概述
方案介绍
Rapidformer是阿里云计算平台部机器学习平台PAI团队推出的PyTorch版的模型训练优化工具。它有机融合了3D混合并行,模型状态切分,MOE稀疏训练,计算图优化,Dynamic Shape等多种优化技术,通过加速开关的方式来组合部分或者全部的优化技术。
Rapidformer的所有优化技术可以无缝对接Huggingface、Megatron、FairSeq提供的Transformer模型库以及用户自定义模型。同时,Rapidformer对吞吐性能以及收敛可靠性进行了基准评测,确保训练工具的可靠性以及优化结果可复现且不会对模型的精度或指标产生非预期影响。
Rapidformer提供了在软件层面单独实施训练加速以及和PAI-EFLOPS协同的软硬一体化加速的解决方案。客户只需要下载PAI官方提供的训练加速专属镜像,就可以快速地搭建针对Transformer模型训练加速的流程,将模型的训练吞吐/收敛速度大幅度提升,降低硬件资源开销。详细介绍请参见阿里云官网:Pytorch训练加速框架(PAI-Rapidformer)
目标读者
针对从事PyTorch深度学习训练的用户。
适用场景
适用于在自然语言处理/计算机视觉/多模态/语音等领域。
对中小规模Transformer模型训练有加速的场景。
对超大规模Transformer模型训练有加速的场景。
方案架构
方案架构图
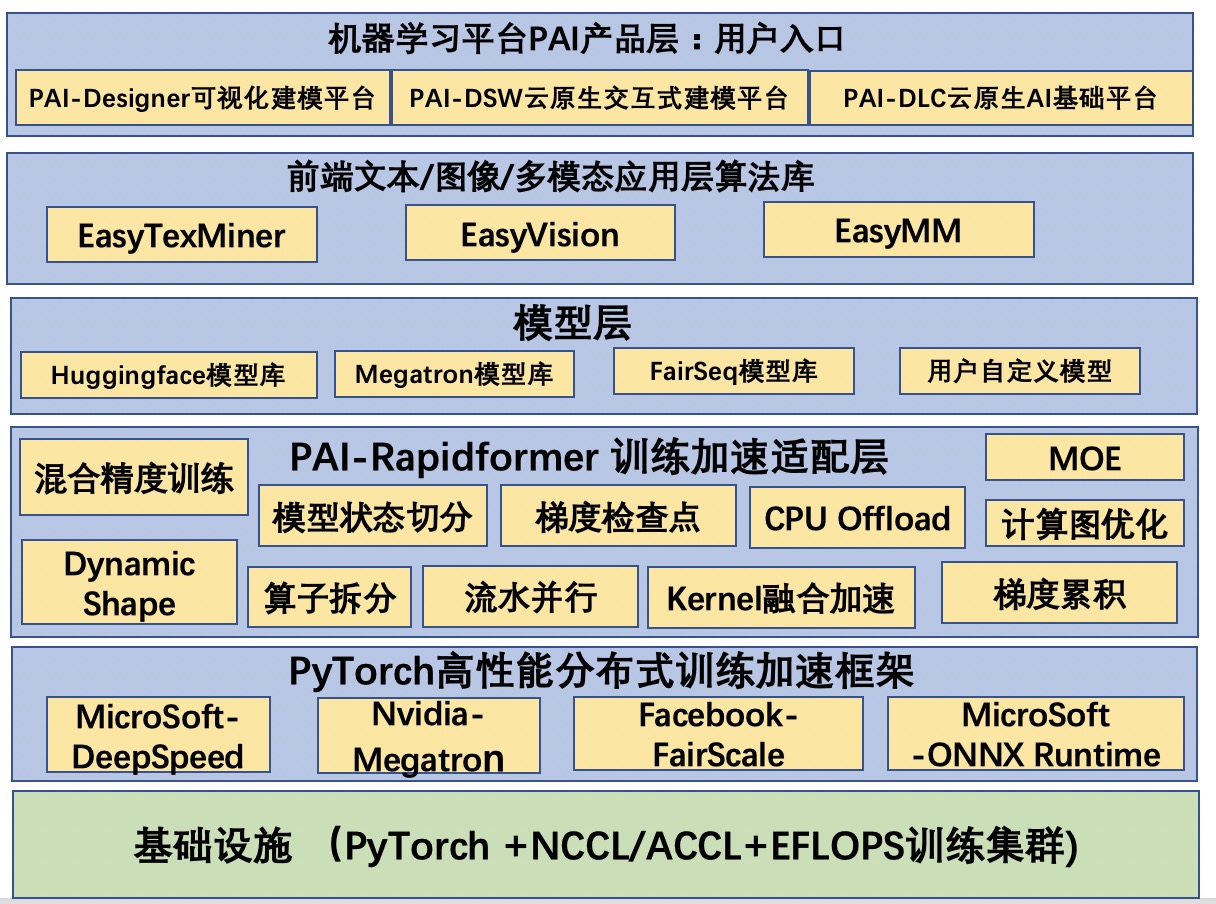
Rapidformer底层依赖于以下四个加速库提供的基础加速功能:
Nvidia-Megatron:提供数据并行,分片模型/流水并行,混合精度训练优化器。
MicroSoft-DeepSpeed:提供Zero Optimizer,Cpu-offload, MoE等支持。
Facebook-fairscale:提供oss,sdp, fsdp等支持。
MicroSoft-ONNX Runtime for Pytorch:提供计算图优化等加速功能。
Rapidformer为以下四种模型库加三种算法库提供加速支持:
Huggingface模型库:包含社区几十种Transformer模型实现,比如Bert,Albert等等。
Megatron模型库:提供模型并行版的Transformer模型,比如Bert,T5,GPT等等。
FairSeq模型库:提供bart,roberta,wav2vec/data2vec等等。
用户自定义模型:Rapidformer可以为用户自研的Transformer模型提供加速。
EasyTexMiner算法库:封装了常见的自然语言处理算法。
EasyVision算法库:封装了常见的计算机视觉算法。
EasyMM算法库:封装了常见的多模态算法。
方案优势
纯软件方案
加速策略丰富,不同维度策略之间自由组合:16+种深度学习领域模型加速策略,覆盖了训练流程加速的各个方面,通过设置加速开关对不同维度加速策略进行有机叠加,进一步提升吞吐速度。
对Huggingface模型库的良好支持且方便加速迁移:Huggingface库中的几十款模型都可以方便对接RF,来提供训练加速能力。基于内置的预训练/微调加速器进行扩展,可以方便的对已有程序实施训练加速迁移。
安装简易且快速上手:基于专属镜像的便捷安装方式,可快速部署到PAI-DSW/DLC产品中实施训练,同时提供了大量的参考示例。
专业可靠的性能基准评测工具:方便快速洞察同一策略维度内部不同算法之间,以及不同维度策略叠加带来的性能收益。
软硬一体化方案

方案实施
PAI-Rapidformer提供了丰富的模型训练加速方法,您只需要安装Rapidformer专属镜像,即可通过黑盒或者白盒化的方式对模型训练进行优化。本文详细介绍如何使用Rapidformer优化PyTorch版的Transformer模型训练。
前提条件
熟悉Rapidformer的API接口使用,详情请见:API接口文档。
熟悉Rapidformer的参数配置指导,详情请见:参数配置指导。
黑盒化加速步骤
利用Rapidformer提供的CLI,可以在不接触代码的情况下通过简单的配置就能实现对模型训练的加速能力,使用黑盒化加速的前提是需要对数据和模型进行注册。完整的参考示例如下:
加速微调Huggingface/ETM模型
步骤一:将您的数据集注册进 HuggingFace 或者ETM的 Dataset Hub 或使用Hub中已有的数据集, 然后通过--dataset-name 开关传递给rapidformer。
Huggingface数据集注册方法参见:https://huggingface.co/docs/datasets/add_dataset.html。
Huggingface查询已有数据集列表参见:https://huggingface.co/datasets。
步骤二:将您的模型注册进HuggingFace 或者ETM的Model Hub或使用Hub中已有的模型,通过--pretrained-model-name-or-path开关传递给rapidformer。
Huggingface模型注册方法参见:https://huggingface.co/docs/transformers/add_new_model。
Huggingface查询已有模型列表参见:https://huggingface.co/models。
步骤三:配置Rapidformer的启动训练CLI,如下所示:
#!/bin/bash
export CUDA_VISIBLE_DEVICES=4,5,6,7
export MASTER_ADDR=localhost
export MASTER_PORT=6010
export NNODES=1
export NODE_RANK=0
rapidformer --task sequence_classification \ #任务名
--pretrained-model-name-or-path 'bert-base-cased' \ #已注册模型名
--data-path glue \ #已注册的数据路径名
--data-name mrpc \ #已注册的数据文件名
--epochs 3 \ #训练迭代轮次
--micro-batch-size 16 \ #每个gpu上的batch size
--global-batch-size 64 \ #分布式训练总的batch size
--lr 2e-5 \ #学习率
--lr-decay-style linear \ #学习率衰减策略
--lr-warmup-iters 100 \ #学习率warmup步数
--weight-decay 1e-2 \ #lr系数
--clip-grad 1.0 \ #梯度clip系数
--mixed-precision \ #开启混合精度训练
--onnx-runtime-training \ #开启计算图优化
--zero-1-memory-optimization \ #开启优化器状态切分优化加速预训练Huggingface/ETM模型
步骤一:制作mmap类型的预训练数据集。参考Megatron提供的数据处理脚本:https://github.com/NVIDIA/Megatron-LM/blob/main/tools/preprocess_data.py 按照如下的脚本提供的命令制作mmap数据集。
python preprocess_data.py \
--input book_wiki_owtv2_small.json \
--output-prefix gpt_small \
--vocab gpt2-vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file gpt2-merges.txt \
--append-eod步骤二:将您的模型注册进HuggingFace 或者ETM的Model Hub或使用Hub中已有的模型,通过--pretrained-model-name-or-path开关传递给rapidformer。
Huggingface模型注册方法参见:https://huggingface.co/docs/transformers/add_new_model
Huggingface查询已有模型列表参见:https://huggingface.co/models
步骤三:配置Rapidformer的启动训练CLI,如下所示:
#!/bin/bash
export CUDA_VISIBLE_DEVICES=4,5,6,7
export MASTER_ADDR=localhost
export MASTER_PORT=6010
export NNODES=1
export NODE_RANK=0
rapidformer --task pretraining \
--pretrained-model-name-or-path 'bert-base-uncased' \
--num-layers 12 \
--hidden-size 768 \
--num-attention-heads 12 \
--micro-batch-size 16 \
--global-batch-size 128 \ #开启梯度累积
--seq-length 512 \
--tokenizer-type BertWordPieceLowerCase \
--max-position-embeddings 512 \
--train-iters 100 \
--data-path book_wiki_owtv2_small_text_sentence \
--vocab-file bert-en-uncased-vocab.txt \
--data-impl mmap \
--split 980,20 \
--lr 1e-3 \
--lr-decay-style linear \
--min-lr 0.0 \
--lr-decay-iters 2000 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--mixed-precision \ #开启混合精度训练
--onnx-runtime-training \ #开启计算图优化
--fsdp-memory-optimization \ #开启模型状态切分优化白盒化加速步骤
利用Rapidformer提供的CLI,用户可以在不接触代码的情况下对任务进行加速。除此之外,Rapidformer还为特定用户提供了基于模板的代码自定义模式,用户可以高度灵活的在代码模板中进行数据或者模型的自定义,然后通过--user-script参数传给Rapidformer的CLI来进行加速。我们将介绍借助Data/Model Hub的白盒化加速示例,以及更加灵活的不借助Data/Model Hub全自定义加速。
使用Data/Model Hub
使用Hub的前提是需要像上面黑盒化加速示例那样,将数据和模型注册进Hub中。
基于Finetuner代码模板的Huggingface/ETM模型微调
下面介绍利用Rapidformer提供的Finetuner代码模板快速构建Huggingface/ETM微调任务。在代码模板中有四个函数需要去实现,分别是制作数据的train_valid_test_datasets_provider, 构造模型/优化器/学习率调节器的model_optimizer_lr_scheduler_provider, 前向运算逻辑run_forward_step,以及run_compute_metrics来进行边train边eval计算精度等。这四个函数详细的API接口请参见:API接口文档。这里对这四个函数的输入输出给予简要的介绍。
class MyFintuner(Finetuner):
def __init__(self, engine):
super().__init__(engine=engine)
# 获取训练/验证/测试数据集
# 输入:无
# 输出:三个对象以及一个对象函数
def train_valid_test_datasets_provider(self):
return train_dataset, valid_dataset, test_dataset, collate_f
# 创建模型/优化器/学习率规划器
# 输入:无
# 输出:三个对象
def model_optimizer_lr_scheduler_provider(self):
return model, optimizer, lr_scheduer
#编写前向逻辑
# 输入:batch 或者 iterator,model
# 输出:loss
def run_forward_step(self, batch_or_iterator, model):
return loss
#编写验证集评估逻辑, 微调专用
# 输入:model,验证集数据加载器
# 输出:metric对象
def run_compute_metrics(self, model, eval_dataloader):
return metric熟悉以上自定义的代码模板后,接下来请先参考黑盒化加速示例的微调任务将数据和模型准备好,然后我们开始尝试构建一个自定义的Finetune文件。
步骤一:导入Rapidformer以及Huggingface/ETM的暴露出来的接口
from transformers/easytexmier import AutoConfig,BertForSequenceClassification
from datasets import load_dataset, load_metric
from rapidformer import RapidformerEngine
from rapidformer import get_args
from rapidformer import get_logger
from rapidformer import get_timers
from rapidformer import Finetuner
from rapidformer import Pretrainer
from rapidformer import build_train_valid_test_datasets_for_huggingface步骤二:完善代码模板中的四个函数,如下所示
class MyFintuner(Finetuner):
def __init__(self,engine):
super().__init__(engine=engine)
def train_valid_test_datasets_provider(self):
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
datasets = load_dataset(args.dataset_path, args.dataset_name)
# Apply the method we just defined to all the examples in all the splits of the dataset
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
tokenized_datasets.rename_column_("label", "labels")
train_dataset = tokenized_datasets["train"]
valid_dataset = tokenized_datasets['validation']
test_dataset = tokenized_datasets['test']
def collate_fn(examples):
return tokenizer.pad(examples, padding="longest", return_tensors="pt")
return train_dataset, valid_dataset, test_dataset, collate_fn
def model_optimizer_lr_scheduler_provider(self):
args = get_args()
model = BertForSequenceClassification.from_pretrained(args.load)
return model, None, None
def run_forward_step(self, batch, model):
output_tensor = model(**batch)
return output_tensor.loss
# after each epoch run metric on eval dataset
def run_compute_metrics(self, model, eval_dataloader):
model = model[0]
metric = load_metric(args.dataset_path, args.dataset_name)
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
metric.add_batch(
predictions=self.gather(predictions),
references=self.gather(batch["labels"]),
)
eval_metric = metric.compute()
return eval_metric
步骤三:初始化rapidformer引擎,创建trainer对象,调用finetune()方法。然后保存成文件并命名为rapidformer_finetune_huggingface_bert_trainer.py。
engine = RapidformerEngine()
trainer = MyFintuner(engine=engine)
trainer.train()步骤四:基于CLI准备启动脚本,设置--user-script=rapidformer_finetune_huggingface_bert_trainer.py,并设置加速开关。
#!/bin/bash
export CUDA_VISIBLE_DEVICES=4,5,6,7
export MASTER_ADDR=localhost
export MASTER_PORT=6010
export NNODES=1
export NODE_RANK=0
rapidformer --user-script rapidformer_finetune_huggingface_bert_trainer.py
--task sequence_classification \
--pretrained-model-name-or-path 'bert-base-cased' \
--data-path glue \
--data-name mrpc \
--epochs 3 \
--micro-batch-size 16 \
--global-batch-size 16 \
--lr 2e-5 \
--lr-decay-style linear \
--lr-warmup-iters 100 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--mixed-precision #开启混合精度训练
--zero-3-memory-optimization \ #开启模型状态切分
--onnx-runtime-training \ #开启计算图优化基于Pretrainer代码模板的Huggingface/ETM模型预训练
熟悉了上面使用Finetuner代码模板来创建用户自定义的微调任务,您可以轻易的继续利用Rapidformer提供的Pretrainer代码模版来快速构建Huggingface/ETM的预训练任务。因为Pretrainer代码模板和Finetuner代码模板使用的是相同的函数train_valid_test_datasets_provider,model_optimizer_lr_scheduler_provider以及run_forward_step。同时由于预训练并不需要在验证集上计算metrics,因此并不需要实现run_compute_metrics。另外需要像黑盒化预训练那样,先制作mmap类型的预训练数据集以及注册好准备预训练的模型。
步骤一:导入Rapidformer以及Huggingface/ETM的暴露出来的接口
注意:由于预训练采用了利用iterator读取数据,这里需要导入mpu来做数据并行。
from megatron import mpu
from transformers import BertConfig, BertForPreTraining
from rapidformer import RapidformerEngine, get_args, PreTrainer
from rapidformer import build_train_valid_test_datasets_for_huggingface步骤二:继承Pretrainer,完善预训练的代码。
class MyBertPreTrainer(PreTrainer):
def __init__(self,engine):
super().__init__(engine=engine)
def train_valid_test_datasets_provider(self, train_val_test_num_samples):
args = get_args()
train_ds, valid_ds, test_ds = build_train_valid_test_datasets_for_huggingface(
data_prefix=args.data_path,
data_impl=args.data_impl,
splits_string=args.split,
train_valid_test_num_samples=train_val_test_num_samples,
max_seq_length=args.seq_length,
masked_lm_prob=args.mask_prob,
short_seq_prob=args.short_seq_prob,
seed=args.seed,
skip_warmup=(not args.mmap_warmup),
binary_head=True)
return train_ds, valid_ds, test_ds
def model_optimizer_lr_scheduler_provider(self):
args = get_args()
model = AutoModelForPreTraining.from_pretrained(args.pretrained_model_name_or_path)
return model, None, None
def run_forward_step(self, data_iterator, model):
# Items and their type.
keys = ['input_ids', 'attention_mask', 'token_type_ids', 'labels', 'next_sentence_label']
datatype = torch.int64
# Broadcast data.
if data_iterator is not None:
data = next(data_iterator)
else:
data = None
data_b = mpu.broadcast_data(keys, data, datatype)
input_ids = data_b['input_ids'].long()
attention_mask = data_b['attention_mask'].long()
token_type_ids = data_b['token_type_ids'].long()
labels = data_b['labels'].long()
next_sentence_label = data_b['next_sentence_label'].long()
output_tensor = model(input_ids=input_ids, attention_mask=attention_mask,
token_type_ids=token_type_ids, labels=labels, next_sentence_label=next_sentence_label)
return output_tensor['loss']步骤三:初始化rapidformer引擎,创建trainer对象,调用pretrain()方法。然后保存成文件并命名为rapidformer_pretrain_huggingface_bert_trainer.py。
engine = RapidformerEngine()
trainer = MyBertPreTrainer(engine=engine)
trainer.train()步骤四:准备启动脚本,设置加速开关。
#!/bin/bash
export CUDA_VISIBLE_DEVICES=4,5,6,7
export MASTER_ADDR=localhost
export MASTER_PORT=6010
export NNODES=1
export NODE_RANK=0
DATA_PATH=book_wiki_owtv2_small_text_sentence
rapidformer --user-script rapidformer_pretrain_huggingface_bert_trainer.py \
--task pretraining \
--pretrained-model-name-or-path 'bert-base-uncased' \
--num-layers 12 \
--hidden-size 768 \
--num-attention-heads 12 \
--micro-batch-size 16 \
--global-batch-size 64 \
--seq-length 512 \
--tokenizer-type BertWordPieceLowerCase \
--max-position-embeddings 512 \
--train-iters 100 \
--data-path $DATA_PATH \
--vocab-file bert-en-uncased-vocab.txt \
--data-impl mmap \ #开启数据加速
--split 980,20 \
--lr 1e-3 \
--lr-decay-style linear \
--min-lr 0.0 \
--lr-decay-iters 2000 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--zero-3-memory-optimization \ #开启模型状态切分
--onnx-runtime-training \ #开启计算图优化
--mixed-precision #混合精度训练用户自定义Trainer的Huggingface/ETM模型微调
针对用户自定义Trainer的程序,Rapidformer提供非常有限的加速能力比如Apex优化器,模型状态切分,计算图优化等等。由于混合精度训练涉及到对用户训练过程较多的修改,因此我们推荐用户使用上面提供的基于代码模板的方法来实施对训练程序的加速。接下来我们针对一个典型的huggingface 微调代码进行侵入式的加速。
import torch
from datasets import load_dataset, load_metric
from torch.utils.data import DataLoader
from transformers import (
AdamW,
AutoModelForSequenceClassification,
AutoTokenizer,
get_linear_schedule_with_warmup,
BertForSequenceClassification,
)
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
datasets = load_dataset("glue", "mrpc")
metric = load_metric("glue", "mrpc")
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
optimizer = AdamW(params=model.parameters(), lr=args.lr, correct_bias=True)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_iters,
num_training_steps=args.train_iters
)
device = torch.device("cuda", args.local_rank)
for epoch in range(args.epochs):
model.train()
for step, batch in enumerate(train_dataloader):
batch.to(device)
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(eval_dataloader):
batch.to(device)
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
metric.add_batch(
predictions=engine.gather(predictions),
references=engine.gather(batch["labels"]))
eval_metric = metric.compute()
print("epoch {}: {}".format(epoch, eval_metric))这段代码存在一些问题比如不支持数据并行训练,优化器也比较慢,同时不支持混合精度训练等等。我们尝试借助Rapidformer提供的API来对这段用户自定义代码进行改造。
步骤一:支持数据并行
首先用户可以创建一个finetuner对象,然后调用finetuner.build_data_loader方法返回数据加载器。该加载器支持数据并行并自动将data 发送到GPU设备,这意味着可以在原始代码中去掉batch.to(device)。
+ from rapidformer import RapidformerEngine
+ engine = RapidformerEngine()
+ finetuner = Finetuner(engine=engine)
- train_dataloader = DataLoader(tokenized_datasets["train"])
- eval_dataloader = DataLoader(tokenized_datasets["train"])
+ train_dataloader = finetuner.build_data_loader(tokenized_datasets["train"])
+ eval_dataloader = finetuner.build_data_loader(tokenized_datasets["validation"])步骤二:数据并行 + Apex优化器
将优化器换成更快的apex fused adam, 去掉原来的optimizer, 换成rapidforemr提供的fused adam。具体方法是调用engine.compose来对模型,优化器,学习率规划器进行封装。
+ from rapidformer import RapidformerEngine
+ engine = RapidformerEngine()
+ finetuner = Finetuner(engine=engine)
- optimizer = AdamW(params=model.parameters(), lr=args.lr, correct_bias=True)
- lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,
num_warmup_steps=args.lr_warmup_iters,
num_training_steps=args.train_iters
)
+ lr_scheduler = partial(
get_linear_schedule_with_warmup,
num_warmup_steps=args.lr_warmup_iters,
num_training_steps=args.train_iters
)
+ model, optimizer, lr_scheduler = engine.compose(model_obj=model, lr_scheduler_fn=lr_scheduler)备注:数据并行 + Apex优化器 + 混合精度
混合精度训练涉及到对训练流程的修改,model切换到fp16,loss scaling等。对无trainer的前端程序改造成本比较大,因此我们提供基于Trainer的解决方案。有个rapidformer的fintuner的加持,我们能做的加速方案就比较多了,除了整合前面的数据并行和apex,pytorch混合精度训练,我们还提供了megatron optimizer混合精度训练,fairscale和deepspeed的显存优化加速等等。
不使用Data/Model Hub
我们以Megatron支持模型并行的模型预训练为例,介绍下不使用Hub的高度灵活模式。
基于Pretrainer代码模板的Megatron模型预训练
熟悉了上面使用Pretrainer代码模板同时基于Data/Model Hub来创建用户自定义的预训练任务,您可以进一步更加灵活的绕过Data/Model Hub,在函数train_valid_test_datasets_provider中编写自定义数据的创建逻辑, 在函数model_optimizer_lr_scheduler_provider中编写自定义创建模型的逻辑,同时在run_forward_step中自定义的前向逻辑。
步骤一:创建自定义数据集。
参考Megatron提供的数据处理脚本:https://github.com/NVIDIA/Megatron-LM/blob/main/tools/preprocess_data.py 按照如下的脚本提供的命令制作mmap数据集。
python preprocess_data.py \
--input /apsarapangu/disk2/jerry.lp/pretrain_datasets/en/book_wiki_owtv2_small.json \
--output-prefix /apsarapangu/disk2/jerry.lp/pretrain_datasets/en/gpt_small \
--vocab gpt2-vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file gpt2-merges.txt \
--append-eod步骤二:继承Pretrainer,完善预训练的代码中的数据自定义函数train_valid_test_datasets_provider,您可以不依赖于任何第三方库来编写自定义的逻辑,用来生成train/valid/test数据集。您的数据集应该继承自torch.utils.data.Dataset,具体代码如下:
from rapidformer import RapidformerEngine, get_args, PreTrainer
class MegatronGPTPreTrainer(PreTrainer):
def __init__(self,
engine,
):
super().__init__(engine=engine)
def train_valid_test_datasets_provider(self, train_val_test_num_samples):
args = get_args()
train_ds, valid_ds, test_ds = build_train_valid_test_datasets(
data_prefix=args.data_path,
data_impl=args.data_impl,
splits_string=args.split,
train_valid_test_num_samples=train_val_test_num_samples,
seq_length=args.seq_length,
seed=args.seed,
skip_warmup=(not args.mmap_warmup))
return train_ds, valid_ds, test_ds步骤三:继承Pretrainer,完善预训练的代码中的模型自定义函数model_optimizer_lr_scheduler_provider。里面,您可以不依赖于任何第三方库来编写自定义的逻辑,用来生成自定义模型对象。您的模型应该是继承自torch.nn.Module。
from rapidformer import RapidformerEngine, get_args, PreTrainer
from yourmodel import GPTModel
class MegatronGPTPreTrainer(PreTrainer):
def __init__(self,
engine,
):
super().__init__(engine=engine)
def model_optimizer_lr_scheduler_provider(self):
model = GPTModel()
return model, None, None步骤四:继承Pretrainer,完善预训练的代码中的前向自定义函数run_forward_step。
from rapidformer import RapidformerEngine, get_args, PreTrainer
class MyGPTPreTrainer(PreTrainer):
def __init__(self,
engine,
):
super().__init__(engine=engine)
def run_forward_step(self, data_iterator, model):
"""Forward step."""
args = get_args()
tokenizer = get_tokenizer()
# Items and their type.
keys = ['text']
datatype = torch.int64
# Broadcast data.
if data_iterator is not None:
data = next(data_iterator)
else:
data = None
data_b = mpu.broadcast_data(keys, data, datatype)
# Unpack.
tokens_ = data_b['text'].long()
labels = tokens_[:, 1:].contiguous()
tokens = tokens_[:, :-1].contiguous()
# Get the masks and postition ids.
attention_mask, loss_mask, position_ids = get_ltor_masks_and_position_ids(
tokens,
tokenizer.eod,
args.reset_position_ids,
args.reset_attention_mask,
args.eod_mask_loss)
output_tensor = model(tokens, position_ids, attention_mask,
labels=labels)
losses = output_tensor.float()
loss_mask = loss_mask.view(-1).float()
loss = torch.sum(losses.view(-1) * loss_mask) / loss_mask.sum()
return loss步骤五:初始化rapidformer引擎,创建trainer对象并调用pretrain()方法。然后保存成文件并命名为rapidformer_pretrain_megatron_gpt_trainer.py。
engine = RapidformerEngine()
trainer = MyGPTPreTrainer(engine=engine)
trainer.train()步骤六:准备启动脚本,设置加速开关。
#!/bin/bash
export CUDA_VISIBLE_DEVICES=4,5,6,7
export MASTER_ADDR=localhost
export MASTER_PORT=6010
export NNODES=1
export NODE_RANK=0
DATA_PATH=book_wiki_owtv2_small_text_sentence
rapidformer --user-script rapidformer_pretrain_megatron_gpt_trainer.py \
--tensor-model-parallel-size 2 \ #开启算子拆分优化
--pipeline-model-parallel-size 2 \ #开启流水并行优化
--num-layers 12 \
--hidden-size 768 \
--num-attention-heads 12 \
--micro-batch-size 16 \
--global-batch-size 128 \ #开启梯度累积优化
--seq-length 512 \
--tokenizer-type GPT2BPETokenizer \
--max-position-embeddings 512 \
--train-iters 100 \
--data-path $DATA_PATH \
--vocab-file gpt2-vocab.json \
--merge-file gpt2-merges.txt \
--data-impl mmap \ #开启数据加速
--split 980,20 \
--lr 1e-3 \
--lr-decay-style linear \
--min-lr 0.0 \
--lr-decay-iters 2000 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--log-interval 1 \
--zero-2-memory-optimization \ #开启模型状态切分
--checkpoint-activations \ #开启梯度检查点
--mixed-precision #开启混合精度训练方案验证
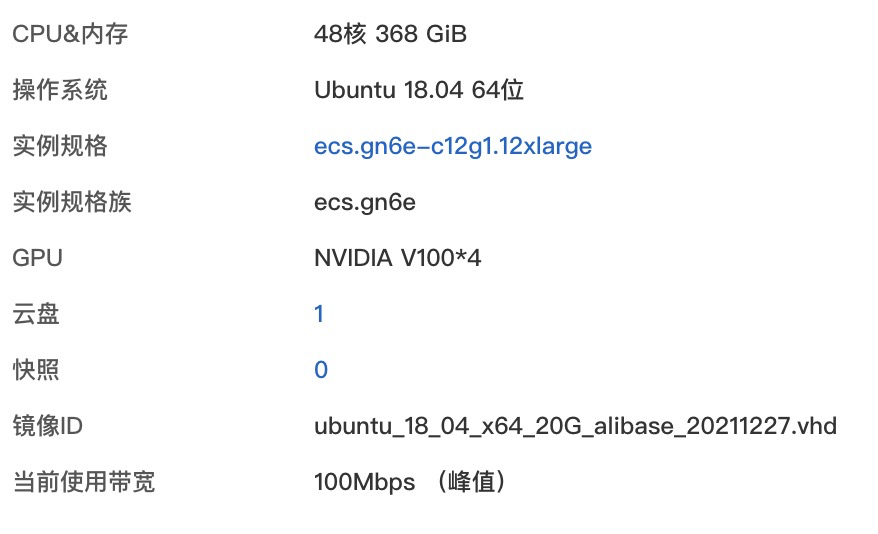
为了验证Rapidformer的加速效果,所有实验均在阿里云ECS服务器上进行,下面是硬件配置
混合精度 :吞吐提升幅度72.8%
实验环境:英文huggingface bert 预训练
num-layers 12
hidden-size 768
num-attention-heads 12
num-params 110106428
local-rank 4
seq-length 512
micro-batch-size 16
global-batch-size 64
方案 | 吞吐 (samples/s) | Peak Memory (MB) |
单精度训练 | 103.07 +/- 1.03 | 17025 |
混合精度训练 | 178.15 +/- 2.10 | 12698 |
模型状态切分:显存降低幅度37.3%
实验环境:英文megatron gpt 预训练
num-layers 24
hidden-size 2048
num-attention-heads 32
num-params 1313722368 (13亿)
local-rank 4
seq-length 1024
micro-batch-size 1
global-batch-size 4
使用pytorch原生的分布式数据并行会导致出现OOM,关键导致OOM原因是这个模型无法放在32G的显卡上,因为Adam 优化器的状态参数就消耗16G显存。
方案 | 吞吐 (samples/s) | Peak Memory (MB) |
无加速技术 | OOM | OOM |
混合精度训练 | 9.57 +/- 0.26 | 25061 |
混合精度训练 + oss模型状态切分 | 6.02 +/- 0.06 | 22077 |
混合精度训练 + oss/sdp模型状态切分 | 7.01 +/- 0.07 | 17113 |
混合精度训练 + fsdp模型状态切分 | NA | NA |
混合精度训练 + Zero-1 | 12.88 +/- 0.10 | 15709 |
混合精度训练 + Zero-2 | 10.27 +/- 0.08 | 15693 |
混合精度训练 + Zero-3 | NA | NA |
3D混合并行:显存降低幅度77.3%
实验环境:英文megatron gpt 预训练
num-layers 24
hidden-size 2048
num-attention-heads 32
num-params 1313722368 (13亿)
local-rank 4
seq-length 1024
micro-batch-size 1
global-batch-size 4
算子拆分 | 流水并行 | 吞吐 (samples/s) | Peak Memory (MB) |
1 | 1 | 9.63 +/- 0.29 | 25061 |
2 | 1 | 7.59 +/- 0.14 | 11300 |
4 | 1 | 6.16 +/- 0.06 | 5673 |
1 | 2 | 8.46 +/- 0.17 | 12375 |
1 | 4 | 8.03 +/- 0.12 | 8141 |
2 | 2 | 7.37 +/- 0.11 | 6211 |
4 | 4 | 6.24 +/- 0.08 | 5673 |
ORT计算图优化:吞吐提升幅度15.6%
实验环境:英文huggingface bert 微调
num-layers 12
hidden-size 768
num-attention-heads 12
num-params 110106428
local-rank 4
seq-length 512
micro-batch-size 16
global-batch-size 64
方案 | 吞吐 (samples/s) | Peak Memory (MB) |
单精度训练 | 479.15 +/- 1.67 | 2112 |
混合精度训练 | 589.66 +/- 4.79 | 2127 |
ORT计算图优化 | 554.24 +/- 1.98 | 2430 |
ORT+混合精度 | 614.70 +/- 8.69 | 2289 |
常见问题
安装Rapidformer镜像,并创建容器后出现字符编码的问题
请在容器中执行export LC_ALL=C.UTF-8来设置语言环境
2. 多机分布式训练如果物理硬件不支持NCCL,出现NCCL相关错误
在配置启动的时候请添加 export NCCL_IB_DISABLE=1