机器学习雾霾天气预测的数据分析流程
本实践主要介绍通过机器学习平台PAI进行雾霾天气预测实验,对数据进行集成、预处理、模型训练及预测和模型评估的全过程进行展示。
前提条件
大数据计算MaxCompute、DataWorks、PAI基于企业版V3.14及以上版本。
背景信息
机器学习平台PAI进行雾霾天气预测实验,对数据进行集成、预处理、模型训练及预测和模型评估的全过程进行展示。
组件介绍
大数据计算服务(MaxCompute)是面向大数据处理的分布式系统,主要提供结构化数据的存储和计算,服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务。MaxCompute的目的是为用户提供一种便捷的分析处理海量数据的手段。用户可以不必关心分布式计算细节,从而达到分析大数据的目的。
DataWorks数据工场为您提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。DataWorks支持离线同步、Shell、ODPS SQL、ODPS MR等多种节点类型,通过节点之间的相互依赖,对复杂的数据进行分析处理。DataWorks提供可视化的代码开发、工作流设计器页面,无需搭配任何开发工具,简单拖拽和开发,即可完成复杂的数据分析任务。
机器学习平台PAI(Platformof Artificial Intelligence)是阿里云人工智能平台,提供一站式的机器学习解决方案,面向企业客户及开发者,提供轻量化、高性价比的云原生机器学习。PAI支持丰富的机器学习算法、一站式的机器学习体验、主流的机器学习框架及可视化的建模。
实践步骤
一、准备机器学习所需计算资源。
首先需要创建大数据MaxCompute的项目,配置计算资源,CPU、内存、存储空间,做大数据计算使用。
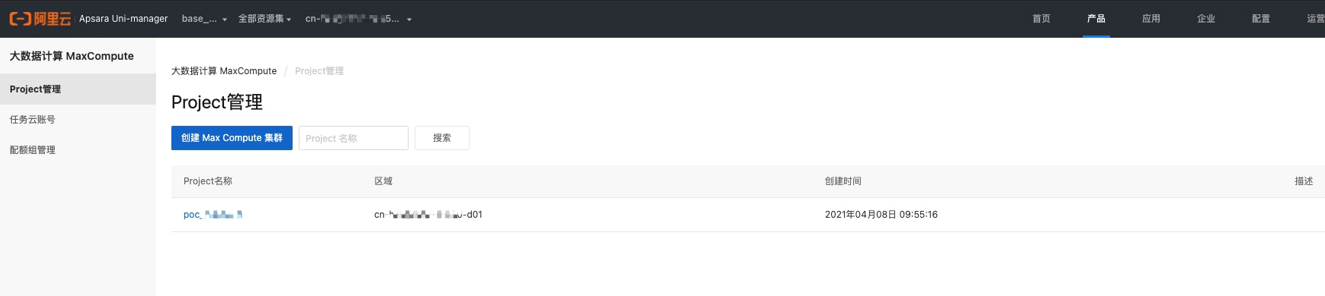
创建大数据MaxCompute项目。
登录Apsara Uni-manager运营控制台,选择大数据计算 MaxCompute,进入大数据计算服务界面。
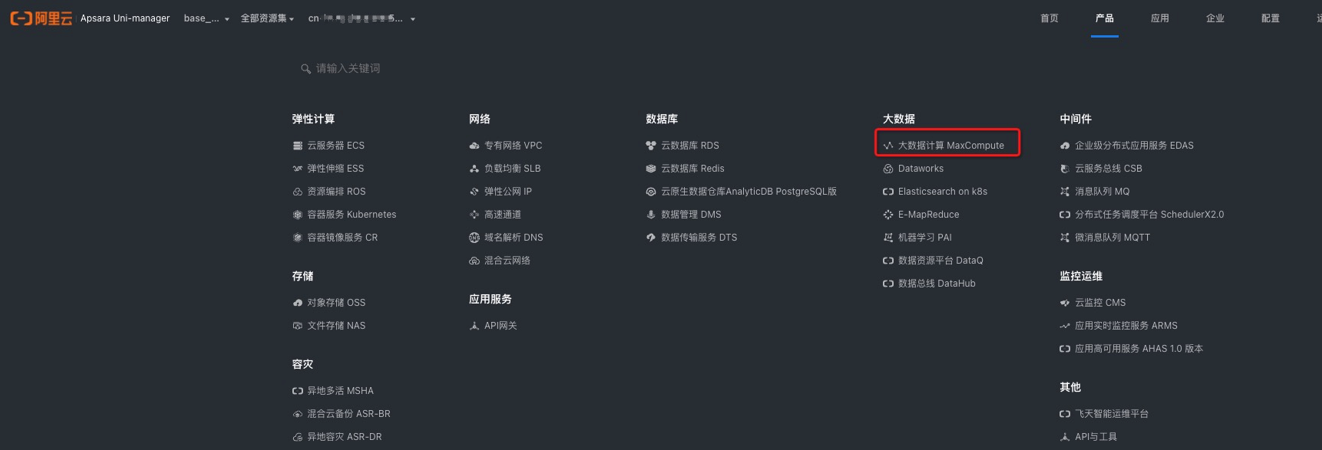
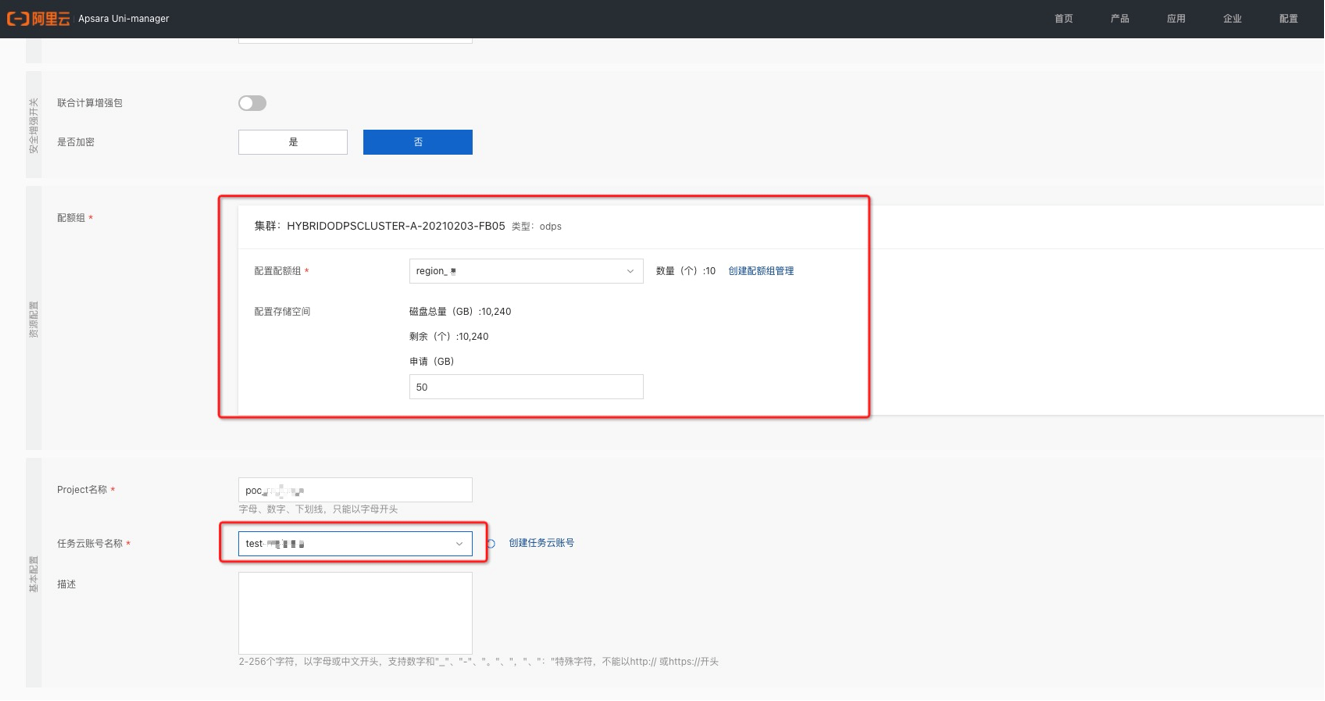
首先,单击创建,创建计算资源配额组作为计算资源使用,单位为cu,1 cu=1 core4G内存,可基于计算所需资源进行设置。

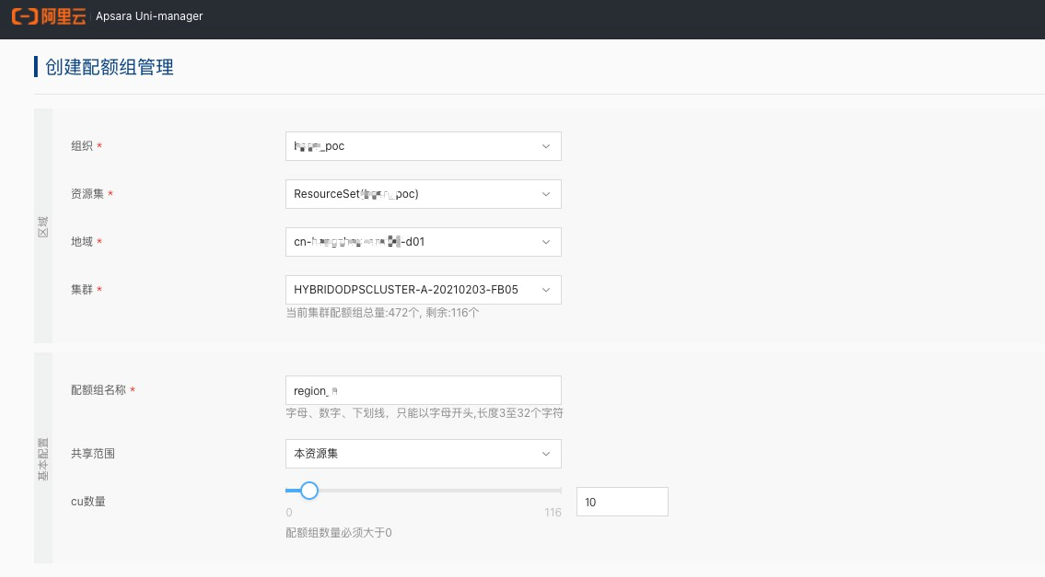

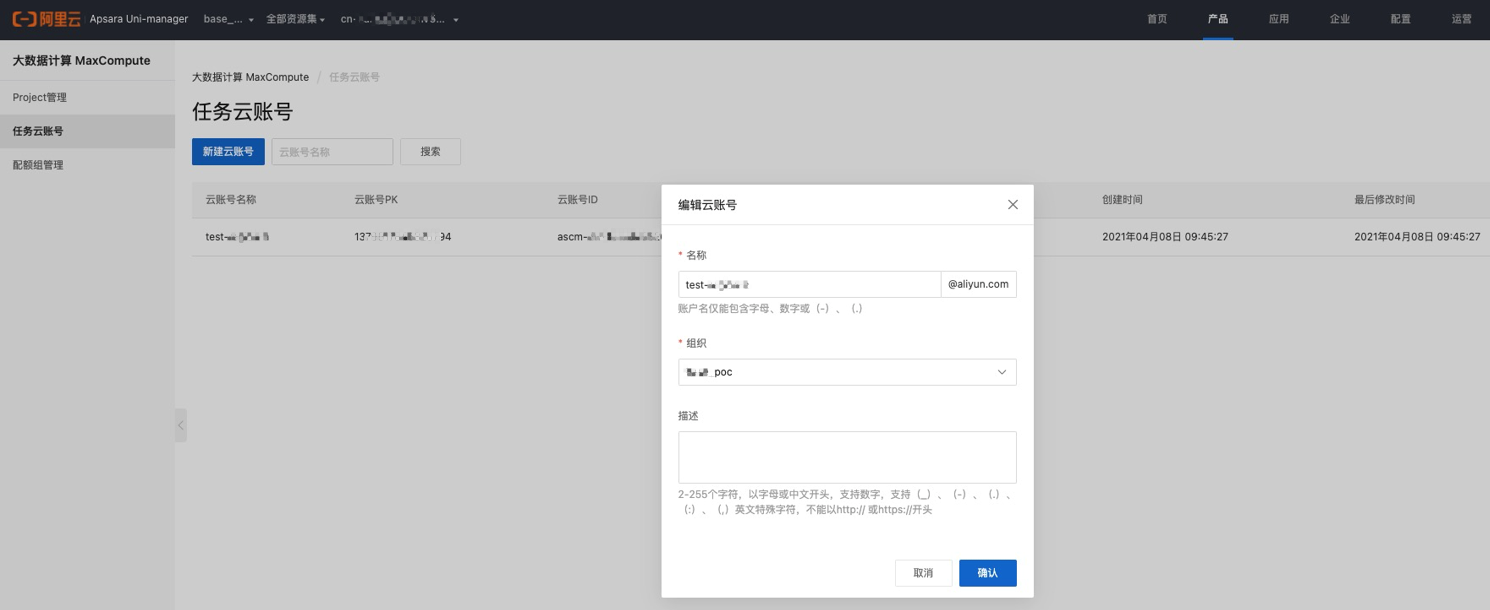
单击新建云账号,创建任务云账号,一个云账号可以关联多个项目资源。
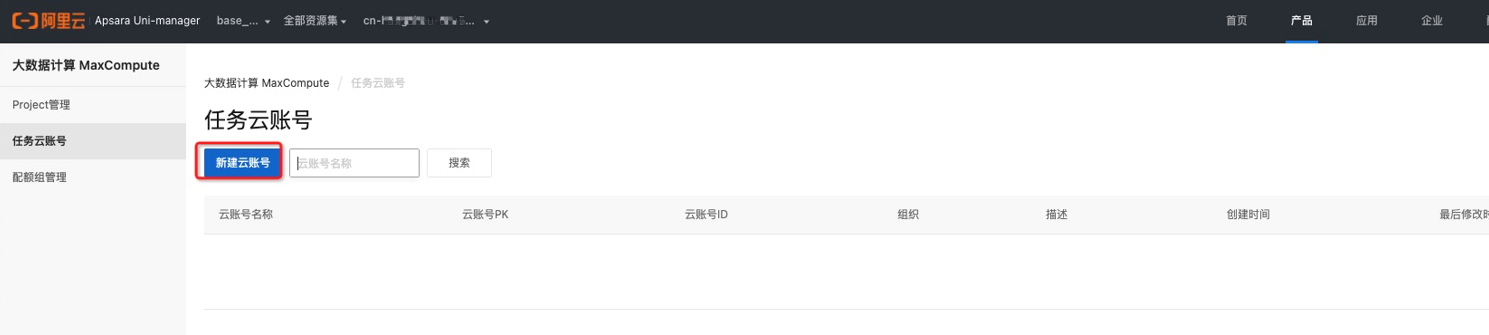

创建Max Compute集群,选择刚创建的配额组和任务云账号,MaxCompute项目之间默认是互相隔离的空间。
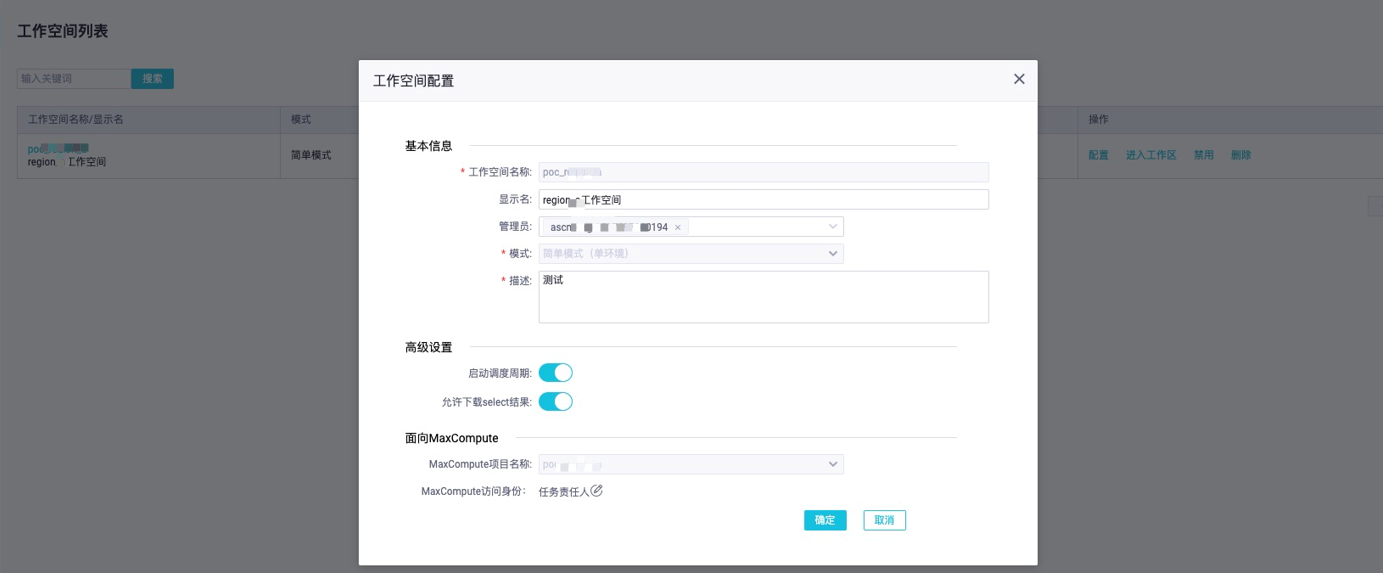
创建DataWorks工作空间。
DataWorks一站式数据管理开发的工具,可以对MaxCompute大数据项目的数据进行开发,需要创建DataWorks工作空间并与MaxCompute项目进行关联。
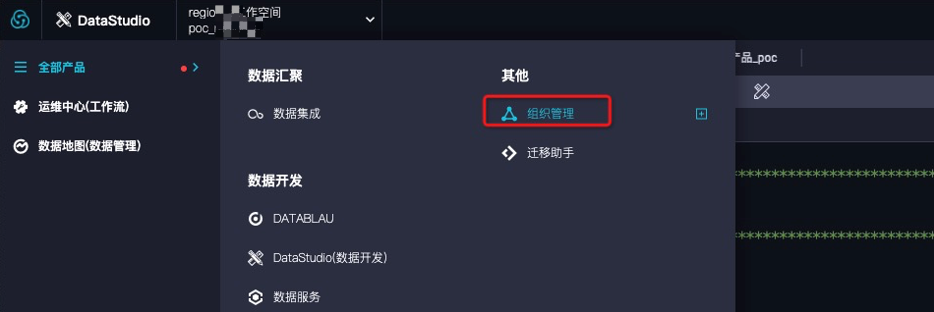
登录Apsara Uni-manager运营控制台,在上方导航栏选择单击产品>大数据>DataWorks。
首先,选择全部产品>组织管理,单击创建工作空间,关联MaxCompute项目。
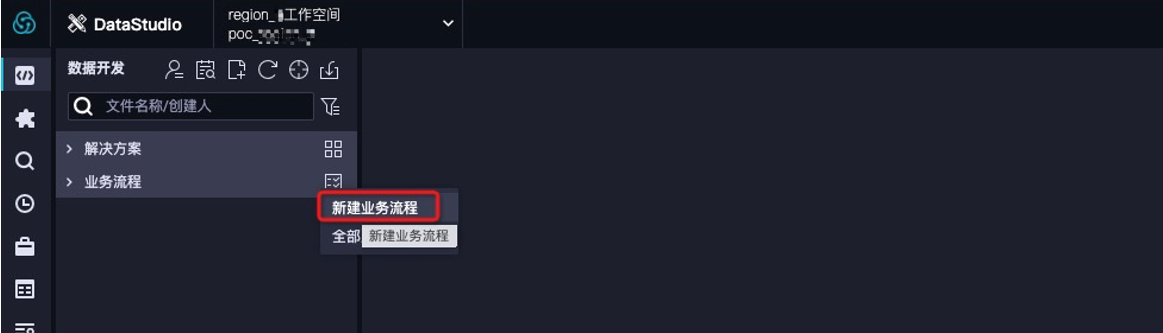
创建工作空间业务流程。
创建完成之后,单击进入工作区,单击新建业务流程,在当前业务流程可以进行数据集成、数据开发等操作。




二、机器学习进行实验分析。
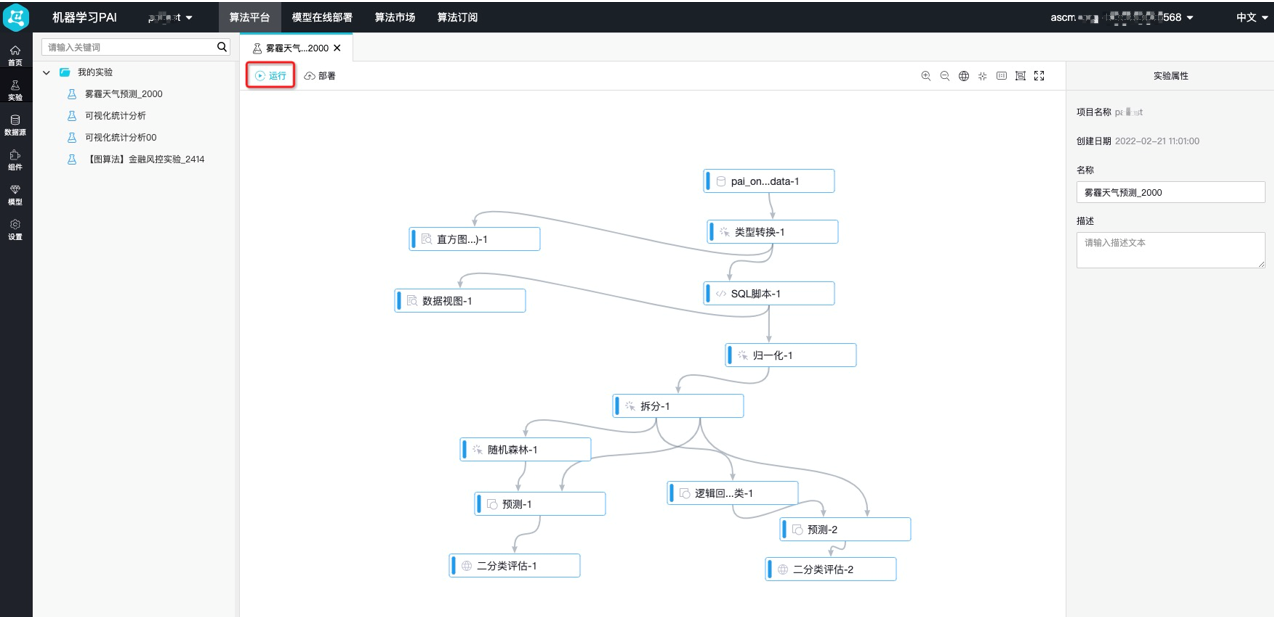
运行雾霾天气预测。
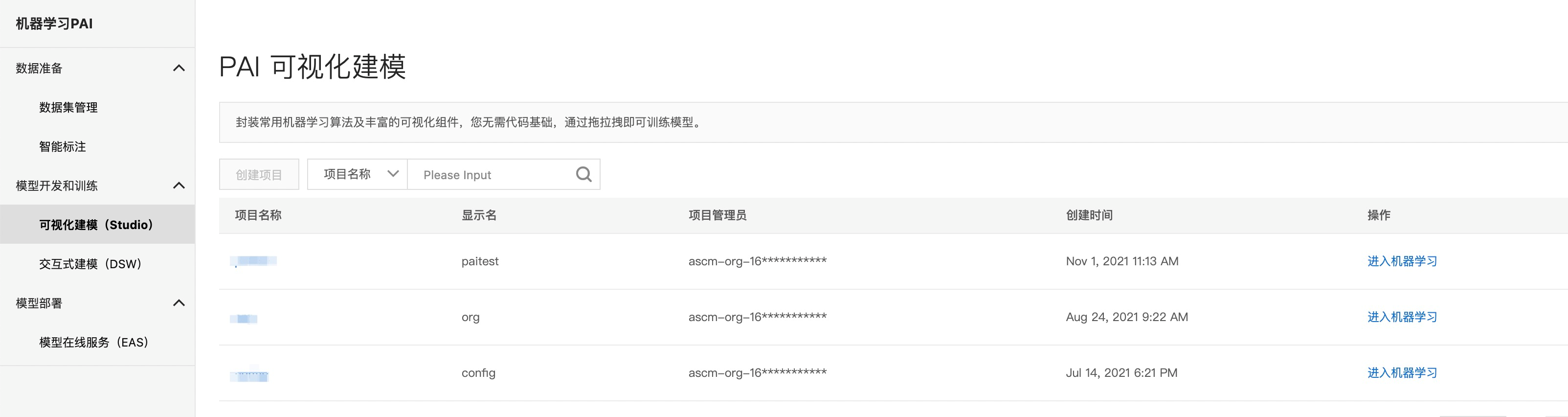
登录Apsara Uni-manager运营控制台,在上方导航栏选择产品>大数据>机器学习 PAI。
选择模型开发和训练>可视化建模(Studio),选择之前创建DataWorks创建的项目名称,单击进入机器学习,进入机器学习PAI页面。
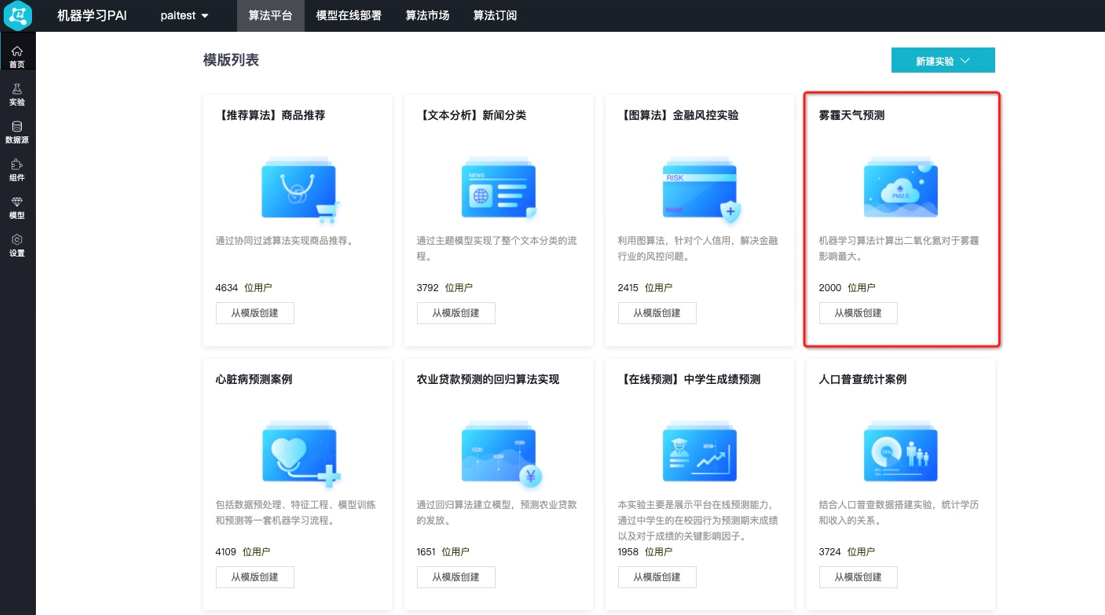
单击左侧首页,可以查看模板列表,包含各行业案例库,选择雾霾天气预测,单击从模板创建,创建雾霾天气预测实验。
单击画布上方的运行,进行雾霾天气预测实验分析。
等所有的运行节点都显示运行完成后即可查看运行结果。
运行结果分析。
本实验通过分析北京2016年的真实天气数据,构建雾霾天气预测模型,从而挖掘对雾霾天气(指PM 2.5)影响最大的污染物。
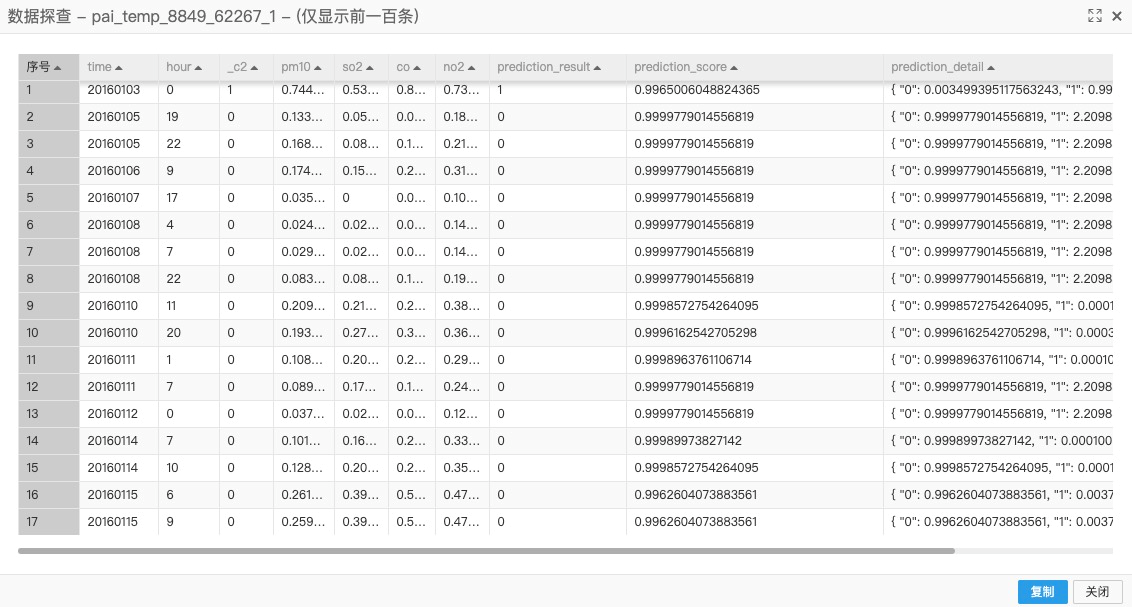
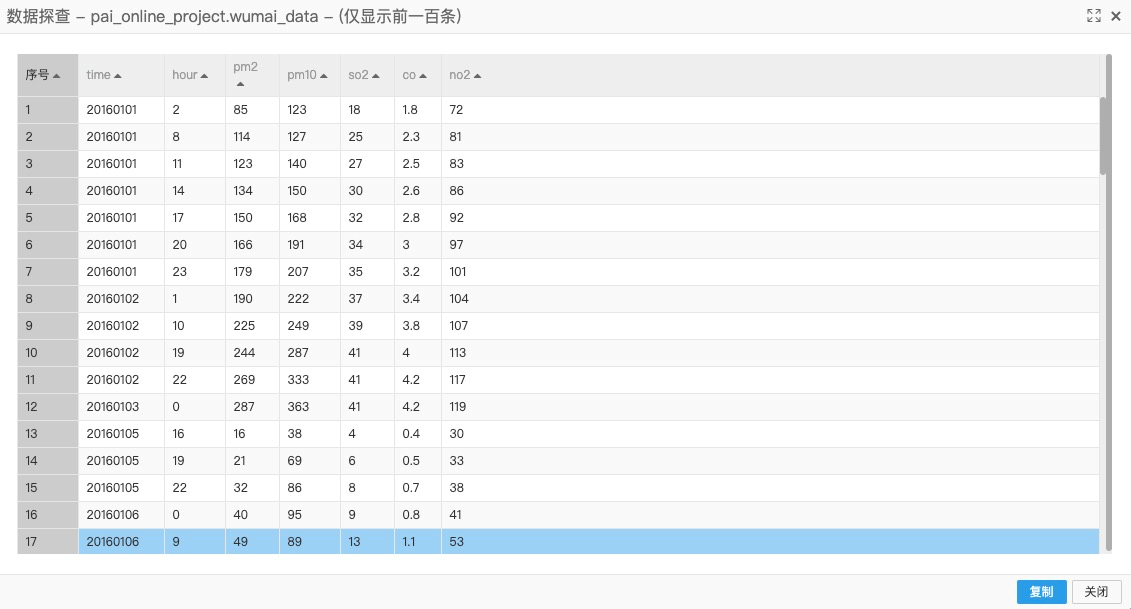
在雾霾天气预测实验分析页面,实验运行完成后,选择pai_online_project.wumai_data数据表,右键单击,选择查看数据,即可查看到2016年全年(以小时为单位)的北京空气指标数据,该数据为输入数据表。
各输入字段含义如下:字段名
类型
描述
time
STRING
日期,精确到天。
hour
STRING
第几小时的数据。
pm2
STRING
PM 2.5指标。
pm10
STRING
PM 10指标。
so2
STRING
二氧化硫指标。
co
STRING
一氧化碳指标。
no2
STRING
二氧化氮指标。
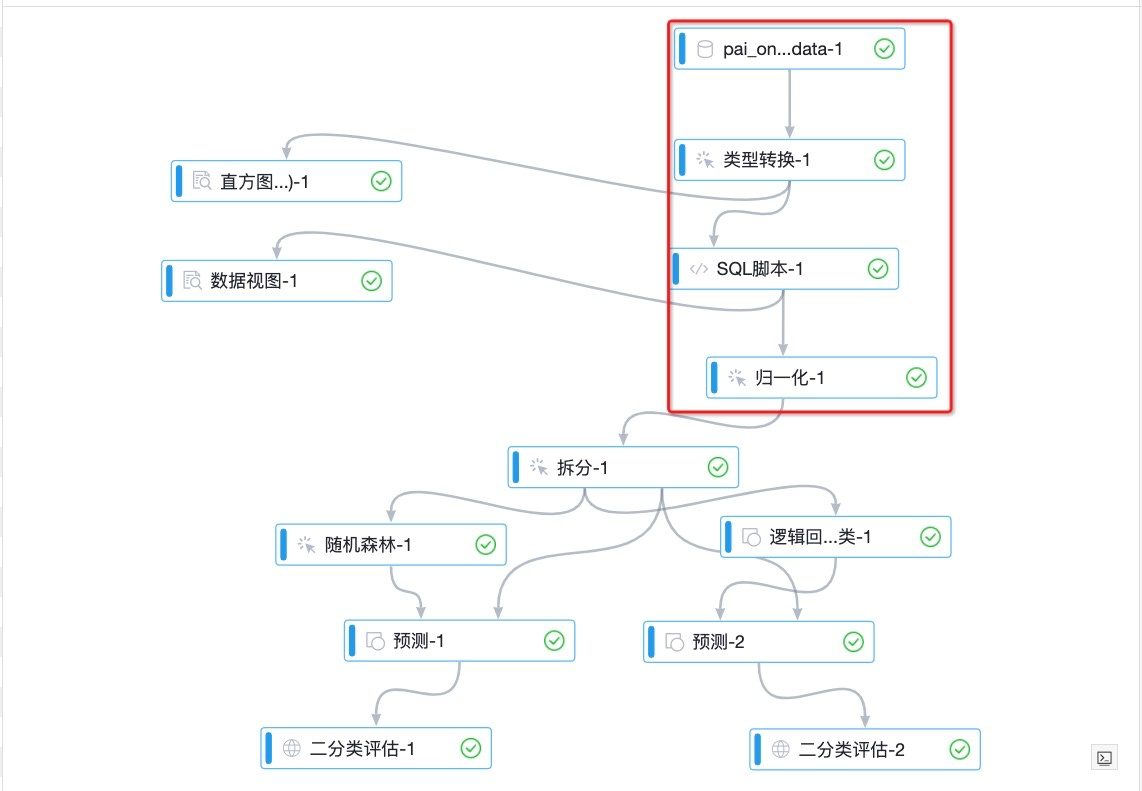
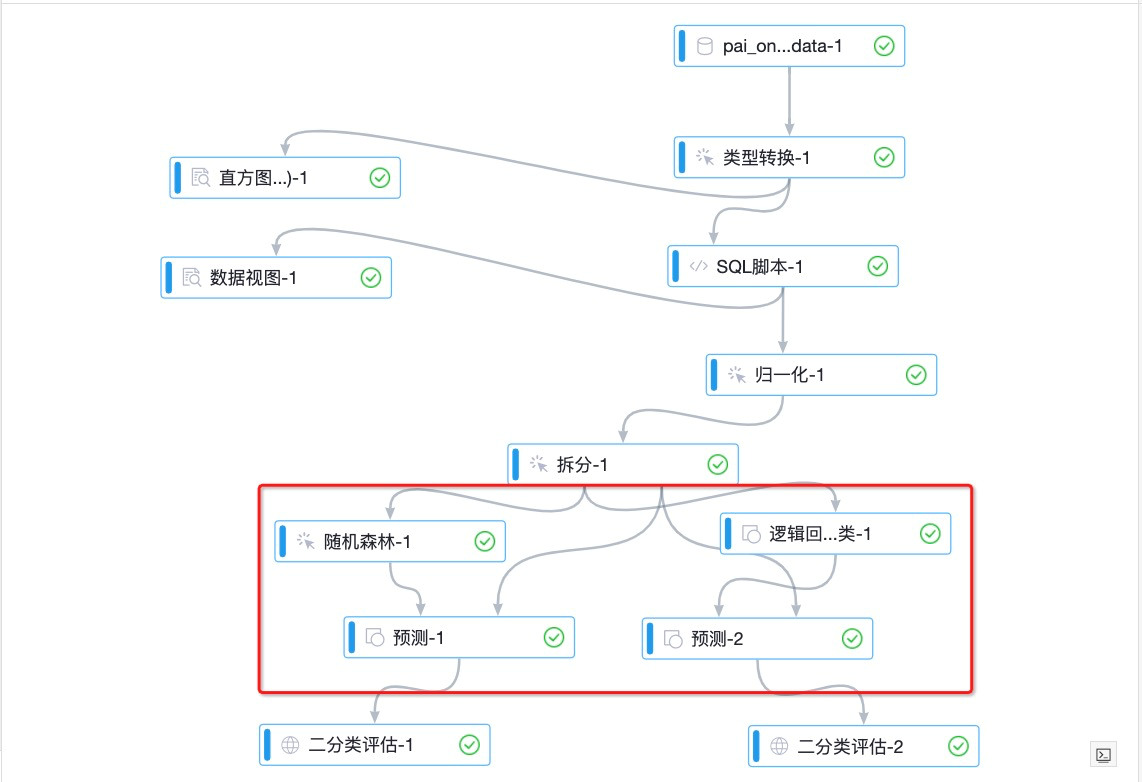
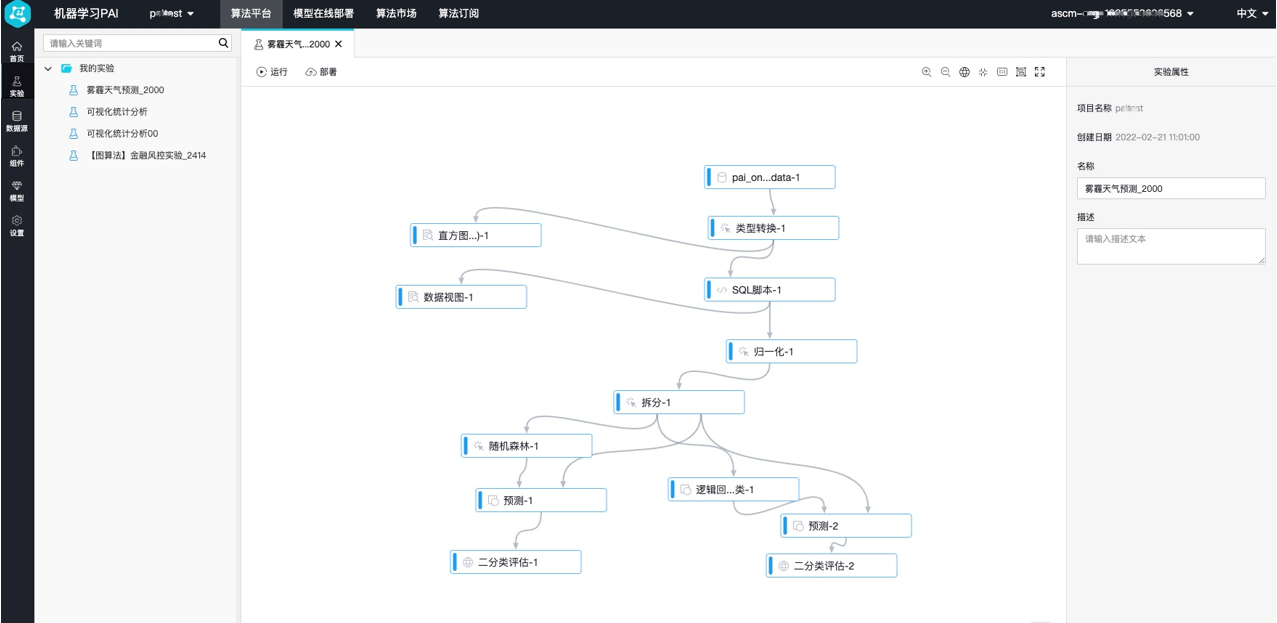
如下图所示红框部分为数据集成及数据预处理过程,将数据源进行归一化转化便于分析。
通过读数据表组件,导入数据源。
通过类型转换组件,将STRING类型的数据转换为DOUBLE类型。
通过SQL脚本组件,将目标列转换为0和1的二值类型。本实验中,pm2列为目标列。数值大于200的作为重度雾霾天气,将其标记为1,反之标记为0。SQL语句如下。
select time,hour,(case when pm2>200then 1 else 0 end),pm10,so2,co,no2 from ${t1};通过归一化组件,去除量纲,即将不同指标污染物的单位统一。
图中红框部分为数据统计分析可视化,可以直观查看数据预处理后的结果,本实验使用的可视化组件为直方图和数据视图。
选择画布中的直方图-1,在快捷菜单,右键单击查看分析报告,可以查看直方图可视化分析。
通过直方图组件以可视化的方式查看每种污染物的分布情况。
以PM2.5为例,数值出现最多的区间为11.74~15.61,共430次,如下图所示。
选择画布中的数据视图-1,在快捷菜单,右键单击查看分析报告,可以查看数据视图可视化分析。
通过数据视图,可以查看每种污染物不同区间对于结果的影响。
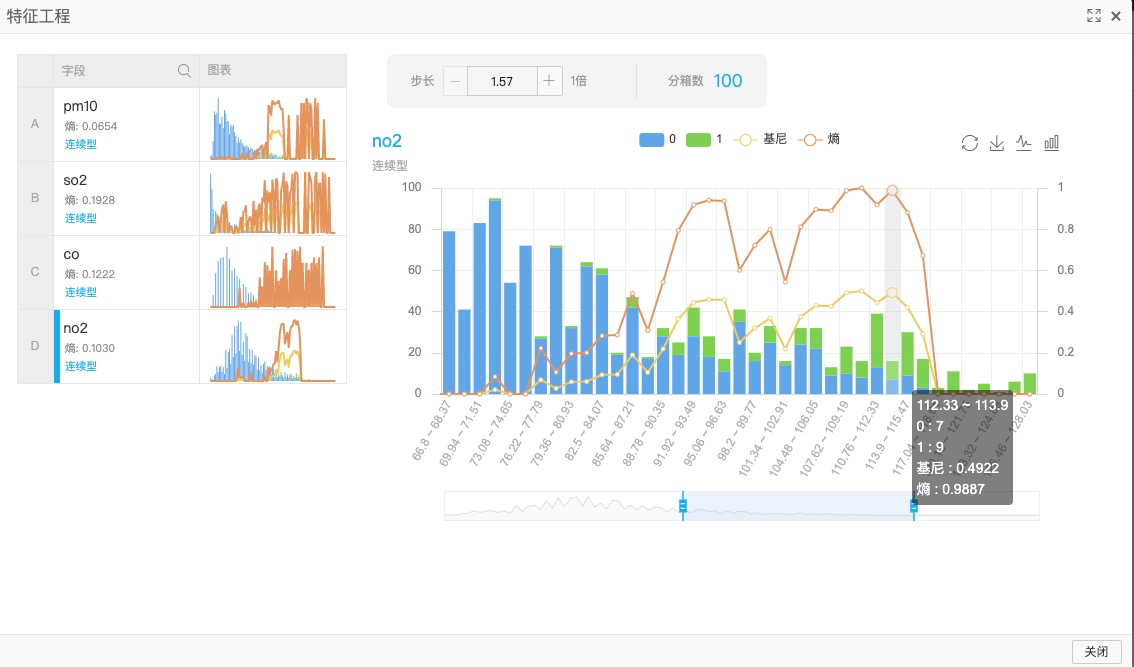
以no2为例,在112.33~113.9区间产生了7个目标列为0的目标和9个目标列为1的目标(如下图所示)。因此,no2在112.33~113.9区间时,出现重度雾霾天气的概率较高。熵和基尼系数表示该特征区间对于目标值的影响(信息量层面的影响),数值越大影响越大。
图中红框部分为模型训练和预测,基于数据进行训练和预测结果,本实验使用的是随机森林和逻辑回归二分类模型。
以随机森林分支为例,右键单击画布中的随机森林-1,在快捷菜单,单击模型选项 > 查看模型,查看该预测模型。
可以查看到随机森林模型训练输出如下:
右键单击画布中的预测-1,在快捷菜单,单击查看数据,即可查看预测数据。
图中红框部分为模型评估,本实验使用的是二分类评估。
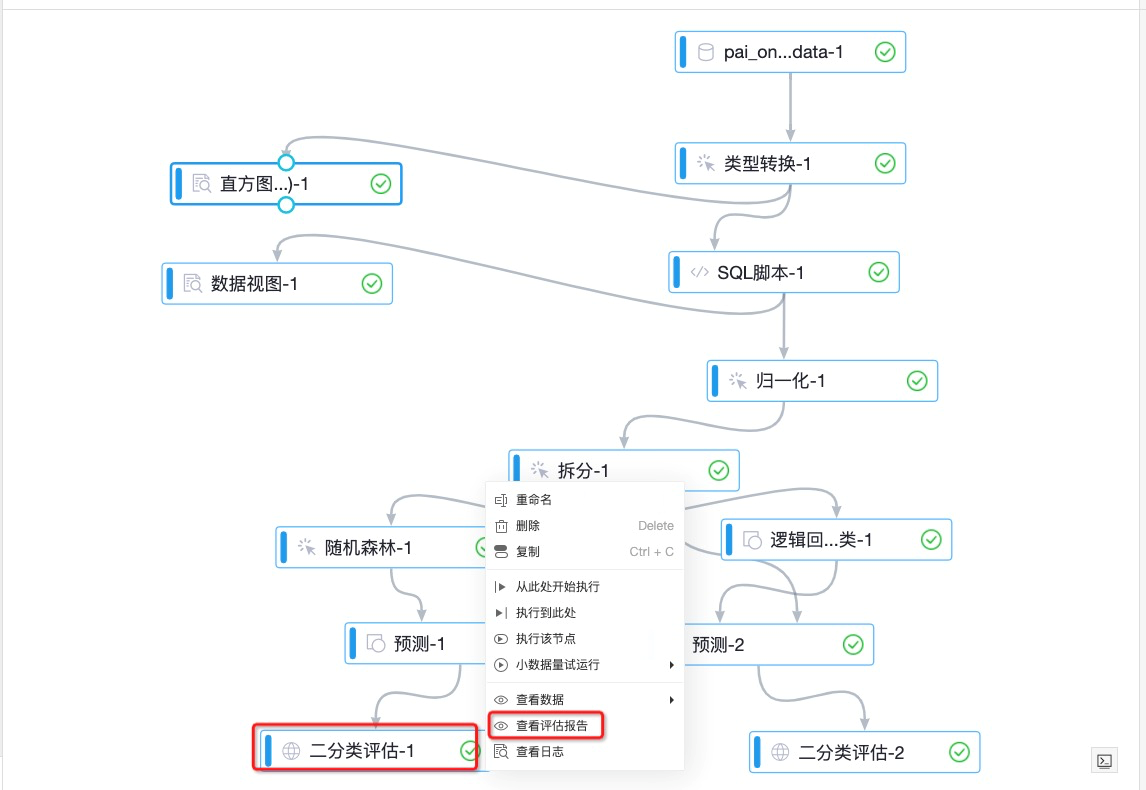
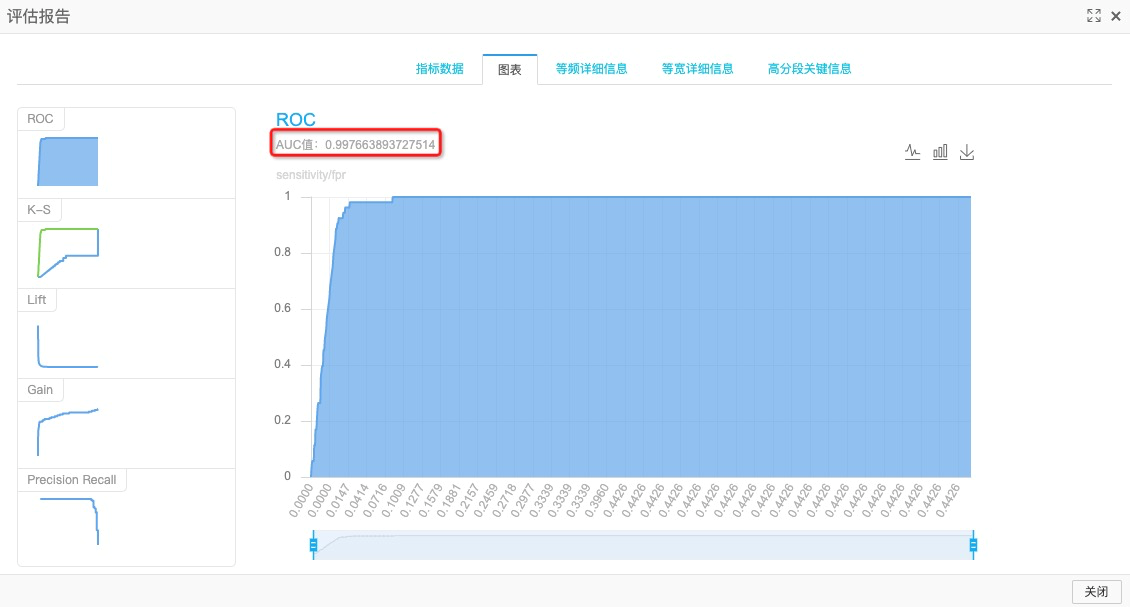
右键单击画布中的二分类评估-1,在快捷菜单,单击查看评估报告。
在评估报告对话框,单击图表页签,即可查看随机森林训练模型的预测效果。AUC的取值表示随机森林组件训练的雾霾天气预测模型的准确率达到了99%以上。



 各输入字段含义如下:
各输入字段含义如下: