Delta Lake和Hudi是数据湖方案中常用的存储机制,为数据湖提供流处理、批处理能力。MaxCompute基于阿里云DLF、RDS或Flink、OSS产品提供了支持Delta或Hudi存储机制的湖仓一体架构。您可以通过MaxCompute查询到实时数据,即时洞察业务数据变化。
背景信息
通常,企业构建和应用数据湖需要经历数据入湖、数据湖存储与管理、数据探索与分析过程。MaxCompute基于阿里云DLF(Data Lake Formation)、RDS(Relational Database Service)或Flink、OSS(Object Storage Service)产品提供了支持Delta Lake或Hudi存储机制的湖仓一体架构,架构图如下。
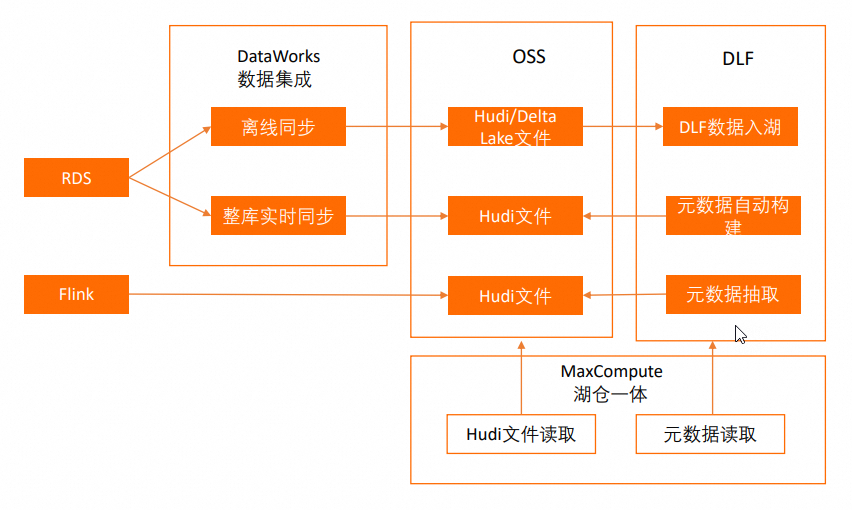
模块 | 对应阿里云产品 | 说明 |
在线数据库 | 准备的入湖数据来源,即数据湖的数据来源。 | |
实时计算 | 准备的入湖数据来源,即数据湖的数据来源。 | |
数据入湖 | 对接在线数据库,管理入湖数据来源。 | |
数据湖存储与管理 | 将在线数据库中的源数据引入数据湖时,OSS会作为数据湖的统一存储,存储机制包含Delta Lake和Hudi两种。同时,DLF采用元数据管理功能管理元数据库和元数据表。 | |
数据湖探索与分析 |
| 对数据湖数据进行分析。 |
前提条件
已开通如下服务或已创建实例、项目:
已开通OSS服务。
更多开通OSS服务操作,请参见开通OSS服务。
已开通DTS服务。
您可以单击此处一键授权,为后续操作MaxCompute项目的阿里云账号授予AliyunDTSDefaultrole角色,授权即表示开通了DTS服务。
已创建RDS MySQL实例或Flink全托管实例。
如果您想实现基于DLF、RDS、OSS支持Delta Lake或Hudi存储机制,需创建RDS MySQL实例,详情请参见创建RDS MySQL实例。
如果您想实现基于DLF、Flink、OSS支持Hudi存储机制,需创建Flink全托管实例,详情请参见开通实时计算Flink版。
已开通DataWorks服务。
更多开通DataWorks操作,请参见开通DataWorks。
已开通DLF。
已创建MaxCompute项目(非External Project)。
更多创建MaxCompute项目信息,请参见创建MaxCompute项目。假设已创建的MaxCompute项目名称为
doc_test_prod,所属地域为华东2(上海)。
使用限制
基于Delta Lake或Hudi存储机制的湖仓一体方案的使用限制如下:
仅华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华南1(深圳)、中国香港、新加坡和德国(法兰克福)地域支持构建湖仓一体能力。
MaxCompute需要与DLF、OSS、RDS或Flink部署在同一地域。
MaxCompute只支持对Hudi、Delta Lake格式文件的全部列进行读取,不支持增量读、快照读以及写等操作。
基于DLF、RDS、OSS支持Delta Lake或Hudi存储机制
操作流程
为操作MaxCompute项目的账号授予访问DLF和OSS的权限。
创建OSS存储空间作为数据湖的统一存储路径。
创建RDS数据库,准备入湖数据。
通过创建数据源对接RDS与DLF。
基于DLF创建数据入湖任务,将RDS数据库中的表数据实时同步并回放到数据湖中。
通过DataWorks控制台的数据湖集成界面创建External Project,对数据湖数据进行分析。
步骤一:授予MaxCompute访问DLF和OSS的权限
步骤二:在OSS中创建存储空间及目录
创建OSS存储空间作为数据湖的统一存储路径。
登录OSS管理控制台。
在左侧导航栏,单击Bucket列表,在Bucket列表页面,单击创建Bucket。
在创建Bucket面板填写Bucket名称,例如
mc-dlf-oss,并选择地域,例如华东2(上海)后,单击确定。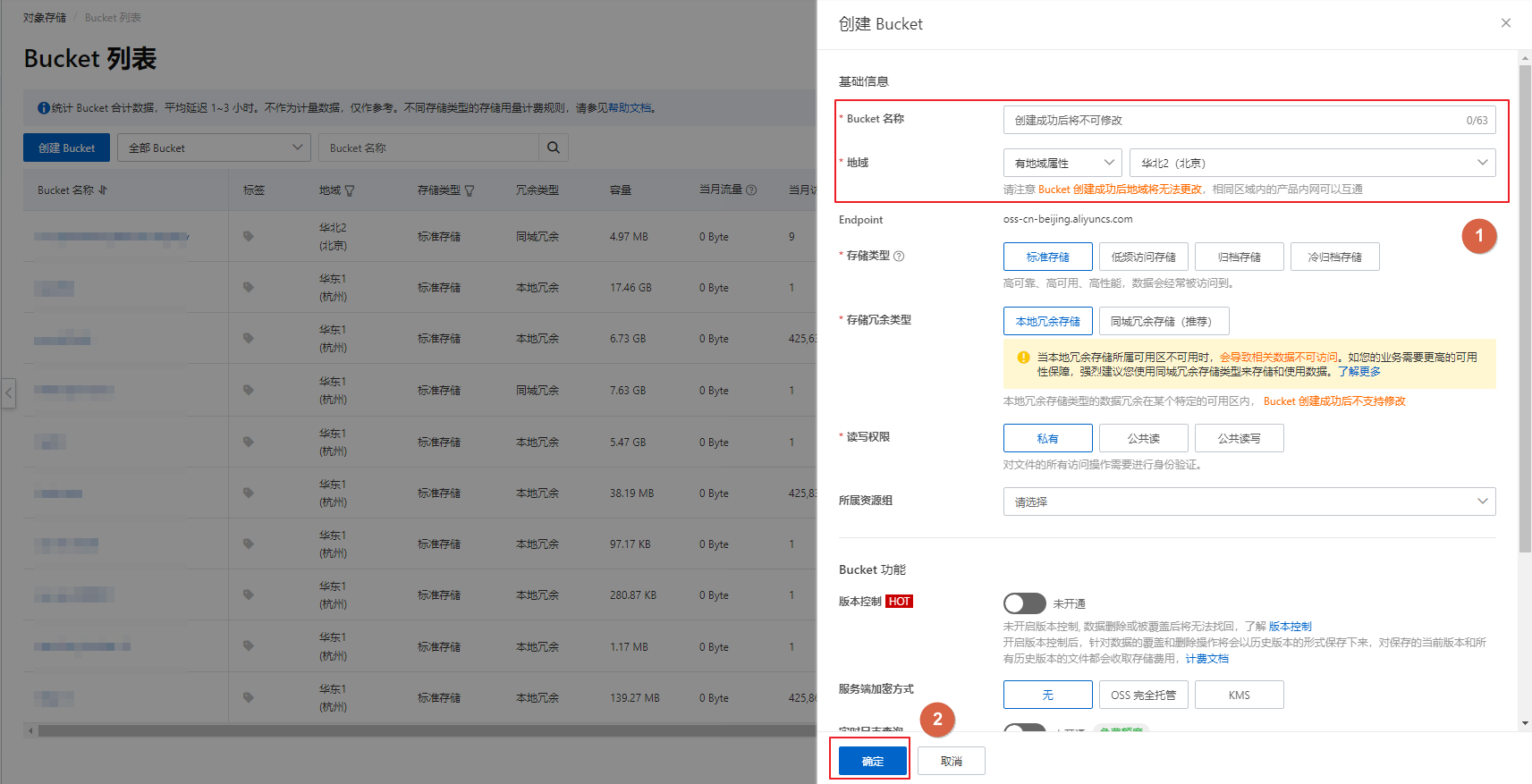
在左侧导航栏,单击文件管理后,在右侧区域单击新建目录并填写目录名,例如
covid-19,单击确定。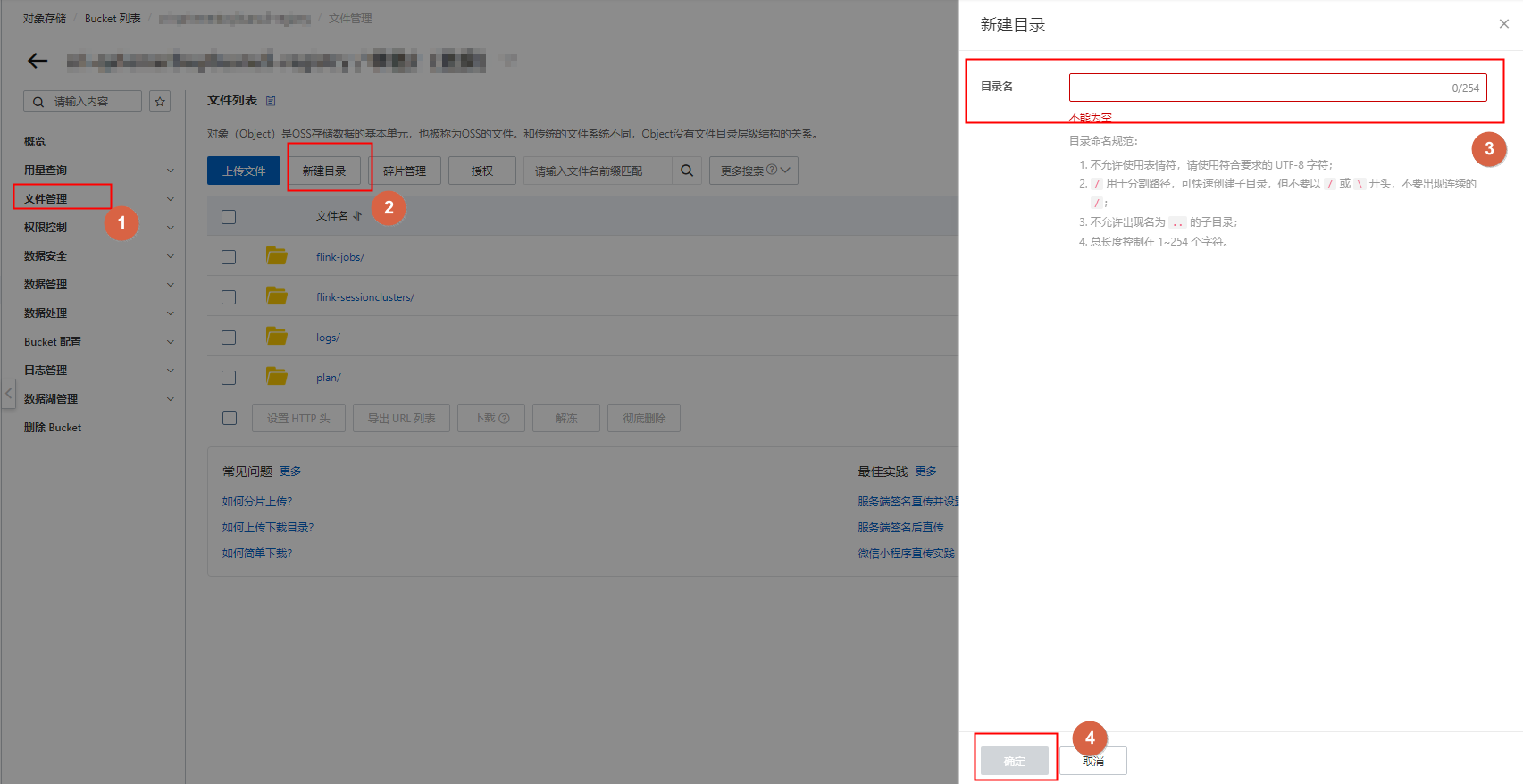
步骤三:准备入湖数据
基于阿里云RDS构造数据库,并创建表、准备入湖数据。
访问RDS实例列表,在上方选择地域。例如
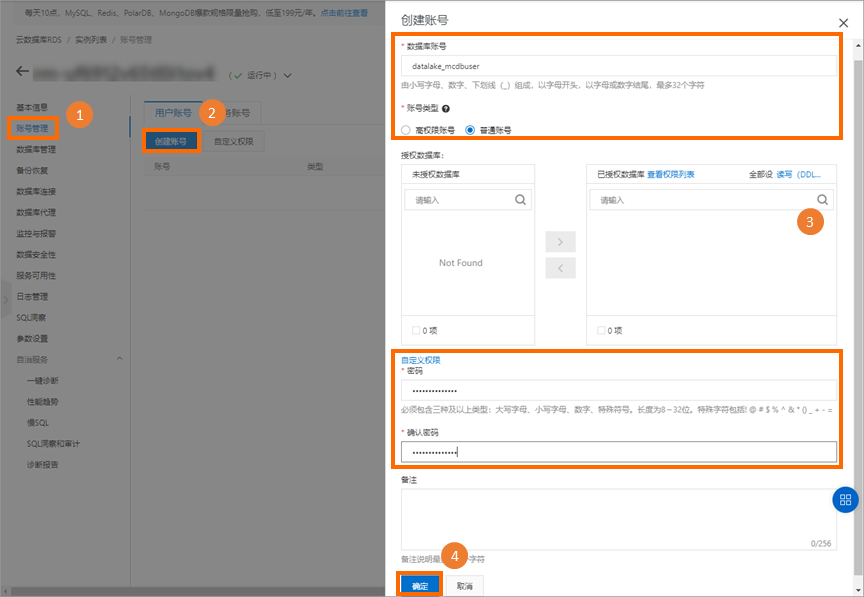
华东2(上海),然后单击目标实例ID。创建RDS数据库账号。在目标实例信息页面的左侧导航栏单击账号管理后,在用户账号页签单击创建账号,并在创建账号面板配置下表所列参数信息,单击确定。
参数名称
说明
样例值
数据库账号
访问RDS数据库的账号。创建RDS数据库时会绑定此信息。
datalake_mcdbuser
账号类型
账号包含如下两种:
普通账号:后续需要绑定至RDS数据库。
高权限账号:无需选择要授权的数据库,拥有实例中所有数据库的权限。
普通账号
密码
账号对应的密码信息。
无
确认密码
再次确认账号对应的密码信息。
无
更多参数解释,请参见创建账号。
创建RDS数据库。在目标实例信息页面的左侧导航栏单击数据库管理>创建数据库,设置如下参数。
参数
说明
数据库(DB)名称
最长63个字符。
由小写字母、数字、中划线、下划线组成。
以字母开头,以字母或数字结尾。
支持字符集
数据库的字符集。
Collate
字符串排序规则。
Ctype
字符分类。
授权账号
设置数据库的所有者,对数据库拥有ALL权限。
备注说明
填写备注信息。
为RDS数据库创建表并插入少量测试数据,具体操作请参见通过DMS登录RDS MySQL。如表名为anti_fraud_result,命令示例如下。
CREATE TABLE `anti_fraud_result` ( `transactionid` varchar(32) NOT NULL, `uid` varchar(32) DEFAULT NULL, `card` varchar(32) DEFAULT NULL, `longitude` double(12,8) DEFAULT '12.00000000', `latitude` double(12,8) DEFAULT '12.00000000', PRIMARY KEY (`transactionid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ; INSERT INTO `anti_fraud_result` values ("12489571","82005","123123",3.14592040,101.12315432); INSERT INTO `anti_fraud_result` values ("12489572","82005","123123",3.14592040,101.12315432); INSERT INTO `anti_fraud_result` values ("12489573","82005","123123",3.14592040,101.12315432); INSERT INTO `anti_fraud_result` values ("12489574","82005","123123",3.14592040,101.12315432);
步骤四:在DLF中创建元数据库(可选)
用于步骤五:创建并启动入湖任务中的单表离线同步方式,如果您使用下述的整库实时同步方式则无需执行此步骤。
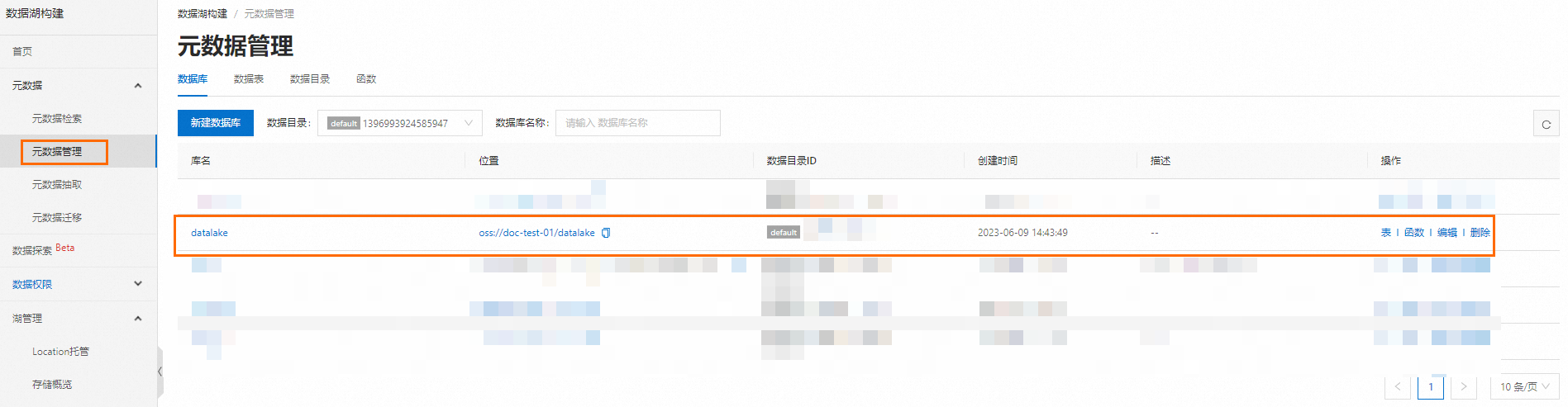
通过创建元数据库来管理DLF湖中的数据。
登录数据湖构建控制台,在左上角选择地域,例如
华东2(上海)。创建元数据库。例如datalake。
在左侧导航栏,选择,在数据库页签,单击新建数据库。
在新建数据库对话框,配置相关参数。
参数
描述
示例
所属数据目录
数据存储的数据库目录。
default
数据库名称
目标数据库的名称。
dlf_db
数据库描述
目标数据库的描述信息。
湖仓一体
选择路径
OSS数据路径。格式为
oss://<Bucket名称>/<OSS目录名称>。oss://doc-test-01/datalake/
单击确定,完成数据库的创建。
步骤五:创建并启动入湖任务
由于DLF中数据入湖功能已经停止更新,如果您有数据入湖需求请参考DLF中数据入湖功能停止更新公告。您可以采用以下两种方式进行Delta Lake和Hudi格式的数据入湖操作。
Delta格式的数据入湖可选择单表离线同步方案。
Hudi格式的数据入湖建议选择整库实时同步方案。对于不带分区的Hudi格式,您也可使用单表离线同步方案,但无需在DataWorks数据开发模块创建离线同步任务,直接在DLF控制台中创建关系数据库全量入湖类型的任务即可,具体操作可参考OSS数据进行格式转换入湖。
单表离线同步
在DataWorks数据开发模块中创建离线同步任务,进行数据入湖操作。
创建离线同步任务。
准备RDS MySQL数据源。
在DataWorks中配置MySQL数据源,具体操作请参见配置MySQL数据源。
准备OSS数据源。
在DataWorks中配置OSS数据源,具体操作请参见配置OSS数据源。
创建并执行数据同步任务。
在DataWorks的数据开发模块中创建离线同步任务,详情请参见通过向导模式配置离线同步任务。关键配置如下:
网络与资源配置。
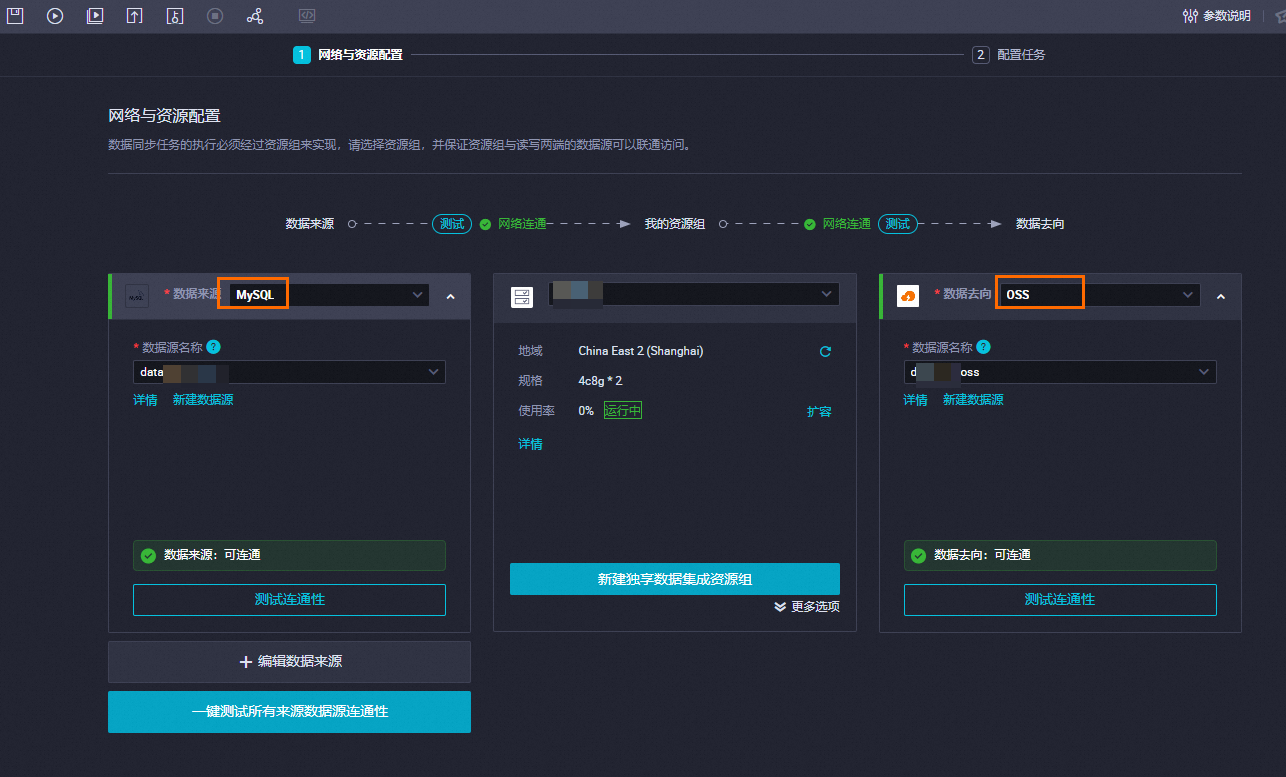
参数
说明
来源
数据来源
MySQL。
数据源名称
已创建的MySQL数据源。
资源组
我的资源组
已创建的数据集成独享资源组。
去向
数据去向
OSS。
数据源名称
已创建的OSS数据源。
配置任务。
在配置任务页签填写表和文件名。
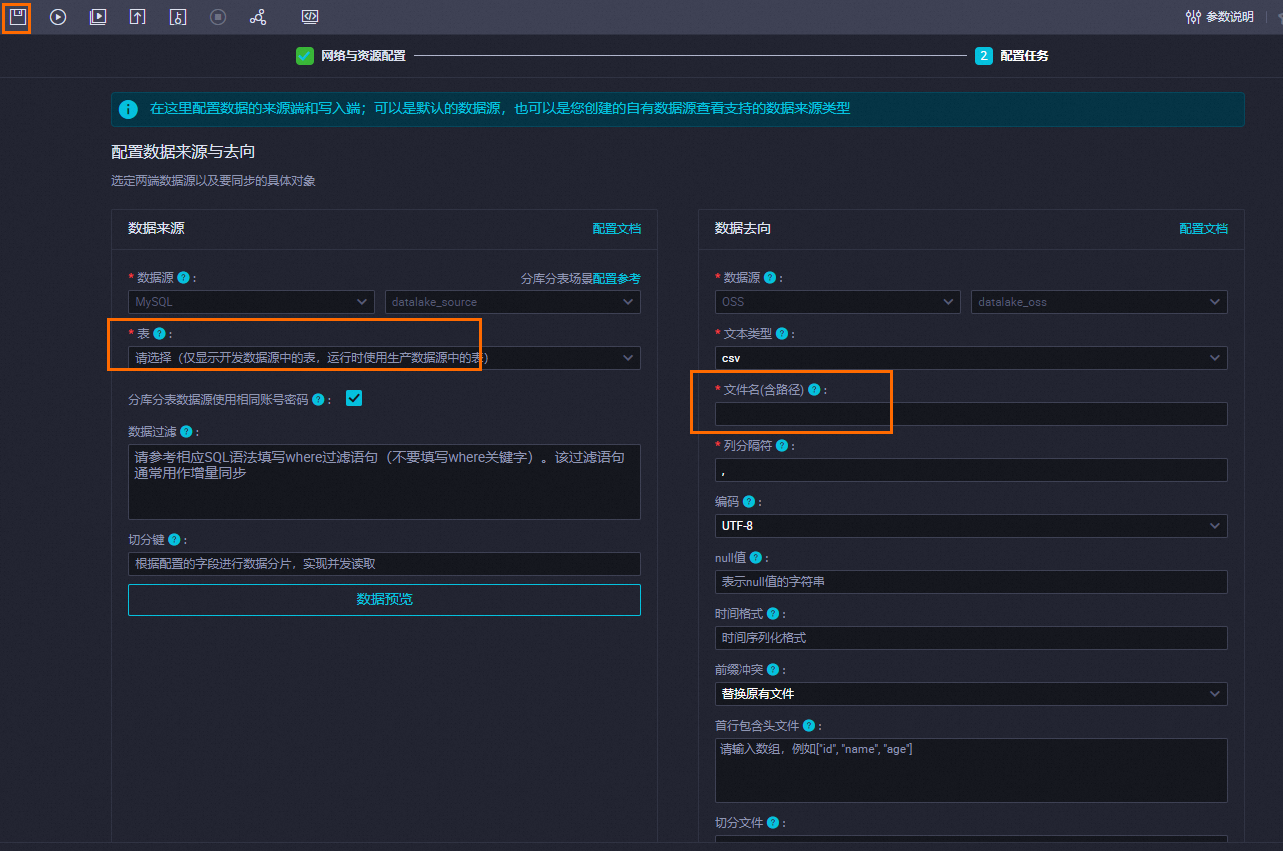
参数
说明
表
RDS数据库中已创建的表名。
文件名(含路径)
格式:<OSS中已创建的文件目录名称>/<待导出至OSS的数据文件>。
例如
doc-test-01/datalake/anti.csv。单击离线同步任务配置页面左上角的
 图标保存配置,然后单击
图标保存配置,然后单击 图标运行任务。
图标运行任务。DataWorks中任务运行成功后,可在OSS数据源配置路径下查看数据是否导入成功。

OSS数据进行格式转换入湖。
登录DLF数据湖构建控制台,在页面顶部选择地域。
在左侧导航栏单击数据入湖 > 入湖任务管理。
在入湖任务管理页面单击新建入湖任务 > OSS数据格式转换,单击下一步。
说明若您想转换为Hudi格式,则需要将任务类型选择为关系数据库全量入湖。
在新建入湖任务页面配置相关参数,未提及的参数保持默认,然后单击确定。
OSS数据格式转换
参数属性
参数名称
说明
示例
配置数据源
OSS存储路径
数据源存储的OSS目录。格式为
oss://<Bucket名称>/<OSS目录名称>/。oss:/doc-test-01/datalake/
存储格式
来源表的数据格式。
CSV
配置目标数据湖信息
目标数据库
存储目标表的数据库。
datalake
目标数据表名称
作业会以此名称来建表。
anti_rds
存储格式
目标表的数据格式。
Delta
数据湖存储位置
数据存储的OSS路径。格式为
oss://<Bucket名称>/<OSS目录名称>/。oss:/doc-test-01/dlf/
配置任务信息
任务实例名称
设置入湖任务名称。
OSS数据入湖格式转换Delta
最大资源并行度
DLF将启动Worker节点完成数据入湖,此配置项表示同时运行的最大Worker数量。
20
关系数据库全量入湖
参数属性
参数名称
说明
示例
配置数据源
数据源连接
展示同Region、同账号下的RDS实例,可在下拉列表中选择目标数据源。
无
表路径
需要同步的源表路径,格式为
<database_name>/<table_name>。无
配置目标数据湖信息
目标数据库
存储目标表的数据库。
database_1
目标数据表名称
作业会以此名称来建表。
anti_rds
存储格式
目标表的数据格式。
Hudi
数据湖存储位置
数据存储的OSS路径。格式为
oss://<Bucket名称>/<OSS目录名称>/。oss:/doc-test-01/dlf/
分区信息
可添加分区,写入数据湖的数据会以此信息作为分区。
无
配置任务信息
任务实例名称
设置入湖任务名称。
Hudi格式数据关系数据库全量入湖
最大资源并行度
DLF将启动Worker节点完成数据入湖,此配置项表示同时运行的最大Worker数量。
20
在DLF控制台的入湖任务管理页面单击目标任务操作列的运行。
当任务执行进度达到100%时,表示OSS数据格式转换成功。
单击元数据管理 > 数据库页签的目标数据库,在目标数据库的表列表页签查看数据表是否生成。

整库实时同步
在DataWorks数据集成模块中创建整库实时同步任务,进行Hudi格式的数据入湖操作,详情请参见MySQL整库实时同步至OSS数据湖。关键配置如下:
准备RDS MySQL数据源。
在DataWorks中配置MySQL数据源,具体操作请参见配置MySQL数据源。
准备OSS数据源。
在DataWorks中配置OSS数据源,具体操作请参见配置OSS数据源。
在同步任务页面设置以下参数。
网络与资源配置。
参数
说明
来源
数据来源
MySQL。
数据源名称
已创建的MySQL数据源。
资源组
同步资源组
已创建的数据集成独享资源组。
去向
数据去向
OSS。
数据源名称
已创建的OSS数据源。
选择要同步的库表。
配置页面的左侧为选择要同步库表的限定条件,用于过滤选择待同步的数据库、数据表。
配置页面的右侧为源端数据库表的预览,是根据上述步骤中配置的数据源预览出来的待同步的数据库表和已选择好要同步的数据库表的预览情况。
您可根据待同步的源端数据库表的数量,参考以下操作建议,快速选择要同步的库表。
如果您的数据库表数量不多,您可以直接在右侧预览模块手动勾选待同步的数据库表,然后添加到已选库表中,此时页面会根据您的勾选情况自动在左侧添加限定条件。
如果您有多个数据源、数据库、数据表,您可以在左侧手动添加限定条件来进行过滤,或者在右侧页面的搜索框中通过关键词搜索出对应的库表进行添加或删除的操作。
入湖配置。
OSS存储路径选择:选择入湖后数据存储在OSS的哪个路径下。
选择元数据库自动构建位置:选择DLF。
元数据库名称前缀:元数据库是根据来源库名自动建立,但是可以手工指定元数据库的名称前缀。指定的前缀,将会应用到所有库中。
数据湖格式:选择Hudi。
分区信息
支持使用${yyyy}(年)、${MM}(月)、${dd}(日)、${HH}(时)这些变量,最小粒度到小时,不支持分钟、秒的时间粒度。
支持将变量结合字符串拼接组合。例如将变量与下划线拼接组合:${yyyy}_${MM}_${dd}_${HH}。
支持设置多个分区使写入的数据表为多级分区表,分区级别与此处设置的分区顺序一致。
设置数据入湖存储时的分区,后续入湖同步写入数据时,根据来源端数据的写入时间落入相应的分区里。分区设置注意事项如下:
单击完成配置 > 确认。
单击已创建的同步任务状态列的启动,查看任务状态。
待同步任务执行成功后,在DLF控制台中单击元数据 > 元数据管理,并单击进入新生成的目标数据库,在表列表页签即可查看到已生成的数据表。
步骤六:基于MaxCompute分析数据湖数据
基于已创建的MaxCompute项目、DLF元数据库、OSS存储空间,创建External Project,用于关联DLF和OSS,并映射至已创建的MaxCompute项目。后续可通过映射的MaxCompute项目对External Project进行数据分析操作。仅MaxCompute项目的所有者(Project Owner)或具备Admin、Super_Administrator角色的用户可以创建External Project。
tenant的Super_Administrator角色可以在MaxCompute控制台的用户管理页签授权。仅主账号或已经拥有tenant的Super_Administrator角色的子账号可以操作授权。详情请参见将角色赋予用户。
在DataWorks控制台创建External Project。
登录DataWorks控制台,选择地域为华东2(上海)。
在DataWorks控制台页面左侧导航栏,选择。
在数据湖集成(湖仓一体)页面,单击现在开始创建。
在新建数据湖集成页面,按照界面指引进行操作。参数示例如下所示。
表 1. 创建数据仓库 参数
说明
外部项目名称
ext_dlf_delta
MaxCompute项目
ms_proj1
表 2. 创建外部数据湖连接 参数
说明
异构数据平台类型
选择阿里云DLF+OSS数据湖连接
无
阿里云DLF+OSS数据湖连接
External Project描述
无
DLF所在区
cn-shanghai
DLF Endpoint
dlf-share.cn-shanghai.aliyuncs.com
DLF数据库名称
datalake
DLF RoleARN
无
单击创建后单击预览。
如果能预览DLF库中表的信息,则表示操作成功。
说明以上是DataWorks控制台创建External Project,如果您需要通过SQL方式创建External Project,请参见使用SQL管理外部项目。
在DataWorks临时查询页面,查看External Project下的表。
命令示例如下。
show tables in ext_dlf_delta;返回结果如下。
ALIYUN$***@aliyun.com:anti_rds说明DataWorks临时查询操作,详情请参见DataWorks临时查询。
在DataWorks临时查询界面,查询External Project中的表数据。
说明如果查询结果出现乱码问题,解决方法请参见如何处理编码格式设置/乱码问题导致的脏数据报错?。
命令示例:
select * from ext_dlf_delta.anti_rds;返回结果:

基于DLF、Flink、OSS支持Hudi存储机制
操作流程
为操作MaxCompute项目的账号授予访问DLF和OSS的权限。
创建OSS存储空间作为数据湖的统一存储路径。
在Flink控制台创建临时表,准备入湖数据。
在DLF中创建元数据库作为存储入湖的数据源。
基于DLF创建元数据抽取任务,将OSS目录下的表数据抽取到数据湖中。
通过DataWorks控制台的数据湖集成界面创建External Project,对数据湖数据进行分析。
步骤一:授予MaxCompute访问DLF和OSS的权限
步骤二:在OSS中创建存储空间及目录
创建OSS存储空间作为数据湖的统一存储路径。
登录OSS管理控制台。
在左侧导航栏,单击Bucket列表,在Bucket列表页面,单击创建Bucket。
在创建Bucket面板填写Bucket名称,例如
mc-dlf-oss,并选择地域,例如华东2(上海)后,单击确定。在左侧导航栏,单击文件管理后,在右侧区域单击新建目录并填写目录名,例如
covid-19,单击确定。
步骤三:准备入湖数据
基于阿里云Flink全托管使用Hudi连接器建表、准备入湖数据。操作详情请参见Flink SQL作业快速入门。
访问Flink实例列表,在上方选择地域,并单击目标实例ID,进入阿里云实时计算页面。
在左侧导航栏单击SQL开发,并新建空白的流作业草稿,单击下一步。
在新建作业草稿对话框中填写作业信息,单击创建。
在SQL编辑区域中输入如下命令,语法详情请参见Hudi连接器。
-- 创建一个datagen临时表,作为数据源。 CREATE TEMPORARY TABLE datagen( id INT NOT NULL PRIMARY KEY NOT ENFORCED, data STRING, ts TIMESTAMP(3) ) WITH ( 'connector' = 'datagen' , 'rows-per-second'='100' ); -- 创建一个flink_hudi_tbl临时表,作为结果表,数据存储指向oss,格式为hudi CREATE TEMPORARY TABLE flink_hudi_tbl ( id INT NOT NULL PRIMARY KEY NOT ENFORCED, data STRING, ts TIMESTAMP(3) ) WITH ( 'connector' = 'hudi', 'oss.endpoint' = 'oss-cn-beijing-internal.aliyuncs.com', 'accessKeyId' = '${secret_values.ak_id}', 'accessKeySecret' = '${secret_values.ak_secret}', 'path' = 'oss://<yourOSSBucket>/<自定义存储位置>', 'table.type' = 'MERGE_ON_READ', 'hive_sync.enable' = 'true', 'hive_sync.mode' = 'hms', 'hive_sync.db' = 'flink_hudi', 'hive_sync.table' = 'flink_hudi_tbl', 'dlf.catalog.region' = 'cn-beijing', 'dlf.catalog.endpoint' = 'dlf-vpc.cn-beijing.aliyuncs.com' ); -- 将源表数据写入到结果表 INSERT INTO flink_hudi_tbl SELECT * from datagen;参数说明:
参数名称
说明
oss.endpoint
Flink实例所在地域的内网Endpoint,各地域Endpoint请参见访问域名和数据中心。
accessKeyId
阿里云账号的AccessKey ID。
accessKeySecret
阿里云账号的AccessKey Secret。
path
OSS Bucket路径。
dlf.catalog.region
阿里云DLF服务的地域名,详情请参见已开通的地域和访问域名。
dlf.catalog.endpoint
DLF服务的Endpoint,详情请参见已开通的地域和访问域名。
说明推荐您设置为DLF的VPC Endpoint。例如,如果您选择的地域为cn-hangzhou地域,则参数值需要配置为dlf-vpc.cn-hangzhou.aliyuncs.com。
进行深度检查和作业部署,详情可参考Flink SQL作业快速入门的步骤四和步骤六。
单击右上角深度检查,成功后会提示深度检查通过。
单击右上角部署,可根据需要填写或选中相关内容,单击确定。
启动作业并查看结果,详情可参考Flink SQL作业快速入门的步骤七。
在左侧导航栏,单击作业运维。
单击目标作业名称操作列中的启动,选择无状态启动后,单击启动。当作业状态变为运行中时,表示作业运行正常。
在作业运维详情页面,查看Flink计算结果。
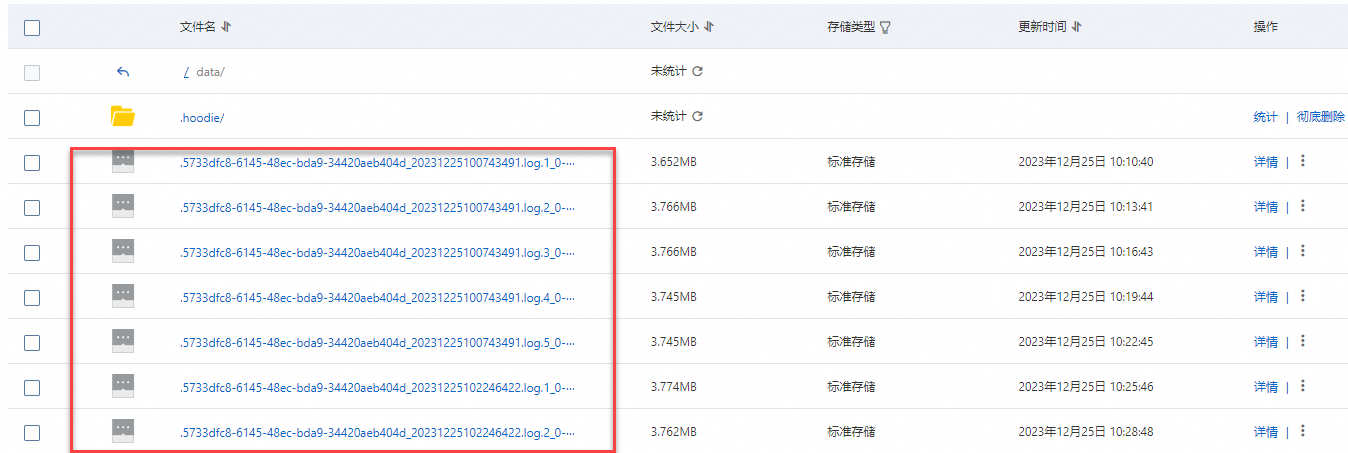
待任务启动成功运行一段时间后,登录OSS控制台,可查看到目录下已写入的数据文件。
步骤四:在DLF中创建元数据库
通过创建元数据库来管理DLF湖中的数据。
登录数据湖构建控制台,在左上角选择地域。
创建元数据库。例如datalake。
在左侧导航栏,选择,在数据库页签,单击新建数据库。
在新建数据库对话框,配置相关参数。
参数
描述
示例
所属数据目录
数据存储的数据库目录。
default
数据库名称
目标数据库的名称。
dlf_db
数据库描述
目标数据库的描述信息。
湖仓一体
选择路径
OSS数据路径。格式为
oss://<Bucket名称>/<OSS目录名称>。oss://doc-test-01/datalake/
单击确定,完成数据库的创建。
步骤五:在DLF上创建并启动元数据抽取任务
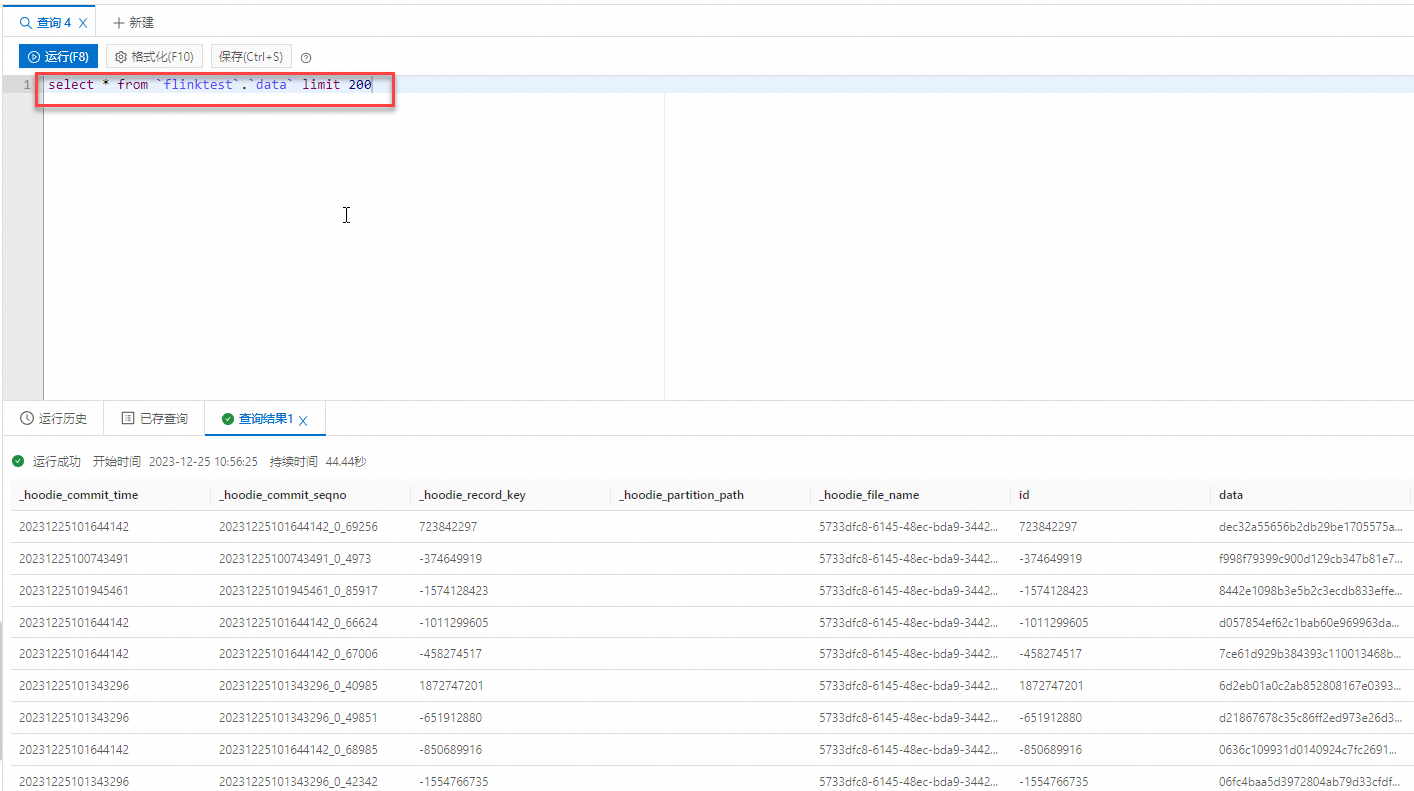
步骤六:基于MaxCompute分析数据湖数据
具体操作请参见步骤六:基于MaxCompute分析数据湖数据。
相关文档
MaxCompute+DLF+OSS湖仓一体的湖查询和湖数据入仓实践,请参见MaxCompute+DLF+OSS湖仓一体的湖查询和湖数据入仓实践。
若您想通过MaxCompute与Hadoop构建湖仓一体,可参见基于Hadoop集群支持Delta Lake或Hudi存储机制。
- 本页导读 (1)