AI之眼:基于PAI-DSW构建多类别医学影像智能分类器
本实验将带您在阿里云PAI-DSW云端开发环境中,完成一个端到端的医学影像多类别分类任务。您将学习如何加载并预处理一个包含多种人体部位影像的数据集,并训练一个强大的深度学习模型(DenseNet),使其能够准确地识别出输入的影像是腹部CT、手部X光片,还是乳腺MRI等,体验AI在自动化医学影像归档与识别中的应用。
实验简介
本实验将带您在阿里云PAI-DSW云端开发环境中,完成一个端到端的医学影像多类别分类任务。您将学习如何加载并预处理一个包含多种人体部位影像的数据集,并训练一个强大的深度学习模型(DenseNet),使其能够准确地识别出输入的影像是腹部CT、手部X光片,还是乳腺MRI等,体验AI在自动化医学影像归档与识别中的应用。
背景知识
医学影像分类(Medical Image Classification): 这是计算机视觉在医疗领域最基础也是最广泛的应用之一。其目标是训练一个模型,使其能够自动识别输入的医学影像属于哪个预定义的类别。例如,判断一张胸片是否有肺炎病灶,或者像本实验一样,识别影像对应的人体部位。这是实现智能诊断、自动化报告等高级功能的第一步。
DenseNet模型:DenseNet(Densely Connected Convolutional Networks)是一种经典的卷积神经网络架构。其核心特点是网络中每一层都与前面所有层直接相连,这种“密集连接”的机制极大地促进了特征的复用和信息的流动,使得模型在参数量更少的情况下,依然能达到非常高的性能,特别适合图像分类任务。
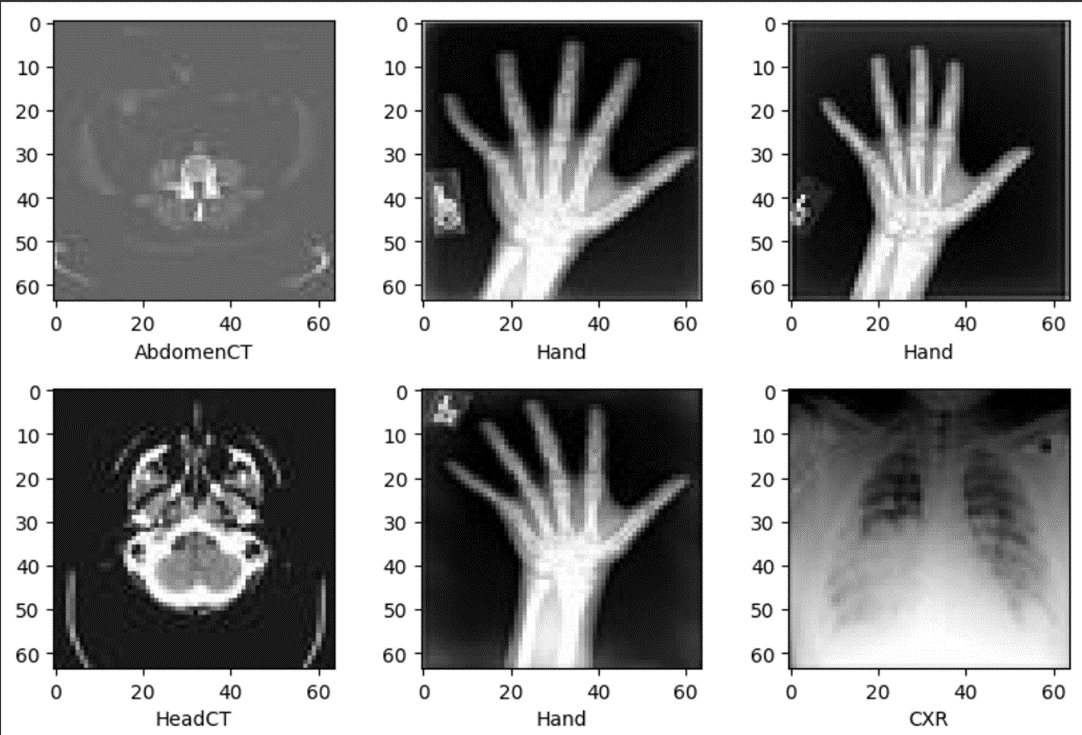
MedNIST数据集:这是一个专为教学和算法快速验证设计的医学影像集合,包含了手部、头部CT、胸部CT等6个不同类别的医学影像。所有图片都被处理成了64x64的统一尺寸,非常适合初学者快速上手,而无需进行复杂的预处理工作。
PAI-DSW: PAI-DSW是一个为开发者量身打造的云端深度学习开发环境。它预置了主流的深度学习框架,并提供了高性能的计算资源(如GPU),用户可以通过其交互式的JupyterLab界面,便捷地完成AI项目的开发、训练和评估。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物 300 元代金券领取。
已通过实名认证且账户余额 ≥0 元。
在实验页面,当您已阅读并同意上述创建资源的目的以及部分资源可能产生的计费规则。
资源消耗说明
本场景主要涉及以下云产品和服务:PAI-DSW、对象存储OSS。
本实验预计产生资源消耗:约10元(以使用ecs.gn6i-c8g1.2xlarge规格的PAI-DSW实例进行1小时的数据处理与模型训练为例估算)。
如果您调整了资源规格、延长了使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
PAI-DSW: 费用主要由DSW实例的运行时长和其规格决定。本实验选用GPU实例进行模型训练,关机后即停止计费。
对象存储 OSS: 费用由数据存储容量和少量外网下行流量(仅在下载结果时产生)决定。
领取专属权益及创建实验资源
第一步:在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第二步:本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。

实验步骤
进入DSW控制台
登录阿里云,进入机器学习PAI控制台,在左侧导航栏选择【工作空间列表】,点击进入您的工作空间
在工作空间内,选择左侧的【模型开发与训练】—【DSW(Data Science Workshop)】
创建DSW实例
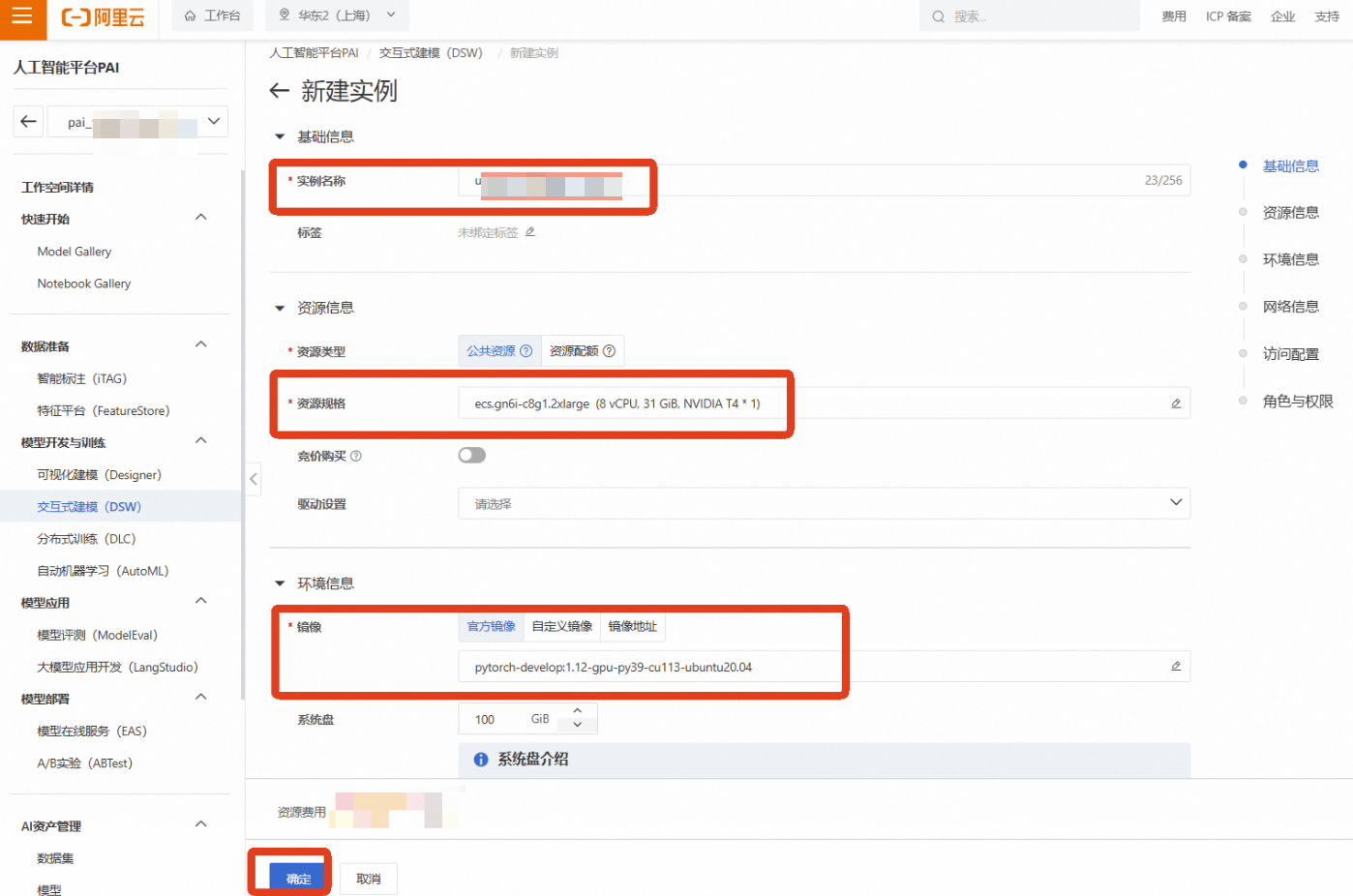
点击【创建实例】

实例名称:自定义一个名称,如 medical-2d-classification
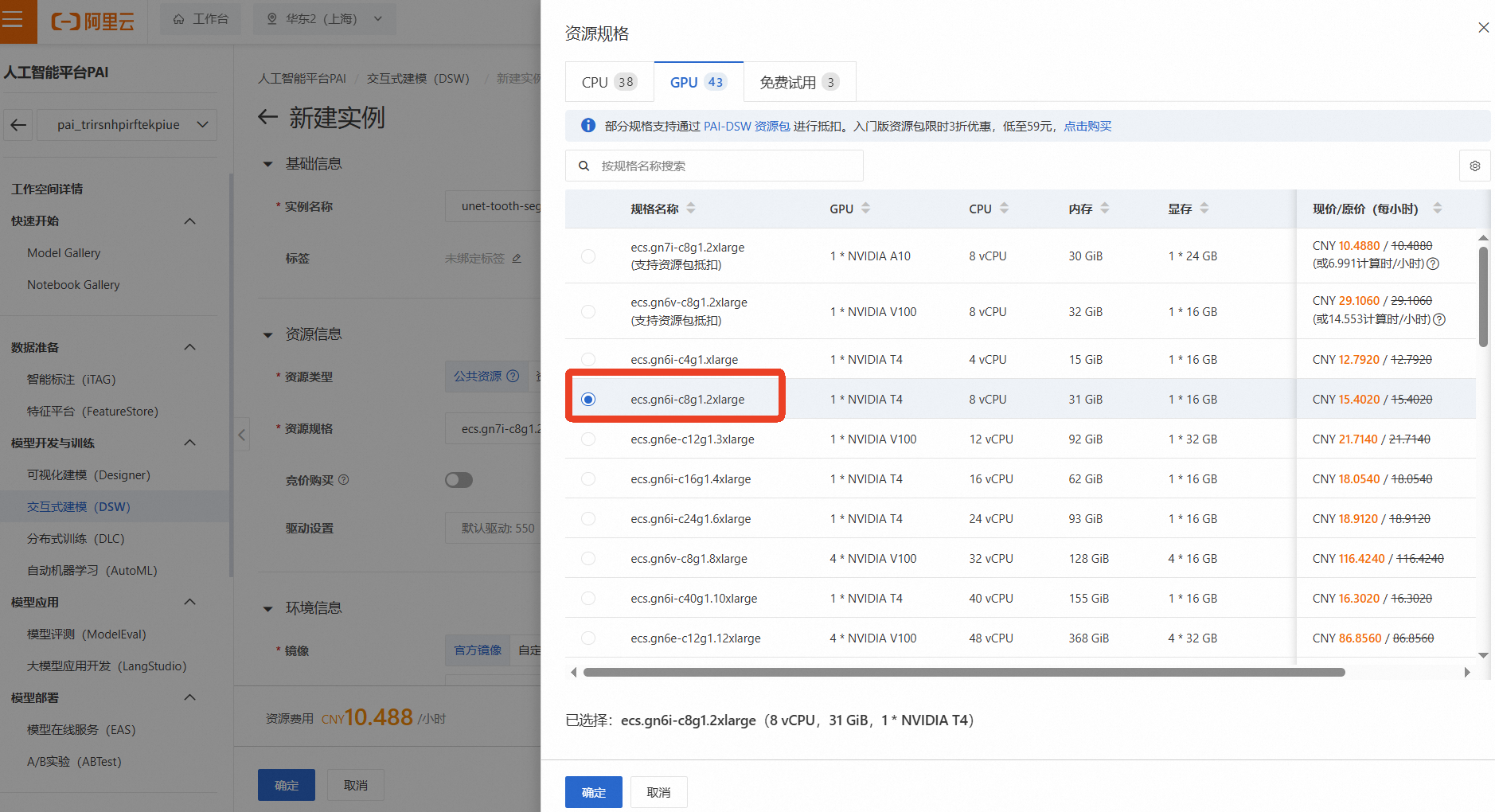
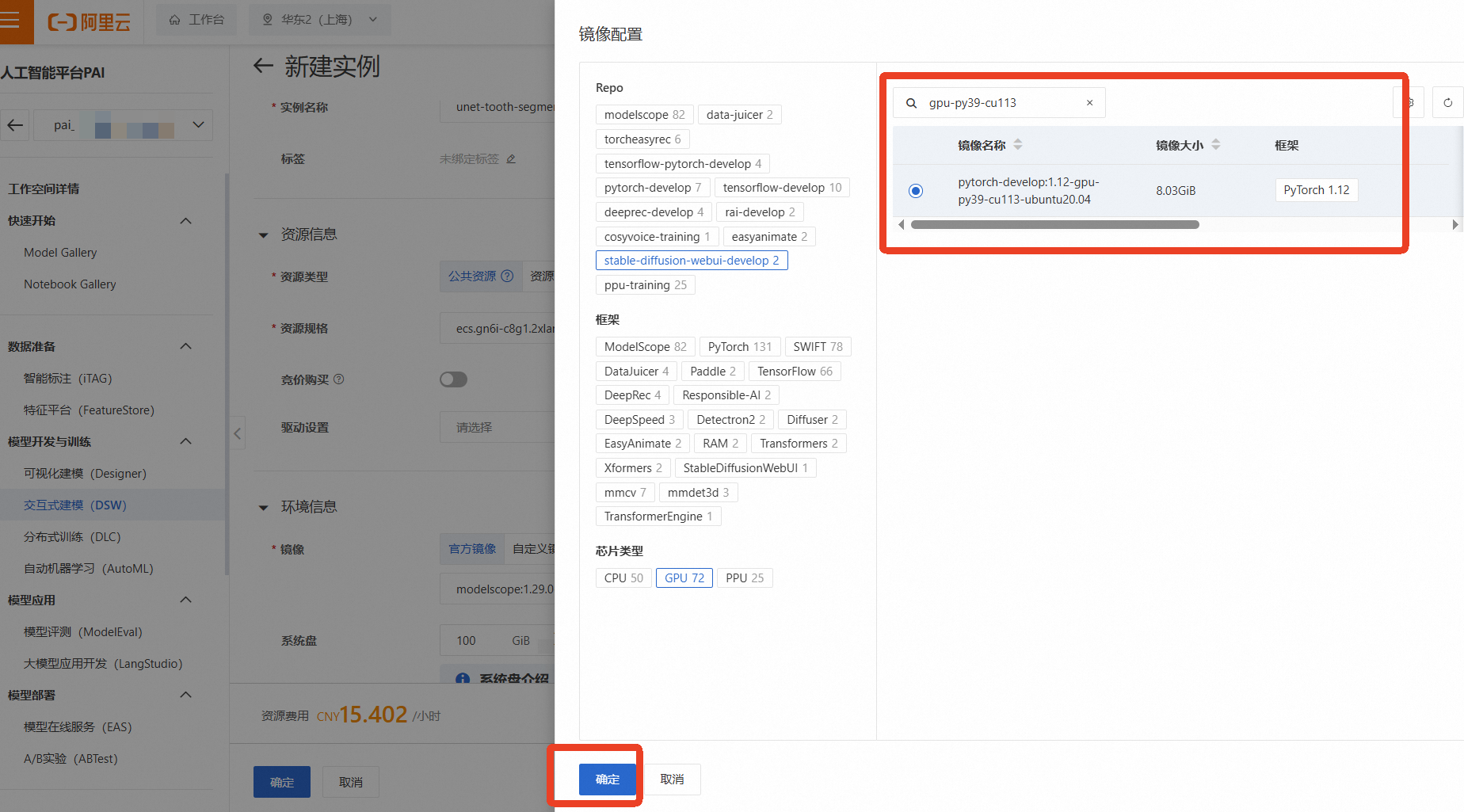
资源组(机型):为了进行深度学习模型训练,我们需要选择GPU实例。点击【筛选】,勾选【GPU】,然后选择一款有库存的GPU机型,例如 ecs.gn6i-c8g1.2xlarge(vCPU: 8, 内存: 32GiB, GPU: NVIDIA T4 16GB)
说明这是成本消耗的主要来源,请务必注意实验后及时停止或删除实例!
镜像:选择一个预置了PyTorch框架的镜像,例如 pytorch:1.12-gpu-py39-cu113-ubuntu20.04
其他保持默认,选择完成后点击【确定】
等待约2-3分钟,直到实例状态变为“运行中”
进入JupyterLab环境
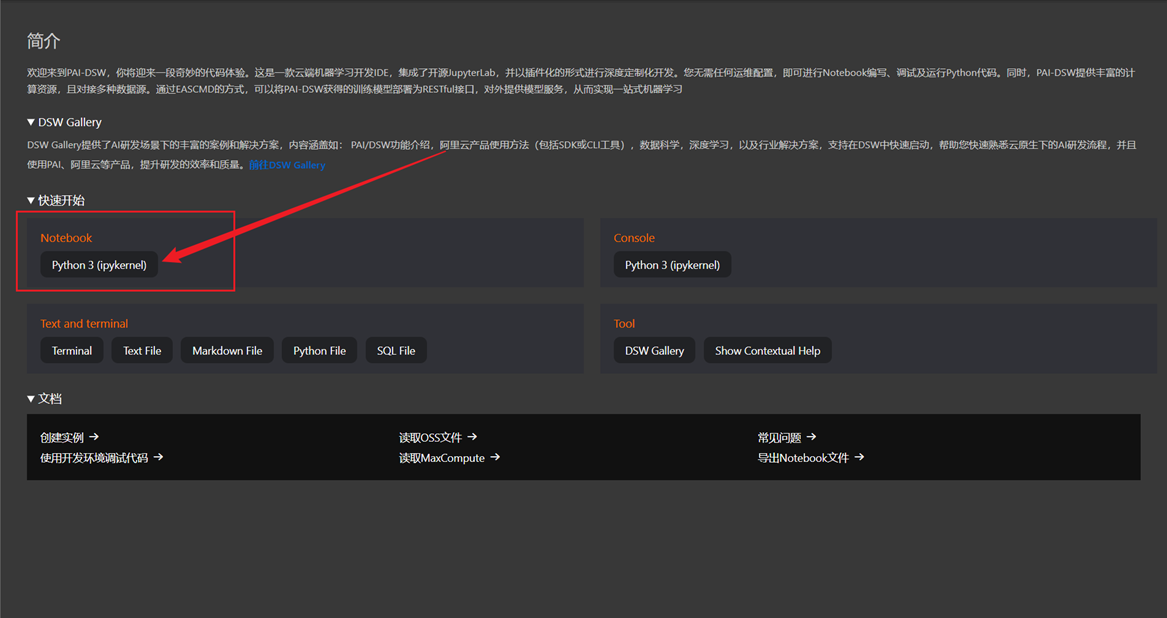
在DSW实例列表中,找到刚刚创建的实例,点击右侧的【打开】
返回JupyterLab的启动器(Launcher)页面,点击【Python 3 (PyTorch 1.12)】
创建一个新的Notebook文件
安装MONAI并导入环境
import os import shutil import tempfile import matplotlib.pyplot as plt import PIL import torch import numpy as np from sklearn.metrics import classification_report from monai.apps import download_and_extract from monai.data import DataLoader from monai.networks.nets import DenseNet121 from monai.transforms import Compose, LoadImage, EnsureChannelFirst, ScaleIntensity, RandRotate, RandFlip, RandZoom from monai.utils import set_determinism # 设置随机种子以保证实验结果可复现 set_determinism(seed=0)自动下载并探查MedNIST数据集
我们将编写代码来自动下载并解压MedNIST数据集
root_dir = tempfile.mkdtemp() # 创建一个临时目录来存放数据 resource = "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/MedNIST.tar.gz" md5 = "0bc7306e7427e00ad1c5526a6677552d" compressed_file = os.path.join(root_dir, "MedNIST.tar.gz") data_dir = os.path.join(root_dir, "MedNIST") if not os.path.exists(data_dir): download_and_extract(resource, compressed_file, root_dir, md5) print(f"数据集已下载并解压至: {data_dir}")下载完成后,我们来查看一下数据集的构成。数据集的文件夹名称即为我们的分类标签
root_dir = tempfile.mkdtemp() # 创建一个临时目录来存放数据 resource = "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/MedNIST.tar.gz" md5 = "0bc7306e7427e00ad1c5526a6677552d" compressed_file = os.path.join(root_dir, "MedNIST.tar.gz") data_dir = os.path.join(root_dir, "MedNIST") if not os.path.exists(data_dir): download_and_extract(resource, compressed_file, root_dir, md5) print(f"数据集已下载并解压至: {data_dir}")
划分数据集并定义预处理流程
我们将全部数据按8:1:1的比例随机划分为训练集、验证集和测试集。
# 整合所有图片路径和对应的标签 image_files_list = [item for sublist in image_files for item in sublist] image_class_list = [i for i, sublist in enumerate(image_files) for _ in sublist] # 划分数据集索引 length = len(image_files_list) indices = np.arange(length) np.random.shuffle(indices) test_split = int(0.1 * length) val_split = int(0.1 * length) + test_split test_indices, val_indices, train_indices = indices[:test_split], indices[test_split:val_split], indices[val_split:] # 创建文件列表和标签列表 train_x = [image_files_list[i] for i in train_indices] train_y = [image_class_list[i] for i in train_indices] val_x = [image_files_list[i] for i in val_indices] val_y = [image_class_list[i] for i in val_indices] test_x = [image_files_list[i] for i in test_indices] test_y = [image_class_list[i] for i in test_indices] print(f"训练集: {len(train_x)}, 验证集: {len(val_x)}, 测试集: {len(test_x)}")- 重要
重点说明:为了让模型学习得更好(提升泛化能力),我们会对训练数据进行“数据增强”,即在每次训练时对图片进行随机的旋转、翻转和缩放,模拟真实世界中可能存在的各种变化。
# 为训练集定义带数据增强的变换 train_transforms = Compose([ LoadImage(image_only=True), EnsureChannelFirst(), ScaleIntensity(), RandRotate(range_x=np.pi / 12, prob=0.5, keep_size=True), RandFlip(spatial_axis=0, prob=0.5), RandZoom(min_zoom=0.9, max_zoom=1.1, prob=0.5), ]) # 验证和测试集不需要数据增强 val_transforms = Compose([LoadImage(image_only=True), EnsureChannelFirst(), ScaleIntensity()])
创建数据集加载器 (DataLoader)
我们定义一个自定义的数据集类,并创建用于训练、验证和测试的数据加载器。
class CustomDataset(torch.utils.data.Dataset): def __init__(self, image_files, labels, transforms): self.image_files = image_files self.labels = labels self.transforms = transforms def __len__(self): return len(self.image_files) def __getitem__(self, index): return self.transforms(self.image_files[index]), self.labels[index] train_ds = CustomDataset(train_x, train_y, train_transforms) train_loader = DataLoader(train_ds, batch_size=300, shuffle=True, num_workers=2) val_ds = CustomDataset(val_x, val_y, val_transforms) val_loader = DataLoader(val_ds, batch_size=300, num_workers=2) test_ds = CustomDataset(test_x, test_y, val_transforms) test_loader = DataLoader(test_ds, batch_size=300, num_workers=2)定义模型并开始训练
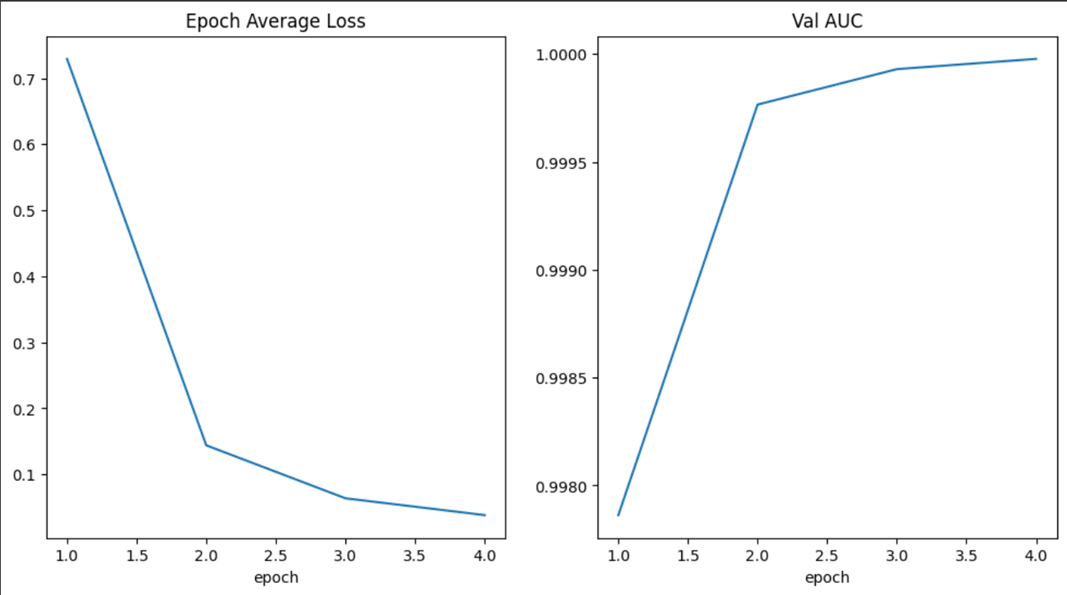
我们选择DenseNet121作为分类模型,并使用Adam优化器和交叉熵损失函数进行训练。为了快速看到效果,我们只训练4个周期(Epoch)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = DenseNet121(spatial_dims=2, in_channels=1, out_channels=num_class).to(device) loss_function = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), 1e-5) max_epochs = 4 best_metric = -1 best_metric_epoch = -1 for epoch in range(max_epochs): print(f"\n--- Epoch {epoch + 1}/{max_epochs} ---") model.train() epoch_loss = 0 for step, batch_data in enumerate(train_loader): inputs, labels = batch_data[0].to(device), batch_data[1].to(device) optimizer.zero_grad() outputs = model(inputs) loss = loss_function(outputs, labels) loss.backward() optimizer.step() epoch_loss += loss.item() epoch_loss /= (step + 1) print(f"Average Training Loss: {epoch_loss:.4f}") # 在验证集上评估模型 model.eval() with torch.no_grad(): y_pred = torch.tensor([], dtype=torch.float32, device=device) y = torch.tensor([], dtype=torch.long, device=device) for val_data in val_loader: val_images, val_labels = val_data[0].to(device), val_data[1].to(device) y_pred = torch.cat([y_pred, model(val_images)], dim=0) y = torch.cat([y, val_labels], dim=0) acc_value = torch.eq(y_pred.argmax(dim=1), y) acc_metric = acc_value.sum().item() / len(acc_value) if acc_metric > best_metric: best_metric = acc_metric best_metric_epoch = epoch + 1 torch.save(model.state_dict(), "best_metric_model.pth") print("New best model saved!") print(f"Validation Accuracy: {acc_metric:.4f}, Best Accuracy: {best_metric:.4f} at Epoch {best_metric_epoch}") print(f"\nTraining completed. Best validation accuracy: {best_metric:.4f}")在测试集上评估最终模型
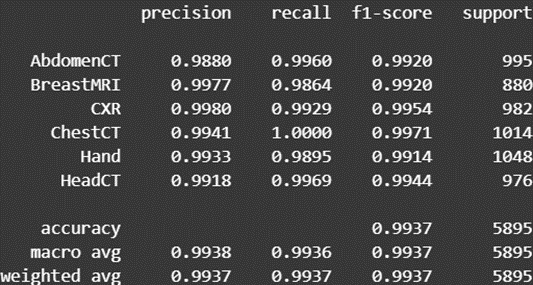
训练完成后,我们加载在验证集上表现最好的模型,并在从未见过的测试集上进行最终评估,以检验模型的泛化能力
model.load_state_dict(torch.load("best_metric_model.pth")) model.eval() y_true = [] y_pred = [] with torch.no_grad(): for test_data in test_loader: test_images, test_labels = test_data[0].to(device), test_data[1].to(device) pred = model(test_images).argmax(dim=1) y_true.extend(test_labels.tolist()) y_pred.extend(pred.tolist()) # 打印详细的分类报告 print(classification_report(y_true, y_pred, target_names=class_names, digits=4))
清理资源
为避免产生不必要的个人扣费,实验完成后请务必按照以下步骤清理所有资源!
释放PAI-DSW实例
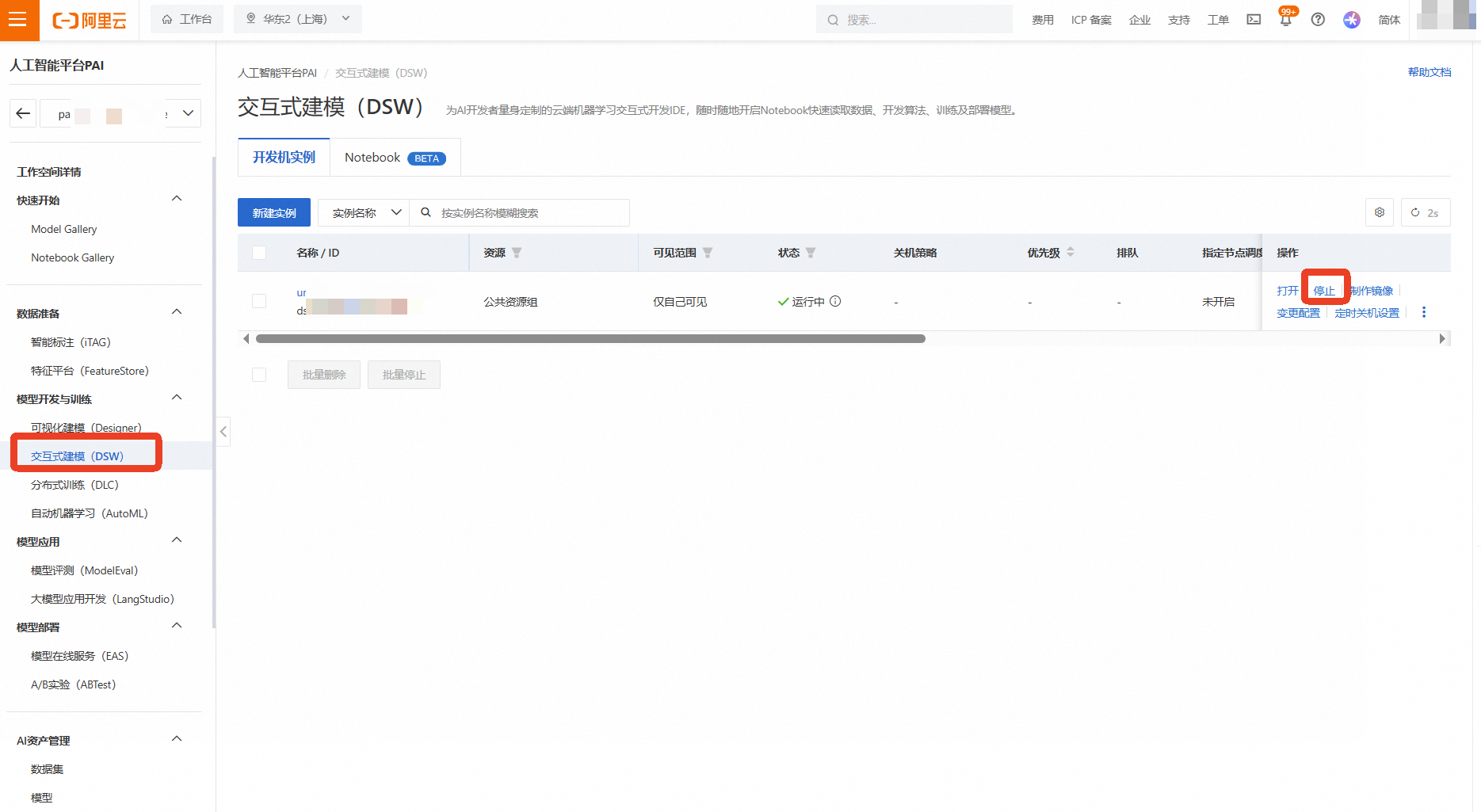
返回 机器学习PAI控制台 的DSW实例列表页面
找到本次实验创建的实例,点击右侧的【停止】
等待实例状态变为“已停止”后,为确保完全释放,再次点击右侧的【...】更多操作,选择【删除】
在弹出的确认框中点击【停止实例】/【删除实例】
等待一段时间检查是否删除成功
删除OSS数据和Bucket
进入 对象存储OSS控制台,找到为本次实验创建的Bucket,点击进入
选中所有上传的数据文件和文件夹,点击【删除】,返回Bucket列表,选中该Bucket,点击【删除】,根据提示完成删除操作(可能需要清空碎片)
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 跳转实验评分
请为本次实验评分,并给出您的建议,点击 确认,结束本次实验