Lora模型微调实现虚拟上装实验
本文将介绍如何基于Diffusers开源库实现虚拟上装的应用。
场景简介
AIGC 是指通过人工智能技术自动生成内容的生产方式,国内外多家公司进入技术竞赛白热化阶段,Microsoft,Google,Meta等公司深度投入,已经成为继互联网时代的下一个产业时代风口。其中,文图生成(Text-to-image Generation)任务是流行的跨模态生成任务,旨在生成与给定文本对应的图像。典型的文图模型例如OpenAI开发的DALL-E和DALL-E2。近期,业界也训练出了更大、更新的文图生成模型,例如Google提出的Parti和Imagen,基于扩散模型的Stable Diffusion等。基于Stable Diffusion形成了庞大的开源社区,并衍生出了许多有趣的应用。
本文将介绍如何基于Diffusers开源库实现虚拟上装的应用。
背景知识
PAI
人工智能平台PAI是阿里云专为开发者打造的一站式机器学习的平台,其主要由可视化建模(Designer)、交互式建模(DSW)、分布式训练(DLC)、模型在线服务(EAS)等核心功能模块组成,为您提供数据标注、模型开发、模型训练、模型部署的AI全链路研发服务,具有支持多种开源框架、多项AI优化能力、灵活易用的优势。
DSW(Data Science Workshop)
DSW是为算法开发者量身打造的一站式AI开发平台,集成了JupyterLab、WebIDE、Terminal多种云端开发环境,提供代码编写、调试及运行的沉浸式体验。提供丰富的异构计算资源,预置多种开源框架的镜像,实现开箱即用的高效开发模式。
Stable Diffusion
Stable Diffusion是强大的图像生成模型,能够生成高质量、高分辨率的图像,并具有良好的稳定性和可控性。
Stable Diffusion WebUI
Stable Diffusion WebUI开源项目在模型的基础上进行封装,基于Gradio开发了可视化图形界面,为用户提供了丰富的生图工具。
AIGC(Artificial Intelligence Generative Content)
AIGC指利用人工智能技术自动生成内容的一种新型技术。这项技术主要基于机器学习和自然语言处理,能够自动化地生成包括文本、图像、音频在内的多种类型的内容。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
本场景主要涉及以下云产品和服务:PAI、DSW
本实验,预计产生资源消耗:约14.553元/小时,本次实验产生的费用将优先使用优惠券进行抵扣。
如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
领取专属权益及开通授权
第一步:在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作。

第二步:领取300元高校专属权益优惠券(若已领取请跳过)。
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
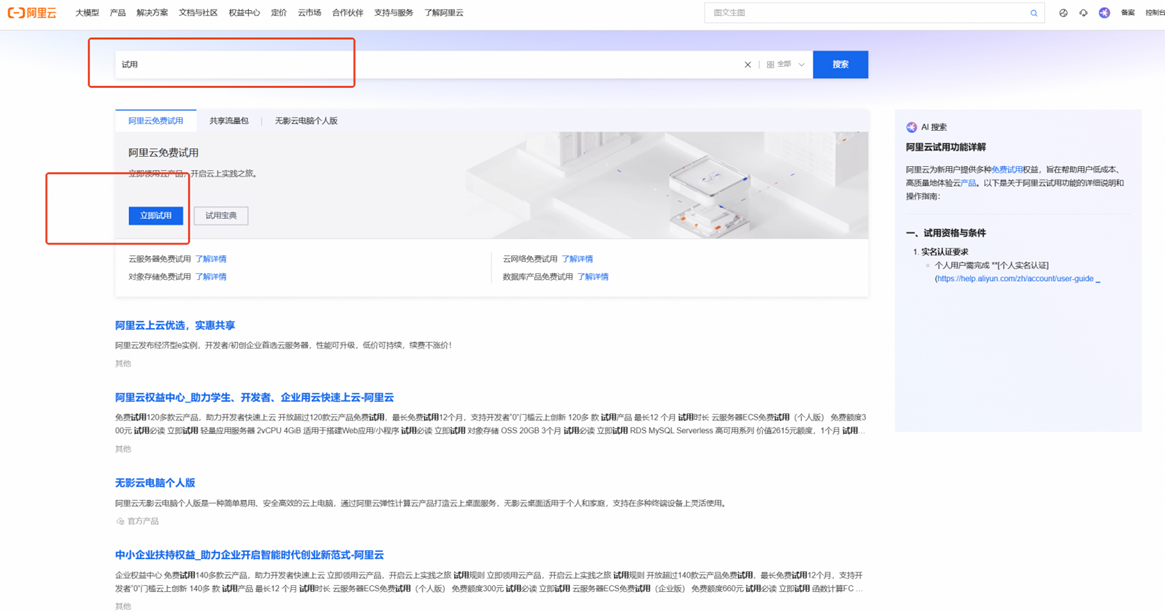
第三步:进入阿里云官网,搜索“试用”,点击“立即试用”
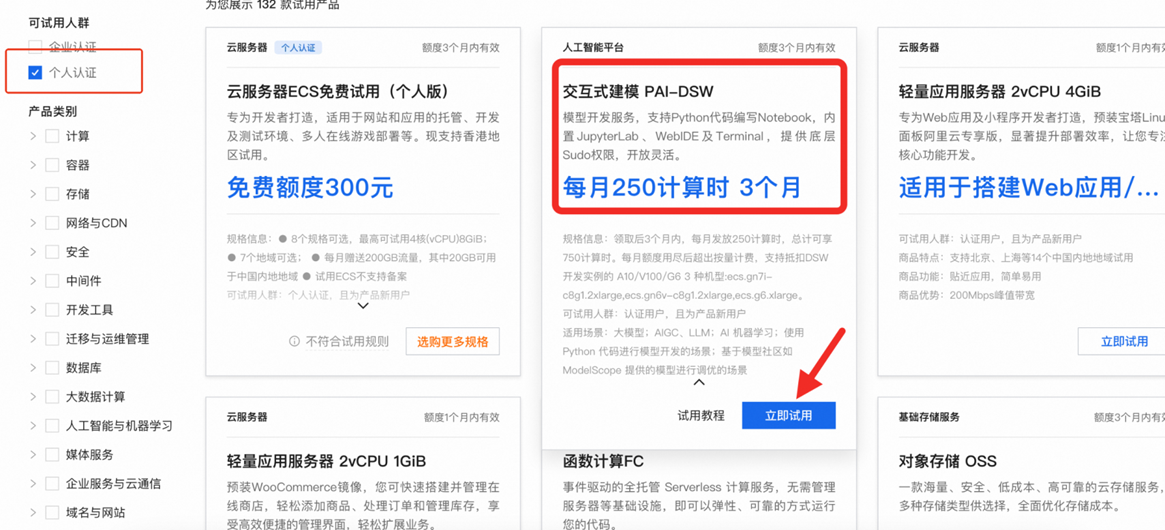
可试用人群选“个人认证”,选择“交互式建模 PAI-DSW”,点击“立即试用”
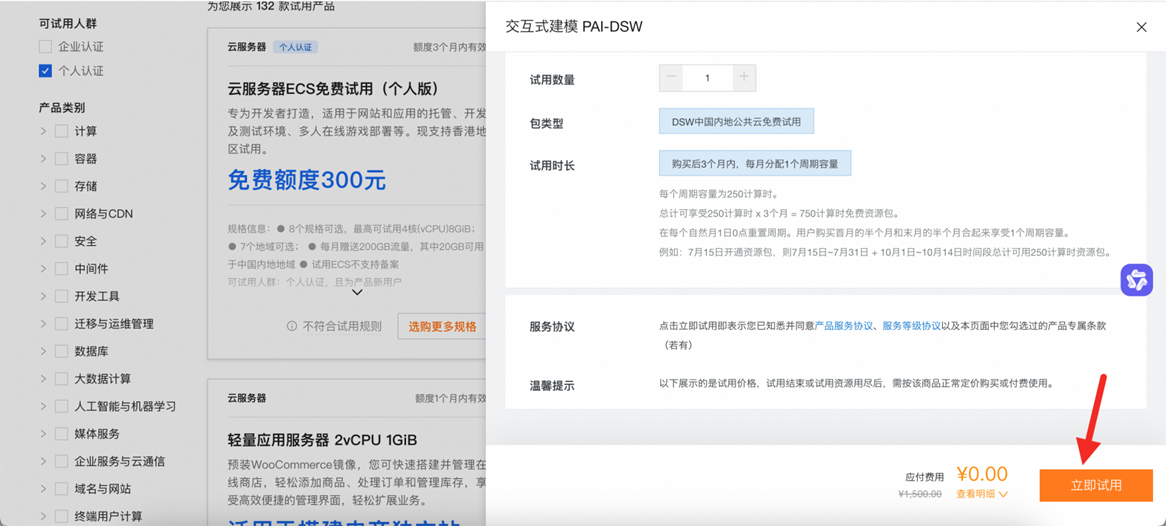
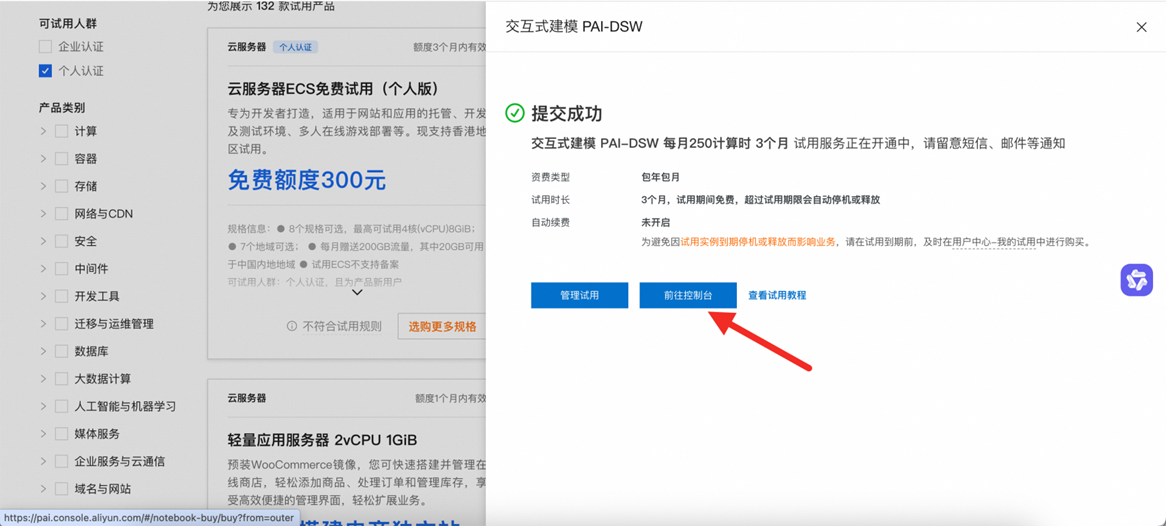
点击“立即试用”

提交成功后,点击“前往控制台”
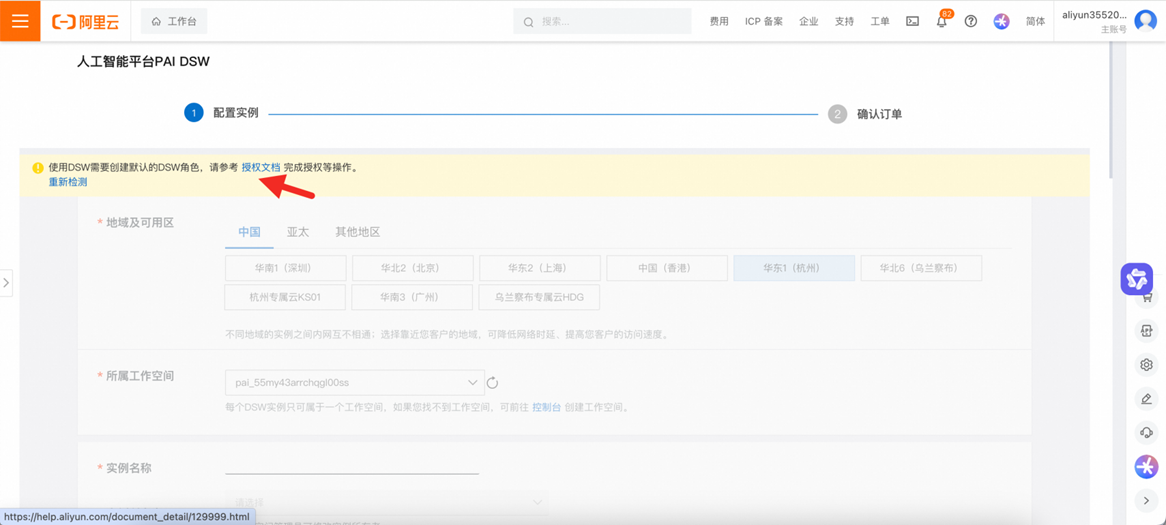
可参考文档完成创建DSW角色及授权等操作
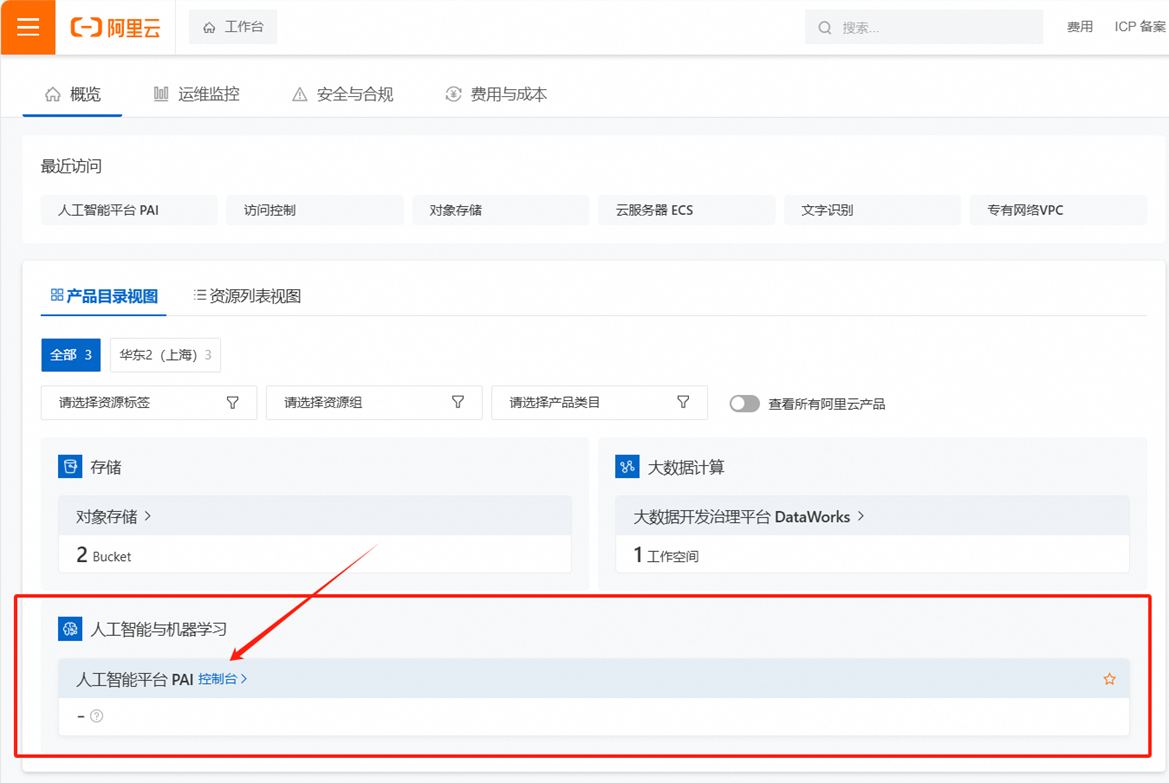
第四步:领取学生专属300元优惠券后,点击访问人工智能平台 PAI——点击“立即开通”,完成PAI平台开通与授权。
后期若想再次进入PAI平台可通过“控制台”进入。
跳转至控制台后,点击人工智能平台PAI,进入PAI平台页面。


实验步骤
一、创建实例
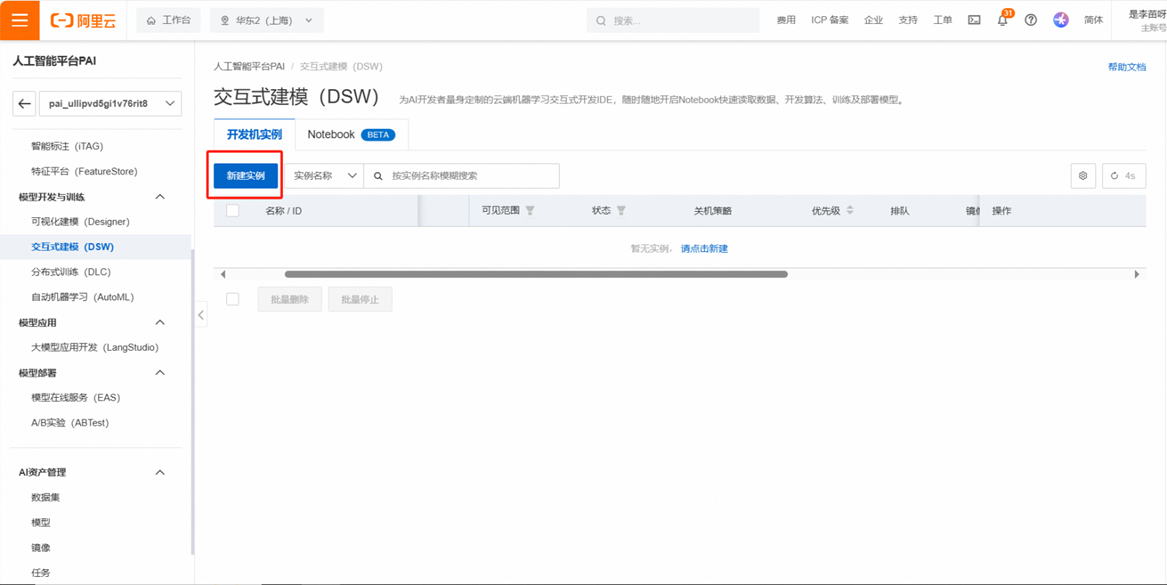
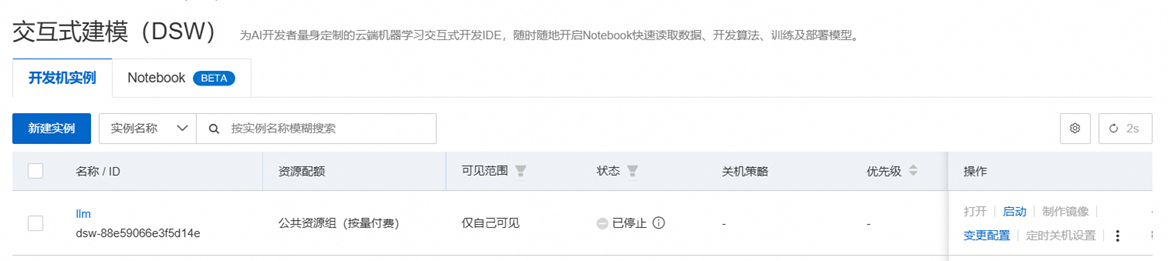
在PAI平台左侧选项卡中找到交互式建模(DSW),点击新建实例。
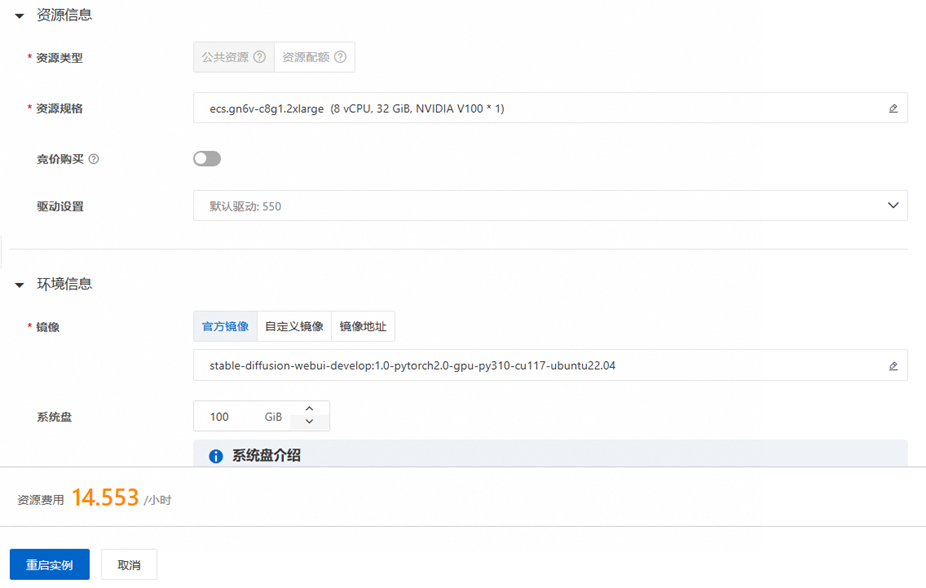
配置实例。
资源规格:ecs.gn6v-c8g1.2xlarge (8 vCPU, 32 GiB, NVIDIA V100 * 1)
镜像:stable-diffusion-webui-develop:1.0-pytorch2.0-gpu-py310-cu117-ubuntu22.04
配置完毕点击确定。
重要本次实验产生的费用将优先使用300元优惠券进行抵扣。
当资源准备完毕后,点击“打开”。
二、进入Notebook调试页面
在左侧文件目录空白处,单击鼠标右键,新建一个Notebook。使用Python3,单击Select。
Diffusers安装。
安装Diffusers开源库
! pip install -U http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/diffusers-0.22.0.dev0-py3-none-any.whl配置accelerate
可以直接运行命令下载默认配置文件,若需要自定义配置则在Terminal中执行命令:accelerate config,并根据DSW实例详情,选择对应配置
! mkdir -p /root/.cache/huggingface/accelerate/ ! wget -c http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com/aigc-data/accelerate/default_config.yaml -O /root/.cache/huggingface/accelerate/default_config.yaml下载stable-diffusion-webui开源库
import os ! apt update ! apt install -y aria2 def aria2(url, filename, d): !aria2c --console-log-level=error -c -x 16 -s 16 {url} -o {filename} -d {d} url_prefix = { "cn-shanghai": "http://pai-vision-data-sh.oss-cn-shanghai-internal.aliyuncs.com", "cn-hangzhou": "http://pai-vision-data-hz2.oss-cn-hangzhou-internal.aliyuncs.com", "cn-shenzhen": "http://pai-vision-data-sz.oss-cn-shenzhen-internal.aliyuncs.com", "cn-beijing": "http://pai-vision-data-bj.oss-cn-beijing-internal.aliyuncs.com", "ap-southeast-1": "http://pai-vision-data-ap-southeast.oss-ap-southeast-1-internal.aliyuncs.com" } dsw_region = os.environ.get("dsw_region") prefix = url_prefix[dsw_region] if dsw_region in url_prefix else "http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com" webui_url = f"{prefix}/aigc-data/code/stable-diffusion-webui-v1.tar.gz" aria2(webui_url, webui_url.split("/")[-1], "./")! tar -xf stable-diffusion-webui-v1.tar.gz ! cd stable-diffusion-webui && wget -c http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com/aigc-data/webui_config/config_tryon.json -O config.json
Stable Diffusion+LORA模型fintune
准备数据集及训练代码
我们提供了训练代码及一个小的示例数据,可以参照该格式准备自定义数据.
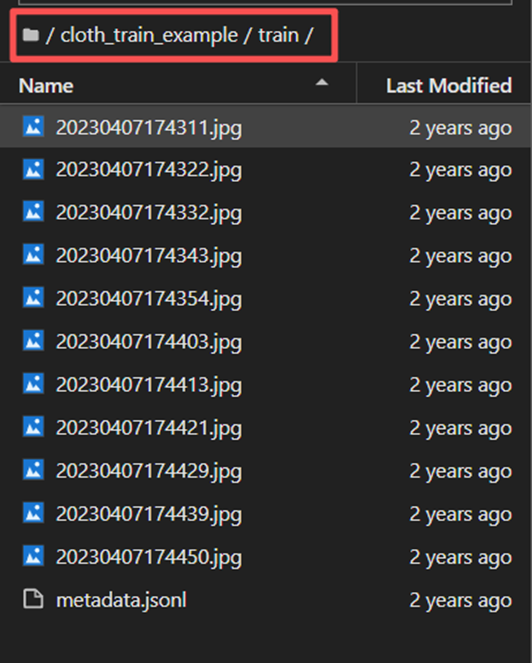
! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/cloth_train_example.tar.gz && tar -xvf cloth_train_example.tar.gz ! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/train_text_to_image_lora_v2.py此过程将会下载各种文件,在页面左侧文件目录处可以查看到。
在此目录中存放的是训练模型用的图片,以及标签文件。
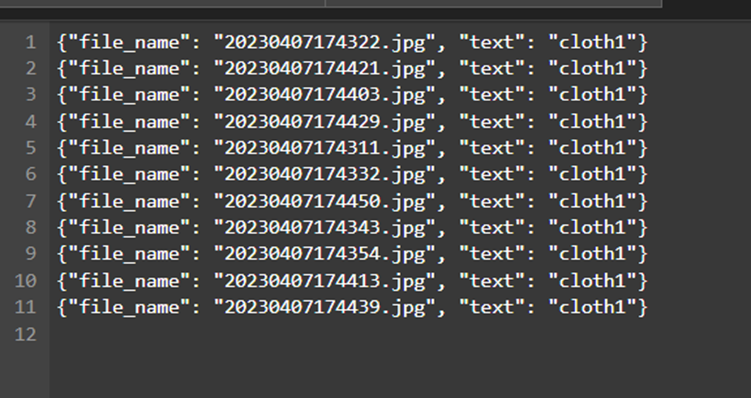
Metadata.jsonl中存放的是标签。
说明拓展:如果在这个文件目录下添加新的图片文件,并在metadata.jsonl中添加对应的标签内容。在之后的步骤:模型训练以及问生图中,将“cloth1”更换成新创建的标签,便可以实现更换衣服。
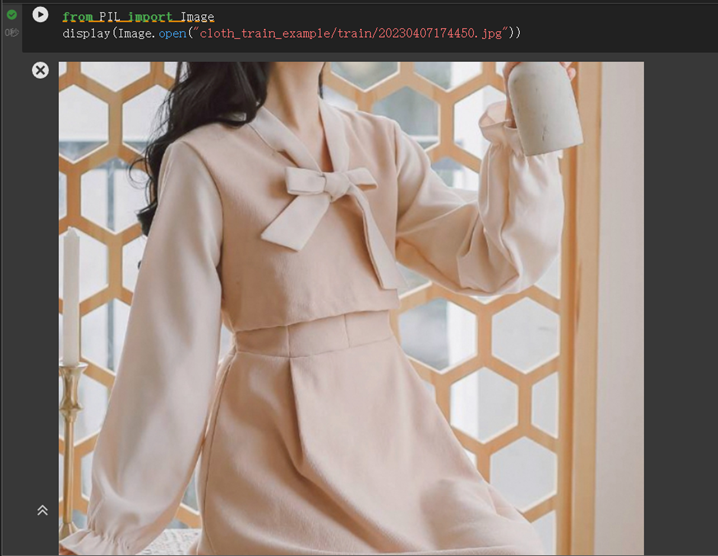
查看示例服装
from PIL import Image display(Image.open("cloth_train_example/train/20230407174450.jpg"))下载预训练模型并转化成diffusers格式
为了加速下载我们在oss做了缓存,用户可以运行如下命令直接下载
safety_checker_url = f"{prefix}/aigc-data/hug_model/models--CompVis--stable-diffusion-safety-checker.tar.gz" aria2(safety_checker_url, safety_checker_url.split("/")[-1], "./") ! tar -xf models--CompVis--stable-diffusion-safety-checker.tar.gz -C /root/.cache/huggingface/hub/ clip_url = f"{prefix}/aigc-data/hug_model/models--openai--clip-vit-large-patch14.tar.gz" aria2(clip_url, clip_url.split("/")[-1], "./") ! tar -xf models--openai--clip-vit-large-patch14.tar.gz -C /root/.cache/huggingface/hub/ model_url = f"{prefix}/aigc-data/sd_models/chilloutmix_NiPrunedFp32Fix.safetensors" aria2(model_url, model_url.split("/")[-1], "stable-diffusion-webui/models/Stable-diffusion/") ! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/convert_original_stable_diffusion_to_diffusers.py ! python convert_original_stable_diffusion_to_diffusers.py \ --checkpoint_path=stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors \ --dump_path=chilloutmix-ni --from_safetensors重要这段代码运行时间较长,大约在10分钟左右,请耐心等待。
模型训练
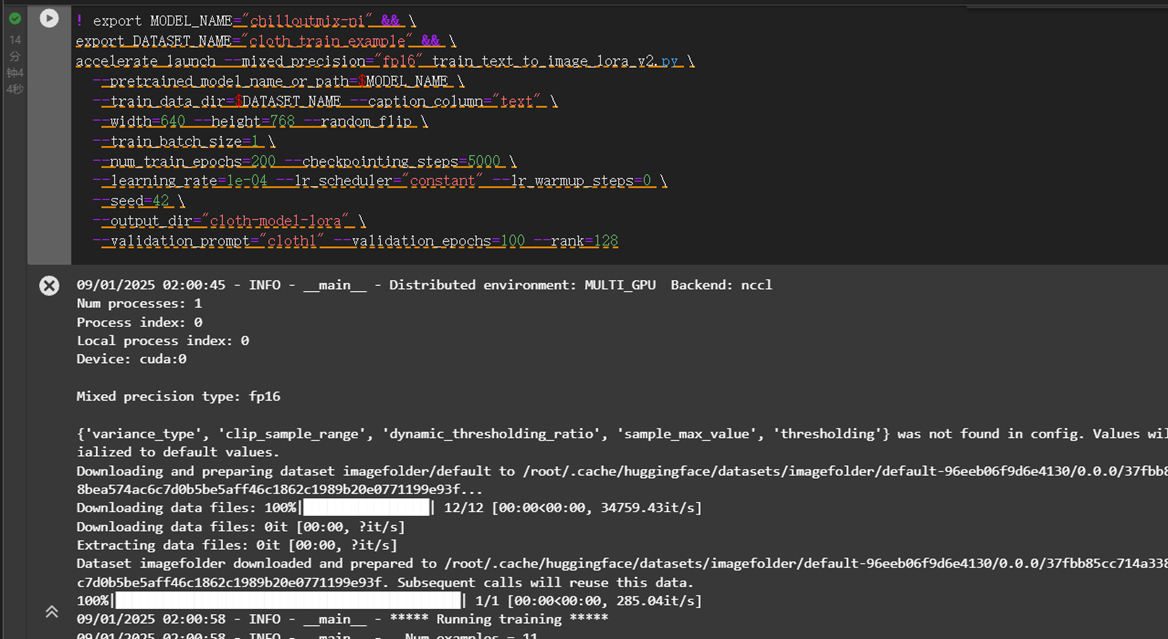
设置num_train_epochs为200,进行lora模型的训练
! export MODEL_NAME="chilloutmix-ni" && \ export DATASET_NAME="cloth_train_example" && \ accelerate launch --mixed_precision="fp16" train_text_to_image_lora_v2.py \ --pretrained_model_name_or_path=$MODEL_NAME \ --train_data_dir=$DATASET_NAME --caption_column="text" \ --width=640 --height=768 --random_flip \ --train_batch_size=1 \ --num_train_epochs=200 --checkpointing_steps=5000 \ --learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \ --seed=42 \ --output_dir="cloth-model-lora" \ --validation_prompt="cloth1" --validation_epochs=100 --rank=128重要这段代码运行时间较长,大约在15分钟左右,请耐心等待。
准备webui所需模型文件
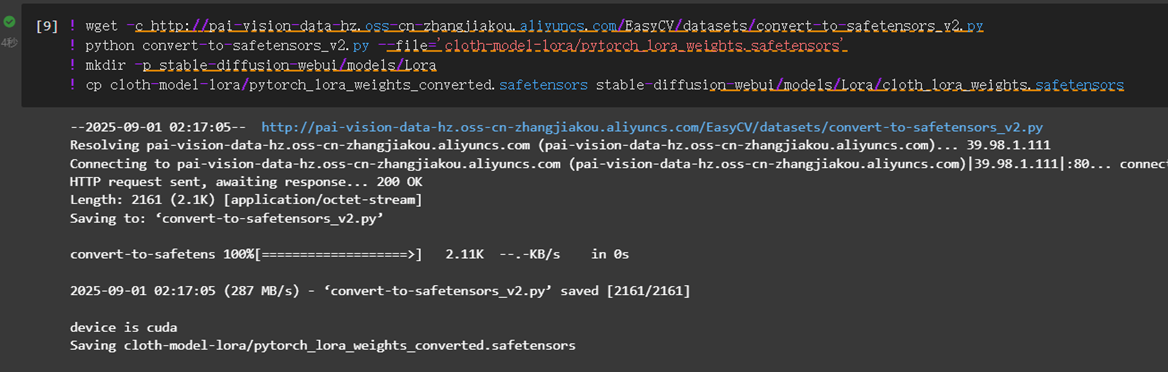
将lora模型拷贝到webui所在目录
! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/convert-to-safetensors_v2.py ! python convert-to-safetensors_v2.py --file='cloth-model-lora/pytorch_lora_weights.safetensors' ! mkdir -p stable-diffusion-webui/models/Lora ! cp cloth-model-lora/pytorch_lora_weights_converted.safetensors stable-diffusion-webui/models/Lora/cloth_lora_weights.safetensors准备额外模型文件
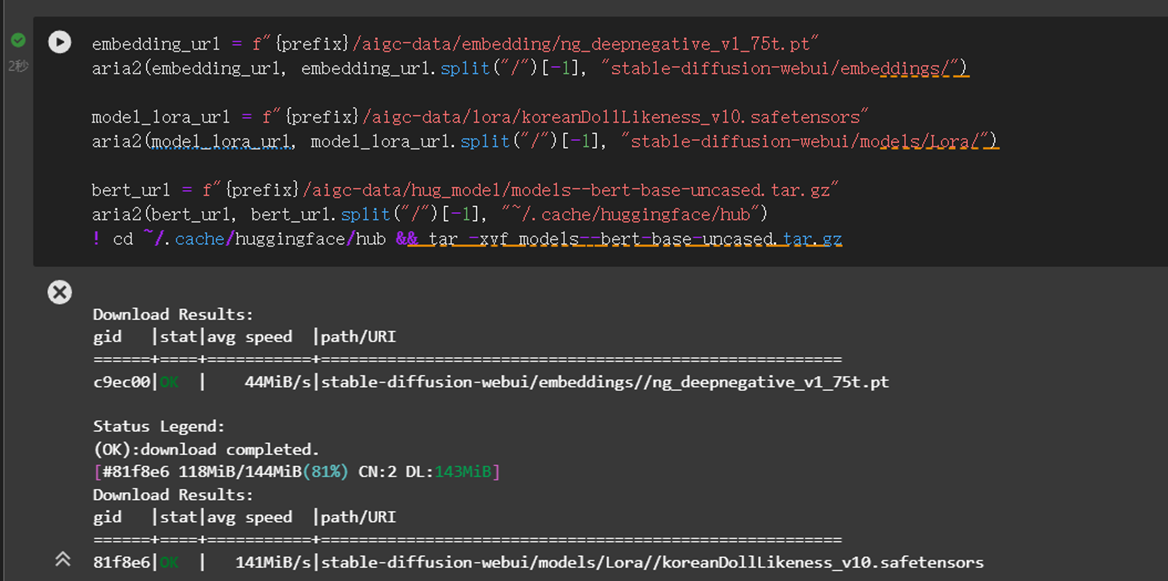
为了加速下载我们在oss做了缓存,用户可以运行如下命令直接下载
embedding_url = f"{prefix}/aigc-data/embedding/ng_deepnegative_v1_75t.pt" aria2(embedding_url, embedding_url.split("/")[-1], "stable-diffusion-webui/embeddings/") model_lora_url = f"{prefix}/aigc-data/lora/koreanDollLikeness_v10.safetensors" aria2(model_lora_url, model_lora_url.split("/")[-1], "stable-diffusion-webui/models/Lora/") bert_url = f"{prefix}/aigc-data/hug_model/models--bert-base-uncased.tar.gz" aria2(bert_url, bert_url.split("/")[-1], "~/.cache/huggingface/hub") ! cd ~/.cache/huggingface/hub && tar -xvf models--bert-base-uncased.tar.gz
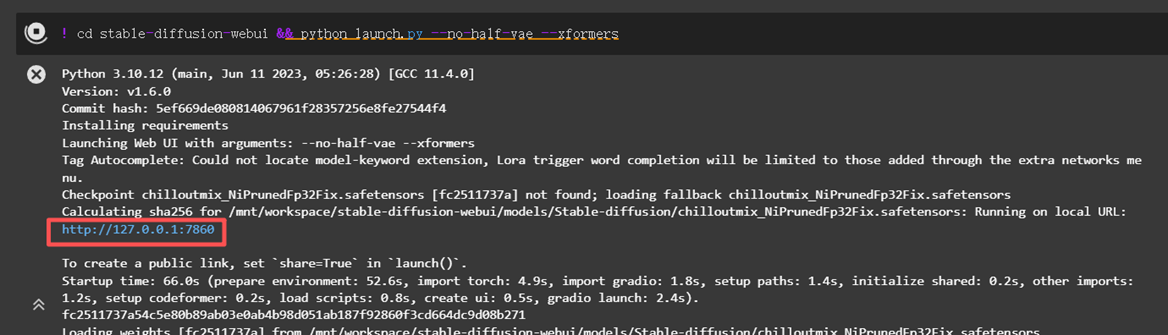
在DSW中启动WebUI。
启动webui服务,左键点击生成的URL:http://127.0.0.1:7860 跳转到webui前端。若下载库失败,请重新尝试。
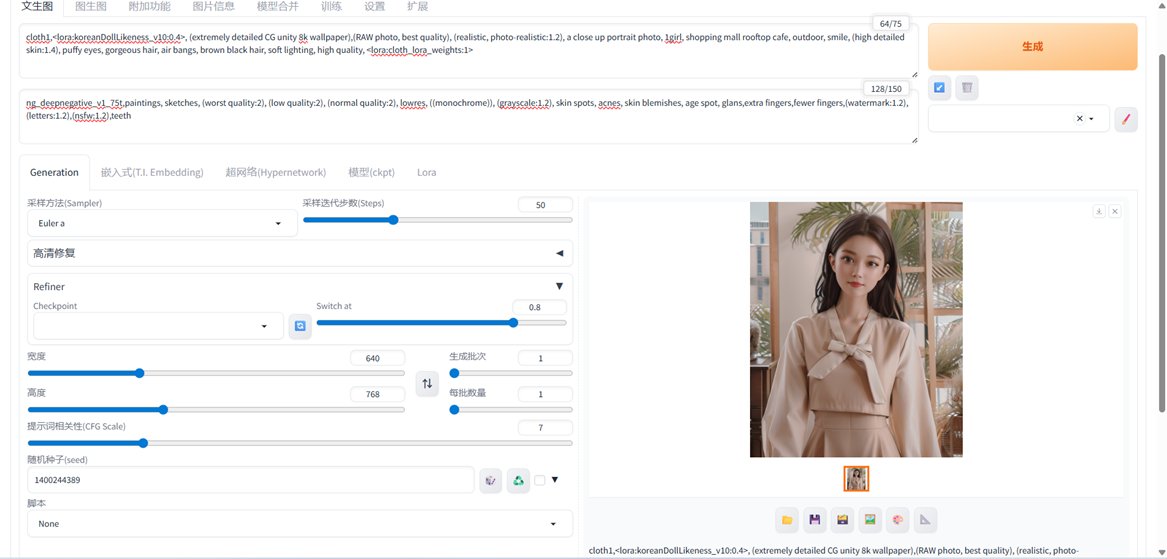
! cd stable-diffusion-webui && python launch.py --no-half-vae --xformers通过下方设置可从示例衣服生成如下图片。
正向prompt: cloth1,<lora:koreanDollLikeness_v10:0.4>, (extremely detailed CG unity 8k wallpaper),(RAW photo, best quality), (realistic, photo-realistic:1.2), a close up portrait photo, 1girl, shopping mall rooftop cafe, outdoor, smile, (high detailed skin:1.4), puffy eyes, gorgeous hair, air bangs, brown black hair, soft lighting, high quality, <lora:cloth_lora_weights:1>
负向prompt:
ng_deepnegative_v1_75t,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), (grayscale:1.2), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,(watermark:1.2),(letters:1.2),(nsfw:1.2),teeth
采样方法: Eular a
采样步数: 50
宽高: 640,768
随机种子: 1400244389
CFG scale 7


清理资源
请同学们一定要按照步骤释放实验资源及时关闭服务,避免资源浪费!
如果需要继续使用,请随时关注账号扣费情况,避免模型会因欠费而被自动停止。
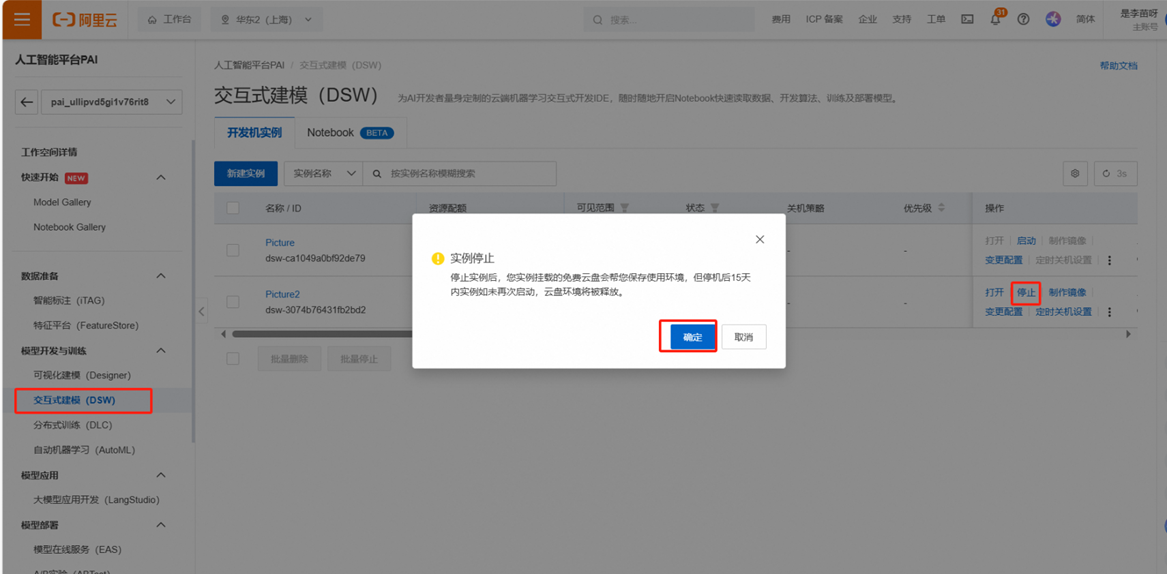
前往PAI控制台
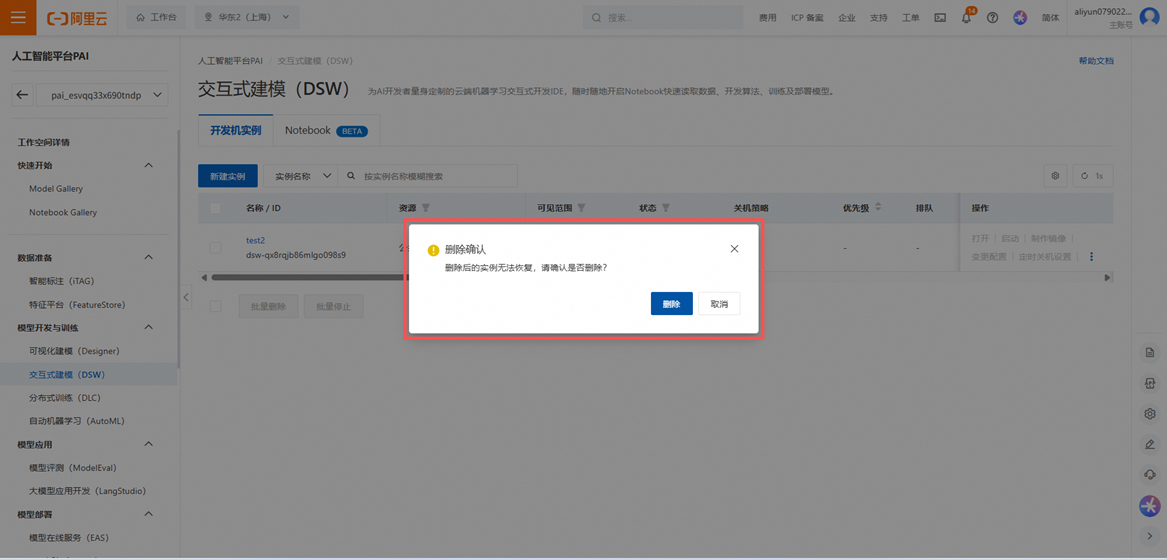
PAI平台页面——模型开发与训练——交互式建模DSW,找到目标服务。先停止正在运行的服务。
之后点击删除。
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 跳转实验评分
请为本次实验评分,并给出您的建议,点击 确认,结束本次实验