构建AI口腔健康助手:基于PAI-DSW与千问大模型
欢迎来到大语言模型的时代!本实验将带您体验一种全新的AI开发范式:不再从零开始训练模型,而是直接“调用”一个已经具备海量知识的超强“大脑”——阿里云千问(Qwen3)大模型。您将在PAI-DSW环境中,学习如何通过简单的代码调用这个强大的模型,构建一个能够回答专业口腔健康问题的智能问答助手。
实验简介
欢迎来到大语言模型的时代!本实验将带您体验一种全新的AI开发范式:不再从零开始训练模型,而是直接“调用”一个已经具备海量知识的超强“大脑”——阿里云千问(Qwen3)大模型。您将在PAI-DSW环境中,学习如何通过简单的代码调用这个强大的模型,构建一个能够回答专业口腔健康问题的智能问答助手。
背景知识
大语言模型 (Large Language Models,LLM):LLM是近年来人工智能领域最引人注目的突破。它们是在海量的文本和代码数据上进行预训练的超大规模神经网络,具备了强大的自然语言理解、生成、推理和知识整合能力。我们不再需要为每一个特定任务都去训练一个新模型,而是可以通过“提问”(Prompt)的方式,引导LLM来完成各种任务。
千问(Qwen): “千问”是阿里云自主研发的超大规模语言模型系列。本实验使用的Qwen3是其最新一代的模型,在推理能力、指令遵循和多语言支持方面都达到了业界领先水平,能够作为我们构建智能应用的强大基座。
提示工程 (Prompt Engineering):这是与大模型交互的核心技术。如何设计出清晰、准确、无歧义的问题(Prompt),将直接决定模型能否给出高质量的回答。在本实验中,您将初步体验到如何通过设计不同的问题来测试和引导模型的能力。
模型推理 (Inference):与之前项目中的“模型训练”不同,本实验的核心是“模型推理”。即加载一个已经训练好的模型,并用它来生成预测结果(在这里是生成问题的答案)。这个过程不涉及反向传播和参数更新,资源消耗主要集中在模型的加载和单次计算上。
PAI-DSW:PAI-DSW为我们提供了运行大语言模型所需的GPU计算环境。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物 300 元代金券领取。
已通过实名认证且账户余额 ≥0 元。
在实验页面,当您已阅读并同意上述创建资源的目的以及部分资源可能产生的计费规则。
资源消耗说明
本场景主要涉及以下云产品和服务:PAI、对象存储OSS。
本实验预计产生资源消耗:约10元(以使用ecs.gn6i-c8g1.2xlarge规格的PAI-DSW实例进行1小时的数据处理与模型训练为例估算)。
如果您调整了资源规格、延长了使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
PAI-DSW: 费用主要由DSW实例的运行时长和其规格决定。本实验选用GPU实例进行模型训练,关机后即停止计费。
对象存储 OSS: 费用由数据存储容量和少量外网下行流量(仅在下载结果时产生)决定。
领取专属权益及创建实验资源
第一步:在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第二步:本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。

实验步骤
进入DSW控制台
登录阿里云,进入机器学习PAI控制台,在左侧导航栏选择【工作空间列表】,点击进入您的工作空间
在工作空间内,选择左侧的【模型开发与训练】—【DSW(Data Science Workshop)】
创建DSW实例
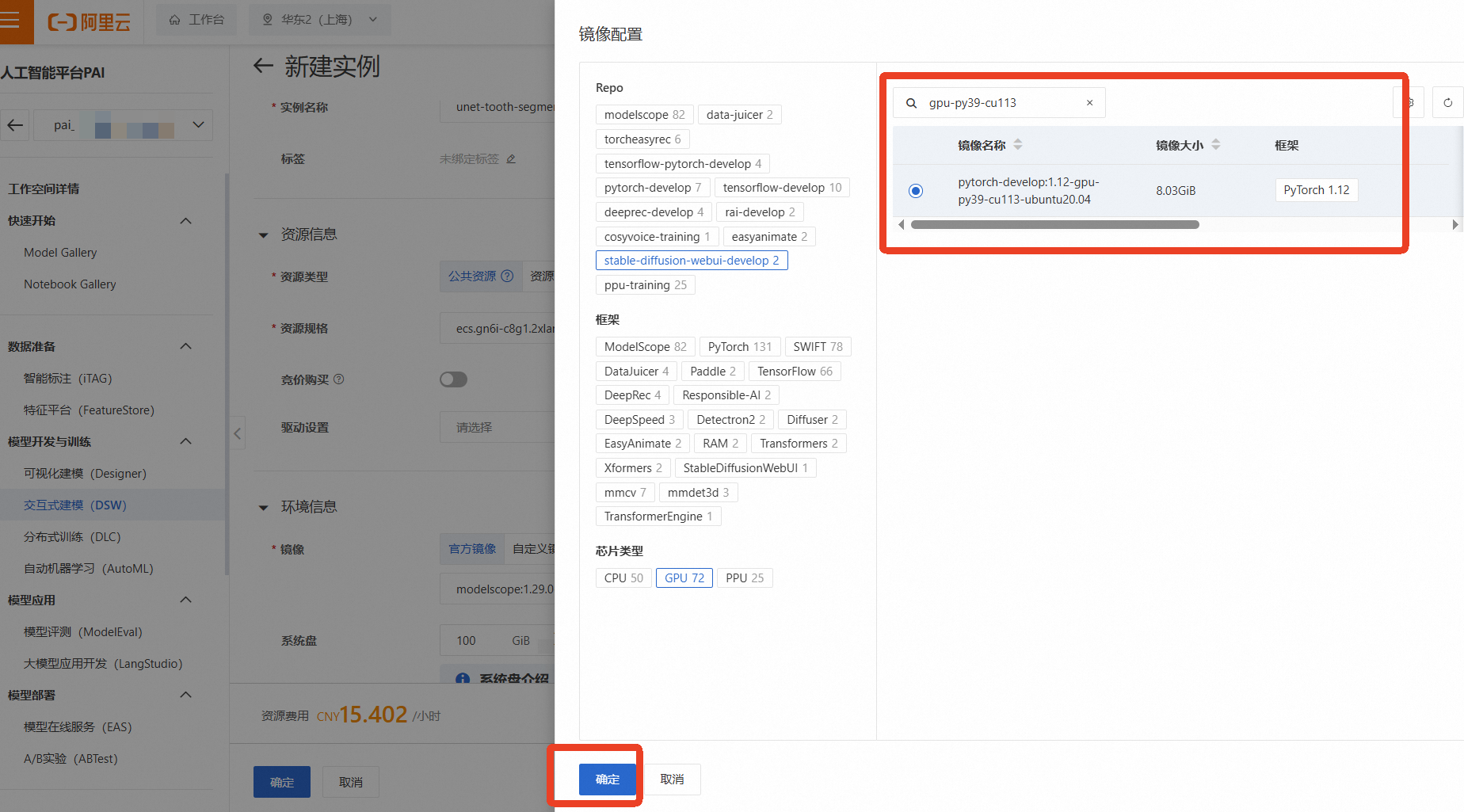
点击【创建实例】

实例名称:自定义一个名称,如 medical-2d-regist
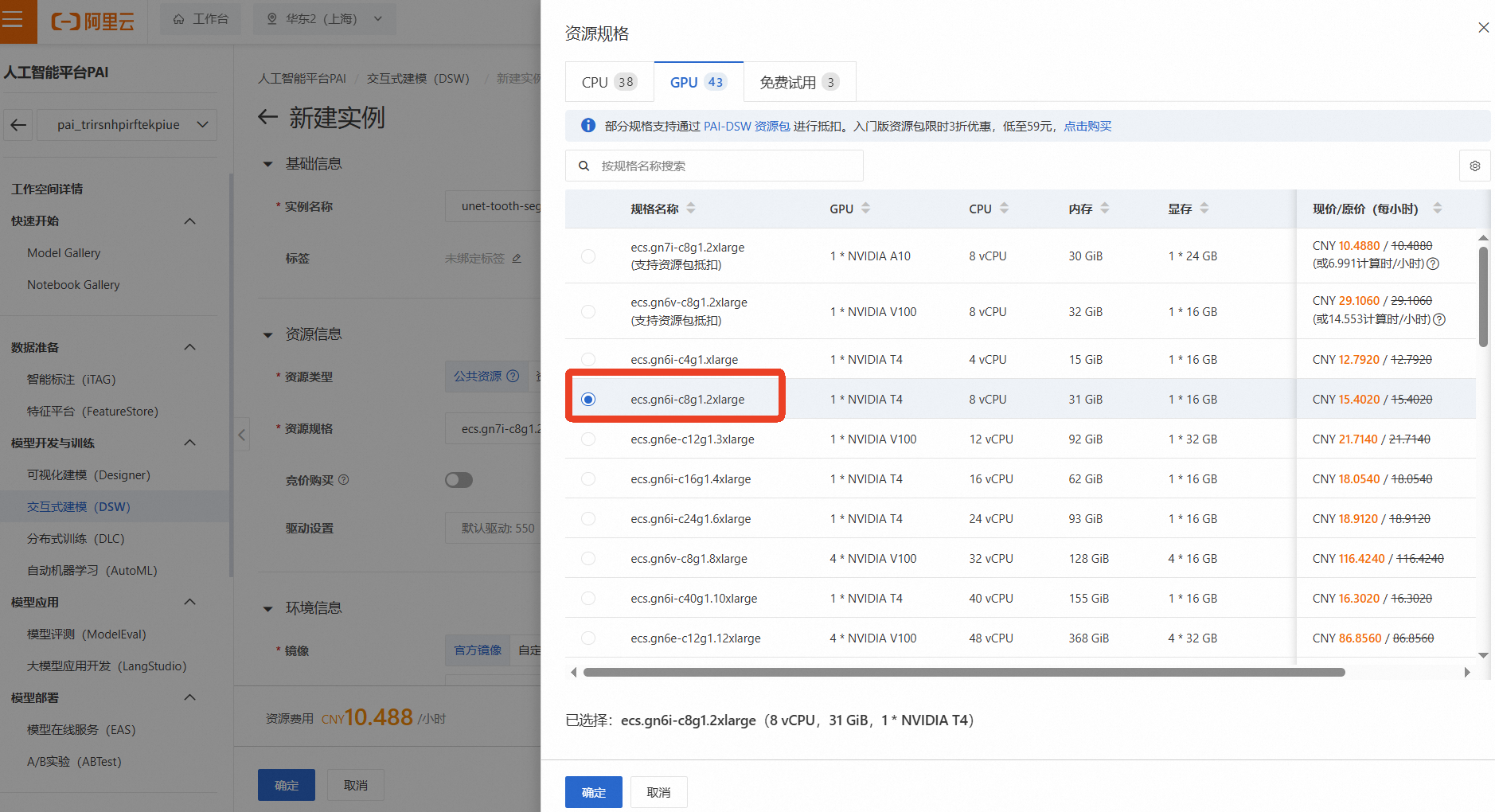
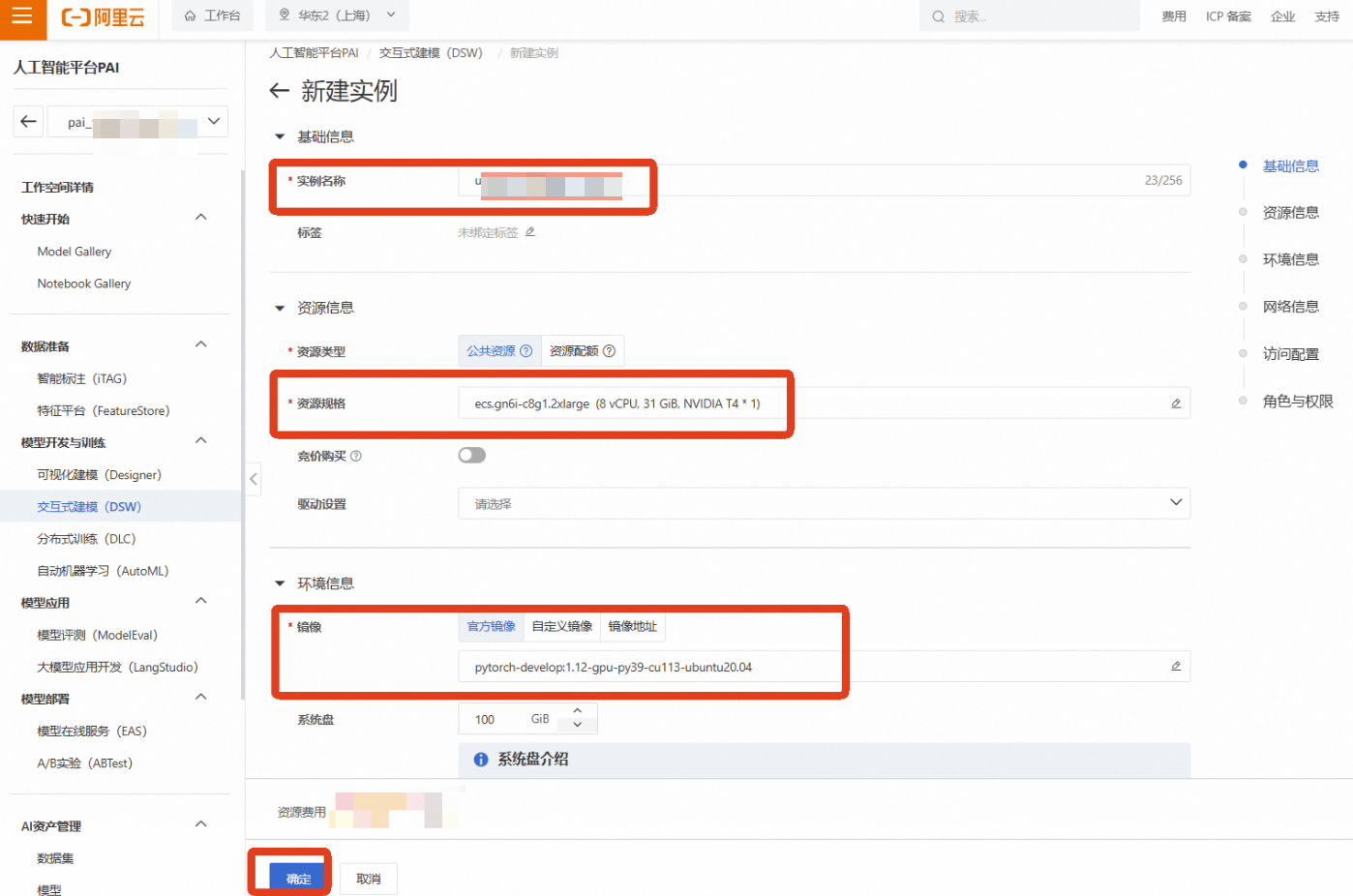
资源组(机型):为了进行深度学习模型训练,我们需要选择GPU实例。点击【筛选】,勾选【GPU】,然后选择一款有库存的GPU机型,例如 ecs.gn6i-c8g1.2xlarge(vCPU: 8, 内存: 32GiB, GPU: NVIDIA T4 16GB)
说明这是成本消耗的主要来源,请务必注意实验后及时停止或删除实例!
镜像:选择一个预置了PyTorch框架的镜像,例如 pytorch:1.12-gpu-py39-cu113-ubuntu20.04
其他保持默认,选择完成后点击【确定】
等待约2-3分钟,直到实例状态变为“运行中”
进入JupyterLab环境
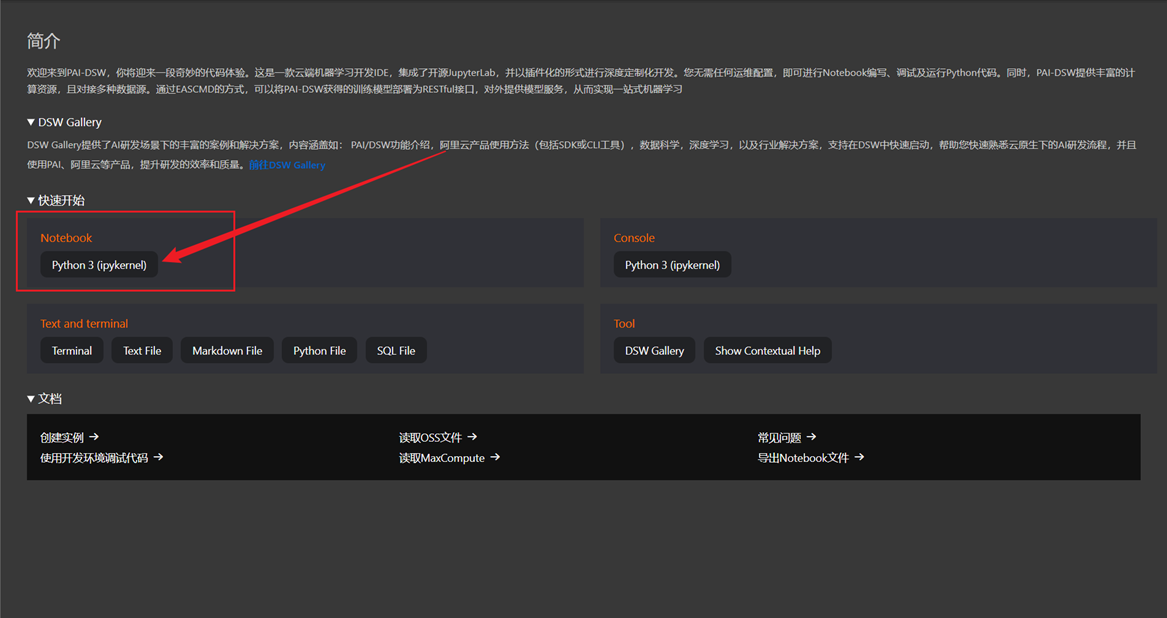
在DSW实例列表中,找到刚刚创建的实例,点击右侧的【打开】
返回JupyterLab的启动器(Launcher)页面,点击【Python 3 (PyTorch 1.12)】
创建一个新的Notebook文件
准备环境
!pip install -U "modelscope" "transformers" from modelscope import AutoModelForCausalLM, AutoTokenizer import torch # 检查GPU是否可用 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}")加载千问Qwen3大模型
- 重要
重点说明: modelscope库可以帮助我们非常方便地从阿里云的ModelScope平台下载并加载预训练好的模型。我们将加载本次实验的主角——Qwen3-0.6B模型。
- 重要
注意: 第一次运行此代码时,会自动从网络下载模型文件(约1.2GB),需要等待几分钟。下载完成后,模型文件会缓存在实例中,后续再次运行时会直接加载,速度很快。
rmodel_name = "Qwen/Qwen3-0.6B" print("正在加载分词器 (Tokenizer)...") tokenizer = AutoTokenizer.from_pretrained(model_name) print("正在加载Qwen3大模型,请稍候...") model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto" ) print("模型加载完成!")
构建口腔健康问答函数
为了方便地进行多次问答,我们把提问和获取答案的逻辑封装成一个函数。
- 重要
重点说明: Qwen3模型有一个独特的“思考模式”,在回答前会生成一段<think>...</think>的内心独白来展示它的思考过程,这非常有助于我们理解模型的推理逻辑。
def ask_qwen(question): """ 向Qwen3模型提问并获取回答的函数。 """ print(f"\n===== 正在处理问题 =====\n问题: {question}\n") # 1. 构建模型的输入格式 messages = [{"role": "user", "content": question}] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=True # 开启思考模式 ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) # 2. 模型生成回答 generated_ids = model.generate( **model_inputs, max_new_tokens=512 # 限制最大生成长度 ) output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # 3. 解析思考过程和最终答案 try: # 寻找 </think> 标签的位置 index = len(output_ids) - output_ids[::-1].index(151668) except ValueError: index = 0 thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n") answer_content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n") print("【模型的思考过程】:") print(thinking_content) print("\n【模型的最终回答】:") print(answer_content)
开始智能问答
现在,您可以调用刚刚创建的函数,向我们的AI口腔健康助手提问了!
实践与探索: 尝试提出不同类型的问题,观察模型的回答质量。例如:
知识型问题: “种植牙和烤瓷牙有什么区别?”
建议型问题: “拔完智齿后应该注意什么?”
常识型问题: “每天刷几次牙比较好?”
# 示例问题1 prompt_1 = "种植牙和烤瓷牙有什么区别?请用普通人能听懂的语言解释。" ask_qwen(prompt_1) # 示例问题2 prompt_2 = "我刚刚拔完智齿,医生说了很多注意事项,但我记不清了。请你帮我总结一下最重要的几点。" ask_qwen(prompt_2)
清理资源
为避免产生不必要的个人扣费,实验完成后请务必按照以下步骤清理所有资源!
释放PAI-DSW实例
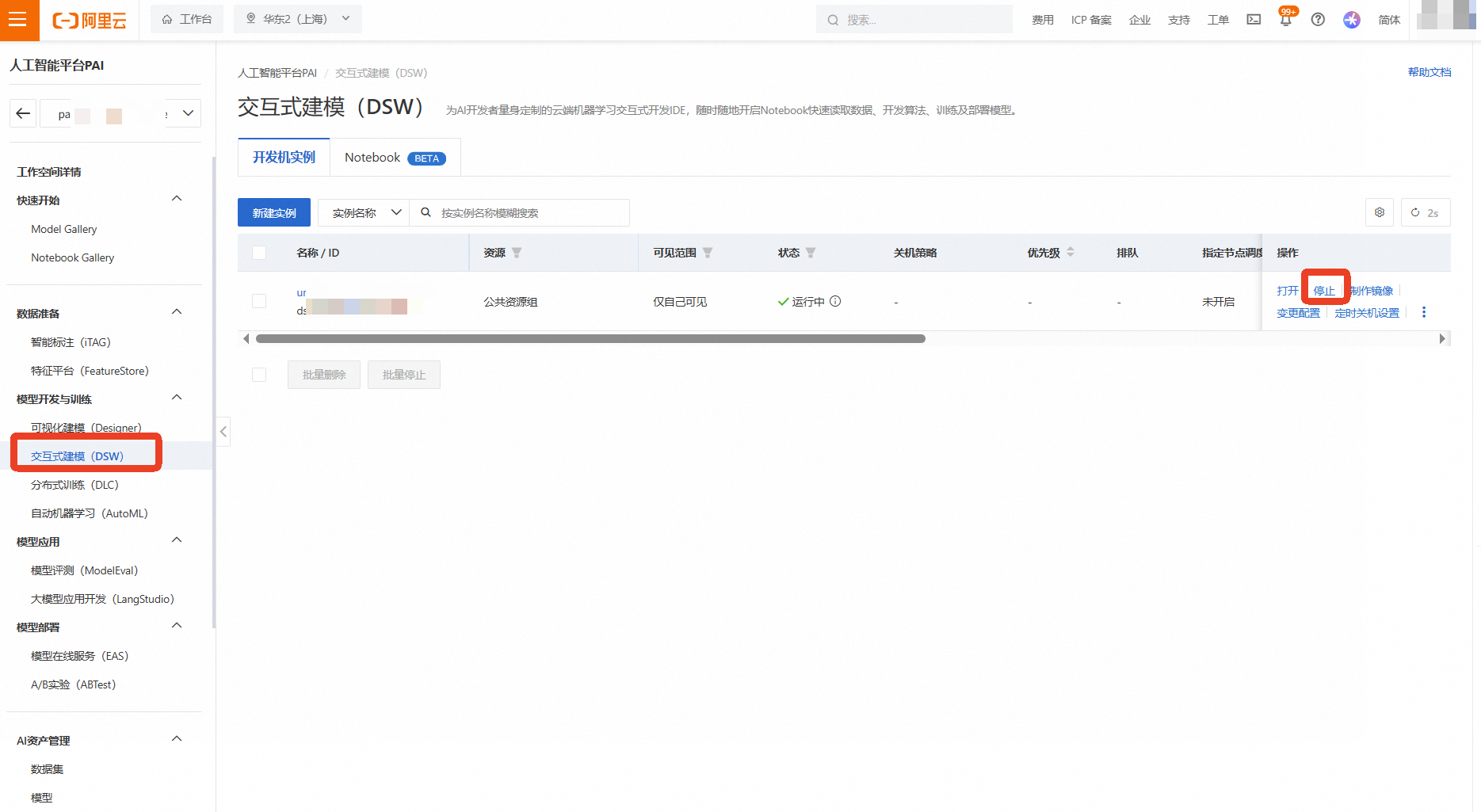
返回 机器学习PAI控制台 的DSW实例列表页面
找到本次实验创建的实例,点击右侧的【停止】
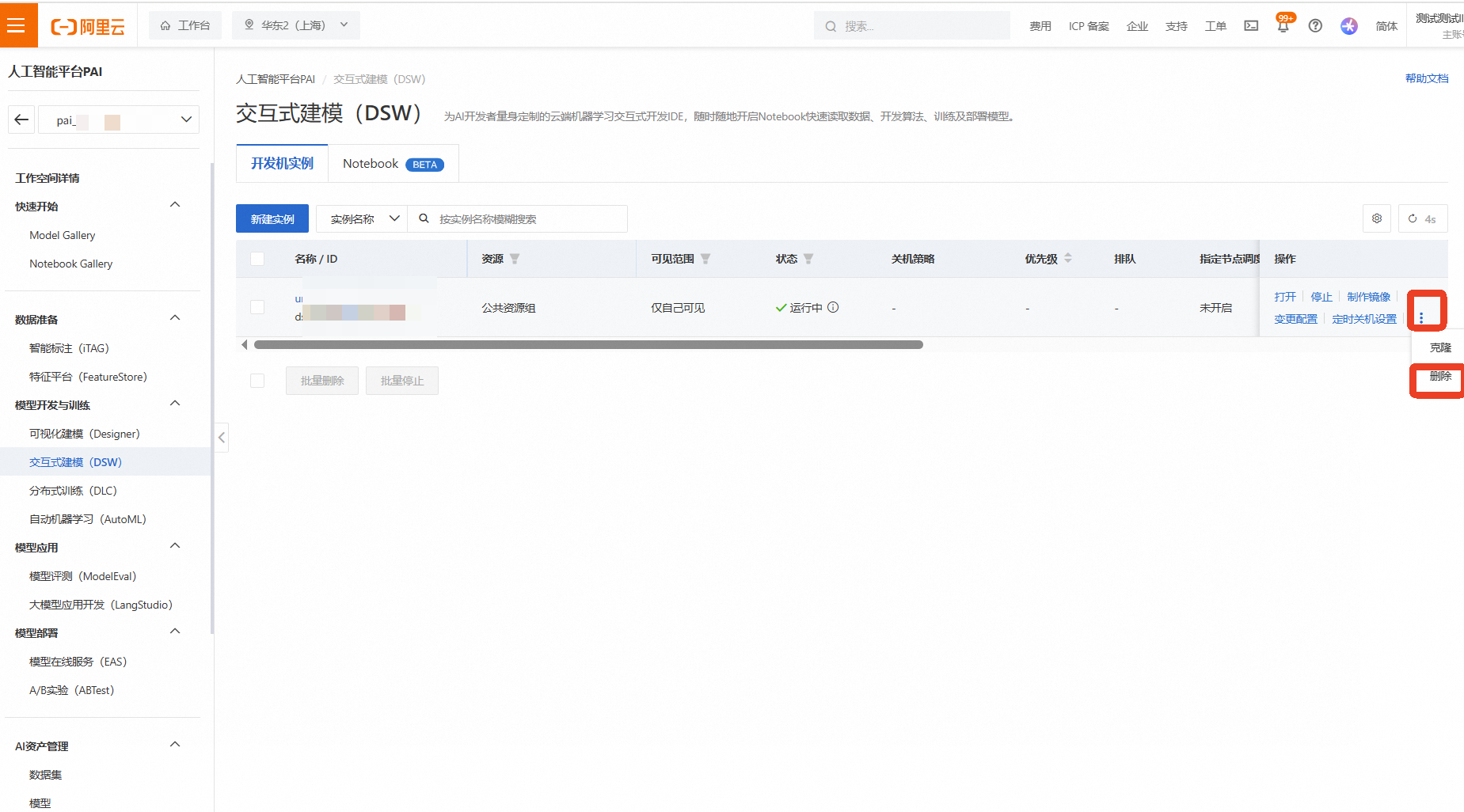
等待实例状态变为“已停止”后,为确保完全释放,再次点击右侧的【...】更多操作,选择【删除】
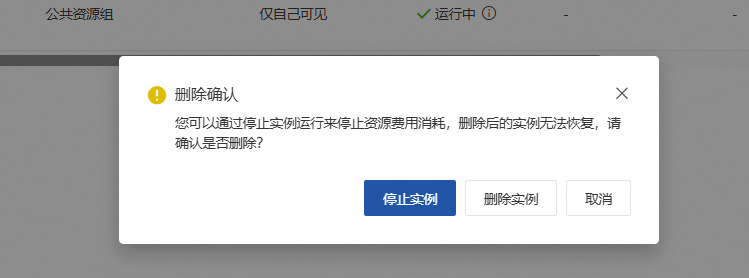
在弹出的确认框中点击【停止实例】/【删除实例】
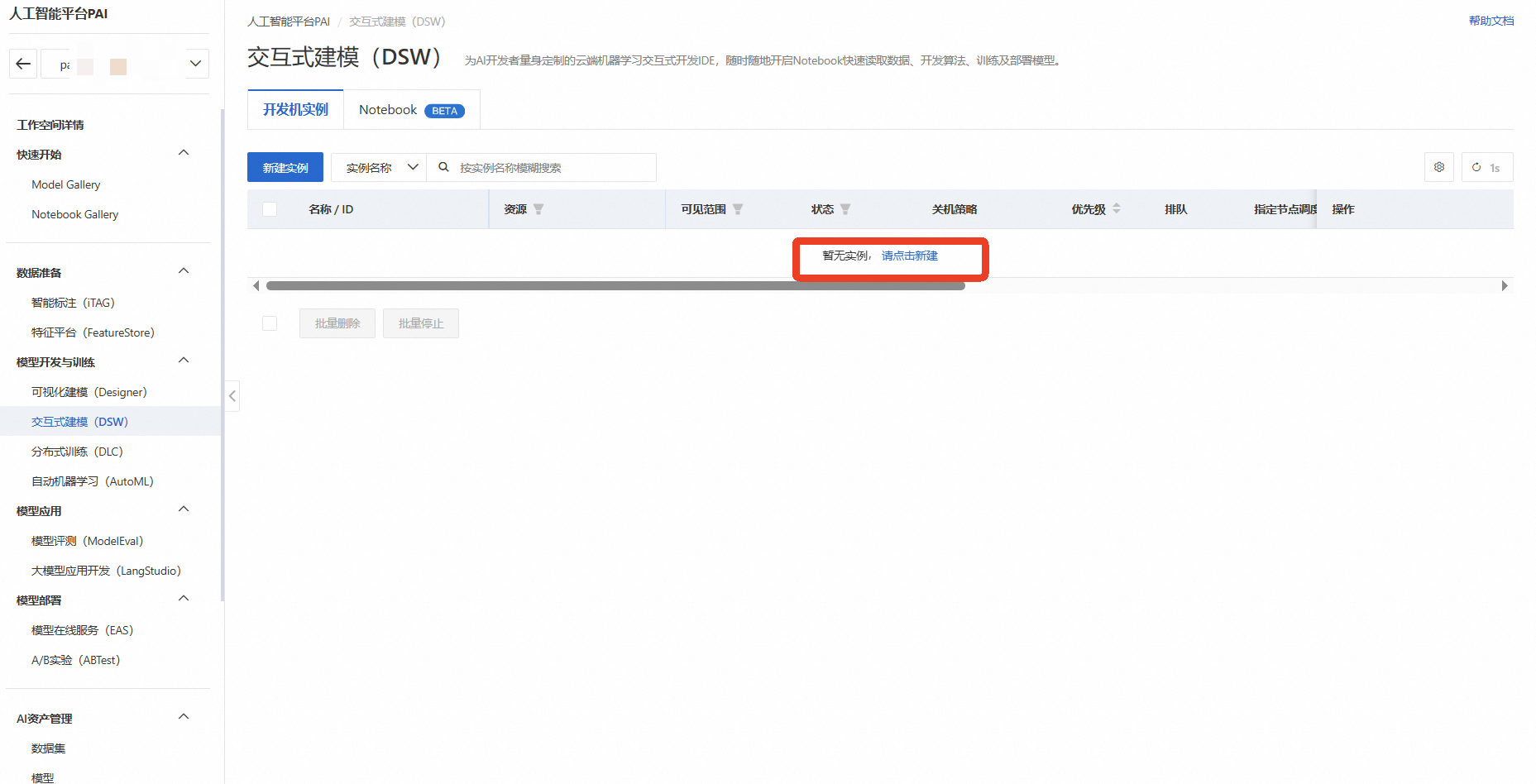
等待一段时间检查是否删除成功
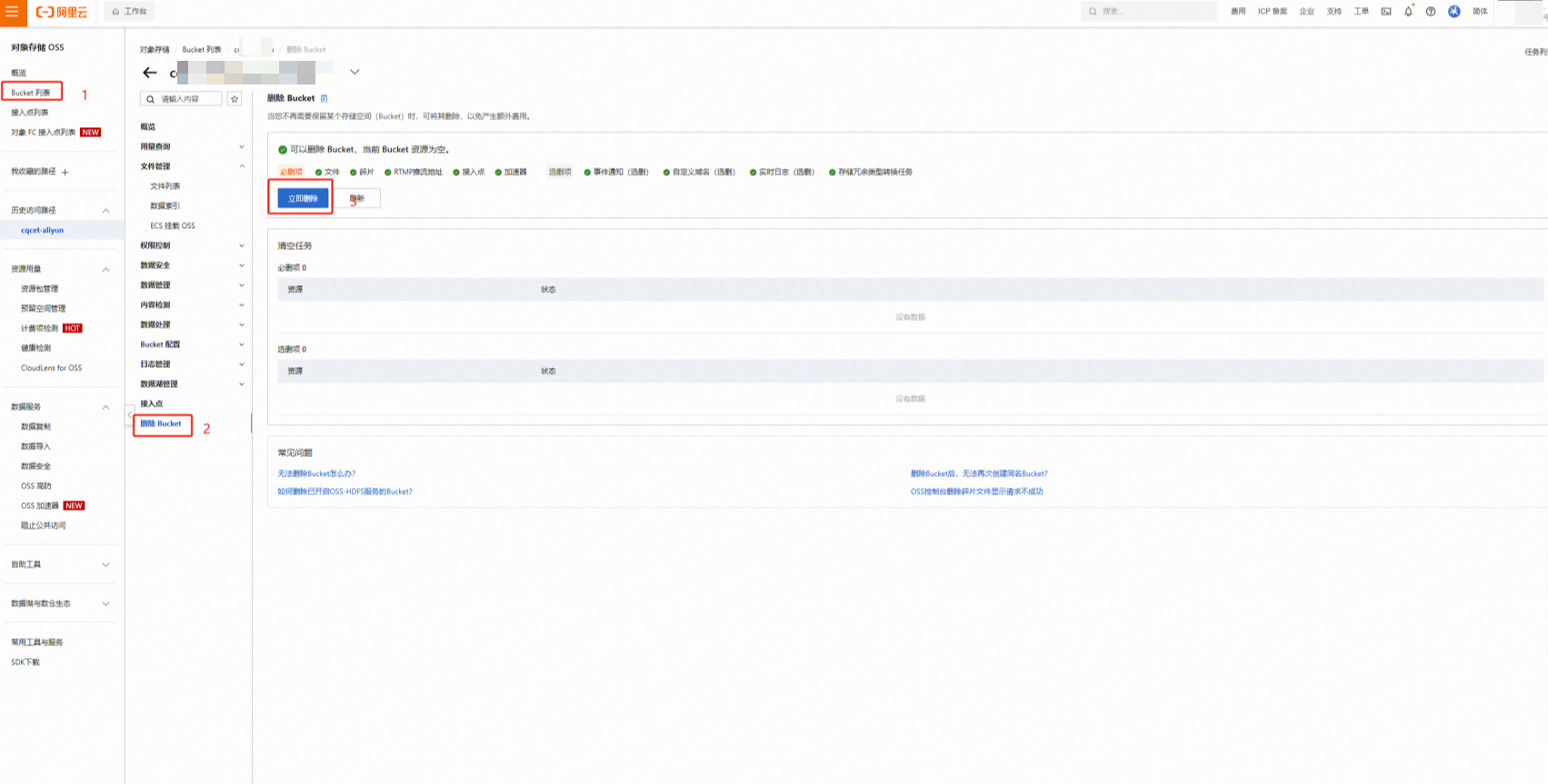
删除OSS数据和Bucket
进入 对象存储OSS控制台,找到为本次实验创建的Bucket,点击进入
选中所有上传的数据文件和文件夹,点击【删除】,返回Bucket列表,选中该Bucket,点击【删除】,根据提示完成删除操作(可能需要清空碎片)
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 跳转实验评分
请为本次实验评分,并给出您的建议,点击 确认,结束本次实验