EdgeLecture—面向AIoT应用的实时课堂语音转写与多语言笔记生成
本实验包含两方面的内容:嵌入式开发端和云端服务程序设计。
实验介绍
本实验包含两方面的内容:嵌入式开发端和云端服务程序设计。
嵌入式端:
嵌入式终端作为系统的感知层,负责通过数字麦克风采集环境声音,利用PDM-PCM功能模块生成流文件,通过Wi-Fi网络将处理后的音频数据持续上传至云端服务器。
云端:
云端构建了一个协同处理平台,采用Java服务接收和存储音频文件并调用语音识别引擎完成转写,同时通过Python服务对转写的文本进行深度处理,包括基于大模型的智能摘要、多语言翻译和对话交互,处理结果既通过WebSocket推送给前端界面实时展示,也持久化存储供历史查询,从而实现了从声音采集到智能文本服务的完整闭环。具体功能参照实现:
实时语音转写工作区
系统核心界面呈现实时语音转写功能,转写内容区域实时滚动展示识别结果,支持中英文混识别和自动标点添加并实时显示语音文字转写时间。
智能内容概括功能
转写完成后,用户可点击"一键总结"按钮,系统将调用深度学习模型对长篇语音内容进行智能摘要。生成的内容概括准确提炼语音核心要点,保持原文语义完整性,并以简洁的段落形式呈现,大大提高信息获取效率。
多语言实时翻译
系统集成智能翻译引擎,用户可选择目标语言并点击"开始翻译"按钮,实时将转写内容转换为所需语言。翻译结果保持原文格式和段落结构,支持中英日韩等多语种互译,满足跨语言交流需求。
多端协同体验
系统在Web端和小程序端提供一致的用户体验,通过统一的导航设计(转写-总结-翻译)确保用户操作直觉性。给予用户多端协同体验,便于用户针对不同的场景使用该系统,提升用户的工作效率。
可视化操作反馈
每个功能操作都配有直观的视觉反馈:转写时,实时显示转写动画;概括生成时,显示处理进度条;翻译过程中,显示语言切换动效并显示历史内容。在使用系统时,多处伴随操作提示文字,这种即时的视觉反馈让用户清晰了解系统状态,提升操作信心和用户体验。
实验环境及资源准备
一、概述
嵌入式端设备需求::CY8CPROTO-062-4343W开发平台,提供两路麦克风输入,内置PDM-PCM模块,提供WiFi网络连接功能;并提供按键功能用于启动系统,在系统启动时,插入静默采样时间,
以消除背景噪声。
部署内容:购买ECS,部署Vue前端程序与Springboot后端服务,以及redis数据库等。
二、软硬件运行平台
硬件需求
嵌入式端设备需求:主控开发板InfineonCY8CPROTO-062-4343W;
云端需求:云服务器(ECS)2核(vCPU)/2GiB内存;
部署内容:前端页面、后端服务,前端利用Vue+UniApp实现多端覆盖,后端采用Java+Python的多语言微服务架构。
软件需求

三、云端实验资源
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

实验资源简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物300元代金券领取。
在实验页面,当您已阅读并同意上述创建资源的目的以及部分资源可能产生的计费规
则,点击【进入实操】继续部署该应用。
领取权益及实验资源开通
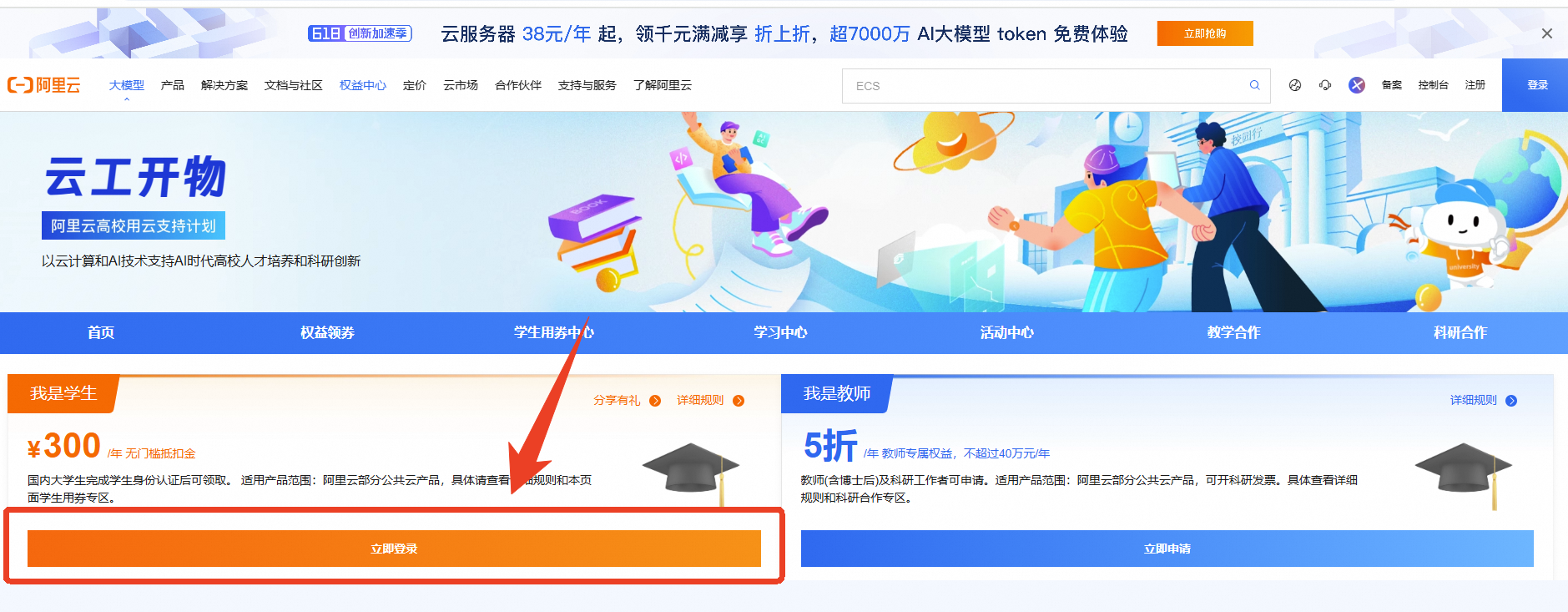
第一步:本次实验需要您通过领取阿里云云工开物300元高校专属权益优惠券(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
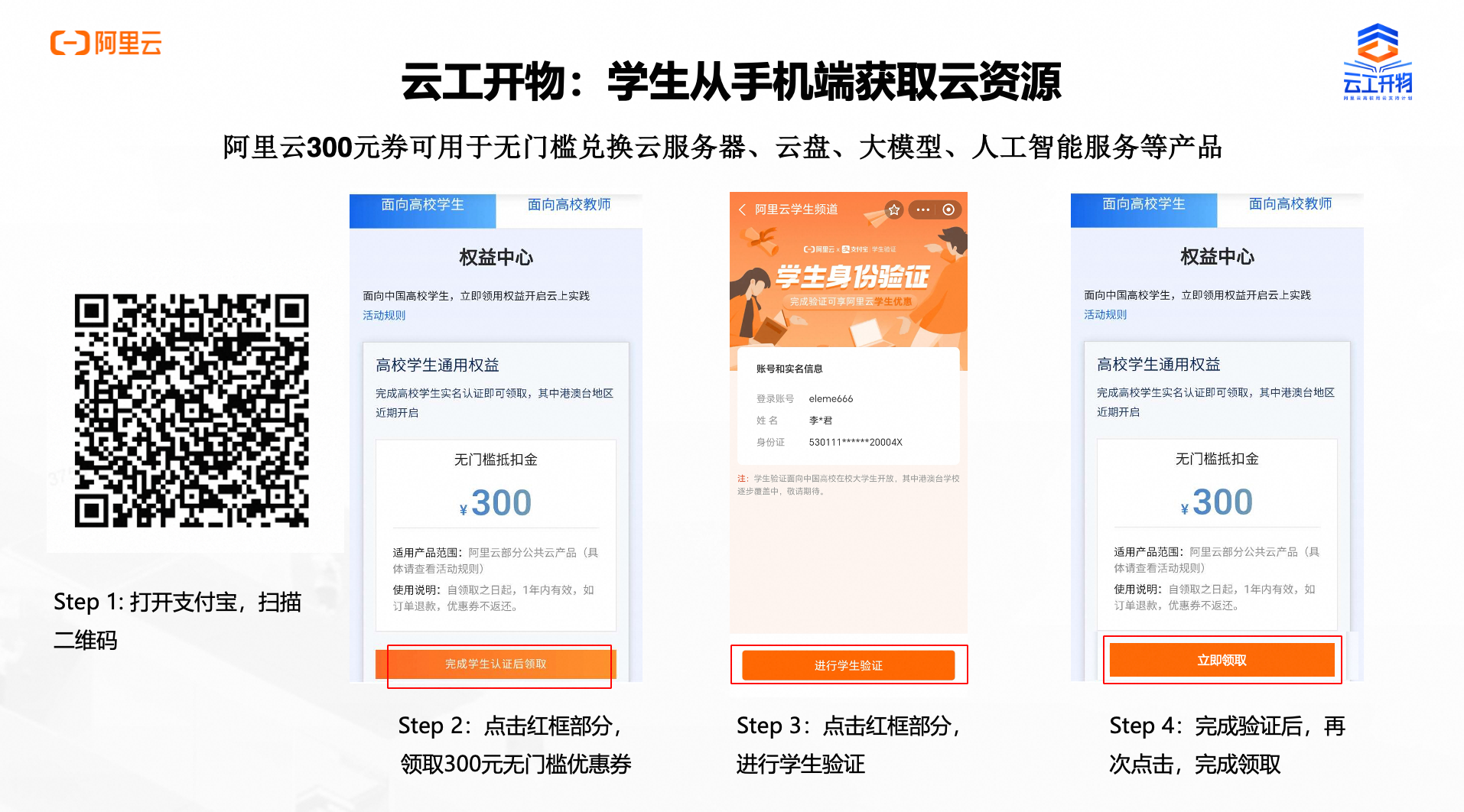
第二步:领取学生专属300元优惠券后,点击进入【学生用券中心】
两种方式
方式一
方式二
实例规格
包年包月
按时收费
资源说明
本场景主要涉及以下云产品和服务:ECS
根据自己的需求选择包年包月 或 按量付费,两种方式均支持抵扣学生300元代金券。
资源消耗
包年包月:
ECS服务器,e实例2核2G三个月:246.43元
按量付费:
只在项目部署、调试和项目演示时付费,约10元以下
购买步骤
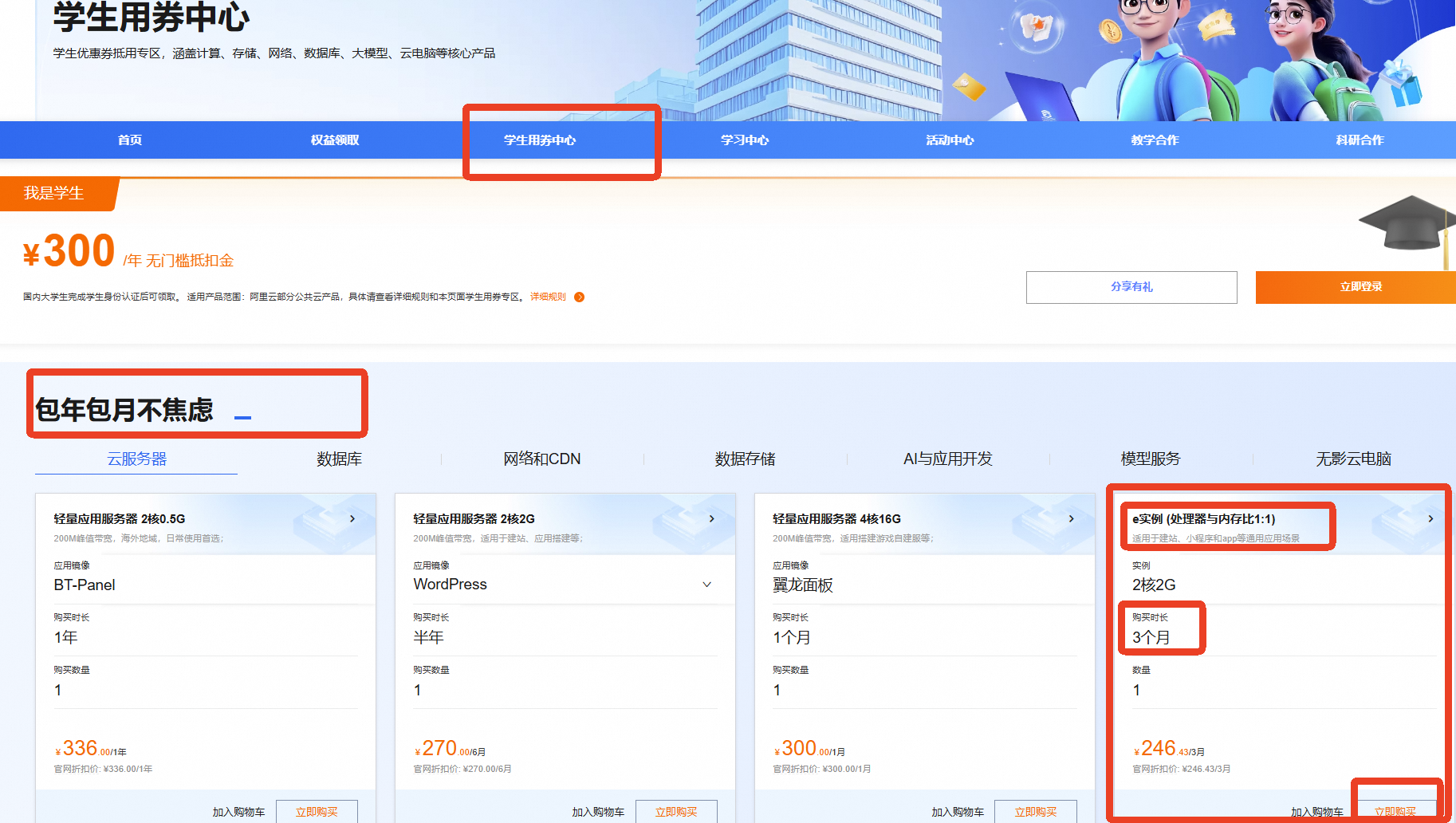
找到【包年包月不焦虑】模块
选择【e实例(处理器与内存比1:1)(3个月)】
点击【立即购买】
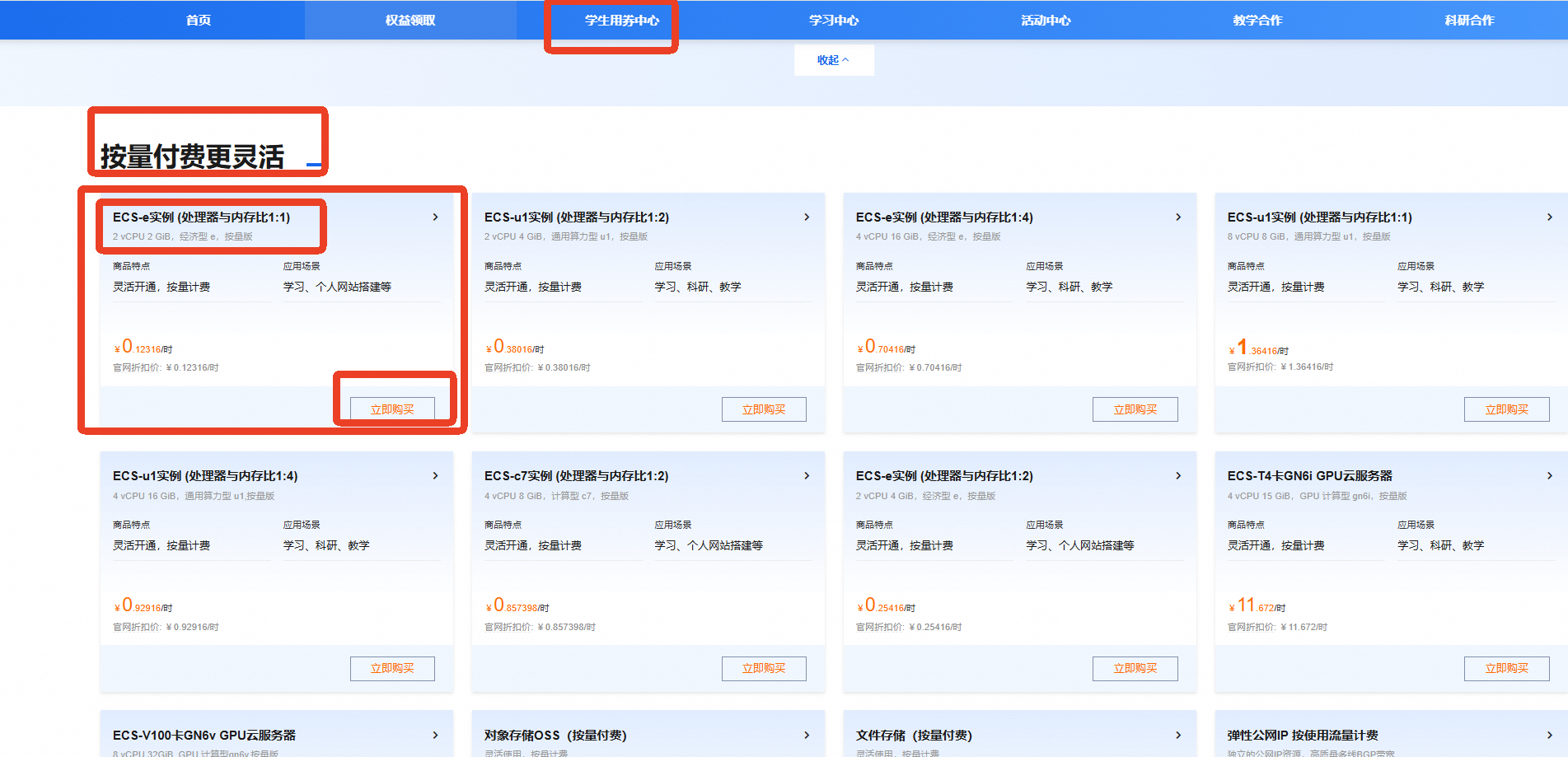
找到【按量付费更灵活】模块
选择【e实例(处理器与内存比1:1)】
点击【立即购买】
 说明
说明如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格为准。
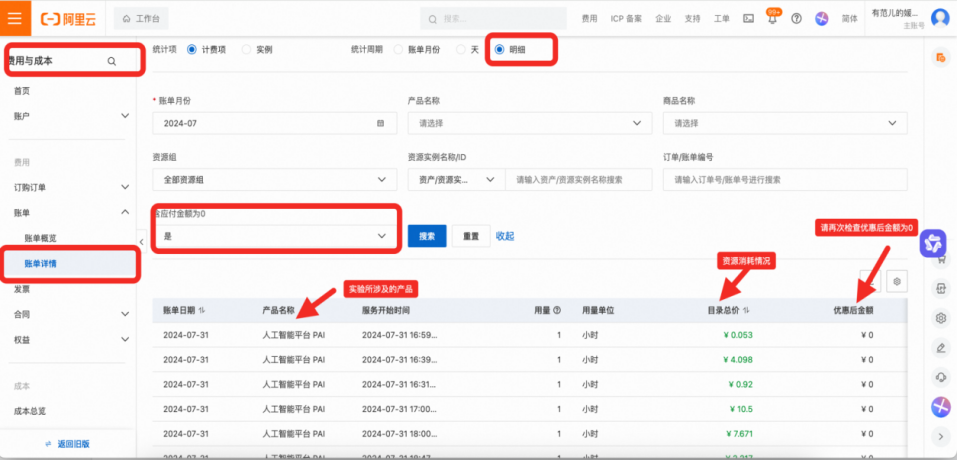
该实验下资源消耗查看方式:
在该实验完成后,在【费用与成本—账单详情—明细】中查看产品的资源消耗情况(按量付费的资源消耗部分会有T+1的延时)。
实验原理及步骤
前期可以在本地实现web应用,联调通过后,再进行ECS端项目部署。
实验实现的技术路径
(1)预备知识
音频信号采集及处理。
HTTP、UDP协议栈。
大语言模型接口调用方法。
web开发技术。
(2)技术路线
系统的整体架构如图1所示。用户通过开发板上的麦克风进行声音采集,开发板对采集到的音频信号进行预处理,随后将处理后的音频数据通过网络上传至云服务器。云端接收到音频后,首先调用基础业务接口,完成语音识别任务,将音频内容准确转换为对应的文本信息。识别得到的文本将被传递至应用层业务接口,根据具体的业务场景进行语义理解、摘要总结,多语言翻译等深度处理。处理后的文本结果将被返回至云服务器,供下游系统或设备调用,实现人机交互、语音控制、信息存储等功能。
该流程实现了从声音采集、边缘预处理、云端识别到语义分析和结果输出的完整链路,确保了数据处理的准确性、实时性与可扩展性,为构建智能语音交互系统提供了坚实的技术支撑。
图1 系统架构图
图2 系统硬件框图
(3)硬件功能介绍
CY8CPROTO-062-4343W以英飞凌PSoC6系列微控制器为核心,具有512KB大小的SRAM,支撑数
据处理需求。连接性上,它支持Micro-USB接口,既可用于编程、调试也可用于供电。双模无线模块使该开发平台具备Wi-Fi和低功耗蓝牙功能。对于音频处理,内置的PDM-PCM模块支持数字麦克风输入,适用于语音识别、音频录制等应用场景。
除此之外,该开发平台还支持FreeRTOS物联网操作系统,允许开发者创建多任务应用程序。
图3 CY8CPROTO-062-4343W开发平台
(4)软件功能介绍
嵌入式端软件:嵌入式端的主要任务是接收音频数据并无损的发向云端。因此,只需要创建两个任务:音频数据收集任务和网络发送音频数据任务。
音频转文本功能是将声音信号转换为对应文字内容的核心模块,通常依托于云服务器上强大的语音识别引擎实现。该功能首先从音频接收模块获取经过预处理和存储的标准格式音频文件,然后调用基础业务接口,将音频文件传入语音识别服务。识别完成后,文本数据会被缓存到高性能内存数据库如Redis中,确保下游业务接口能够快速获取最新的转写结果,提高系统响应速度。语音转文本功能不仅实现了人机语音交互的基础,还为语义理解、自然语言处理、智能助理等应用提供了必要的数据输入。
文本处理与摘要提取功能是基于转写文本进行深度语义分析和信息提炼的关键环节,旨在从大量的语音转写文本中提取核心信息和关键要点,辅助业务决策和用户理解。系统将云服务器缓存中的最新文本数据传递给应用业务接口。该接口集成了自然语言处理(NLP)技术,包括分词、词性标注、命名实体识别、句法分析和语义理解等模块。文本经过多层语义分析后,系统可以识别用户意图、关键实体和情感倾向,为后续的智能回复、指令执行或数据挖掘提供基础。摘要提取则利用自动文本摘要算法,如抽取式摘要和生成式摘要方法,快速从长文本中挑选或生成简洁明了的核心内容,帮助用户快速掌握重点信息。该功能广泛应用于客服机器人、会议纪要自动生成、新闻摘要以及智能问答系统中。为了保证摘要质量,系统会结合上下文信息和领域知识进行优化,同时支持多轮交互,动态调整摘要内容。
为了实现高效、灵活且安全的语音处理服务,系统将各项功能部署在远程云服务器上,充分利用云计算资源的弹性和高可用性。远程服务器负责承载音频接收、语音转文本、文本处理与摘要提取等核心业务模块,通过RESTfulAPI对外提供统一接口,支持多终端并发访问。服务器部署结合负载均衡和容错机制,保证服务在高并发环境下的稳定运行。Web功能还支持多种客户端接入方式,如PC端、移动端和嵌入式设备,增强系统的适用范围和用户体验。
图4 系统业务逻辑总图
1)基础业务端
基础业务端主要对传输的语音进行存储与转文本,实现语音转文本的基础功能。业务逻辑图如下所示。
图5 基础业务流程图
音频接收控制器(AudioController)
这段代码实现了音频数据的接收端点。通过HTTPPOST请求接收原始音频数据,记录接收到的数据大小,并将数据传递给音频服务处理。如果处理过程中出现错误,会返回500错误响应。这是整个系统的入口点,负责接收来自客户端的音频数据流。
@PostMapping publicResponseEntity<String>handleAudioData(@RequestBodybyte[]audioData){ try{ log.info("接收到音频数据:{}字节",audioData.length); audioService.handleAudioData(audioData); returnResponseEntity.ok("{\"status\":\"success\",\"message\":\"Data receivedandsaved\"}"); }catch(IOExceptione){ log.error("处理音频数据时出错",e); returnResponseEntity.internalServerError() .body("{\"error\":\"Failedtoprocessaudiodata:"+e.getMessage()+ "\"}"); } }音频接收控制器(AudioController)
这段代码实现了音频数据的缓冲机制。使用ArrayList存储接收到的音频数据块,当累积的数据块达到配置的大小时,才进行处理。这种机制可以有效地处理流式音频数据,避免频繁的文件操作,提高系统效率。
privatefinalList<byte[]>buffer=newArrayList<>(); privateintcurrentReads=0; @Override publicsynchronizedvoidhandleAudioData(byte[]audioData)throwsIOException{ buffer.add(audioData); currentReads++; if(currentReads>=audioConfig.getChunkSize()){ //处理缓冲区数据... } }WAV文件生成和保存(AudioServiceImpl)
这段代码负责将PCM音频数据转换为WAV格式并保存。首先生成WAV文件头(包含采样率、位深度、声道数等信息),然后将文件头和音频数据写入文件。这个过程确保了音频文件符合WAV格式规范,可以被其他音频处理软件正确识别。
privatevoidsaveWavFile(Stringfilename,byte[]pcmData)throwsIOException{ byte[]header=WavUtil.createWavHeader( pcmData.length, audioConfig.getSampleRate(), audioConfig.getBitsPerSample(), audioConfig.getChannels() ); try(FileOutputStreamfos=newFileOutputStream(filename)){ fos.write(header); fos.write(pcmData); } }异步语音转写处理
这段代码实现了异步的语音转写功能。使用CompletableFuture在后台线程中处理语音转写,避免阻塞主线程。转写完成后,结果被存储在Redis中,便于快速检索。这种异步设计确保了系统的响应性,即使语音转写需要较长时间。
CompletableFuture.runAsync(()->{ try{ FileaudioFile=newFile(filename); Stringtext=speechToTextService.convertToText(audioFile); redisTemplate.opsForValue().set(filename,text); log.info("转写结果已保存到Redis,文件:{}",filename); }catch(ExceptionsttException){ log.error("语音转写失败,文件:{}",filename,sttException); } });各种配置(Config)
这段代码定义了讯飞语音服务的配置类。使用SpringBoot的@ConfigurationProperties注解,可以从配置文件中自动加载配置项。这种设计使得系统配置更加灵活,可以在不修改代码的情况下改变服务参数。
@Configuration @ConfigurationProperties(prefix="xfyun.lfasr") publicclassXfyunConfig{ privateStringappId; privateStringapiKey; privateStringapiSecret; privateStringhost="http://raasr.xfyun.cn/api"; //... }这段代码配置了Redis缓存服务。创建了一个RedisTemplatebean,用于处理Redis操作。使用StringRedisSerializer确保了键值对都以字符串形式存储,便于处理转写结果的存储和检索。
@Configuration publicclassRedisConfig{ @Bean publicRedisTemplate<String,String>redisTemplate(RedisConnectionFactory connectionFactory){ RedisTemplate<String,String>template=newRedisTemplate<>(); template.setConnectionFactory(connectionFactory); template.setDefaultSerializer(newStringRedisSerializer()); returntemplate; } }这段代码配置了Web相关的设置。设置了默认的内容类型为JSON,确保API返回的数据格式统一。这种配置使得API接口更加规范,客户端可以预期固定的响应格式。
@Configuration publicclassWebConfigimplementsWebMvcConfigurer{ @Override publicvoidconfigureContentNegotiation(ContentNegotiationConfigurer configurer){ configurer.defaultContentType(MediaType.APPLICATION_JSON); } }
2)应用端
应用端主要对得到的文本进行进一步分析与加工,实现文本摘要与翻译功能。
图6 文本总结流程图
文本摘要功能主要基于FastAPI框架,整体分为4各部分,各个部分各司其职。
服务框架和中间件配置部分。首先用FastAPI()创建了服务实例,然后添加CORSMiddleware中间件,让前端页面无论部署在哪个域名都能无障碍调用API。这部分也设置了允许的方法类型(GET/POST/PUT等),以及可接受所有请求头,这样前端调用就能更加灵活通畅,不再受浏览器同源策略限制。
数据模型定义部分。代码中通过pydantic定义了SummaryRequest和SummaryResponse模型。这意味着前端请求必须是一个JSON对象,其中必须有text字段,而服务返回给前端时,也会以规范化后的JSON形式提供summary结果。这种类型校验让接口更加安全、规范,也方便自动生成API文档。
调用Deepseek服务的核心逻辑。summarize_text()函数是整个服务的核心逻辑,它接收到前端传入的原始文本后,会在前面拼接一段明确的总结任务描述,然后通过requests.post()向Deepseek的大模型API发送对话任务。你可以看到,代码中提前设置好了DEEPSEEK_API_KEY和DEEPSEEK_API_URL,并把请求内容(包括用户消息)封装成payload,通过HTTP头部传入API密钥认证。
#组装用户消息(添加总结提示词) prompt="请你总结一下这段文字,只需要总结内容,总结成一段话:" user_message=f"{prompt}{request.text.strip()}" #调用Deepseek模型接口 headers={ "Authorization":f"Bearer{DEEPSEEK_API_KEY}", "Content-Type":"application/json" } payload={ "model":"deepseek-chat", "messages":current_history } #发出POST请求 response=requests.post(DEEPSEEK_API_URL,headers=headers,json=payload) response.raise_for_status()#检查HTTP错误 response_data=response.json()返回时,函数会对响应JSON逐层检查,比如先找choices[0].message.content,找不到时再去找response、answer、output之类的通用字段,最后提取出实际模型生成的总结内容。这种多重检查是为了增强对不同模型返回结构的兼容性。
if"choices"inresponse_dataandlen(response_data["choices"])>0: content=response_data["choices"][0]["message"]["content"] else: #按照其他可能返回字段顺序检查 if"response"inresponse_data: content=response_data["response"] elif"answer"inresponse_data: content=response_data["answer"] elif"output"inresponse_data: content=response_data["output"] elif"message"inresponse_data: content=response_data["message"] else: raiseHTTPException(status_code=500,detail="无法解析AI响应格式") #返回标准化结果 returnSummaryResponse(summary=content)翻译功能
图7 翻译功能流程图
文本翻译功能同样基于FastAPI框架,借助讯飞提供的接口实现功能。
首先使用FastAPI框架对外提供翻译接口,前端只需发送一段文本,就能得到对应目标语言的翻译结果。程序一开始创建FastAPI实例,并配置CORS中间件,这意味着无论客户端来自什么域名,都能直接调用该服务,解决前端跨域问题,为部署在生产环境中提供了便利。
接下来是模型与参数定义部分,代码中通过pydantic定义了TranslationRequest和
TranslationResponse模型,这样前端必须按规范提交text(要翻译的文本)、from_lang(源语言)、to_lang(目标语言),服务也能返回标准化JSON响应,包括翻译后的文本与源、目标语言信息。这一部分的设计提高了接口可用性与可维护性,减少类型错误。
核心逻辑在translate_text()函数中,这部分详细描述了与讯飞翻译API通信的过程。将用户提交的原始文本用Base64编码后,按照讯飞接口规范组装请求体,再用hmac-sha256生成签名,添加到Authorization头中,最后通过requests.post()向讯飞翻译服务发送HTTP请求。在接收到响应后,代码检查返回JSON中的状态码与翻译结果字段,成功时提取dst译文并封装成TranslationResponse,出错时则返回对应HTTP错误给前端。
try: #对文本进行Base64编码 text_base64=base64.b64encode(request.text.encode('utf-8')).decode('utf-8') #构建请求体 body={ "common":{ "app_id":XFYUN_APP_ID }, "business":{ "from":request.from_lang, "to":request.to_lang }, "data":{ "text":text_base64 } } #将请求体转为JSON body_json=json.dumps(body) #获取当前时间,格式化为RFC1123格式 date=datetime.utcnow().strftime('%a,%d%b%Y%H:%M:%SGMT') #计算请求体的digest digest= base64.b64encode(hashlib.sha256(body_json.encode('utf-8')).digest()).decode('utf-8') #构建签名原始字段 signature_origin=f"host:{XFYUN_HOST}\ndate:{date}\nPOST/v2/itsHTTP/1.1\ndigest: SHA-256={digest}" #使用hmac-sha256算法计算签名 signature_sha=hmac.new( XFYUN_API_SECRET.encode('utf-8'), signature_origin.encode('utf-8'), digestmod=hashlib.sha256 ).digest() #Base64编码获取最终签名 signature=base64.b64encode(signature_sha).decode('utf-8') #构建Authorization字段 authorization=f'api_key="{XFYUN_API_KEY}",algorithm="hmac-sha256",headers="host daterequest-linedigest",signature="{signature}"' #设置请求头 headers={ "Content-Type":"application/json", "Accept":"application/json,version=1.0", "Host":XFYUN_HOST, "Date":date, "Digest":f"SHA-256={digest}", "Authorization":authorization } #发送请求 response=requests.post(XFYUN_URL,headers=headers,data=body_json) response.raise_for_status() #解析响应 result=response.json() print(f"讯飞翻译API响应:{json.dumps(result,ensure_ascii=False,indent=2)}")问答功能
图8 问答功能流程图
问答功能同样基于FastAPI框架,借助Deepseek提供的API接口实现智能问答功能。首先使用FastAPI框架对外提供问答接口,前端只需发送问题文本,就能得到AI智能回答。创建FastAPI实例,并配置CORS中间件后,配置模型与参数定义部分。代码中通过pydantic定义了QuestionRequest、QuestionResponse、ConversationRequest和ConversationResponse模型,前端必须按规范提交question(问题文本)、context(可
选上下文)或messages(对话历史),服务也能返回标准化JSON响应,包括答案、原始问题以及多种格式的答案输出。核心逻辑分为两个主要功能:单次问答和多轮对话。在answer_question()函数中,程序根据是否有上下文信息构建不同的提示词,然后组装成符合DeepseekAPI规范的请求体,设置模型参数如temperature=0.7(保证答案创造性)、max_tokens=1000(限制答案长度),最后通过requests.post()向Deepseek
服务发送HTTP请求。在conversation_chat()函数中,程序维护对话历史记录,支持多轮连续对话,每次请求都会将历史消息一并发送给AI模型,确保上下文连贯性。
#调用DeepseekAPI headers={ "Authorization":f"Bearer{DEEPSEEK_API_KEY}", "Content-Type":"application/json" } payload={ "model":"deepseek-chat", "messages":current_history, "temperature":0.7,#问答需要一定的创造性 "max_tokens":1000#限制答案长度 } try: response=requests.post(DEEPSEEK_API_URL,headers=headers,json=payload) response.raise_for_status() response_data=response.json() #解析DeepseekAPI响应 if"choices"inresponse_dataandlen(response_data["choices"])>0: if"message"inresponse_data["choices"][0]: content=response_data["choices"][0]["message"]["content"] else: content=f"无法解析choices中的message字段" else: #尝试其他可能的格式 if"response"inresponse_data: content=response_data["response"] elif"answer"inresponse_data: content=response_data["answer"]








云端项目部署
服务器购买配置
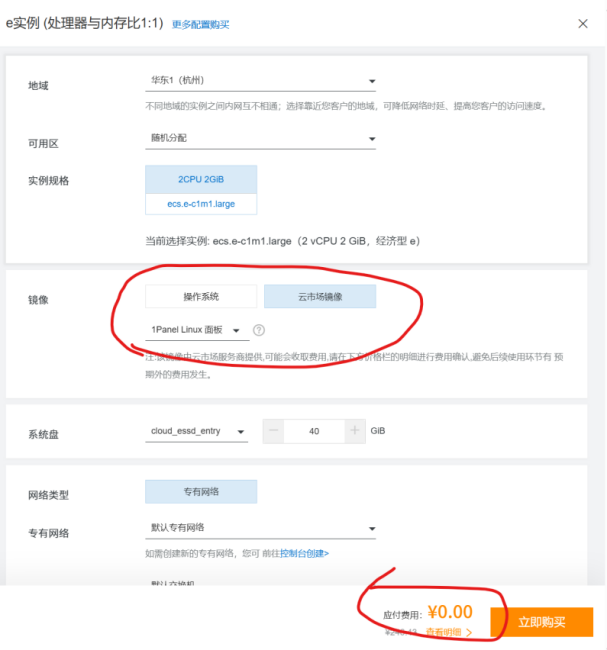
点击【立即购买】后,默认大部分配置,修改镜像为【云市场镜像】——【1Panel Linux】,最下方保证关闭自动续费,然后立即购买。注意此时下方金额应该显示0元。
后面自行确认订单即可
连接云服务器
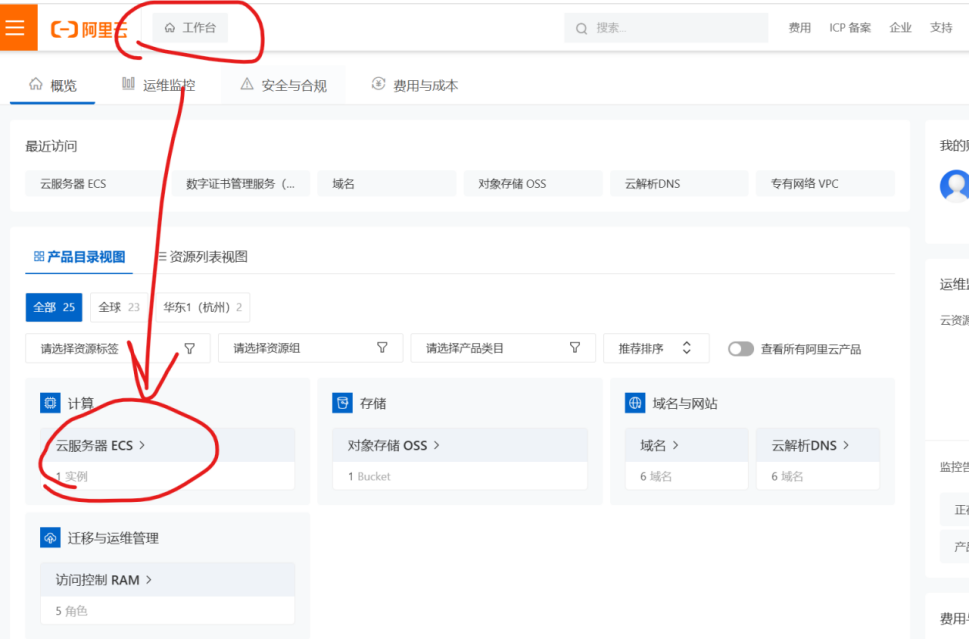
打开阿里云,【工作台】——【云服务器ECS】
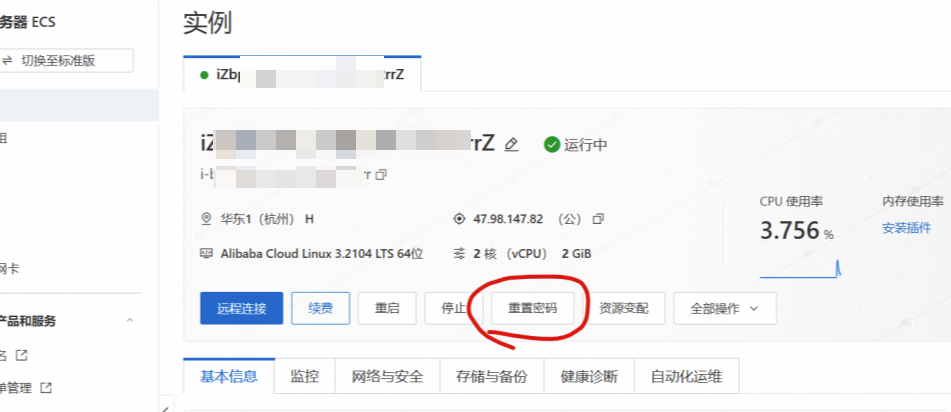
重置密码
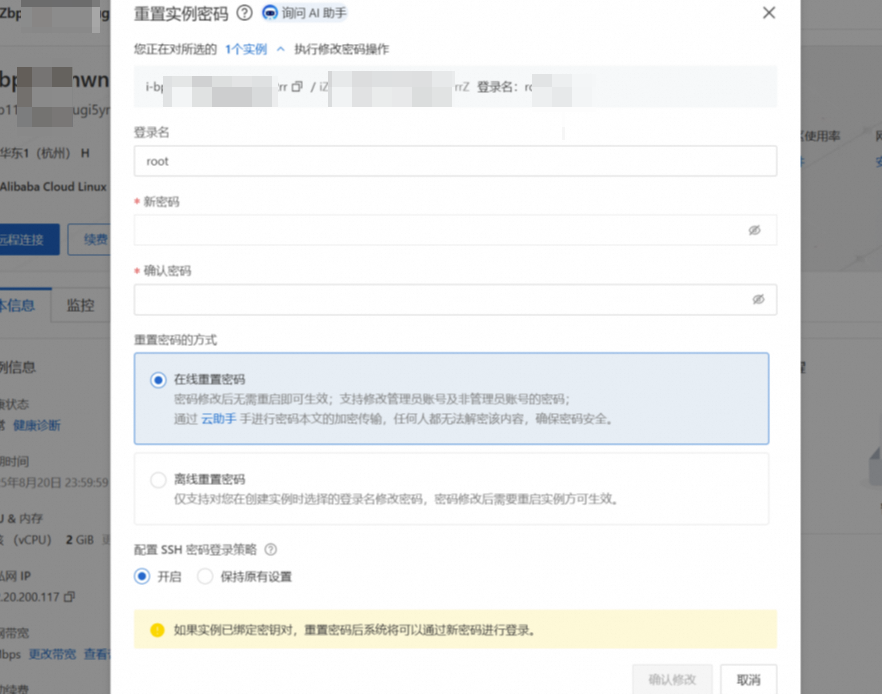
点击重置密码按钮,自行设置新密码
打开Xshell并连接服务器
连接成功
配置Java环境
首先输入sudoaptupdate&&sudoaptupgrade-y更新应用商店
更新成功后输入aptinstalldefault-jdk安装Java环境
这里输入Y继续
安装完成后输入java-version验证是否安装成功,出现版本号则表示安装成功
输入sudoaptinstallredis-server安装redis数据库
输入Y继续后,输入sudosystemctlstatusredis查看redis数据库状态,这里表示正在运行
接下来创建一个新的文件夹存放项目,首先输入mkdirmaosys新建文件夹maosys,然后输入cdmaosys,跳转到当前目录的maosys文件夹,再输入mkdirjava新建java项目,最后输入cdjava跳转到java文件夹
打开XFTP,在刚刚新建的文件夹中上传Java文件
上传完成后输入java-jaraudio-server-1.0-SNAPSHOT.jar试运行项目
运行成功可以看到这是一个SpringBoot项目
最后输入nohupjava-jaraudio-server-1.0-SNAPSHOT.jar&后台运行程序
配置Python环境
首先输入cd..回到maosys文件夹,然后输入mkdirpython创建一个python文件夹,最后输入cdpython进入文件夹
在XFTP中上传Python文件
输入pipinstallfastapiuvicornpydanticrequestsstarlette-i
https://mirrors.aliyun.com/pypi/simple/--trusted-hostmirrors.aliyun.com安装python环境包
安装成功后输入python3run.py试运行
试运行成功后输入nohuppython3run.py&把它放在后台运行
配置Vue项目
首先输入cd..返回maosys文件夹,输入curl-fsSLhttps://deb.nodesource.com/setup_18.x|sudo-Ebash-下载node
随后输入sudoaptinstall-ynodejs安装node
安装完成后分别输入node-v和npm-v来验证是否安装成功,显示版本号则代表安装成功
随后输入npmconfigsetregistryhttps://registry.npmmirror.com设置国内镜像,并输入npmconfigget registry检查设置的国内镜像
输入sudonpminstall-g@vue/cli安装cli
安装成功
输入mkdirvue新建一个vue文件夹,随后输入cdvue进入该文件夹
在XFTP中上传Vue项目文件
输入npminstall安装项目所需要的包
安装完成后输入npmrunserve运行
运行完成后输入nohupnpmrunserve&后台运行
关闭防火墙
输入sudoufwdisable关闭阿里服务器的防火墙
打开阿里云【工作台】-【云服务器ECS】-【安全组】,许可需要的端口号
输入地址+端口号,验证python是否部署成功
验证Java是否部署成功
最后输入前端的端口号,可以看到项目部署成功


































实验资源释放
无论购买的是包年包月还是按量付费方式,都需要手动释放资源。
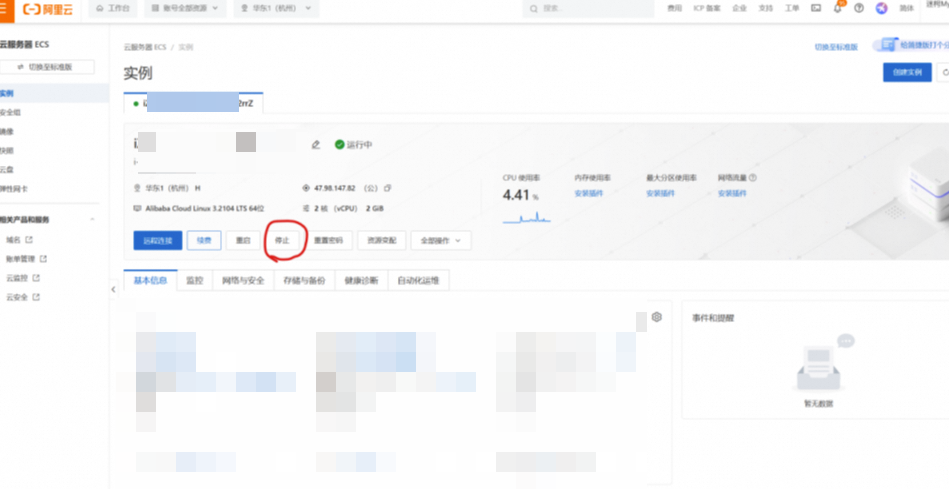
停止服务器,避免流量超支产生费用:
不再需要示例时请删除示例:
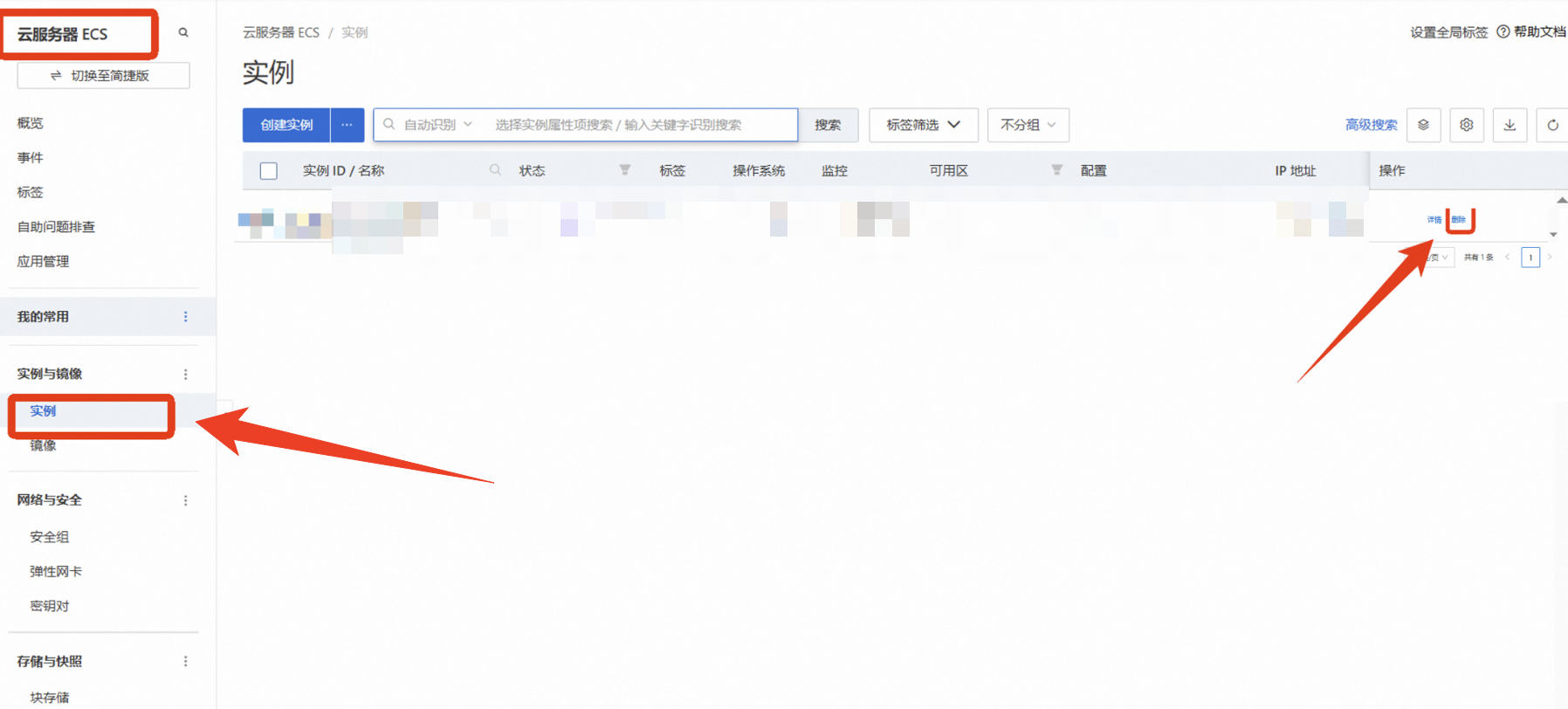
点击 云服务器ECS—实例—复制实例ID,点击【删除】
在弹窗粘贴实例ID,并进行勾选,点击【确定删除】
完成安全验证后,即可成功释放实例。
检查是否成功释放资源



关闭实验
完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验