基于PAI-DSW的牙齿语义分割:2D口腔X-Ray影像分析
本实验将带您体验如何使用阿里云PAI(Platform for AI)中的DSW(Data Science Workshop)模块,通过搭建一个深度学习环境,对2D口腔全景X光片(panoramic X-ray)进行牙齿的语义分割,从而实现对医学影像的智能分析。
实验简介
本实验将带您体验如何使用阿里云PAI(Platform for AI)中的DSW(Data Science Workshop)模块,通过搭建一个深度学习环境,对2D口腔全景X光片(panoramic X-ray)进行牙齿的语义分割,从而实现对医学影像的智能分析。
背景知识
语义分割: 语义分割是计算机视觉中的一项核心任务,其目标是对图像中的每个像素点进行分类,从而识别出属于不同语义类别(如天空、地面、汽车、人)的区域。在医学影像分析中,它可以精确地勾勒出器官、病灶或特定解剖结构(如本实验中的牙齿)的轮廓,为计算机辅助诊断(CAD)提供关键信息。
口腔X光影像分析: 2D口腔全景X光片是口腔科最常用的检查手段之一,能够高效地发现肉眼不可见的龋齿、阻生智齿、多生牙等问题。通过人工智能算法自动分割出每颗牙齿的精确位置和形状,可以极大地提高医生的诊断效率和准确性。
STS23挑战赛: 本实验所使用的数据集源自MICCAI 2023 ToothFairy研讨会的一部分——半监督牙齿分割(STS)挑战赛。该挑战赛旨在推动牙齿分割算法的发展,提供了高质量的2D口腔X光影像和3D CBCT数据,是进行相关研究的宝贵资源。
PAI-DSW: 阿里云PAI-DSW是一个为开发者量身打造的云端深度学习开发环境。它预置了主流的深度学习框架(如TensorFlow, PyTorch),并提供了高性能的计算资源(如GPU),用户可以通过其交互式的JupyterLab界面,便捷地完成数据准备、模型开发、模型训练和评估等全流程工作。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物 300 元代金券领取。
已通过实名认证且账户余额 ≥0 元。
在实验页面,当您已阅读并同意上述创建资源的目的以及部分资源可能产生的计费规则。
资源消耗说明
本场景主要涉及以下云产品和服务:PAI-DSW、对象存储OSS。
本实验预计产生资源消耗:约10元(以使用ecs.gn6i-c8g1.2xlarge规格的PAI-DSW实例进行1小时的数据处理与模型训练为例估算)。
如果您调整了资源规格、延长了使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
PAI-DSW: 费用主要由DSW实例的运行时长和其规格决定。本实验选用GPU实例进行模型训练,关机后即停止计费。
对象存储 OSS: 费用由数据存储容量和少量外网下行流量(仅在下载结果时产生)决定。
领取专属权益及创建实验资源
第一步:在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第二步:本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。

实验步骤
进入DSW控制台
登录阿里云,进入机器学习PAI控制台,在左侧导航栏选择【工作空间列表】,点击进入您的工作空间
在工作空间内,选择左侧的【模型开发与训练】—【DSW(Data Science Workshop)】
创建DSW实例
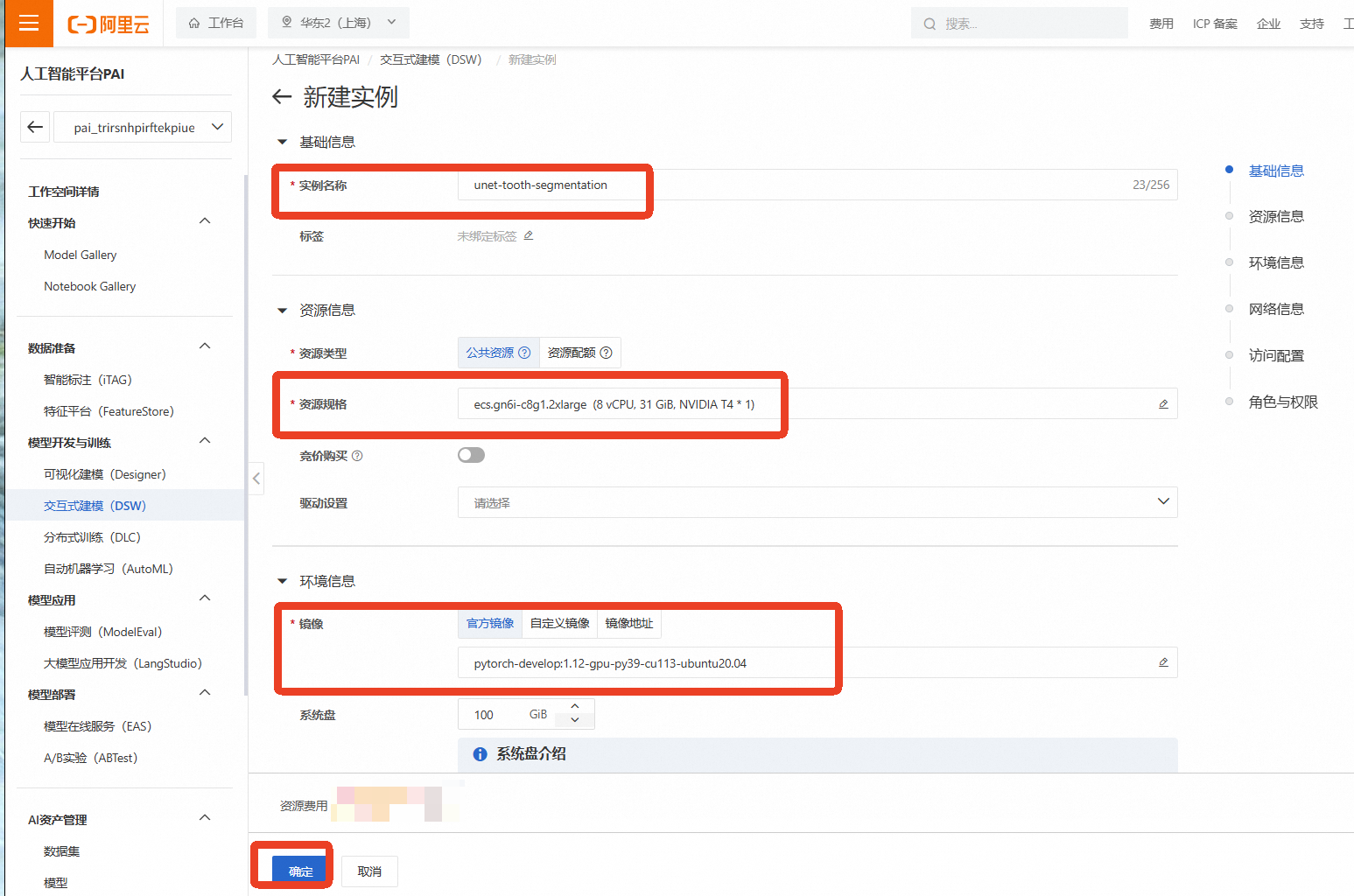
点击【创建实例】

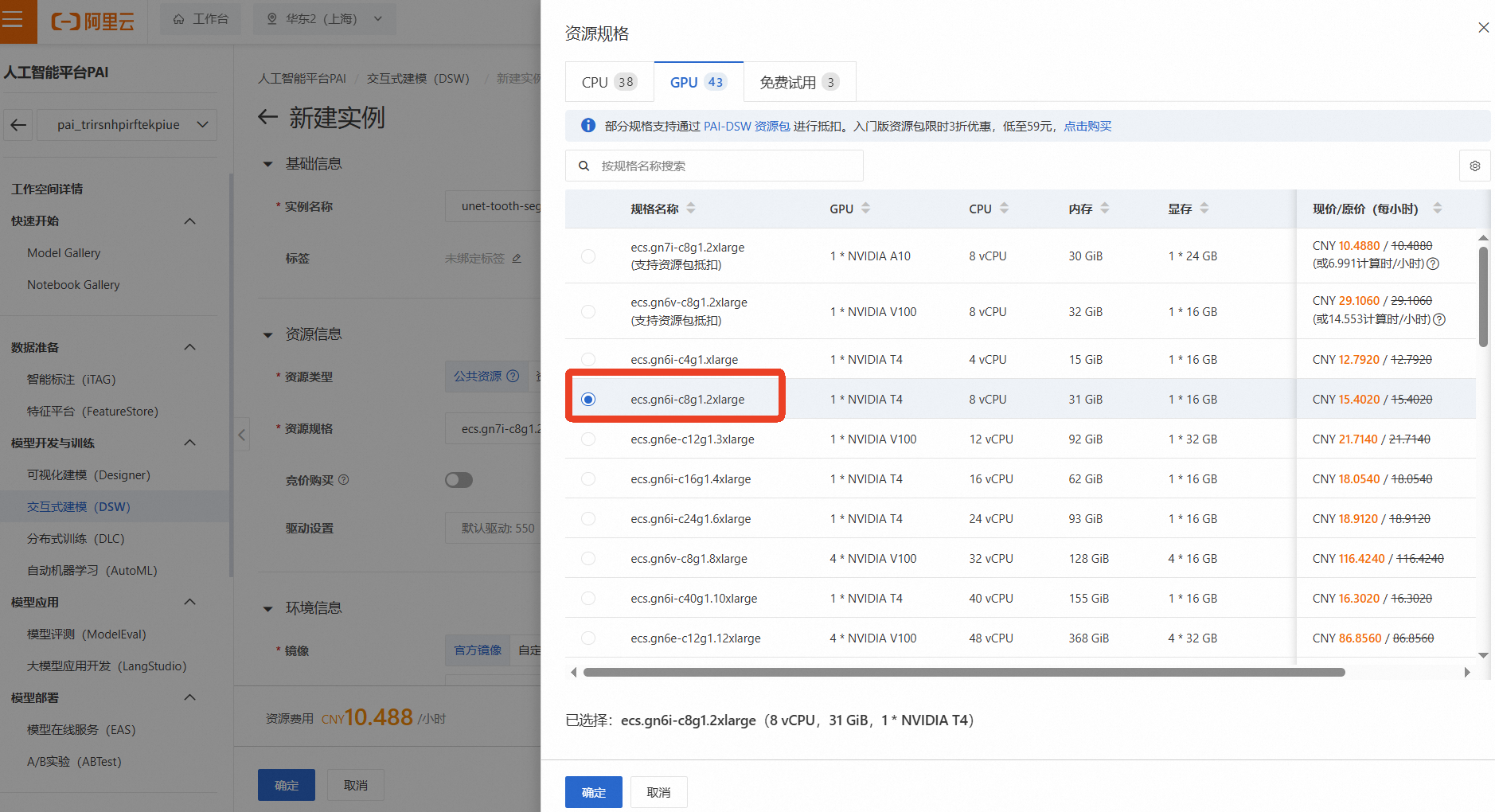
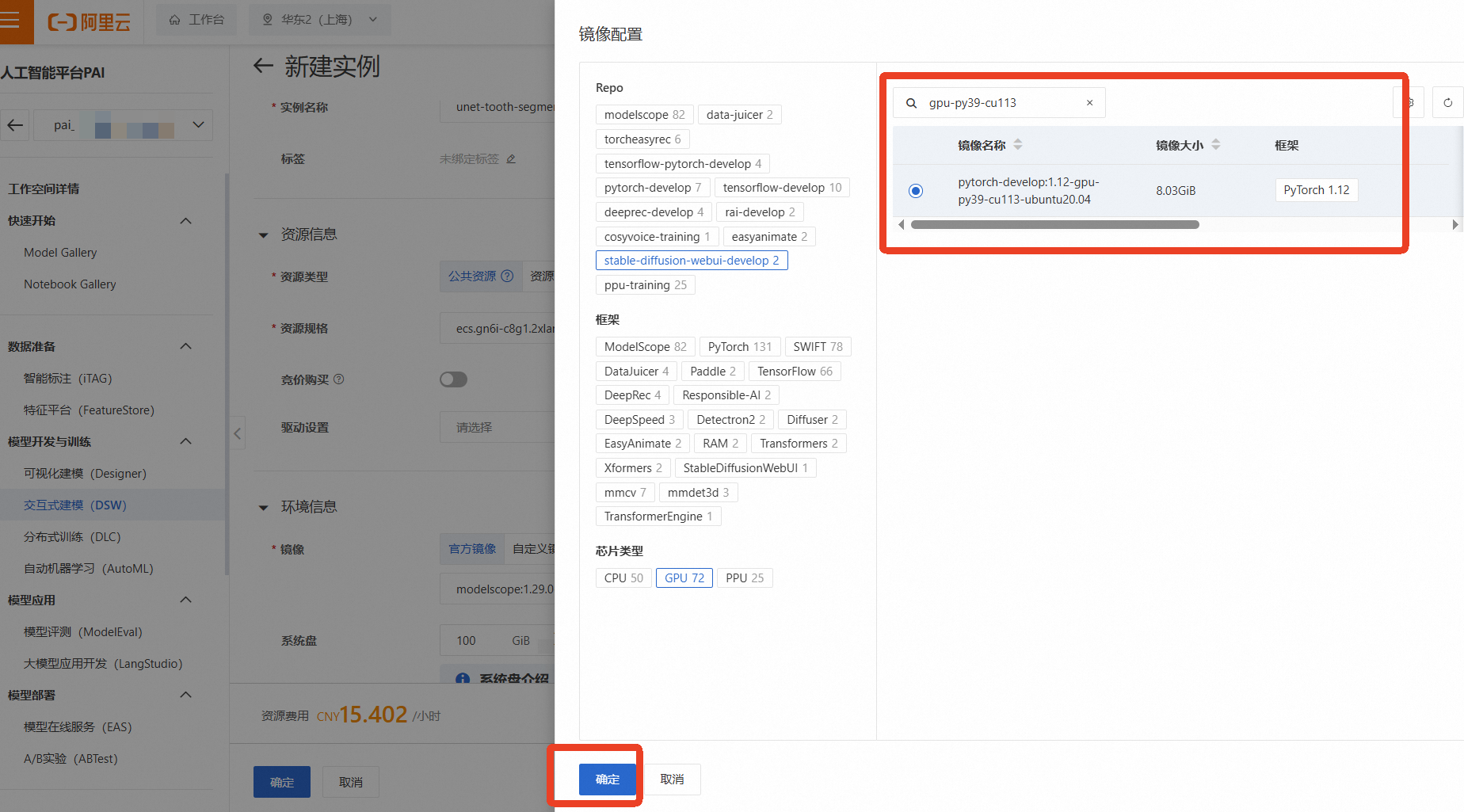
实例名称:自定义一个名称,如 unet-tooth-segmentation
资源组(机型):为了进行深度学习模型训练,我们需要选择GPU实例。点击【筛选】,勾选【GPU】,然后选择一款有库存的GPU机型,例如 ecs.gn6i-c8g1.2xlarge(vCPU: 8, 内存: 32GiB, GPU: NVIDIA T4 16GB)
说明这是成本消耗的主要来源,请务必注意实验后及时停止或删除实例!
镜像:选择一个预置了PyTorch框架的镜像,例如 pytorch:1.12-gpu-py39-cu113-ubuntu20.04
其他保持默认,选择完成后点击【确定】
等待约2-3分钟,直到实例状态变为“运行中”
进入JupyterLab环境
在DSW实例列表中,找到刚刚创建的实例,点击右侧的【打开】,这将带您进入一个交互式的JupyterLab开发环境
下载并解压数据集
进入JupyterLab后,点击启动器(Launcher)中的【终端】(Terminal)打开一个命令行窗口
在终端中,依次输入并执行以下命令来下载并解压数据集
# 下载数据集(文件约350MB,请耐心等待) wget https://zenodo.org/records/10597292/files/STS23_Task1.zip创建Notebook并安装依赖
返回JupyterLab的启动器(Launcher)页面,点击【Python 3 (PyTorch 1.12)】创建一个新的Notebook文件
在Notebook的第一个代码单元格(Cell)中,输入并运行以下代码来安装我们需要的额外库
!pip install opencv-python tqdm -i https://pypi.tuna.tsinghua.edu.cn/simpletqdm 是一个可以显示进度条的库,能让我们的训练过程看起来更直观
重要请将以下代码块依次复制到您的Notebook的不同单元格中,并按顺序执行
预处理数据集
import os import shutil import random from tqdm import tqdm print("开始划分数据集...") # 原始数据路径 original_data_dir = '/mnt/workspace/sts23' # 解压后的实际数据路径 original_image_dir = os.path.join(original_data_dir, 'image') original_mask_dir = os.path.join(original_data_dir, 'mask') # 新的数据集根目录 base_dir = 'data' os.makedirs(base_dir, exist_ok=True) # 创建训练、验证、测试目录结构 train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'val') test_dir = os.path.join(base_dir, 'test') for d in [train_dir, validation_dir, test_dir]: os.makedirs(os.path.join(d, 'image'), exist_ok=True) os.makedirs(os.path.join(d, 'mask'), exist_ok=True) # 获取所有图片文件名 fnames = os.listdir(original_image_dir) random.shuffle(fnames) # 打乱顺序 # 定义划分比例 train_split = int(0.8 * len(fnames)) validation_split = int(0.9 * len(fnames)) # 0.8 -> 0.9, so 10% for validation # 划分文件名 train_fnames = fnames[:train_split] validation_fnames = fnames[train_split:validation_split] test_fnames = fnames[validation_split:] # 复制文件函数 def copy_files(filenames, split_name): for fname in tqdm(filenames, desc=f'Copying to {split_name}'): # 复制图片 src_img = os.path.join(original_image_dir, fname) dst_img = os.path.join(base_dir, split_name, 'image', fname) shutil.copyfile(src_img, dst_img) # 复制Mask (Mask文件名和图片名相同) src_mask = os.path.join(original_mask_dir, fname) dst_mask = os.path.join(base_dir, split_name, 'mask', fname) shutil.copyfile(src_mask, dst_mask) # 执行复制 copy_files(train_fnames, 'train') copy_files(validation_fnames, 'val') copy_files(test_fnames, 'test') print("数据集划分完成!") print(f"训练集大小: {len(train_fnames)}") print(f"验证集大小: {len(validation_fnames)}") print(f"测试集大小: {len(test_fnames)}")导入必要的库s
这是我们的第一步,导入所有需要用到的Python库
import os import cv2 import random import numpy as np from tqdm import tqdm import torch import torch.nn as nn from torch.utils.data import Dataset, DataLoader from torchvision import transforms import matplotlib.pyplot as plt # 检查是否有可用的GPU device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}")定义超参数和路径
我们将所有可配置的参数集中放在这里,方便后续修改
# 数据集路径 DATA_ROOT = 'STS23_Task1' TRAIN_IMG_DIR = os.path.join(DATA_ROOT, 'train', 'images') TRAIN_MASK_DIR = os.path.join(DATA_ROOT, 'train', 'masks') TEST_IMG_DIR = os.path.join(DATA_ROOT, 'test', 'images') # 模型训练参数 IMAGE_SIZE = 256 # 将所有图片缩放到256x256 BATCH_SIZE = 8 EPOCHS = 20 # 为了快速演示,只训练20个周期。实际应用中可能需要更多。 LEARNING_RATE = 1e-4创建自定义数据集类(Dataset)
我们需要定义一个类来读取、预处理我们的图片和对应的标注(Mask),并将其转换为PyTorch能够处理的Tensor格式
class TeethDataset(Dataset): def __init__(self, image_dir, mask_dir, transform=None): self.image_dir = image_dir self.mask_dir = mask_dir self.transform = transform self.image_ids = os.listdir(image_dir) def __len__(self): return len(self.image_ids) def __getitem__(self, idx): img_name = self.image_ids[idx] img_path = os.path.join(self.image_dir, img_name) mask_path = os.path.join(self.mask_dir, img_name) # mask文件名和image文件名相同 # 读取图片和mask,注意mask是灰度图 image = cv2.imread(img_path) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE) # 将mask中的像素值进行二值化处理(大于0的都设为1,代表牙齿) _, mask = cv2.threshold(mask, 0, 255, cv2.THRESH_BINARY) mask[mask == 255] = 1 if self.transform: image = self.transform(image) # mask也需要同样缩放,但不需要归一化 mask = cv2.resize(mask, (IMAGE_SIZE, IMAGE_SIZE), interpolation=cv2.INTER_NEAREST) mask = torch.from_numpy(mask).long() # 转换为LongTensor return image, mask # 定义图像预处理流程 transform = transforms.Compose([ transforms.ToTensor(), transforms.Resize((IMAGE_SIZE, IMAGE_SIZE), antialias=True), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) # 实例化数据集和数据加载器 train_dataset = TeethDataset(TRAIN_IMG_DIR, TRAIN_MASK_DIR, transform=transform) train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)定义U-Net模型结构
这里我们实现一个基础的U-Net网络。它由一个“编码器”(用于提取特征)和一个“解码器”(用于恢复图像尺寸并进行像素级预测)组成,中间通过“跳跃连接”来融合深层和浅层的特征
codePython downloadcontent_copyexpand_less # 定义U-Net中的一个卷积块 def conv_block(in_channels, out_channels): return nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ) class UNet(nn.Module): def __init__(self, in_channels=3, out_channels=2): # out_channels=2, 分别代表背景和牙齿 super(UNet, self).__init__() # 编码器部分 self.enc1 = conv_block(in_channels, 64) self.enc2 = conv_block(64, 128) self.enc3 = conv_block(128, 256) self.enc4 = conv_block(256, 512) self.pool = nn.MaxPool2d(2) # 瓶颈层 self.bottleneck = conv_block(512, 1024) # 解码器部分 self.upconv4 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2) self.dec4 = conv_block(1024, 512) self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2) self.dec3 = conv_block(512, 256) self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2) self.dec2 = conv_block(256, 128) self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2) self.dec1 = conv_block(128, 64) # 输出层 self.out_conv = nn.Conv2d(64, out_channels, kernel_size=1) def forward(self, x): # 编码 e1 = self.enc1(x) e2 = self.enc2(self.pool(e1)) e3 = self.enc3(self.pool(e2)) e4 = self.enc4(self.pool(e3)) # 瓶颈 b = self.bottleneck(self.pool(e4)) # 解码与跳跃连接 d4 = self.upconv4(b) d4 = torch.cat((d4, e4), dim=1) d4 = self.dec4(d4) d3 = self.upconv3(d4) d3 = torch.cat((d3, e3), dim=1) d3 = self.dec3(d3) d2 = self.upconv2(d3) d2 = torch.cat((d2, e2), dim=1) d2 = self.dec2(d2) d1 = self.upconv1(d2) d1 = torch.cat((d1, e1), dim=1) d1 = self.dec1(d1) # 输出 return self.out_conv(d1) # 实例化模型并移动到GPU model = UNet(in_channels=3, out_channels=2).to(device)开始训练模型
定义损失函数和优化器,然后编写训练循环。我们会遍历数据集EPOCHS次,并在每个周期结束后打印损失值
# 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE) # 训练循环 for epoch in range(EPOCHS): model.train() running_loss = 0.0 # 使用tqdm显示进度条 progress_bar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{EPOCHS}") for images, masks in progress_bar: images = images.to(device) masks = masks.to(device) # 梯度清零 optimizer.zero_grad() # 前向传播 outputs = model(images) # 计算损失 loss = criterion(outputs, masks) # 反向传播和优化 loss.backward() optimizer.step() running_loss += loss.item() # 更新进度条上的损失显示 progress_bar.set_postfix(loss=loss.item()) epoch_loss = running_loss / len(train_loader) print(f"Epoch [{epoch+1}/{EPOCHS}], Loss: {epoch_loss:.4f}") print("训练完成!") # 保存模型权重 torch.save(model.state_dict(), 'unet_teeth_segmentation.pth')结果可视化
最后,我们加载训练好的模型,随机选择几张训练图片进行预测,并将原始图、真实标注和我们的模型预测结果并排展示,直观地评估模型效果
# 加载模型并设置为评估模式 model.load_state_dict(torch.load('unet_teeth_segmentation.pth')) model.eval() def visualize_predictions(dataset, num_samples=3): plt.figure(figsize=(15, 5 * num_samples)) indices = random.sample(range(len(dataset)), num_samples) for i, idx in enumerate(indices): image, mask = dataset[idx] image_for_plot = image.numpy().transpose(1, 2, 0) # 反归一化以便显示 mean = np.array([0.5, 0.5, 0.5]) std = np.array([0.5, 0.5, 0.5]) image_for_plot = std * image_for_plot + mean image_for_plot = np.clip(image_for_plot, 0, 1) with torch.no_grad(): input_tensor = image.unsqueeze(0).to(device) output = model(input_tensor) # 获取概率最大的类别作为预测结果 pred_mask = torch.argmax(output, dim=1).squeeze(0).cpu().numpy() plt.subplot(num_samples, 3, i * 3 + 1) plt.title("Original Image") plt.imshow(image_for_plot) plt.axis('off') plt.subplot(num_samples, 3, i * 3 + 2) plt.title("Ground Truth Mask") plt.imshow(mask.numpy(), cmap='gray') plt.axis('off') plt.subplot(num_samples, 3, i * 3 + 3) plt.title("Predicted Mask") plt.imshow(pred_mask, cmap='gray') plt.axis('off') plt.tight_layout() plt.show() # 可视化结果 visualize_predictions(train_dataset, num_samples=3)


清理资源
为避免产生不必要的个人扣费,实验完成后请务必按照以下步骤清理所有资源!
释放PAI-DSW实例
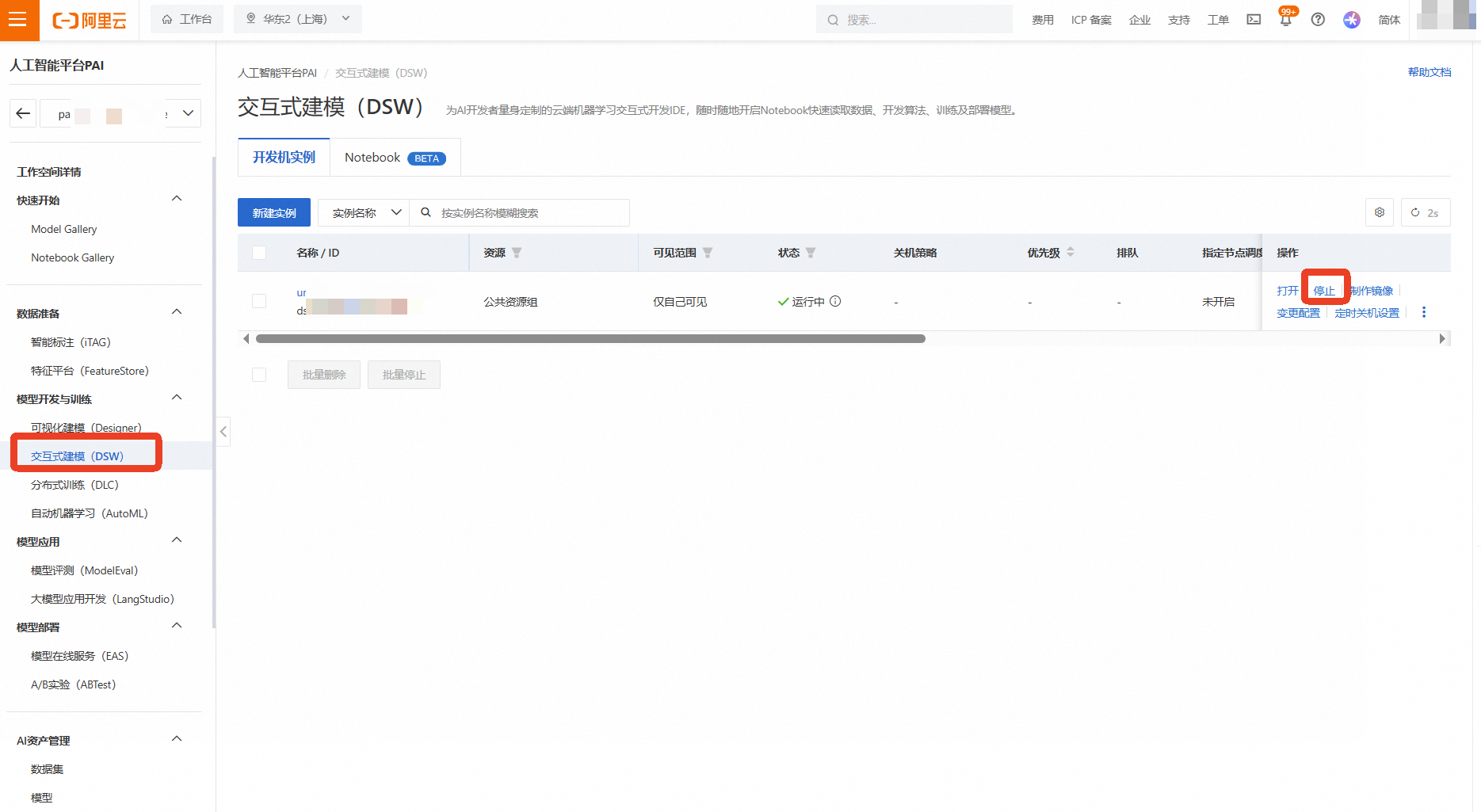
返回 机器学习PAI控制台 的DSW实例列表页面
找到本次实验创建的实例,点击右侧的【停止】
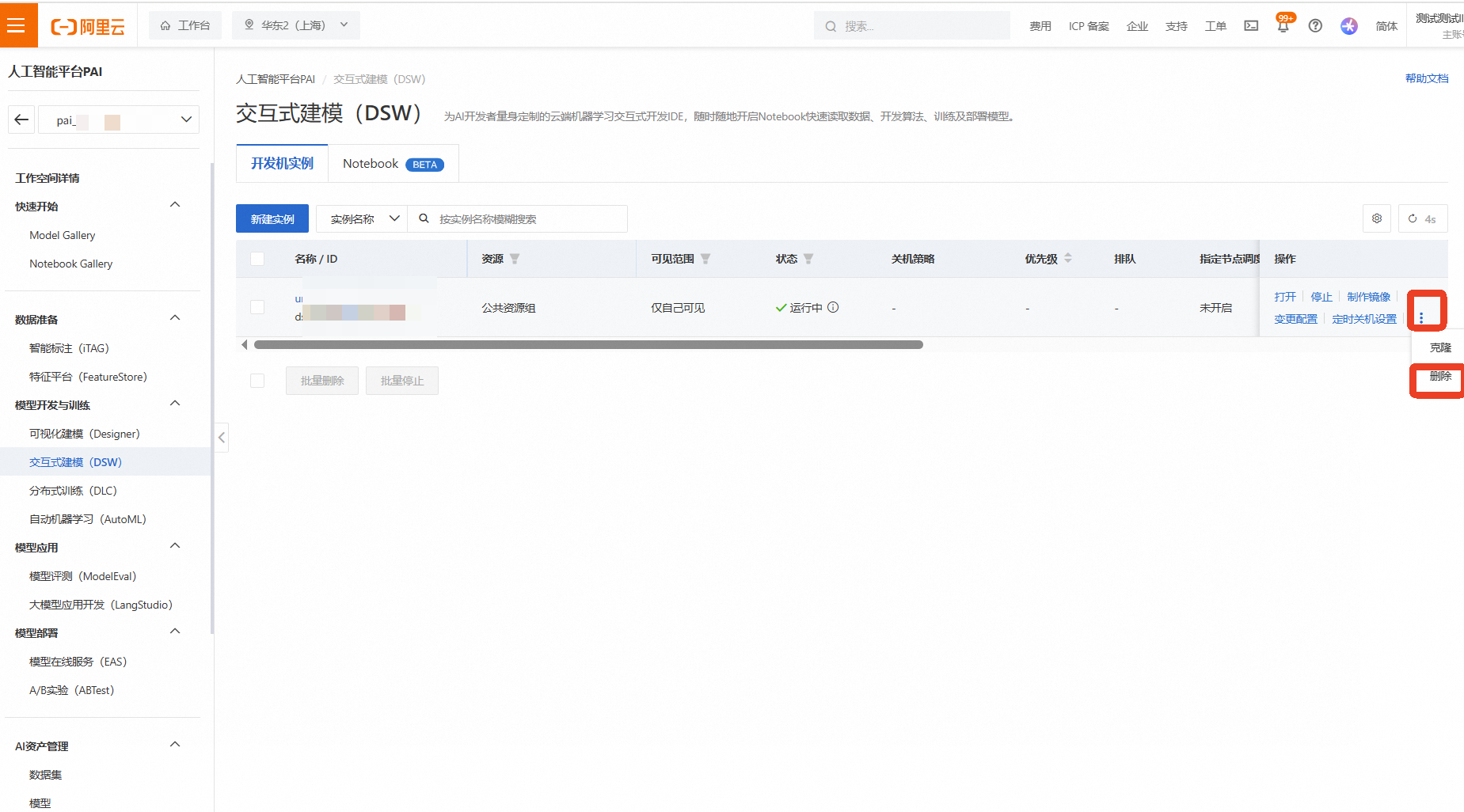
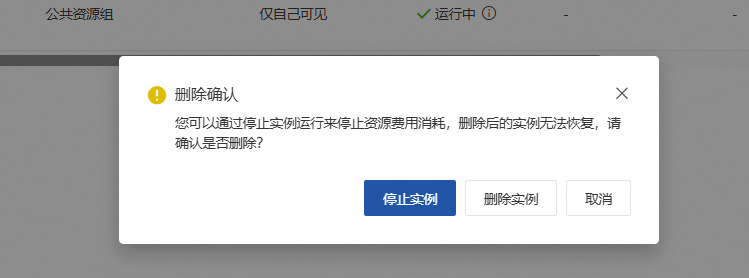
等待实例状态变为“已停止”后,为确保完全释放,再次点击右侧的【...】更多操作,选择【删除】
在弹出的确认框中点击【停止实例】/【删除实例】
等待一段时间检查是否删除成功
删除OSS数据和Bucket
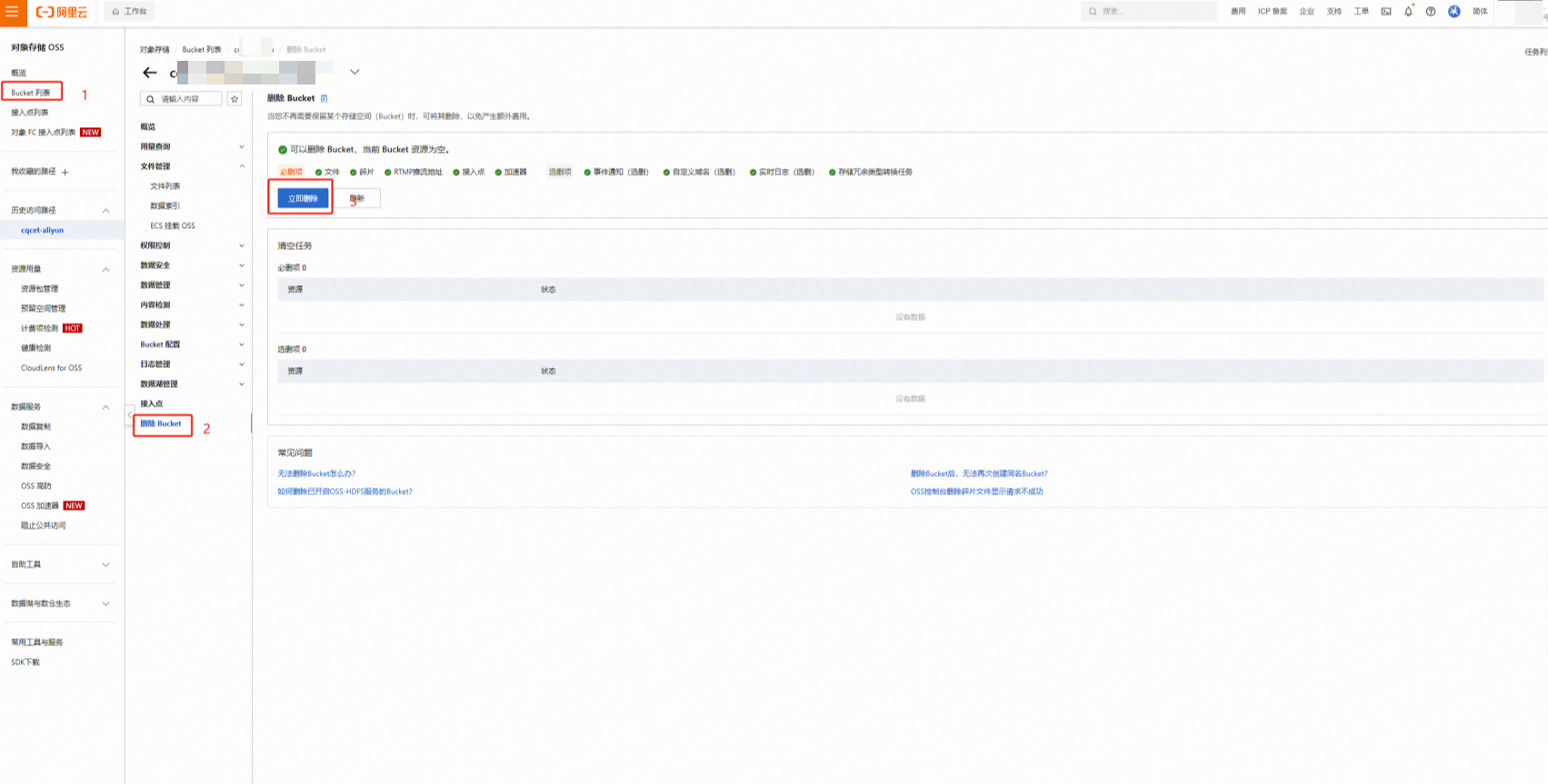
进入 对象存储OSS控制台,找到为本次实验创建的Bucket,点击进入
选中所有上传的数据文件和文件夹,点击【删除】,返回Bucket列表,选中该Bucket,点击【删除】,根据提示完成删除操作(可能需要清空碎片)
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 跳转实验评分
请为本次实验评分,并给出您的建议,点击 确认,结束本次实验