基于Flink+Kafka实现订单评论实时分析
本文为您介绍如何将MySQL整库同步Kafka,从而降低多个任务对MySQL数据库造成的压力。
场景简介
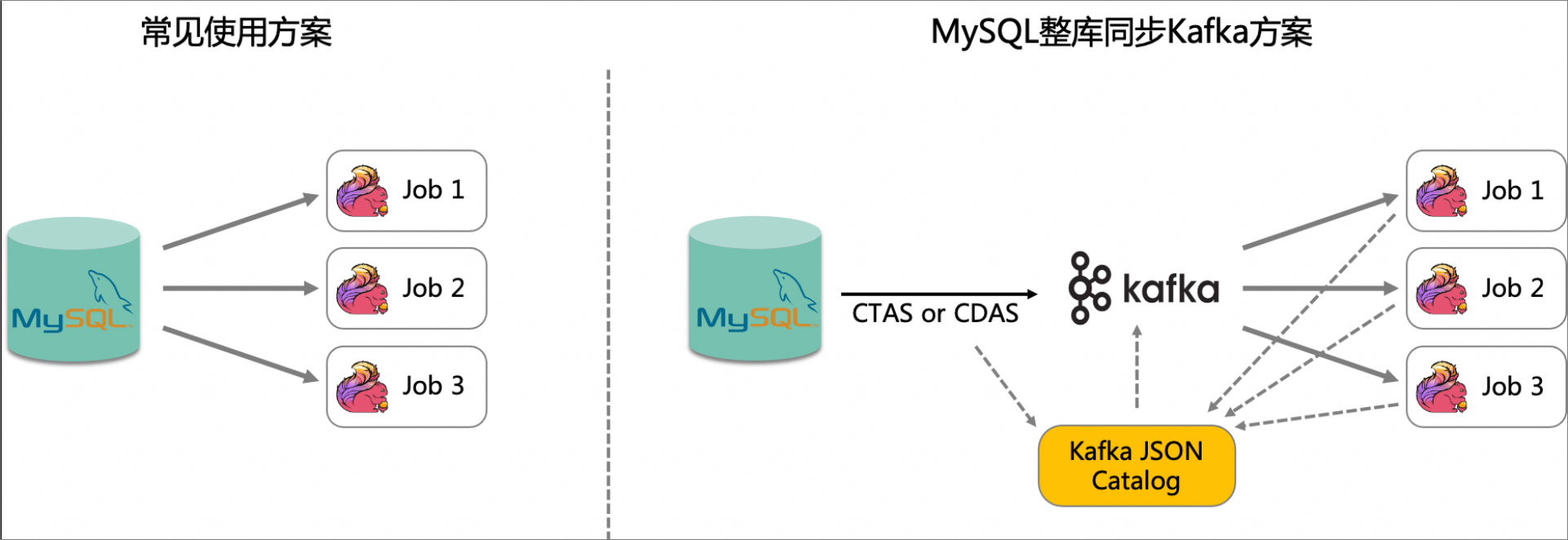
MySQL CDC数据表主要用于获取MySQL数据,并可以实时同步数据表中的修改,经常用在复杂的计算场景。例如,作为一张维表和其他数据表做Join操作。在使用中,同一张MySQL表可能被多个作业依赖,当多个任务使用同一张MySQL表做处理时,MySQL数据库会启动多个连接,对MySQL服务器和网络造成很大的压力。
实践场景
例如,在订单评论实时分析场景下,假设有用户表(user),订单表(order)和用户评论表(feedback)三张表。各个表包含数据如下图所示。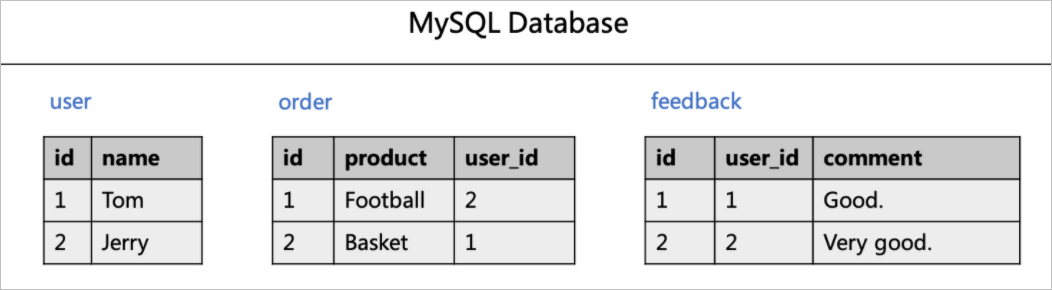
在展示用户订单信息和用户评论时,需要通过关联用户表(user)来获取用户名(name字段)信息。SQL示例如下。
-- 将订单信息和用户表做join,展示每个订单的用户名和商品名。SELECT order.id as order_id, product, user.name as user_name
FROM order LEFT JOIN userON order.user_id = user.id;
-- 将评论和用户表做join,展示每个评论的内容和对应用户名。SELECT feedback.id as feedback_id, comment, user.name as user_name
FROM feedback LEFT JOIN userON feedback.user_id = user.id;对于以上两个SQL任务,user表在两个作业中都被使用了一次。运行时,两个作业都会读取MySQL的全量数据和增量数据。全量读取需要创建MySQL连接,增量读取需要创建Binlog Client。随着作业的不断增多,MySQL连接和Binlog Client资源也会对应增长,会给上游数据库产生极大的压力,为了缓解对上游MySQL数据库的压力,通过CDAS或CTAS语法将上游的MySQL数据实时同步到Kafka中,提供给多个下游作业消费。
方案架构
为缓解上游MySQL数据库的压力,阿里云Flink实时计算已提供将MySQL整库同步至Kafka的能力。该方案通过引入Kafka作为中间层,并采用CDAS整库同步或CTAS整表同步至Kafka来实现。在一个作业中,上游MySQL的数据实时同步至Kafka,每张MySQL表以Upsert方式写入相应的Kafka Topic,然后使用Kafka JSON Catalog读取Topic中的数据替代访问MySQL表,从而有效降低多个任务对MySQL数据库造成的压力。
费用说明
本实验预计1个小时产生费用2.42元。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
背景知识
创建实验资源
在实验页面,勾选我已阅读并同意《阿里云云起实践平台服务协议》和我已授权阿里云云起实践平台创建、读取及释放实操相关资源后,单击开始实操。
创建资源需要10分钟左右的时间,请您耐心等待。
重要创建资源前需注意余额需满足创建资源费用要求,否则会出现资源创建失败。查看账户余额请到费用与成本。
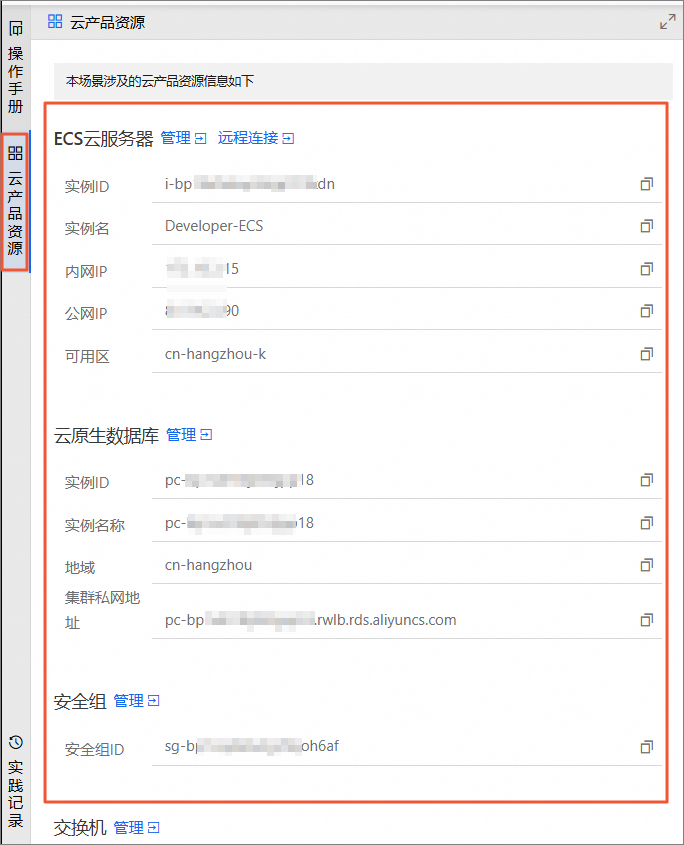
在云产品资源列表,您可以查看本场景涉及的云产品资源信息。
准备数据源
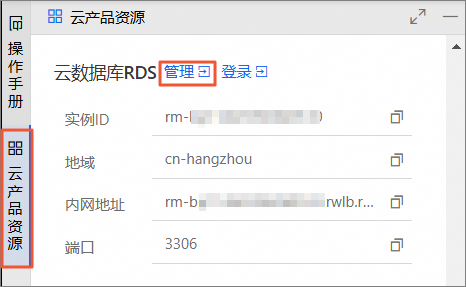
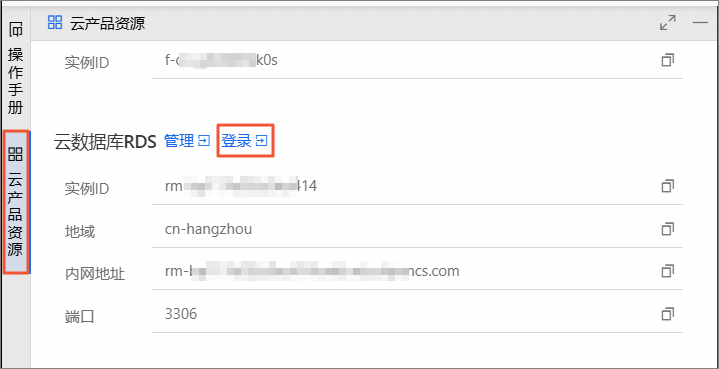
在云产品资源列表的云数据库RDS区域,单击管理。
创建数据库账号。
单击左侧导航栏账号管理。

单击创建账号打开创建账号页签。

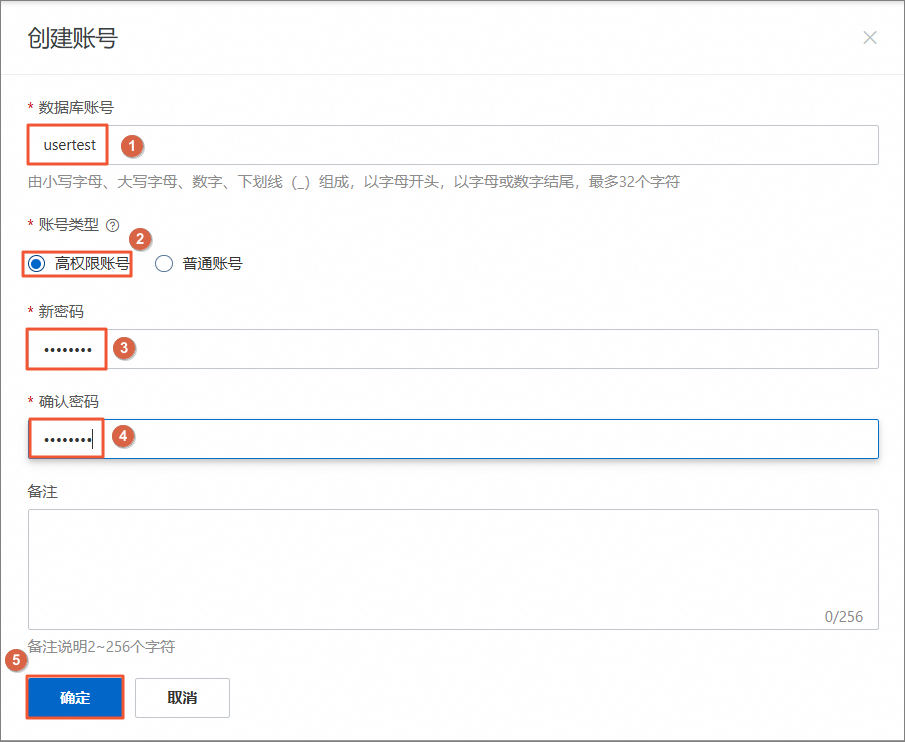
在创建账号页签中,设置如下账号参数,单击确定。
填写数据库账号,本实验设置数据库账号为
usertest。选择账号类型,本实验以创建高权限账号为例。
创建数据库。
单击左侧导航栏数据库管理。
单击创建数据库按钮打开创建数据库页签。
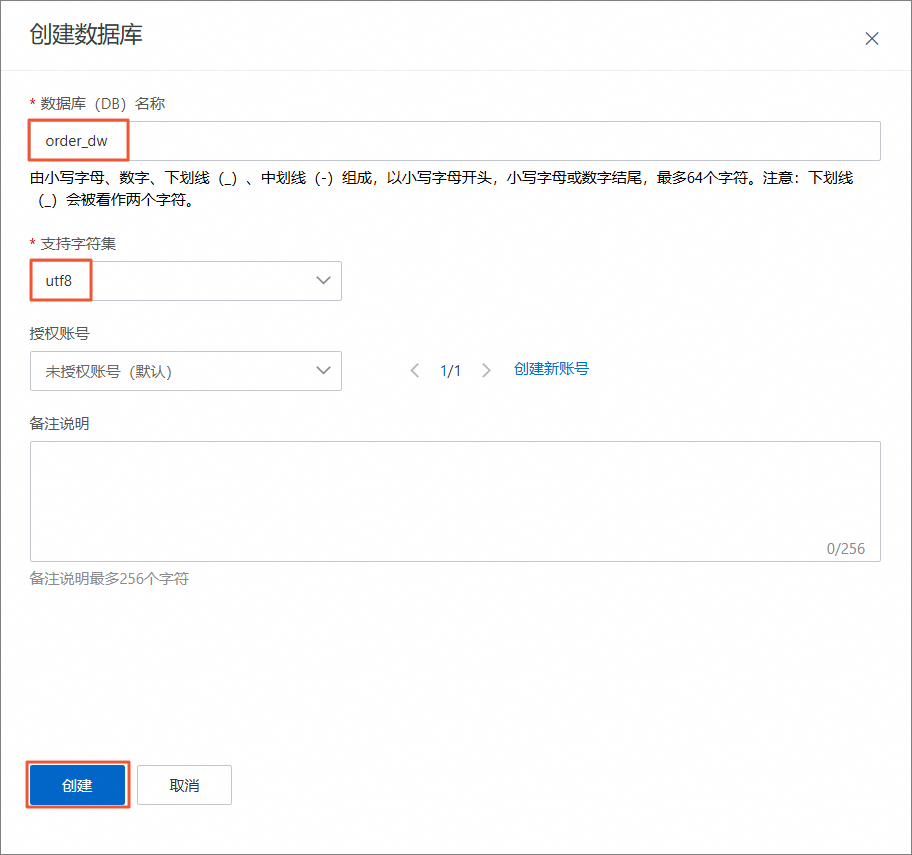
在创建数据库页签中,设置如下数据库参数,单击创建。
本教程设置数据库(DB)名称为
order_dw。支持字符集为utf8。
准备MySQL CDC数据源。
在云产品资源列表的云数据库RDS区域,单击登录。
在弹出的DMS页面中,填写创建的数据库账号名和密码,然后单击登录。
说明可根据实际需求切换访问方式。
登录成功后,在左侧数据库实例列表中,双击目标实例下的
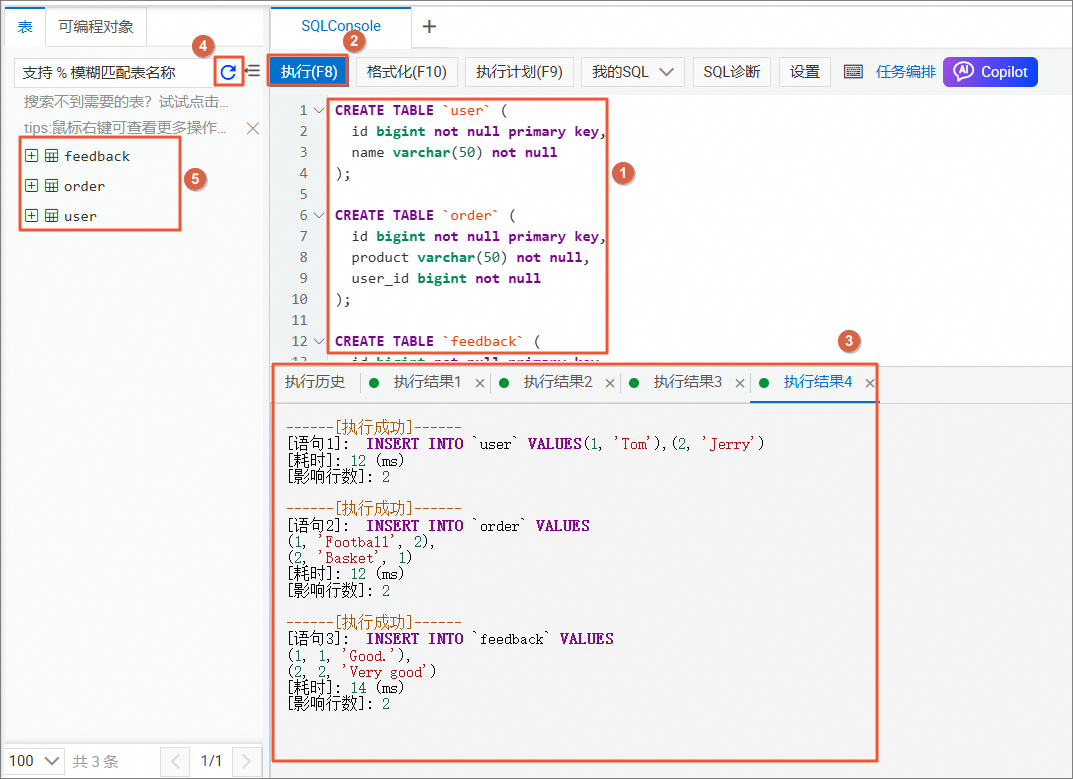
order_dw数据库,切换数据库。在SQL Console区域,执行如下命令,编写三张业务表的建表DDL以及插入的数据语句。
CREATE TABLE `user` ( id bigint not null primary key, name varchar(50) not null ); CREATE TABLE `order` ( id bigint not null primary key, product varchar(50) not null, user_id bigint not null ); CREATE TABLE `feedback` ( id bigint not null primary key, user_id bigint not null, comment varchar(50) not null ); -- 准备数据 INSERT INTO `user` VALUES(1, 'Tom'),(2, 'Jerry'); INSERT INTO `order` VALUES (1, 'Football', 2), (2, 'Basket', 1); INSERT INTO `feedback` VALUES (1, 1, 'Good.'), (2, 2, 'Very good');


创建云消息队列Kafka Topic和Group资源
登录消息队列Kafka版控制台。
在左侧导航栏中选择实例列表,本教程示例地域为杭州,单击目标实例名称,进入实例详情页。
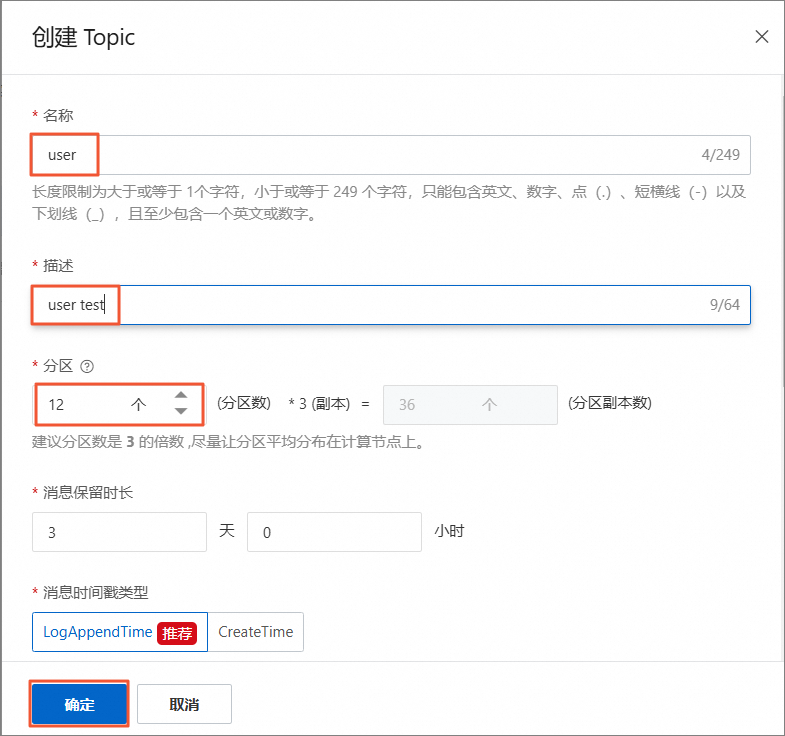
创建Topic。
在左侧导航栏,单击Topic管理。
在Topic管理页面,单击创建Topic。
在创建Topic面板,根据如下参数设置Topic属性,其他参数默认,然后单击确定。
参数
说明
示例
名称
Topic名称。
user描述
Topic的简单描述。
user test
分区数
Topic的分区数量。
12
根据上述步骤分别创建名称为
order、feedback两个Topic。
创建Group。
在左侧导航栏,单击Group管理。
在Group管理页面,单击创建Group。
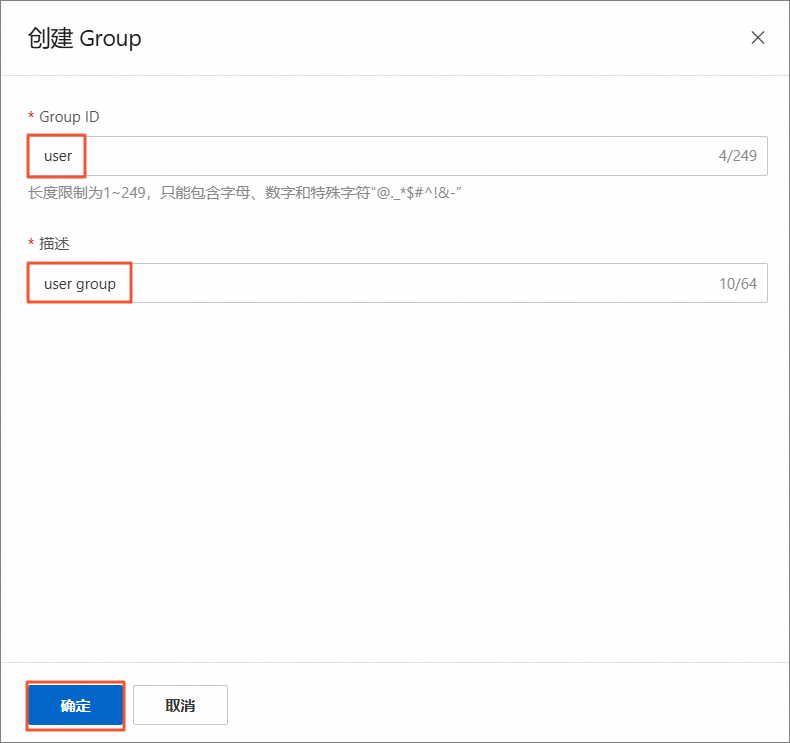
在创建Group面板,根据如下参数设置Group属性,然后单击确定。
参数
说明
示例
Group ID
Group名称。
user描述
Group的简单描述。
user group
根据上述步骤分别创建名称为
order、feedback两个Group。
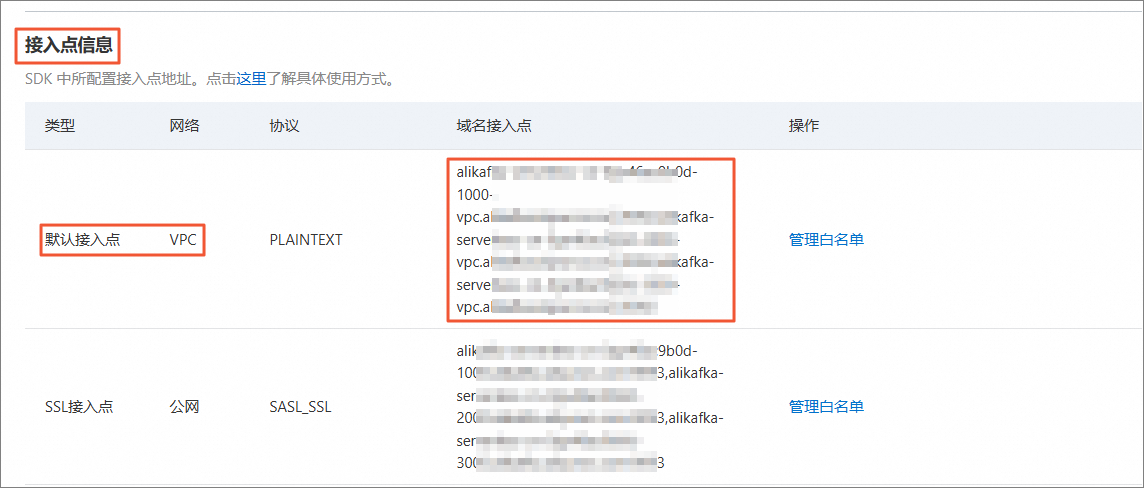
查看Kafka Broker地址。
在左侧导航栏,单击实例详情。
在接入点信息区域,找到类型为默认接入点,复制域名接入点,在后续创建Kafka JSON Catalog中会用到。



创建Catalog
创建MySQL Catalog。
在云产品资源列表的实时计算Flink区域,单击管理。
单击目标工作空间操作列下的控制台。
在左侧导航栏,单击数据管理。
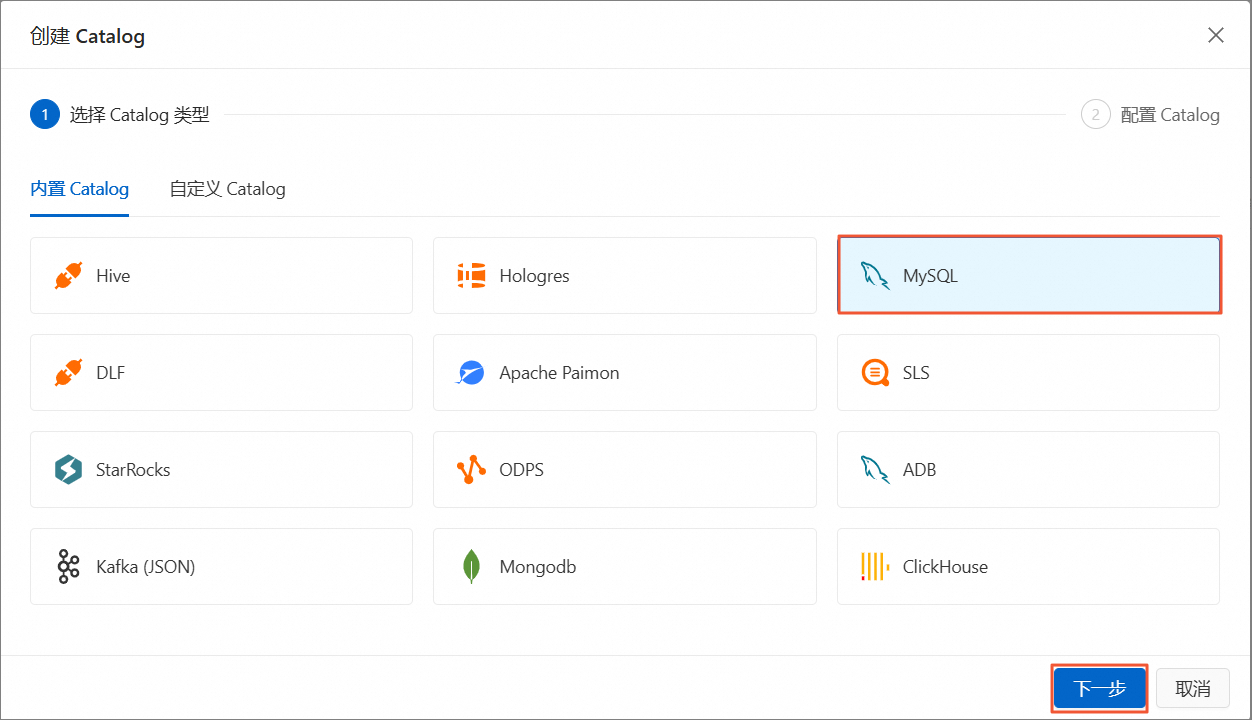
单击创建Catalog,选择MySQL,单击下一步。
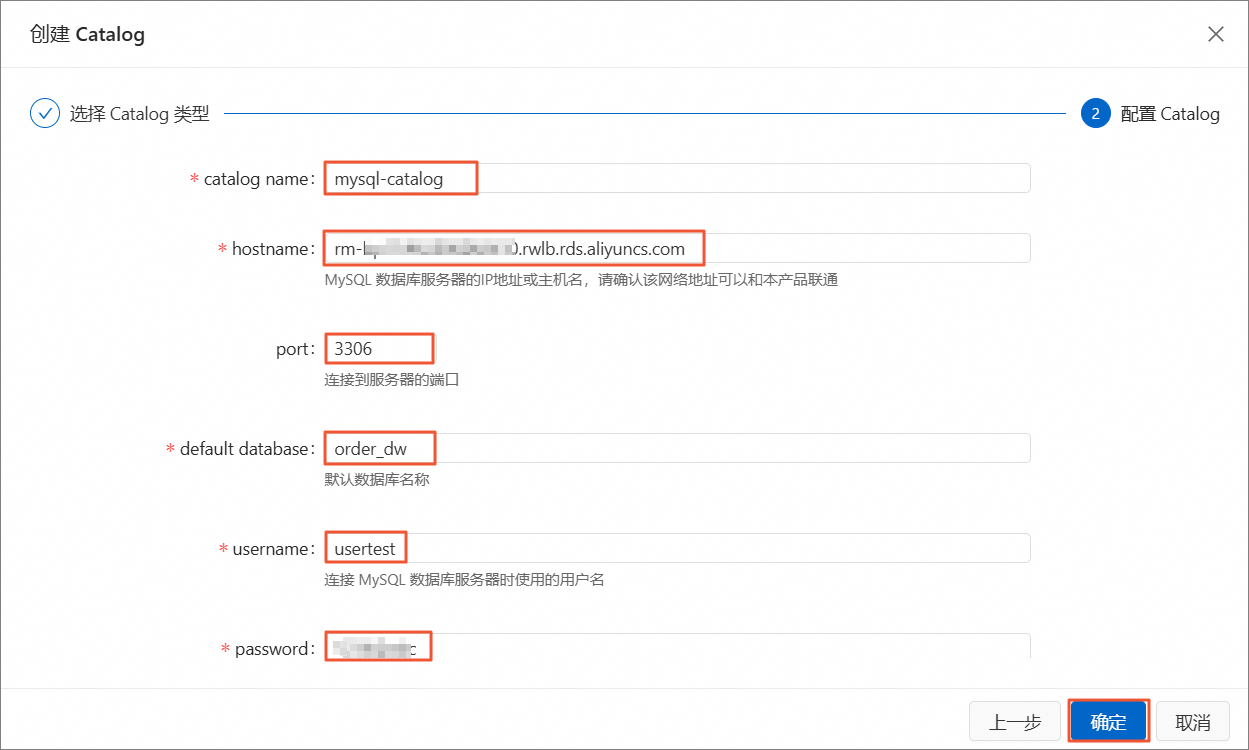
在配置Catalog页签下,配置如下参数,单击确定。
重要Catalog创建完成后不支持修改以下配置信息。如需修改,请删除已创建的Catalog后重新创建。
参数
说明
是否必填
catalogname
自定义MySQL Catalog名称,示例名称为
mysql-catalog。是
hostname
MySQL数据库的内网地址,可在云产品资源列表中的云数据库RDS区域查看。
是
port
MySQL数据库服务的端口号,默认值为
3306。否
default-database
默认的MySQL数据库名称,示例数据库名称为
order_dw。是
username
MySQL数据库服务的用户名,示例用户名为
usertest。是
password
MySQL数据库服务的密码。刚刚创建RDS数据库账号时设置的密码。
是
创建成功后,如下图所示。
创建Kafka JSON Catalog。
在左侧导航栏选择,单击查询脚本页签。
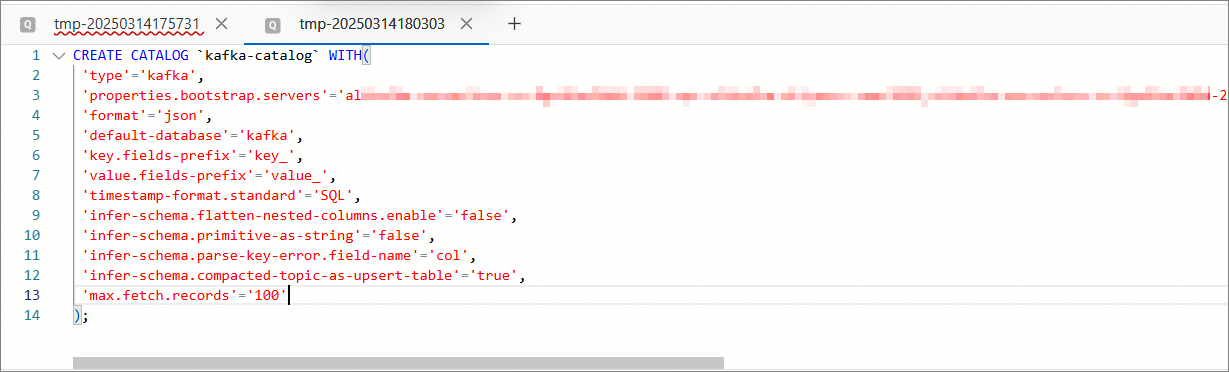
单击
,新建查询脚本。在文本编辑区域,输入以下配置Kafka JSON Catalog的命令。CREATE CATALOG <YourCatalogName> WITH( 'type'='kafka', 'properties.bootstrap.servers'='<brokers>', 'format'='json', 'default-database'='kafka', 'key.fields-prefix'='key_', 'value.fields-prefix'='value_', 'timestamp-format.standard'='SQL', 'infer-schema.flatten-nested-columns.enable'='false', 'infer-schema.primitive-as-string'='false', 'infer-schema.parse-key-error.field-name'='col', 'infer-schema.compacted-topic-as-upsert-table'='true', 'max.fetch.records'='100' );参数
类型
说明
是否必填
备注
YourCatalogName
String
Kafka JSON Catalog名称。
是
请填写为自定义的英文名,示例名称为
`kafka-catalog`。重要参数替换为您的Catalog名称后,需要去掉尖括号(<>),否则语法检查会报错。
type
String
Catalog类型。
是
固定值为kafka。
properties.bootstrap.servers
String
Kafka Broker地址。
是
格式为
host1:port1,host2:port2,host3:port3。以英文逗号(,)分割。
format
String
Kafka消息格式。
是
目前只支持配置为JSON。Flink会解析JSON格式的Kafka消息,来获取Schema。
default-database
String
Kafka集群名称。
否
默认值为kafka。Catalog要求三层结构定位一张表,即catalog_name.db_name.table_name。此处是配置默认的db_name,由于Kafka没有Database的概念,您可以在此处使用任意字符串指代Kafka集群作为database的定义。
key.fields-prefix
String
自定义添加到消息键(Key)解析出字段名称的前缀,来避免Kafka消息键解析后的命名冲突问题。
否
默认值为key_。例如,如果您的key字段名为a,则系统默认解析key后的字段名称为key_a。
说明key.fields-prefix的配置值不可以是value.fields-prefix的配置值的前缀。例如value.fields-prefix配置为test1_value_,则key.fields-prefix不可以配置为test1_。
value.fields-prefix
String
自定义添加到消息体(Value)解析出字段名称的前缀,来避免Kafka消息体解析后的命名冲突问题。
否
默认值为value_。例如,如果您的value字段名为b,则系统默认解析value后的字段名称为value_b。
说明value.fields-prefix的配置值不可以是key.fields-prefix的配置值的前缀。例如key.fields-prefix配置为test2_value_,则value.fields-prefix不可以配置为test2_。
timestamp-format.standard
String
解析JSON格式消息中Timestamp类型字段的格式,首先尝试通过您配置的格式去解析,解析失败后再自动尝试使用其他格式解析。
否
可配置的值有以下两种:
SQL(默认值)
ISO-8601
infer-schema.flatten-nested-columns.enable
Boolean
解析JSON格式消息体(Value)时,是否递归式地展开JSON中的嵌套列。
否
参数取值如下:
true:递归式展开。
对于被展开的列,Flink使用索引该值的路径作为名字。例如,对于
{"nested": {"col": true}}中的列col,它展开后的名字为nested.col。说明设置为true时,建议和CREATE TABLE AS(CTAS)语句配合使用,目前暂不支持其它DML语句自动展开嵌套列。
false(默认值):将嵌套类型当作String处理。
infer-schema.primitive-as-string
Boolean
解析JSON格式消息体(Value)时,是否推导所有基本类型为String类型。
否
参数取值如下:
true:推导所有基本类型为String。
false(默认值):按照基本规则进行推导。
infer-schema.parse-key-error.field-name
String
解析JSON格式消息键(Key)时,如果消息键不为空,且解析失败,会添加key.fields-prefix前缀拼接此配置项的值为列名,类型为VARBINARY的字段到表Schema,表示消息键部分的数据。
否
默认值为col。如:消息体解析出的字段为value_name,消息键不为空但解析失败,则默认返回的Schema包含两个字段:key_col,value_name。
infer-schema.compacted-topic-as-upsert-table
Boolean
当Kafka topic的日志清理策略为compact且消息键(Key)不为空时,是否作为Upsert Kafka表使用。
否
默认值为true。使用CTAS或CDAS语法同步数据到阿里云消息队列Kafka版时需要配置为true。
说明
仅实时计算引擎VVR 6.0.2及以上版本支持该参数。
max.fetch.records
Int
解析JSON格式消息时,最多尝试消费的消息数量。
否
默认值为100。
aliyun.kafka.accessKeyId
String
阿里云账号AccessKey ID,详情请参见创建AccessKey。
否
使用CTAS或CDAS语法同步数据到阿里云消息队列Kafka版时需要配置。
说明
仅实时计算引擎VVR 6.0.2及以上版本支持该参数。
aliyun.kafka.accessKeySecret
String
阿里云账号AccessKey Secret,详情请参见创建AccessKey。
否
使用CTAS或CDAS语法同步数据到阿里云消息队列Kafka版时需要配置。
说明
仅实时计算引擎VVR 6.0.2及以上版本支持该参数。
aliyun.kafka.instanceId
String
阿里云Kafka消息队列实例ID,可在什么是云消息队列 Kafka 版?实例详情界面查看。
否
使用CTAS或CDAS语法同步数据到阿里云消息队列Kafka版时需要配置。
说明
仅实时计算引擎VVR 6.0.2及以上版本支持该参数。
aliyun.kafka.endpoint
String
阿里云Kafka API服务接入地址,详情请参见服务接入点。
否
使用CTAS或CDAS语法同步数据到阿里云消息队列Kafka版时需要配置。
说明
仅实时计算引擎VVR 6.0.2及以上版本支持该参数。
aliyun.kafka.regionId
String
Topic所在实例的地域ID,详情请参见服务接入点。
否
使用CTAS或CDAS语法同步数据到阿里云消息队列Kafka版时需要配置。
说明
仅实时计算引擎VVR 6.0.2及以上版本支持该参数。
选中创建Catalog的代码后,单击左侧代码行数上的运行。
重要若弹出创建Session集群对话框,单击确定等待集群环境启动后,重新运行代码。
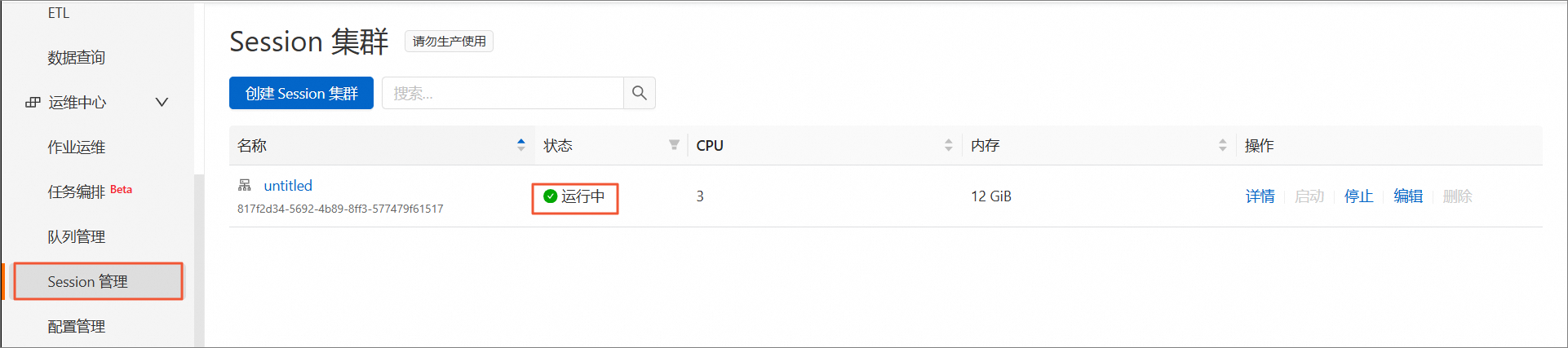
在弹出的创建Session集群对话框中,单击确定。
单击左侧导航栏的,等待目标Session 集群状态变为运行中。
返回也,重新选中创建Catalog的代码后,单击左侧代码行数上的运行。
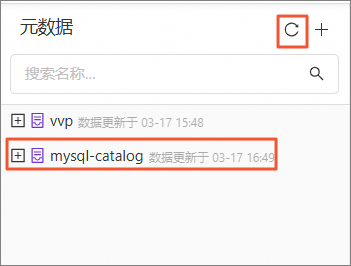
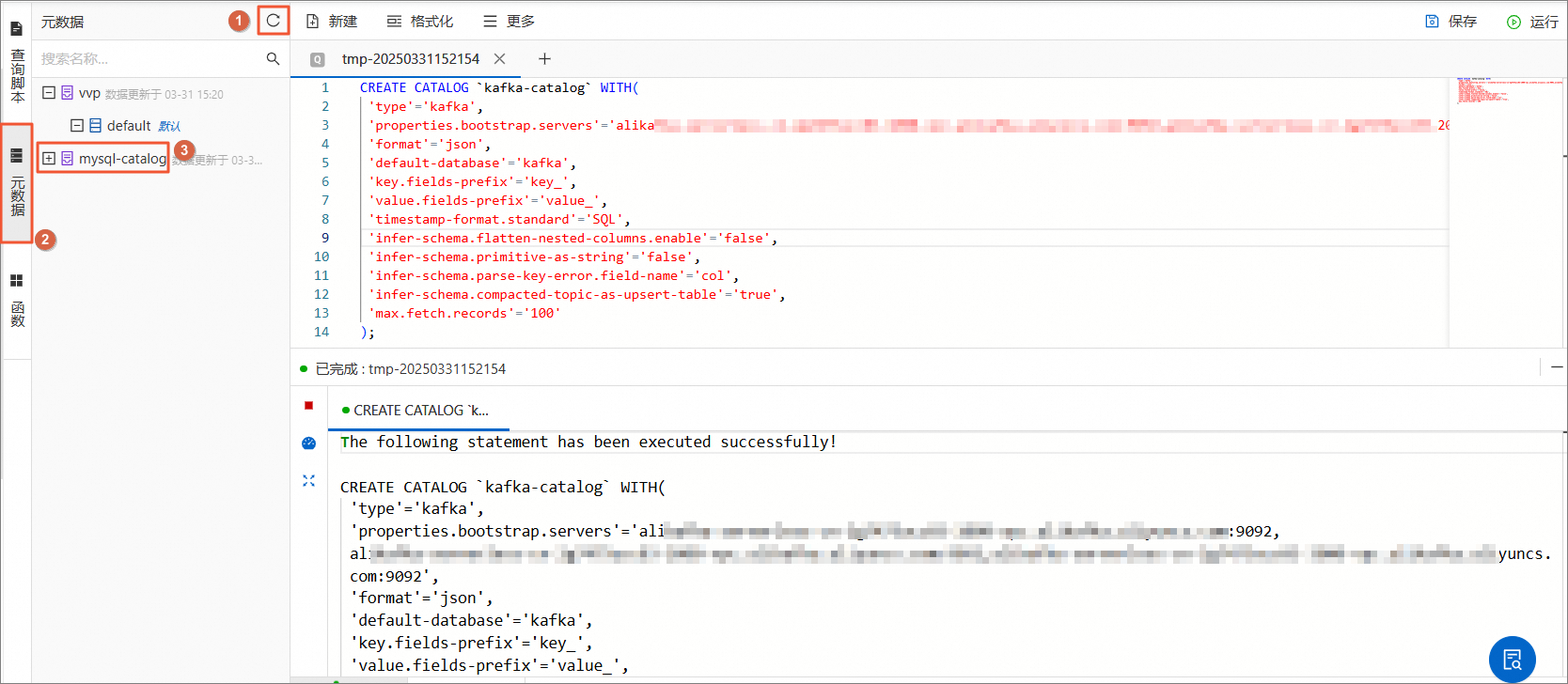
在左侧列表中选择元数据,单击刷新按钮,可看到创建的
kafka-catalog。


创建并启动一个CDAS同步任务
将上游的MySQL数据实时同步到Kafka中,提供给多个下游作业消费。
整库同步任务建立的Kafka topic名称和MySQL表名相同,分区数和副本数会使用Kafka集群的默认配置,并且cleanup.policy会设置为compact。
进入页面,单击图标
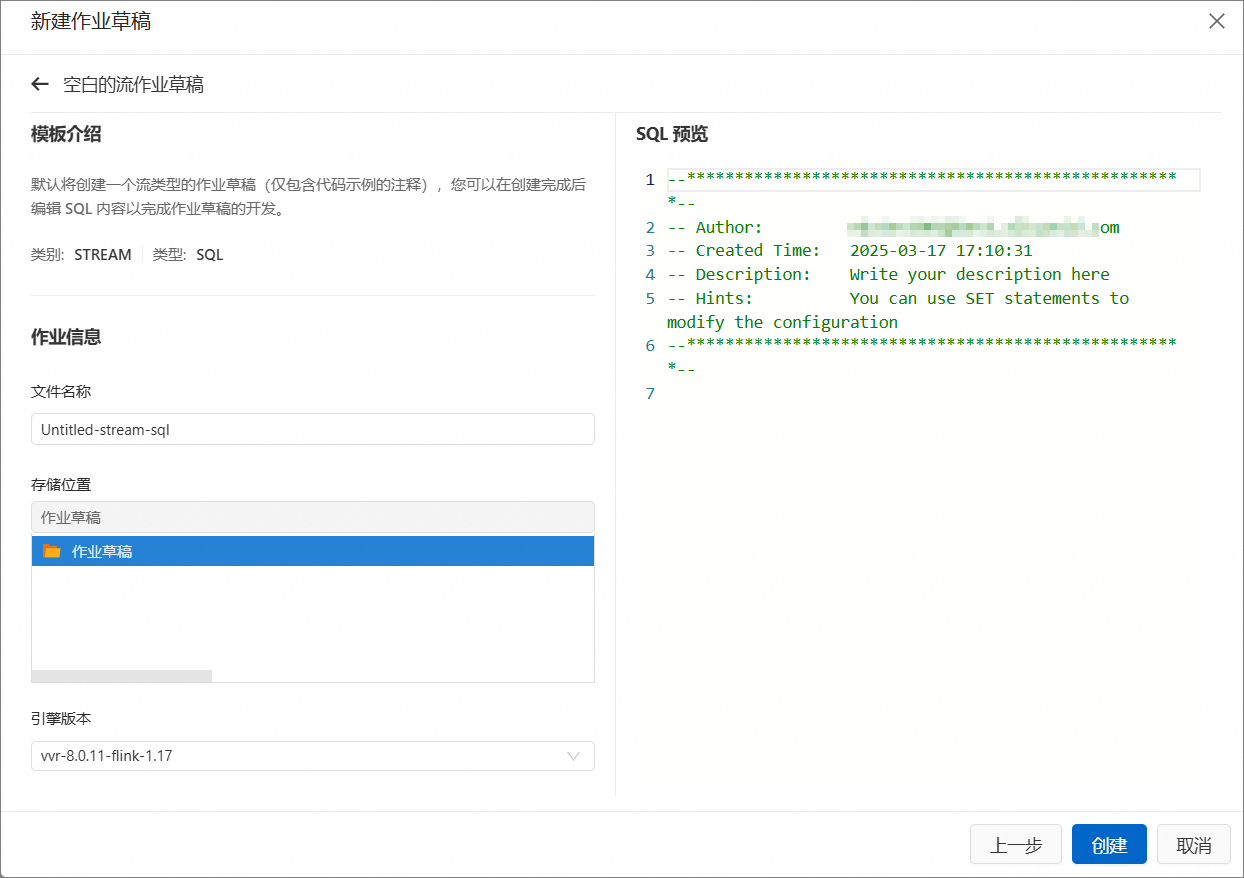
新建图标,新建SQL流作业草稿。在新建作业草稿页面,选择,单击下一步。
根据实际需求设置文件名称和引擎版本信息,单击创建。
将如下命令粘贴至SQL编辑器中,单击右上方的部署,进行作业部署。
CREATE DATABASE IF NOT EXISTS `kafka-catalog`.`kafka` AS DATABASE `mysql-catalog`.`order_dw` INCLUDING ALL TABLES;说明由于Kafka本身没有数据库的概念,所以不存在创建数据库的操作,使用时需要结合IF NOT EXISTS来跳过建库。
说明如需深入了解CDAS相关语句,请参考CREATE DATABASE AS(CDAS)语句。
在部署新版本对话框中,单击确定。
单击左侧导航栏的,单击目标作业操作列的启动,选择无状态启动后单击启动。
等待作业状态为运行中。
查询作业结果。
登录消息队列Kafka版控制台。
在左侧导航栏中选择实例列表,本教程示例地域为杭州,单击目标实例名称,进入实例详情页。
在左侧导航栏,单击Topic管理。
在Topic管理页面,单击已创建好的Topic,这里以
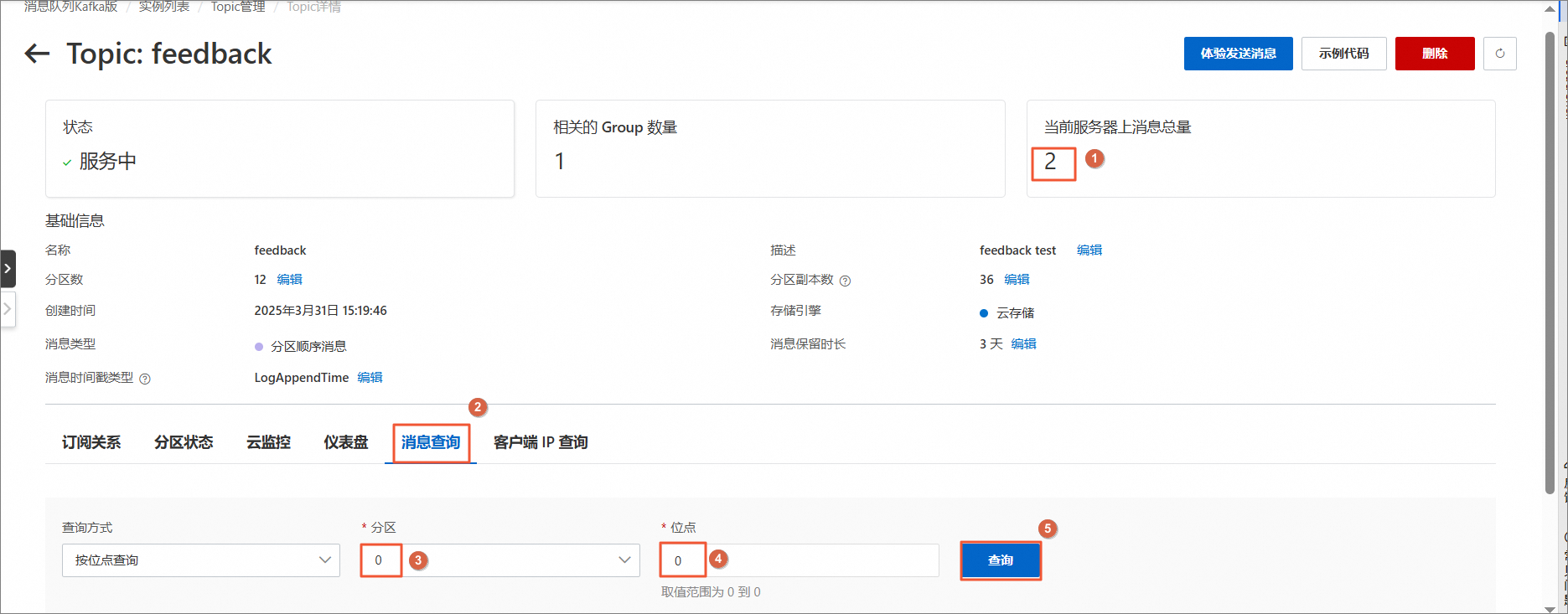
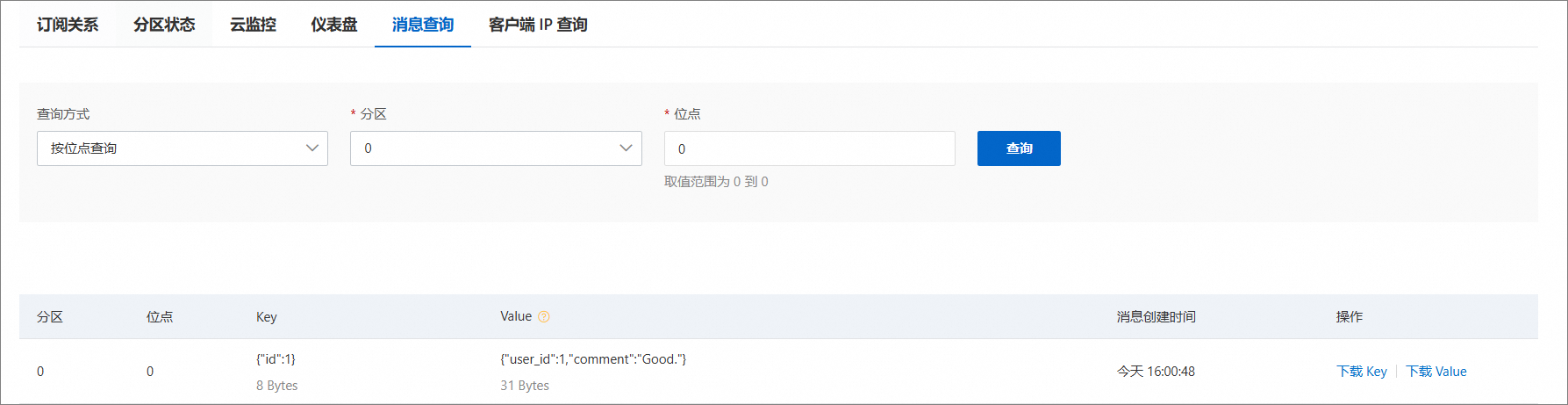
feedbackTopic举例。进入Topic详情后,可在右上角看到当前服务器上消息总量。切换至消息查询选项卡,查询方式选择按位点查询,分区及位点保持默认,单击右侧查询按钮。
在下方可以看到,查询的消息结果。
 新建图标,新建SQL流作业草稿。
新建图标,新建SQL流作业草稿。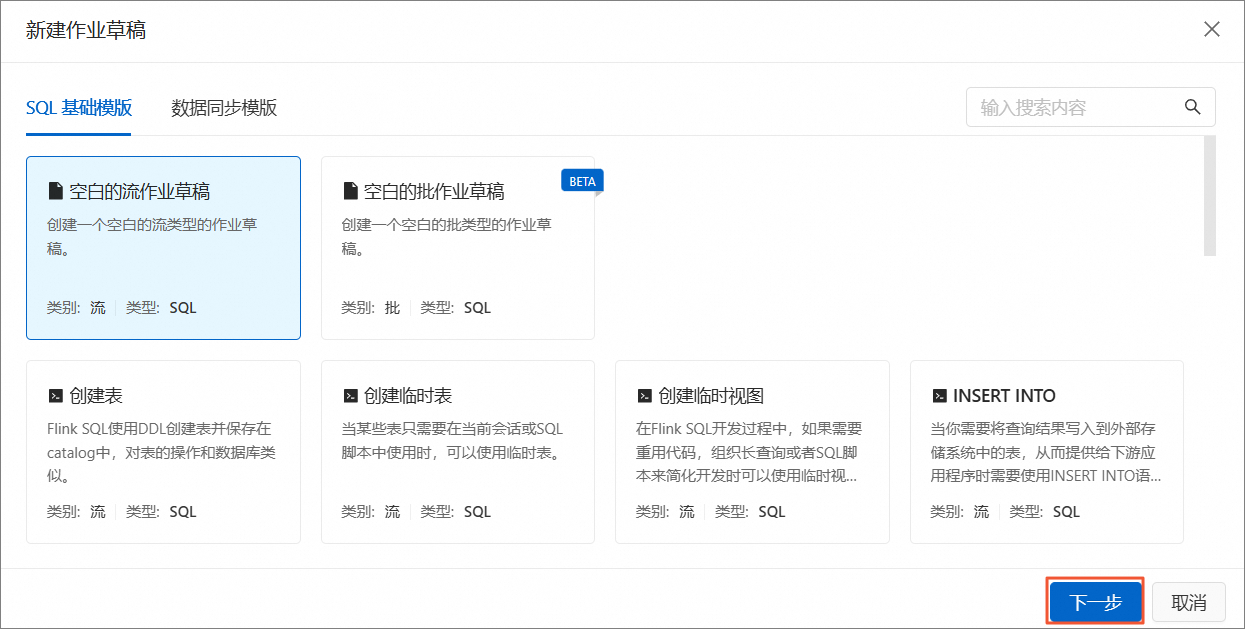



通过Catalog实时消费Kafka数据
上游MySQL数据库中的数据会以JSON格式写入Kafka中,一个Kafka Topic可以提供给多个下游作业消费,下游作业消费Topic中的数据来获取数据库表的最新数据。
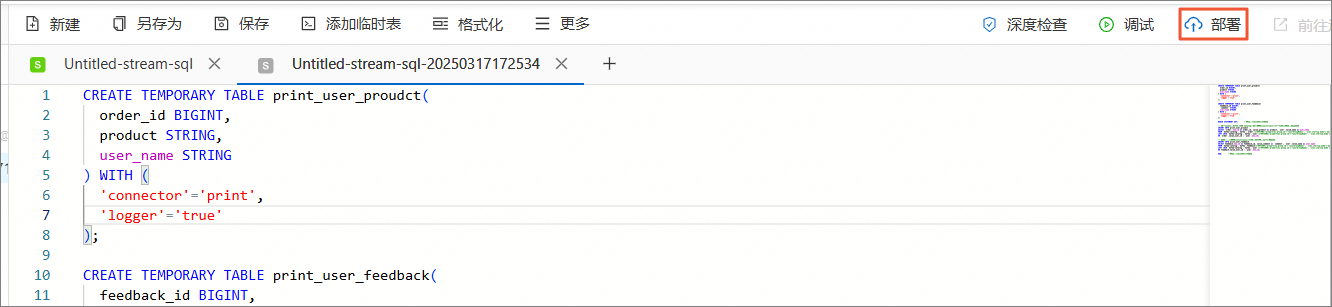
在页面,新建SQL流作业,并将如下代码拷贝到SQL编辑器。
CREATE TEMPORARY TABLE print_user_proudct( order_id BIGINT, product STRING, user_name STRING ) WITH ( 'connector'='print', 'logger'='true' ); CREATE TEMPORARY TABLE print_user_feedback( feedback_id BIGINT, `comment` STRING, user_name STRING ) WITH ( 'connector'='print', 'logger'='true' ); BEGIN STATEMENT SET; --写入多个Sink时,必填。 -- 将订单信息和Kafka JSON Catalog中的用户表做join,展示每个订单的用户名和商品名。 INSERT INTO print_user_proudct SELECT `order`.key_id as order_id, value_product as product, `user`.value_name as user_name FROM `kafka-catalog`.`kafka`.`order`/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as `order` --指定group和启动模式 LEFT JOIN `kafka-catalog`.`kafka`.`user`/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as `user` --指定group和启动模式 ON `order`.value_user_id = `user`.key_id; -- 将评论和用户表做join,展示每个评论的内容和对应用户名。 INSERT INTO print_user_feedback SELECT feedback.key_id as feedback_id, value_comment as `comment`, `user`.value_name as user_name FROM `kafka-catalog`.`kafka`.feedback/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as feedback --指定group和启动模式 LEFT JOIN `kafka-catalog`.`kafka`.`user`/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as `user` --指定group和启动模式 ON feedback.value_user_id = `user`.key_id; END; --写入多个Sink时,必填。单击右上方的部署,进行作业部署。
单击左侧导航栏的,单击目标作业操作列的启动,选择无状态启动后单击启动。
等待作业状态为运行中。


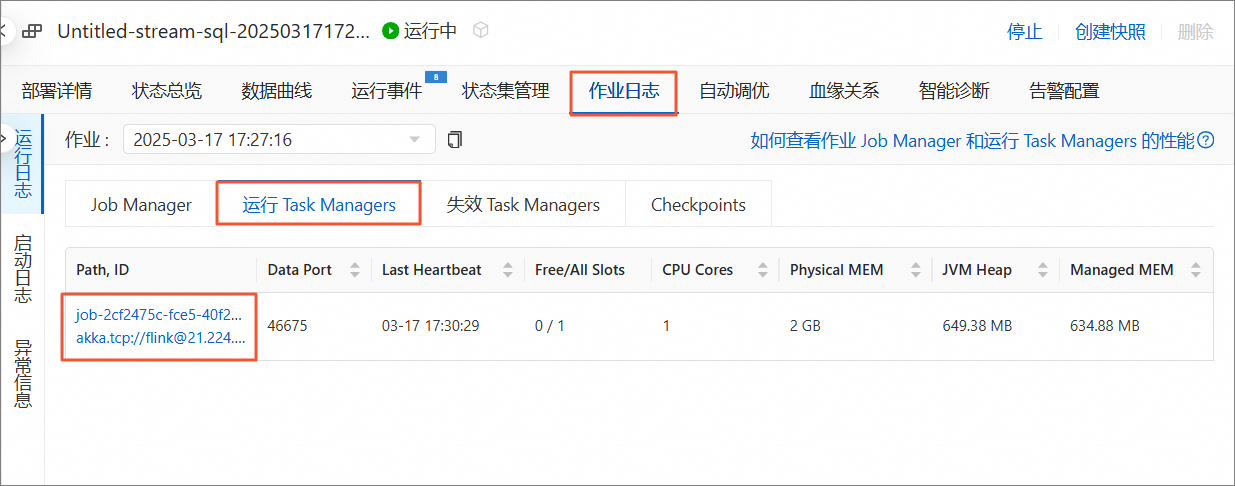
查看作业结果
单击左侧导航栏的,单击目标作业。
在作业日志页签,单击运行Task Managers页签下的Path, ID的任务。
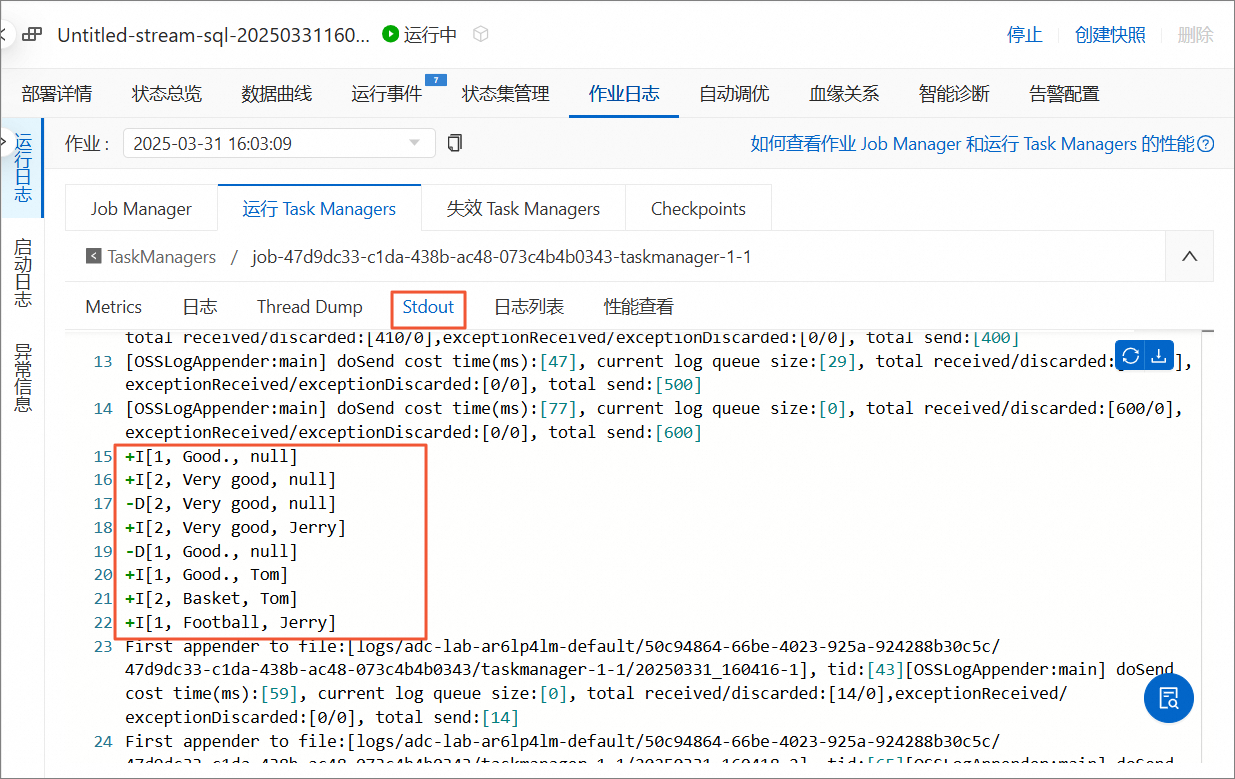
单击Stdout选项卡,下滑页面可看到相关的日志信息。
本示例通过Print连接器直接打印结果,您也可以输出到连接器的结果表中进一步分析计算。写入多个SINK语法,详情请参见INSERT INTO语句。
说明在直接使用时,由于可能发生了Schema变更,Kafka JSON Catalog解析出的Schema可能与MySQL对应表存在差异,例如出现已经删除的字段,部分字段可能出现为null的情况。
Catalog读取出的Schema由消费到的数据的字段组成。如果存在删除的字段且消息未过期,则会出现一些已经不存在的字段,这样的字段值会为null,该情况无需特殊处理。

清理资源
在完成实验后,如果无需继续使用资源,选择不保留资源,单击结束实操。在结束实操对话框中,单击确定。
在完成实验后,如果需要继续使用资源,选择付费保留资源,单击结束实操。在结束实操对话框中,单击确定。请随时关注账户扣费情况,避免发生欠费。