Flink全托管产品(Flink Serverless)是一款基于Apache Flink构建的全托管产品,为您提供全托管一站式的实时计算服务,具有免运费、高增值、低成本等特性。本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
概述
适用场景
Flink各类任务迁移。
数据准确性校验。
业务稳定性验证。
Flink集群容量评估。
技术架构
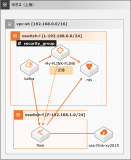
本实践方案基于如下图所示的技术架构和主要流程编写操作步骤:
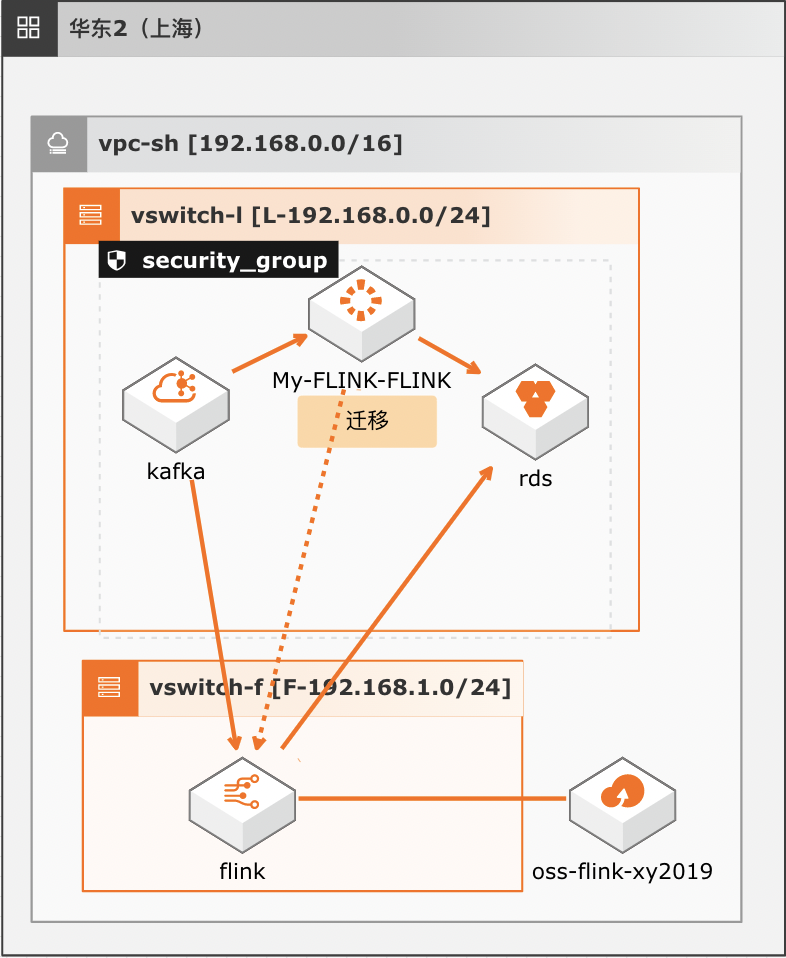
迁移实施流程如下:

方案优势
您只需要专注于业务开发,无需关心集群运维。
Flink全托管产品提供,提交作业、管理作业、收集指标和监控报警等一站式功能,提高作业开发运维效率。
与开源Flink完全兼容,提供GeminiStateBackend(自研高性能状态存储引擎)等高增值功能,提升作业稳定性。开源使用Auto-Pilot功能进行作业调优。
按CU售卖,根据业务需要按需购买,降低成本。
基础环境搭建
1. 创建资源
1.1 使用CADT创建资源
登录CADT控制台,选择官方模板新建。


设置EMR集群登录密码。
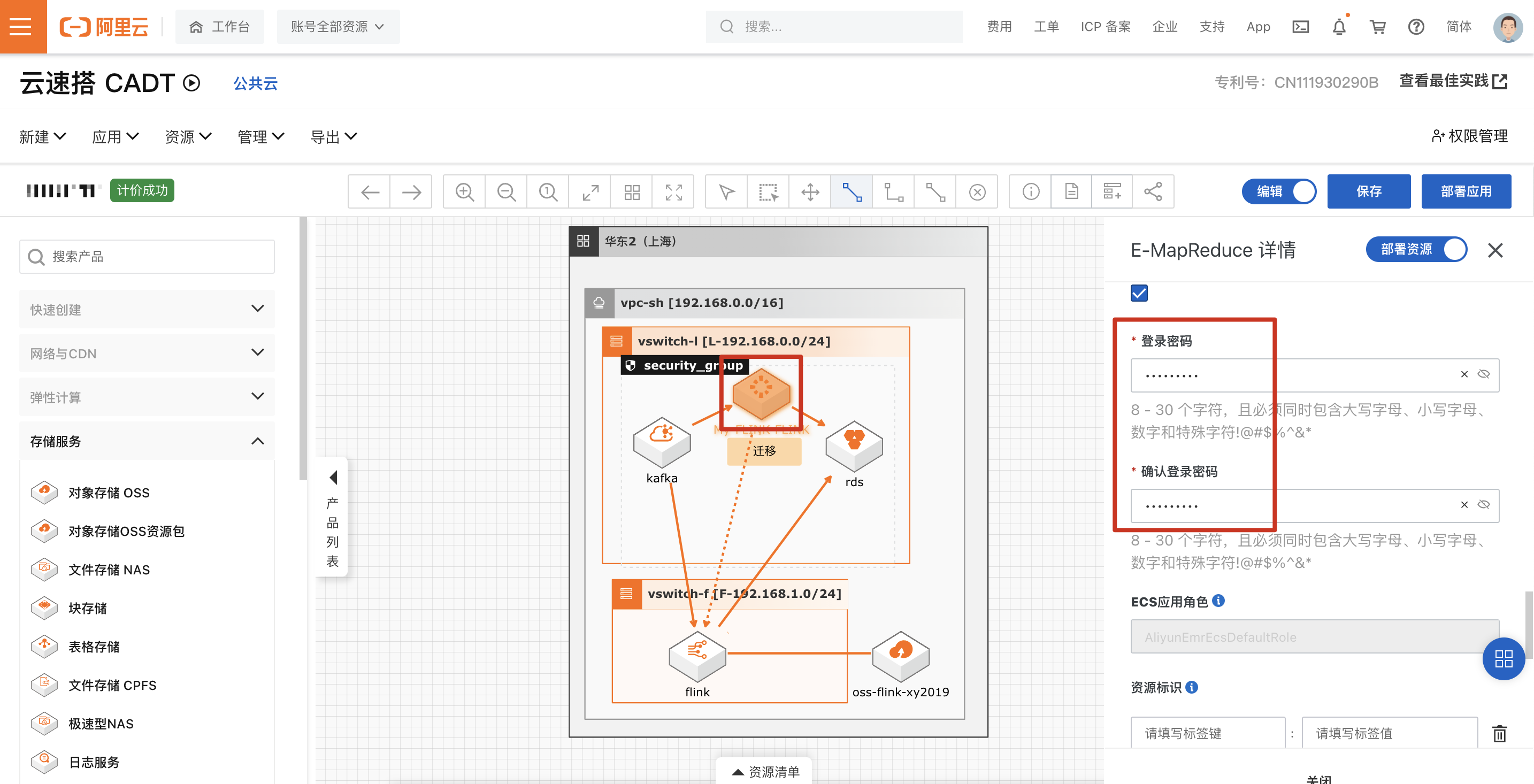
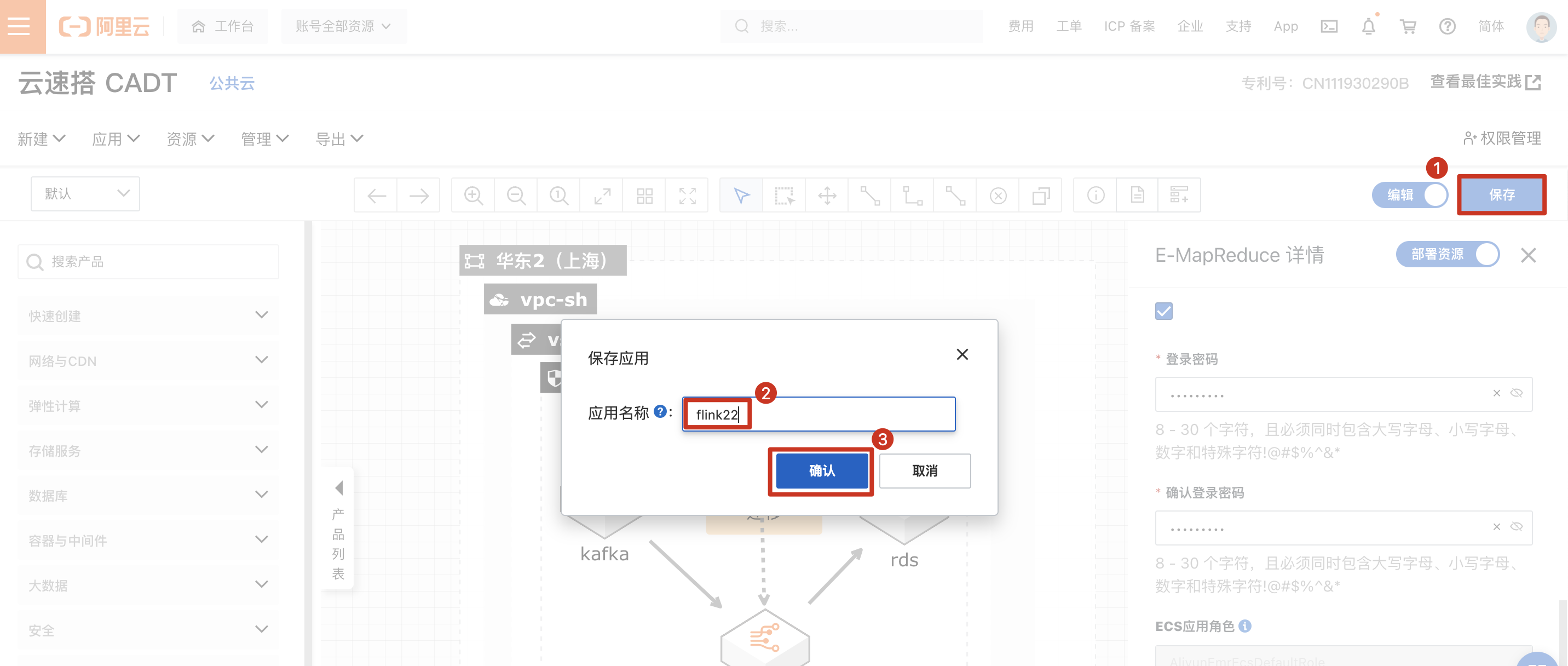
输入标题名称,保存应用。
开始部署应用,按照默认配置确认下一步,等待部署完成。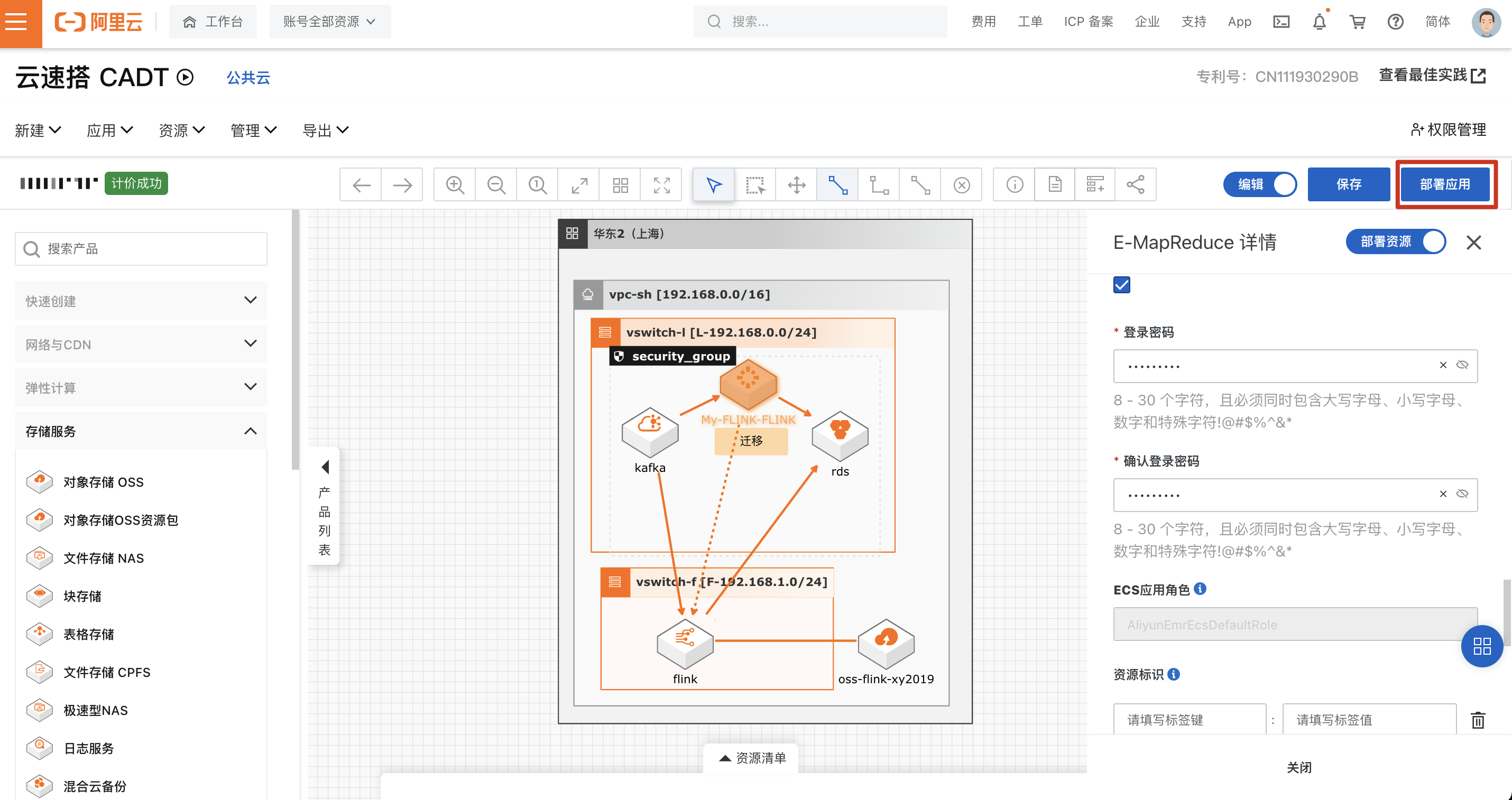
等待资源创建完成。
等待部署完成,创建数据库账号密码。
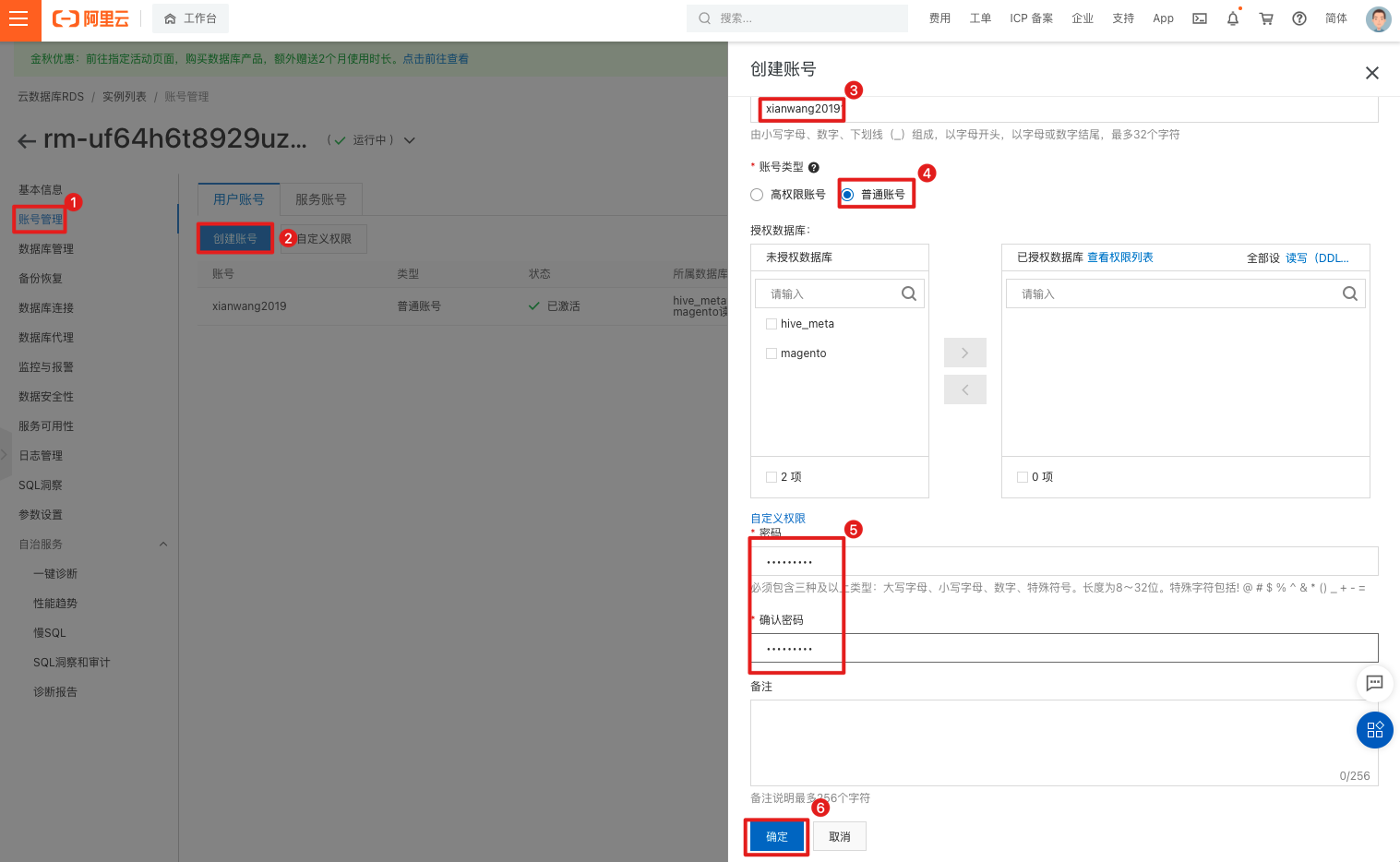
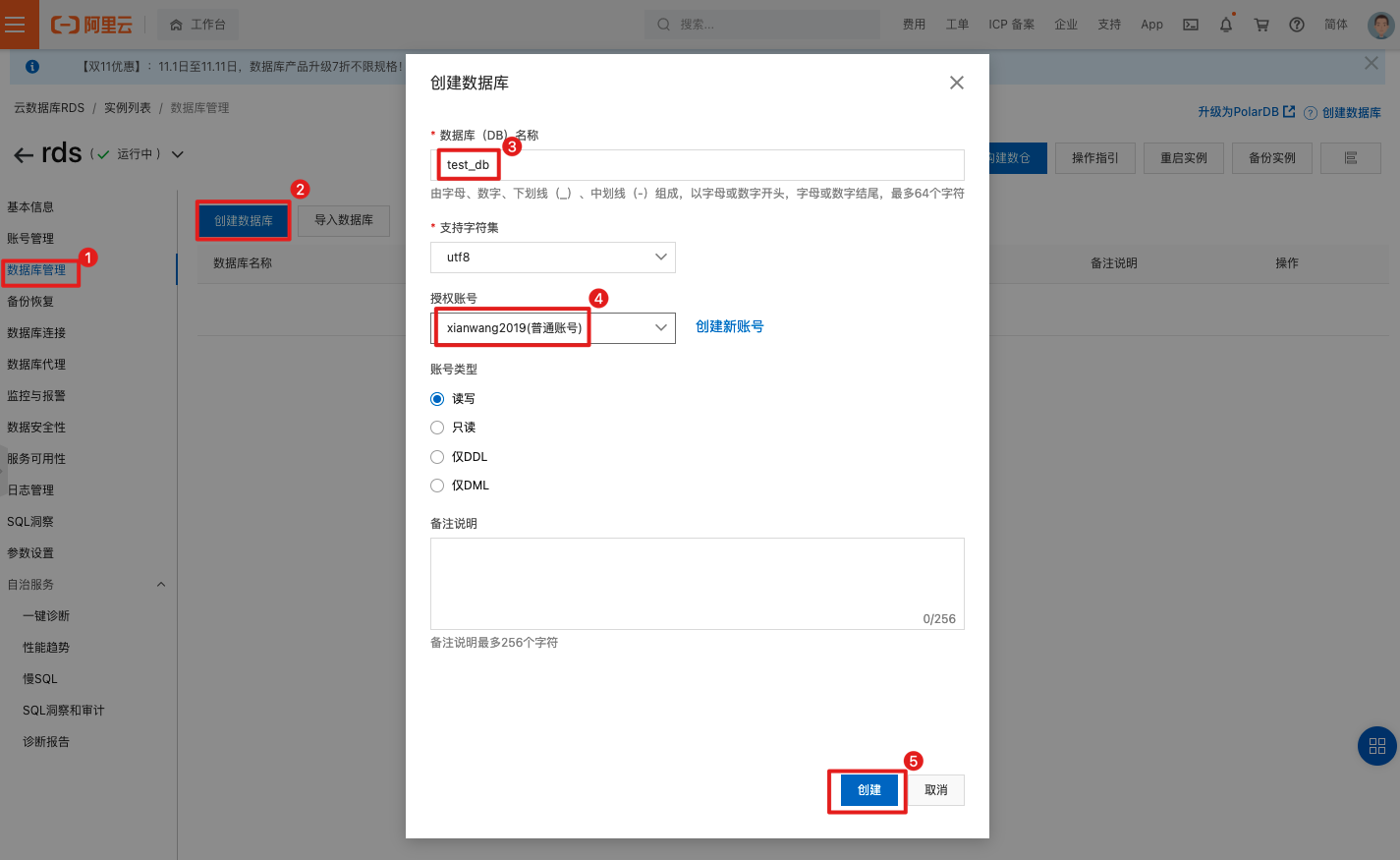
创建测试数据库(test_db)。
1.2 Flink集群资源评估
阿里云实时计算Flink版产品按照 CU 计费,1CU=1Core + 4G MEM,参考产品官方介绍,每个计算的 CU 节点每秒钟处理能力如下:
作业类型 |
处理能力 |
注意事项 |
简单作业(指仅仅进行数据同步,或者在数据同步中涉及一些简单的过滤清洗) |
每个计算 CU 可处理 5000 条数据,平均每条数据 1kb |
需要考虑用户作业数,每个作业的 JM 不提供计算能力,但需要至少 0.5CU |
中等作业(指包含维表 Join,基础窗口的作业) |
每个计算 CU 可处理 1000 条数据,平均每条数据 1kb |
需要考虑用户作业数,每个作业的 JM 不提供计算能力,但需要至少0.5CU |
高等作业(指包含双流 Join,大状态存储的作业) |
每个计算 CU 可处理 500 条数据,平均每条数据 1kb |
需要考虑用户作业数,每个作业的 JM 不提供计算能力,但需要至少 0.5CU 以上估算方法是一种非常粗略的估算方法,仅供参考;同时,对于一般用户来说,需要按照自己数据的最高峰的情况来规划资源。 |
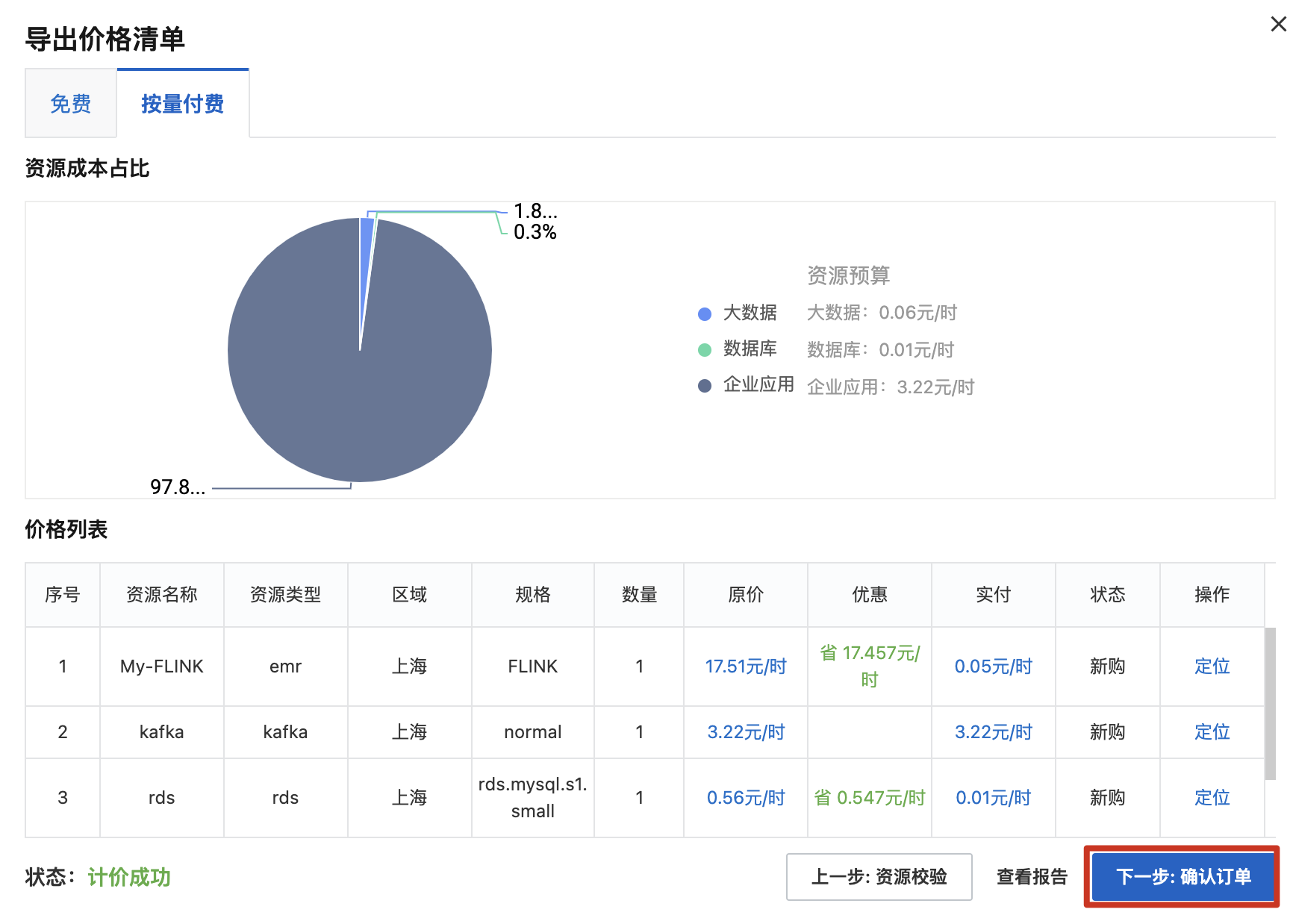
考虑到本文档案例是自建开源 Flink 集群平迁至阿里云实时计算Flink版本产品,按照当前集群的实际资源使用情况(Vcores:48,Memory:80 GB)即可估算迁移后的 CU 数,即:MAX(48,80/4)=48CU。
2. 构建测试数据
2.1 创建kafka topic
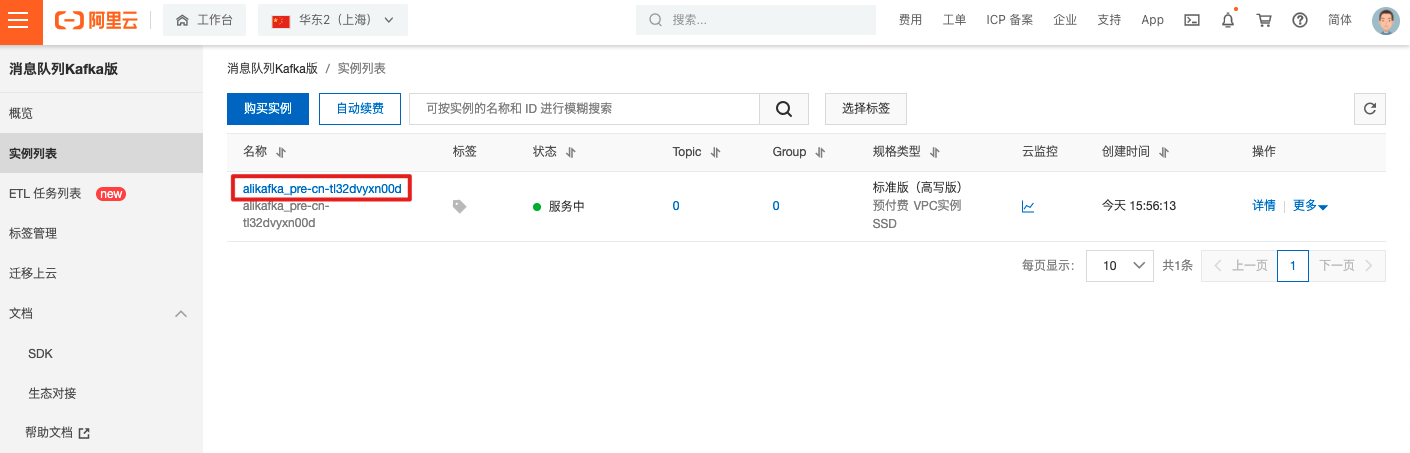
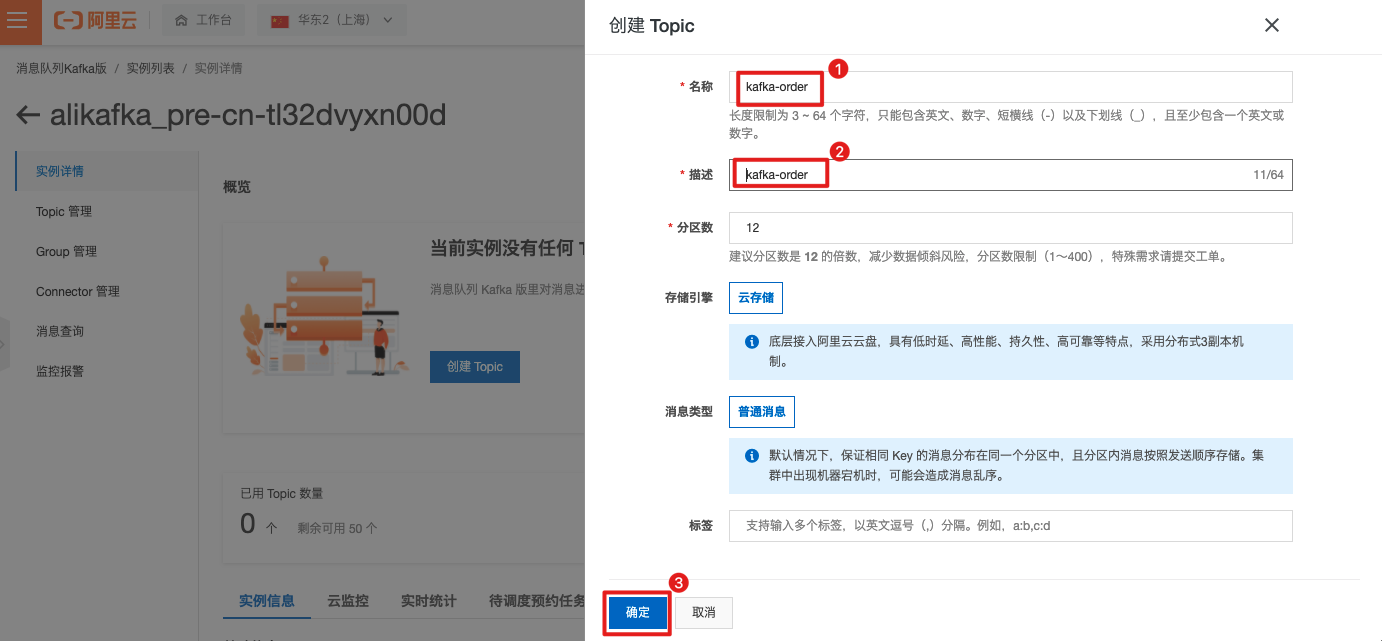
登录云kafka控制台,进入实例详情,创建Topic。
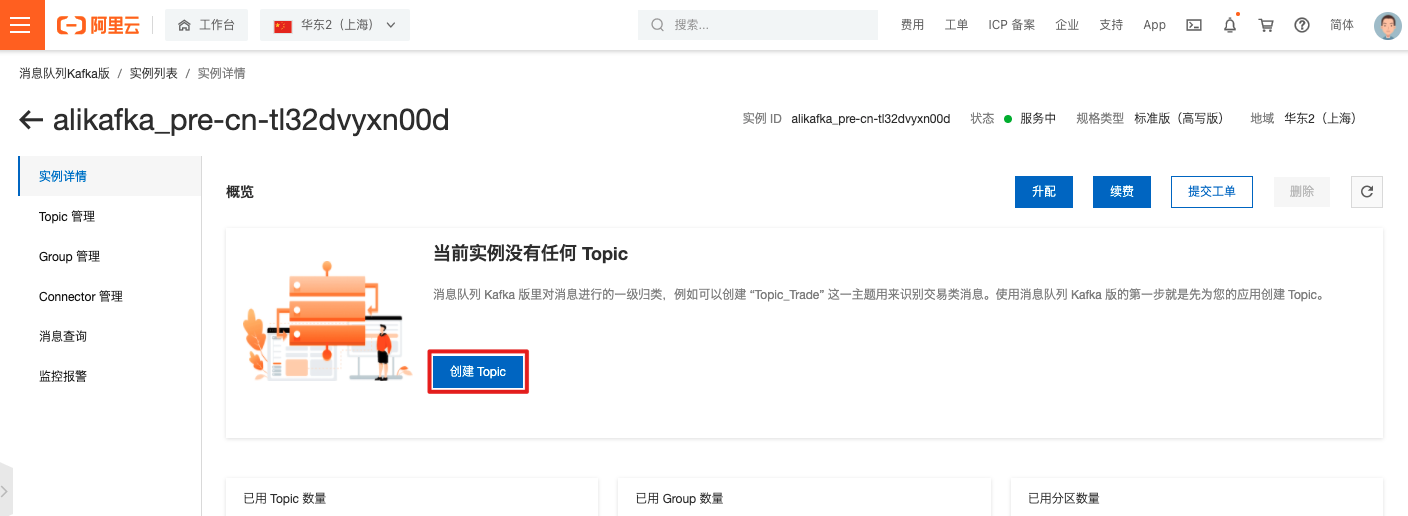
输入kafka 名称和描述,创建Topic。
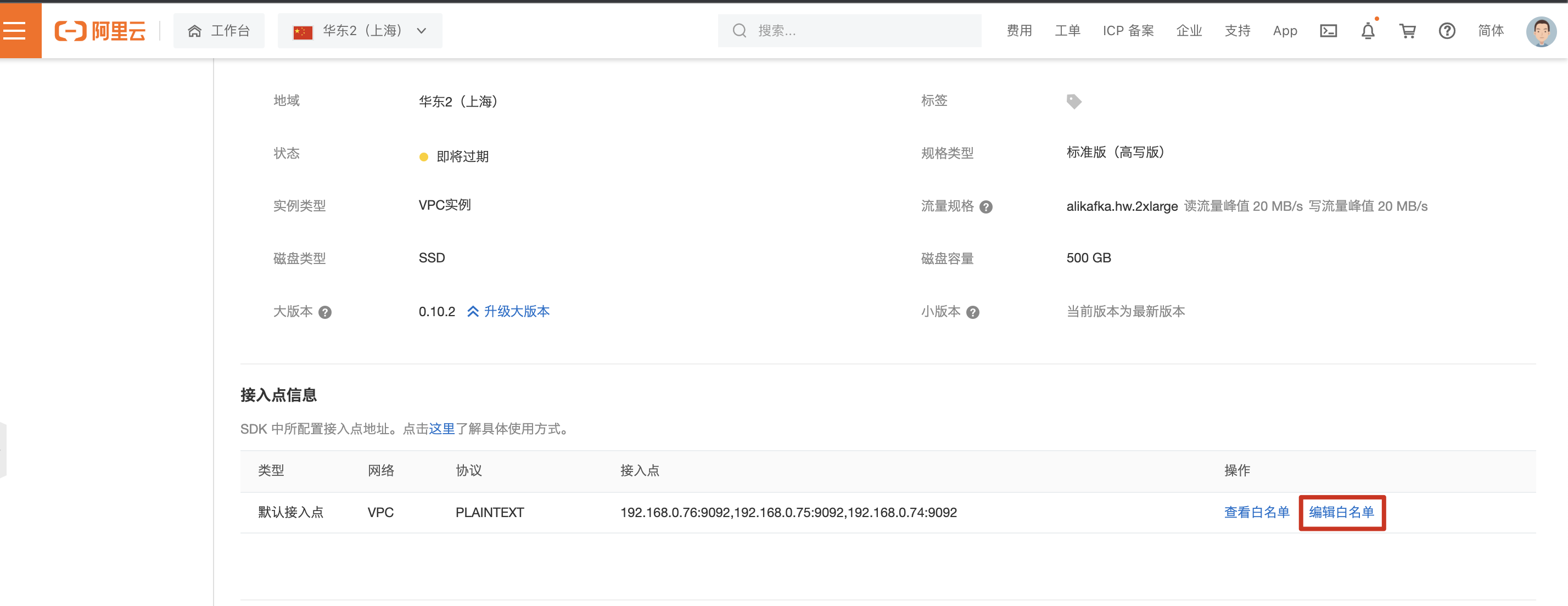
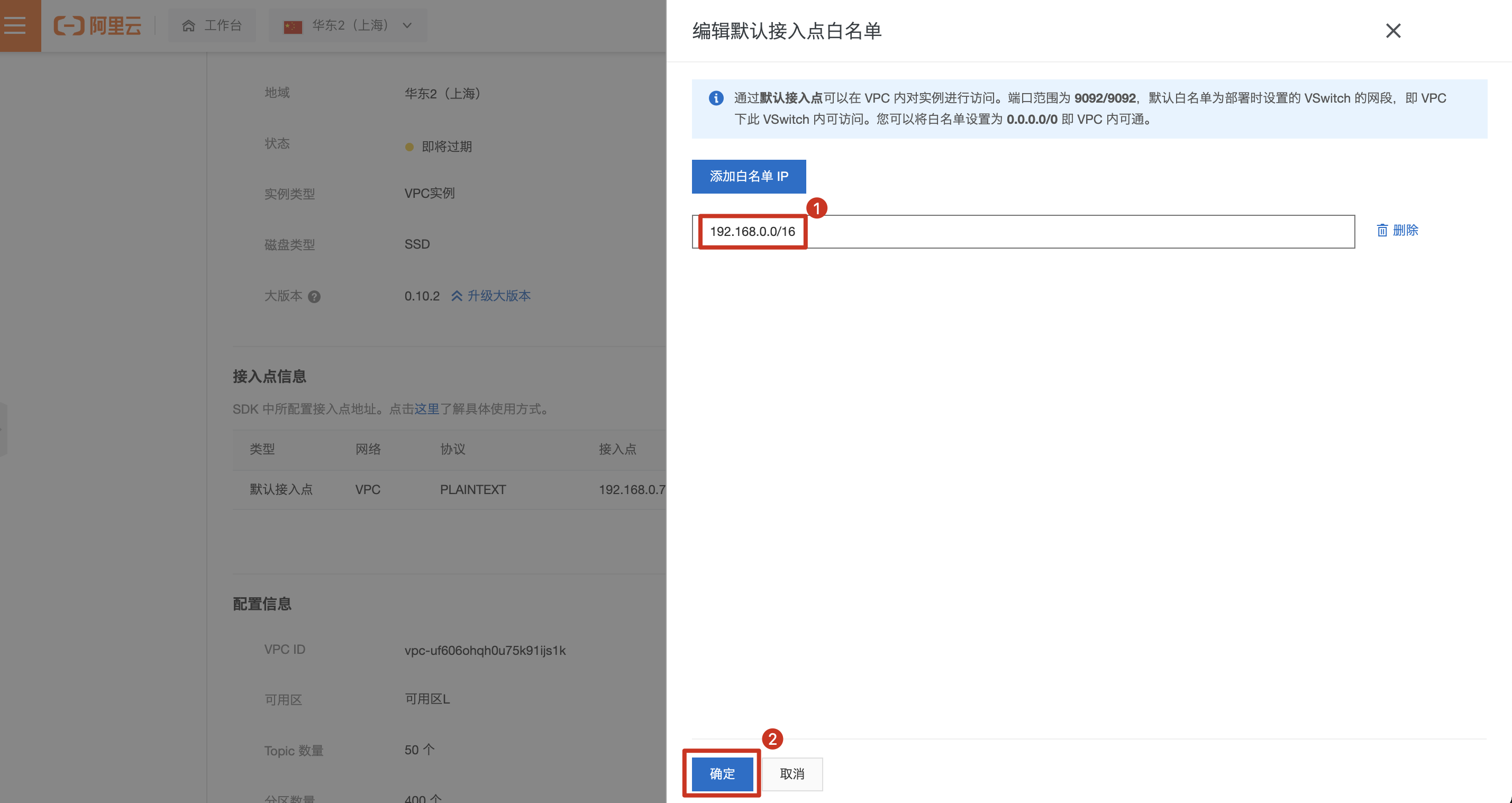
调整kafka 白名单为VPC网段。
2.2 测试数据生产
源表为 Kafka 中的订单表,topic 名为 kafka-order,存储格式为 CSV,Schema 如下:

这里使用Flink往kafka实时写入测试数据,首先创建Flink作业。输入作业名称创建作业。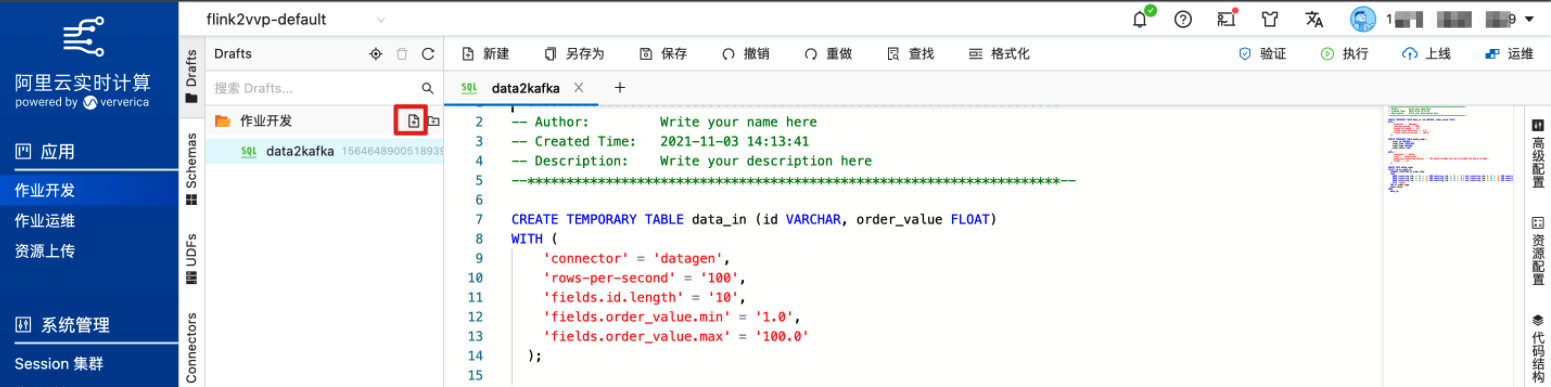
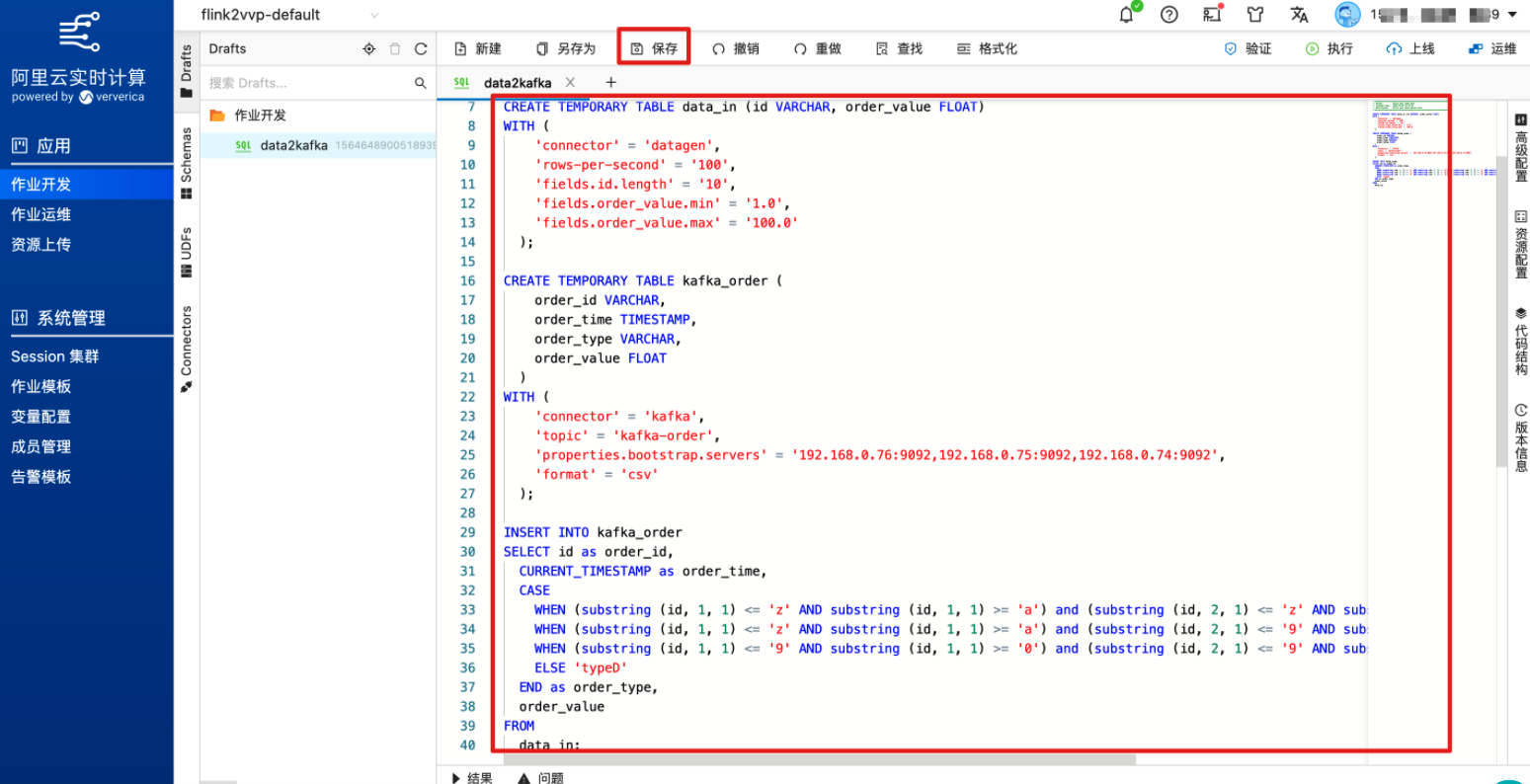
在Flink SQL中添加以下作业,注意修改properties.bootstrap.servers为前面创建的kafka的接入点。
CREATE TEMPORARY TABLE data_in (id VARCHAR, order_value FLOAT)
WITH (
'connector' = 'datagen',
'rows-per-second' = '100',
'fields.id.length' = '10',
'fields.order_value.min' = '1.0',
'fields.order_value.max' = '100.0'
);
CREATE TEMPORARY TABLE kafka_order (
order_id VARCHAR,
order_time TIMESTAMP,
order_type VARCHAR,
order_value FLOAT
)
WITH (
'connector' = 'kafka',
'topic' = 'kafka-order',
'properties.bootstrap.servers' = '192.168.0.224:9092,192.168.0.225:9092,192.168.0.226:9092',
'format' = 'csv'
);
INSERT INTO kafka_order
SELECT id as order_id,
CURRENT_TIMESTAMP as order_time,
CASE
WHEN (substring (id, 1, 1) <= 'z' AND substring (id, 1, 1) >= 'a') and (substring (id, 2, 1) <= 'z' AND substring (id, 2, 1) >= 'a') THEN 'typeA'
WHEN (substring (id, 1, 1) <= 'z' AND substring (id, 1, 1) >= 'a') and (substring (id, 2, 1) <= '9' AND substring (id, 2, 1) >= '0') THEN 'typeB'
WHEN (substring (id, 1, 1) <= '9' AND substring (id, 1, 1) >= '0') and (substring (id, 2, 1) <= '9' AND substring (id, 2, 1) >= '0') THEN 'typeC'
ELSE 'typeD'
END as order_type,
order_value
FROM
data_in;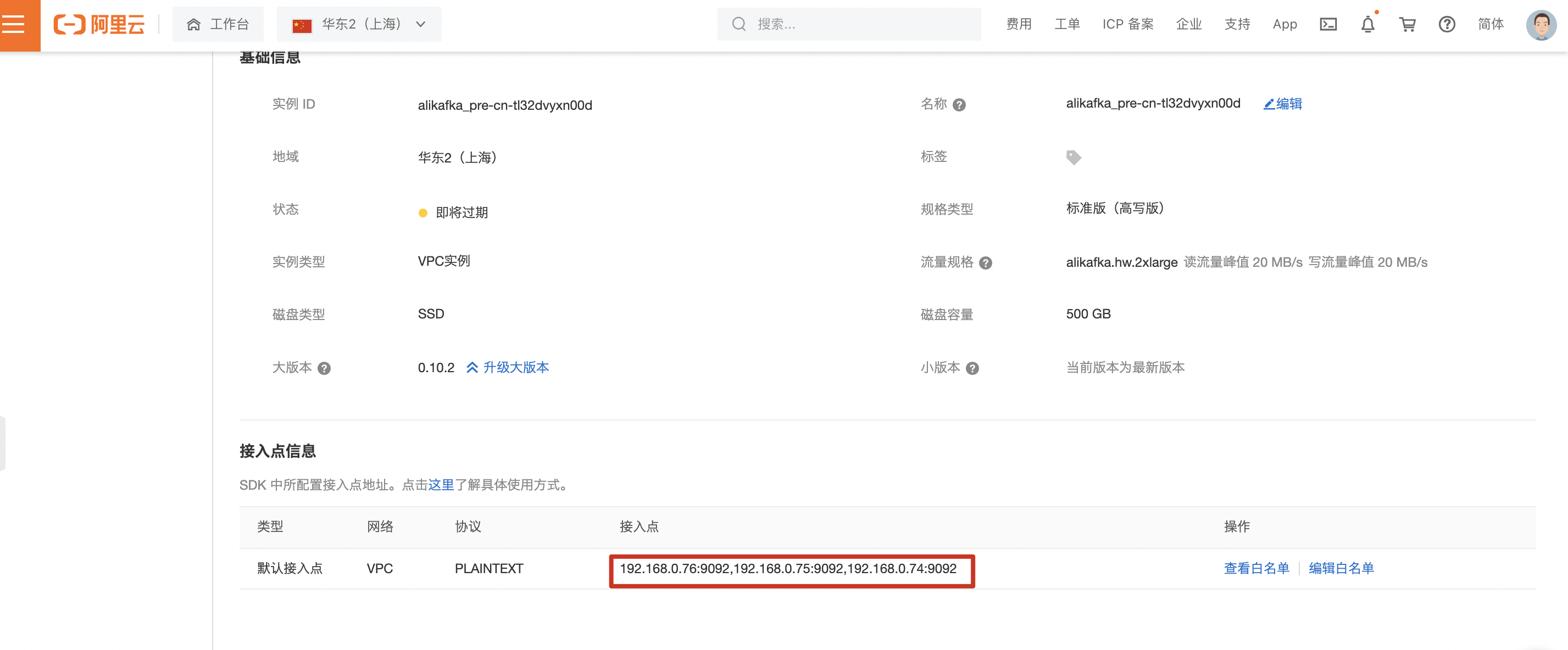
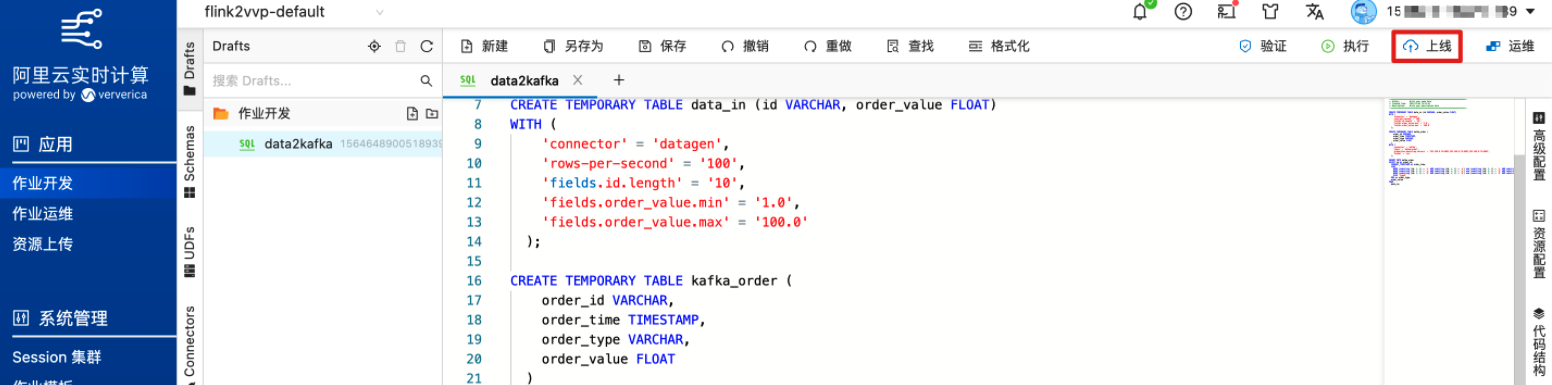
提交作业上线,并启动作业。
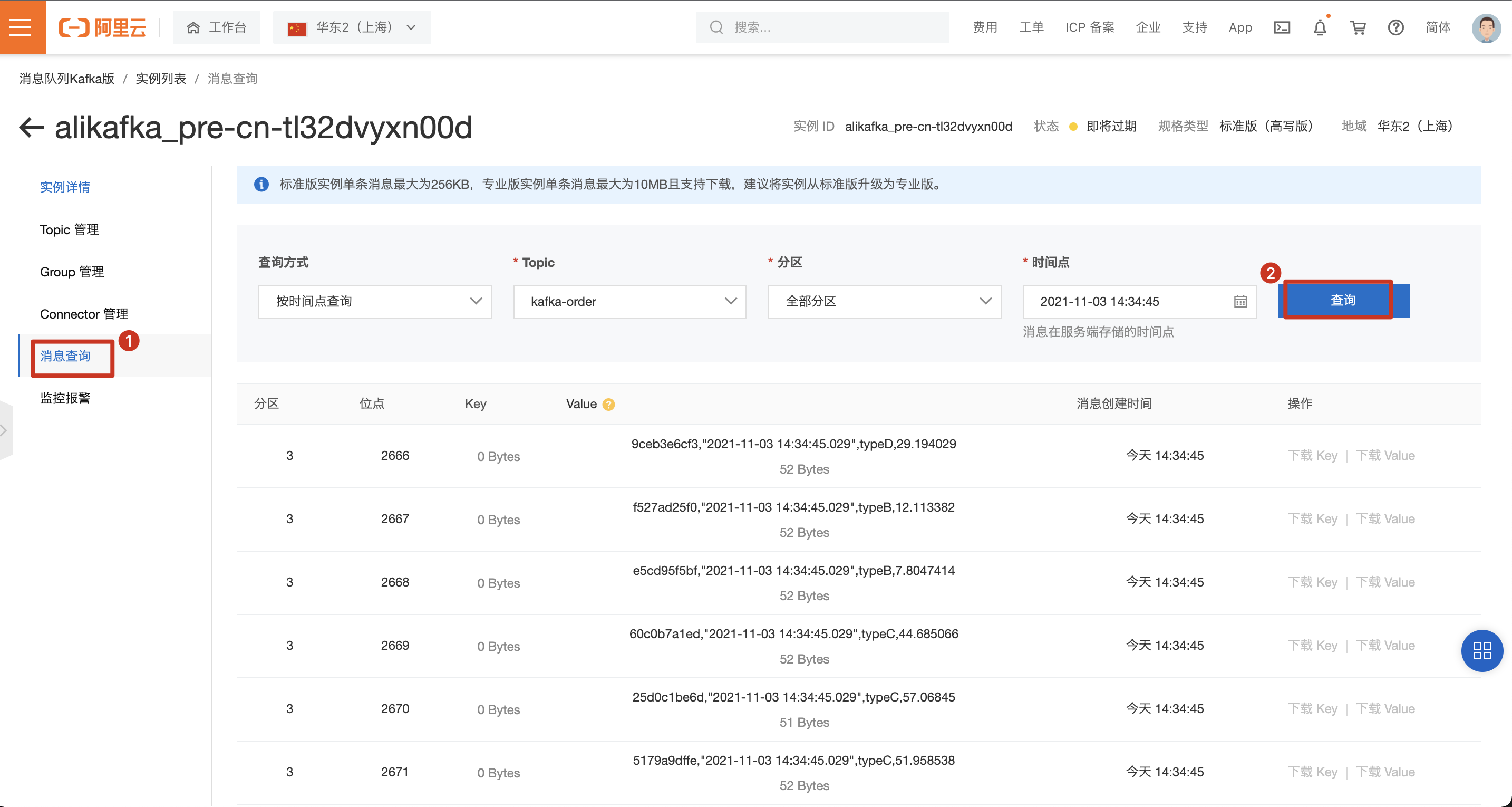
待作业成功运行后,在kafka中查询消息,可见测试数据已成功生成。
作业迁移
原始集群计算说明:
Flink 中的计算逻辑为:统计每5分钟窗口内订单的订单总量和订单总金额。
为便于介绍,以上计算逻辑在自建集群上分别使用三种 API(Datastream、Table/SQL、PyFlink) 来实现。
请先下载实现代码。
Datastream:参考 DataStreamJobKafka2Rds.java。
Table/SQL:参考 TableJobKafka2Rds.java。
PyFlink:参考 pyflinkjobkafka2rds_old.py(迁移前)和pyflinkjobkafka2rds_new.py(迁移后) 。
1. Table/SQL JAR迁移至SQL
场景说明:

本场景将自建 Flink 集群上的 Table/SQL JAR 作业,迁移至实时计算Flink全托管的 SQL 作业类型中。
自建 Flink 集群上提交作业的命令如下:

flink run -d -t yarn-per-job -p 2 -ynm 'tablejobkafka2rds' -yjm 1024m -ytm 2048m -yD yarn.appmaster.vcores=1 -yD yarn.containers.vcores=1 -yD state.checkpoints.dir=hdfs:///flink/flink-checkpoints -yD execution.checkpointing.interval="180s" -c com.alibaba.realtimecompute.TableJobKafka2Rds ./flink2vvp-1.0-SNAPSHOT.jar 1.1 构建自建集群测试作业
登录RDS数据库创建自建集群的sink表(rds_old_table1)。
CREATE TABLE `rds_old_table1` (
`window_start` timestamp NOT NULL,
`window_end` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`order_type` varchar(8) NOT NULL,
`order_number` bigint NULL,
`order_value_sum` double NULL,
PRIMARY KEY ( `window_start`, `window_end`, `order_type` )
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;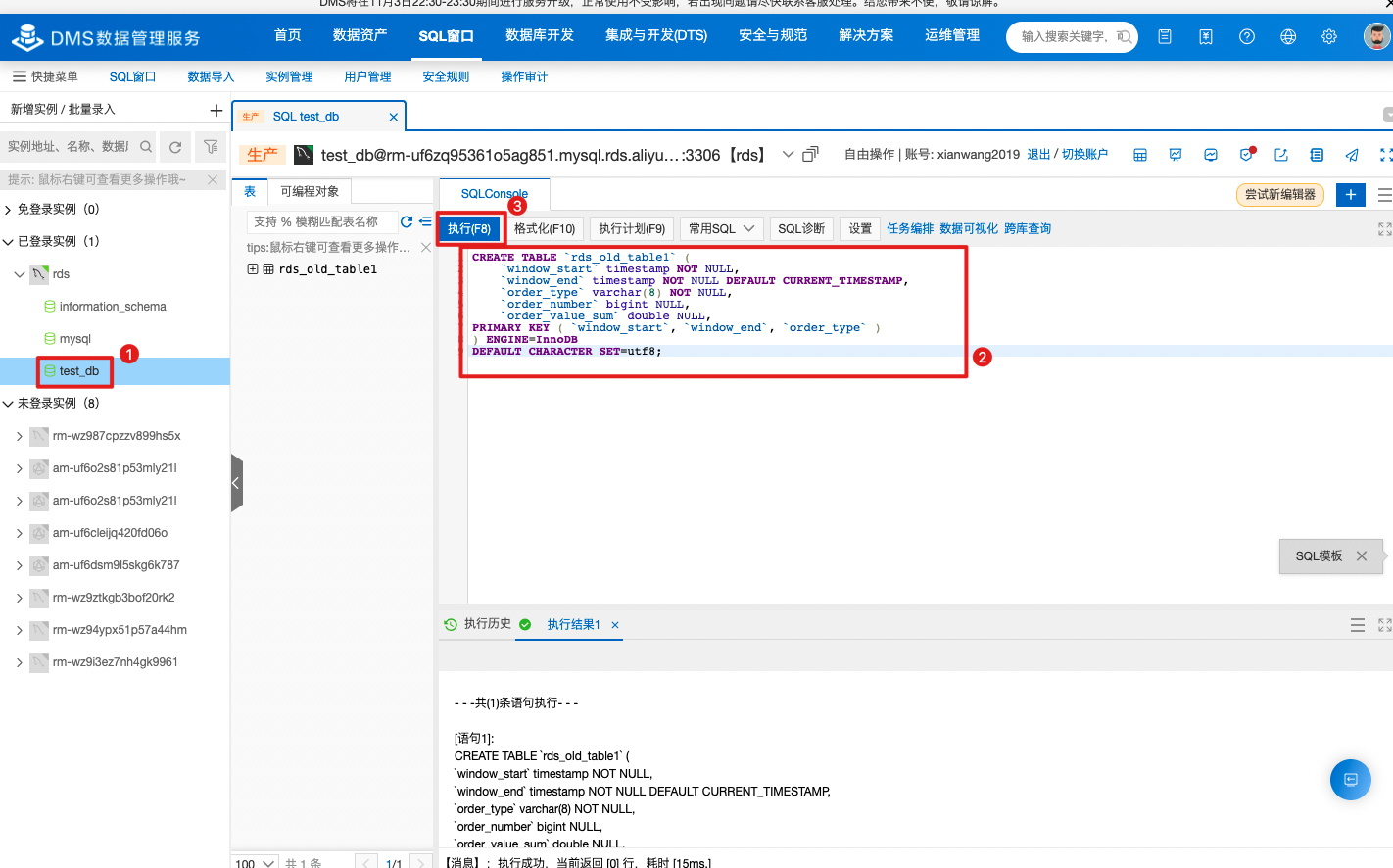
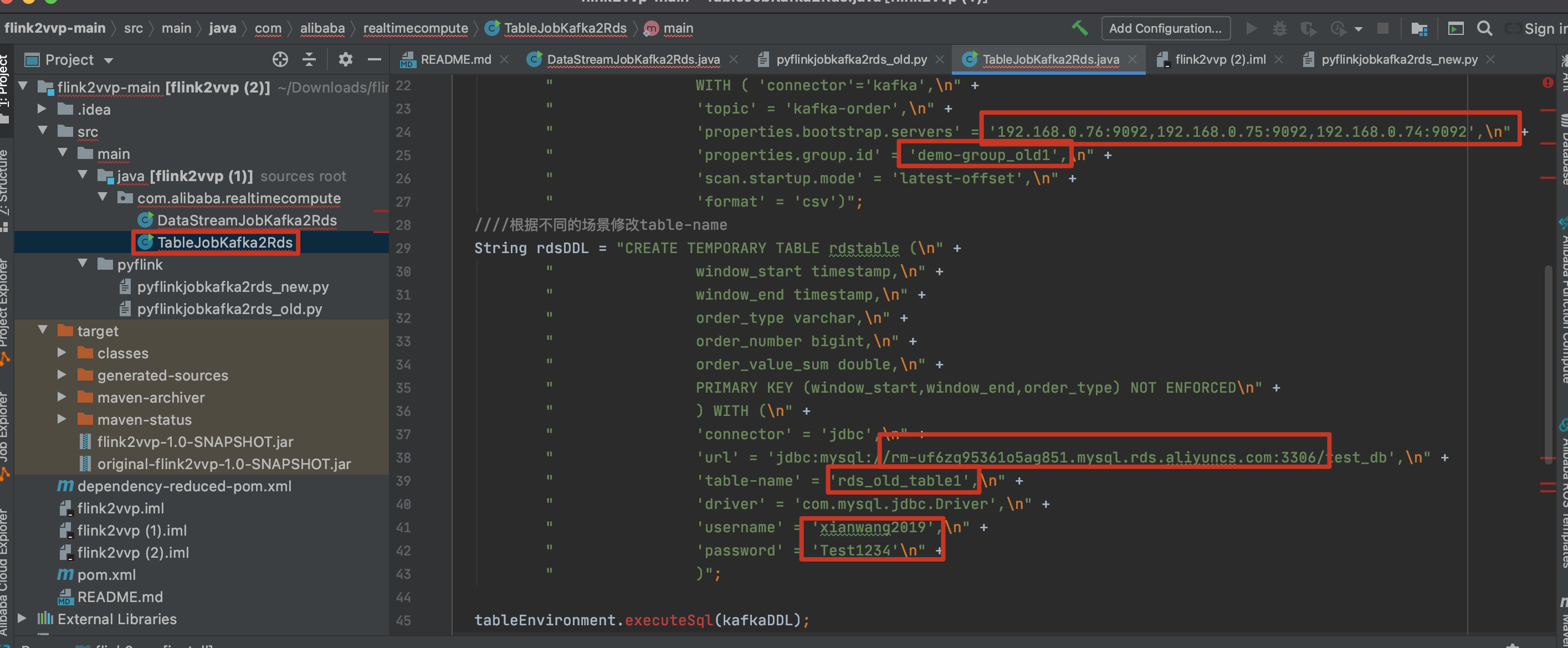
调整kafka和RDS的连接信息(注意kafka消费组保持唯一)。
调整pom文件中的依赖。

使用mvn clean package构建Jar包(如果没有mvn命令请先安装)。

构建成功后可以在target目录下找到相应的jar包。

拷贝jar包到自建flink集群。
scp {jar包路径} root@{自建flink master ip}:/

登录集群,使用flink run命令运行flink作业。
cd /
flink run -d -t yarn-per-job -p 2 -ynm 'tablejobkafka2rds' -yjm 1024m -ytm 2048m -yD yarn.appmaster.vcores=1 -yD yarn.containers.vcores=1 -yD state.checkpoints.dir=hdfs:///flink/flink-checkpoints -yD execution.checkpointing.interval="180s" -c com.alibaba.realtimecompute.TableJobKafka2Rds ./flink2vvp-1.0-SNAPSHOT.jar
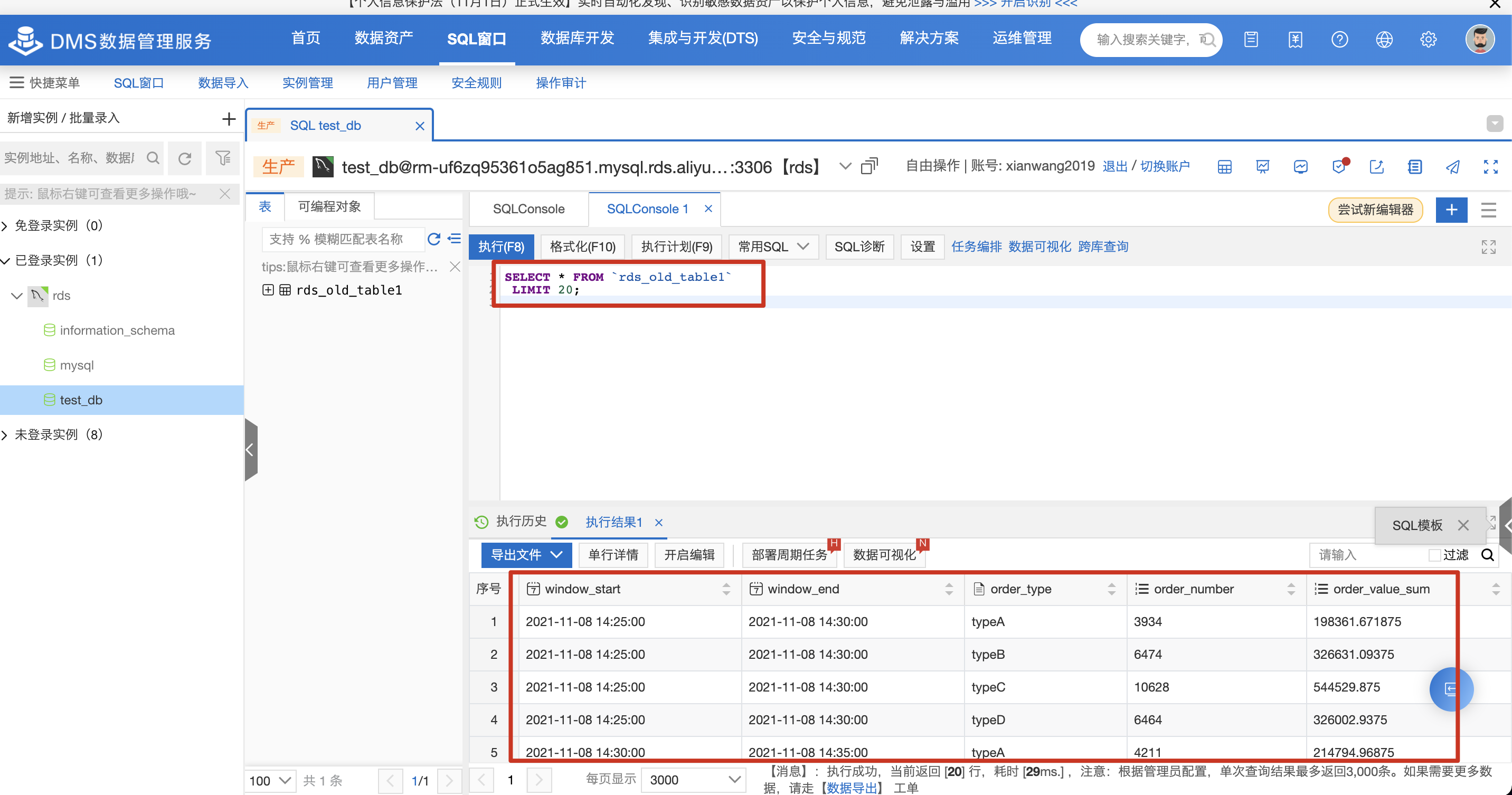
在DMS控制台查看写入RDS的结果,可见flink作业正常消费kafka数据成功写入RDS数据库。
1.2 Table作业迁移至SQL
在RDS控制台创建新表(rds_new_table1),对于DDL如下:
CREATE TABLE `rds_new_table1` (
`window_start` timestamp NOT NULL,
`window_end` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`order_type` varchar(8) NOT NULL,
`order_number` bigint NULL,
`order_value_sum` double NULL,
PRIMARY KEY ( `window_start`, `window_end`, `order_type` )
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;

在实时计算Flink控制台,填写作业名称,选择文件类型为流作业/SQL,新建作业。

根据业务逻辑及自建集群对应Table/SQL代码,修改为纯SQL代码,如下:
修改kafka连接地址,避免冲突使用新的kafka consumer group id(注意在kafka控制台新建消费组并名称保持一致),数据库连接信息等。
CREATE TEMPORARY TABLE kafkatable (
order_id varchar,
order_time timestamp (3),
order_type varchar,
order_value float,
WATERMARK FOR order_time AS order_time - INTERVAL '2' SECOND
)
WITH (
'connector' = 'kafka',
'topic' = 'kafka-order',
'properties.bootstrap.servers' = '192.168.0.76:9092,192.168.0.75:9092,192.168.0.74:9092',
'properties.group.id' = 'demo-group_new1',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
CREATE TEMPORARY TABLE rdstable (
window_start timestamp,
window_end timestamp,
order_type varchar,
order_number bigint,
order_value_sum double,
PRIMARY KEY (window_start, window_end, order_type) NOT ENFORCED
)
WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://rm-uf6zq95361o5ag851.mysql.rds.aliyuncs.com:3306/test_db',
'table-name' = 'rds_new_table1',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'xianwang2019',
'password' = 'Test1234'
);
INSERT INTO rdstable
SELECT TUMBLE_START (order_time, INTERVAL '5' MINUTE) as window_start,
TUMBLE_END (order_time, INTERVAL '5' MINUTE) as window_end,
order_type,
COUNT (1) as order_number,
SUM (order_value) as order_value_sum
FROM
kafkatable
GROUP BY TUMBLE (order_time, INTERVAL '5' MINUTE), order_type;
由于使用了 JDBC connector,需要通过“高级配置”-“附加依赖文件” 增加“mysql-connector-java-8.0.27.jar”和“flink-connector-jdbc_2.11-1.13.0.jar”(可通过https://search.maven.org/ 页面下载),注意请将依赖文件的版本与 Flink 集群的“引擎版本”保持一致。

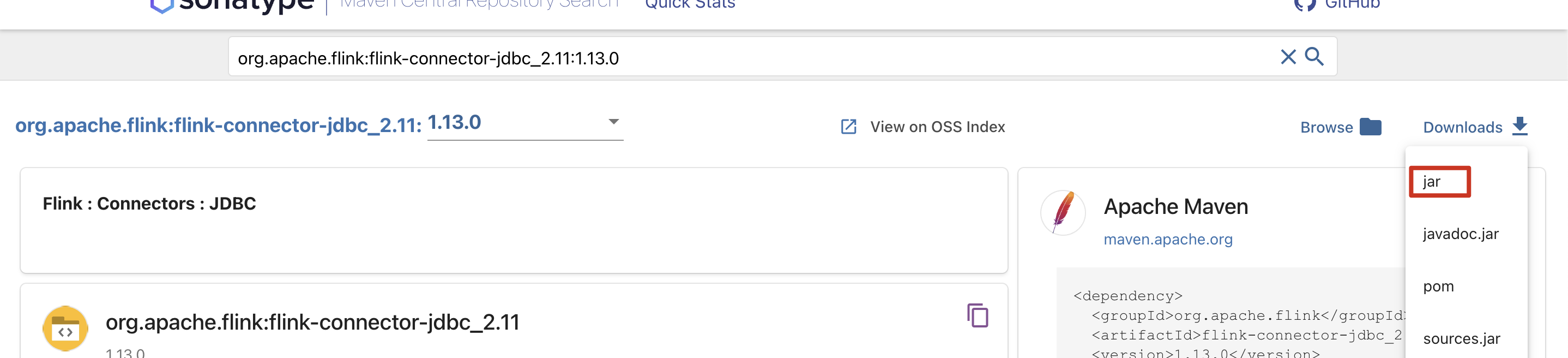
上传刚下载的2个jar包。
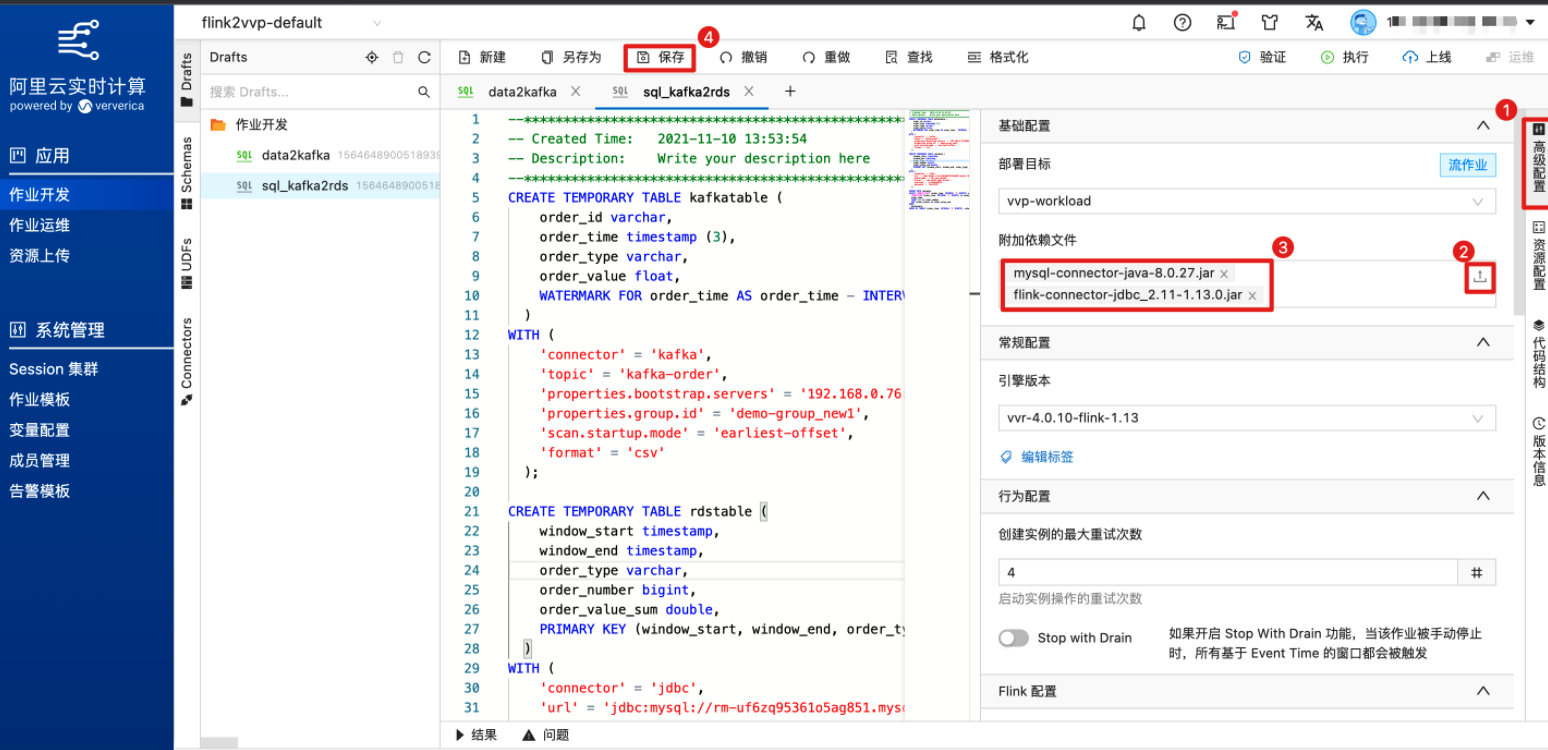
(可选)通过“资源配置”配置作业的资源,本示例参考自建 Flink 集群作业运行命令设置作业并发度为2。
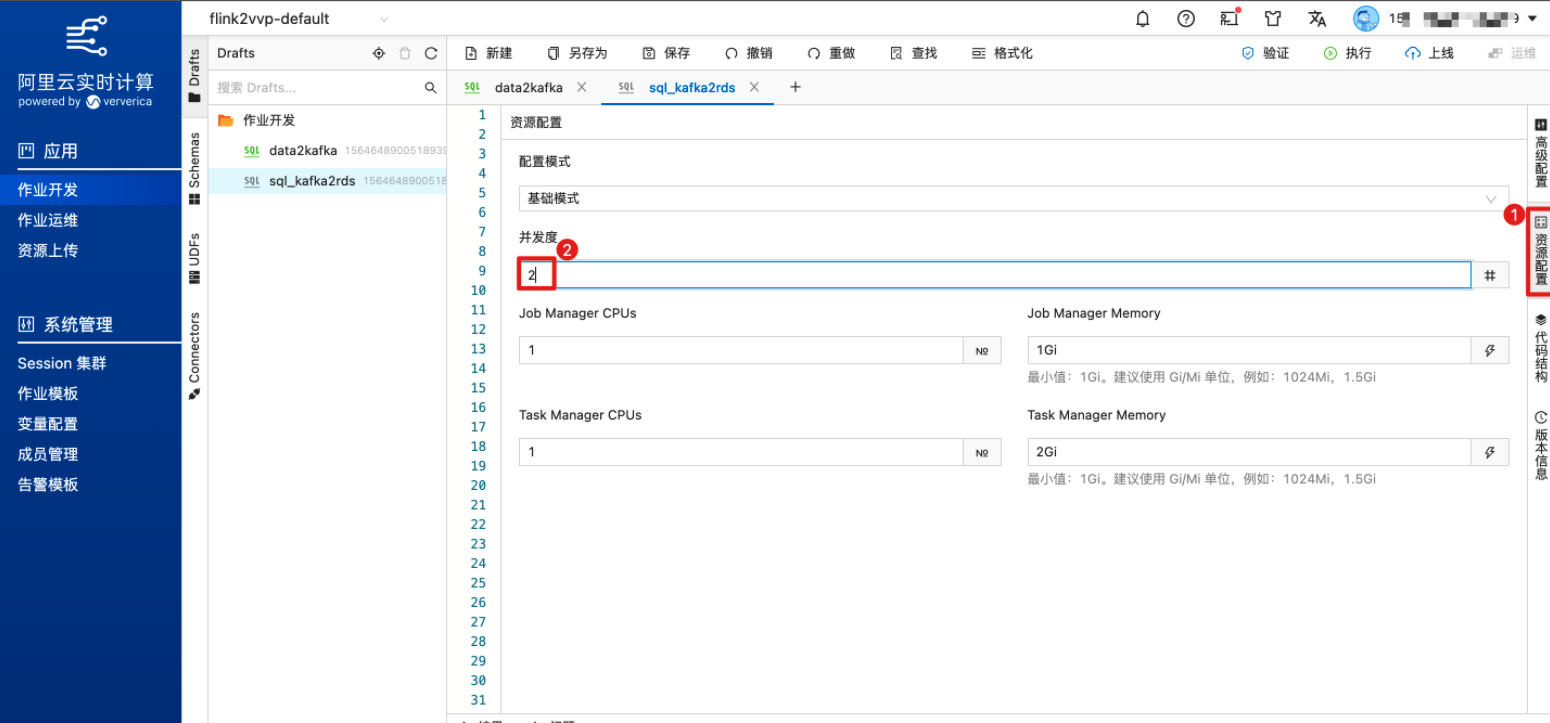
(可选)可以点击右上角“验证”对SQL 代码进行语法检查,也可以通过“执行”对作业进行本地调试。
点击右上角“上线”,将作业提交至集群。
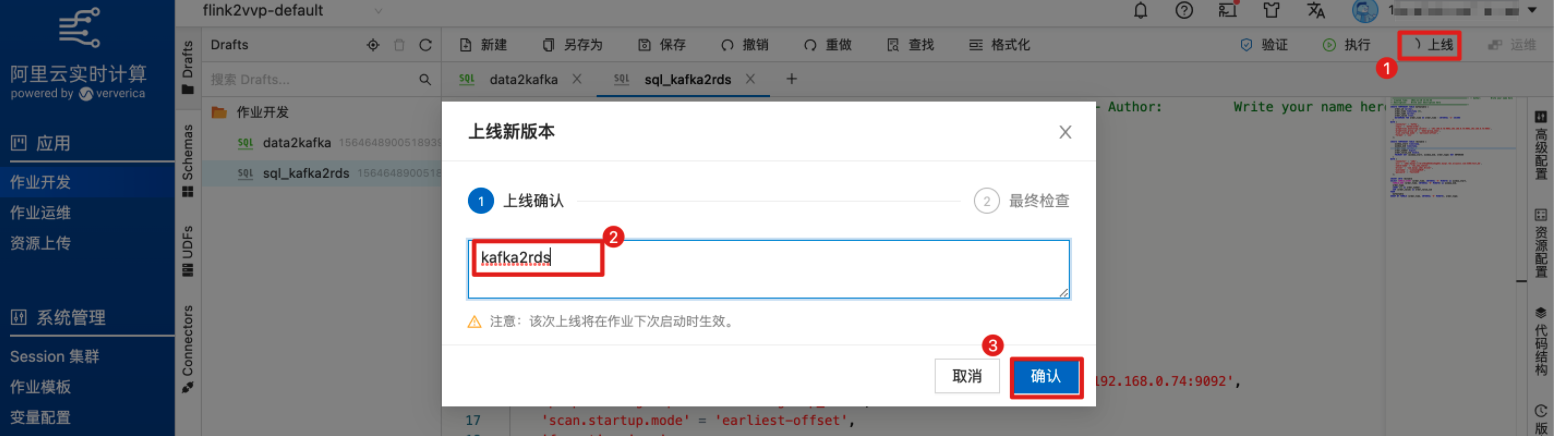
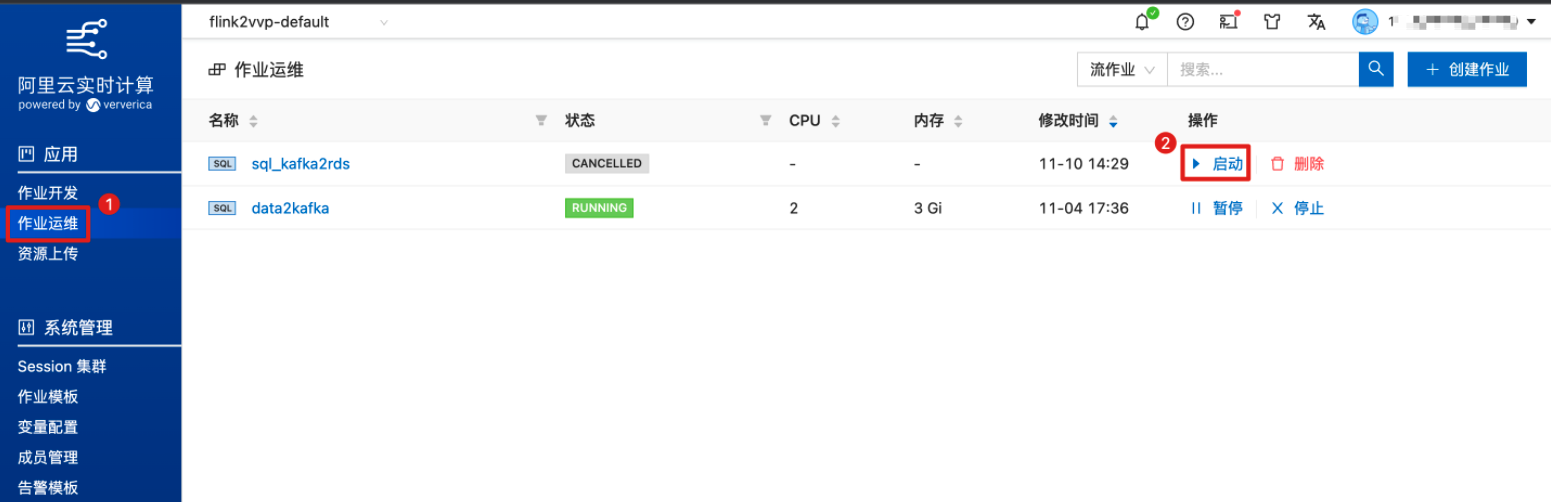
在作业运维中启动作业。

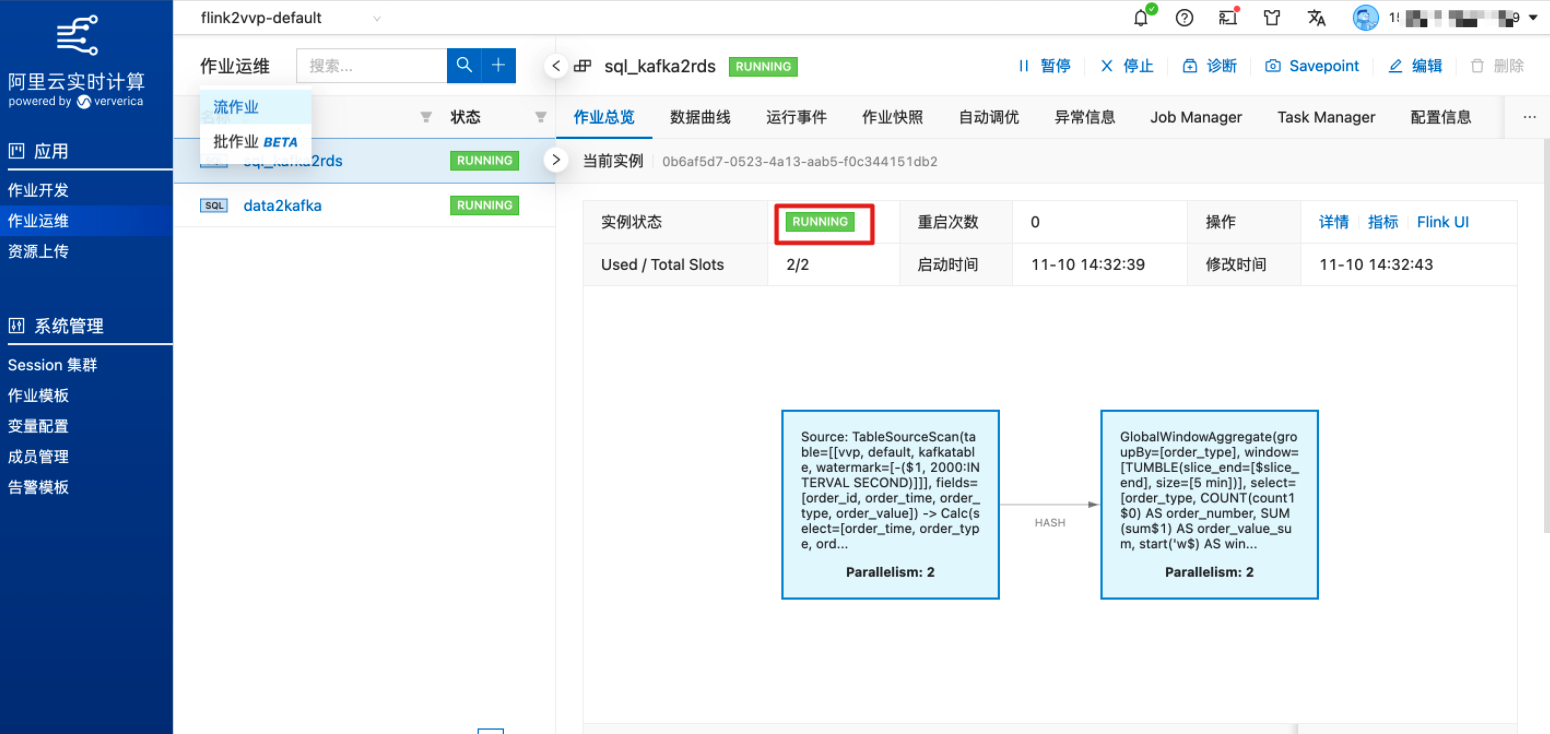
待作业状态从“TRANSITIONING”变为“RUNNING”,表示作业已正常运行

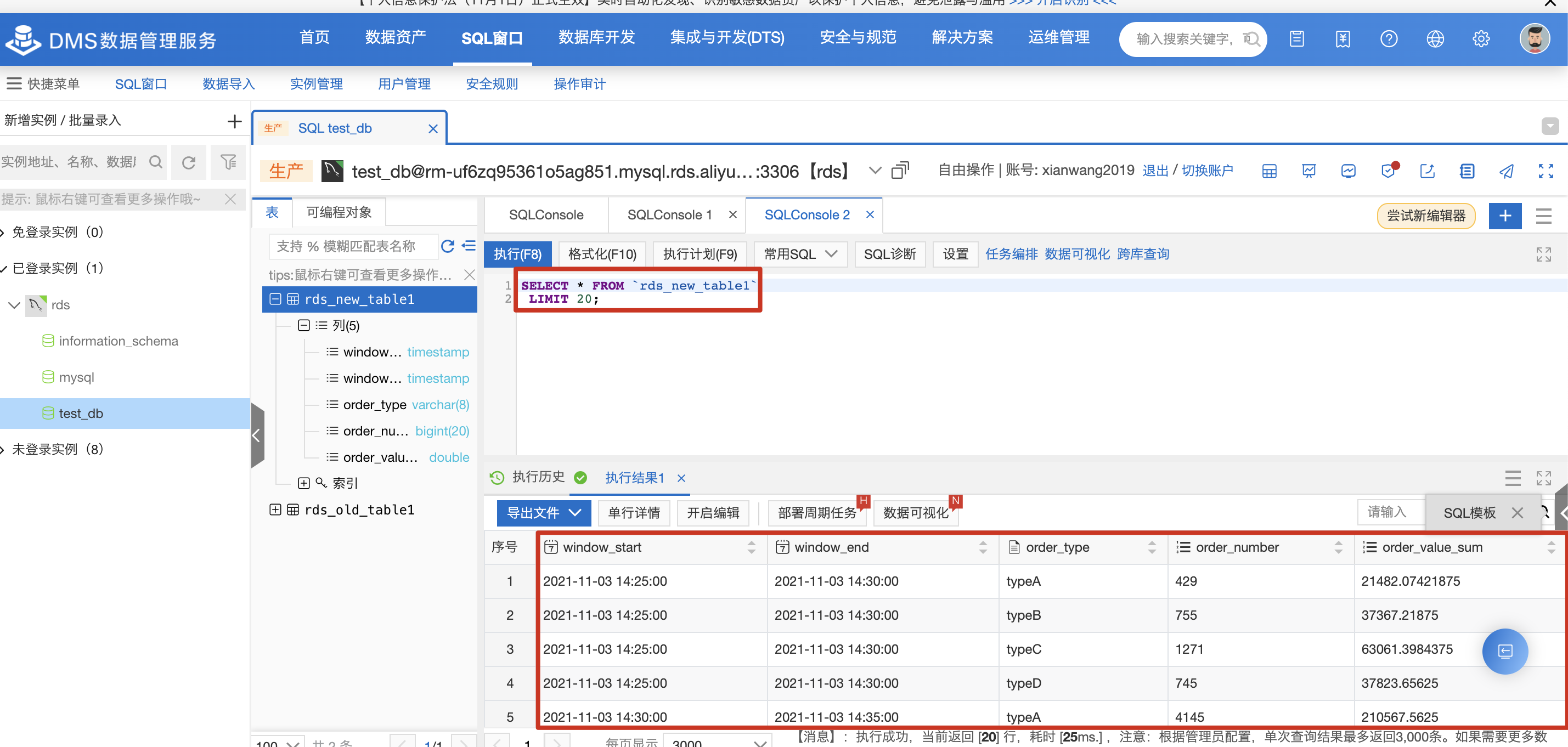
5分钟后即可到 RDS 上查询对应的计算结果(假定上游 Kafka 有持续的流数据)。
以上的方式使用的是开源 jdbc connector 写阿里云RDS,因此在上述步骤5中需要额外增加“附加依赖文件”,实时计算Flink全托管版集群内置提供了商业化的 RDS connector,用户也可替换开源 jdbc connector,具体可参考产品官网文档。
2. Datastream JAR迁移
场景说明:

本场景将自建 Flink 集群上的 Datastream JAR作业,迁移至实时计算Flink全托管的 JAR 作业类型中。 自建 Flink 集群上提交作业的命令如下:
自建 Flink 集群上提交作业的命令如下:
flink run -d -t yarn-per-job -p 2 -ynm 'datastreamjobkafka2rds_old' -yjm 1024m -ytm 2048m -yD yarn.appmaster.vcores=1 -yD yarn.containers.vcores=1 -yD state.checkpoints.dir=hdfs:///flink/flink-checkpoints -yD execution.checkpointing.interval="180s" -c com.alibaba.realtimecompute.DataStreamJobKafka2Rds ./flink2vvp-1.0-SNAPSHOT.jar2.1 构建自建集群测试作业
登录RDS数据库创建自建集群的sink表(rds_old_table2)。
CREATE TABLE `rds_old_table2` (
`window_start` timestamp NOT NULL,
`window_end` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`order_type` varchar(8) NOT NULL,
`order_number` bigint NULL,
`order_value_sum` double NULL,
PRIMARY KEY ( `window_start`, `window_end`, `order_type` )
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;
调整kafka和RDS的连接信息(注意kafka消费组保持唯一,并在kafka控制台创建)。

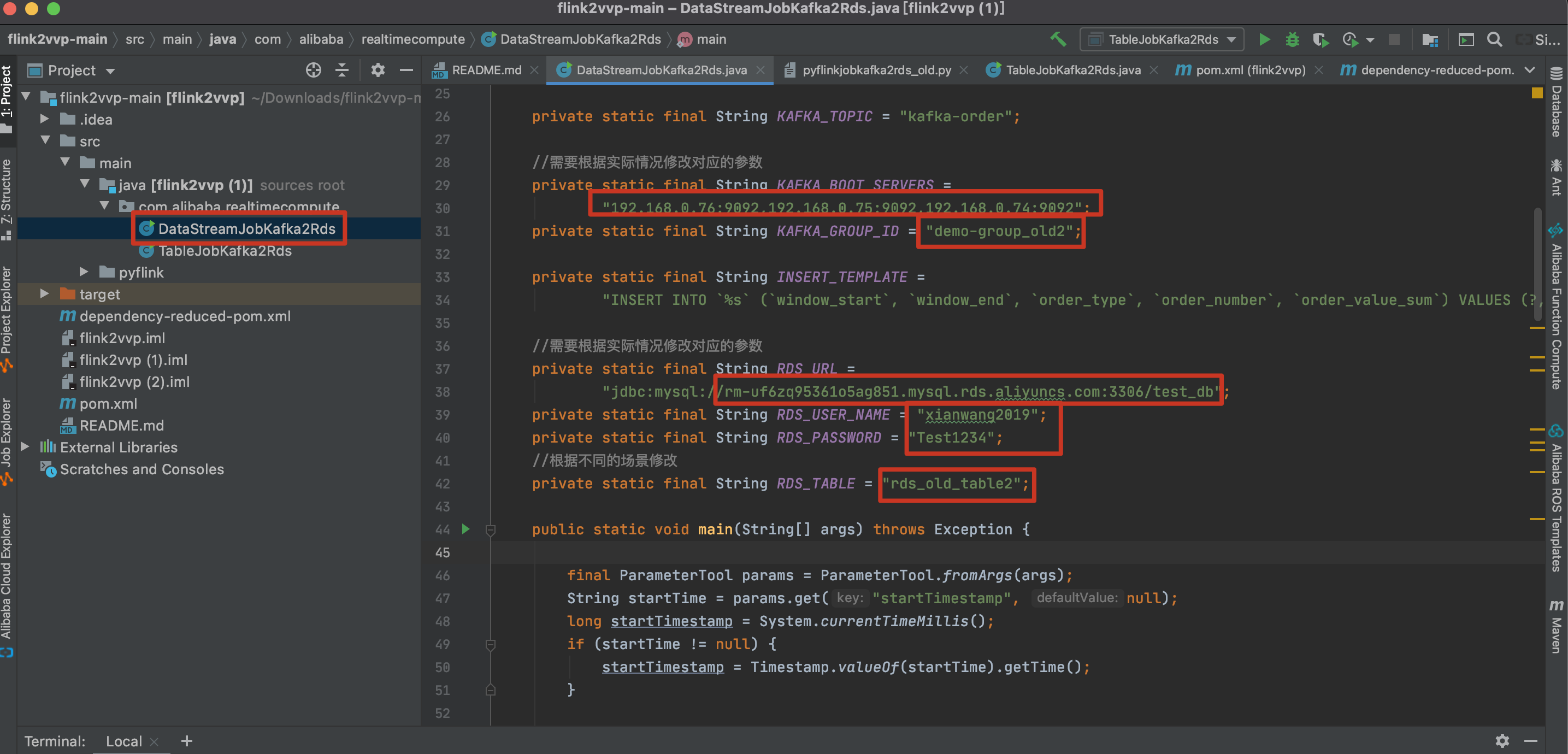
使用mvn clean package构建Jar包(如果没有mvn命令请先安装)。

构建成功后可以在target目录下找到相应的jar包。
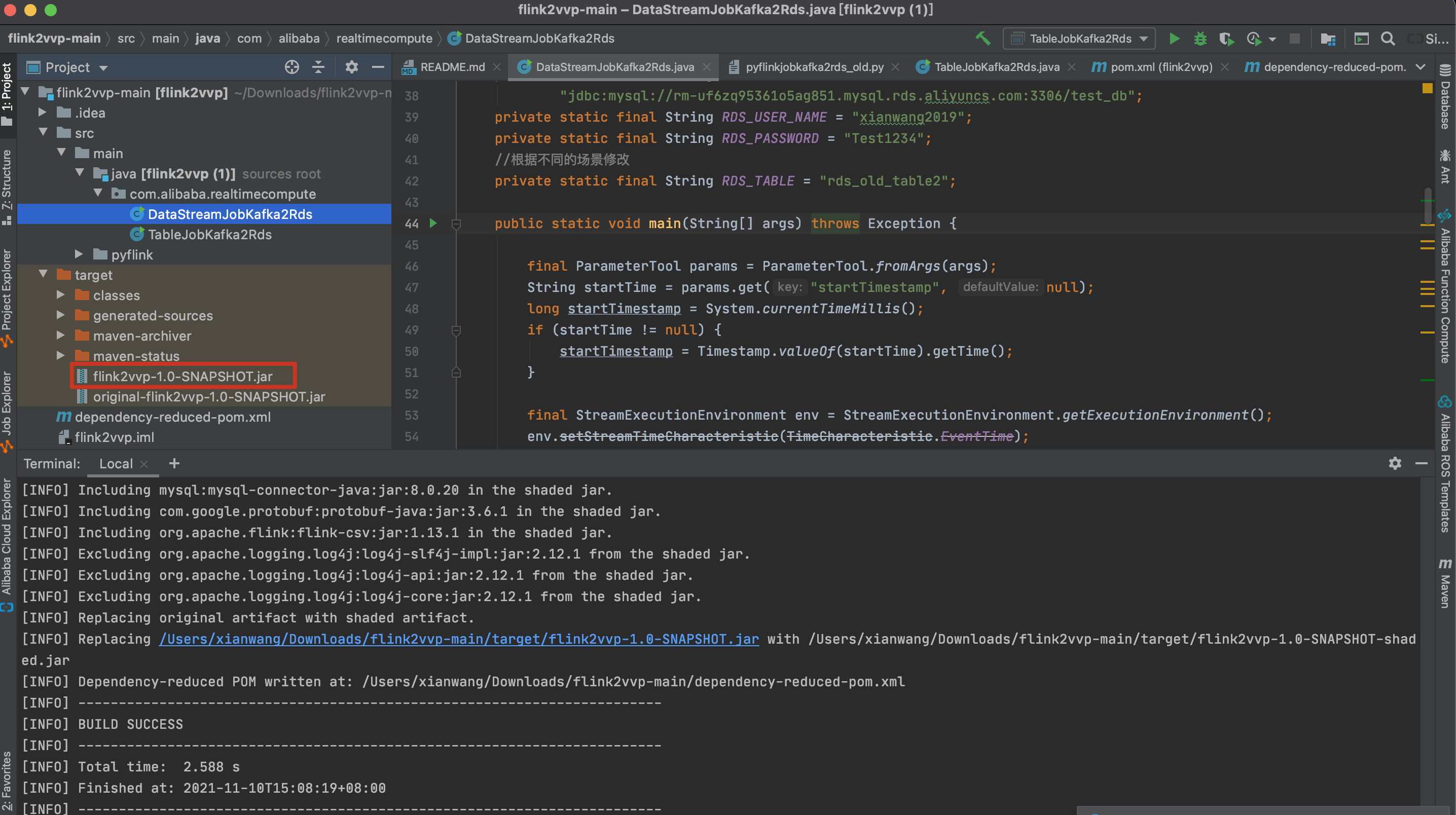
拷贝jar包到自建flink集群。
scp {jar包路径} root@{自建flink master ip}:/

登录集群,使用flink run命令运行flink作业。
cd /
flink run -d -t yarn-per-job -p 2 -ynm 'datastreamjobkafka2rds_old' -yjm 1024m -ytm 2048m -yD yarn.appmaster.vcores=1 -yD yarn.containers.vcores=1 -yD state.checkpoints.dir=hdfs:///flink/flink-checkpoints -yD execution.checkpointing.interval="180s" -c com.alibaba.realtimecompute.DataStreamJobKafka2Rds ./flink2vvp-1.0-SNAPSHOT.jar
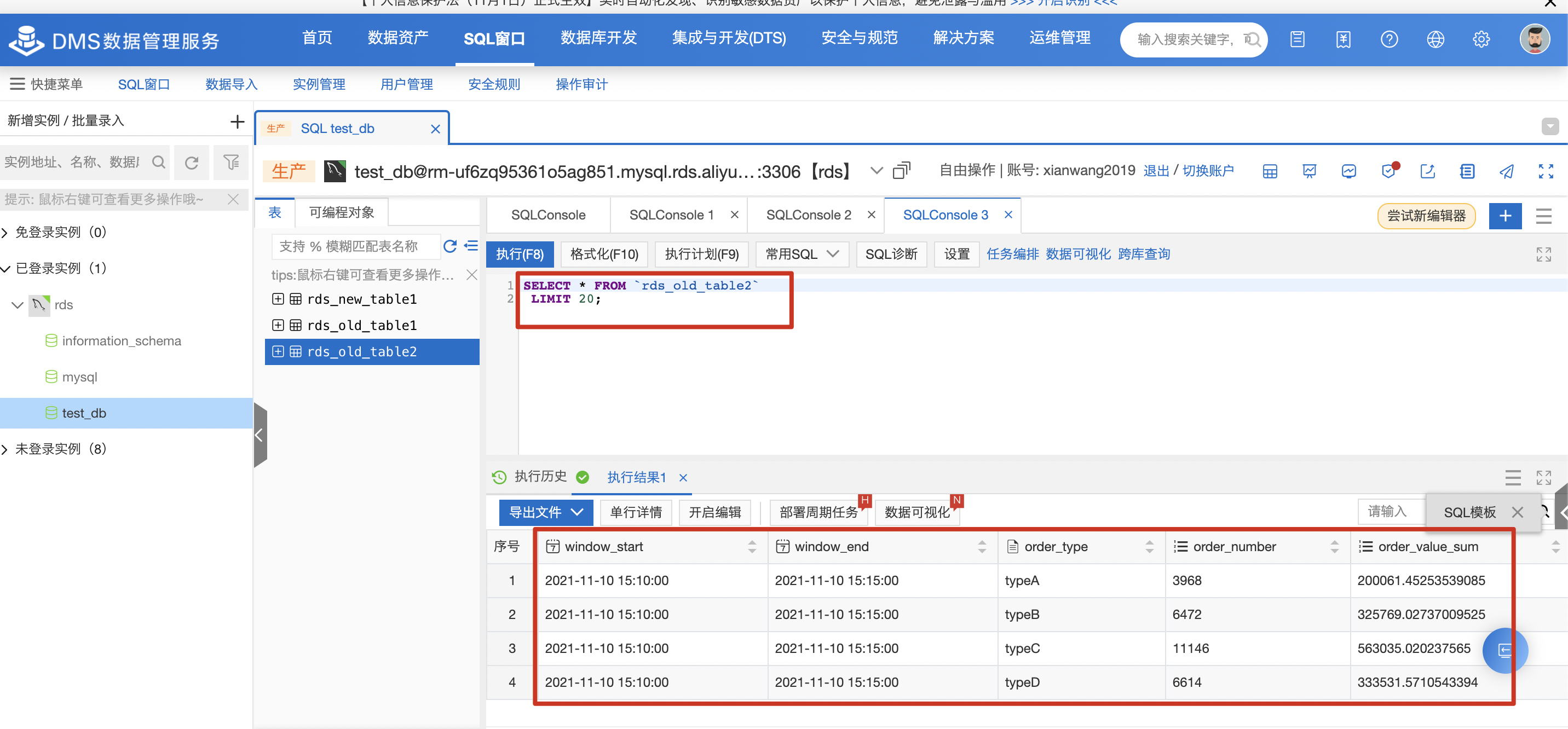
等待5分钟左右,在DMS控制台查看写入RDS的结果,可见flink作业正常消费kafka数据成功写入RDS数据库。
2.2 Datastream JAR迁移
在RDS控制台创建新表(rds_new_table2),对于DDL如下:
CREATE TABLE `rds_new_table2` (
`window_start` timestamp NOT NULL,
`window_end` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`order_type` varchar(8) NOT NULL,
`order_number` bigint NULL,
`order_value_sum` double NULL,
PRIMARY KEY ( `window_start`, `window_end`, `order_type` )
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;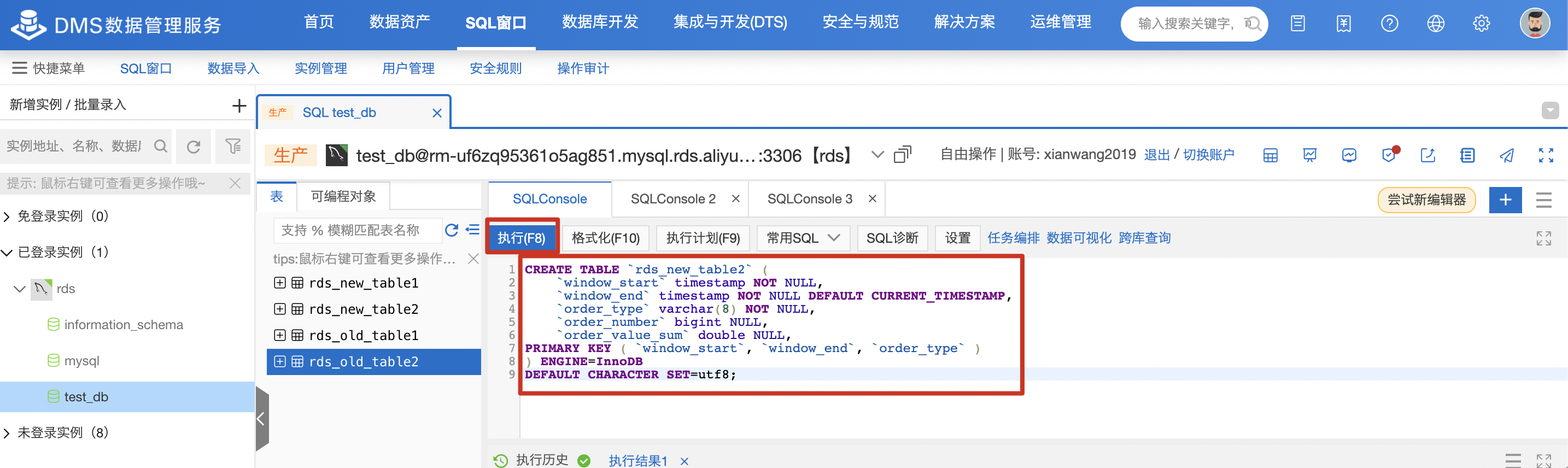
修改源代码中的结果表为rds_new_table2,避免冲突使用新的kafka consumer group id(注意在kafka控制台创建消费组)。
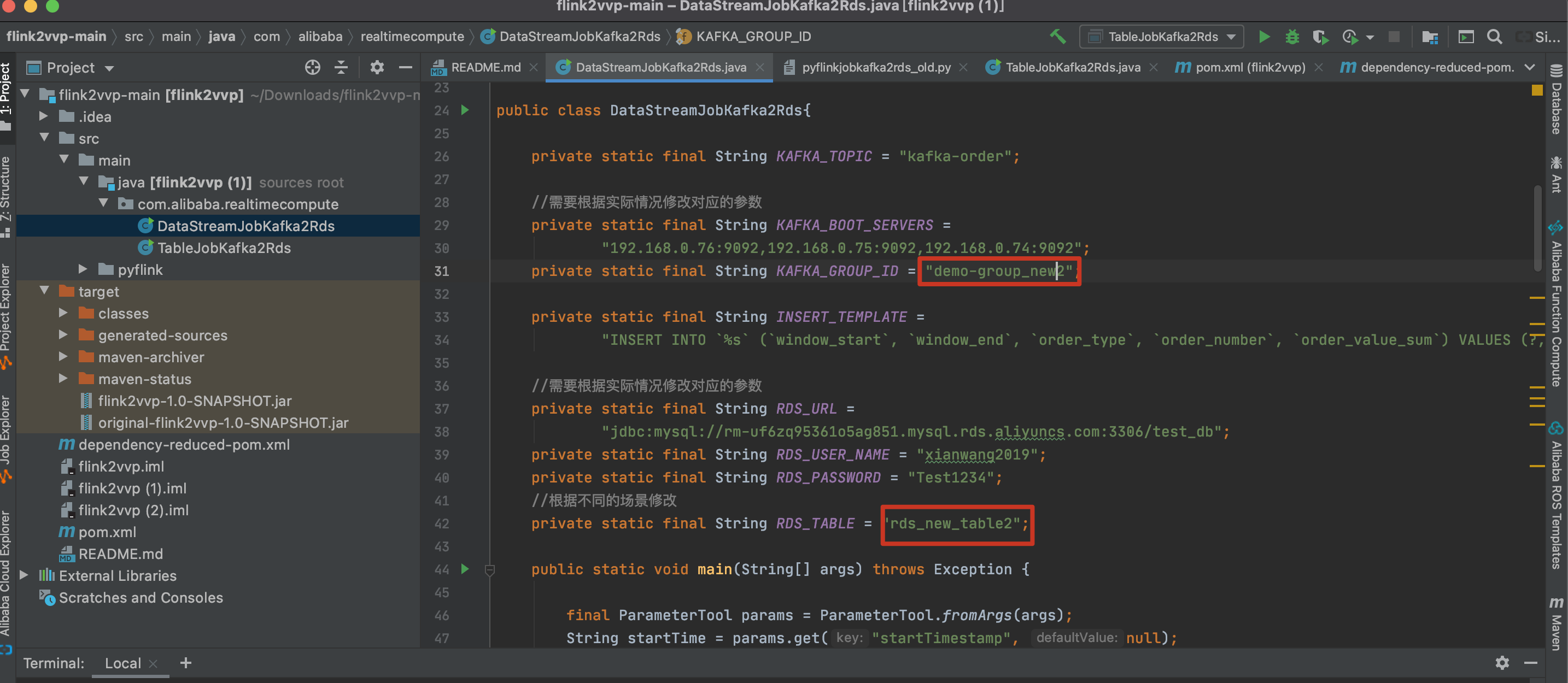
使用mvn clean package构建新Jar包。
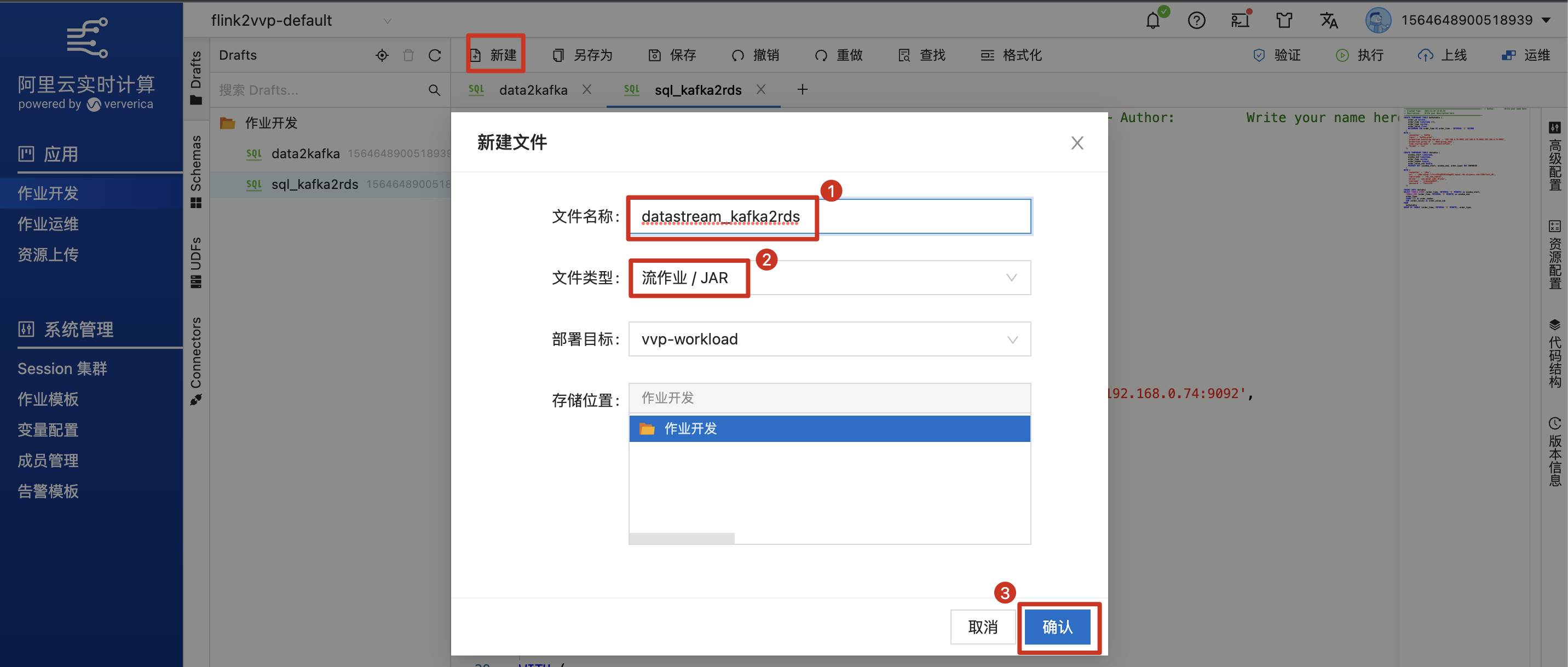
在实时计算Flink控制台,填写作业名称,选择文件类型为流作业/JAR,新建作业。
上传刚编译好的JAR包或者填写对应的 JAR URI,指定主类名“Entrypoint Class”和“Entrypoint main args”, 并根据自建集群作业的资源配置情况,设置“并发度”为2。
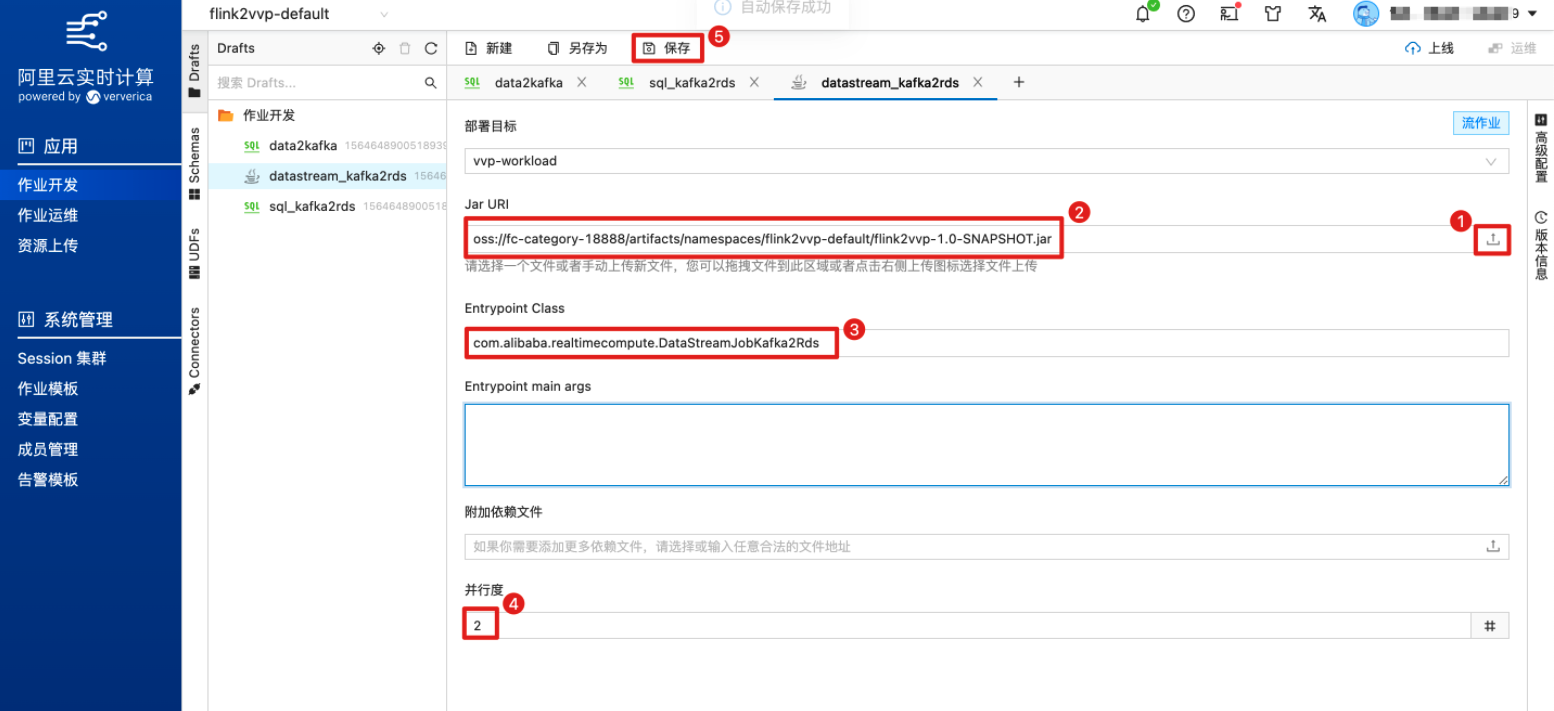
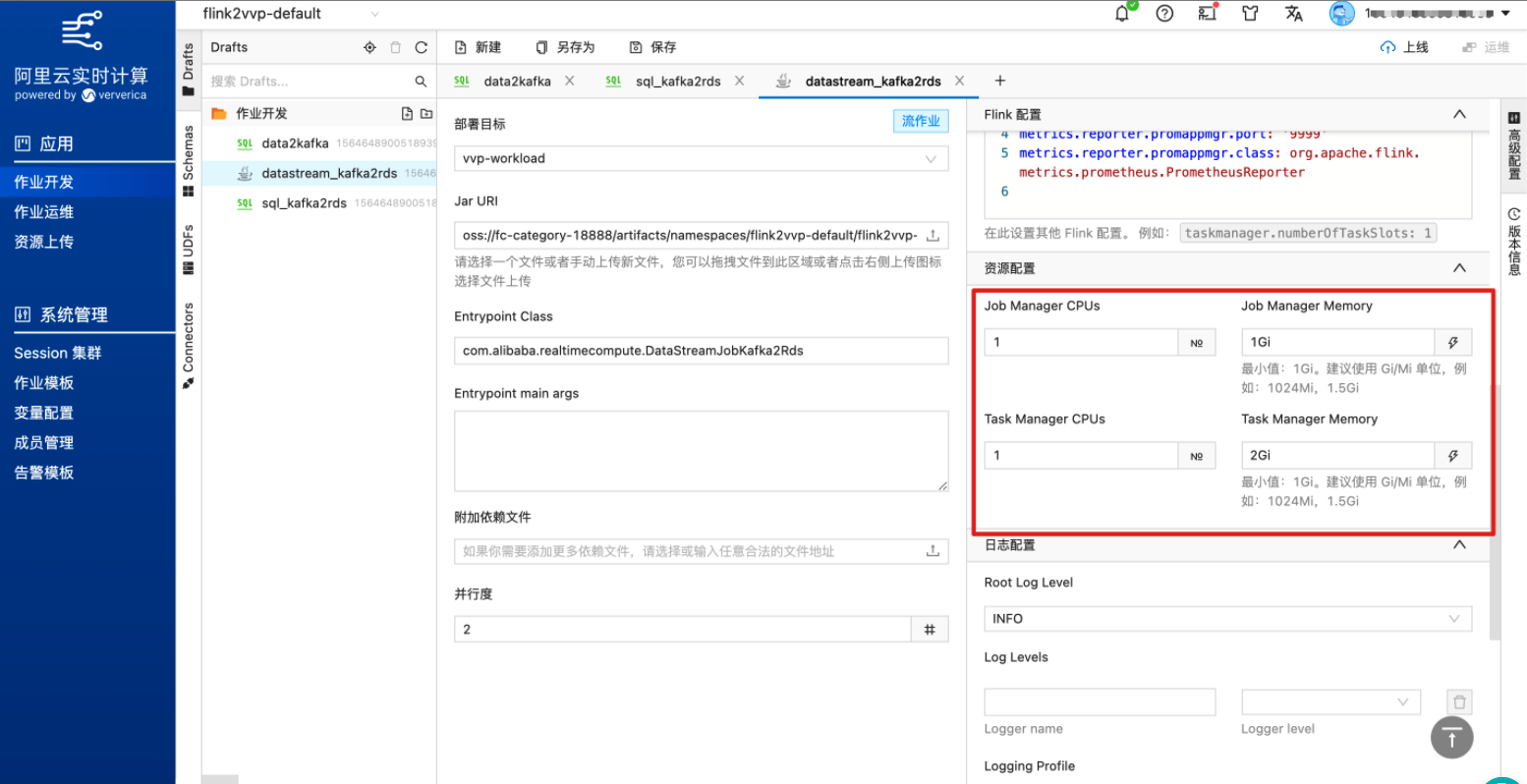
(可选)在“高级配置”页面配置 JM 和 TM 的资源量。
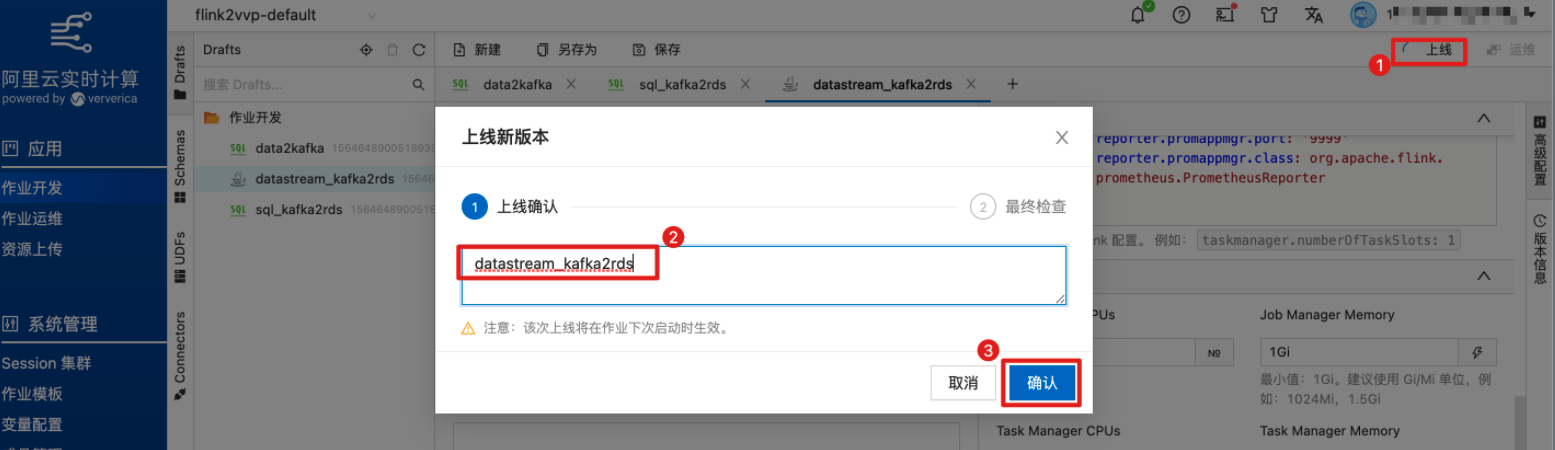
点击右上角“上线”,将作业提交至集群。
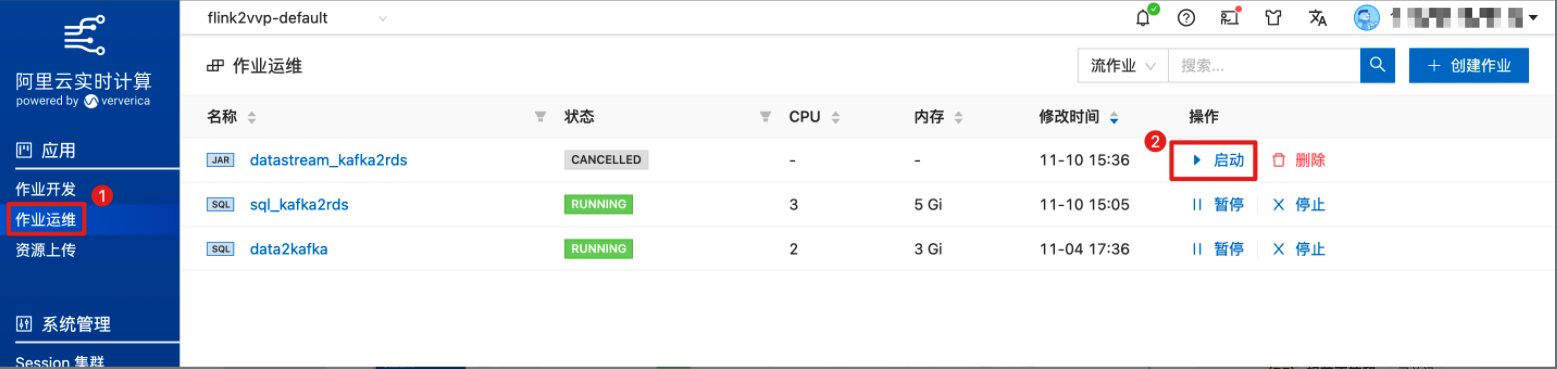
在作业运维中启动作业。
待作业状态从“TRANSITIONING”变为“RUNNING”,表示作业已正常运行

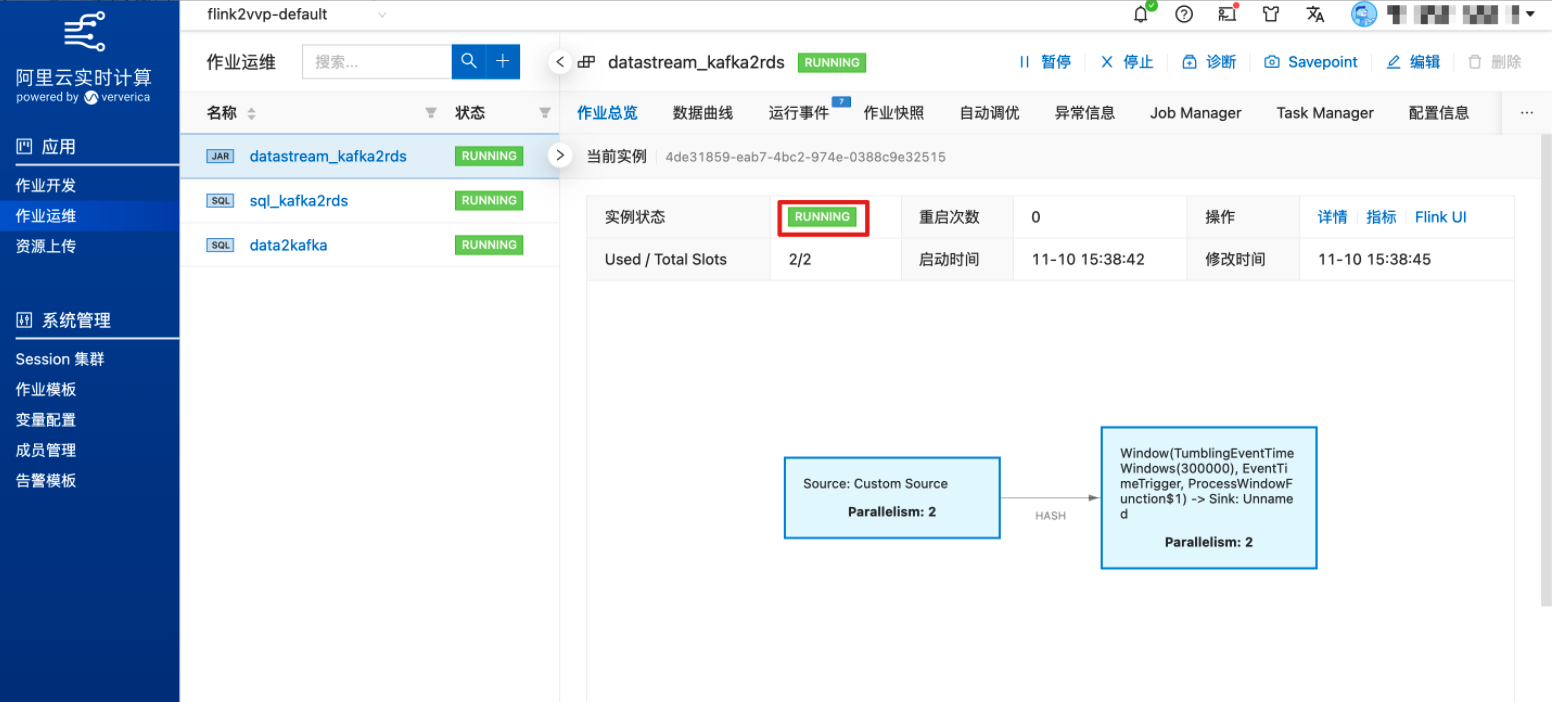
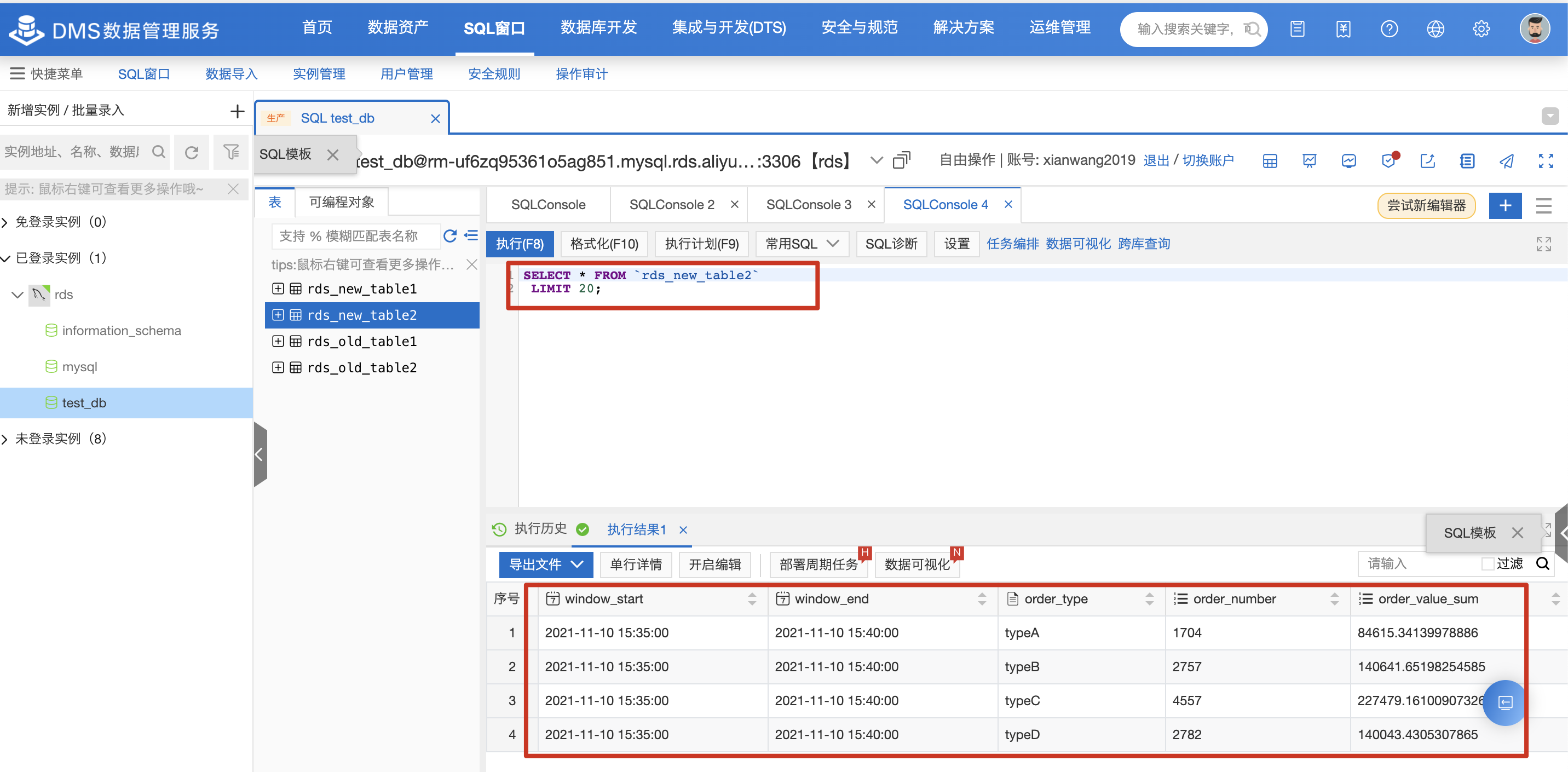
5分钟后即可到 RDS上查询对应的计算结果(假定上游 Kafka 有持续的流数据)。
3. Table/SQL JAR迁移
场景说明:

本场景将自建 Flink 集群上的 Table/SQL JAR 作业,迁移至实时计算Flink全托管的JAR作业。
自建 Flink 集群上提交作业的命令如下:
flink run -d -t yarn-per-job -p 2 -ynm 'tablejobkafka2rds' -yjm 1024m -ytm 2048m -yD yarn.appmaster.vcores=1 -yD yarn.containers.vcores=1 -yD state.checkpoints.dir=hdfs:///flink/flink-checkpoints -yD execution.checkpointing.interval="180s" -c com.alibaba.realtimecompute.TableJobKafka2Rds ./flink2vvp-1.0-SNAPSHOT.jar 由于作业类型未发生变化,原则上不需要对代码进行相应的修改,但需要将原有的 RDS sink 表名“rds_ old_table1”替换为“rds_new_table3”,并重新编译打包。
3.1 构建自建集群测试作业
说明:本场景无需重新构建自建集群的作业,同场景一作业。
3.2 Table作业迁移
在RDS控制台创建新表(rds_new_table3),对于DDL如下:
CREATE TABLE `rds_new_table3` (
`window_start` timestamp NOT NULL,
`window_end` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`order_type` varchar(8) NOT NULL,
`order_number` bigint NULL,
`order_value_sum` double NULL,
PRIMARY KEY ( `window_start`, `window_end`, `order_type` )
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;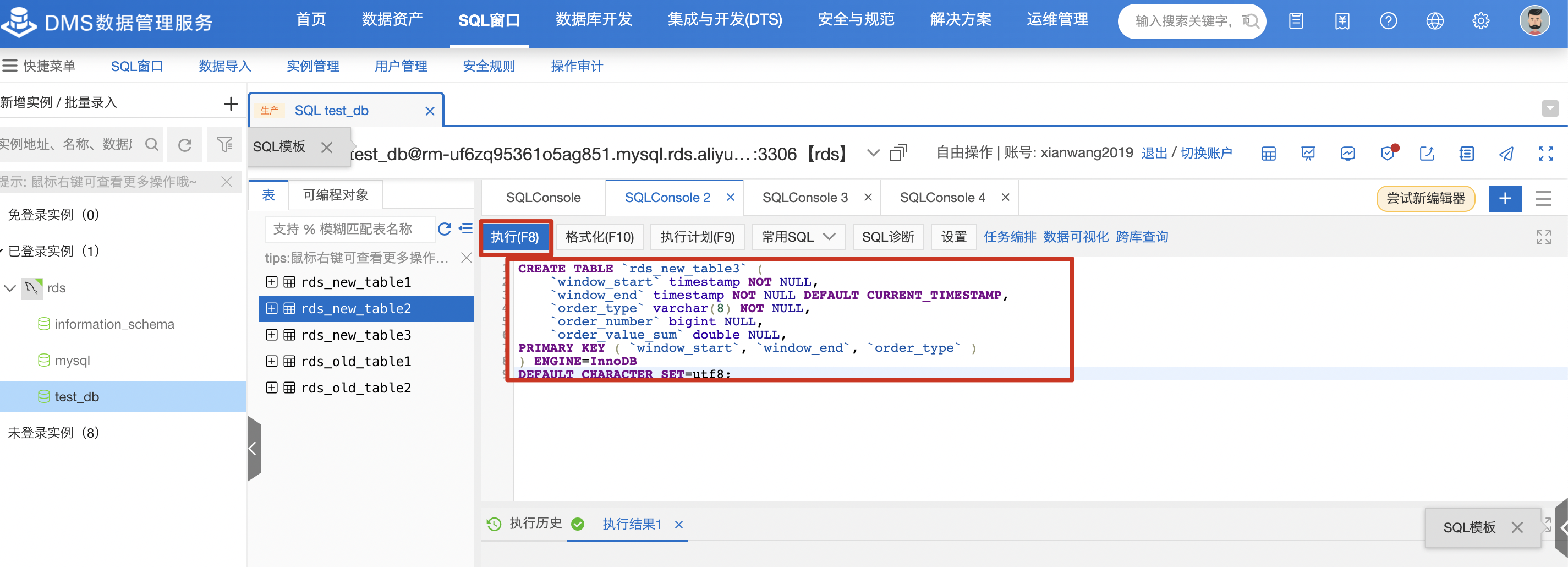
修改源代码中的结果表为rds_new_table3,避免冲突使用新的kafka consumer group id(注意在kafka控制台创建消费组)。

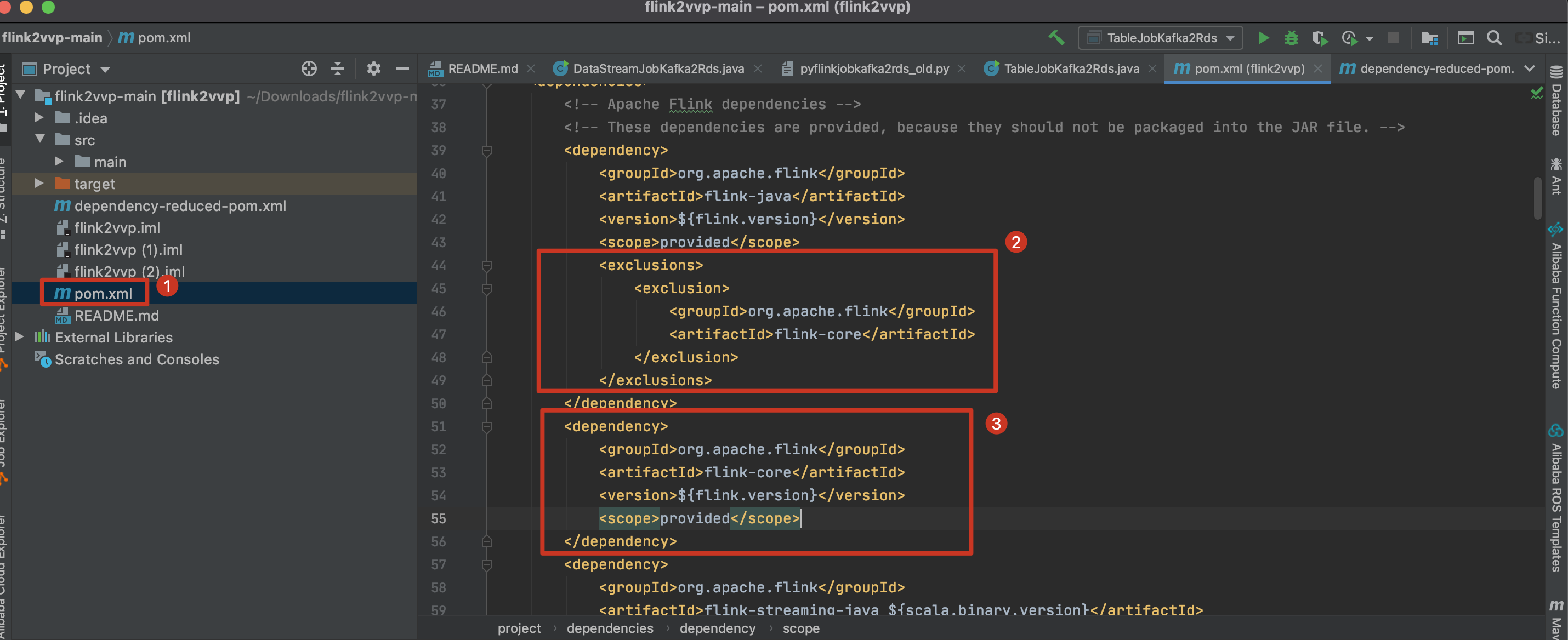
在pom中移除2.1.1步骤3添加的依赖,参考如下。
新:

旧:
使用mvn clean package构建新Jar包。
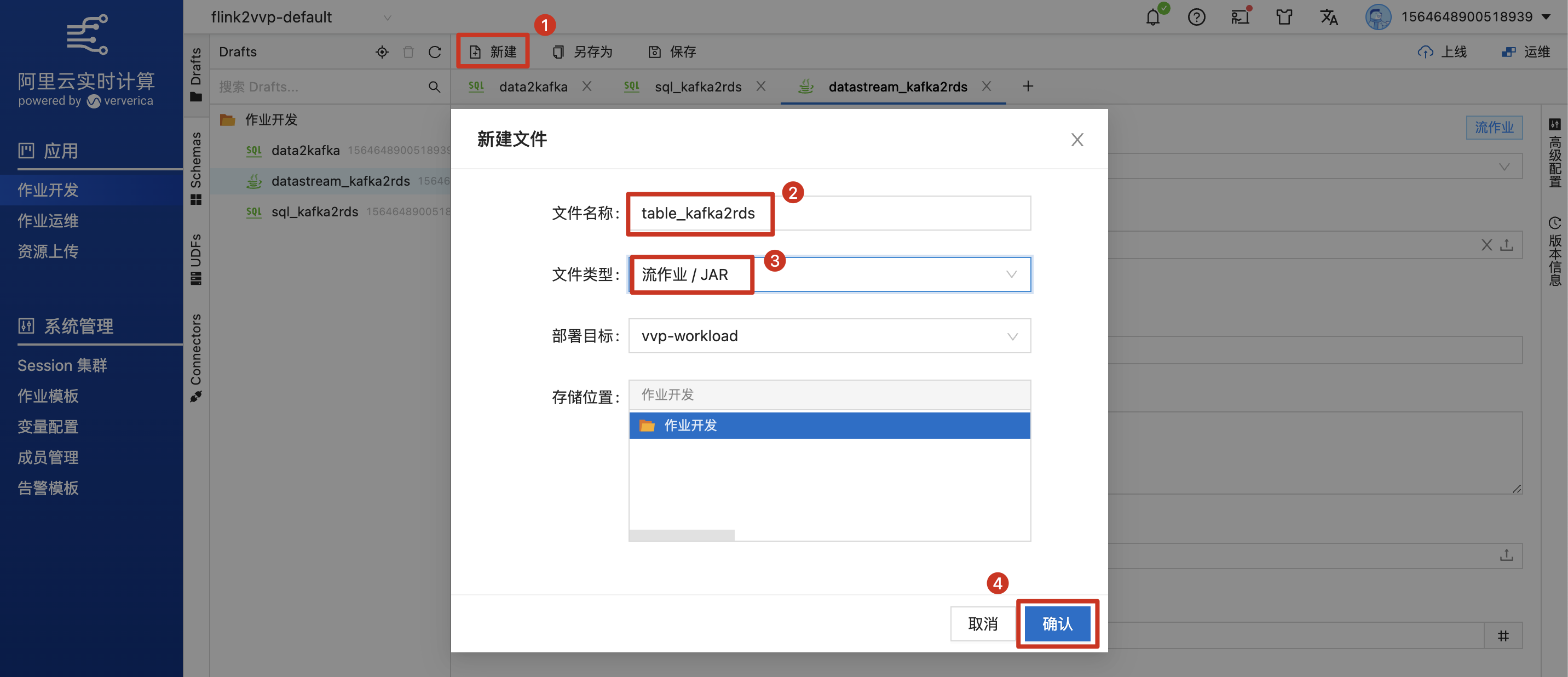
在实时计算Flink控制台,填写作业名称,选择文件类型为流作业/JAR,新建作业。
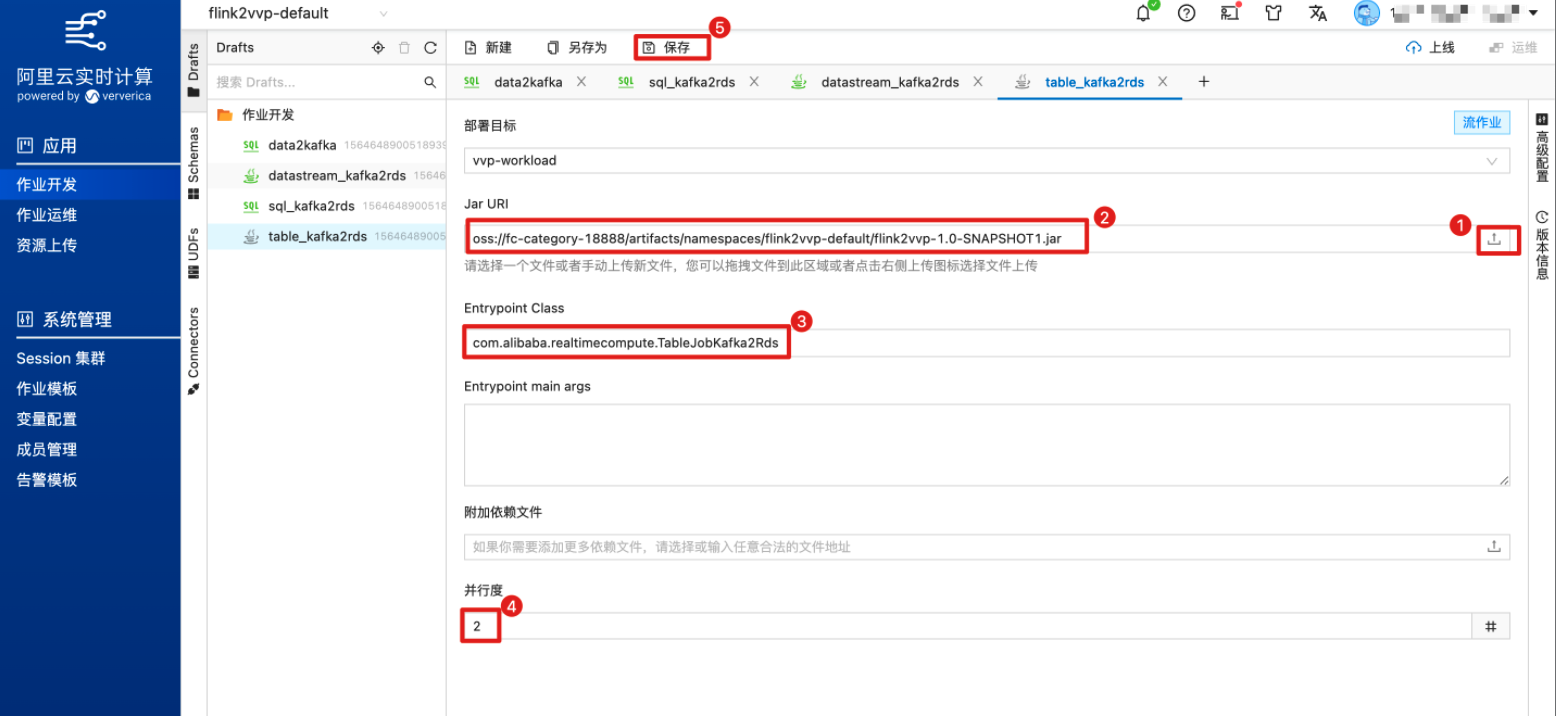
上传刚编译好的JAR包或者填写对应的 JAR URI,指定主类名“Entrypoint Class”和“Entrypoint main args”, 并根据自建集群作业的资源配置情况,设置“并发度”为2。
为了不影响之前作业运行,这里对新打的jar包进行了更名后上传。
(可选)在“高级配置”页面配置 JM 和 TM 的资源量。
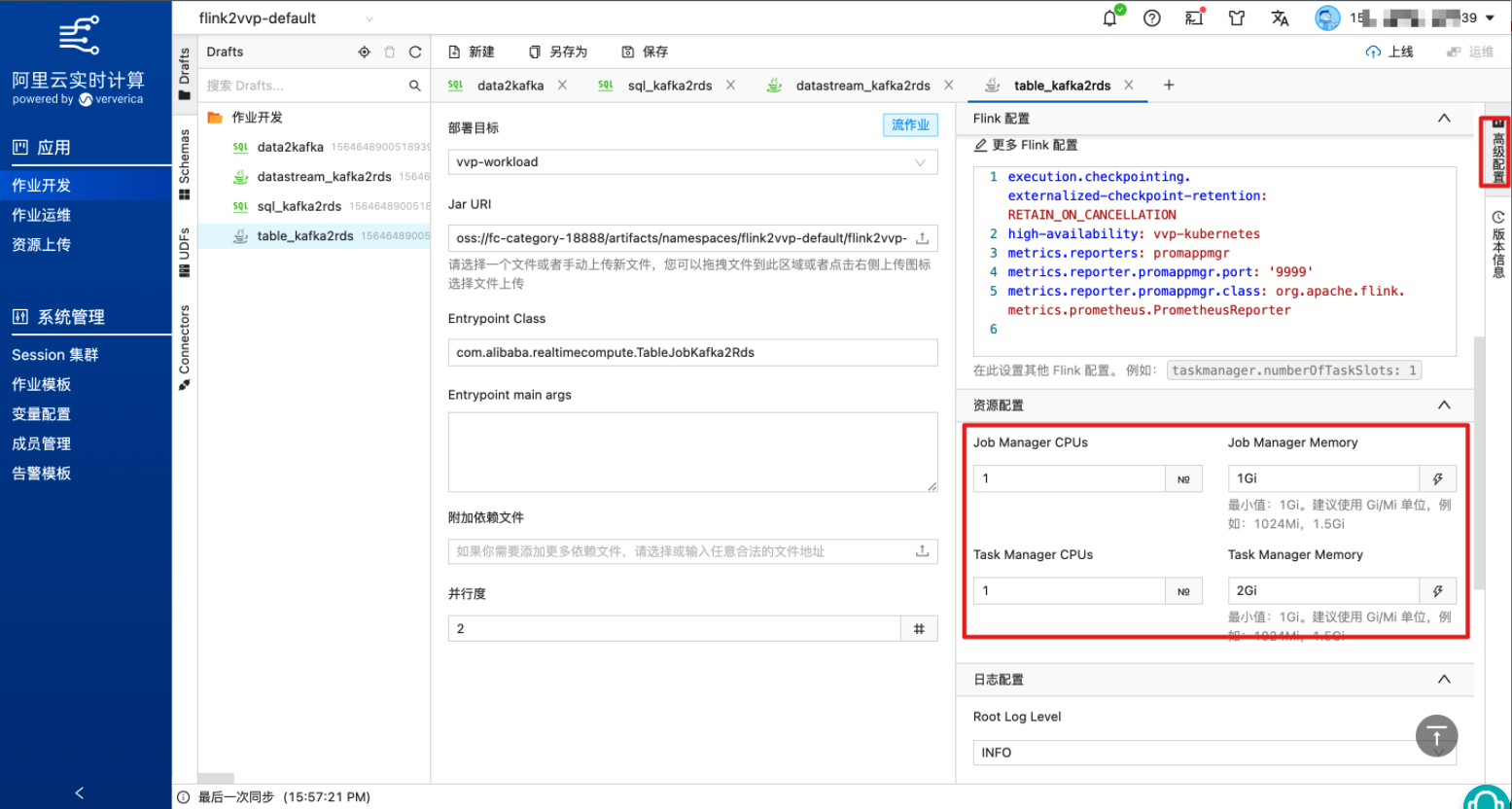
点击右上角“上线”,将作业提交至集群。
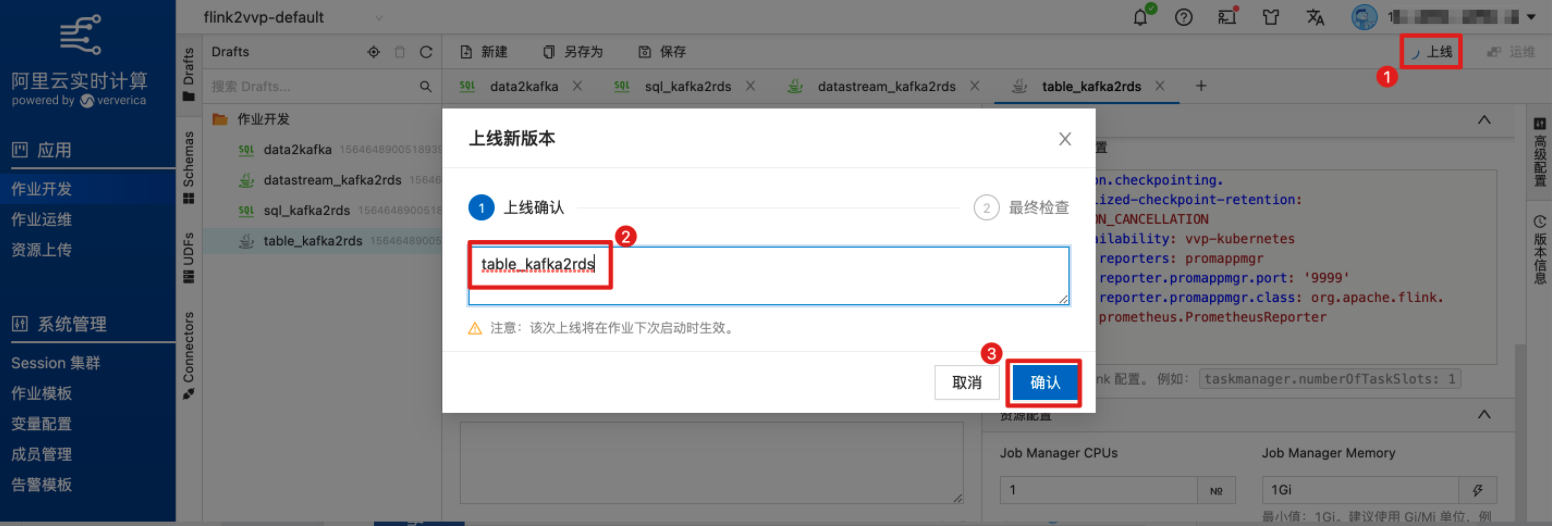
在作业运维中启动作业。
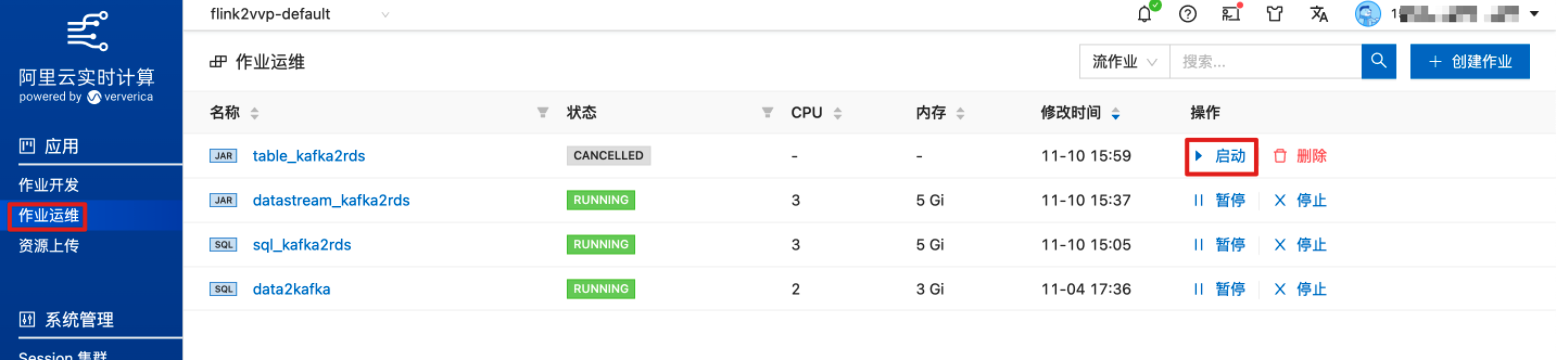
待作业状态从“TRANSITIONING”变为“RUNNING”,表示作业已正常运行

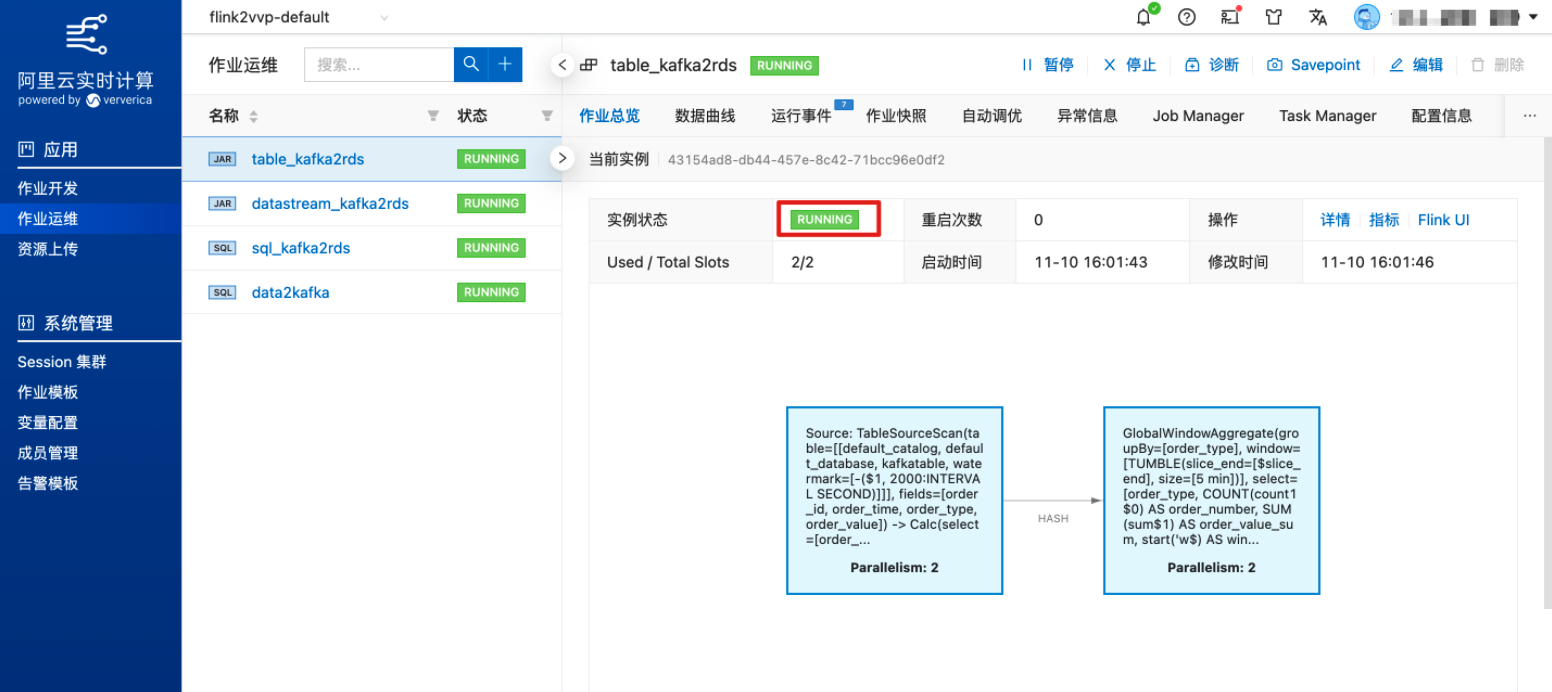
5分钟后即可到 RDS 上查询对应的计算结果(假定上游 Kafka 有持续的流数据)。
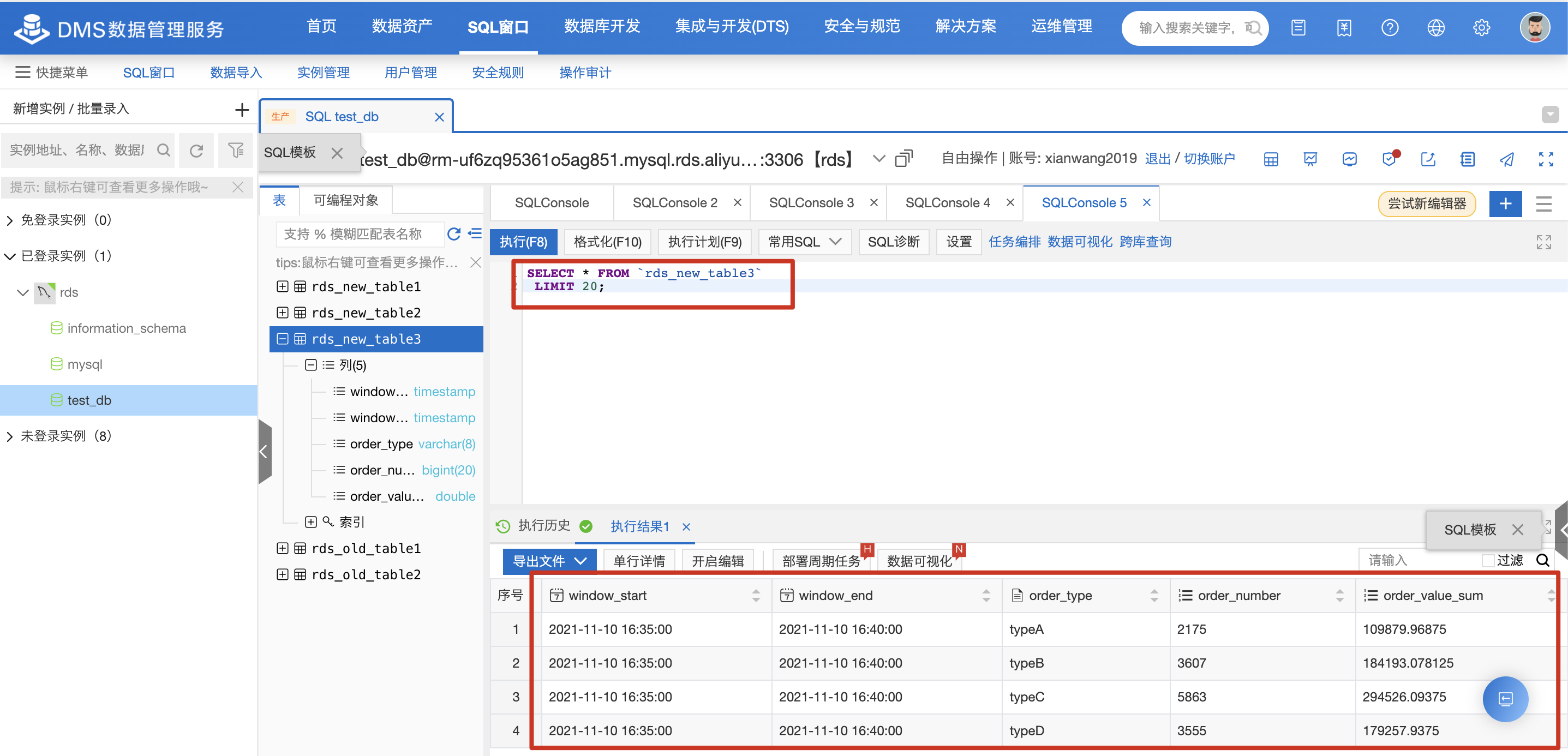
附录
1. 数据正确性验证
数据质量是实时计算数据产出对业务的重要保障,和实时计算任务日常变更一样,迁移工作也需要对新任务产出的数据质量进行验证。
如前文所述一般建议采用迁移新任务和原有任务两条链路并行双跑、对新旧链路产出的数据进行对比验证方式的,在新链路运行一段时间,满足数据对比条件后,验证新任务和原有任务的数据产出是否一致,达到预期的数据质量。理想情况下,迁移的新任务数据产出和原任务完全一致,那就无需额外的差异分析。
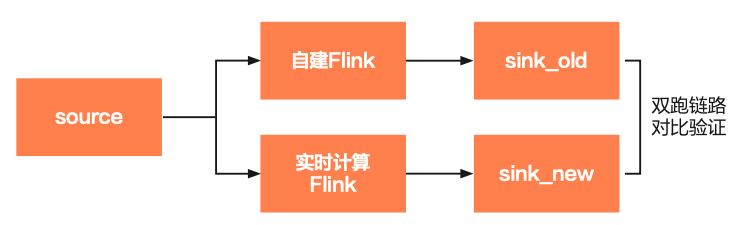
根据任务产出的生成周期特性和数据规模,以下对比方法可供参考(具体对比还需要结合业务的实 际情况进行:
1.1 数据生成的周期特性
实时任务7x24小时持续在运行,但很多情况下产出的数据还是具备时间周期特性的,这就给数据对比提供了可行性。比如聚合任务按小时、天维度计算的聚合值,清洗任务加工的按天分区表等,在数据对比时就可以根据对应的时间周期来进对比,比如小时周期的任务实际已完整处理多个小时数据 后,就可以对比处理过的小时数据,而天维度的聚合值,一般就需要等待新任务处理完完整的一天数据后才能对比。
1.2 数据规模
中小数据规模:建议进行全量数据对比,比如窗口聚合逻辑的数据,对每一个 key、每一个窗口的聚合结果进行一一对比,验证其正确性。
较大数据规模:如果全量对比的代价高、可行性低,可以考虑采用抽样的方式进行,比如窗口聚合逻辑的数据,随机抽取部分 key、部分窗口的聚合结果进行一一对比,验证其正确性。但需注意抽样 方式的合理性, 避免单一性产生对比漏洞从而误判数据质量。
2. 业务稳定性验证
业务稳定性和数据质量同样重要,任务的稳定性通常要求实现较长时间的平稳运行(一般建议 7 天), 进入稳定性观察期后,建议开启和原任务相同级别的监控、报警设置,期间主要观察任务运行时的处理延迟、有无异常 Failover 以及 Checkpoint 情况是否健康等, 如果达到了和原有任务同等或更高的稳定性,那稳定性验证就完成了。
3. 业务迁移
业务迁移是整个过程的最后一步,按照建议的步骤,在验证完成数据正确性和业务稳定性后,进行最终的迁移工作,将新任务使用的备用结果表替换原有任务的结果表提供给业务方使用,并将原有生产链路停止下线,整个迁移工作就圆满结束了。
4. 迁移FAQ
跨版本迁移时需要注意什么?
建议参考迁移目标版本的 Release Notes(如 Release Notes - Flink 1.13),结合迁移作业的业务代码确定是否修改。一般建议将 pom.xml 中的 flink.version 修改为目标版本,然后重新编译打包。
需要注意将其他的依赖(如 Connector)版本也修改为目标版本对应的版本。
2. 打包时需要注意什么?
JAR中不要包含 Flink 相关的依赖,因为平台的镜像中已经存在这些 lib, 否则会出现依赖冲突的问题,若遇到依赖冲突问题,可参考官网 FAQ:如何解决Flink依赖冲突问题?
3. 如果作业中依赖部分不在云上的服务,怎么处理?
如果作业依赖的配置中心、作业的输入和输出的持久层等不在云上的服务,需要找网络运维人员进行网络打通,网络打通后即可直接使用这些服务。可参考官网 FAQ:Flink全托管集群如何访问公网?
4. 在实时计算Flink版产品上如何使用自定义的依赖?
用户自定义的 connector、三方依赖、算法 so 文件等,可以通过“资源上传”,上传依赖。

并在作业中添加依赖文件即可。

5. 本地已有的 state 可以迁移到实时计算Flink版产品吗?
目前不支持从本地已有的 state 恢复。
实时计算产品已经默认为作业设置了 state 相关的配置,请用户不要在代码中设置 state 相关配置: state.checkpoints.dir。
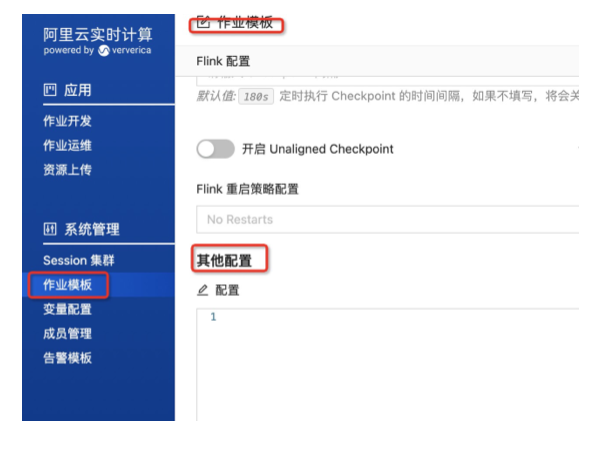
6. 如何设置集群级别的 Flink 配置?
可以通过作业模板实现,可以做到一次配置,所有作业生效。
7. 如何在 main 函数中读取本地文件?
通过“资源上传”,上传本地文件。

使用如下代码段,在代码中读取对应的本地文件。
注:代码中"/flink/usrlib/"是平台存放用户通过“资源上传”功能上传文件的目录,不能修改。
File f = new File("/flink/usrlib/", fileName); 5. 其他操作指引
Flink SQL 性能优化操作指引请参见Flink SQL性能优化。
基于 AutoPilot 的自动调优操作指引。
前置说明
AutoPilot配置请参见AutoPilot配置。
细粒度资源配置请参见细粒度资源配置。
推荐引擎版本:vvr-4.x.x-flink-1.13 版本及以上下面围绕作业上线、运行两方面介绍 AutoPilot 的使用场景。
作业上线最佳实践
新上线作业资源配置
新的 SQL 作业或者 DataStream 类型的作业在部署时,配置合适的资源和运行参数是很常见的需求。 尤其在算子拓扑复杂、开发人员不熟悉 flink 底层运行机制时,配置合适的资源和并发更加有挑战性。
我们推荐使用 AutoPilot 来支持新上线作业的资源配置:
1.作业开发完成后,直接上线运行作业(注意 dataStream 作业不要在代码中指定并发度,否则自动调优会无法生效)。
2.在自动调优页面把 AutoPilot 状态置为 Active,AutoPilot 会对资源进行调整(使用限制可以参考用 户文档使用限制部分)。
3.等待20~30分钟后,查看作业运行状况。
a.如果运行平稳,延迟指标正常,AutoPilot 不再进行迭代,意味着作业已经达到稳定状态。如果能接受 AutoPilot 自动调优带来的作业重启,可以保持 AutoPilot 继续在 Active 状态运行,否则可以将 AutoPilot 状态置为 monitor 状态来监控作业的运行。
b.如果作业延迟还在继续,同时 AutoPilot 仍然在迭代的话,继续迭代多轮观察作业能否到达到稳态。 如果长期不能达到稳定状态,可以查看是否有上下游系统瓶颈、数据倾斜等问题。
作业运行最佳实践
处于运行过程中的作业,经常会因业务流量变化而需要不同的处理能力。固定的资源配置可能会在业
务高峰的处理能力不足而造成延迟,也有可能会在业务低峰期作业仍然维持着一个较高的资源分配而
造成资源配置的浪费。
AutoPilot 会根据业务延迟变化、流量变化和资源利用率等指标自动调节作业使用的资源。
1. 作业发生延迟时,使用 AutoPilot 进行资源调整
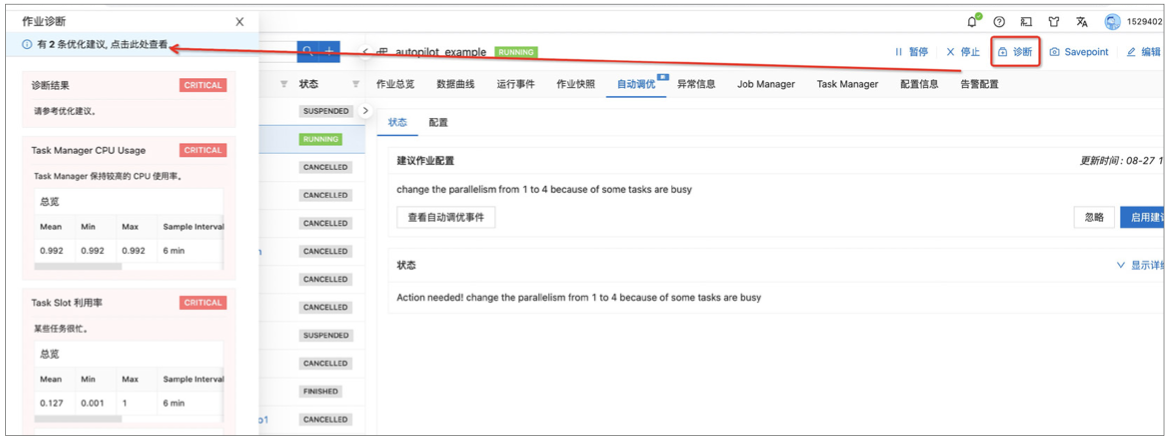
当作业运行资源不足,业务延迟增大时,如果配置了 Active 模式,智能调优会识别作业的瓶颈,并且会用新的配置自动重启作业。如果智能调优是 monitor 模式(默认工作方式),在这个页面会给 出推荐的作业配置,并且提供了一键启用建议配置的功能来方便的恢复作业数据重启(如下图)。

触发调优的指标阈值、进行调优的时最大资源和最大并发限制都可以通过参数的方式来自动调节,相关的配置参数有resources.cu.max、parallelism.scale-up.interval 等。当默认参数不能满足作业 的调优要求时,我们可以手动调整这些值来满足要求(指标含义和说明可以参看用户文档)。
2. 业务长时间低流量、低负载时段,使用 AutoPilot 缩容降低资源成本
当作业的流量长时间(默认24h)都处于较低水位时,如果作业的资源有下降空间,AutoPilot 会根据该时段内流量分布和系统负载推荐到一个资源更优的配置。
同样的,Active 模式下,智能调优会自动调低作业的并发或者资源,完全不需要人工介入。Monitor模式下,自动调优运维页面会提供建议的资源配置,也可以通过运维界面上的启用建议配置一键应用。
相关的参数parallelism.scale-down.interval、mem.scale-down.interval 等可以控制调低资源的间隔和行为。
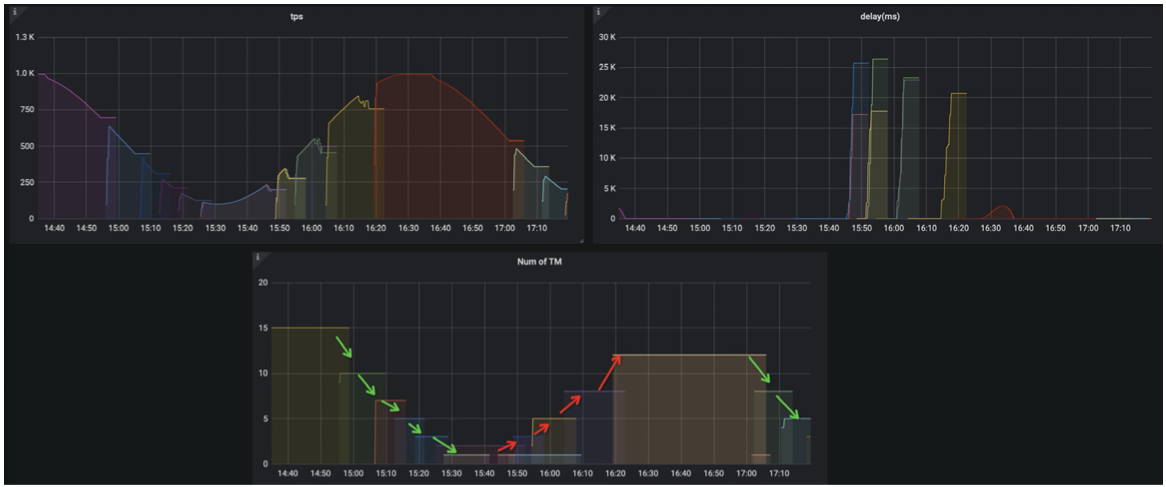
3. 业务流量周期变化,启用 AutoPilot 实现自动扩缩容,降低资源使用成本
如果作业有明显的流量变化,能接受作业在自动调优带来的重启时间段的延迟的话。推荐将自动调优的模式设置为Active,同时根据业务特征调节 parallelism.scale-up.interval 和 parallelism.scale- down.interval 参数,从而使 AutoPilot 检测流量变化更加及时。这样无须第三方系统介入,作业就能自动的实现资源的弹性扩缩容,有效降低资源的使用。(下图是一个典型场景)
另外,运行中的作业也会因为各种因素导致 failover,AutoPilot 针对一些可自愈的 failvoer 也提供了根因的检测和自动恢复手段。
4. 作业发生异常时使用 AutoPilot 进行诊断和恢复
从作业提交运行到结束运行的整个生命周期,AutoPilot 都会监控作业的健康状态,并会在出现异常时尝试进行一些异常的恢复和自愈。
目前支持的常见异常检测包括:资源使用、数据倾斜、checkPoint 状态、作业状态等方面。 我们可以直接点击作业上方的诊断按钮来获取当前作业的诊断结果:
对于一些可自愈的异常,像作业的内存配置不足,导致 JM 或者 TM OOM,AutoPilot 页面给出推荐的内存配置;如果开启了 AutoPilot 的状态为 Active,可自愈的异常会自动恢复。
问题排查操作指引
作业启动中报错
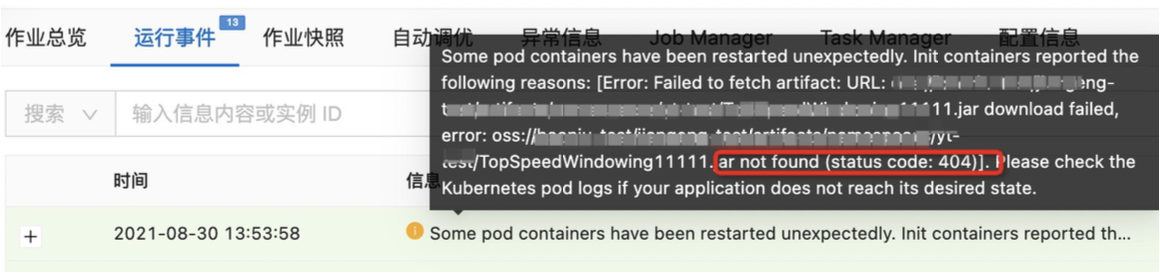
声明依赖的文件无法找到。
对于 jar 作业依赖的 jar 或者其他三方包。在启动的过程中会出现因为无法从文件系统找到或者文件地址中存在空格,导致失败。
解决办法:
去资源上传,先确定一下,依赖的文件是否存在
2. 资源和并发不一致
1.13之前的版本,系统根据用户设置,启动资源。作业正常运行需要:最大并发数 = taskmanager 个数。
对于 jar 作业,需要查看一下代码,是否通过代码设置了并发。 ·通过 Flink UI 打开作业详情,看到作业一直处于 created 的状态。
3. jobmanager 或者 taskmanager 资源设置有问题

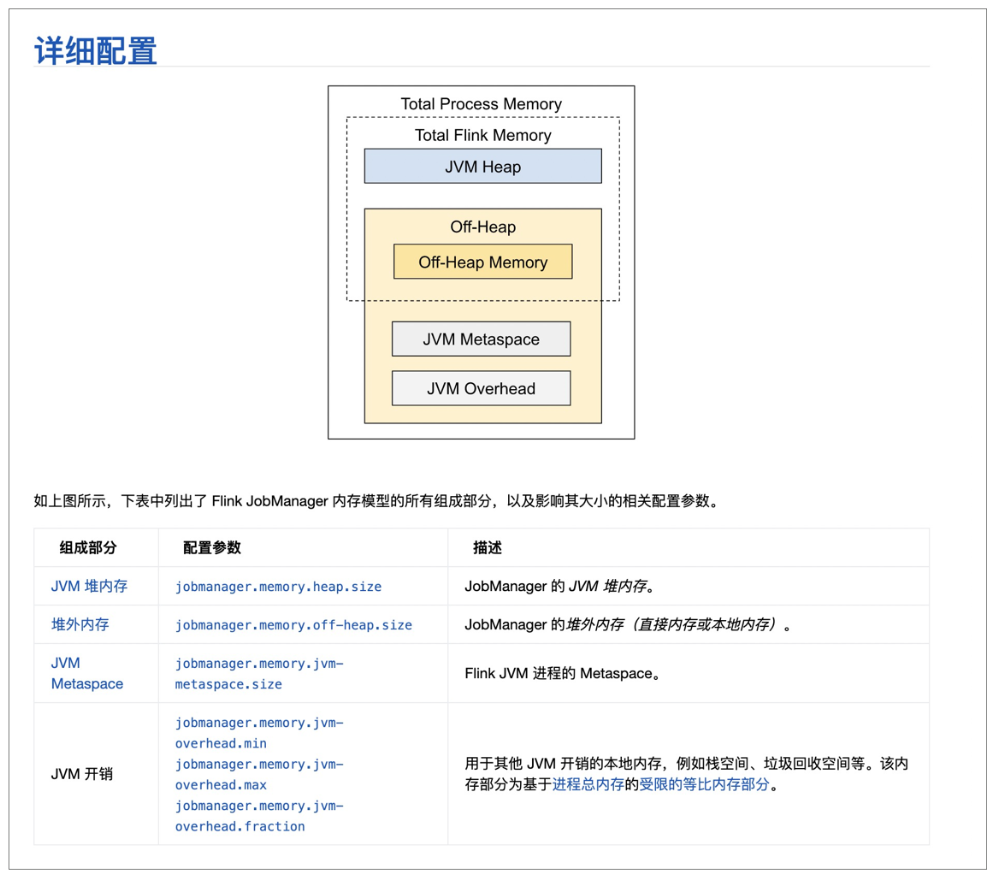
解决办法:根据下图内存模型,判断是否存在资源配置问题,详细可参考 flink资源。

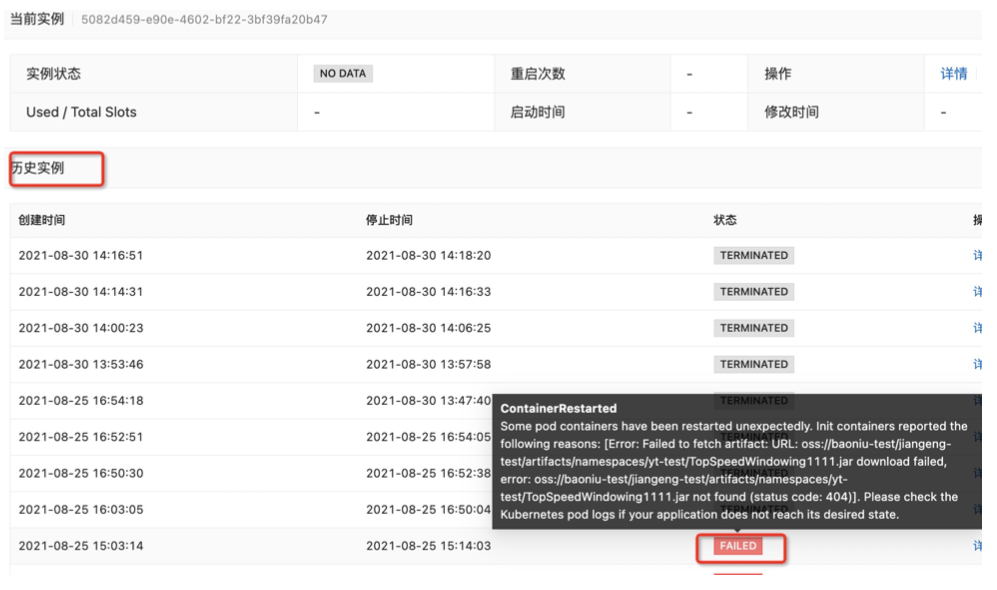
通过历史实例查看异常原因。
通过 metric 系统查看系统指标。
常见问题
taskmanager timeout exception
可以查看 taskmanager 的 gc 日志确定一下是否是因为 gc 导致 taskmanager 超时。
2. 出现脏数据,导致系统异常,可以通过查看异常信息。
3. 作业failover,可以通过重启次数确定,作业是否发生过 failover,可通过异常信息确定 failover 原因。