
本文档介绍了EMAS应用监控的OOM监控,详细说明了如何使用本功能,通过全面的信息采集与分析,有效监控治理OOM现象,帮助用户提升OOM问题处理效率。
概述
OOM (Out of Memory) 是导致应用闪退的严重问题之一。EMAS 应用监控的 OOM 分析功能能够自动捕获应用在用户设备上发生的 OOM 异常,并聚合上报详细的诊断数据。通过可视化的趋势图、分布图以及包含堆栈、设备信息、内存摘要在内的现场数据,帮助您快速定位并解决导致内存溢出的代码,提升应用稳定性。
当前支持检测的OOM类型包括:
Android 端:Java OOM、Native OOM
iOS 端:FOOM
OOM原因与表现
OOM 是指应用因内存使用超出系统限制而被系统强制终止的现象。
Android
在Android平台,内存管理是一个复杂但关键的系统,每个应用进程有独立的Java堆内存和Native内存上限。如果App使用内存量达到了上述对应上限,就会出现OOM。
iOS
iOS 系统基于动态内存管理策略,当应用(尤其是前台应用)的内存占用超出系统设定的阈值(JetSam 机制)时,系统会强制终止应用,以回收内存资源。
OOM检测方式
Android
在Android平台,对于Java OOM和Native OOM使用不同的检测方式。
Java OOM检测
包括
OutOfMemoryError、OutOfDirectMemoryError、CursorWindowAllocationException、StackOverflowError。
Native OOM检测
如果是32位系统,判断虚拟内存 > 2.8GB。
Logcat日志如果有
Out Of Memory、OOM或者std::bad_alloc关键字,视为Native OOM。
iOS
OOM检测
由于强制终止应用的
SIGKILL信号是由系统内核(JetSam 机制)直接发出,应用进程内无法通过常规机制捕获。我们采用业界前沿的启发式算法,在应用启动时,通过分析上次运行终止前的各项关键指标(如应用内存水位、系统内存压力、应用状态切换等),推断是否发生了一次 OOM 事件。
该机制为间接推断,可能存在少量误判或漏判,但整体具备较高的准确率与业务参考价值,是目前业界主流的 OOM 监控方案。
OOM诊断信息
在开启「内存分配监控」后,SDK 会在应用内存分配处插桩,记录内存分配调用堆栈及分配大小,并在 OOM 推断成立时随事件一并上报。上报信息有助于开发者还原 OOM 发生前的关键内存增长路径,快速定位高内存消耗模块。
最大上传20个内存分配堆栈记录
内存分配调用堆栈最多取64帧
请在性能允许的环境下开启内存分配监控,以获得更完整的 OOM 诊断上下文。
准备工作
Android
已按照Android SDK接入文档接入了内存分析。
iOS
已按照iOS SDK接入文档接入了内存分析。
功能说明
趋势分析
OOM趋势展示筛选条件下,OOM指标的趋势图,查看OOM问题的波动和影响面。
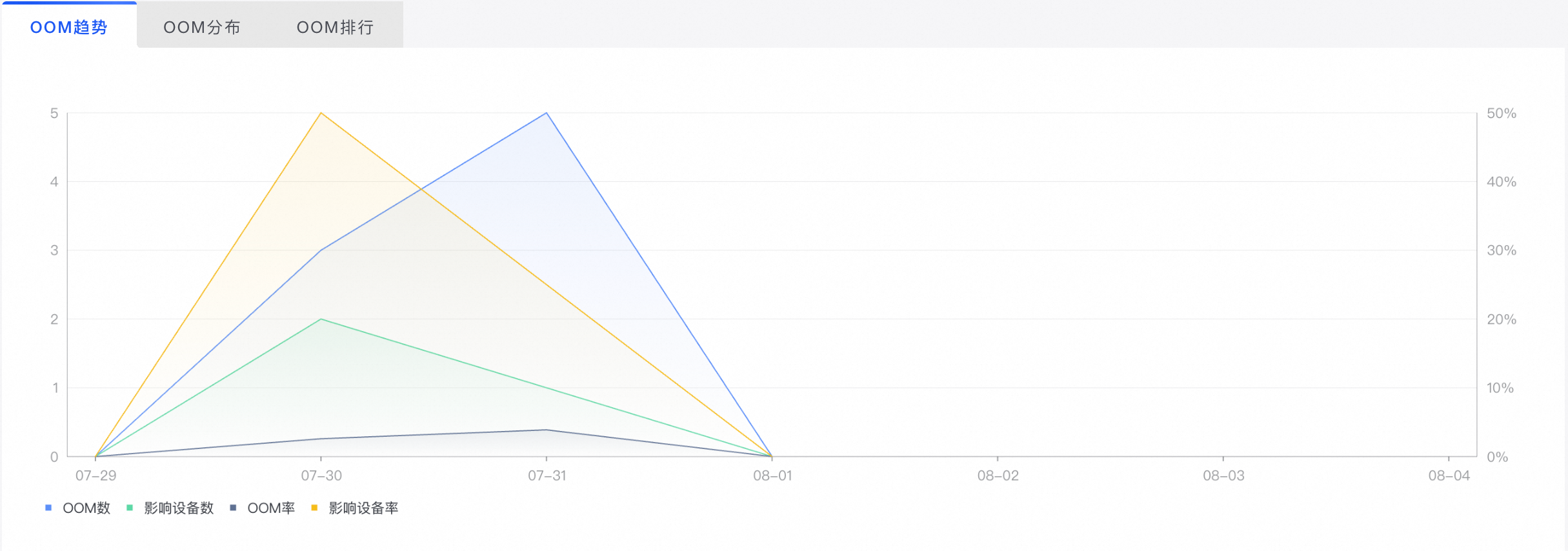
指标 | 指标说明 |
OOM数 | 发生OOM的次数 |
影响设备数 | 发生OOM影响的设备数量(按设备去重的OOM数) |
OOM率 | OOM数/设备总启动次数 |
影响设备率 | 影响设备数(按设备去重的OOM数)/启动总设备数(按设备去重的启动次数) |
分布分析
分布分析支持通过多维统计(如应用版本、操作系统版本、机型等)来观测OOM发生的分布情况以及定位问题。

默认以应用版本、系统版本、机型、品牌四个维度展示OOM分布情况,支持点击“分布维度”按钮下拉勾选维度替换默认维度,最少选择1个,最多选择4个。
点击
 可以切换视图:分布排行、列表排行。
可以切换视图:分布排行、列表排行。
排行分析
排行分析展示OOM问题的排行情况,包含当天所有类型TOP10、当天新增类型TOP10、占比变化TOP10,帮助开发者聚焦当天变化最大的问题类型。
OOM列表
OOM列表展示了聚合后的OOM问题类型,包括发生OOM数、OOM率、影响设备数、影响设备率、首现版本和问题状态。
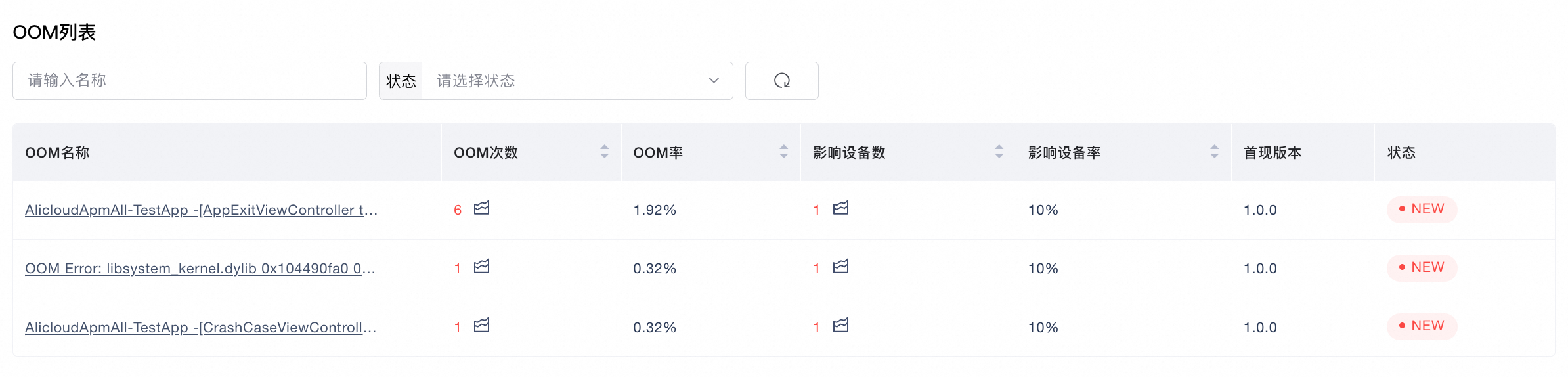
排序方式:指标支持排序,默认按照OOM数从高到低排序。
查看详情:点击OOM名称,进入到对应的OOM问题详情分析页。
OOM详情
OOM详情支持针对具体问题做详细下钻分析,提供该问题汇总的基本信息、趋势分析、分布分析和调用堆栈分析的问题分析能力,并提供每一次客户端上报的详细信息。
基本信息
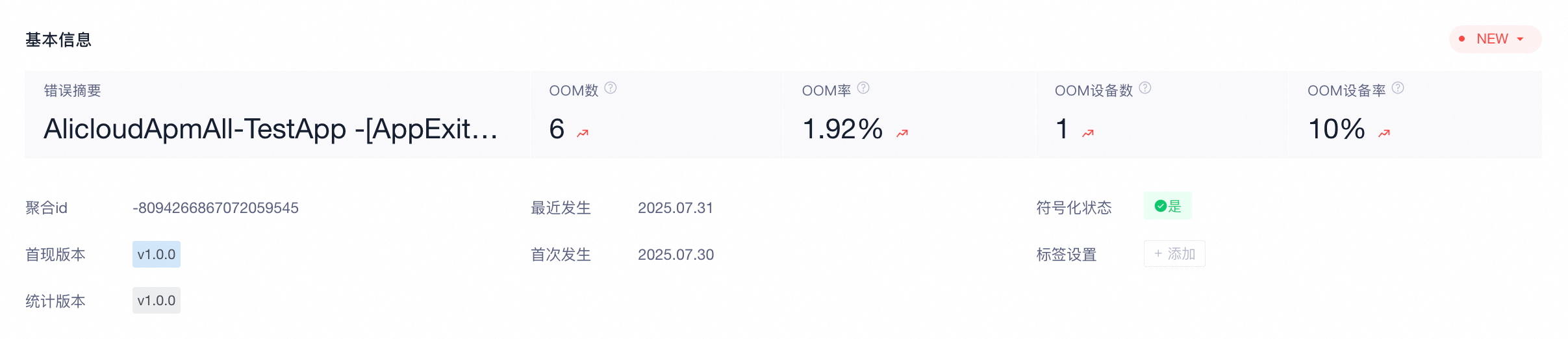
参数 | 说明 |
错误摘要 | 错误类型名称 |
聚合ID | 根据错误的特征生成的64位唯一ID |
OOM数 | OOM数=所选时间段内该页面发生OOM的总次数 |
OOM率 | OOM率=筛选条件下发生OOM次数/筛选条件下设备总启动次数 |
影响设备数 | 影响用户数=筛选条件下发生OOM的设备数量 |
影响设备率 | 影响设备率=筛选条件下影响设备数(按设备去重的OOM数)/筛选条件下启动总设备数(按设备去重的启动次数) |
首次发生 | 所选时间段内首次发生的时间 |
最近发生 | 所选时间段内最近发生的时间 |
首现版本 | 首次在哪个版本出现此OOM类型 |
统计版本 | 出现此OOM类型统计的版本 |
符号化状态 | 错误是否已经被解混淆 |
标签设置 | 对此错误类型添加标签,便于管理 一个错误信息最多支持10个标签,一个标签最多显示15个字符 |
问题状态 | 问题状态支持修改,便于排查和追踪问题是否解决
|
详细信息
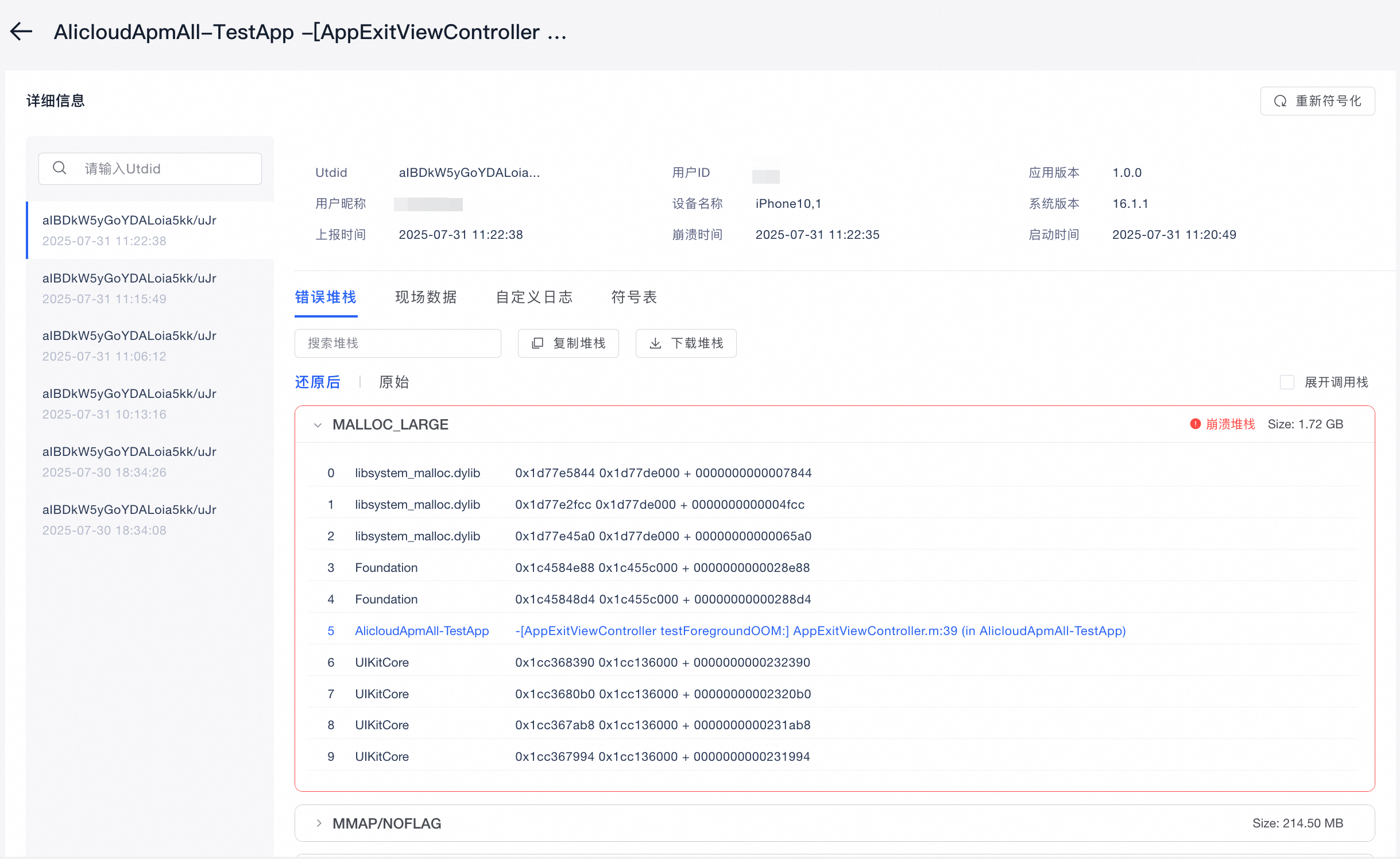
展示同一OOM问题的所有客户端上报实例。左侧按照OOM发生的时间顺序排列,点击后右侧展示此次OOM的详细上报信息,包含错误堆栈(Android)/内存分配堆栈(iOS)、现场数据、ConsoleLog、自定义日志和进程信息等。详情信息操作与崩溃分析的详情信息操作类似,请参考查看详细信息文档。
治理技巧
解决OOM问题并非一蹴而就,而是一个发现、定位、解决、预防的持续过程。EMAS平台提供了一套完整的工具链,帮助您系统化地进行OOM治理。本章节将指导您如何有效利用平台功能,建立高效的OOM问题处理流程。
在锁定一个具体的OOM问题后,进入 OOM详情 页面,利用平台提供的丰富现场信息进行根源定位。
Java OOM
分析错误堆栈:这是最直接的线索。在 详细信息 选项卡中,仔细阅读 错误堆栈。堆栈顶部通常会明确指出是哪个类的哪个对象在分配时失败(如 new byte[] 或 Bitmap.createBitmap)。
追溯分配源头:沿着堆栈向上追溯,找到是哪个业务逻辑触发了这次内存分配。例如,堆栈是否指向了图片加载、JSON解析或数据库查询等模块?
结合内存摘要:查看 现场数据 中的 内存摘要。Java Heap 的大小和使用率可以告诉您,OOM是由于一次性申请超大对象导致,还是因为整体内存已接近耗尽,任何小的分配都可能成为“最后一根稻草”。
Native OOM
审查Logcat日志:Native OOM的堆栈可能不明确,此时 ConsoleLog 中的Logcat日志至关重要。在发生OOM的时间点前后,搜索Out Of Memory、std::bad_alloc等关键字,上下文日志可能会暴露是哪个so库或操作导致的内存激增。
排查JNI调用:重点关注Native堆栈中与JNI相关的调用。检查是否有从Java层传递Bitmap、Direct Buffer等大对象到Native层后,未被正确释放。
FOOM
聚焦内存分配堆栈:对于,内存分配堆栈 是最有价值的诊断信息。该列表按内存占用大小倒序排列,记录了导致内存持续增长的关键分配操作。
识别高耗内存对象:重点关注列表顶部的堆栈。查看是哪个类或函数(如 -[UIImage imageNamed:], +[NSData dataWithContentsOfURL:], 或自定义业务类)在大量或频繁地分配内存。
还原业务场景:结合 内存分配堆栈 和 ConsoleLog/自定义日志,还原用户发生OOM前的操作路径。例如,日志显示用户正在浏览图片信息流,同时内存分配堆栈顶部是图片相关操作,那么问题基本可以锁定在图片浏览模块的内存管理上。