AI的外科手术刀:基于PAI-DSW的3D脑肿瘤多模态分割
本实验将带您挑战医疗AI领域最经典、最核心的任务之一:3D脑肿瘤分割。您将在阿里云PAI-DSW环境中,学习如何处理多模态(Multi-modal)的3D脑部MRI影像,并训练一个先进的3D分割网络(SegResNet),使其能够像一把精准的“AI外科手术刀”一样,自动识别并勾勒出肿瘤的不同子区域(如肿瘤核心、水肿区等)。
实验简介
本实验将带您挑战医疗AI领域最经典、最核心的任务之一:3D脑肿瘤分割。您将在阿里云PAI-DSW环境中,学习如何处理多模态(Multi-modal)的3D脑部MRI影像,并训练一个先进的3D分割网络(SegResNet),使其能够像一把精准的“AI外科手术刀”一样,自动识别并勾勒出肿瘤的不同子区域(如肿瘤核心、水肿区等)。
背景知识
3D医学影像分割:与分割2D“切片”不同,3D分割直接在立体的三维空间中进行操作,能够捕捉到肿瘤完整的空间形态和结构信息,这对于手术规划和放疗剂量的精确计算至关重要。
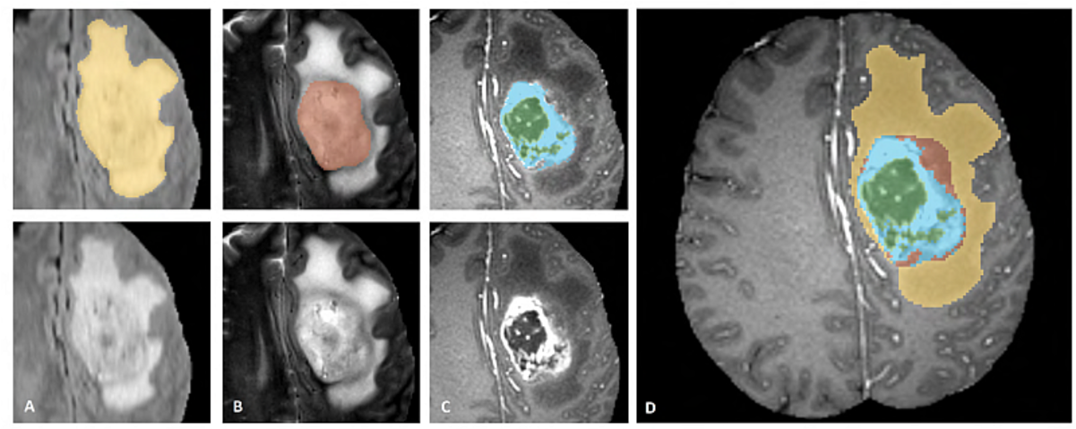
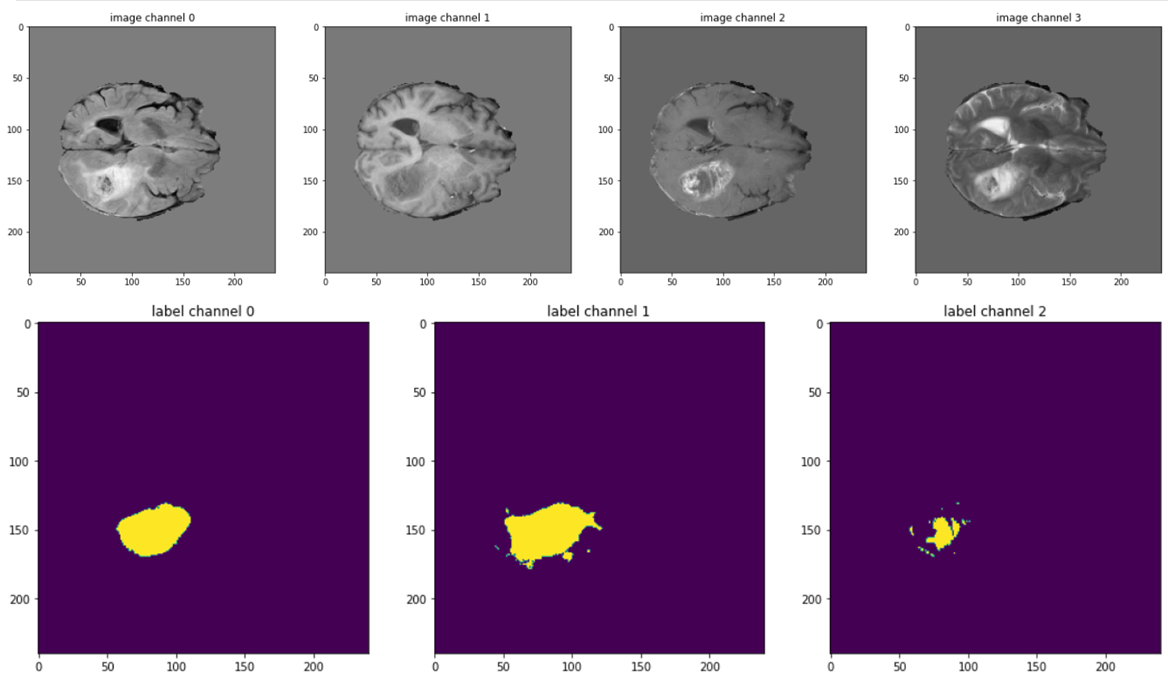
多模态MRI:临床上,医生常常会结合多种不同成像参数的MRI扫描来诊断脑肿瘤,因为不同模态能突显不同的组织特性(例如,T1模态看解剖结构,T2-FLAIR模态看水肿区域,T1Gd模态看增强的活性肿瘤区)。本实验将教会您如何将这4种模态的影像作为模型的4个输入通道,为AI提供最全面的信息来进行决策。
多模态MRI:临床上,医生常常会结合多种不同成像参数的MRI扫描来诊断脑肿瘤,因为不同模态能突显不同的组织特性(例如,T1模态看解剖结构,T2-FLAIR模态看水肿区域,T1Gd模态看增强的活性肿瘤区)。本实验将教会您如何将这4种模态的影像作为模型的4个输入通道,为AI提供最全面的信息来进行决策。
滑窗推理 (Sliding Window Inference):由于完整的3D MRI影像非常大,通常无法一次性放入GPU显存进行计算。因此,我们训练时使用固定大小的图像块(Patch),而在推理(预测)时,则采用“滑窗”策略:在完整的大图像上依次滑动一个小窗口进行预测,最后将所有窗口的预测结果智能地拼接起来,从而得到完整、平滑的分割结果。
ONNX模型部署:ONNX是一种开放的神经网络交换格式,它允许模型在不同的AI框架和硬件平台之间轻松迁移和部署。学习将训练好的PyTorch模型转换为ONNX格式,是模型从研究走向实际应用的关键一步。
PAI-DSW: PAI-DSW是一个为开发者量身打造的云端深度学习开发环境。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物 300 元代金券领取。
已通过实名认证且账户余额 ≥0 元。
在实验页面,当您已阅读并同意上述创建资源的目的以及部分资源可能产生的计费规则。
资源消耗说明
本场景主要涉及以下云产品和服务:PAI、对象存储OSS。
本实验预计产生资源消耗:约10元(以使用ecs.gn6i-c8g1.2xlarge规格的PAI-DSW实例进行1小时的数据处理与模型训练为例估算)。
如果您调整了资源规格、延长了使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
PAI-DSW: 费用主要由DSW实例的运行时长和其规格决定。本实验选用GPU实例进行模型训练,关机后即停止计费。
对象存储 OSS: 费用由数据存储容量和少量外网下行流量(仅在下载结果时产生)决定。
领取专属权益及创建实验资源
第一步:在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第二步:本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。

实验步骤
进入DSW控制台
登录阿里云,进入机器学习PAI控制台,在左侧导航栏选择【工作空间列表】,点击进入您的工作空间
在工作空间内,选择左侧的【模型开发与训练】—【DSW(Data Science Workshop)】
创建DSW实例
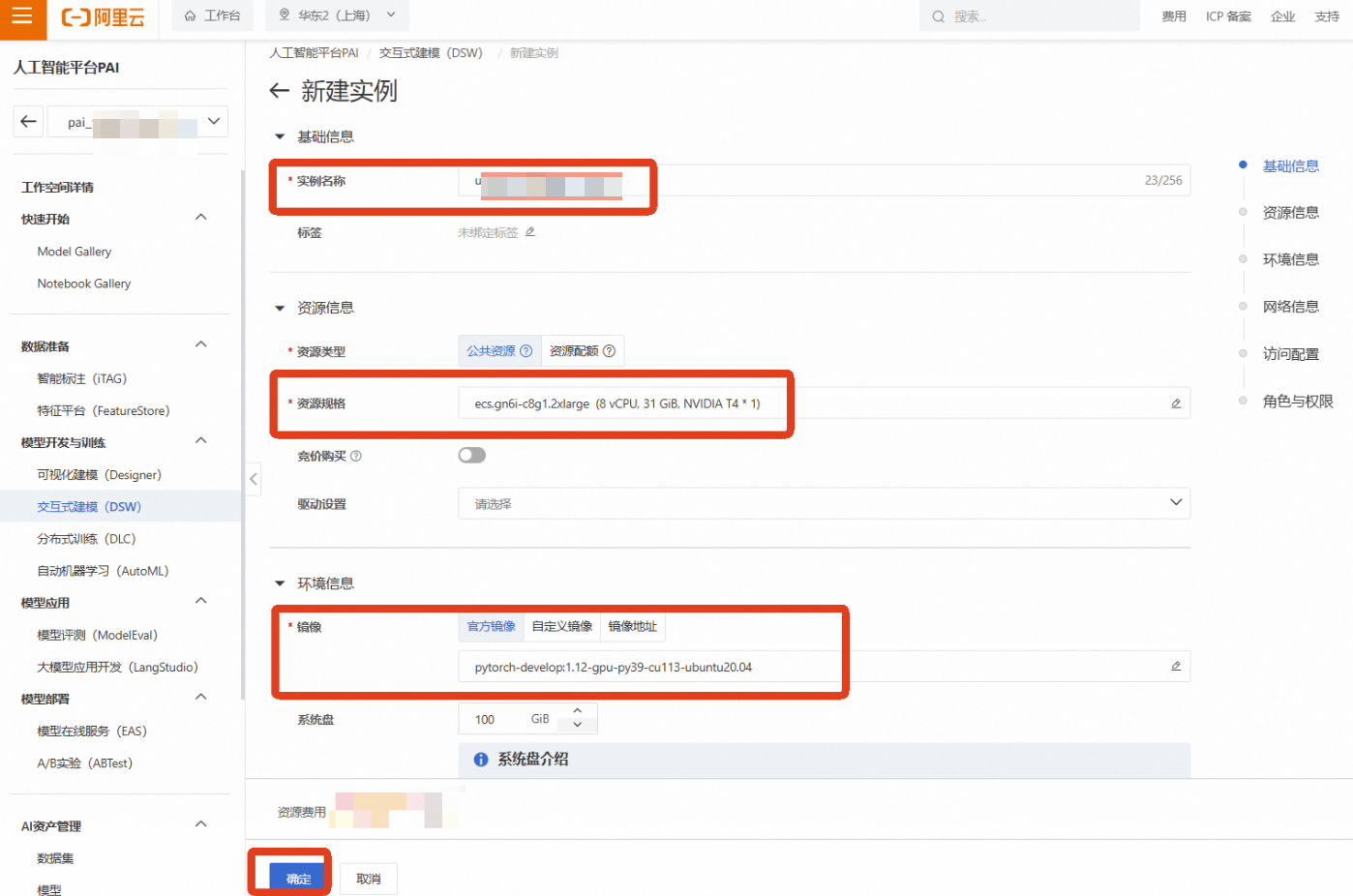
点击【创建实例】

实例名称:自定义一个名称,如 medical-2d-regist
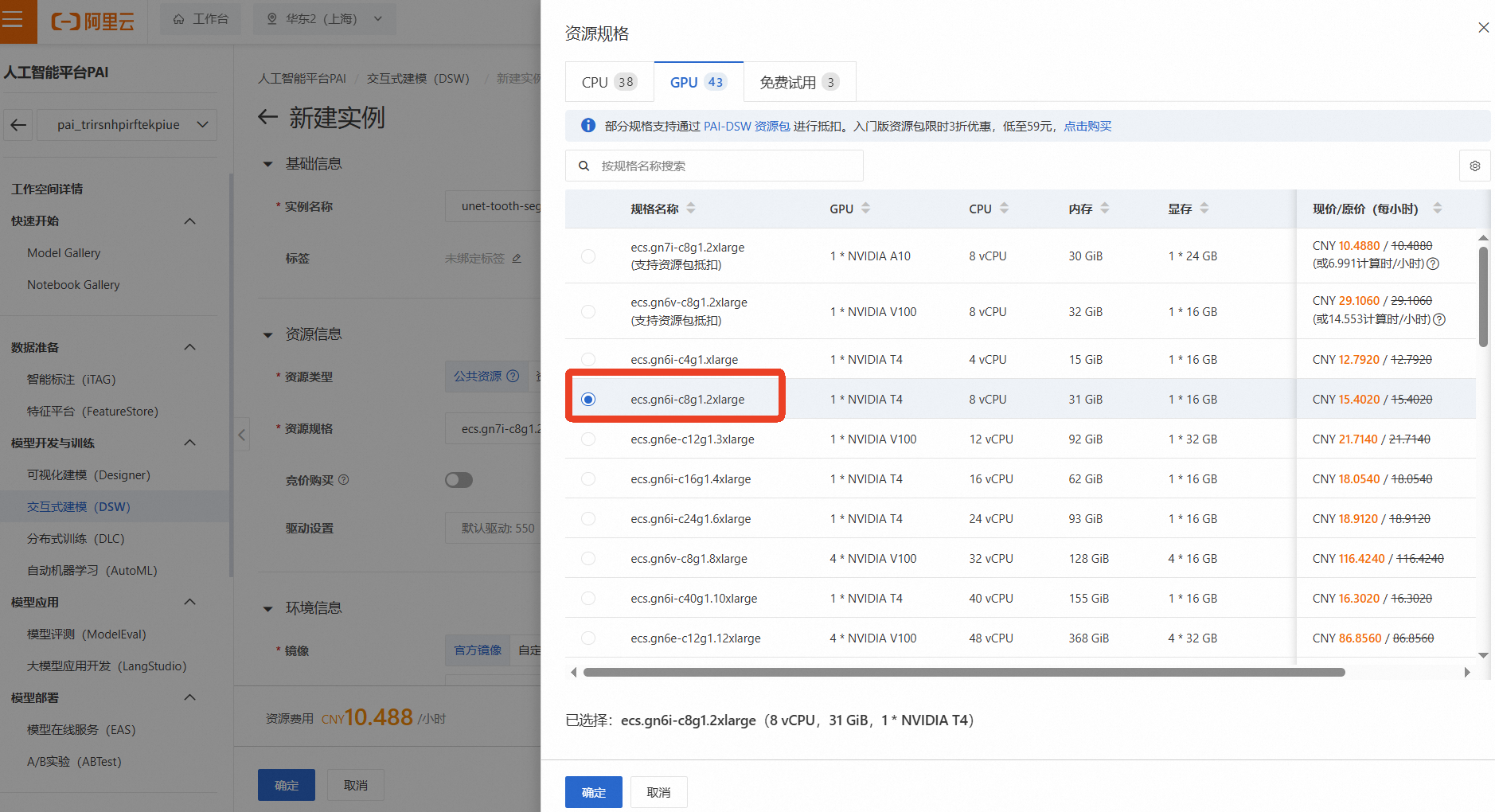
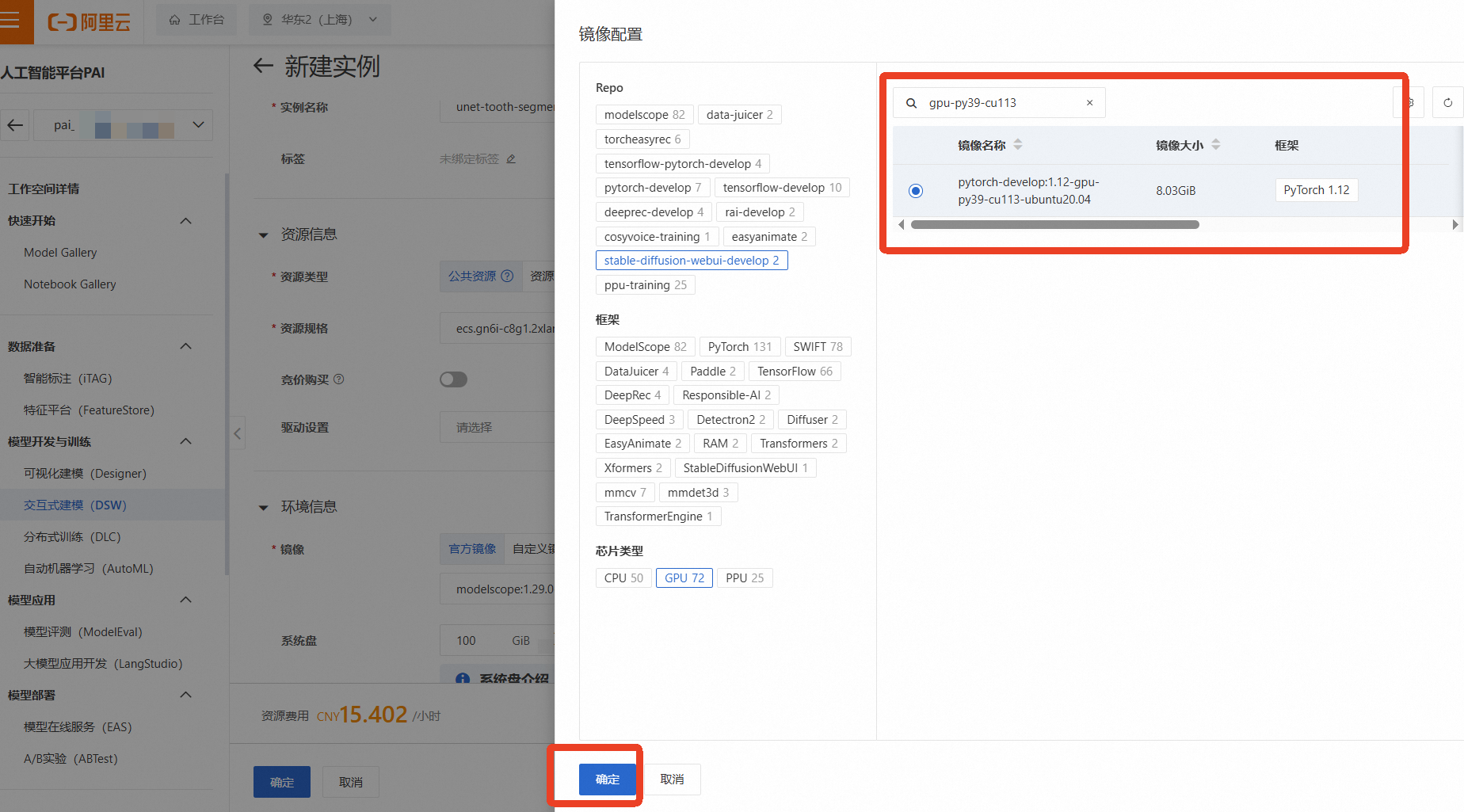
资源组(机型):为了进行深度学习模型训练,我们需要选择GPU实例。点击【筛选】,勾选【GPU】,然后选择一款有库存的GPU机型,例如 ecs.gn6i-c8g1.2xlarge(vCPU: 8, 内存: 32GiB, GPU: NVIDIA T4 16GB)
说明这是成本消耗的主要来源,请务必注意实验后及时停止或删除实例!
镜像:选择一个预置了PyTorch框架的镜像,例如 pytorch:1.12-gpu-py39-cu113-ubuntu20.04
其他保持默认,选择完成后点击【确定】
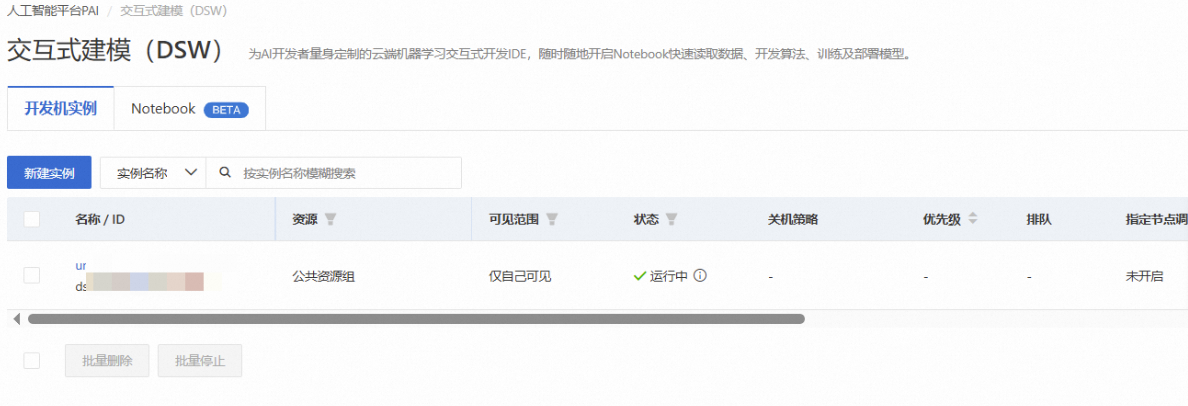
等待约2-3分钟,直到实例状态变为“运行中”
进入JupyterLab环境
在DSW实例列表中,找到刚刚创建的实例,点击右侧的【打开】
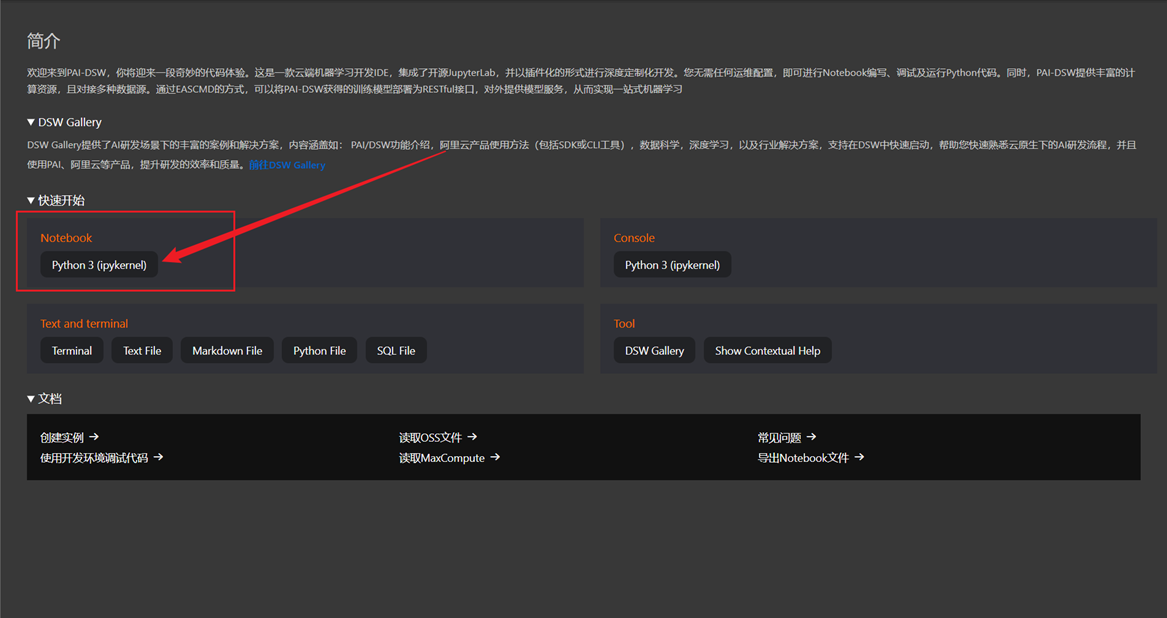
返回JupyterLab的启动器(Launcher)页面,点击【Python 3 (PyTorch 1.12)】
创建一个新的Notebook文件
安装MONAI并导入环境
在Notebook的第一个代码单元格中,运行以下代码来安装必要的AI开发库。onnxruntime用于后续的模型部署推理。
!pip install -q "monai-weekly[nibabel, tqdm]" onnxruntime在下一个单元格中,导入本实验所需的所有Python库。
import os import tempfile import matplotlib.pyplot as plt import torch from monai.apps import DecathlonDataset from monai.data import DataLoader, decollate_batch from monai.losses import DiceLoss from monai.inferers import sliding_window_inference from monai.metrics import DiceMetric from monai.networks.nets import SegResNet from monai.transforms import Compose, MapTransform, LoadImaged, EnsureChannelFirstd, NormalizeIntensityd, RandFlipd, RandSpatialCropd, Spacingd, Activations, AsDiscrete from monai.utils import set_determinism set_determinism(seed=0) device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
下载并准备BraTS数据集
我们将使用内置的数据集工具自动下载并解压医学分割十项全能挑战赛中的“任务一:脑肿瘤”数据集。
root_dir = tempfile.mkdtemp() # 该工具会自动下载数据,如果检测到已存在则跳过 train_ds = DecathlonDataset( root_dir=root_dir, task="Task01_BrainTumour", section="training", download=True, cache_rate=0.0 # 不缓存数据以节省内存 ) val_ds = DecathlonDataset( root_dir=root_dir, task="Task01_BrainTumour", section="validation", download=False, cache_rate=0.0 ) print(f"数据集准备完成,训练集: {len(train_ds)} 个, 验证集: {len(val_ds)} 个。")定义数据预处理流程
- 重要
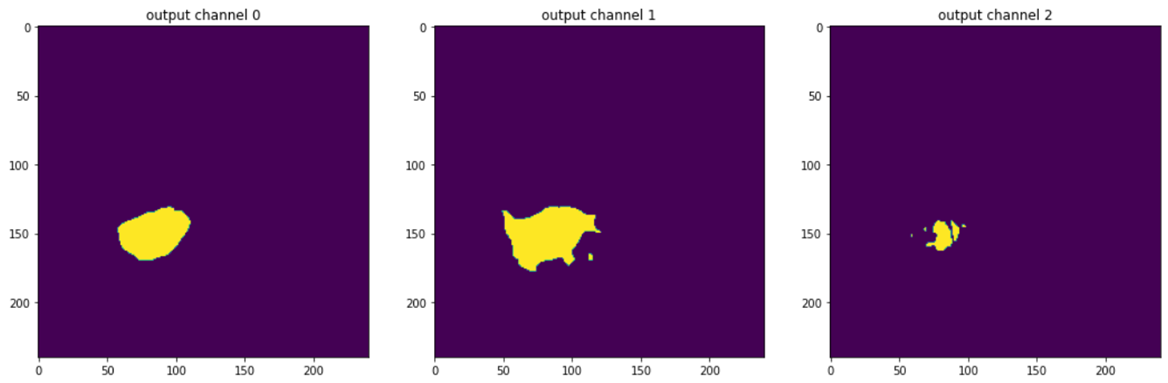
重点说明: 首先,我们需要定义一个自定义变换,将原始的单通道标签(1, 2, 3...)转换为模型需要预测的3个独立通道(肿瘤核心、完整肿瘤、增强肿瘤)。
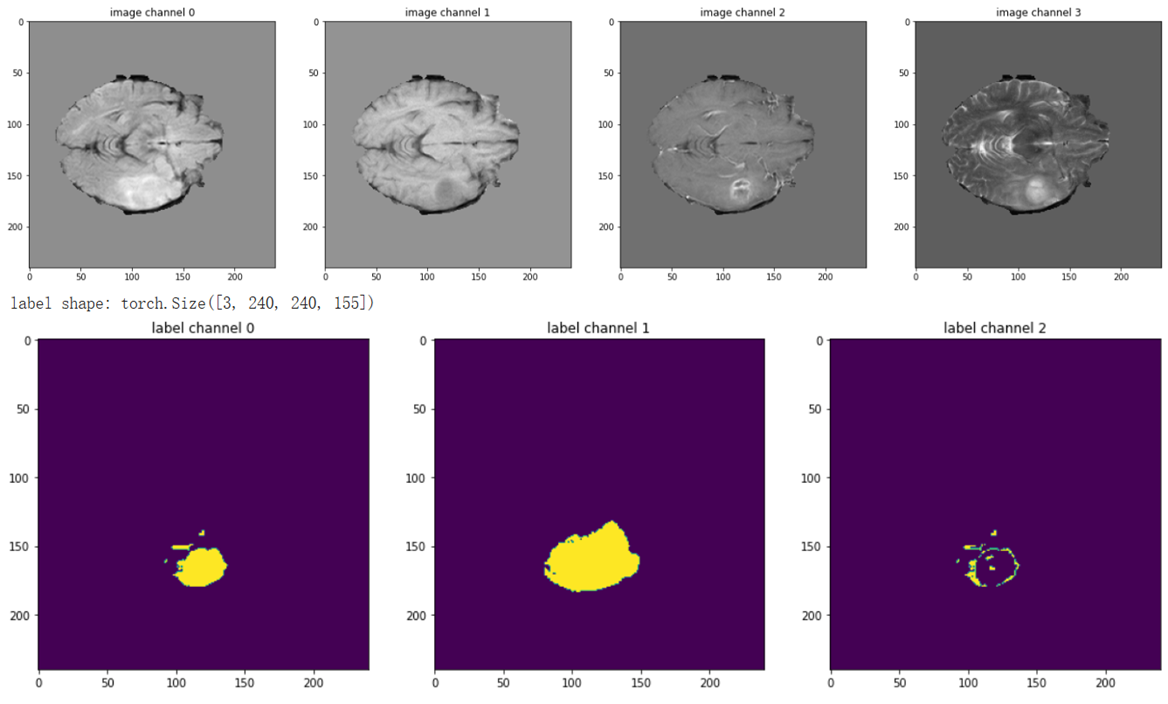
class ConvertToMultiChannel(MapTransform): def __call__(self, data): d = dict(data) for key in self.keys: label = d[key] # 肿瘤核心区(TC) = 原始标签2或3 tc = torch.logical_or(label == 2, label == 3) # 完整肿瘤区(WT) = 原始标签1或2或3 wt = torch.logical_or(tc, label == 1) # 增强肿瘤区(ET) = 原始标签2 et = (label == 2) d[key] = torch.stack([tc, wt, et], axis=0).float() return d 接下来,构建完整的预处理流水线。其中包括重采样到1x1x1mm的各向同性空间(Spacingd),以及从大影像中随机裁剪出224x224x144大小的训练块(RandSpatialCropd)。
train_transform = Compose([ LoadImaged(keys=["image", "label"]), EnsureChannelFirstd(keys="image"), ConvertToMultiChannel(keys="label"), Spacingd(keys=["image", "label"], pixdim=(1.0, 1.0, 1.0), mode=("bilinear", "nearest")), RandSpatialCropd(keys=["image", "label"], roi_size=[224, 224, 144], random_size=False), RandFlipd(keys=["image", "label"], prob=0.5, spatial_axis=0), NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True), ]) val_transform = Compose([ LoadImaged(keys=["image", "label"]), EnsureChannelFirstd(keys="image"), ConvertToMultiChannel(keys="label"), Spacingd(keys=["image", "label"], pixdim=(1.0, 1.0, 1.0), mode=("bilinear", "nearest")), NormalizeIntensityd(keys="image", nonzero=True, channel_wise=True), ])
创建模型、损失、优化器和数据加载器
train_ds.transform = train_transform val_ds.transform = val_transform train_loader = DataLoader(train_ds, batch_size=1, shuffle=True, num_workers=4) val_loader = DataLoader(val_ds, batch_size=1, shuffle=False, num_workers=4) model = SegResNet( in_channels=4, out_channels=3, init_filters=16, blocks_down=[1, 2, 2, 4], blocks_up=[1, 1, 1], ).to(device) loss_function = DiceLoss(sigmoid=True) # 使用Sigmoid激活,因为是多标签输出 optimizer = torch.optim.Adam(model.parameters(), 1e-4) dice_metric = DiceMetric(include_background=True, reduction="mean_batch")
开始训练(包含滑窗推理验证)
- 重要
重点说明: 训练过程是标准的,但在验证(Evaluation)阶段,我们将使用sliding_window_inference函数对完整的、未经裁剪的验证图像进行推理。
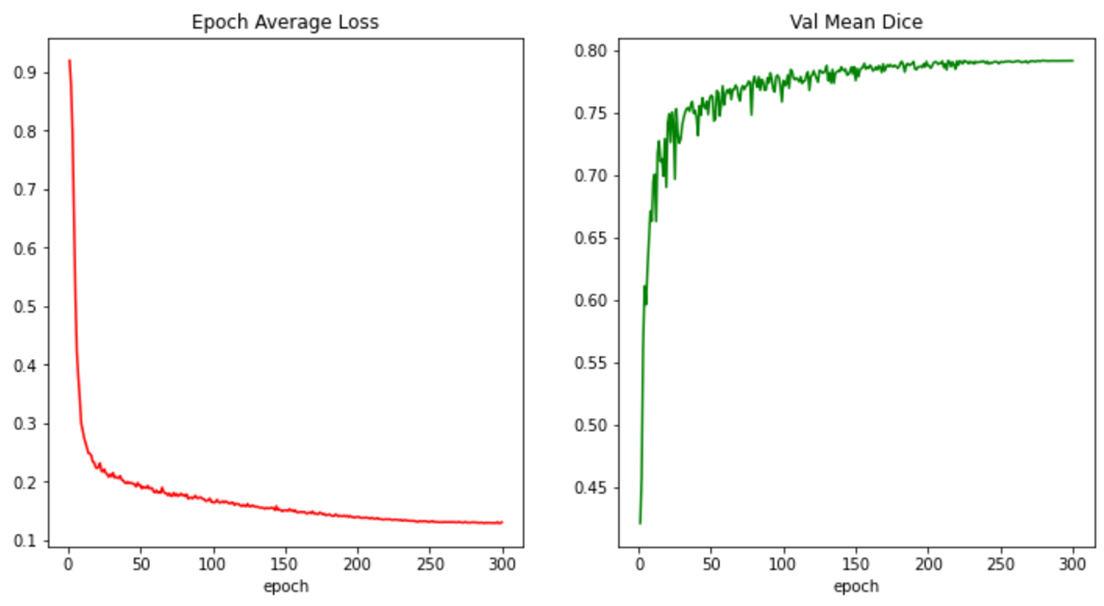
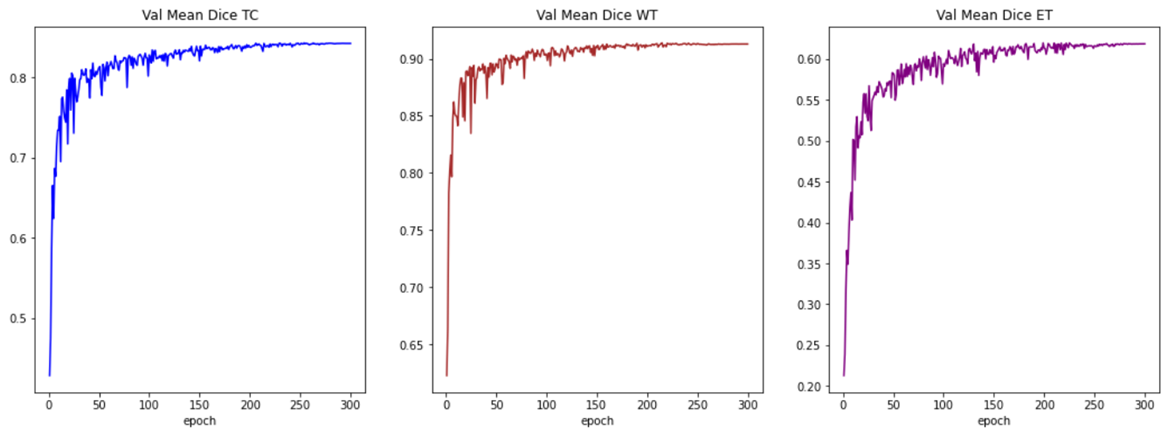
# 为快速演示,只训练少量周期 max_epochs = 5 val_interval = 1 best_metric = -1 best_metric_epoch = -1 for epoch in range(max_epochs): model.train() for batch_data in train_loader: inputs, labels = batch_data["image"].to(device), batch_data["label"].to(device) optimizer.zero_grad() outputs = model(inputs) loss = loss_function(outputs, labels) loss.backward() optimizer.step() # 验证过程 if (epoch + 1) % val_interval == 0: model.eval() with torch.no_grad(): for val_data in val_loader: val_inputs, val_labels = val_data["image"].to(device), val_data["label"].to(device) # 使用滑窗推理 val_outputs = sliding_window_inference(val_inputs, (224, 224, 144), 4, model) val_outputs = [Activations(sigmoid=True)(i) for i in decollate_batch(val_outputs)] val_outputs = [AsDiscrete(threshold=0.5)(i) for i in val_outputs] dice_metric(y_pred=val_outputs, y=val_labels) metric_batch = dice_metric.aggregate() metric = metric_batch.mean().item() dice_metric.reset() if metric > best_metric: best_metric = metric best_metric_epoch = epoch + 1 torch.save(model.state_dict(), "best_metric_model_brats.pth") print(f"Epoch {epoch + 1} Val Mean Dice: {metric:.4f}, Best: {best_metric:.4f} at Epoch {best_metric_epoch}")
(高级)模型转换与ONNX推理
我们将训练好的PyTorch模型转换为通用的ONNX格式,并使用ONNX Runtime进行推理,验证其与原始模型的一致性。
import onnxruntime # 加载最佳模型 model.load_state_dict(torch.load("best_metric_model_brats.pth")) model.eval() # 转换模型 dummy_input = torch.randn(1, 4, 224, 224, 144, device=device) # 创建一个符合模型输入的假数据 onnx_path = "best_metric_model.onnx" torch.onnx.export(model, dummy_input, onnx_path, verbose=False) print(f"模型已成功转换为 ONNX 格式并保存至: {onnx_path}") # 使用ONNX Runtime进行推理 ort_session = onnxruntime.InferenceSession(onnx_path) val_input = val_ds[0]["image"].unsqueeze(0).to(device) # 取一个验证样本 def onnx_predictor(inputs): ort_inputs = {ort_session.get_inputs()[0].name: inputs.cpu().numpy()} ort_outs = ort_session.run(None, ort_inputs) return torch.tensor(ort_outs[0]).to(device) onnx_output = sliding_window_inference(val_input, (224, 224, 144), 4, onnx_predictor) print("使用 ONNX 模型完成滑窗推理。") plt.show()
清理资源
为避免产生不必要的个人扣费,实验完成后请务必按照以下步骤清理所有资源!
释放PAI-DSW实例
返回 机器学习PAI控制台 的DSW实例列表页面
找到本次实验创建的实例,点击右侧的【停止】
等待实例状态变为“已停止”后,为确保完全释放,再次点击右侧的【...】更多操作,选择【删除】
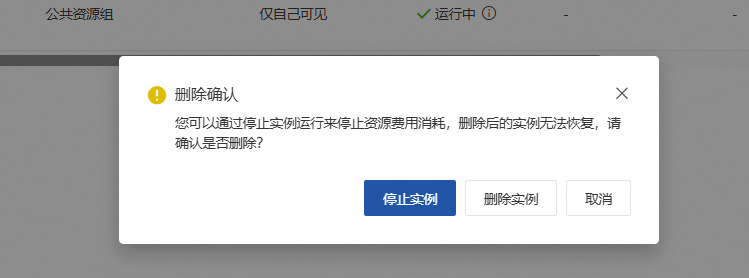
在弹出的确认框中点击【停止实例】/【删除实例】
等待一段时间检查是否删除成功
删除OSS数据和Bucket
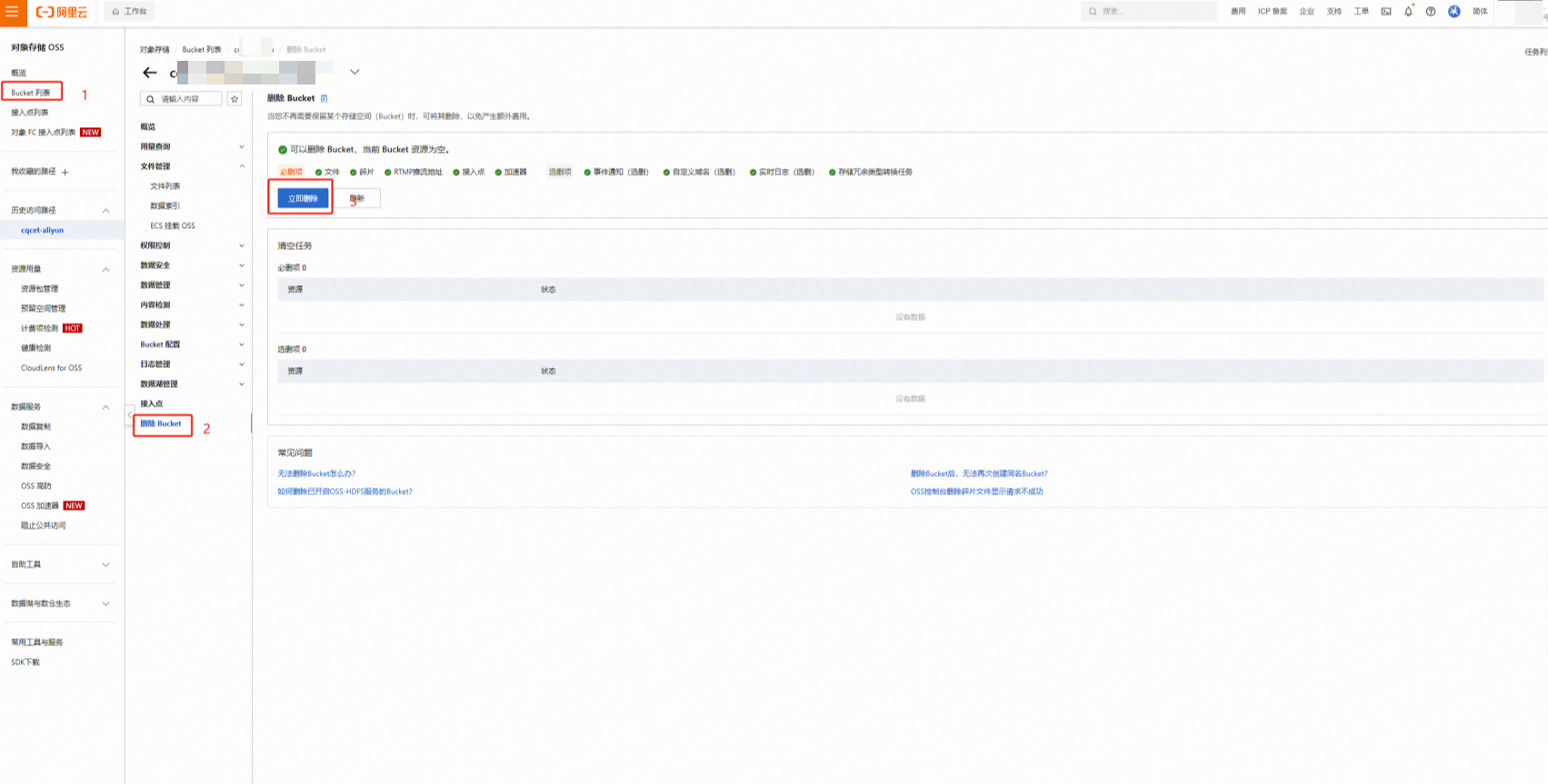
进入 对象存储OSS控制台,找到为本次实验创建的Bucket,点击进入
选中所有上传的数据文件和文件夹,点击【删除】,返回Bucket列表,选中该Bucket,点击【删除】,根据提示完成删除操作(可能需要清空碎片)
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 跳转实验评分
请为本次实验评分,并给出您的建议,点击 确认,结束本次实验