智慧物流场景下的货物目标感知与数量自动识别
实验简介
利用阿里云平台中PAI 平台(原机器学习平台)对Yolov8m 目标分割模型进行在线训练,通过制作数据集过程完成VOC 格式数据集到YOLO 数据集转换,上传至阿里云OSS 容器,完成在线训练,下载训练日志以及pt 模型文件,构建预测代码完成本地部署,实现商品货物的数量检测。
背景知识
本实验需要理解VOC 数据格式与YOLO 数据格式的异同,需要掌握Python 语言,需要对深度学习训练过程与部署过程做一定了解。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
本场景主要涉及以下云产品和服务:人工智能平台 PAI 与对象容器 OSS
本实验,预计产生资源消耗:约10.488元/小时,实验耗时预计<1小时。总计资源消耗<12元。
算力需求资源: ecs.gn7i-c8g1.2xlarge
规格:
GPU:1xA10
显存:1x24GB
CPU:8vCPU
内存:30GiB
如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
领取专属权益及开通授权
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第一步:领取300元专属权益
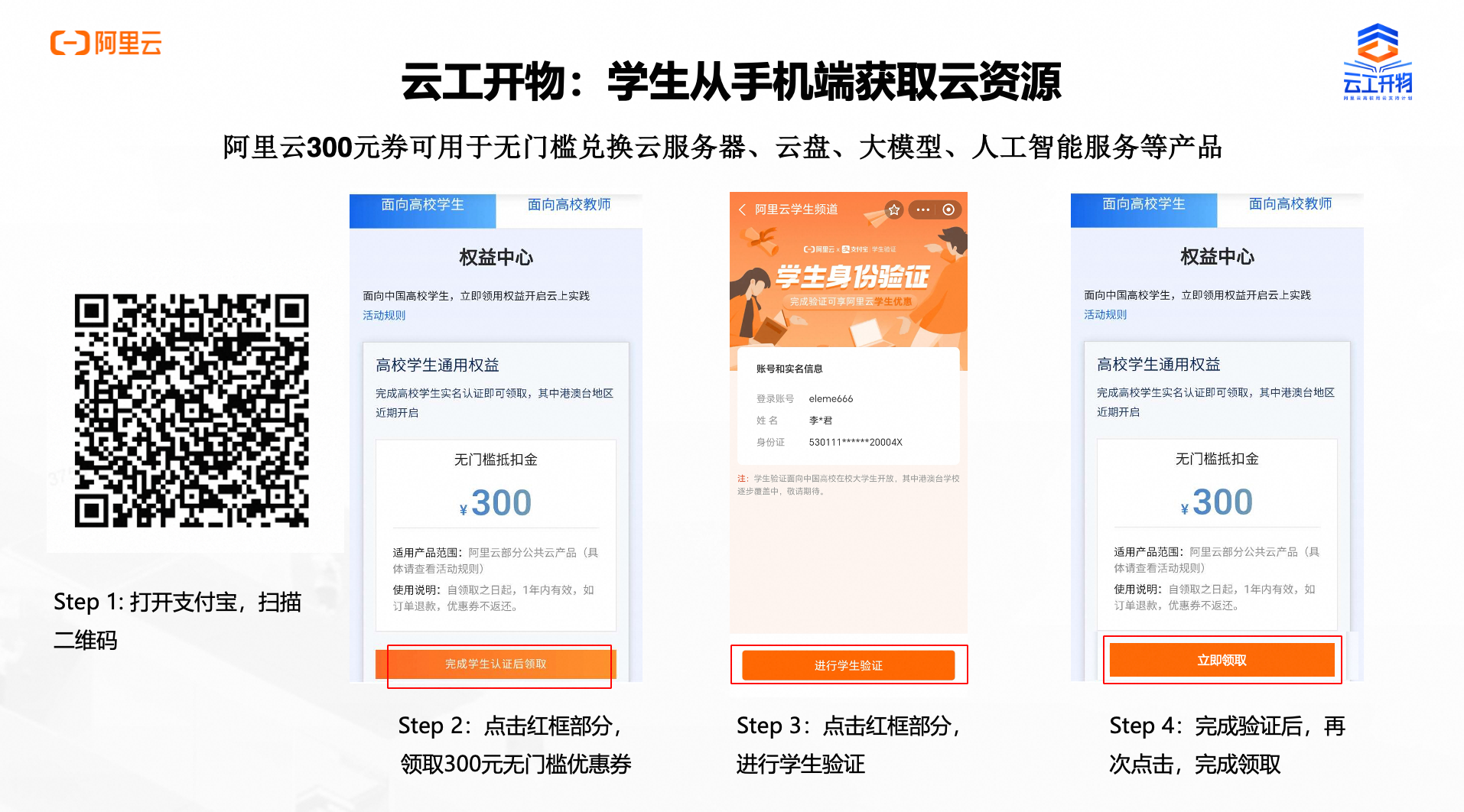
本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
第二步:PAI平台的授权与开通
如果您已开通PAI 并且有工作空间,请您跳过该步骤!!
单独开通PAI 产品并创建默认的工作空间不收取费用。后续使用各个子产品时,各个计费项将分别计费,费用明细将出现在PAI 的产品账单中。
领取学生专属300元优惠券后,点击访问人工智能平台 PAI首页,点击右上角按钮【人工智能平台PAI控制台】进入PAI控制台,或点击该链接进入PAI控制台
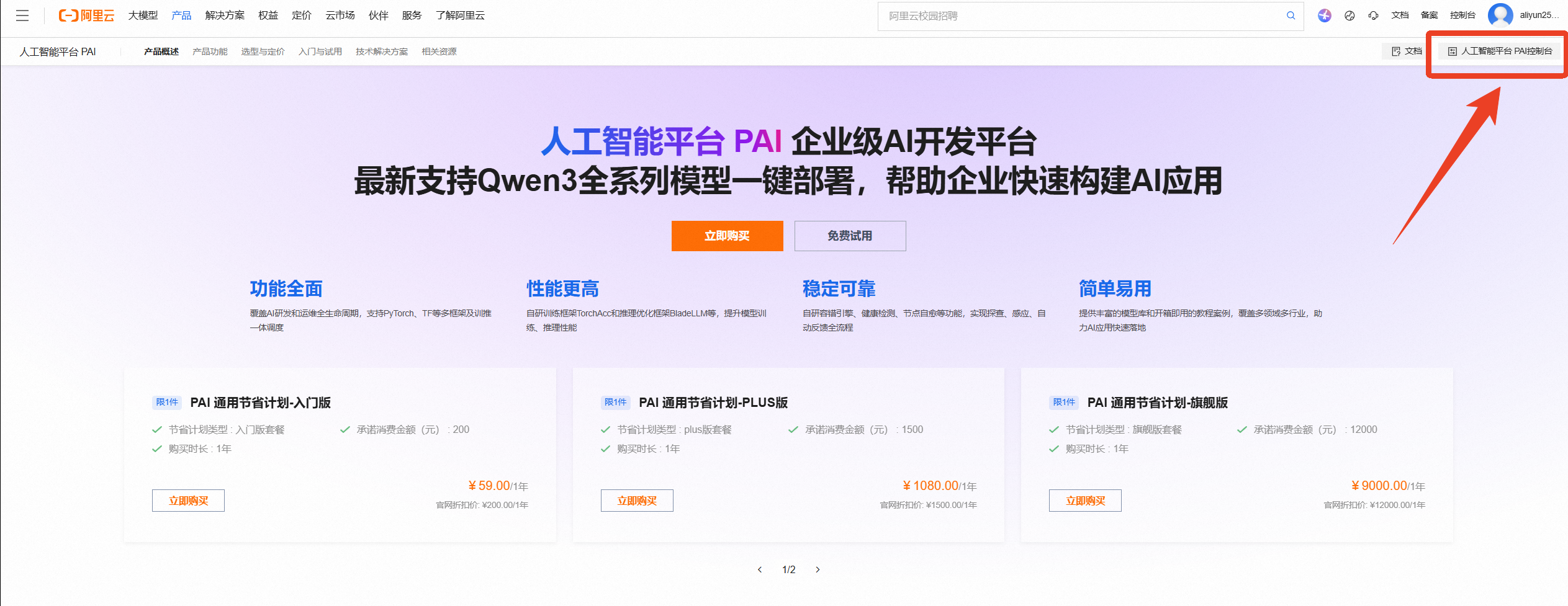
进入PAI控制台页面后,可在左上角选择地域
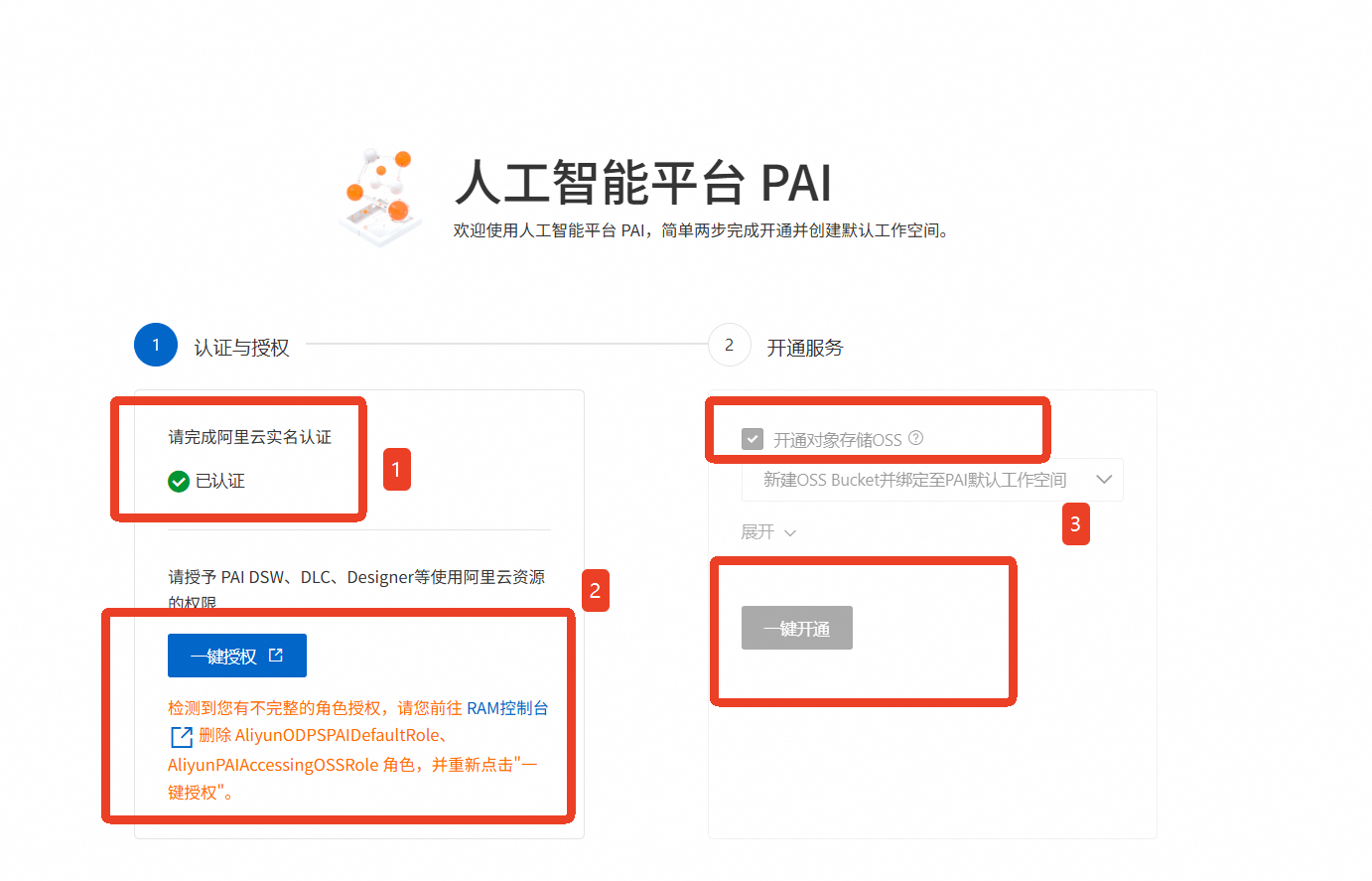
开通人工智能平台PAI需要完成【认证与授权】及【开通服务】两步
如果您已开通PAI 并且有工作空间,请您跳过该步骤!!

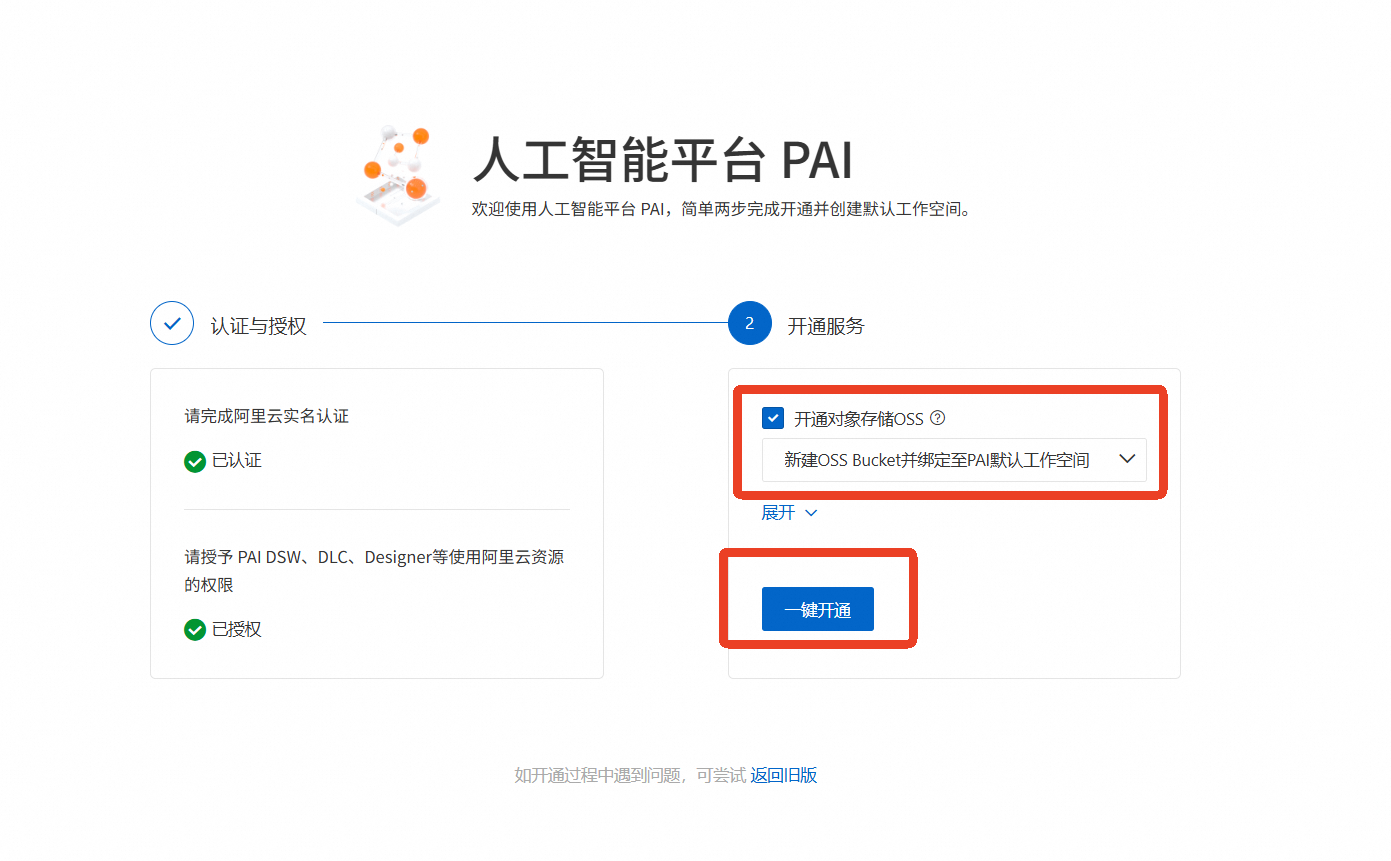
完成【实名认证】,直到显示“已认证”
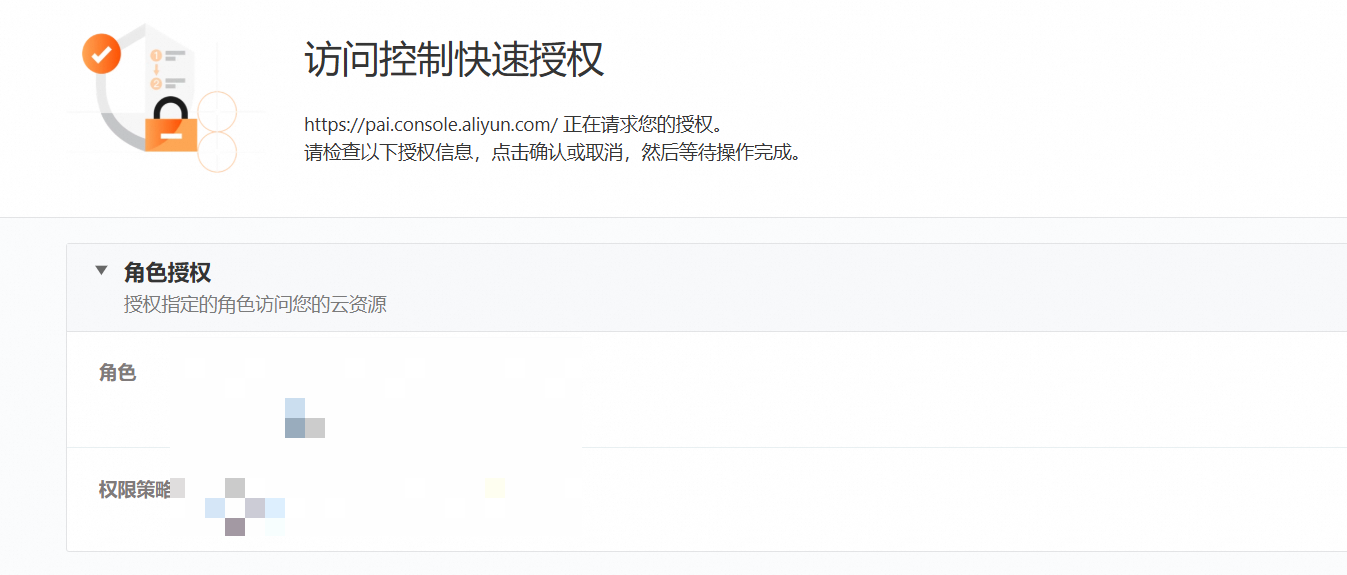
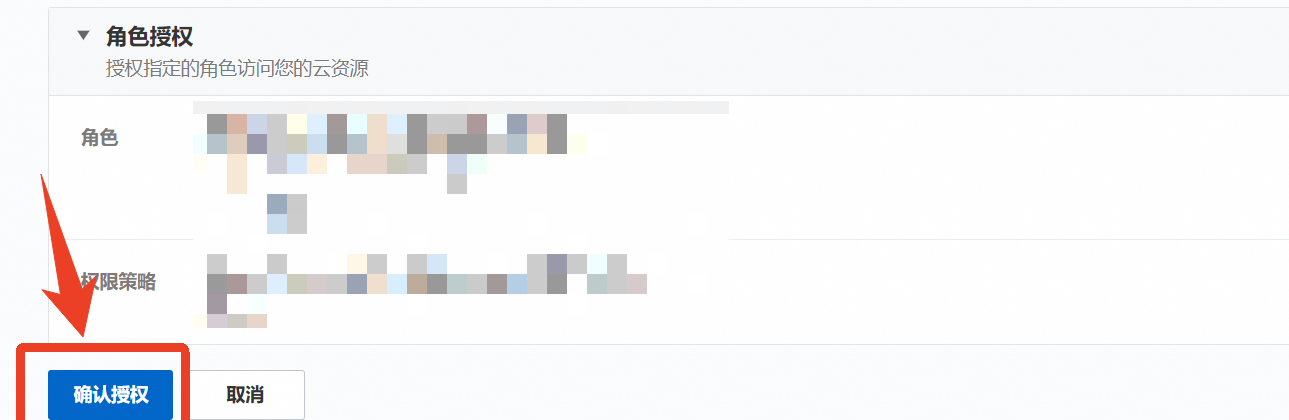
点击【一键授权】,进入授权确认页面,点击【确认授权】
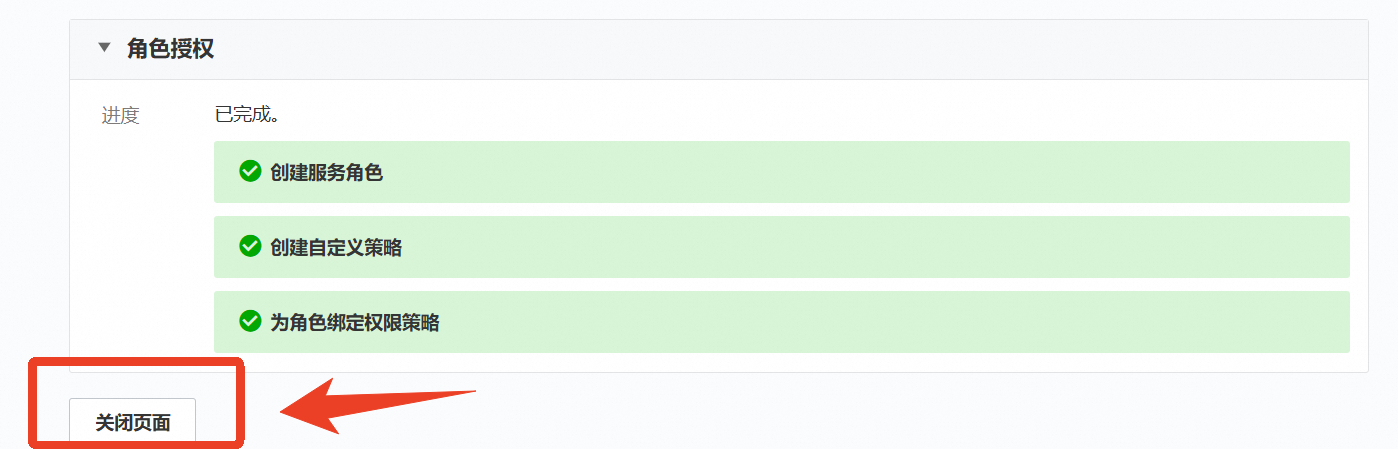
完成安全认证并提示已完成角色创建后,点击【关闭页面】
回到PAI控制台页面,勾选【开通对象存储OSS】,点击【一键开通】
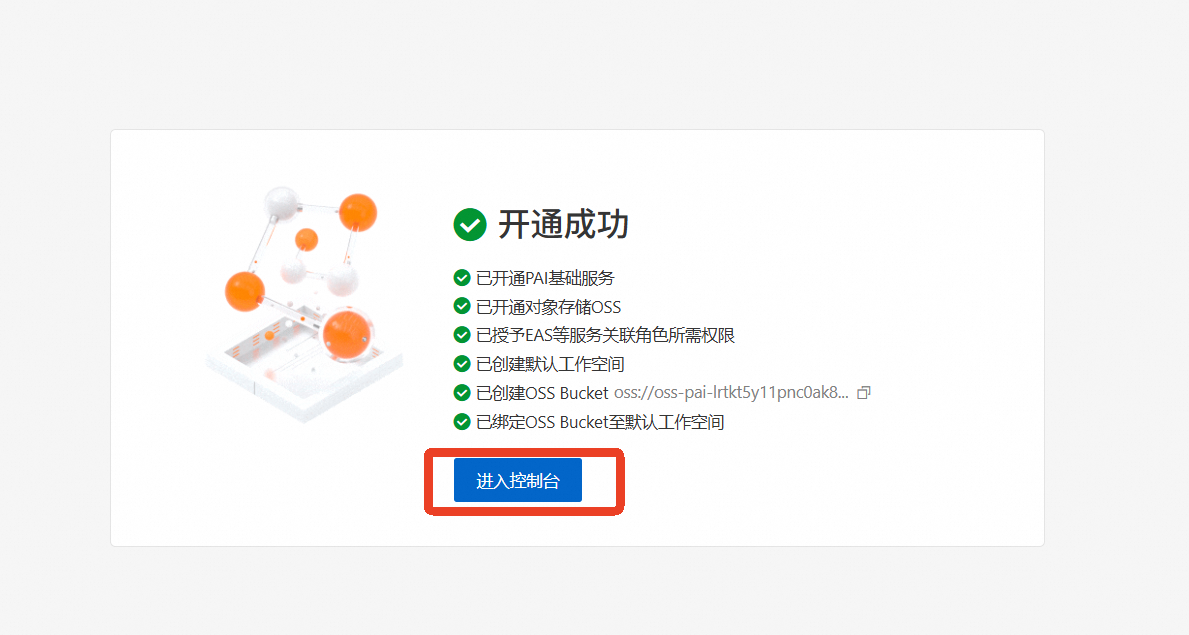
开通完成后,点击【进入控制台】
实验步骤
一、详细实验步骤
确保完成安装Pycharm 社区版编辑器
配置Python 解释器路径,本实验要求的版本Python>=3.8
确保本地已配置好pytorch 深度学习推理框架
下载YOLO 格式的数量检测数据集:https://www.alipan.com/s/jHw28Hq4X9b
检查YOLO 格式的数量检测数据集
labels:包含txt 文件,用于存放数据集的划分信息,训练集和验证集。
images:存放源图片,即用于训练和测试的图像文件。
dataset:规定数据集划分的类别id
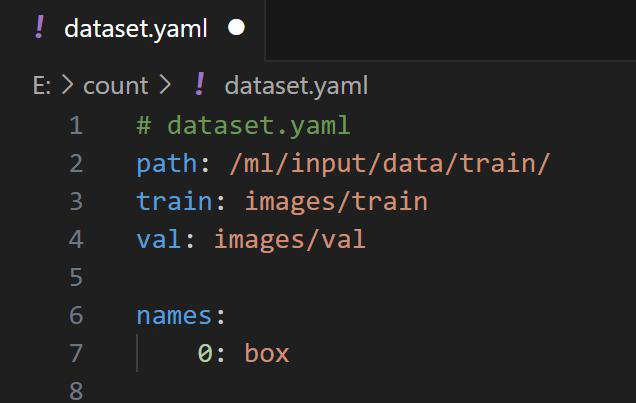
检查PAI 平台中需求的数据集格式
查看dataset 中的类别ID 和labels 中的txt 文件,检查labels 中的文件是否符合dataset 中的格式规范
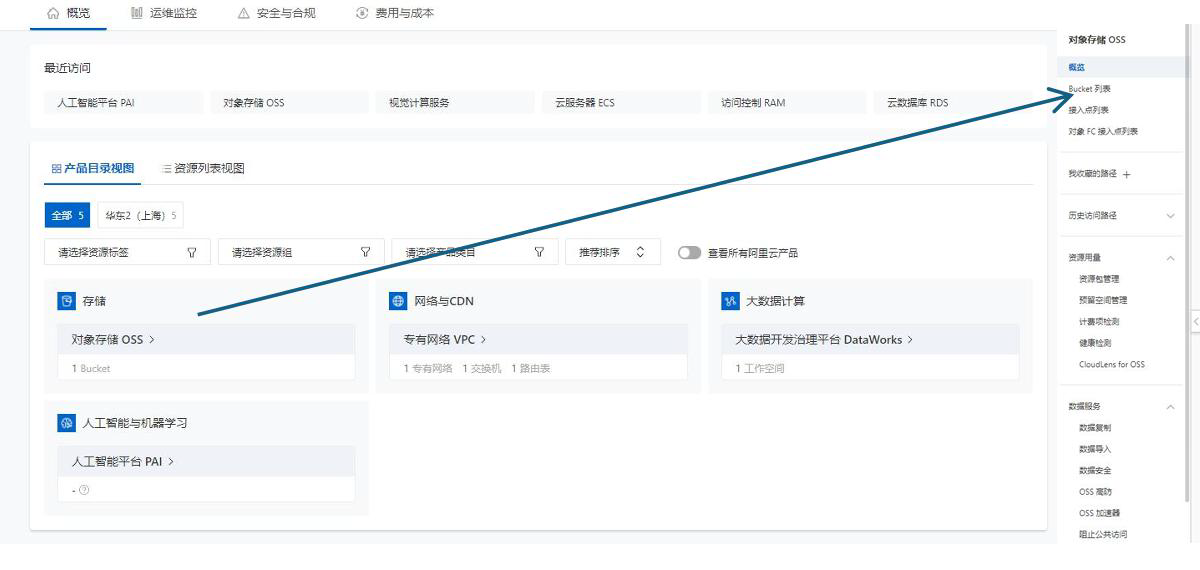
检查数据集无误后,开始上传数据集,在主界面中点击控制台,选择OSS 对象储存,点击Bucket 列表
点击创建Bucket,shawll为实例名称,名称不可重复,这一步代表Bucket 创建成功。
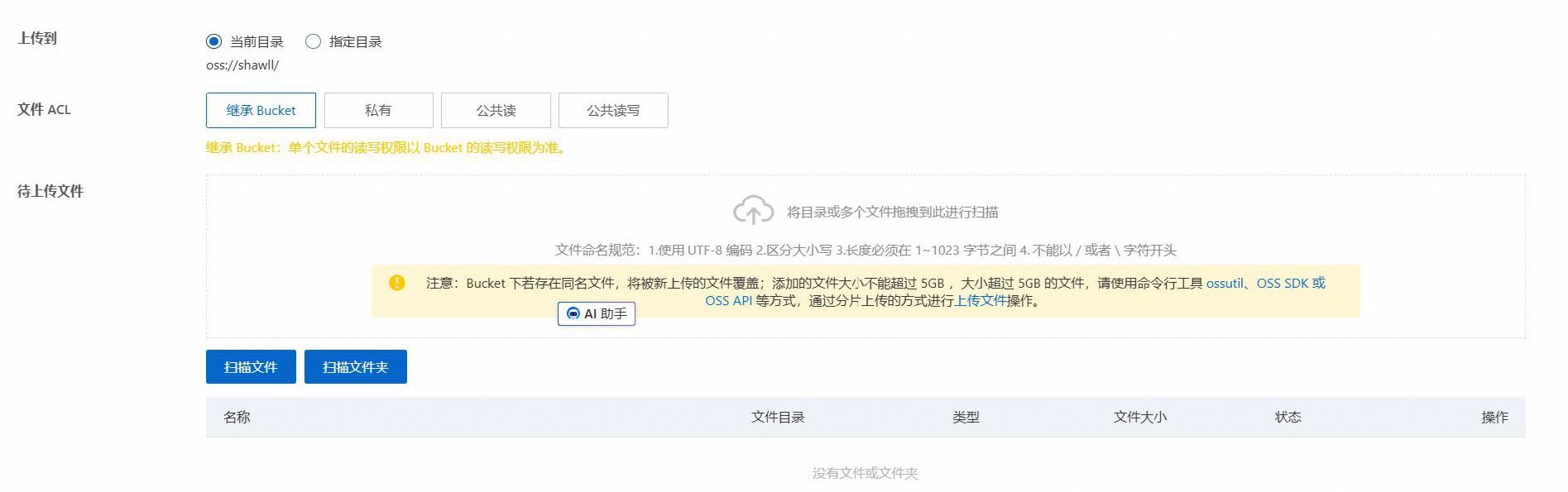
进入Bucket,点击上传文件
将count 文件夹拖入上传区域即可,根据后续提示完成上传即可
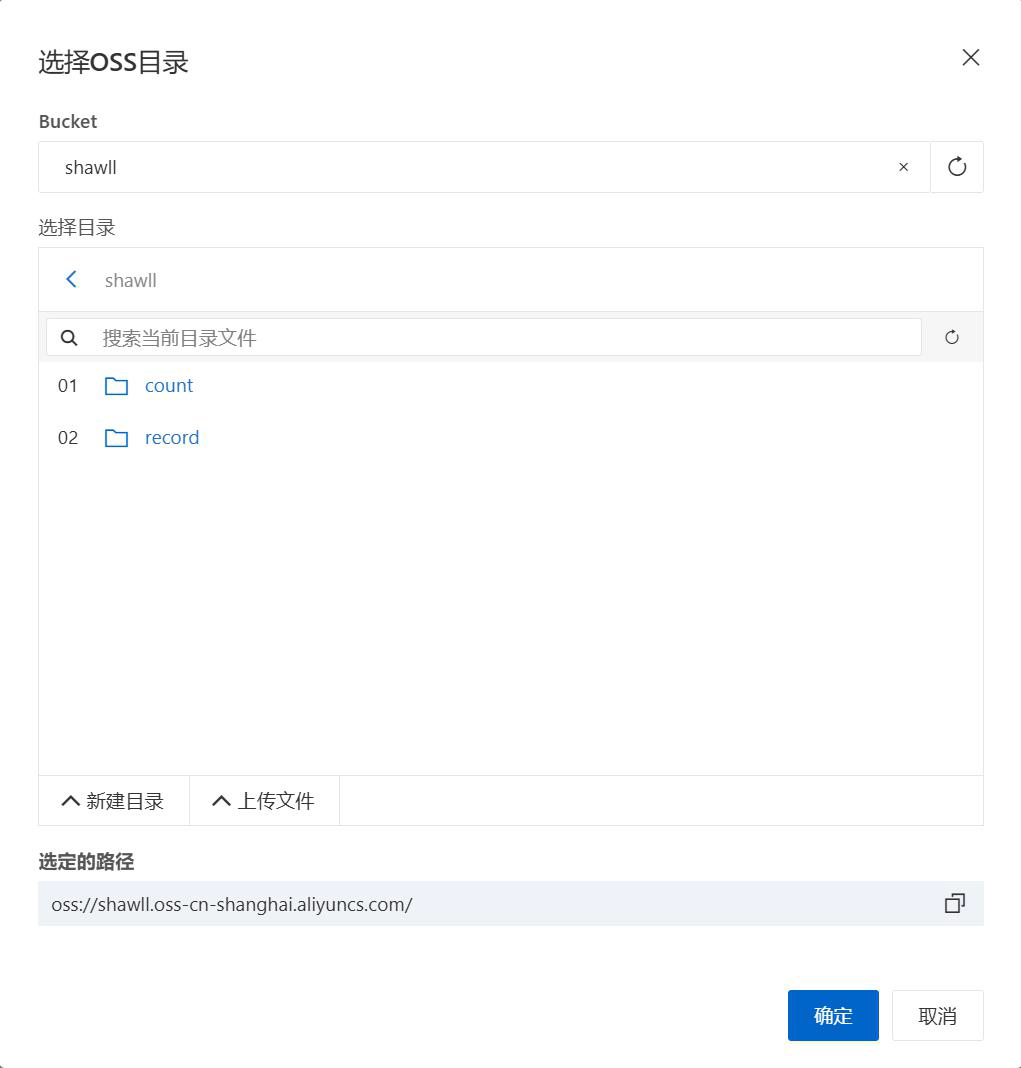
返回人工智能平台PAI,选择数据集,在导入配置中选择上传的数据集count,并新建record 文件夹作为后续的训练日志存储文件夹。
返回选择modelGallery,选择YOLOv8M 目标检测模型-中型,选择训练选项。
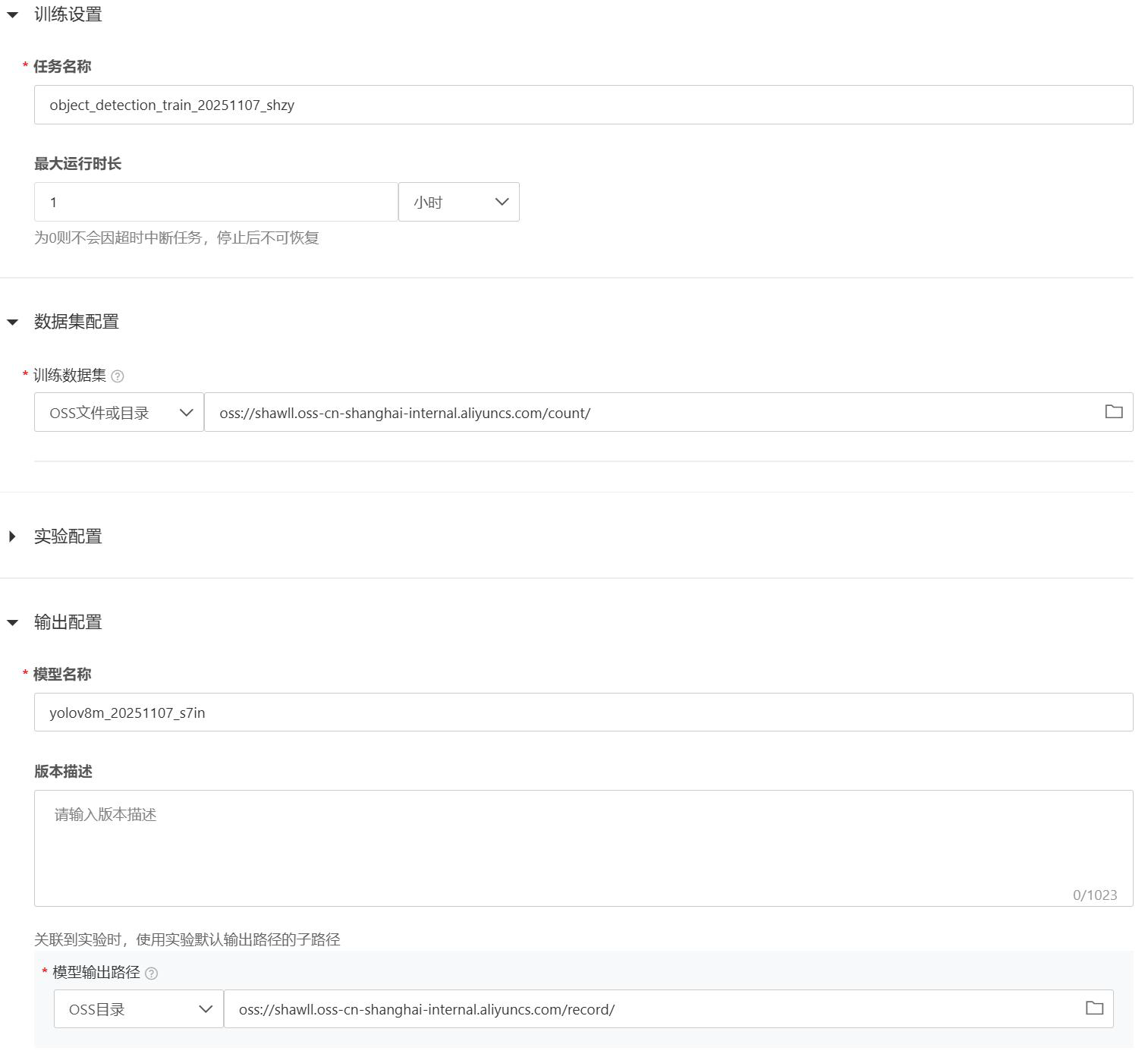
训练时长:1 小时
训练数据集:选择刚刚添加的数据集count
模型输出:选择为record
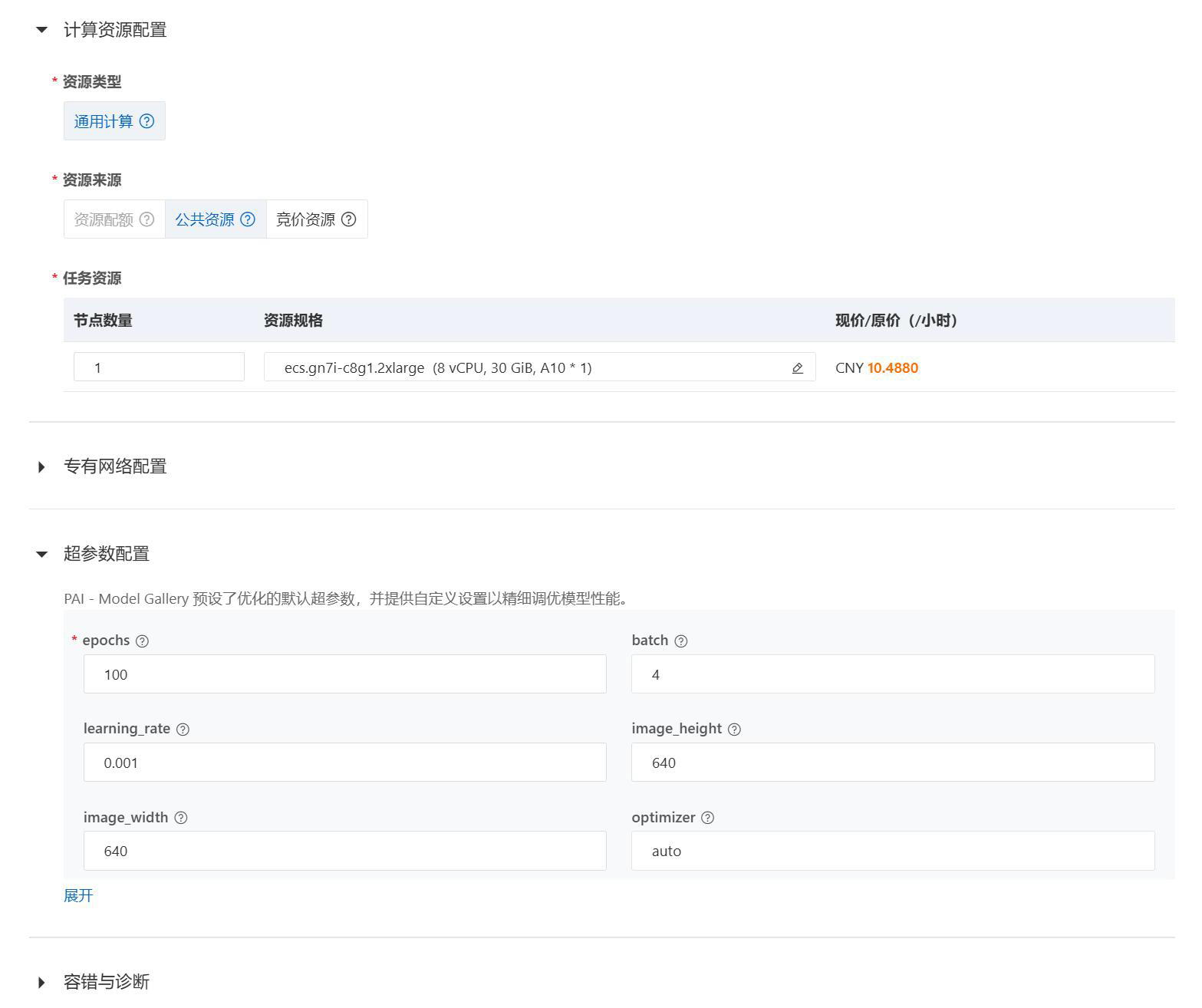
资源配置如图所示。超参数配置如图所示。为了保证实验资源消耗在预估范围内,注意批次配置,时间配置,资源配置与图中保持一致。
开始训练
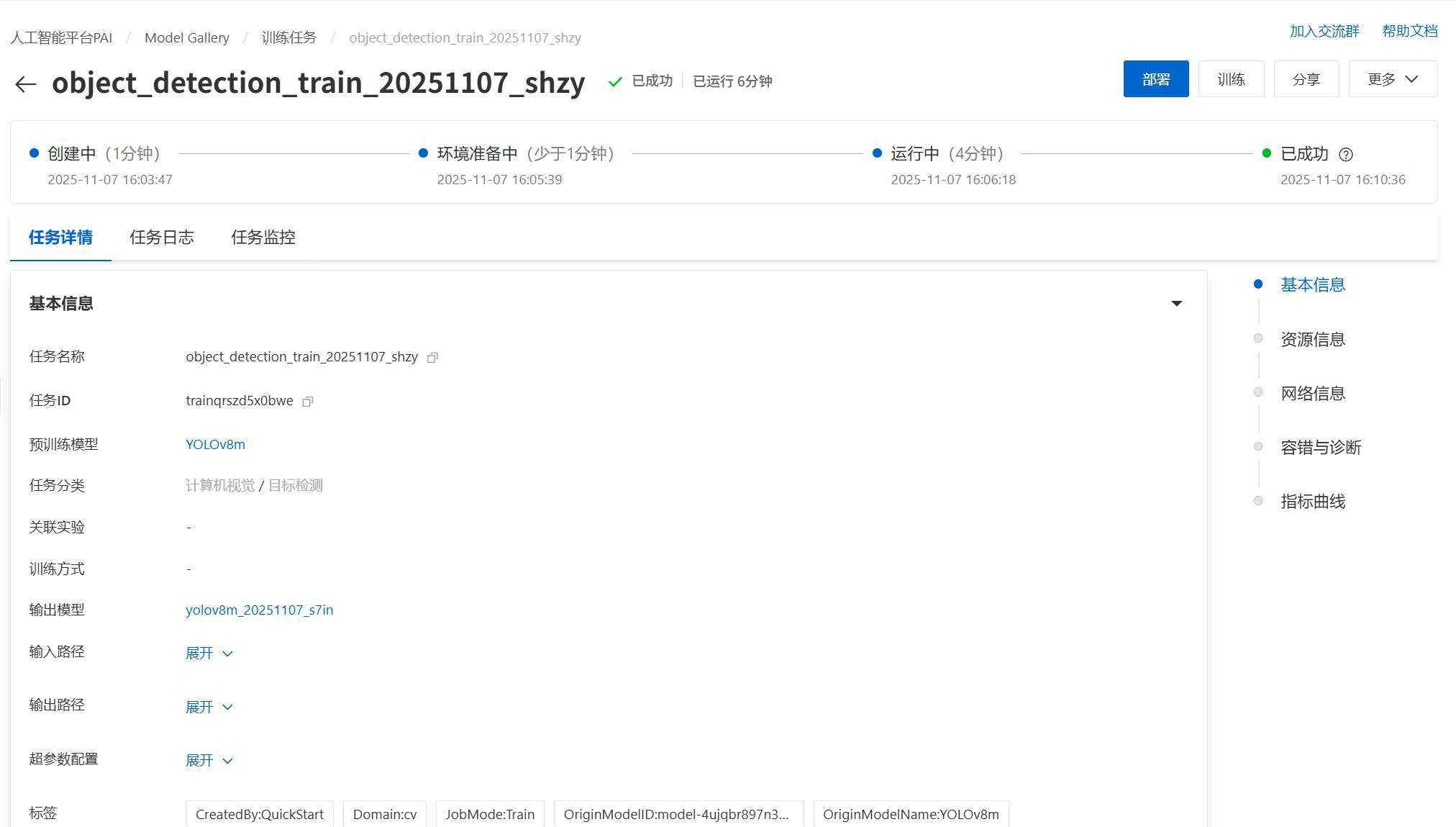
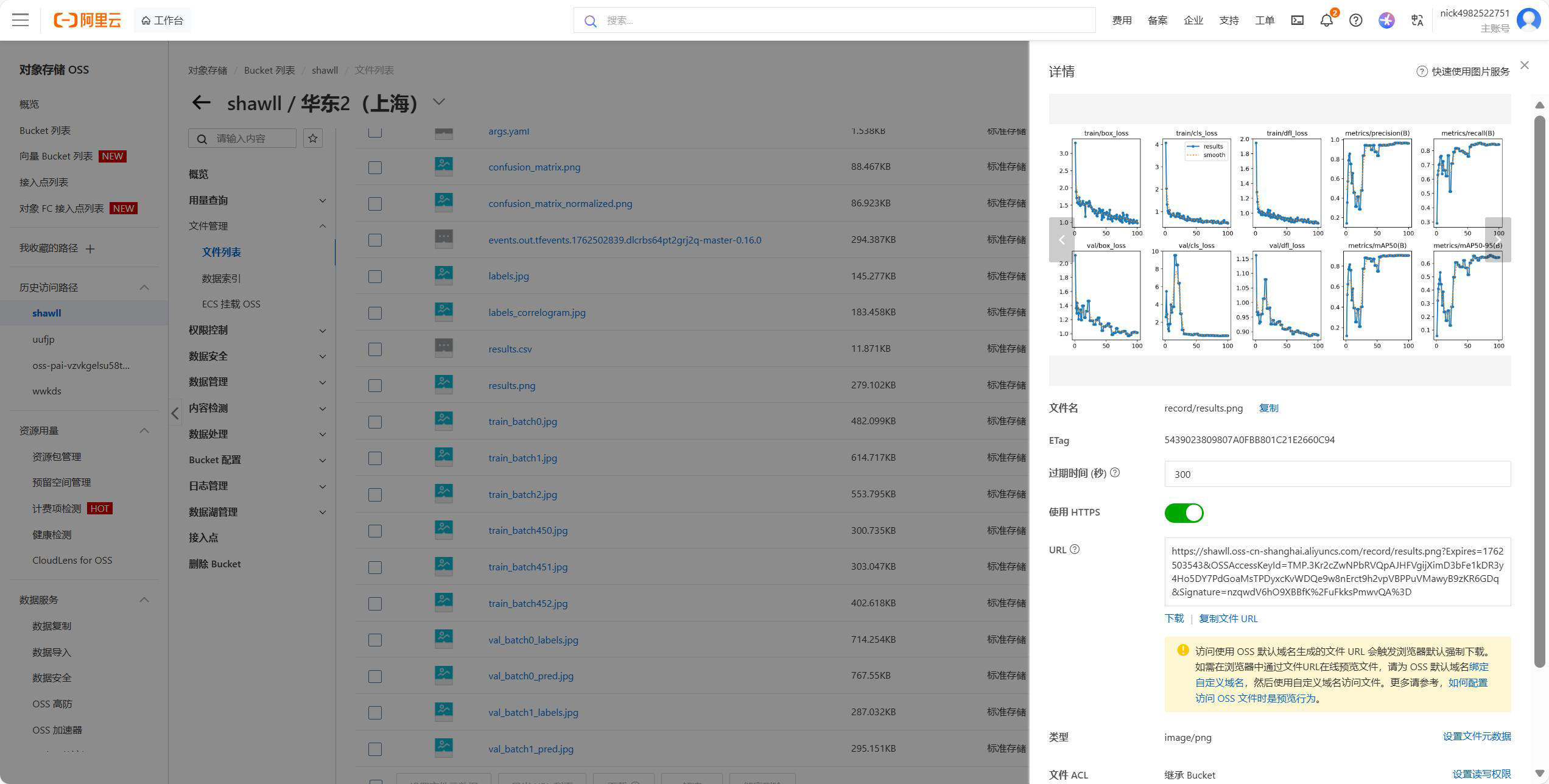
完成训练后,在record 中找到训练日志
在weight 文件中找到best.pt 文件作为权重文件,点击下载。需要注意,下载后的格式为zip,请手动重命名为.pt 格式
打开Pycharm 编辑器,创建项目,配置python 环境,将该pt 模型放置与main 主要预测代码同一目录下,main 代码参考如下:
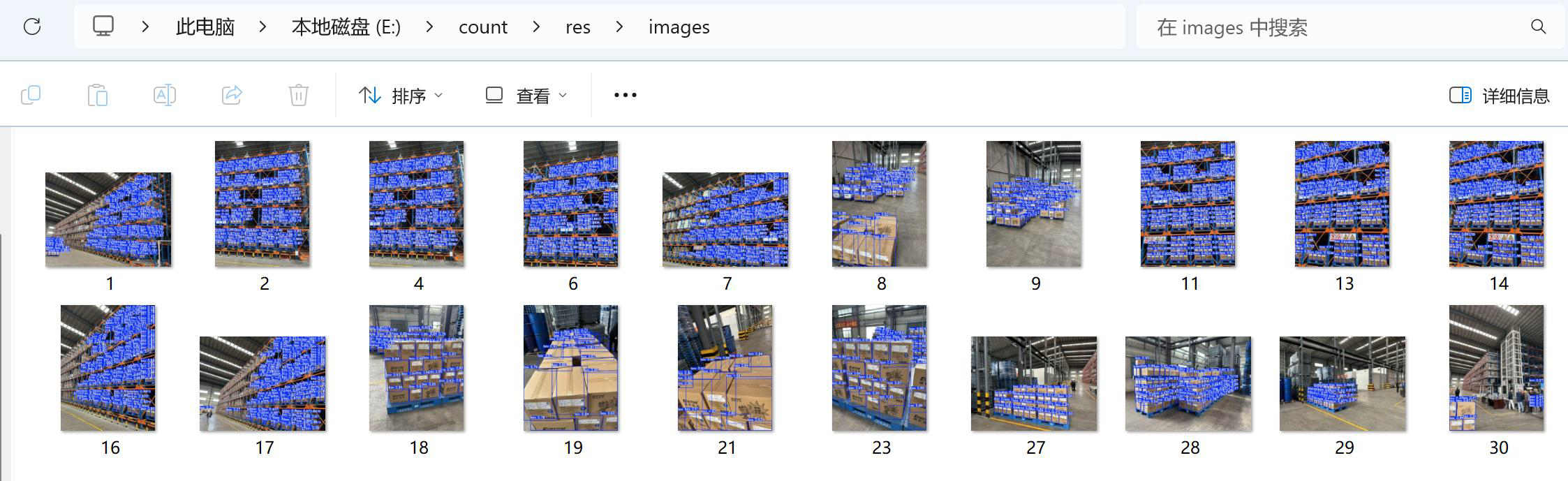
import os 2. from pathlib import Path 3. from ultralytics import YOLO 4. from PIL import Image 5. # ================== 配置区================== 6. MODEL_PATH = r"E:\count\best.pt" # best.pt 路径 7. INPUT_DIR = r"E:\count\images\train" # 输入图像文件夹 8. OUTPUT_DIR = r"E:\count\res" # 输出结果目录 9. SAVE_IMAGES = True # 是否保存带框的图像 10. # ========================================= 11. # 创建输出目录 12. os.makedirs(OUTPUT_DIR, exist_ok=True) 13. if SAVE_IMAGES: 14. img_out_dir = os.path.join(OUTPUT_DIR, "images") 15. os.makedirs(img_out_dir, exist_ok=True) 16. # 加载模型 17. print("正在加载模型...") 18. model = YOLO(MODEL_PATH) 19. print("模型加载成功!") 20. # 支持的图像格式 21. IMG_EXTENSIONS = {'.jpg', '.jpeg', '.png', '.bmp', '.tiff'} 22. # 获取所有图像文件 23. input_path = Path(INPUT_DIR) 24. image_files = [f for f in input_path.iterdir() if f.suffix.lower() in IMG_EXTENSIONS] 25. image_files.sort() 26. if not image_files: 27. print(f" 在{INPUT_DIR} 中未找到任何图像文件!") 28. exit(1) 29. print(f"共找到{len(image_files)} 张图像,开始检测...") 30. results_list = [] 31. for img_file in image_files: 32. try: 33. # 推理 34. results = model(img_file, verbose=False) # verbose=False 避免每张图都打印日志 35. # 获取检测数量 36. boxes = results[0].boxes # 第一个结果的检测框 37. count = len(boxes) if boxes is not None else 0 38. results_list.append((img_file.name, count)) 39. print(f"{img_file.name}: 检测到{count} 个箱子") 40. # 保存带检测框的图像 41. if SAVE_IMAGES: 42. res_plotted = results[0].plot() # 返回带框的BGR numpy 图像 43. # 转为PIL 并保存 44. res_img = Image.fromarray(res_plotted[..., ::-1]) # BGR → RGB 45. res_img.save(os.path.join(img_out_dir, img_file.name)) 46. except Exception as e: 47. print(f" 处理{img_file.name} 时出错: {e}") 48. results_list.append((img_file.name, -1)) 49. # 保存结果到文本文件 50. output_txt = os.path.join(OUTPUT_DIR, "results.txt") 51. with open(output_txt, "w", encoding="utf-8") as f: 52. f.write("文件名,箱子数量\n") 53. for name, cnt in results_list: 54. f.write(f"{name},{cnt}\n") 55. print(f"\n 检测完成!结果已保存至:{output_txt}") 56. if SAVE_IMAGES: 57. print(f"可视化图像已保存至:{img_out_dir}")创建输出文件夹,运行代码,完成数量检测
二、实验资源释放
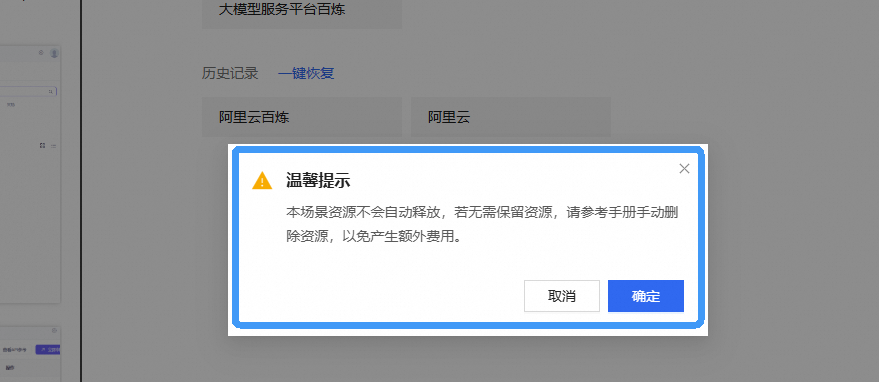
实验完成后,务必释放训练资源!!
选择停止后进行删除操作,如完成训练,则直接进行删除操作,并在控制台中检查容器OSS 是否释放以及资源配置是否释放。







关闭实验
完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验