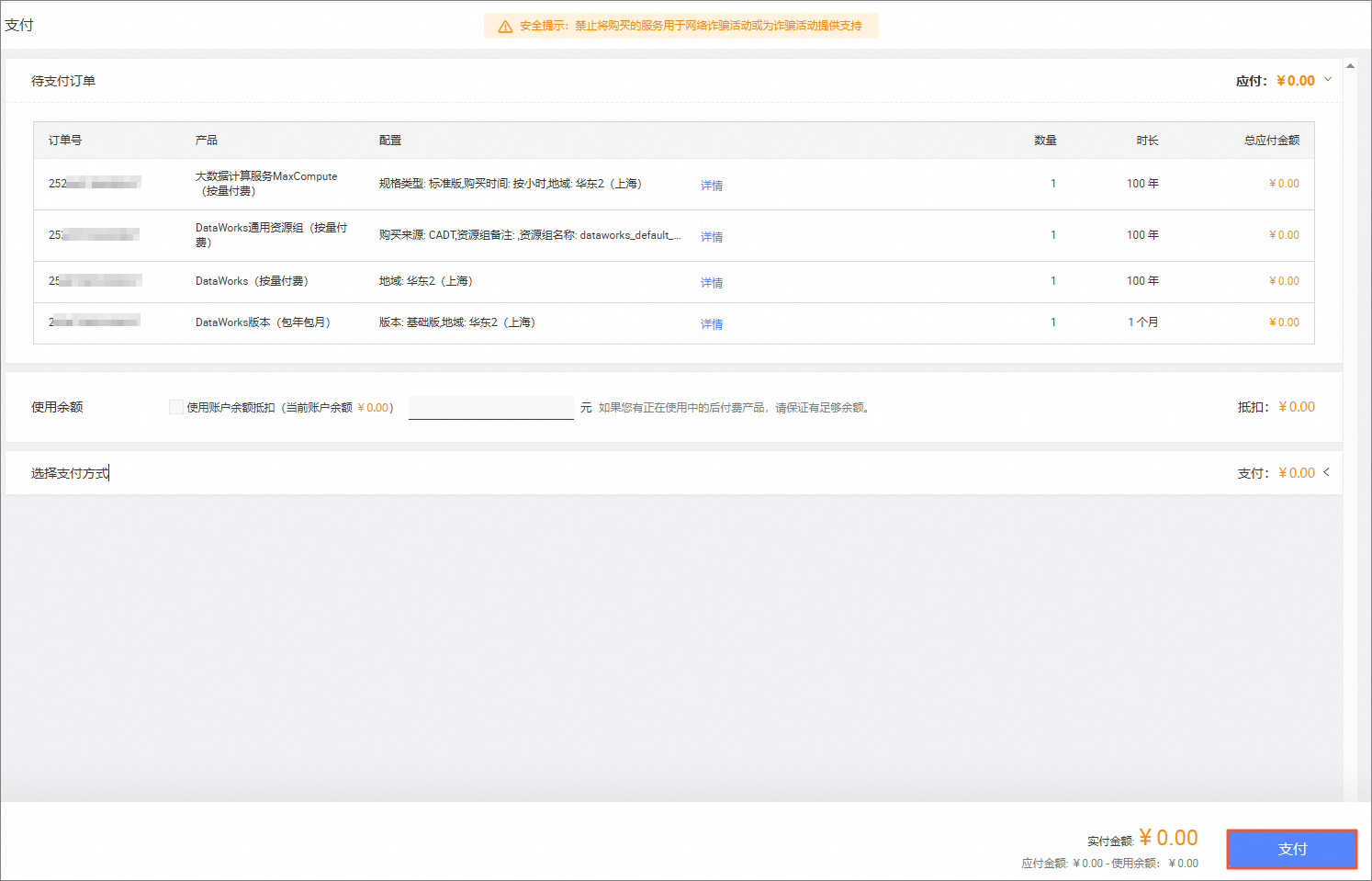
在支付页面,确认信息无误后,单击支付。
在DataWorks开通成功页面,单击进入DataWorkds管理控制台。
在左侧导航栏中,单击工作空间。
在工作空间列表页面,找到默认工作空间,单击工作空间名称。
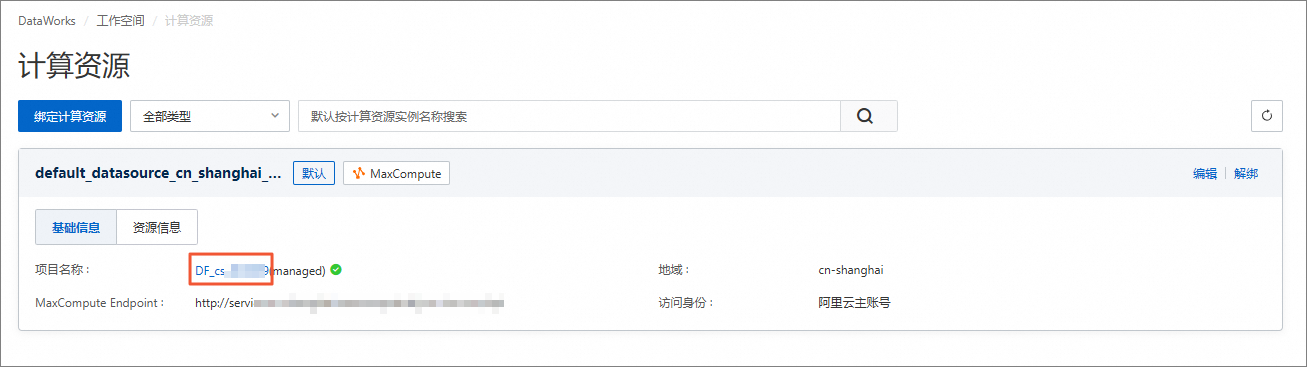
在左侧导航栏中,单击计算资源。
在计算资源页面,查看MaxCompute的项目名称。
说明后续步骤需要使用MaxCompute的项目名称。
返回至上一页,在左侧导航栏中,单击资源组。
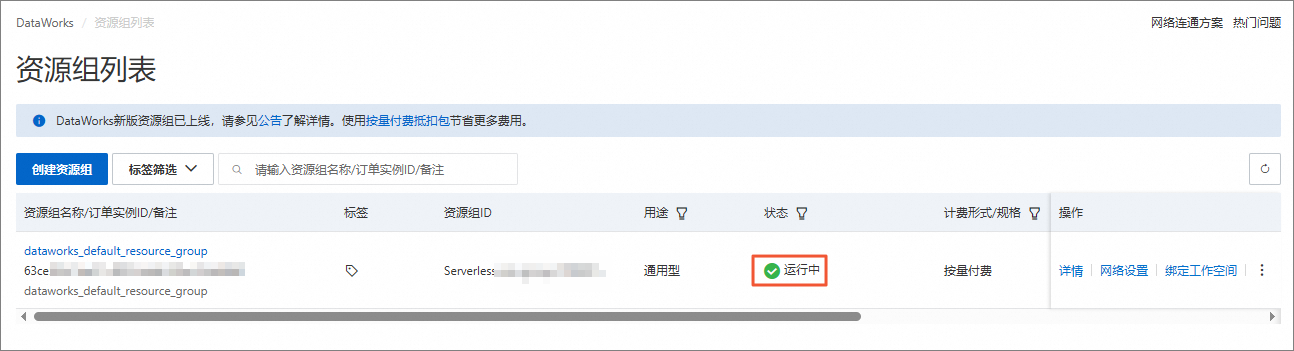
在资源组列表页面,等待目标资源组的状态变为运行中,即可正常使用资源组。
创建阿里云AccessKey
在本实验完成后,若不再使用,建议参考实验手册步骤及时删除阿里云AccessKey。
前往AccessKey管理。
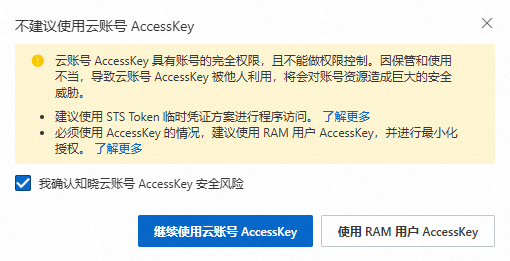
在不建议使用云账号AccessKey对话框,阅读创建主账号AccessKey的风险,如果必须要创建主账号AccessKey,则勾选我确认知晓云账号AccessKey安全风险,然后单击继续使用云账号AccessKey。
在AccessKey页面,单击创建AccessKey。
根据界面提示完成安全验证。
在创建云账号AccessKey对话框,再次阅读创建主账号AccessKey的风险及主账号AccessKey使用限制,如果确定要创建主账号AccessKey,则勾选我确认知晓云账号AccessKey安全风险,然后单击继续使用云账号AccessKey。
在创建AccessKey对话框,保存AccessKey ID和AccessKey Secret,然后勾选我已保存好AccessKey Secret,最后单击确定。
数据初始化
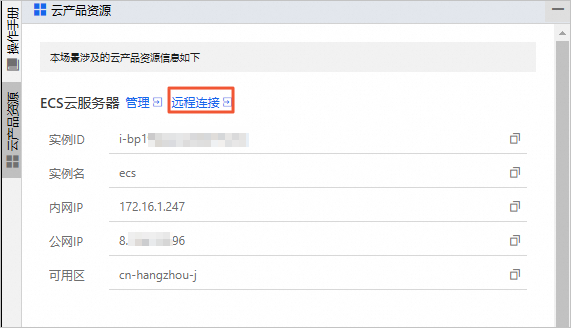
在云产品资源列表的ECS云服务器区域,单击远程连接。
在登录实例对话框中,连接方式选择免密连接,单击登录。
安装PyODPS。
执行如下命令,升级pip和setuptools的版本。
pip3 install -U pip setuptools执行如下命令,安装Cython和pandas依赖。
pip3 install cython pandas执行如下命令,安装PyODPS。
pip3 install pyodps执行如下命令,检查PyODPS是否安装成功。
python3 -c "from odps import ODPS"若无返回值和报错信息表示安装成功。
下载并解压初始化数据脚本文件。
执行如下命令,安装解压缩zip工具。
yum install zip -y执行如下命令,下载脚本压缩包。
wget https://developer-labfileapp.oss-cn-hangzhou.aliyuncs.com/MaxCompute/init_table_task.zip执行如下命令,将脚本压缩包解压到root目录下。
unzip init_table_task.zip
执行如下两条命令,进入脚本目录,开始数据初始化。
说明您需要将命令中的AKID、AKSecret和项目名称修改为实际获取的AccessKey ID、AccessKey Secret和MaxCompute的项目名称。
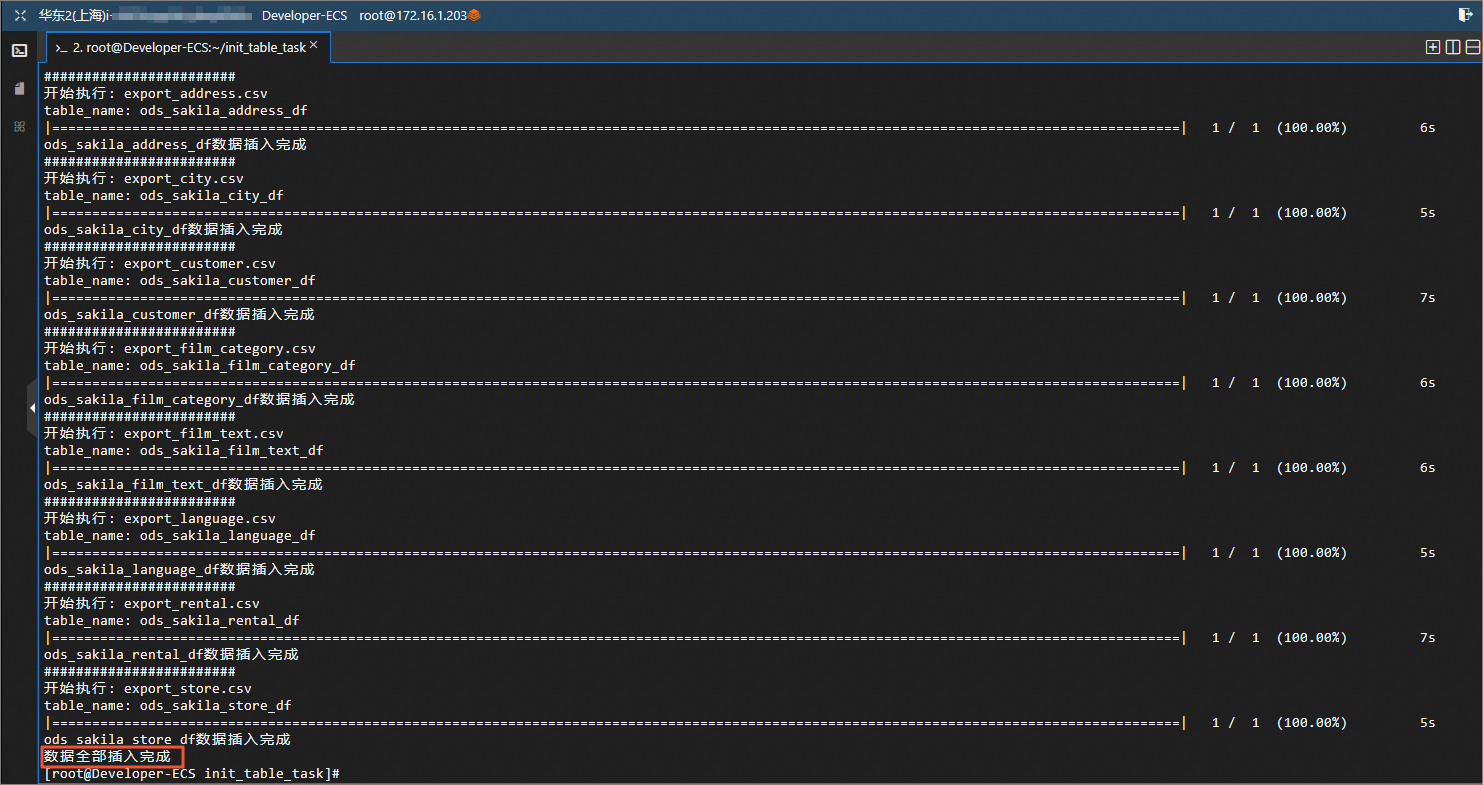
cd /root/init_table_task/ /usr/bin/python3.6 table_2_odps.py AKID AKSecret 项目名称等待数据上云完毕。


分析业务过程
业务过程可以概括为一个个不可拆分的行为事件。用户的业务系统中,通过埋点或日常积累,通常已经获取了充足的业务数据。为理清数据之间的逻辑关系和流向,首先需要理解用户的业务过程,了解过程中涉及到的数据系统。
您可以采用过程分析法,将整个业务过程涉及的每个环节一一列清楚,包括技术、数据、系统环境等。在分析企业的工作职责范围(部门)后,您也可以借助工具通过逆向工程抽取业务系统的真实模型。您可以参考业务规划设计文档以及业务运行(开发、设计、变更等)相关文档,全面分析数据仓库涉及的源系统及业务管理系统:
每个业务会生成哪些数据,存在于什么数据库中。
对业务过程进行分解,了解过程中的每一个环节会产生哪些数据,数据的内容是什么。
数据在什么情况下会更新,更新的逻辑是什么。
业务过程可以是单个业务事件,例如交易的支付、退款等;也可以是某个事件的状态,例如当前的账户余额等;还可以是一系列相关业务事件组成的业务流程。具体取决于您分析的是某些事件过去发生情况、当前状态还是事件流转效率。
选择粒度:在业务过程事件分析中,您需要预判所有分析需要细分的程度和范围,从而决定选择的粒度。 识别维表、选择好粒度之后,您需要基于此粒度设计维表,包括维度属性等,用于分析时进行分组和筛选。最后,您需要确定衡量的指标。
salika租赁模型中,业务过程还是比较简单的,经过简单梳理如下:

划分数据域
数据仓库是面向主题(数据综合、归类并进行分析利用)的应用。数据仓库模型设计除横向的分层外,通常也需要根据业务情况纵向划分数据域。数据域是联系较为紧密的数据主题的集合,是业务对象高度概括的概念,目的是便于管理和应用数据。
通常,您需要阅读各源系统的设计文档、数据字典和数据模型,研究逆向导出的物理数据模型。进而,可以进行跨源的主题域合并,跨源梳理出整个企业的数据域。
数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。为保障整个体系的生命力,数据域需要抽象提炼,并长期维护更新。在划分数据域时,既能涵盖当前所有的业务需求,又能让新业务在进入时可以被包含进已有的数据域或扩展新的数据域。数据域的划分工作可以在业务调研之后进行,需要分析各个业务模块中有哪些业务活动。
数据域可以按照用户企业的部门划分,也可以按照业务过程或者业务板块中的功能模块进行划分。例如A公司电商营销业务板块可以划分为如下数据域,数据域中每一部分都是实际业务过程经过归纳抽象之后得出的。
数据域 | 业务过程 |
会员店铺域 | 注册、登录、装修、开店、关店 |
商品域 | 发布、上架、下架、重发 |
日志域 | 曝光、浏览、单击 |
交易域 | 下单、支付、发货、确认收货 |
服务域 | 商品收藏、拜访、培训、优惠券领用 |
采购域 | 商品采购、供应链管理 |
本实验我们只抽象一个数据域,定义为交易域,业务过程我们只分析影碟的租赁与归还。
数据域 | 业务过程 |
交易域 | 租赁影碟、归还影碟 |
定义维度和确定粒度
结合对业务过程的分析定义维度。
在影碟租赁的业务过程中,有以下维度:
客户
店铺
日期
电影
店员
在影碟归还的业务过程中,有以下维度:
客户
店铺
日期
电影
作为维度建模的核心,在企业级数据仓库中必须保证维度的唯一性。以实验电影维度为例,有且只允许有一种维度定义。对于任何业务过程所传达的信息都是一致的。
事实表的粒度,我们一般选择最细粒度,这样可以得出几乎任何的指标。本例选择的粒度是一次租赁信息
构建事实维度矩阵
明确每个数据域下有哪些业务过程后,即可构建事实维度矩阵。您需要明确业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。如下所示是A本例构建的事实维度矩阵,我们定义了客户、店铺、日期、电影、店员等维度。
数据域/过程 | 一致性维度 | |||||
客户 | 店铺 | 日期 | 电影 | 店员 | ||
交易 | 影碟租赁 | Y | Y | Y | Y | Y |
影碟归还 | Y | Y | Y | Y | N | |
说明:Y代表包含该维度,N代表不包含。
MaxCompute中建表
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的工作空间。
在工作空间列表页面,找到默认工作空间,选择其右侧操作列下的。
在左侧导航栏中,单击
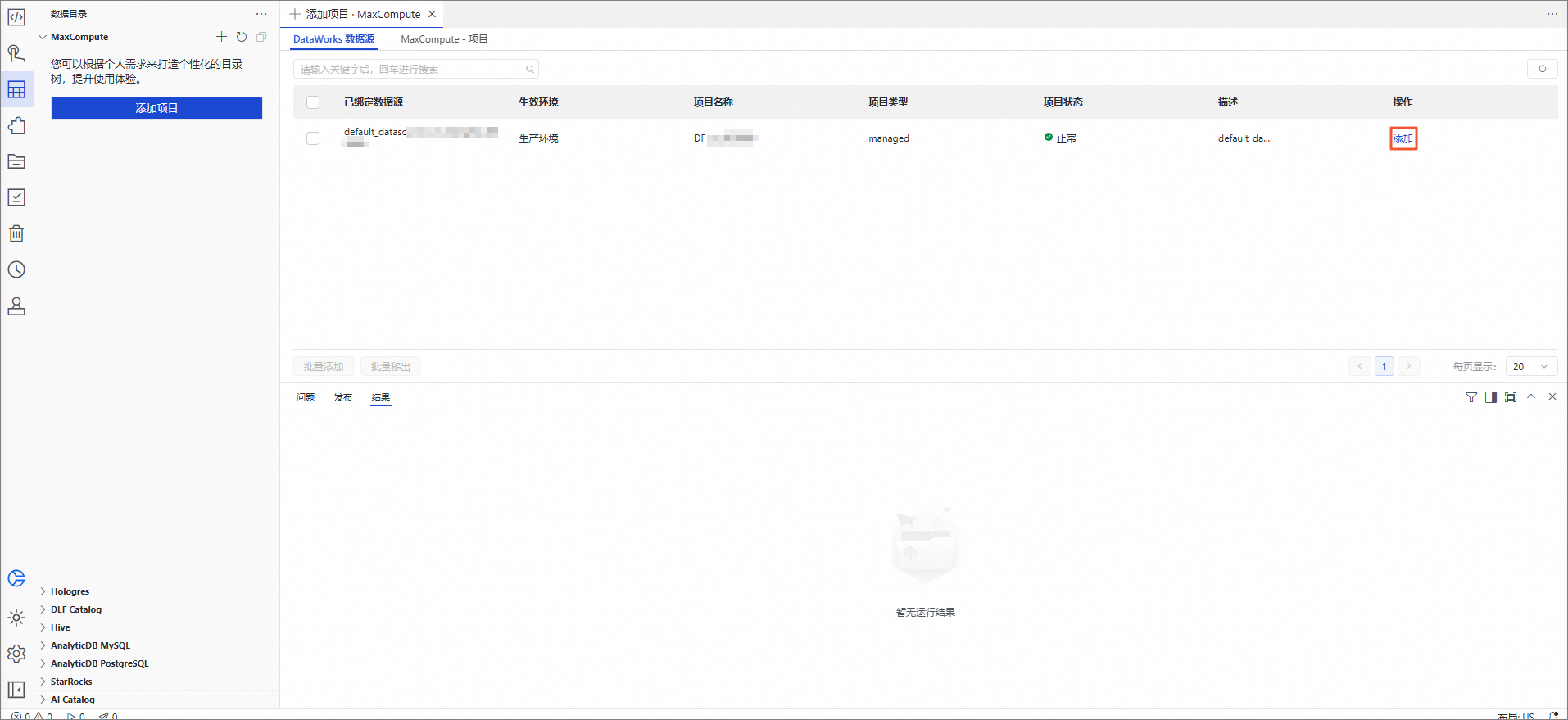
图标进入数据目录。在数据目录区域,单击MaXCompute目录右侧的
图标。在DataWorks数据源页签,找到已绑定数据源中的MaxCompute项目,单击其右侧操作下列的添加,将其添加至MaxCompute目录下。
在左侧导航栏中,单击
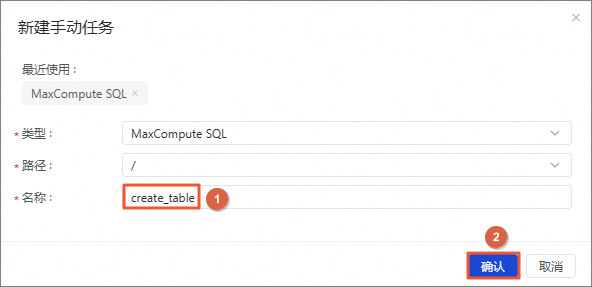
图标进入手动。在手动区域,单击手动任务目录右侧的
图标,选择。在新建手动任务对话框中,名称输入为create_table,单击确认。
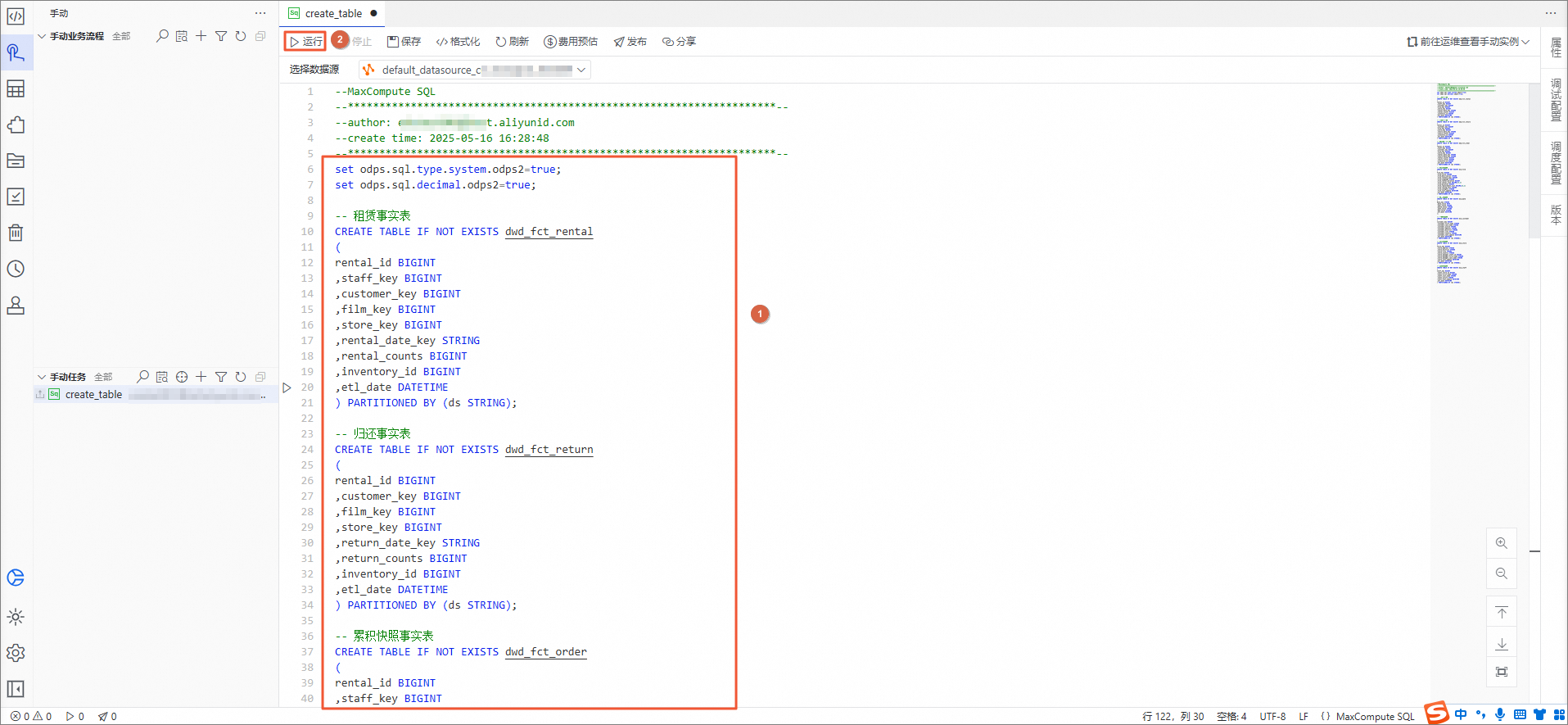
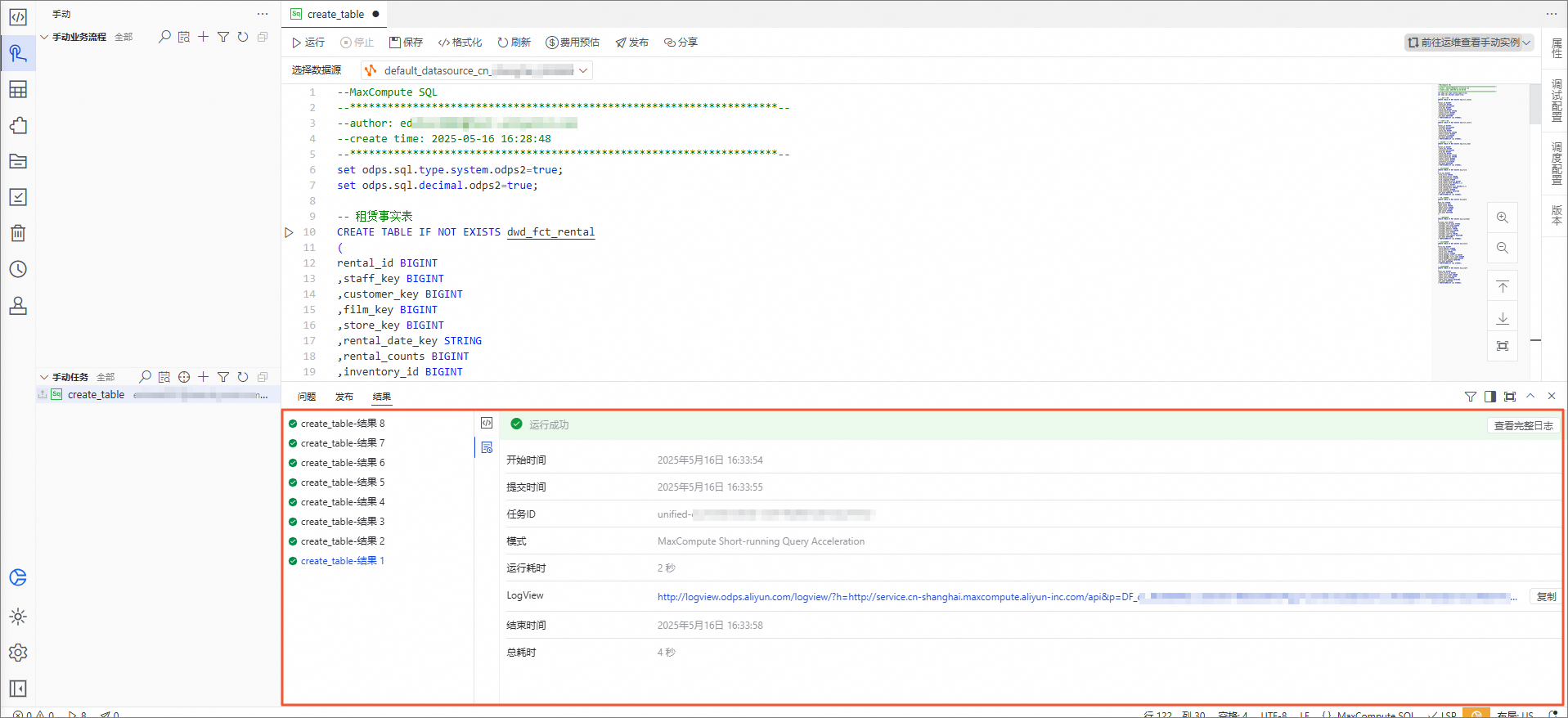
在create_table编辑页面,将如下模型的建表语句复制并粘贴进去,然后单击运行。
说明本次实验环境,只有一个项目空间,无法做到ods cdm ads的数仓分层,因此以表名前缀区分分层,比如ods_开头的代表ods层的表,dim_和dwd_开头的表代表cdm层的表。
set odps.sql.type.system.odps2=true; set odps.sql.decimal.odps2=true; -- 租赁事实表 CREATE TABLE IF NOT EXISTS dwd_fct_rental ( rental_id BIGINT ,staff_key BIGINT ,customer_key BIGINT ,film_key BIGINT ,store_key BIGINT ,rental_date_key STRING ,rental_counts BIGINT ,inventory_id BIGINT ,etl_date DATETIME ) PARTITIONED BY (ds STRING); -- 归还事实表 CREATE TABLE IF NOT EXISTS dwd_fct_return ( rental_id BIGINT ,customer_key BIGINT ,film_key BIGINT ,store_key BIGINT ,return_date_key STRING ,return_counts BIGINT ,inventory_id BIGINT ,etl_date DATETIME ) PARTITIONED BY (ds STRING); -- 累积快照事实表 CREATE TABLE IF NOT EXISTS dwd_fct_order ( rental_id BIGINT ,staff_key BIGINT ,customer_key BIGINT ,film_key BIGINT ,store_key BIGINT ,rental_date_key STRING ,return_date_key STRING ,rental_counts BIGINT ,return_counts BIGINT ,inventory_id BIGINT ,etl_date DATETIME ) PARTITIONED BY (ds STRING); -- 电影维度表 CREATE TABLE IF NOT EXISTS dim_film ( film_key BIGINT ,film_title STRING ,film_description STRING ,film_release_year BIGINT ,film_language STRING ,film_rental_duration BIGINT ,film_rental_rate DECIMAL(4,2) ,film_duration BIGINT ,film_replacement_cost DECIMAL(6,2) ,film_rating_text STRING ,film_category STRING ,film_last_update DATETIME ,etl_date DATETIME ) PARTITIONED BY (ds STRING); -- 日期维度表 CREATE TABLE IF NOT EXISTS dim_date ( date_key STRING ,date_value DATE ,year_value STRING ,month_value STRING ,week_value STRING ,day_value STRING ,etl_date DATETIME ); -- 客户维度表 CREATE TABLE IF NOT EXISTS dim_customer ( customer_key BIGINT ,customer_first_name STRING ,customer_last_name STRING ,customer_active STRING ,customer_address STRING ,customer_district STRING ,customer_city STRING ,customer_country STRING ,customer_last_update DATETIME ,etl_date DATETIME ) PARTITIONED BY (ds STRING); -- 店铺维度表 CREATE TABLE IF NOT EXISTS dim_store ( store_key BIGINT ,store_address STRING ,store_district STRING ,store_city STRING ,store_country STRING ,store_manager_staff_id BIGINT ,store_manager_first_name STRING ,store_manager_last_name STRING ,store_last_update DATETIME ,etl_date DATETIME ) PARTITIONED BY (ds STRING); -- 店员维度表 CREATE TABLE IF NOT EXISTS dim_staff ( staff_key BIGINT ,staff_store_id BIGINT ,staff_first_name STRING ,staff_last_name STRING ,staff_active STRING ,staff_last_update DATETIME ,etl_date DATETIME ) PARTITIONED BY (ds STRING);返回结果如下,表示模型的建表已完成。
 图标进入数据目录。
图标进入数据目录。
 图标。
图标。
 图标进入手动。
图标进入手动。

代码开发
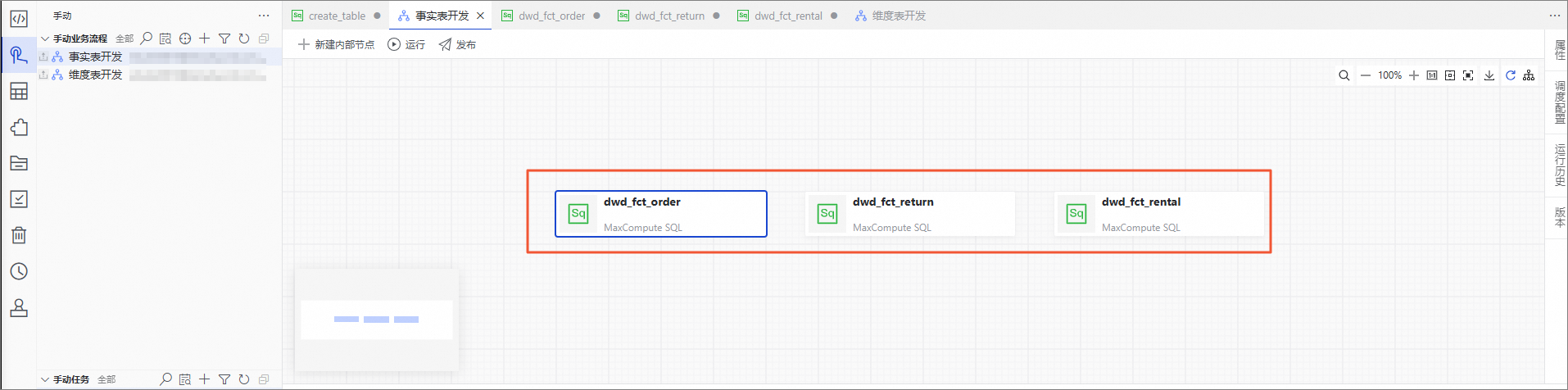
创建事实表开发和维度表开发两个业务流程。
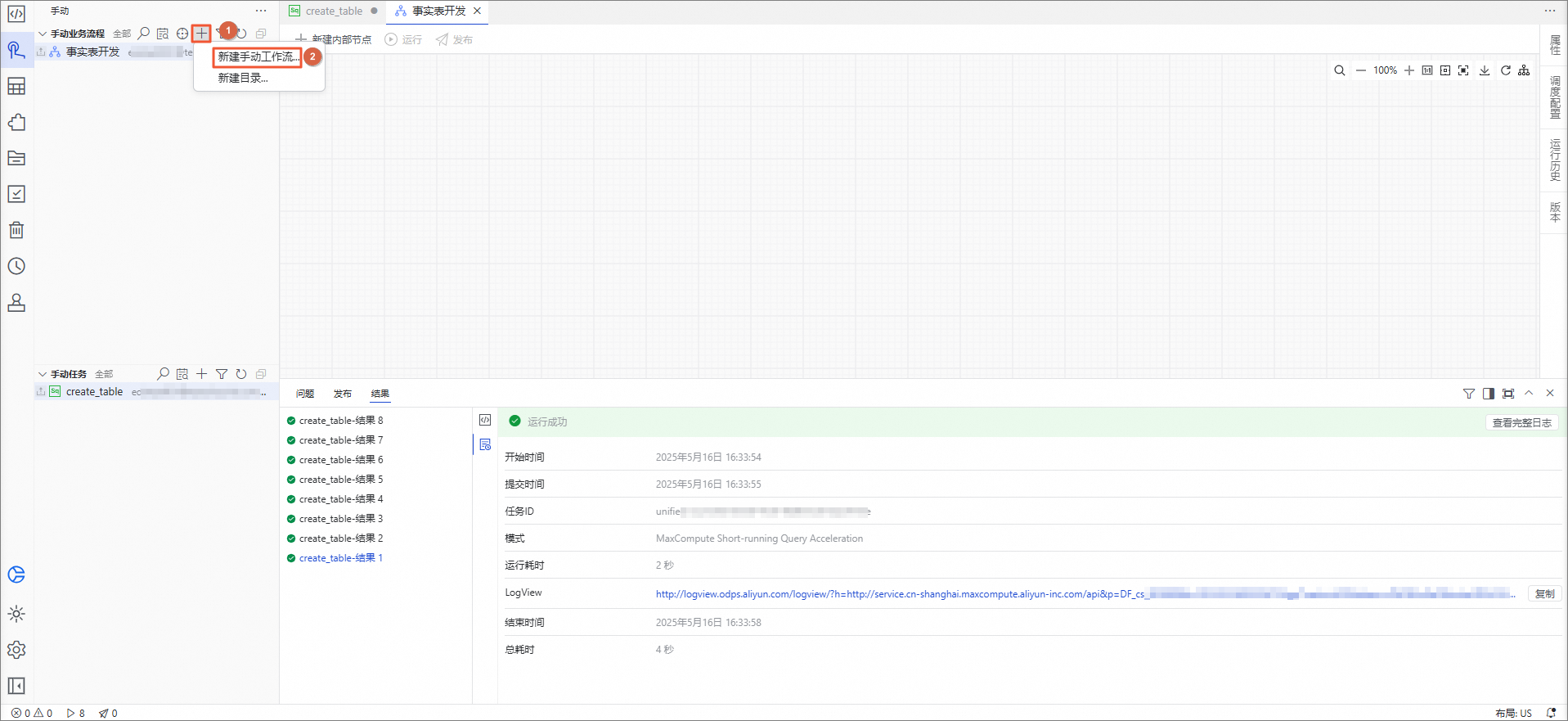
在手动区域,单击手动业务流程目录右侧的
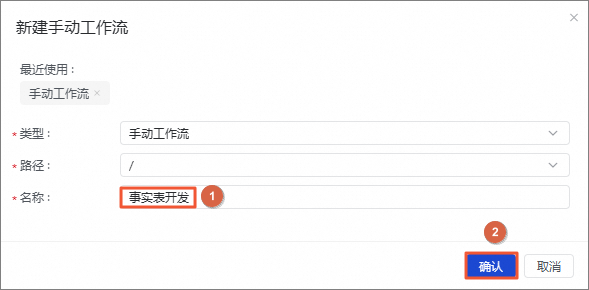
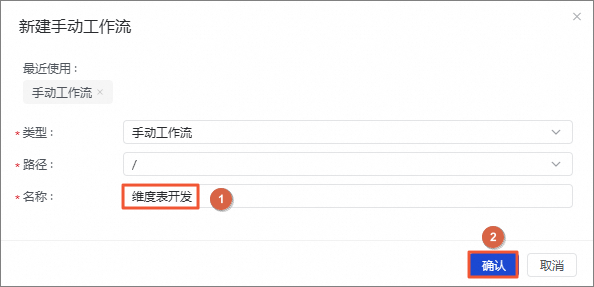
图标,单击新建手动工作流。 在新建手动工作流对话框中,名称输入事实表开发,单击确认。
在手动区域,单击手动业务流程目录右侧的
图标,单击新建手动工作流。在新建手动工作流对话框中,名称输入维度表开发,单击确认。
影碟租赁事实表开发。
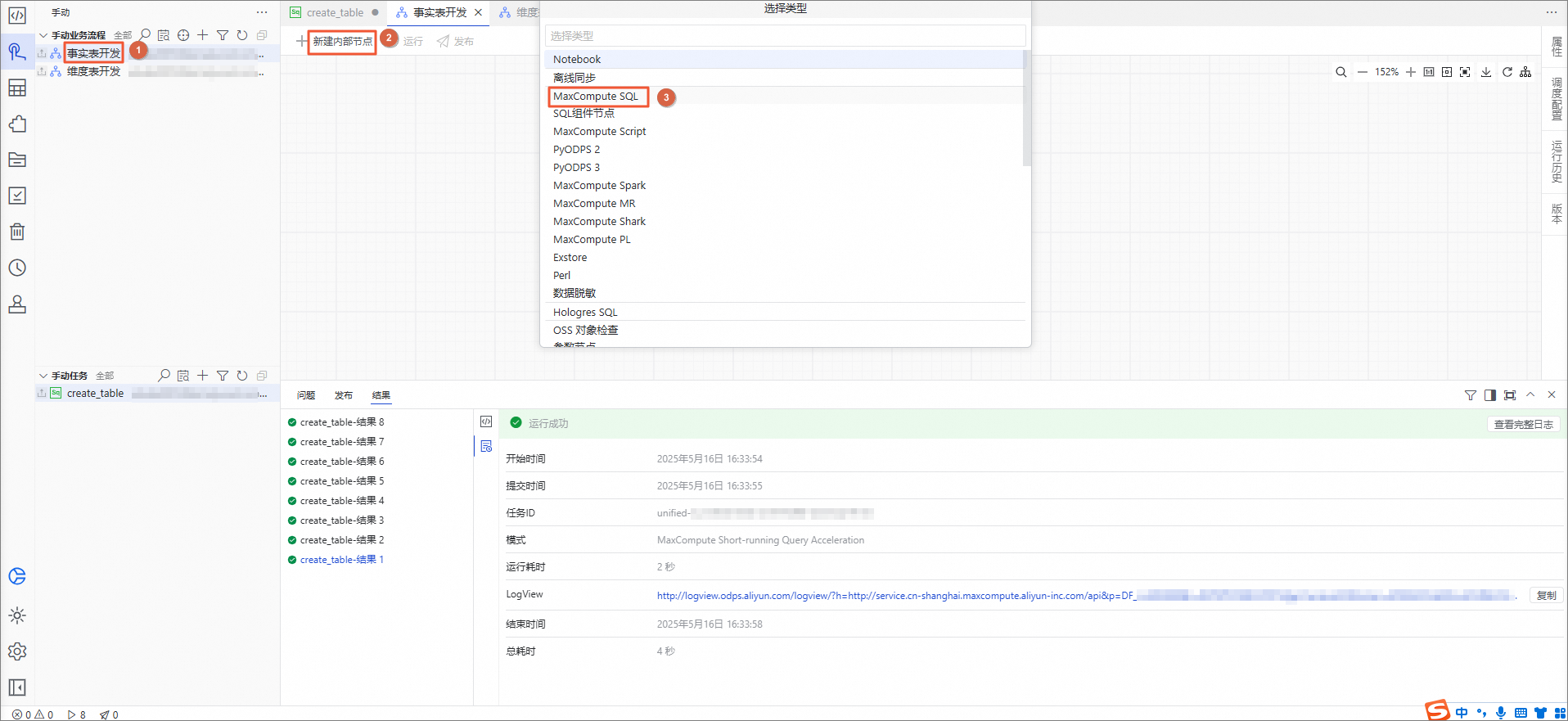
在手动业务流程目录下,单击事实表开发,在右侧的编辑页面中选择
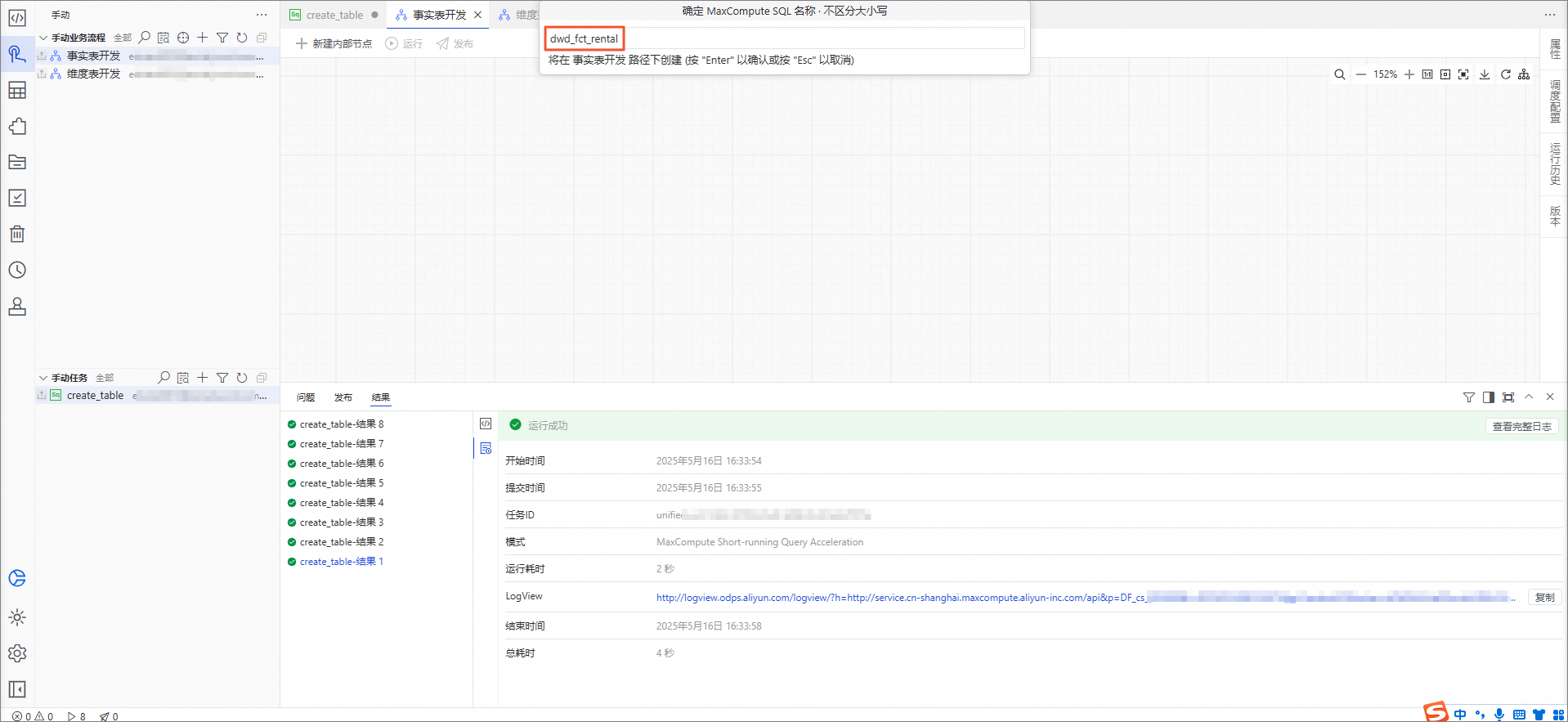
在弹出的对话框中,名称输入dwd_fct_rental,按下
Enter键确认。在事实表开发编辑页面,双击dwd_fct_rental节点。
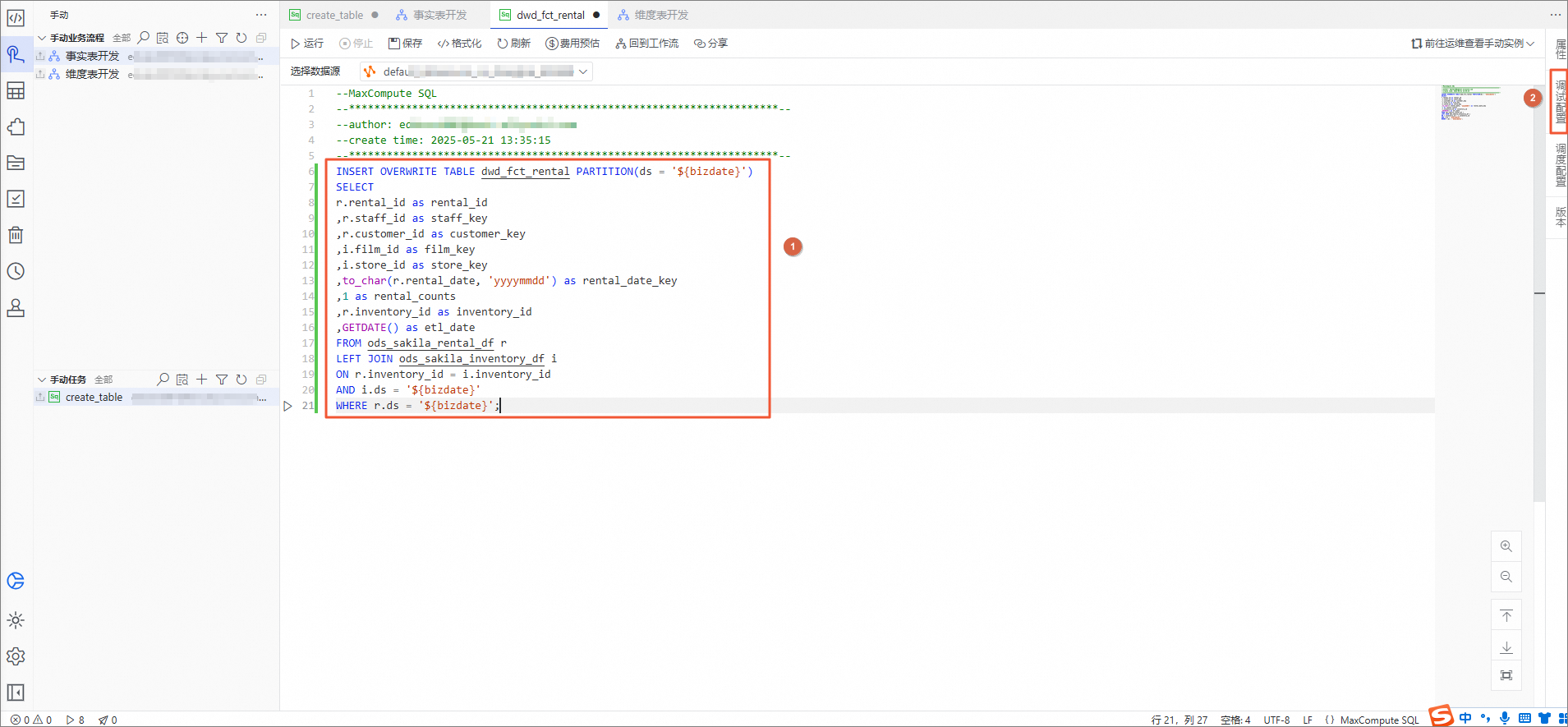
在dwd_fct_rental节点编辑页面,将如下插入数据SQL语句复制到并粘贴进去,然后单击右侧的调试配置。
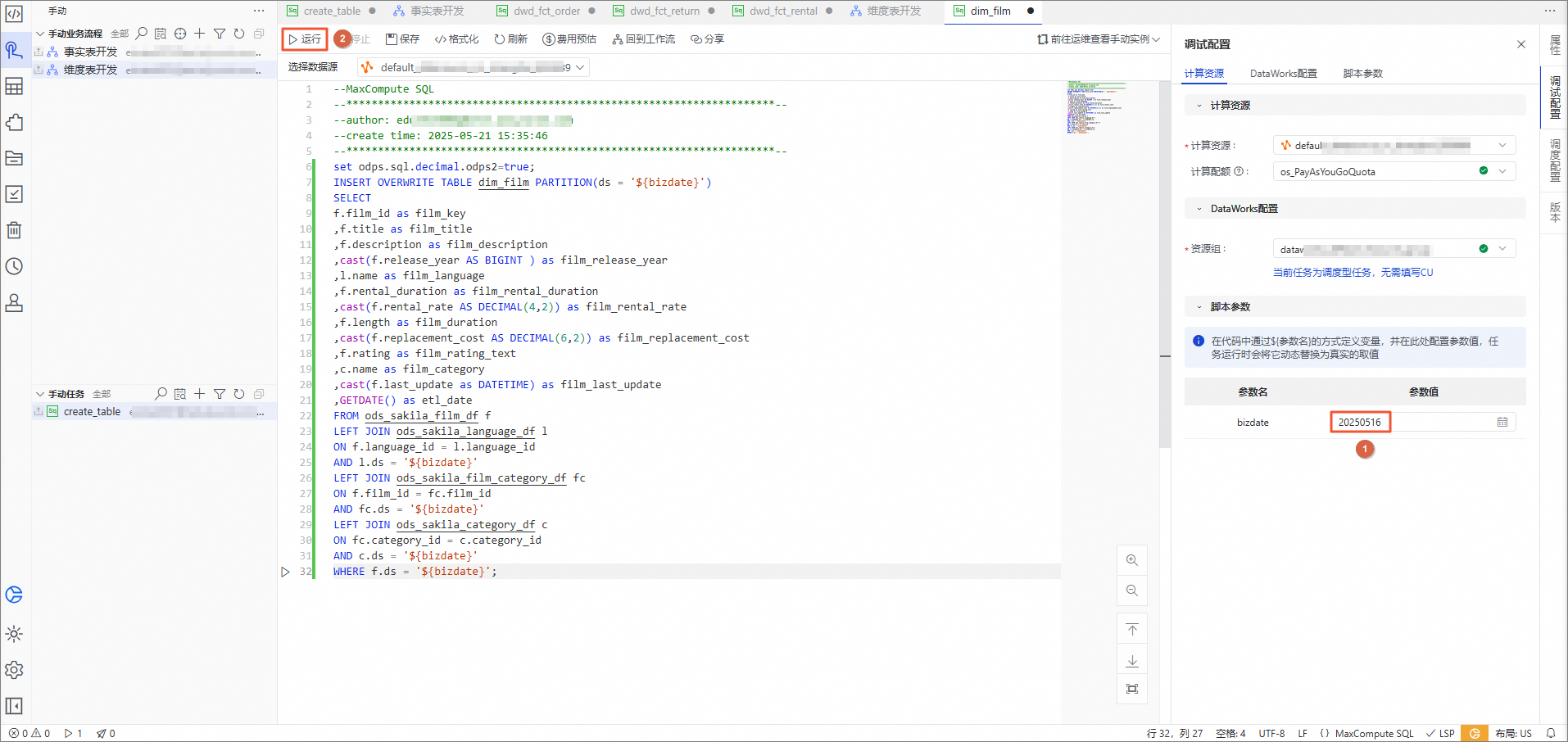
说明bizdate表示当天日期。
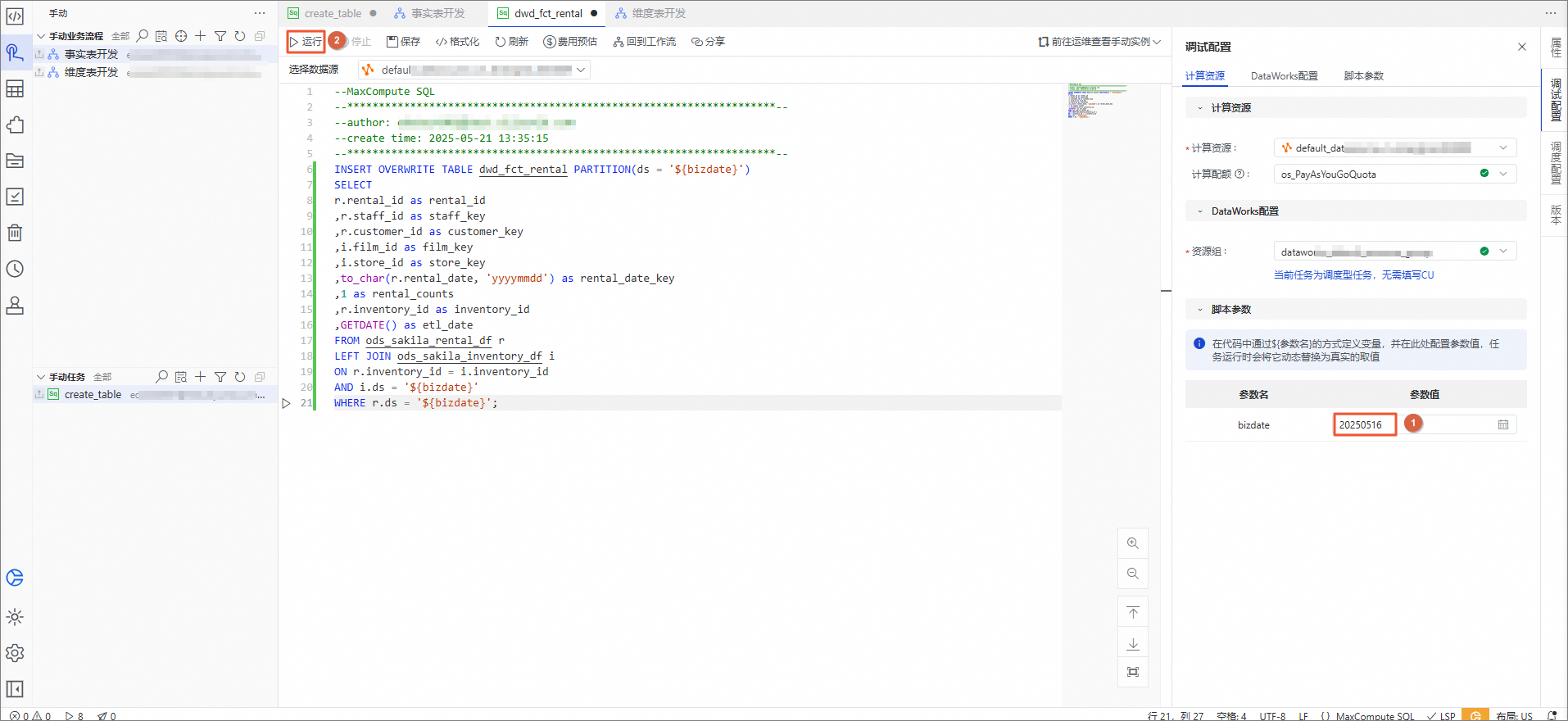
INSERT OVERWRITE TABLE dwd_fct_rental PARTITION(ds = '${bizdate}') SELECT r.rental_id as rental_id ,r.staff_id as staff_key ,r.customer_id as customer_key ,i.film_id as film_key ,i.store_id as store_key ,to_char(r.rental_date, 'yyyymmdd') as rental_date_key ,1 as rental_counts ,r.inventory_id as inventory_id ,GETDATE() as etl_date FROM ods_sakila_rental_df r LEFT JOIN ods_sakila_inventory_df i ON r.inventory_id = i.inventory_id AND i.ds = '${bizdate}' WHERE r.ds = '${bizdate}';在调试配置面板,将bizdate的参数值改为当天日期,单击运行。
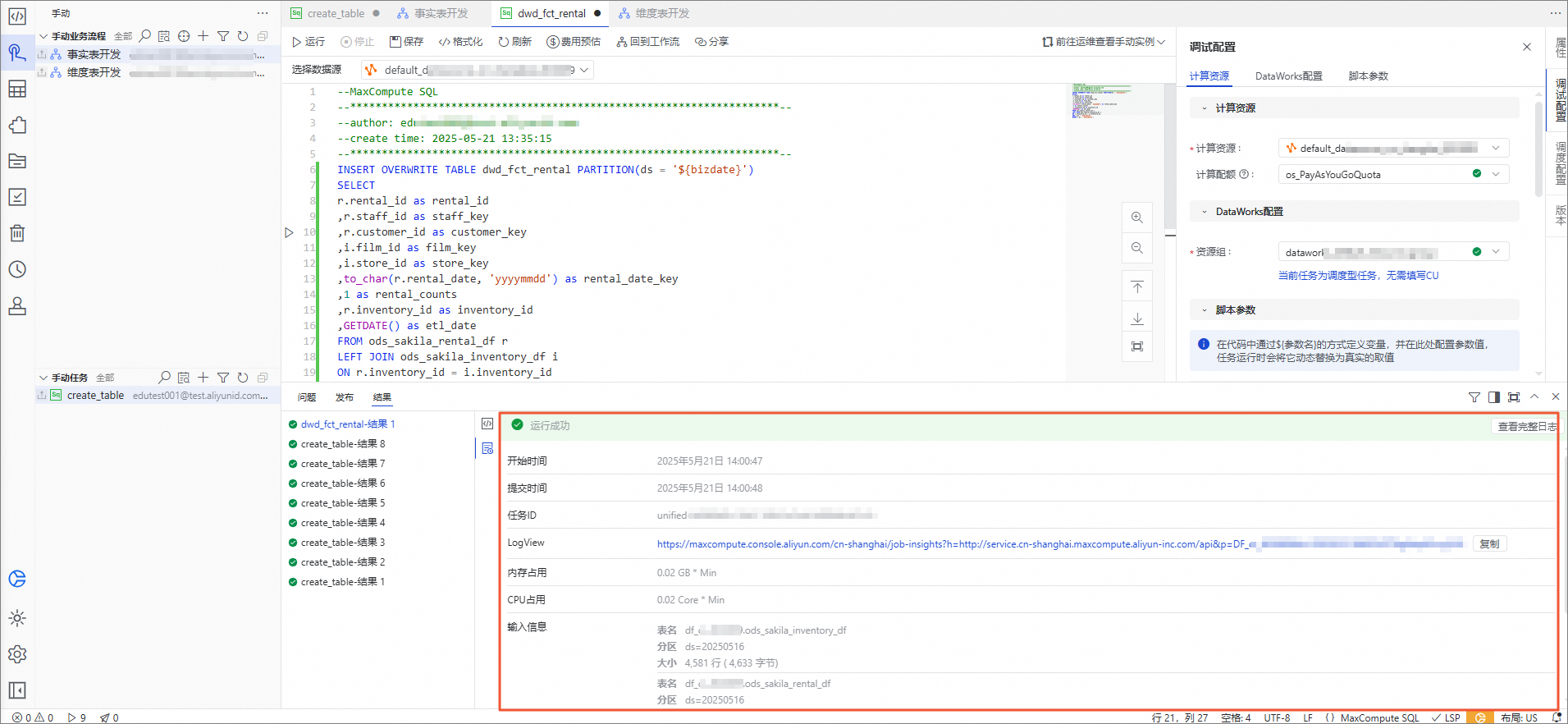
返回结果如下,表示模型的建表已完成。
影碟归还事实表开发。
根据步骤3.a~3.e,在事实表开发业务流程中,创建名称为dwd_fct_return的MaxCompute SQL节点,复制并粘贴如下插入数据SQL语句,在调试配置中将bizdate的参数值改为当天日期,然后运行。
INSERT OVERWRITE TABLE dwd_fct_return PARTITION(ds = '${bizdate}') SELECT r.rental_id as rental_id ,r.customer_id as customer_key ,i.film_id as film_key ,i.store_id as store_key ,to_char(r.return_date, 'yyyymmdd') as return_date_key ,1 as return_counts ,r.inventory_id as inventory_id ,GETDATE() as etl_date FROM ods_sakila_rental_df r INNER JOIN ods_sakila_inventory_df i ON r.inventory_id = i.inventory_id AND i.ds = '${bizdate}' AND r.return_date IS NOT NULL WHERE r.ds = '${bizdate}';累积快照事实表开发。
根据步骤3.a~3.e,在事实表开发业务流程中,创建名称为dwd_fct_order的MaxCompute SQL节点,复制并粘贴如下插入数据SQL语句,在调试配置中将bizdate的参数值改为当天日期,然后运行。
INSERT OVERWRITE TABLE dwd_fct_order PARTITION(ds = '${bizdate}') SELECT r.rental_id as rental_id ,r.staff_id as staff_key ,r.customer_id as customer_key ,i.film_id as film_key ,i.store_id as store_key ,to_char(r.rental_date, 'yyyymmdd') as rental_date_key ,to_char(r.return_date, 'yyyymmdd') as return_date_key ,1 as rental_counts ,case when i.inventory_id is not null then 1 else 0 end as return_counts ,r.inventory_id as inventory_id ,GETDATE() as etl_date FROM ods_sakila_rental_df r LEFT JOIN ods_sakila_inventory_df i ON r.inventory_id = i.inventory_id AND i.ds = '${bizdate}' WHERE r.ds = '${bizdate}';到这里,我们的事实表就开发完成。
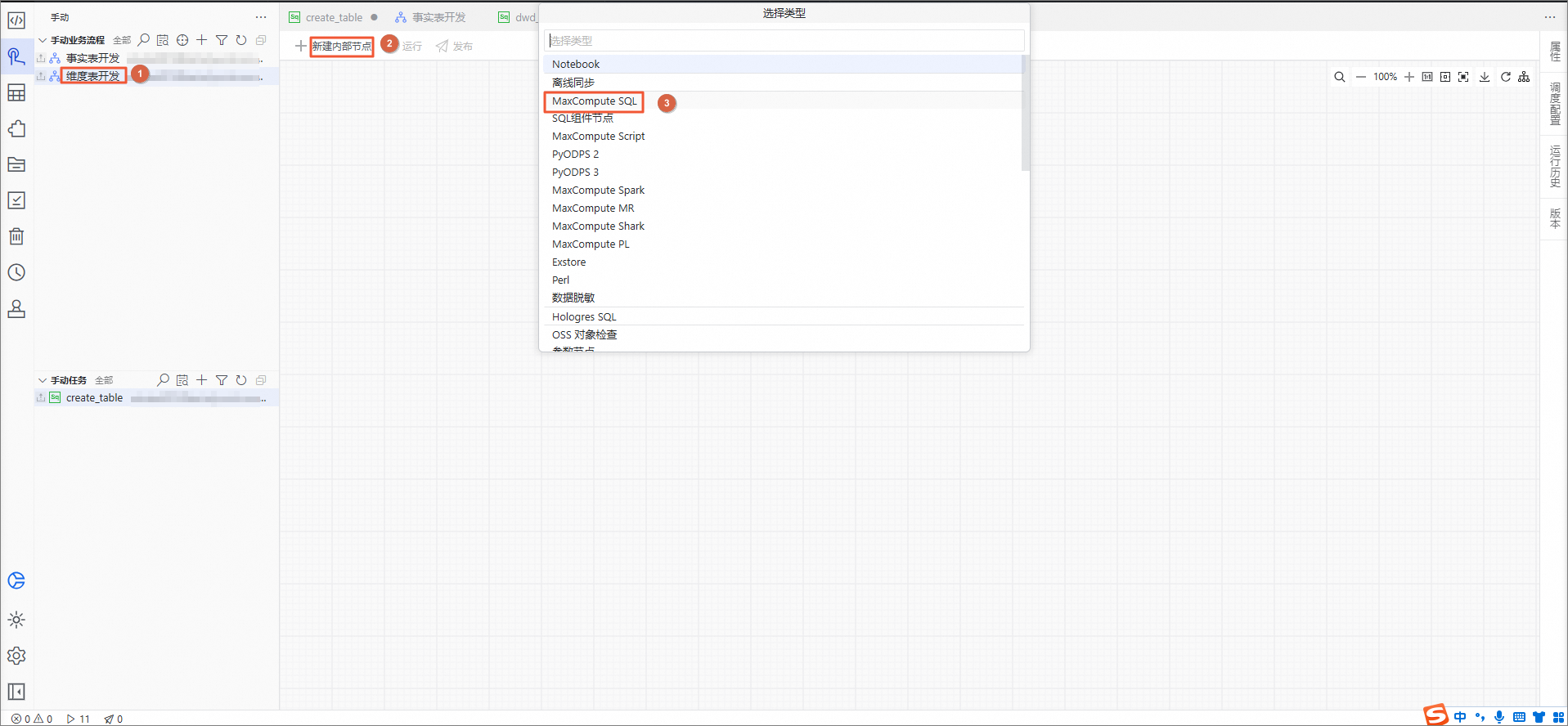
电影维度表开发。
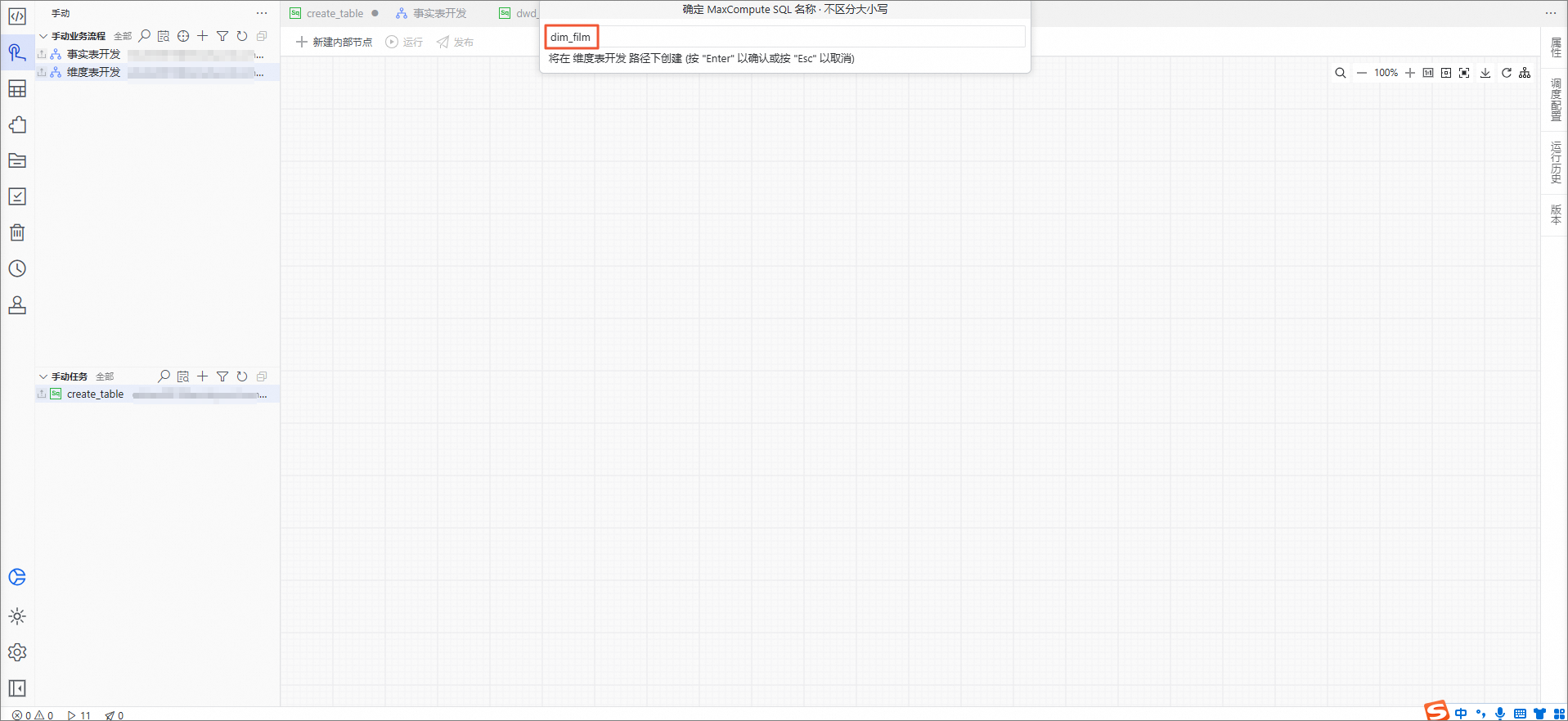
在手动业务流程目录下,单击维度表开发,在右侧的编辑页面中选择
在弹出的对话框中,名称输入dim_film,按下
Enter键确认。在维度表开发编辑页面,双击dim_film节点。
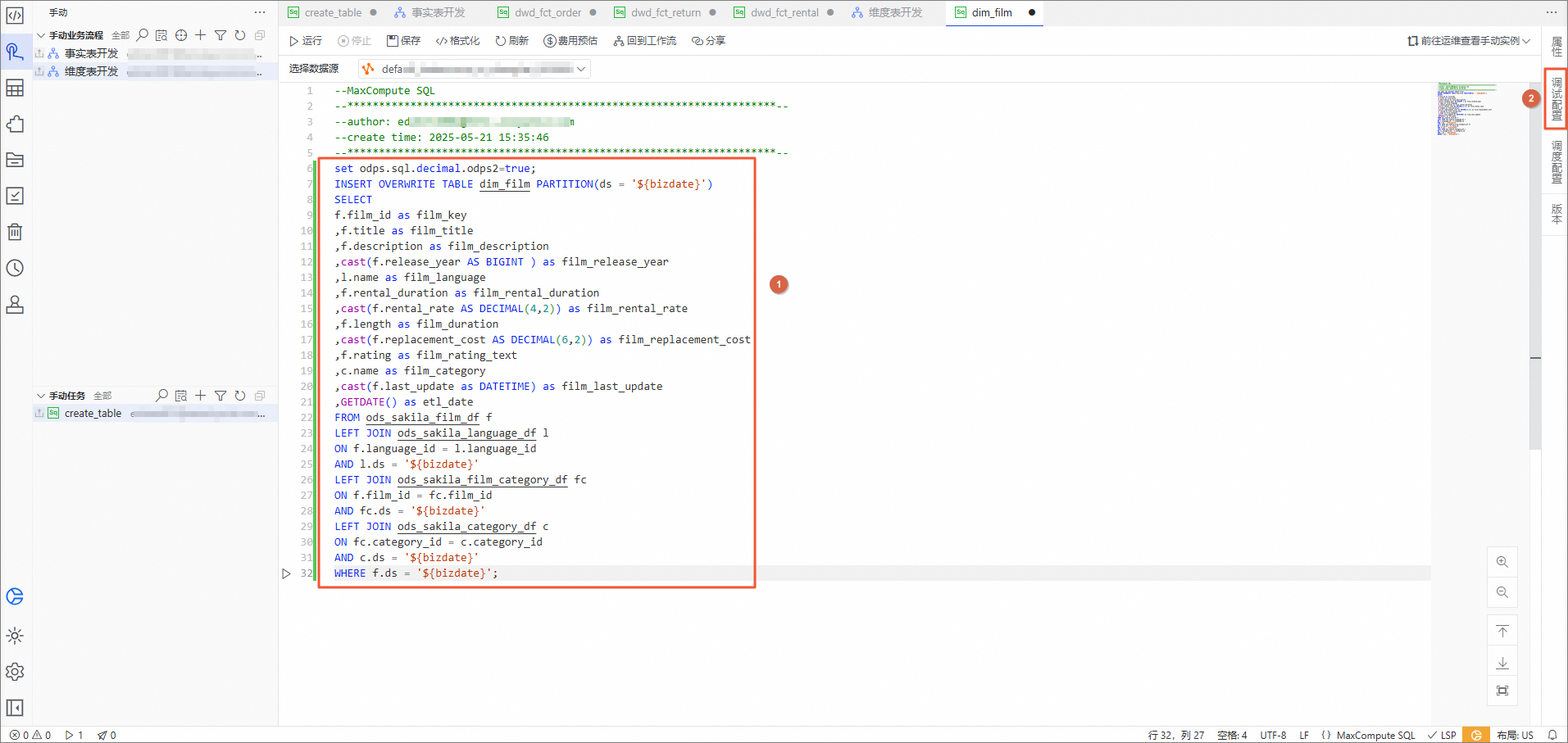
在dim_film节点编辑页面,将如下插入数据SQL语句复制到并粘贴进去,然后单击右侧的调试配置。
说明bizdate表示当天日期。
set odps.sql.decimal.odps2=true; INSERT OVERWRITE TABLE dim_film PARTITION(ds = '${bizdate}') SELECT f.film_id as film_key ,f.title as film_title ,f.description as film_description ,cast(f.release_year AS BIGINT ) as film_release_year ,l.name as film_language ,f.rental_duration as film_rental_duration ,cast(f.rental_rate AS DECIMAL(4,2)) as film_rental_rate ,f.length as film_duration ,cast(f.replacement_cost AS DECIMAL(6,2)) as film_replacement_cost ,f.rating as film_rating_text ,c.name as film_category ,cast(f.last_update as DATETIME) as film_last_update ,GETDATE() as etl_date FROM ods_sakila_film_df f LEFT JOIN ods_sakila_language_df l ON f.language_id = l.language_id AND l.ds = '${bizdate}' LEFT JOIN ods_sakila_film_category_df fc ON f.film_id = fc.film_id AND fc.ds = '${bizdate}' LEFT JOIN ods_sakila_category_df c ON fc.category_id = c.category_id AND c.ds = '${bizdate}' WHERE f.ds = '${bizdate}';在调试配置面板,将bizdate的参数值改为当天日期,单击运行。
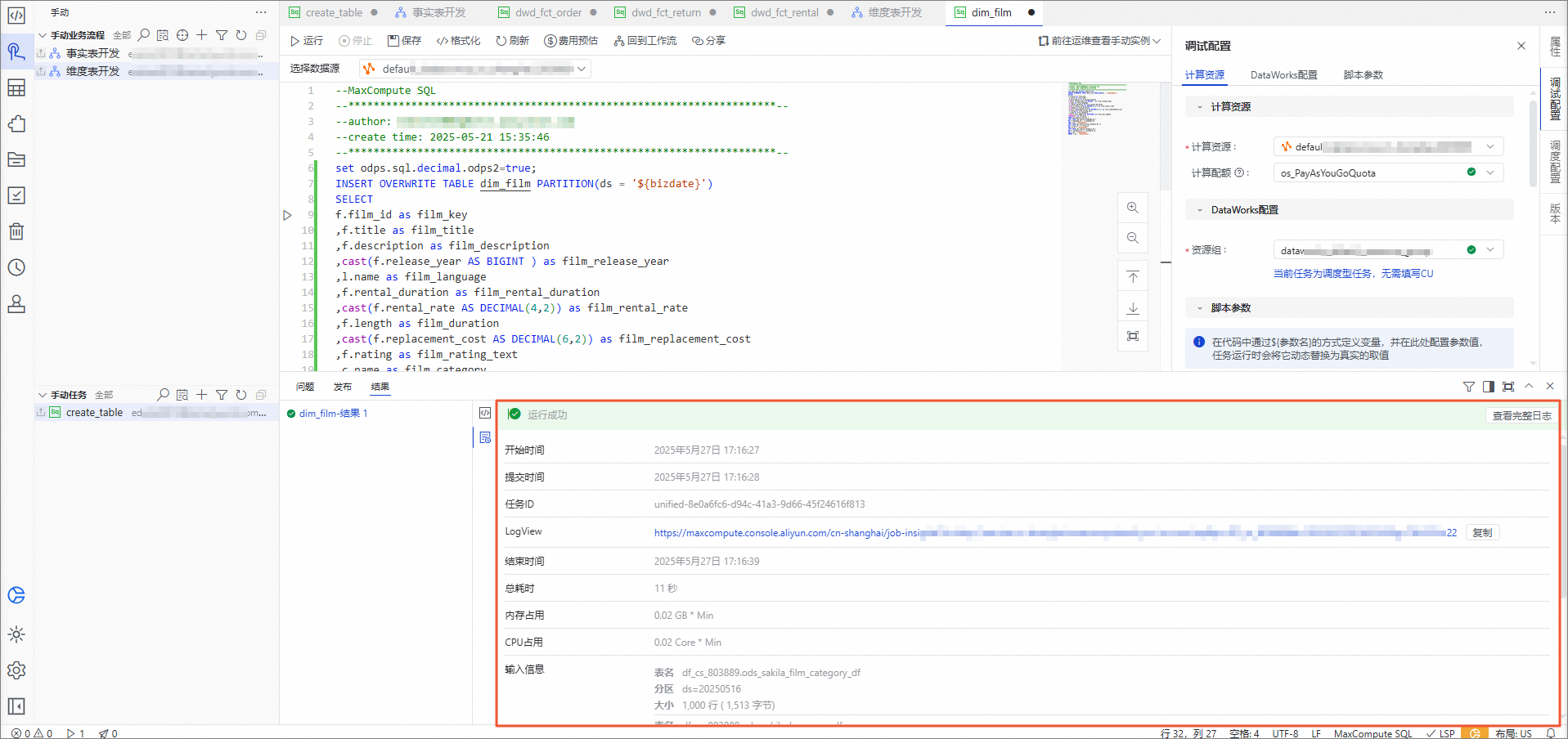
返回结果如下,表示模型的建表已完成。
日期维度表开发。
根据步骤6.a~6.e,在维度表开发业务流程中,创建名称为dim_date的MaxCompute SQL节点,复制并粘贴如下插入数据SQL语句,然后运行。
set odps.sql.type.system.odps2=true; INSERT OVERWRITE TABLE dim_date SELECT TO_CHAR(dt, 'yyyymmdd') as date_key ,dt as date_value ,SUBSTRING(dt,1,4) as year_value ,SUBSTRING(dt,6,2) as month_value ,WEEKOFYEAR(dt) as week_value ,SUBSTRING(dt,9,2) as day_value ,GETDATE() as etl_date FROM ( SELECT DATE_ADD('2005-01-01', cast(rn AS BIGINT)) AS dt FROM ( SELECT transform( 'for i in `seq 0 7000`; do echo $i; done' ) USING 'sh' AS rn ) a ) b;客户维度表开发。
根据步骤6.a~6.e,在维度表开发业务流程中,创建名称为dim_customer的MaxCompute SQL节点,复制并粘贴如下插入数据SQL语句,在调试配置中将bizdate的参数值改为当天日期,然后运行。
set odps.sql.decimal.odps2=true; INSERT OVERWRITE TABLE dim_customer PARTITION(ds = '${bizdate}') SELECT c.customer_id as customer_key ,c.first_name as customer_first_name ,c.last_name as customer_last_name ,c.active as customer_active ,a.address as customer_address ,a.district as customer_district ,ct.city as customer_city ,cy.country as customer_country ,cast(c.last_update as DATETIME) as customer_last_update ,GETDATE() as etl_date FROM ods_sakila_customer_df c LEFT JOIN ods_sakila_address_df a ON c.address_id = a.address_id AND a.ds = '${bizdate}' LEFT JOIN ods_sakila_city_df ct ON a.city_id = ct.city_id AND ct.ds = '${bizdate}' LEFT JOIN ods_sakila_country_df cy ON ct.country_id = cy.country_id AND cy.ds = '${bizdate}' WHERE c.ds = '${bizdate}';店铺维度表开发。
根据步骤6.a~6.e,在维度表开发业务流程中,创建名称为dim_store的MaxCompute SQL节点,复制并粘贴如下插入数据SQL语句,在调试配置中将bizdate的参数值改为当天日期,然后运行。
set odps.sql.decimal.odps2=true; INSERT OVERWRITE TABLE dim_store PARTITION(ds = '${bizdate}') SELECT s.store_id as store_key ,a.address as store_address ,a.district as store_district ,ct.city as store_city ,cy.country as store_country ,s.manager_staff_id as store_manager_staff_id ,st.first_name as store_manager_first_name ,st.last_name as store_manager_last_name ,cast(s.last_update as DATETIME) as store_last_update ,GETDATE() as etl_date FROM ods_sakila_store_df s LEFT JOIN ods_sakila_address_df a ON s.address_id = a.address_id AND a.ds = '${bizdate}' LEFT JOIN ods_sakila_city_df ct ON a.city_id = ct.city_id AND ct.ds = '${bizdate}' LEFT JOIN ods_sakila_country_df cy ON ct.country_id = cy.country_id AND cy.ds = '${bizdate}' LEFT JOIN ods_sakila_staff_df st ON s.manager_staff_id = st.staff_id WHERE s.ds = '${bizdate}' AND st.ds = '${bizdate}';店员维度表开发。
根据步骤6.a~6.e,在维度表开发业务流程中,创建名称为dim_staff的MaxCompute SQL节点,复制并粘贴如下插入数据SQL语句,在调试配置中将bizdate的参数值改为当天日期,然后运行。
INSERT OVERWRITE TABLE dim_staff PARTITION(ds = '${bizdate}') SELECT s.staff_id as staff_key ,s.store_id as staff_store_id ,s.first_name as staff_first_name ,s.last_name as staff_last_name ,s.active as staff_active ,cast(s.last_update as DATETIME)as staff_last_update ,GETDATE() as etl_date FROM ods_sakila_staff_df s WHERE ds = '${bizdate}';到这里,我们的维度表就开发完成。
最终我们的模型。
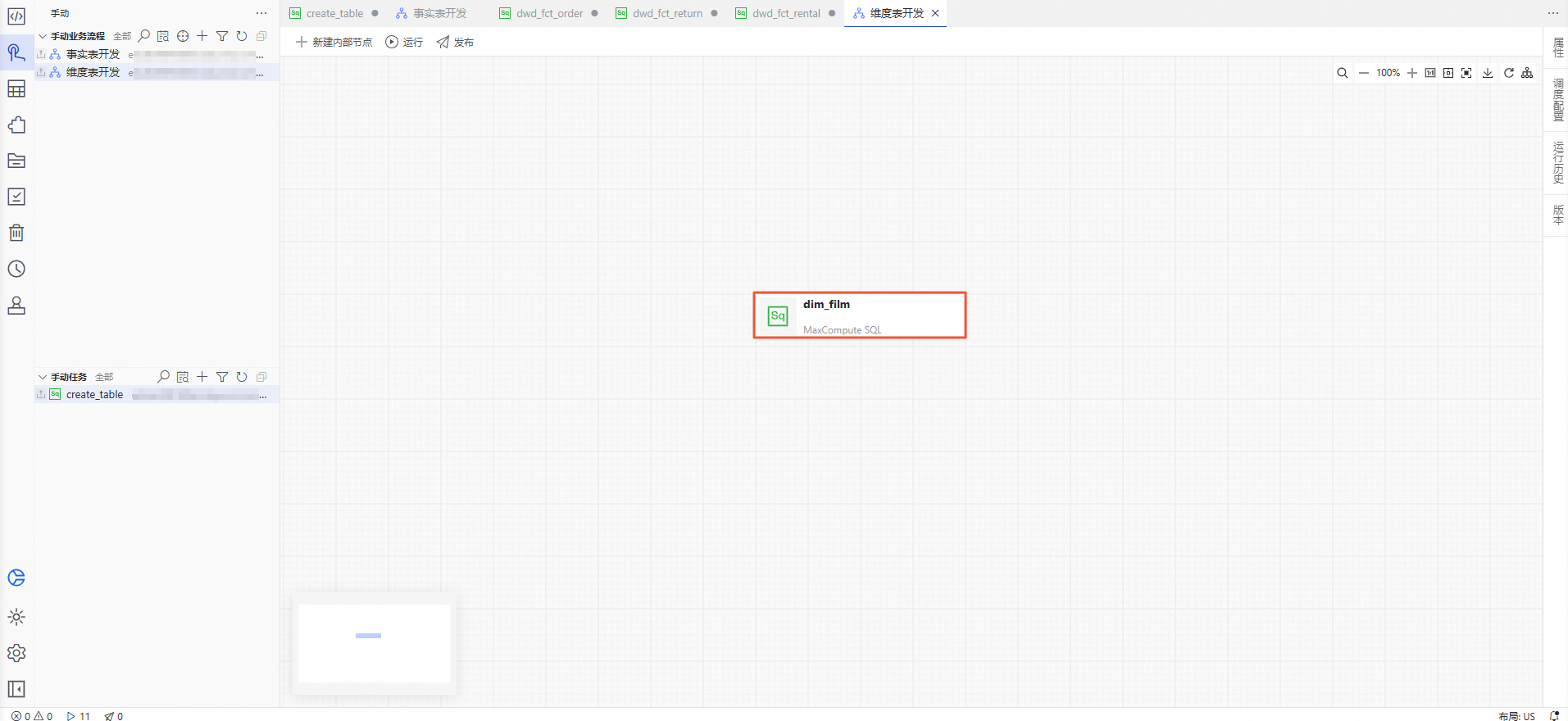
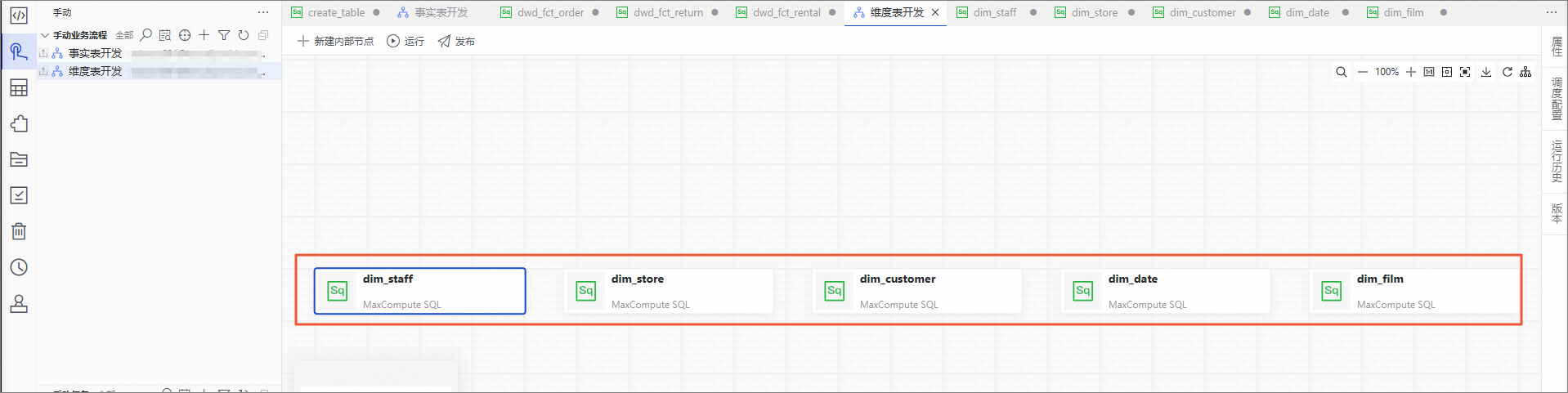
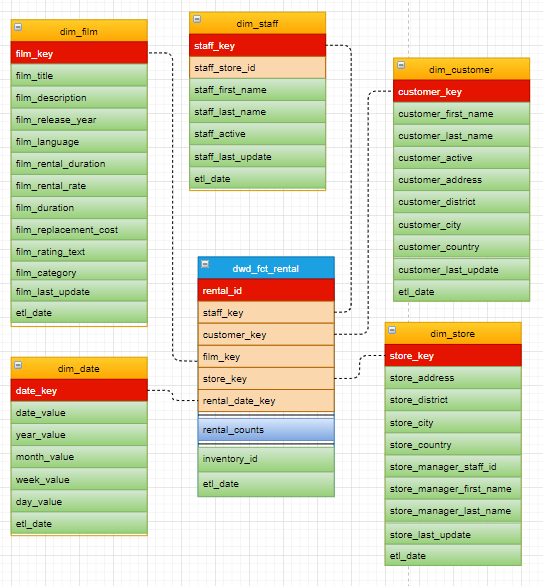
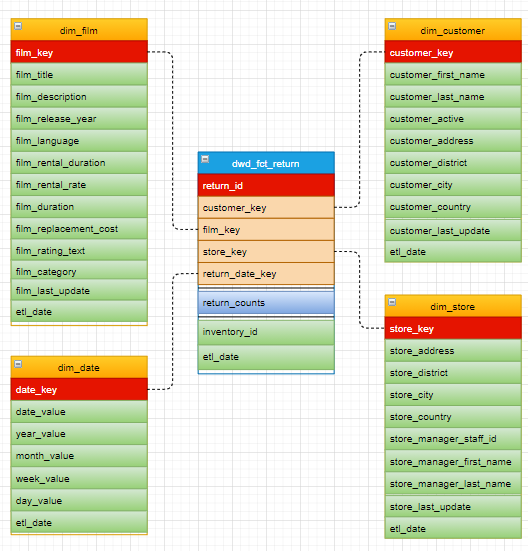
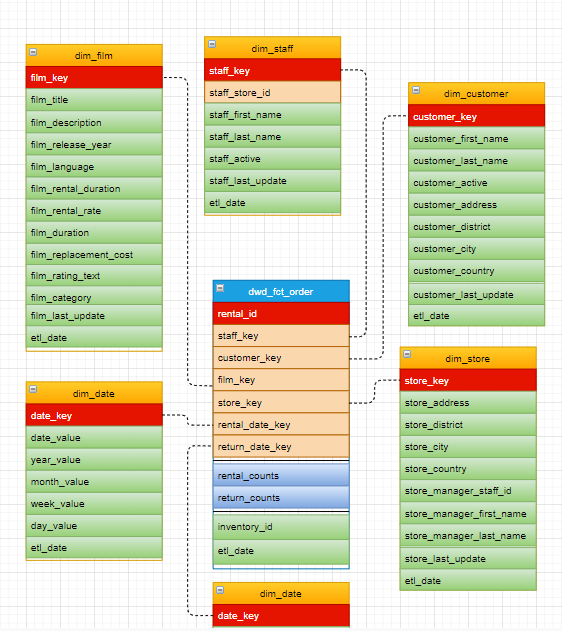
清理资源
在完成实验后,如果无需继续使用资源,请根据以下步骤,先删除相关资源后,再结束实操,否则资源会持续运行产生费用。
删除资源组和工作空间。
登录DataWorks控制台。
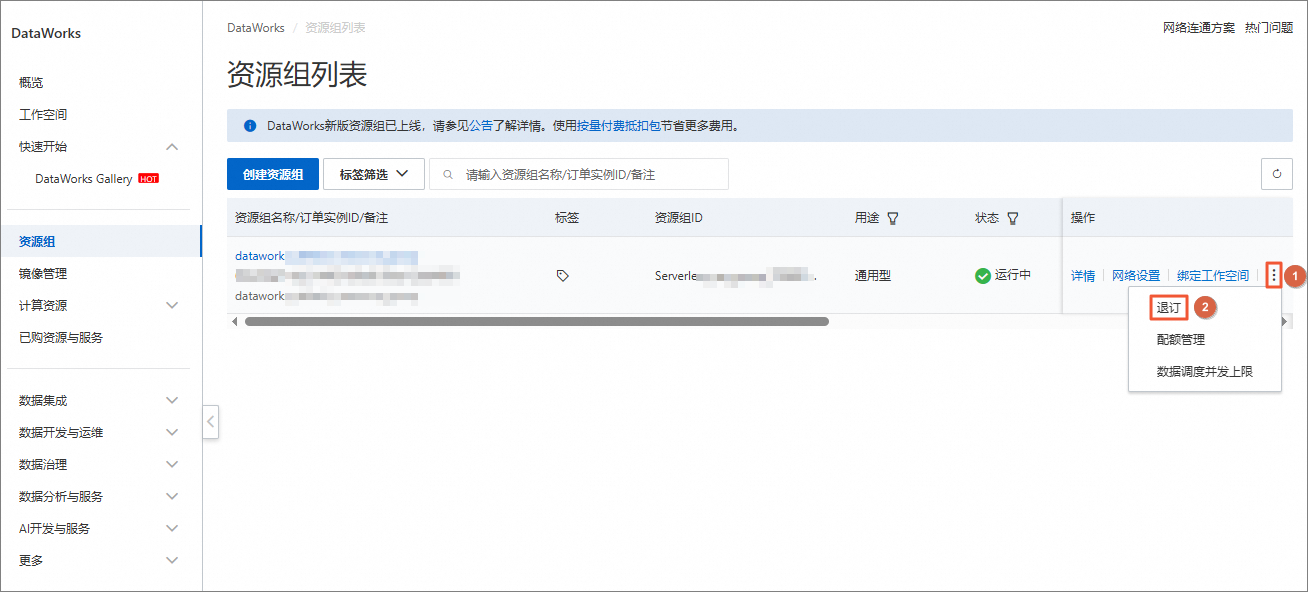
在页面上方,地域切换至华东2(上海),然后在左侧导航栏中,单击资源组。
在资源组列表页面,找到目标资源组,选择其右侧操作列下的
> 退订。在退订对话框中,单击确认。
在左侧导航栏中,单击工作空间列表。
在工作空间列表页面,找到目标工作空间,单击其右侧操作列下的删除。
在删除工作空间对话框中,勾选我确认该DataWorks空间及其所包含的所有实体将被永久删除,且不可恢复和我确认该DataWorks空间对应的AI工作空间将被永久删除,且不可恢复,单击确认。
删除MaxCompute项目。
在页面上方的菜单栏中,地域切换至华东2(上海)。在项目管理页面,找到创建DataWorks时绑定的MaxCompute项目,单击其右侧操作列下的删除。
在删除项目对话框中,勾选你确认要继续执行删除MaxCompute项目的操作吗,单击确定。
删除相关资源后,单击结束实操。在结束实操对话框中,单击确定。
在完成实验后,如果需要继续使用资源,您可跳过释放相关资源的操作,直接单击结束实操。在结束实操对话框中,单击确定。请随时关注账户扣费情况,避免发生欠费。
 > 退订
> 退订