本文为您介绍将自建开源Flink集群的流式作业(包含Table API、SQL和Datastream)迁移至阿里云实时计算Flink全托管版的迁移优势、迁移方案和相关文档。
迁移优势
Flink全托管产品按CU售卖,根据业务需要按需购买,可以降低成本。另外提供提交作业、管理作业、收集指标和监控报警等一站式功能,可以提高作业开发运维效率。与开源Flink完全兼容,提供GeminiStateBackend(自研高性能状态存储引擎)等高增值功能,可以提升作业稳定性。将开源自建Flink迁移至Flink全托管后,您只需专注于业务开发,无需关心工作空间运维,也可以直接使用开源的Auto-Pilot功能进行作业调优。
迁移方案
技术架构如下图所示。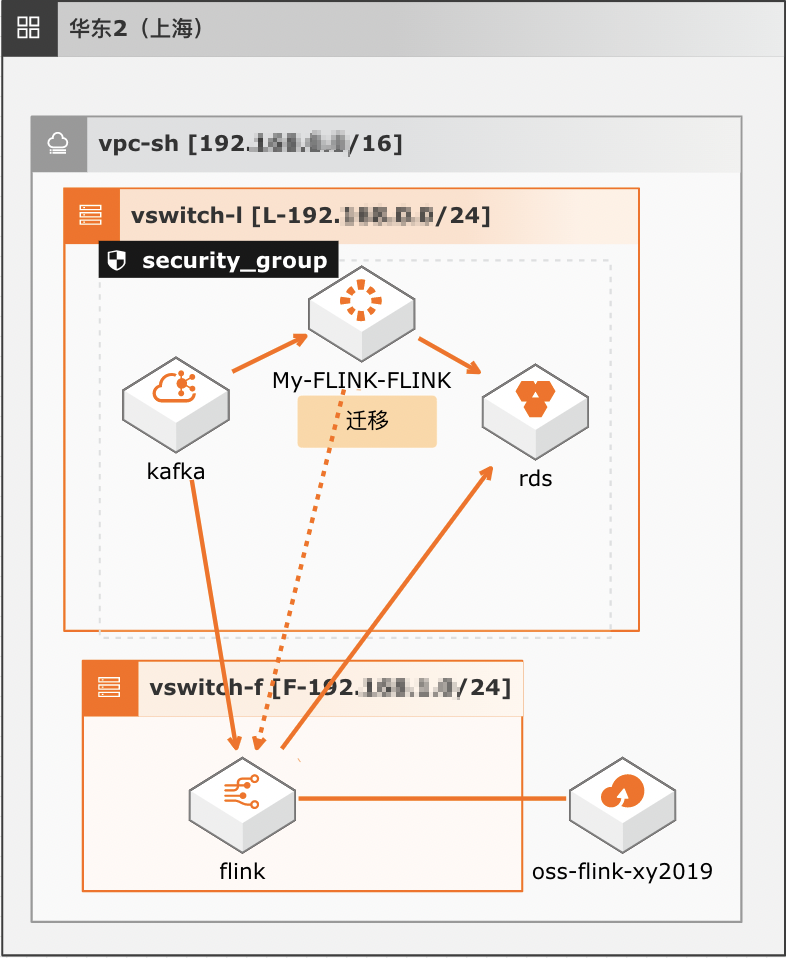
迁移实施流程如下图所示。

主要包括以下几个环节:
创建工作空间
资源估算
在创建Flink全托管工作空间前,需要评估Flink全托管的资源。
Flink全托管的基本计量单位为Compute Unit(CU),即计算资源,1 CU=1核CPU+4 GiB内存+20 GB本地存储(放置日志、系统检查点等信息),CU对应实时计算底层系统的CPU计算能力。1个实时计算作业(Job)的CU使用量取决于此Job输入数据流的QPS、计算复杂程度,以及具体的输入数据分布情况。您可以根据业务规模以及实时计算的计算能力,估算所需购买的资源数量。实时计算1 CU的处理能力如下表所示。
处理场景
处理能力
简单的流式压测处理
例如,过滤、清洗等操作。
1 CU每秒可以处理40000~55000条数据。
复杂的流式压测处理
例如,聚合操作、复杂UDF计算等。
1 CU每秒可以处理5000~10000条数据。
说明上述计算能力估值仅限于实时计算内部处理能力,不包括对外数据读取和写入部分。外部数据的读写效率会影响您对实时计算能力的评估,例如:
如果实时计算需要从日志服务(LogService)读取数据,但LogService对于请求调用配额(Quota)存在一定限制,则实时计算整体的计算能力将被限制在LogService允许的范围内。
如果实时计算引用的RDS数据存储存在连接数或者TPS限制,则实时计算吞吐能力将受限于RDS本身的流控限制。
如果作业中使用窗口函数,CU的使用量会比简单作业高,建议至少购买4 CU。
创建
使用阿里云账号创建Flink全托管工作空间,以便将自建Flink作业迁移过来。为了保证上下游迁移后的网络连通性,创建时请选择和自建Flink集群相同VPC。创建Flink全托管工作空间的步骤详情请参见开通Flink全托管,计费项请参见计费项。
作业迁移
您需要将自建Flink集群上的作业包,修改相关的配置后,手动上传到Flink全托管控制台,并创建对应的作业。不同类型的作业迁移步骤示例详情,请参见概述。
数据正确性验证
数据质量是实时计算数据产出对业务的重要保障,和实时计算任务日常变更一样,迁移工作也需要对新任务产出的数据质量进行验证。通常,建议您采用迁移新任务和原有任务并行双跑的方式,在新运行一段时间,满足数据对比条件后,验证新任务和原有任务的数据产出是否一致,达到预期的数据质量。理想情况下,迁移的新任务数据产出和原任务完全一致,就无需进行额外的差异分析。

实时任务7x24小时持续在运行,但在大部分情况下产出的数据还是具备时间周期特性的,这就给数据对比提供了可行性。例如,聚合任务按小时或天维度计算聚合值,清洗任务加工任务按天进行分区等。在数据对比时就可以根据对应的时间周期来进行对比。例如小时周期的任务实际已完整处理数据多个小时后,就可以对比处理过的小时数据,而天维度的聚合值,通常就需要等待新任务处理完完整的一天数据后才能对比。
根据任务产出的生成周期特性和数据规模,您可以结合业务的实际情况,使用恰当的对比方法。对比方法详情如下表所示。
数据规模
对比
中小数据规模
建议进行全量数据对比。例如,窗口聚合逻辑的数据,对每一个key、每一个窗口的聚合结果进行一一对比,验证其正确性。
较大数据规模
如果全量对比的代价高、可行性低,则可以考虑采用抽样的方式进行。例如窗口聚合逻辑的数据,随机抽取部分key、部分窗口的聚合结果进行一一对比,验证其正确性。但需注意抽样方式的合理性,避免单一性产生对比漏洞从而误判数据质量。
业务稳定性验证
业务稳定性和数据质量同样重要,任务的稳定性通常要求实现较长时间的平稳运行(建议至少7天)。进入稳定性观察期后,建议开启和原任务相同级别的监控、报警设置,期间主要观察任务运行时的处理延迟、有无异常Failover以及Checkpoint情况是否健康等。如果达到了和原有任务同等或更高的稳定性,即完成稳定性验证。
业务迁移
数据正确性、业务性能和稳定性确认后,即可开展业务迁移工作,即将Flink作业中使用的备用结果表替换原有任务的结果表,提供给业务方使用,并将原有生产链路停止下线,整个迁移工作就圆满结束了。
相关文档
- 本页导读 (1)