基于ComfyUI-FLUX的数据集打标和模型训练
实验简介
本指南详细介绍了如何通过LoRA(Low-Rank Adaptation)技术对Flux基础模型进行微调训练,使用户能够创建具有统一风格特征的个性化AI图像生成模型。文档面向设计师、AI艺术创作者和数字内容生产者,提供了从零开始的完整训练流程。
内容涵盖高质量数据集构建的关键要点,包括图像筛选标准、尺寸规范(1024×1024/1536×1024/1024×1536像素)和数量建议(20-30张);详细演示了使用ComfyUI工具进行图像智能打标的完整工作流;并逐步指导如何通过Kohya专享版工具进行模型训练,包括参数配置(network rank、alpha值设定)、触发词设置和训练步数计算等核心技术细节。
通过本教程,创作者无需编程基础即可掌握定制专属AI模型的能力,无论是打造个人艺术风格、品牌视觉系统,还是创建特定主题(如植物、空间设计、非遗元素)的生成模型,都能实现高度一致且专业的视觉输出。训练完成的LoRA模型可直接部署至主流AI绘画平台,为创意工作流注入个性化AI能力。
这份实操指南将技术细节与艺术创作需求紧密结合,是设计师和内容创作者进入AI定制化模型训练领域的理想入门资源,帮助用户从被动使用通用模型转变为主动塑造专属AI创作伙伴。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
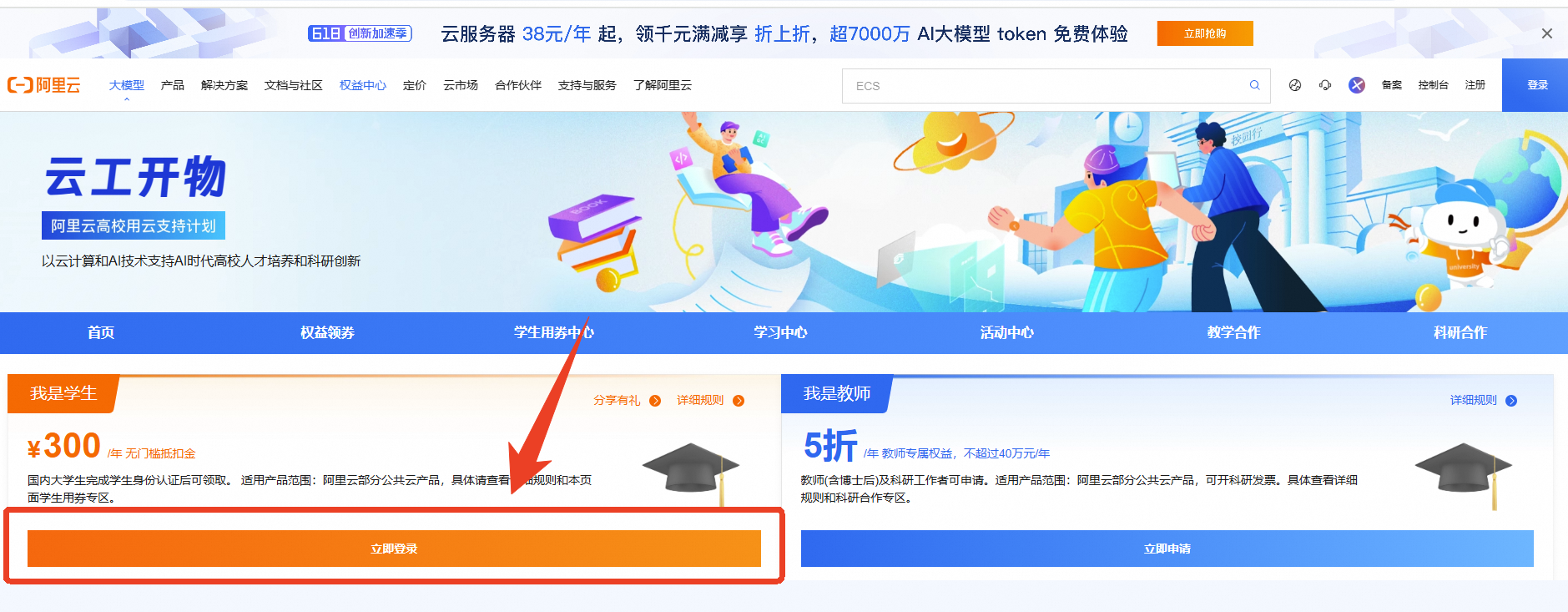
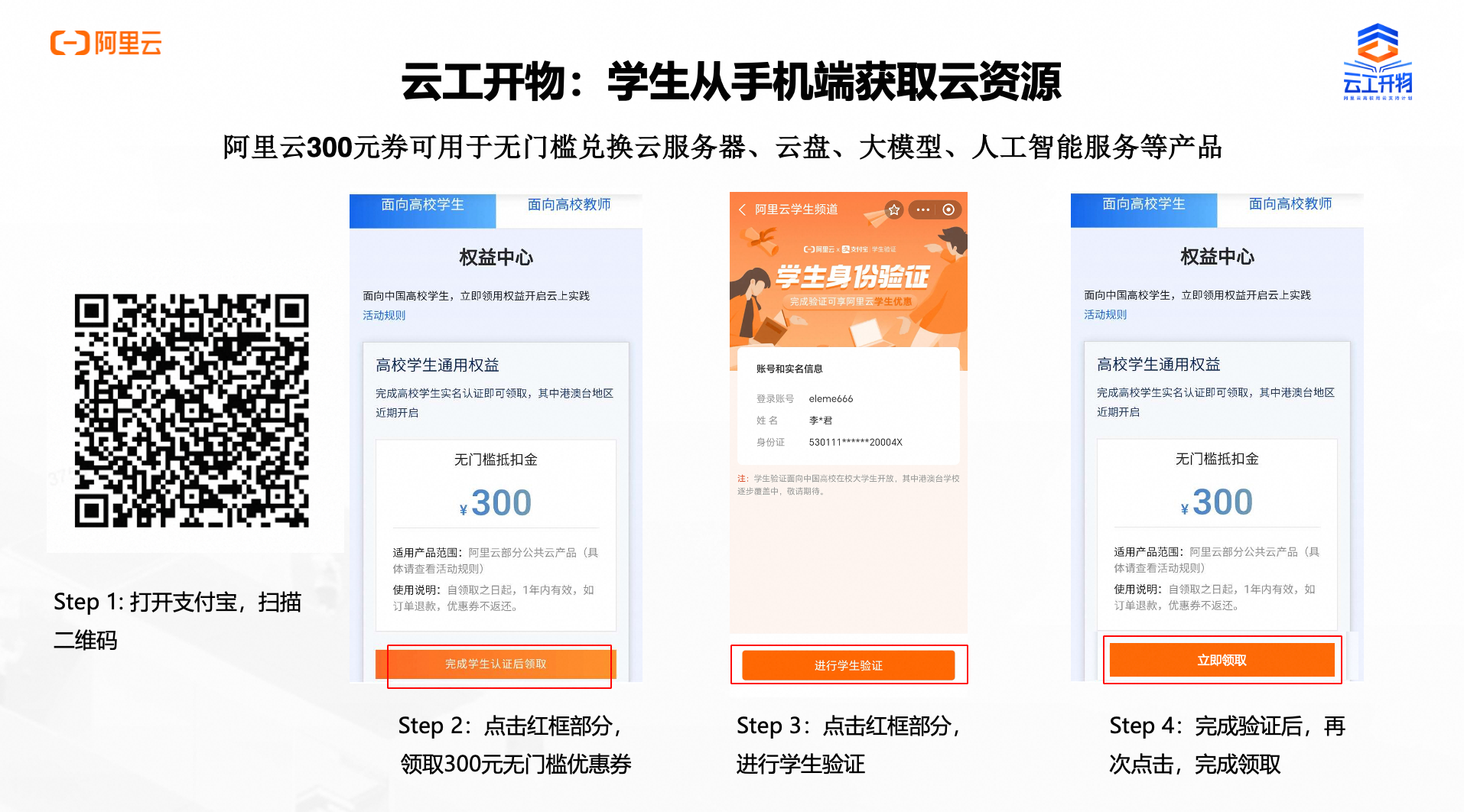
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
如果您调整了资源规格,使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
领取专属权益及开通授权
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第一步:本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
第二步:进入并开通PAI ArtLab并授权
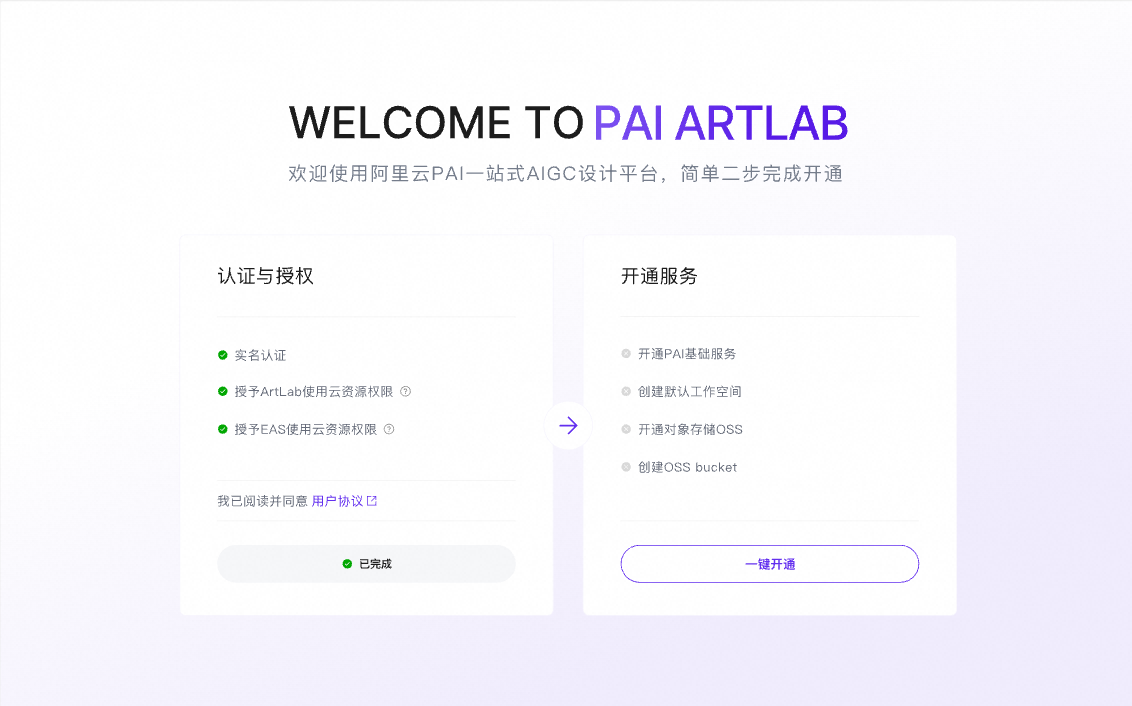
点击访问PAI ArtLab平台
初次进入平台,依次点击两步,完成PAI ArtLab平台开通与授权

实验步骤
一、素材收集
图像收集
为了实现风格一致的设计内容生成,本实验首先需要构建一个高质量的图像数据集,用于训练基于 Flux 的LoRA模型。数据收集应遵循以下要求:
图像类型与风格要求
图像应拥有统一的特征,如植物、公园、品牌、空间类型、某类非遗元素、人物形象、ip形象、视觉特征等。
建议选择和专业相关的图像集。
图像中不存在文字/水印/logo等干扰因素。
从个人角度出发,图像应该具备“美”的特征或者具备其他特色。
图像尺寸
FLUX LoRA建议使用高分辨率图像进行训练,所有图片应统一裁切或缩放为1024×1024/1536×1024/1024×1536 像素区间的图像。
如原图不为正方形,请通过居中裁剪或背景填充的方式处理,保持图像完整性。
图像数量
建议每个主题收集20-30张高质量图片。
二、数据集准备
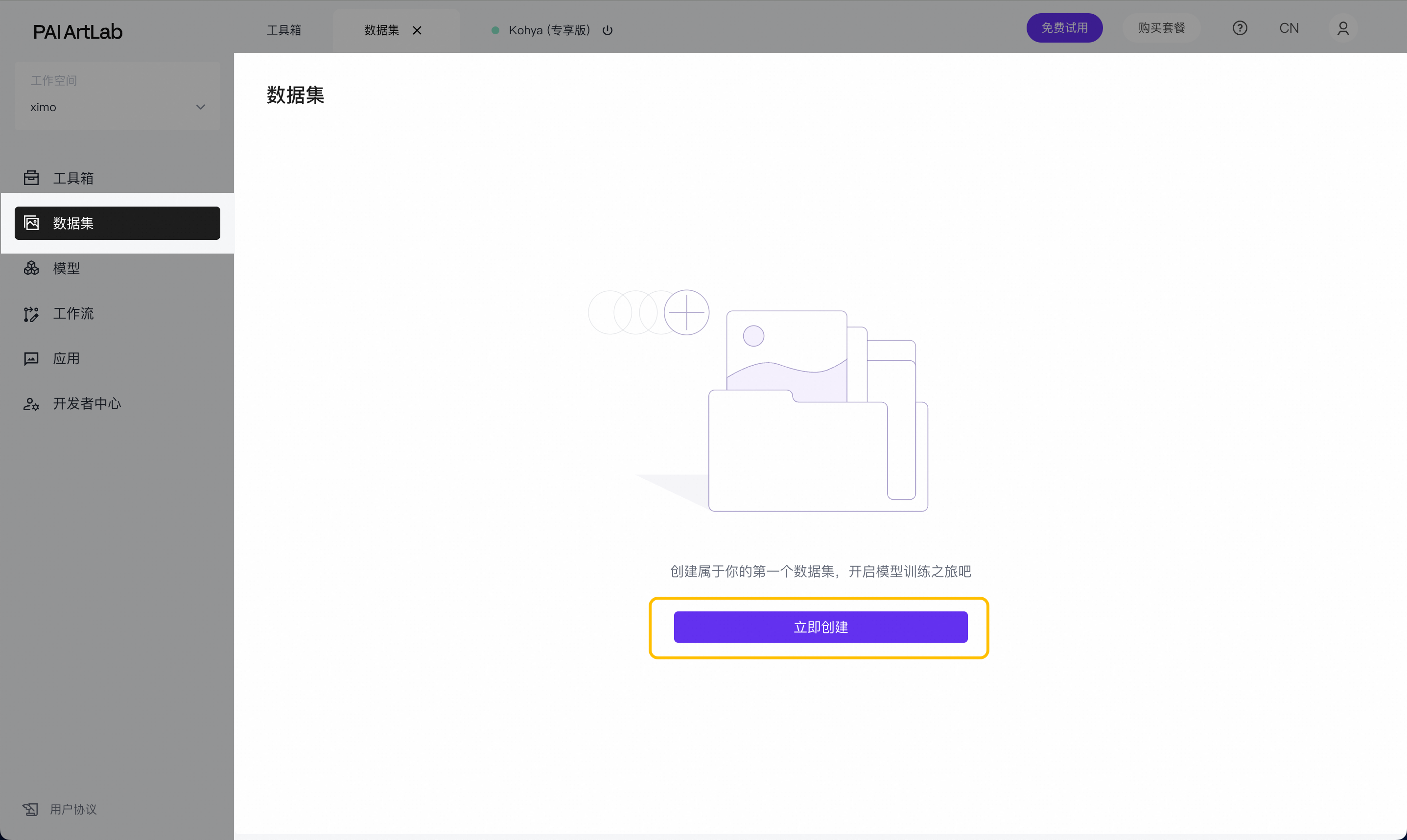
创建数据集
左导航选择数据集,点击‘立即创建’

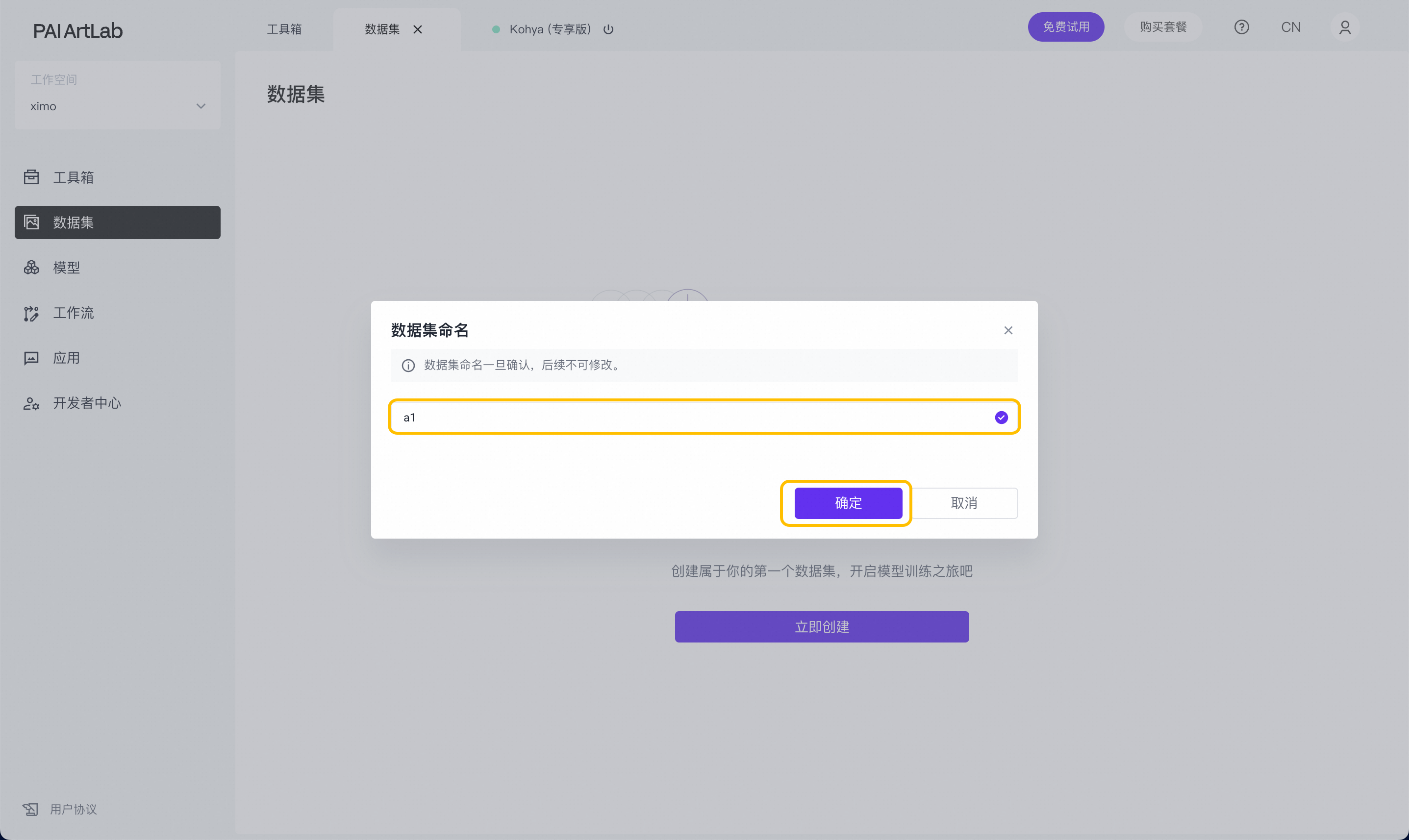
数据集命名,给数据集起任意名称,方便自己后续分辨不同数据集(*命名需要用字母开头,一经命名后续无法修改进行重命名)
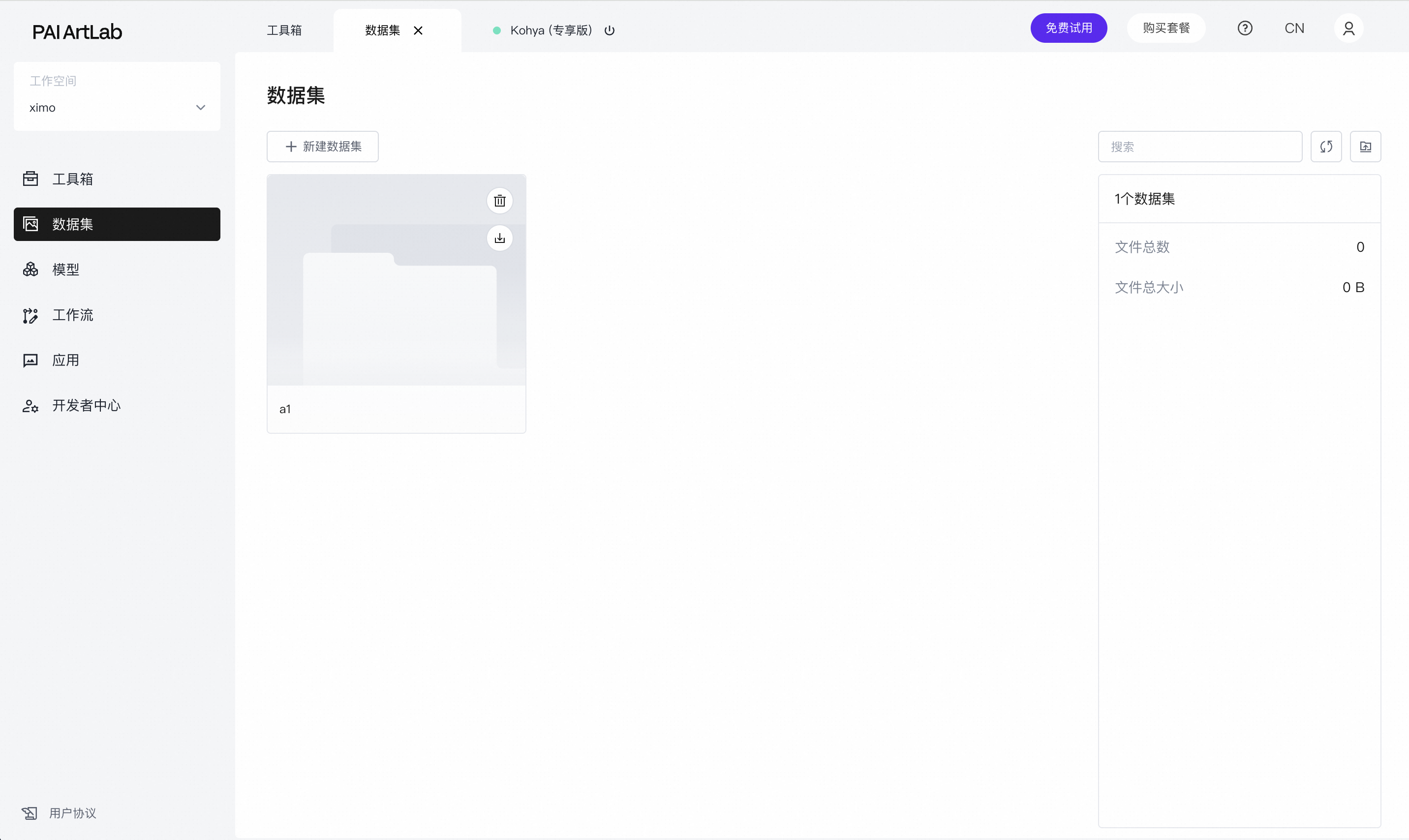
命名后,数据集就创建好了
上传数据集文件
上传数据集文件有两种情况
情况一:有打标好的数据集图像
情况二:无打标好的数据集图像,需要借助工具来给图像打标
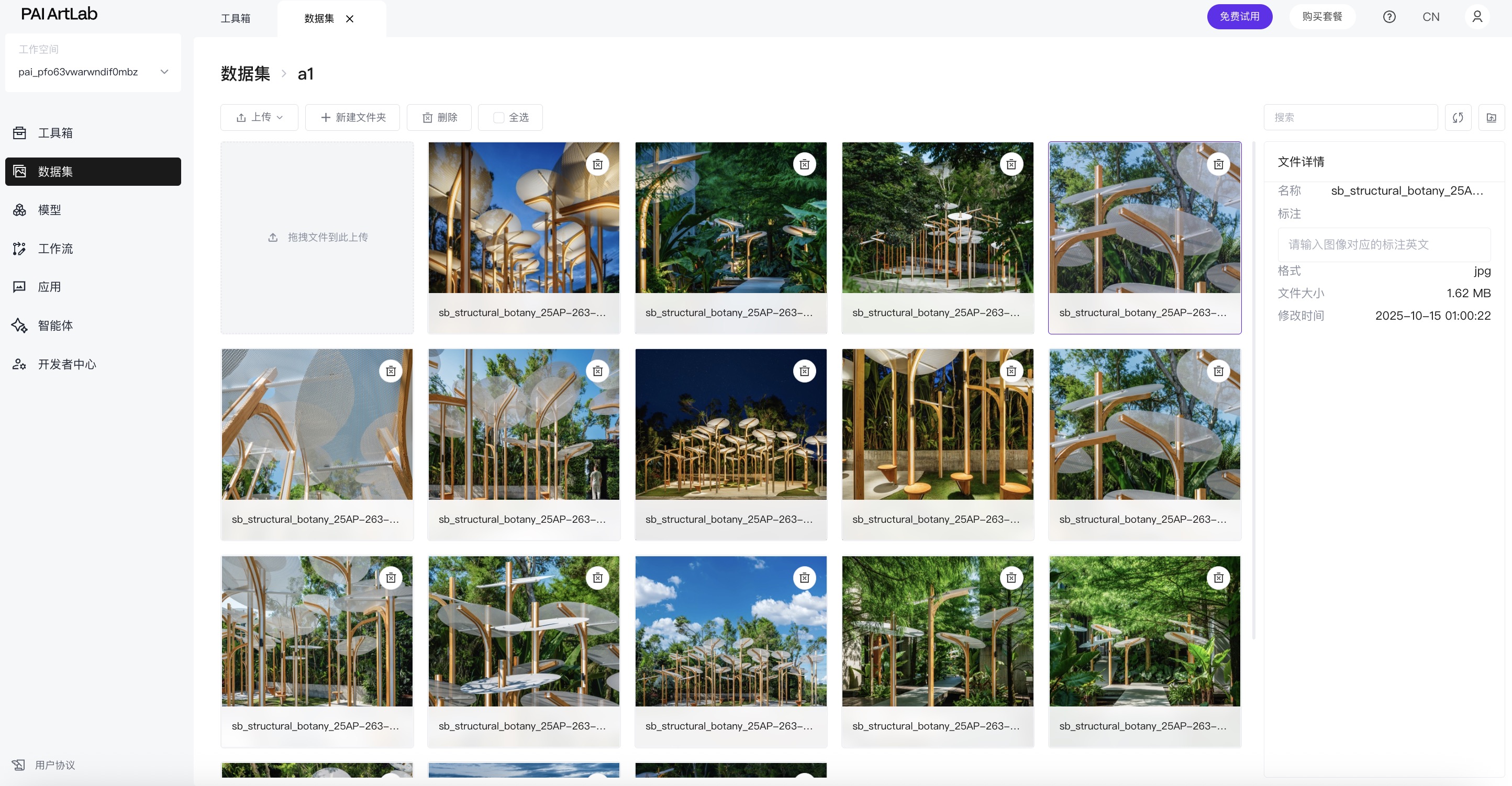
情况一:有打标好的数据集图像,如何上传
点击创建好的数据集卡片
进入到此数据集
本地准备可以直接用于进行模型训练的,已经打好标的图像文件夹,并且严格遵照‘数字_任意名称’,这个格式来命名文件夹
将文件夹,拖拽到数据集里面上传,即可
情况一:情况二:没打标好的数据集图像,需要接下来借助平台工具来打标,该如何上传
上传打标图像
本地准备好需要进行打标的图片(*这里需要注意,图片比例尽可能一致,如1:1、16:9等等)
将这些图片,拖拽到数据集里面上传(*这里注意,不要传文件夹到数据集里面,是直接上传所有图片到数据集里面)
需要打标的图片就上传完毕了
建立打标图像存储数据集与文件夹
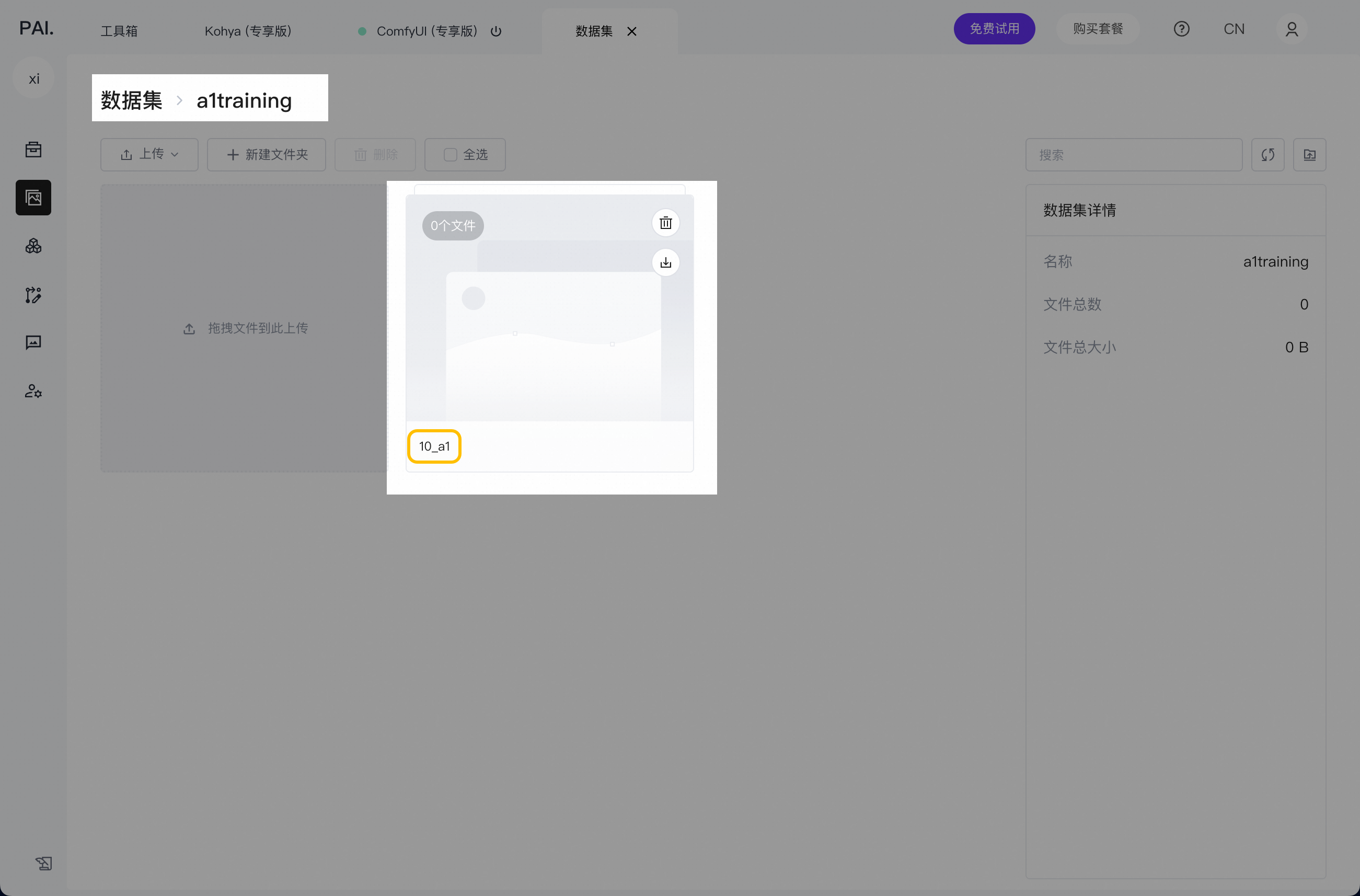
额外我们还需要再创建一个数据集,用来存储打标好的图像,并且可以直接用于做模型训练。点击‘+新建数据集’
数据集命名,给数据集起任意名称,方便自己后续分辨不同数据集(*命名需要用字母开头,一经命名后续无法修改进行重命名
创建好了,点击创建好的数据集卡片
进入数据集
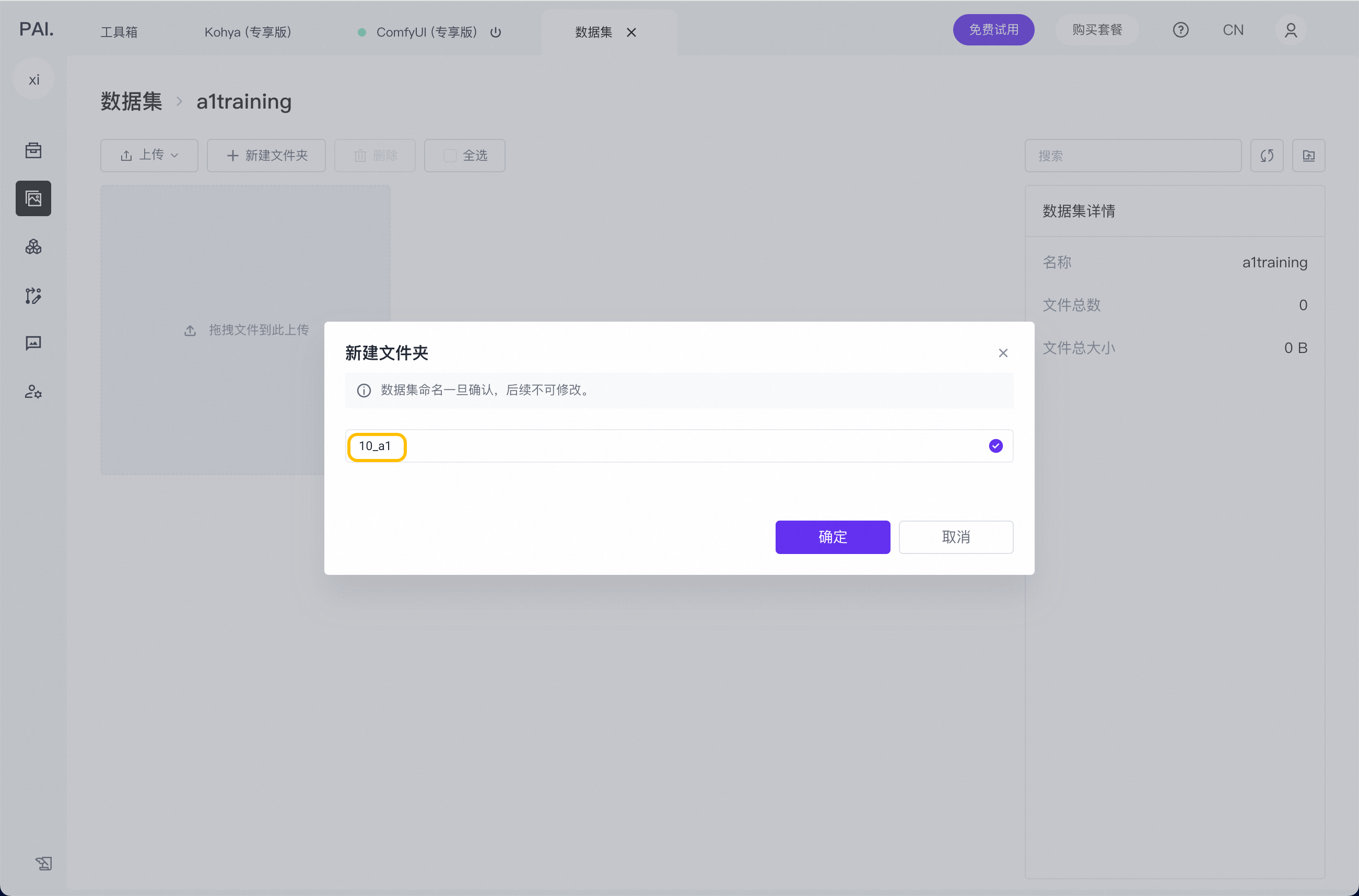
点击‘+新建文件夹’
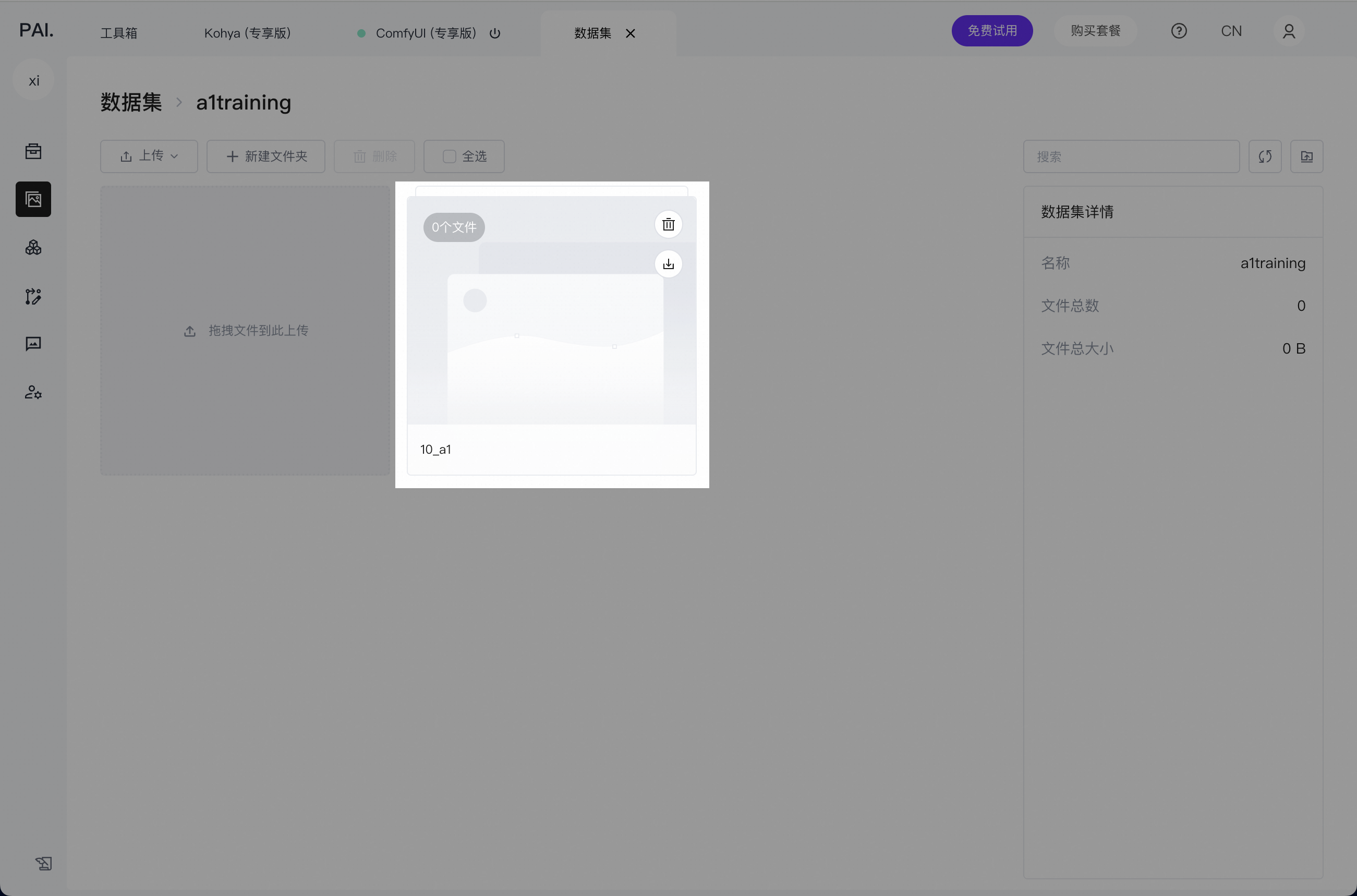
给文件夹命名,这里需要注意,文件夹命名格式,需要严格遵照,‘数字_任意名称’,这个格式,例:‘10_a1’
创建好了
说明这里补充一些知识点
为什么用于训练的数据集文件夹需要严格遵照,‘数字_任意名称’,这个格式来命名
首先,这个格式,是kohya工具对训练数据集的要求
其次,以一个30张的数据集为例,简单讲一下这里涉及的知识点
模型训练总步数公式:模型训练总步数图片数量 * repeat 数量 * epoch / batch_size
模型训练总步数:控制在3000-4000步实现比较基础成型的效果。
repeat值:数据集文件夹,‘数字_任意名称’,这里的数字,代表的是训练时的repeat值,这个repeat值,是在数据集文件夹命名时候赋予好的,代表训练工具会读取多少次这个图像。
epoch值:整个数据集被完整的训练多少轮,并且与lora产出有关
常见训练数值:repeat:10-15,epoch:10-15,来训练
如果我们将数据集命名为10_a2,epoch设置为10,30(图片数)*10(repeat值)*15(epoch值)4500步(训练总步数)
为什么要额外创建这个文件夹
首先,是用于存储打标后的数据集图像
其次,是用于模型训练



三、数据集打标
启动ComfyUI专享版工具
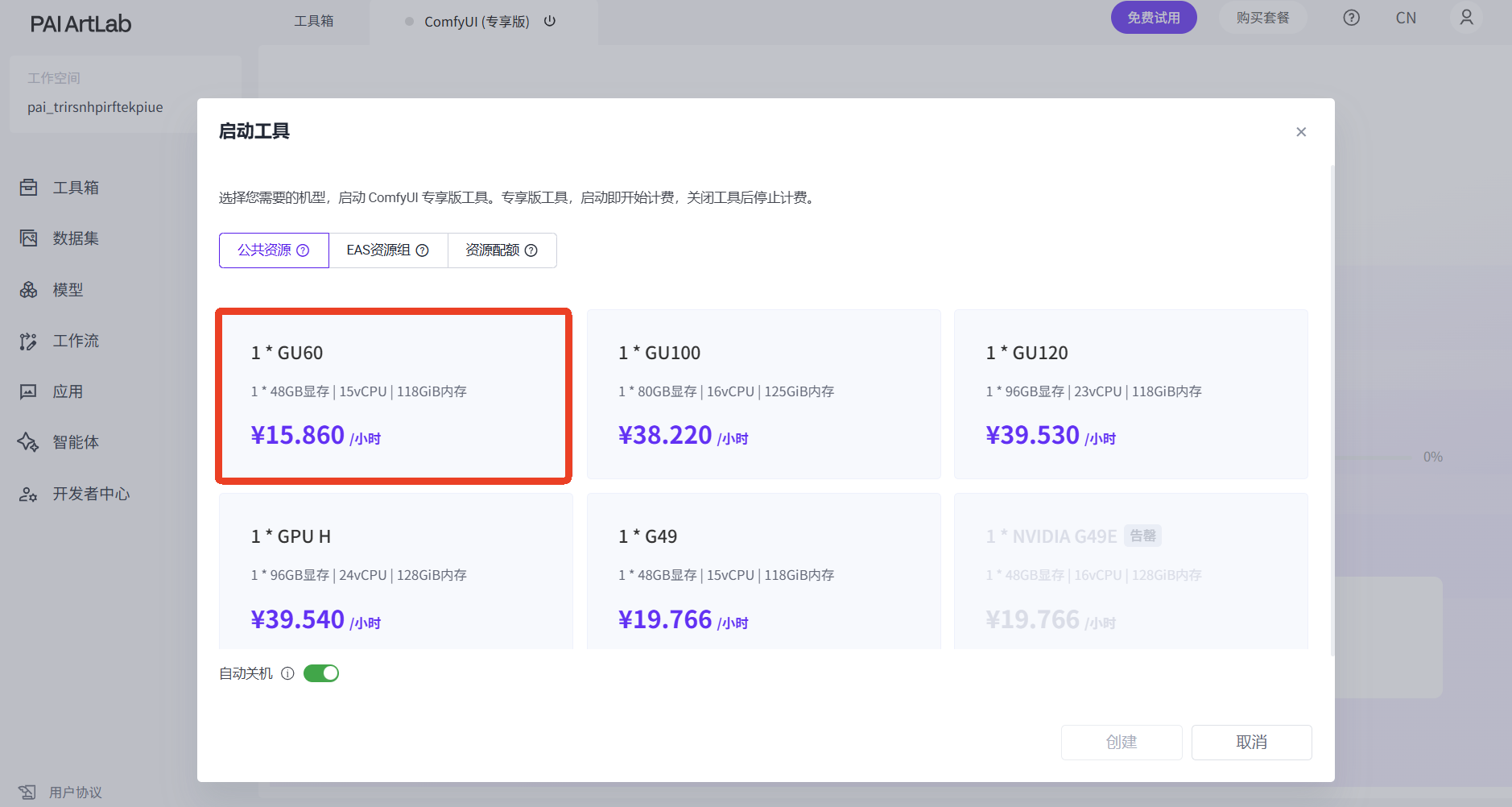
我们借助ComfyUI专享版工具,通过一个工作流,来完成flux系列模型训练所需要的数据集图像打标,来到首页工具箱,选择ComfyUI专享版工具卡片,点击卡片,选择机型,启动工具(初次启动工具需要一些时间,请耐心等待)
下载打标工作流
将此打标工作流图像,下载到本地电脑桌面
下载到本地以后,将上方工作流图片,拖拽到ComfyU界面,打开此工作流
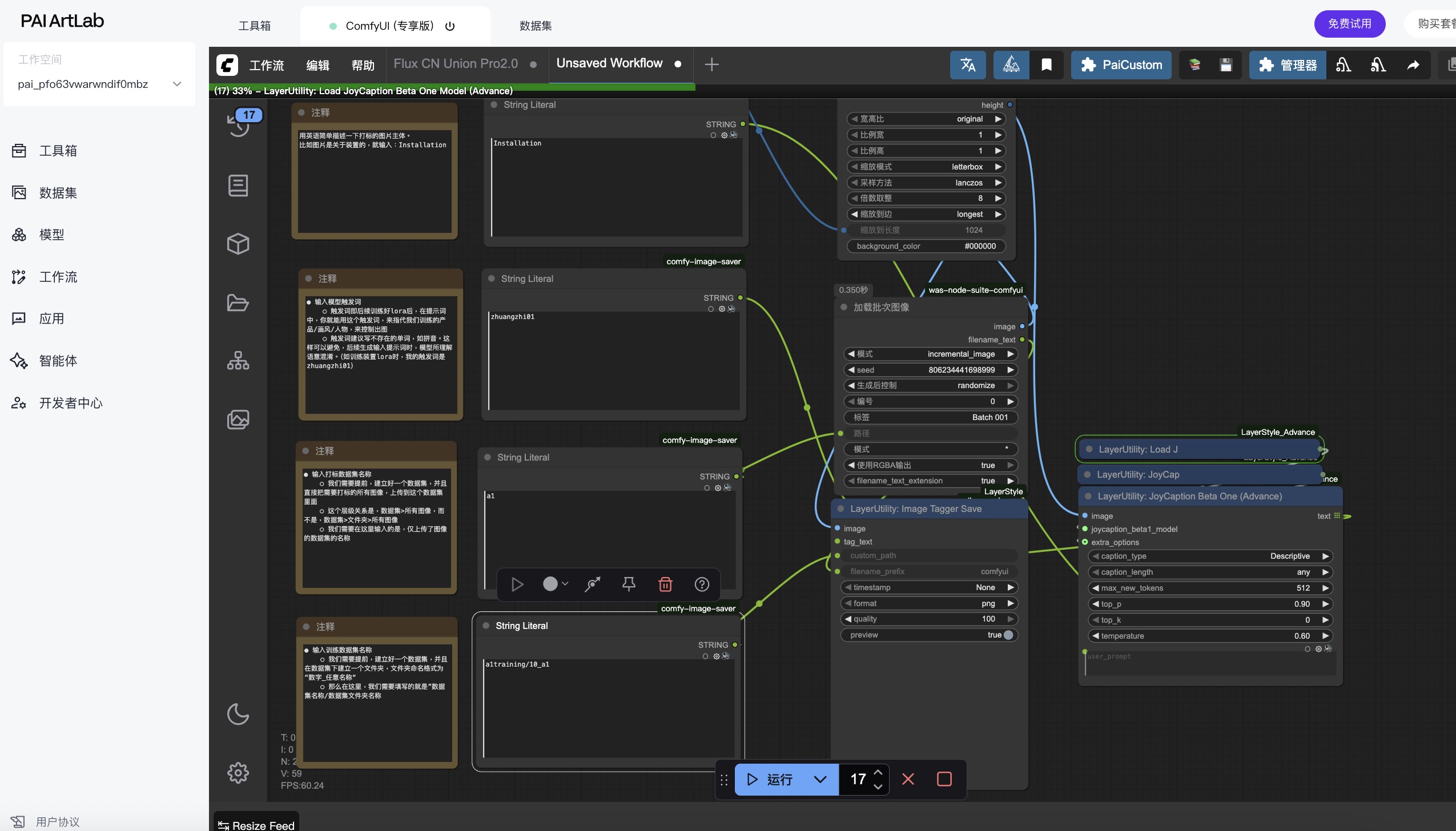
输入打标配置开始打标
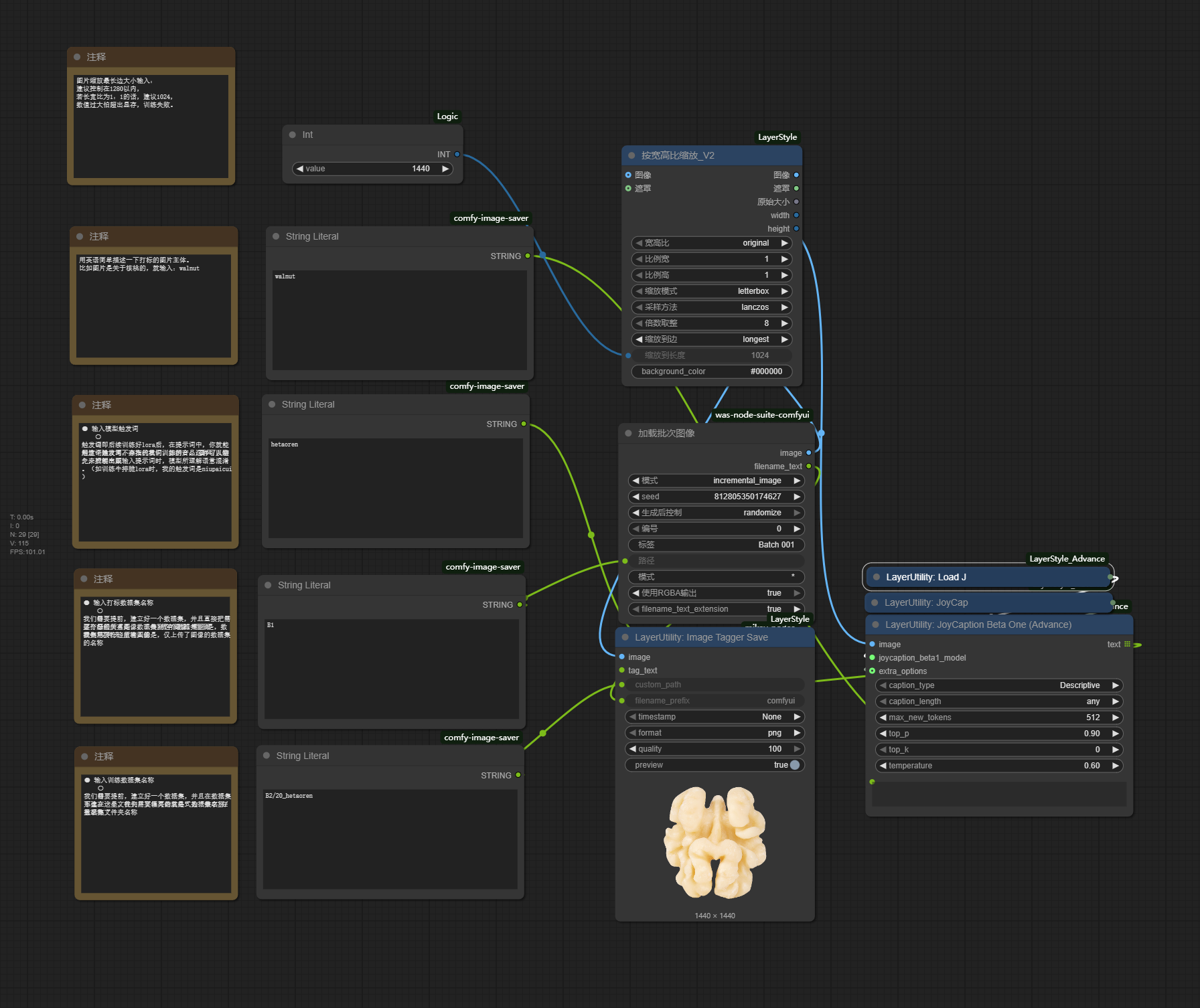
输入模型触发词
触发词即后续训练好lora后,在提示词中,你就能用这个触发词,来指代我们训练的产品/画风/人物,来控制出图
触发词建议写不存在的单词,如拼音。这样可以避免,后续生成输入提示词时,模型所理解语意混淆。(如训练装置lora时,我的触发词是zhuangzhi01)
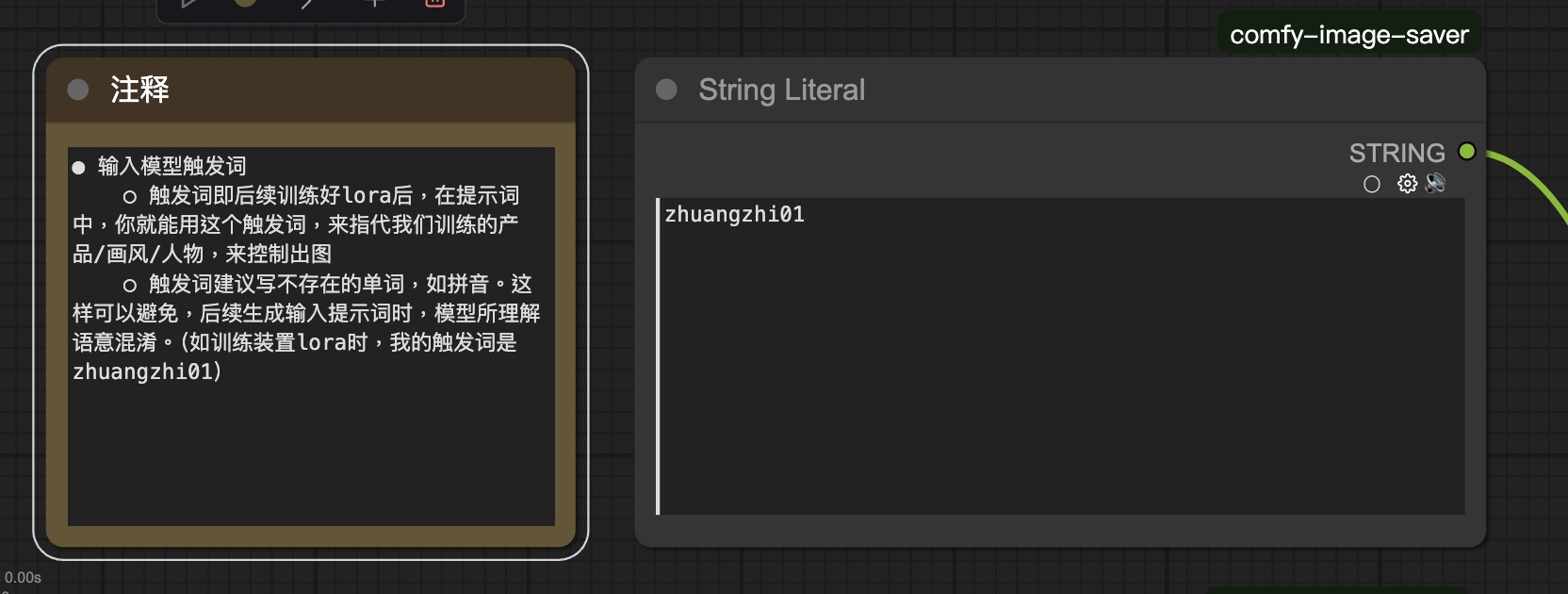
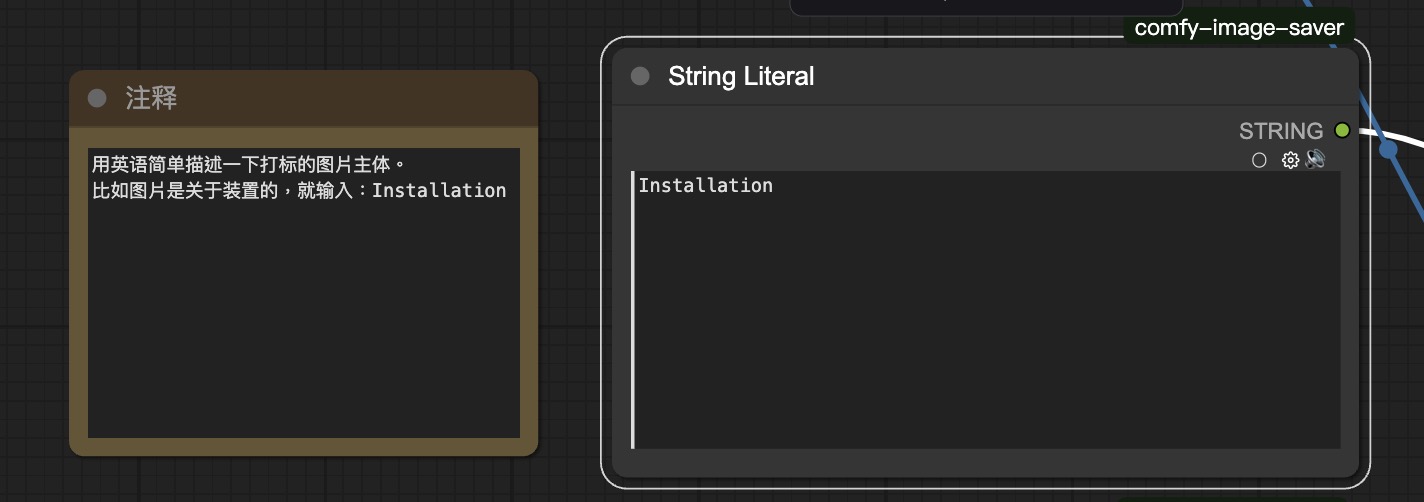
输入打标主体的英文名称
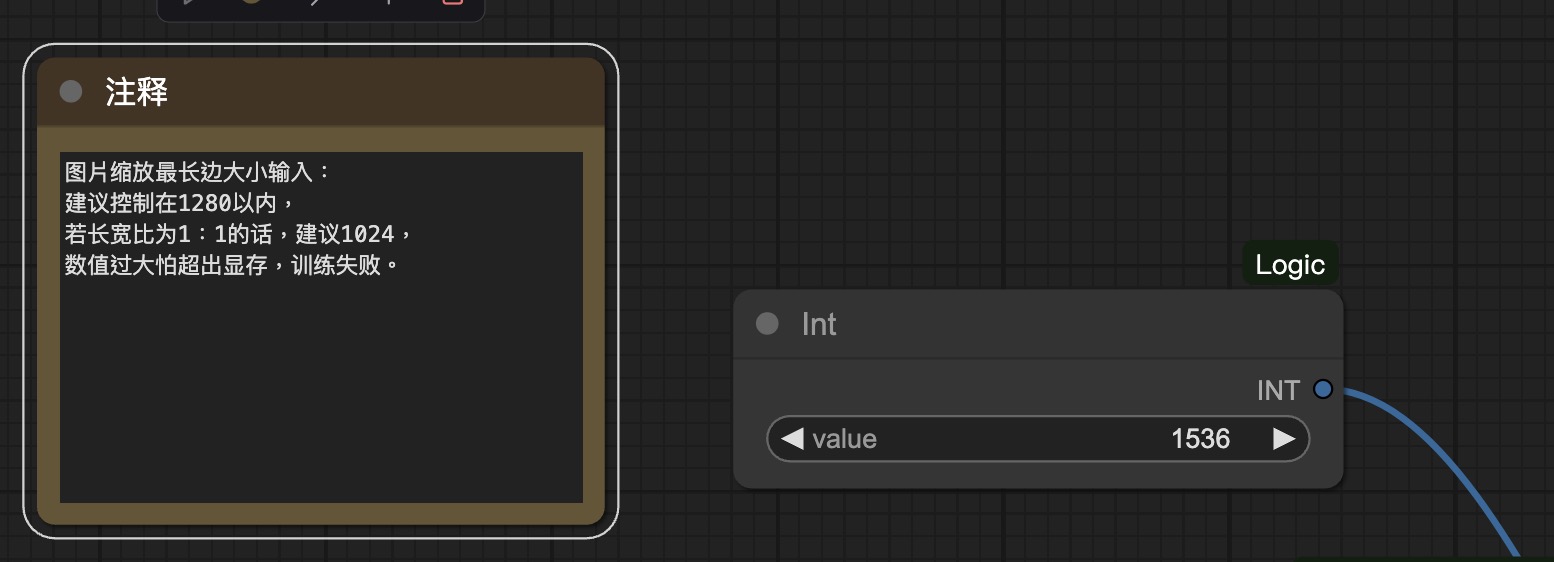
图片大小调整:
此处采用最长边缩放的方式,在保持图片比例的情况下,通过调整最长边长度,来进行图片的控制。可在右侧int内输入你希望最长边的长度。
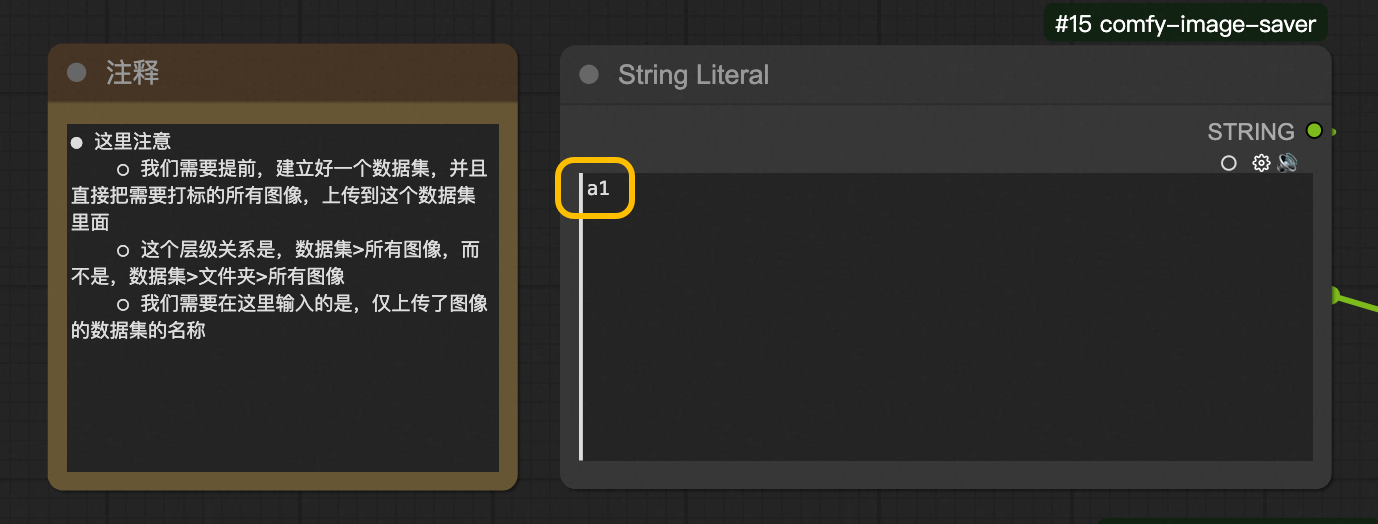
输入打标数据集名称
前面我们创建好了一个用来做图像打标的数据集,里面只有需要打标的图像,那个数据集的名称叫做a1,那我们这里就填写a1
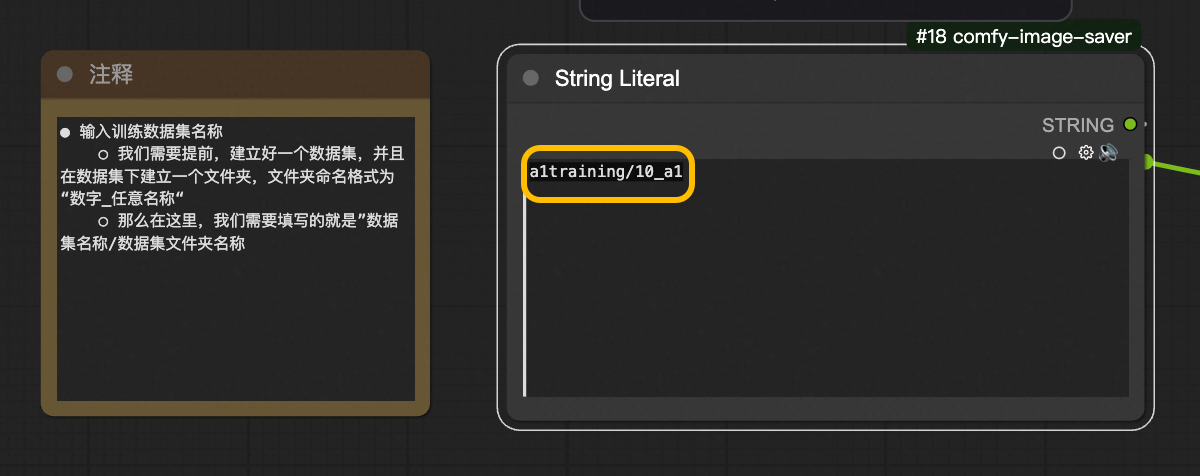
输入训练数据集名称
前面我们还额外创建好一个,用来存储打标好图像的数据集跟数据集文件夹,我们填写那个数据集和数据集文件夹的名称
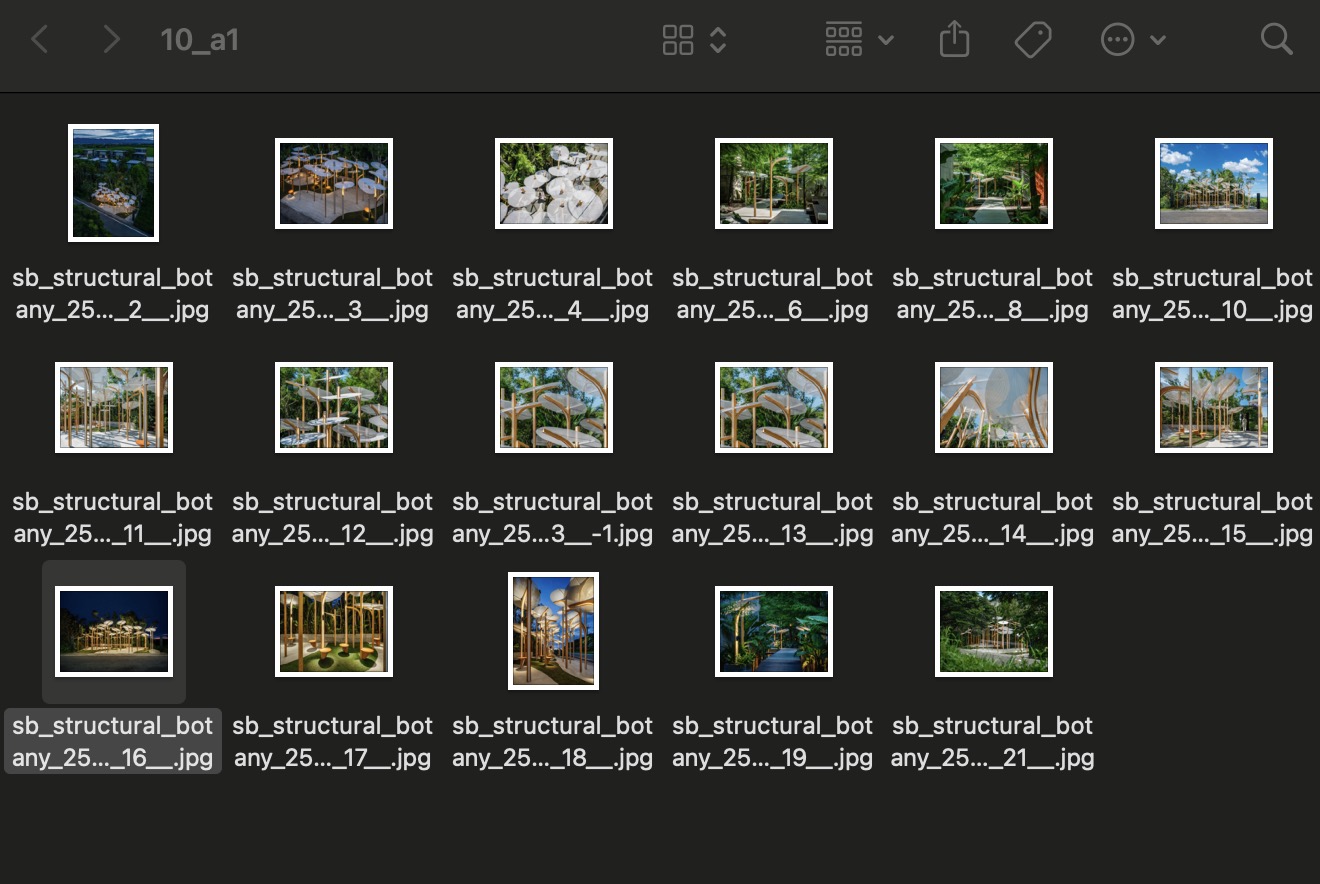
完成输入配置后,我们需要在运行的按钮旁边,输入我们上传需要打标的数据集图像数量,比如案例里我们上传到数据集的是17张图像,这里我输入17,然后点击运行
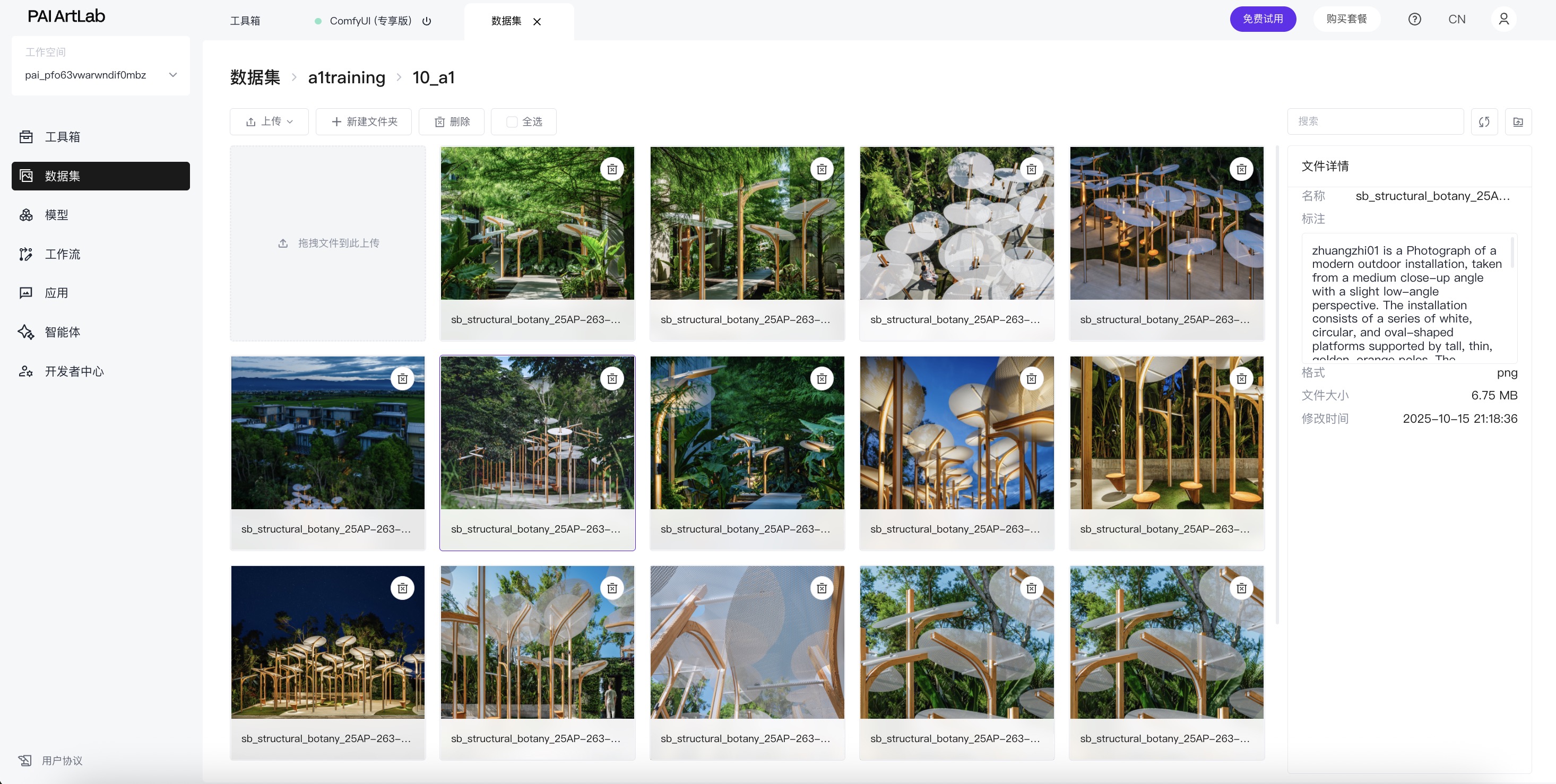
检查打标数据集
打标完成后,我们返回到存储打标数据集图像的文件夹,点击右上角刷新按钮,“
”检查每一张图像上,是否都打好了标注
四、模型训练
启动Kohya专享版工具
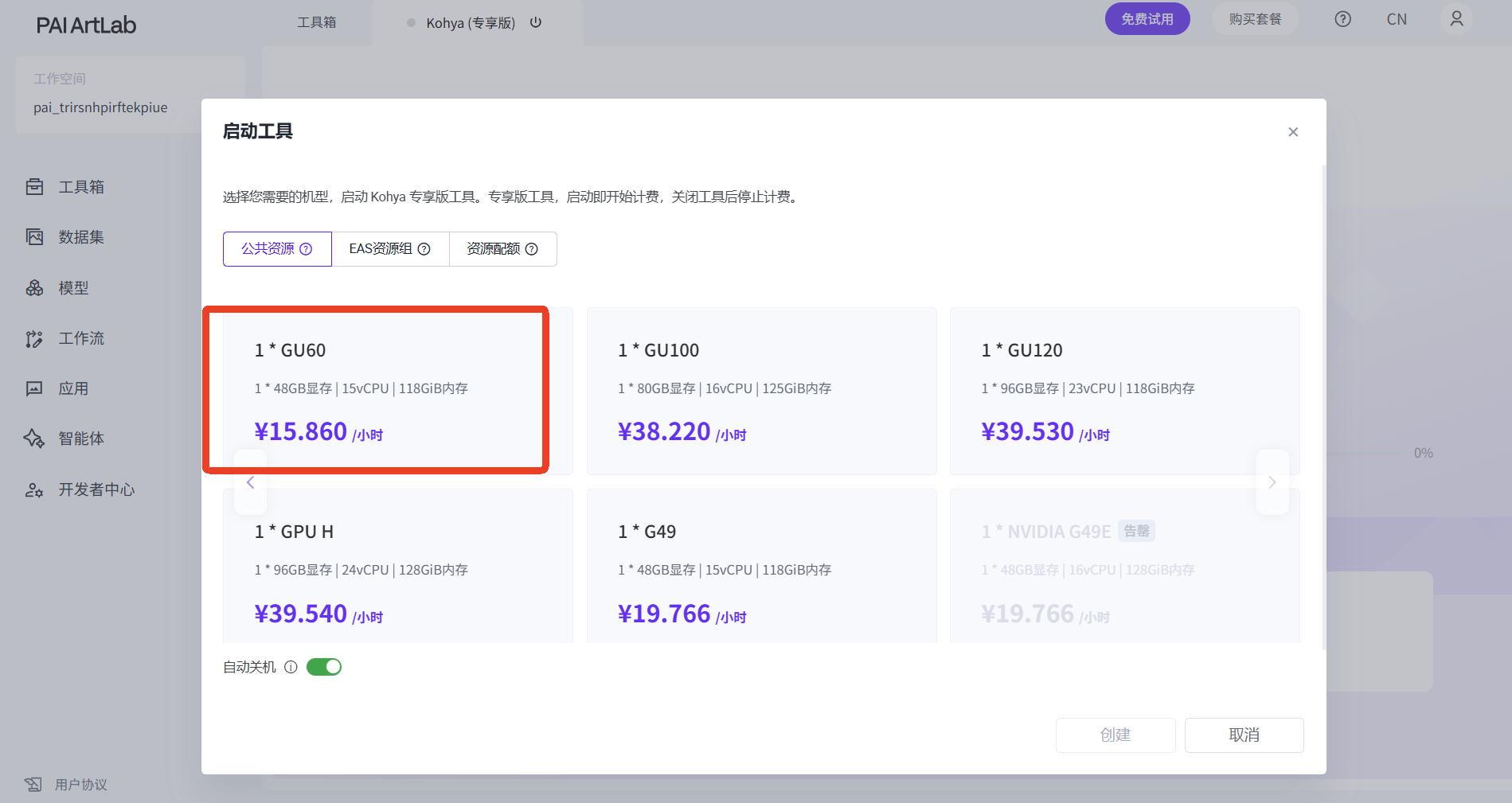
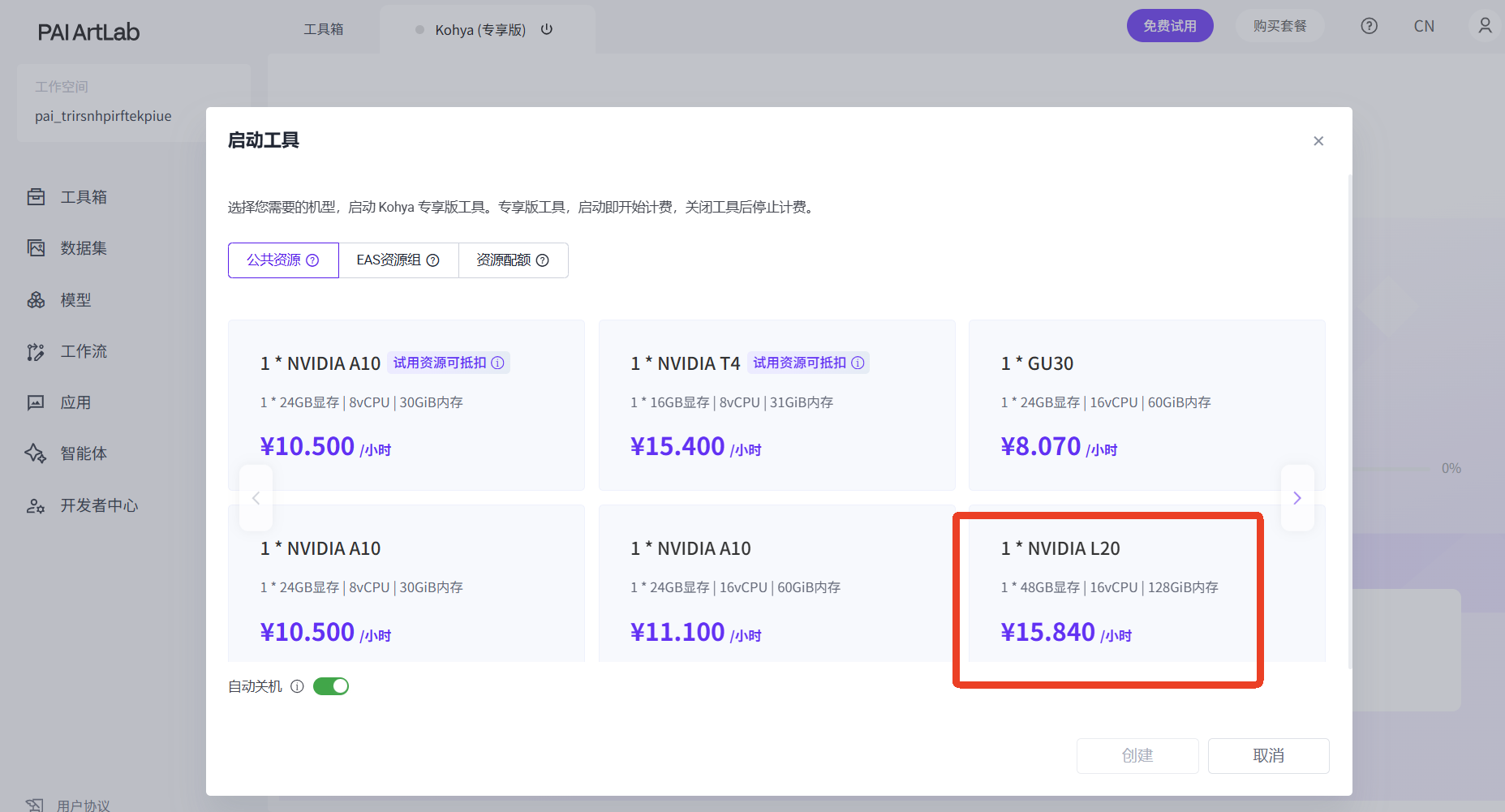
来到首页工具箱,选择Kohya专享版工具卡片,点击卡片,选择机型,启动工具(初次启动工具需要一些时间,请耐心等待)
选择GU60或L20这两款显卡
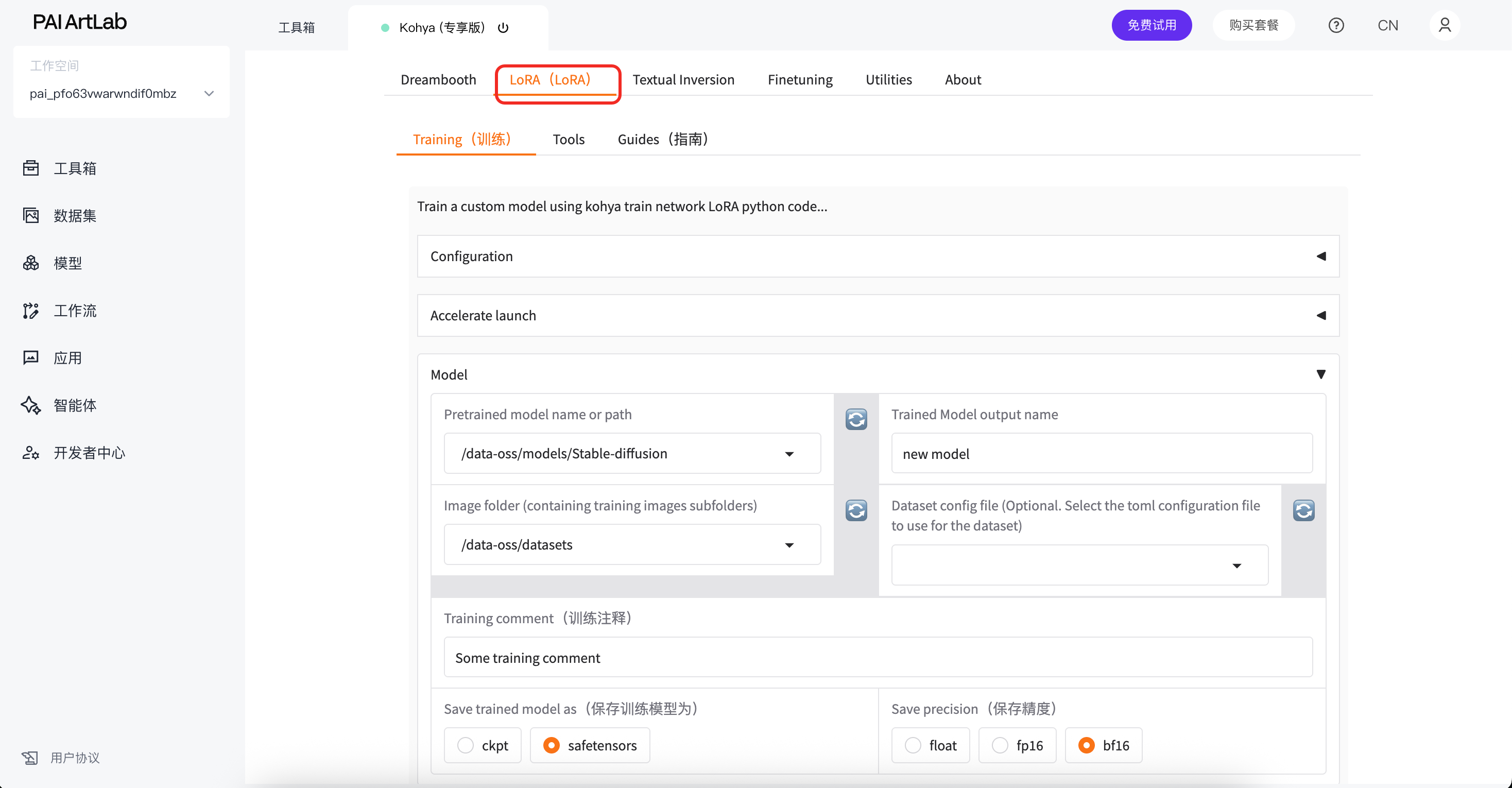
进入Kohya界面,选择LoRA
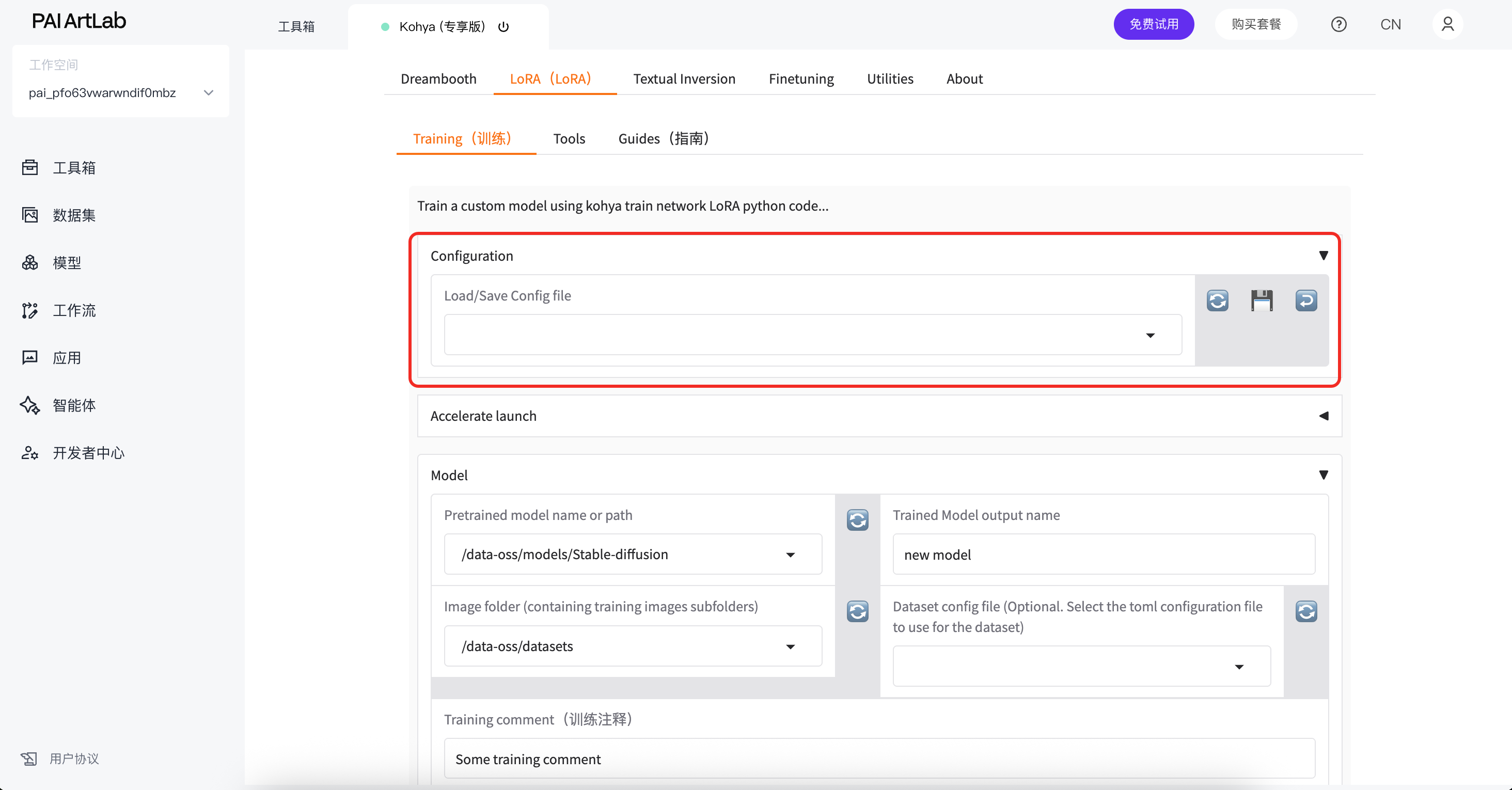
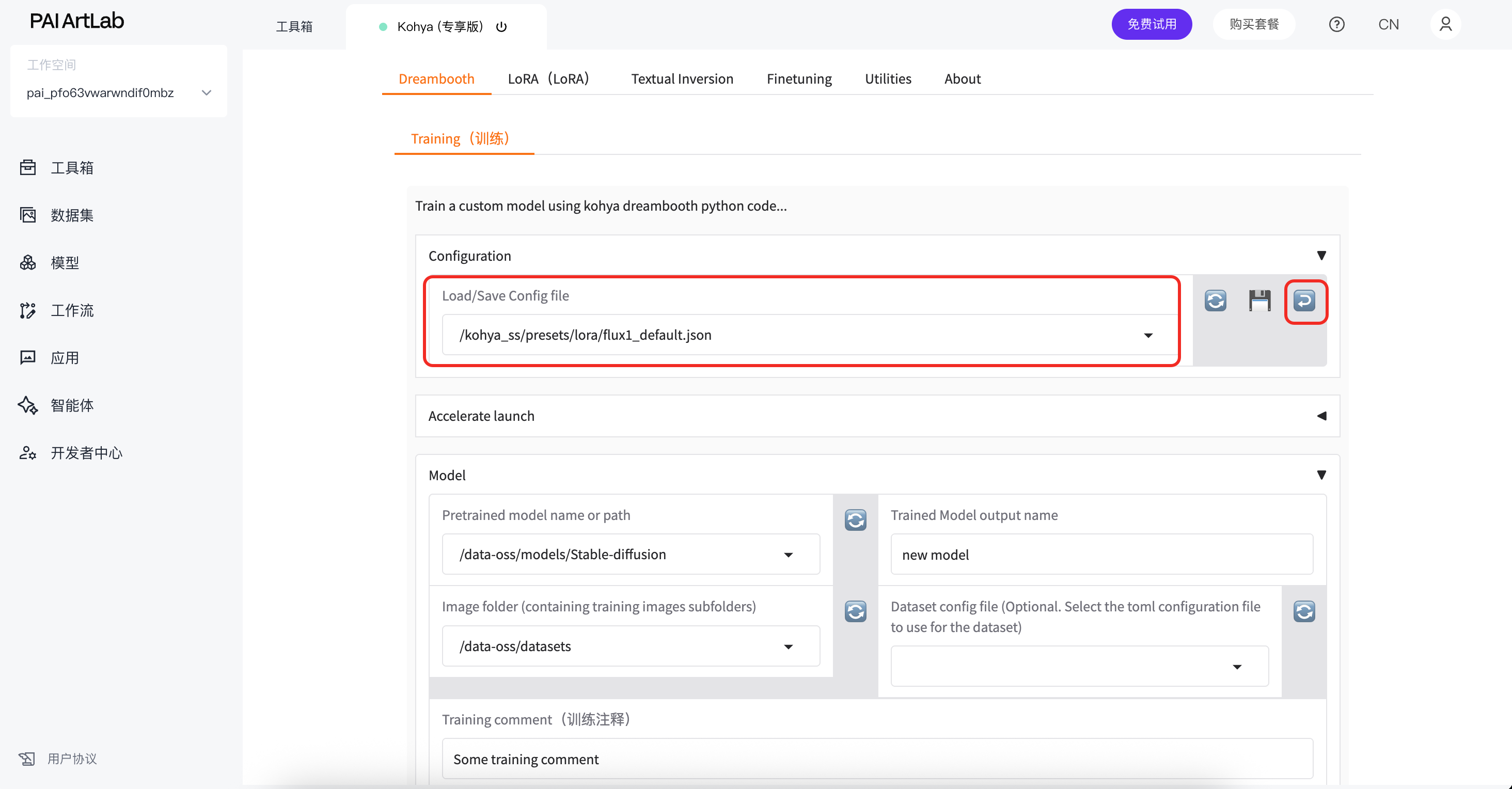
点击Configuration
选择如图预设并点击回车按钮载入预设
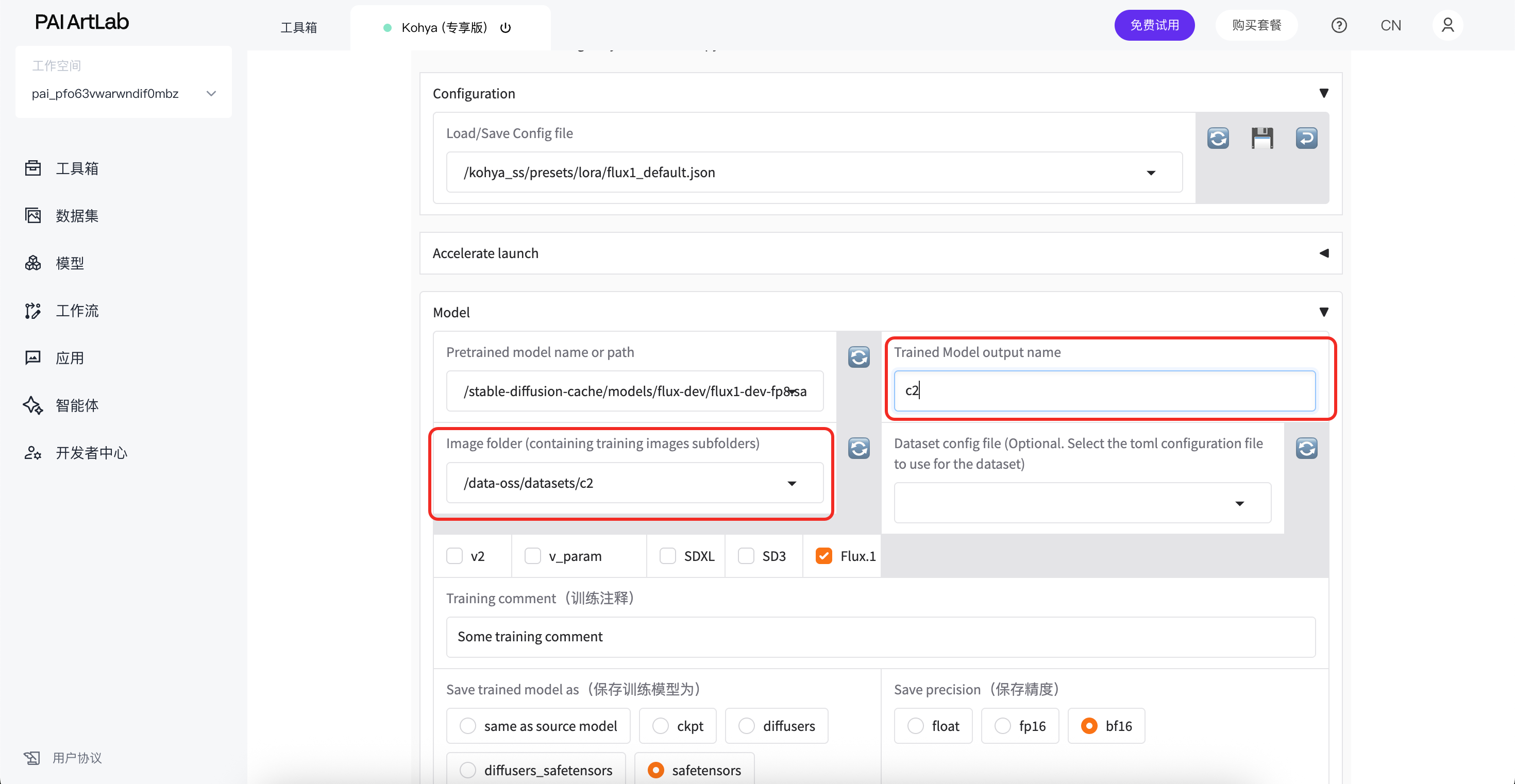
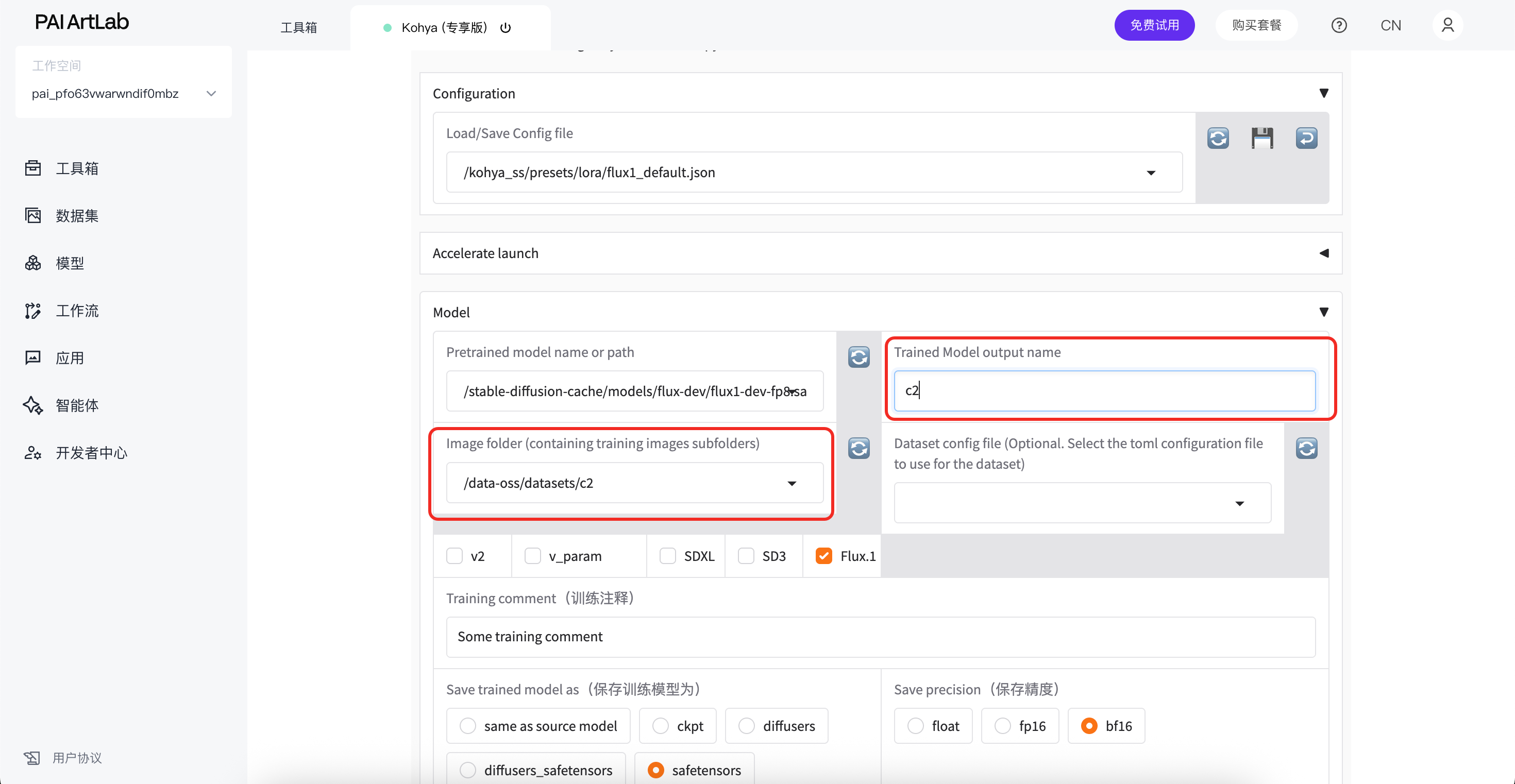
在image folder选择带标注的文件夹的上级文件夹
在trained model output name 属于模型保存名
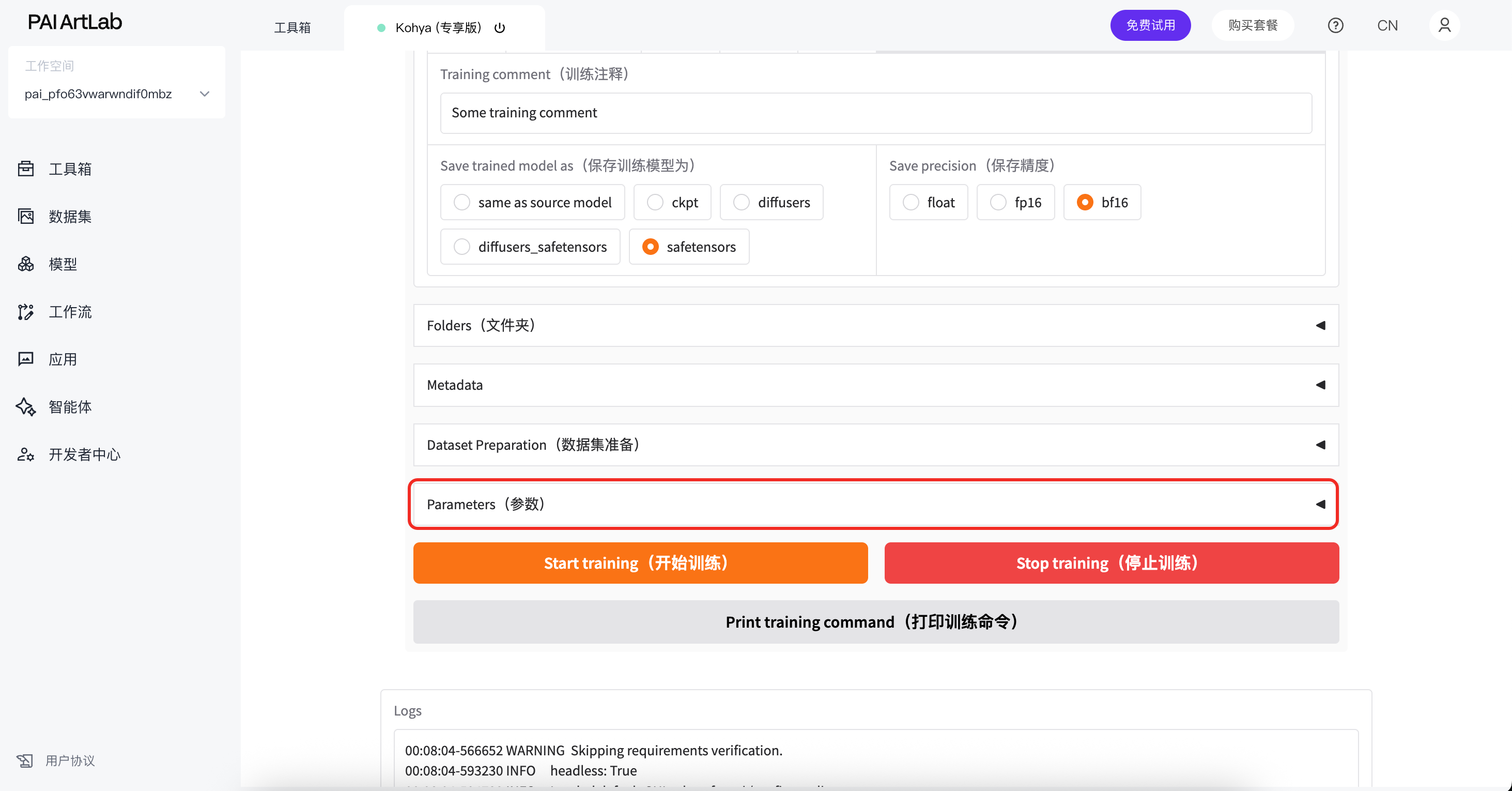
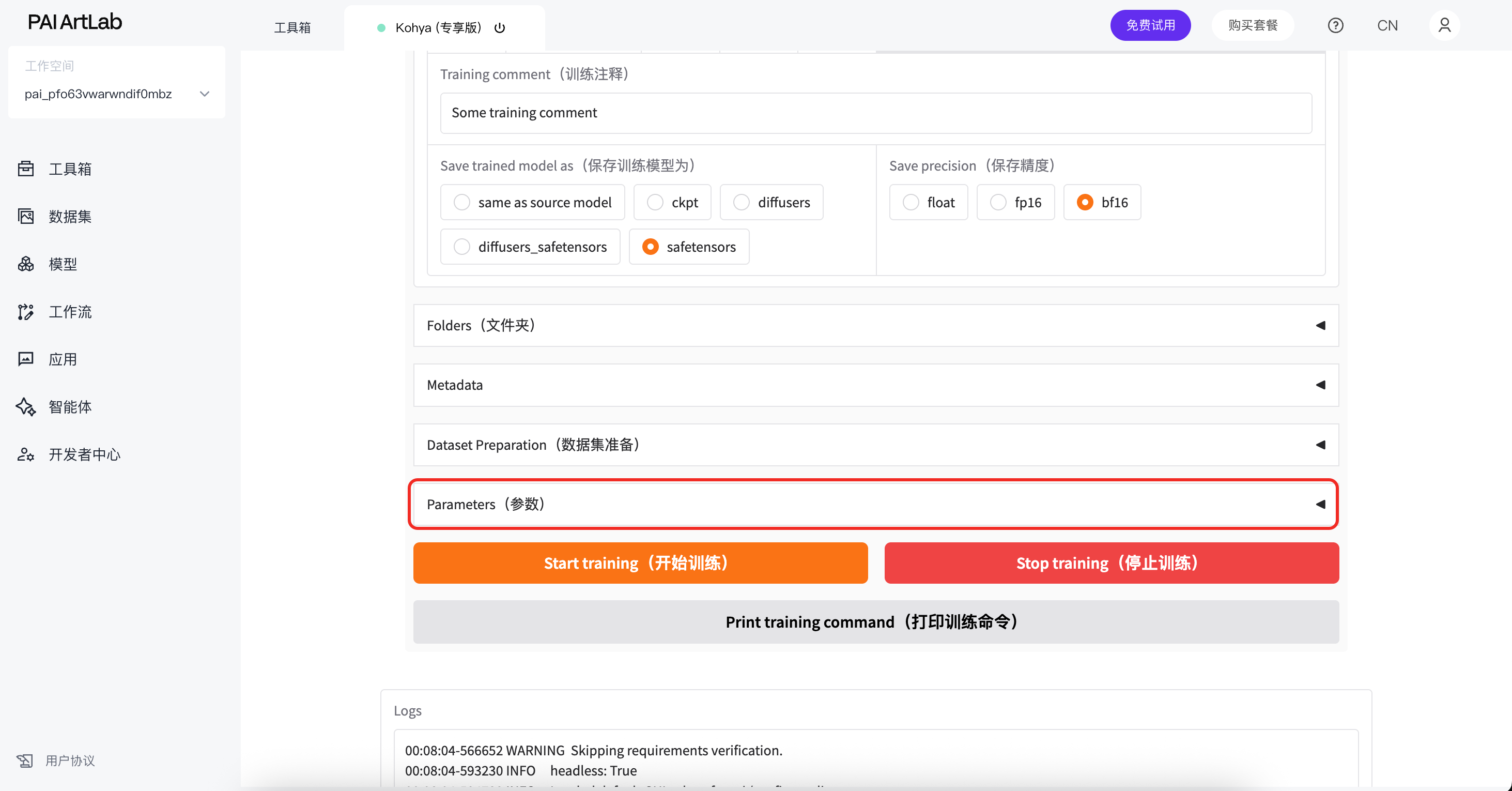
点击parameters参数
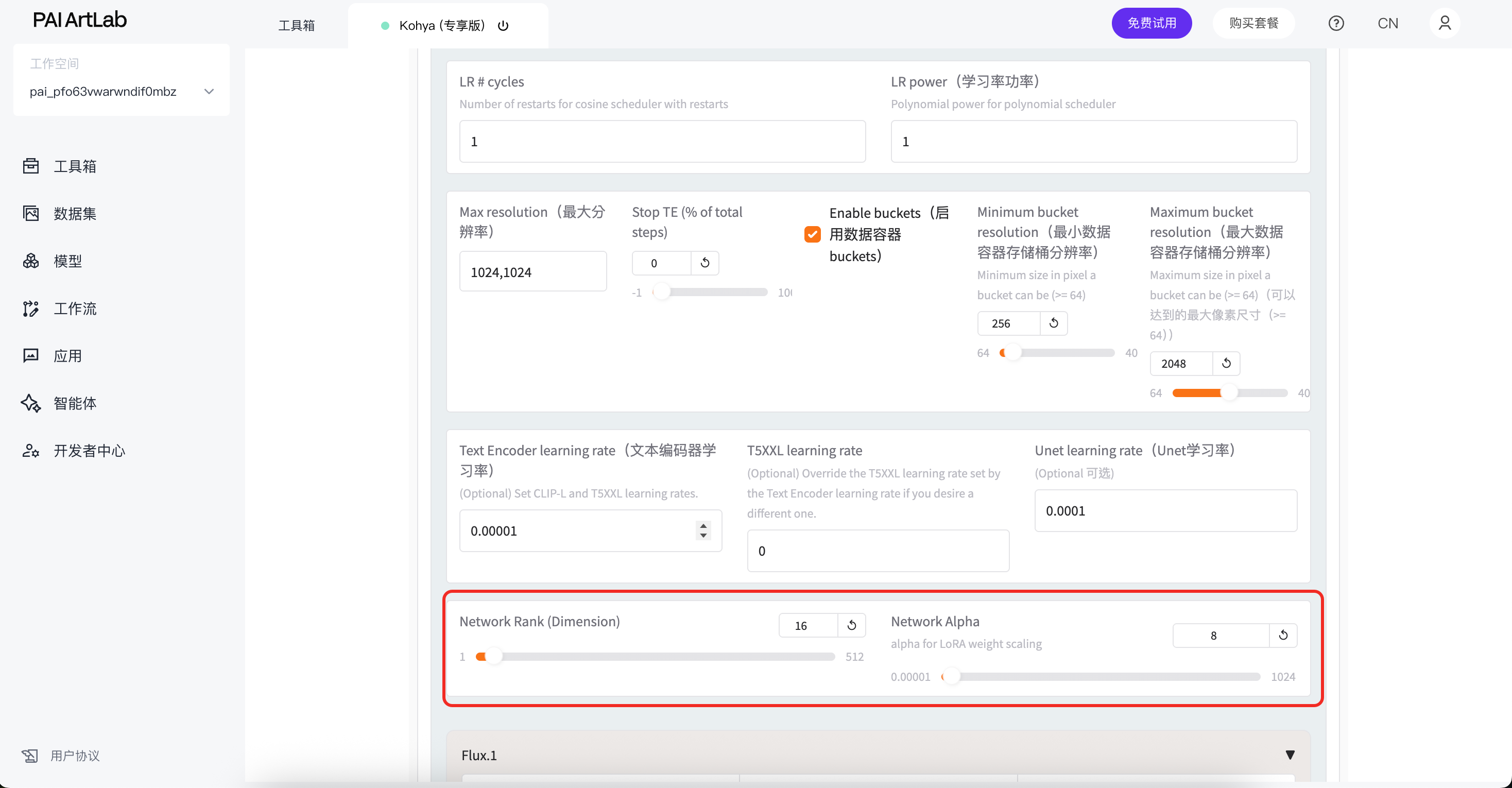
找到learning rate Unet 改为0,0001
按图修改network rank为16,alpha为8
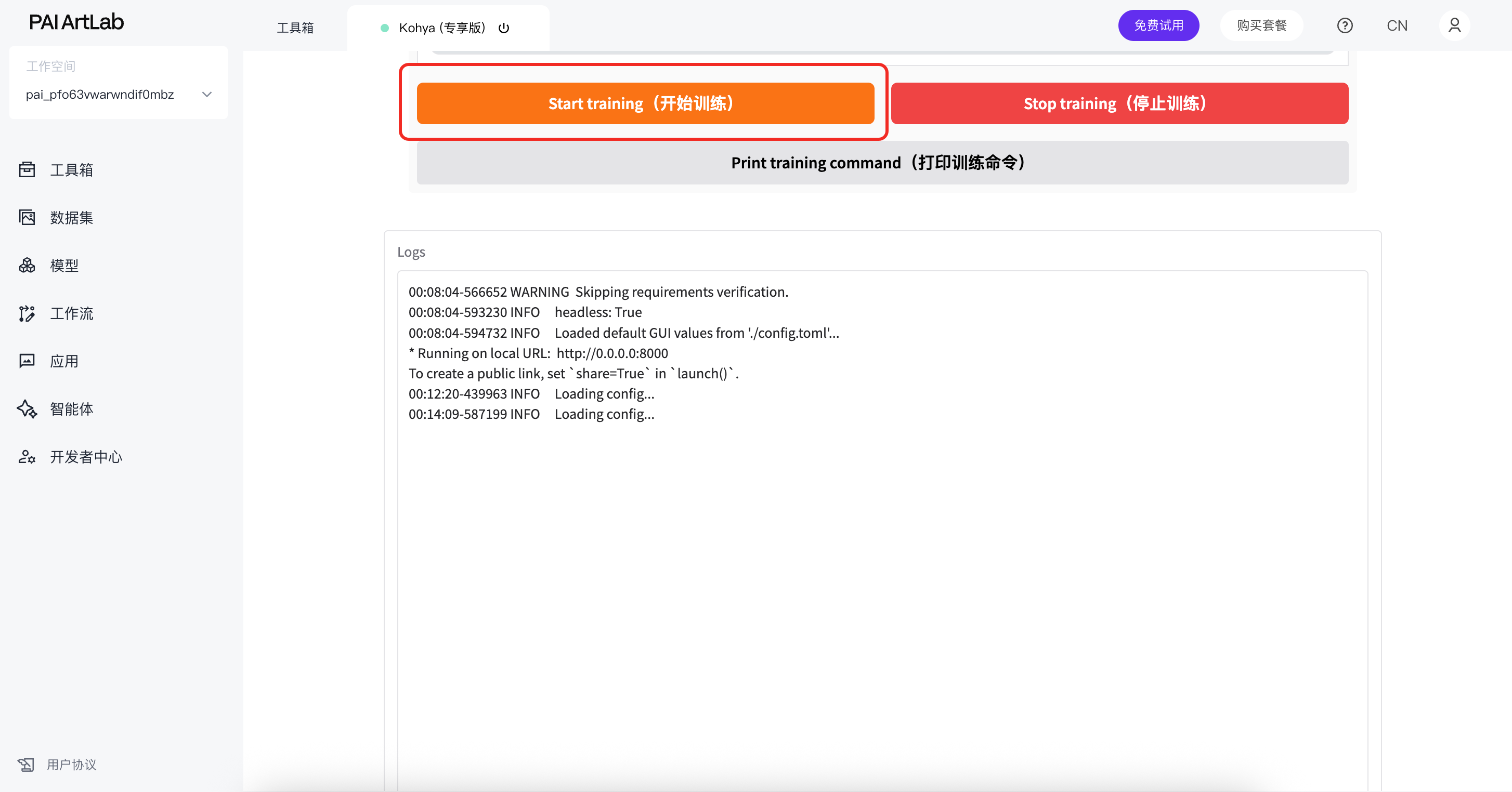
点击开始训练
实验资源释放
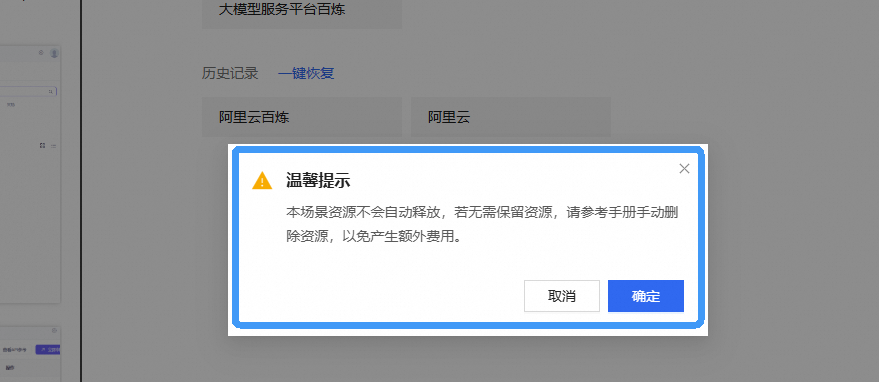
实验结束后,点击关闭释放实验资源,避免不必要的扣费。
在PAI ArtLab控制台中,关闭ComfyUI(共享版)页签,EAS模型服务将会停止,不会继续收费。
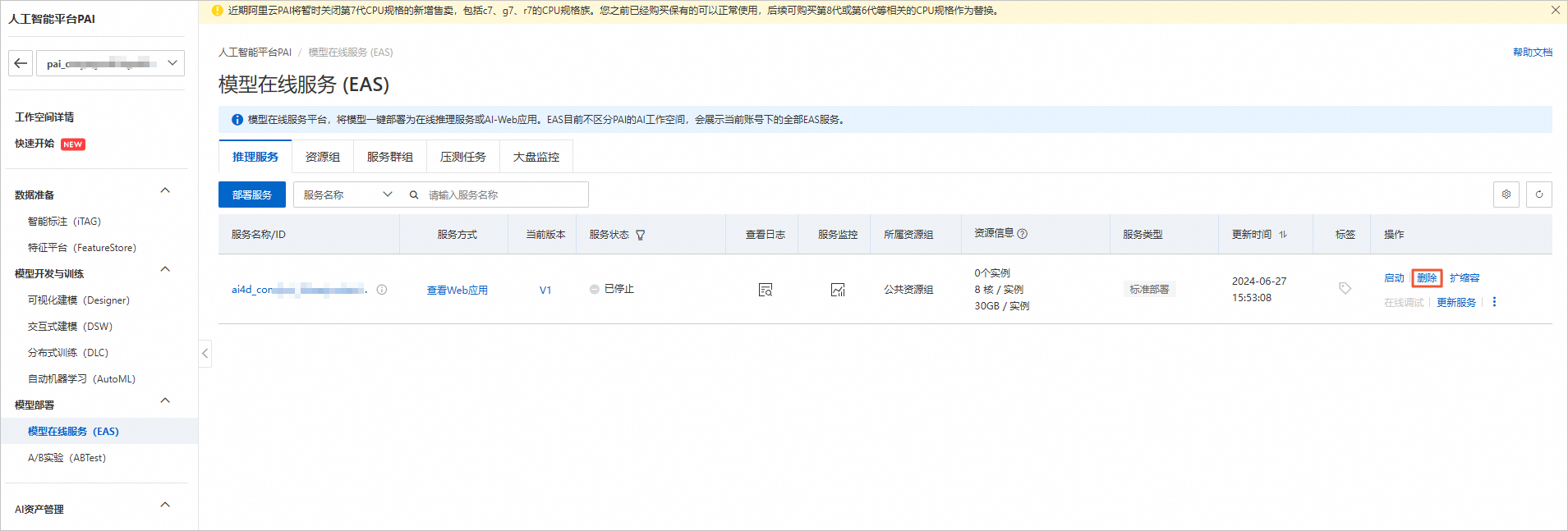
在工作空间页面的左侧导航栏中单击模型在线服务(EAS)。在模型在线服务(EAS)页面,找到目标服务。单击其右侧操作列下的删除
若未找到服务,点击左上角切换模型所在地域,或左侧导航栏切换工作空间列表查看
如果需要继续使用,请随时关注账号扣费情况,避免模型因欠费而被自动停止。

背景知识
一、核心技术路径
本文档介绍了一种基于LoRA(Low-Rank Adaptation)技术对Flux基础模型进行微调的完整工作流。LoRA是一种高效的参数微调方法,通过在预训练模型中注入低秩矩阵,实现对特定风格或内容的精确控制,同时保持较小的模型体积和高效的训练过程。整个技术路径包括:高质量数据集构建→图像智能标注→LoRA参数配置→模型训练与部署,形成了一套从数据到应用的闭环系统。
二、专业知识体系
数据科学基础
图像质量标准:统一风格特征(如特定植物、空间类型、非遗元素等),无文字/水印干扰
分辨率规范:1024×1024/1536×1024/1024×1536像素,保持比例一致性
数据集规模理论:20-30张高质量图像的科学依据,平衡过拟合与欠拟合风险
机器学习训练机制
训练步数计算公式:总步数 = 图片数量 × repeat值 × epoch / batch_size
超参数设计原理:network rank (16)与alpha (8)的比值关系决定模型适应能力
repeat值与epoch的协同作用:前者控制单图训练频次,后者控制全数据集轮次
建议3000-4000总训练步数的理论依据
模型架构特性
Flux模型特点:高分辨率图像生成能力,对1024+分辨率有更好的支持
LoRA技术优势:通过低秩分解减少参数量,避免全参数微调的资源消耗
触发词机制:通过自定义不存在的词汇(如拼音)作为激活标识,避免语义混淆
工作流工程知识
数据集命名规范:"数字_名称"格式的技术含义(数字代表repeat值)
工具链协同:ComfyUI(图像标注)与Kohya(模型训练)的专业分工
硬件选择标准:GU60或L20显卡对训练效率的影响
应用场景理论
风格一致性原理:通过有限高质量样本实现风格迁移的神经网络机制
专业领域适应:针对设计、艺术创作等专业场景的模型微调策略
无需编码的技术民主化:通过工具封装降低AI模型定制门槛
此技术路径代表了当前AIGC领域中"小样本精调大模型"的前沿实践,将专业设计需求与深度学习技术有机结合,使创作者能够构建具有个人/品牌特色的专属AI生成能力,实现从通用模型到个性化创作助手的转变。
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验