Qwen3大模型在阿里云ACS GPU极简部署教程
本实验带您体验如何在容器计算服务ACS集群中,借助vLLM服务框架快速部署Qwen3模型,并通过OpenWebUI提供对外交互界面。
场景简介
本实验介绍了在容器计算服务ACS集群中,借助vLLM服务框架快速部署Qwen3模型,并通过OpenWebUI提供对外交互界面。本实验使用Qwen3-0.6B模型,您也可以使用其他模型来提供推理服务。
费用说明
本实验时长2个小时,预计产生费用为12元,为保障实验顺利进行,请确保账户余额高于100元。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
ACS集群不收取集群管理费,所产生的费用包括ACS容器算力费用和云产品资源计费。
本场景资源不会自动释放,若无需保留资源,请参考手册手动删除资源,以免产生额外费用。
背景知识
本场景主要涉及以下云产品和服务:
阿里云容器计算服务ACS(Alibaba Cloud Container Compute Service,ACS)是以K8s为使用界面供给容器算力资源的云计算服务,提供符合容器规范的算力资源。算力交付模式为Serverless形态,您无需关注底层节点及集群的运维管理。ACS支持按需弹性和资源预留的资源使用方式,以及秒级的按量付费模式。算力资源可同时支持您的容器应用负载和云产品的负载。
Qwen3
通义千问Qwen3是Qwen系列最新推出的首个混合推理模型。旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相比,表现出极具竞争力的结果。此外,小型MoE模型Qwen3-30B-A3的激活参数数量是QwQ-32B的10%,表现更胜一筹,甚至像Qwen3-4B这样的小模型也能匹敌Qwen2.5-72B-Instruct的性能。Qwen3支持多种思考模式,用户可以根据具体任务控制模型进行思考的程度。Qwen3模型支持119种语言和方言, 同时也加强了对MCP的支持。更多信息请参考《Qwen3:思深,行速》。
vLLM
vLLM是一个高效易用的大语言模型推理服务框架,vLLM支持包括通义千问在内的多种常见大语言模型。vLLM通过PagedAttention优化、动态批量推理(continuous batching)、模型量化等优化技术,可以取得较好的大语言模型推理效率。
OpenWebUI
OpenWebUI是一个可扩展、功能丰富且用户友好的自托管AI平台,旨在完全离线运行。它支持各种LLM运行器(例如 Ollama)和兼容OpenAI的API,并内置RAG推理引擎,使其成为强大的AI部署解决方案。
开通并授权容器计算服务ACS
首次使用时,您需要开通容器计算服务ACS,并为其授权相应云资源的访问权限。
如果您的阿里云账号已开通过容器计算服务ACS并且已完成角色授权,请跳过此小节步骤。
登录容器计算服务控制台,首次登录会跳转到开通引导页面。
在容器计算服务(ACS)页面,单击前往开通。

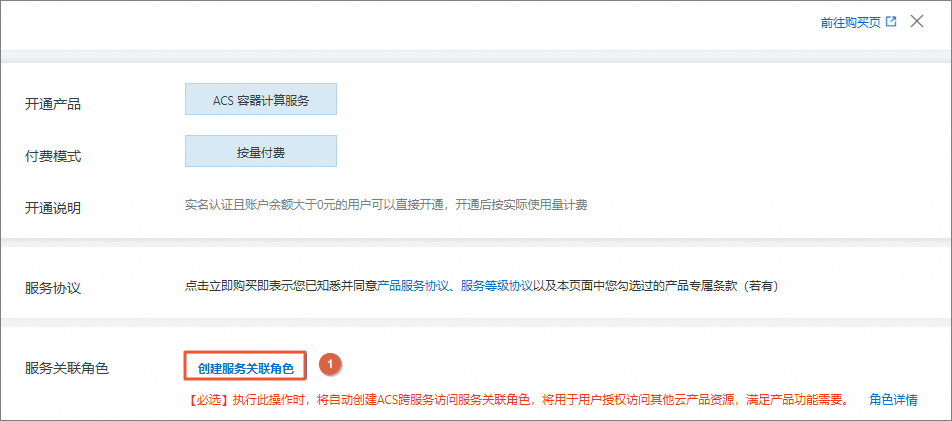
在开通容器计算服务(ACS)面板,单击创建服务关联角色,当服务关联角色显示已创建后,单击立即购买。
返回容器计算服务(ACS)页面,单击刷新,当容器计算服务(ACS)服务显示为已开通状态时,单击下一步。
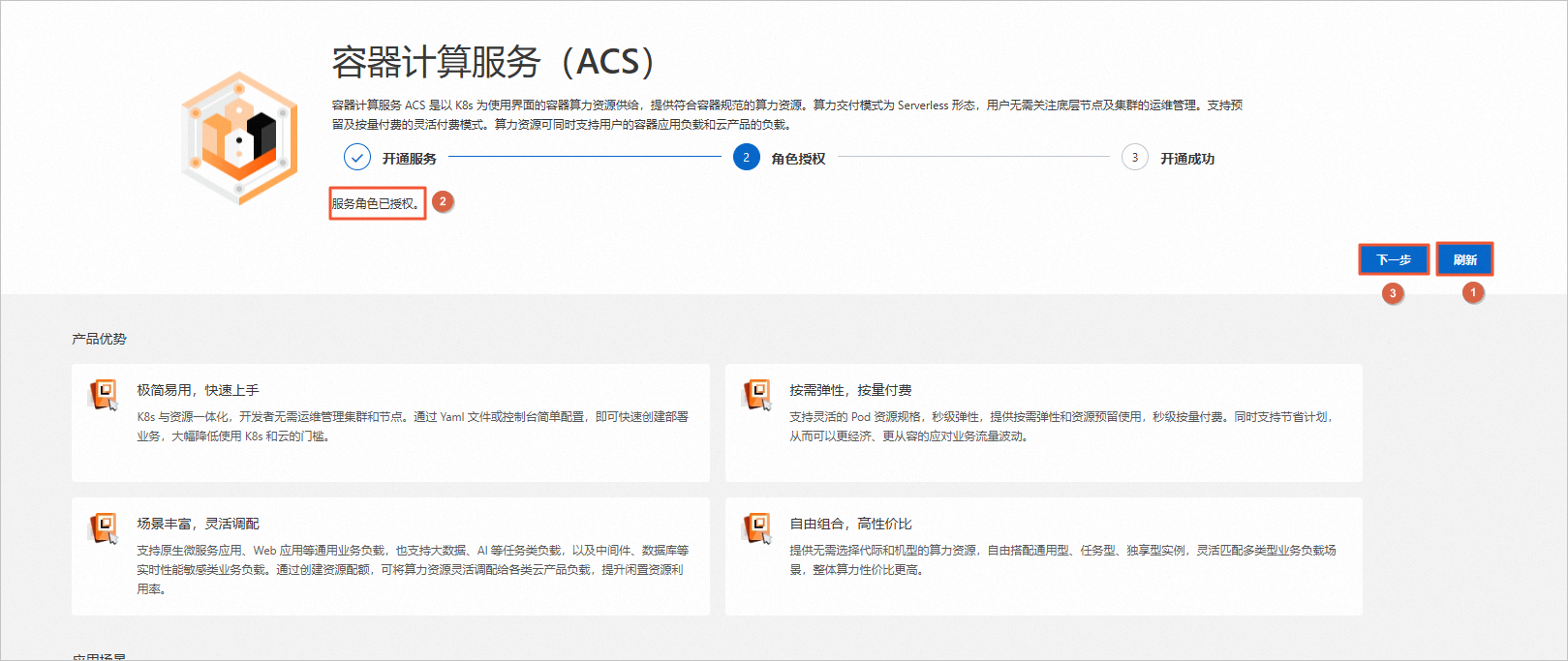
在容器计算服务(ACS)页面,单击前往授权。
在访问控制快速授权页面,单击确认授权。

返回容器计算服务(ACS)页面,单击刷新,当显示服务角色已授权时,单击下一步。
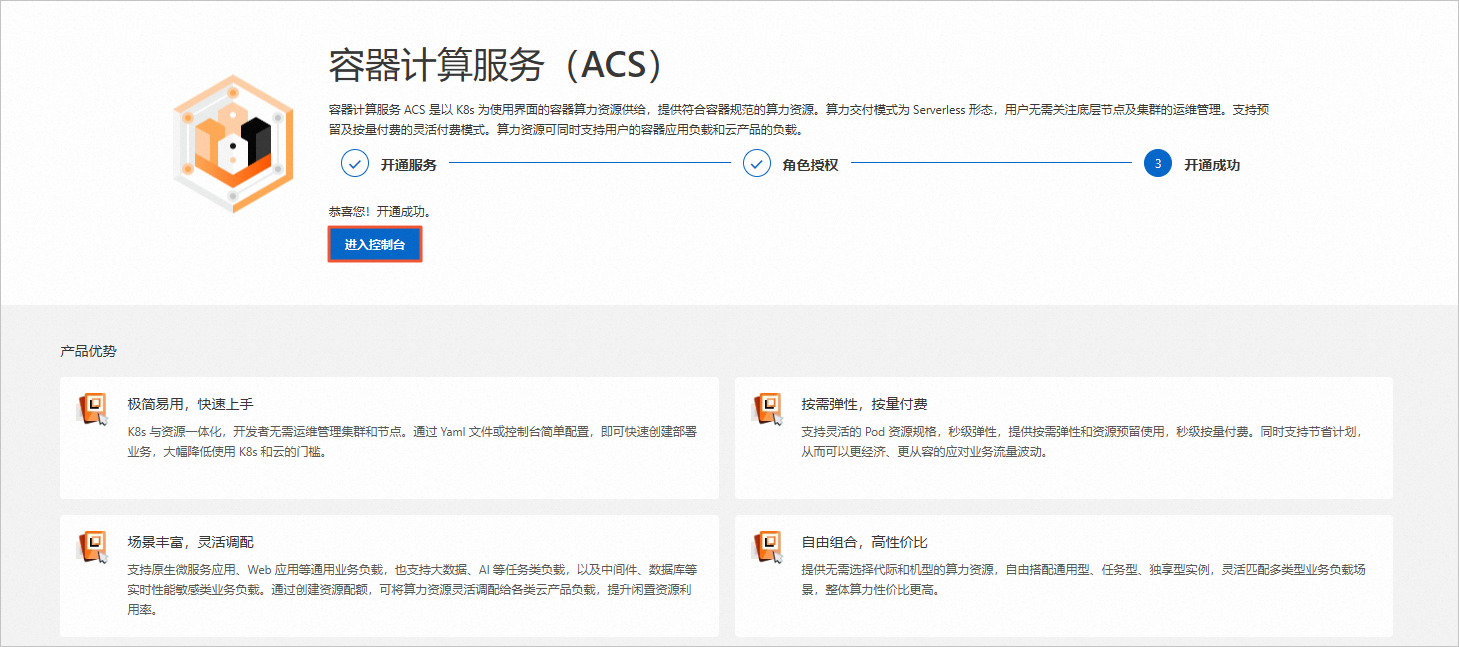
在容器计算服务(ACS)页面,单击进入控制台。
返回如下页面,表示您已成功开通并授权容器计算服务ACS。

创建ACS集群
本步骤介绍如何快速创建一个ACS集群。
登录容器计算服务控制台。
在集群列表页面,单击创建集群。
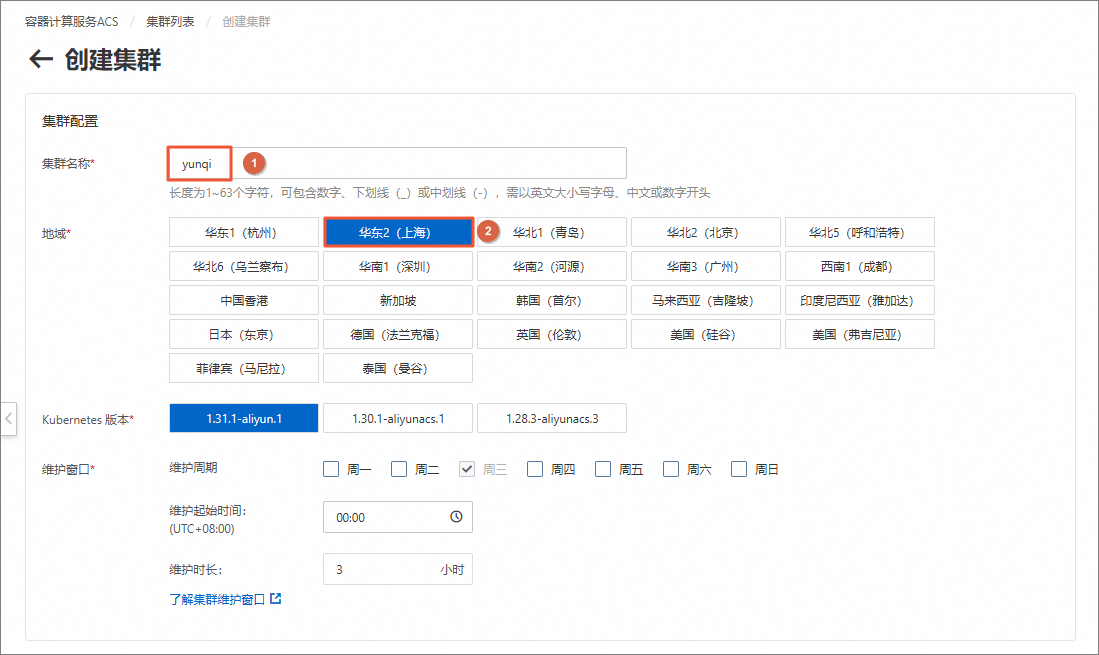
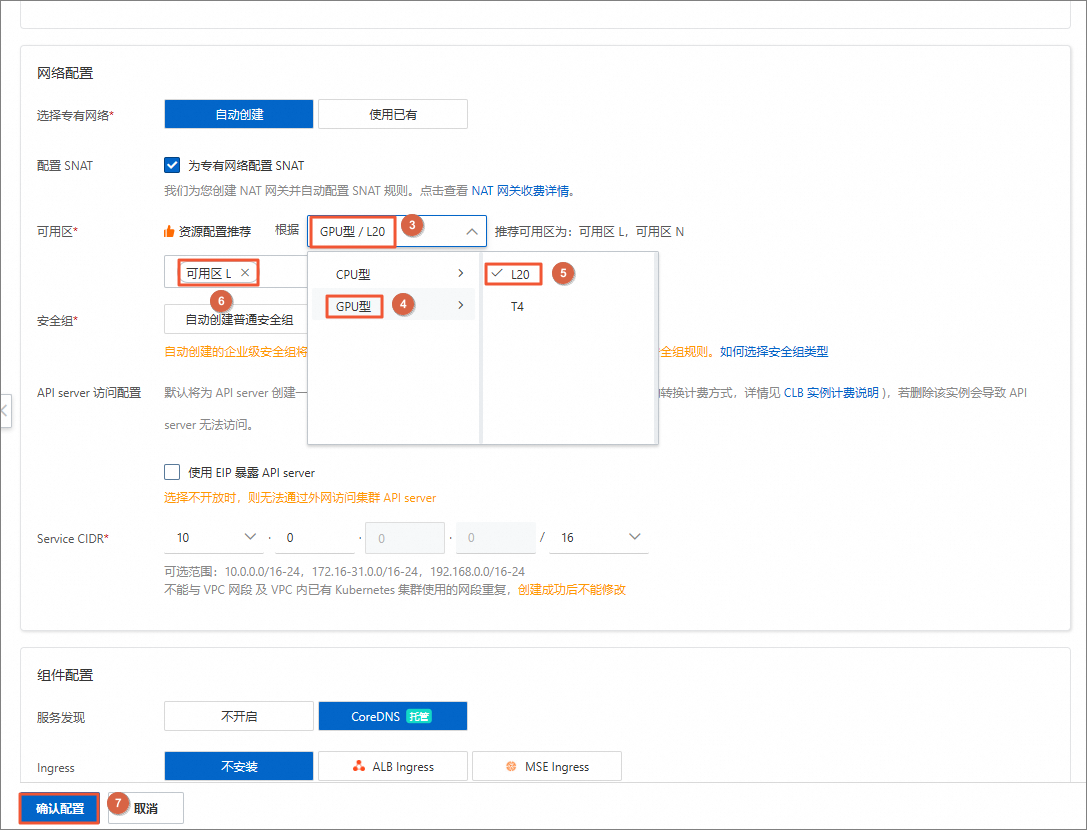
在创建集群页面,根据如下说明配置参数,未提及的参数保持默认即可,单击确认配置。
配置项
说明
示例
集群名称
自定义集群的名称。
yunqi
地域
选择集群所在的地域。
本实验中的示例镜像仓库在上海地域,选择上海可以加速服务启动。
华东2(上海)
可用区
不同的可用区可分配的物理资源不同。
本实验需要使用到GPU L20,不是所有可用区都有L20物理资源,因此需要提前选定要使用的资源类型,然后根据资源配置推荐明确集群所在的可用区。如果上海地域无L20可用区,可以换其他地域。
可用区L
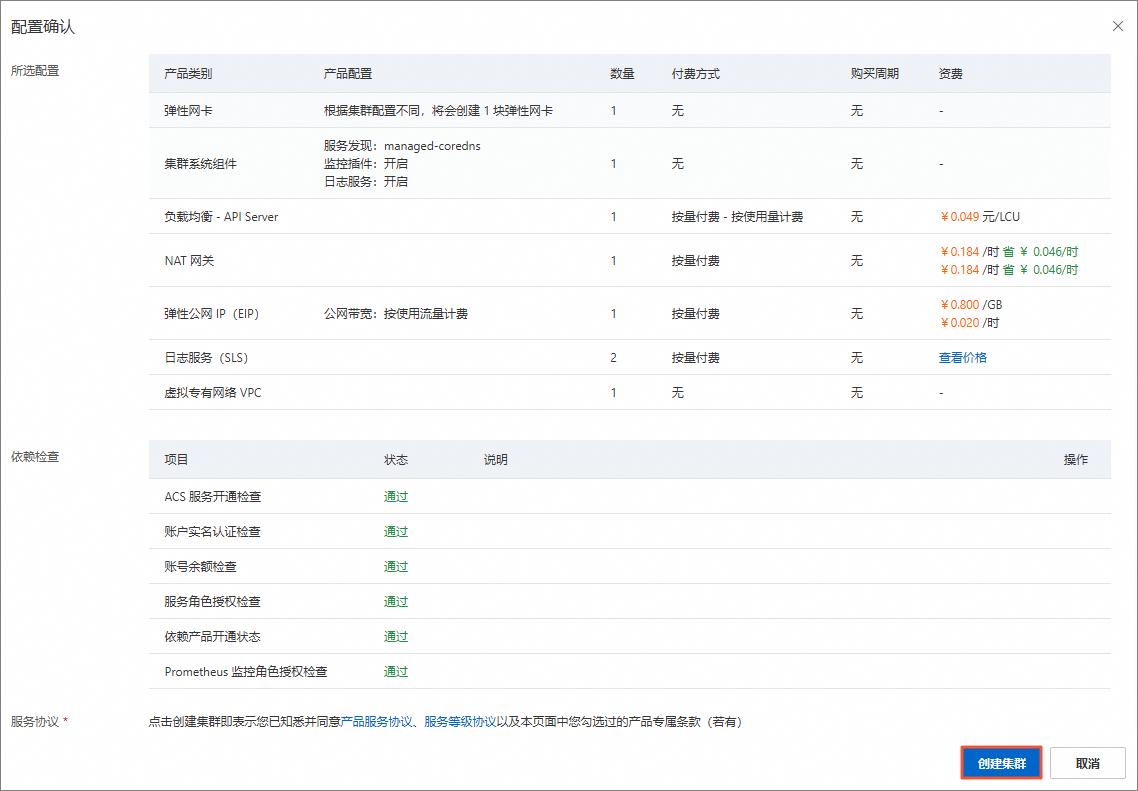
在配置确认面板,确认所选配置,待依赖检查全部通过后,单击创建集群。
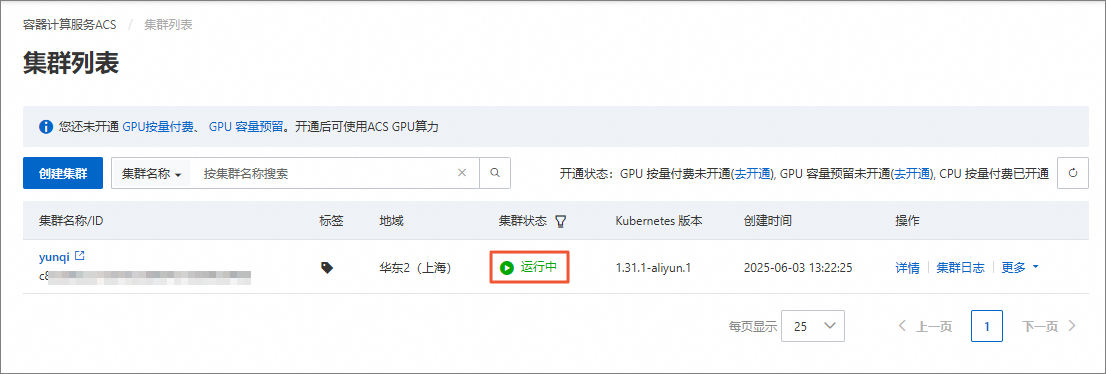
在集群列表页面,请您耐心等待集群创建,集群的创建时间一般约为10分钟。当集群状态变为运行中时,表示已成功创建ACS集群。
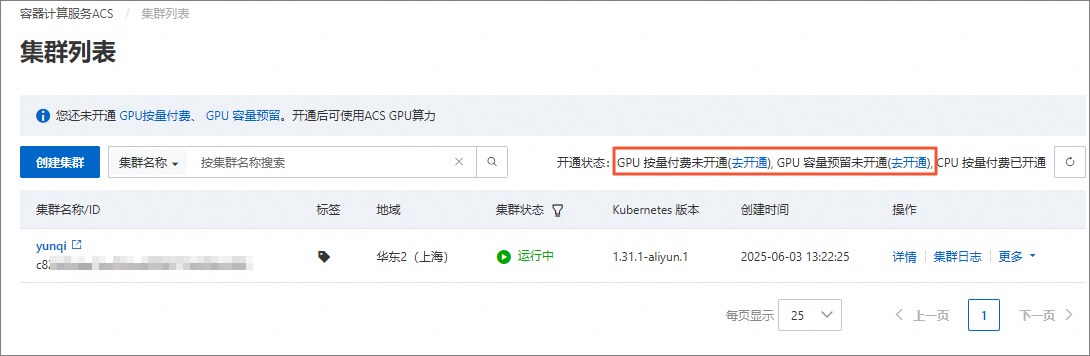
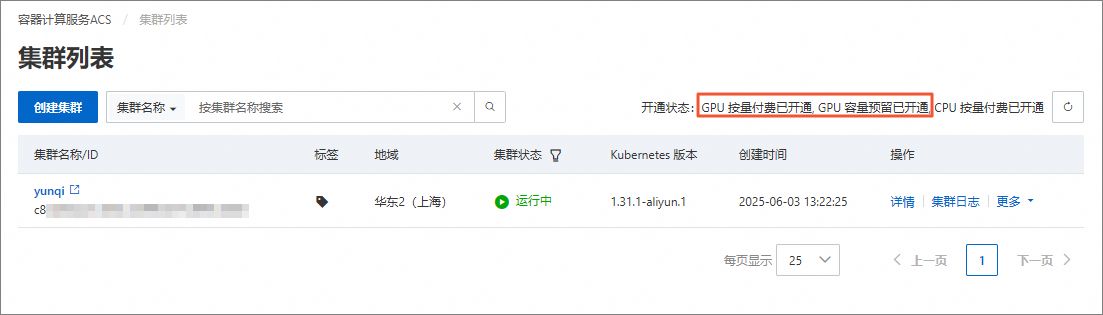
开通GPU按量付费和GPU容量预留。
在集群列表页面,根据页面提示开通GPU按量付费和GPU容量预留。
说明本实验使用ACS提供的GPU算力,您需要根据页面提示开通相关服务。若您已开通相关服务,可跳过此步骤。
在集群列表页面,可查看相关服务开通状态。
使用ACS控制台部署模型推理服务
本步骤指导您如何在新创建的ACS集群中使用通用型实例快速部署一个无状态应用(Deployment),并将该应用RESTful API在集群内公开(Service)。关于创建Deployment的详细参数描述,请参见创建无状态工作负载Deployment。
本实验使用ACS提供的GPU算力,通过Labels中指定alibabacloud.com/compute-class=gpu进行资源声明。
在集群列表页面,单击目标集群名称(即yunqi)。
在左侧导航栏中,选择。
在无状态页面,单击使用YAML创建资源。
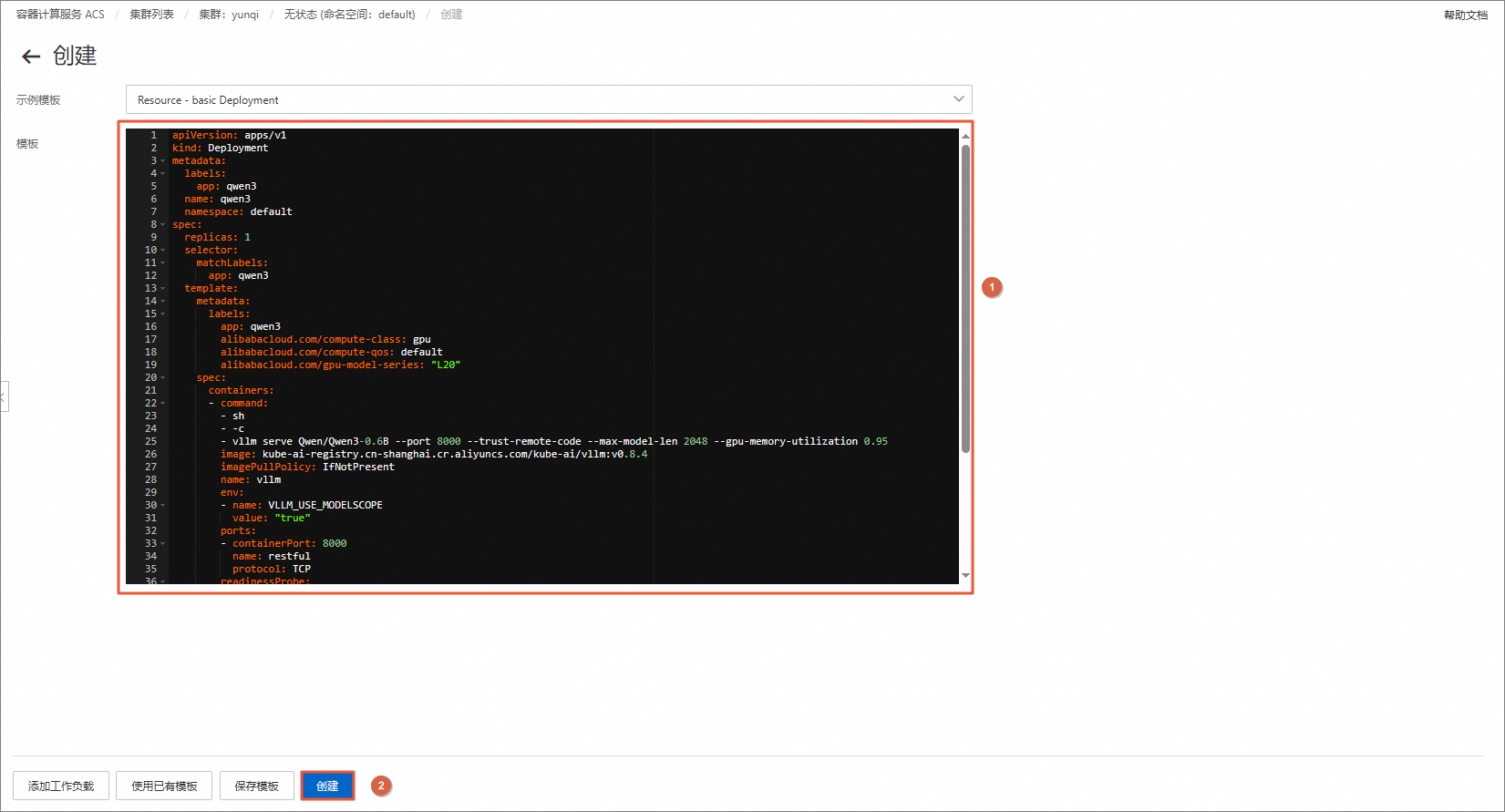
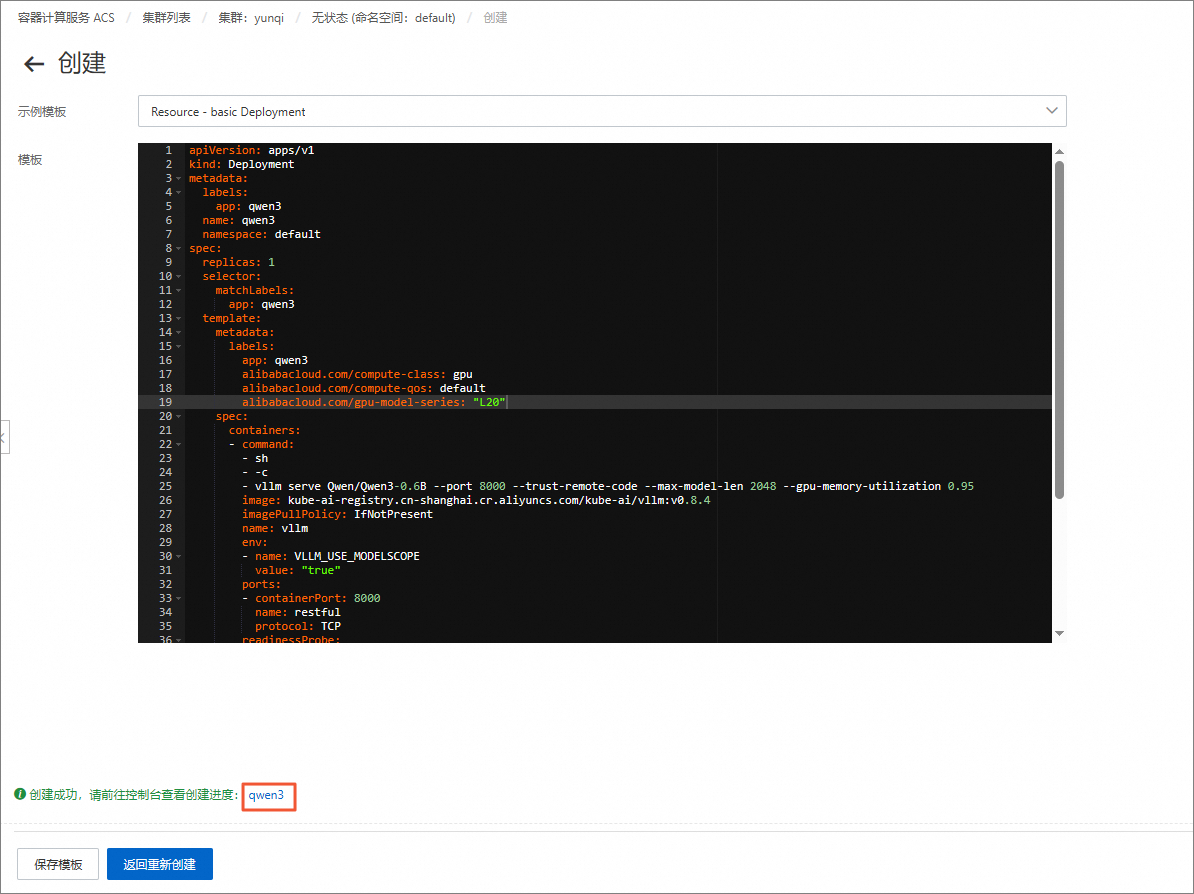
在创建页面,清空模板中的默认内容,将下方model-deploy.yaml的内容复制并粘贴到模板中,然后单击创建。
apiVersion: apps/v1 kind: Deployment metadata: labels: app: qwen3 name: qwen3 namespace: default spec: replicas: 1 selector: matchLabels: app: qwen3 template: metadata: labels: app: qwen3 alibabacloud.com/compute-class: gpu alibabacloud.com/compute-qos: default alibabacloud.com/gpu-model-series: "L20" spec: containers: - command: - sh - -c - vllm serve Qwen/Qwen3-0.6B --port 8000 --trust-remote-code --max-model-len 2048 --gpu-memory-utilization 0.95 image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.8.4 imagePullPolicy: IfNotPresent name: vllm env: - name: VLLM_USE_MODELSCOPE value: "true" ports: - containerPort: 8000 name: restful protocol: TCP readinessProbe: tcpSocket: port: 8000 initialDelaySeconds: 30 resources: limits: nvidia.com/gpu: "1" cpu: 8 memory: 16Gi requests: nvidia.com/gpu: "1" cpu: 8 memory: 16Gi在创建页面,单击下方的qwen3。
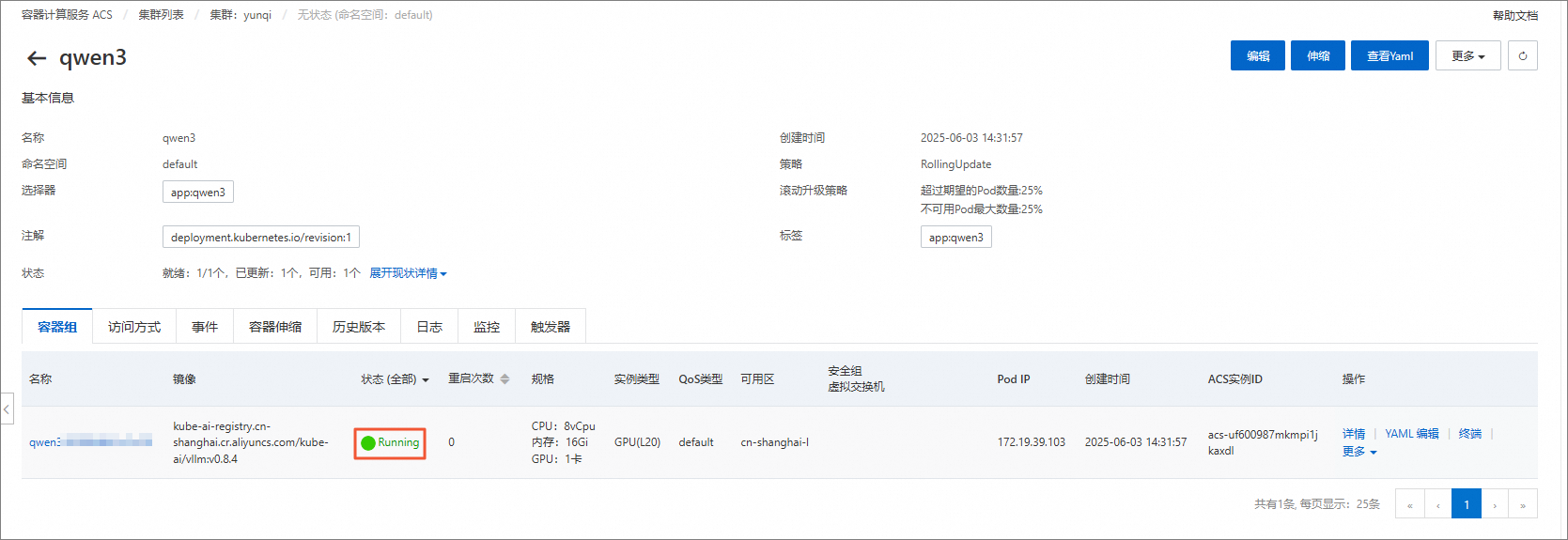
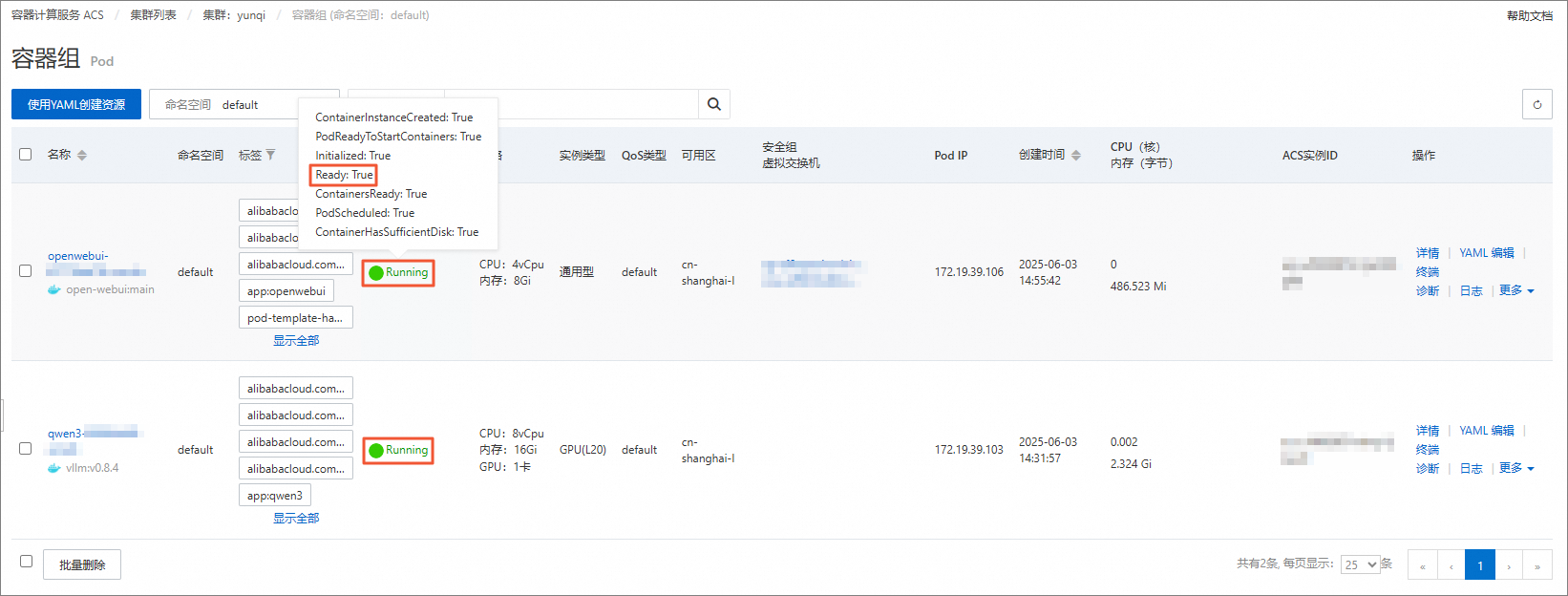
在容器组页签,可以看到容器是否已经成功就绪,当Pod进入Running状态时表示已经完成服务启动。
说明示例镜像kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.8.4本身有8GB大小,另外服务启动后要拉取模型Qwen/Qwen3-0.6B,有1.5GB大小,视网络情况可能存在10~25分钟的服务就绪时间,服务就绪之前,可以先进行后续其他准备步骤。
在左侧导航栏中,选择。
在服务页面,单击使用YAML创建资源。
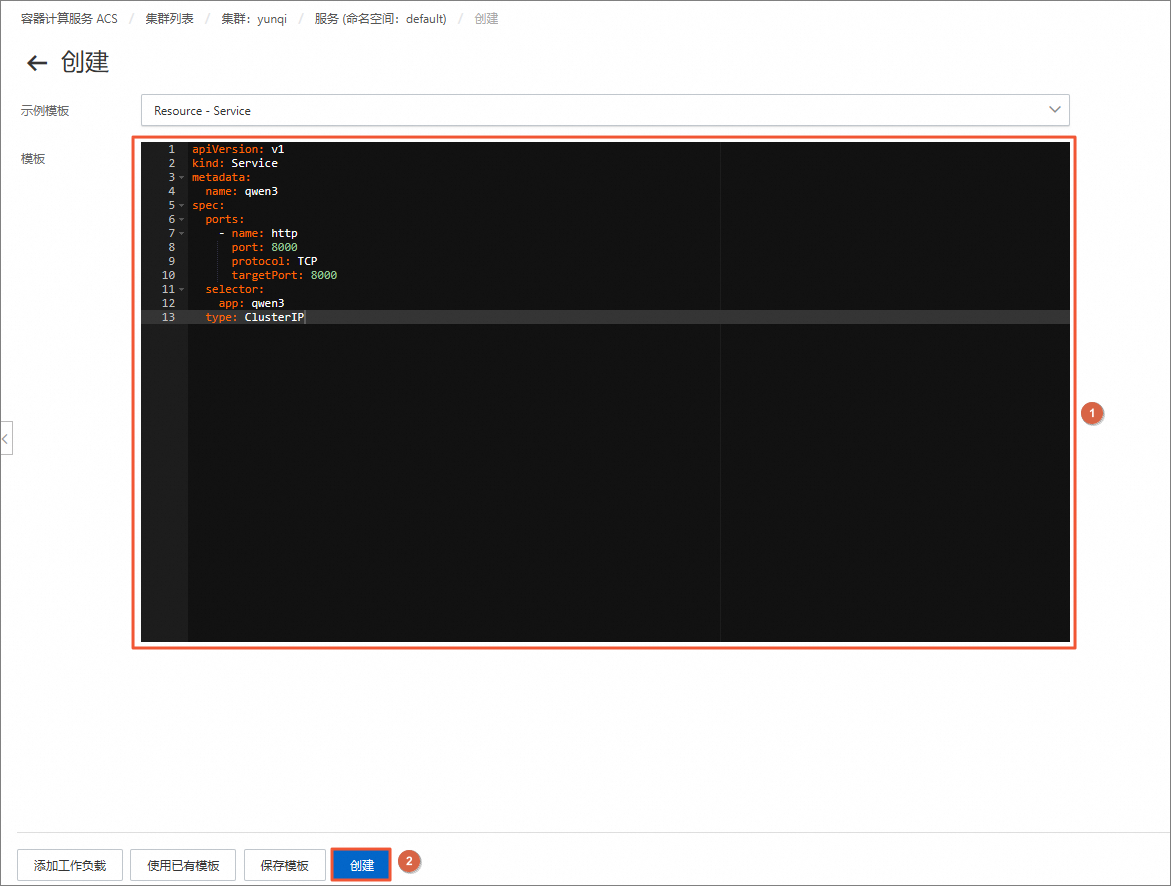
在创建页面,清空模板中的默认内容,将下方model-svc.yaml中的内容复制并粘贴到模板中,然后单击创建。
apiVersion: v1 kind: Service metadata: name: qwen3 spec: ports: - name: http port: 8000 protocol: TCP targetPort: 8000 selector: app: qwen3 type: ClusterIP


使用ACS控制台部署模型交互服务
本步骤指导您如何部署open-webui提供的模型交互界面。并通过k8s service提供的LoadBalancer方式将模型服务暴露到公网上。
在左侧导航栏中,选择。
在无状态页面,单击使用YAML创建资源。
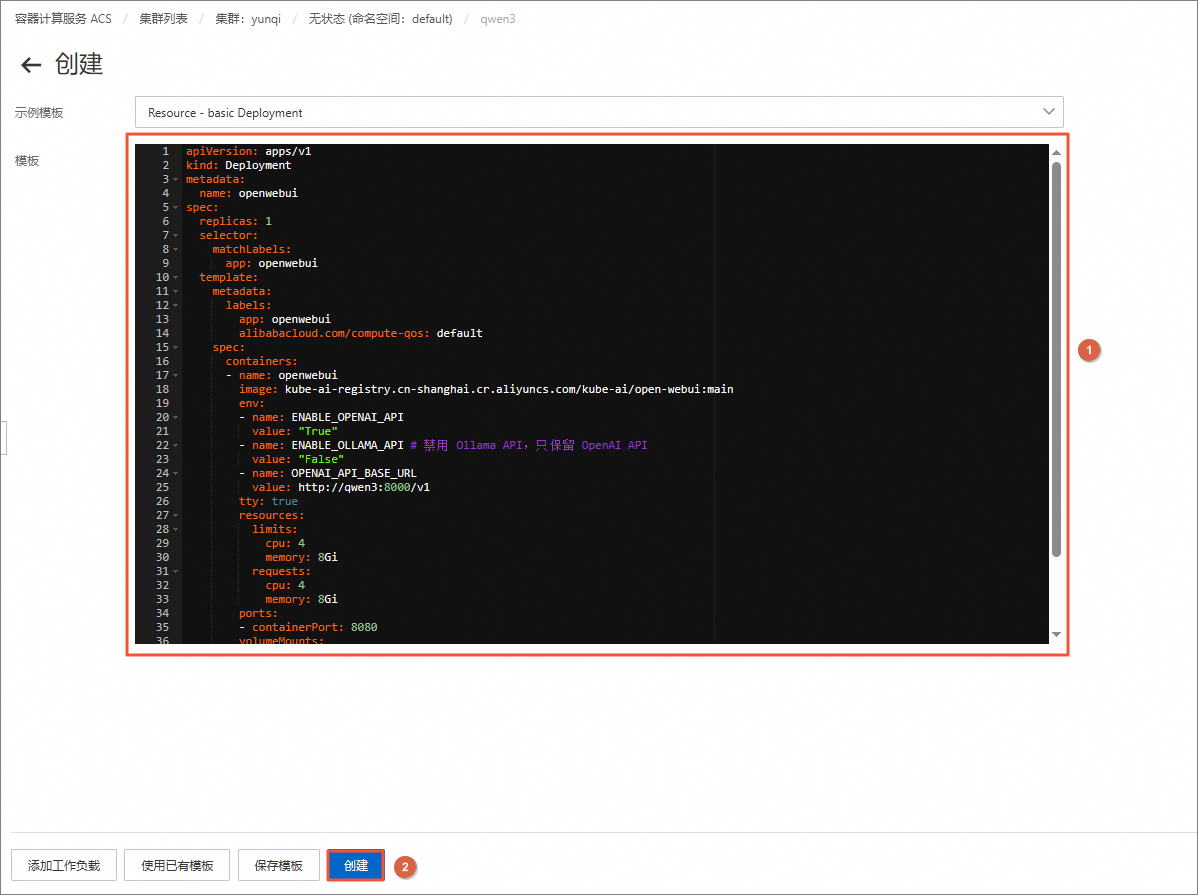
在创建页面,清空模板中的默认内容,将下方openwebui-deploy.yaml中的内容复制并粘贴到模板中,然后单击创建。
apiVersion: apps/v1 kind: Deployment metadata: name: openwebui spec: replicas: 1 selector: matchLabels: app: openwebui template: metadata: labels: app: openwebui alibabacloud.com/compute-qos: default spec: containers: - name: openwebui image: kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/open-webui:main env: - name: ENABLE_OPENAI_API value: "True" - name: ENABLE_OLLAMA_API # 禁用 Ollama API,只保留 OpenAI API value: "False" - name: OPENAI_API_BASE_URL value: http://qwen3:8000/v1 tty: true resources: limits: cpu: 4 memory: 8Gi requests: cpu: 4 memory: 8Gi ports: - containerPort: 8080 volumeMounts: - name: data-volume mountPath: /app/backend/data volumes: - name: data-volume emptyDir: {}在左侧导航栏中,选择。
在服务页面,单击使用YAML创建资源。
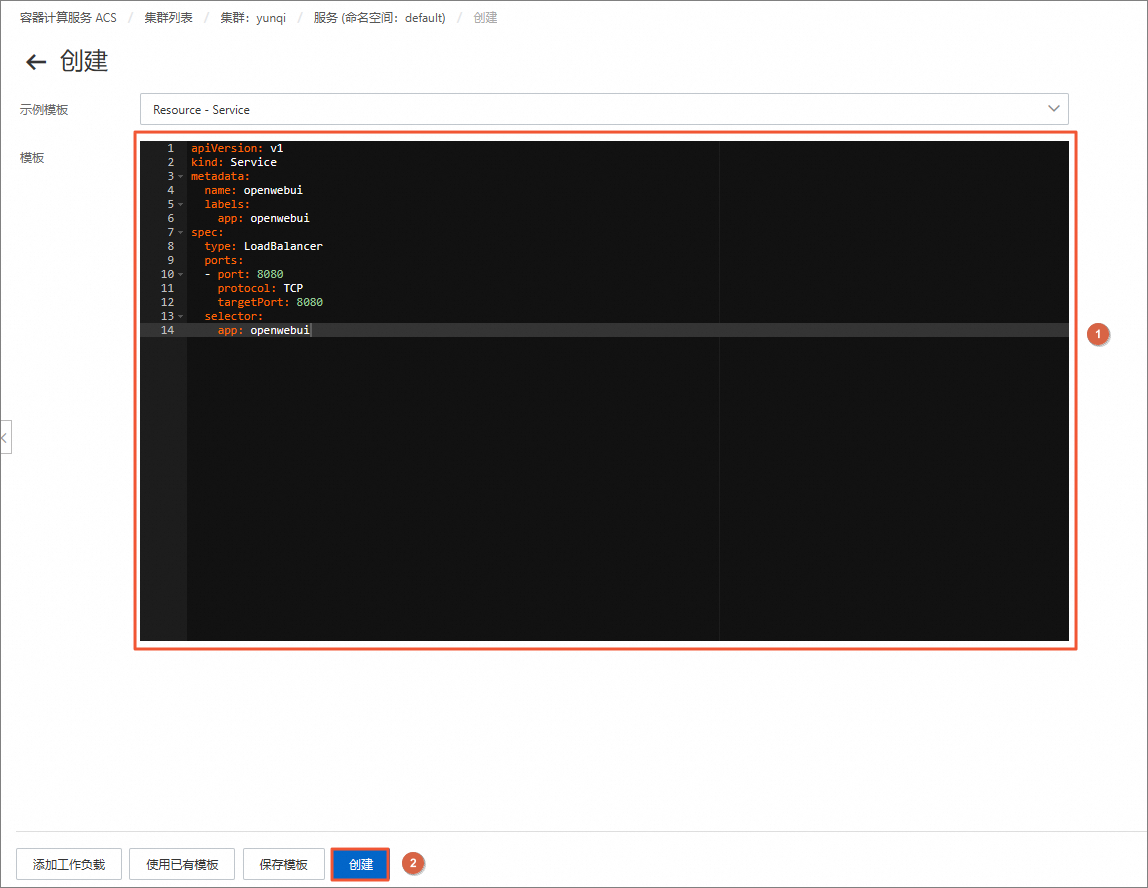
在创建页面,清空模板中的默认内容,将下方openwebui-svc.yaml中的内容复制并粘贴到模板中,然后单击创建。
apiVersion: v1 kind: Service metadata: name: openwebui labels: app: openwebui spec: type: LoadBalancer ports: - port: 8080 protocol: TCP targetPort: 8080 selector: app: openwebui


使用大模型推理服务
本步骤指导您如何在公网上使用任何一个浏览器上,访问部署的模型服务。
使用模型服务之前,需要确认底层容器资源都已经就绪。
在左侧导航栏中,选择。
在容器组页面,确认模型推理服务(即qwen3)和模型交互服务(即openwebui)的容器资源已经就绪。
确认部署的service已经就绪,特别是openwebui对应的外部IP地址。
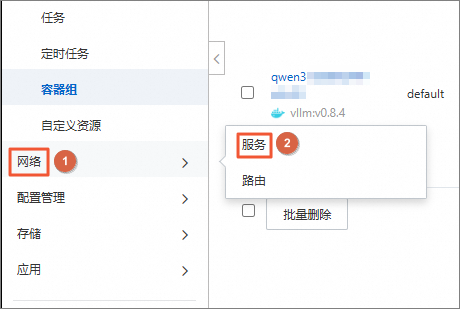
在左侧导航栏中,选择。
在服务页面,确认qwen3和openwebui的service已经就绪,查看openwebui的外部IP地址是否生成。
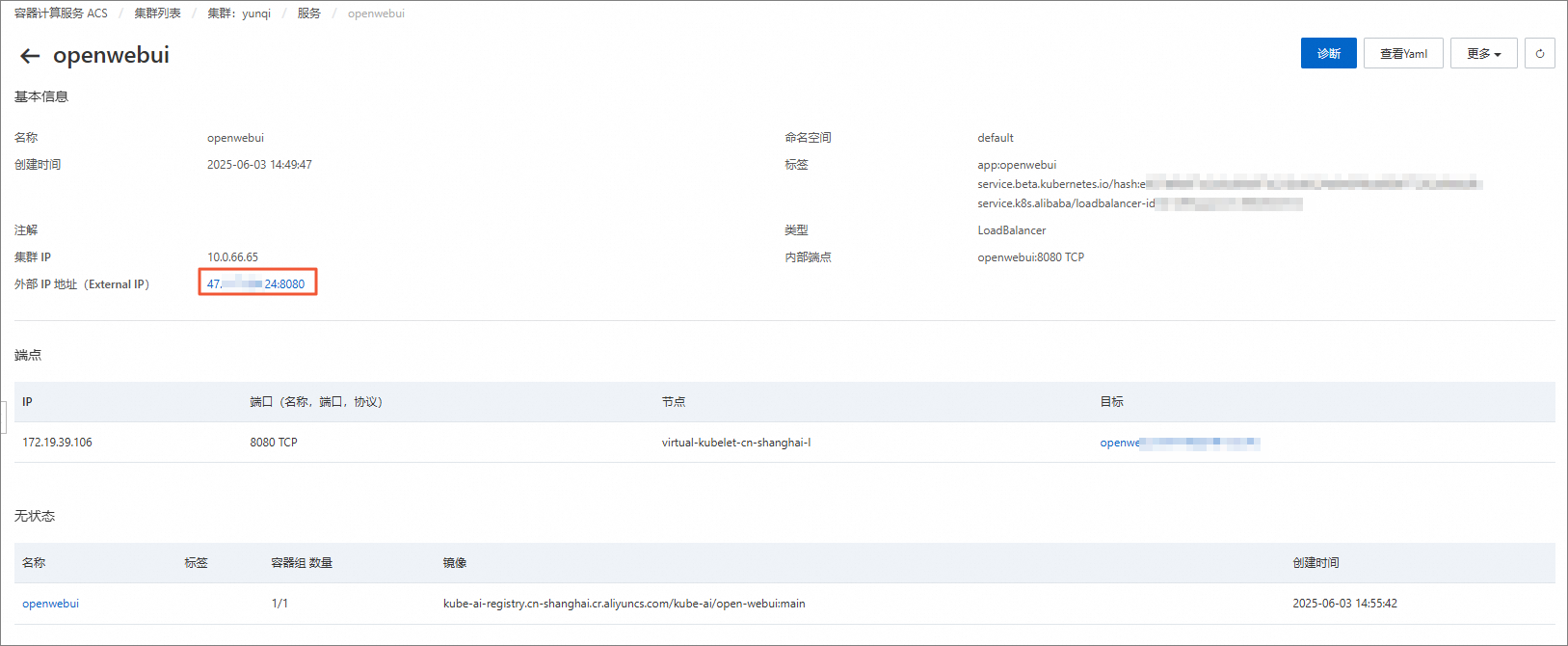
在服务页面,单击openwebui。
在openwebui的基本信息区域中,查看对外暴露的完整URL(即外部IP地址)。
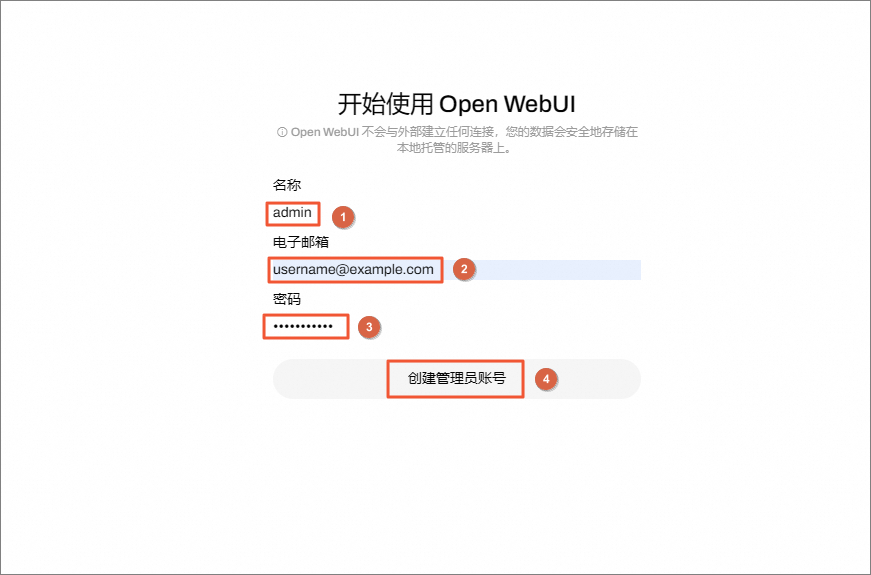
在本地电脑上使用浏览器访问openwebui的外部IP地址,进入OpenWebUI页面,单击开始使用。
首次登录时,请根据页面提示创建管理员账号。
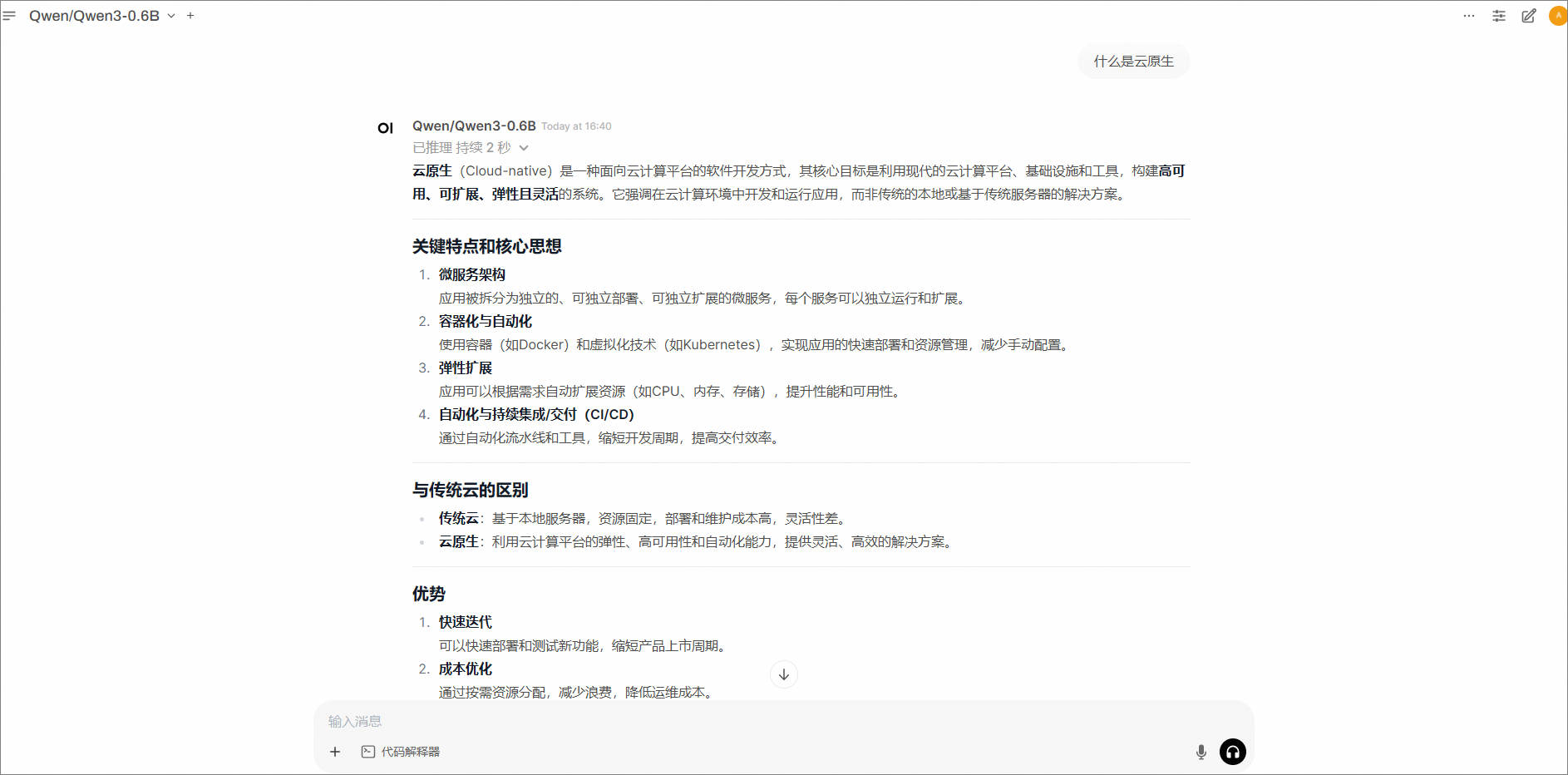
现在您就可以在OpenWebUI页面使用大模型服务,使用效果如下。




释放资源
在完成实验后,如果无需继续使用资源,请根据以下步骤,先删除相关资源后,再结束实操,否则资源会持续运行产生费用。
删除容器计算服务ACS集群。
登录容器计算服务控制台。
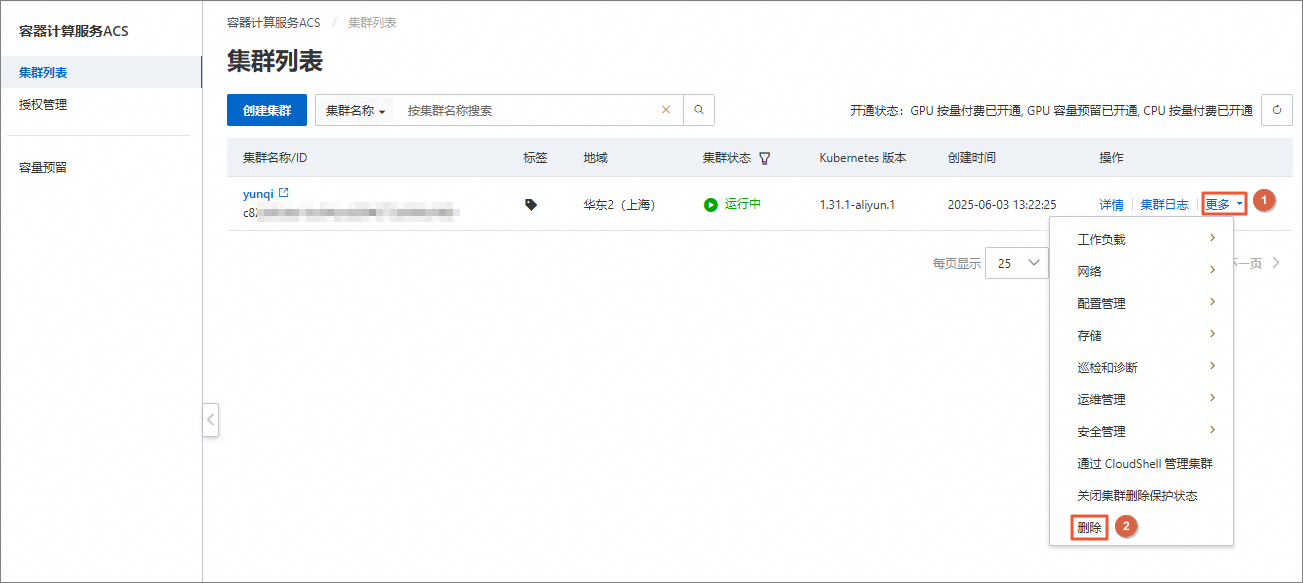
在集群列表页面,找到目标ACS集群,选择其右侧操作列下的
在关闭集群删除保护状态对话框中,关闭集群删除保护的开关,单击确定。
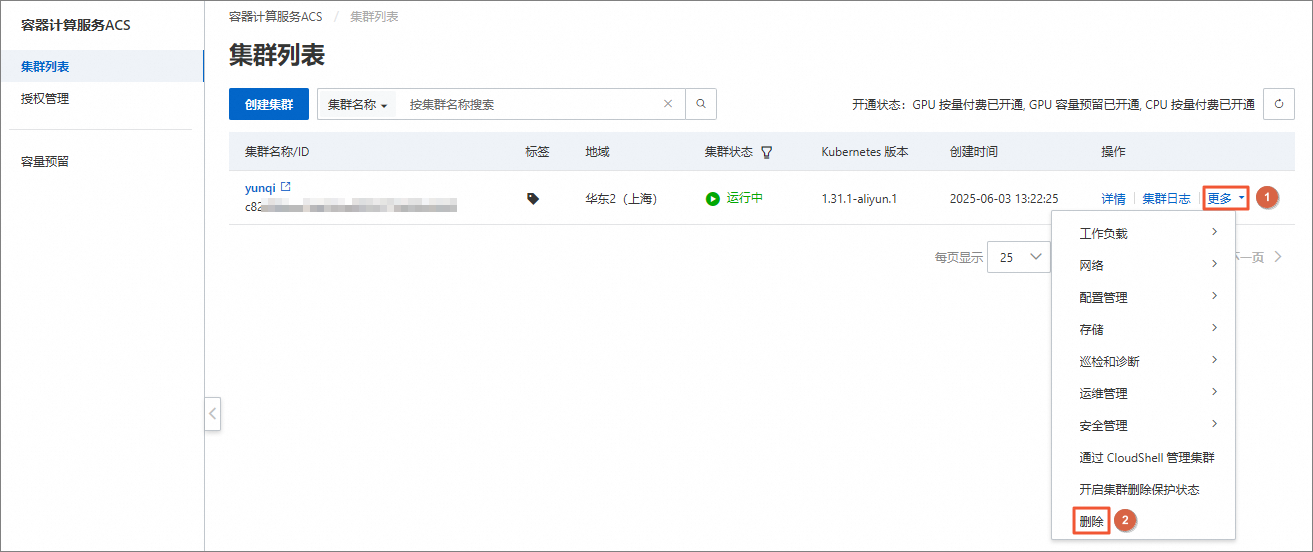
在集群列表页面,找到目标ACS集群,选择其右侧操作列下的。
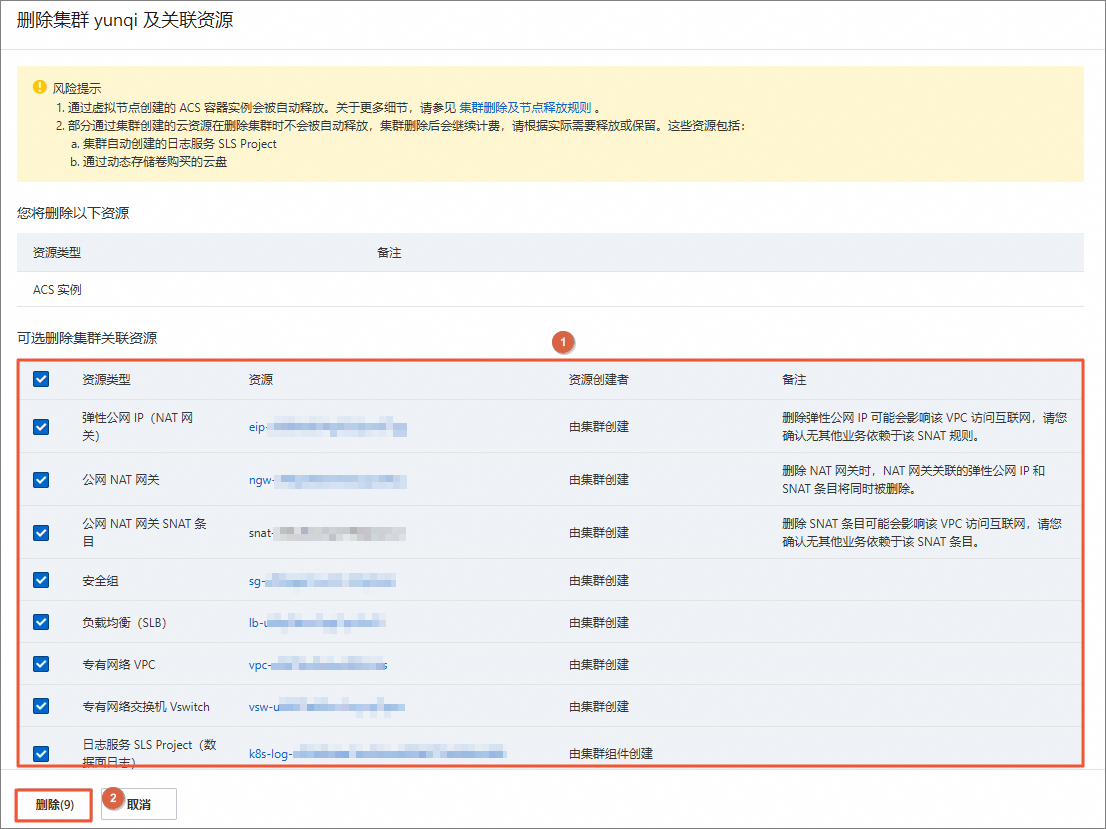
在删除集群及关联资源面板,选择删除所有的集群关联资源,单击删除。
在确认删除集群对话框中,输入需要删除的集群名称,勾选我已知晓以上信息并确认删除,单击确认删除。
删除容器计算服务ACS集群后,单击结束实操。在结束实操对话框中,单击确定。
在完成实验后,如果需要继续使用资源,选择付费保留资源,单击结束实操。在结束实操对话框中,单击确定。请随时关注账户扣费情况,避免发生欠费。