DSW入门实验
本文将以线性回归的案例,带领您快速入门DSW。
场景简介
PAI(Platform of Artificial Intelligence) 是集数据处理、模型开发/训练、模型部署为一体的人工智能平台,并为企业级算法团队和数据科学团队提供了一站式开箱即用的解决方案,包括可视化建模 PAI-Designer、交互式开发 PAI-DSW(Data Science Workshop)、分布式训练 PAI-DLC(Deep Learning Containers) 和 模型在线服务 PAI-EAS(Elastic Algorithm Service) 等产品。
其中,PAI-DSW(Data Science Workshop) 是为算法开发者量身打造的一站式AI开发平台,使读取数据、开发、训练及部署模型更简单高效且安全。DSW集成了Jupyterlab、WebIDE、Terminal多种云端开发环境,提供代码编写、调试及运行的沉浸式体验。DSW提供丰富的异构计算资源,支持挂载OSS、NAS、CPFS类型的数据集,预置了多种开源框架的镜像,支持实例的生命周期管理,实现开箱即用的高效开发模式。
本文将以线性回归的案例,带领您快速入门DSW。
背景知识
PAI
人工智能平台PAI是阿里云专为开发者打造的一站式机器学习的平台,其主要由可视化建模(Designer)、交互式建模(DSW)、分布式训练(DLC)、模型在线服务(EAS)等核心功能模块组成,为您提供数据标注、模型开发、模型训练、模型部署的AI全链路研发服务,具有支持多种开源框架、多项AI优化能力、灵活易用的优势。
DSW(Data Science Workshop)
DSW是为算法开发者量身打造的一站式AI开发平台,集成了JupyterLab、WebIDE、Terminal多种云端开发环境,提供代码编写、调试及运行的沉浸式体验。提供丰富的异构计算资源,预置多种开源框架的镜像,实现开箱即用的高效开发模式。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
本场景主要涉及以下云产品和服务:PAI、DSW
本实验,预计产生资源消耗:约6.991元/小时,本次实验产生的费用将优先使用优惠券进行抵扣。
如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
领取专属权益及开通授权
第一步:在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作。

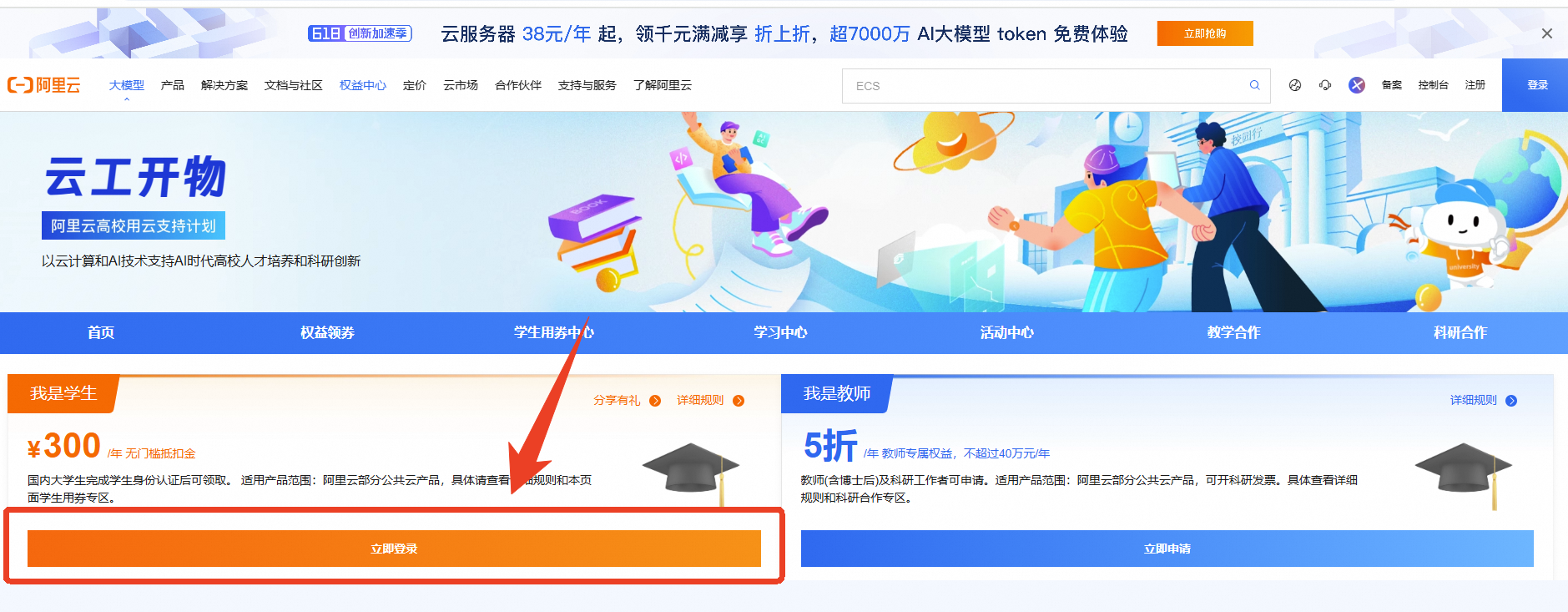
第二步:领取300元高校专属权益优惠券(若已领取请跳过)。
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
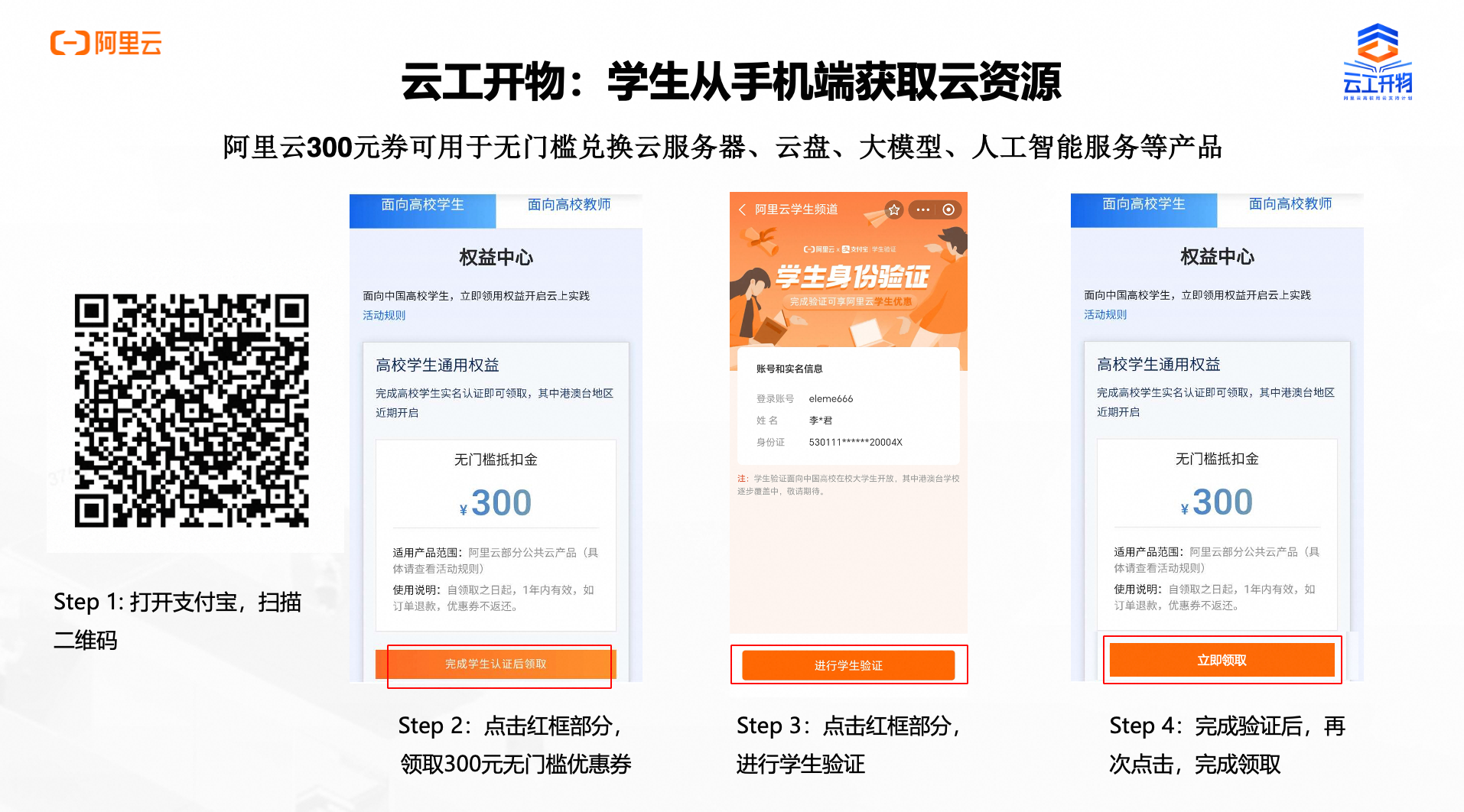
第三步:进入阿里云官网,搜索“试用”,点击“立即试用”
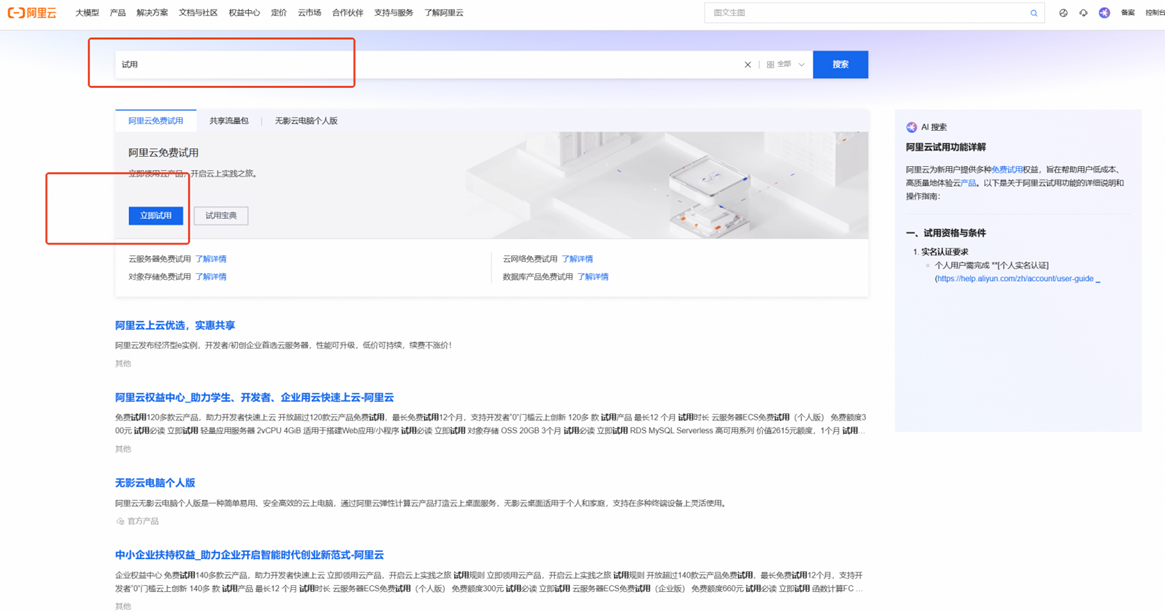
可试用人群选“个人认证”,选择“交互式建模 PAI-DSW”,点击“立即试用”
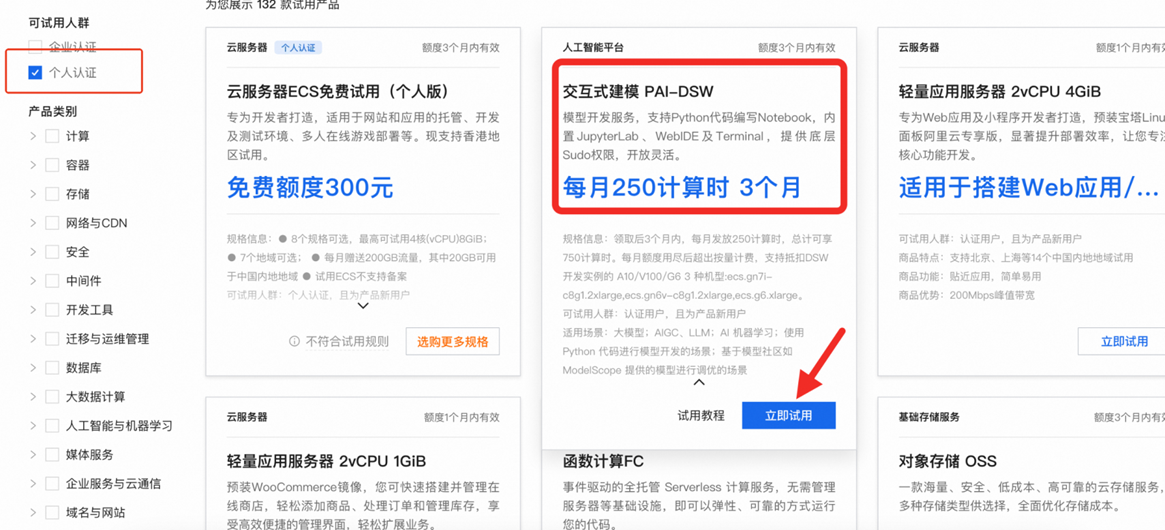
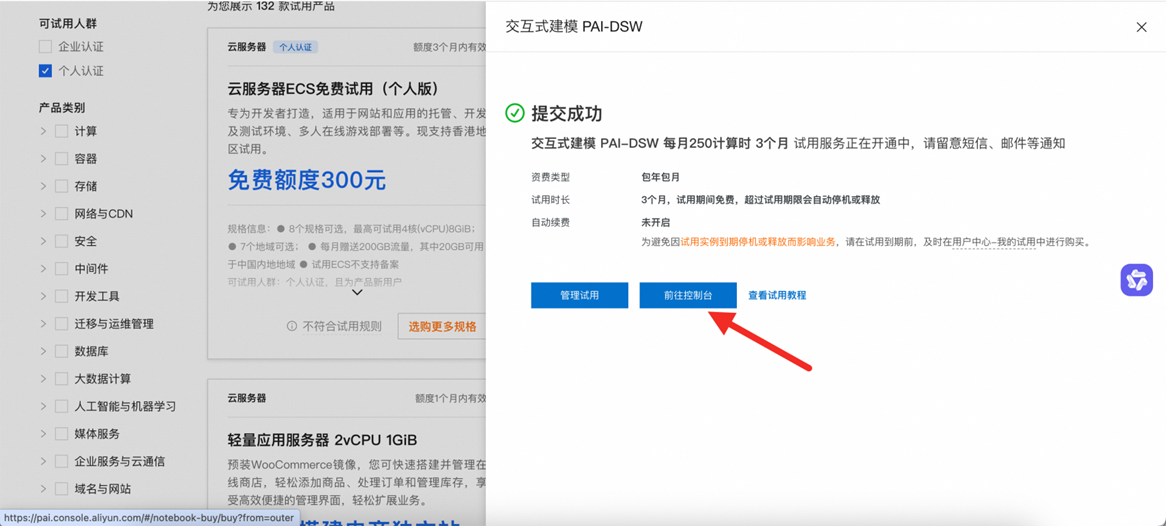
点击“立即试用”

提交成功后,点击“前往控制台”
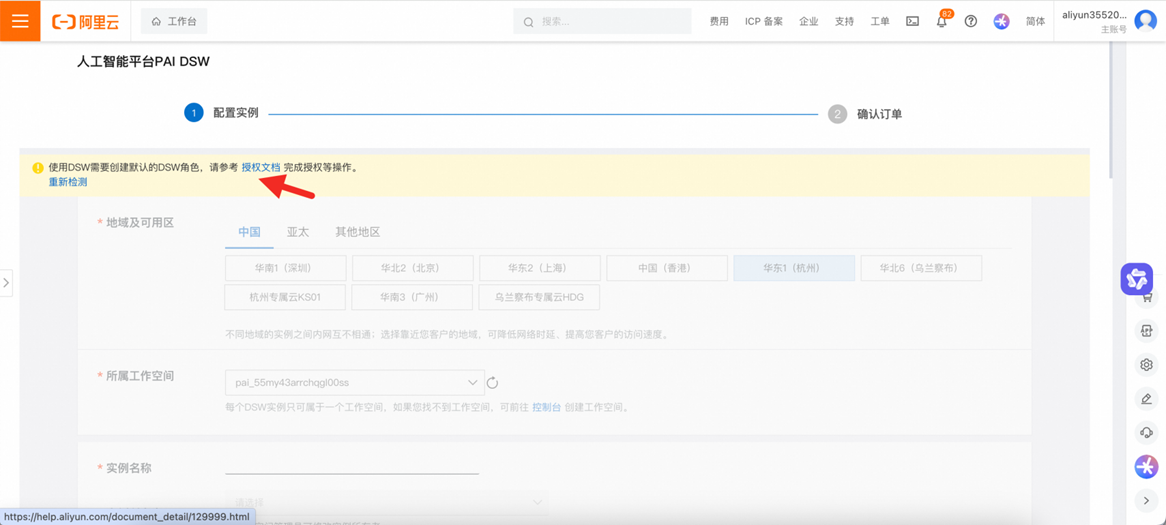
可参考文档完成创建DSW角色及授权等操作
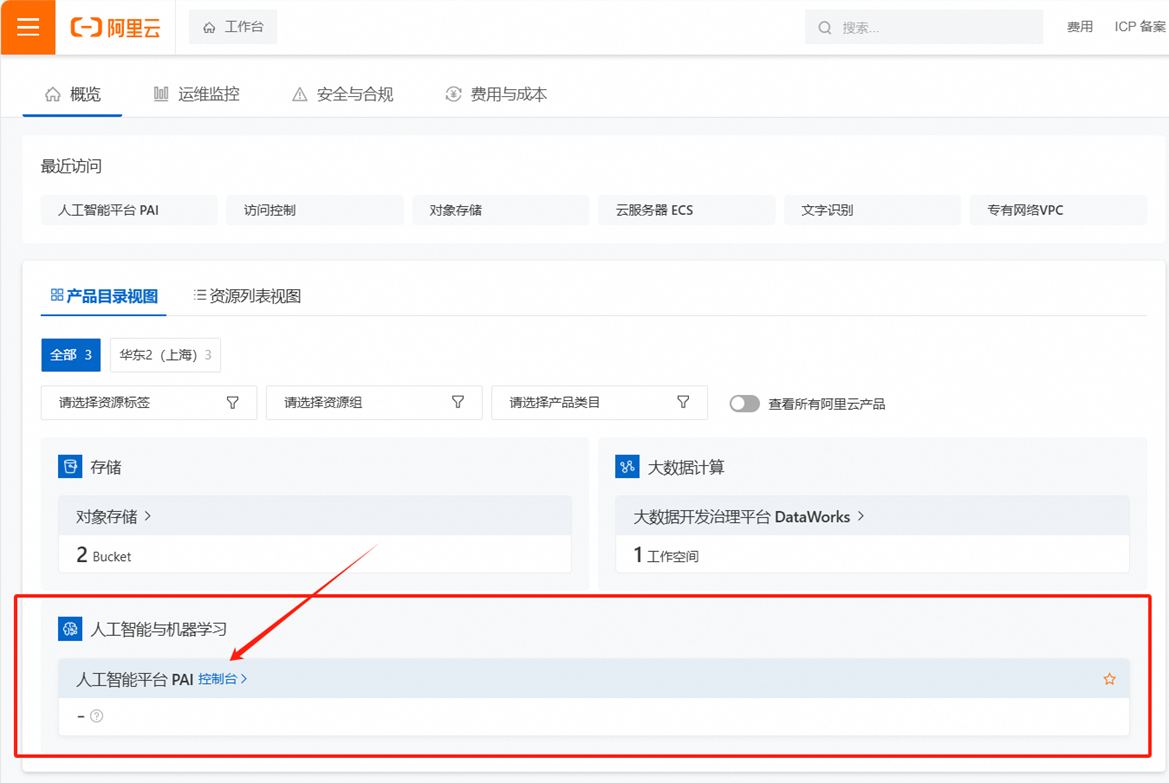
第四步:领取学生专属300元优惠券后,点击访问人工智能平台 PAI——点击“立即开通”,完成PAI平台开通与授权。
后期若想再次进入PAI平台可通过“控制台”进入。
跳转至控制台后,点击人工智能平台PAI,进入PAI平台页面。


实验步骤
一、创建实例
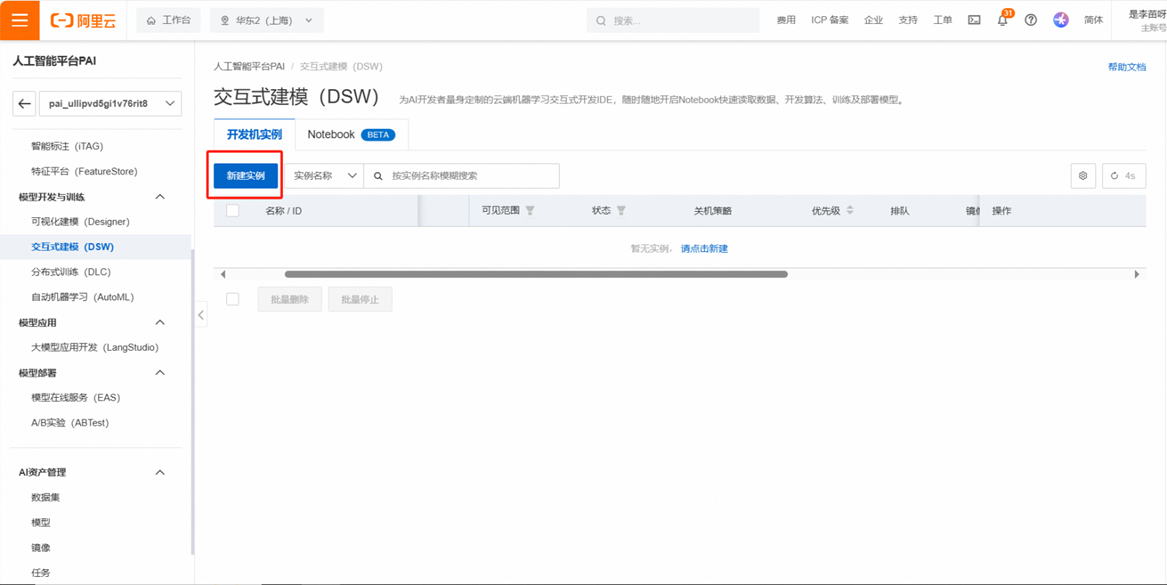
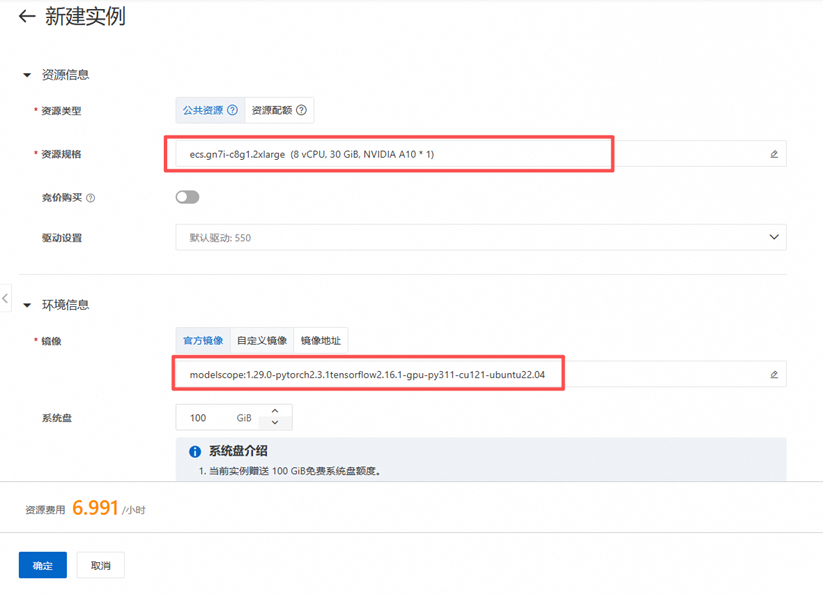
在PAI平台左侧选项卡中找到交互式建模(DSW),点击新建实例。
配置实例。
资源规格:ecs.gn7i-c8g1.2xlarge (8vCPU, 30 GiB, NVIDIA A10 * 1)
镜像:modelscope:1.29.0-pytorch2.3.1tensorflow2.16.1-gpu-py311-cu121-ubuntu22.04
配置完毕点击确定。
重要本次实验产生的费用将优先使用300元优惠券进行抵扣。
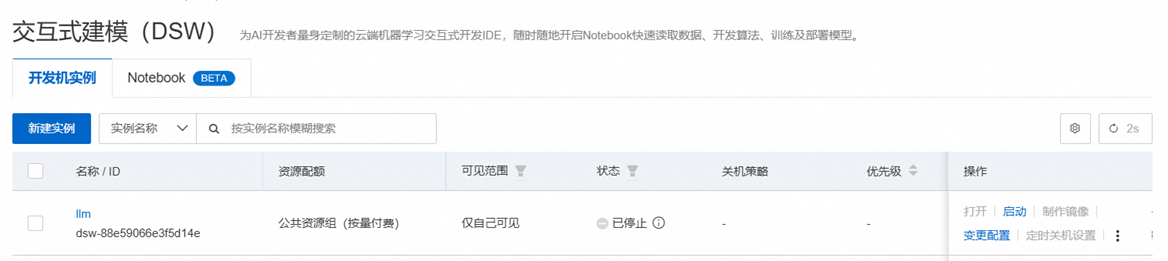
当资源准备完毕后,点击“打开”。
二、进入Notebook调试页面
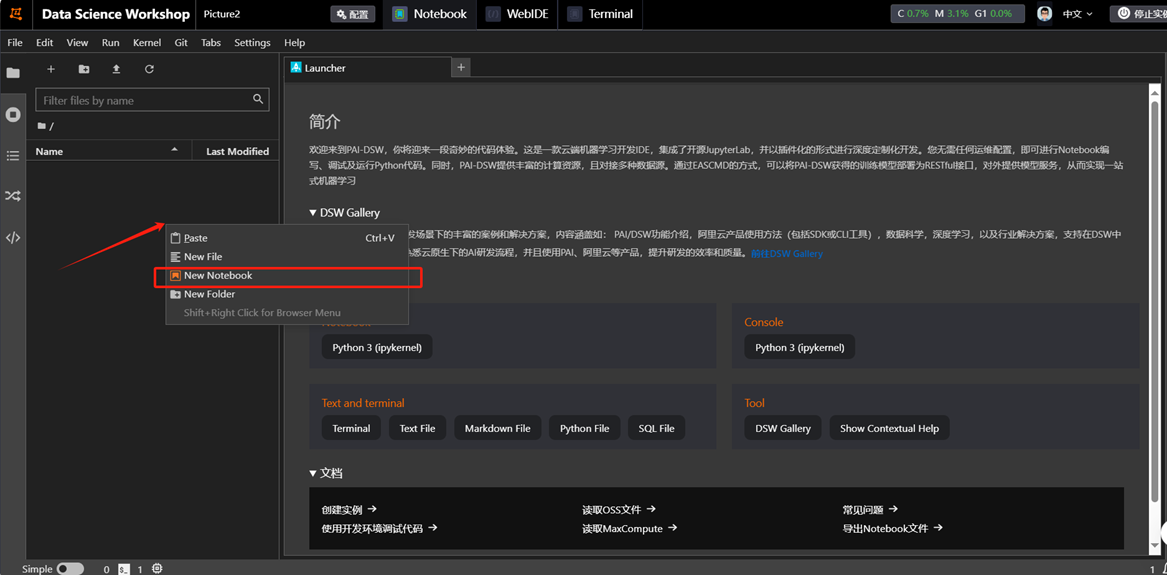
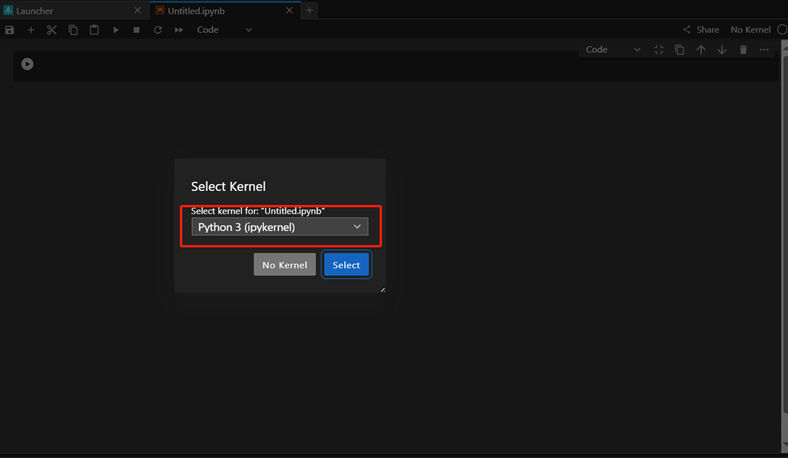
在左侧文件目录空白处,单击鼠标右键,新建一个Notebook。使用Python3,单击Select。
安装依赖。
如下示范了如何利用Jupyter的快速安装此案例中需要的依赖。
!pip install pandas待代码运行完毕,将鼠标置于刚运行的代码块的下侧,如图所示,单击“+Code”来新建一个代码框:
!pip install scikit-learn!pip install matplotlib引入依赖。
import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn import datasets, linear_model from sklearn.metrics import mean_squared_error, r2_score使展示的图可以直接在Notebook内显示。
# 使展示的图可以直接在Notebook内显示 %matplotlib inline加载数据,构建模型和训练。
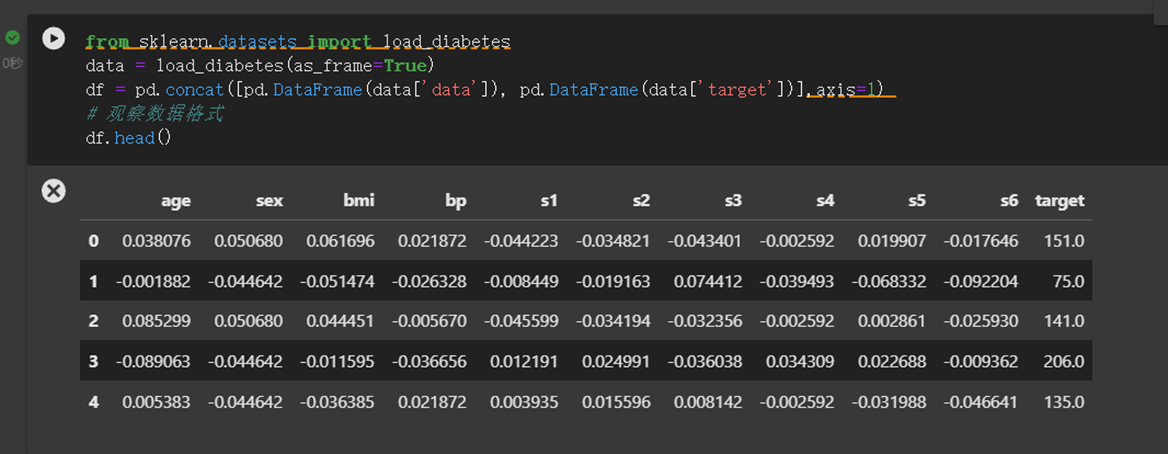
from sklearn.datasets import load_diabetes data = load_diabetes(as_frame=True) df = pd.concat([pd.DataFrame(data['data']), pd.DataFrame(data['target'])],axis=1) # 观察数据格式 df.head()构造训练与测试集,如我们假设BMI指数和糖尿病指数相关,并通过线性回归模型来找出关系。
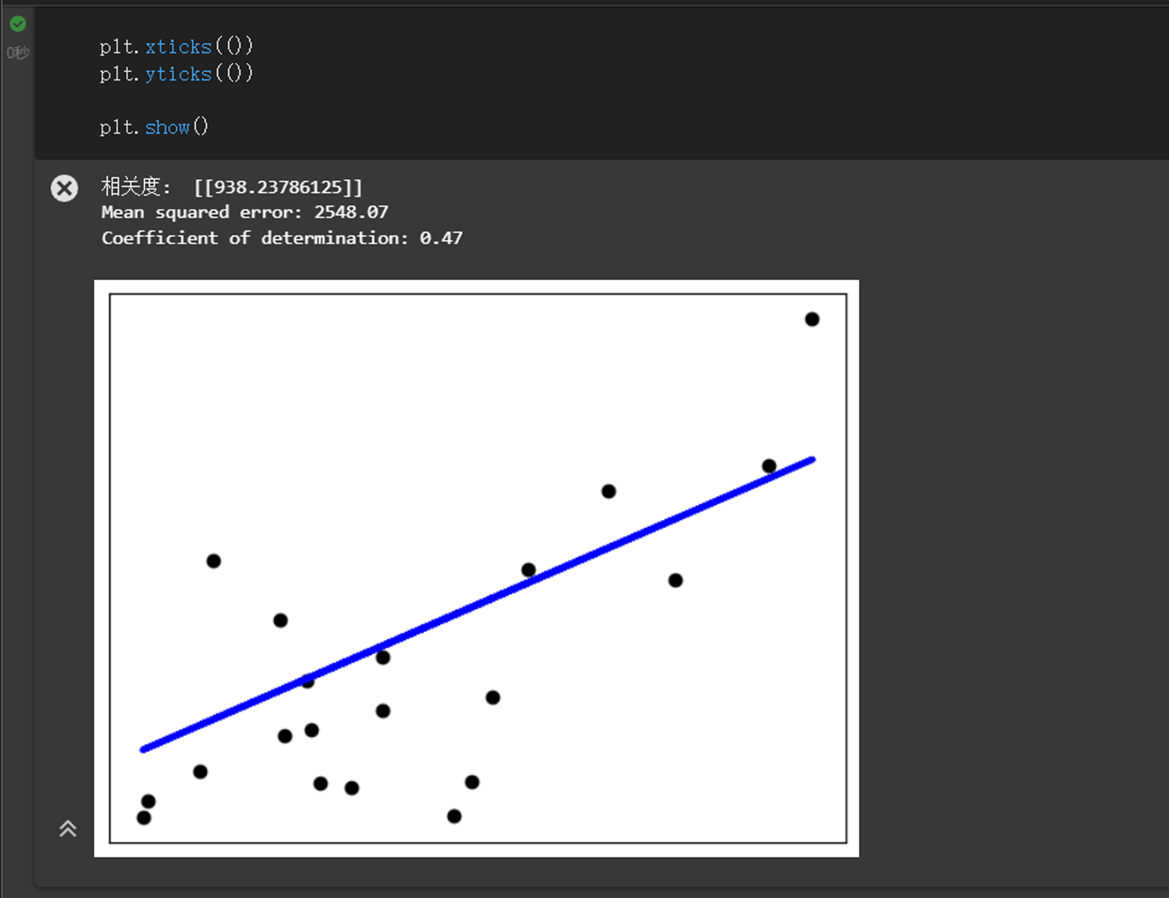
diabetes_X = np.array([df['bmi']]).transpose() diabetes_y = np.array([df['target']]).transpose() # 构造训练与测试数据 diabetes_X_train = diabetes_X[:-20] diabetes_X_test = diabetes_X[-20:] diabetes_y_train = diabetes_y[:-20] diabetes_y_test = diabetes_y[-20:] # 构造模型并训练 regr = linear_model.LinearRegression() regr.fit(diabetes_X_train, diabetes_y_train) # 预测 diabetes_y_pred = regr.predict(diabetes_X_test) # 输出对应指标 print("相关度: ", regr.coef_) print("Mean squared error: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred)) print("Coefficient of determination: %.2f" % r2_score(diabetes_y_test, diabetes_y_pred)) # 可视化训练结果 plt.scatter(diabetes_X_test, diabetes_y_test, color="black") plt.plot(diabetes_X_test, diabetes_y_pred, color="blue", linewidth=3) plt.xticks(()) plt.yticks(()) plt.show()


清理资源
请同学们一定要按照步骤释放实验资源及时关闭服务,避免资源浪费!
如果需要继续使用,请随时关注账号扣费情况,避免模型会因欠费而被自动停止。
前往PAI控制台
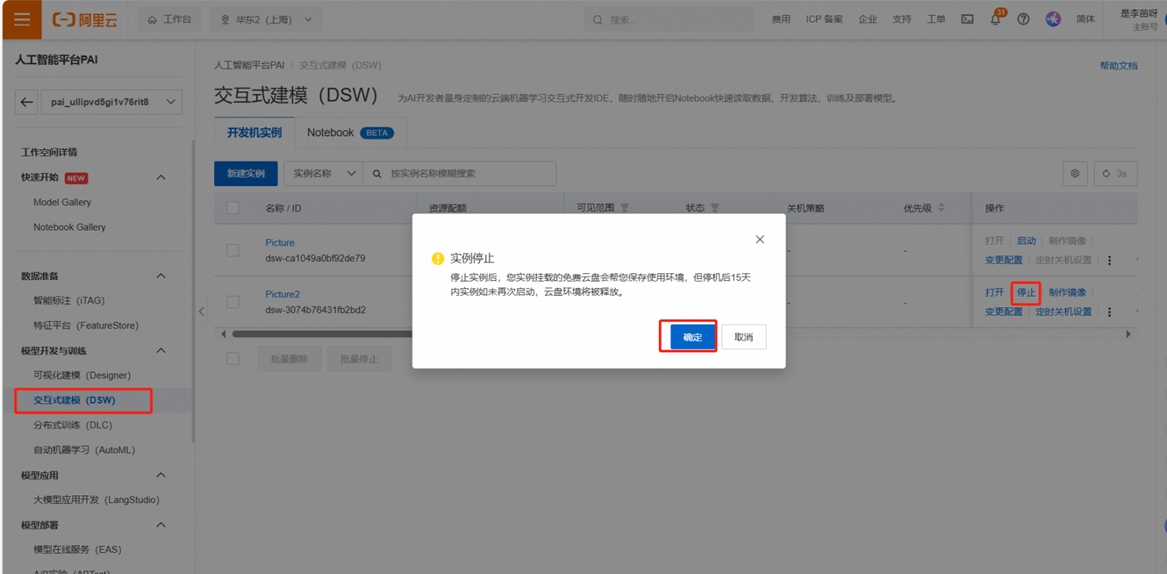
PAI平台页面——模型开发与训练——交互式建模DSW,找到目标服务。先停止正在运行的服务。
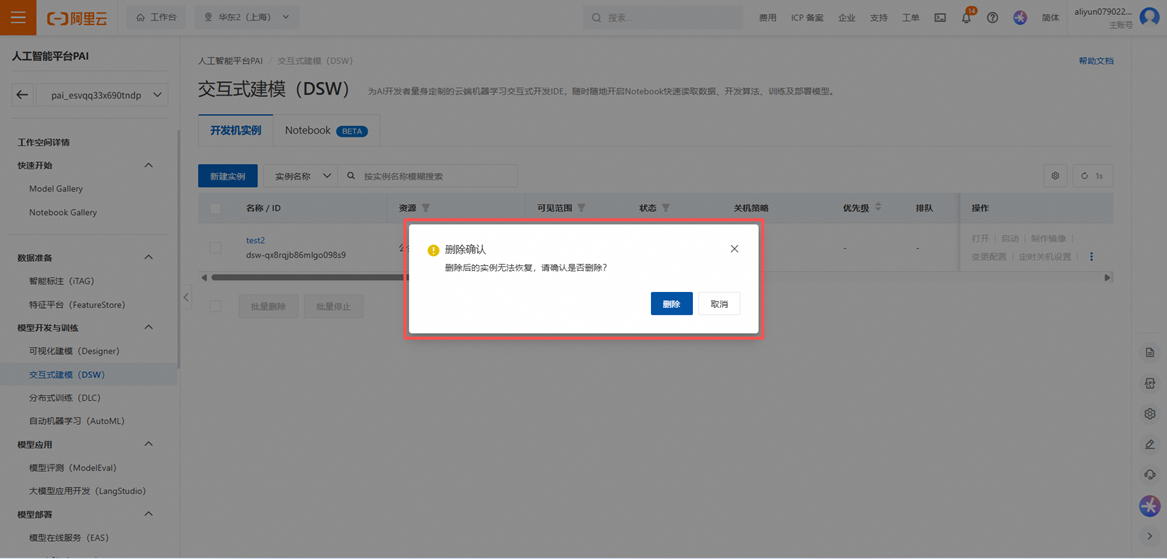
之后点击删除。
关闭实验
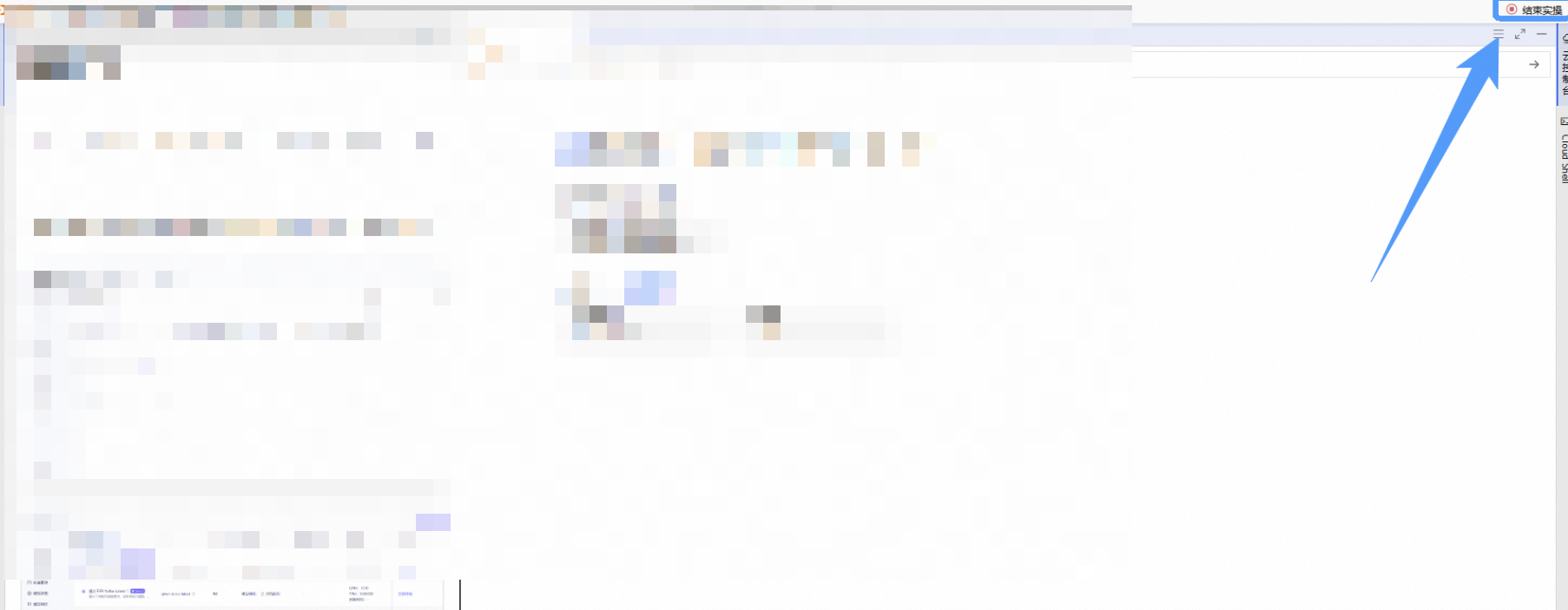
在完成实验后,点击 结束实操
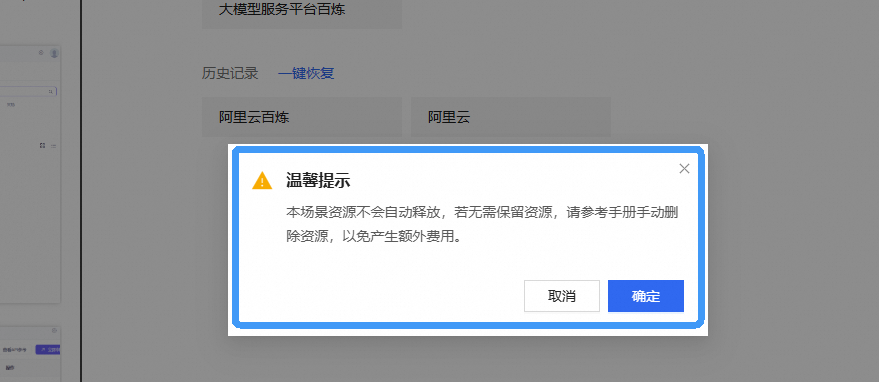
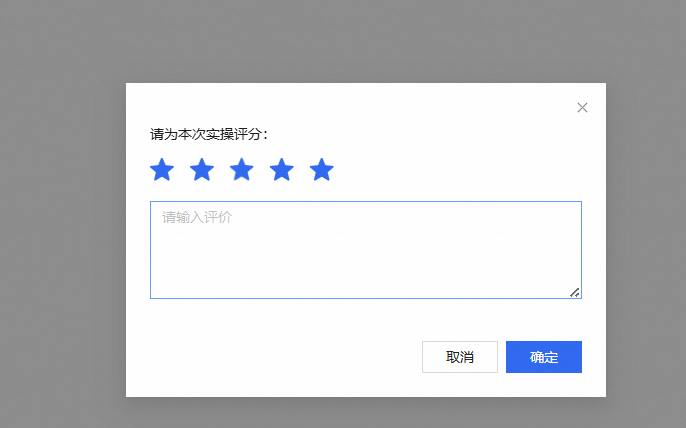
点击 取消 回到实验页面,点击 确定 跳转实验评分
请为本次实验评分,并给出您的建议,点击 确认,结束本次实验