
ACK集群高可用方案
方案概述
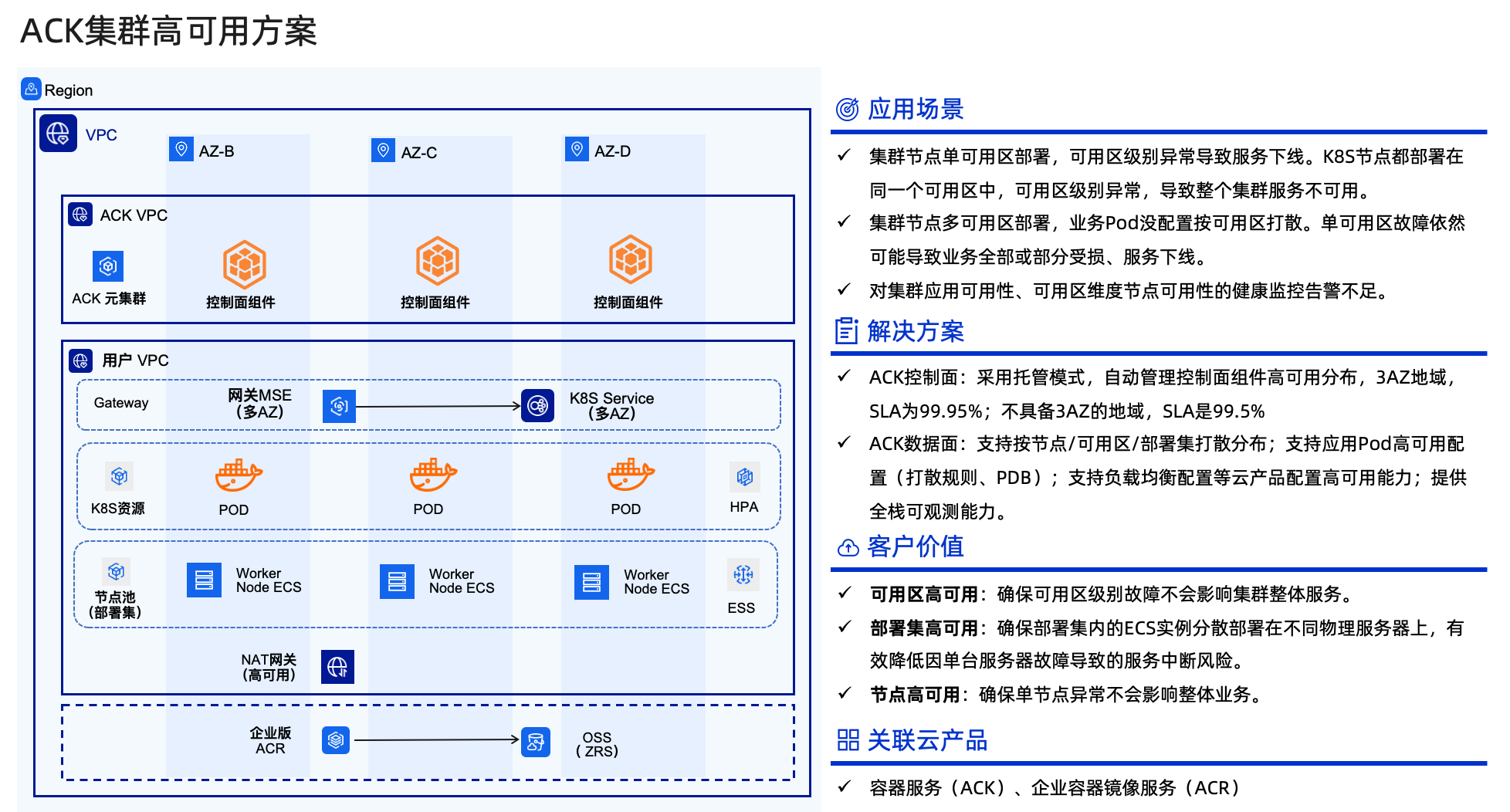
阿里云容器服务ACK(Alibaba Cloud Container Service for Kubernetes)高可用架构基于全链路冗余设计,覆盖控制面、数据面、应用层及基础设施,为企业关键业务提供99.95% SLA保障。
本方案通过节点多可用区部署、自动弹性伸缩、应用负载多可用区部署及相关联云产品多可用区容灾等核心能力,实现从集群基础设施到上层业务的端到端容灾能力,满足金融、电商、制造等行业对稳定性与连续性要求严苛的场景需求。
方案优势
提供全方位ACK集群高可用指导
覆盖了从控制面、数据面各项关键配置。方案会详细介绍在配置ACK集群过程中要参考以下这几个原则:
按节点/可用区/部署集打散分布
支持应用Pod高可用配置(打散、PDB、探针)
支持负载均衡配置等云产品配置高可用的产品能力
支持对应用可用性的可观测能力
客户场景
单ACK高可用架构
场景描述
生产环境中部署了ACK集群,希望ACK具备高可用架构容灾设计,提升业务稳定性。
适用客户
使用容器服务(ACK)的客户。
对ACK高可用容灾架构有需求。
对ACK需要有端到端的高可用的需求。
方案架构

从这张架构图中我们可以看到其中ACK控制面组件以Pod形式运行在ACK的元集群当中,使用KoK的架构进行管理,ACK负责管理控制面组件的全生命周期。数据面资源在用户的VPC中,这块有几点最佳实践需要参考:
1、节点/可用区高可用
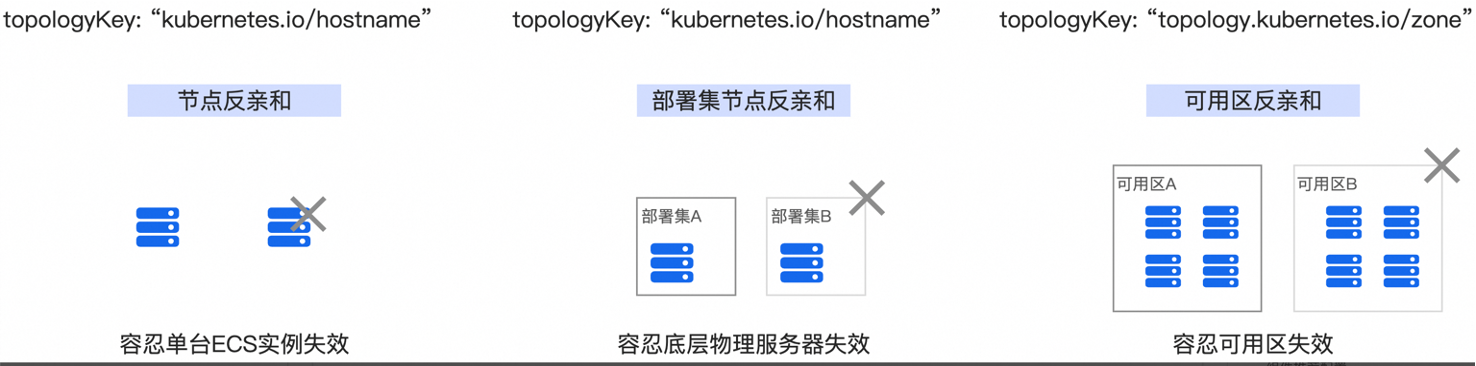
1.1 业务按节点打散部署
配置Pod的按节点反亲和调度策略,实现Pod按节点打散,达到业务的节点级别高可用。即某台ECS不可用了,但对业务不影响。
1.2 业务按部署集节点打散部署
通过配置Pod的反亲和调度策略并结合部署集,可实现业务在物理机级别的高可用性。部署集是一种用于控制ECS实例分布的策略,确保ECS实例分散部署在不同的物理服务器上,从而避免因单台物理机故障而导致多台ECS实例同时宕机的情况。为节点池指定部署集后,在节点池扩容时生成的ECS实例将自动分散到不同的物理机上,进一步提升系统的稳定性和可靠性。
1.3 业务按可用区打散部署
配置Pod的按AZ反亲和调度策略,实现Pod按可用区均匀打散,达到业务的可用区级别高可用。在同城容灾场景下,推荐采用按可用区打散部署。
2、工作负载高可用
2.1 配置Pod拓朴分布约束
通过使用拓扑分布约束(Topology Spread Constraints),可以实现Pod在不同节点和可用区之间的均匀分布,从而有效提升应用程序的高可用性和稳定性。该功能适用于多种工作负载类型,包括Deployment、StatefulSet、DaemonSet、Job以及CronJob等,能够满足不同场景下的调度需求,确保业务的平稳运行。
2.2 配置Pod反亲和
Pod反亲和(PodAntiAffinity)用于调度Pod到不同节点,以提高应用程序的高可用性和故障隔离能力。
2.3 配置Pod Disruption Budget
PDB允许定义一个最小可用副本数,当节点处于维护或故障状态时,集群将确保至少有指定数量的副本保持运行。PDB可以防止过多的副本同时终止,尤其适合多副本处理流量型的场景。
2.4 配置Pod健康检测与自愈
配置不同类型的探针来监测和管理容器的状态和可用性,包括存活探针(Liveness Probes)、就绪探针(Readiness Probes)、启动探针(Startup Probes)。
存活检查(Liveness):用于检测何时重启容器。
就绪检查(Readiness):确定容器是否已经就绪,且可以接受流量。
启动探测(Startup Probes):用于检测何时启动容器。
3、企业版容器镜像服务高可用配置
生产环境使用企业版容器镜像服务,不使用个人版容器镜像服务,因为前者支持高可用、安全扫描等产品能力。
对于企业版镜像服务,在支持OSS同城冗余的地域,创建实例默认会创建支持同城冗余的OSSBucket,实现跨可用区高可用;如果OSS在地域新增支持同城冗余,用户可以在OSS控制台将镜像服务Bucket转换为同城冗余,进而实现镜像服务的同城冗余能力。
4、云资源高可用及K8S配置
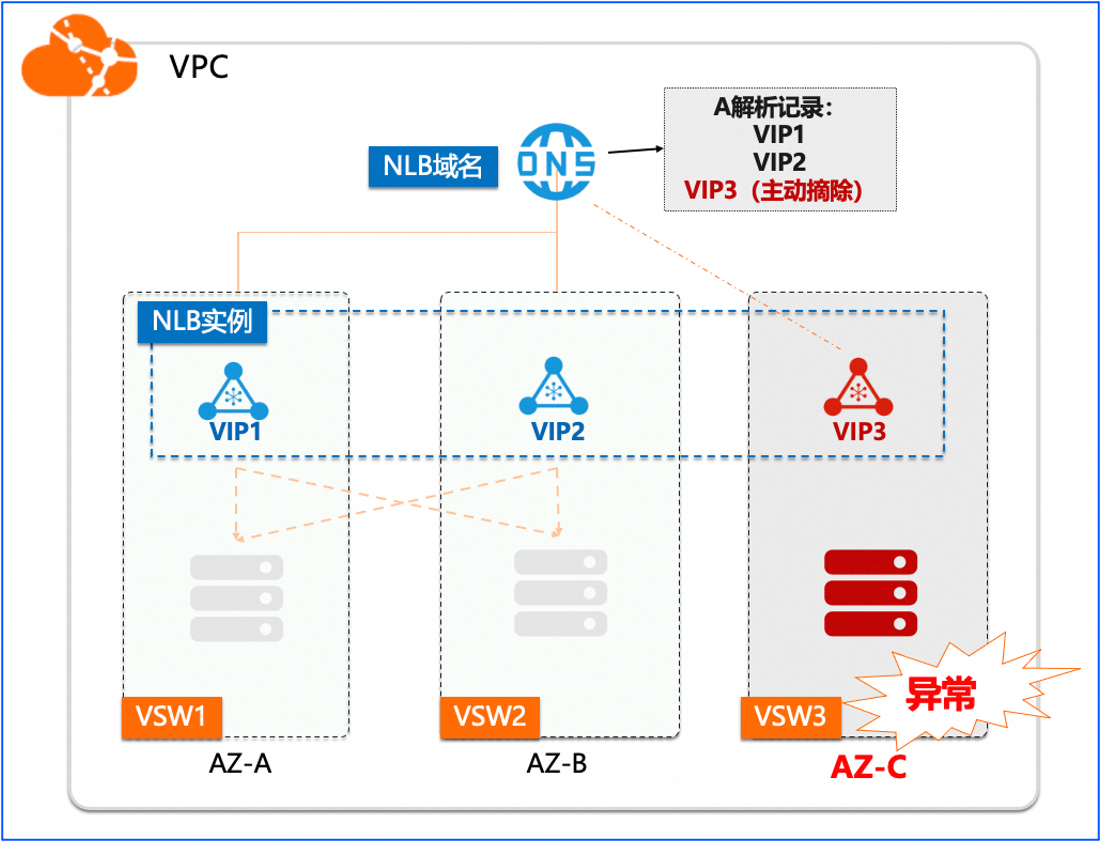
网络相关产品CLB/NLB/ALB支持跨AZ容灾。可以通过 K8SService Annotation 来指定 CLB 的主备可用区;指定NLB的多可用区。可以通过ALBConfig指定ALB的多可用区。
应该与节点池中 ECS 可用区保持一致,可以减少跨可用区数据转发,提升网络访问性能。
5、应用可用性和可用区内节点可用性监控告警
5.1 配置应用负载副本不可用的监控告警
基于kube-state-metrics与工作负载副本相关的指标:
kube_deployment_status_replicas_unavailable
kube_deployment_status_replicas
kube_daemonset_status_number_unavailable
kube_statefulset_status_replicas
kube_statefulset_status_replicas_available 等等
来聚合分析应用负载 Deployment/Statefulset/Daemonset的不可用副本数、副本总数等。
基于该类指标可以发现应用是否存在不可用副本以及不可用副本占总副本数的百分比,实现服务部分受影响、全部影响的监控告警。 ACK默认集成开启。
Prometheus告警示例如下:

5.2 集群可用区内不健康节点百分比的监控告警
K8S 的 kube-controller-manager 组件有统计可用区内的不健康节点数、健康节点百分比和节点总数,可以配置相关告警。
Prometheus告警示例如下:

产品费用及名词
产品费用
产品名称 | 产品说明 | 产品费用 |
容器服务 | 容器服务 Kubernetes 版 ACK(Container Service for Kubernetes)是全球首批通过Kubernetes一致性认证的容器服务平台,提供高性能的容器应用管理服务,支持企业级Kubernetes容器化应用的生命周期管理,让您轻松高效地在云端运行Kubernetes容器化应用。 | 收费,具体可以查看官方文档 |
节点池 | 节点池是具有相同属性的一组节点的逻辑集合,允许对节点进行统一的管理和运维,例如节点升级、弹性伸缩等。 | 支持ECS实例的节点池及弹性伸缩组类型。具体收费见官方文档 |
容器镜像服务 | 阿里云容器镜像服务(Alibaba Cloud Container Registry,简称ACR)提供安全的应用镜像托管能力,精确的镜像安全扫描功能,稳定的国内外镜像构建服务,便捷的镜像授权功能,方便用户进行镜像全生命周期管理。容器镜像服务简化了Registry的搭建运维工作,支持多地域的镜像托管,并联合容器服务等云产品,打造云上使用Docker的一体化体验。 | 收费,具体可以查看官方文档 |
名词解释
名称 | 说明 |
可用区 | 可用区(Availability Zone,简称AZ) 是指在同一地域内,电力和网络互相独立的物理区域。 |
同城冗余 | 同城冗余(Zone-redundant storage,简称ZRS) 是一种数据冗余存储机制,采用多可用区(Availability Zone,AZ)内的数据分布存储方式,将用户的数据冗余存储在同一地域(Region)的多个可用区。 |
安全性
容器服务ACK通过等保三级认证
您可以为您的集群开启等保加固、配置基线检查策略,基于Alibaba Cloud Linux实现等保2.0三级版以及配置等保合规的基线检查,以便满足等保合规要求。
注意事项
集群API Server的SLB访问控制策略
API Server的SLB的ACL控制规则必须放行以下网段。
容器服务 Kubernetes 版管控的网段100.104.0.0/16。
集群专有网络VPC的主网段及附加网段(如有),或集群节点所在的交换机vSwitch网段。
其他需访问API Server连接端点的客户端出口网段。
ACK Edge集群还需放行边缘节点出口网段。
ACK灵骏集群还需放行灵骏VPD网段。
配置访问控制策略白名单时,务必将以上放行网段添加到白名单;配置访问控制策略黑名单时,请勿将以上放行网段添加到黑名单。
实施步骤
实施准备
确保账号内余额充足,并且在账号内规划好网络拓朴,便于实际配置ACK。
已经在账号内开通了ACR企业版,并完成相关配置,便于从ACK拉取镜像。
实施规划
本次实施将完成单ACK集群高可用容灾架构搭建,帮助客户构建一个同城容灾、高可用的ACK集群。ACK数据面资源在用户的VPC中,这块需要用户关注以下关键部署:
节点池和虚拟节点高可用配置
工作负载高可用配置
负载均衡高可用配置
容器镜像服务开启同城容灾配置
部署清单
涉及部署地域为在上海(cn-shanghai)Region,双可用区为E区(cn-shanghai-e)和F区(cn-shanghai-f)和G区(cn-shanghai-g)。部署内容及详细说明如下:
部署账号 | 部署内容 |
生产账号 |
|
实施时长
在实施准备工作完成的情况下,本方案实施预计时长:30分钟。
操作步骤
1. 节点池和虚拟节点池高可用配置
1.1. ECS节点实例规格配置
为了更好地保证集群的稳定性和可靠性,推荐您选择合适的ECS实例规格作为集群节点。使用大规格ECS有以下优势:
网络优势:网络带宽大,对于大带宽类的应用,资源利用率高。同时,容器在一台ECS内建立通信的比例增大,将减少网络传输。
镜像拉取优势:拉取镜像的效率更高。因为镜像只需要拉取一次就可以被多个容器使用。而对于小规格的ECS拉取镜像的次数就会增多,若需要联动ECS伸缩集群,则需要花费更多的时间,反而达不到立即响应的目的。
1.1.1. 选择Worker节点规格
节点规格为4核 8 GB及以上。
根据Pod资源要求,确定CPU和Memory的配比,例如1:2、1:4等。对于使用内存较多的应用例如Java类应用,建议考虑使用1:8的机型。
确定整个集群日常使用的总核数和可用性要求。
例如,集群总的核数有160核,可以容忍10%的错误。那么最小选择10台16核ECS,并且高峰运行的负荷不要超过160 ×90%=144核。如果容忍度是20%,那么最小选择5台32核ECS,并且高峰运行的负荷不要超过160×80%=128核。这样即使有一台ECS出现故障,剩余ECS仍可以支持现有业务正常运行。
1.2. 节点池高可用配置
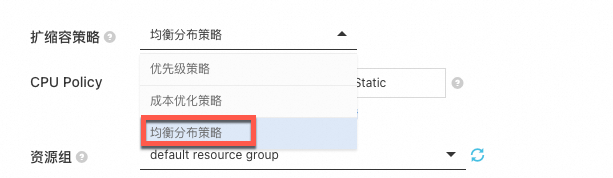
ACK支持多AZ节点池。在节点池的创建和运行过程中,推荐您为节点池选择多个不同AZ的vSwitch,并在配置扩缩容策略时选择均衡分布策略,允许在伸缩组指定的多可用区(即指定多个专有网络交换机)之间均匀分配ECS实例。
基于节点的弹性伸缩、部署集、多AZ分布等手段,结合K8S调度中的拓扑分布约束(Topology Spread Constraints),可以实现不同级别的故障域隔离能力。ACK节点池上所有节点会自动添加拓扑相关的label,例如kubernetes.io/hostname、topology.kubernetes.io/zone、topology.kubernetes.io/region等。您可以使用拓扑分布约束来控制Pod在不同故障域之间的分布,提升对底层基础设施故障的容忍能力。
1.3. 虚拟节点池高可用配置
配置虚拟节点的ECI Profile,指定跨不同AZ的vSwitch,实现跨多AZ应用部署。
ECI会把创建Pod的请求分散到所有的vSwitch中,从而达到分散压力的效果。
如果创建Pod的请求在某一个vSwitch中无库存,会自动切换到下一个vSwitch继续尝试创建。
apiVersion: v1
data:
kube-proxy: "true"
privatezone: "true"
quota-cpu: "192000"
quota-memory: 640Ti
quota-pods: "4000"
regionId: cn-hangzhou
resourcegroup: ""
securitygroupId: sg-xxx
vpcId: vpc-xxx
vSwitchIds: vsw-xxx,vsw-yyy,vsw-zzz
kind: ConfigMap2. 工作负载高可用配置
工作负载的高可用能够保障在故障发生时,应用Pod能够正常运行,或迅速恢复。通过配置拓扑分布约束(Topology Spread Constraints)、Pod反亲和(PodAntiAffinity)、Pod Disruption Budget(PDB)、Pod健康检测与自愈等来实现应用Pod的高可用。
2.1. 配置拓朴分布约束
拓扑分布约束(Topology Spread Constraints)是一种在Kubernetes集群中管理Pod分布的功能。它可以确保Pod在不同的节点和可用区之间均匀分布,以提高应用程序的高可用性和稳定性。该技术适用于Deployment、StatefulSet、DaemonSet、Job、CronJob等工作负载类型。
设置maxSkew.topologyKey等配置来控制Pod的分布,以确保Pod在集群中按照期望的拓扑分布进行部署,例如指定工作负载在不同的可用区之间均匀分布,以提高可靠性和可用性。示例如下。
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-run-per-zone
spec:
replicas: 3
selector:
matchLabels:
app: app-run-per-zone
template:
metadata:
labels:
app: app-run-per-zone
spec:
containers:
- name: app-container
image: app-image
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: DoNotSchedule2.2. 配置Pod反亲和
Pod反亲和(PodAntiAffinity)是Kubernetes中的一种调度策略,用于在调度Pod时确保它们不会被调度到同一个节点上,以提高应用程序的高可用性和故障隔离能力。示例如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-run-per-node
spec:
replicas: 3
selector:
matchLabels:
app: app-run-per-node
template:
metadata:
labels:
app: app-run-per-node
spec:
containers:
- name: app-container
image: app-image
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- app-run-per-node
topologyKey: "kubernetes.io/hostname"2.3. 配置Pod健康检测与自愈
在ACK集群中,您可以配置不同类型的探针来监测和管理容器的状态和可用性,包括存活探针(Liveness Probes)、就绪探针(Readiness Probes)、启动探针(Startup Probes)。这三个探针分别作用:
存活探针:用于判断容器是否处于健康状态。如果探测失败,Kubernetes 的 kubelet 会杀死该容器,并根据容器的重启策略进行处理。【可以做端口检测】
就绪探针:就绪探针用于判断容器是否已准备好接收流量。只有达到 Ready 状态的 Pod 才会被加入到 Service 的后端 Endpoint 列表中。【可以做7层/health检测】
启动探针:启动探针用于判断容器何时完成启动。适用于慢启动容器,可以避免在容器启动完成前被存活探针误判为不健康。
您可以通过在Pod配置中添加相应的探针和重启策略来进行配置。
apiVersion: v1
kind: Pod
metadata:
name: app-with-probe
spec:
containers:
- name: app-container
image: app-image
livenessProbe:
httpGet:
path: /health
port: 80
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
startupProbe:
exec:
command:
- cat
- /tmp/ready
initialDelaySeconds: 20
periodSeconds: 15
restartPolicy: Always3. 负载均衡高可用配置
3.1. 指定CLB实例主备可用区
传统型负载均衡CLB已在大部分地域部署了多可用区,以实现同地域下的跨机房容灾。您可以通过Service Annotation来指定CLB实例的主备可用区,使得主备可用区与节点池中ECS可用区保持一致,减少跨可用区数据转发,提升网络访问性能。
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-master-zoneid: "cn-hangzhou-a"
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-slave-zoneid: "cn-hangzhou-b"
name: nginx
namespace: default
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer故障排除
如何排查ACK集群出现的问题?
步骤一:检查集群节点
执行以下命令,查看集群中的节点状态,确认所有的Node节点都存在并且状态是Ready。
kubectl get nodes如果所有的节点都存在并且状态是Ready,表明集群节点没有问题。
如果节点异常,请执行步骤2。
执行以下命令,查看节点上的详细信息以及节点上的事件。替换
[$NODE_NAME]为您的节点名称。kubectl describe node [$NODE_NAME]
步骤二:检查集群组件
如果检查完集群Node节点后仍然无法确认问题,请继续在控制平面上检查集群组件日志。
执行以下命令,查看kube-system命名空间下所有的组件。
kubectl get pods -n kube-system执行以下命令,查看其日志信息,定位并解决问题。替换
[$Component_Name]为异常组件名称。kubectl logs -f [$Component_Name] -n kube-system
步骤三:检查kubelet组件
执行以下命令,查看kubelet的运行状态。
systemctl status kubelet如果您的kubelet运行状态不是active (running),那么您需要执行以下命令,进一步查看kubelet的日志,定位并解决问题。
journalctl -u kubelet
存量迁移方案
备份中心可用于解决同一地域内Kubernetes集群的应用备份与恢复,实现集群的备份容灾能力。
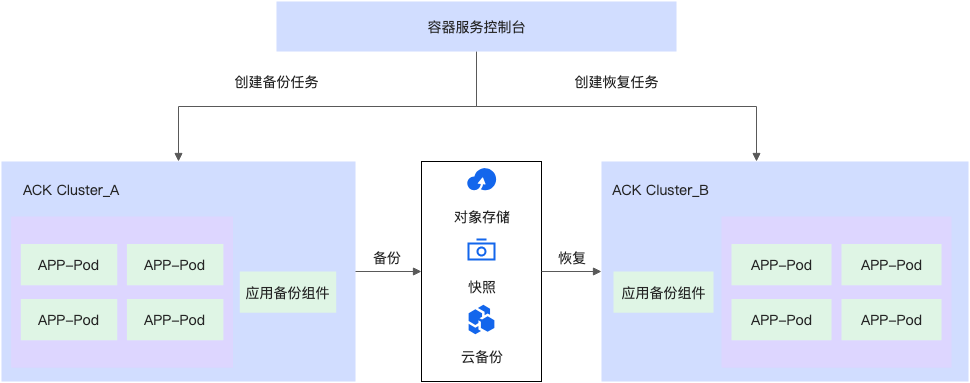
具体可以查看备份中心。