流利说基于Terraform的自动化实践
流利说简介
流利说®(NYSE:LAIX)是卓越的科技驱动的教育公司,由王翌博士和胡哲人、林晖博士于 2012 年 9 月共同创立。作为智能教育的倡行者,公司拥有一支优秀的人工智能团队,其自主研发的人工智能英语老师,基于深度学习技术,能够为每一位用户提供个性化、自适应的学习课程。创立九年时间,流利说®连续推出了多样化、覆盖不同兴趣类别和细分人群的产品,包括“流利说®英语”、“流利说®阅读”等英语教育App以及“流利说®懂你英语®A+”、“流利说®发音”等英语学习产品。截至2021年6月,流利说®旗下产品累计注册用户超过2亿,用户覆盖175个国家和中国384个城市。同时,其搭建的巨型“中国人英语语音数据库”已累积实现记录超39亿分钟的对话和537亿句录音。
自动化的驱动力
面对瞬息万变的市场,业务团队希望快速响应市场的需求,打造更多有创意的产品。在这背后,要求Cloud Infra团队提供更敏捷的基础设施,提升用云的管理水平,主要体现在:
加速资源供应:支持业务团队以自服务的方式快速获取云资源;
降低总体成本:充分利用云的弹性能力,提升资源利用率以降低总体的成本;
提升运维和管理效率:提升运维的效率,减少重复性的人工操作。
流利说的自动化实践
我们的自动化实现不是一蹴而就的,而是逐步构建的过程,这一过程中我们总结出来的原则是:
1)把日常重复性的工作进行自动化,让大家切身体会到自动化带来的价值,构建自动化的文化;
2)以价值导向对自动化的优先级进行排序,释放自动化的业务价值。
我们从以下三个维度进行自动化的探索,可以说随着自动化的深入,我们的管理成熟度也越来越高:
部署自动化
管理自动化
治理自动化
部署自动化:资源供给的流程化和自动化
云资源的供给是所有工作开始的第一步,也是我们日常工作之一。在没有自动化之前,所有的操作都在控制台上完成,看似简单,但实际应用中会有许多的问题:
资源无法统一管理,没有统一的仓库去记录这些资源的归属与规格变更等信息,非常容易出现变动带来的混乱;
手工变更误操作影响线上服务正常运行,并难以回滚。人机交互过多,原来的便捷就变成了容易出错,最可怕的就是“点错了”,还忘了原来是什么样;
创建重复资源时,需要重复人工页面操作,耗时且无法标准化。
因此,我们基于Terraform、Luban(自研管理平台)、GitLab实现了完全的资源供给自动化,将供应效率从原来的小时级降低到分钟级,并且将运维支撑效率提升100%。
整体实现的架构如下:
通过Luban实现流程的自动化,基于Chatbox提升了效率和体验;
基于GitLab实现对IaC的资源配置库统一管理;
基于Terraform实现在阿里云的资源创建和变更操作。
以下我们将介绍详细的架构和实现方案。
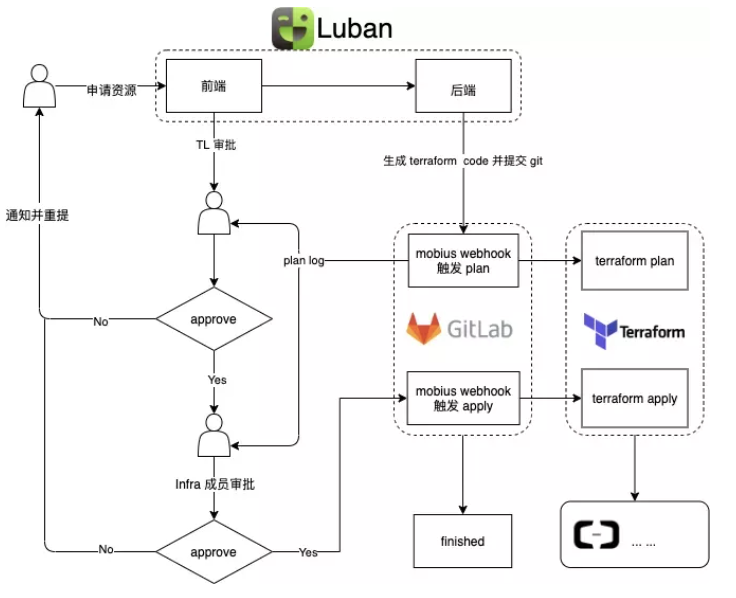
1)在 Luban 平台申请资源
我们给研发团队提供的各种窗口链接都放在了一个叫做 Luban 的平台上,申请人只需要在前端选择必要的参数,提交申请,对于申请人来说需要做的事情就结束了,接下来就是等待审批结果。例如,我想要申请一个阿里云 ECS 实例,如果直接写 Terraform,那大概要写一个如下的文件:
resource "alicloud_instance" "instance" {
# cn-beijing
availability_zone = "cn-beijing-b"
security_groups = alicloud_security_group.group.*.id
# series III
instance_type = "ecs.n4.large"
system_disk_category = "cloud_efficiency"
system_disk_name = "test_foo_system_disk_name"
system_disk_description = "test_foo_system_disk_description"
image_id = "ubuntu_18_04_64_20G_alibase_20190624.vhd"
instance_name = "test_foo"
vswitch_id = alicloud_vswitch.vswitch.id
internet_max_bandwidth_out = 10
data_disks {
name = "disk2"
size = 20
category = "cloud_efficiency"
description = "disk2"
encrypted = true
kms_key_id = alicloud_kms_key.key.id
}
}看起来好像很容易看懂但有的地方又有点疑惑,接着就要去查 alicloud provider documentation 各个参数的意思然后改参数,对于一个没有写过 Terraform 的人来说还是比较麻烦的。所以我们做了一个前端申请页面后,只需要选择必定的参数,Luban 后端就会按既定的规则在相应目录下进行代码生成并触发 GitOps 流程,对于申请人来说,只需要等审批结果了。
2)运行Terraform Plan检查
这一步骤是后台自动执行的,触发 mobius webhook 进行 terraform plan。mobius 是 Luban 后端非常重要的一个引擎,它能够集成 GitLab 的 webhook, 处理 merge request 的 create/update/merge/cancel 事件,能够处理 Terraform 流程的 int/plan/apply, 并输出日志。
git 提交后,mobius 会自动进行 terraform plan 的 Pipeline。
Tech Leader 通过前端的申请历史,可以看到对应资源申请的详细进展,查看 plan 结果是否符合预期,符合点击 approve 进入下个流程,由基础设施成员进行复审。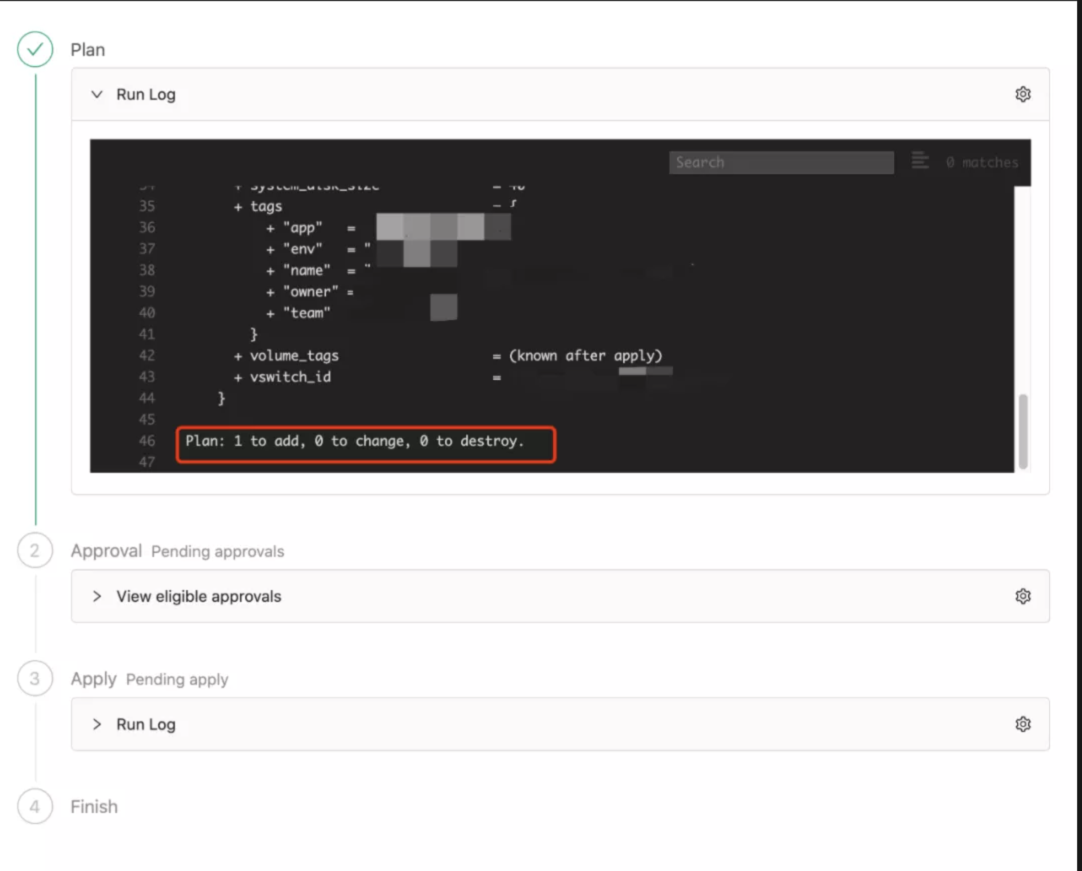
3)提示值班人员进行资源变更审批
在Plan运行成功之后,自动进入到下一环节,Luban Bot模块提示Infra团队的值班人员进行资源变更审批。
4)自动化对线上资源进行变更
Infra团队的值班人员在GitLab审批通过后,触发mobius webhook 进行 terraform apply 即对线上做出变更,apply 成功后,mobius 自动进行代码 merge, 至此一个申请流程结束,而申请人也会在内部Chat上收到 Luban Bot发出的资源申请成功的通知。
从以上四个步骤可以看出,资源的供应不仅是完全自动化的,而且非常的严谨,再也不需要人员专门去学习写 Terraform, 重点就放在 review terraform plan 输出的变化是不是符合预期,并且通过ChatBot的触发性通知,提升了效率。
管理自动化:弹性伸缩自动化
我们的业务受到用户在一天内的使用习惯影响,在一天内不同时段呈现明显的波峰波谷;同时,定期的运营活动、市场促销活动也会带来用户访问的激增。在业务波峰时增加云资源、在业务波谷期释放资源,毫无疑问将可以帮助我们降低云上的成本。
如果只是根据业务活动计划手动调整资源,或者在负载高水位被动进行人工的配置,显然这对用户体验不是最佳的,也并不能动态实时响应降低成本。因此我们将开始着手研究如何实现弹性伸缩的自动化。
经过一段时间的摸索,我们做到了基于规则配置或业务指标监控根据业务的变化自动调节资源数量,实际应用效果来看,在相同的业务负载下,成本节约超过20%。
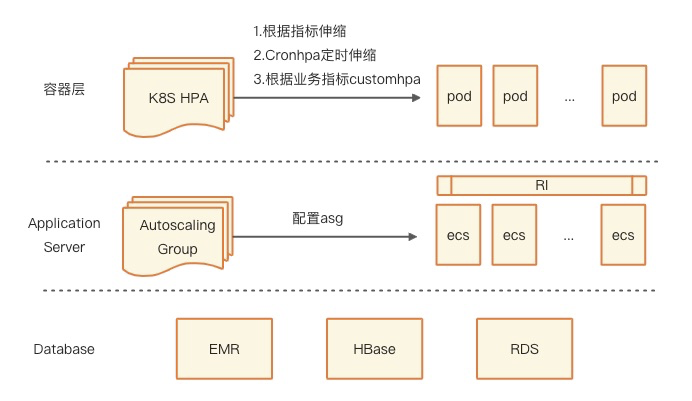
在技术上,我们从容器层、应用服务器层和数据库层各层都实现了自动化的弹性伸缩:
容器层:使用HPA进行pod伸缩,触发伸缩的事件有:监控指标、业务指标和定时任务;
服务器层:使用弹性伸缩组,基于服务器指标实现ECS的伸缩;
数据库层:使用云原生的数据库实现弹性,如EMR可定时或者根据cpu/mem指标弹出ECS。
治理自动化:成本管理自动化
对于流利说这样成长在云上的企业来说,成本管理是我们的关键任务。如何有效的管理云上开支、利用技术的手段杜绝资源浪费是我们要解决的首要问题;而成本如何自动化的分摊到各个业务团队,是我们进行成本管理的基础。
1)基于标签进行成本分摊
云上成本分摊其实没有想象中的那么复杂,云厂商在对应的云资源上面均有对应的 Tags 体系,K8s 的各种资源同样具有 Labels 体系,两个标签体系中其实是可以到很好的关联的;同时阿里云也有账单相关 API 可调用。
我们自研了Catalog系统,来进行资源与 App 的绑定,同时明确各个 App 的 Owner、Team,并且以此作为公司内部所有资源使用归属与统计的唯一数据源。至此我们已经具备了基于 Catalog 源数据管理来进行成本分摊的能力。
当资源有归属者转换,我们只需要修改 Catalog 系统即可,极致轻巧且高效。当然我们也有部分资源因为长久以往的积累,导致多个团队混用的情况发生。我们依靠大部分可以明确关系的资源均摊成本后,依靠此比例的准确性再来进行无法分摊的资源分摊,并与各个业务线达成共识。
2)自动化的成本分析报告
对于公共支持团队,比如大数据、基础设施、业务中台等资源,我们通过在整体成本已经明确的业务线占比,再将公共支持团队成本均摊到各个业务线。同时我们也计算了研发环节对于整个成本在各个业务的占比情况,并将所有成本数据做好同比环比。
综上,基于 Catalog + Tags/Lables 进行明确资源关系,通过绝大部分精准的数据来进行分摊,解决公共资源的分摊难问题,最终每月有一份详细的自动化的成本分析报告给到各个业务线,同时也有相对简单的实时监控大盘。
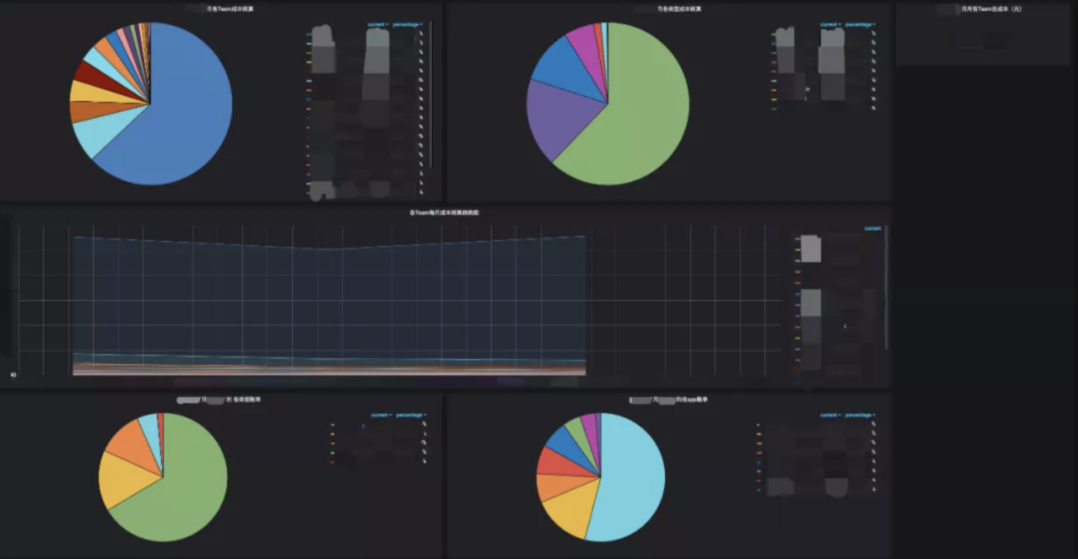
此外,我们还基于 Prometheus 中各种资源的历史监控数据,统计了资源 CPU & Memory 利用率、存储资源 CPU & Memory & Iops 利用率,做到了按每周为一个计算周期自动化发送,报表核心模板如下:

我们基于数据说话对低利用率资源进行合理的降配,至今没有出现任何反弹的情况、也没有出现任何线上生产事故。
总结
通过自动化的应用,对于我们Cloud Infra团队来说提高了工作的效率、提升我们的管理水平;同时对于业务也带来了显著的好处,包括更快的交付资源、更透明的成本开支。
作者介绍
流利说 技术部 Cloud Infra 团队