基于comfyUI工作流搭建复杂多模态模型
本实验通过在用阿里云PAI ArtLab平台上的ComfyUI(共享版)环境,通过搭建一个复杂的图生视频工作流,来运行万相2.1模型,以实现图生视频。
实验任务: 构建浙大西迁主题的故事剧本与视频生成工作流
一、实验目标
本实验通过在用阿里云PAI ArtLab平台上的ComfyUI(共享版)环境,通过搭建一个复杂的图生视频工作流,来运行万相2.1模型,以实现图生视频。
完成本实验后,学生应能够:
独立部署一个在线可交互的大语言模型应用;熟练掌握 PAI ArtLab 平台上 ComfyUI(共享版)的基本操作。
独立搭建一个基于万相2.1模型的复杂图生视频(Image-to-Video)工作流。
理解并能配置 VRAM 优化关键节点,如 wanvideo blockswap(内存卸载)和 wanvideo model loader(FP8量化)。
掌握多模态输入(静态图像 和文本提示 )在工作流中的编码与处理方法。
成功基于一张静态图片和文本提示,生成一段符合预期的动态视频。
二、实验介绍
“浙大西迁”是具有重要教育与社会意义的历史事件,现有图文资料丰富但传播形式以静态为主,难以在课堂或展陈中呈现时空脉络与人物情感。基于 ComfyUI 的可视化工作流,可以将权威出处的历史图片与文字介绍生成带有历史感与沉浸叙事的短视频,让人物与场景“动起来”。
三、相关知识点
本实验的关键作用在于展示如何通过工作流引擎(ComfyUI)的灵活性,主动干预和优化模型的计算流程,以突破硬件限制。相关关键概念包括:
ComfyUI: 一个基于节点式(Node-based)界面的工作流引擎,用于搭建、配置和运行复杂的人工智能(特别是AIGC)模型。
图生视频 (Image-to-Video): 一种多模态生成技术,它以一张静态图像作为内容和风格的强参考,结合文本提示(Prompt)中的动态描述,生成一段连续的视频帧序列。
FP8 量化 (Quantization): 一种模型压缩技术。在此实验中,通过加载fp8_e4m3fn格式的模型 ,大幅降低模型对显存的占用,并可能提升在兼容硬件上的计算速度。
Blockswap (内存交换): 一种显存(VRAM)优化技术。wanvideo blockswap 节点允许在计算过程中,将模型中暂时不用的“块”(Transformer blocks)从显存卸载到CPU内存中,从而实现在低显存显卡上运行大模型。
VAE (变分自动编码器): 在此工作流中,wanvideo vae loader 加载的VAE负责两个关键任务:1. 将输入的静态图压缩到潜空间;2. 将采样器生成的潜空间视频帧(samples)解码为像素图像(images)。
多模态编码器 (T5 & CLIP): 工作流使用 load wanvideo t5 textencoder 来理解文本提示(Prompt),并使用 load wanvideo clip encoder 来分析和理解输入的参考图像。
四、实验环境配置
平台与工具:PAI ArtLab平台
硬件要求:联网计算机
软件环境:Web浏览器(建议Chrome)
资源文件:
示例文件:

示例结果展示:
账户设置:注册阿里云账号并完成高校师生认证;开通PAI ArtLab平台
模型选择:万相Wan2.1
五、实验内容与步骤
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
所有实验操作将保留至您的账号,请谨慎操作。
平台仅提供手册参考,不会对资源做任何操作。
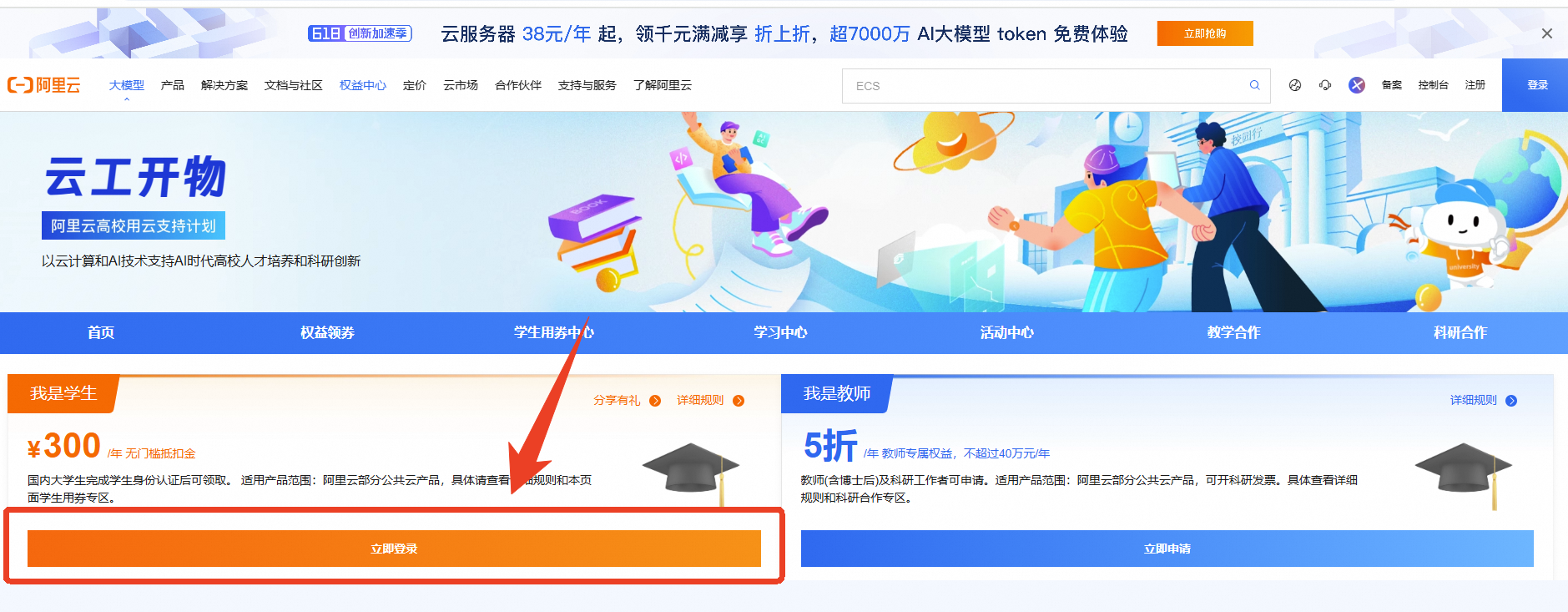
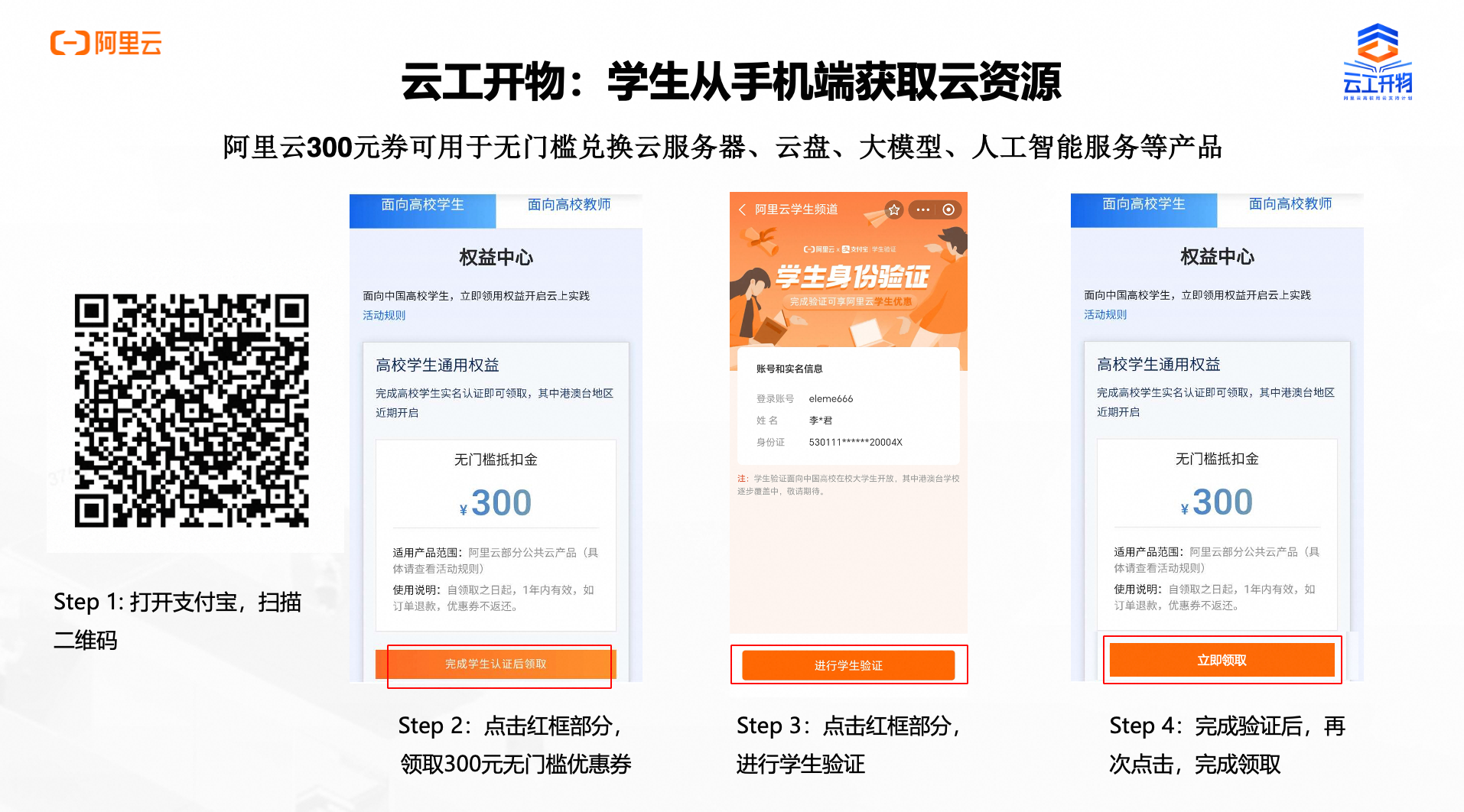
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
本实验,预计产生费用:约0.012元(以仅用SDWebUI(共享版)生成一张512*512最简单的图(393kb,1.66sec)为例估算)
本实验产生的费用优先使用优惠券。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
领取专属权益
第一步:点击“进入实操”
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第二步:领取300元优惠券
本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
进入并开通PAI ArtLab并授权
点击访问PAI ArtLab平台
初次进入平台,依次点击两步,完成PAI ArtLab平台开通与授权


完成PAI ArtLab平台开通与授权,进入到首页
创建comfyUI工作空间
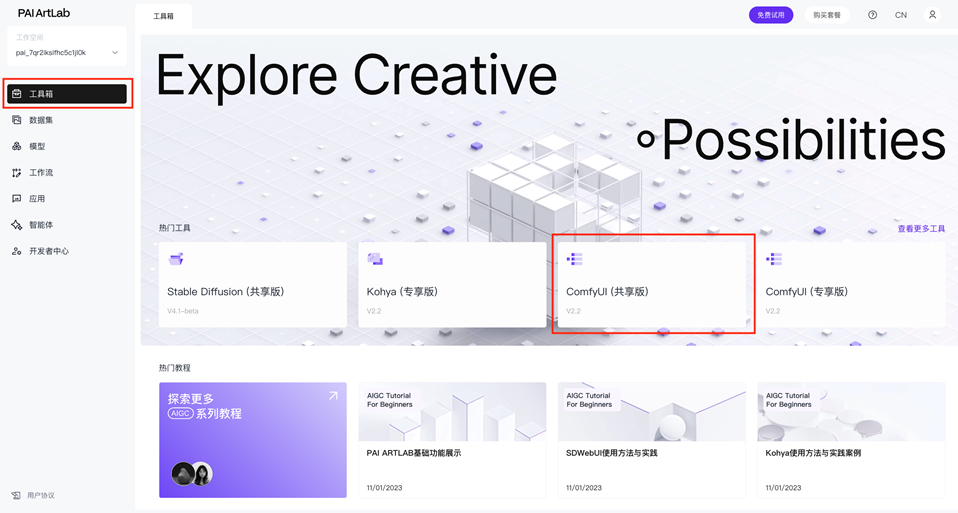
1. 点击访问PAI ArtLab平台并登录,在工具箱处点击进入comfyUI(共享版)。
2. 创建空白工作流
工作流设置
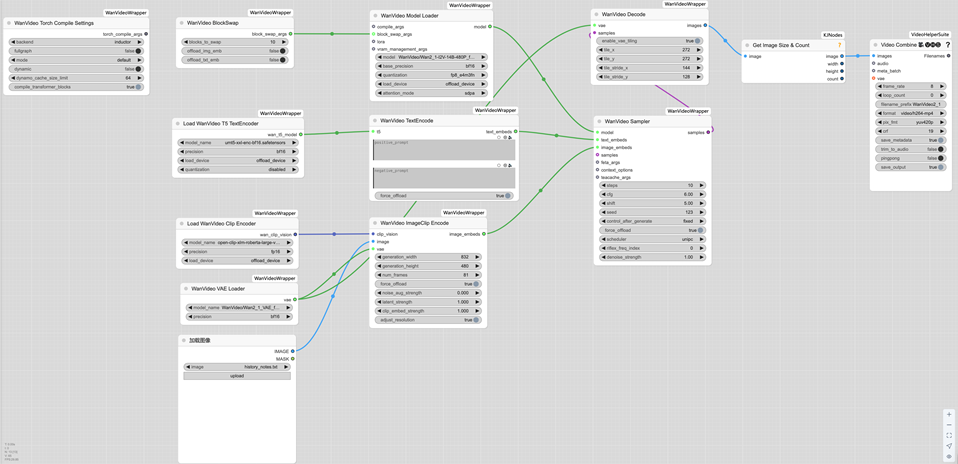
节点参数及连接设置
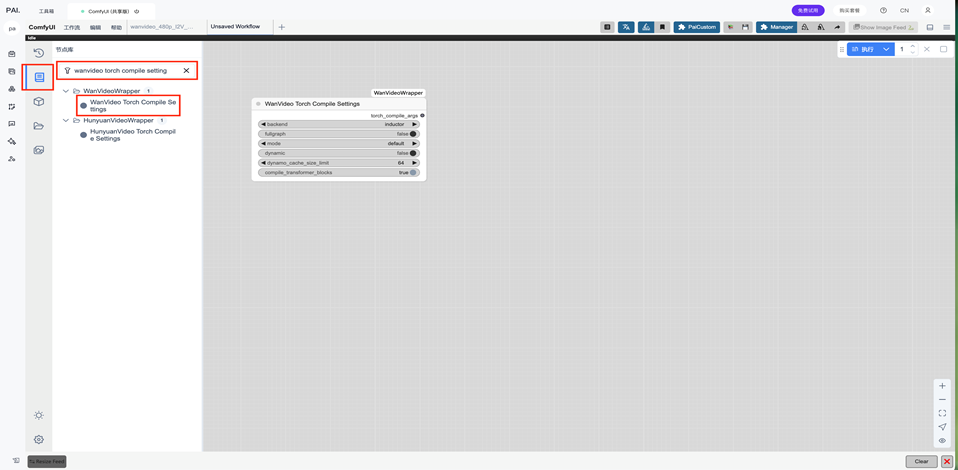
wanvideo torch compile setting:
没有连接线
参数无需改动,详见截图
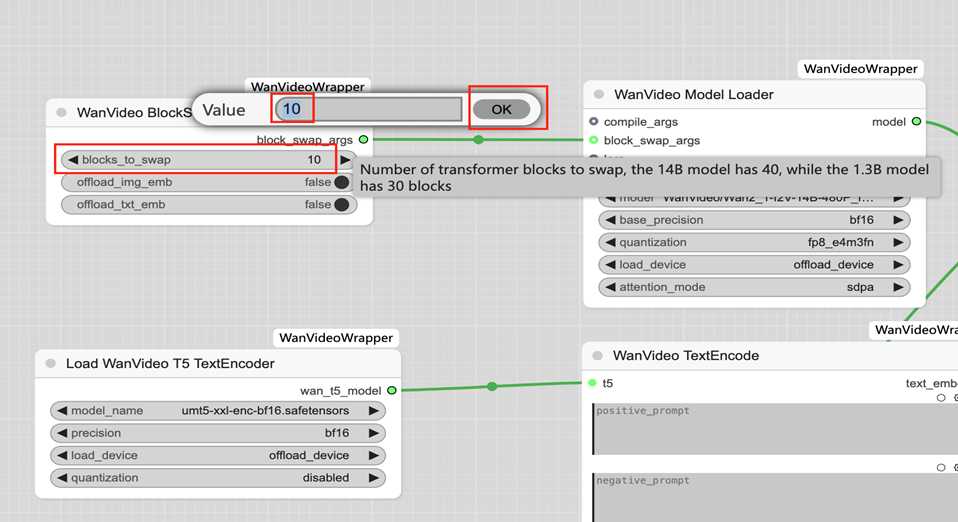
wanvideo blockswap:
blocks_to_swap的值改为10
输出block_swap_args作为wanvideo model loader的输入
其余参数不变,详见截图
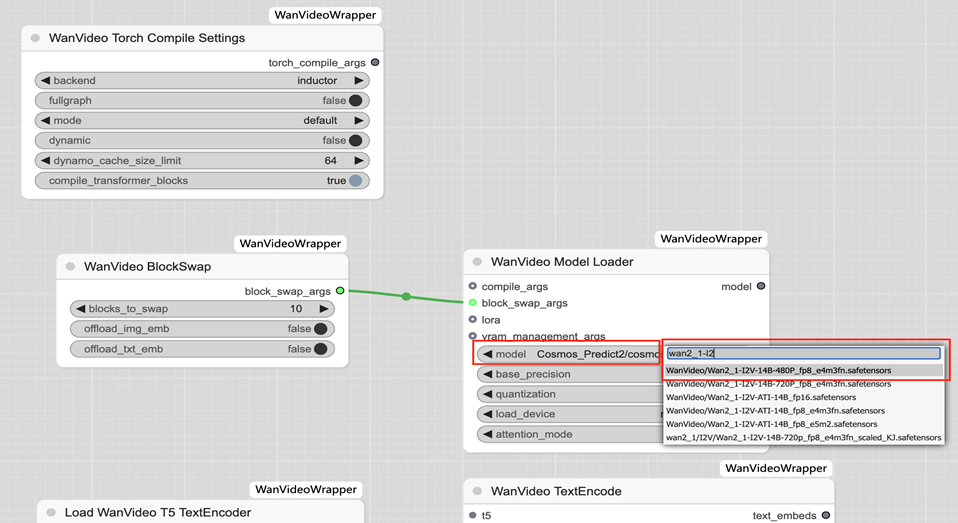
wanvideo model loader:
model搜索并选择wanvideo\wan2_1-i2v-14b-48p_fp8_e4m3fn.safetensors
quantization选择fp8_e4m3fn
load_device选择offload_device
输出model作为wanvideo sampler的model输入
其余参数不变,详见截图
load wanvideo t5 textencoder:
model_name搜索并选择umt5-xxl-enc-bf16.sefetensors
输出wan_t5_model作为wanvideo textencode的输入
其余参数不变,详见截图
wanvideo textencode:
输出text_embeds作为wanvideo sampler的text_embeds输入
其余参数不变,详见截图
load wanvideo clip encoder:
model_name搜索并选择open-clip-xlm-roberta-large-vit-huge-14_fp16.safetensors,输出wan_clip_vision作为wanvideo imageclip encode的wan_clip_vision输入,其余参数不变详见截图
wanvideo vae loader:
model_name搜索并选择wanvideo\wan2_1_vae_bf16.safetensors,输出vae作为wanvideo imageclip encode的vae输入以及wanvideo decode的vae输入,其余参数不变详见截图
加载图像:
输出image作为wanvideo imageclip encode的image输入
其余参数不变,详见截图
wanvideo imageclip encode:
generation_width和generation_height可以根据上传突袭那个的大小来调整
输出image_embeds作为wanvideo sampler的image_embeds输入
其余参数不变,详见截图
wanvideo sampler:
steps的值改为10
seed的值改为123
control_after_genrate选择fixed
scheduler选择unpic
输出samples作为wanvideo decode的samples输入
其余参数不变,详见截图
wanvideo decode:
输出image作为get image size & count的输入
其余参数不变,详见截图
get image size & count:
输出image作为video combine的images输入
其余参数不变,详见截图
video combine:
frame_rate的值改为16
filename_prefix改为WanVideo2_1
format改为video/h264-mp4
其余参数不变,详见截图
完整工作流如下:
工作流配置说明
内存与模型加载
wanvideo torch compile setting :
一个模型编译器节点,能够利用 PyTorch 2.0+ 的 torch.compile 功能,将万相模型(model)在A卡(AMD)或N卡(NVIDIA)上进行深度优化和编译,以大幅提升视频生成的速度并可能降低一些显存占用。
wanvideo blockswap:
一个显存(VRAM)优化技术,Blockswap允许用户只把当前计算需要的部分保留在显存中,把暂时不用的部分(这里是10个块)“卸载”到CPU内存里。这会牺牲一点速度,但是能在显存不足的卡上(比如12GB或16GB)成功运行模型。
wanvideo model loader:
选择的是万相2.1的主模型,有140亿参数,一次最多能生成48帧。
编码器加载 (Prompt 理解)
load wanvideo t5 textencoder:
一个非常巨大且强大的文本模型。
wanvideo textencode:
把实际输入的text_positive转换成模型能理解的数字向量传递给wanvideo sampler。
load wanvideo clip encoder:
个CLIP图像编码器用于分析你上传的图片内容。
wanvideo vae loader:
加载专为万相2.1配套的VAE(变分自动编码器),在输入端配合imageclip encode将起始图片压缩到潜空间,在输出端wanvideo decode节点会用它来把生成的视频从潜空间解码为用户能看到的像素图像。
输入处理(Image-to-Video)
加载图像:
用于上传视频起点的第一帧图像。
wanvideo imageclip encode:
是一个图像编码器,用于接收你的图像、VAE和CLIP图像编码器,然后生成image_embeds(图像嵌入),调整generation_width/height可以让你在这里就设定好你想要的输出视频的分辨率。
核心采样 (视频生成)
wanvideo sampler:
是一个视频生成引擎,用于接收文本提示、图像提示和潜空间图像,通过一步步“去噪”计算,生成最终的视频潜空间帧序列。
输出合成 (生成文件)
wanvideo decode:
是一个解码器,用于接收来自Sampler的潜空间视频帧(samples),并使用前面加载的VAE,将它们解码成一序列的像素图像帧。
get image size & count:
是一个辅助节点,接收解码后的图像帧,检查它们的大小和数量,然后把这一整批(batch)图像传递给下一个节点。
video combine:
是一个视频合成器,用于将所有解码后的独立图像帧按照设定的帧率(FPS)打包组合成一个单独的、可播放的视频文件(如MP4)。
该工作流参数配置的目的
使用 FP8 量化 和 Blockswap 内存卸载技术,来运行 140亿参数的 T5-XXL + ViT-Huge 双编码器图生视频模型,并使用高效的 unpic 调度器在 10 步内快速生成一个 16 FPS 的 MP4 视频。
测试
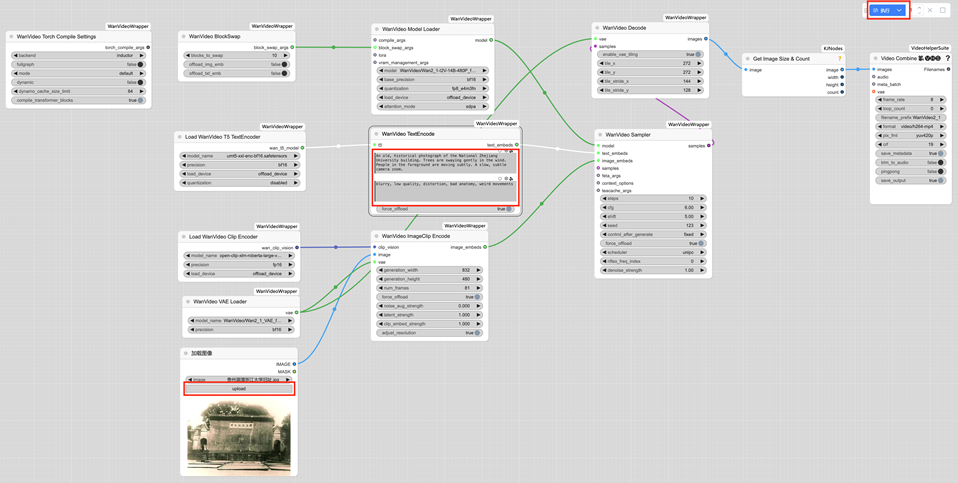
点击加载图像的【upload】,并在wanvideo textencode里输入正向和负向prompt,最后点击【执行】。
示例图像:
可供参考的prompt:
正向:
Anold, historical photograph of the National Zhejiang University building. Trees are swaying gently in the wind. People in the foreground are moving subtly. A slow, subtle camera zoom.
负向:
blurry,low quality, distortion, bad anatomy, weird movements
图生视频测试示例:
示例结果展示:
清理资源
如果无需继续使用工具,您可以按照以下操作步骤停止或删除工具。
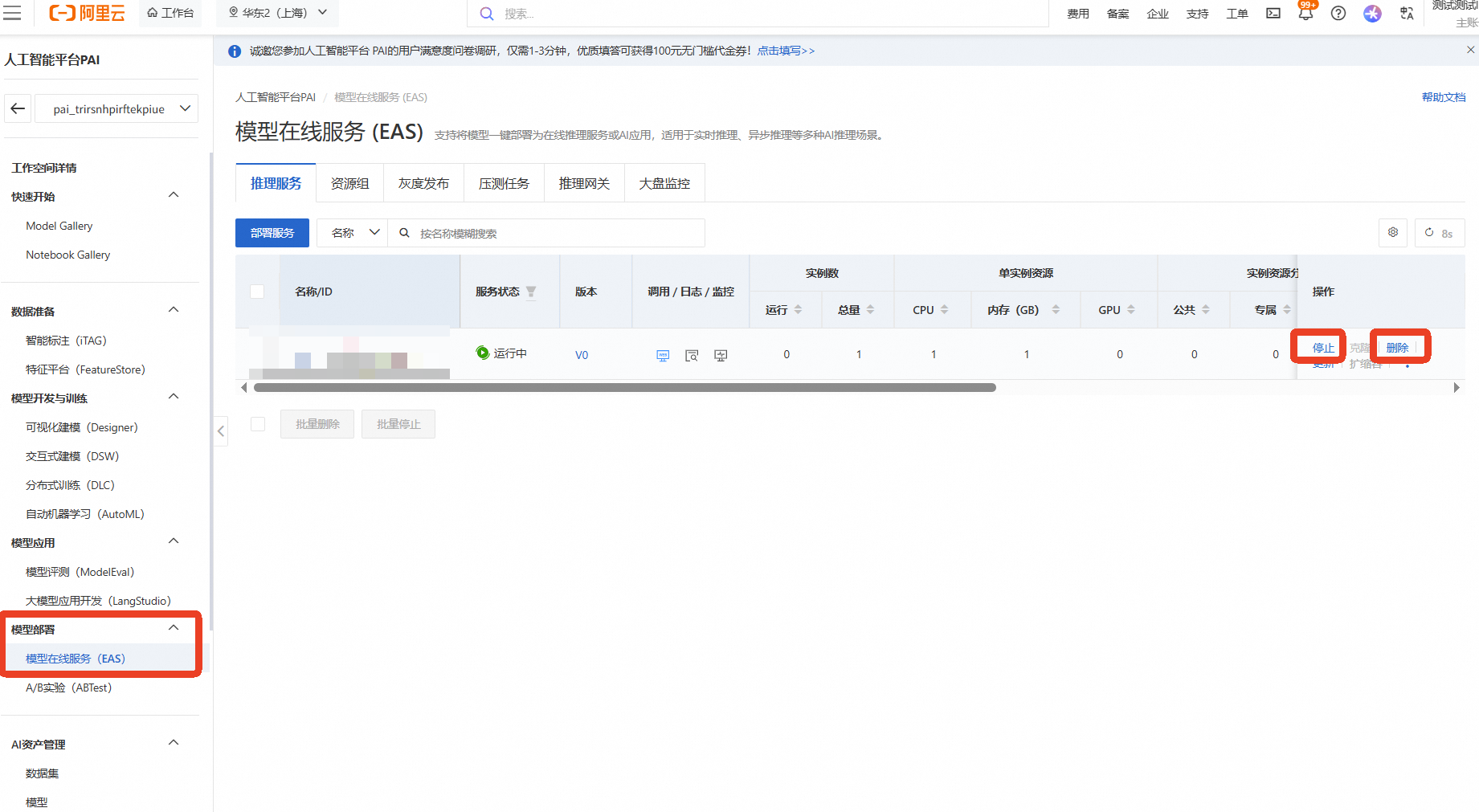
在PAI ArtLab控制台中,关闭comfyUI(共享版)页签,EAS模型服务将会停止,不会继续收费。
在页面左上方,选择模型所在地域
在工作空间页面的左侧导航栏中单击模型在线服务(EAS)。在模型在线服务(EAS)页面,找到目标服务。单击其右侧操作列下的删除
如果点击停止后续需要继续使用comfyUI(共享版),请随时关注账号扣费情况,避免模型会因欠费而被自动停止。

六、结果与验证
实验的预期输出包括:
一个在ComfyUI界面中完整搭建、所有节点连接正确并可成功运行的多模态工作流。
成功在输出目录中生成一个以 WanVideo2_1 为前缀的video/h264-mp4 格式的视频文件。
生成的视频内容应基于上传的静态图片(如“贵州湄潭浙江大学旧址”),并能视觉上体现出正面提示词中描述的动态效果(如“Trees are swaying gently in the wind”)。
验证提示词对话结果的方法包括:
视觉一致性检查:对比生成的视频和原始图片,检查核心元素(如建筑、人物)是否保持了风格和内容的一致性,未发生严重扭曲。
动态效果评估:评估视频中的动态效果(如树叶、人物、镜头)是否自然、流畅,是否准确响应了正面提示词的指令。
负面提示词验证:检查视频中是否有效规避了负面提示词中描述的不良属性(如 blurry, distortion, weird movements)。
七、拓展与思考
本实验花了很多精力去“压缩”一个140亿参数的超大模型,才让它能在普通显卡上运行。我们为什么不干脆训练一个参数少(比如10亿)的小模型,让它能直接在普通显卡上运行呢?请思考:一个140亿参数的“大模型”和一个10亿参数的“小模型”,它们生成视频的能力(如真实感、创造力、动作幅度)会有什么根本不同吗?
本实验证明了可以在低显存显卡上运行大模型,但这并不是“免费”的。结合 Blockswap(在显存和内存间交换数据)和 FP8(使用更低精度)的原理,你认为这种优化的“代价”最可能是什么?(提示:可以从生成视频的速度、视频的清晰度或质量等方面来考虑。)
使用“图生视频”(I2V)技术让一张静态的历史照片(浙大西迁旧址)“活”了起来。你认为这项技术最大的应用潜力在哪里?它可能会对哪些行业(如电影制作、广告创意、历史教育、个人相册)产生什么样的变革?
让静态图片(尤其是人物照片)“动”起来,也带来了一些风险。比如,如果有人用这项技术处理一张公开的人物照片,并配上不实的文本提示(Prompt),可能会带来什么问题?(例如在新闻、证据或社交媒体领域)。我们应如何从技术或规范上应对这种挑战?
八、常见问题
comfyUI工作流实现图生视频实验的常见问题与解决方案:
常见问题 | 解决方案 |
启动工作流时报错,提示显存不足 (Out of Memory) | 启用了 wanvideo torch compile setting 后首次运行非常缓慢或报错 |
无法加载模型,提示 "File not found" | 启用了 wanvideo torch compile setting 后首次运行非常缓慢或报错 |
生成的视频内容扭曲或有严重伪影 | 检查 wanvideo textencode 中的负向提示词(Negative Prompt)是否已正确填写(如 blurry, low quality, distortion)44。如果已填写,请尝试更改 wanvideo sampler 中的 seed 值 45 以获取不同的随机结果 |
启用了 wanvideo torch compile setting 后首次运行非常缓慢或报错 | torch.compile 46首次运行时需要编译模型,耗时较长属正常现象。如果报错,可能是该功能与当前模型或驱动不兼容,可将其断开连接,不使用该节点 47 |
九、实验报告要求
基于实验学生应提交完整的实验报告,要求包含以下内容:
实验目的与任务描述;
实验环境配置截图;
三版以上Prompt与生成动画对比结果;
对“七、拓展与思考”问题的回答;
实验总结与个人反思。
十、关闭实验
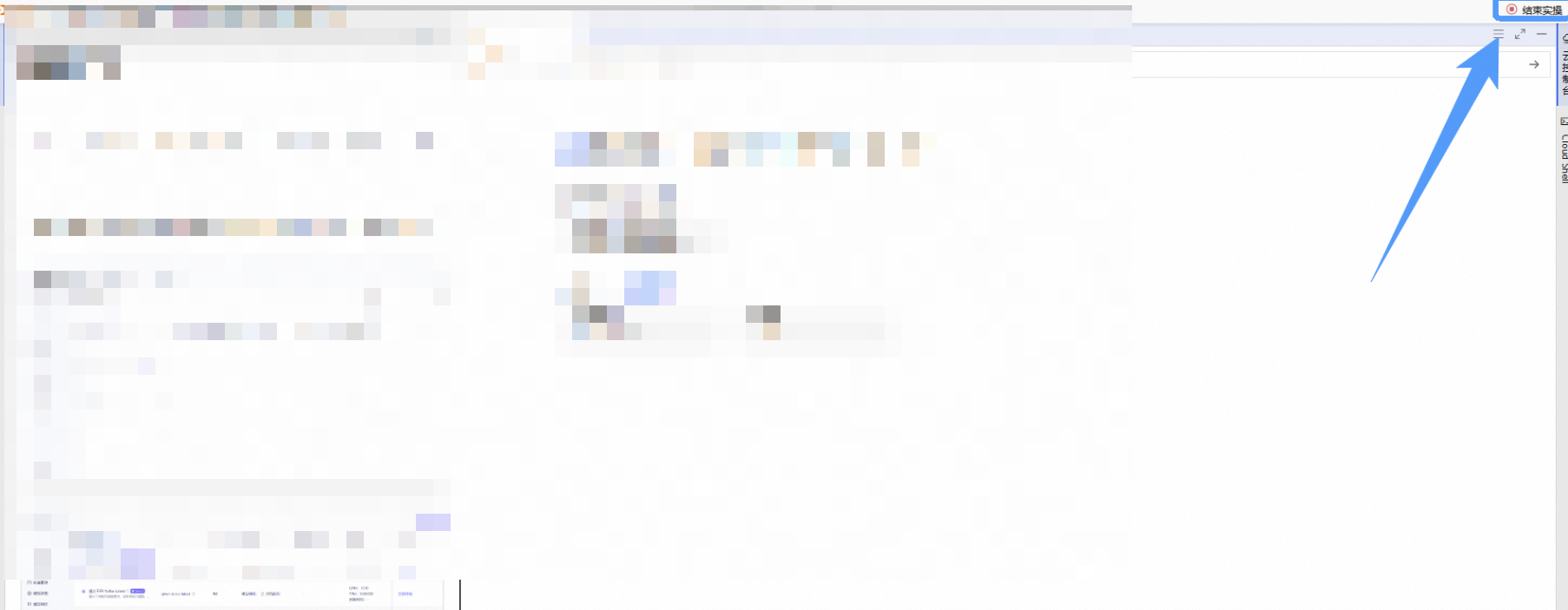
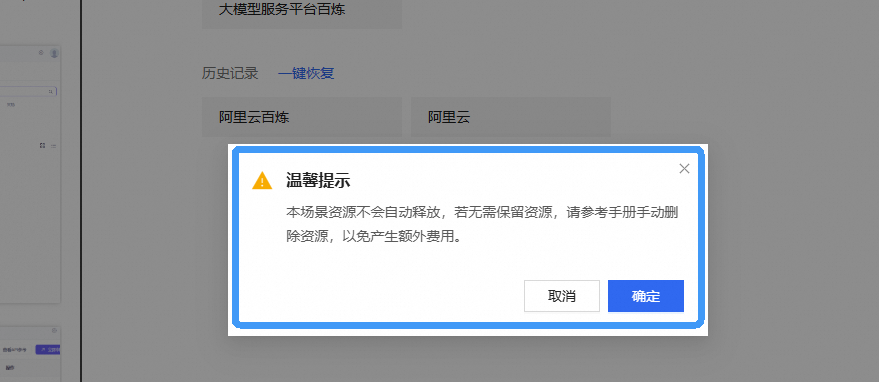
完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验