
在AIGC、视频处理等复杂的模型推理场景中,由于推理耗时较长,存在长连接超时导致请求失败或实例负载不均衡等问题,不适用于同步推理场景。为了解决这些问题,PAI提供了异步推理服务,支持通过订阅或轮询的方式来获取推理结果。本文为您介绍如何使用异步推理服务。
背景信息
功能介绍
异步推理
对于实时性要求比较高的在线推理场景,通常使用同步推理,即客户端发送一个请求,同步等待结果返回。
对于推理耗时比较长或者推理时间无法确定的场景,同步等待结果会带来HTTP长连接断开、客户端超时等诸多问题。通常需要使用异步推理来解决上述问题,即请求发送至服务端,客户端不再同步等待结果,而是选择定期去查询结果,或通过订阅的方式在请求计算完成后等待服务端的结果推送。
队列服务
对于准实时推理场景,比如短视频、视频流或语音流的处理或计算复杂度很高的图像处理等场景,不需要实时返回结果,但需要在指定时间内获取推理结果,该场景存在以下几类问题:
负载均衡算法不能选择round robin算法,需要根据各个实例的实际负载情况进行请求的分发。
实例异常,该实例尚未完成计算的任务需要重新分配给其他实例进行计算。
PAI推出了一套独立的队列服务框架,用来解决以上请求分发的问题。
实现原理

在创建异步推理服务时,会在服务内部集成两个子服务,分别是推理子服务和队列子服务。队列子服务拥有两个内置的消息队列,即输入(input)队列和输出(sink)队列。服务请求会先发送到队列子服务的输入队列中,推理子服务实例中的EAS服务框架会自动订阅队列以流式地方式获取请求数据,调用推理子服务中的接口对收到的请求数据进行推理,并将响应结果写入到输出队列中。
当输出队列满时,即无法向输出队列中写入数据时,服务框架也会停止从输入队列中接收数据,避免无法将推理结果输出到输出队列。
如果您不需要输出队列,例如将推理结果直接输出到OSS或者您自己的消息中间件中,则可以在同步的HTTP推理接口中返回空,此时输出队列会被忽略。
创建一个高可用的队列子服务,用于接收客户端发送的请求。推理子服务的实例根据自己所能承受的并发度来订阅指定个数的请求,队列子服务会保证每个推理子服务实例上处理的请求不会超过订阅的窗口大小,通过该方式来保证不会存在实例过载,最终将订阅或查询的数据返回给客户端。
说明比如每个推理子服务实例只能处理5路语音流,则从队里子服务中订阅消息时,将window size配置为5。当推理子服务实例处理完一路语音流后将结果commit,队列子服务会为推理子服务实例重新推送一路新的语音流,保证该实例上处理的语音流最多不超过5路。
队列子服务通过检测推理子服务实例的连接状态,对其进行健康检查,如果因该实例异常导致连接断开,队列子服务会将该实例标记为异常,已经分发给该实例进行处理的请求会重新推送给其他正常实例进行处理,以此来保证在异常情况下请求数据不会丢失。
创建异步推理服务
在创建异步推理服务时,为了方便您的使用和理解,系统会自动创建和异步推理服务同名的服务群组。同时,队列子服务会随异步推理服务自动创建,并集成到异步推理服务内。队列子服务默认启动1个实例,并根据推理子服务的实例数量动态伸缩,但最多不超过2个实例,每个实例默认配置为1核和4 GB内存。如果队列子服务的实例数的默认配置不能满足您的需求,请参照队列子服务参数配置及说明进行配置。
EAS的异步推理服务可以实现同步推理逻辑到异步推理的转换,支持以下两种部署方式:
通过控制台部署服务
进入自定义部署页面,并配置以下关键参数,其他参数配置详情,请参见自定义部署。
部署方式:选择镜像部署或processor部署。
异步服务:选中异步服务。
参数配置完成后,单击部署。
通过eascmd客户端部署服务
准备服务的配置文件service.json。
部署方式为模型+processor部署服务。
{ "processor": "pmml", "model_path": "http://example.oss-cn-shanghai.aliyuncs.com/models/lr.pmml", "metadata": { "name": "pmmlasync", "type": "Async", "cpu": 4, "instance": 1, "memory": 8000 } }其中关键参数说明如下。其他参数配置说明,请参见JSON部署。
type:配置为Async,即可创建异步推理服务。
model_path:替换为您的模型的地址。
部署方式为镜像部署服务。
{ "metadata": { "name": "image_async", "instance": 1, "rpc.worker_threads": 4, "type": "Async" }, "cloud": { "computing": { "instance_type": "ecs.gn6i-c16g1.4xlarge" } }, "queue": { "cpu": 1, "min_replica": 1, "memory": 4000, "resource": "" }, "containers": [ { "image": "eas-registry-vpc.cn-beijing.cr.aliyuncs.com/pai-eas/chat-llm-webui:3.0.1", "script": "python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-7B-Chat", "port": 8000 } ] }其中关键参数说明如下。其他参数配置说明,请参见JSON部署。
type:配置该参数为Async,即可创建异步推理服务。
instance:推理子服务的实例数量,不包含队列子服务的实例。
rpc.worker_threads:为异步推理服务中EAS服务框架的线程数,该参数与订阅队列数据的窗口大小一致。线程数设置为4,即一次最多只能从队列中订阅4条数据,在这4条数据处理完成前,队列子服务不会给推理子服务推送新数据。
例如:某视频流处理服务,单个推理子服务实例一次只能处理2条视频流,则该参数可以设置为2,队列子服务最多将2个视频流的地址推送给推理子服务,在推理子服务返回结果前,不会再推送新的视频流地址。如果推理子服务完成了其中一个视频流的处理并返回结果,则队列子服务会继续再推送一个新的视频流地址给该推理子服务的实例,保证一个推理子服务的实例最多同时处理不超过2路视频流。
创建服务。
您可以登录eascmd客户端后使用create命令创建异步推理服务,如何登录eascmd客户端,请参见下载并认证客户端,使用示例如下。
eascmd create service.json
访问异步推理服务
如上文介绍,系统会默认为您创建和异步推理服务同名的服务群组,因群组内的队列子服务拥有群组流量入口,您可以直接通过下述路径访问队列子服务,详情请参见访问队列服务。
地址类型 | 地址格式 | 示例 |
输入队列地址 |
|
|
输出队列地址 |
|
|
管理异步推理服务
您可以像管理普通服务一样管理异步推理服务,该服务的子服务会由系统自动管理。比如,当您删除异步推理服务时,队列子服务和推理子服务都将被同时删除。或者当您更新推理子服务时,队列子服务维持不变以获取最大的可用性。
由于采用了子服务架构,虽然您为异步推理子服务配置了1个实例,实例列表中仍会额外显示一个队列子服务实例。

异步推理服务的实例数量指的是推理子服务实例的数量,队列子服务的实例数量会随着推理子服务的实例数量自动变化。比如,当您将推理子服务实例数量扩容到3时,队列子服务的实例数量扩容到了2。
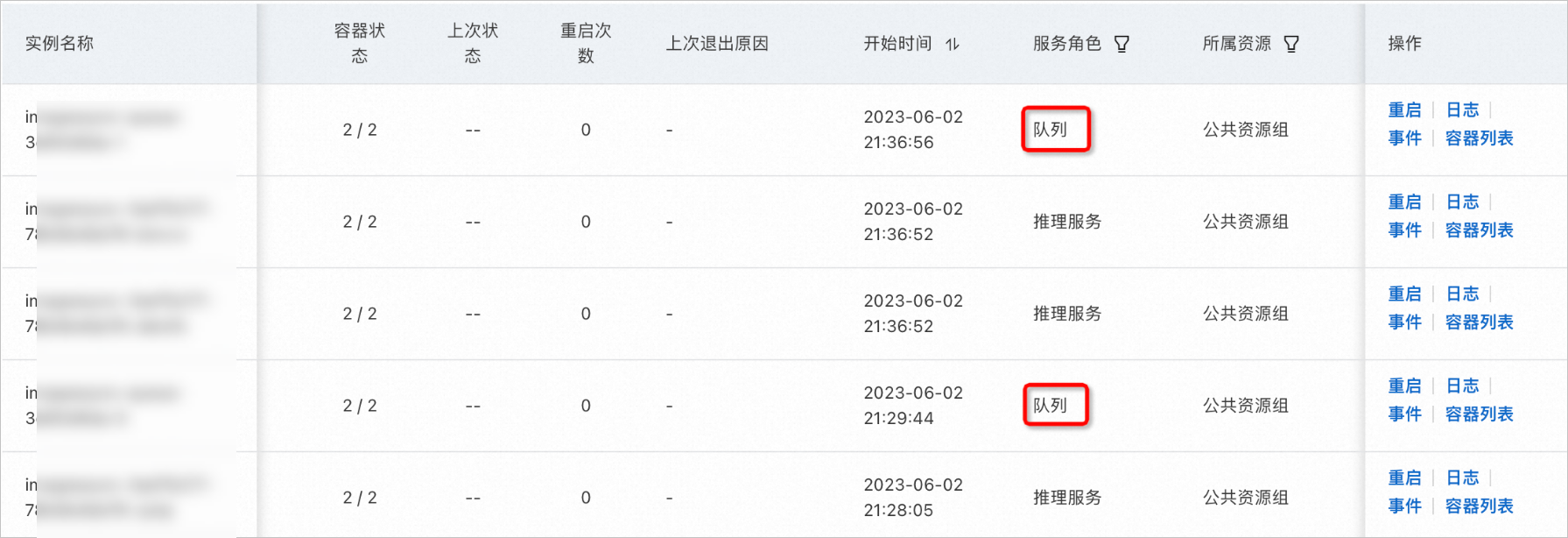
两个子服务间的实例数量配比规则如下:
当异步推理服务被停止,则队列子服务和推理子服务的实例数量均会缩容到0,这时看到的实例列表为空。
当推理子服务的实例数量为1时,队列子服务的实例数量也将为1,除非您配置了队列子服务的参数。
当推理子服务的实例数量超过2时,队列子服务的实例数量将保持为2,除非您配置了队列子服务的参数。
当您为异步推理服务配置了自动扩缩容功能,且配置了最小的实例数量为0,则当推理子服务缩容到0时,队列子服务将保持1个实例待命。
队列子服务参数配置及说明
大多数情况下,队列子服务使用默认配置即可正常使用。如果有特殊需求,您可以通过在JSON文件中最外层的queue配置块来配置队列实例。示例如下:
{
"queue": {
"sink": {
"memory_ratio": 0.3
},
"source": {
"auto_evict": true,
}
}下面介绍具体的配置项。
配置队列子服务资源
队列子服务的资源会默认按照metadata中的字段进行配置,但是在有些使用场景下,您需要参考本章节,对队列子服务的资源进行单独配置。
通过queue.resource声明队列子服务所使用的资源组。
{ "queue": { "resource": eas-r-slzkbq4tw0p6xd**** # 默认跟随推理子服务资源组。 } }队列子服务默认跟随推理子服务的资源组。
当您需要使用公共资源组部署队列子服务时,可以声明resource为空字符串(""),这在您的专属资源组CPU和内存不充足时非常有用。
说明推荐使用公共资源组部署队列子服务。
通过queue.cpu和queue.memory声明每个队列子服务实例所使用的CPU(单位:核数)和内存大小(单位:MB)。
{ "queue": { "cpu": 2, # 默认值为1。 "memory": 8000 # 默认值为4000。 } }如果您没有进行资源配置,队列子服务将按照1 CPU核、4 GB内存进行默认配置。这可以满足大多数场景的需求。
重要如果您的订阅者(比如推理子服务实例的数量)数量超过200时,建议将CPU核数配置为2核以上。
不建议在生产环境中缩小队列子服务的内存配置。
通过queue.min_replica配置队列子服务实例的最小数量。
{ "queue": { "min_replica": 3 # 默认为1。 } }在使用异步推理服务时,队列子服务实例的数量将根据推理子服务实例的运行时数量自动调整,默认的调整区间为
[1, min{2, 推理子服务实例的数量}]。特殊情况下,如果配置异步推理服务的自动扩缩容规则并允许将实例数量缩小到0时,将自动保留1个队列子服务实例。您也可以通过queue.min_replica调整最小保留的队列子服务实例数量。说明增加队列子服务实例的数量可以提高可用性,但不能提高队列子服务的性能。
配置队列子服务功能
队列子服务拥有多项可配置的功能,您可以通过以下配置方法进行调整。
通过queue.sink.auto_evict或者queue.source.auto_evict分别配置输出/输入队列自动数据驱逐功能。
{ "queue": { "sink": { "auto_evict": true # 输出队列打开自动驱逐,默认为false。 }, "source": { "auto_evict": true # 输入队列打开自动驱逐,默认为false。 } } }默认情况下队列子服务的自动数据驱逐功能处于关闭状态,如果您的队列已满将无法继续输入数据。在某些场景下,如果您允许数据在队列中溢出,可以选择打开自动数据驱逐功能,队列将自动驱逐最老的数据以允许新数据写入。
通过queue.max_delivery配置最大投递次数。
{ "queue": { "max_delivery": 10 # 最大投递次数为10,默认值:5。当配置为0时,最大投递次数关闭, 数据可以被无限次投递。 } }当单条数据的尝试投递次数超过设定阈值时,该数据将被视为无法处理,并将其标记为死信。详情请参见队列实例的死信策略。
通过queue.max_idle配置数据的最大处理时间。
{ "queue": { "max_idle": "1m" # 配置单条数据最大处理时长为1分钟,如果超过该时间将被投递给其它订阅者, 投递完毕后投递次数+1。默认值为0,即没有最大处理时长。 } }示例中配置的时间长度为1分钟,支持多种时间单位,如h(小时)、m(分钟)、s(秒)。如果单条数据处理的时间超过了这里配置的时长,则有两种可能:
如果未超过queue.max_delivery设定的阈值,该条数据会被投递给其他订阅者。
如果已超过queue.max_delivery设定的阈值,该条数据将会被执行死信策略。
通过queue.dead_message_policy配置死信策略。
{ "queue": { "dead_message_policy": "Rear" # 枚举值为Rear(默认值)或者Drop, Rear即为放入队列末尾,Drop将该条数据删除。 } }
配置队列最大长度或最大数据体积
队列子服务的最大长度和最大数据体积是此消彼长的关系,计算关系如下所示:

队列子服务实例内存是固定的,因此如果调整单条数据最大体积,则会导致该队列最大长度减小。
在4 GB内存的默认配置下,由于最大数据体积默认为8 KB,则输入输出队列均可以存放230399条数据,如果您需要在队列子服务中存放更多数据项,可以参考上文中的内存配置,将内存大小按照需要提高。系统将占用总内存的10%。
对于同一个队列,不能同时配置最大长度和最大数据体积。
通过queue.sink.max_length或者queue.source.max_length分别配置输出队列/输入队列的最大长度。
{ "queue": { "sink": { "max_length": 8000 # 配置输出队列最大长度为8000条数据。 }, "source": { "max_length": 2000 # 配置输入队列最大长度为2000条数据。 } } }通过queue.sink.max_payload_size_kb或者queue.source.max_payload_size_kb分别配置输出队列/输入队列单条数据最大数据体积。
{ "queue": { "sink": { "max_payload_size_kb": 10 # 配置输出队列单条数据最大体积是10 KB, 默认8 kB。 }, "source": { "max_payload_size_kb": 1024 # 配置输入队列单条数据最大体积是1024 KB(1MB), 默认是8 kB。 } } }
配置内存分配倾斜
通过queue.sink.memory_ratio来调整输入输出两个队列占用的内存大小。
{ "queue": { "sink": { "memory_ratio": 0.9 # 配置输出队列内存占比,默认值为0.5。 } } }说明默认配置下,输入队列和输出队列均分队列子服务实例的内存。如果您的服务需要输入文本、输出图片,并期望在输出队列存放更多数据,则可以将queue.sink.memory_ratio相应提高;相反,如果您期望输入图片、输出文本,则可以将queue.sink.memory_ratio相应减小。
配置水平自动扩缩容
工作原理
在异步推理场景中,系统可以根据队列的状态动态地对推理服务的实例数量进行伸缩,并且支持在队列为空时将推理服务的实例数缩容到0以进一步降低成本。异步推理服务自动扩缩容的原理示意图如下:

配置方法
在服务列表中,单击目标服务名称,进入服务详情页面。
切换到自动伸缩页签,在弹性伸缩区域,单击开启弹性伸缩。
在自动弹性扩缩容设置对话框,进行参数配置。
基础配置:
参数
说明
示例值
最小实例数
服务实例自动缩容的下限数量,最小值为0。
0
最大实例数
服务实例自动扩容的上限数量。最大为 1000。
10
常规扩缩容指标
用于触发扩缩容的内置性能指标。
其中,异步队列长度表示当前队列任务平均到每个实例处理的数量。
选择异步队列长度,阈值配置为10。
高级配置:
参数
说明
示例值
扩容生效时长
扩容决策的观察窗口。触发扩容后,系统会在此段时间内观察指标,若指标值回落至阈值以下,则取消本次扩容。单位为秒。
默认值为
0秒,即立即执行扩容。0
缩容生效时长
缩容决策的观察窗口,是防止服务抖动的关键参数。系统会确认指标值在此段时间内持续低于阈值后,才执行缩容。单位为秒。
默认值为
300秒。此值是防止服务因流量波动而频繁缩容的核心保障。不建议设置过小,以免影响服务稳定性。300
缩容到0的生效时长
当最小实例数设为
0时,此参数定义了从满足缩容条件到实例数缩减至0的等待时间。600
从0扩容的实例数
服务从
0个实例冷启动时,一次性扩容到的实例数量。1
更多参数说明及eascmd客户端使用参见水平自动扩缩容。