
如果希望增强RAG(Retrieval-Augmented Generation)知识库数据的安全性,可以加密文本块和向量(向量也可能泄露原始语义),从而使用密文进行存储与网络传输。对于向量加密需采用特殊加密算法使得加密后向量仍能进行相似度检索。本文将在DSW开发环境中,以使用LangChain框架为例,介绍如何构建支持知识库加密的 RAG 应用。
方案概览
关键流程:
加密存储:文档解析分块向量化后,加密文本块(chunk)和嵌入向量,将密文存入向量数据库。
本文加解密将使用Python的
rai_sam库,其加密方式如下:文本块加密:使用行业通用的AES-CTR-256加密算法。
向量加密:使用DCPE加密算法(支持密态向量相似度计算与排序),其安全性高于保序加密,更多安全性说明请参见DCPE论文。
解密推理:用户问题向量化并加密后,检索向量数据库,将检索结果(密文)在推理服务中解密,然后与问题(原文)一起输入大语言模型(LLM)进行推理返回结果。

一、开发环境准备
进入DSW开发环境(您也可以使用本地或其他开发环境)。
创建DSW实例。本文使用的DSW配置如下:
官方镜像:
modelscope:1.26.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04。资源规格:
ecs.gn7i-c8g1.2xlarge。
在交互式建模(DSW)页面,单击目标实例操作列下的打开。
在Notebook页签,单击创建Notebook。
安装运行代码所需依赖。
!pip install -U langchain langchain-community langchain_huggingface !pip install -U pypdf !pip install -U modelscope !pip install -U alibabacloud-ha3engine-vector !pip install -U pymilvus !pip install -U rai_sam !pip install -U flask下载嵌入模型,以便后续将文本块转换成向量。本文使用bge-large-zh-v1.5,您可根据数据类型及语言或特定领域(如法律)选择其他合适的嵌入模型。
from modelscope import snapshot_download model_dir = snapshot_download('BAAI/bge-large-zh-v1.5', cache_dir='.')准备加密密钥。使用rai_sam模块进行加密,需要自定义加密密钥(长度为4 ~ 48字节)和密钥标识(长度为4 ~ 128字节)。本文加密使用的密钥为LD_Secret_0123456789,密钥标识为LD_ID_123456,采用如下方式配置到环境变量,后续通过环境变量获取。实际应用建议使用更安全的方式管理密钥(如密钥管理服务KMS)。
import os # 自定义密钥标识(长度为4 ~ 48字节) os.environ["SAM_KEY_ID"] = "LD_ID_123456" # 自定义密钥(长度为4 ~ 128字节) os.environ["SAM_KEY_SECRET"] = "LD_Secret_0123456789"
二、文档处理与加密存储
本节介绍如何将文件加密存储至向量数据库。
2.1 文件分块与向量化
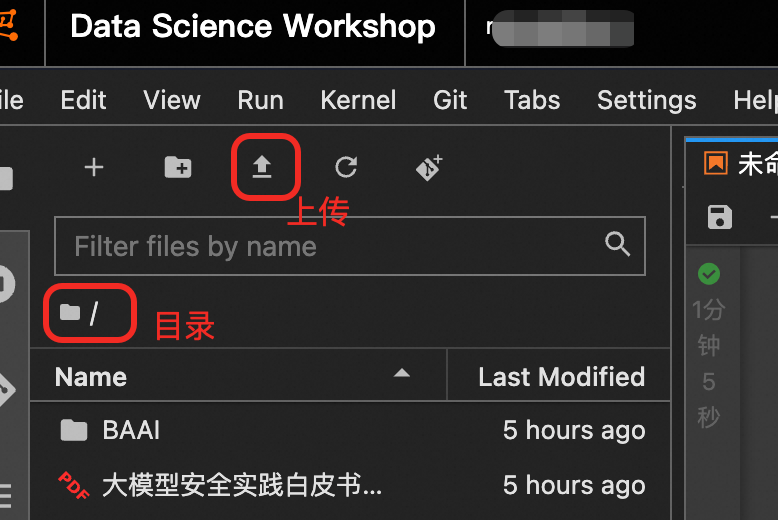
单击下图所示图标,上传文件大模型安全实践白皮书2024.pdf至DSW开发环境的当前工作目录下。
执行以下代码完成文件分块与向量化。
from langchain_community.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_huggingface import HuggingFaceEmbeddings # 1. 加载知识库文件 # 文件所在路径 doc_name = "./大模型安全实践白皮书2024.pdf" file_path = ( doc_name ) loader = PyPDFLoader(file_path) docs = loader.load() print(len(docs)) # 2. 文本解析分块。将已加载的文档对象进一步拆分成更小的文本块(chunk) text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) split_docs = text_splitter.split_documents(docs) print(len(split_docs)) # 3. 文本向量化 # 加载嵌入模型 embeddings_model = HuggingFaceEmbeddings(model_name="./BAAI/bge-large-zh-v1.5") # 文本转向量 documents = [] for i in range(len(split_docs)): documents.append(split_docs[i].page_content) embeddings = embeddings_model.embed_documents(documents) print(len(embeddings), len(embeddings[0])) # 向量维度 embedding_dimension = len(embeddings[0])
三、部署模型服务
为了数据安全,请求模型服务的向量检索结果是密文,需解密后输入到大语言模型(LLM)中进行推理。您可以参考示例app.py修改您的在线预测代码文件以适配加密知识库。
为方便测试,本节在DSW开发环境中使用上述app.py代码文件启动一个推理服务。
下载模型代码。
# 模型下载 from modelscope import snapshot_download model_dir = snapshot_download('Qwen/Qwen2.5-3B-Instruct', cache_dir='/mnt/workspace/')启动推理服务。打开Terminal,在app.py所在目录执行以下命令:
# 设置临时环境变量 export SAM_KEY_ID=LD_ID_123456 export SAM_KEY_SECRET=LD_Secret_0123456789 # 运行python代码文件 python app.py出现如下结果,说明服务启动成功。
四、向量检索与推理
生产环境应用
如果您想要在生产环境中应用如上方案,可以参考以下内容使用阿里云向量数据库,并在模型推理服务(EAS)中部署安全加密的推理服务,以增强您的应用安全性。
使用阿里云向量数据库
请参考如下代码使用阿里云向量数据库 Milvus、OpenSearch、Elasticsearch进行加密数据的存储与检索。
阿里云Milvus
其中关键配置说明如下:
demo_collection_name:Milvus实例的Collection名称,例如milvus_demo_collection。
uri:Milvus实例的访问地址,支持内网或公网访问。格式为
http://<访问地址>:<port>。token:格式为
User:Password,即Milvus实例用户名:Milvus实例密码。db_name:配置为已创建的数据库名称,例如default。
阿里云OpenSearch
其中:
instance_id:配置为OpenSearch的实例ID。
table_name:配置为OpenSearch索引表名称。
access_user_name:配置为OpenSearch实例的用户名。
access_pass_word:配置为OpenSearch实例的密码。
阿里云Elasticsearch
其中:
index_name:在Elasticsearch实例页面,更新YML文件配置为允许自动创建索引后,即可自定义索引名称。
<Elasticsearch URL>:配置为Elasticsearch实例访问地址,支持内网或公网访问。格式为
http://<地址>:<端口>。<YourPassword>:配置为Elasticsearch实例的登录密码。
部署PAI-EAS模型服务
EAS支持配置安全加密环境,通过配置系统信任管理服务,保证服务部署和调用的过程中数据、模型和代码等信息可以安全加密,实现安全可验证的推理服务。详情请参考安全加密推理服务。