
本文介绍PolarDB高压缩引擎(X-Engine)的产品优势、架构及适用场景。
专家面对面
关于高压缩引擎X-Engine的使用问题和RDS X-Engine迁移至PolarDB X-Engine问题请进钉钉群咨询,群号:24490017825。
挑战和诉求:历史数据归档
历史数据归档的挑战
大部分业务数据的读写特征,都是最新产生的数据会被更频繁地读取或更新,而更久之前的数据(如1年前的聊天记录或订单信息)很少被访问。 随着业务发展,数据库系统中会积累大量访问频率很低甚至为0的数据,这些数据的积累容易导致如下问题:
历史数据和最新数据存储在同一数据库系统中,导致磁盘空间不足。
大量数据共享数据库系统的内存、缓存空间、磁盘IOPS等,导致性能问题。
数据量太大导致数据备份时间过长甚至备份失败;同时如何存放备份数据也是一个问题。
针对如上问题,一种做法是对历史数据做归档,将长期不使用的数据迁移至以文件形式存储的廉价存储设备上,如阿里云OSS或者阿里云数据库DBS服务。然而,在实际业务中,历史数据并不完全是静态的,针对几个月甚至几年前的历史数据,依旧可能存在实时地、低频地查询甚至更新需求。例如,在阿里巴巴内部,对淘宝或天猫历史订单的查询、对企业级办公软件钉钉历史聊天记录的查询或对菜鸟海量历史物流订单的查询等。
历史数据归档的诉求
为了解决历史数据的读取和更新问题,可以使用一个单独的数据库用来存储归档的数据,即高压缩引擎(X-Engine)。业务对单独的高压缩引擎(X-Engine)一般有如下诉求:
具备大容量存储空间,支持业务持续将线上数据保存到高压缩引擎(X-Engine)中,而无需担心容量问题。
与在线数据库系统使用相同的访问接口,如都支持MySQL协议等,确保应用程序端无需修改任何代码即可同时访问在线库和高压缩引擎(X-Engine)。
成本低廉,如支持通过压缩减少数据所占磁盘空间、使用廉价存储介质等,确保可以使用较小的代价保存海量的数据。
具备一定的读写能力,能够满足低频读写的需求。
MySQL作为世界上使用最广泛的开源数据库系统,一直缺乏一个既能满足大容量低成本要求,又具备一定读写能力的历史数据归档存储方案。虽然业界曾经推出过一些高压缩引擎,如TokuDB、MyRocks等,但受限于单物理机磁盘容量限制,存储的数据量有限。
解决方案:PolarDB高压缩引擎(X-Engine)
为应对如上历史数据归档存储方面的挑战和诉求,PolarDB基于如下技术创新和突破,推出了高压缩引擎(X-Engine)产品系列:
阿里巴巴自研的基于LSM-tree架构的存储引擎X-Engine提供了强大的数据压缩能力,满足了归档数据库低存储成本的要求。通过LSM-Tree(Log-Structured Merge-Tree)层次化架构和Zstandard(ZSTD)压缩算法实现了更高的数据压缩率,对比使用InnoDB作为存储引擎,最高可节省70%的存储空间。更多关于X-Engine存储引擎的详情,请参见X-Engine简介。但由于采用了X-Engine引擎,在使用高压缩引擎(X-Engine)时也存在一些限制(尤其是与MySQL的兼容性限制),具体限制请参见使用说明。
PolarDB借助于共享分布式存储服务,实现了存储容量在线平滑扩容,同时计算资源和存储资源间采用高速网络互联,并通过RDMA协议进行数据传输,使I/O性能不再成为瓶颈。集成到PolarDB的X-Engine引擎同样获得了这些技术优势。
如下技术创新将X-Engine移植进PolarDB,从而进入PolarDB双引擎时代:
合并X-Engine的事务WAL日志流和InnoDB的REDO日志流,实现了一套日志流和传输通道同时服务于InnoDB引擎和X-Engine引擎,管控逻辑以及与共享存储的交互逻辑无需做任何改变,同时新增其他引擎时也可以复用这套架构。
将X-Engine的IO模块对接到PolarDB InnoDB所使用的用户态文件系统PFS上,实现了InnoDB与X-Engine共享同一个分布式块设备。同时依靠底层分布式存储实现了快速备份。
高压缩引擎(X-Engine)计算节点架构
高压缩引擎(X-Engine)采用多节点架构基于共享存储实现了一写多读,集群中有一个主节点(可读可写)和至少一个只读节点,支持独享规格和通用规格两个子系列。
高压缩引擎(X-Engine)多节点架构可用于保障集群的高可用,当系统发生故障时,可读写的主节点和只读节点之间会自动进行故障切换(Failover),保证了服务可用性不低于99.99%。高压缩引擎(X-Engine)多节点架构图如下: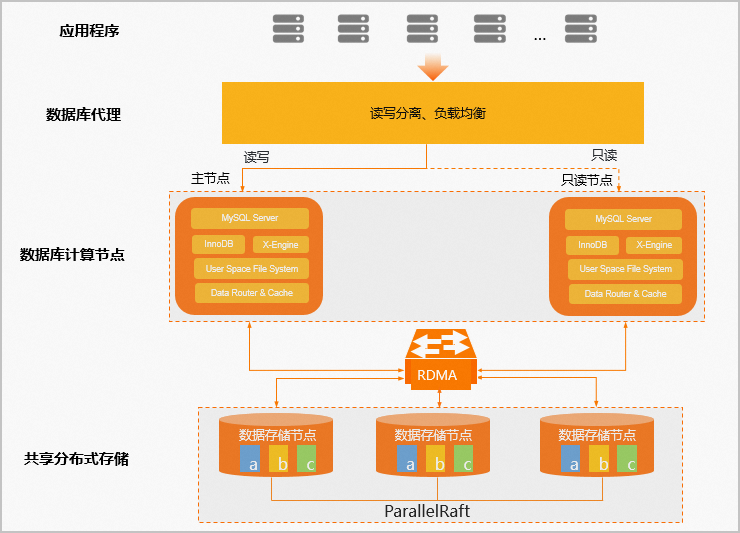
产品优势
超大存储容量。200 TB的存储空间加上X-Engine数据压缩能力,可提供500 TB以上的原始数据存储容量,同时存储空间采用Serverless方式,购买时无需选择容量,随着数据增长而在线自动扩容,只按实际数据量大小收费。
PolarDB高压缩引擎(X-Engine)与官方MySQL的协议一致,相比于将历史数据备份到HBase等NoSQL产品,应用程序端无需修改任何代码即可同时访问在线库和高压缩引擎(X-Engine)。
借助PolarDB底层共享存储的快速备份能力,实现对海量数据的快速备份,备份数据可以上传到OSS等廉价存储设备,确保数据不丢失。
高压缩引擎(X-Engine)多节点架构借助X-Engine引擎的数据压缩能力,不仅能够有效降低存储成本,还可用于保障集群的高可用。当系统发生故障时,可读写的主节点和只读节点之间会自动进行故障切换(Failover),保证了服务可用性不低于99.99%。
在Sysbench测试场景下,与集群版的单InnoDB引擎相比较,这种双引擎(InnoDB和X-Engine)混合部署方式,使集群整体性能下降控制在20%以内。当业务数据的存储空间达到一定规模(几百GB或几百TB),在集群整体性能可控范围内,用户能明显地享受到降本红利。
适用场景
PolarDB高压缩引擎(X-Engine)提供了超大存储容量,它可以同时作为多个业务历史数据的汇聚地,以方便对所有历史数据进行集中存储和管理,主要适用于如下几个场景:
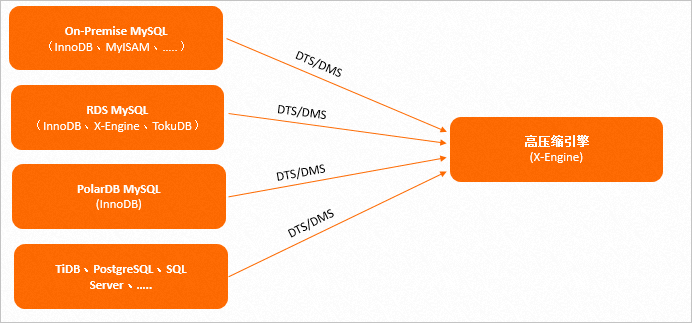
将PolarDB高压缩引擎(X-Engine)作为线下自建数据库实例的冷数据存储地,线下自建数据库包括但不限于MySQL、TiDB、PostgreSQL、SQL Server等关系型数据库。
将PolarDB高压缩引擎(X-Engine)作为阿里云RDS MySQL或者PolarDB MySQL版数据库服务的归档存储地,将访问较少的历史数据迁移到PolarDB MySQL版 X-Engine中存储,释放在线数据库的空间以降低成本并提升性能。
直接将PolarDB高压缩引擎(X-Engine)作为大容量关系数据库使用,以满足一些写入数据量巨大,但读频次较低的业务的需求(如系统监控日志等)。
您可以通过阿里云DTS持续实时地将在线库的数据迁移至PolarDB 高压缩引擎(X-Engine),或通过阿里云DMS周期性地将在线数据批量导入到PolarDB 高压缩引擎(X-Engine)。
版本要求
您的集群内核版本需满足以下条件:
MySQL 8.0.1,且修订版本需为8.0.1.1.31及以上。
MySQL 8.0.2,且修订版本需为8.0.2.2.12及以上。
节点规格与定价
高压缩引擎(X-Engine)支持通用规格和独享规格。更多详情,请参见企业版计算节点规格。
关于高压缩引擎(X-Engine)的计费规则,请参见计算节点计费规则。