数据分析报告
本实验中,您将学会使用阿里云DataV-Note进行多维数据的分析探索,通过借助大模型的能力,在“零代码”模式下发现复杂多维数据背后的价值。
实验简介
DataV-Note(智能数据分析报告)是DataV系列下基于大模型面向数据分析的智能工具;它支持通过自然语言对话进行Python、SQL等数据分析,并提供丰富的数据可视化能力,支持面向PC、手机等多种使用场景的数据报告分享。
本实验中,您将学会使用阿里云DataV-Note进行多维数据的分析探索,通过借助大模型的能力,在“零代码”模式下发现复杂多维数据背后的价值。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
所有实验操作将保留至您的账号,请谨慎操作。
平台仅提供手册参考,不会对资源做任何操作。
- 说明
使用个人账户资源,在创建资源时,可能会产生一定的费用,请您及时关注相关云产品资源的计费概述。
已通过实名认证且账户余额≥0元。
本次实验使用DataV Note标准版,实验资源消耗将从资源包中抵扣。
实操结束后,您可以选择继续付费保留资源,但这将导致持续产生费用,否则请根据实验手册释放资源。
实操结束后,无需对阿里云百炼进行注销。
开通高校实验资源包
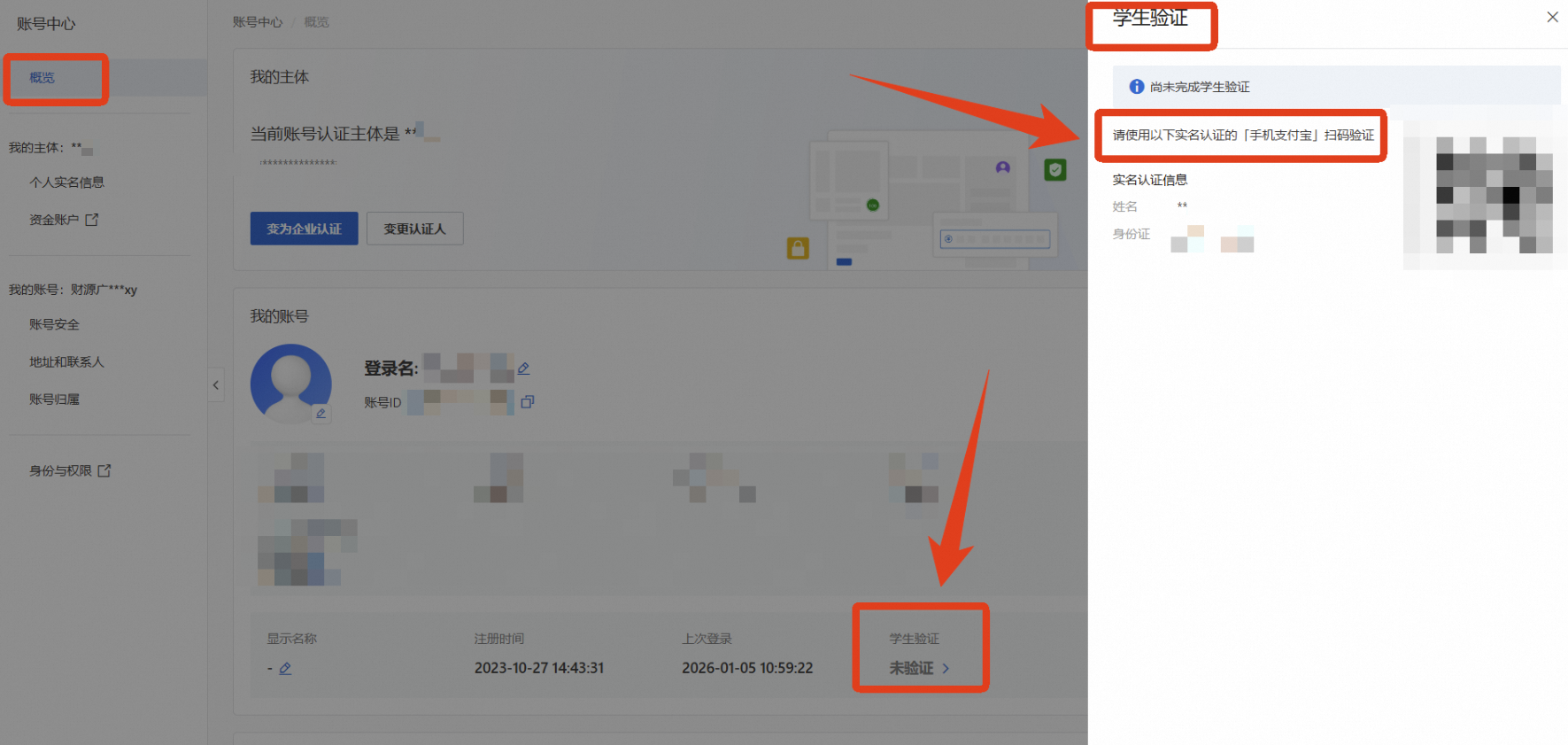
进行学生认证
点击前往阿里云账号中心,进行学生验证
获取资源
方式一:领取合作高校专属300元实验资源券,并完成DataV-Note标准版资源兑换
DataV-Note数据分析报告是DataV系列下基于大模型面向数据分析的智能工具;它支持通过自然语言对话进行Python、SQL等数据分析,并提供丰富的数据可视化能力。
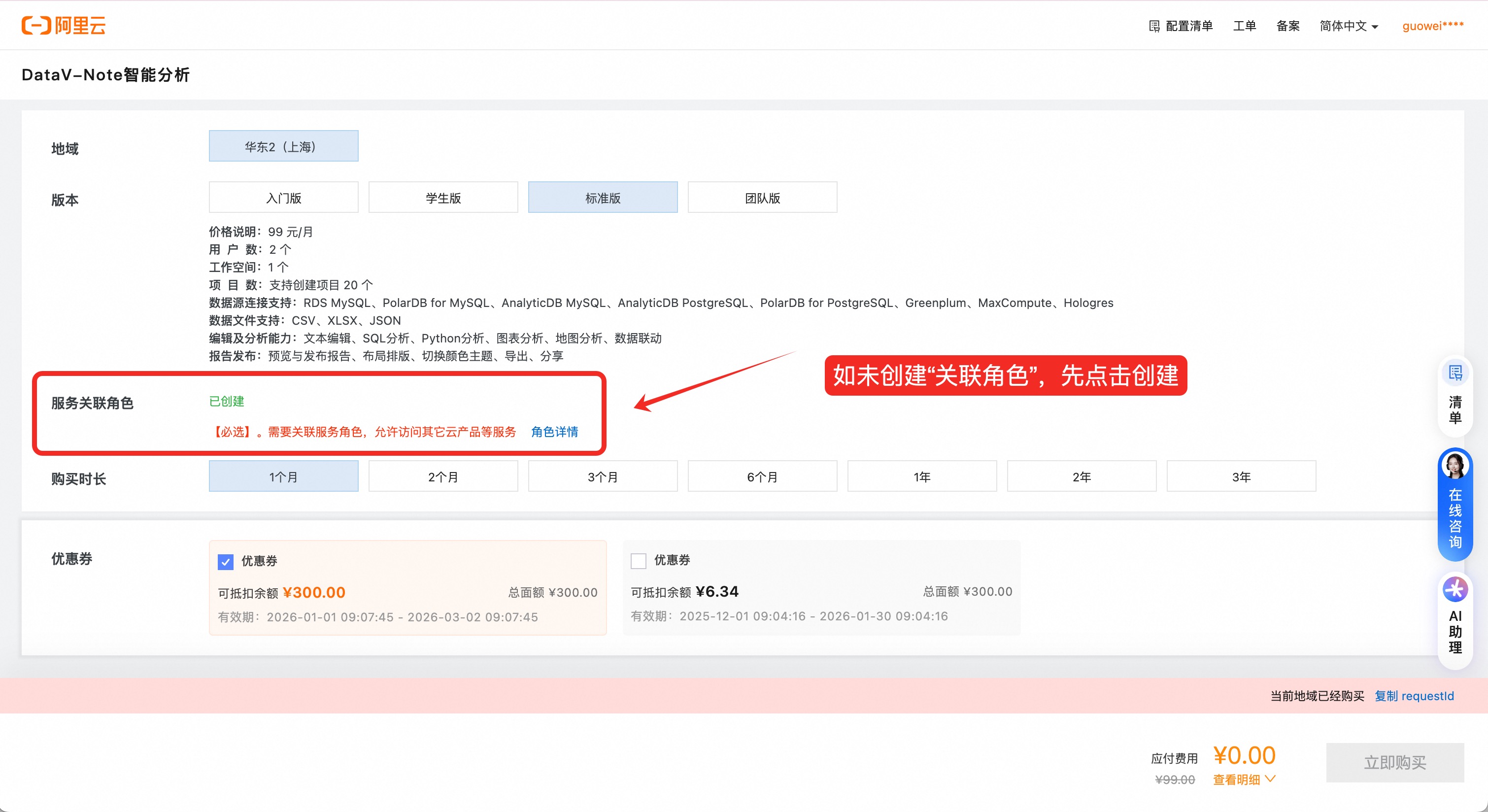
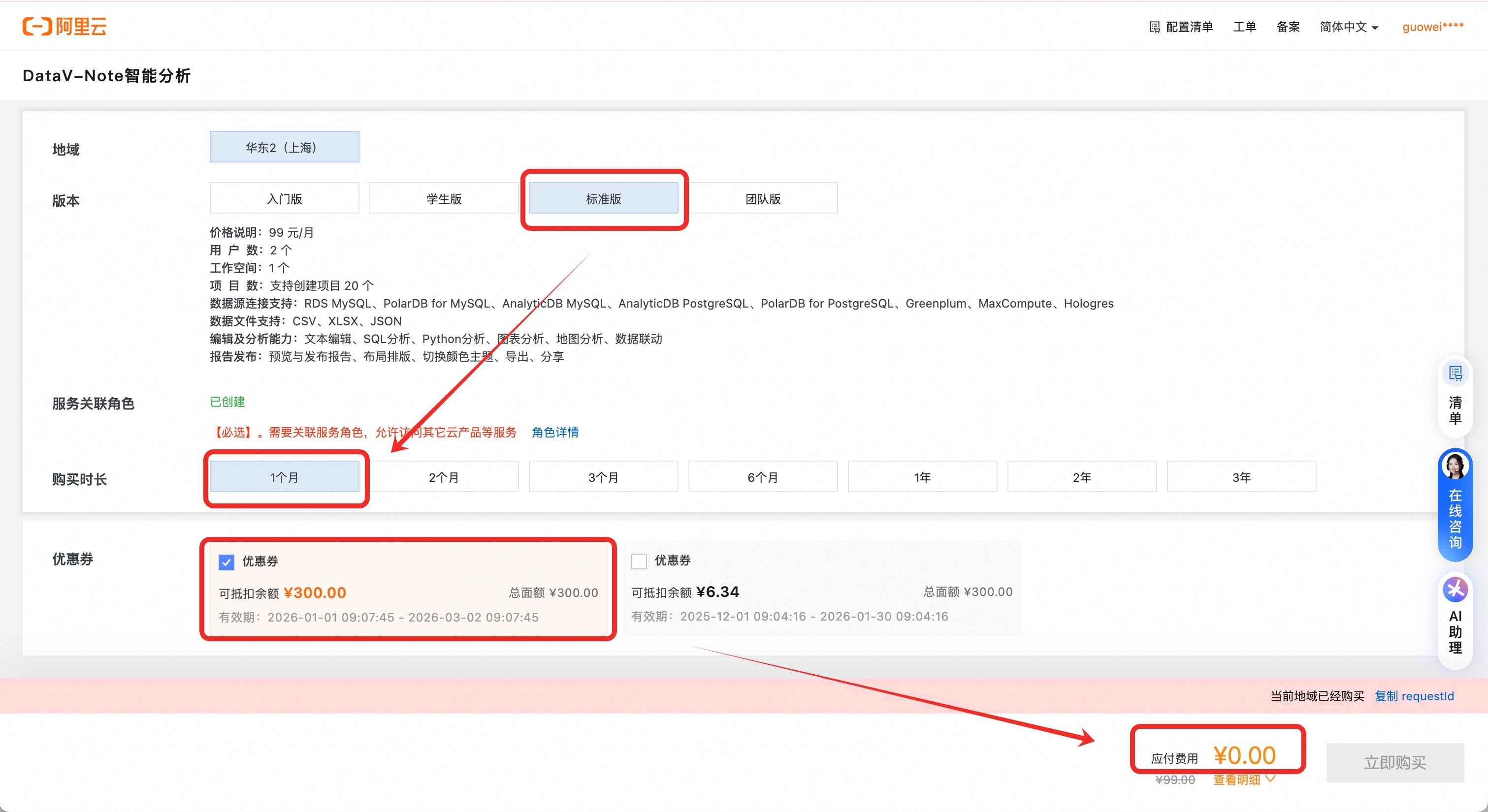
点击购买DataV-Note标准版,选择:【标准版】—【1个月】,先检查【关联角色】是否创建(如未创建关联角色,先点击创建)核对无误后点击【 立即购买】
重要如已购资源包,可跳过此步骤,无需重复下单!!
并使用云工开物代金券支付(确认勾选代金券,实际支付金额0元)
方式二:下单开通实验所需资源包
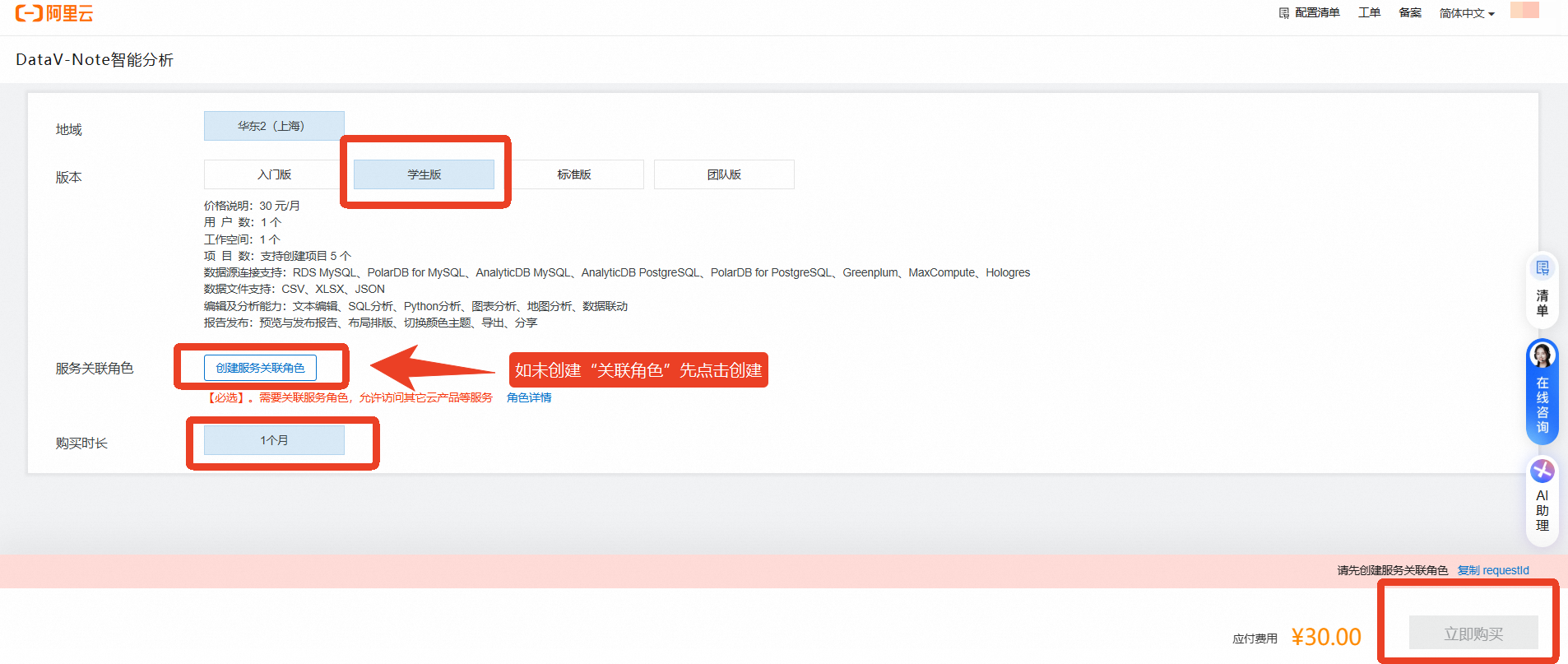
点击购买DataV-Note学生版资源包,承诺消费金额选择30元,有效期1个月,点击 立即购买
重要购买DataV-Note学生版请先完成学生认证,否则无法进行购买
如已购资源包,可跳过此步骤,无需重复下单!!
实验步骤
本实验包括统计性指标分析、复杂指标智能探索、地理数据分析、智能报告(扩展实践)4部分;
为酿酒选合适的葡萄品种:对不同品种的葡萄糖度稳定性进行分析,提供酿酒参考;
根据偏好筛选葡萄品种:对不同品种的葡萄多维性状数据进行智能探索,对品种选择提供数据支持;
入侵物种地理分布分析:利用AI对多维地理数据进行智能增强,实现快速上图写报告;
AI自动写报告(扩展实践):探索运用AI对复杂多维数据自动化探索并撰写分析报告;
登录DataV Note工作台
实验(一):为酿酒选择合适的葡萄品种-性状稳定性分析
在葡萄酒酿造中,糖度的稳定性至关重要;糖度非常稳定,风味可控性强,糖度波动大,酿酒风格可能不一致。
在育种性状数据分析中,变异系数 (CV) 是衡量“稳定性”与“波动性”的核心指标。它通过将标准差与均值进行归一化处理,让我们能够跨越不同量级和单位(如糖度 vs. 产量)直接比较波动程度。
本节内容对几个品种葡萄的多年糖分数据进行分析,筛选高产且稳定的品种,用于酿造风格一致的葡萄酒。
1.1 下载数据备用
数据说明:
本数据为mock数据,不保证真实性/合理性
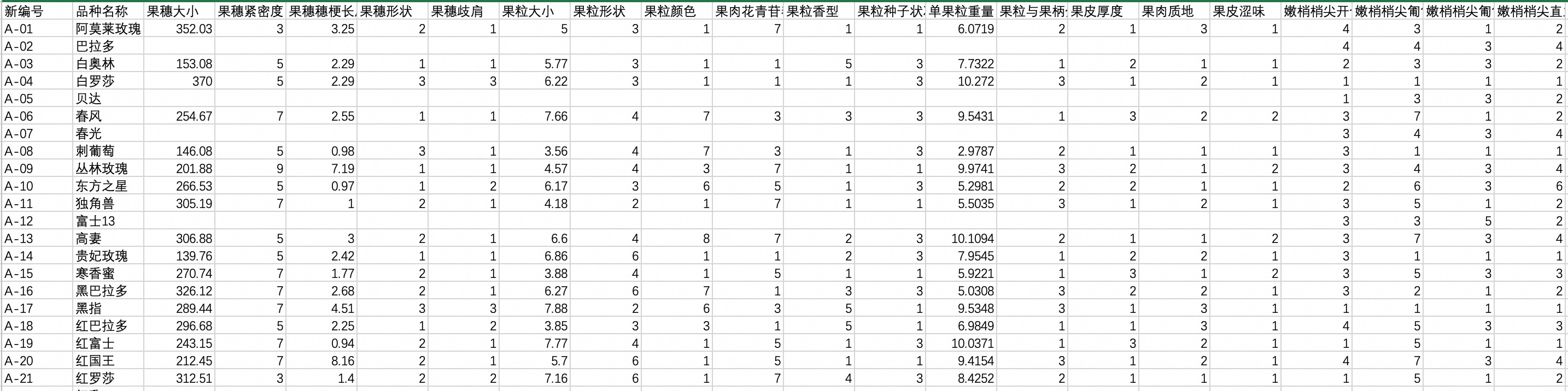
数据概览

数据下载:
点击以下链接下载数据,1-不同品种产量数据.csv
说明注意:数据下载后,不要用Excel或其他软件打开/修改;直接进行数据上传学习平台操作
1.2 上传数据
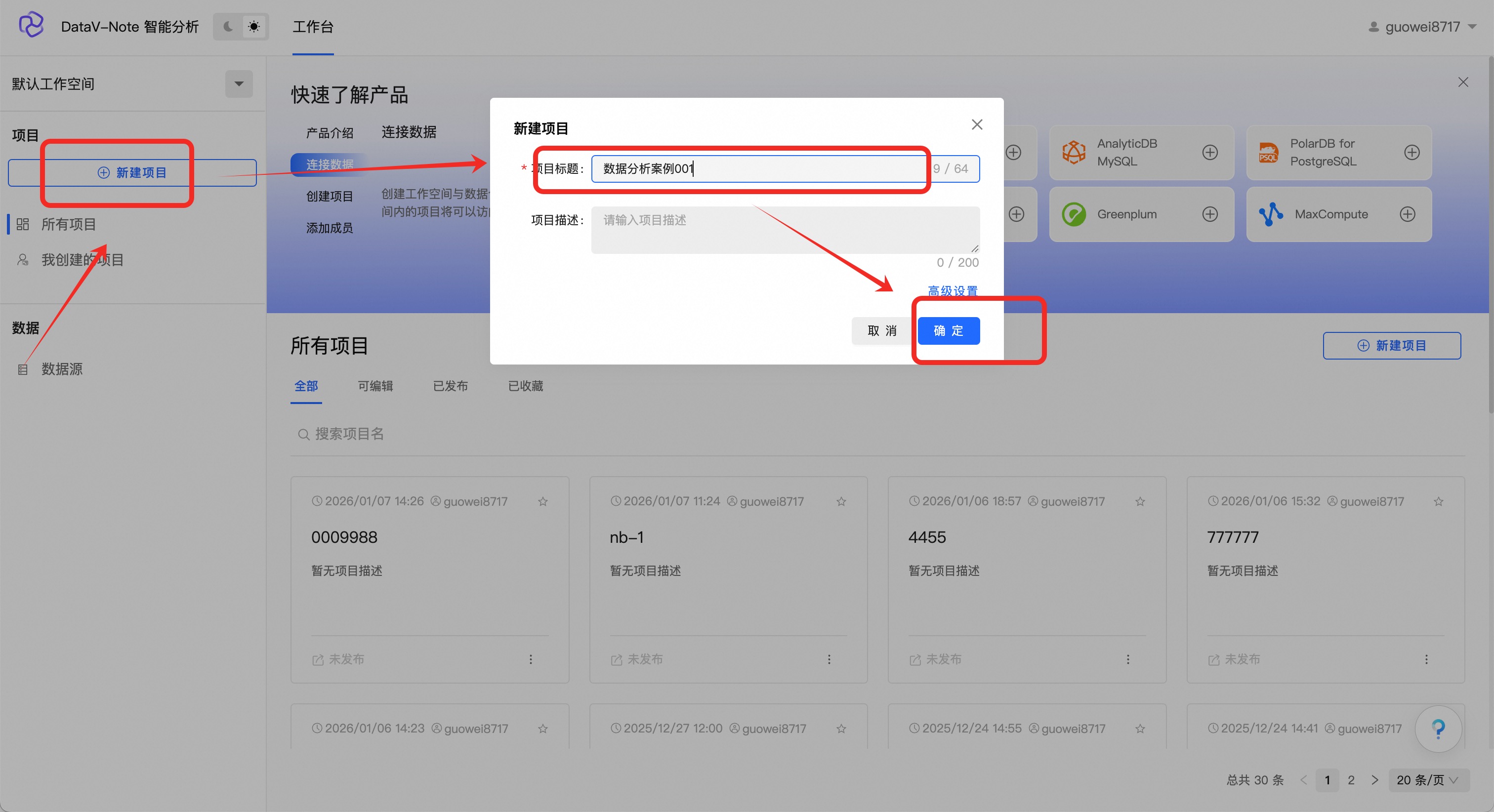
(1.2.1)新建分析项目
登录产品后,点击左侧工具栏“新建项目”按钮
项目命名
点击项目,进入编辑器
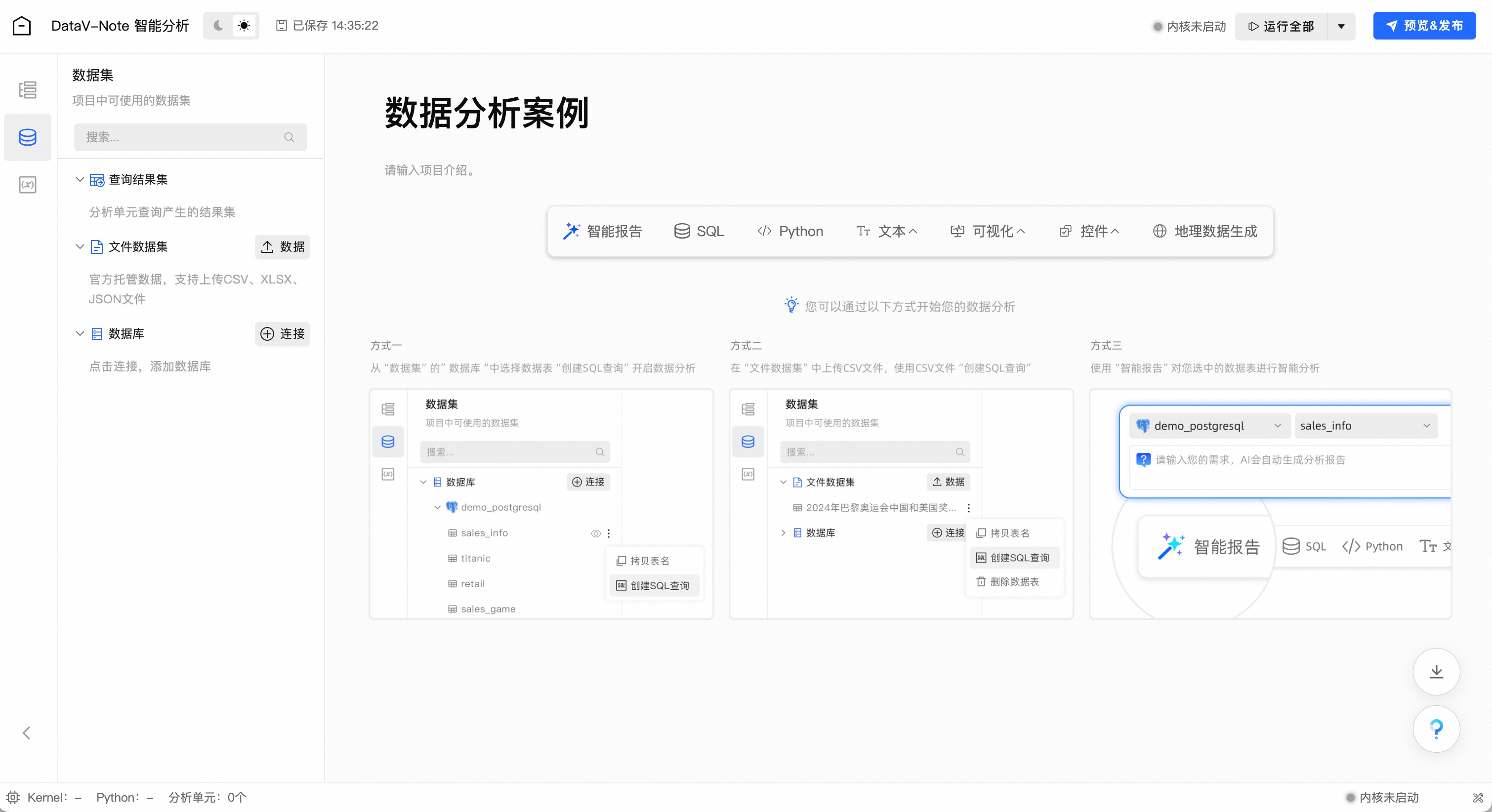
进入编辑器状态
(1.2.2)上传数据
点击工具栏左侧—文件数据集—数据
弹出对话框,选择刚刚下载的数据
数据解析完毕后点击“确认”
(1.2.3)载入数据到分析区
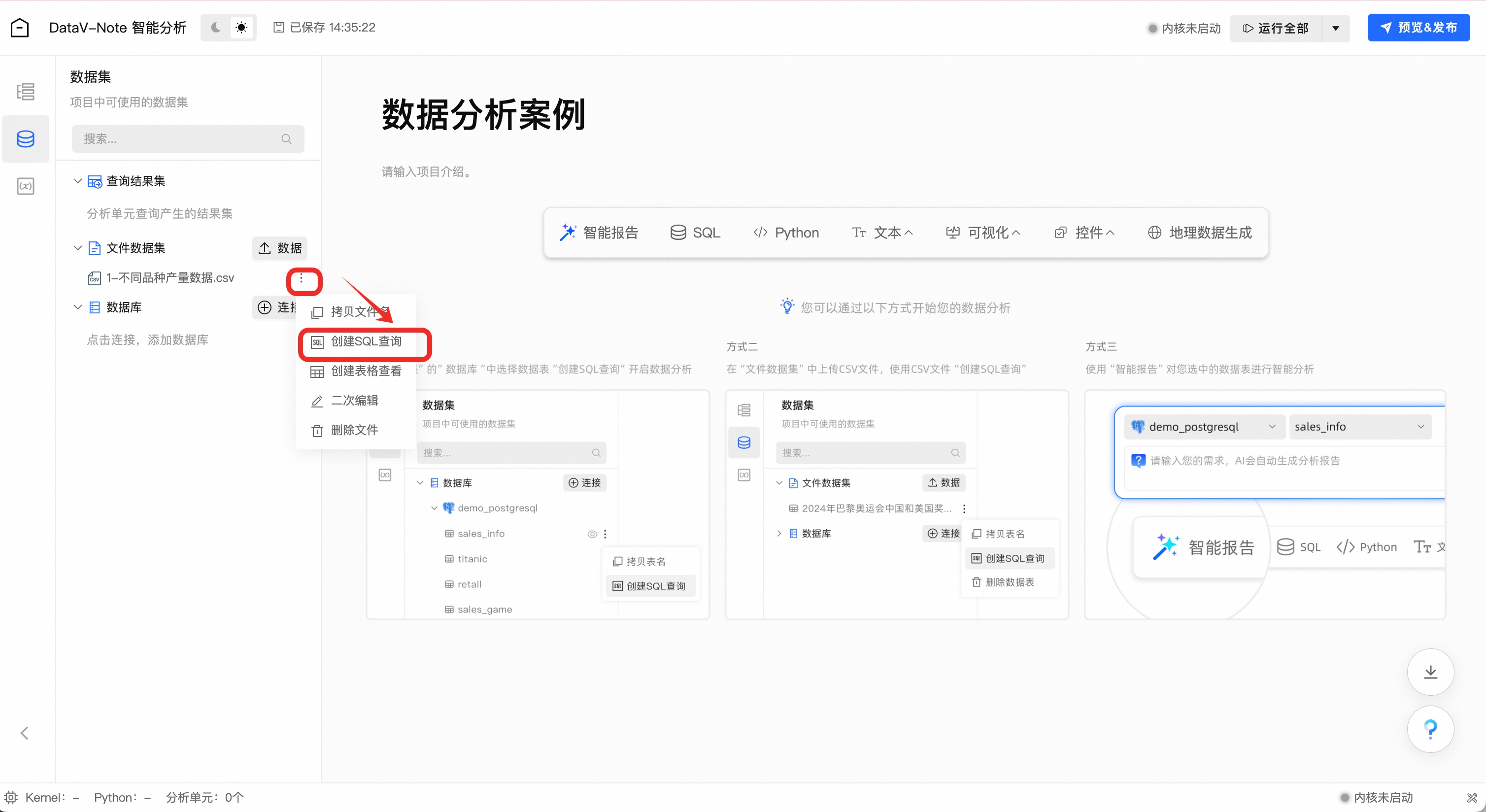
点击工具栏左侧—文件数据集—刚上传数据旁边的三个小点菜单,在弹出的菜单中选择“创建SQL查询”选项
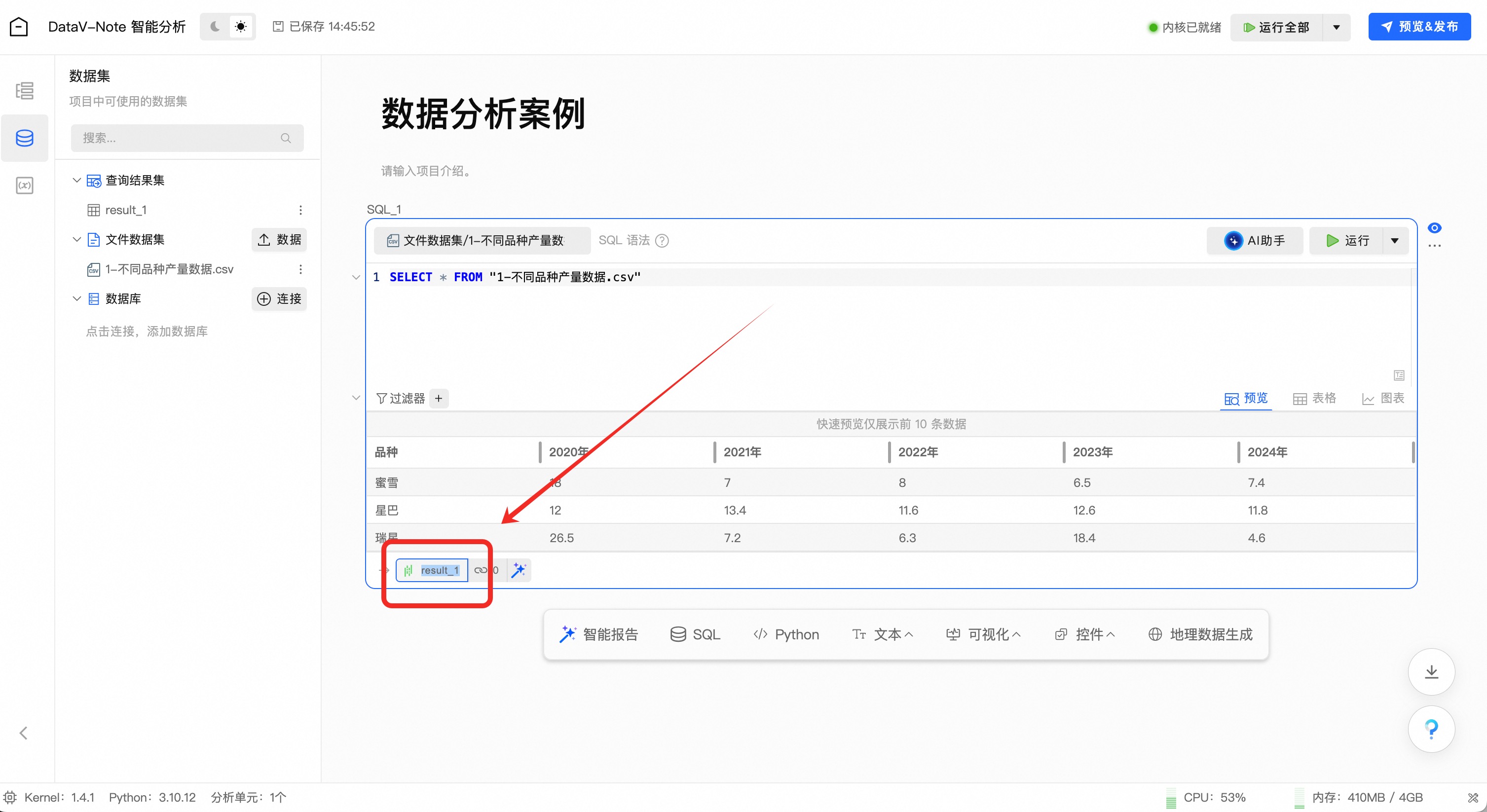
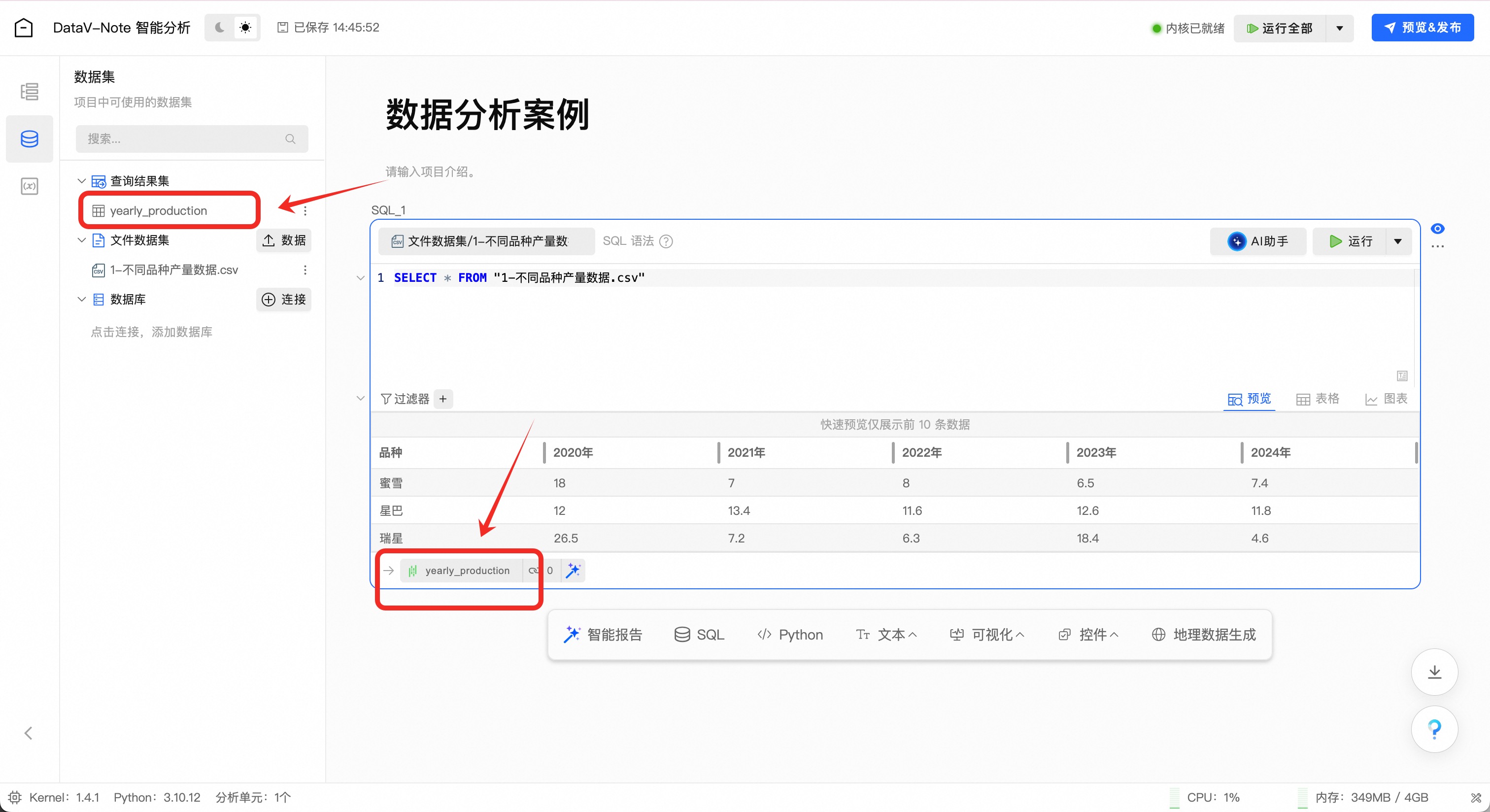
(1.2.4)变量重命名
鼠标双击左下角数据表名“result_1”,将表名改为“yearly_production”
说明注意:非常重要!表名“yearly_production”是后续python数据分析中引用的变量名称,如不一致后续大模型提示词会出错!
检查电影名称数据是否正确命名为“yearly_production”
1.3 数据分析
(1.3.1)背景知识:大模型提示词工程与python数据分析介绍
大模型通过自然语言到代码(如NL2Python)的转换技术,使用户无需编程即可高效完成Python数据分析;DataV Note通过对话式交互自动生成数据查询与可视化,显著降低技术门槛。
提示词工程(Prompt Engineering)是通过设计和优化提示词(Prompt)来引导大语言模型(LLM)生成符合预期输出的技术,是通过自然语言到代码进行Python数据分析的核心技能之一,其核心在于将用户需求转化为大模型可理解的指令,从而提升Python数据分析代码输出的准确性、相关性和可控性。
提示词工程(Prompt Engineering)关键要素及其重要性:
角色定义:为模型分配身份或视角(如“资深python数据分析师”),影响输出的语气、专业性和知识范围。例如,明确角色可使模型输出更贴合特定数据分析需求,减少歧义。
任务描述:明确指令的核心目标(如“对观众评论数量最多的十部电影进行排序输出”),确保模型聚焦于具体任务,避免偏离方向。清晰的任务描述能显著提升输出的针对性。
数据输入/输出:通过上下文、示例和输出指示控制输入信息和输出格式。例如,提供数据输入的变量名称,而输出指定数据变量名称,方便下一步做图表可视化操作。
约束条件:通过角色、任务、上下文等要素隐含或显式设定约束(如禁止修改原始输入数据等),降低模型“胡说八道”的风险,增强输出的一致性。
(1.3.2)提示词样例
提示词样例:分析不同品种的年均产量与稳定性
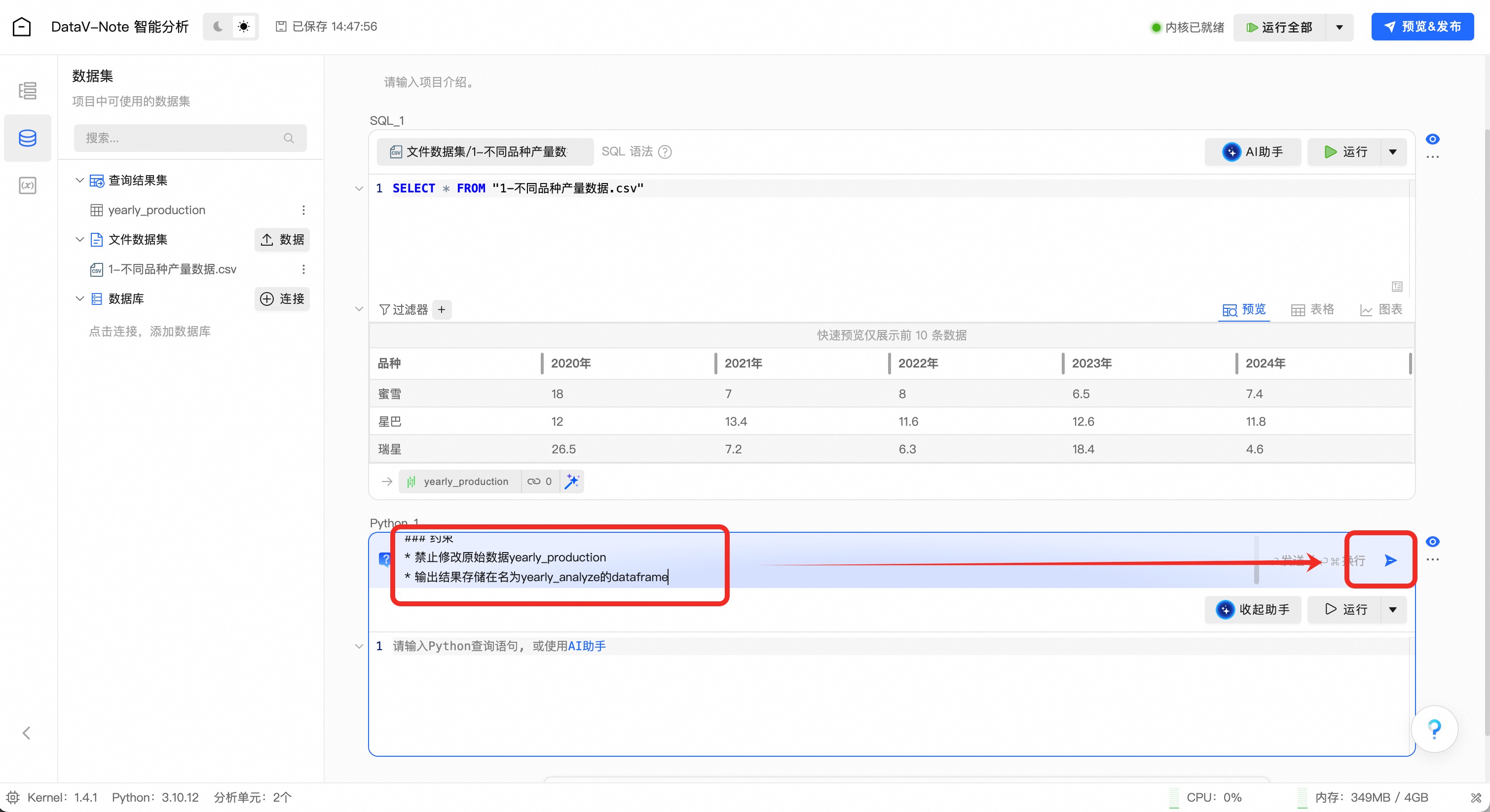
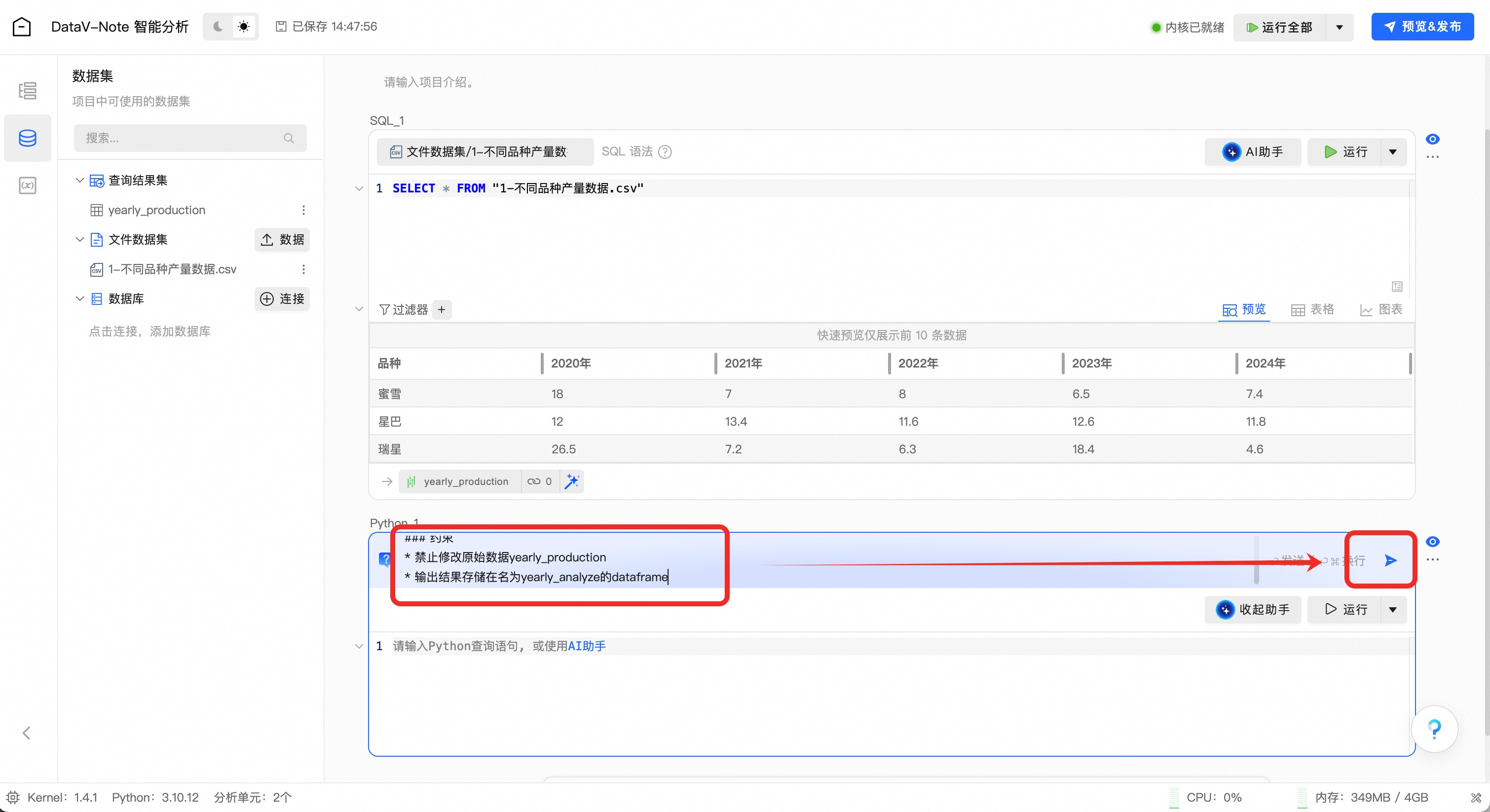
### 角色 你是一位Python数据分析专家,擅长高效处理大规模多维复杂数据。 ### 任务 * 根据三个植株品种从2020年到2024年间每单位面积的产量,分析年均产量与稳定性: * 分析这三个植株品种的年产量均值; * 分析这三个植株品种的年产量变异系数; ### 输入数据 * 原始数据为yearly_production,代表三个植株品种从2020年到2024年每单位面积的产量 * 不允许修改原始数据,可以复制原始数据进行分析 ### 输出要求 * 输出这三个植株品种的年产量均值 * 输出这三个植株品种的年产量变异系数 * 输出结果存储在名为yearly_analyze的dataframe ### 约束 * 禁止修改原始数据yearly_production * 输出结果存储在名为yearly_analyze的dataframe(1.3.3)AI助手通过提示词进行python数据分析
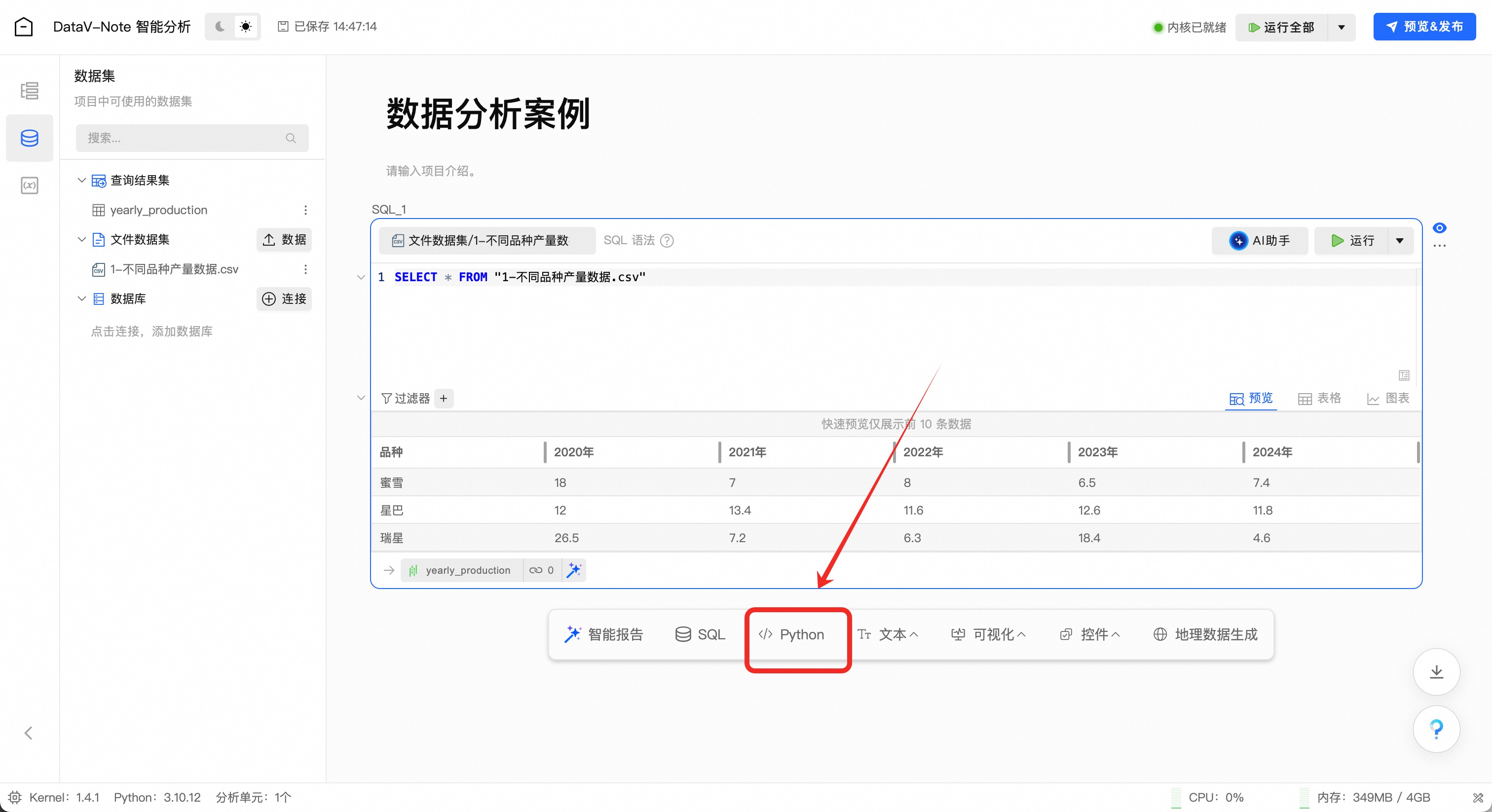
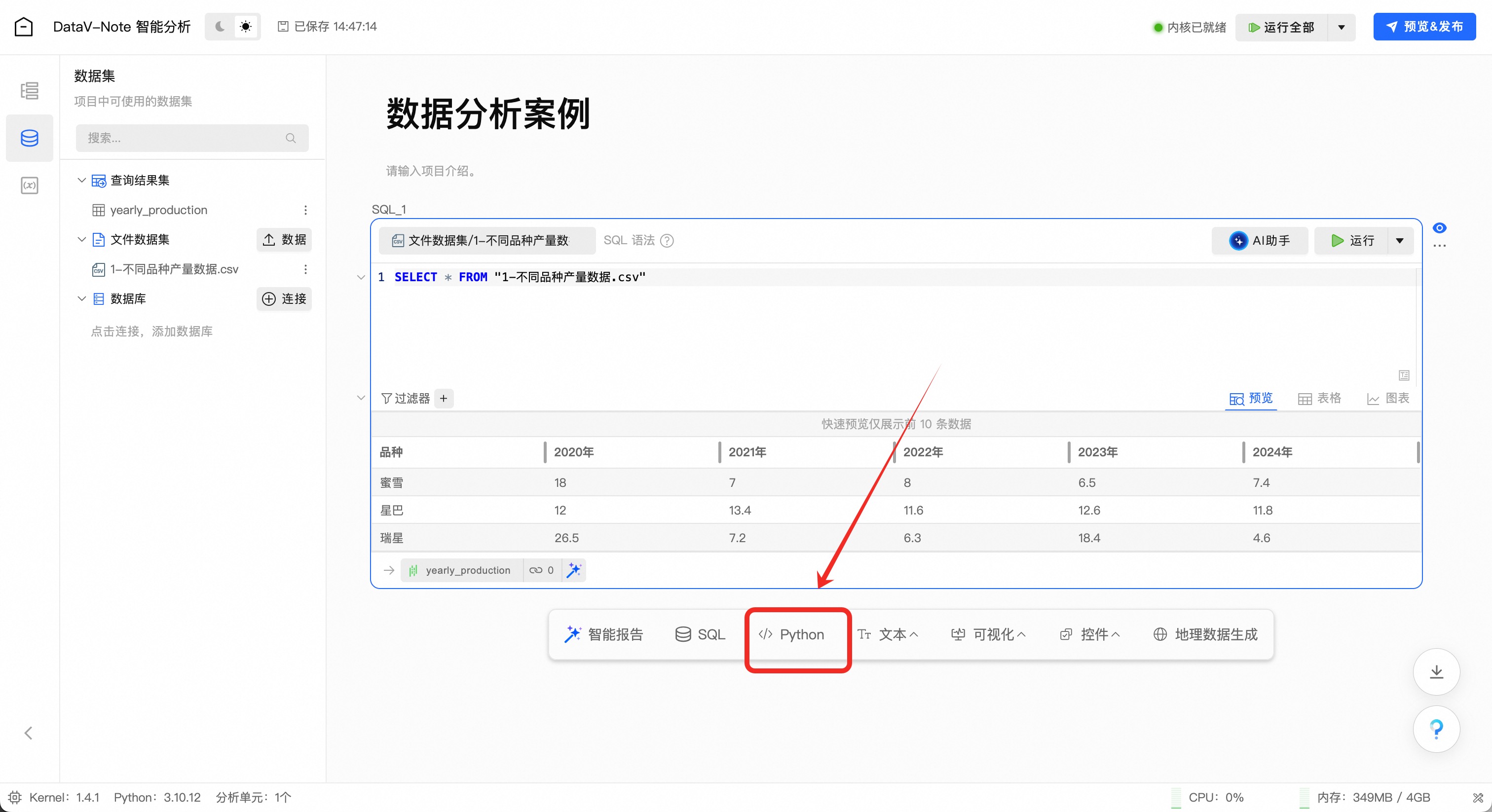
点击下方工具栏“Python”按钮
在新增的python代码框右上角,点击“AI助手”
将大模型提示词复制后粘贴到AI助手输入框中,并点击输入框右侧按钮
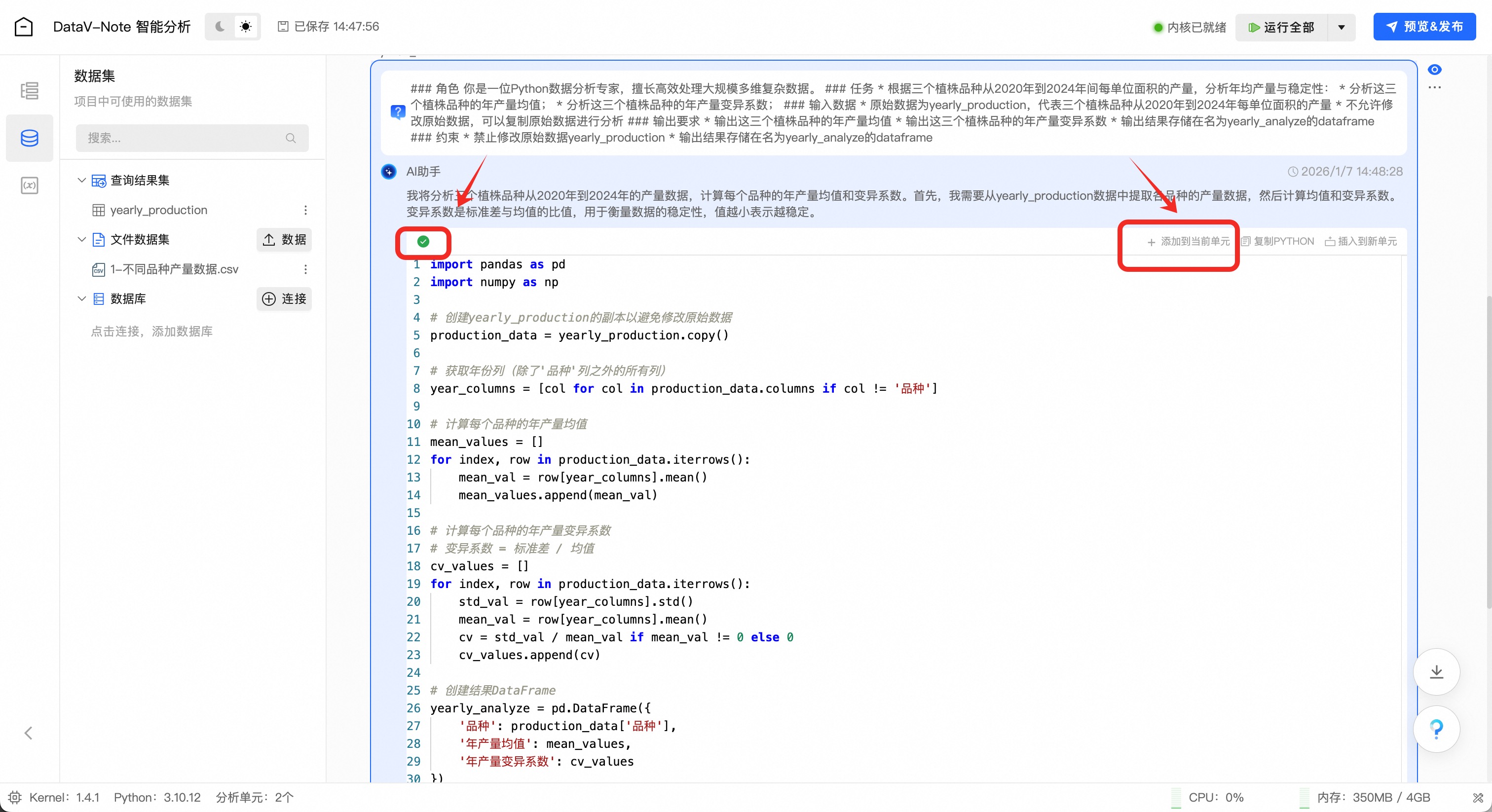
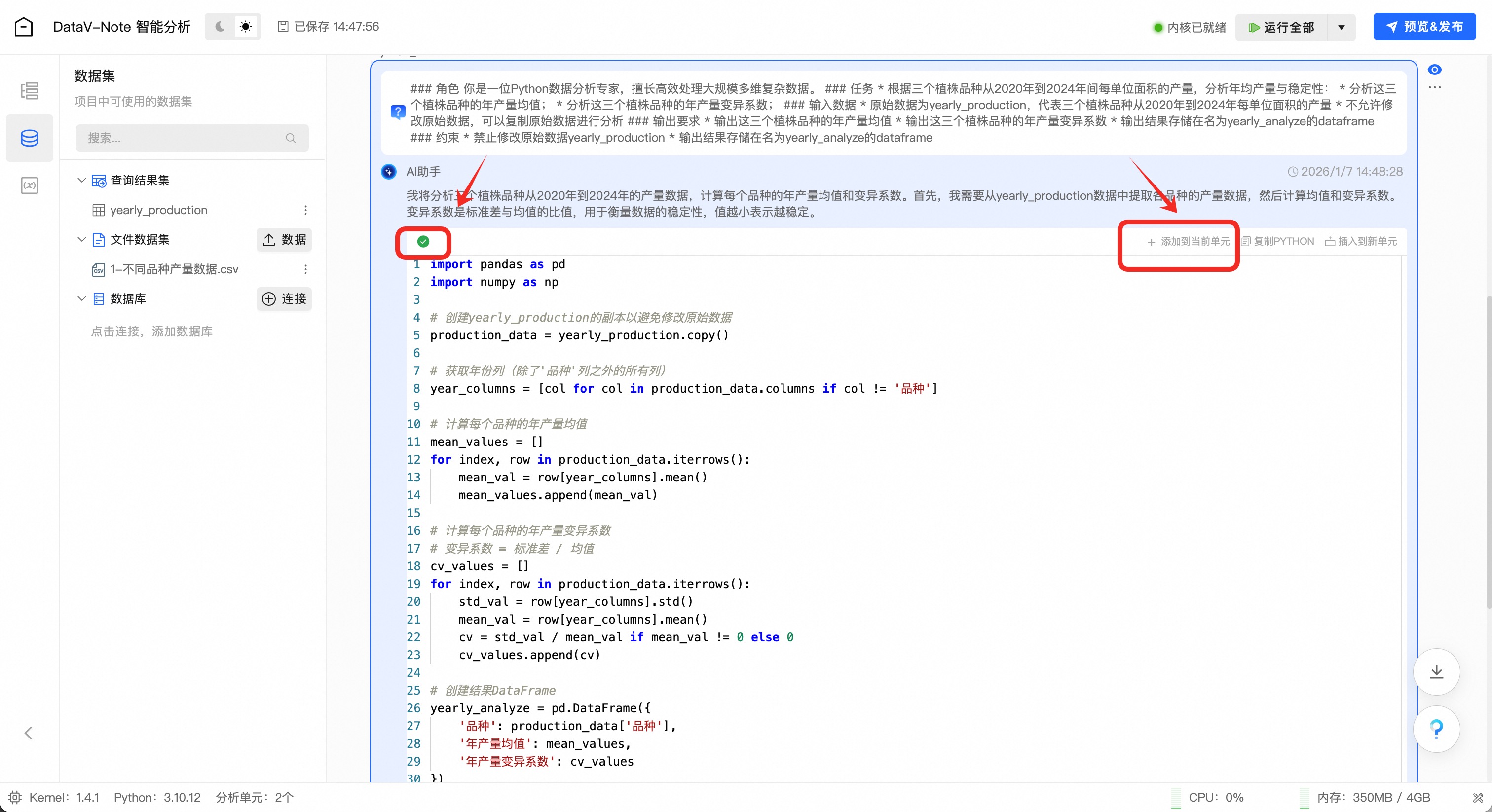
大模型生成Python数据分析代码之后(左侧提示灯变绿),点击代码框右上角“添加到当前单元”按钮
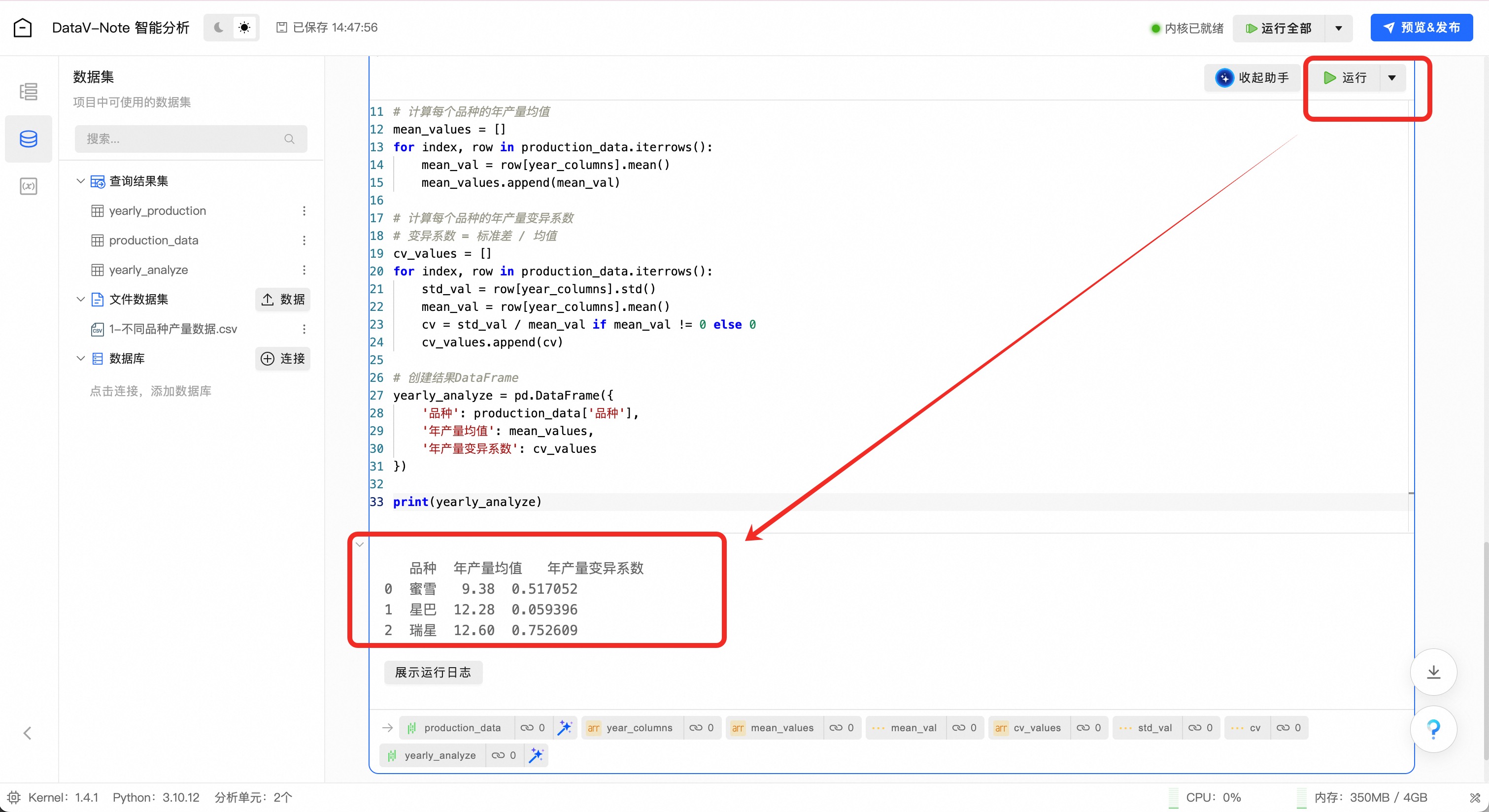
添加代码到编辑框后,点击编辑框右上角的“运行”按钮:
运行代码之后,可以看到分析结果已经出现
1.4 分析结果可视化与解读
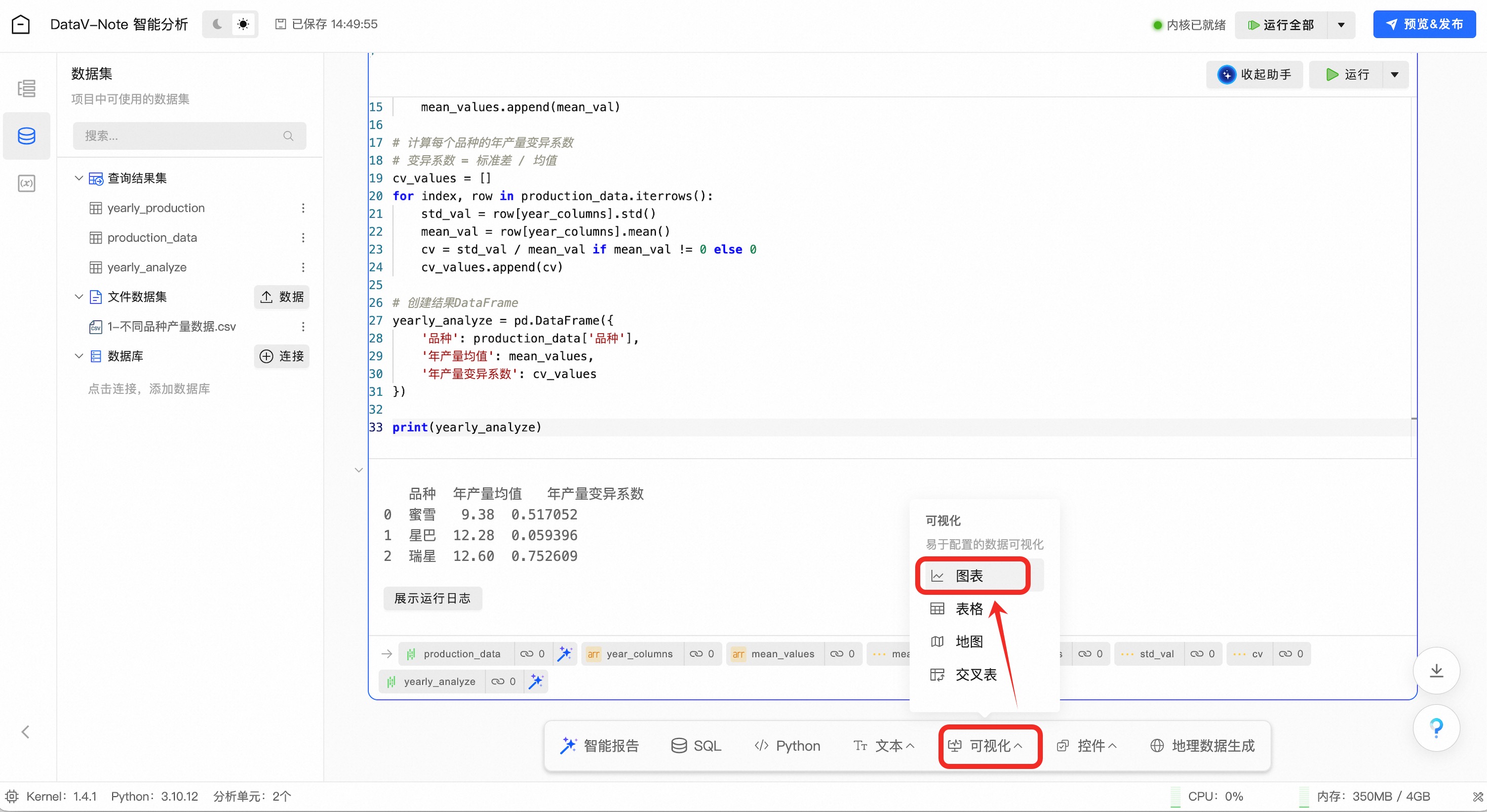
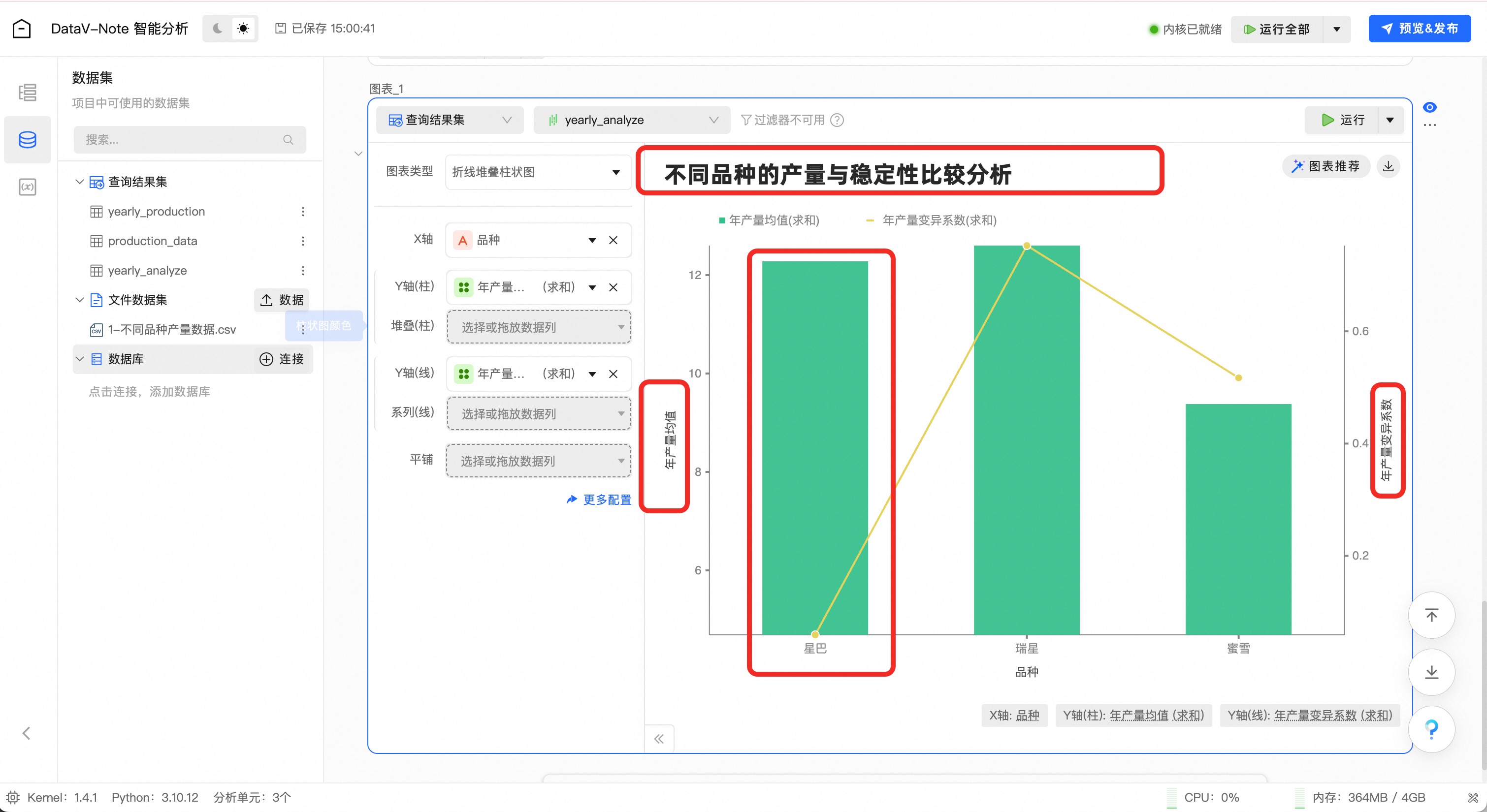
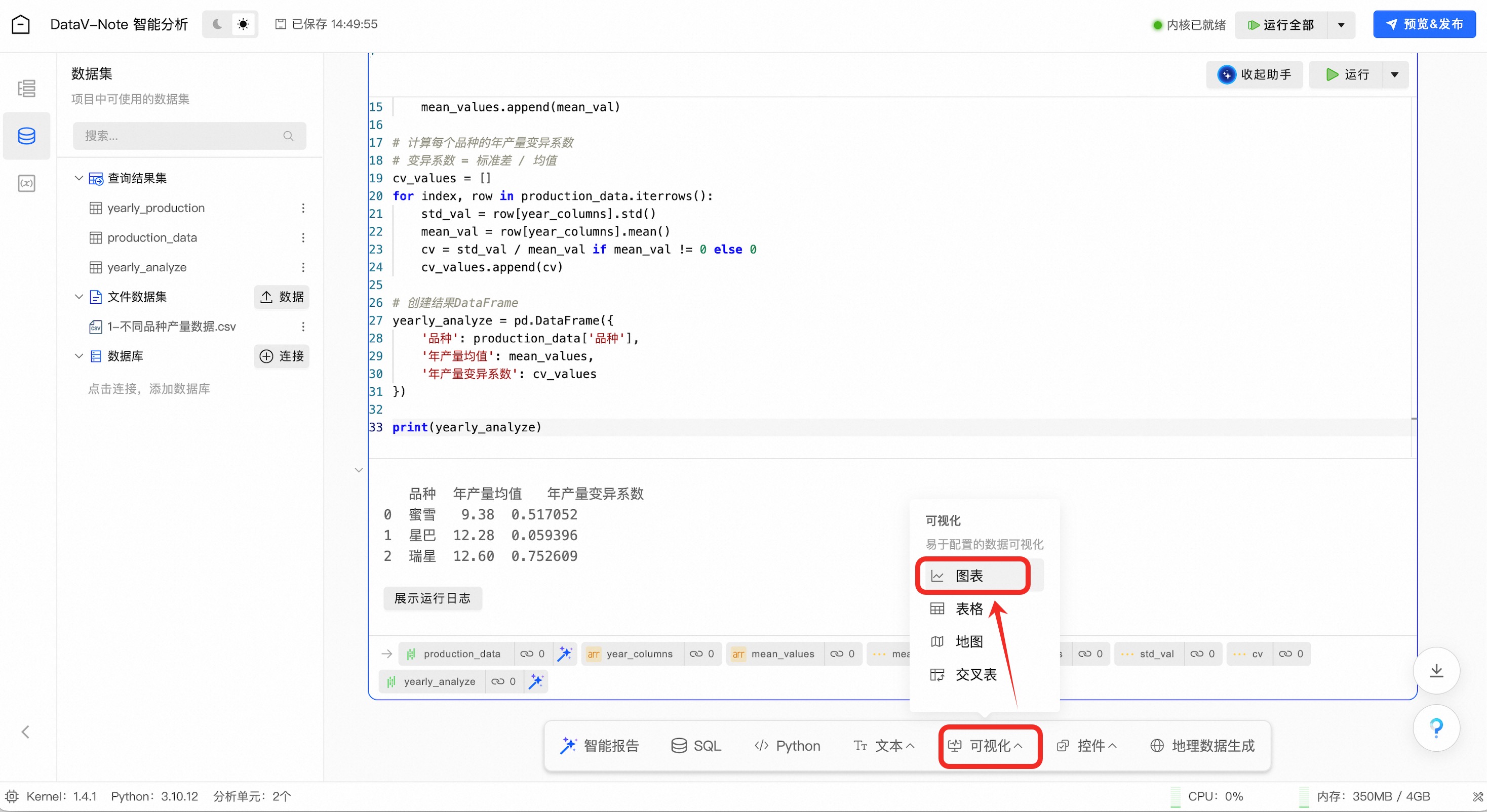
在底部工具栏点击“可视化”按钮,在弹出的菜单中选择“图表”
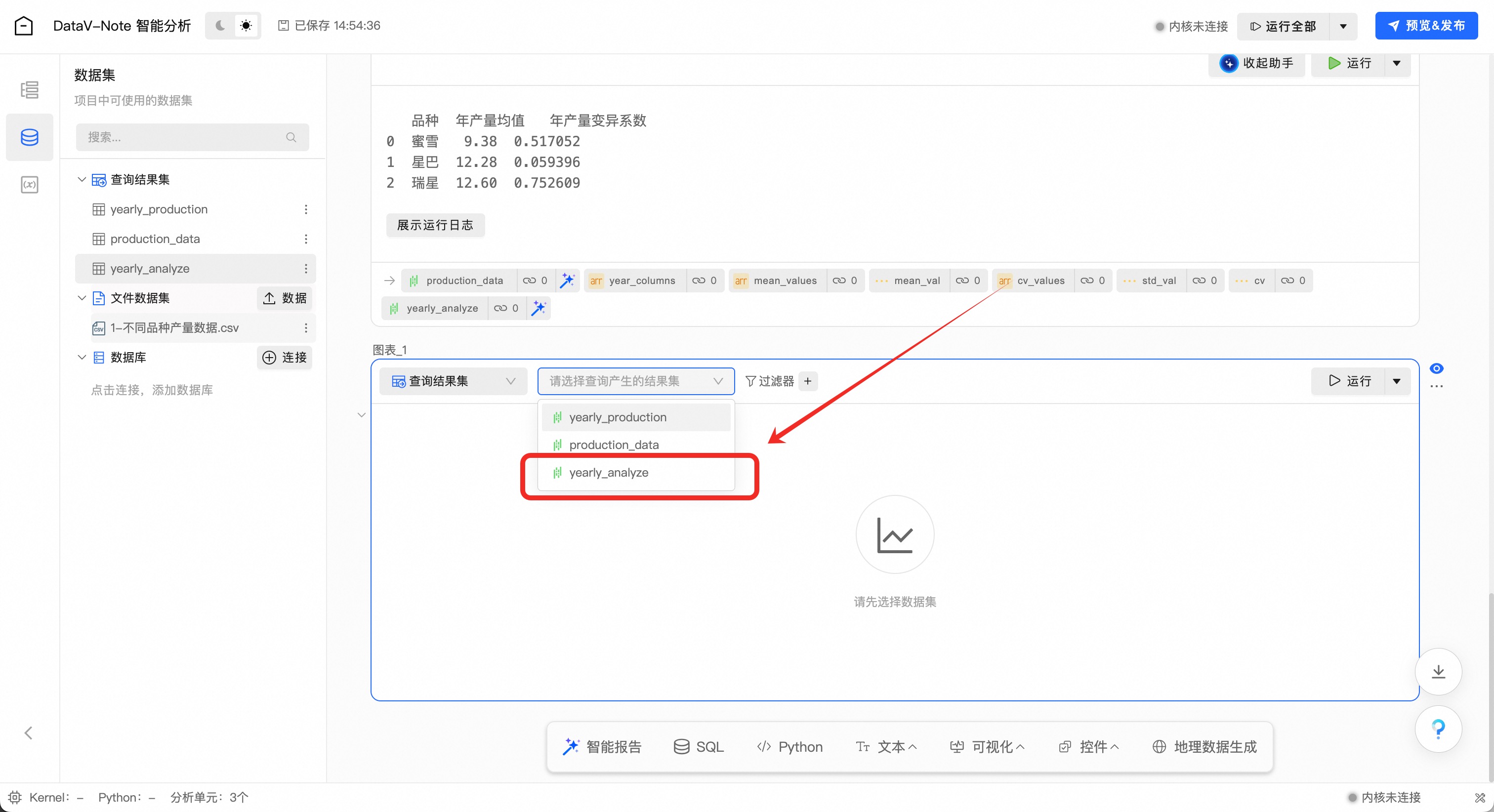
点击图表单元顶端的数据选择下拉菜单,选择刚刚处理生成的数据集:yearly_analyze
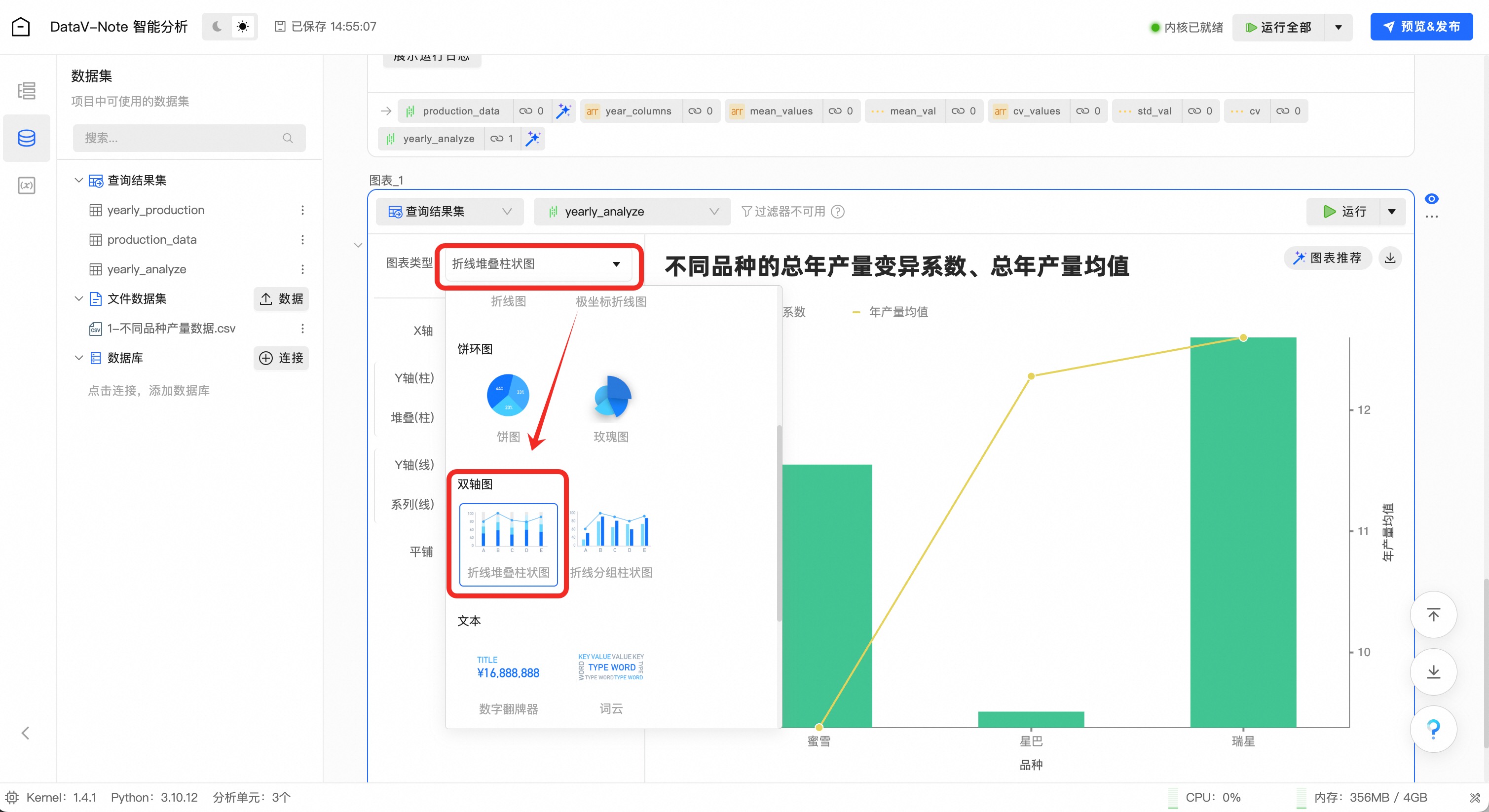
在图表类型中,选择适合的图表形式,例如“双轴折线柱状图”
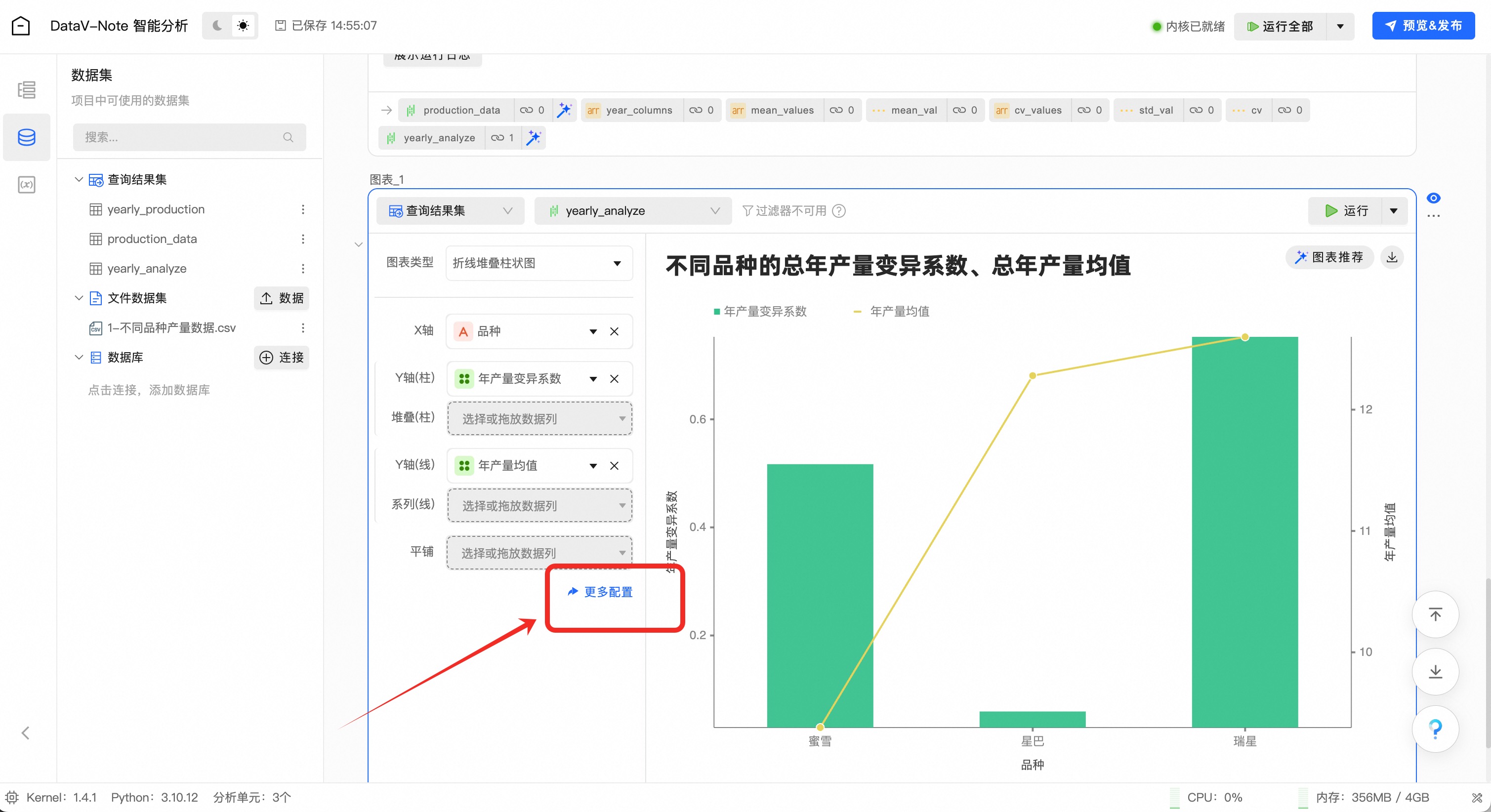
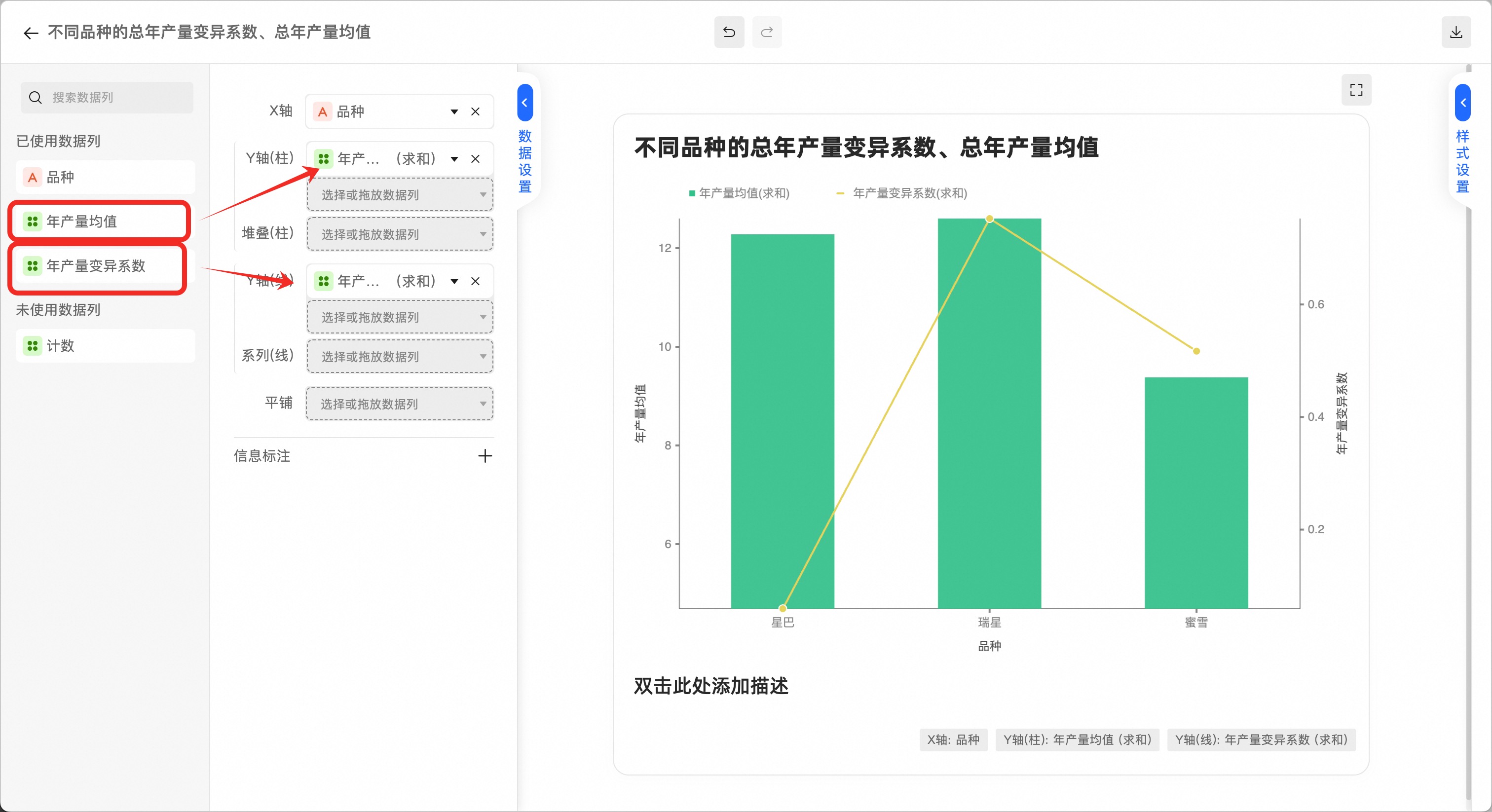
点击“更多配置”,修改数据映射项、标题等图表选项
将“年产量均值”拖放映射为柱状图例
将“年产量变异系数”拖放映射为折线图例
修改完后,点击左上角返回数据分析界面
至此,三个品种植株的年产量数据分析完成,可以发现“星巴”这个品种不仅平均含糖量高且变异系数低,是一个高产且稳定的酿酒好品种;
实验(二):根据偏好筛选葡萄品种-多维性状数据智能分析
“数据是育种的指南针” :通过系统的数据分析,育种者可以在海量的基因库中精准定位,快速筛选出具备优良遗传潜力的个体,极大缩短育种周期,提升选育效率。
植物性状数据分析是现代育种的核心驱动力。它不仅揭示了表型差异背后的遗传机制,还帮助育种家精准定位抗逆性、产量与品质等关键性状的遗传变异。这种“数字化育种”策略能显著加速品种选育过程,使得从基因组到田间表现的转化更加高效、科学。
本节内容通过AI工具探索分析多维性状数据:通过口味、耐存储维度,筛选合适的植株品种;
2.1 下载数据备用
数据说明:
本数据为样本数据
数据概览
数据下载:
点击以下链接下载数据,3-葡萄性状表-修正版-final.csv
说明注意:数据下载后,不要用Excel或其他软件打开/修改;直接进行数据上传学习平台操作
2 .2 上传数据
(2.2.1)新建分析项目
请参考【1.2.1】的章节内容;
说明注意:项目名称不要和现存项目重名
(2.2.2)上传数据
请参考【1.2.2】的章节内容;
点击工具栏左侧-文件数据集-数据
(2.3.3)载入数据到分析区
请参考【1.2.3】的章节内容;
点击工具栏左侧—文件数据集—刚上传数据旁边的三个小点菜单,在弹出的菜单中选择“创建SQL查询”选项
(2.3.4)变量重命名
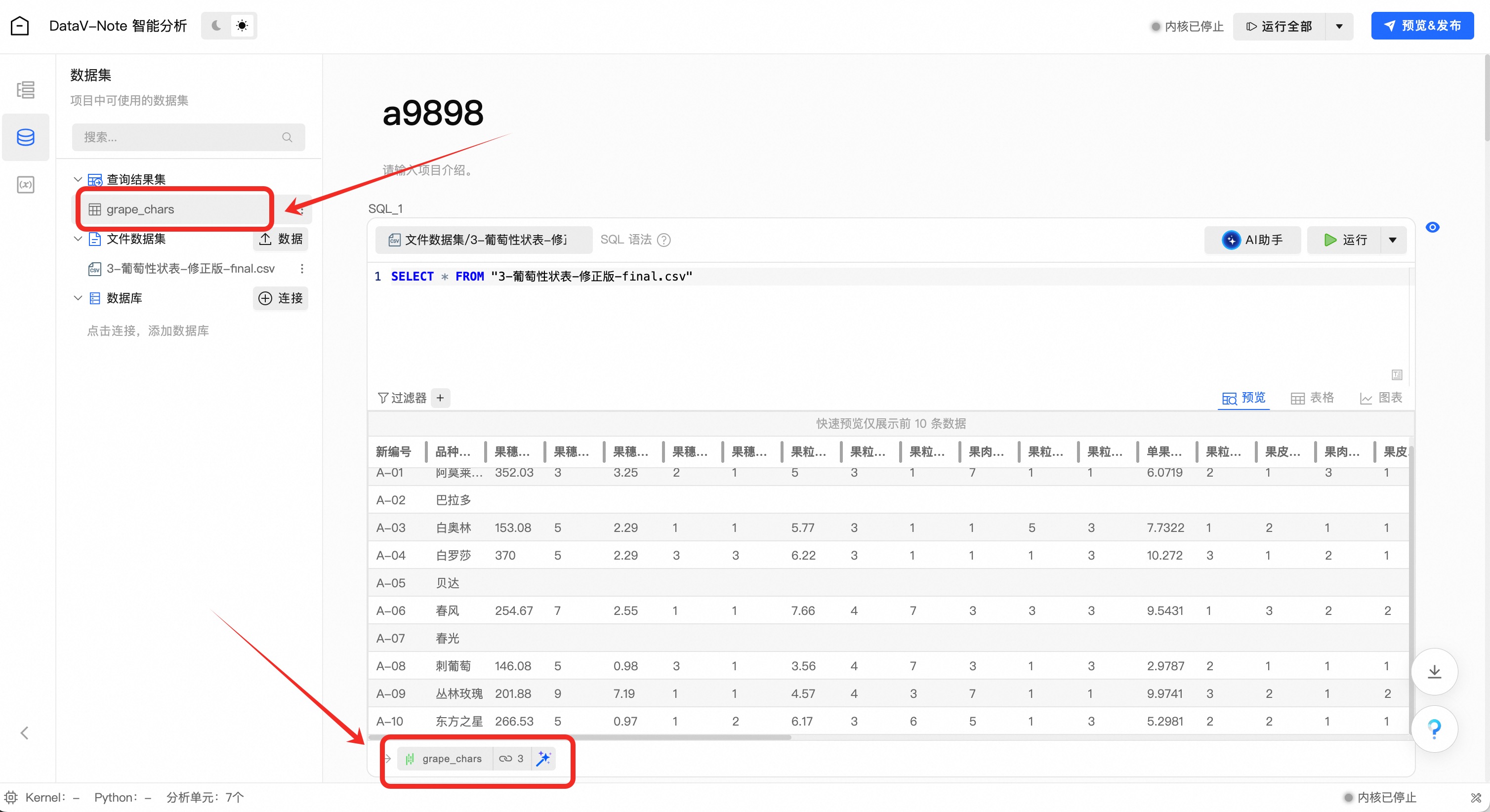
鼠标双击左下角数据表名“result_1”,将表名改为“grape_chars”
说明注意:非常重要!表名“grape_chars”是后续python数据分析中引用的变量名称,如不一致后续大模型提示词会出错!
2.3 数据分析
(2.3.1)提示词样例
从样例葡萄性状数据中为3套筛选方案各自筛选出5个最优葡萄品种,提示词样例如下:
说明注意:本提示词主要示意如何撰写提示词进行python数据分析,对于专业领域的正确性/可用性不保证;
### 角色 你是一位Python数据分析专家,擅长高效处理大规模多维复杂数据。 ### 任务 * 从原数据grape_chars复制一份数据另存为grape_chars_copy; * 从“口味”和“耐存储”两个方面设计3套方案筛选葡萄优良品种: * 口味优先型方案:“口味”占权重0.7,“耐存储”占权重0.3; * 耐存储优先型方案:“口味”占权重0.3,“耐存储”占权重0.7; * 均衡型方案:“口味”占权重0.5,“耐存储”占权重0.5; * “口味”方面包含以下字段: * 果粒香型 * 果粒颜色 * 果肉花青苷着色程度 * 果粒种子状况 * 果皮涩味 * 单果粒重量 * “耐存储”方面包含以下字段: * 果皮厚度 * 果粒与果柄分离难易程度 * 果肉质地 * 果穗大小 * 果穗紧密度 * 把“口味”和“耐存储”两方面包含的各个字段转换为数值型后再标准化为0~1之间;如果有值小于等于0或者空缺,则设为0; * 从数据grape_chars_copy中为3套筛选方案各自筛选出5个最优葡萄品种,各方案葡萄品种综合得分按降序排列;结果存为变量grape_best_multi(包含“品种名称”、“综合得分”、“方案类型”3个字段) ### 输入数据 * 原始数据为grape_chars,包括葡萄的各种性状字段; ### 输出要求 * 输出结果存为变量grape_best_multi(包含“品种名称”、“综合得分”、“方案类型”3个字段) ### 约束 * 禁止修改原始数据grape_chars(2.3.2)AI助手数据分析
点击下方工具栏“python”按钮
在新增的python代码框右上角,点击“AI助手”
将上述的大模型提示词复制后粘贴到AI助手输入框中,并点击输入框右侧按钮
大模型生成Python数据分析代码之后(左侧提示灯变绿),点击代码框右上角“添加到当前单元”按钮
添加代码到编辑框后,点击编辑框右上角的“运行”按钮:
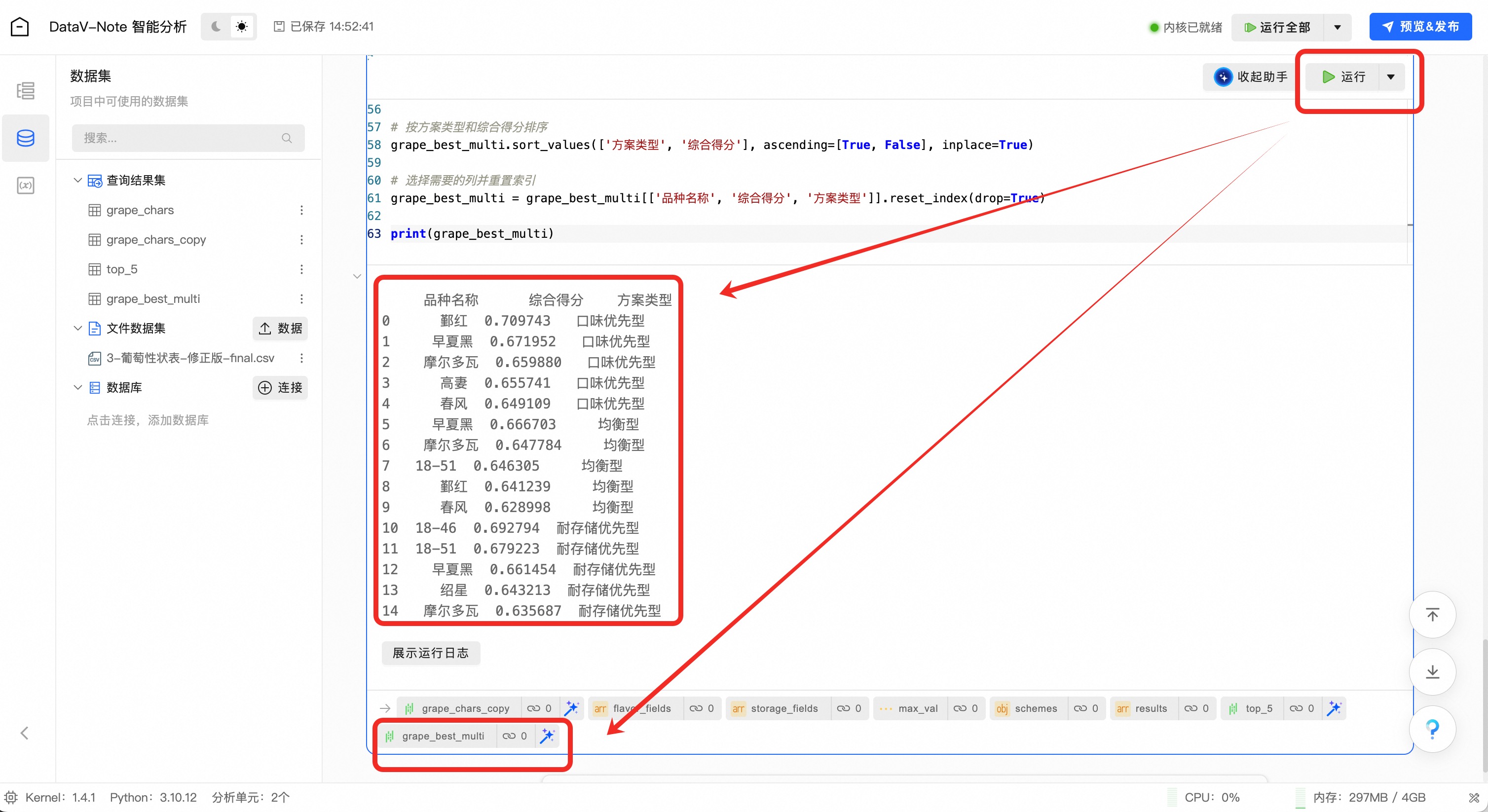
运行代码之后,可以看到分析结果已经出现
AI助手已经完成3套方案筛选,并把结果存入了grape_best_multi变量
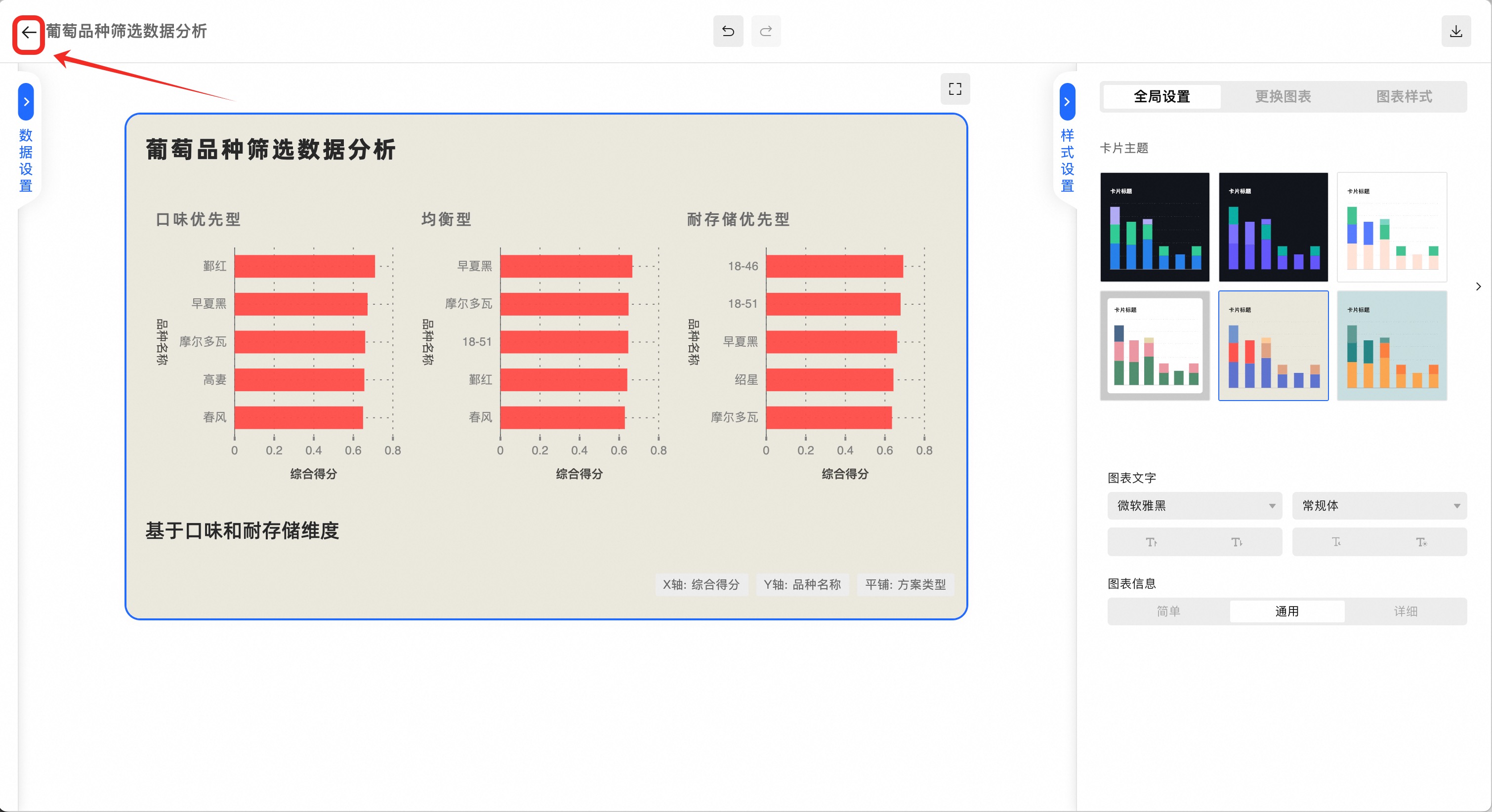
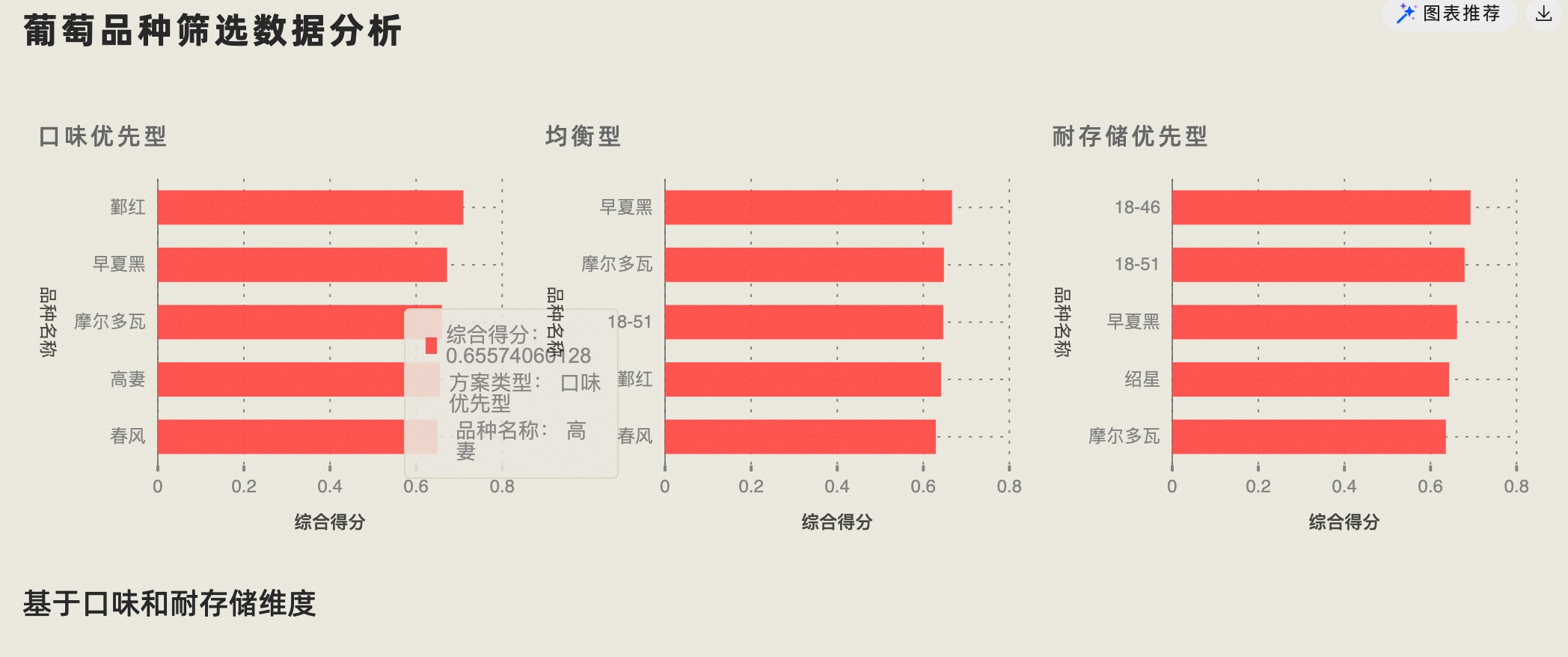
2.4 数据可视化与结果解读
(2.4.1)分析数据可视化
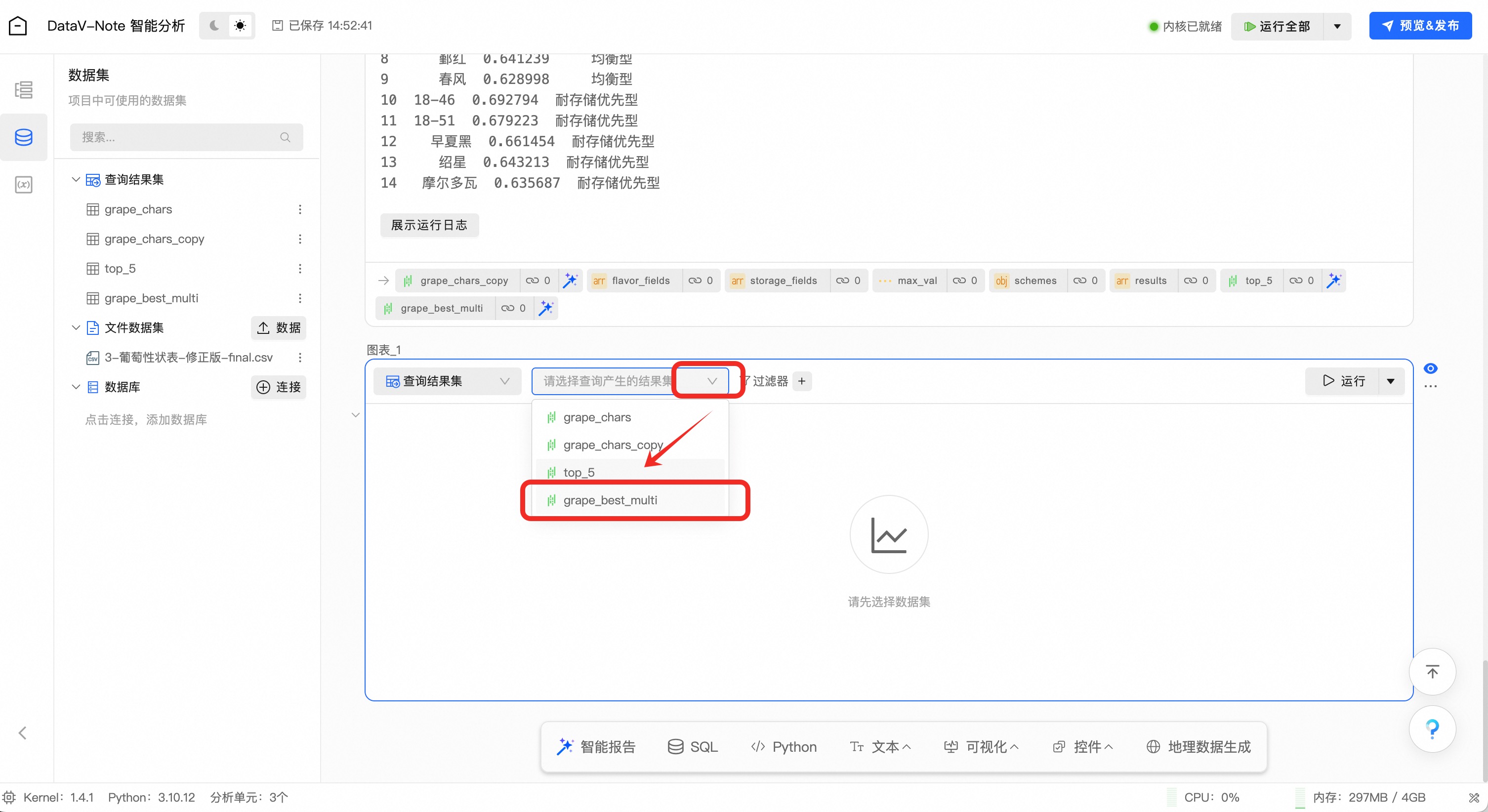
在底部工具栏点击“可视化”按钮,在弹出的菜单中选择“图表”
点击图表单元顶端的数据选择下拉菜单,选择刚刚处理生成的数据集grape_best_multi
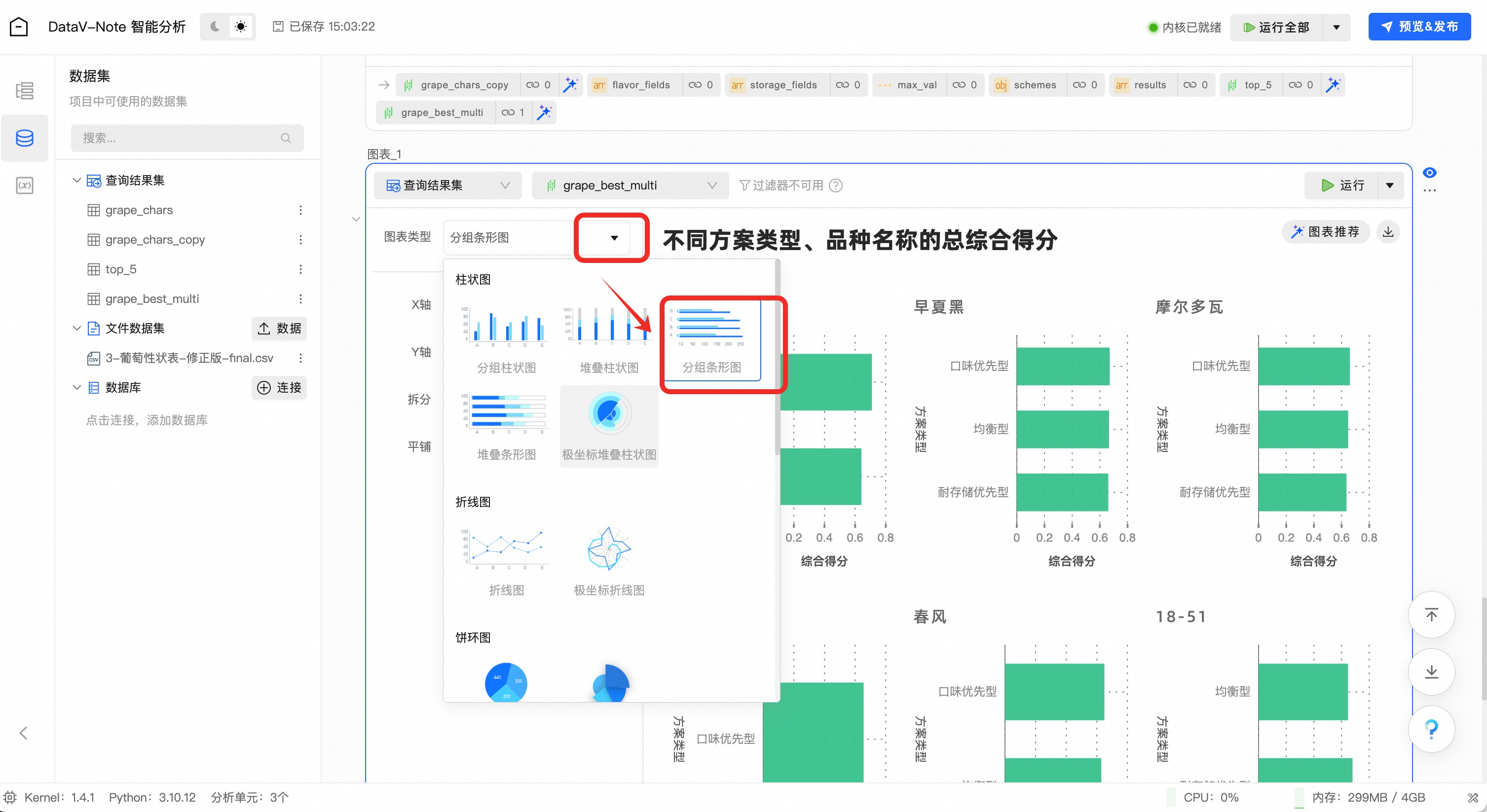
在图表类型下拉菜单,选择“分组条形图”
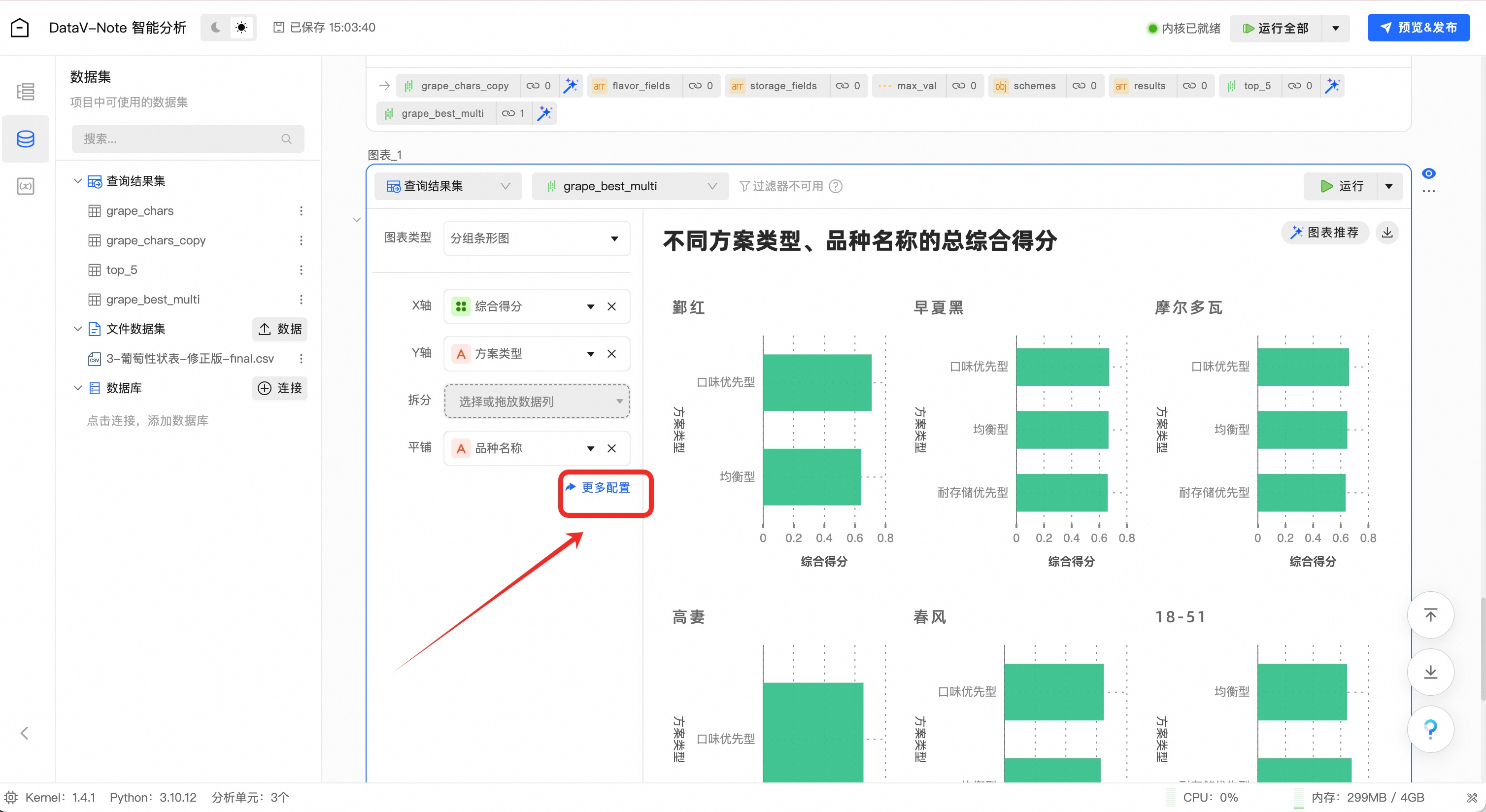
点击“更多配置”,进行数据映射和标题等样式设置
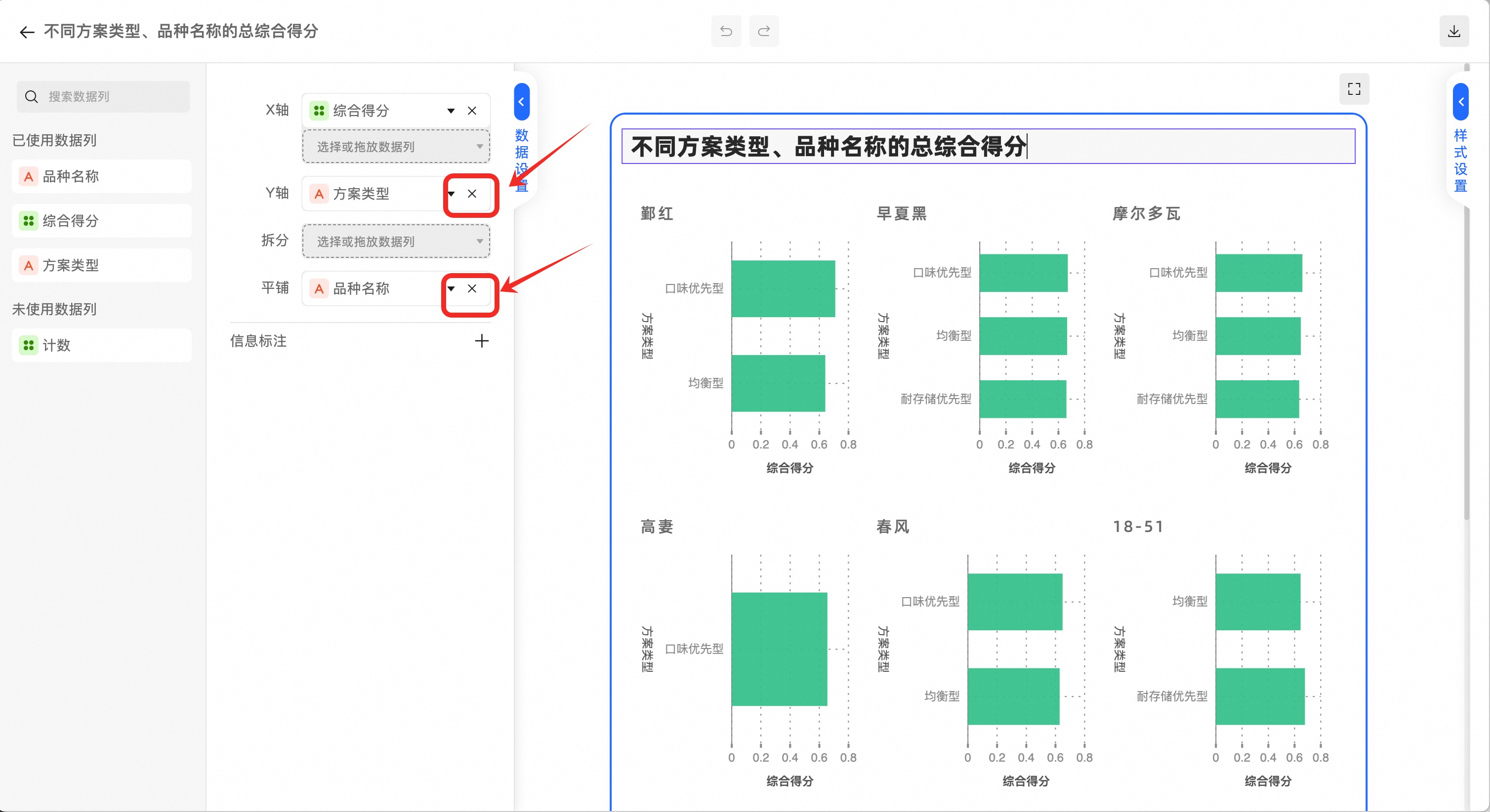
先将默认的数据映射清除,点击x按钮
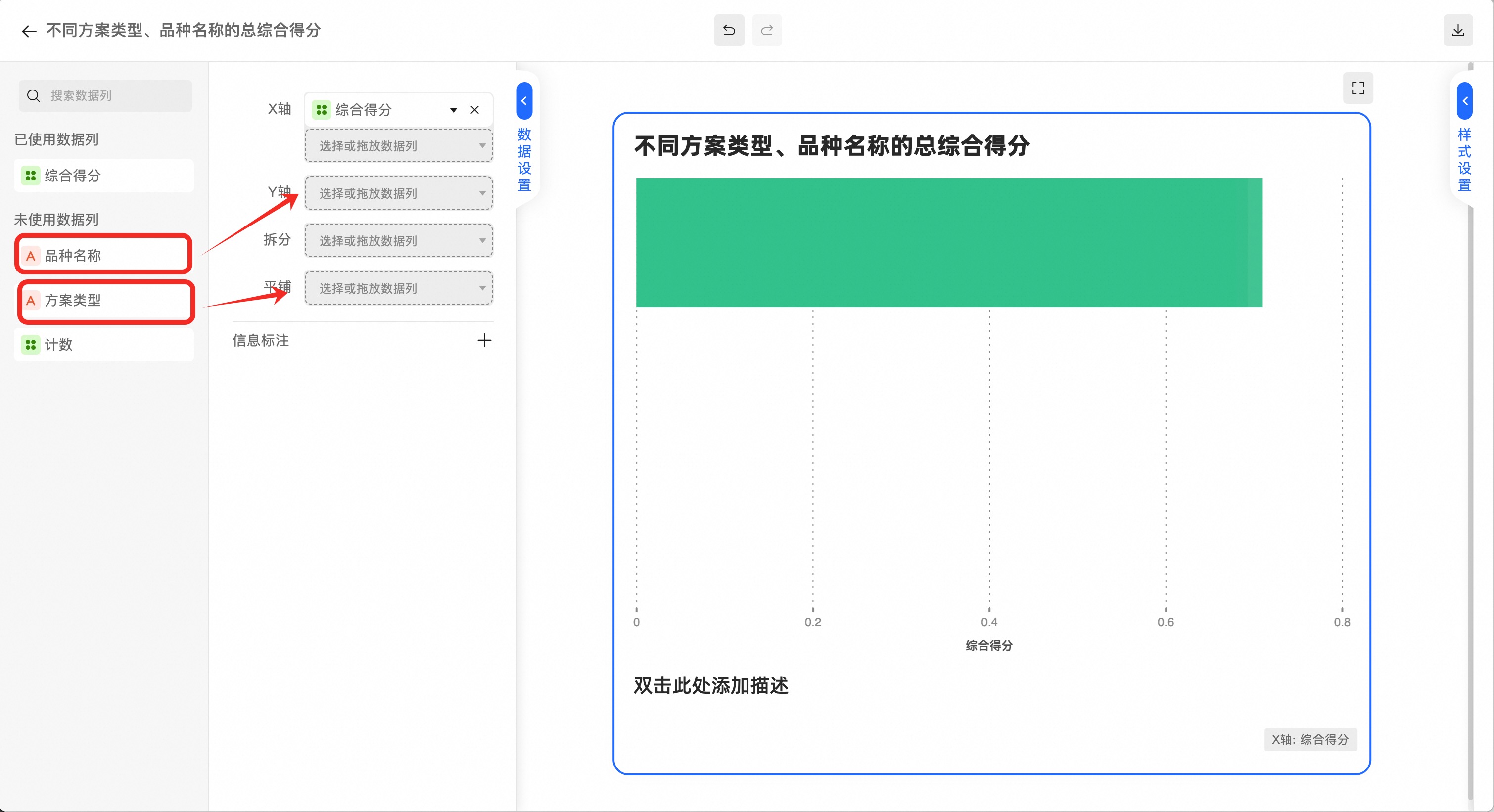
将数据项拖放到如图位置
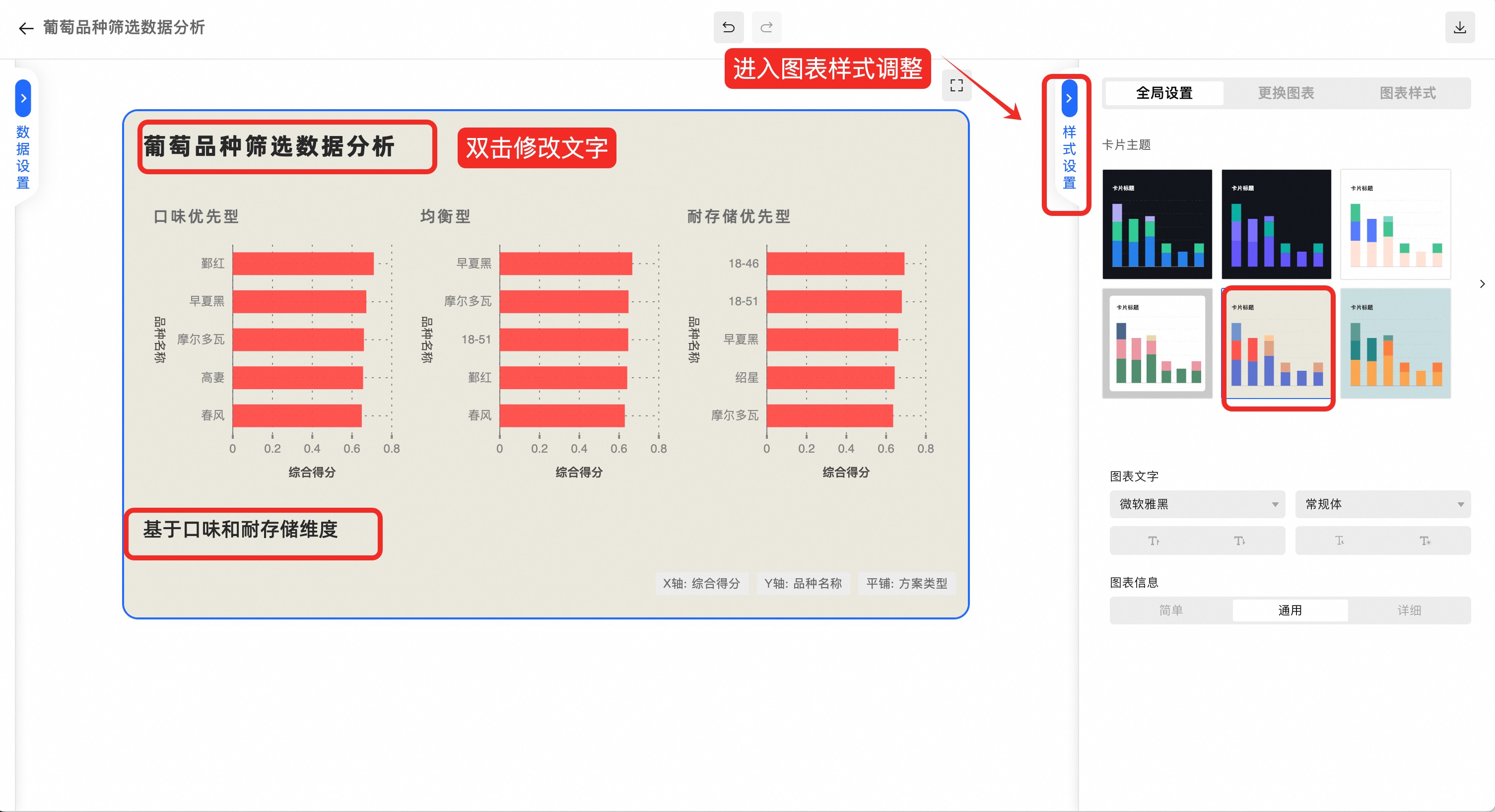
再进行图表标题和样式美化:
点击左上角返回按钮,完成数据可视化操作:
(2.4.2)分析结果解读
最终大模型按提示词需求,按口味和耐存储的不同偏好,筛选出了3套品种选择。
实验(三):入侵物种分析-地理数据增强上图
常规隐性地理数据如只具备行政区域编码代号的数据放上地图是一件比较复杂的工作,需要根据代码进行数据的收集和加工处理,再用专业地图工具进行展示;如实验二的操作步骤。
本节内容将借助大模型,实现隐性地理数据AI增强与快速上图;
3.1 下载数据备用
数据说明:
本数据为样本数据
数据概览
数据下载:
点击以下链接下载数据,宁波入侵物种-全部-原始数据.csv
说明注意:数据下载后,不要用Excel或其他软件打开/修改;直接进行数据上传学习平台操作
3.2 上传数据
(3.2.1)新建分析项目
请参考【1.2.1】的章节内容;
说明注意:项目名称不要和现存项目重名
(3.2.2)上传数据
请参考【1.2.2】的章节内容;
点击工具栏左侧-文件数据集-数据
(3.2.3)载入数据到分析区
请参考【1.2.3】的章节内容;
点击工具栏左侧—文件数据集—刚上传数据旁边的三个小点菜单,在弹出的菜单中选择“创建SQL查询”选项
(3.2.4)变量重命名
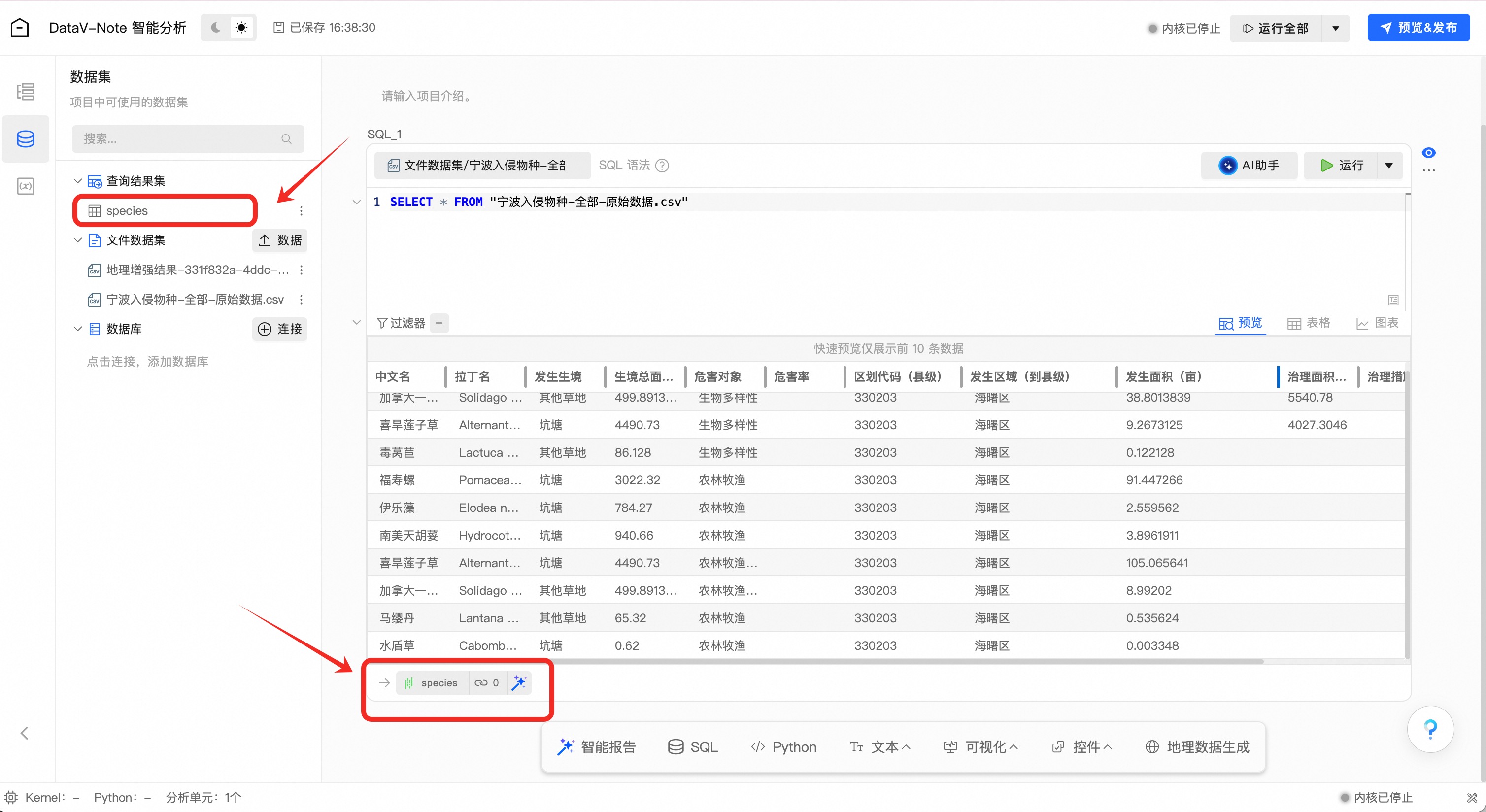
鼠标双击左下角数据表名“result_1”,将表名改为“species”
说明注意:非常重要!表名“species”是后续python数据分析中引用的变量名称,如不一致后续大模型提示词会出错!
3.3 地理数据智能增强
(3.3.1)提示词样例
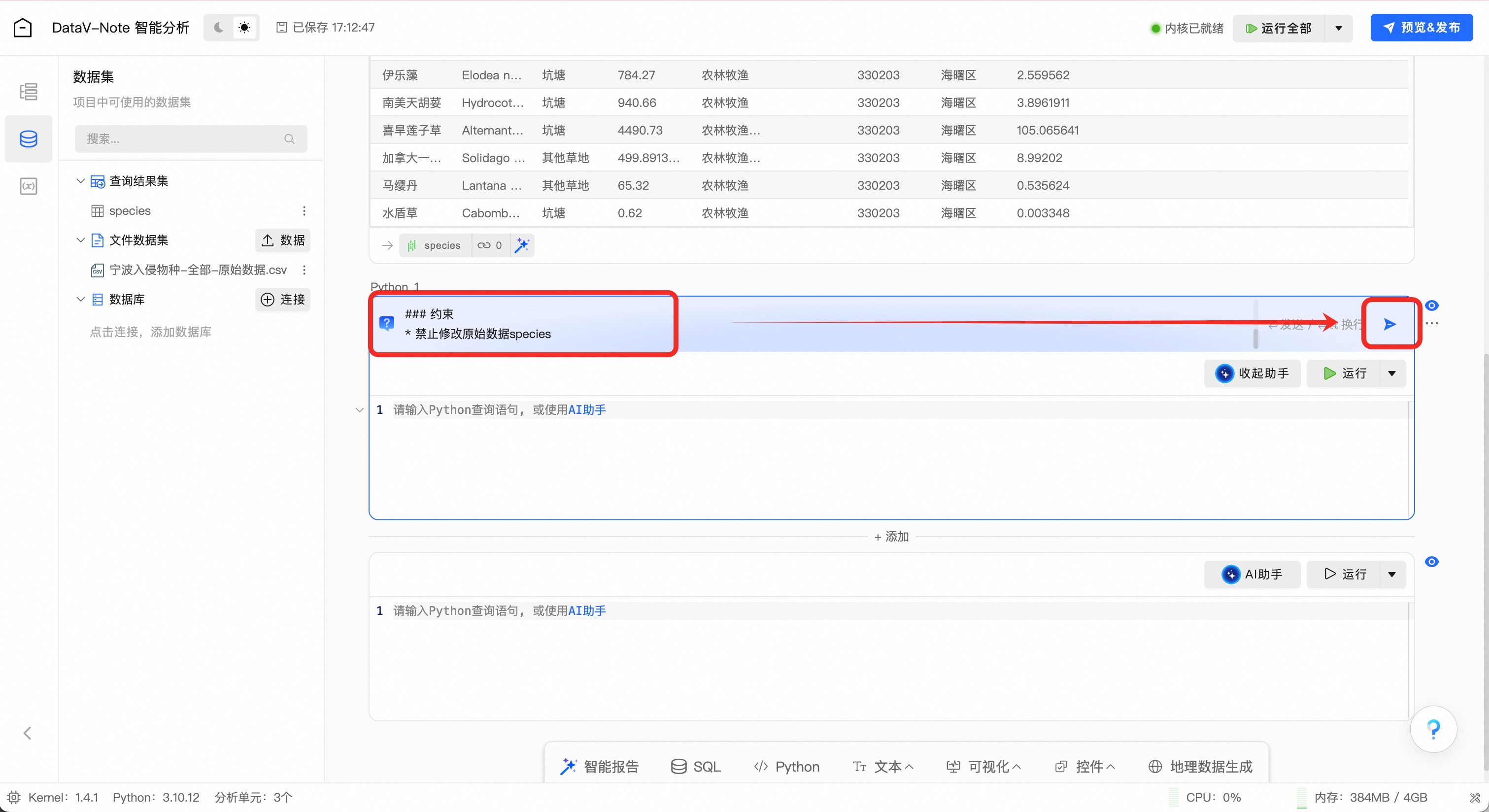
提示词将入侵物种原始详细数据按“区划代码(县级)”列,对发生面积(亩)进行聚合:
### 角色 你是一位Python数据分析专家,擅长高效处理大规模多维复杂数据。 ### 任务 * 从原数据species拷贝如下字段并存为新数据species_copy:中文名、区划代码(县级)、发生区域(到县级)、发生面积(亩); * 将数据species_copy中“发生面积(亩)”字段转为数值型; * 数据species_copy按“区划代码(县级)”列,对发生面积(亩)进行聚合;聚合结果输出为species_region(包含区划代码(县级)、发生区域(到县级)、发生入侵总面积(亩)三个字段) ### 输出要求 * 聚合结果输出为species_region(包含区划代码(县级)、发生区域(到县级)、发生入侵总面积(亩)三个字段) ### 约束 * 禁止修改原始数据species(3.3.2)详情数据聚合为区县汇总
点击下方工具栏“python”按钮
在新增的python代码框右上角,点击“AI助手”
将上述的大模型提示词复制后粘贴到AI助手输入框中,并点击输入框右侧按钮
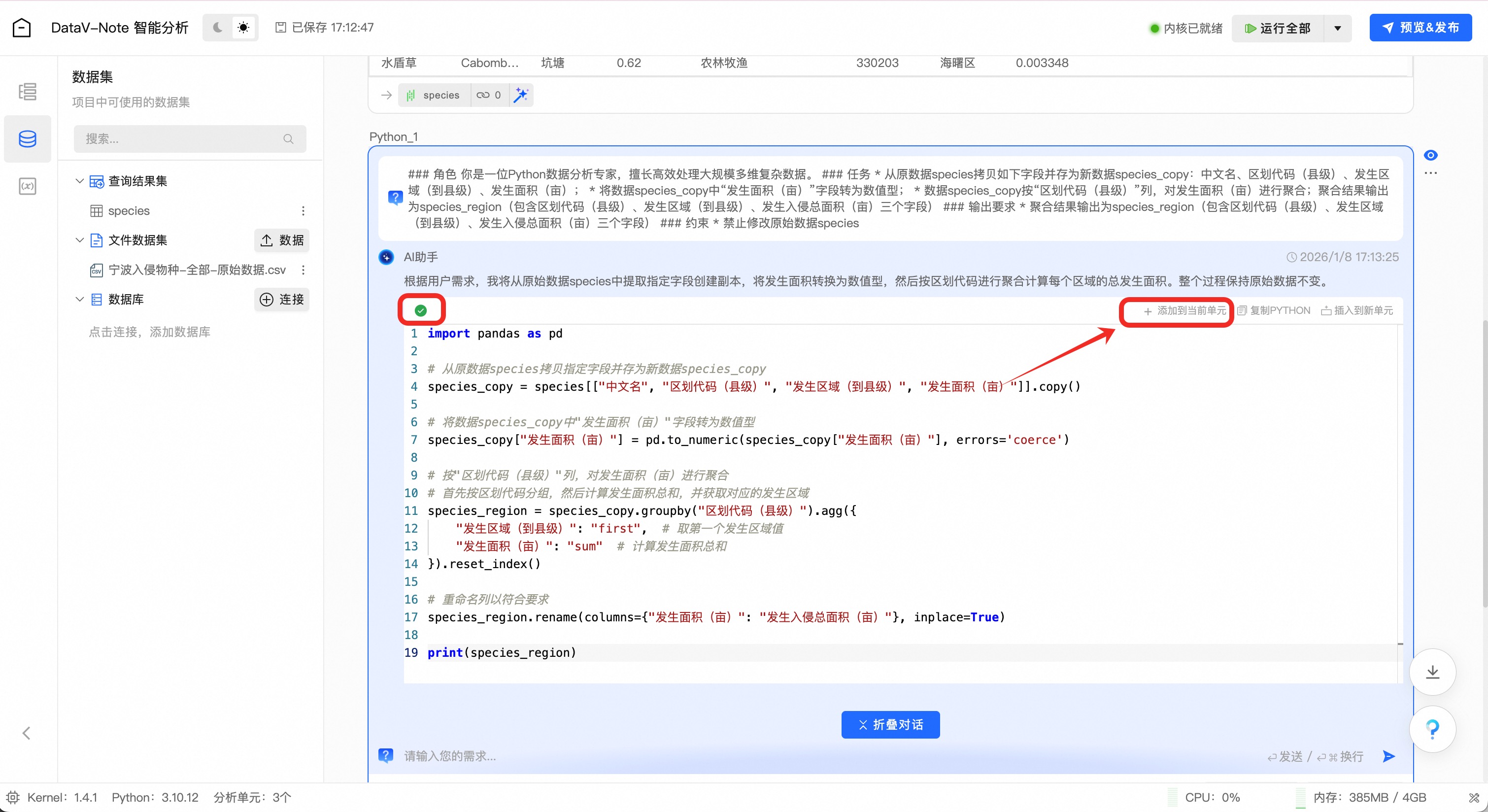
大模型生成Python数据分析代码之后(左侧提示灯变绿),点击代码框右上角“添加到当前单元”按钮
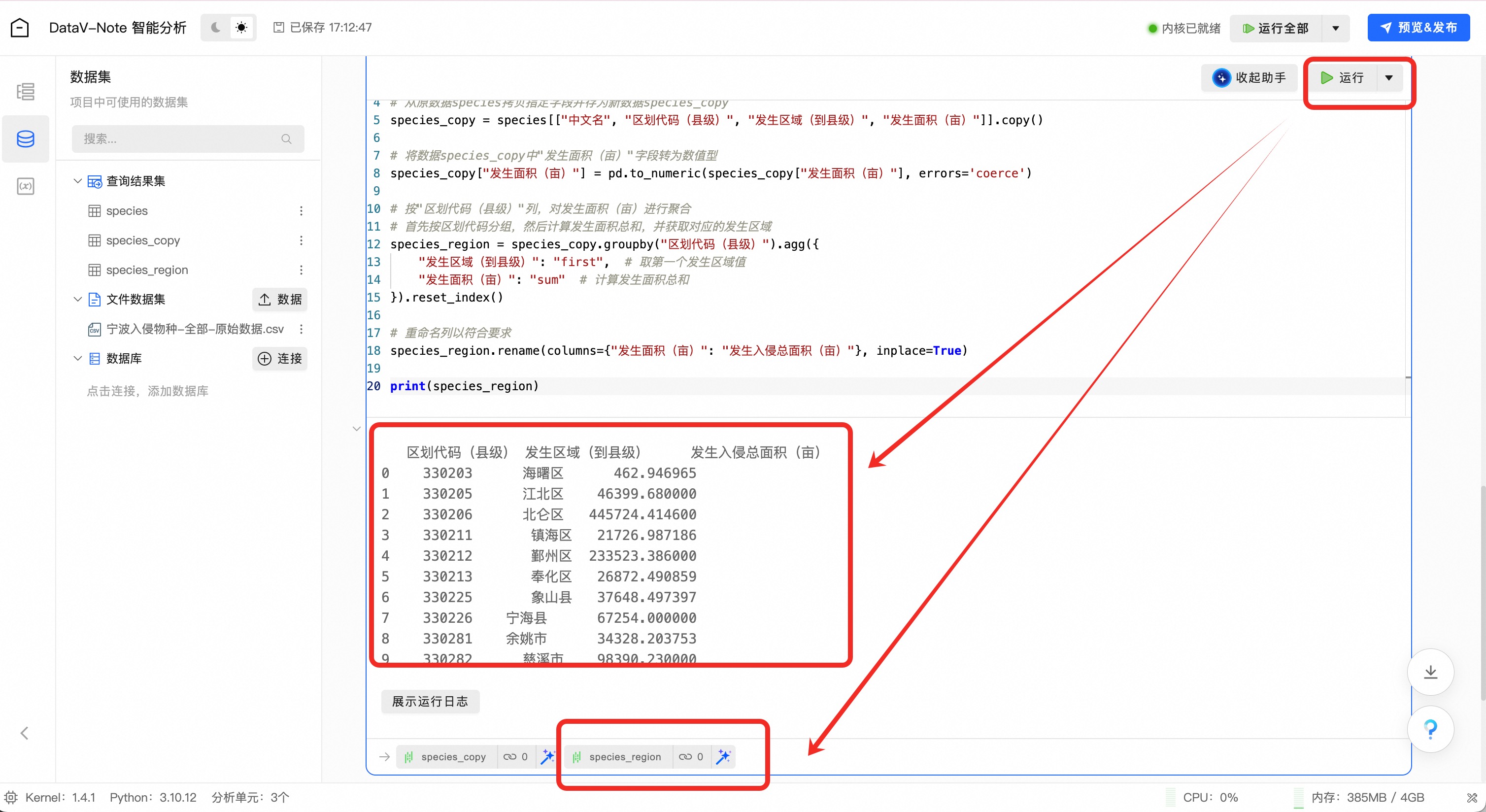
添加代码到编辑框后,点击编辑框右上角的“运行”按钮:
运行代码之后,可以看到分析结果已经出现
AI助手已经完成3套方案筛选,并把结果存入了grape_best_multi变量
(3.3.3)隐性地理数据增强
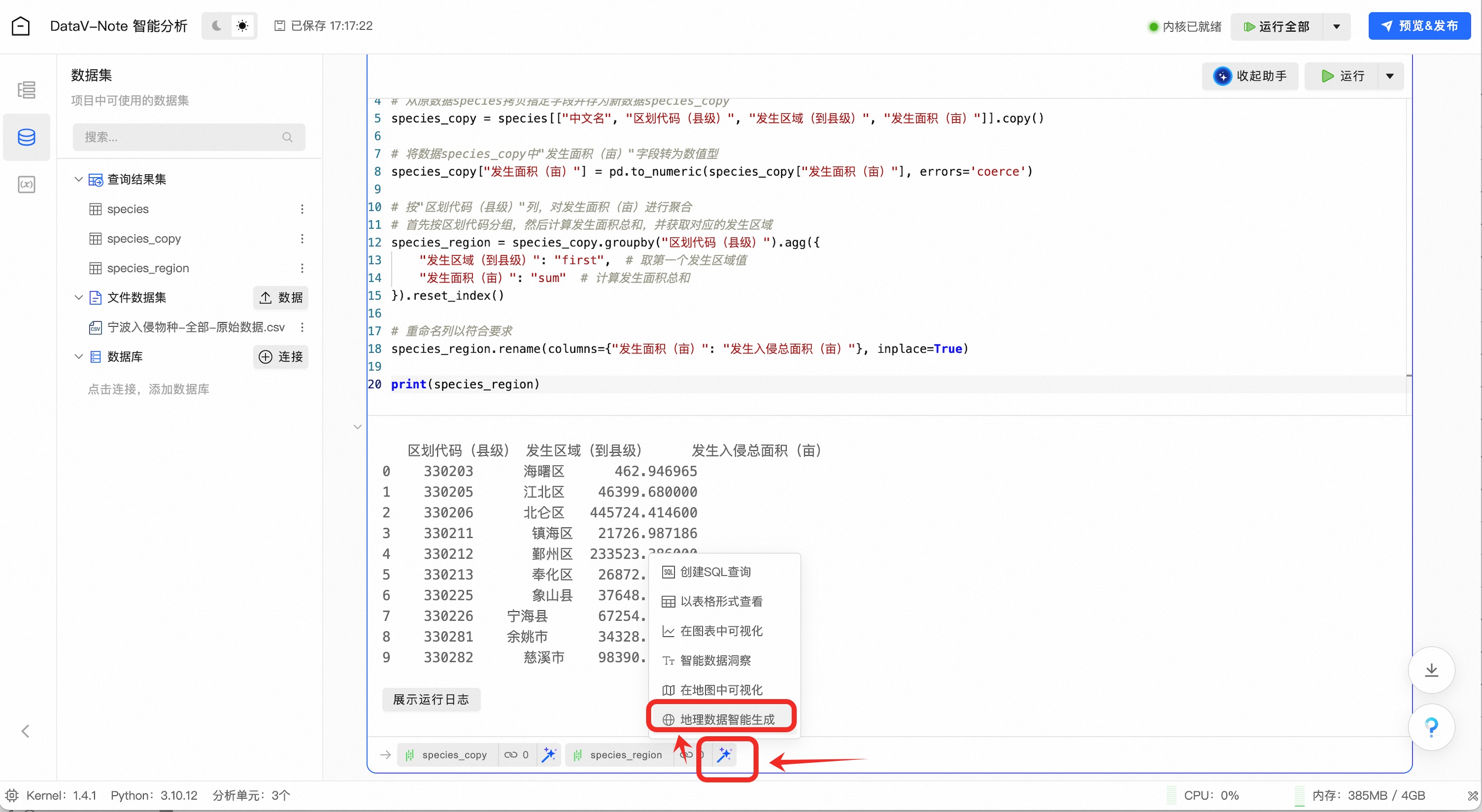
点击生成的species_region变量右侧的魔术棒图标,弹出菜单选择“地理数据智能生成”
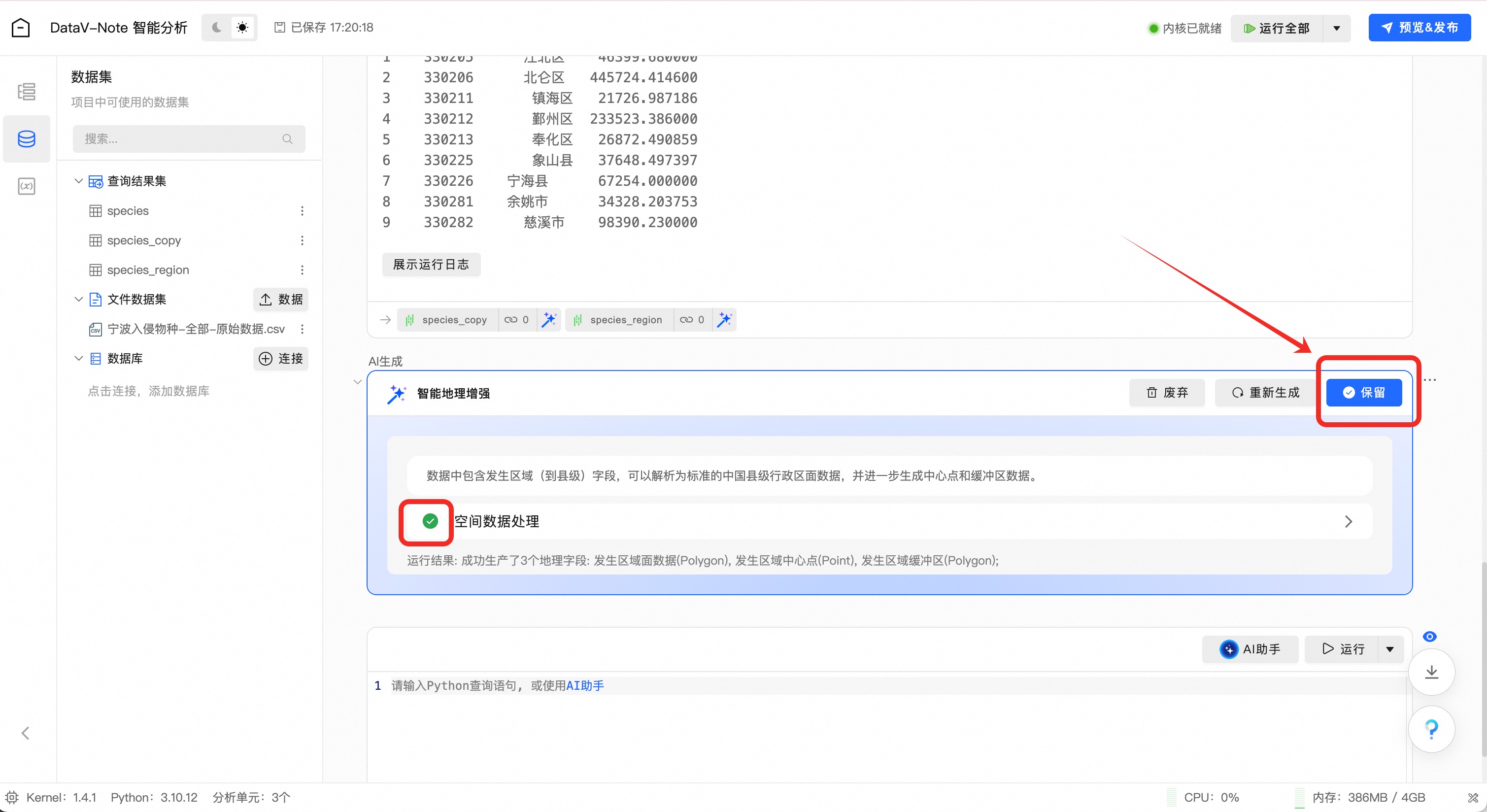
地理数据增强完成之后,点击右上角“保留”按钮
3.4 数据可视化与结果解读
(3.4.1)地理数据可视化
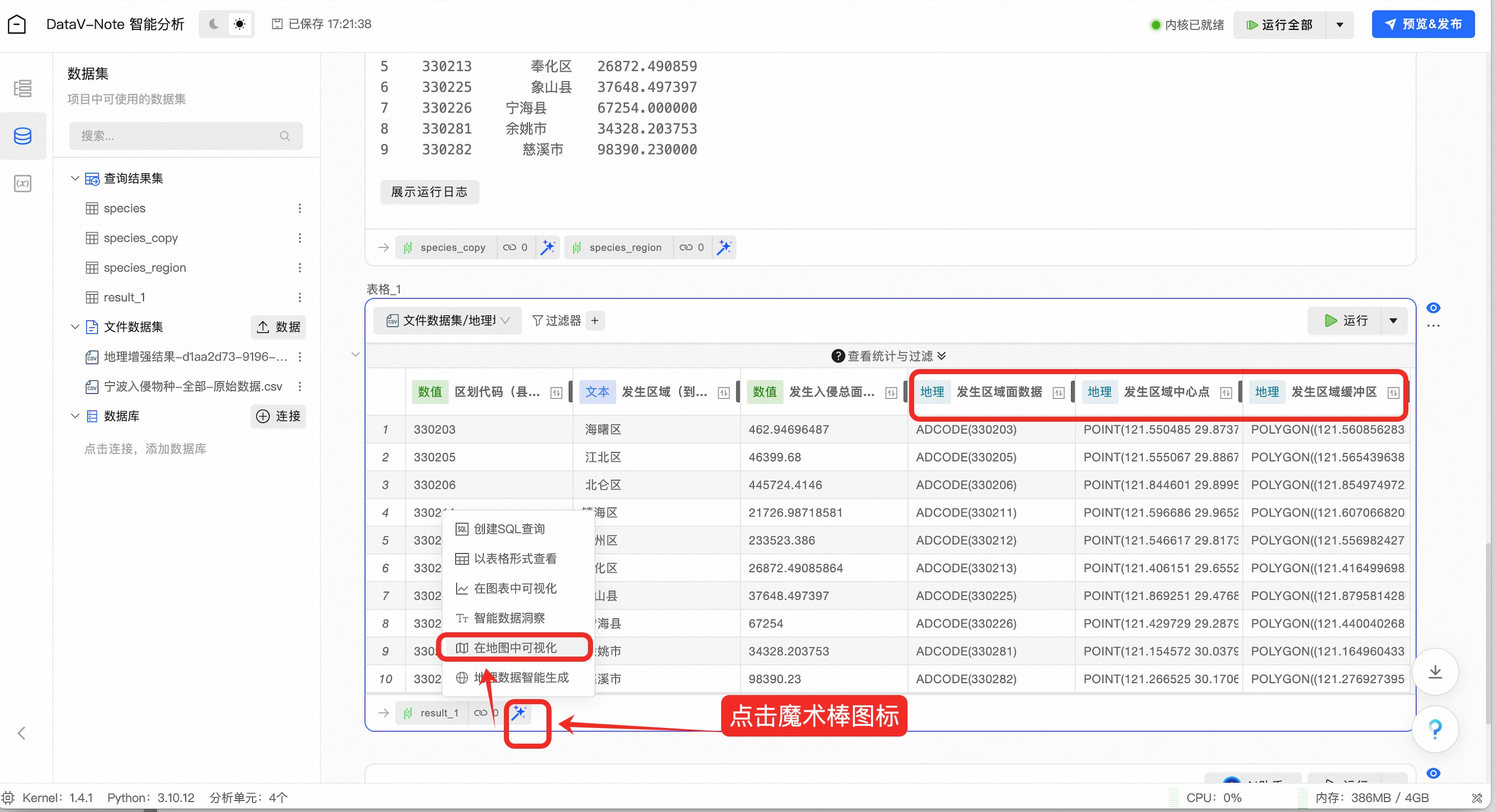
AI助手已经完成地理数据增强,并把结果存入了变量result_1
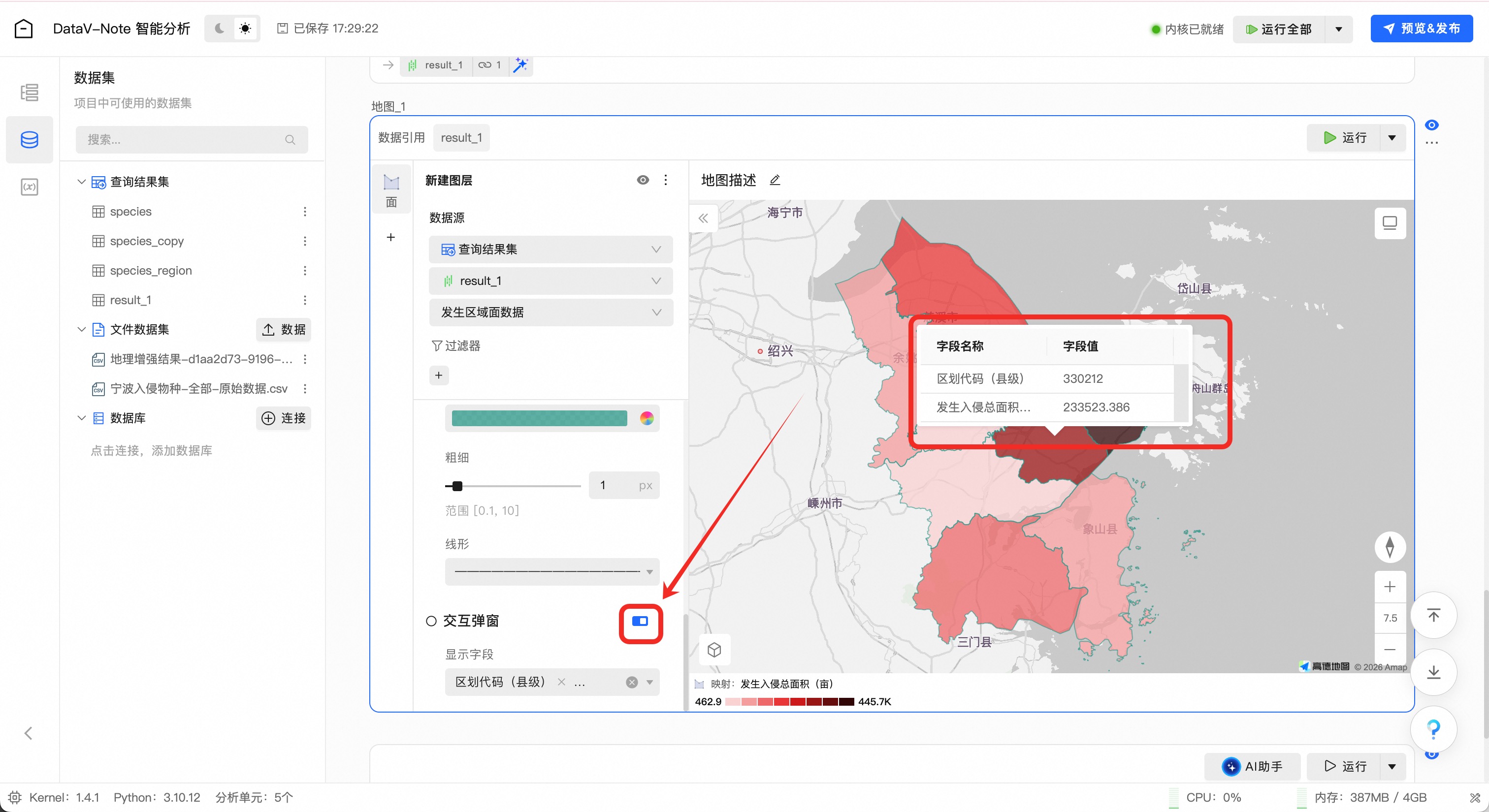
点击生成的result_1变量右侧的魔术棒图标,弹出菜单选择“在地图中可视化”:
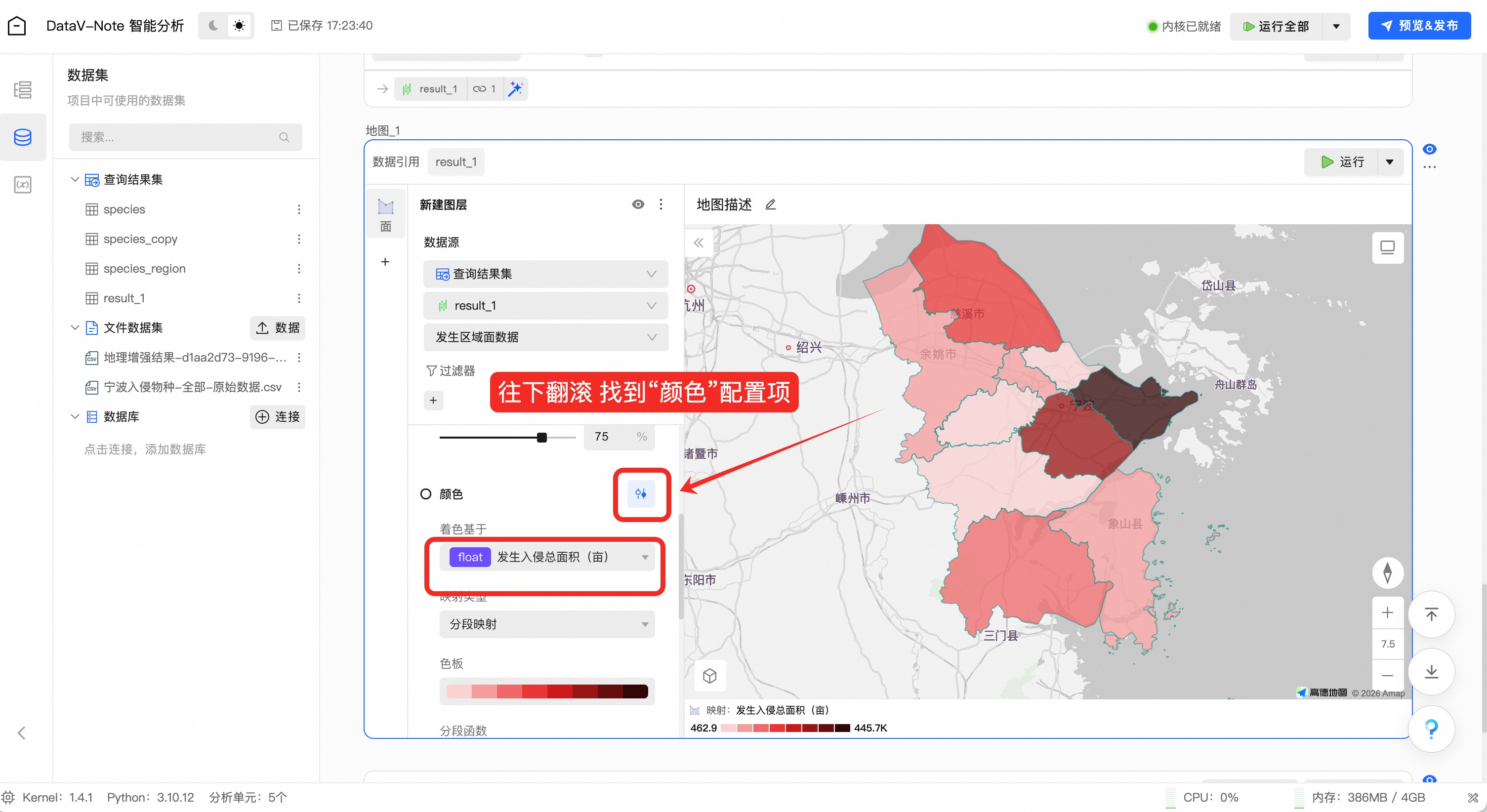
在地图左侧配置面板,往下翻滚找到“颜色”配置项,点击映射开关;
选择“发生入侵总面积(亩)”字段
继续往下翻滚,开启“交互弹窗”选项
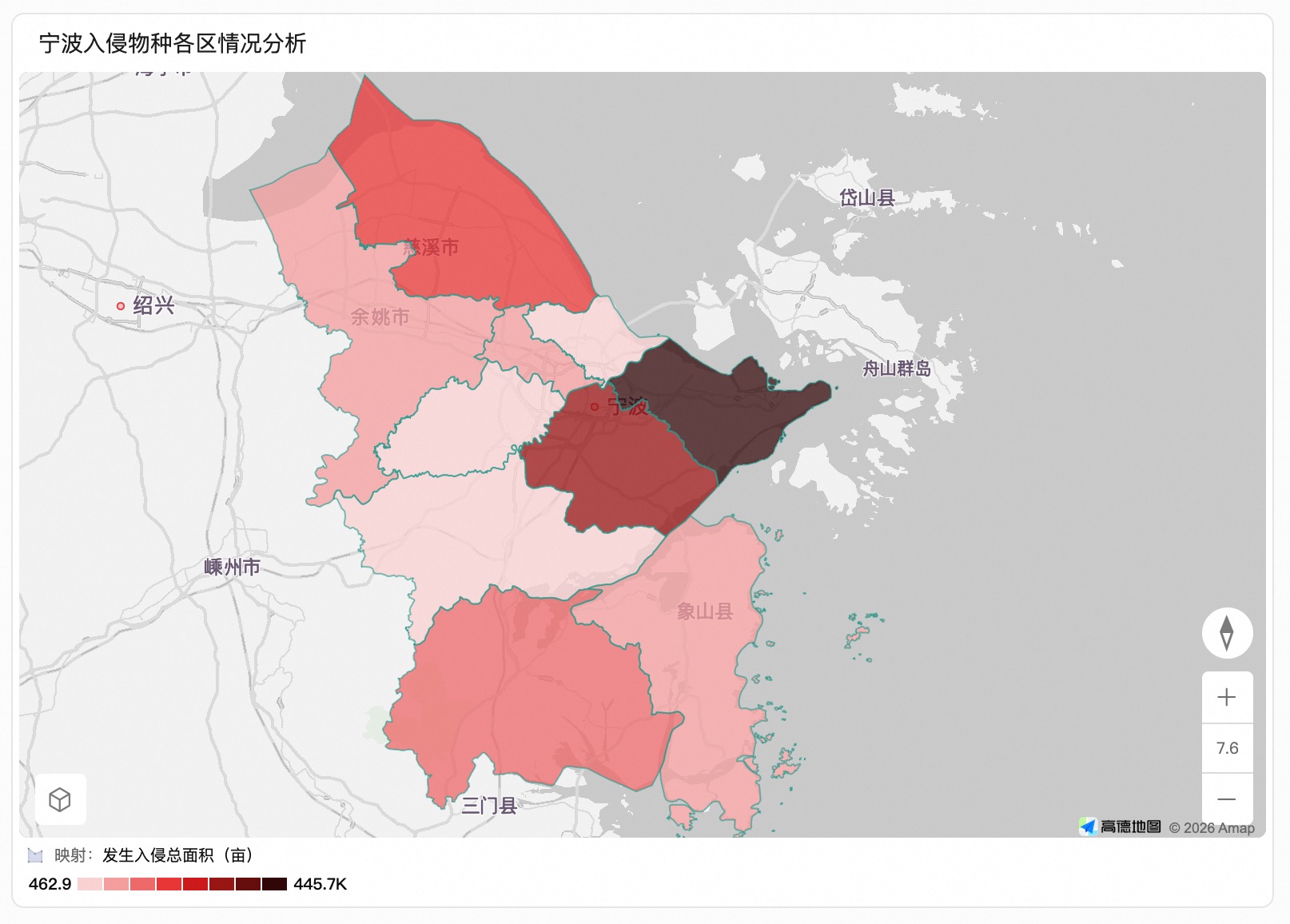
至此,完成了AI增强地理数据并完成地图制作,省去了复杂的数据处理和地图组件搭建工作,提升了地理数据分析与可视化应用效率。
实验(四)课外作业:AI自动写报告-数据智能洞察
本节内容通过AI工具探索分析多维性状数据,并自动撰写报告。
说明注意:大模型自动分析数据并撰写报告属于比较复杂的规划任务,耗时较久,建议课后操作本节内容;AI报告不能替代人类的决策判断,可以将报告结果导出word等中间参考过程,进一步精修。
4.1 下载数据备用
数据说明:
本数据为样本数据
数据概览
数据下载:
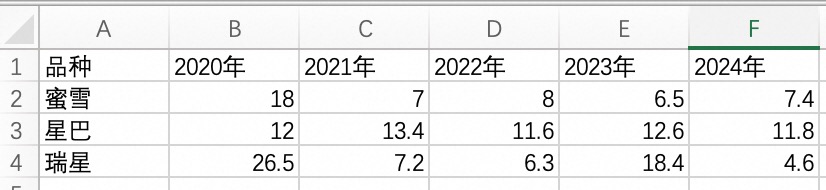
点击以下链接下载数据,葡萄性状表-智能报告数据.xlsx
说明注意:数据下载后,不要用Excel或其他软件打开/修改;直接进行数据上传学习平台操作
4.2 上传数据
(4.2.1)新建分析项目
请参考【1.2】的章节内容;
说明注意:项目名称不要和现存项目重名
4.3 用AI自动撰写分析报告
(4.3.1)选择需要分析的数据
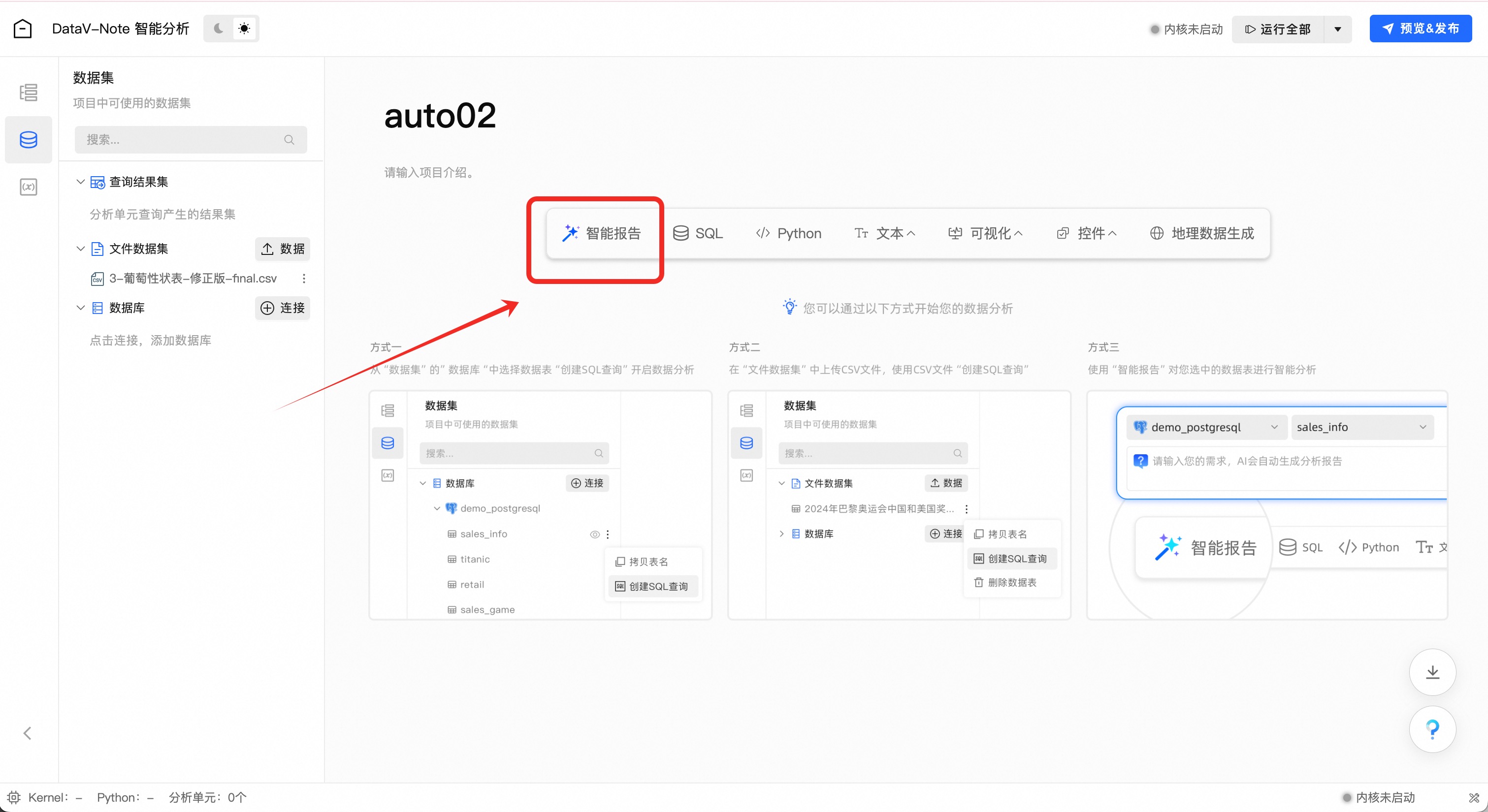
点击工具栏的“智能报告”按钮
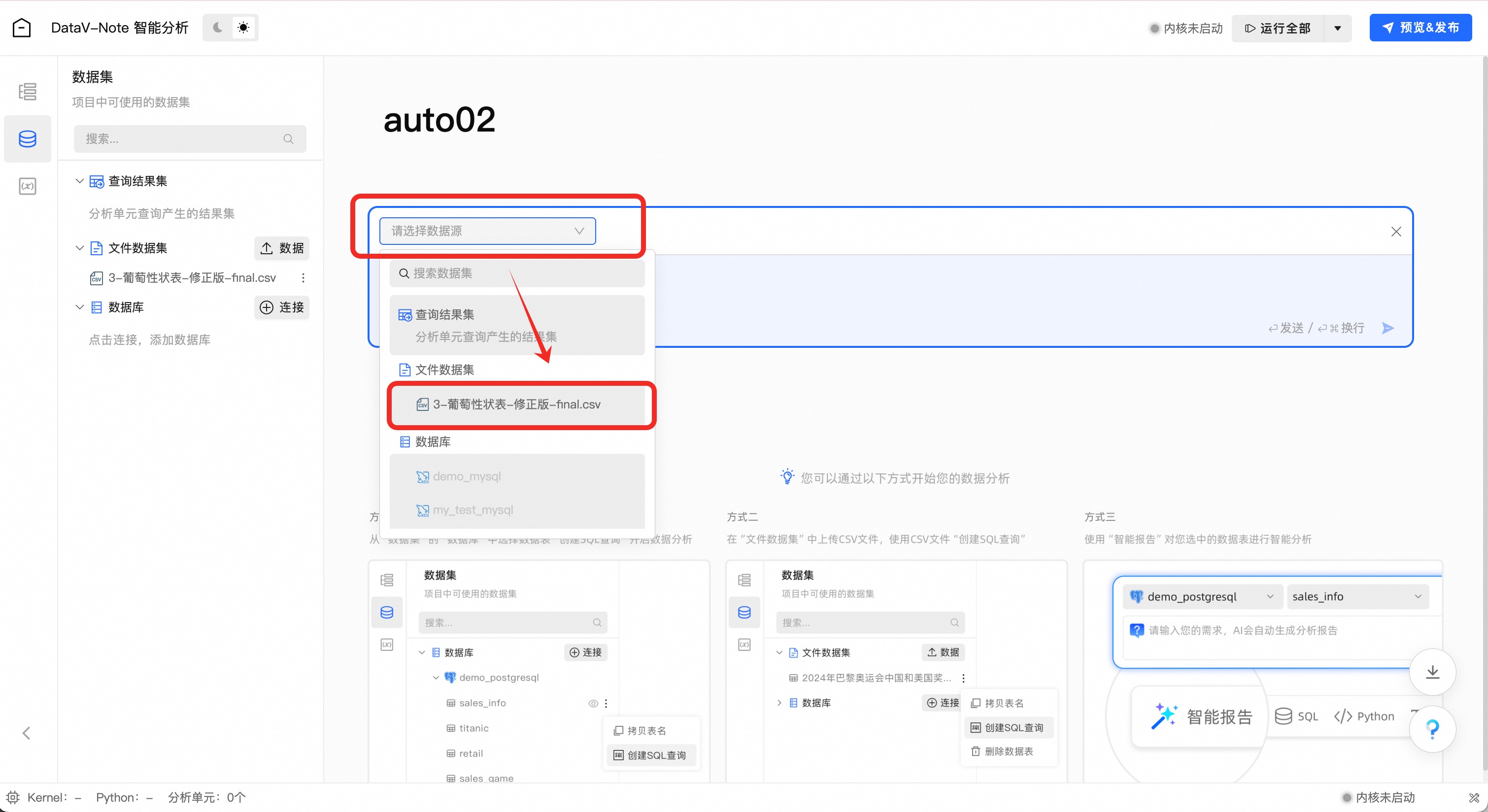
在弹出的对话框上方数据源选择菜单中,找到刚刚上传的XLS表格数据
(4.3.2)参考提示词
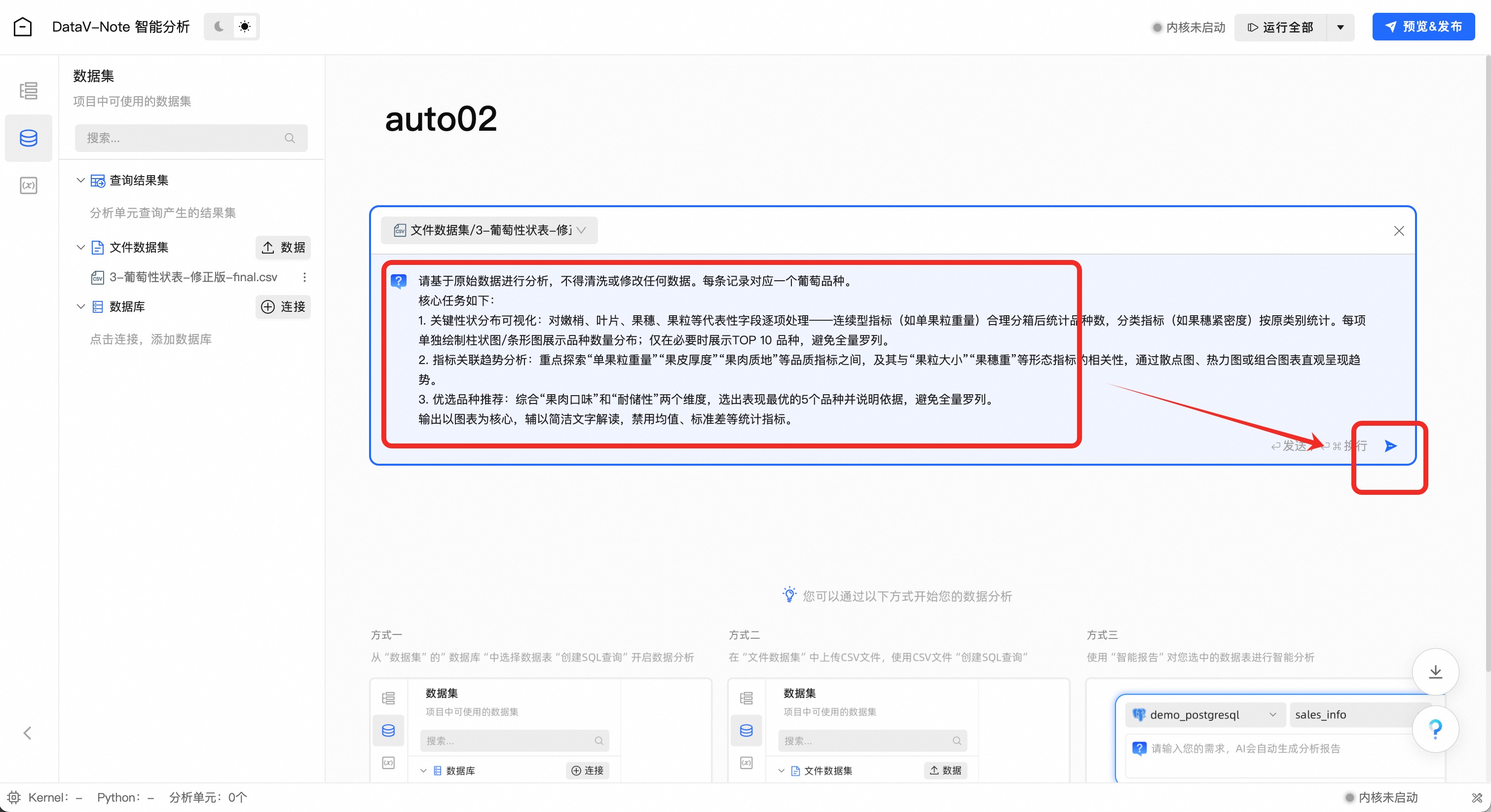
基于葡萄性状数据,尝试综合“果肉口味”和“耐储性”两个维度,选出表现最优的5个品种,并撰写分析报告
参考提示词如下:
说明注意:提示词加入了葡萄各个性状代码的解释对照,来源于标准:《NYT 2563-2014 植物新品种特异性、一致性和稳定性测试指南-葡萄》
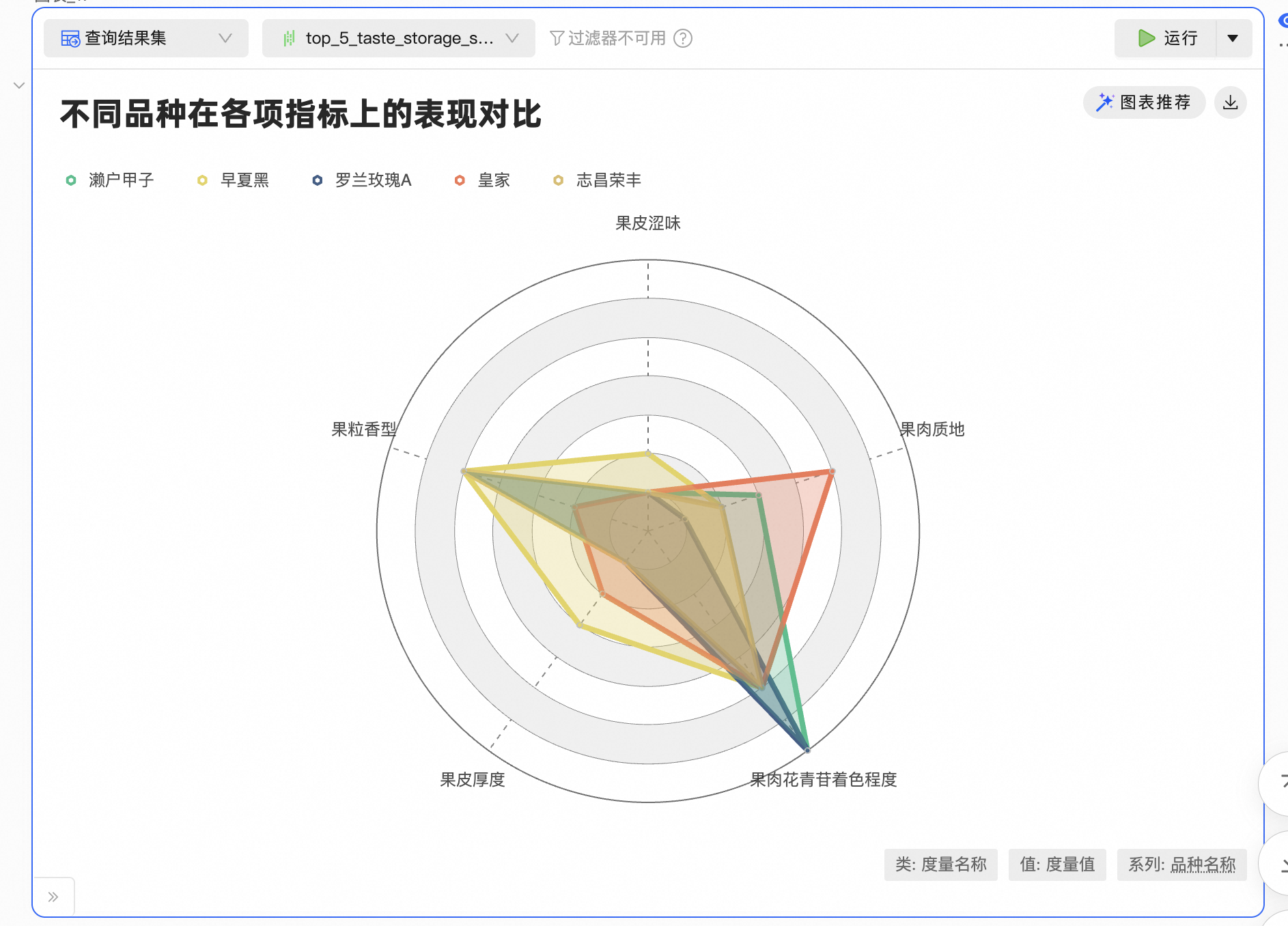
### 角色 你是一位Python数据分析专家,擅长高效处理大规模多维复杂数据。 ### 指标列字段介绍: * 1. 数值指标:成龄叶锯齿长度与锯齿宽度之比、成龄叶锯齿长度与锯齿宽度之比、成龄叶柄长度与中脉长度之比、果穗大小、果穗梗长度、果粒大小、单果粒重量、成龄叶锯齿长度、成龄叶大小。 * 2. 类别型指标: * 2.1. 有序分类指标:嫩梢尖开合程度(1-闭合、2-轻度闭合、3-半开张、4-半开张到开张、5-开张)、嫩梢尖匍匐绒毛密度(1-无或极疏、3-疏、5-中、7-密、9-极密)、嫩梢尖匍匐绒毛花-青甙显色强度(1-无或极弱、3-弱、5-中、7-强、9-极强)、嫩梢尖直立绒毛密度(1-无或极疏、2-疏、3-中、4-密、5-极密)、幼叶背面主脉间匍匐绒毛密度、幼叶背面主脉上直立-绒毛密度(1-无或极疏、2-疏、3-中、4-密、5-极密)、新梢节间直立绒毛密度(1-无或极疏、2-疏、3-中、4-密、5-极密)、成龄叶正面主脉上花青-甙显色强度(1-无或极弱、3-弱、5-中、7-强、9-极强)、成龄叶背面主脉间匍匐-绒毛密度(1-无或极疏、3-疏、5-中、7-密、9-极密)、成龄叶背面主脉上直立绒毛密度(1-无或极疏、3-疏、5-中、7-密、9-极密)、成龄叶泡状凸起(1-极浅、3-浅、5-中、7-深、9-极深)、成龄叶上裂片深度、果肉花青苷着色程度(1-无或极弱、3-弱、5-中、7-强、9-极强)、果粒与果柄分离难易程度(1-易、2-中、3-难)、果肉质地(1-软、2-脆、3-硬)、果皮涩味(1-无或弱、2-中、3-强)、果粒种子状况(1-无、2-败育类型Ⅰ、3-败育类型Ⅱ、4-正常)、成龄叶裂片数(1-无、2-三裂、3-五裂、4-七裂、5-多于七裂)、成龄叶柄洼开叠类型(1-极开张、2-开张、3-半开张、4-闭合、5-轻度重叠、6-中度重叠、7-高度重叠)、果穗紧密度(1-极松、3-松、5-中、7-紧、9-极紧)、果粒形状(1-圆柱形、2-长椭圆形、3-椭圆形、4-圆形、5-扁圆形、6-卵圆形、7-钝卵圆形、8-倒卵圆形、9-弯形、10-束腰形)、成龄叶柄洼受叶脉限制类型(1-无或极弱、3-弱、5-中、7-强、9-极强)、成龄叶上裂片开叠类型(1-开张、3-闭合、5-重叠)、成龄叶下裂片开叠类型(1-开张、3-闭合、5-重叠)、果穗歧肩(1-无歧肩、2-单歧肩、3-双歧肩、4-多歧肩)、果皮厚度(1-薄、2-中、3-厚)。 * 2.2. 无序分类指标:幼叶正面颜色(1-黄绿色、2-绿色、3-绿色带有红色斑、4-浅红褐色、5-深红褐色、6-紫红色)、新梢节间背侧颜色(1-绿色、2-绿色带红条纹、3-红色)、新梢节腹侧颜色(1-绿色、2-绿色带红条纹、3-红色)、新梢节背侧颜色(1-绿色、2-绿色带红条纹、3-红色)、成龄叶锯齿形状(1-两侧凸、2-两侧直、3-两侧凹、4-一侧凸一侧凹、5-两侧直与两侧凸混合型)、成龄叶横截面形状(1-平、2-V形、3-内卷、4-外卷、5-波状)、成熟枝条主要色泽(1-黄色、2-黄褐色、3-深褐色、4-红褐色、5-紫色)、果粒颜色(1-绿色、2-黄绿色、3-黄色、4-粉红色、5-红色、6-暗红色、7-紫黑色、8-蓝黑色)、成龄叶形状(1-心形、2-近三角形、3-近五角形、4-近圆形、5-肾形)、果粒香型(1-无、2-玫瑰香型、3-草莓香型、4-狐香型、5-青草型、6-其他)、果穗形状(1-圆柱形、2-圆锥形、3-分枝形)。 ### 核心任务如下: * 1. 关键性状分布可视化:对嫩梢、叶片、果穗、果粒等代表性字段逐项处理——连续型指标(如单果粒重量)合理分箱后统计品种数,分类指标(如果穗紧密度)按原类别统计。每项单独绘制柱状图/条形图展示品种数量分布;仅在必要时展示TOP 10 品种,避免全量罗列。 * 2. 指标关联趋势分析:重点探索“单果粒重量(数值指标)”“果皮厚度(有序分类指标)”“果肉质地(有序分类指标)”等品质指标之间,及其与“果粒大小(数值指标)”“果穗大小(数值指标)”等形态指标的相关性,通过散点图、热力图或组合图表直观呈现趋势。 * 3. 优选品种推荐:综合“果肉口味”和“耐储性”两个维度(果实厚度、果肉质地、果皮涩味、果粒香型等指标),选出表现最优的5个品种,对这5 个品种的各关键指标数据进行展示,可以使用雷达图,避免全量罗列。 ### 输出要求 * 输出以图表为核心,辅以简洁文字解读,禁用均值、标准差等统计指标。 ### 约束 * 禁止修改原始数据将提示词贴入对话框,并点击开始按钮
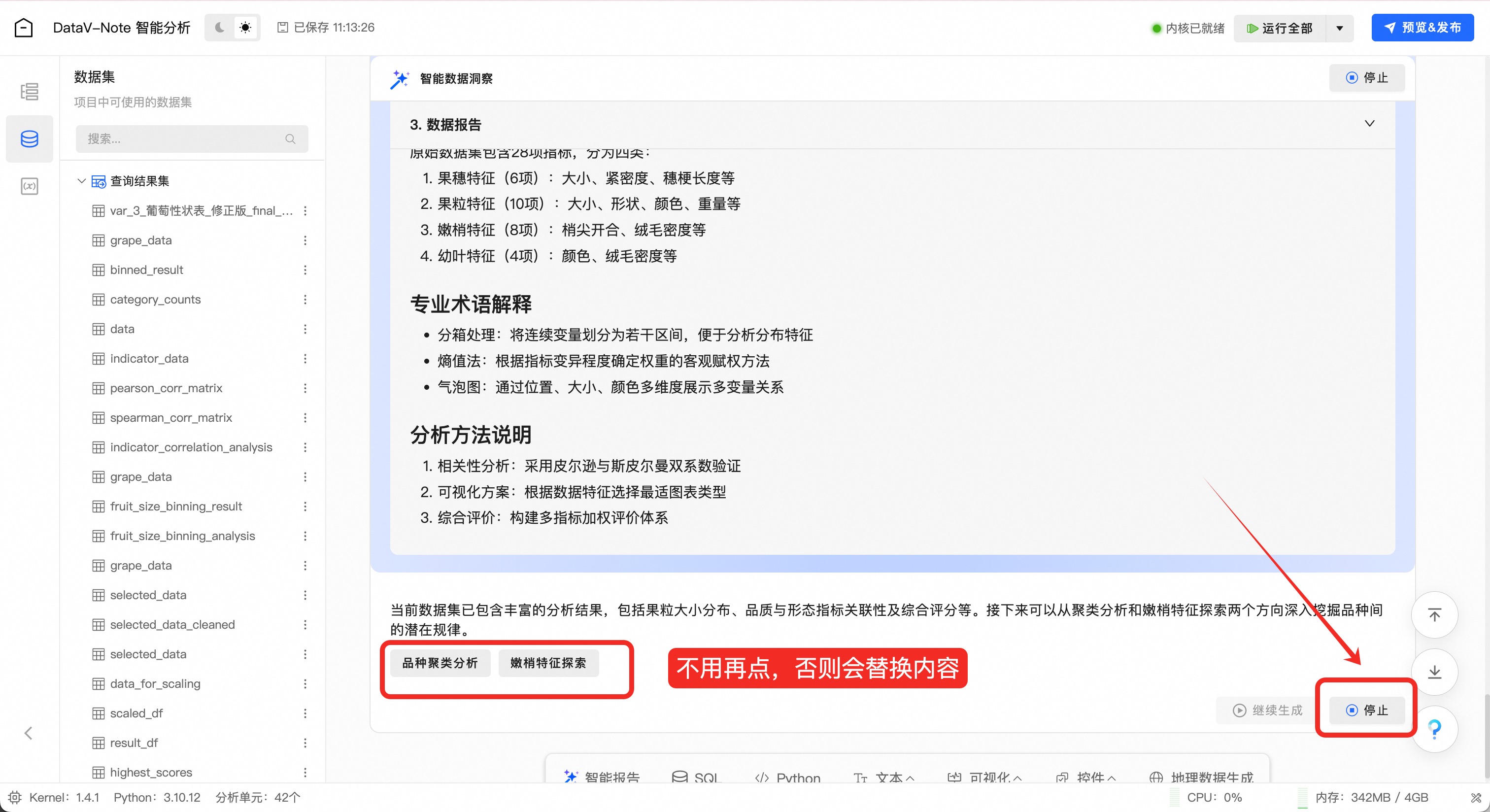
报告生成完成后,会有新增分析方向的建议,如不需要扩展分析,可以点击“停止”按钮
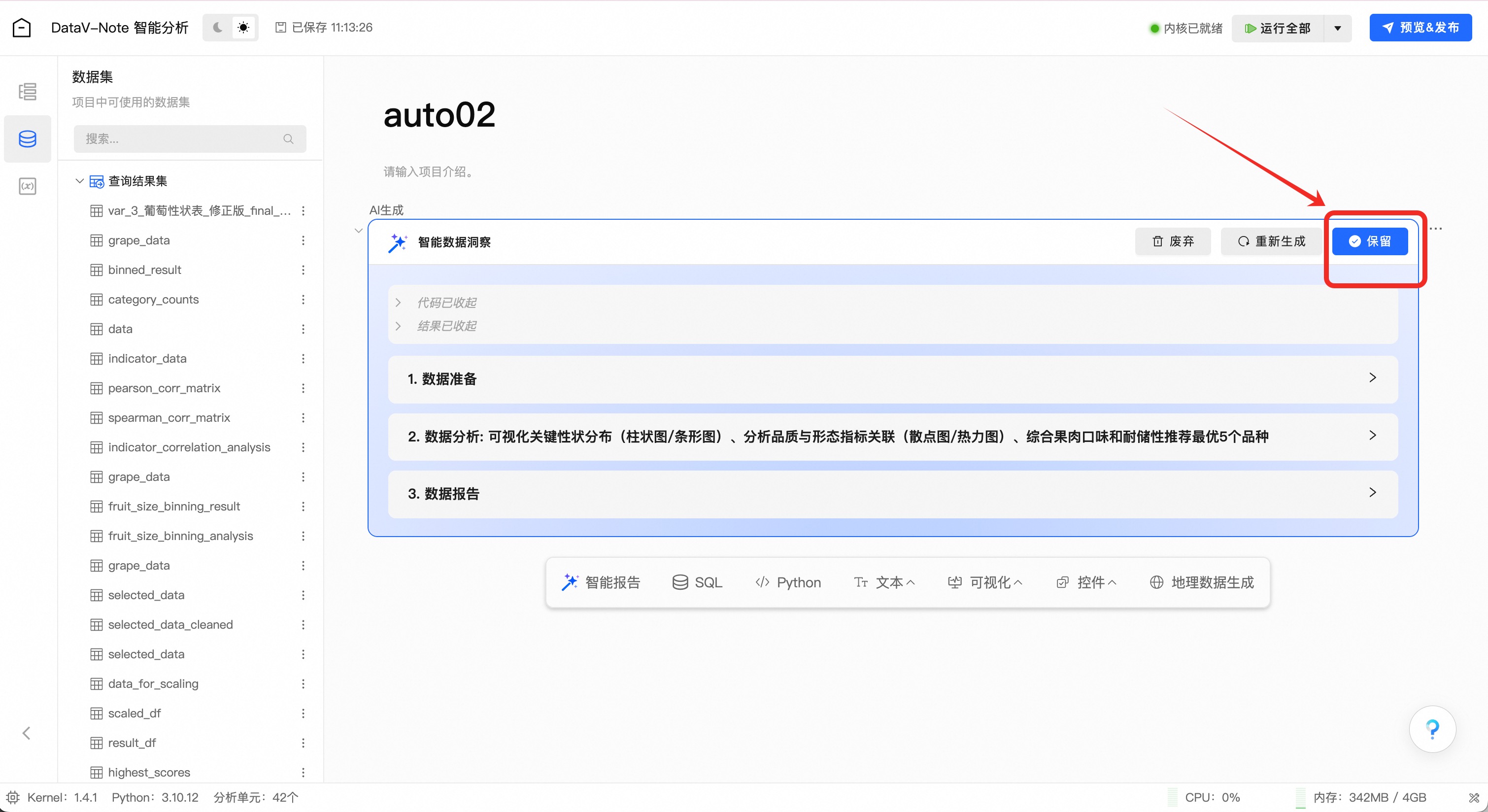
在新出现的对话框右上角,点击“保留”按钮
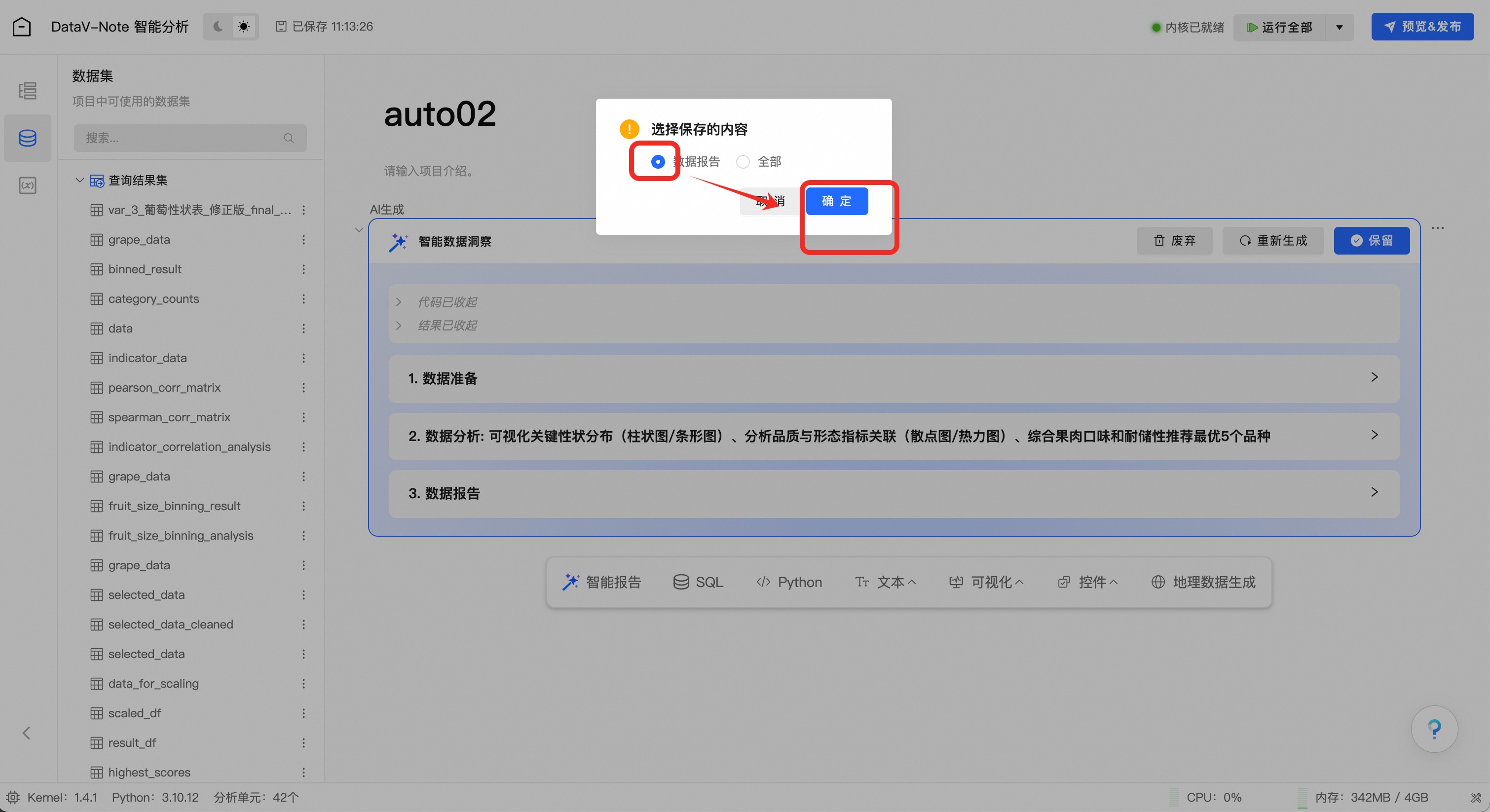
在弹框中选择“数据报告”选项,并点击确定
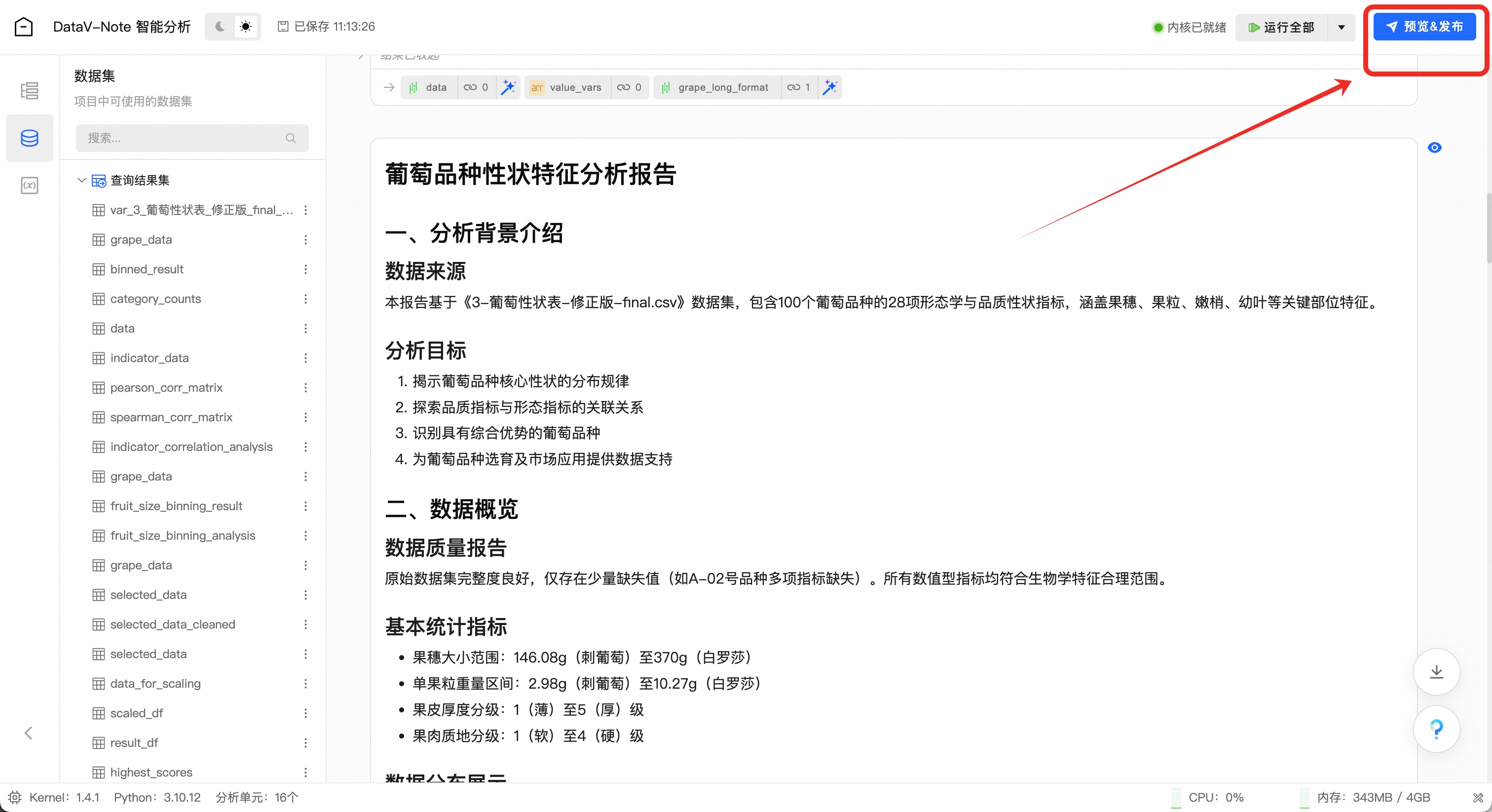
完成报告生成之后,点击右上角“预览&发布”按钮,可以将报告进行发布/分享
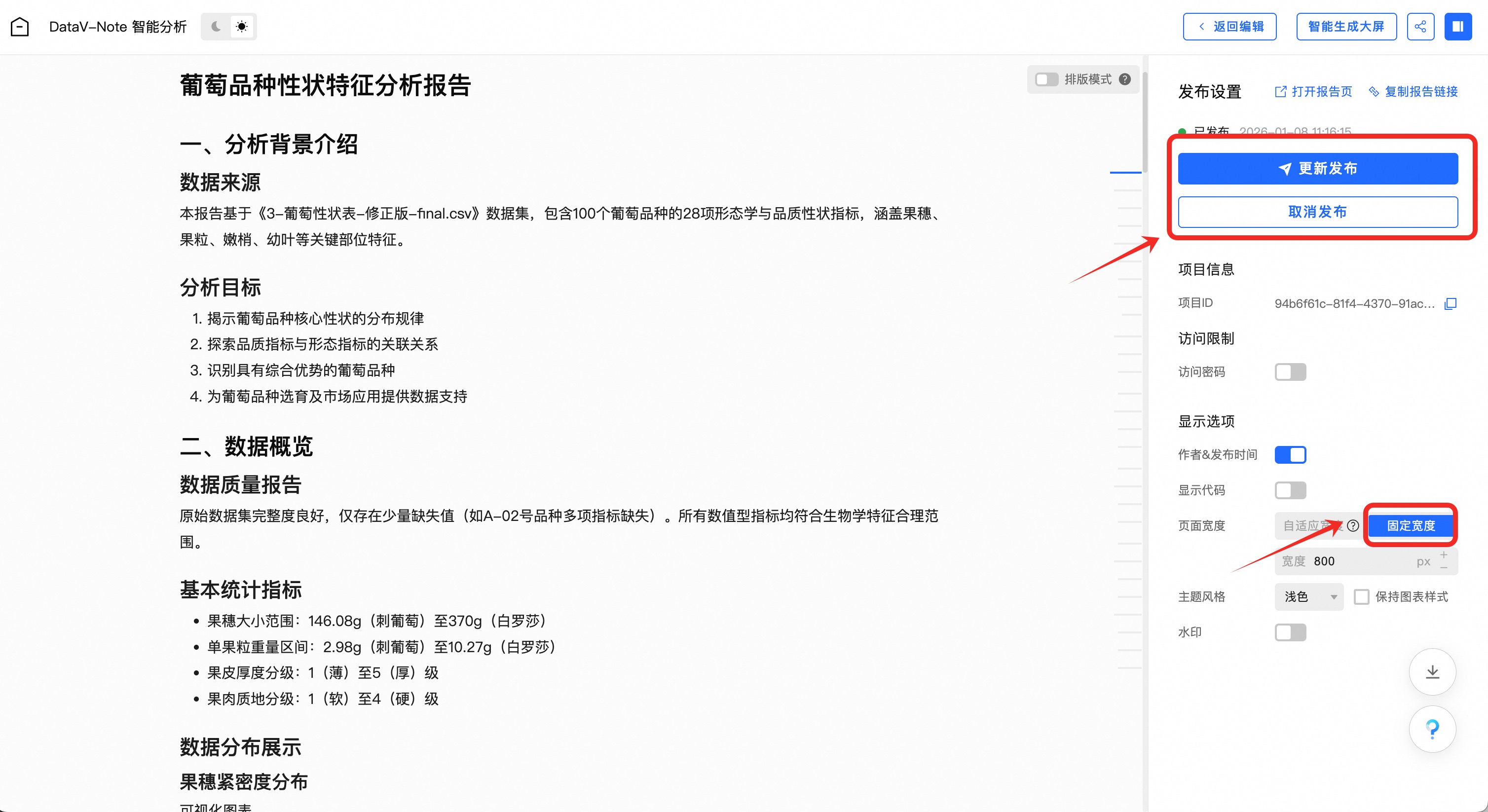
在发布报告设置页,可以进行页面宽度、分享密码等配置设置
点击右上角的“导出与分享”按钮,可以将报告导出为word、图片等格式,或者通过微信、钉钉分享
4.4 报告样例
自动生成的报告样例:
核心结论摘取
报告完整案例(注意:大模型每次生成的报告可能都会不一样)
实验资源释放
实验结束,DataV产品是包年/包月预付费形式,无需退订/释放资源

关闭实验
完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验
说明账号无需注销,DataV产品是包年/包月预付费形式,无需退订/释放资源,可直接关闭实验