基于魔搭模型训练平台的数据集打标和图像编辑模型训练
实验简介
本实验旨在指导用户通过PAI ArtLab平台的魔搭模型训练工具,完成从数据集准备到图像编辑模型训练的完整流程。实验聚焦于构建高质量的成对图像数据集,并利用LoRA(Low-Rank Adaptation)技术对Qwen Image Edit基础模型进行微调,从而创建能够实现特定图像转换效果的定制化模型。
实验核心内容
数据集构建:收集并准备20-30组风格统一、尺寸规范(1024×1024/1536×1024/1024×1536像素)的成对图像,每组包含原图和目标图,两者之间需呈现一致的转换关系。
数据标注:通过专业提示词工程,为每组图像编写精确的英文转换指令,详细描述从原图到目标图的变化过程,为模型训练提供高质量的语义指导。
模型训练:在魔搭模型训练平台上配置训练参数(包括训练轮数、单张次数、LoRA保存精度等),使用Qwen Image Edit 2509作为基础模型,进行不少于6000步的专业训练。
模型应用:训练完成后,自定义的LoRA模型将自动部署至平台,可用于实时图像编辑任务,实现如工业建筑改造、艺术风格转换等专业应用场景。
本实验不仅提供了端到端的AI图像编辑模型训练技术指导,还特别强调了数据质量、提示词工程和参数优化等关键环节,适合建筑、设计、数字艺术等领域的专业人员掌握前沿AI图像处理技术。通过本实验,学习者能够建立对图像编辑模型训练的系统性认知,并具备独立开发定制化图像转换模型的能力。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
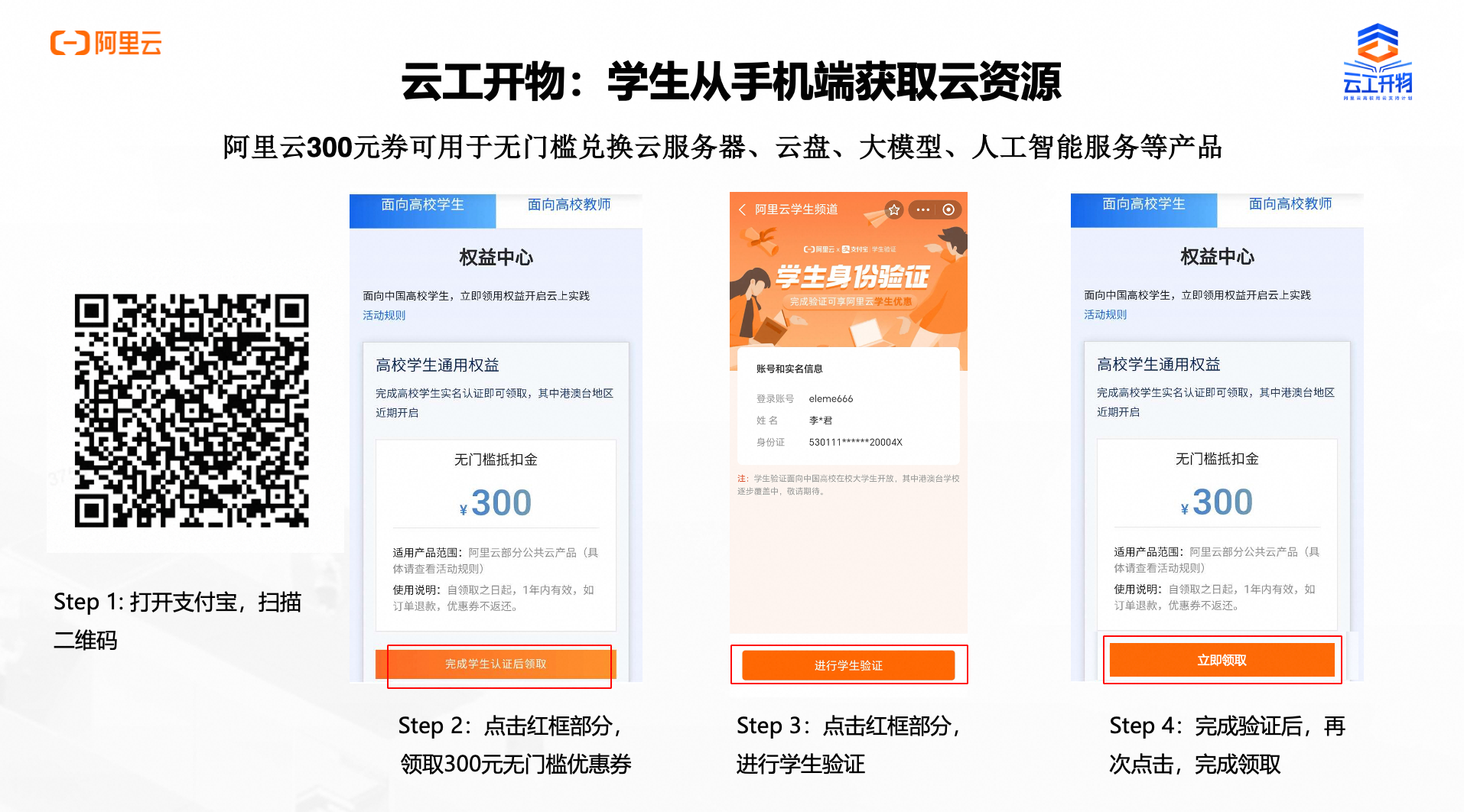
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
如果您调整了资源规格,使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
领取专属权益及开通授权
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作
第一步:本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
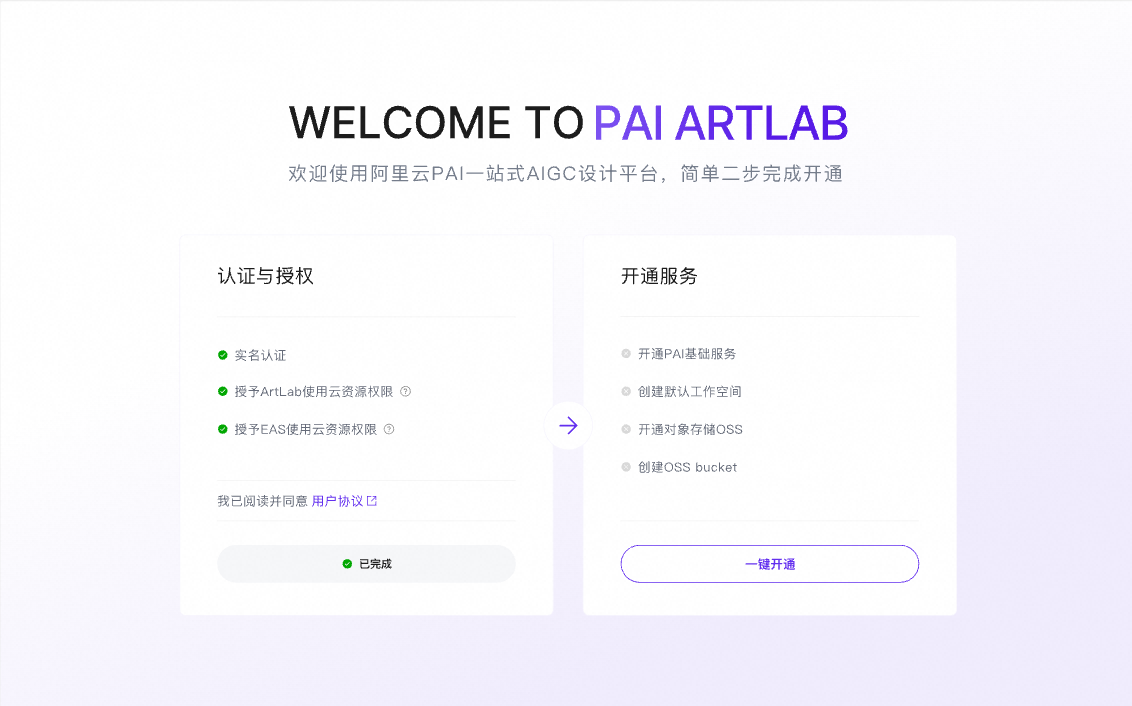
第二步:进入并开通PAI ArtLab并授权
点击访问PAI ArtLab平台
初次进入平台,依次点击两步,完成PAI ArtLab平台开通与授权

实验步骤
一、素材收集
图像收集
为了实现风格一致的设计内容生成,本实验首先需要构建一个高质量的图像数据集,用于训练基于呜哩平台的LoRA模型。数据收集应遵循以下要求:
图像类型与风格要求
图像应当拥有统一的特征,如植物、公园、品牌、空间类型、某类非遗元素、人物形象、ip形象、视觉特征等。
每组图像应分为A、B两张图,两者之间应存在相互对应的关系,组间关系也应呈现统一的变化关系。
建议选择和专业相关的图像集。
图像中不存在文字/水印/logo等干扰因素。
从个人角度出发,图像应该具备“美”的特征或者具备其他特色。
图像尺寸
图像编辑模型建议使用高分辨率图像进行训练,所有图片应统一裁切或缩放为1024×1024/1536×1024/1024×1536 像素区间的图像。
同一组的A、B两张图片,尺寸应完全一致,不同组间的图像尺寸可有些许不同。
图像数量
建议每个主题收集20-30组高质量图片。
案例











二、数据集准备
2.1 打开PAI ArtLab平台
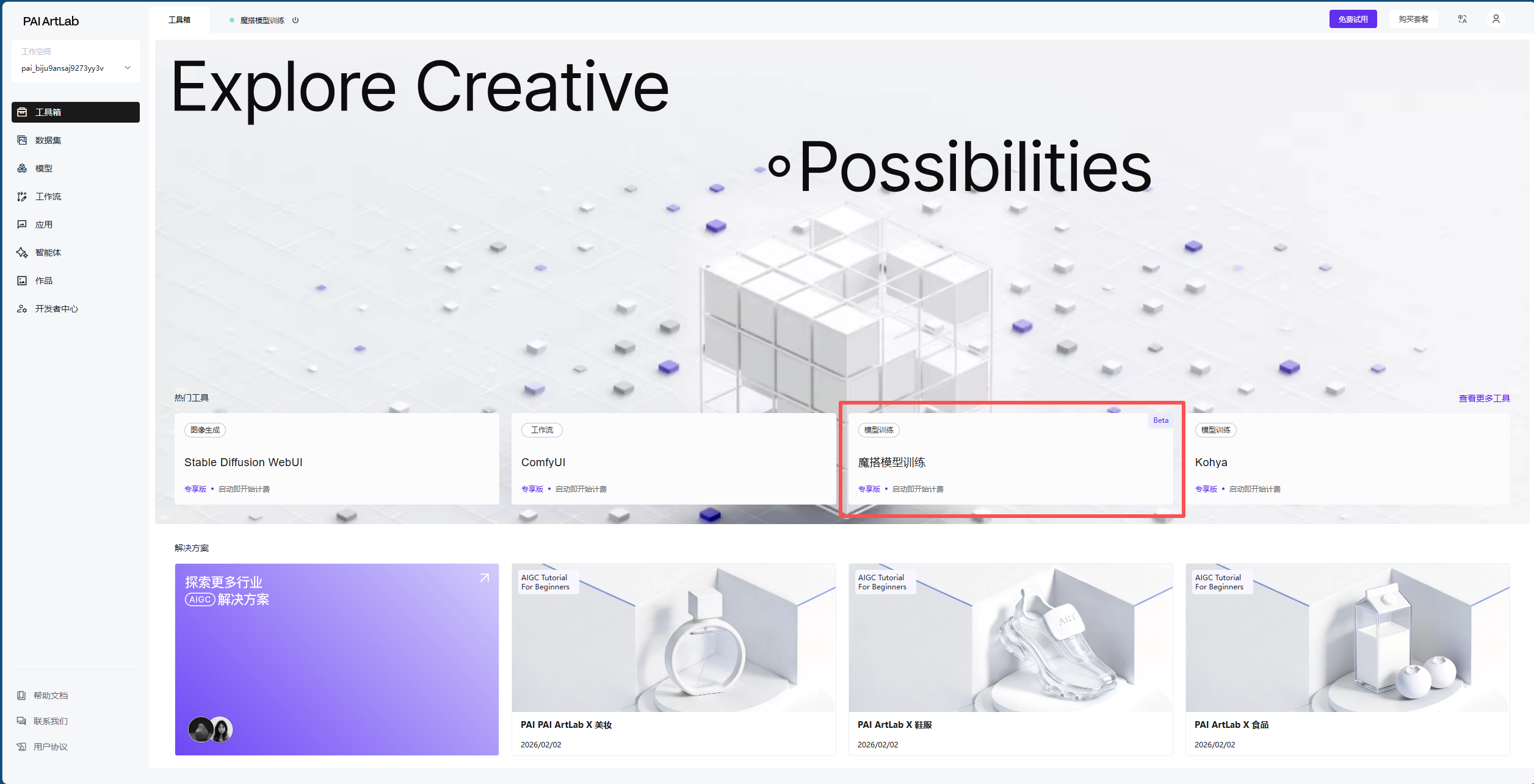
进入PAI ArtLab平台,在工作台选择“魔搭模型训练”
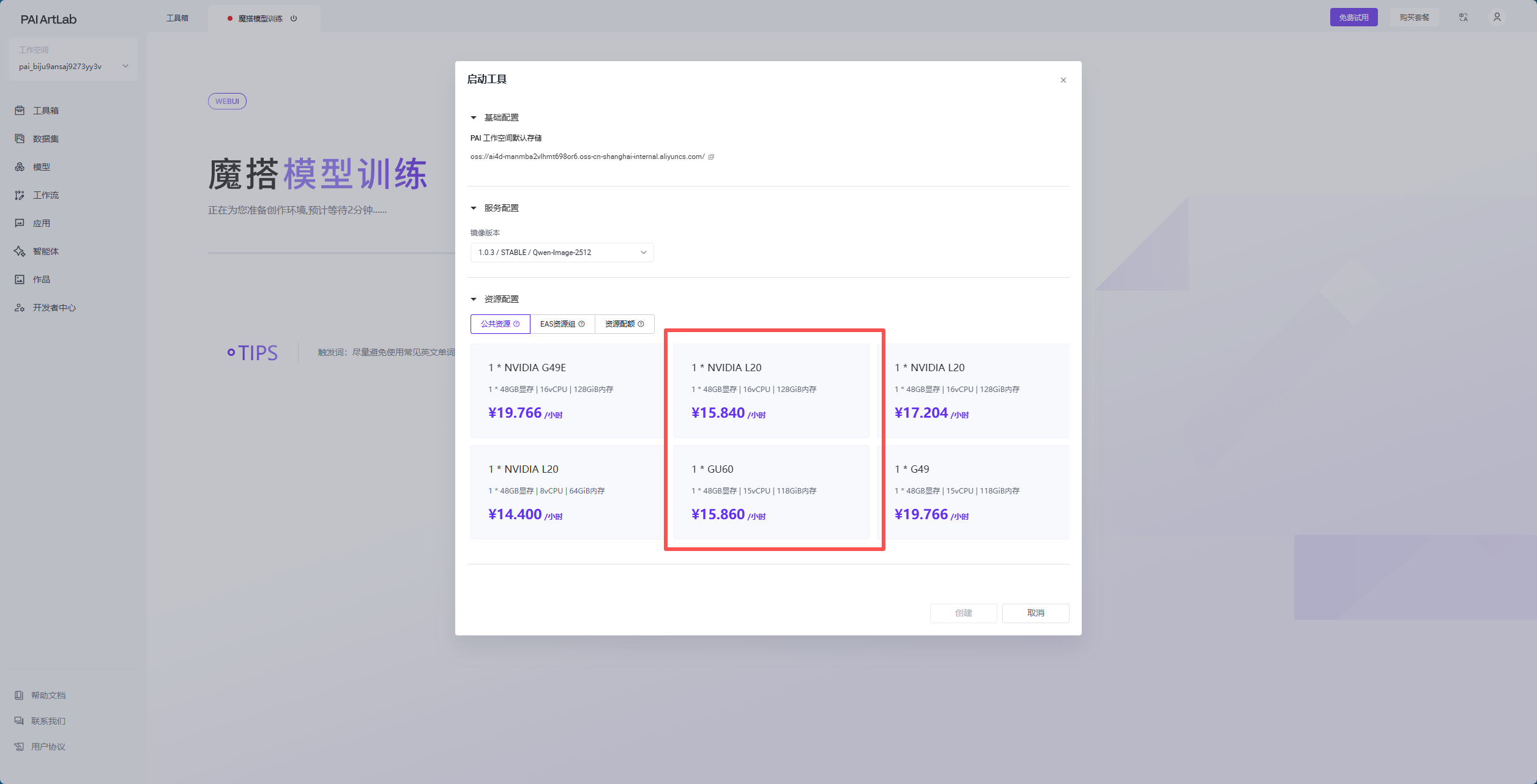
打开后选择“GU60/L20”
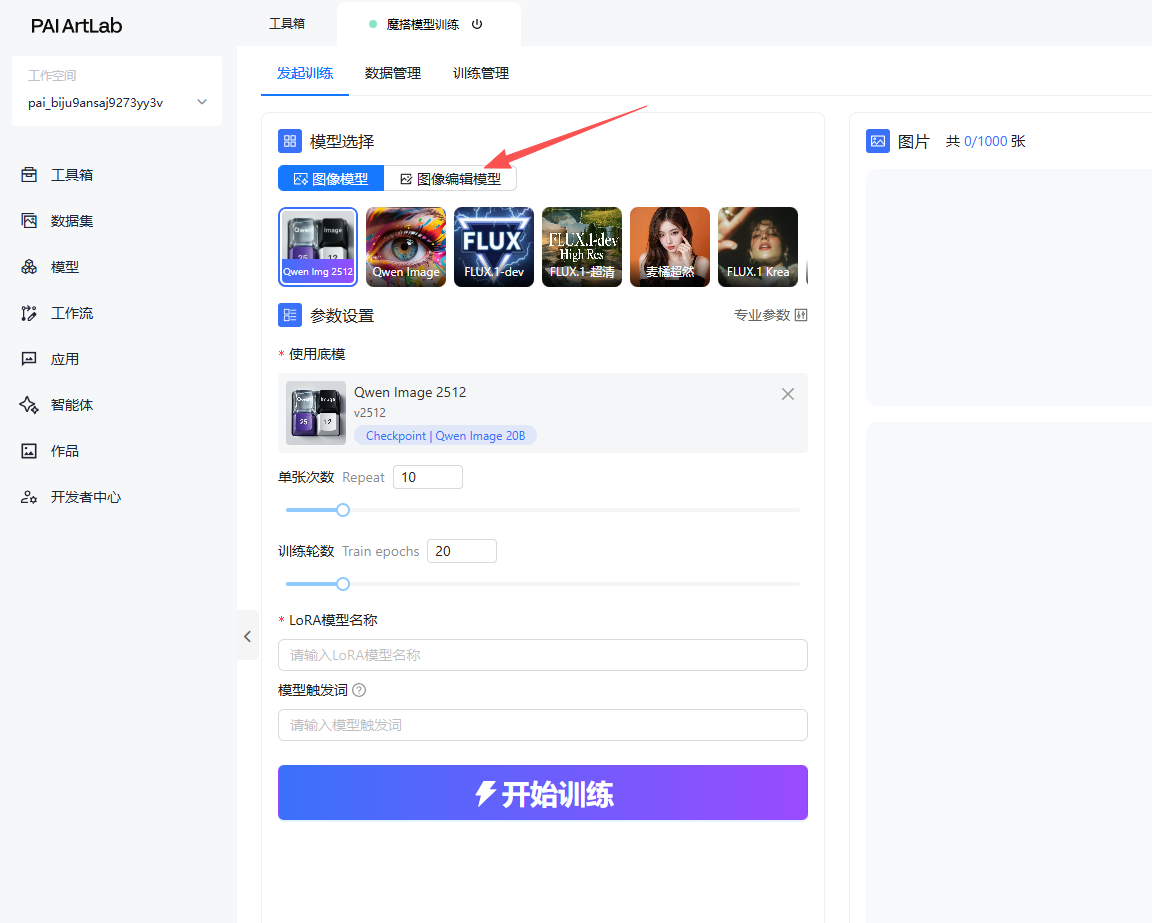
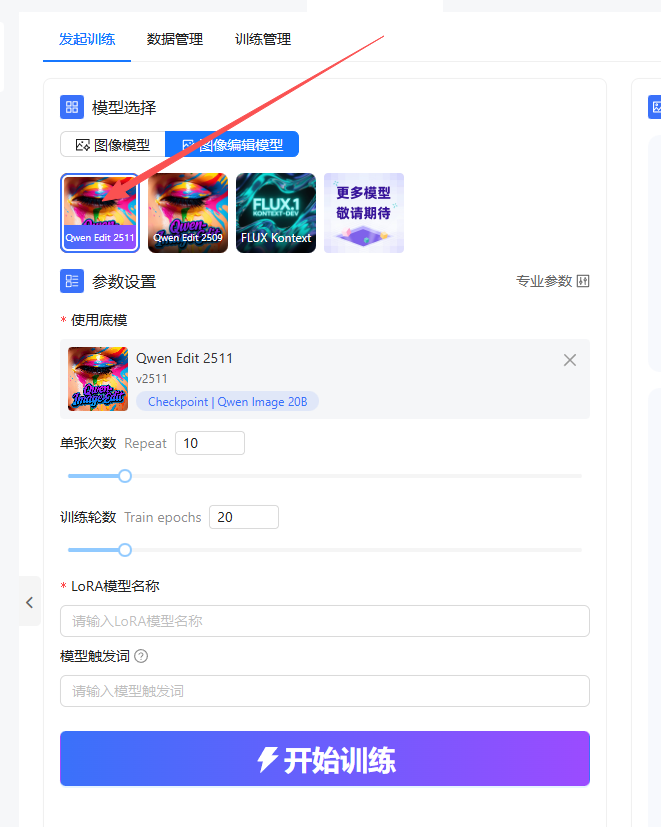
等待打开后,在左侧选择“图像编辑模型”
选择后,选择QWen Edit 2511
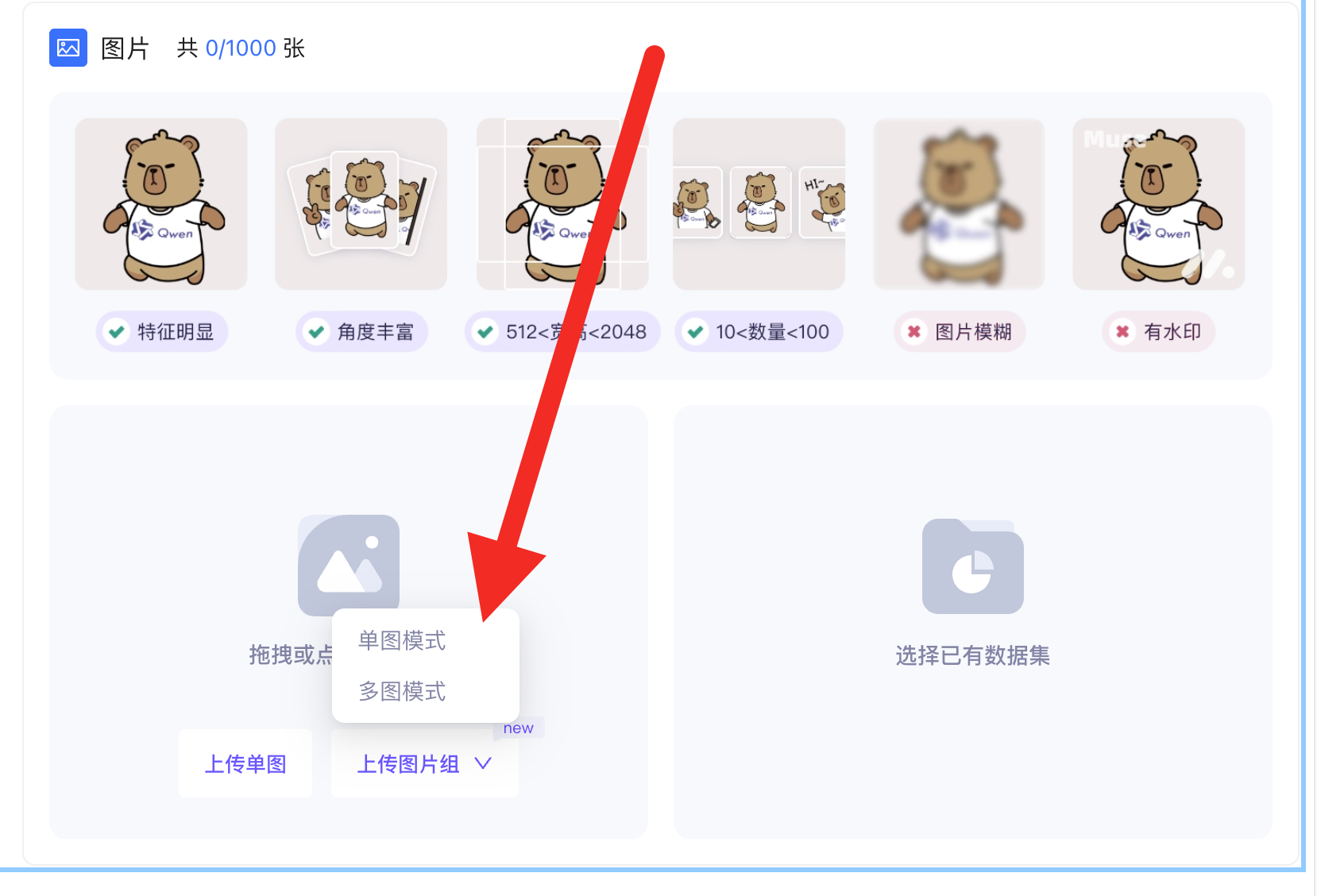
2.2 上传数据集
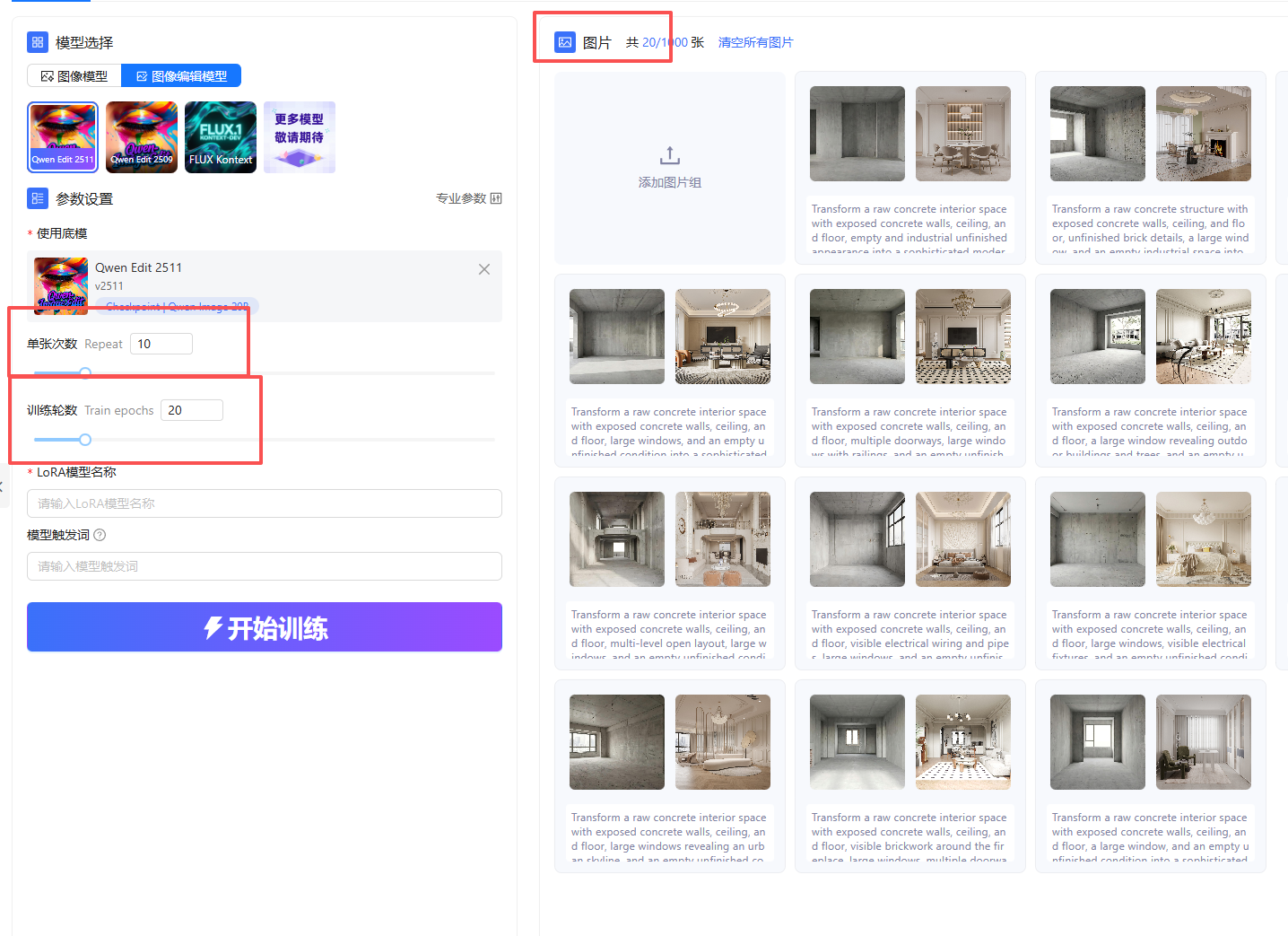
在右侧图片栏,选择“上传图片组”,随后选择“单图模式”
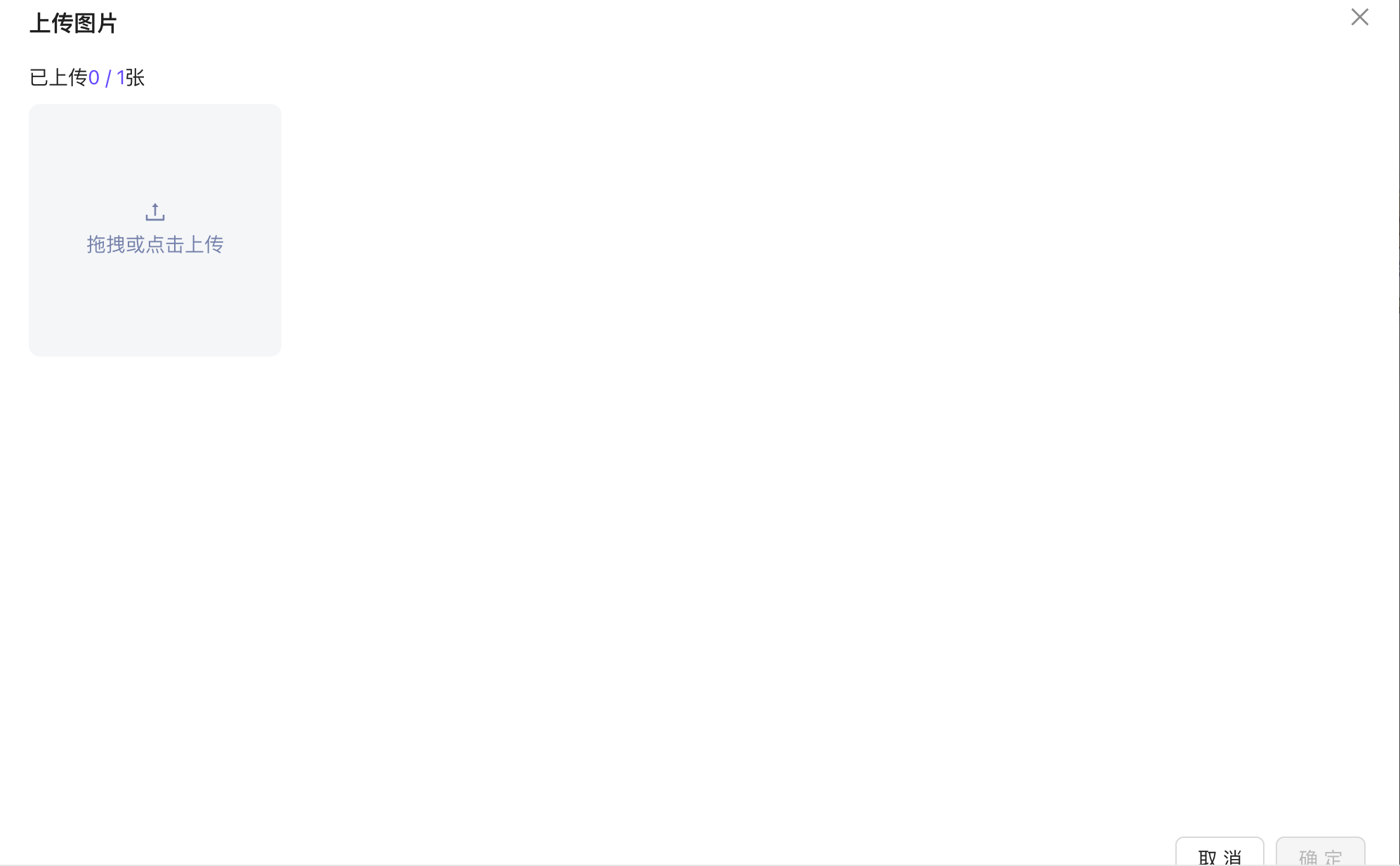
之后会弹出上传原图和目标图的上传框
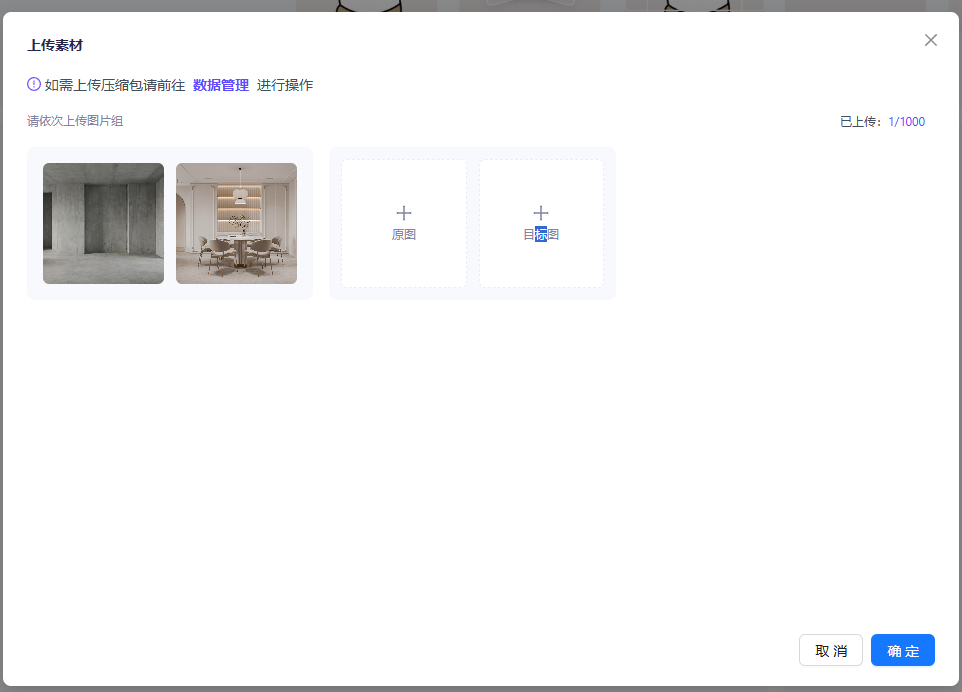
点选原图,在随后弹出的上传框进行拖拽或者点击图片上传
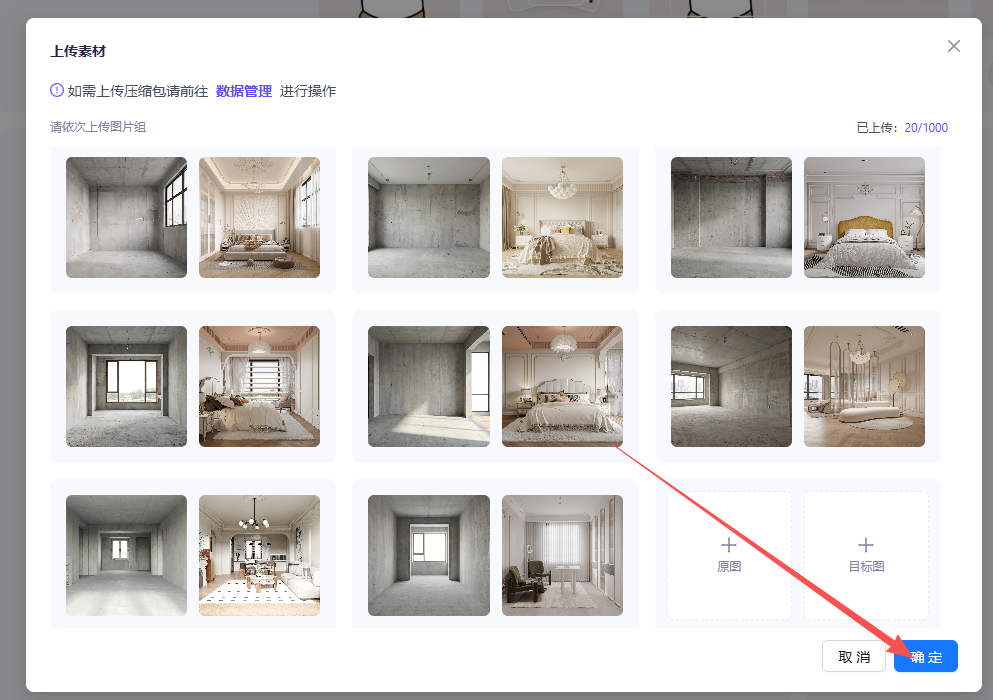
对原图和目标图都进行上传,如此即为上传好了一组图片,按照这种操作,将所有的图像组都进行上传
都上传后点击确定
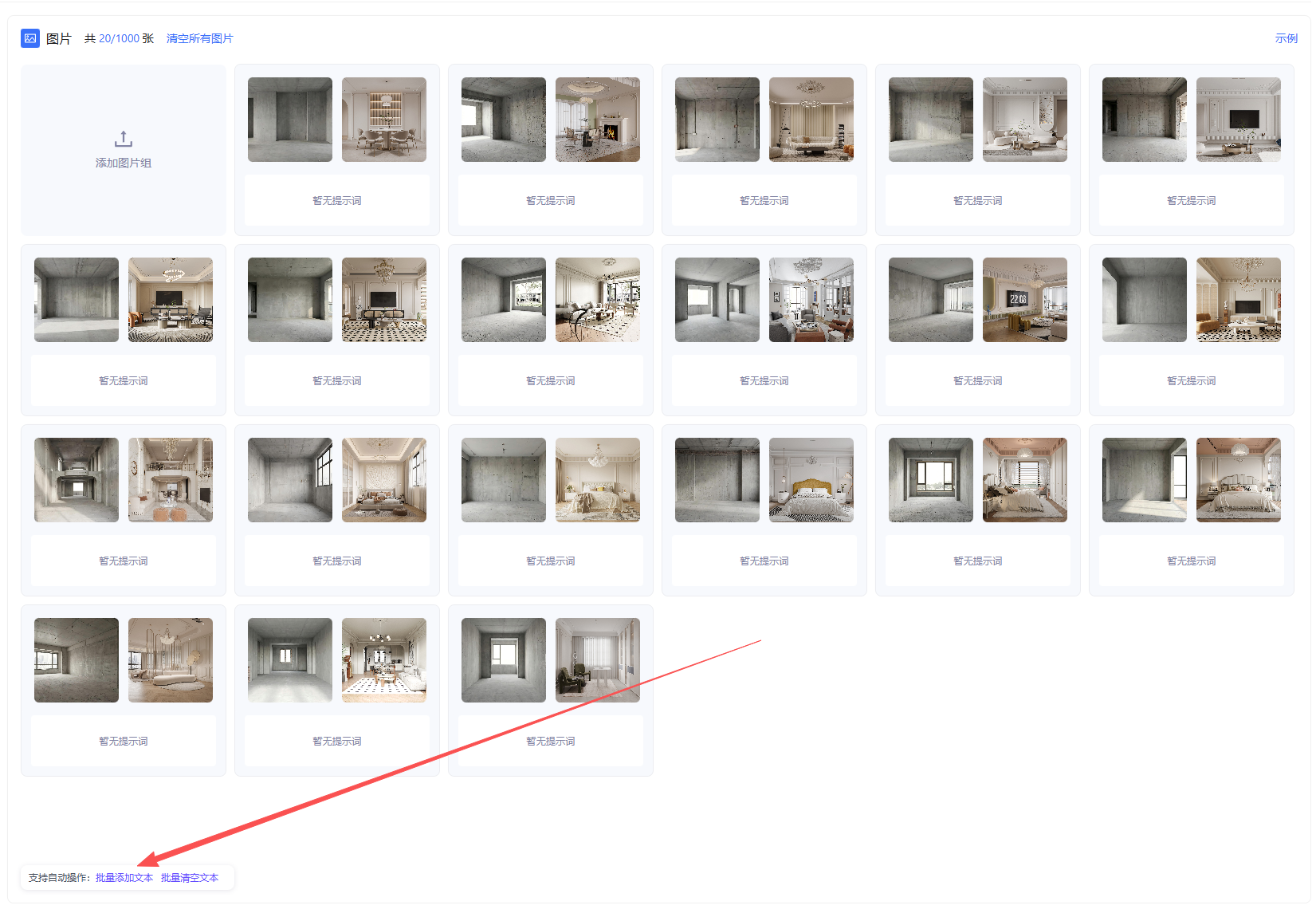
2.3 数据集打标
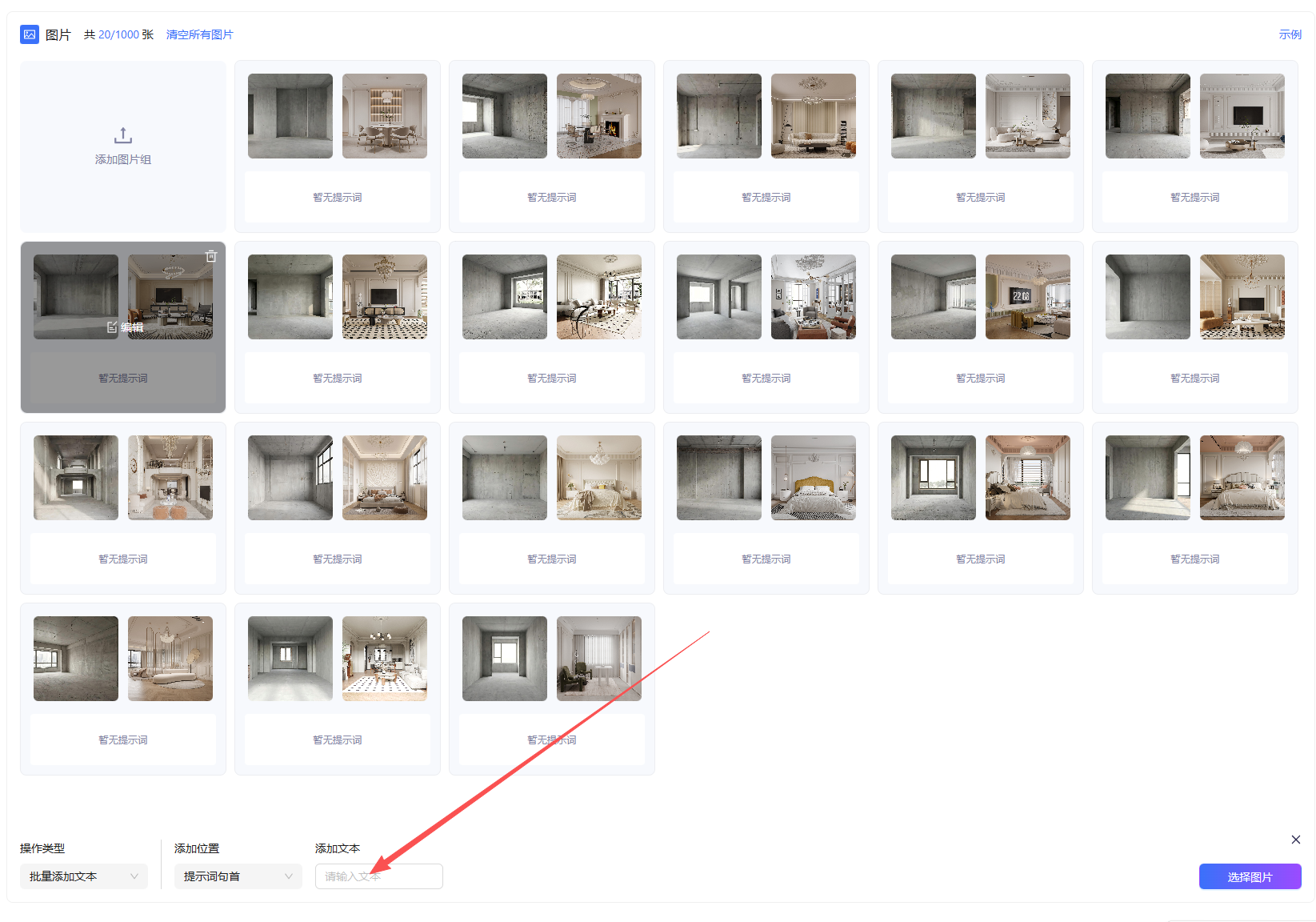
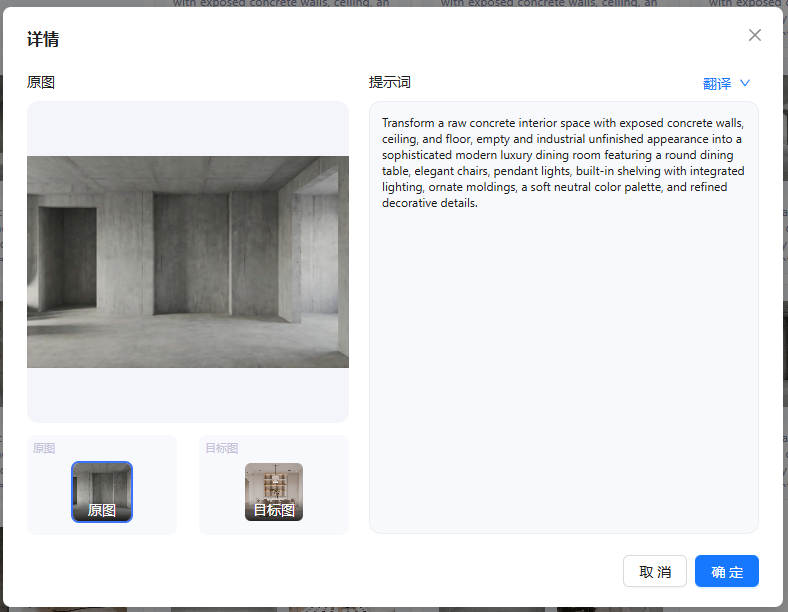
点击确定后,如果你的图像编辑前后变化较为单一,不存在过多的变化,则选择“批量添加文本”
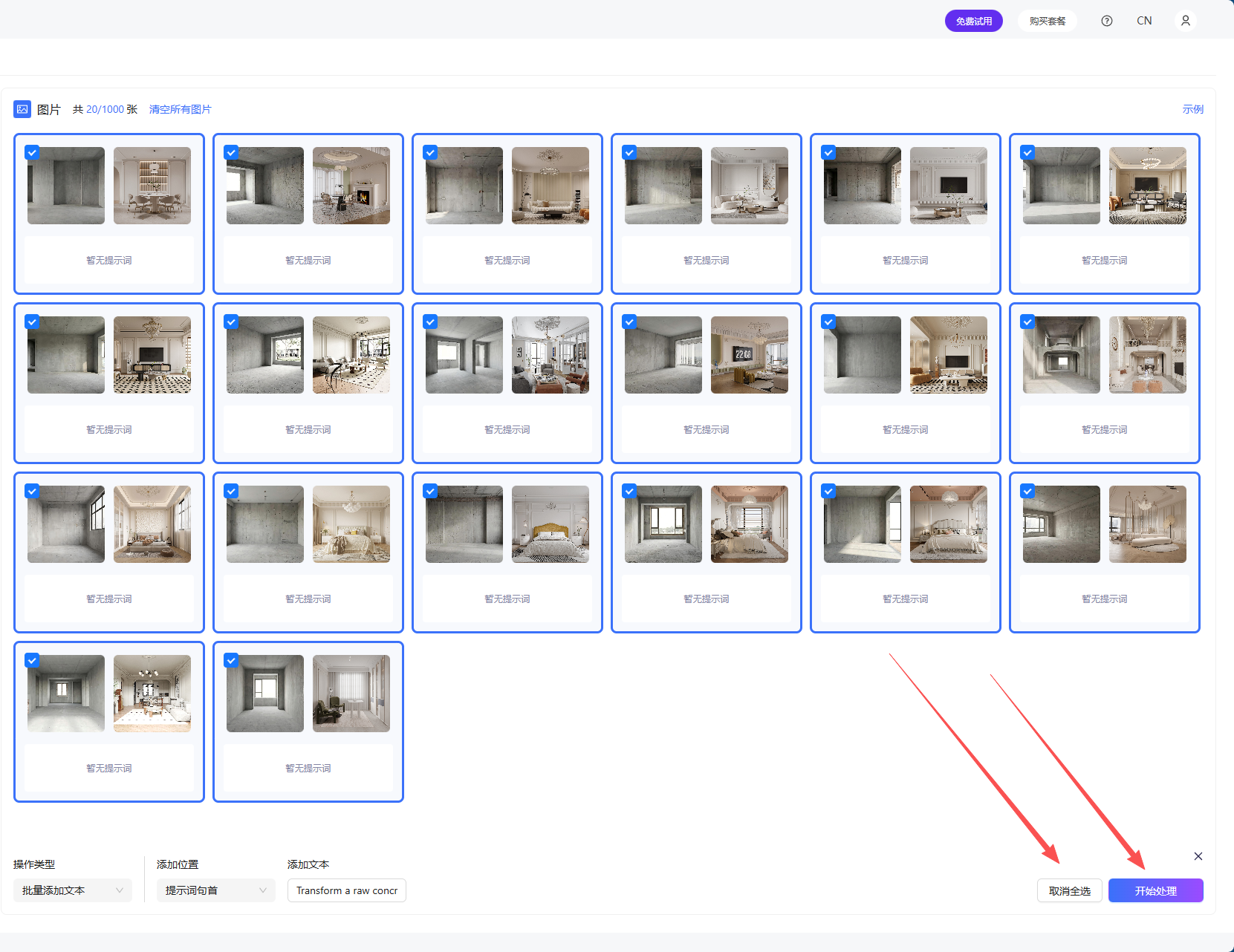
在添加的文本里用英文书写你的每一组对应的原图与目标图之间的关系,将A、B组的图像上传至千问,并提出“你是一名资深的建筑师和提示词工程师,接下来我会给你一组图片,你需要生成从第一张图到第二张图的可用于图像编辑模型的提示词,结构大致为“将一张这样的图像转化为那样的图像”,需要是指令形式的,并且是英文”。得到指令之后将其复制进文本框,输入后选择“全部选择”、“开始处理”
需要注意的是,这里的文字输入应当尽量详细地阐述是如何从A到B的变化过程。
点击开始处理之后,仍可以对单张图像点击编辑进行单独标注,用于某一组图像具有较为特殊的对应条件时
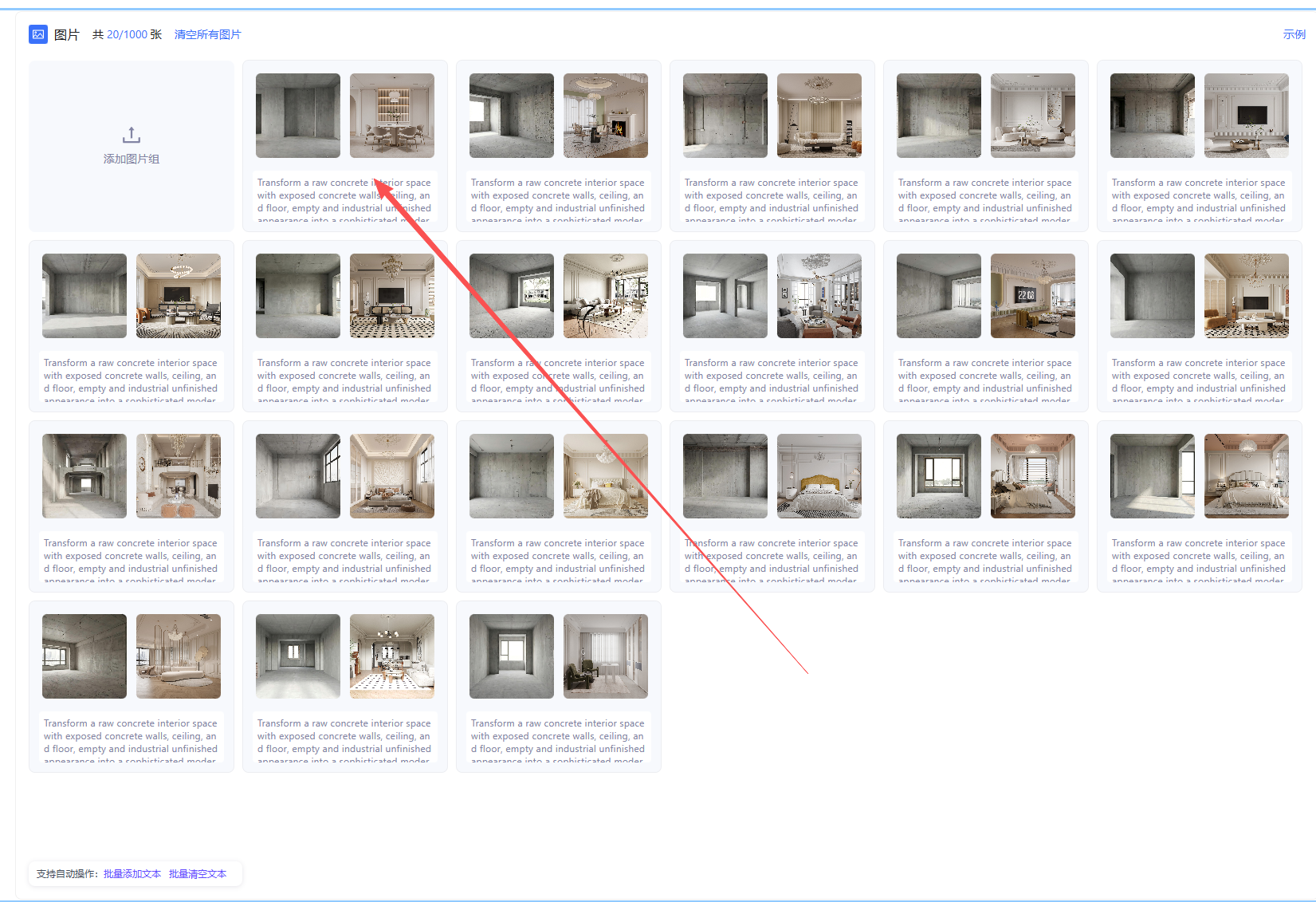
全部图像组都上传并进行打标后,数据集的准备即告完成。
需要注意的是,如果数据集的AB组变化较为丰富,则应当每一对数据都单独进行提示词生成。

三、模型训练
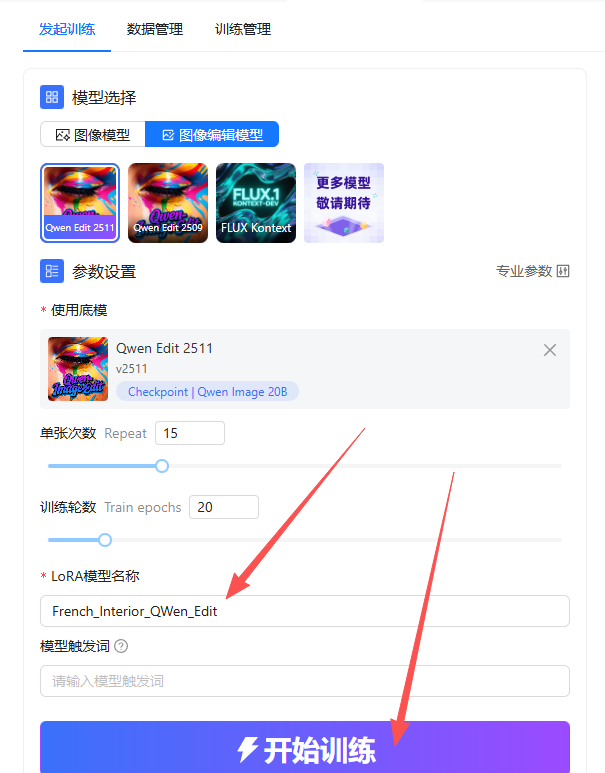
3.1进行参数调整
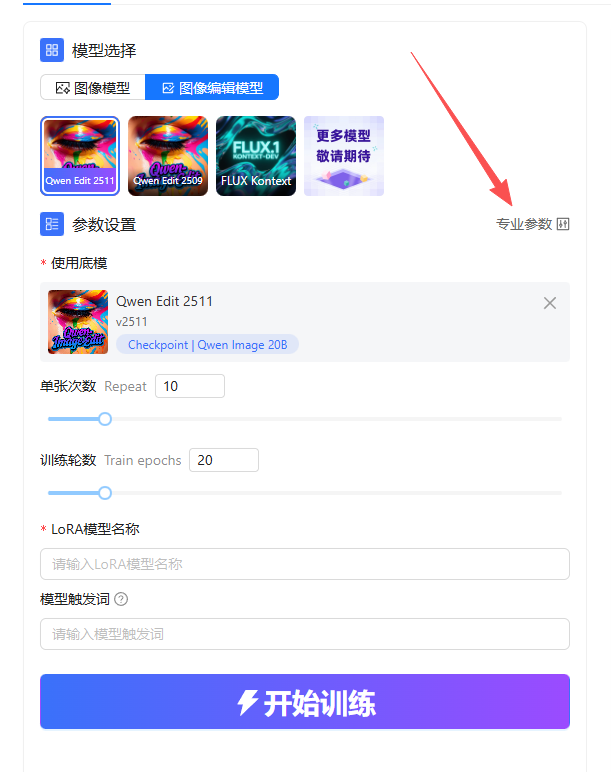
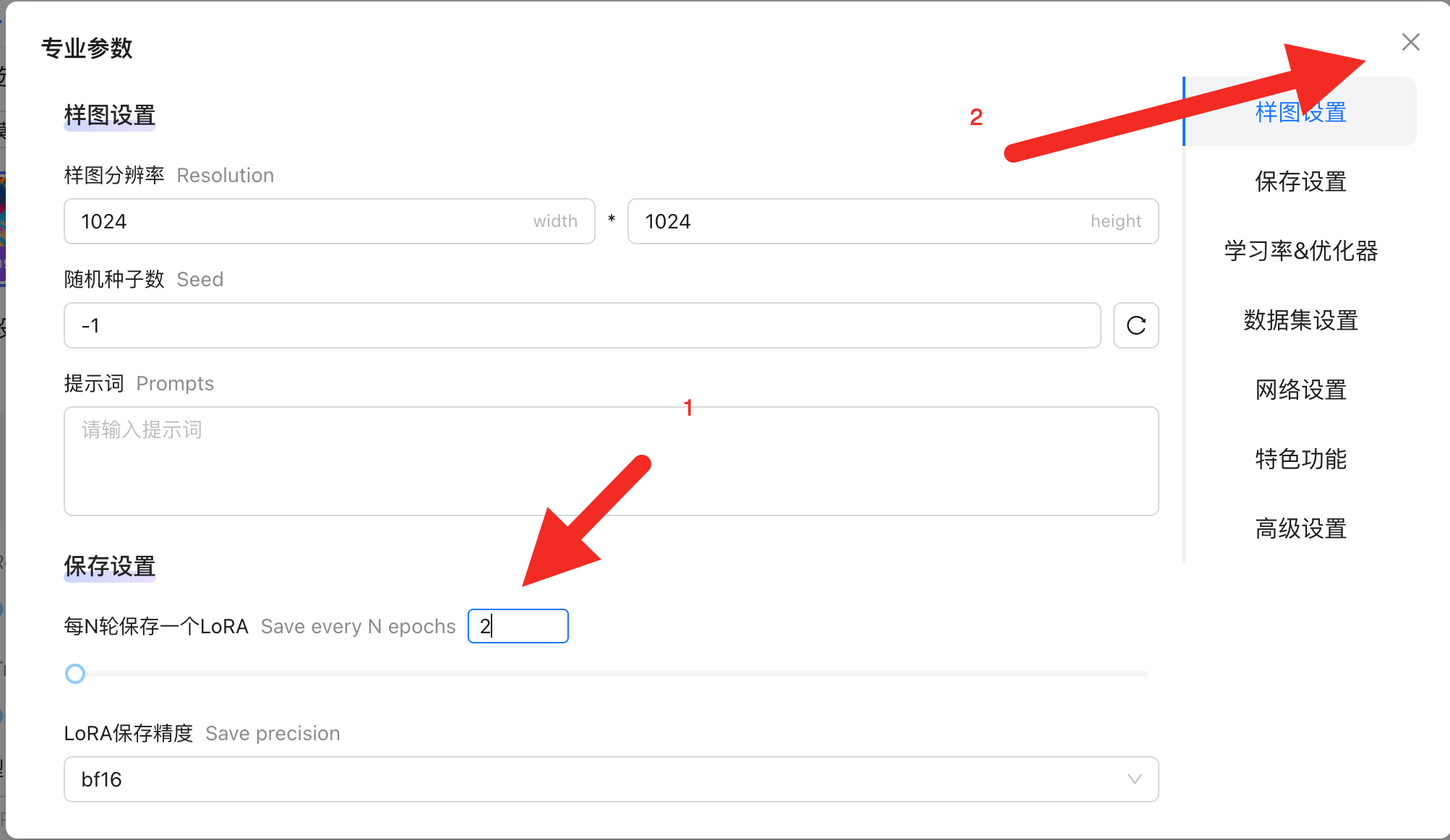
来到界面左侧,对参数进行调整,点击专业参数
将每N轮保存一个LoRA,设置为2,设置好后即可关闭
3.2训练步数计算
应尽量保障训练步数大于6000,其计算方法为单张次数X训练轮数X图片组数
调整后输入LoRA模型名称,即可点击开始训练
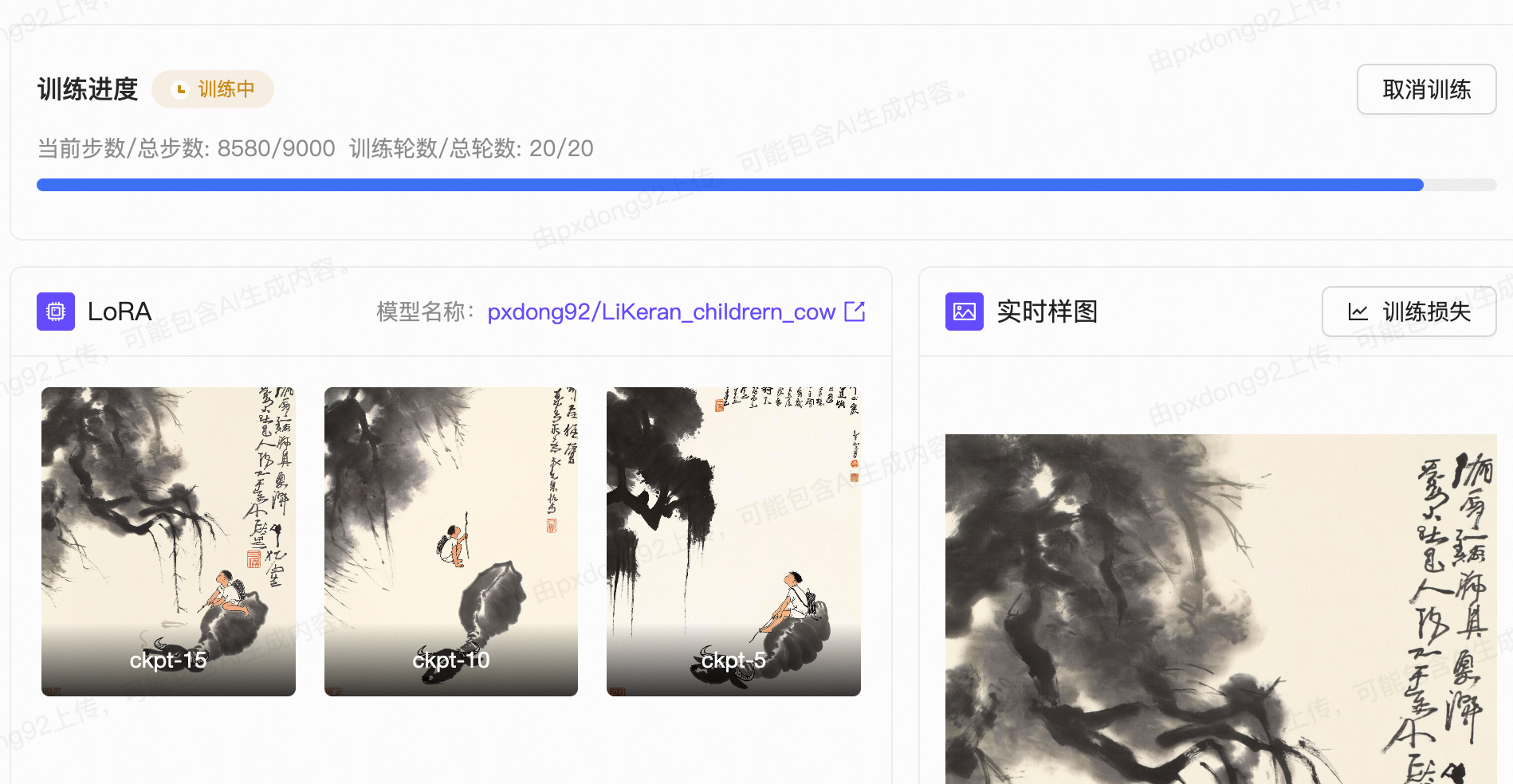
3.3训练状态查看
发起训练后可以在“训练管理”页面查看当前的训练状态
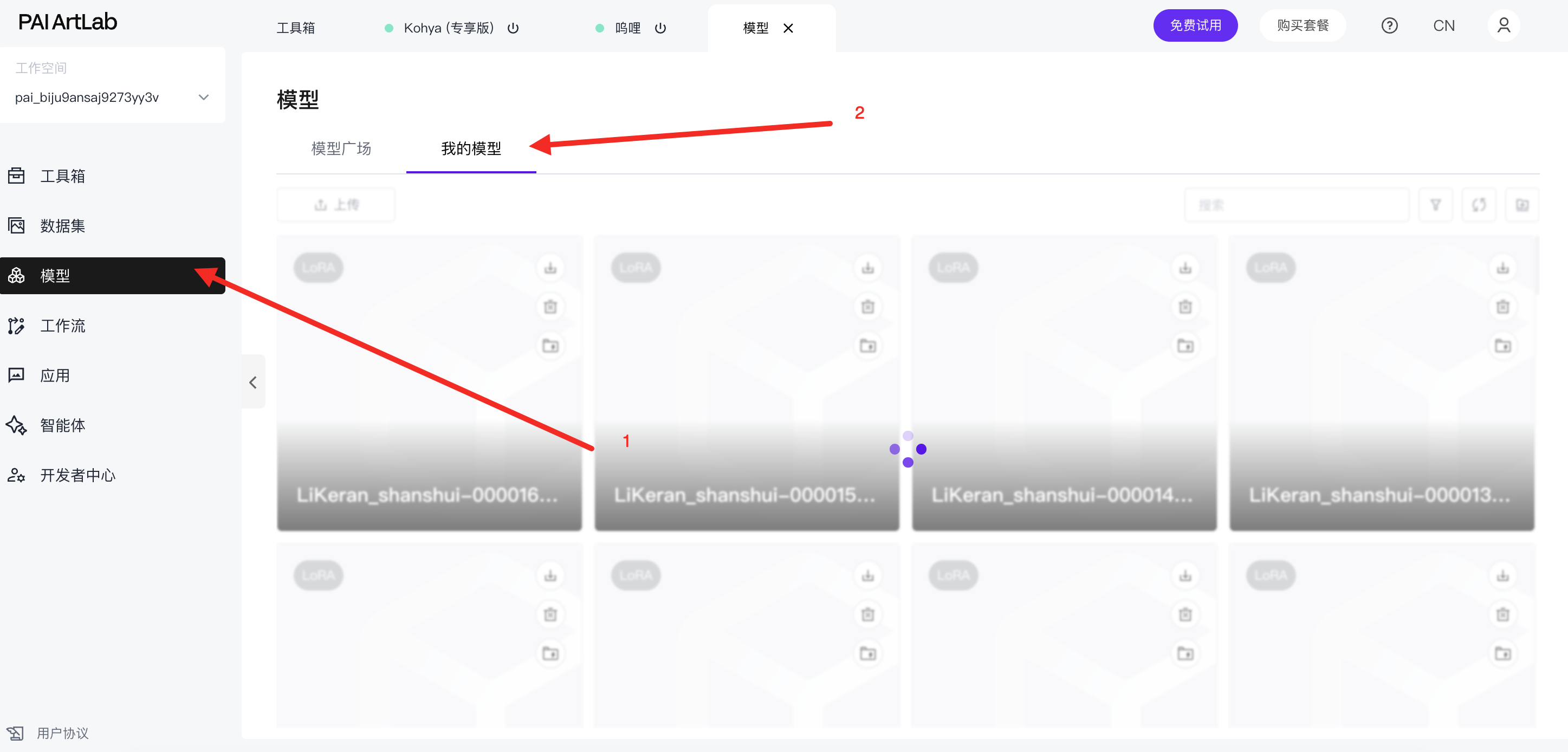
训练结束后的模型会出现在左侧工具栏“模型”-“我的模型”当中,一般训练时长为8-10小时。
实验资源释放
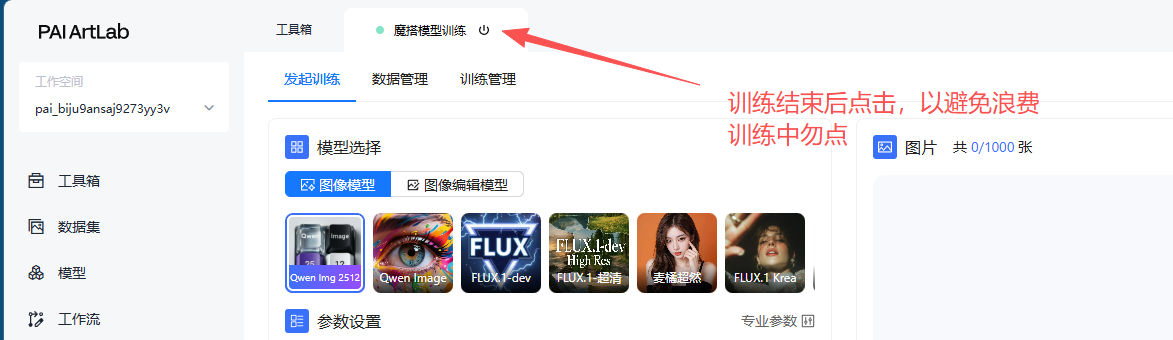
实验结束后,点击关闭释放实验资源,避免不必要的扣费。
在PAI ArtLab控制台中,开始训练之后可以直接关闭浏览器或者关机,训练会在后台持续进行,在训练彻底结束后可以关闭魔搭模型训练服务器,避免不必要的扣费。
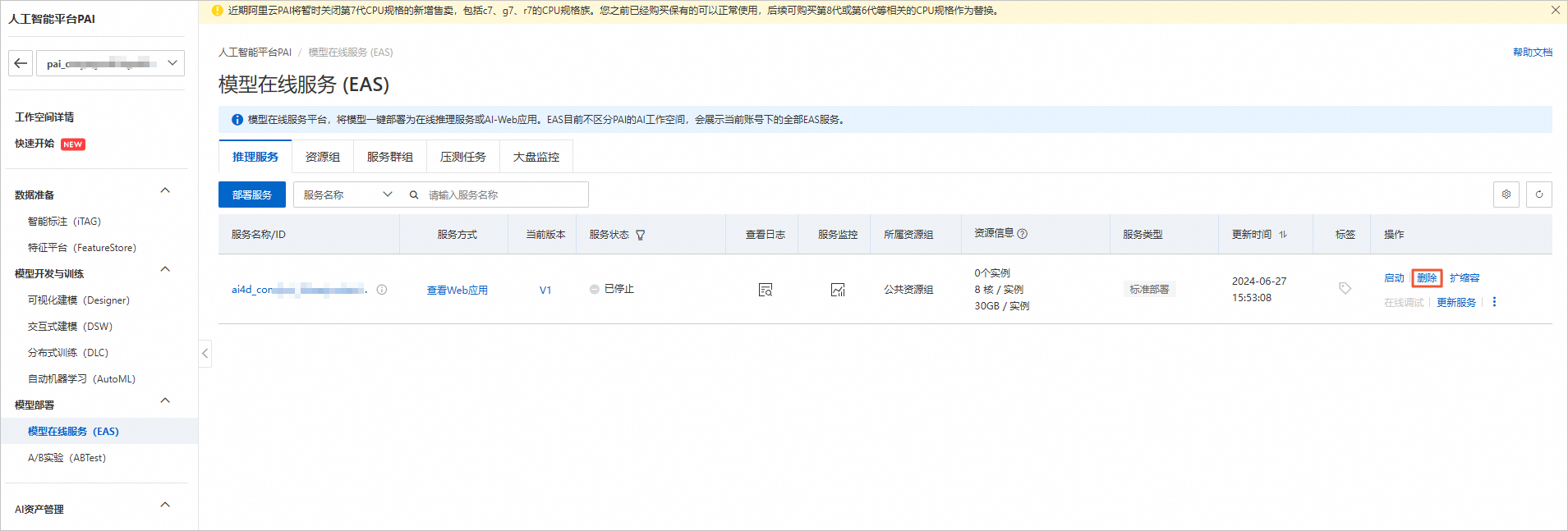
在工作空间页面的左侧导航栏中单击模型在线服务(EAS)。在模型在线服务(EAS)页面,找到目标服务。单击其右侧操作列下的删除
若未找到服务,点击左上角切换模型所在地域,或左侧导航栏切换工作空间列表查看
如果需要继续使用,请随时关注账号扣费情况,避免模型因欠费而被自动停止。
背景知识
核心技术路径
图像编辑模型技术架构
本实验采用的Qwen Image Edit 2509模型属于先进的扩散模型(Diffusion Model)架构,专门针对图像编辑任务进行优化。扩散模型通过逐步添加噪声到数据中学习数据分布,再通过反向过程从噪声中生成目标图像。在图像编辑场景下,模型需要理解原图的语义内容,并根据提示词(prompt)指导实现精准的视觉转换,保持图像一致性的同时完成指定的风格或内容变化。
LoRA微调技术
LoRA(Low-Rank Adaptation)是一种参数高效的微调方法,通过在预训练模型的关键层中插入低秩矩阵来实现模型适应特定任务,而不改变原始模型权重。这种技术具有显著优势:
参数效率:仅需训练少量参数(通常不到原始模型的1%)
存储优化:生成的LoRA适配器文件体积小,便于存储和分享
快速部署:可以灵活地与基础模型组合使用
避免灾难性遗忘:保持原始模型的基础能力
提示词工程与视觉语义对齐
图像编辑模型的核心在于建立精确的视觉-语言对齐关系。本实验通过专业化的提示词工程,将图像转换过程语义化,使模型能够理解从原图到目标图的变换逻辑。高质量的提示词需要:
明确描述转换目标和过程
保持指令式语气
包含足够的细节信息
采用标准化结构增强模型理解
专业知识体系
数据集构建科学
成功的图像编辑模型依赖于高质量的配对数据集。本实验构建的数据集需遵循严格的科学原则:
视觉一致性:同一数据集内的图像应具有统一的视觉特征或转换逻辑
几何规整性:图像分辨率标准化(1024×1024/1536×1024/1024×1536像素)确保模型训练稳定性
语义对齐度:原图与目标图之间必须存在清晰、一致的转换关系
多样性平衡:在保持转换逻辑一致的前提下,涵盖不同角度、光照和构图的变化
模型训练优化理论
专业级的模型训练需要深入理解优化理论:
训练步数计算:总训练步数 = 单张次数 × 训练轮数 × 图片组数,建议大于6000步以确保充分收敛
学习率调度:适当的训练轮数(epochs)设置平衡模型拟合与泛化能力
精度控制:bf16精度保存在保持模型性能的同时优化存储效率
中间检查点:每N轮保存一个LoRA模型,便于回溯最佳性能点
工程实践知识体系
成功的实验实现需要综合性的工程知识:
计算资源管理:理解L20 GPU(48GB显存)的性能特点与任务匹配
数据预处理流水线:从原始素材到标准训练数据的完整处理流程
模型评估方法:通过实时样图监控制训练质量,避免过拟合或欠拟合
部署与应用集成:训练后模型自动部署至平台,实现无缝应用
跨学科融合知识
本实验体现了多学科知识的融合:
建筑学与设计理论:理解建筑改造、空间设计等专业领域的视觉表达
计算机视觉基础:掌握图像特征提取、空间变换等底层原理
自然语言处理:精准构建提示词与视觉内容的映射关系
人机交互设计:优化用户与AI模型的交互体验,实现直观的图像编辑
这一背景知识体系不仅支撑了当前实验的技术实现,也为后续在建筑改造、艺术创作、数字孪生等领域的深入应用奠定了坚实基础,体现了AI技术与专业领域知识融合的前沿发展方向。
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验