
本文为您介绍实时计算Flink版系统检查点或作业快照相关的常见问题。
开启minibatch,table.exec.state.ttl过期后,为什么无新数据更新?
当minibatch开启时,数据是以批量方式进行计算并存储在State中,而State中的数据是基于之前的全量计算结果。如果State由于TTL过期而被清除,之前的累积计算结果也消失了,导致无法根据minibatch的结果更新数据。
相反,如果未开启minibatch,当State由于TTL过期时,对应过期key下的数据将重新开始累计计算并输出,不会存在无数据更新的情况,但因为数据更新频率增加会导致数据处理延迟等其他影响。
因此,您需要根据自身业务场景来配置minibatch与TTL的使用方式。
如何计算下一次周期性Checkpoint的开始时间?
目前间隔时间和最小间隔两个参数能够影响下一次Checkpoint开始时间。当某一时刻同时满足以下两个条件时,下一次Checkpoint开始触发。其中:
间隔时间:
<上一次开始时间,下一次开始时间>的最小时间差。最小间隔:
<上一次结束时间,下一次开始时间>的最小时间差。
以两个场景进行说明,两个场景Checkpoint间隔时间为3分钟,最小间隔时间为3分钟,超时时间为10分钟。
场景一:作业正常运行(Checkpoint每次都成功)
12:00第一次开始执行Checkpoint,12:00:02 Checkpoint成功,第二次Checkpoint开始时间为12:03:00。
场景二:作业不正常(Checkpoint因某些原因超时或者失败,本场景以超时为例)
12:00第一次开始执行Checkpoint,12:00:02 Checkpoint成功,12:03:00第二次开始执行Checkpoint,12:13:00超时创建失败,第三次Checkpoint开始时间为12:16:00。
Checkpoint最小间隔时间设置详情请参见Tuning Checkpoint。
VVR 8.x和VVR 6.x使用的GeminiStateBackend有什么区别?
实时计算Flink版计算引擎VVR 6.x默认使用V3版本的GeminiStateBackend,VVR 8.x默认使用V4版本的GeminiStateBackend。
分类 | 详情 |
基础能力 |
|
状态懒加载参数 |
|
Managed Memory使用差异 | 仅在RSS(Resident Set Size)指标上有区别:
说明 关于Managed Memory的更多解释请参见TaskManager Memory。 |
关于GeminiStateBackend技术解读详情,请参见阿里云实时计算企业级状态存储引擎 Gemini 技术解读。
从VVR 6.x升级到VVR 8.x时,遇到
You are using the new V4 state engine to restore old state data from a checkpoint报错,解决方案请参见报错:You are using the new V4 state engine to restore old state data from a checkpoint。
全量Checkpoint与增量Checkpoint的大小一致,是否正常?
如果您在使用Flink的情况下,观察到全量Checkpoint与增量Checkpoint的大小一致,您需要:
检查增量快照是否正常配置并生效。
是否为特定情况。在特定情况下,这种现象是正常的,例如:
在数据注入前(18:29之前),作业没有处理任何数据,此时Checkpoint只包含了初始化的源(Source)状态信息。由于没有其他状态数据,此时的Checkpoint实际上是一个全量Checkpoint。
在18:29时注入了100万条数据。假设数据在接下来的Checkpoint间隔时间(3分钟)内被完全处理,并且期间没有其他数据注入,此时发生的第一个增量Checkpoint将会包含这100万条数据产生的所有状态信息。
在这种情况下,全量Checkpoint和增量Checkpoint的大小一致是符合预期的。因为第一个增量Checkpoint需要包含全量数据状态,以确保能够从该点恢复整个状态,这导致它实际上也是一个全量Checkpoint。
增量Checkpoint通常是从第二个Checkpoint开始体现出来的,在数据稳定输入且没有大规模的状态变更时,后续的增量Checkpoint应该显示出大小上的差异,表明系统正常地只对状态的增量部分进行快照。如果仍然一致,则需要进一步审查系统状态和行为,确认是否存在问题。
Python作业,如果Checkpoint慢怎么办?
问题原因
Python算子内部有一定的缓存,在进行Checkpoint时,需要将缓存中的数据全部处理完。因此,如果Python UDF的性能较差,则会导致Checkpoint时间变长,从而影响作业执行。
解决方案
将缓存调小,您需要在其他配置中设置以下参数,具体操作请参见如何配置自定义的作业运行参数?。
python.fn-execution.bundle.size:默认值为100000,单位是条数。 python.fn-execution.bundle.time:默认值为1000,单位是毫秒。参数的详细信息请参见Flink Python配置。
作业出现Checkpoint异常,该如何排查?
诊断异常类型
在监控告警页签或者状态集管理中查看Checkpoint历史信息,确认异常类型。例如,Checkpoint超时或者写入失败等。
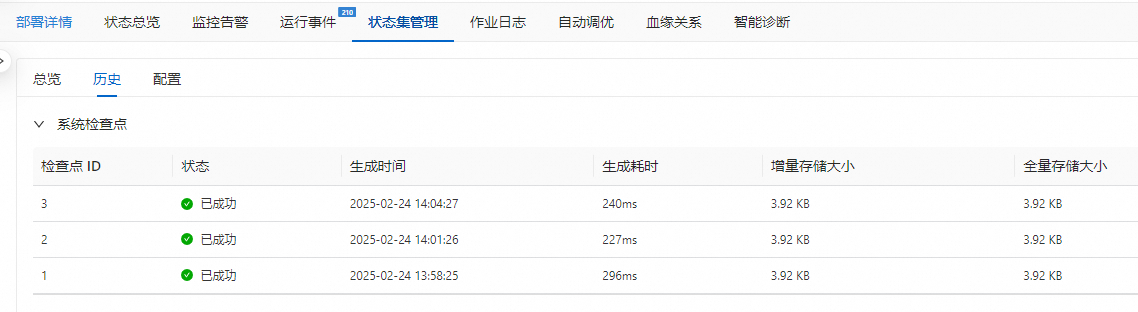
分类定位与处理
场景一:频繁Checkpoint超时:需排查作业是否存在反压,分析反压根源,定位慢算子并进行对应处理(资源调整或者配置调整),排查方法详情请参见如何排查作业反压问题?
场景二:Checkpoint写入失败:按以下步骤查找TM日志,并根据日志提示进行原因分析和定位。
在作业日志页签的Checkpoints界面,单击Checkpoints历史。
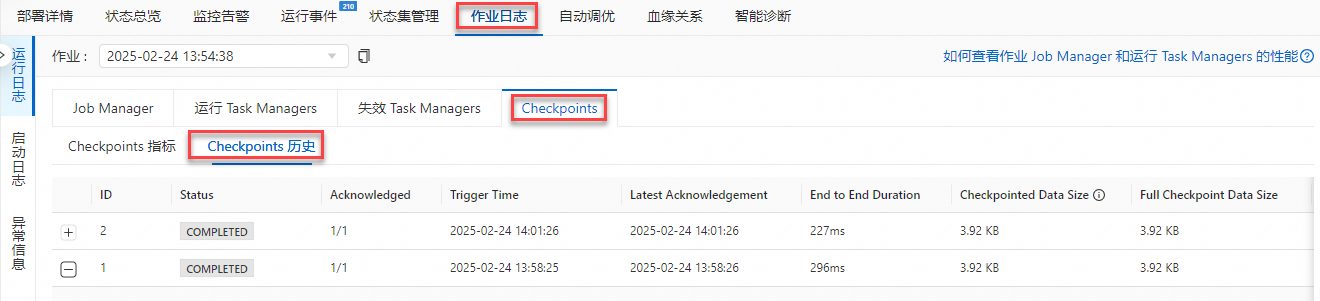
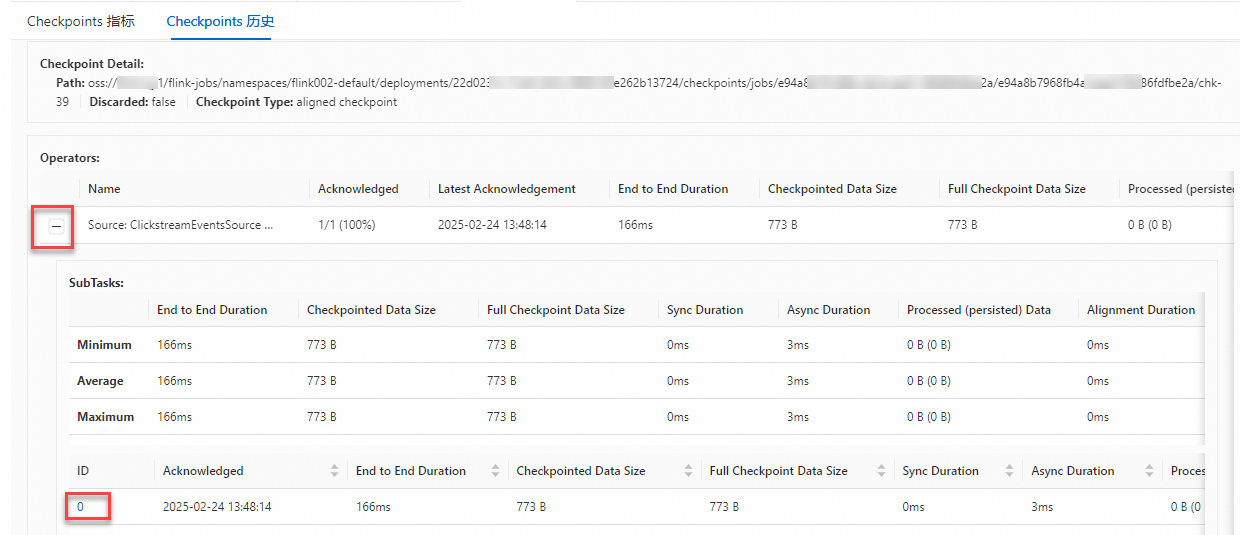
点击异常Checkpoints左侧的+号后,查看Operator的Checkpoint情况。
点击异常的Operators左侧的+号后,点击异常的SubTasks ID,单击ID跳转至对应的TM中。
报错:You are using the new V4 state engine to restore old state data from a checkpoint
报错详情
从VVR 6.x升级到VVR 8.x时,报
You are using the new V4 state engine to restore old state data from a checkpoint。报错原因
VVR 6.x与8.x使用的Gemini状态后端版本不一致,Checkpoint不兼容。
解决方案
您可以采用以下任何一种方式解决:
无状态重启作业。
(不推荐)继续使用旧版本Gemini。需要配置
state.backend.gemini.engine.type: STREAMING后重启作业才能生效。参数配置方法请参见如何配置作业运行参数?(不推荐)继续使用 VVR 6.x 版本的引擎启动作业。
报错:java.lang.NegativeArraySizeException
报错详情
当作业使用了List State,在作业运行过程中,会出现以下异常。
Caused by: java.lang.NegativeArraySizeException at com.alibaba.gemini.engine.rm.GUnPooledByteBuffer.newTempBuffer(GUnPooledByteBuffer.java:270) at com.alibaba.gemini.engine.page.bmap.BinaryValue.merge(BinaryValue.java:85) at com.alibaba.gemini.engine.page.bmap.BinaryValue.merge(BinaryValue.java:75) at com.alibaba.gemini.engine.pagestore.PageStoreImpl.internalGet(PageStoreImpl.java:428) at com.alibaba.gemini.engine.pagestore.PageStoreImpl.get(PageStoreImpl.java:271) at com.alibaba.gemini.engine.pagestore.PageStoreImpl.get(PageStoreImpl.java:112) at com.alibaba.gemini.engine.table.BinaryKListTable.get(BinaryKListTable.java:118) at com.alibaba.gemini.engine.table.BinaryKListTable.get(BinaryKListTable.java:57) at com.alibaba.flink.statebackend.gemini.subkeyed.GeminiSubKeyedListStateImpl.getOrDefault(GeminiSubKeyedListStateImpl.java:97) at com.alibaba.flink.statebackend.gemini.subkeyed.GeminiSubKeyedListStateImpl.get(GeminiSubKeyedListStateImpl.java:88) at com.alibaba.flink.statebackend.gemini.subkeyed.GeminiSubKeyedListStateImpl.get(GeminiSubKeyedListStateImpl.java:47) at com.alibaba.flink.statebackend.gemini.context.ContextSubKeyedListState.get(ContextSubKeyedListState.java:60) at com.alibaba.flink.statebackend.gemini.context.ContextSubKeyedListState.get(ContextSubKeyedListState.java:44) at org.apache.flink.streaming.runtime.operators.windowing.WindowOperator.onProcessingTime(WindowOperator.java:533) at org.apache.flink.streaming.api.operators.InternalTimerServiceImpl.onProcessingTime(InternalTimerServiceImpl.java:289) at org.apache.flink.streaming.runtime.tasks.StreamTask.invokeProcessingTimeCallback(StreamTask.java:1435)报错原因
List State中单个key对应的State数据过大,即超过了2 GB。State数据过大产生的过程如下:
在作业正常运行时,List State中单个Key下Append的Value会通过Merge进行组合(例如在包含Window的List State中),State数据不断累积。
在State数据累积到一定程度时,一开始会触发OOM。而在作业从故障中恢复之后,List State的Merge过程会进一步导致StateBackend申请的临时Byte数组的大小超过可用的限制,从而出现该异常。
说明RocksDBStateBackend也会遇到类似的问题并触发ArrayIndexOutOfBoundsException或者Segmentation fault。详情请参见The EmbeddedRocksDBStateBackend。
解决方案
如果是Windows算子导致的State数据过大,则建议减小窗口大小。
如果是作业逻辑不合理,则建议调整作业逻辑,例如将Key进行拆分。
报错:org.apache.flink.streaming.connectors.kafka.FlinkKafkaException: Too many ongoing snapshots.
报错详情
org.apache.flink.streaming.connectors.kafka.FlinkKafkaException: Too many ongoing snapshots. Increase kafka producers pool size or decrease number of concurrent checkpoints报错原因
该错误是在使用Kafka作为Sink时,连续多次的Checkpoint失败导致。
解决方案
通过
execution.checkpointing.timeout参数调整Checkpoint的超时时长,以确保它不会因为超时而失败。参数配置详情请参见如何配置自定义的作业运行参数?
报错:Exceeded checkpoint tolerable failure threshold
报错详情
org.apache.flink.util.FlinkRuntimeException:Exceeded checkpoint tolerable failure threshold. at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleJobLevelCheckpointException(CheckpointFailureManager.java:66)报错原因
设置的Checkpoint容忍次数过低,导致超过该次数的Checkpoint失败后作业触发Failover。未设置该参数时默认无法容忍任何Checkpoint失败。
解决方案
设置
execution.checkpointing.tolerable-failed-checkpoints: num参数的num值来调整任务允许Checkpoint失败的次数。num需要为0或正整数。如果num为0,则表示不允许存在任何Checkpoint异常或者失败。参数配置详情请参见如何配置自定义的作业运行参数?