为了确保模型在正式部署前达到上线标准,您可以使用模型分析优化工具对模型进行性能压测、模型分析、模型优化等操作,对模型的性能进行分析优化。本文以PyTorch官方提供的Resnet18模型、GPU类型为V100卡为例,介绍如何使用模型分析优化工具。
前提条件
集群类型为ACK Pro版且版本不低于1.20,集群中至少包含一个GPU节点。关于升级集群的具体操作,请参见升级ACK集群。
已创建Bucket空间,并创建PV和PVC。更多信息,请参见通过控制台方式使用OSS静态存储卷。
背景信息
大部分数据科学关心模型精度,而研发工程师更关心模型性能。当数据科学家和研发工程师对彼此的领域不熟悉时,容易出现理解偏差,导致模型上线后,出现性能不达标的情况。因此,在模型部署前,通常需要对模型的性能进行测试。如果不达标,则需要对模型进行分析,找到性能瓶颈,优化后才能在线上进行部署。
模型分析工具简介
AI套件提供了模型分析优化工具,在模型正式部署前,对模型进行性能压测,分析模型网络结构、每个算子耗时、GPU使用情况等,找到性能瓶颈,然后使用TensorRT等优化模型,达到上线标准后再进行部署。模型分析优化工具的生命周期如下图所示。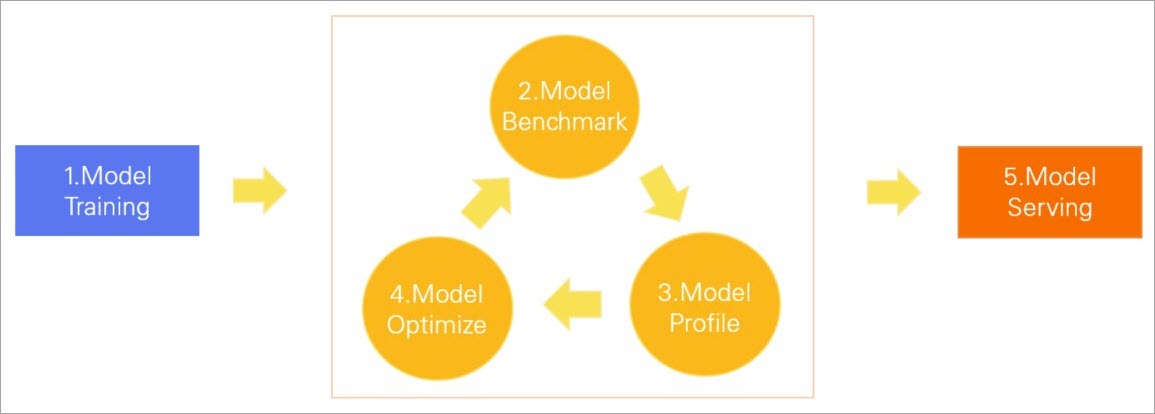
Model Training: 模型训练,通过数据集训练出模型。
Model Benchmark:模型压测,测试模型的Latency、Throughout、GPU利用率等性能指标。
Model Profile: 模型分析,分析模型中可优化性能的地方。
Model Optimize:模型优化,通过TensorRT等方式,优化模型在GPU上的推理性能。
Model Serving:模型服务,将模型部署为在线服务。
若您的模型经过一次优化后未达到上线标准,您可以持续对模型进行压测、分析和优化操作。
交互方式
模型分析优化工具通过Arena命令行方式进行交互,支持在ACK Pro版集群中提交分析、优化、压测和评测任务。您可以通过执行arena model --help命令,查看相应的操作。
submit a model analyze job.
Available Commands:
profile Submit a model profile job.
evaluate Submit a model evaluate job.
optimize Submit a model optimize job.
benchmark Submit a model benchmark job
Usage:
arena model [flags]
arena model [command]
Available Commands:
benchmark Submit a model benchmark job
delete Delete a model job
evaluate Submit a model evaluate job
get Get a model job
list List all the model jobs
optimize Submit a model optimize job, this is a experimental feature
profile Submit a model profile job步骤一:准备模型
PyTorch模型部署推荐使用TorchScript的方式。本文以使用PyTorch官方提供的Resnet18模型为例。
模型转换。将Resnet18模型转换为TorchScript格式,并进行保存。
import torch import torchvision model = torchvision.models.resnet18(pretrained=True) # Switch the model to eval model model.eval() # An example input you would normally provide to your model's forward() method. dummy_input = torch.rand(1, 3, 224, 224) # Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing. traced_script_module = torch.jit.trace(model, dummy_input) # Save the TorchScript model traced_script_module.save("resnet18.pt")参数
说明
model_name模型名称。
model_platform模型平台或框架,如
torchscript、onnx。model_path模型存储路径。
inputs输入参数,支持一个或多个参数。
outputs输出参数,支持一个或多个参数。
模型转换完成后,将
resnet18.pt上传至OSS,路径为oss://bucketname/models/resnet18/resnet18.pt。具体操作,请参见控制台上传文件。
步骤二:压测性能
在模型正式部署前,需要对模型进行性能压测,查看是否符合性能要求,本文使用Arena提供的性能压测工具,以集群default命名空间下名为oss-pvc的PVC为例。更多信息,请参见通过控制台方式使用OSS静态存储卷。
准备并上传模型配置文件。
创建模型配置文件,本文以名为
config.json的模型配置文件为例。{ "model_name": "resnet18", "model_platform": "torchscript", "model_path": "/data/models/resnet18/resnet18.pt", "inputs": [ { "name": "input", "data_type": "float32", "shape": [1, 3, 224, 224] } ], "outputs": [ { "name": "output", "data_type": "float32", "shape": [ 1000 ] } ] }将模型配置文件上传至OSS,路径为
oss://bucketname/models/resnet18/config.json。
使用以下命令在ACK Pro版集群提交模型压测任务。
arena model benchmark \ --name=resnet18-benchmark \ --namespace=default \ --image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2 \ --gpus=1 \ --data=oss-pvc:/data \ --model-config-file=/data/models/resnet18/config.json \ --report-path=/data/models/resnet18 \ --concurrency=5 \ --duration=60参数
说明
--gpus使用的GPU卡数。
--data集群PVC及挂载到容器后的路径。
--model-config-file配置文件路径。
--report-path测试报告保存路径。
--concurrency并发请求数量。
--duration压测的具体时间,单位为秒。
重要--requests和--duration两个参数互斥,性能压测时只能指定其中一个。如果同时配置两个参数,系统默认使用--duration参数。如果需要指定压测的总请求数量,请配置
--requests参数。
使用以下命令查看任务状态。
arena model list -A预期输出:
NAMESPACE NAME STATUS TYPE DURATION AGE GPU(Requested) default resnet18-benchmark COMPLETE Benchmark 0s 2d 1查看压测报告。当
STATUS显示为COMPLETE时,代表压测完成。此时,可以在上一步中配置的测试报告保存路径--report-path下查看名为benchmark_result.txt的压测报告。预期输出:
{ "p90_latency":7.511, "p95_latency":7.86, "p99_latency":9.34, "min_latency":7.019, "max_latency":12.269, "mean_latency":7.312, "median_latency":7.206, "throughput":136, "gpu_mem_used":1.47, "gpu_utilization":21.280 }压测报告中的各项指标信息如下表所示。
指标名称
说明
单位
p90_latency
90%请求耗时
毫秒
p95_latency
95%请求耗时
毫秒
p99_latency
99%请求耗时
毫秒
min_latency
最小请求耗时
毫秒
max_latency
最大请求耗时
毫秒
mean_latency
平均值
毫秒
median_latency
中值
毫秒
throughput
吞吐量
次
gpu_mem_used
GPU显存使用
GB
gpu_utilization
GPU利用率
百分比
步骤三:分析模型
当压测完成后,如果发现性能不达标,可以使用arena model profile命令分析模型,找到性能瓶颈和可优化点。
使用以下命令在ACK Pro版集群提交模型分析任务。
arena model profile \ --name=resnet18-profile \ --namespace=default \ --image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2 \ --gpus=1 \ --data=oss-pvc:/data \ --model-config-file=/data/models/resnet18/config.json \ --report-path=/data/models/resnet18/log/ \ --tensorboard \ --tensorboard-image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2参数
说明
--gpus使用的GPU卡数。
--data集群PVC及挂载到容器后的路径。
--model-config-file配置文件路径。
--report-path分析结果保存路径。
--tensorboard是否启用Tensorboard查看分析结果。
--tensorboard-imageTensorboard镜像地址。
使用以下命令查看任务状态。
arena model list -A预期输出:
NAMESPACE NAME STATUS TYPE DURATION AGE GPU(Requested) default resnet18-profile COMPLETE Profile 13s 2d 1使用以下命令查看Tensorboard状态。
kubectl get service -n default预期输出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE resnet18-profile-tensorboard NodePort 172.16.158.170 <none> 6006:30582/TCP 2d20h使用以下命令进行端口转发,访问Tensorboard。
kubectl port-forward svc/resnet18-profile-tensorboard -n default 6006:6006预期输出:
Forwarding from 127.0.X.X:6006 -> 6006 Forwarding from [::1]:6006 -> 6006在浏览器中通过
http://localhost:6006查看分析结果。在左侧导航栏单击Views,可查看不同维度的分析结果。您可以根据分析结果找到模型的可优化点。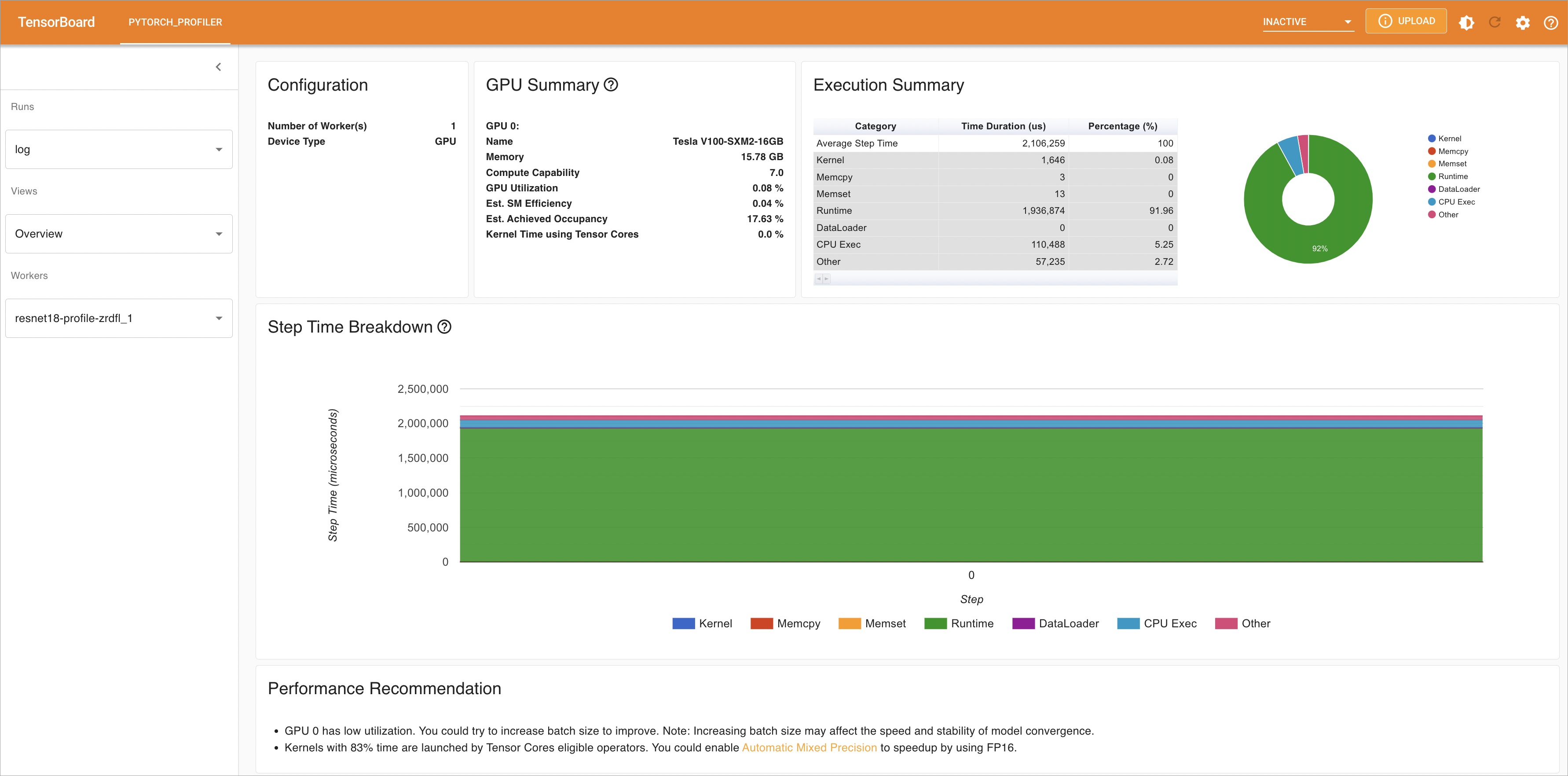
步骤四:优化模型
Arena提供模型优化工具。
使用以下命令在ACK Pro版集群提交模型优化任务。
arena model optimize \ --name=resnet18-optimize \ --namespace=default \ --image=registry.cn-beijing.aliyuncs.com/kube-ai/easy-inference:1.0.2 \ --gpus=1 \ --data=oss-pvc:/data \ --optimizer=tensorrt \ --model-config-file=/data/models/resnet18/config.json \ --export-path=/data/models/resnet18参数
说明
--gpus使用的GPU卡数。
--data集群PVC及挂载到容器后的路径。
--optimizer指定优化方式。优化方式:
(默认)
tensorrt。aiacc-torch,更多信息,请参见什么是神龙AI加速引擎AIACC。
--model-config-file配置文件路径。
--export-path优化后的模型保存路径。
使用以下命令查看任务状态。
arena model list -A预期输出:
NAMESPACE NAME STATUS TYPE DURATION AGE GPU(Requested) default resnet18-optimize COMPLETE Optimize 16s 2d 1查看优化后的模型文件。当
STATUS显示为COMPLETE时,表示优化任务执行完成。此时,可以在--export-path目录下查看名为opt_resnet18.pt的模型文件。修复模型压测配置文件中的
--model_path,再次进行压测。关于压测性能的具体操作,请参见步骤二:压测性能。优化前后模型的性能指标如下表所示。
指标
优化前
优化后
p90_latency
7.511毫秒
5.162毫秒
p95_latency
7.86毫秒
5.428毫秒
p99_latency
9.34毫秒
6.64毫秒
min_latency
7.019毫秒
4.827毫秒
max_latency
12.269毫秒
8.426毫秒
mean_latency
7.312毫秒
5.046毫秒
median_latency
7.206毫秒
4.972毫秒
throughput
136次
198次
gpu_mem_used
1.47 GB
1.6 GB
gpu_utilization
21.280%
10.912%
对比优化前后的各项指标数据,可以发现模型经过优化后,模型性能有了较大的提升,且GPU利用率降低。如果模型性能仍不达标,可继续进行模型分析和模型优化。
步骤五:部署模型
模型性能达到要求后,可在线上进行部署操作。Arena支持使用Nvidia Triton Server部署TorchScript模型。关于Nvidia Triton Server的更多信息,请参见Nvidia Triton Server。
创建名为
config.pbtxt的配置文件。重要这个文件名称不能修改。
name: "resnet18" platform: "pytorch_libtorch" max_batch_size: 1 default_model_filename: "opt_resnet18.pt" input [ { name: "input__0" format: FORMAT_NCHW data_type: TYPE_FP32 dims: [ 3, 224, 224 ] } ] output [ { name: "output__0", data_type: TYPE_FP32, dims: [ 1000 ] } ]说明关于配置文件的参数说明,请参见Nvidia Triton Server模型仓库。
在OSS上按照如下结构组织目录。
oss://bucketname/triton/model-repository/ resnet18/ config.pbtxt 1/ opt_resnet18.pt说明1/是Nvidia Triton Server的规范,表示版本号。一个模型目录下可以有多个版本。更多信息,请参见 Nvidia Triton Server模型仓库。使用Arena进行部署。模型部署支持GPU独占和共享两种方式。
GPU独占:对于稳定性要求特别高的推理服务,可以采用独占的方式,一个卡上只部署一个模型,不会出现资源竞争。您可以使用以下命令以GPU独占的方式进行部署。
arena serve triton \ --name=resnet18-serving \ --gpus=1 \ --replicas=1 \ --image=nvcr.io/nvidia/tritonserver:21.05-py3 \ --data=oss-pvc:/data \ --model-repository=/data/triton/model-repository \ --allow-metrics=trueGPU共享:对于一些长尾推理服务,或者对成本比较敏感的推理服务,可以使用GPU共享,在一个卡上部署多个模型,每个模型限定显存使用量。您可以使用以下命令以GPU共享的方式进行部署。
GPU共享部署时,需要指定
--gpumemory参数,即每个Pod占用的显存大小,此参数值可以根据模型性能压测结果中的gpu_mem_used进行设定。例如,压测结果中gpu_mem_used参数为1.6 GB,由于--gpumemory只能是正整数,单位为GB,因此设为2。arena serve triton \ --name=resnet18 \ --gpumemory=2 \ --replicas=1 \ --image=nvcr.io/nvidia/tritonserver:21.12-py3 \ --data=oss-pvc:/data \ --model-repository=/data/triton/model-repository \ --allow-metrics=true
使用以下命令查看部署情况。
arena serve list -A预期输出:
NAMESPACE NAME TYPE VERSION DESIRED AVAILABLE ADDRESS PORTS GPU default resnet18-serving Triton 202202141817 1 1 172.16.147.248 RESTFUL:8000,GRPC:8001 1当
AVAILABLE的实例数等于DESIRED,表示模型部署成功。
- 本页导读 (1)